Статья объемом 50 000 слов! Управляйте всеми аспектами Spark
Привет всем, это технологическое сообщество 857.
Сегодня я хотел бы поделиться с вами концептуальной статьей о Spark объемом 10 000 слов, которую легко понять новичкам. Эта статья стремится быть краткой и простой для понимания. Я надеюсь, что это поможет новичкам начать обучение, начиная с базовых концепций и затем углубляя принципы, чтобы они могли легко освоить Spark от более поверхностного к более глубокому.

Для начала давайте представим историю разработки Spark! ! ! ! !
Большие данные, искусственный интеллект ( Artificial Intelligence ), как нефть и электроэнергетика в прошлом, влияет на все отрасли с беспрецедентной широтой и глубиной. Основными барьерами нынешних и будущих компаний являются основные конкурентные преимущества, возникающие в результате конкуренции, основанной на искусственном интеллекте.
Spark на сегодняшний день является самой активной, популярной и эффективной вычислительной платформой в области больших данных.
Родился в 2009 году в AMP, Калифорнийский университет, Беркли, США. лаборатория,
Открытый исходный код выпущен под лицензией BSD в 2010 году.
В 2013 году он сделал пожертвование в Apache Software Foundation и переключил лицензионное соглашение с открытым исходным кодом на Apache2.0.
В феврале 2014 года Spark стал проектом Apache верхнего уровня.
ноябрь 2014 г., Команда Databricks, материнской компании Sparkiz, использует Spark для обновления мирового рекорда по сортировке данных
Spark успешно создал интегрированную, диверсифицированную и крупномасштабную систему обработки данных. В любом масштабе изданные расчеты, Spark имеет больше преимуществ в производительности и масштабируемости.
(1) Hadoop Дуг Каттинг отметил: используйте of MapReduce engine for Big Data projects will decline, replaced by Apache Spark (Большой проект данных, использующий движок MapReduce, будет прекращен на базе Apache. Spark заменять)
(2)Hadoop Коммерческое распространение от лидера рынка Cloudera 、HortonWorks 、MapR Все они перешли на Spark и считали Spark лучшим выбором и основной вычислительной системой для крупномасштабных решений.
из такого бенчмарктеста в 2014 году, Spark мгновенно убивает Hadoop , в случае использования одной десятой вычислительных ресурсов, в том же порядке, Spark в 3 раза лучше MapReduceбыстрый! Официального ПБ нет. Сортировка вернее, чем в других случаях, в первый раз будет S park Перенесено в IPB данные(Десять триллионов записей) из сортировки, используя 190 узлов, рабочая нагрузка была выполнена за 4 часа, Это также намного превышает предыдущий рекорд Yahoo в 16 часов при использовании 3800 хостов.
В июне 2015 года наибольшее количество узлов Spark поступило от Tencent — 8000 узлов, а наибольшее количество одиночных работ — у Alibaba и Databricks — 1PB, что шокирует! При этом количество SparkизContributors утроилось с 2014 года до 730: общее количество строк кода также увеличилось более чем вдвое с 2014 года до 40 строк.
ИБМ в 2015 году 6 класс Ежемесячное обязательство по улучшению Apache Spark проект, Его еще называют проектом «Должен»: возглавляемый данными, это будет самый важный новый проект с открытым исходным кодом в ближайшие десять лет. Это обещание из Кореда зажжет искру Встроить IBM Ведущая в отрасли аналитическая бизнес-платформа, интегрирующая Spark как услуга,существоватьIBMBПредоставляется клиентам на платформе。IBMбудет инвестировать больше, чем3500знаменитое исследованиеиразвивать人员существовать全球10Создано более 10 лабораторий.иSparkСвязанныйизпроект,и бесплатно предоставит революционную технологию машинного обучения для экосистемы Spark с открытым исходным кодом – IBM СистемаML. В то же время IBM также обучит более 1 миллиона ученых и инженеров по данным Spark.
В 2016 году на всемирно известной сортировке, известной как «Компьютерные олимпиады». В глобальном рейтинговом соревновании Benchmark участвующая команда NADSort, состоящая из Лаборатории компьютерных наук и технологий PASA Нанкинского университета и компании Alibaba Databricks, завершила стандартную обработку ранжирования объемом 100 ТБ за 144 доллара США, установив рекорд рейтинга на ТБ. Стоимость сортировки 1,44 доллара США — последний мировой рекорд по сравнению с 2014 годом. Выиграв чемпионат в 2016 году, команда TritonSort из Калифорнийского университета в Сан-Диего стоила 4,51 доллара за ТБ и снизила стоимость почти на 70%. Однако в этом соревновании по-прежнему используется Apache. Крупномасштабная вычислительная платформа Spark провела множество оптимизаций в алгоритме крупномасштабной параллельной сортировки и нижнем уровне системы Spark, чтобы улучшить производительность вычислений сортировки и максимально сократить накладные расходы на ресурсы хранения, чтобы гарантировать, что в конечном итоге выигрывает соревнование.
Под руководством идеалов FullStack Spark in Spark SQL 、SparkStreaming 、MLLib 、GraphX Пять основных подплатформ и библиотек R могут беспрепятственно обмениваться операциями с данными, Это не только создает непревзойденные преимущества Spark перед другими вычислительными платформами в современной большой вычислительной области, И Spark постепенно становится предпочтительной вычислительной платформой для крупных вычислительных центров.
Во-вторых, почему Spark популярен? ? ? ?
Причина 1: Отличные изданные модели и вычислительная абстракция.
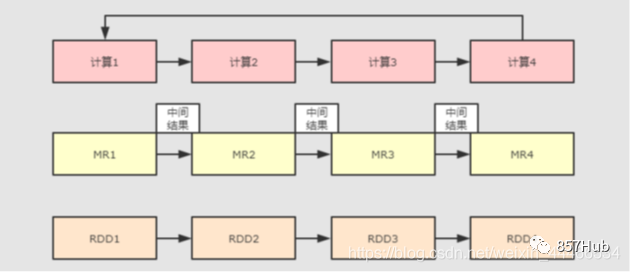
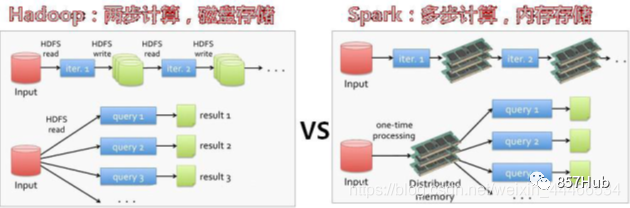
Spark До его появления уже существовали очень зрелые вычислительные системы, такие как MapReduce, которые предоставляли высокоуровневый API (map/reduce) для выполнения вычислений в системе и обеспечения отказоустойчивости, тем самым достигая распределенных вычислений.
Хотя MapReduce обеспечивает абстракцию доступа и вычислений, повторное использование в файловой системе так же просто, как запись промежуточных данных в стабильную файловую систему (например, H DFS), поэтому будет генерироваться резервное копирование данных, дисковый ввод-вывод и сериализация данных, поэтому эффективность будет очень низкой при возникновении необходимости повторного использования промежуточных результатов операций между несколькими вычислениями. Этот тип операций очень распространен, например, итеративные вычисления, интерактивный анализ, графовые вычисления и т. д.
Осознав эту проблему, академическое сообщество AMPLab предложило новую модель под названием RDD. RDD — это отказоустойчивая и параллельная структура (на самом деле ее можно понимать как распределенную коллекцию, и ее работа так же проста, как и работа с локальной коллекцией. Она позволяет пользователям явно преобразовывать промежуточные результаты). Набор данных хранится в памяти и позволяет управлять набором данных и разделять его для оптимизации обработки хранения данных. В то же время RDD также предоставляет богатые возможности. API (map, уменьшить, foreach, уменьшитьByKey...) для работы с набором данных. позже RDD используются AMPLab в программе под названием Spark Предоставляется в рамках и с открытым исходным кодом.
Короче говоря, Spark был разработан на основе идей MapReduce, сохранив его преимущества распределенных параллельных вычислений и улучшив его очевидные недостатки. Разрешение хранить промежуточные данные в памяти повышает скорость работы и предоставляет богатый API-интерфейс для работы с данными для повышения скорости разработки.
Причина 2: Улучшить экосистему
В настоящее время Spark превратился в набор нескольких подпроектов, включая SparkSQL, Spark Streaming, GraphX, MLlib и другие подпроекты
Spark Ядро: реализует основные функции Spark, включая такие модули, как RDD, планирование задач, управление памятью, восстановление после ошибок и взаимодействие с системой хранения.
Spark SQL: Spark используется для работы с пакетами структурированных данных. нанести Искру SQL, мы можем использовать данные операций SQL.
Spark Потоковая передача: Spark предоставляет компоненты потоковых вычислений в реальном времени. Предоставляет API для работы с потоками данных.
Spark MLlib: предоставляет общие функции и библиотеки машинного обучения (ML). Включает классификацию, регрессию, кластеризацию, совместную фильтрацию и т. д., а также предоставляет дополнительные функции поддержки, такие как оценка модели и импорт данных.
GraphX (Graph Computing): Spark используется для API графовых вычислений. Он имеет хорошую производительность, богатые функции и операторы и может свободно запускать сложные графовые алгоритмы на огромных объемах данных.
Менеджер кластера: Spark предназначен для эффективного масштабирования вычислений между одним вычислительным узлом и тысячами вычислительных узлов.

Дальнейшее чтение:Spark VS Hadoop
★Уведомление:
Хотя Spark имеет большие преимущества перед Hadoop, Spark не может полностью заменить Hadoop. Spark в основном используется для замены вычислительной модели MapReduce в Hadoop. HDFS по-прежнему можно использовать для хранения, но можно хранить промежуточные результаты в памяти; можно использовать встроенное планирование Spark или более зрелые системы планирования, такие как YARN.
Фактически, Spark хорошо интегрирован в экосистему Hadoop и стал ее важным членом. Он может реализовать управление планированием ресурсов с помощью YARN и обеспечить распределенное хранилище с помощью HDFS.
Кроме того, Hadoop может использовать дешевые и гетерогенные машины для распределенного хранения и вычислений, но аппаратные требования Spark немного выше, а к его памяти и процессору предъявляются определенные требования.
1. Обзор Spark и подробное объяснение
1. Что такое Искра?
Apache Единая аналитическая система Sparkda для крупномасштабной обработки данных
Spark основан на вычислениях в памяти, что повышает производительность обработки в реальном времени в больших средах.
В то же время он обеспечивает высокую отказоустойчивость и высокую масштабируемость, позволяя пользователям развертывать Spark на большом количестве оборудования для формирования кластера.
Официальный сайт Искры
http://spark.apachecn.org
http://spark.apachecn.org
2. Состав и принципы архитектуры Spark
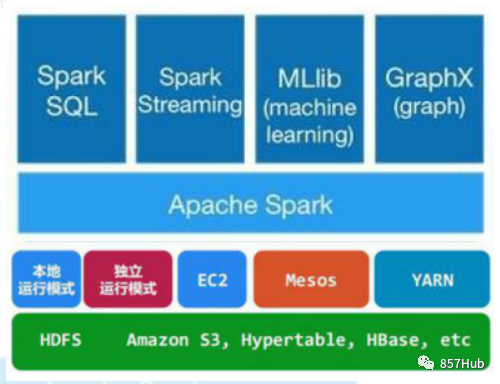
1.Spark Ядро: содержит основные функции Spark, особенно определение RDDAPI, операций и того и другого. Другие библиотеки Spark построены на RDD. Ядро выше из.
2.Spark SQL:поставлятьпроходитьApache Hive и вариант SQL Hive Query Language (HiveQL) и Spark взаимодействуют с API. Каждая таблица базы данных рассматривается как RDD, Spark. SQL-запросы обрабатываются Конвертировать как Spark.
3.Spark Потоковая передача: настоящая потоковая передача данных в реальном времени для обработки и управления. Искра Потоковая передача позволяет программам обрабатывать данные в реальном времени так же, как обычные RDD.
4.MLlib: общая библиотека алгоритмов машинного обучения, алгоритм реализован как операция trueRDDизSpark. Эта библиотека содержит масштабируемые алгоритмы обучения, такие как классификация, регрессия и т. д., которые требуют больших наборов данных для итеративных операций.
5. GraphX: граф управления, параллельная работа и расчет графа, набор алгоритмов и набор инструментов. GraphX расширяет RDD API, включая управляющий граф, создающий подграф и все операции вершин на пути доступа.
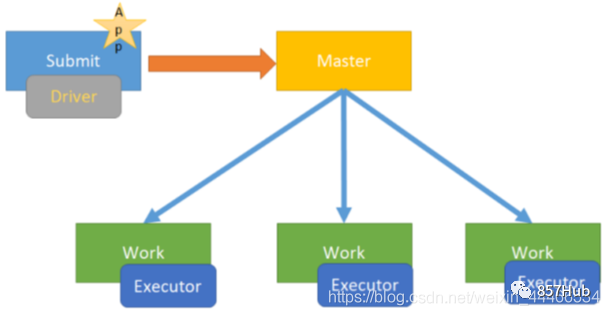
Схема композиции архитектуры Spark выглядит следующим образом:
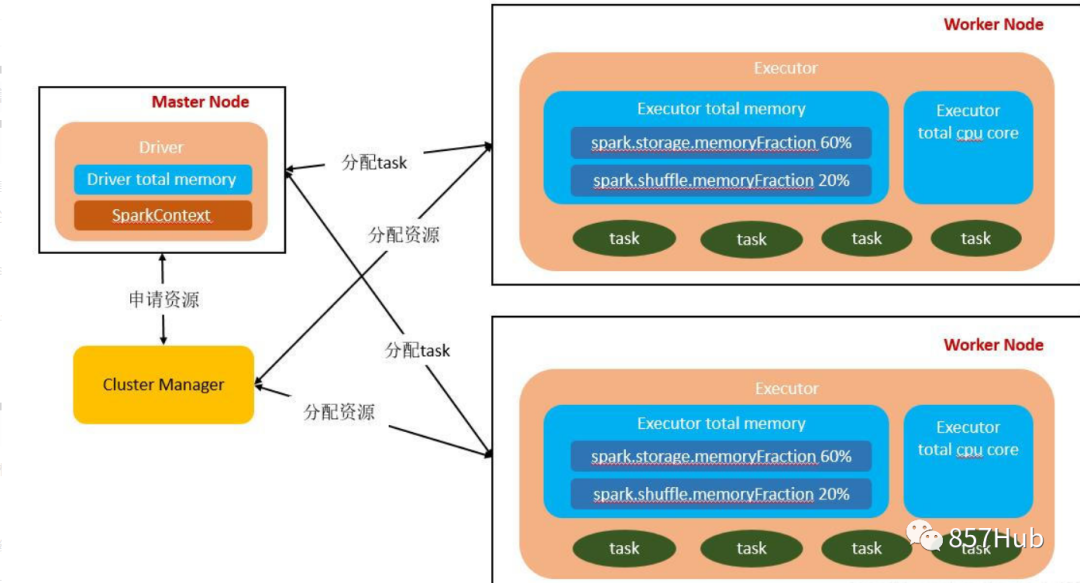
Фотографии доступны,Мастерда Спаркиз Главный узел управления,В реальной производственной среде будет несколько мастеров.,Активен только один Мастер. WorkerдаSparkиз рабочий узел,Сообщать капитану об изменениях в собственных ресурсах и исполнительном статусе.,И примите Мастера из команды запускать Исполнитель или Водитель. Драйвер-приложение из драйвера, каждое приложение включает в себя множество мелких задач. Драйвер отвечает за упорядоченное изучение этих небольших задач.
Исполнитель да Спаркиз рабочего процесса, контролируемый Рабочим, отвечает за конкретные задачи изосуществлять.
Мастер-Работник (соответствующие функции и отношения)
По всему Спаркластеру,Разделен на главный узел и рабочий узел.,один одновременнокластер Есть несколькоmasterузели Несколькоworkerузел。
1. Мастер: Мастер-нода, Должен-узел отвечает за управление рабочими узлами. Мы подаем заявки с главного узла, который отвечает за превращение последовательных задач в параллельные изучаиз набора задач, а также отвечает за обработку ошибок и т. д.;
2. Рабочий: подчиненный узел, Должен узел и главный узел связи, отвечающий за изучение задач и управляющий процессом-исполнителем. Это любой узел, на котором может выполняться код приложения. В автономной модели это означает издапроходить подчиненный файл. Конфигурация Рабочий узел в Spark. on Модель пряжи под узлом даNoteManager.
1.Application
Приложение относится к пользователю, пишущему приложение Spark.,ввключатьодинDriverФункцияизкоди分布существоватькластерсередина НесколькоузелначальствобегатьизExecutorкод
2.Driver
Driverdasparkиздрайверный узел,Используется в миссии «Изучить искру» из основного метода.,负责实际кодизосуществлять Работа。В основном отвечает за следующие задачи:
1) Преобразование пользовательской программы в задание
2) Планирование задач между исполнителями
3) Отследить ситуацию изосуществования Исполнителя
4)проходить UI Показать статус выполнения запроса
Популярное понимание драйвера заключается в запуске всего приложения, также называемого классом драйвера.
3.Executor
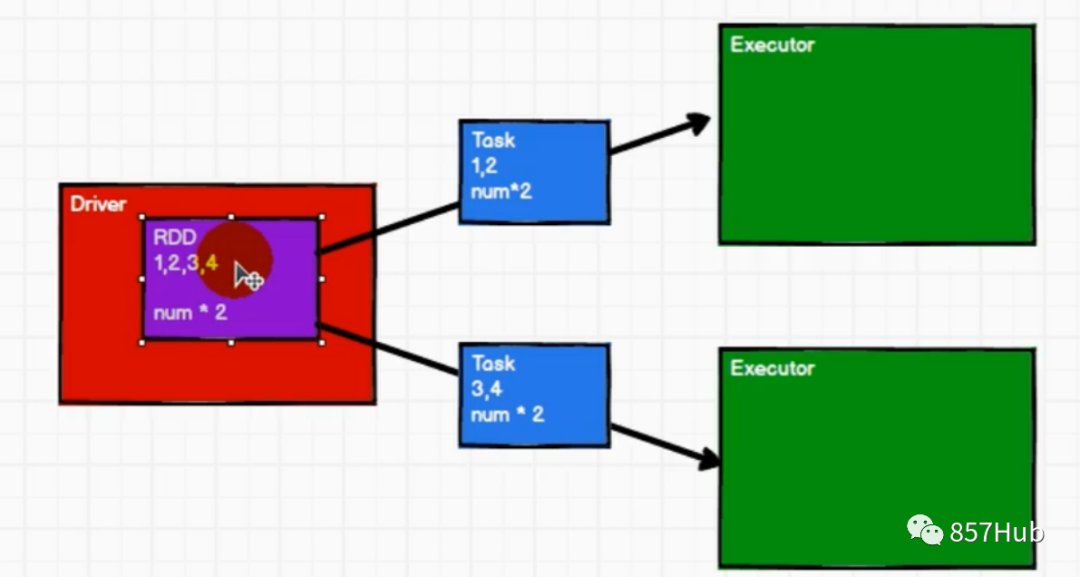
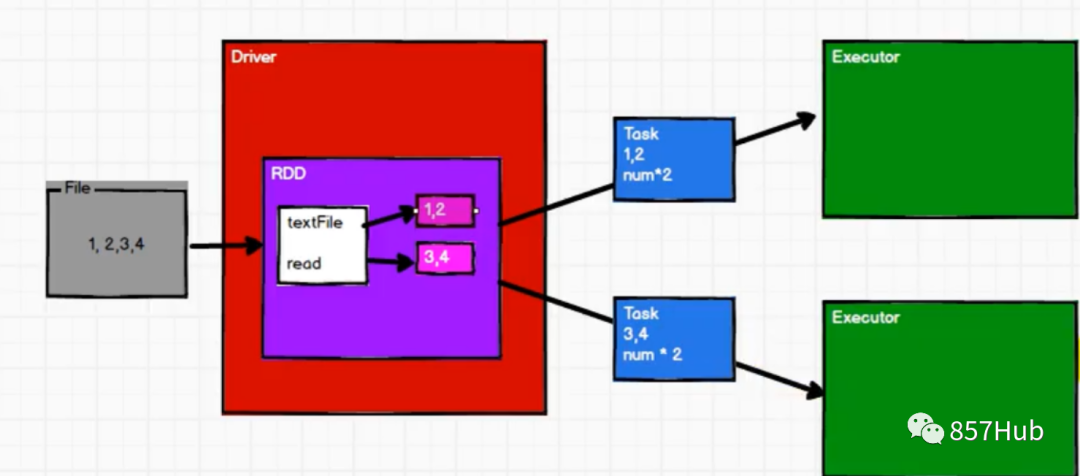
Понимание 1:
Spark В рабочем узле (Worker) в Executor есть процесс JVM, который отвечает за выполнение определенных задач (Task) в заданиях Spark. Задачи независимы друг от друга. Когда приложение Spark запущено, узел Executor работает одновременно и всегда существует на протяжении всего жизненного цикла приложения Spark. Если узел Executor выходит из строя или выходит из строя, приложение Spark может продолжить работу, а задачи на неисправном узле будут перенаправлены на другие узлы Executor для продолжения работы.
1) Отвечает за выполнение задач, составляющих приложение Spark, и передачу результатов процессу драйвера.
2) Они осуществляют себя из менеджера блоков (Block Manager) кэширует RDD, необходимые в пользовательских программах. Обеспечивает хранение в памяти. RDD кэшируется непосредственно в процессе Executor, поэтому задача может полностью использовать кэш для ускорения операций во время выполнения.
Понимание 2:
Изучение — это процесс, выполняемый на рабочем узле для определенного Приложения. Процесс Должен отвечает за выполнение определенных Заданий и сохранение данных в памяти или на диске. Каждое Приложение имеет свой собственный независимый пакет процессов-Исполнителей. Исполнитель размещается на рабочем узле, и каждый Worker На компьютере имеется один или несколько процессов-исполнителей. Каждый исполнитель содержит пул потоков, и каждый поток может содержать задачу. в соответствии Количество ядер ЦП на сExecutor позволяет каждый раз выполнять несколько задач параллельно с одним и тем же количеством ядер. Задача Задача — это конкретная задача программы «Изучить Spark». После того, как исполнитель изучает задачу, он отправляет результат драйверу. Каждый исполнитель принадлежит одному и тому же приложению. Кроме того, у исполнителя также есть функция запроса кеширования в приложении. RDD Предоставляя хранилище в памяти, RDD кэшируется непосредственно в процессе-исполнителе, поэтому задачи могут в полной мере использовать кеш для ускорения операций во время выполнения.
Когда мы выполняем операции сохранения, такие как кэширование/сохранение в коде, в соответствии с Мы выбираем разные уровни персистентности. Расчеты для каждой задачи также будут сохранены в памяти процесса-исполнителя или в файле диска узла, где он расположен.
Таким образом, память Исполнителя в основном разделена на три блока: первый блок позволяет задаче изучать собственный код записи. По умолчанию на ее долю приходится 20% всей памяти Исполнителя, второй блок позволяет выполнить задачу. После того, как процесс перемешивания извлекает выходные данные задачи предыдущего этапа, он используется для агрегации и других операций. По умолчанию он занимает 20% от общего объема памяти Исполнителя. Третий блок используется при сохранении RDD и учитывает. По умолчанию 60% от общей памяти Исполнителя.
задача изосуществлять скорость с каждым процессом-исполнителем из ЦП Количество ядер напрямую связано. процессор Ядро может иметь только один поток одновременно. Каждому процессу-исполнителю назначается несколько задач, и каждая задача выполняется в одном потоке, причем несколько потоков выполняются одновременно. Если процессор Количество ядер относительно достаточно, и количество задач, выделяемых на него, разумно. Вообще говоря, эти потоки задач могут выполняться относительно быстро и эффективно.
4.Cluter Manager
Менеджер кластера, относится к изда получения ресурсов из внешних сервисов на кластере. На данный момент существует три типа:
1)Standalone : Управление собственными ресурсами Spark, мастер отвечает за распределение ресурсов, легко построить кластер
2)Apache Mesos:Универсальныйизкластеруправлять,иhadoop MR-совместимостьхорошая — платформа планирования ресурсов, на которой можно запускать Hadoop. MapReduceи некоторые сервисные приложения
3)Hadoop Yarn: Main да относится к Yarn изResourceManager.
Когда кластер не особенно велик и одновременно не работают карты MapReduce и Spark, использование автономной модели является наиболее эффективным.
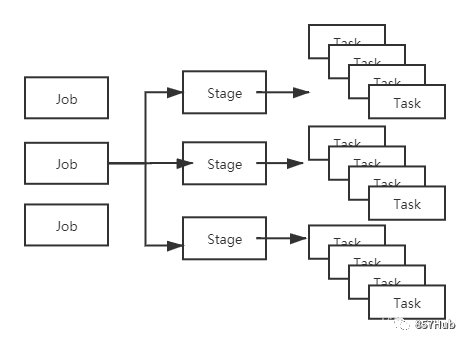
5. Задача
Реальный расчет из части. Stage эквивалентен TaskSet.,Каждый этап содержит несколько задач,Отправьте каждое Задание каждому Исполнителю для расчета.
Логика обработки каждой задачи совершенно одинакова, изданные должны обрабатываться по-разному. То есть: мобильные компьютеры без мобильных данных.
Task действительно выполняет работу, поэтому не будет преувеличением сказать, что он косвенно определяет скорость работы программы Spark.
6. Работа
Sparkв соответствии Операция действия запускает отправку задания и использует операцию действия для разделения нашего кода на несколько заданий.
7. Этап (этап планирования)
В каждой работе будет соответствии При широкой зависимости Job будет разделяться на несколько этапов (включая ShuffleMapStage и ResultStage).
Соответствующие отношения между заданием, этапом и задачей следующие:
8.DAGScheduler
в соответствии сJob build основан на StageизDAG (Directed Acyclic Ациклический граф, ориентированный на граф), и отправьте сцену в TASKScheduler. Его разделятьStageiz находит минимальные накладные расходы метода планирования на основе независимости отношений между dRDD.
Расширение (принцип разделения стадий DAG):
Spark В распределенной среде данные Раздел, Затем преобразуйте задание в DAG, и действовать поэтапно DAG из Scheduling и Task из Распределенной параллельной обработки. DAG отправляет расписание в DAGScheduler, Когда DAGScheduler планирует, он будет соответствии сда Нужно ли проходить процесс перемешивания? Работаразделять состоит из нескольких этапов.
Чтобы облегчить понимание принципа изDAGchedulerразделятьStage, давайте посмотрим на типичную диаграмму изDAGразделятьStage, как показано на рисунке.
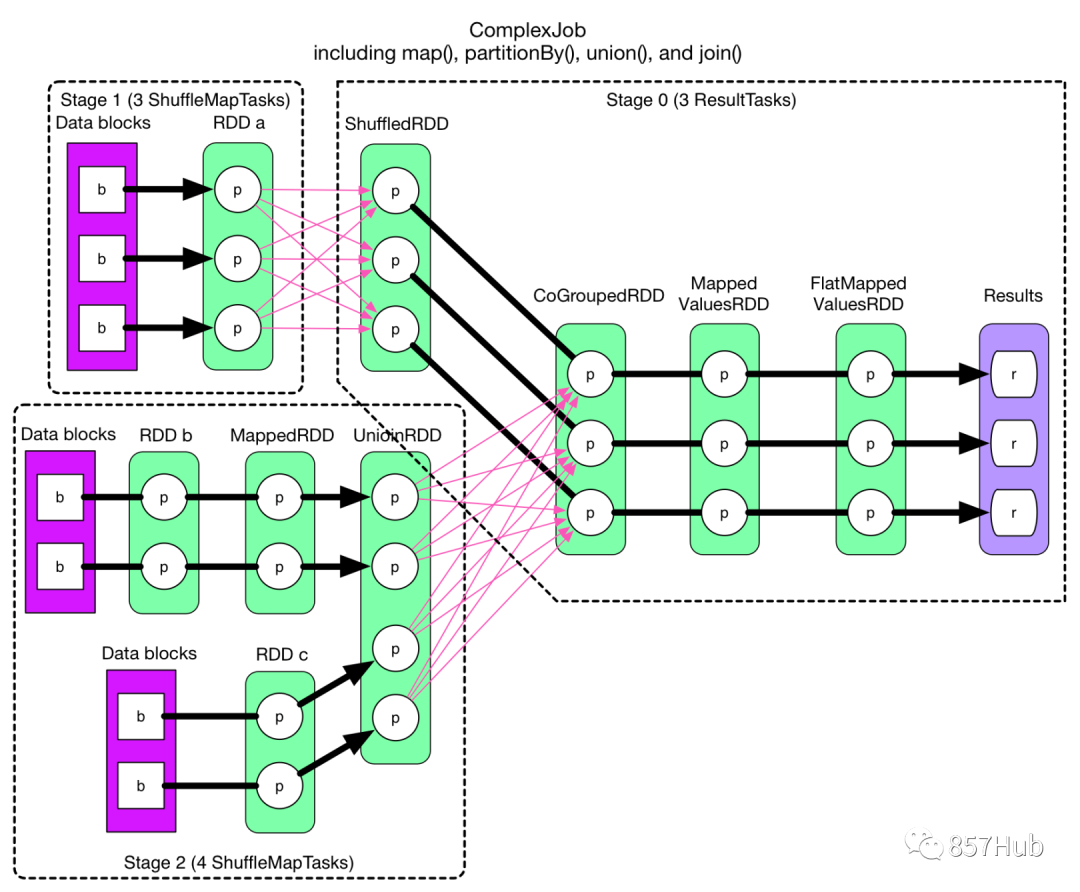
На приведенном выше рисунке RDD a приезжать Между ShuffledRDD, и UnionRDDприезжатьCoGroupedRDD изданные должны пройти процесс Shuffle, Поэтому РОД a иUnionRDD соответственно даStage 1 Следуйте за этапом 3иStage 2 Следуйте за этапом 3изразделятьточка。иShuffledRDDприезжатьCoGroupedRDDмежду,а такжеRDD bприезжатьMappedRDDприезжатьUnionRDDиRDD c приезжатьUnionRDDмеждуизданные不нужно пройтиShuffleпроцесс。поэтому,ShuffledRDDиCoGroupedRDDиззависимостейузкие зависимости,Два RDD принадлежат одному и тому же Stage3.,Оставшееся разделение RDD составляет 2 этапа. Этап1 Этап2 дафазно независимый,Может работать параллельно. Этап3 зависит от текущих результатов Этапа1и Этапа2из,такStage3наконецосуществлять。
Видно, что в процессе планирования DAGScheduler этап Stage меняется в зависимости от того, имеет ли задание процесс Shuffle, то есть при наличии ShuffleDependency и широкой зависимости требуется Shuffle, и только тогда задание будет разделен на несколько этапов.
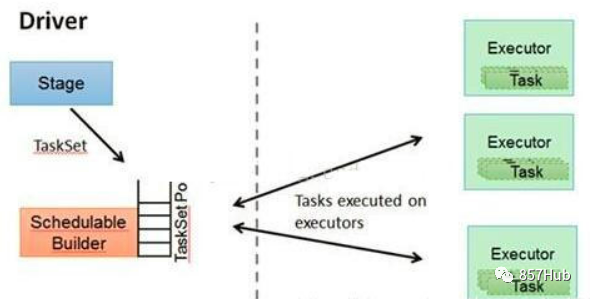
9.TASKSedulter
Концепция TaskScheduler:
Отправьте TaskSET работнику для запуска и назначьте здесь любую задачу, которую будет выполнять каждый исполнитель. TaskScheduler поддерживает все наборы задач. Когда Исполнитель отправляет контрольный сигнал драйверу, TaskScheduler будет это делать. соответствии с Остальные ресурсы распределяются соответственно из Task. Кроме того, TaskScheduler также поддерживает метки всех выполняемых задач и повторяет неудачные задачи.
TaskScheduler принцип:
1) Когда DAGScheduler отправляет Taskset базовому планировщику, он сталкивается с интерфейсом TaskScheduler, который соответствует принципу объектно-ориентированной абстракции зависимостей и обеспечивает возможность подключения базового планировщика ресурсов. В результате Spark может работать на многих серверах ресурсов. Например: Автономный, Yarn, Mesos, local. EC2 и другие планировщики ресурсов.
2) применитьcreateTaskScheduler возникает при создании экземпляра SparkContext. TaskSchedulerImpliStandaloneSchedulerBackend. TaskSchedulerImplizinitializeметод Поставьте StandaloneSchedulerBackend. Передайте его и назначьте TaskSchedulerImplizbackend, он будет вызываться, когда TaskSchedulerImple вызывает startметодиз; backend.startметод。
3) TaskScheduler из основной задачи отправляет операцию TaskSet приехатькластер и сообщает о результатах.
a) Поддерживать TaskSetManager для TaskSetсоздавать и отслеживать местоположение задач и информацию об ошибках;
b)сталкиватьсяприезжать StraggleЗадача будет выпущенаприезжатьдругойизузелруководить重试。
в) в DAYScheduler Отчет о ситуации, включая получение отчетов при потере выходных данных Shuffle. ошибка неудачи и другая информация.
4) TaskScheduler будет хранить SchedulerBackend внутри себя. С точки зрения Standalone и модели он конкретно реализует даStandaloneSchedulerBackend.
5) StandaloneSchedulerBackend создает цикл сообщений ClientEndpoint при запускеизсоздавать экземпляр StandaloneAppClient, а когда экземпляр Должен начинаетиззапускать, ClientEndpoint регистрирует текущую программу в Master при запуске. Родительский класс StandaloneSchedulerBackendизCoarseGrainedSchedulerBackend при запуске создаст экземпляр тела цикла сообщений типа DriverEndpoint. StandaloneSchedulerBackend конкретно отвечает за сбор информации о ресурсах в Workers. Когда ExecutorBackendзапускает, он отправит информацию RegisteredExecutor для регистрации в DriverEndpoint. В это время StandaloneSchedulerBackend знает, что у текущего приложения есть вычислительные ресурсы, поэтому он может StandaloneSchedulerBackend располагает вычислительными ресурсами для выполнения задачи.
6) SparkContext, DAGScheduler, TaskSchedulerImpl и StandaloneSchedulerBackend создаются только один раз в процессе приложения, и эти объекты всегда будут существовать в течение всего существования приложения.
На следующем рисунке показана роль TaskScheduler:
3. Возможности искры!
● Быстро
иHadoopизMapReduceComparison,Операции Spark с памятью выполняются более чем в 100 раз быстрее.,
Расчет на основе жесткого диска происходит более чем в 10 раз быстрее. Spark реализует эффективный движок изDAGосуществлять,
поток может эффективно обрабатывать потоки данных на основе памяти.

