Стратегия оптимизации YOLOv8: Google запускает оптимизатор Lion, который имеет меньший объем памяти и более высокую эффективность, убивая Адама(W) за секунды
1. Знакомство с оптимизатором Lion

бумага:https://arxiv.org/abs/2302.06675
код:automl/lion at master · google/automl · GitHub
1.1 Просто, эффективно использует память и быстрее
1) По сравнению с AdamW и различными адаптивными оптимизаторами, которым необходимо сохранять моменты как первого, так и второго порядка, Lion требует только импульса, вдвое сокращая дополнительный объем памяти;
2) Благодаря простоте Lion, в наших экспериментах Lion имеет более быстрое время работы (шаг/с), обычно на 2–15 % быстрее, чем AdamW и Adafactor;

1.2 Превосходная производительность оптимизатора Lion на различных моделях, задачах и полях
1.2.1 Классификация изображений
- Lion превосходит AdamW на различных сетевых моделях, обученных с нуля на ImageNet или предварительно обученных на ImageNet-21K.
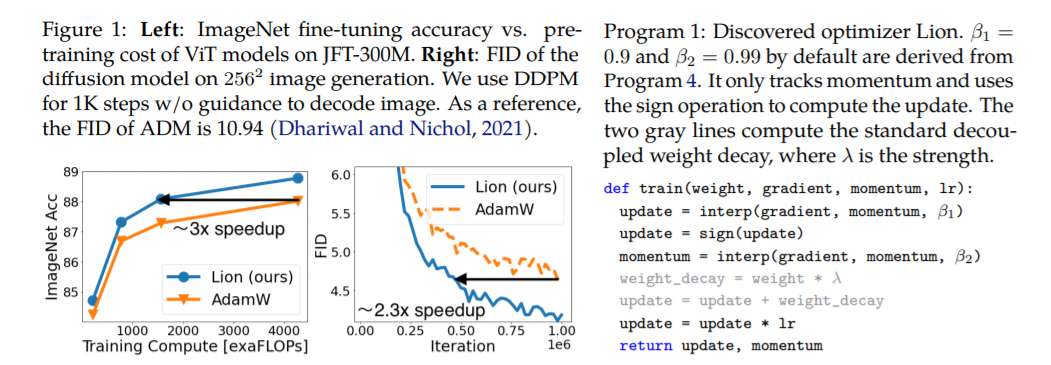
1.3 Гиперпараметры Lion и выбор размера партии
1) Путем спаривания Lion Анализ показывает,Прирост производительности увеличивается с увеличением размера обучающего пакета.。этоТакже требуется меньшая скорость обучения, чем у Адама, поскольку символьная функция создает большую норму обновления.。
2) Еще одно потенциальное ограничение оптимизатора — размер пакета (batch size)。экспериментально,В документе отмечается Lion Эффект не так хорош, как у AdamW, когда размер пакета небольшой (менее 64).
2. Оптимизатор Lion импортирует Yolov8
2.1 Измените ultralytics/yolo/engine/trainer.py.
Основной код:
# Copyright 2023 Google Research. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""PyTorch implementation of the Lion optimizer."""
import torch
from torch.optim.optimizer import Optimizer
class Lion(Optimizer):
r"""Implements Lion algorithm."""
def __init__(self, params, lr=1e-4, betas=(0.9, 0.99), weight_decay=0.0):
"""Initialize the hyperparameters.
Args:
params (iterable): iterable of parameters to optimize or dicts defining
parameter groups
lr (float, optional): learning rate (default: 1e-4)
betas (Tuple[float, float], optional): coefficients used for computing
running averages of gradient and its square (default: (0.9, 0.99))
weight_decay (float, optional): weight decay coefficient (default: 0)
"""
if not 0.0 <= lr:
raise ValueError('Invalid learning rate: {}'.format(lr))
if not 0.0 <= betas[0] < 1.0:
raise ValueError('Invalid beta parameter at index 0: {}'.format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError('Invalid beta parameter at index 1: {}'.format(betas[1]))
defaults = dict(lr=lr, betas=betas, weight_decay=weight_decay)
super().__init__(params, defaults)
@torch.no_grad()
def step(self, closure=None):
"""Performs a single optimization step.
Args:
closure (callable, optional): A closure that reevaluates the model
and returns the loss.
Returns:
the loss.
"""
loss = None
if closure is not None:
with torch.enable_grad():
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
# Perform stepweight decay
p.data.mul_(1 - group['lr'] * group['weight_decay'])
grad = p.grad
state = self.state[p]
# State initialization
if len(state) == 0:
# Exponential moving average of gradient values
state['exp_avg'] = torch.zeros_like(p)
exp_avg = state['exp_avg']
beta1, beta2 = group['betas']
# Weight update
update = exp_avg * beta1 + grad * (1 - beta1)
p.add_(torch.sign(update), alpha=-group['lr'])
# Decay the momentum running average coefficient
exp_avg.mul_(beta2).add_(grad, alpha=1 - beta2)
return loss
我正существоватьучаствоватьНа третьем этапе специального тренировочного лагеря Tencent Technology Creation 2023 года будет проводиться конкурс сочинений. Соберите команду, чтобы выиграть приз!



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
