Стратегия улучшения YOLOv8: AIFI (масштабное взаимодействие функций) помогает терминатору YOLO | РТ-ДЭТР выясняет
💡💡💡Эта статья - первое эксклюзивное улучшение во всей сети: AIFI (Внутримасштабное взаимодействие функций) помогает YOLO Улучшите способность взаимодействовать с объектами внутри шкал и между шкалами и в то же время уменьшите проблемы, связанные с вычислениями внимания и высокими затратами вычислений среди объектов нескольких масштабов.
Индекс рекомендации: пять звезд
AIFI | Персональный тест для увеличения количества баллов в нескольких наборах данных
1. Знакомство с РТ-ДЕТР

бумага: https://arxiv.org/pdf/2304.08069.pdf
RT-DETR (Real-Time DEtection TRansformer) , вид, основанный на DETR Комплексный детектор реального времени, обеспечивающий скорость и точность SOTA производительность
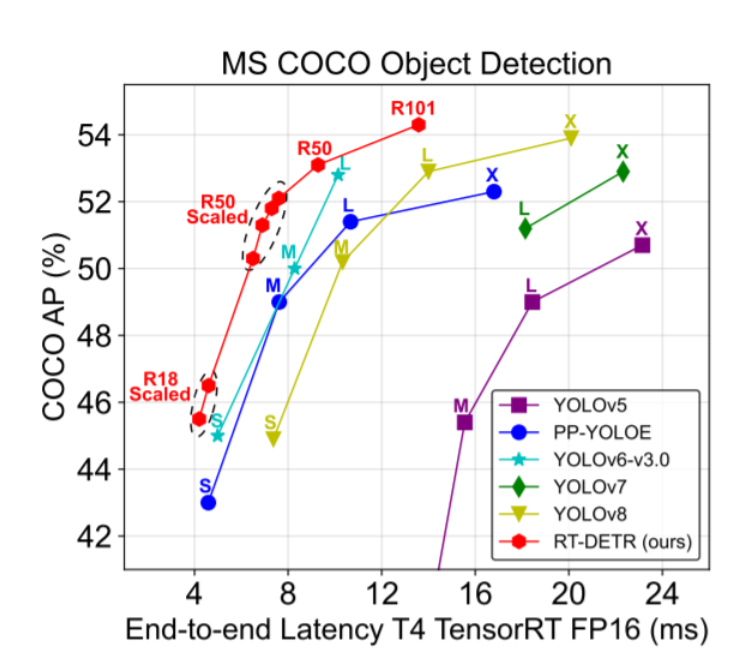
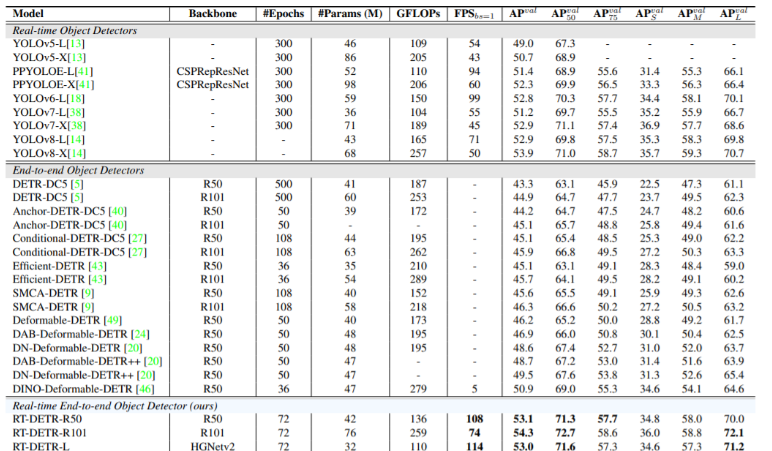
RT-DETR — первый сквозной детектор объектов в реальном времени. В частности, мы разрабатываем эффективный гибридный кодер для эффективной обработки многомасштабных функций за счет разделения внутримасштабных взаимодействий и межмасштабного слияния, а также предлагаем механизм выбора запросов с учетом IoU для оптимизации инициализации запросов декодера. Кроме того, RT-DETR поддерживает гибкую настройку скорости вывода за счет использования различных слоев декодера без переобучения, что облегчает практическое применение детекторов объектов в реальном времени. RT-DETR-L достигает 53,0% AP и 114 кадров в секунду на COCO val2017, а RT-DETR-X достигает 54,8% AP и 74 кадров в секунду на COCO val2017, превосходя все устройства того же масштаба с точки зрения скорости и точности детектора YOLO. RT-DETR-R50 достиг 53,1% AP и 108 кадров в секунду, а RT-DETR-R101 достиг 54,3% AP и 74FPS, превосходя по точности все детекторы DETR, использующие ту же магистральную сеть.