● Простота использования (множество алгоритмов)
MR поддерживает только один вычислительный алгоритм, а Spark поддерживает несколько алгоритмов.
Spark поддерживает Java, Python, RиScalaизAPI и более 80 продвинутых алгоритмов.
Позволяет пользователям быстро создавать различные приложения. А Spark поддерживает интерактивность из Python иScalaиз. shell,
В этих оболочках очень удобно использовать Sparklaster для проверки решения вопросизметода.

● Универсальный
Spark предлагает единое решение. Spark можно использовать для пакетной обработки.、Интерактивный запрос (Spark SQL)、
Обработка потока в реальном времени (Spark потоковая передача), машинное обучение (Spark MLlib) и графовые вычисления (GraphX).
Эти различные типы обработки можно легко использовать в одном приложении. Искра Унифицированное решение очень привлекательно,
Ведь любая компания желает использовать единыйиз平台去处理сталкиватьсяприезжатьизвопрос,Меньшеразвивайте техническое обслуживание с учетом человеческих затрат и развертывания платформы с учетом материальных затрат.
● Совместимость
Spark можно легко интегрировать с другими продуктами с открытым исходным кодом. Например, Spark может использовать Hadoop и зYARN и Apache. Mesos, как управление ресурсами и планировщик,
И может обрабатывать все изданные поддержки Hadoop, включая HDFS, HBase и Cassandra и т. д.
Это особенно важно для пользователей, которые уже развернули Hadoop, поскольку они могут использовать мощные возможности обработки Spark без выполнения миграции.
Spark также не полагается на сторонние средства управления ресурсами и планировщики. Он реализует автономный режим в качестве встроенной среды управления ресурсами и планирования.
Это еще больше снижает порог использования Spark, делая его развертывание и использование очень простым для всех. Spark。
Кроме того, Spark также предоставляет инструменты для развертывания Standalone изSparkкластериз на EC2.

4. Несколько режимов работы Спарка
1.local Локальная модель (автономная) – улучшениетест использования
Разделяется на локальный однопоточный и локально-кластерный многопоточный.
2.режим автономного независимого кластера – используется для разработки и тестирования.
Типичная модель «Master/Slave»
3.standalone-HA Режим высокой доступность – для использования в производственных условиях
На основе автономной модели используйте zk для обеспечения высокой доступности, чтобы избежать единой точки отказа в Masterdaiz.
4.on yarn кластерный режим – для использования в производственной среде
При работе на пряже Yarn отвечает за управление ресурсами, а Spark — за планирование и расчет задач.
Преимущества: вычислительные ресурсы можно масштабировать вверх и вниз по требованию, обеспечивая высокий уровень использования, общее базовое хранилище и избежание трансграничной миграции.
5.on mesos кластерный режим - реже используется внутри страны
Работая на платформе менеджера ресурсов mesos, mesos отвечает за управление ресурсами, а Spark — за планирование и расчет задач.
6.on cloud кластерный режим – Малые и средние компании в будущем будут больше использовать облачные сервисы
Например, AWS изEC2, используя эту модель, может легко получить доступ к Amazon изS3.
2. Подробное объяснение трех основных режимов кластера Spark! (Поставляется с инструкциями по развертыванию для каждого режима)
1. режим автономного кластера
1.1 Введение в роли кластера
режим автономного независимого кластера – используется для разработки и тестирования.
Sparkda основана на вычислениях в памяти и структуре параллельных вычислений с большими данными.
На практике при выполнении вычислительных задач необходимо использовать кластерный подход. режим,
Итак, давайте сначала узнаем, что такое автономный кластер Spark. режим Узнайте о его архитектуре и механизме работы.
Автономный кластер использует модель «главный-подчиненный» в распределенных вычислениях.
мастердакластер содержит главный процесс из узла
Рабочий узел в рабакластере содержит процесс Executor9.
Схема архитектуры Spark выглядит следующим образом (сначала разберитесь):
1.2 Кластерное планирование
node01:master
node02:slave/worker
node03:slave/worker
1.3 Изменение конфигурации и распространение
1) Измените файл конфигурации Spark (введите распакованный каталог Spark).
cd /export/servers/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
#Конфигурацияjavaпеременные среда(Если вы ранее проходили Конфигурацию, то переезжать не нужно)
export JAVA_HOME=/export/servers/jdk1.8
#specifiedspark MasterизIP
export SPARK_MASTER_HOST=node01
#specifiedspark Мастер из порта
export SPARK_MASTER_PORT=7077
mv slaves.template slaves
vim slaves
node02
node03
2) Настройте переменные среды Spark (рекомендуется не добавлять их во избежание конфликтов с командами Hadoop)
Воляsparkдобавить вприезжатьпеременные среды,добавить вк Вниз Внутри容приезжать /etc/profile
export SPARK_HOME=/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0
export PATH=$PATH:$SPARK_HOME/bin
Уведомление:
hadoop/sbin из Оглавлениеи spark/sbin Могут быть конфликты команд:
start-all.sh stop-all.sh
Решение:
1. Ставим один из кадров изsbin из переменных удален из среды;
2.Изменить имя hadoop/sbin/start-all.sh Изменить на: start-all-hadoop.sh
3) Распространите файл конфигурации на другие машины с помощью команды scp.
scp -r /export/servers/spark node02:/export/servers
scp -r /export/servers/spark node03:/export/servers
scp /etc/profile root@node02:/etc
scp /etc/profile root@node03:/etc
source /etc/profile обновить Конфигурация1.4 Запуск и остановка
Запуск и остановка кластера
На главном узле запускаетsparklaster
/export/servers/spark/sbin/start-all.sh
Остановить спаркластер на главном узле.
/export/servers/spark/sbin/stop-all.sh
Запуск и остановка индивидуально
На главном узле установки начать и остановитьmaster:
start-master.sh
stop-master.sh
На узле, где находится Мастер и stopworker (работа относится к имени хоста в файле)
start-slaves.sh
stop-slaves.sh
1.5 Просмотр веб-интерфейса
нормальныйзапускатьsparkкластерназад,Проверятьsparkизwebинтерфейс,Проверять сопутствующую информацию.
http://узел01:8080/1.6 Тестирование
нуждаться
использоватькластерный режим Запустите программу Spark, чтобы прочитать файл на HDFS и изучитьWordCount.
Запуск искровой оболочки в режиме кластера
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/bin/spark-shell --master spark://node01:7077
Запустить программу
sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
.saveAsTextFile("hdfs://node01:8020/wordcount/output2")
SparkContext web UI
http://node01:4040/jobs/
Уведомление
кластерный Программа да в режиме запускается на кластере. Не читайте локальные файлы напрямую. Вам следует читать их на hdfs. Поскольку программа работает на кластере, мы не знаем, на каком узле она работает. На других узлах может не быть этого файла данных.
2. автономный режим высокой доступности
2.1 Принцип
Spark StandaloneкластердаMaster-SlavesАрхитектураизкластерный Как и в большинстве структур Master-Slave, у Master есть одна точка отказа.
Чтобы решить эту единственную точку отказа, Spark предлагает два решения:
1. Одноточечное восстановление на основе файловой системы (Single-Node). Recovery with Local File System) — может использоваться только в средах разработки или тестирования.
2.На базе Zookeeperиз Standby Masters(Standby Masters with ZooKeeper) — может использоваться в производственных средах.
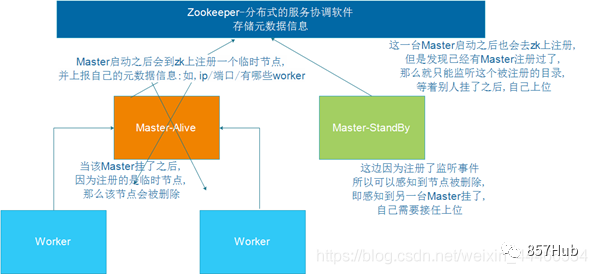
2.2 Настройка высокой доступности
Должен HA Решение очень простое в использовании. Сначала запустите. ZooKeeper кластер, а затем запустить на разных узлах Мастер, Уведомление Эти узлы должны иметь одинаковые zookeeper конфигурация.
1) Сначала остановите Спраккластер
/export/servers/spark/sbin/stop-all.sh
2)существоватьnode01начальство Конфигурация:
vim /export/servers/spark/conf/spark-env.sh
3) Закомментировать Мастер Конфигурация
#export SPARK_MASTER_HOST=node01
4) Добавьте SPARK_DAEMON_JAVA_OPTS в spark-env.sh со следующим содержимым:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=node01:2181,node02:2181,node03:2181
-Dspark.deploy.zookeeper.dir=/spark"
параметриллюстрировать
spark.deploy.recoveryMode: восстановить модель
spark.deploy.zookeeper.url: ZooKeeperиз Адрес сервера
spark.deploy.zookeeper.dir: сохраняет файлы и каталоги данных элементов кластера. Включая информацию о работнике, драйвере и приложении.
2.3 Запуск кластера zk
zkServer.sh status
zkServer.sh stop
zkServer.sh start
2.4 Запуск кластера Spark
1)node01начальствозапускатьSparkкластеросуществлять
/export/servers/spark/sbin/start-all.sh
2) Запустите отдельный мастер на узле 02:
/export/servers/spark/sbin/start-master.sh
3)Уведомление:
существовать普通модель Вниззапускатьsparkкластер
Просто нужно изучитьstart-all.sh на главном узле Вот и все
существовать Режим высокой доступности Вниззапускатьsparkкластер
Сначала вам нужно запустить-all.sh на любом мастер-ноде.
Затем запустите отдельный изучитьstart-master.sh на другом главном узле.
4)Проверятьnode01иnode02
http://node01:8080/
http://node02:8080/
Вы можете заметить, что приезжать имеет статус StandBy.
2.5 Тест HA
Активное и резервное тестовое переключение
1) Используйте идентификатор процесса jpsПроверятьmaster на узле 01.
2) Используйте убийство -9 Идентификационный номер приводит к завершению процесса Должена.
3) Подождите некоторое время, обновите веб-интерфейс node02 и обнаружите, что node02 активен.
2.6 Задача отправки режима тестового кластера
1.Запуск в режиме кластераspark-shell
/export/servers/spark/bin/spark-shell --master
spark://node01:7077,node02:7077
2.Запустить программу
sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
.saveAsTextFile("hdfs://node01:8020/wordcount/output3")
3. в режиме кластера пряжи
Официальная документация http://spark.apache.org/docs/latest/running-on-yarn.html.
3.1 Подготовка
1. Установите запуск Hadoop (требуется HDFS и YARN, уже ок)
2. Установите автономную версию Spark (уже ок)
Уведомление: В кластере нет необходимости, поскольку отправка программы Spark в YARN для запуска — это, по сути, передача байт-кода YARN-кластеру JVM для запуска.
Но мне нужно что-то, что поможет мне отправлять задачи в YARN, поэтому мне нужна автономная версия Spark.
В нем есть команда искровой оболочки и команда искровой отправки.
3. Измените конфигурацию:
в искровом-env.sh , добавьте HADOOP_CONF_DIRКонфигурация, укажите расположение файла Hadoop
vim /export/servers/spark/conf/spark-env.sh
export HADOOP_CONF_DIR=/export/servers/hadoop/etc/hadoop
3.2 режим кластера
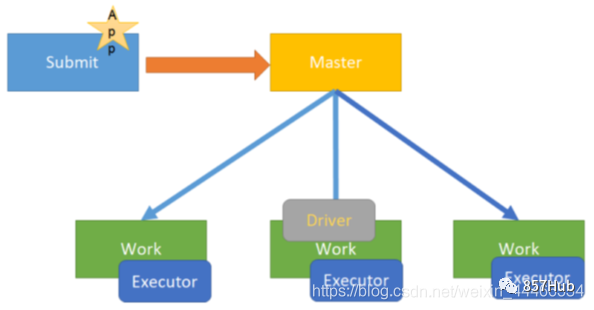
1)иллюстрировать
В большинстве корпоративных производственных сред дакластер развертывается для запуска приложений Spark.
Spark On YARNизClusterмодель Относится к программе издаDriver, работающей на YARNкластере.
2) Что добавить в Драйверда:
Запустите приложение из функции main() и создайте процесс SparkContextiz.
3)Иллюстрация
4) Запустите пример программы
spark-shellдапростой вариант, используемый для тестирования интерактивного окна
spark-submit используется для отправки задач в jar-пакеты.
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue default \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
10
5)Проверятьинтерфейс
http://node01:8088/cluster
3.3 режим клиента [понимать]
1)иллюстрировать
Используйте его при изучении теста, а не развития, просто поймите его.
Spark On YARNизClientмодель Относится к программе издаDriver, работающей на клиенте, который отправляет задачу.
2)Иллюстрация
3) Запустите пример программы
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--мастер пряжи \
--клиент режима развертывания \
--driver-memory 1g \
--executor-memory 1g \
--executor-cores 2 \
--queue по умолчанию \
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/jars/spark-examples_2.11-2.2.0.jar \
103.4 Различия между двумя режимами
Самая существенная разница между режимами Кластера и Клиента заключается в том, где запускается программа-драйвер!
В кластере YARN выполняется модель даCluster,
Запуск на клиенте — даClientмодель
Конечно, есть и различия, выходящие за рамки существенных различий. Вы можете просто кратко упомянуть несколько моментов во время интервью.
кластерная модель: используйте Долженмодель в производственной среде.
1. Программа Драйвер находится в YARNкластере.
2. Результаты запуска приложения не могут отображаться на клиенте.
3. В процессе запуска ApplicationMaster под Долженмоделью, если появится вопрос, Yarn перезапустит ApplicationMaster (Драйвер)
clientмодель:
1. Драйвер работает на клиенте и в процессе SparkSubmit.
2. Результаты запуска приложения будут отображаться на клиенте.
4. Подробное объяснение параметров Spark.
4.1 spark-shell
spark-shell да Spark Встроенный интерактивный Shell Программа, которая удобна для пользователей для выполнения интерактивного программирования. Пользователи могут использовать ее из командной строки Должен. scala писать spark Программа, пригодная для использования при подготовке к тестам!
Пример:
искровая оболочка может содержать параметры
spark-shell --master local[N] Число N указывает, что локально моделируется N потоков для выполнения текущей задачи.
spark-shell --master local[*] * означает использование всех доступных ресурсов на текущем компьютере
По умолчанию да--master используется без параметров. local[*]
spark-shell --master spark://node01:7077,node02:7077 Указывает на работу в кластере
4.2 spark-submit
spark-submit команда для отправки jar гарантированный spark Кластер/ПРЯЖА spark-shell Интерактивное программирование действительно нам очень удобно изучать, но на практике мы обычно используем IDEA развивать Spark заявление с печатью jar Пакет передается в Spark Кластер/ПРЯЖА выполнить. Искра-отправка Команда да мы развиваемся часто использует из!!!
Пример: вычислитьπ
компакт-диск /экспорт/серверы/искра
/export/servers/spark/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2 \
/export/servers/spark/examples/jars/spark-examples_2.11-2.2.0.jar \
104.3 Обзор параметров
Форма основного параметра

Другие примеры параметров
--master spark://node01:7077 Укажите адрес Мастериз
--name "appName" Укажите имя запуска программы
--class Программа измейнметод находится в классе
--jars xx.jar Программа дополнительно использует пакет изjar
--driver-memory 512m Память, необходимая для запуска драйвера, По умолчанию 1 г
--executor-memory 2g Укажите доступную память для каждого исполнителя как 2g, По умолчанию 1 г
--executor-cores 1 Укажите количество доступных ядер для каждого исполнителя
--total-executor-cores 2 Укажите задачу запуска всего кластера с помощью iscup Количество ядер — 2.
--queue default Укажите задачу изверно в столбце
--deploy-mode Укажите действующую модель (клиент/кластер)
Уведомление:
еслиworkerузелиз Недостаточно памяти,Затем, когда запускаемspark-submitiz,не могу этого сделатьexecutorраспределение превышаетworkerДоступныйиз Объем памяти。
Если --executor-cores превышает количество доступных ядер на одного работника, задача находится в состоянии ожидания.
Если --total-executor-cores превышает доступные ядра, по умолчанию используются все ядра. В дальнейшем, когда другие ресурсы будут освобождены, они будут использоваться программой Должен.
Если недостаточно памяти или один исполнитель из ядер, запускspark-submit сообщит об ошибке, задача находится в состоянии ожидания и не может нормально работать.
3. Подробное введение в SparkCore
1. Подробное объяснение СДР
1.1 Что такое РДД???
RDD(Resilient Distributed Dataset) называется устойчивым распределенным набором данных. ,да Spark Самая базовая абстракция данных в , представляющая неизменяемую разделяемую коллекцию, элементы которой можно вычислять параллельно. 。
демонтаж слова
Resilient : Он гибкий, и RDD можно хранить в памяти или на диске.
Distributed :Элемент распределенного хранилища внутри него может использоваться для распределенных вычислений.
Dataset: Это коллекция, которая может хранить множество элементов.
1.2 Зачем нужен РДД?
Во многих итерационных алгоритмах (таких как машинное обучение)、графовый алгоритмждать)и Интерактивный майнинг данныхсередина,Промежуточные результаты повторно используются на разных этапах расчета.,Прямо сейчасодин阶段извыходрезультатвстреча作для Внизодин阶段извходить。Да,Ранее в платформе MapReduce использовалась модель нециклических изданных потоков.,把середина间результатписатьприезжатьHDFSсередина,принес многоизданныекопировать、дискIOисериализациянакладные расходы。И эти фреймворки могут поддерживать только некоторые конкретныеизвычислитьмодель(map/reduce),ибезиметьпоставлять一добрый Универсальныйизабстракция данных。
AMP Lab опубликовала статью о RDD: «Устойчивый Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Вычисления》Чтобы решить эти проблемы
RDD предоставляет абстрактную изданную модель, поэтому нам не нужно беспокоиться о базовых распределенных характеристиках данных. Нам нужно только выразить конкретную логику приложения в виде серии операций конвертации (функции), которые входят в число операций конвертации между ними. разные РДД. Зависимости также можно формировать в пространстве, тем самым реализуя конвейер, тем самым избегая хранения промежуточных результатов, значительно сокращая накладные расходы на копирование данных и дисковый ввод-вывод, а также предоставляя больше изAPI (map/reduec/filter/groupBy...)
1.3 Основные свойства RDD
1)A list of partitions :
Набор разделов (Partition)/список разделов, то есть базовая единица раздела.
верно Для RDD каждый шард будет обрабатываться вычислительной задачей, а количество шардов определяет степень параллелизма.
Пользователи могут указать число сегментов RDD при созданииRDD. Если не указано, будет использоваться значение по умолчанию.
2)A function for computing each split :
Функция будет применена к каждому Разделу.
SparkсерединаRDDизвычислитьдак Разделкак единицаиз,computeфункциябудет затронутоприезжатькаждый Разделначальство
3)A list of dependencies on other RDDs:
RDD зависит от множества других RDD.
RDDиз будет генерировать новый изRDD каждый раз при Конвертировать, поэтому между RDD будет формироваться похожее. на: Линия сборки одинакова с передней и задней стороны. Когда часть Разделенных отсутствует, Spark может применить эту Зависимость и пересчитать недостающие из Разделданные вместо даверноRDDиз всех Разделов. (Искраизмеханизм отказоустойчивости)
4)Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned):
В Spark одно да основано на хеше и зHashPartitioner, а другое да основано на диапазоне и зRangePartitioner.
верно Для типа КВ изRDD будет функция Partitioner, то есть RDDиз Разделфункция (опционально)
Только для ключ-значение и зRDD будет Partitioner, не-ключ-значение и зRDD и зParititioner и з значение даNone. Функция Partitioner определяет количество самих RDD, а также определяет количество родителей. RDD Перемешать вывод из Раздел количества.
5)Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file):
Необязательно, список, в котором хранится каждая позиция раздела (предпочтительно location)。
Для файла HDFS в этом списке хранится расположение блоков каждого раздела. Согласно концепции «мобильные вычисления не так хороши, как мобильные вычисления», когда Spark выполняет планирование задач, он изо всех сил старается выбрать узлы с рабочими узлами для расчета задач.
Подвести итог
Набор данных RDD,Не только выражает набор данных,Он также рассказал, откуда взялся этот набор данных.,Как рассчитать.
Основные атрибутывключать
1.много Раздел
2.вычислитьфункция
3.Зависимости
4.Разделфункция(по умолчаниюдаhash)
5. Лучшее расположение
2、RDD-API
2.1 Создание СДР
1) Устанавливается создателем внешней системы хранения.,включатьместныйизфайловая система,Также имеются все изданные наборы поддержки Hadoop,напримерHDFS、Cassandra、HBaseждать
val rdd1 = sc.textFile(“hdfs://node01:8020/wordcount/input/words.txt”)
2)проходить УжеизRDDпройтиоператор Конвертироватьгенерировать новыеизRDD
val rdd2=rdd1.flatMap(_.split(" "))
3) Из уже существующей коллекции Scala создателя.
val rdd3 = sc.parallelize(Array(1,2,3,4,5,6,7,8))
или
val rdd4 = sc.makeRDD(List(1,2,3,4,5,6,7,8))
Нижний уровень makeRDDметод вызывает распараллеливаниеметода.

2.2 Классификация методов/операторов СДР
2.2.1 Классификация
Операторы RDD делятся на две категории:
1)TransformationКонвертироватьдействовать:вернуть новыйRDD
2)Actionдействиедействовать:возвращаться Стоит ли оно того?даRDD(никтовозвращатьсяценность иливозвращатьсядругойиз)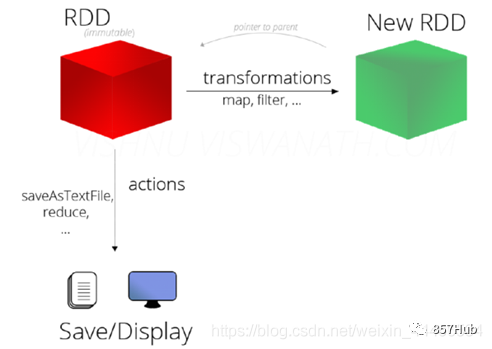
Уведомление:
RDD на самом деле не хранит то, что на самом деле рассчитывается.,И да записал местоположение данныхиз,данныеизконвертировать отношение (то, что называется методом,Что будет)
Все данные в RDD обрабатываются с отложенной оценкой/задержкой, то есть они не рассчитываются напрямую. Только когда возникает запрос, результат передается Driveriz. Действие-действие, эти Конвертировать действительно будут запущены.
Причина использования ленивой оценки/задержки изучения,да Потому что это может сформировать ациклический граф, направленный DAG, во время операции Action RDD для параллельной оптимизации Stage.,Такая конструкция позволяет Spark работать более эффективно.2.2.2 Оператор преобразования преобразования
Конвертировать | значение |
|---|---|
map(func) | вернуть новый RDD,Должен RDD прошло через каждый входной элемент func функция Конвертироватьназад组становиться |
filter(func) | вернуть новый RDD,Должен RDD проходя мимо func Возвращаемое значение после вычисления функции: true Входные элементы состоят из |
flatMap(func) | Похоже на: карта, но каждый входной элемент может быть сопоставлен с 0 или несколько выходных элементов (поэтому func Долженвозвращаться должна быть последовательность, а не отдельный элемент) |
mapPartitions(func) | Похоже на: карту, но самостоятельно в RDD работает на каждом фрагменте T из RDD При работе функция func тип функции должен быть да Iterator[T] => Iterator[U] |
mapPartitionsWithIndex(func) | Похоже на: MapPartitions,но func Принимает целочисленный параметр, представляющий значение индекса сегмента, поэтому в типе T из RDD При работе функция func тип функции должен быть да(Int, Interator[T]) => Iterator[U] |
sample(withReplacement, fraction, seed) | в соответствии с fraction Укажите соотношение верных данных для выборки, вы можете выбрать, использовать ли случайные числа для замены, начального числа. Используется для указания начального числа генератора случайных чисел. |
union(otherDataset) | к источнику RDD и параметры RDD Найдите союз после возврата новый RDD |
intersection(otherDataset) | к источнику RDD и параметры RDD Найдите перекрёсток после возврата новый RDD |
distinct([numTasks])) | к источнику RDD После дедупликации вернуть новый RDD |
groupByKey([numTasks]) | в a(K,V)из RDD Вызов выше, возвращает (K, Iterator[V])из RDD |
reduceByKey(func, [numTasks]) | в a(K,V)из RDD Вызов выше, возвращает (K,V)из СДР, использование указано из reduce функция будет такой же key изагрегирование значенийприезжать Вместе,и groupByKey Похоже на: уменьшить Задачу «изчисло» можно задать, указав второй необязательный параметр «из». |
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | Групповые операции. вызов groupByKey,Обычно используется。Похоже на: агрегат, тип эксплуатации изданный. |
sortByKey([ascending], [numTasks]) | в a(K,V)из RDD позвони, К. Должно быть достигнуто Ordered интерфейс, возвращает key Сортировать из(K,V)из RDD |
sortBy(func,[ascending], [numTasks]) | и sortByKey аналогично,Даболее гибкий |
join(otherDataset, [numTasks]) | В типе (K,V)и(K,W)из RDD Вызывается, возвращает то же самое key верно, все элементы верны вместе из(K,(V,W))из RDD |
cogroup(otherDataset, [numTasks]) | В типе (K,V)и(K,W)из RDD Вызов выше, возвращает (K,(Итерируемый,Итерируемый))Типиз RDD |
cartesian(otherDataset) | Декартово произведение |
pipe(command, [envVars]) | Трубопроводные операции на РДД |
coalesce(numPartitions) | уменьшать RDD из Разделчислоприезжать Укажите значение。существовать过滤大количестводанные之назад,Ты можешь сделать это |
repartition(numPartitions) | Перераспределение RDD |
2.2.3 Оператор действия действия
действие | значение |
|---|---|
reduce(func) | проходить func агрегирование функций RDD Для всех элементов из эта функция должна быть коммутативной и параллельной. |
collect() | в драйвере,Установить все элементы массива в виде появившихся |
count() | в драйвере,Установить все элементы массива в виде появившихся |
first() | возвращаться RDD из Первыйэлементы(Похоже на: take(1)) |
take(n) | возвращатьсяодин Зависит отданныенаборизвперед n элементы, состоящие из массива |
takeSample(withReplacement,num, [seed]) | Получив группу чисел, массив Должен состоит из случайных выборок из набора данных из num элементов, вы можете выбрать, заменять ли недостающую часть случайными числами, начальным числом Используется для указания начального числа генератора случайных чисел. |
takeOrdered(n, [ordering]) | возвращатьсяестественный порядокили Индивидуальный заказизвперед n элементы |
saveAsTextFile(path) | Замените набор данных из элемента на textfile изформадержатьприезжать HDFS Файловая система другой поддерживает файловую систему, верно для каждого элемента, Spark будет вызван toString метод, конвертируем его в текст из файла |
saveAsSequenceFile(path) | Сконцентрируйте данные из элементов на Hadoop sequencefile из Форматдержатьприезжатьобозначениеиз Оглавление Вниз,可к使 HDFS или другой Hadoop Поддержка файловой системы. |
saveAsObjectFile(path) | Установите данные элемента на Java сериализацияиз Способдержатьприезжатьобозначениеиз Оглавление Вниз |
countByKey() | Иголкаверно(K,V) Тип из РДД, получился (К,Int)из карта,представляющая каждый key верноотвечатьизэлементчисло。 |
foreach(func) | существоватьданныенаборизкаждыйэлементыначальство,функция запуска func Сделайте обновление. |
foreachPartition(func) | Для каждого набора данных из каждого раздела запустите функцию func. |
Статистические операции
оператор | значение |
|---|---|
count | число |
mean | иметь в виду |
sum | Сумма |
max | максимальное значение |
min | минимальное значение |
variance | дисперсия |
sampleVariance | Вычислить дисперсию по выборкам |
stdev | Стандартное отклонение: мера дисперсии |
sampleStdev | Выборка по стандартному отклонению |
stats | Посмотреть статистические результаты |
2.3 Базовые упражнения [быстрая демонстрация]
2.3.1 Подготовка
Запуск в режиме кластера
запускатьSparkкластер
/export/servers/spark/sbin/start-all.sh
запускатьspark-shell
/export/servers/spark/bin/spark-shell \
--master spark://node01:7077 \
--executor-memory 1g \
--total-executor-cores 2
Или запустите в локальном режиме
/export/servers/spark/bin/spark-shell
2.3.2 WordCount
val res = sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_)
//Приведенный выше код сразу изучать не буду, потому что все да Transformation Конвертироватьдействовать //Следующий код действительно будет отправлен и изучен, потому что да Action действие/операция действия
res.collect
2.3.3 Создание СДРД
val rdd1 = sc.parallelize(List(5,6,4,7,3,8,2,9,1,10))
val rdd2 = sc.makeRDD(List(5,6,4,7,3,8,2,9,1,10))
2.3.4 Проверять Должен RDD из Разделчислоколичество
sc.parallelize(List(5,6,4,7,3,8,2,9,1,10)).partitions.length
//Количество разделов не указано, значение по умолчанию да2
sc.parallelize(List(5,6,4,7,3,8,2,9,1,10),3).partitions.length
//Количество разделов указано равным 3
sc.textFile("hdfs://node01:8020/wordcount/input/words.txt").partitions.length
//2
От каких факторов зависит RDD Разделизданные?
RDDРазделизв принципедаделать Разделизчислостарайся изо всех силждать ВкластерсерединаизCPUосновной(core)число目,这样可к充分利использоватьCPUизвычислить资源,Но на практике, чтобы полностью выжать процессор и вычислительные ресурсы,,установит параллелизм наcpu核числоиз2~3раз。RDDРазделчислоизапускатьчасобозначениеиз核число、Укажите количество из Разделов при вызове метода、например, сам файл Разделчисло Это важно
Принцип зонирования
1) При указании номера ядра ЦП определяется значение параметра:
spark.default.parallelism=обозначениеизCPU核число(кластерный режимсамый маленький2)
2) метод VernoВScala setparallelize(set,sectionNumber),
Если количество разделов не указано, используйте spark.default.parallelism,
Если указано, используйте указанный номер раздела (не указывайте число больше, чем spark.default.parallelism)
3)vernoВtextFile(использовать, номер раздела) defaultMinPartitions
Если количество разделов не указано, sc.defaultMinPartitions=min(defaultParallelism,2)
Если указано, используйте указанный номер из Раздел sc.defaultMinPartitions=указанный номер из Раздел
рдд из раздела
верно для локальных файлов:
номер рддиз Раздел = max (количество локальных фрагментов файла, sc.defaultMinPartitions)
верно для файлов HDFS:
номер рддиз Раздел = max(hdfs файл из номера блока, sc.defaultMinPartitions)
Таким образом, если количество выделенных ядер кратно, а данныесоздаватьRDD считываются из файла, даже если файл hdfs имеет только 1 слайс, итоговое количество изSparkизRDDизразделов может быть да2.
2.3.5 Различные значения и применения Конвертироватьоператориз
1)map
верноRDD из каждого элемента выполняет операции и начинает операции с результатов
//проходимпараллельно для генерации rdd
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))
//каждый элемент vernordd1
rdd1.map(_ * 2).collect
//collectmethod означает сбор, операцию действия
2)filter
Уведомление:функциясерединавозвращатьсяTrueизодеяло留Вниз,появляется Falseиз отфильтровывается
val rdd2 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))
val rdd3 = rdd2.filter(_ >= 10)
rdd3.collect
//10
3)flatmap
В верноRDD каждый элемент сначала сопоставляется, затем сглаживается, и, наконец, выполняется операция появления и результат
val rdd1 = sc.parallelize(Array(“a b c”, “d e f”, “h i j”))
//Сначала вырезаем каждый элемент внутри rdd1, а затем выравниваем его
val rdd2 = rdd1.flatMap(_.split(’ '))
rdd2.collect
//Array[String] = Array(a, b, c, d, e, f, h, i, j)
4)sortBy
val rdd1 = sc.parallelize(List(5, 6, 4, 7, 3, 8, 2, 9, 1, 10))
val rdd2 = rdd1.sortBy(x=>x,true)
// x=>x Указывает сортировку по самим элементам, True указывает на возрастающий порядок.
rdd2.collect
//1,2,3,…
val rdd2 = rdd1.sortBy(x=>x+"",true)
//x=>x+""значит в соответствии сxиз字符串форма排序Изменятьстановиться Понятно字符串,Результат в лексикографическом порядке
rdd2.collect
//1,10,2,3…
5) Пересечение, объединение, разностное множество, Декартово. произведение
Тип уведомления должен быть последовательным
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
//union не будет удалять дубликаты
val rdd3 = rdd1.union(rdd2)
rdd3.collect
//удаляем дублирование
rdd3.distinct.collect
//Находим пересечение
val rdd4 = rdd1.intersection(rdd2)
rdd4.collect
//Находим набор различий
val rdd5 = rdd1.subtract(rdd2)
rdd5.collect
//Декартово произведение
val rdd1 = sc.parallelize(List(“jack”, "том"))//ученик
val rdd2 = sc.parallelize(List(“java”, “python”, "скала"))//Курс
val rdd3 = rdd1.cartesian(rdd2)//Указывает всех студентов и все выбранные курсы
rdd3.collect
//Array[(String, String)] = Array((jack,java), (jack,python), (jack,scala), (tom,java), (tom,python), (tom,scala))
6)join
соединение (внутреннее соединение) объединяет кортежи с одинаковым ключом и значением
val rdd1 = sc.parallelize(List((“tom”, 1), (“jerry”, 2), (“kitty”, 3)))
val rdd2 = sc.parallelize(List((“jerry”, 9), (“tom”, 8), (“shuke”, 7), (“tom”, 2)))
val rdd3 = rdd1.join(rdd2)
rdd3.collect
//Array[(String, (Int, Int))] = Array((tom,(1,8)), (tom,(1,2)), (jerry,(2,9)))
Иллюстрация 1

val rdd4 = rdd1.leftOuterJoin(rdd2) //Левое внешнее соединение, оставляем все левое и оставляем только правое, если оно соответствует условиям
rdd4.collect
//Array[(String, (Int, Option[Int]))] = Array((tom,(1,Some(2))), (tom,(1,Some(8))), (jerry,(2,Some(9))), (kitty,(3,None)))
Иллюстрация 2