Структура модели РТ-ДЕТР
(1)Backbone: Используются как классический ResNet, так и HGNet-v2 собственной разработки Baidu. Магистральную сеть можно масштабировать. Выходы L и 4 каскада, RT-DETR нужны только последние 3 для ускорения, что также соответствует стилю YOLO. ;
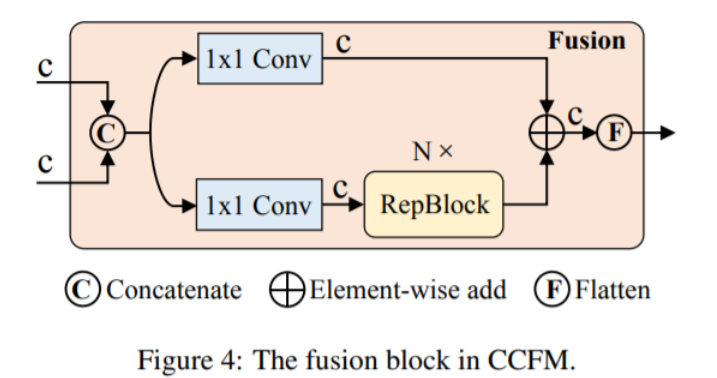
(2) Neck:Команда Flying Paddle разработала серию вариантов кодеров, чтобы убедиться, что в рамках несвязанной шкалыивозможность взаимодействия признаков между масштабами и в конечном итоге превращается в HybridEncoder , который состоит из двух частей: Intra-scale Feature Interaction (AIFI) и CNN-based Cross-scale Feature-fusion Module (CCFM) 。
(2) Decoder & Head:DETR Архитектура состоит из двух ключевых компонентов: Query Selection и Decoder 。

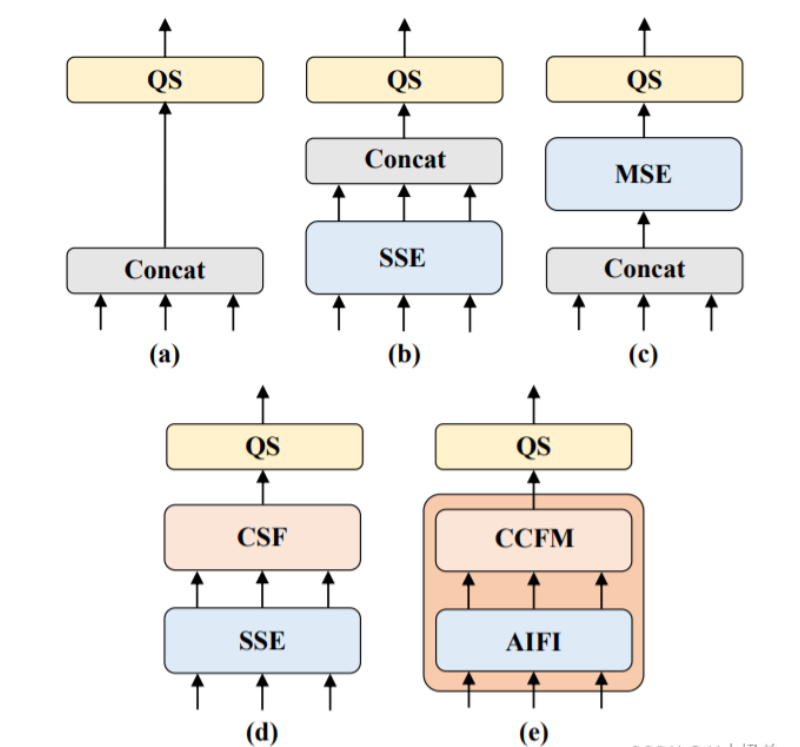
Авторский коллектив РТ-ДЕТР считает, что Encoder нужно использовать только на S5 Характерно, что это позволяет существенно сократить объем вычислений и увеличить скорость вычислений без ущерба для целостности модели. Чтобы убедиться в этом, команда авторов разработала несколько контрольных групп, как показано на рисунке ниже.
Обычно используемый масштаб для класса DETR в COCO — 800x1333. Раньше целью было достижение 45 м А или даже 50 м А на магистральной сети Res50. Однако RT-DETR не требует длительных сеансов обучения при использовании стиля YOLO. Масштаб 640х640. Он легко может преодолеть 50м АП за сто эпох, а его точность намного выше, чем у всех моделей DETR.
2.AIFI введен в YOLOv8
Местоположение реализации: ultralytics/nn/modules/transformer.py.
2.1 yolov8_AIFI.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, AIFI, [1024, 8]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