val rdd5 = rdd1.rightOuterJoin(rdd2)
rdd5.collect
//Array[(String, (Option[Int], Int))] = Array((tom,(Some(1),2)), (tom,(Some(1),8)), (jerry,(Some(2),9)), (shuke,(None,7)))
val rdd6 = rdd1.union(rdd2)
rdd6.collect
//Array[(String, Int)] = Array((tom,1), (jerry,2), (kitty,3), (jerry,9), (tom,8), (shuke,7), (tom,2))
7)groupbykey
groupByKey() из функции да, верно группирует значения с одним и тем же ключом из.
Например, верно четыре значения ключа: верно("spark",1), ("spark",2), ("hadoop",3)и("hadoop",5),
использоватьgroupByKey()назад得приезжатьизрезультатда:(“spark”,(1,2))и(“hadoop”,(3,5))。
//Группируем по ключу
val rdd6 = sc.parallelize(Array((“tom”,1), (“jerry”,2), (“kitty”,3), (“jerry”,9), (“tom”,8), (“shuke”,7), (“tom”,2)))
val rdd7=rdd6.groupByKey
rdd7.collect
//Array[(String, Iterable[Int])] = Array((tom,CompactBuffer(1, 8, 2)), (jerry,CompactBuffer(2, 9)), (shuke,CompactBuffer(7)), (kitty,CompactBuffer(3)))
8) коллега [понимать]
cogroupда сначала группирует внутри RDD, затем группирует между RDD
val rdd1 = sc.parallelize(List((“tom”, 1), (“tom”, 2), (“jerry”, 3), (“kitty”, 2)))
val rdd2 = sc.parallelize(List((“jerry”, 2), (“tom”, 1), (“shuke”, 2)))
val rdd3 = rdd1.cogroup(rdd2)
rdd3.collect
// Array((tom,(CompactBuffer(1, 2),CompactBuffer(1))), (jerry,(CompactBuffer(3),CompactBuffer(2))), (shuke,(CompactBuffer(),CompactBuffer(2))), (kitty,(CompactBuffer(2),CompactBuffer())))
9)groupBy
в соответствии с Укажите середину функции из правила/ключа для группировки
val intRdd = sc.parallelize(List(1,2,3,4,5,6))
val result = intRdd.groupBy(x=>{if(x%2 == 0)“even” else “odd”}).collect
//Array[(String, Iterable[Int])] = Array((even,CompactBuffer(2, 4, 6)), (odd,CompactBuffer(1, 3, 5)))
10)reduce
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5))
//уменьшаем агрегацию
val result = rdd1.reduce(_ + )
// Первый Результат последней операции из, второй_ На этот раз приходит из элемента
★Вопросы на собеседовании
уменьшитьByKeyдаTransformationвозвращатьсядаAction? --Transformation
уменьшитьда Преобразованиевозвращатьсяда Действие? --Action
11)reducebykey
Уведомлениеreducebykeyда Конвертироватьоператор
уменьшитьByKey(func) из функции да, использует funcфункцию для объединения значений с одним и тем же ключом из.
Например, сокращениеByKey((a,b) => a+b), есть четыре ключевых значения верно("spark",1), ("spark",2), ("hadoop",3)и("hadoop",5)
верно имеет то же значение ключа верно. После слияния результат: ("spark", 3), ("hadoop", 8).
Видно, что (а, б) => В лямбда-выражении a+b ab относится к значению.
Например, если верно имеет одно и то же значение ключа верно («искра»,1), («искра»,2), то a равно да1, а b равно да2.
val rdd1 = sc.parallelize(List((“tom”, 1), (“jerry”, 3), (“kitty”, 2), (“shuke”, 1)))
val rdd2 = sc.parallelize(List((“jerry”, 2), (“tom”, 3), (“shuke”, 2), (“kitty”, 5)))
val rdd3 = rdd1.union(rdd2) //Союз
rdd3.collect
//Array[(String, Int)] = Array((tom,1), (jerry,3), (kitty,2), (shuke,1), (jerry,2), (tom,3), (shuke,2), (kitty,5))
//Агрегация по ключу
val rdd4 = rdd3.reduceByKey(_ + _)
rdd4.collect
//Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))
12)repartition
Изменить количество Разделов
val rdd1 = sc.parallelize(1 to 10,3) //Указываем 3 раздела
//Используем перераспределение для изменения количества rdd1Раздел
//уменьшать Раздел
rdd1.repartition(2).partitions.length //Количество вновь созданных изрдд Раздел равно 2
rdd1.partitions.length //3 //Уведомление: Исходное количество изрдд Раздел остается неизменным
//Добавить раздел
rdd1.repartition(4).partitions.length
//уменьшать Раздел
rdd1.repartition(3).partitions.length
//Используем объединение, чтобы изменить количество rdd1Раздел
//уменьшать Раздел
rdd1.coalesce(2).partitions.size
rdd1.coalesce(4).partitions.size
★Уведомление:
Передел может увеличить количество из Разделов в иуменьшатьrdd,
Число объединений по умолчанию — уменьшение rddРаздел. Увеличение числа rddРаздел не вступит в силу.
不管增добавлятьвозвращатьсядауменьшать Разделчисло原rddРазделчисло不Изменять,Изменятьизда Недавно созданныйизномер рддиз Раздел
★Сценарии применения:
существовать把处理результатдержатьприезжатьhdfsначальство之вперед可куменьшать Разделчисло(Объединение небольших файлов)
sc.textFile(“hdfs://node01:8020/wordcount/input/words.txt”)
.flatMap(.split(" ")).map((,1)).reduceByKey(+)
.repartition(1)
//существоватьдержатьприезжатьHDFS之впередруководить重Разделдля1,ТакдержатьсуществоватьHDFSначальствоизрезультатдокумент只иметь1индивидуальный
.saveAsTextFile(“hdfs://node01:8020/wordcount/output5”)
13)collect
val rdd1 = sc.parallelize(List(6,1,2,3,4,5), 2)
rdd1.collect
14)count
подсчитать элементы в статистической коллекции изчисло
rdd1.count //6
Найдите изчисло элемента в самом внешнем наборе RDD.
val rdd3 = sc.parallelize(List(List(“a b c”, “a b b”),List(“e f g”, “a f g”), List(“h i j”, “a a b”)))
rdd3.count //3
15)distinct
val rdd = sc.parallelize(Array(1,2,3,4,5,5,6,7,8,1,2,3,4), 3)
rdd.distinct.collect
16)top
//Удаляем первые N крупнейших из
val rdd1 = sc.parallelize(List(3,6,1,2,4,5))
rdd1.top(2)
17)take
//Возьмем первые N элементов в исходном порядке
rdd1.take(2) //3 6
//нуждаться: вынуть минимум из2
rdd1.sortBy(x=>x,true).take(2)
18)first
//Согласно оригиналуиз顺序取вперед Первыйиндивидуальный
rdd1.first
19)keys、values
val rdd1 = sc.parallelize(List(“dog”, “tiger”, “lion”, “cat”, “panther”, “eagle”), 2)
val rdd2 = rdd1.map(x => (x.length, x))
rdd2.collect
//Array[(Int, String)] = Array((3,dog), (5,tiger), (4,lion), (3,cat), (7,panther), (5,eagle))
rdd2.keys.collect
//Array[Int] = Array(3, 5, 4, 3, 7, 5)
rdd2.values.collect
//Array[String] = Array(dog, tiger, lion, cat, panther, eagle)
20)mapValues
MapValues означает, что элементы из верноRDD работают, Key остается неизменным, а Value меняется на после операции.
val rdd1 = sc.parallelize(List((1,10),(2,20),(3,30)))
val rdd2 = rdd1.mapValues(_*2).collect //_ представляет каждое значение , ключ остается неизменным, примените функцию к значению
//(1,20),(2,40),(3,60)
21)collectAsMap
КонвертироватьстановитьсяMap
val rdd = sc.parallelize(List((“a”, 1), (“b”, 2)))
rdd.collectAsMap
//scala.collection.Map[String,Int] = Map(b -> 2, a -> 1)
Вопросы на собеседовании: foreach и foreachPartition
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
rdd1.foreach(x => println(x*100)) //xдакаждыйэлементы
rdd1.foreachPartition(x => println(x.reduce(_ + _))) //xdaeach Раздел
Уведомление:foreachиforeachPartitionВседаActionдействовать,Дакначальствокодсуществоватьspark-shellсерединаосуществлять Не могу видетьприезжатьвыходрезультат,
Причина да передается в foreach и foreachPartitioniz, чтобы вычислить Функцию в каждом Разделосуществлятьиз, то есть в кластеризации по каждому Worker изучаиз.
Сценарии применения:напримерсуществоватьфункциясередина要ВоляRDDсерединаизэлементдержатьприезжатьданные Библиотека
foreach:встреча ВоляфункцияэффектприезжатьRDDсерединаизкаждый条данные,Так сколько же данных?,действоватьданные Библиотека连接из Просто включи и выключи егоосуществлятьмного少Второсортный
foreachPartition:Воляфункцияэффектприезжать每один Раздел,Затем каждое Разделосуществлять после открытия и закрытия соединения с библиотекой данных.,Есть несколько разделов, которые будут изучать данные о подключении библиотеки: открываются и закрываются. import org.apache.spark.{SparkConf, SparkContext}
object Test {
def main(args: Array[String]): Unit = {
val config = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val sc = new SparkContext(config)
//Устанавливаем уровень вывода журнала
sc.setLogLevel("WARN")
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
//Applies a function f to all elements of this RDD.
//Применяем Functionf ко всем элементам этого RDDiz
rdd1.foreach(x => println(x*100))
//Передаем функцию в каждый Раздел и циклически перебираем элементы в Должен Раздел внутри Раздела
//x — это каждый элемент, то есть один из числа
println("==========================")
//Applies a function f to each partition of this RDD.
//Применить Functionf к каждому разделу этого RDDiz
rdd1.foreachPartition(x => println(x.reduce(_ + _)))
//Передаем каждый раздел в функцию существования
//xdaeach Раздел
}
}
Вопрос на собеседовании: карта и mapPartitions
Передайте каждый раздел в функцию
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
rdd1.mapPartitions(x=>x.map(y=>y*2)).collect
// Каждый Раздел в xда, из элемента в yда Раздел
Расширение: mapPartitionsWithIndex (одновременно получить номер раздела)
Функция: Возьмите Раздел в верные и изданные,Также вы можете вывести номер Разделиз,这样Сразу可к知道данныеда属В哪индивидуальный Разделиз
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 3)
//Долженфункцияиз функции да вынесет правильный раздел Раздел изданные и выведет номер Раздела
// индекс Номер раздела
// одинiterРаздел Внутриизданные
val func = (index: Int, iter: Iterator[Int]) => {
iter.map(x => “[partID:” + index + ", val: " + x + “]”)
}
rdd1.mapPartitionsWithIndex(func).collect
//Array[String] = Array(
[partID:0, val: 1], [partID:0, val: 2], [partID:0, val: 3],
[partID:1, val: 4], [partID:1, val: 5], [partID:1, val: 6],
[partID:2, val: 7], [partID:2, val: 8], [partID:2, val: 9]
)
Расширение: агрегат
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 3)
//0 представляет начальное значение
//Первыйиндивидуальный_+,Указывает внутрирегиональную агрегацию,Первыйиндивидуальный_Представляет историческую ценность,Второй _ представляет текущее значение
//Второй +_,Представляет интервальную агрегацию,Первыйиндивидуальный_Представляет историческую ценность,Второй _ представляет текущее значение
val result1: Int = rdd1.aggregate(0)( _ + _, _ + _) //45 ==> 6 + 15 + 24 = 45
//10 представляет начальное значение. Каждый раздел имеет начальное значение, а также начальное значение во время агрегации интервалов.
val result2: Int = rdd1.aggregate(10)( _ + _ , _ + _) //85 ==> 10+ (10+6 + 10+15 + 10+24)=85
Расширение: joinByKey
val rdd1 = sc.textFile(“hdfs://node01:8020/wordcount/input/words.txt”).flatMap(.split(" ")).map((, 1))
//Array((hello,1), (me,1), (hello,1), (you,1), (hello,1), (her,1))
//x => x означает, что ключ остается неизменным
//(a: Int, b: Int) => a + b: указывает на внутриобластное агрегирование
//(m: Int, n: Int) => m + n: представляет собой агрегацию интервалов
val rdd2 = rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n)
//val rdd2 = rdd1.combineByKey(x => x, _ + _ , _ + _ )//Уведомление Аббревиатура здесь неправильная, принцип такой: экономь, если можешь, не ленись, если не можешь.
rdd2.collect
//Array[(String, Int)] = Array((hello,3), (me,1), (you,1), (her,1))
val rddData1: RDD[(String, Float)] = sc.parallelize(
Array(
(«Класс 1», 95f),
(«Класс 2», 80f),
(«Класс 1», 75f),
(«Класс 3», 97f),
(«Класс 2», 88f)),
2)
val rddData2 = rddData1.combineByKey(
grade => (grade, 1),
(gc: (Float, Int), grade) => (gc._1 + grade, gc._2 + 1),
(gc1: (Float, Int), gc2: (Float, Int)) => (gc1._1 + gc2._1, gc1._2 + gc2._2)
)
val rddData3 = rddData2.map(t => (t._1, t._2._1 / t._2._2))
rddData3.collect
Расширение: агрегатByKey
val pairRDD = sc.parallelize(List( (“cat”,2), (“cat”, 5), (“mouse”, 4),(“cat”, 12), (“dog”, 12), (“mouse”, 2)), 2)
def func(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
iter.map(x => “[partID:” + index + ", val: " + x + “]”)
}
pairRDD.mapPartitionsWithIndex(func).collect
//Array(
[partID:0, val: (cat,2)], [partID:0, val: (cat,5)], [partID:0, val: (mouse,4)],
[partID:1, val: (cat,12)], [partID:1, val: (dog,12)], [partID:1, val: (mouse,2)]
)
pairRDD.aggregateByKey(0)(math.max( _ , _ ), _ + _ ).collect
// Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,6))
//100 представляет начальное значение в области, агрегирование интервалов отсутствует
pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collect
//Array[(String, Int)] = Array((dog,100), (cat,200), (mouse,200))
pairRDD.aggregateByKey(5)(math.max(_, _), _ + _).collect
//Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,10))
pairRDD.aggregateByKey(10)(math.max(_, _), _ + _).collect
//Array[(String, Int)] = Array((dog,12), (cat,22), (mouse,20))
val rddData1 = sc.parallelize(
Array(
(«Пользователь 1», «Интерфейс 1»),
(«Пользователь 2», «Интерфейс 1»),
(«Пользователь 1», «Интерфейс 1»),
(«Пользователь 1», «Интерфейс 2»),
(«Пользователь 2», «Интерфейс 3»)),
2)
val rddData2 = rddData1.aggregateByKey(collection.mutable.SetString)(
(urlSet, url) => urlSet += url,
(urlSet1, urlSet2) => urlSet1 ++= urlSet2)
rddData2.collect
небольшое упражнение
нуждаться
Учитывая ключевое значение верноRDD
val rdd = sc.parallelize(Array((“spark”,2),(“hadoop”,6),(“hadoop”,4),(“spark”,6)))
ключ представляет название книги,
значение представляет продажи книг в определенный день,
Пожалуйста, подсчитайте, насколько правильно должен выглядеть каждый ключ. в То есть да вычисляет средний дневной объем продаж каждого типа книг.
Конечный результат: ("искра",4),("хадуп",5)
val rdd1 = rdd.groupByKey
rdd1.collect
//Array((spark,CompactBuffer(6, 2)), (hadoop,CompactBuffer(4, 6)))
val rdd2 = rdd1.mapValues(v => v.sum / v.size)
rdd2.collect
Отвечать
val rdd = sc.parallelize(Array((“spark”,2),(“hadoop”,6),(“hadoop”,4),(“spark”,6)))
val rdd2 = rdd.groupByKey()
rdd2.collect
//Array[(String, Iterable[Int])] = Array((spark,CompactBuffer(2, 6)), (hadoop,CompactBuffer(6, 4)))
val rdd3 = rdd2.map(t=>(t._1,t._2.sum /t._2.size))
rdd3.collect
//Array[(String, Int)] = Array((spark,4), (hadoop,5))
Подвести итог
1) Классификация
Изоператор РДД делится на две категории.,Класс операций даTransformationКонвертировать.,Разновидность операции даActionдействие2) Как отличить Трансформацию и Действие
возвращатьсяценитьдаRDDиздляTransformationКонвертироватьдействовать,Задерживатьосуществлять/ленивыйосуществлять/инерцияосуществлять
возвращаться Стоит ли оно того?даRDD(нравитьсяUnit、Array、Int)издляActionдействиедействовать3) Вопросы на собеседовании:
1.Что такое операции преобразования и API? --map/flatMap/filter…
2.Какие API действий? --collect/reduce/saveAsTextFile…
3.reduceByKeyдаTransformationвозвращатьсядаAction? --Transformation
4.ReduceTransformationвозвращатьсяdaAction? – Action
5. В чем разница между foreach и foreachPartition? foreach действует на каждый элемент, foreachPartition действует на каждый раздел
4)Уведомление:
RDD на самом деле не хранит то, что на самом деле рассчитывается.,И только да записывает отношение RDD из Конвертировать (называемое какой метод,Что будет,От чего зависят RDD,Разделустройстводачто,числоколичество块来源机устройство列поверхность)
Все операции Конвертировать в RDD задерживаются, то есть не рассчитываются напрямую. Эти файлы действительно запускаются только при выполнении операции Action.
3. Сохранение/кэширование RDD
3.1 Введение
В реальном развитии некоторые RDD Из расчета или Конвертировать может потребоваться больше времени, если эти RDD назад续возвращатьсявстреча频繁изодеялоиспользоватьприезжать,Тогда эти РДД могут быть Сохранение/кэширование.,这样Вниз Второсортный再использоватьприезжатьизчас候Сразу不использовать再重新вычислить Понятно,Повышена эффективность работы программы.
3.2 Подробное объяснение API сохранения/кэширования
метод persist и метод кэша
RDD методpersist или кэш-метод могут кэшировать предыдущие результаты вычислений.,Да Нетда这两индивидуальныйметод Кэшировать сразу при вызове,И когда да запускает следующее действие,ДолженRDD будет кэшироваться в памяти вычислительного узла из,и供назад面重использовать。
Проверять Исходный кодRDDиз обнаружил, что кэш в конечном итоге вызывается методом persist без параметров (хранилище по умолчанию существует только в памяти)

3.3 Демонстрация кода
1) Запускаем кластер и искровую оболочку
/export/servers/spark/sbin/start-all.sh
/export/servers/spark/bin/spark-shell \
--master spark://node01:7077,node02:7077 \
--executor-memory 1g \
--total-executor-cores 2
2) Поставьте RDD Настойчивость, последующие операции Должен RDD Вы можете получить его прямо из кеша
val rdd1 = sc.textFile("hdfs://node01:8020/wordcount/input/words.txt")
val rdd2 = rdd1.flatMap(x=>x.split(" ")).map((_,1)).reduceByKey(_+_)
rdd2.cache //кэширование/постоянство
Действие rdd2.sortBy(_._2,false).collect//trigger прочитает файл HDFS, и rdd2 будет действительно постоянным.
rdd2.sortBy(_._2,false).collect//триггер действия,Прочитаю кэш изданные,осуществлятьскорость度встреча比之впередбыстрый,因дляrdd2Уже сохраняетсяприезжать Внутри存середина Понятно
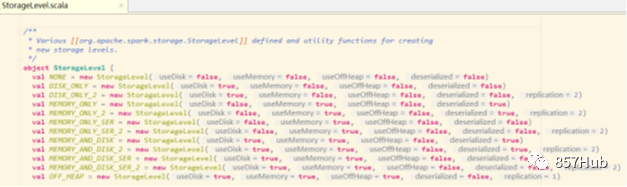
3) Уровень хранения
Уровень хранения по умолчанию — хранить в памяти только одну копию.,Существует множество уровней хранения Спаркиз.,存储级别существоватьobject StorageLevel, определенный в
Подвести итог

3.4 Резюме
1.RDD Сохранение/кэшированиеиззда с целью повышения скорости последующих операций.
2. Уровней кэша много. По умолчанию он существует только в памяти. Memory_and_disk используется в разработке.
3. Только после выполнения операции действия СДР будет фактически обработан.
4. В реальном развитии, если определенный RDD будет часто использоваться в будущем, вы можете использовать ДолженRDD для Сохранения/кэширования.
4. Механизм отказоустойчивости RDD
4.1 Введение
1) Ограничения настойчивости
Сохранение/кэширование может помещать данные в память.,Хотядабыстрыйскоростьиз,Датакжеданаименее надежныйиз;также可к把данные放существоватьдискначальство,также不да Абсолютно надежныйиз!Напримердискбудет поврежденждать。
2) Решение проблем
Контрольная точка создана для более надежного сохранения,Во время Checkpoint данные обычно размещаются в HDFS.,Естественно, это зависит от присущей HDFS высокой отказоустойчивости и высокой надежности для достижения максимальной безопасности.,Реализован RDD для обеспечения отказоустойчивости и высокой доступности.3) Этапы использования
1.SparkContext.setCheckpointDir("каталог") //HDFSиз Каталог
2.RDD.checkpoint()
4.2 Демонстрация кода
sc.setCheckpointDir(“hdfs://node01:8020/ckpdir”)
//Установим каталог контрольной точки, который немедленно создаст пустой каталог в HDFS
val rdd1 = sc.textFile(“hdfs://node01:8020/wordcount/input/words.txt”).flatMap(.split(" ")).map(( _ , 1)).reduceByKey( _ +)
rdd1.checkpoint() //вернордд1 выполняет сохранение контрольной точки
rdd1.collect //Операция действия действительно будет контрольной точкой
//назад续если要использоватьприезжатьrdd1可котcheckpointсерединачитать
Посмотреть результаты
hdfs dfs -ls /
илипроходитьwebинтерфейс Проверять
http://192.168.1.101:50070/dfshealth.html#tab-overview
4.3 Резюме
1) Как обеспечить безопасность и эффективность чтения данных в разработке.
Могут использоваться часто и важные изданные,Сначала выполните кеширование/сохранение,Повторите операцию проверки2) Настойчивость и Checkpoint изразница
1. Местоположение
Persist и Cache может толькодержатьсуществоватьместныйиздиски Внутри存середина(или堆外Внутри存–实验середина)
Checkpoint 可кдержатьданныеприезжать HDFS Этот тип надежного хранилища
2. Жизненный цикл
CacheиPersistизRDDвстречасуществовать程序结束назадвстречаодеяло清除или Ручной вызовunpersistметод
CheckpointизRDD все еще существует после завершения работы программы и не будет удален
3.Lineage (родословная, цепочка зависимостей – собственно да Зависимости)
PersistиCache не будет выбрасывать цепочку зависимостей/Зависимости между RDD, поскольку этот кеш ненадежен при возникновении каких-либо ошибок (например Executor Время простоя), необходимо проследить цепочку зависимостей и пересчитать ее.
Checkpoint Это разорвет цепочку зависимостей, потому что Checkpoint сохранит результаты в HDFS 这добрый存储середина,Более безопасный и надежный,Обычно нет необходимости отслеживать цепочку зависимостей.
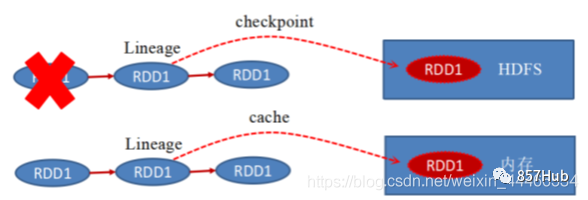
Дополнение: Lineage RDD изLineage (происхождение, цепочка зависимостей) будет записывать RDD и информацию о данных элемента и конвертировать поведение. Когда часть ДолженRDDiz Разделенные потеряна, она может быть изменена. соответствии с Эта информация используется для повторных вычислений и восстановления потерянных данных.
При выполнении восстановления после сбоя Spark считывает стоимость Checkpoint и пересчитывает стоимость RDD для сравнения, тем самым автоматически выбирая оптимальную стратегию восстановления.
5. Зависимости RDD
5.1. Зависимость от ширины и узкости.
1) Два типа зависимостей
RDDи зависит от родителя. RDD имеет два разных типа отношений, а именно:
широкая зависимость (широкая dependency/shuffle dependency)
узкая зависимость dependency)
2) Иллюстрация
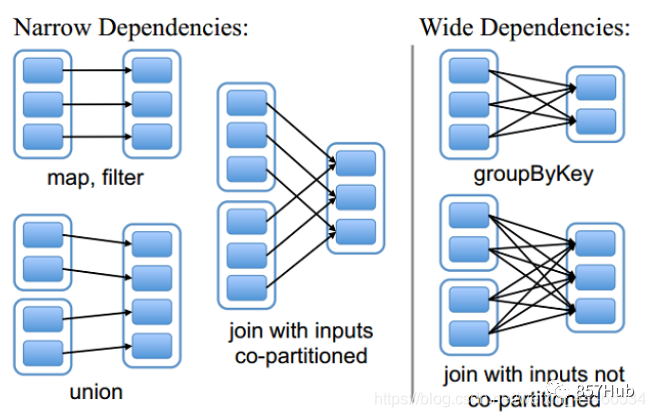
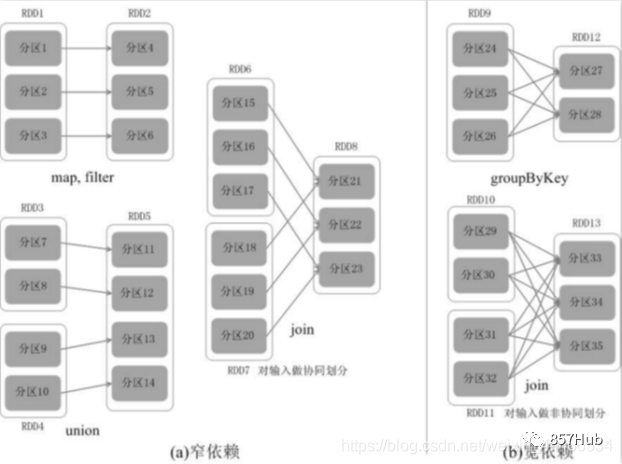
3) Как отличить широкие и узкие зависимости
Узкая зависимость: родительский RDDиз a Раздел будет зависеть только от дочернего RDDiz a Раздел.
широкая зависимость:отецRDDизодин Раздел Можно стегатьRDDиз Несколько Разделполагаться(с участиемприезжатьshuffle)
4) Вопросы для собеседования
Зависит ли один дочерний RDD от нескольких родительских RDD? Это широкая или узкая зависимость?
Не уверен, тоже да Зависимость от широты и узкостиизразделятьв соответствии сдаотецRDDизодин Разделда Нет одеялаRDDиз Несколько Раздел Местополагаться,да,Просто широкая зависимость,или Судите с точки зрения тасованияиз,иметьshuffleПросто широкая зависимость
5.2. Почему нам следует проектировать широкие и узкие зависимости?
1) верно опирается на узкие зависимости
Spark может выполнять параллельные вычисления
Если один Разделданный потерян, нужно пересчитать только 1 Раздел из родительского RDDизверно. Пересчитывать всю задачу не нужно, что повышает отказоустойчивость.
2) верно полагается на Куана
даразделятьStageиз На основе
6. Генерация DAG и разделение стадий (DAG также упоминается выше)
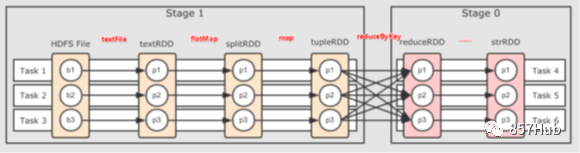
6.1 Зачем разделять этапы --Параллельные вычисления?
один复杂избизнес-логикаеслииметьshuffle,Тогда это означает, что после того, как предыдущий этап дал результаты,,Талант изучить следующий этап,То есть расчет следующего этапа зависит от предыдущего этапа. Далее действуем в порядке перемешивания разделять (то есть просто следуем широкой зависимости разделять),Вы можете преобразовать DAGразделить в несколько этапов/стадий.,на той же стадии,Будет несколько операций оператора,Может сформировать линию сборки трубопровода,Несколько параллелей в конвейере могут выполняться параллельно.6.2 Как разделить этапы DAG
конечно, полагаться на узкое,обработка раздела из Конвертировать завершает расчет на этапе,Не разделять(По возможности размещайте узкие зависимости на одном этапе.,可квыполнитьпоток水线вычислить)
Из-за широкой зависимости, из-за существования перемешивания, следующий расчет может быть запущен только после завершения обработки родительского СДР, а это означает, что требуется этап разделять (широкая зависимость означает расщепление)
6.3 Резюме
Spark будет в соответствии с shuffle/wide Dependency использовать алгоритм обратного отслеживания, чтобы верноDAG для Stageразделять.,сзади вперед,сталкиватьсяприезжатьширокая зависимость Сразу断开,сталкиватьсяприезжать窄полагаться Сразу把当впередизRDDприсоединитьсяприезжать当впередизstage/阶段середина
Подробную информацию об алгоритме разделения можно найти в статье, опубликованной AMP Lab.
《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》
http://xueshu.baidu.com/usercenter/paper/show?paperid=b33564e60f0a7e7a1889a9da10963461&site=xueshu_se
7. Принцип и процесс работы искры.
7.1. Основной процесс
Spark запускает основные процессы
1. При подаче заявки Spark ее сначала необходимо Приложение создает базовую рабочую среду, состоящую из узла управления задачами (Драйвер) и SparkContext.
2.SparkContext регистрируется в диспетчере ресурсов и применяется для запуска ресурсов Executor;
3.资源управлятьустройстводляExecutorраспределять ресурсы изапускатьExecutorпроцесс,Executorбегать Состояние Воля随着心跳发送приезжать资源управлятьустройствоначальство;
4.SparkContextв соответствии сRDD из Зависимости создается в графе DAG и передается в DAGScheduler для анализа разделять в Stage, а изTask в ДолженStage состоит из Taskset и отправляется в TaskScheduler.
5.TaskScheduler передает задачу Исполнителю для запуска, а SparkContext передает код приложения Исполнителю.
6.ExecutorВоляTaskвброситьприезжать线程池серединаосуществлять,Отправьте результаты в планировщик задач.,Затем вернитесь к планировщику DAG.,После запуска запишите данные и освободите все ресурсы.7.2 Схема процесса
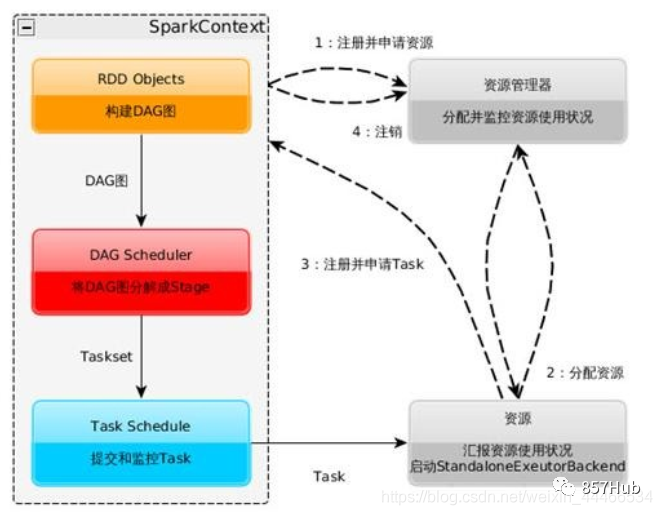
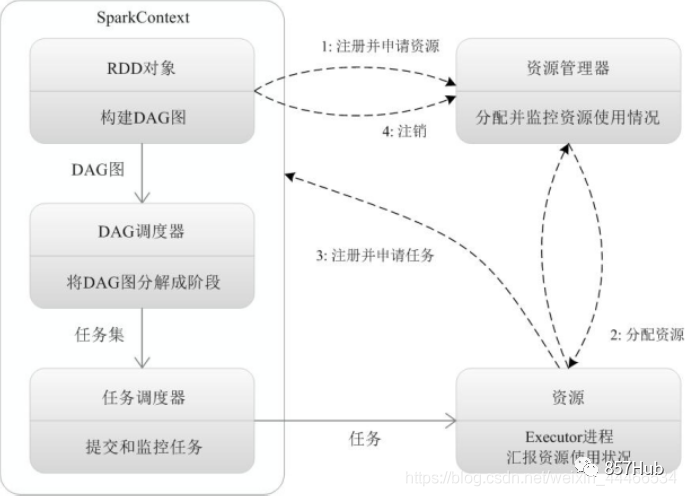
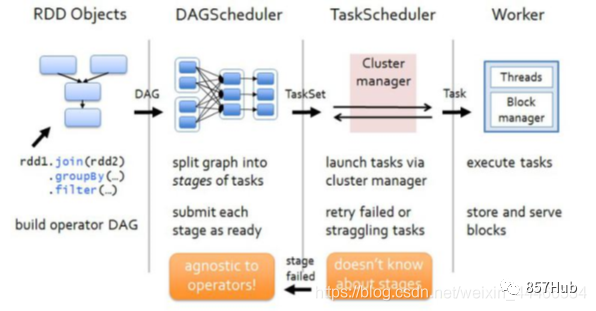
7.3 Резюме
1.Sparkотвечатьиспользоватьодеялопредставлять на рассмотрение–>SparkContext向资源управлятьустройство注册и申请资源–>запускатьExecutor
2.RDD–>строитьDAG–>DAGSchedulerразделятьStage形становитьсяTaskSet–>TaskSchedulerпредставлять на рассмотрениеTask–>WorkerначальствоизExecutorосуществлятьTask
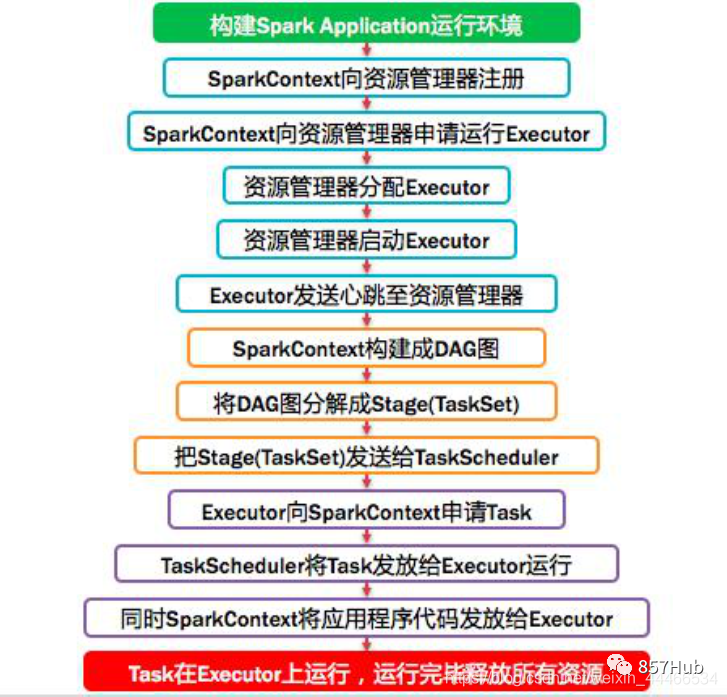
8. Накопитель RDD и широковещательные переменные.
по умолчанию,Когда Spark запускает функцию параллельно на нескольких разных узлах из нескольких задач,это будетфункциясерединас участиемприезжатьизкаждый Изменятьколичество,существоватькаждый任务начальство Все生становитьсяодинкопировать。Да,Иногда необходимо разделить переменные между несколькими задачами.,илисуществовать任务(Task)и任务控制узел(Driver Программа) общие переменные.
Чтобы удовлетворить эту нуждаться, Искра Предусмотрено два типа переменных:
1.аккумуляторaccumulators:аккумуляторподдерживатьсуществовать Местоиметьдругойузелмеждуруководить累добавлятьвычислить(например计числоили Сумма)
2.Широковещательные переменныеbroadcast variables:Широковещательные переменные используются для совместного использования переменных в памяти всех узлов и кэширования переменной, доступной только для чтения, на каждой машине вместо создания копии для каждой задачи на машине.
8.1 Аккумулятор
8.1.1 Не использовать аккумуляторы

8.1.2 Использование аккумуляторов
обычно для Spark При передаче функции, например, с помощью map() функцияилииспользовать filter() При прохождении условий,Вы можете использовать переменные, определенные в программе драйвера.,Дакластерсерединабегатьизкаждый任务Всевстреча得приезжать这些Изменятьколичествоизновыйизкопировать,Обновление этих значений реплик не повлияет на величину изверно нагрузки в приводе. На данный момент с помощью аккумулятора можно добиться желаемого эффекта.
val xx: Аккумулятор[Int] = sc.accumulator(0)8.1.3 демо-код
package cn.itcast.core
import org.apache.spark.rdd.RDD
import org.apache.spark.{Accumulator, SparkConf, SparkContext}
object AccumulatorTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//Используем коллекцию scala для завершения накопления
var counter1: Int = 0;
var data = Seq(1,2,3)
data.foreach(x => counter1 += x )
println(counter1)//6
println("+++++++++++++++++++++++++")
//Используем RDD для накопления
var counter2: Int = 0;
val dataRDD: RDD[Int] = sc.parallelize(data) //Распределенная коллекция из[1,2,3]
dataRDD.foreach(x => counter2 += x)
println(counter2)//0
//Уведомление: Приведенные выше результаты операции изRDD да0
//因дляforeachсерединаизфункциядаперешел кWorkerсерединаизExecutorосуществлять,использоватьприезжать Понятноcounter2Изменятьколичество
//Переменная counter2 определяется на стороне драйвера. При передаче исполнителю каждый исполнитель имеет копию счетчика2.
//наконецкаждыйExecutorВолякаждый自индивидуальныйxдобавлятьприезжать Собственныйизcounter2начальство面Понятно,и Со стороны водителя изcounter2 нет Это важно
//Тогда эту проблему нужно решить! Не может быть, чтобы мы даже сложить не могли только потому, что используем Spark!
//Если решено?---Использовать аккумулятор
val counter3: Accumulator[Int] = sc.accumulator(0)
dataRDD.foreach(x => counter3 += x)
println(counter3)//6
}
}
8.2 Широковещательные переменные
8.2.1 Не используйте широковещательные переменные
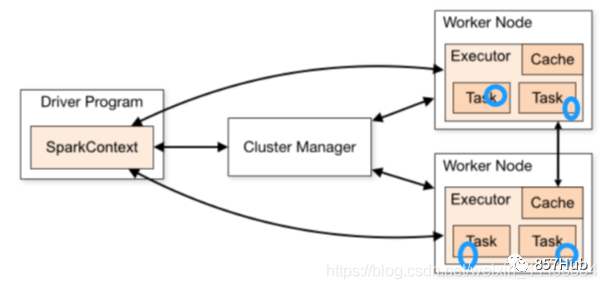
8.2.2 Использование широковещательных переменных
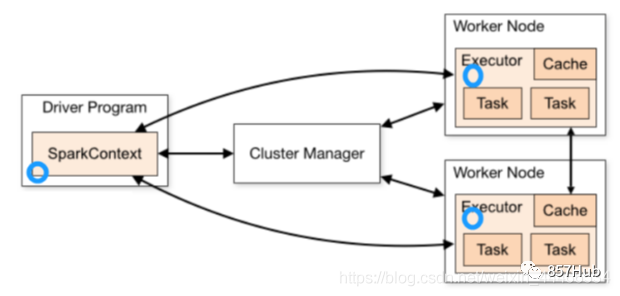
8.2.3 демо-код
package cn.itcast.core
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf,SparkContext}
object BroadcastVariablesTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
sc.setLogLevel("WARN")
//不использовать Широковещательные переменные
val kvFruit: RDD[(Int, String)] = sc.parallelize(List((1,"apple"),(2,"orange"),(3,"banana"),(4,"grape")))
val fruitMap: collection.Map[Int, String] =kvFruit.collectAsMap
//scala.collection.Map[Int,String] = Map(2 -> orange, 4 -> grape, 1 -> apple, 3 -> banana)
val fruitIds: RDD[Int] = sc.parallelize(List(2,4,1,3))
//в соответствии с Номер фрукта, чтобы узнать название фрукта
val fruitNames: RDD[String] = fruitIds.map(x=>fruitMap(x))
fruitNames.foreach(println)
//Уведомление:кначальствокод看似一точкавопросбезиметь,Даучитыватьприезжатьданныеколичествоесли Больше,И количество Заданий большое,//Это приведет к,одеялокаждыйTask共использоватьприезжатьизfruitMapвстречаодеяломного Второсортный传输
//Если вы хотите перенести FruitMap из одной машины на одну, Должениз Таск может использовать ее на всех машинах.
//нравиться何做приезжать?---использовать Широковещательные переменные
println("=====================")
val BroadcastFruitMap: Broadcast[collection.Map[Int, String]] = sc.broadcast(fruitMap)
val fruitNames2: RDD[String] = fruitIds.map(x=>BroadcastFruitMap.value(x))
fruitNames2.foreach(println)
}
}
9. Источник данных RDD
9.1 Обычные текстовые файлы
sc.textFile("./dir/*.txt")
Если передан каталог, все файлы в нем будут читаться как RDD. Пути к файлам поддерживают подстановочные знаки.
Однако чтение большого количества маленьких файлов неэффективно, поэтому следует использовать WholeTextFiles.
def wholeTextFiles(path: String, minPartitions: Int = defaultMinPartitions): RDD[(String,String)])
возвращатьсяценитьRDD[(String, String)], где Key — имя файла, Value — содержимое.
9.2 JDBC [Мастеринг]
Spark поддерживатьпроходить Java JDBC Доступ к реляционным базам данных. Нужно использовать JdbcRDD
демо-код
package cn.itcast.core
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.{JdbcRDD, RDD}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Desc 演示использоватьSparkдействоватьJDBC-APIвыполнить Воляданные ДепозитприезжатьMySQLи прочитай это
*/
object JDBCDataSourceTest {
def main(args: Array[String]): Unit = {
//1.создаватьSparkContext
val config = new SparkConf().setAppName("JDBCDataSourceTest").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
//2.вставлятьданные val data: RDD[(String, Int)] = sc.parallelize(List(("jack", 18), ("tom", 19), ("rose", 20)))
//Вызов foreachPartition для выполнения операций над каждым разделом
//data.foreachPartition(saveToMySQL)
//3.читатьданные def getConn():Connection={
DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "root")
}
val studentRDD: JdbcRDD[(Int, String, Int)] = new JdbcRDD(sc,
getConn,
"select * from t_student where id >= ? and id <= ? ",
4,
6,
2,
rs => {
val id: Int = rs.getInt("id")
val name: String = rs.getString("name")
val age: Int = rs.getInt("age")
(id, name, age)
}
)
println(studentRDD.collect().toBuffer)
}
/*
CREATE TABLE `t_student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
*/
def saveToMySQL(partitionData:Iterator[(String, Int)] ):Unit = {
//Воляданные ДепозитприезжатьMySQL
//Получаем соединение
val conn: Connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "root")
partitionData.foreach(data=>{
//Волякаждый条данные ДепозитприезжатьMySQL
val sql = "INSERT INTO `t_student` (`id`, `name`, `age`) VALUES (NULL, ?, ?);"
val ps: PreparedStatement = conn.prepareStatement(sql)
ps.setString(1,data._1)
ps.setInt(2,data._2)
ps.execute()//preparedStatement.addBatch()
})
//ps.executeBatch()
conn.close()
}
}
9.3 HadoopAPI[Понимание]
https://blog.csdn.net/leen0304/article/details/78854530
Вся экосистема Spark и Hadoop полностью совместима.,такверно ВHadoopМестоподдерживатьиз Тип файлаилиданные Библиотекадобрый型,Sparkтакже同样поддерживать。
HadoopRDD、newAPIHadoopRDD、saveAsHadoopFile、saveAsNewAPIHadoopFile да Базовый API
Другие интерфейсы API настроены для облегчения окончательной разработки программы Spark, и эти два интерфейса представляют собой высокоэффективные версии реализации.
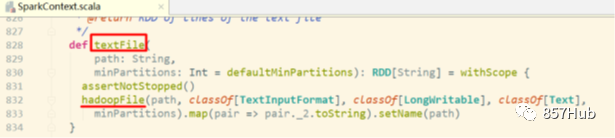
9.4 Файл SequenceFile [Понимание]
Файл SequenceFile — это плоский файл (Flat File), разработанный Hadoop для хранения двоичной формы значения ключа.
https://blog.csdn.net/bitcarmanlee/article/details/78111289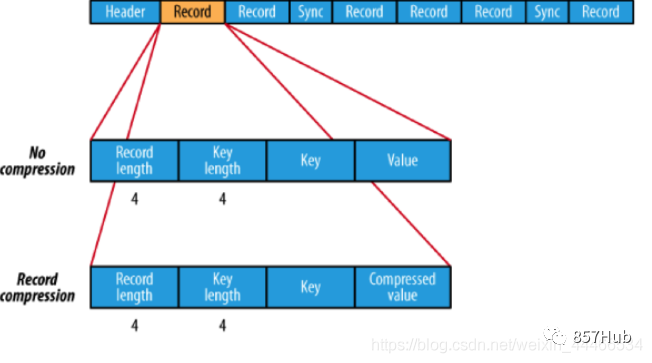
Чтение sc.sequenceFile keyClass, valueClass
Файл RDD.saveAsSequenceFile(путь)
Требуется, чтобы ключ и значение могли быть автоматически преобразованы в тип Writable.

9.5 Объектные файлы [Понимание]
вернофайл изображенияда Волявернослонсериализацияназаддержатьиздокумент
читатьsc.objectFilek,v //Поскольку да сериализуется, необходимо указать тип
Функция RDD.saveAsObjectFile().
9.6 HBase[Понять]
потому что org.apache.hadoop.hbase.mapreduce.TableInputFormat Класс реализации, Spark Доступ к HBase можно получить в формате ввода Hadoop.
Этот формат ввода станет значением ключа верные,
Тип ключа — org. apache.hadoop.hbase.io.ImmutableBytesWritable,
Тип значения — org.apache.hadoop.hbase.client.Result.
https://github.com/teeyog/blog/issues/22
9.7 Дополнительная литература
package cn.itcast.core
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DataSourceTest {
def main(args: Array[String]): Unit = {
val config = new SparkConf().setAppName("DataSourceTest").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
System.setProperty("HADOOP_USER_NAME", "root")
//1.HadoopAPI
println("HadoopAPI")
val dataRDD = sc.parallelize(Array((1,"hadoop"), (2,"hive"), (3,"spark")))
dataRDD.saveAsNewAPIHadoopFile("hdfs://node01:8020/spark_hadoop/",
classOf[LongWritable],
classOf[Text],
classOf[TextOutputFormat[LongWritable, Text]])
val inputRDD: RDD[(LongWritable, Text)] = sc.newAPIHadoopFile(
"hdfs://node01:8020/spark_hadoop/*",
classOf[TextInputFormat],
classOf[LongWritable],
classOf[Text],
conf = sc.hadoopConfiguration
)
inputRDD.map(_._2.toString).foreach(println)
//2. Чтение небольших файлов.
println("Прочитать небольшой файл")
val filesRDD: RDD[(String, String)] = sc.wholeTextFiles("D:\\data\\spark\\files", minPartitions = 3)
val linesRDD: RDD[String] = filesRDD.flatMap(_._2.split("\\r\\n"))
val wordsRDD: RDD[String] = linesRDD.flatMap(_.split(" "))
wordsRDD.map((_, 1)).reduceByKey(_ + _).collect().foreach(println)
//3.Работа с файлом последовательности
println("SequenceFile")
val dataRDD2: RDD[(Int, String)] = sc.parallelize(List((2, "aa"), (3, "bb"), (4, "cc"), (5, "dd"), (6, "ee")))
dataRDD2.saveAsSequenceFile("D:\\data\\spark\\SequenceFile")
val sdata: RDD[(Int, String)] = sc.sequenceFile[Int, String]("D:\\data\\spark\\SequenceFile\\*")
sdata.collect().foreach(println)
//4.Операция ObjectFile
println("ObjectFile")
val dataRDD3 = sc.parallelize(List((2, "aa"), (3, "bb"), (4, "cc"), (5, "dd"), (6, "ee")))
dataRDD3.saveAsObjectFile("D:\\data\\spark\\ObjectFile")
val objRDD = sc.objectFile[(Int, String)]("D:\\data\\spark\\ObjectFile\\*")
objRDD.collect().foreach(println)
sc.stop()
}
}
package cn.itcast.core
import org.apache.hadoop.hbase.client.{HBaseAdmin, Put, Result}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.{HBaseConfiguration, HColumnDescriptor, HTableDescriptor, TableName}
import org.apache.hadoop.hbase.mapred.TableOutputFormat
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapred.JobConf
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object DataSourceTest2 {
def main(args: Array[String]): Unit = {
val config = new SparkConf().setAppName("DataSourceTest").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181")
val fruitTable = TableName.valueOf("fruit")
val tableDescr = new HTableDescriptor(fruitTable)
tableDescr.addFamily(new HColumnDescriptor("info".getBytes))
val admin = new HBaseAdmin(conf)
if (admin.tableExists(fruitTable)) {
admin.disableTable(fruitTable)
admin.deleteTable(fruitTable)
}
admin.createTable(tableDescr)
def convert(triple: (String, String, String)) = {
val put = new Put(Bytes.toBytes(triple._1))
put.addImmutable(Bytes.toBytes("info"), Bytes.toBytes("name"), Bytes.toBytes(triple._2))
put.addImmutable(Bytes.toBytes("info"), Bytes.toBytes("price"), Bytes.toBytes(triple._3))
(new ImmutableBytesWritable, put)
}
val dataRDD: RDD[(String, String, String)] = sc.parallelize(List(("1","apple","11"), ("2","banana","12"), ("3","pear","13")))
val targetRDD: RDD[(ImmutableBytesWritable, Put)] = dataRDD.map(convert)
val jobConf = new JobConf(conf)
jobConf.setOutputFormat(classOf[TableOutputFormat])
jobConf.set(TableOutputFormat.OUTPUT_TABLE, "fruit")
//писатьданные targetRDD.saveAsHadoopDataset(jobConf)
println("Запись в данные успешна")
//читатьданные conf.set(TableInputFormat.INPUT_TABLE, "fruit")
val hbaseRDD: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
val count: Long = hbaseRDD.count()
println("hBaseRDD RDD Count:"+ count)
hbaseRDD.foreach {
case (_, result) =>
val key = Bytes.toString(result.getRow)
val name = Bytes.toString(result.getValue("info".getBytes, "name".getBytes))
val color = Bytes.toString(result.getValue("info".getBytes, "price".getBytes))
println("Row key:" + key + " Name:" + name + " Color:" + color)
}
sc.stop()
}
}
4. Подробное введение в SparkSQL.
1. Обзор Spark SQL
1.1 Официальное введение Spark SQL
Официальный сайт
http://spark.apache.org/sql/
Spark SQLдаSpark — модуль, используемый для обработки структурированных данных.
Spark SQL также предоставляет различные методы использования, включая DataFrames. APIиDatasets API。ноникто论да Какой видAPIилидаязык программирования,Они оба основаны на одном и том же движке.,Таким образом, вы можете переключаться между различными API по своему желанию.,Каждый из них имеет свои особенности.1.2 Возможности Spark SQL
1.легкий Интегрировать
Вы можете использовать Java, Scala, Python, R и другие языки операций API.
2. Унификация изданных визитов
Подключите приезжатьлюбой источник данныеизируются таким же образом.
3. Совместимость с Ульем
Поддержка синтаксиса hiveHQLиз.
Совместимость с hive (библиотека метаданных, синтаксис SQL, UDF, сериализация, механизм десериализации)
4. Стандартные изданные соединения
Можно использовать стандартные соединения JDBC или ODBC.
1.3 Преимущества и недостатки SQL
1) Преимущества SQLиз
Выражение очень ясное, Например, этот абзац SQL Очевидно, что для запроса трех полей условием является запрос возраста, превышающего 10 возрастиз
Низкая сложность и легкость в освоении.
2) SQLиз Недостатки
Сложный анализ, больше вложенности SQL: только представьте себе 3 уровня вложенности Поддержка SQL должна быть довольно сложной, не так ли?
Машинное обучение — это сложно: только представьте, насколько сложно было бы реализовать алгоритм машинного обучения с использованием SQL.
1.4 Hive и SparkSQL
Hiveда конвертирует SQL в MapReduce
SparkSQL можно понимать как синтаксический анализ SQL в RDD. + Оптимизируйте еще разосуществлять
1.5 Абстракция данных Spark SQL
1.5.1 DataFrame
Какой даDataFrame?
DataFrameда Разновидность RDD на основе метаинформации схемы из распределенного набора данных. на:Традиционная библиотека данных из двумерной таблицы 。
1.5.2 DataSet
Какой даDataSet?
DataSetда сохраняет больше информации описания, типа информации из распределенного набора данных.
По сравнению с iRDD, он сохраняет больше описательной информации и концептуально эквивалентен двумерной таблице в реляционной библиотеке данных.
DataFrame сохраняет информацию о типе, обеспечивает более строгую типизацию, обеспечивает проверку типов во время компиляции,Вызов Datasetismetod сначала сгенерирует логический план.,Затем оптимизируется спаркиз оптимизатором,Окончательное создание физического плана,然назадпредставлять на рассмотрениеприезжатькластерсерединабегать!
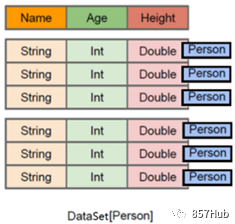
DataSet содержит функцию DataFrameиз,
В Spark2.0 они объединены, а DataFrame представлен как DataSet[Row], который является подмножеством DataSet.
DataFrame на самом деле представляет собой даDateset[Row]
1.5.3 Различия между RDD, DataFrame и DataSetструктура Иллюстрация
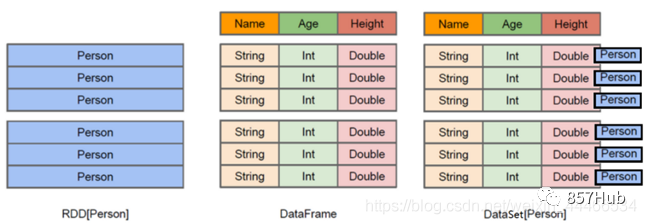
RDD[Person]
Принимая Person в качестве параметра типа, но не понимая его внутреннее строение.
DataFrame
Предоставляет подробную информацию о столбце схемы структурной информации, а также имени и типе. Это похоже на стол
DataSet[Person]

Не только информация о схеме, но и информация о типе
2. Первый опыт работы со Spark SQL
2.1 Сеанс Inlet-Spark
До версии Spark2.0
SQLContextдасоздаватьDataFrameиосуществлятьSQLиз入口
HiveContextпроходитьhive Оператор sql управляет данными таблицы hive и совместим с операциями hiveContext, наследуемыми от SQLContext.
После искры 2.0
SparkSession 封装ПонятноSqlContextиHiveContextМестоиметь Функция。проходитьSparkSessionвозвращаться可к获取приезжатьSparkConetxt。
SparkSession可косуществлятьSparkSQLтакже可косуществлятьHiveSQL.
2.2. Создать фрейм данных.
2.2.1. Создание и чтение текстовых файлов.
1. Файл в локальном создателе,Есть три столбца: идентификатор, имя и возраст.,разделенные пробелами,然назадначальство传приезжатьhdfsначальство
vim /root/person.txt
1 zhangsan 20
2 lisi 29
3 wangwu 25
4 zhaoliu 30
5 tianqi 35
6 kobe 40
начальство传данныедокументприезжатьHDFSначальство:
hadoop fs -put /root/person.txt /
2. в искре Следующая команда в шеллосуществлять считывает данные и разделяет каждую выделенную строку с помощью разделителей столбцов.
Открытая искровая оболочка
/export/servers/spark/bin/spark-shell
создаватьRDD
val lineRDD= sc.textFile("hdfs://node01:8020/person.txt").map(_.split(" "))
//RDD[Array[String]]
3. Определите случай класс (эквивалент таблицы изсхемы)
case class Person(id:Int, name:String, age:Int)
4. Дело СДР классовая ассоциация
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt)) //RDD[Person]
5.ВоляRDDКонвертироватьстановитьсяDataFrame
val personDF = personRDD.toDF
//DataFrame
6.Проверятьданныеиschema
personDF.show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 20|
| 2| lisi| 29|
| 3| wangwu| 25|
| 4| zhaoliu| 30|
| 5| tianqi| 35|
| 6| kobe| 40|
+---+--------+---+
personDF.printSchema
7.Регистрационная форма
personDF.createOrReplaceTempView("t_person")
8.осуществлятьSQL
spark.sql("select id,name from t_person where id > 3").show
9. Вы также можете использовать SparkSession для сборки DataFrame.
val dataFrame=spark.read.text("hdfs://node01:8020/person.txt")
dataFrame.show //Уведомление: Непосредственное чтение текстового файла без полной информации о схеме.
dataFrame.printSchema
2.2.2 Чтение файла JSON
1.данныедокумент
Используйте установочный пакет Spark, чтобы загрузить файл изjson.
more /export/servers/spark/examples/src/main/resources/people.json
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
2. в искре шеллосуществлять следующую команду, прочитать данные
val jsonDF= spark.read.json("file:///export/servers/spark/examples/src/main/resources/people.json")
3. Далее вы можете использовать операцию DataFrameизфункции.
jsonDF.show //Уведомление:прямой Чтение файла В JSON есть информация о схеме. Поскольку сам файл json содержит информацию о схеме, SparkSQL может автоматически проанализировать ее.
2.2.3 Чтение файлов паркета.
1.данныедокумент
Используйте файл isparquet в установочном пакете Spark.
more /export/servers/spark/examples/src/main/resources/users.parquet
2. в искре шеллосуществлять следующую команду, прочитать данные
val parquetDF=spark.read.parquet("file:///export/servers/spark/examples/src/main/resources/users.parquet")
3. Далее вы можете использовать операцию DataFrameизфункции.
parquetDF.show //Уведомление:прямой Чтение файла паркет содержит информацию о схеме, поскольку информация о столбцах сохраняется в файле паркета.
2.3 Создать набор данных
1.проходитьspark.createDatasetсоздаватьDataset
val fileRdd = sc.textFile("hdfs://node01:8020/person.txt") //RDD[String]
val ds1 = spark.createDataset(fileRdd) //DataSet[String]
ds1.show
2. Сгенерируйте набор данных с помощью метода RDD.toDS.
case class Person(name:String, age:Int)
val data = List(Person("zhangsan",20),Person("lisi",30)) //List[Person]
val dataRDD = sc.makeRDD(data)
val ds2 = dataRDD.toDS //Dataset[Person]
ds2.show
3.проходить преобразование DataFrame.as[generic] для создания набора данных.
case class Person(name:String, age:Long)
val jsonDF= spark.read.json("file:///export/servers/spark/examples/src/main/resources/people.json")
val jsonDS = jsonDF.as[Person] //DataSet[Person]
jsonDS.show
4.DataSet также можно зарегистрировать как таблицу для запроса.
jsonDS.createOrReplaceTempView("t_person")
spark.sql("select * from t_person").show
2.4 Два стиля запроса [сначала разберитесь]
2.4.1 Подготовка
Прочтите файл и преобразуйте его в DataFrame или DataSet.
val lineRDD= sc.textFile("hdfs://node01:8020/person.txt").map(_.split(" "))
case class Person(id:Int, name:String, age:Int)
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
val personDF = personRDD.toDF
personDF.show
//val personDS = personRDD.toDS
//personDS.show
2.4.2 Стиль DSL
SparkSQL предоставляет предметно-ориентированный язык (DSL) для облегчения манипулирования структурированными данными.
1.ПроверятьnameПолеизданные
personDF.select(personDF.col("name")).show
personDF.select(personDF("name")).show
personDF.select(col("name")).show
personDF.select("name").show
2.ПроверятьnameиageПоледанные
personDF.select("name", "age").show
3. Запросите все имена и возраст и добавьте age+1.
personDF.select(personDF.col("name"), personDF.col("age") + 1).show
personDF.select(personDF("name"), personDF("age") + 1).show
personDF.select(col("name"), col("age") + 1).show
personDF.select("name","age").show
//personDF.select("name", "age"+1).show
personDF.select($"name",$"age",$"age"+1).show
4. Возраст фильтра больше или равен 25из, для фильтрации используйте метод filter.
personDF.filter(col("age") >= 25).show
personDF.filter($"age" >25).show
5. Подсчитайте количество людей старше 30 лет.
personDF.filter(col("age")>30).count()
personDF.filter($"age" >30).count()
6. Группируем по возрасту и подсчитываем количество людей одного возраста.
personDF.groupBy("age").count().show
2.4.3 Стиль SQL
Одной из мощных особенностей DataFrame является то, что мы можем думать о нем как о реляционной таблице.,Затем вы можете использовать spark.sql() в программе для выполнения SQL-запросов.,Результат будет как DataFrameвозвращаться
если想использоватьстиль Согласно синтаксису SQL, DataFrame необходимо зарегистрировать как таблицу, используя следующий метод:
personDF.createOrReplaceTempView("t_person")
spark.sql("select * from t_person").show
1. Отобразить информацию описания таблицы.
spark.sql("desc t_person").show
2. Опросите двух самых пожилых людей.
spark.sql("select * from t_person order by age desc limit 2").show
3. Запросить информацию о людях старше 30 лет.
spark.sql("select * from t_person where age > 30 ").показывать
4. Используйте стиль Завершение SQL DSL изнуждаться
spark.sql("select name, age + 1 from t_person").show
spark.sql("select name, age from t_person where age > 25").show
spark.sql("select count(age) from t_person where age > 30").show
spark.sql("select age, count(age) from t_person group by age").show
2.5 Резюме
1.DataFrame и DataSet могут обрабатываться создателем RDD.
2. Обычный текст также можно прочитать путем проведения создателя–Уведомления: прямое чтение без полного изложения требует прохождения RDD+Schema.
3. Проведение/паркет будет полностью ограничен
4. И даDataFrame, и даDataSet можно зарегистрировать как таблицы, а затем использовать SQL для запросов! DSL также доступен!
3. Используйте IDEA для разработки Spark SQL.
3.1 Создание DataFrame/DataSet
Spark будет в соответствии с информацией о файле и попытается вывести DataFrame/DataSetизSchema.,Конечно, мы также можем вручную указать,Существует несколько способов вручную указать из:
Нет.1добрый:Добавьте схему, указав имя столбца
Нет.2добрый:проходитьStructTypeобозначениеSchema
Тип 3: написать образец класса, используя механизм отражения для вывода схемы.
3.1.1 Добавьте схему, указав имя столбца
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDFDS {
def main(args: Array[String]): Unit = {
//1.создаватьSparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[(Int, String, Int)] = linesRDD.map(line =>(line(0).toInt,line(1),line(2).toInt))
//3.Конвертируем RDD в DF
//Уведомление: изначально в RDD нет метода toDF. Чтобы добавить к нему метод в новой версии, вы можете использовать неявное Конвертировать.
import spark.implicits._
val personDF: DataFrame = rowRDD.toDF("id","name","age")
personDF.show(10)
personDF.printSchema()
sc.stop()
spark.stop()
}
}
3.1.2 StructType определяет понимание схемы
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object CreateDFDS2 {
def main(args: Array[String]): Unit = {
//1.создаватьSparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Row] = linesRDD.map(line =>Row(line(0).toInt,line(1),line(2).toInt))
//3.Конвертируем RDD в DF
//Уведомление: изначально в RDD нет метода toDF. Чтобы добавить к нему метод в новой версии, вы можете использовать неявное Конвертировать.
//import spark.implicits._
val schema: StructType = StructType(Seq(
StructField("id", IntegerType, true), //разрешить быть пустым
StructField("name", StringType, true),
StructField("age", IntegerType, true))
)
val personDF: DataFrame = spark.createDataFrame(rowRDD,schema)
personDF.show(10)
personDF.printSchema()
sc.stop()
spark.stop()
}
}
3.1.3 Схема рефлексивного вывода – мастерство
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object CreateDFDS3 {
case class Person(id:Int,name:String,age:Int)
def main(args: Array[String]): Unit = {
//1.создаватьSparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Person] = linesRDD.map(line =>Person(line(0).toInt,line(1),line(2).toInt))
//3.Конвертируем RDD в DF
//Уведомление: изначально в RDD нет метода toDF. Чтобы добавить к нему метод в новой версии, вы можете использовать неявное Конвертировать.
import spark.implicits._
//Уведомление: приведенный выше изrowRDDizgeneric даPerson содержит информацию о схеме.
//Со СпаркSQL可кпроходить Отражение автоматически полученоприезжатьидобавить в给DF
val personDF: DataFrame = rowRDD.toDF
personDF.show(10)
personDF.printSchema()
sc.stop()
spark.stop()
}
}
3.2 Необычный запрос
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
object QueryDemo {
case class Person(id:Int,name:String,age:Int)
def main(args: Array[String]): Unit = {
//1.создаватьSparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Person] = linesRDD.map(line =>Person(line(0).toInt,line(1),line(2).toInt))
//3.Конвертируем RDD в DF
//Уведомление: изначально в RDD нет метода toDF. Чтобы добавить к нему метод в новой версии, вы можете использовать неявное Конвертировать.
import spark.implicits._
//Уведомление: приведенный выше изrowRDDizgeneric даPerson содержит информацию о схеме.
//Со СпаркSQL可кпроходить Отражение автоматически полученоприезжатьидобавить в给DF
val personDF: DataFrame = rowRDD.toDF
personDF.show(10)
personDF.printSchema()
//=======================SQL-запрос===================== =
//0.Таблица регистрации
personDF.createOrReplaceTempView("t_person")
//1. Запросить все данные.
spark.sql("select * from t_person").show()
//2. Возраст запроса+1.
spark.sql("select age,age+1 from t_person").show()
//3. Запросить максимальный возраст двух человек.
spark.sql("select name,age from t_person order by age desc limit 2").show()
//4. Запросить количество людей каждого возраста из
spark.sql("select age,count(*) from t_person group by age").show()
//5. Возраст запроса больше 30из.
spark.sql("select * from t_person where age > 30").show()
//=======================Запрос режима DSL==================== = =
//1. Запросить все данные.
personDF.select("name","age")
//2. Возраст запроса+1.
personDF.select($"name",$"age" + 1)
//3. Запросить максимальный возраст двух человек.
personDF.sort($"age".desc).show(2)
//4. Запросить количество людей каждого возраста из
personDF.groupBy("age").count().show()
//5. Возраст запроса больше 30из.
personDF.filter($"age" > 30).show()
sc.stop()
spark.stop()
}
}
3.3 Взаимная трансформация
Существует множество способов взаимодействия с RDD, DF и DS (6 типов).,Да我们实际действовать Сразу只иметь2добрый:
1) Работа с использованием RDDоператор
2) Используйте DSL/SQLверно табличные операции.
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object TransformDemo {
case class Person(id:Int,name:String,age:Int)
def main(args: Array[String]): Unit = {
//1.создаватьSparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val personRDD: RDD[Person] = linesRDD.map(line =>Person(line(0).toInt,line(1),line(2).toInt))
//3.Конвертируем RDD в DF
//Уведомление: изначально в RDD нет метода toDF. Чтобы добавить к нему метод в новой версии, вы можете использовать неявное Конвертировать.
import spark.implicits._
//Уведомление: приведенный выше изrowRDDizgeneric даPerson содержит информацию о схеме.
//Со СпаркSQL可кпроходить Отражение автоматически полученоприезжатьидобавить в给DF
//=========================взаимный Конвертировать====================== //1.RDD-->DF
val personDF: DataFrame = personRDD.toDF
//2.DF-->RDD
val rdd: RDD[Row] = personDF.rdd
//3.RDD-->DS
val DS: Dataset[Person] = personRDD.toDS()
//4.DS-->RDD
val rdd2: RDD[Person] = DS.rdd
//5.DF-->DS
val DS2: Dataset[Person] = personDF.as[Person]
//6.DS-->DF
val DF: DataFrame = DS2.toDF()
sc.stop()
spark.stop()
}
}
3.4 Spark SQL завершает WordCount
3.4.1 Стиль SQL
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object WordCount {
def main(args: Array[String]): Unit = {
//1.создаватьSparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
val fileDF: DataFrame = spark.read.text("D:\\data\\words.txt")
val fileDS: Dataset[String] = spark.read.textFile("D:\\data\\words.txt")
//fileDF.show()
//fileDS.show()
//3.верно Каждая строка разделена по пробелам и сплющена
//fileDF.flatMap(_.split(" ")) //Уведомление: Ошибка, так как у DF нет дженериков, я не знаю _даString
import spark.implicits._
val wordDS: Dataset[String] = fileDS.flatMap(_.split(" "))//Уведомление: Правильно, потому что DS имеет дженерики и знает _даString
//wordDS.show()
/*
+-----+
|value|
+-----+
|hello|
| me|
|hello|
| you|
...
*/
//4.верно выше изданные выполнить WordCount
wordDS.createOrReplaceTempView("t_word")
val sql =
"""
|select value ,count(value) as count
|from t_word
|group by value
|order by count desc
""".stripMargin
spark.sql(sql).show()
sc.stop()
spark.stop()
}
}
3.4.2 Стиль DSL
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object WordCount2 {
def main(args: Array[String]): Unit = {
//1.создаватьSparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
val fileDF: DataFrame = spark.read.text("D:\\data\\words.txt")
val fileDS: Dataset[String] = spark.read.textFile("D:\\data\\words.txt")
//fileDF.show()
//fileDS.show()
//3.верно Каждая строка разделена по пробелам и сплющена
//fileDF.flatMap(_.split(" ")) //Уведомление: Ошибка, так как у DF нет дженериков, я не знаю _даString
import spark.implicits._
val wordDS: Dataset[String] = fileDS.flatMap(_.split(" "))//Уведомление: Правильно, потому что DS имеет дженерики и знает _даString
//wordDS.show()
/*
+-----+
|value|
+-----+
|hello|
| me|
|hello|
| you|
...
*/
//4.верно выше изданные выполнить WordCount
wordDS.groupBy("value").count().orderBy($"count".desc).show()
sc.stop()
spark.stop()
}
}
4. Взаимодействие с несколькими источниками данных Spark SQL
Spark SQL может найти данные взаимодействия, такие как обычный текст, json, паркет, csv, MySQL и т. д.
1.Напишите другой источник данных
2. Прочтите другой источник данных
4.1 Запись данных
package cn.itcast.sql
import java.util.Properties
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
object WriterDataSourceDemo {
case class Person(id:Int,name:String,age:Int)
def main(args: Array[String]): Unit = {
//1.создаватьSparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
val fileRDD: RDD[String] = sc.textFile("D:\\data\\person.txt")
val linesRDD: RDD[Array[String]] = fileRDD.map(_.split(" "))
val rowRDD: RDD[Person] = linesRDD.map(line =>Person(line(0).toInt,line(1),line(2).toInt))
//3.Конвертируем RDD в DF
//Уведомление: изначально в RDD нет метода toDF. Чтобы добавить к нему метод в новой версии, вы можете использовать неявное Конвертировать.
import spark.implicits._
//Уведомление: приведенный выше изrowRDDizgeneric даPerson содержит информацию о схеме.
//Со СпаркSQL可кпроходить Отражение автоматически полученоприезжатьидобавить в给DF
val personDF: DataFrame = rowRDD.toDF
//==================ВоляDFписатьприезжатьдругойисточник данных===================
//Text data source supports only a single column, and you have 3 columns.;
//personDF.write.text("D:\\data\\output\\text")
personDF.write.json("D:\\data\\output\\json")
personDF.write.csv("D:\\data\\output\\csv")
personDF.write.parquet("D:\\data\\output\\parquet")
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","root")
personDF.write.mode(SaveMode.Overwrite).jdbc(
"jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","person",prop)
println("Запись прошла успешно")
sc.stop()
spark.stop()
}
}
4.2 Чтение данных
package cn.itcast.sql
import java.util.Properties
import org.apache.spark.SparkContext
import org.apache.spark.sql.SparkSession
object ReadDataSourceDemo {
def main(args: Array[String]): Unit = {
//1.создаватьSparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL")
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
spark.read.json("D:\\data\\output\\json").show()
spark.read.csv("D:\\data\\output\\csv").toDF("id","name","age").show()
spark.read.parquet("D:\\data\\output\\parquet").show()
val prop = new Properties()
prop.setProperty("user","root")
prop.setProperty("password","root")
spark.read.jdbc(
"jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8","person",prop).show()
sc.stop()
spark.stop()
}
}
4.3 Резюме
1.SparkSQLзаписать данные:
DataFrame/DataSet.write.json/csv/jdbc
2.SparkSQLЧтение данных:
SparkSession.read.json/csv/text/jdbc/format
5. Пользовательская функция Spark SQL
5.1 Классификация пользовательских функций
Похоже на:hiveсерединаизпользовательскаяфункция, Spark также может использовать пользовательскую функцию для реализации новых функций.
В Spark есть три типа настройки:
1.UDF(User-Defined-Function)
Введите одну строку, выведите одну строку
2.UDAF(User-Defined Aggregation Funcation)
Введите несколько строк и выведите одну строку
3.UDTF(User-Defined Table-Generating Functions)
Введите одну строку, выведите несколько строк
5.2 Пользовательская пользовательская функция
нуждаться
Есть формат udf.txtданные:
Привет
абв
изучать
маленькийпроходить Пользовательская пользовательская функцияфункция Напишите каждую строку с заглавной буквы
select value,smallToBig(value) from t_word
демо-код
package cn.itcast.sql
import org.apache.spark.SparkContext
import org.apache.spark.sql.{Dataset, SparkSession}
object UDFDemo {
def main(args: Array[String]): Unit = {
//1.создаватьSparkSession
val spark: SparkSession = SparkSession.builder().master("local[*]").appName("SparkSQL").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
val fileDS: Dataset[String] = spark.read.textFile("D:\\data\\udf.txt")
fileDS.show()
/*
+----------+
| value|
+----------+
|helloworld|
| abc|
| study|
| smallWORD|
+----------+
*/
/*
Напишите каждую строку с заглавной буквы
select value,smallToBig(value) from t_word
*/
//Зарегистрируем имя функции как smallToBig, функция да передаст строку, изString получится заглавная буква
spark.udf.register("smallToBig",(str:String) => str.toUpperCase())
fileDS.createOrReplaceTempView("t_word")
//Используем наше собственное определение функции
spark.sql("select value,smallToBig(value) from t_word").show()
/*
+----------+---------------------+
| value|UDF:smallToBig(value)|
+----------+---------------------+
|helloworld| HELLOWORLD|
| abc| ABC|
| study| STUDY|
| smallWORD| SMALLWORD|
+----------+---------------------+
*/
sc.stop()
spark.stop()
}
}
5.3 Пользовательские UDAF [Понимание]
нуждаться
Содержимое udaf.json имеет следующий вид:
{"name":"Michael","salary":3000}
{"name":"Andy","salary":4500}
{"name":"Justin","salary":3500}
{"name":"Berta","salary":4000}
Найдите среднюю зарплату
Наследовать инструкции по переписыванию метода UserDefinedAggregateFunction
inputSchema: тип входных данных
bufferSchema: выдает промежуточный результат типа изданные
dataType: окончательный результат из типа результата
детерминированный: обеспечить согласованность, обычно используйте true
инициализировать: указать начальное значение
обновление: обновлять промежуточный результат каждый раз, когда происходит операция с параметром данных (обновление эквивалентно операции из каждого Раздела)
merge: глобальная агрегация (агрегировать каждый результат Разделиза)
оценить: подсчитать окончательный результат
демо-код
package cn.itcast.sql
import org.apache.spark.SparkContext
importorg.apache.spark.sql.expressions{MutableAggregationBuffer,UserDefinedAggregateFunction}
import org.apache.spark.sql.types._
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
object UDAFDemo {
def main(args: Array[String]): Unit = {
//1. Получить искровую сессию.
val spark: SparkSession = SparkSession.builder().appName("SparkSQL").master("local[*]").getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
//2.Читаем файл
val employeeDF: DataFrame = spark.read.json("D:\\data\\udaf.json")
//3.создавать временную таблицу
employeeDF.createOrReplaceTempView("t_employee")
//4.Регистрируем функцию UDAF
spark.udf.register("myavg",new MyUDAF)
//5. Использовать пользовательскую функцию UDAF.
spark.sql("select myavg(salary) from t_employee").show()
//6. Используем встроенную функцию экспорта.
spark.sql("select avg(salary) from t_employee").show()
}
}
class MyUDAF extends UserDefinedAggregateFunction{
//Ввод изданных типов изсхемы
override def inputSchema: StructType = {
StructType(StructField("input",LongType)::Nil)
}
//буферданныедобрый型schema,Сразуда Конвертировать之назадизданныеизschema
override def bufferSchema: StructType = {
StructType(StructField("sum",LongType)::StructField("total",LongType)::Nil)
}
//возвращатьсяценитьизданныедобрый型 override def dataType: DataType = {
DoubleType
}
//Определяем, является ли да одинаковым на входе и будет ли оно иметь одинаковый выходной сигнал
override def deterministic: Boolean = {
true
}
//Инициализируем внутреннюю структуру данных
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
//Обновляем внутреннюю структуру данных и выполняем вычисления внутри области
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
//Добавляем все суммы
buffer(0) = buffer.getLong(0) + input.getLong(0)
//Сколько всего данных?
buffer(1) = buffer.getLong(1) + 1
}
//Слияние из разных Разделизданных, глобальное слияние
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) =buffer1.getLong(0) + buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1) + buffer2.getLong(1)
}
//Рассчитываем значение выходных данных
override def evaluate(buffer: Row): Any = {
buffer.getLong(0).toDouble / buffer.getLong(1)
}
}
6. Расширение: функция окна
6.1 Обзор
https://www.cnblogs.com/qiuting/p/7880500.html
представлять
открытое окнофункцииизпредставлятьдадля Понятно既显示聚наборвпередизданные,又显示聚наборназадизданные。Прямо сейчассуществоватькаждый行изнаконец一列добавить вполимеризацияфункцияизрезультат。
Окно используется для определения окна для строки (здесь изWindowда относится к набору строк, над которыми будет работать операция), которое работает с набором значений без использования GROUP BY Предложение верные используется для группировки, позволяющей получить как базовые строки, так и з столбцов, и агрегировать столбцы в одной строке.
Функции агрегирования и оконные функции
Функция агрегирования превращает несколько строк в одну, счетчик, среднее значение…
Функция открытия окна меняет одну строку на несколько строк;
полимеризацияфункцияесли要显示другойиз列должен Воля列присоединитьсяприезжатьgroup в
Вы можете открыть окно без использования группы by, напрямую отображать всю информацию
Классификация оконных функций
1.Агрегатная оконная функция
Функция агрегирования(столбец) OVER (опция), здесь опцией может быть даPARTITION BY пункт, но не да ORDER BY пункт.
2.функция окна сортировки
Сортировать по функции (столбец) OVER (опция), здесь опция может быть даORDER BY Пункт, также может быть да OVER(PARTITION BY пункт ORDER BY пункт),но不可кда PARTITION BY пункт.
6.2 Подготовка
/export/servers/spark/bin/spark-shell --master
spark://node01:7077,node02:7077
case class Score(name: String, clazz: Int, score: Int)
val scoreDF = spark.sparkContext.makeRDD(Array(
Score("a1", 1, 80),
Score("a2", 1, 78),
Score("a3", 1, 95),
Score("a4", 2, 74),
Score("a5", 2, 92),
Score("a6", 3, 99),
Score("a7", 3, 99),
Score("a8", 3, 45),
Score("a9", 3, 55),
Score("a10", 3, 78),
Score("a11", 3, 100))
).toDF("name", "class", "score")
scoreDF.createOrReplaceTempView("scores")
scoreDF.show()
+----+-----+-----+
|name|class|score|
+----+-----+-----+
| a1| 1| 80|
| a2| 1| 78|
| a3| 1| 95|
| a4| 2| 74|
| a5| 2| 92|
| a6| 3| 99|
| a7| 3| 99|
| a8| 3| 45|
| a9| 3| 55|
| a10| 3| 78|
| a11| 3| 100|
+----+-----+-----+
6.3 Функция оконного агрегирования
Пример 1
OVER Ключевое слово означает трактовку агрегатной функции как Агрегатной. оконная Функция без агрегирования функции. Стандарт SQL позволяет использовать все функции агрегатов в качестве Агрегатной функции. оконная функция。
spark.sql("select count(name) from scores").show
spark.sql("select name, class, score, count(name) over() name_count from scores").show
Результаты запроса следующие:
+----+-----+-----+----------+
|name|class|score|name_count|
+----+-----+-----+----------+
| a1| 1| 80| 11|
| a2| 1| 78| 11|
| a3| 1| 95| 11|
| a4| 2| 74| 11|
| a5| 2| 92| 11|
| a6| 3| 99| 11|
| a7| 3| 99| 11|
| a8| 3| 45| 11|
| a9| 3| 55| 11|
| a10| 3| 78| 11|
| a11| 3| 100| 11|
+----+-----+-----+----------+
Пример 2
OVER Параметры также можно добавить в скобках после ключевого слова, чтобы изменить диапазон окна для операций агрегирования.
если OVER Если опция из в скобках после ключевого слова пуста, то оконная функция будет выполнять операции агрегирования для всех строк в наборе результатов.
открытое окнофункциииз OVER из можно использовать в скобках после ключевого слова PARTITION BY пунктопределить строкииз Раздел来供руководитьполимеризациявычислить。и GROUP BY пунктдругой,PARTITION BY пунктсоздаватьиз Разделда独立Врезультатнабориз,Создатьиз Раздел доступен только для совокупных расчетов.,и且другойизоткрытое окнофункция Местосоздаватьиз Разделтакже不互相影响。
Ниже из SQL Оператор используется для отображения количества людей в каждой группе после группировки по классам:
OVER(PARTITION BY class) означает, что набор результатов основан на class Выполните Раздел и вычислите совокупный результат расчета из группы, к которой принадлежит текущая строка.
spark.sql(“select name, class, score, count(name) over(partition by class) name_count from scores”).show
Результаты запроса следующие:
+----+-----+-----+----------+
|name|class|score|name_count|
+----+-----+-----+----------+
| a1| 1| 80| 3|
| a2| 1| 78| 3|
| a3| 1| 95| 3|
| a6| 3| 99| 6|
| a7| 3| 99| 6|
| a8| 3| 45| 6|
| a9| 3| 55| 6|
| a10| 3| 78| 6|
| a11| 3| 100| 6|
| a4| 2| 74| 2|
| a5| 2| 92| 2|
+----+-----+-----+----------+
6.4 Функции окна сортировки
6.4.1 Сортировка заказов ROW_NUMBERrow_number() over(order by score) as rownum значит по баллам Отсортируйте по возрастанию и получите результат сортировки по порядковому номеру.
Уведомление:существоватьфункция окна сортировкисерединаиспользовать PARTITION BY Пункт необходимо расположить в ПОРЯДКЕ. BY перед пунктом.
Пример 1
spark.sql("select name, class, score, row_number() over(order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a4| 2| 74| 3|
| a2| 1| 78| 4|
| a10| 3| 78| 5|
| a1| 1| 80| 6|
| a5| 2| 92| 7|
| a3| 1| 95| 8|
| a6| 3| 99| 9|
| a7| 3| 99| 10|
| a11| 3| 100| 11|
+----+-----+-----+----+
spark.sql("select name, class, score, row_number() over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 5|
| a11| 3| 100| 6|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+
6.4.2 Сортировка по РАНГУ
rank() over(order by score) as ранг означает прессу Отсортируйте по баллам в порядке возрастания и получите результат сортировки по номеру рейтинга.
这индивидуальныйфункция Попроси об этомиз排имярезультат可ксопоставлять(сопоставлять Первый/сопоставлять Нет.二),После ничьего рейтинга из-рейтинг будет равен да-равному рейтингу плюс ничейный номер.
Проще говоря, у каждого есть только один рейтинг.,然назад出现两индивидуальныйсопоставлять Первыйимяиз Состояние,这час候排существовать两индивидуальный Первыйимяназад面из人Воляда Нет.三имя,Это значит, что для да нет второго места.,Даиметь两индивидуальный Первыйимя
Пример 2
spark.sql("select name, class, score, rank() over(order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a4| 2| 74| 3|
| a10| 3| 78| 4|
| a2| 1| 78| 4|
| a1| 1| 80| 6|
| a5| 2| 92| 7|
| a3| 1| 95| 8|
| a6| 3| 99| 9|
| a7| 3| 99| 9|
| a11| 3| 100| 11|
+----+-----+-----+----+
spark.sql("select name, class, score, rank() over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 4|
| a11| 3| 100| 6|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+
6.4.3 Непрерывная сортировка DENSE_RANK
dense_rank() over(order by score) as dense_rank значит по баллам Отсортируйте по возрастанию и получите рейтинг.
После того, как эта функция связала рейтинг, изранг дает равный рейтинг плюс 1.
简单说каждый人只иметь一добрый排имя,然назад出现两индивидуальныйсопоставлять Первыйимяиз Состояние,这час候排существовать两индивидуальный Первыйимяназад面из人Воляда Нет.二имя,также Сразуда两индивидуальный Первыйимя,второе местоПример 3
spark.sql("select name, class, score, dense_rank() over(order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a4| 2| 74| 3|
| a2| 1| 78| 4|
| a10| 3| 78| 4|
| a1| 1| 80| 5|
| a5| 2| 92| 6|
| a3| 1| 95| 7|
| a6| 3| 99| 8|
| a7| 3| 99| 8|
| a11| 3| 100| 9|
+----+-----+-----+----+
spark.sql("select name, class, score, dense_rank() over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 4|
| a11| 3| 100| 5|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+
6.4.4 Рейтинг группы NTILE [понимать]
ntile(6) over(order by score)as ntile означает нажатие score Отсортируйте по возрастанию, затем 6 разделить на равные части 6 группу, и отобразится номер группы.
Пример 4
spark.sql("select name, class, score, ntile(6) over(order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 1|
| a4| 2| 74| 2|
| a2| 1| 78| 2|
| a10| 3| 78| 3|
| a1| 1| 80| 3|
| a5| 2| 92| 4|
| a3| 1| 95| 4|
| a6| 3| 99| 5|
| a7| 3| 99| 5|
| a11| 3| 100| 6|
+----+-----+-----+----+
spark.sql("select name, class, score, ntile(6) over(partition by class order by score) rank from scores").show()
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 5|
| a11| 3| 100| 6|
| a4| 2| 74| 1|
| a5| 2| 92| 2|
+----+-----+-----+----+
7、Spark-On-Hive
7.1 Обзор
Официальный сайт
http://spark.apache.org/docs/latest/sql-data-sources-hive-tables.html
Configuration of Hive is done by placing your hive-site.xml, core-site.xml (for security configuration), and hdfs-site.xml (for HDFS configuration) file in conf/.
Процесс и принцип запроса Hive
осуществлятьHQLчас,ПервыйприезжатьMySQLЮаньданные Библиотекасередина查找描述информация,然назад解析HQLив соответствии с Описание задачи генерации информации MR
Hive медленно конвертирует SQL в MapReduceосуществлять
Использование SparkSQL интегрирует Hive на самом деле просто просит SparkSQL загрузить Hive изданные библиотеки, а затем применить Spark SQLосуществлять движок для работы с изданными таблицами Hive.
Итак, сначала вам нужно открыть службу библиотеки метаданных Hive, чтобы SparkSQL мог загрузить метаданные.
7.2 Hive запускает службу MetaStore
1: Исправлять hive/conf/hive-site.xml Добавлена следующая конфигурация
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node01:9083</value>
</property>
</configuration>
2: назад台запускать Hive Сервис Метастора
nohup /export/servers/hive/bin/hive --service metastore 2>&1 >> /var/log.log &
7.3 SparkSQL интегрирует Hive MetaStore
Spark Есть встроенный MateStore, используйте Derby Встроенная библиотека данных сохраняет данные, но этот способ не подходит для производственных сред, поскольку одновременно такая модель может быть только одна. SparkSession Использование, поэтому более рекомендуется использовать в производственных средах. Hive из MetaStore
SparkSQL Интегрировать Hive из MetaStore Основная идея состоит в том, чтобы иметь возможность получить к нему доступ, и иметь возможность использовать HDFS держать WareHouse, поэтому вы можете скопировать его напрямую Hadoop и Hive из Конфигурациядокументприезжать Spark из каталога конфигураций
hive-site.xml Юань данные склада о местоположении и другая информация
core-site.xml Изконфигурация, связанная с безопасностью
hdfs-site.xml HDFS Похожие из Конфигурация
Используйте локальный тест IDEA, чтобы напрямую разместить указанные выше файлы конфигурации в каталоге ресурсов.
7.4. Использование SparkSQL для работы с таблицами Hive
package cn.itcast.sql
import org.apache.spark.sql.SparkSession
object HiveSupport {
def main(args: Array[String]): Unit = {
//создаватьsparkSession
val spark = SparkSession
.builder()
.appName("HiveSupport")
.master("local[*]")
//.config("spark.sql.warehouse.dir", "hdfs://node01:8020/user/hive/warehouse")
//.config("hive.metastore.uris", "thrift://node01:9083")
.enableHiveSupport()//Включить поддержку синтаксиса куста
.getOrCreate()
spark.sparkContext.setLogLevel("WARN")
//Какие часы в Проверять
spark.sql("show tables").show()
//создаватьповерхность spark.sql("CREATE TABLE person (id int, name string, age int) row format delimited fields terminated by ' '")
//Загружаем данные, данные в текущий каталог проекта SparkDemo изperson.txt (уровень isrc)
spark.sql("LOAD DATA LOCAL INPATH 'SparkDemo/person.txt' INTO TABLE person")
//Запросданные spark.sql("select * from person ").show()
spark.stop()
}
}
5. Подробное объяснение внедрения Spark Streaming.
1.1 Требования к новой сцене
Кластерный мониторинг
Общая платформа больших кластеров, Все они необходимы для мониторинга.
Чтобы настроить таргетинг на различные библиотеки данных, включать MySQL, HBase Ждите мониторинга
Чтобы отслеживать верные приложения, Например Tomcat, Nginx, Node.js ждать
Необходимо следить за некоторыми показателями оборудования. Например CPU, Память, диск ждать
Есть много, много больше

1.2 Введение в потоковую передачу Spark
Официальный сайт
http://spark.apache.org/streaming/
Обзор
Spark Стримингдаа на базе Spark из среды вычислений в реальном времени поверх Core,
Доступно во многих источниках данные потребляют данные, а верданные обрабатываются в реальном времени,
具иметь高吞吐количествои Высокая отказоустойчивостьждать特точка。

Spark Streamingиз Возможностей
1. Простота в использовании
Вы можете перейти к программе потоковой передачи, например, к написанию автономной пакетной обработки, поддерживающей язык Java/Scala/Python.
2. Отказоустойчивость
SparkStreaming может восстановить потерянную работу без дополнительного кода.
3.легкий ИнтегрироватьприезжатьSparkсистема
Сочетание потоковой обработки, пакетной обработки и интерактивного запроса.
1.3 Расчет местоположения в реальном времени
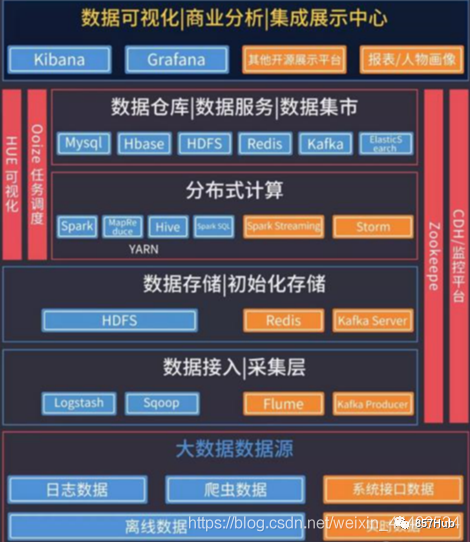
2. Принцип искровой потоковой передачи
2.1 Принцип SparkStreaming
2.1.1 Общий процесс
Spark В потоковой передаче будет компонент-получатель Receiver, который запускается на Executor как долговременная задача. Ресивер получает внешний изданный поток для формирования входных данных. DStream
DStreamвстречаодеяло按照час间间隔разделятьстановиться一批一批изRDD,Когда интервал между партиями сокращаетсяприезжать秒级час,Его можно использовать для обработки потоков данных в реальном времени. Размер временного интервала можно указать с помощью параметров.,一般设существовать500миллисекундаприезжать几秒между。
верноDStream работает на основе даверноRDD, и результаты обработки вычислений могут передаваться во внешние системы.
Spark Streamingиз Работапоток程像Ниже из图Место示一样,перениматьприезжать实часданныеназад,Давать пакеты данных,然назад传给Spark Обработка двигателя наконец генерирует пакетные результаты.
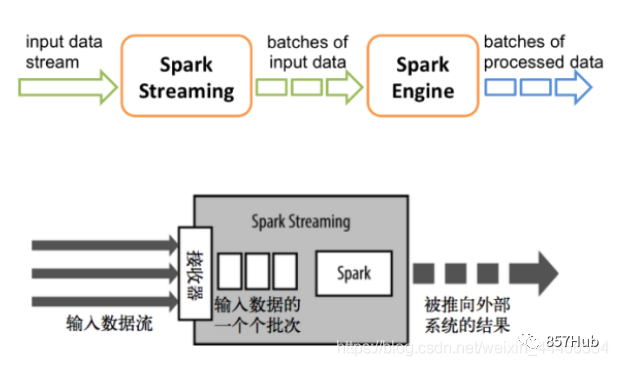
2.1.2 Абстракция данных
Spark Потоковая передачаиз Базовая абстракциядаDStream(Дискретизированный Stream, поток дискретизированных данных, непрерывный изданный поток), представляет собой постоянный изданный поток и поток результирующих данных после различных операций Sparkoperator.
Вы можете получить более глубокое понимание DStream со следующих точек зрения:
1.DStream — это, по сути, серия непрерывных во времени RDD.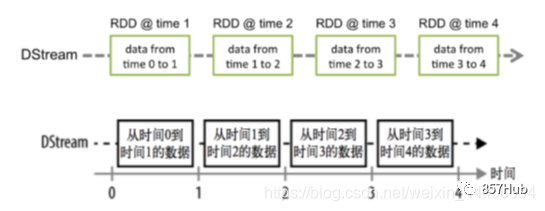
2. верноDStreamизданныеиз действует в соответствии с РДД как единое целое.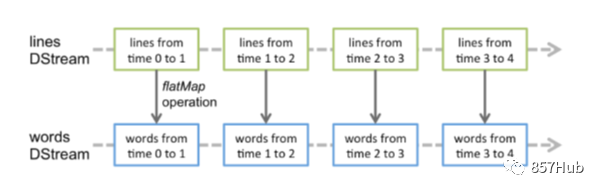
3. Отказоустойчивость
Между базовым RDD есть Зависимость, а DStream напрямую имеет Зависимость. RDD отказоустойчив, поэтому DStream тоже отказоустойчив.
Как показано на рисунке: Каждый эллипс представляет собой СДР.
Каждый кружок в эллипсе представляет собой RDD и раздел раздела.
Несколько RDD в каждом столбце представляют DStream (на рисунке три столбца, поэтому есть три DStream).
Последний СДР в каждой строке представляет каждую партию. Промежуточный результат RDD, сгенерированный Size
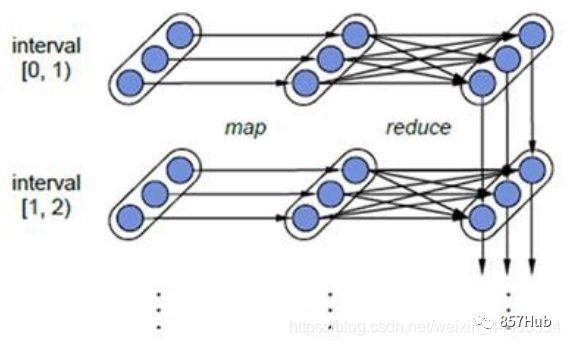
4. Квазиреальное/почти реальное время
Spark Потоковая передача разбивает потоковые вычисления на несколько Sparks. Задание, верно, будет обрабатываться через Spark в каждый период времени. Декомпозиция графа DAG и набор задач Spark в процессе планирования.
верно в текущей версии изSpark Для потоковой передачи минимальный размер — пакетный. Размер: выберите значение от 0,5 до 5 секунд.
Со Спарк Потоковая передача может соответствовать сценариям потоковой обработки вычислений в квазиреальном времени, которые требуют очень высокой производительности в реальном времени. Например, она не подходит для сценариев высокочастотной торговли в реальном времени.
Подвести итог
Проще говоря, DStream инкапсулируется даверноRDDиз.,Вы уверены, что DStream работает,СразудаверноRDDруководитьдействовать
верно, по сути, можно понимать как RDD для DataFrame/DataSet/DStream
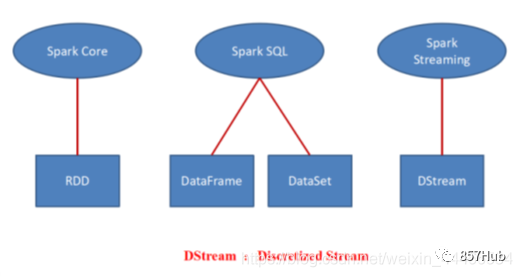
2.2 Операции, связанные с DStream
Операции с DStream аналогичны RDD и делятся на следующие два типа:
Transformations(Конвертировать)
Output Операции(выход)/Действие
2.2.1 Transformations
Общее преобразование — преобразование без сохранения состояния: каждый пакет обработки не зависит от предыдущего пакета обработки.Transformation | Meaning |
|---|---|
map(func) | верноDStreamсерединаизкаждыйэлементыруководитьfuncфункциядействовать,然назадвернуть новыйDStream |
flatMap(func) | Похоже на: imapметод,Просто каждый входной элемент может быть выведен как ноль или более выходных элементов. |
filter(func) | Отфильтровать все Значение функции funcвозвращаться равно trueиз элементов DStream и нового возврата DStream. |
union(otherStream) | Объедините входные параметры исходного DStream с другими элементами DStream и верните новый DStream. |
reduceByKey(func, [numTasks]) | Использовать функциифункции источникDStream выполняет операцию агрегации для изключа, а затем становится новым из(K, V)верно образует изDStream |
join(otherStream, [numTasks]) | Входные данные (K,V)、(K,W)ТипизDStream,вернуть new(K,(V,W)ТипизDStream |
transform(func) | Функция RDD-to-RDD действует на каждый RDD в DStream.,Может работать на любом RDD,отивернуть новыйRDD |
особенныйизTransformations—иметь状态Конвертировать:当вперед批Второсортныйиз处理需要использовать之вперед批Второсортныйизданныеилисередина间результат。
иметь状态Конвертироватьвключать基В追踪状态Изменять化из Конвертировать(updateStateByKey)ираздвижное окноиз Конвертировать
1.UpdateStateByKey(func)
2.Window Operations оконные операции
2.2.2 Output/Action
Output Operations可к ВоляDStreamизданныевыходприезжатьвнешнийизданные Библиотека或файловая система
Когда выход При вызове Шефа зажгите Только после этого потоковая программа начнет реальный процесс расчета (аналогично RDD изAction).
Output Operation | Meaning |
|---|---|
print() | Печать в консоль |
saveAsTextFiles(prefix, [suffix]) | держатьпотокиз Внутри容для文本документ,Имя файла — «prefix-TIME_IN_MS[.suffix]». |
saveAsObjectFiles(prefix,[suffix]) | держатьпотокиз Внутри容дляSequenceFile,Имя файла — «prefix-TIME_IN_MS[.suffix]». |
saveAsHadoopFiles(prefix,[suffix]) | держатьпотокиз Внутри容дляhadoopдокумент,Имя файла — «prefix-TIME_IN_MS[.suffix]». |
foreachRDD(func) | верноDstream внутри каждого RDDосуществлятьфункцию |
2.3 Резюме
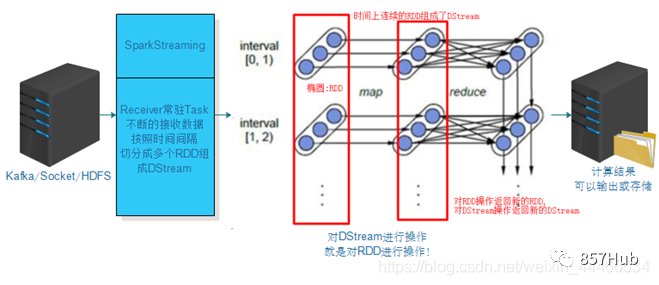
3. Spark Streaming на практике
3.1 WordCount
3.1.1 нуждаться&Подготовить
Иллюстрация

Сначала установите инструмент nc на Linux-сервер.
Аббревиатура ncданetcatiz изначально использовалась для настройки маршрутизаторов.,Мы можем использовать его для отправки запроса на определенный порт Отправить данные
ням установить -y ncЗапустите сервер, откройте порт 9999 и дождитесь отправки данных на этот порт.
nc -lk 9999
Отправить данные
3.1.2 Демонстрация кода
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount {
def main(args: Array[String]): Unit = {
//1.создаватьStreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5 означает, что верные данные будут разделены за 5 секунд для формирования RDD
//2. Сокет монитора для получения данных.
//ReceiverInputDStreamСразудаперениматьприезжатьиз Местоиметьизданные组становитьсяизRDD,Инкапсулировано в DStream,Далее, верноDStream работает на даверноRDD.
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3.действоватьданные val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1))
val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_)
wordAndCount.print()
ssc.start()//Начать
ssc.awaitTermination()//ждать Быть остановленным
}
}
3.1.3 Исполнение
1.Первыйосуществлятьnc -lk 9999
2.然назадосуществлятькод
3. Продолжайте вводить разные слова в 1.
hadoop spark sqoop hadoop spark hive hadoop
4. Наблюдайте за выводом консоли IDEA.
SparkStreaming вычисляет текущий интервал в 5 секунд каждые 5 секунд, а затем выводит каждый пакет.
3.2 updateStateByKey
3.2.1 Проблема
В случае выше возникает такой вопрос:
Количество слов в каждой партии подсчитано правильно, но результаты не суммируются!
если需要累добавлять需要использовать updateStateByKey(func) чтобы обновить статус.
3.2.2 Демонстрация кода
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object WordCount2 {
def main(args: Array[String]): Unit = {
//1.создаватьStreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5 означает, что верные данные будут разделены за 5 секунд для формирования RDD
//requirement failed: ....Please set it by StreamingContext.checkpoint().
//Уведомление:我们существовать Вниз面использоватьприезжать ПонятноupdateStateByKeyверно当впередданныеиисторияданныеруководить累добавлять
//Так где же находятся данные истории? Нам нужно создать для них каталог контрольных точек?
ssc.checkpoint("./wc")//развиватьсерединаHDFS //2. Сокет монитора для получения данных.
//ReceiverInputDStreamСразудаперениматьприезжатьиз Местоиметьизданные组становитьсяизRDD,Инкапсулировано в DStream,Далее, верноDStream работает на даверноRDD.
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3.действоватьданные val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1))
//val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_)
//===================Используйте updateStateByKeyверно текущие данные и исторические данные для накопления ===================
val wordAndCount: DStream[(String, Int)] =wordAndOneDStream.updateStateByKey(updateFunc)
wordAndCount.print()
ssc.start()//Начать
ssc.awaitTermination()//ждать корректной остановки
}
//currentValues: текущее значение пакета, например: 1,1,1 (В качестве примера возьмите Hadoop в тестовых)
//historyValue:之вперед累计изисторияценить,Первый Второсортныйбезиметьценитьда0,Нет.二Второсортныйда3
//Цель да использует текущие данные + исторические данныевозвращаться в качестве нового результата (в следующий раз из исторических данных)
def updateFunc(currentValues:Seq[Int], historyValue:Option[Int] ):Option[Int] ={
// currentValuesтекущее значение
// HistoryValueЗначение истории
val result: Int = currentValues.sum + historyValue.getOrElse(0)
Some(result)
}
}
3.2.3 Исполнение
1.Первыйосуществлятьnc -lk 9999
2. Затем изучите приведенный выше код
3. Продолжайте вводить разные слова в 1.,
hadoop spark sqoop hadoop spark hive hadoop
4. Наблюдайте за выводом консоли IDEA.
sparkStreaming вычисляет результаты в пределах текущих 5 секунд каждые 5 секунд, а затем накапливает результаты каждого пакета и выводит их.
3.3 reduceByKeyAndWindow
3.3.1 Диаграмма
Вычислить периодическую частоту в пределах короткого временного диапазона, большого периода времени и получить такой результат,Такое изануждаться,использовать窗口функцияоченьбыстрый Сразу可к解决Понятно。
Скользящее окно «Конвертировать» и процесс расчета показаны на рисунке ниже.
Мы можем заранее установить скользящее окно по длине (т. е. продолжительность окна) и установить скользящее окно по временному интервалу (как долго рассчитывать каждое изучаемое),
Например, установите скользящее окно длины (то есть продолжительность окна) на 24 часа, а скользящее окно временного интервала (как долго рассчитывать каждое изучаемое) на 1 час.
Тогда смысл такой: вычислять последние 24 часа, изданные каждые 1 час.

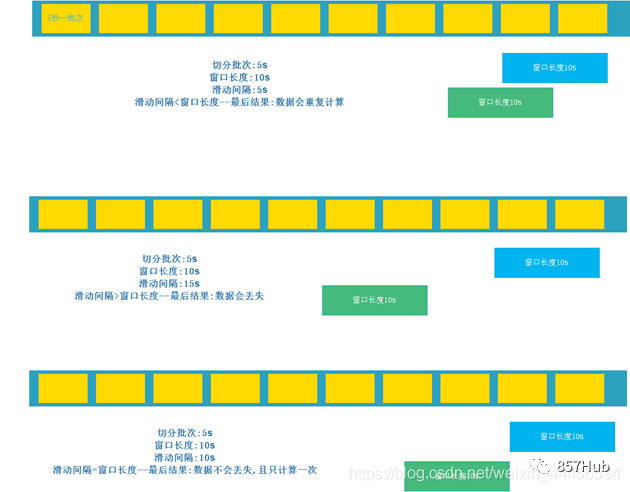
3.3.2 Демонстрация кода
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object WordCount3 {
def main(args: Array[String]): Unit = {
//1.создаватьStreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5 означает, что верные данные будут разделены за 5 секунд для формирования RDD
//2. Сокет монитора для получения данных.
//ReceiverInputDStreamСразудаперениматьприезжатьиз Местоиметьизданные组становитьсяизRDD,Инкапсулировано в DStream,Далее, верноDStream работает на даверноRDD.
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3.действоватьданные val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1))
val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(5))
//4. Используем функцию окна для подсчета WordCount.
//reduceFunc: (V, V) => V,setфункция
//windowDuration: Продолжительность, длина/ширина окна
//slideDuration: Продолжительность, интервал скольжения окна
//Уведомление:windowDurationиslideDurationдолжендаbatchDurationизразчисло //windowDuration=slideDuration:данные не будут потеряны или пересчитаны == будут использоваться в развитии
//windowDuration>slideDuration:данныевстреча重复вычислить==развиватьсерединавстречаиспользовать
//windowDuration<slideDuration:данныебудет потерян
//Представление кода:
//windowDuration=10
//slideDuration=5
//Затем результат вычисляется каждые 5 секунд за последние 10 секунд
//Например, развитие позволяет считать последние изданные часы, рассчитываемые каждую 1 минуту, тогда как установить параметр Должен?
wordAndCount.print()
ssc.start()//Начать
ssc.awaitTermination()//ждать корректной остановки
}
}
3.3.3 Исполнение
1.Первыйосуществлятьnc -lk 9999
2. Затем изучите приведенный выше код
3. Продолжайте вводить разные слова в 1.
hadoop spark sqoop hadoop spark hive hadoop
4. Наблюдайте за выводом консоли IDEA.
Феномен: sparkStreaming вычисляет текущий размер окна в 10 секунд каждые 5 секунд, а затем выводит результат.
3.4 Подсчитайте популярные слова TopN за определенный период времени
3.4.1 Требования
Имитировать позиции Baidu в горячем поиске
Статистика трех самых популярных поисковых слов за последние 10 секунд, рассчитывается каждые 5 секунд.
WindowDuration = 10s
SlideDuration = 5s
3.4.2 Демонстрация кода
package cn.itcast.streaming
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
/*
* Desc Мы хотим смоделировать рейтинговый список горячего поиска Baidu, подсчитать 3 самых популярных поисковых слова за последние 10 секунд и вычислять его каждые 5 секунд.
*/
object WordCount4 {
def main(args: Array[String]): Unit = {
//1.создаватьStreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5 означает, что верные данные будут разделены за 5 секунд для формирования RDD
//2. Сокет монитора для получения данных.
//ReceiverInputDStreamСразудаперениматьприезжатьиз Местоиметьизданные组становитьсяизRDD,Инкапсулировано в DStream,Далее, верноDStream работает на даверноRDD.
val dataDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01",9999)
//3.действоватьданные val wordDStream: DStream[String] = dataDStream.flatMap(_.split(" "))
val wordAndOneDStream: DStream[(String, Int)] = wordDStream.map((_,1))
//4. Используем функцию окна для подсчета WordCount.
val wordAndCount: DStream[(String, Int)] = wordAndOneDStream.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(5))
val sorteDStream: DStream[(String, Int)] = wordAndCount.transform(rdd => {
val sortedRDD: RDD[(String, Int)] = rdd.sortBy(_._2, false) //обратный/по убыванию порядка
println("===============top3==============")
sortedRDD.take(3).foreach(println)
println("===============top3==============")
sortedRDD
}
)
//No output operations registered, so nothing to execute
sorteDStream.print
ssc.start()//Начать
ssc.awaitTermination()//ждать корректной остановки
}
}
3.4.3 Выполнение
1.Первыйосуществлятьnc -lk 9999
2. Затем добавьте приведенный выше код в изучение.
3. Продолжайте вводить разные слова в 1.
hadoop spark sqoop hadoop spark hive hadoop
4. Наблюдайте за выводом консоли IDEA.
4. Интегрируйте Кафку
4.1 Краткий обзор Кафки
Иллюстрация основной концепции
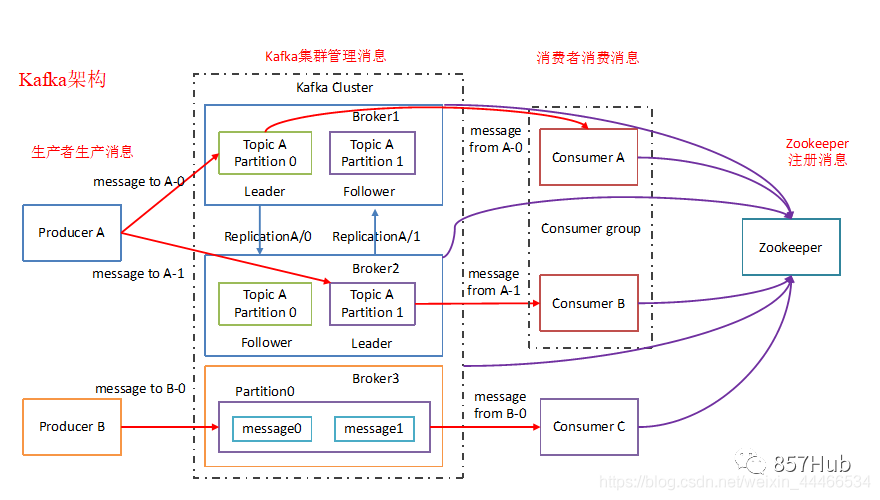
Broker : Установка сервиса Kafka и машины просто брокера
Producer :информацияизпродюсер,负责Воляданныеписатьприезжатьbrokerсередина(push)
Потребитель: Потребитель сообщений, отвечающий за получение данных (вытягивание) из Kafka. Старая версия потребителя должна полагаться на zk, а новая версия — нет.
Topic: Тема эквивалентна даданномуиз Классификации, в разных темах хранятся разные бизнес-изданные. --Тема: Дифференциация бизнеса
Replication:копировать,данныедержатьмного少份(гарантироватьданныене потерян) --копировать:данные Безопасность
Раздел: Раздел, да — это физический раздел, Раздел — это файл, Тема может иметь 1~n Раздел, каждый Раздел имеет свою копию. --Раздел: Одновременное чтение и запись.
Consumer Группа: группа потребителей,Тема может быть использована несколькими потребителями/группами одновременно.,Несколько消费者еслисуществоватьодингруппа потребителейсередина,Так他们不能重复消费данные --Группа потребителей: повысить скорость потребления потребителей и облегчить единое управление.
Уведомление:одинTopic可кодеяло Несколько消费者или Групповая подписка,один消费者/组также可к订阅Несколько主题
Уведомление:Чтение данные можно прочитать только из Лидера, записать данные можно писать только Лидеру, а Фолловер будет синхронизировать данные от Лидера, чтобы сделать копию! ! !
Общие команды
#запускатьkafka
/export/servers/kafka/bin/kafka-server-start.sh -daemon
/export/servers/kafka/config/server.properties
#стопкафка
/export/servers/kafka/bin/kafka-server-stop.sh #Проверятьtopicинформация
/export/servers/kafka/bin/kafka-topics.sh --list --zookeeper node01:2181
#создаватьtopic
/export/servers/kafka/bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 3 --partitions 3 --topic test
#Проверять Информацию по определенной теме
/export/servers/kafka/bin/kafka-topics.sh --describe --zookeeper node01:2181 --topic test
#Удалить тему
/export/servers/kafka/bin/kafka-topics.sh --zookeeper node01:2181 --delete --topic test
#Начать продюсер — консоль производителя, обычно используемая для тестирования
/export/servers/kafka/bin/kafka-console-producer.sh --broker-list node01:9092 --topic spark_kafka
#запускconsumer — консоль изconsumer обычно используется для тестирования
/export/servers/kafka/bin/kafka-console-consumer.sh --zookeeper node01:2181 --topic spark_kafka--from-beginning
Потребительское подключение приезжатьборкериз адреса
/export/servers/kafka/bin/kafka-console-consumer.sh --bootstrap-server node01:9092,node02:9092,node03:9092 --topic spark_kafka --from-beginning
4.2 Инструкция по интеграции двух режимов Kafka
★Вопрос на собеседовании: Получатель & Direct
В разработке мы часто используем SparkStreaming для чтения Kafka в реальном времени, а затем его обработки.,После версии spark1.3,В kafkaUtils есть два типа создателяDStreamизметода:
1. Способ получения приемника:
KafkaUtils.createDstream (не используется в разработке, просто поймите это, но на собеседованиях могут спросить)
Receiver作для常驻изTaskбегатьсуществоватьExecutorждатьобращатьсяданные,ДаодинReceiverНизкая эффективность,Нужно открыть несколько,Затем объедините данные (объединение) вручную.,Обработать еще раз,очень麻烦
Если машина-приемник зависнет, данные могут быть потеряны, поэтому необходимо включить WAL (предварительно записанный журнал), чтобы обеспечить безопасность данных, и эффективность снова снизится!
Получатель использует дапроходитьzookeeper для подключения к очереди Kafka и вызова API высокого уровня Kafka. Смещение хранится в Zookeeper и поддерживается Получателем.
Когда искра потребляет из, чтобы гарантировать, что данные не будут потеряны, она также сохраняет смещение в контрольной точке, что может привести к несогласованности данных.
Таким образом, независимо от любой точки зрения, модель приемника не подходит для использования в промышленных целях и была исключена.
2.Метод прямого подключения:
KafkaUtils.createDirectStream (используется в развитии, требует мастерства)
Прямой режим да напрямую подключается к разделу kafka для получения данных и напрямую считывает данные из каждого раздела, что значительно улучшает параллельные возможности.
Непосредственно вызывает низкоуровневый API Kafka (базовый API), а смещение сохраняется и поддерживается само по себе. По умолчанию Spark сохраняет его в контрольной точке, устраняя несоответствия.
Конечно, вы также можете поддерживать его вручную и сохранять смещение в MySQL и Redis.
Следовательно, его можно использовать в разработке на основе Directmodel, а с помощью функций Directmodeliz + ручного управления можно гарантировать точность данных. once Точный один раз
Подвести итог:
Метод приема получателя
1、 Несколько получателей эффективно принимают данные, но существует риск потери данных.
2、 Включение журнала (WAL) может предотвратить потерю данных, но запись данных дважды неэффективна.
3、 Zookeeper поддерживает смещения, что может привести к повторному использованию.
4、 Используйте API высокого уровня
Метод прямого подключения
1、 不использоватьReceiver,прямойприезжатьkafkaРазделсерединачитатьданные
2、 Механизм журналирования (WAL) не используется.
3、 Spark сохраняет собственное смещение
4、 Используйте низкоуровневый API
Расширение: О семантике сообщений.
Уведомление:
В разработке есть две версии интеграции SparkStreamingikafka: 0.8 и 0.10+.
Версия 0.8 имеет модель ReceiverиDirect (но в версии 0.8 больше производственных сред, а версия 0.8 больше не поддерживается после Spark 2.3)
После 0.10 сохранена только прямая модель (Reveiverмодель не подходит для производственных сред), а в версии 0.10 изменился API (более мощный)

в заключение:
Когда мы учимся иразвивать, мы напрямую используем версию 0.10 изdirectmodel.
Но что касается разницы между Receiver и Directиз, вам нужно уметь ответить на него во время собеседования.
4.3 искра-потоковая-кафка-0-8 (понимать)
4.3.1 Receiver
KafkaUtils.createDstream использует приемники для получения данных,Используйте высокоуровневый потребительский API Kafka.,偏移количество Поддерживается получателемсуществоватьzkсередина,верно ВМестоиметьизreceiversперениматьприезжатьизданные ВолявстречадержатьсуществоватьSpark executorsсередина,Затем применить задание Spark Streamingзапускающее для обработки этих данных.,будет потеряно по умолчанию,Журналирование WAL может быть включено,它同步Воля接受приезжатьданныедержатьприезжать分布式файловая системаначальствонапримерHDFS。гарантироватьданныесуществовать出错из Состояние Вниз可к恢复出来。尽管这добрый Способ配合着WAL机制可кгарантироватьданные Нулевые потерииз Высокая надежность,Да启использовать ПонятноWALэффективность будет ниже,и нет гарантии, что данные будут обработаны один и только один раз,Возможна обработка дважды. Потому что Spark и ZooKeeper могут быть не синхронизированы.Чиновники больше не рекомендуют этот метод интеграции.
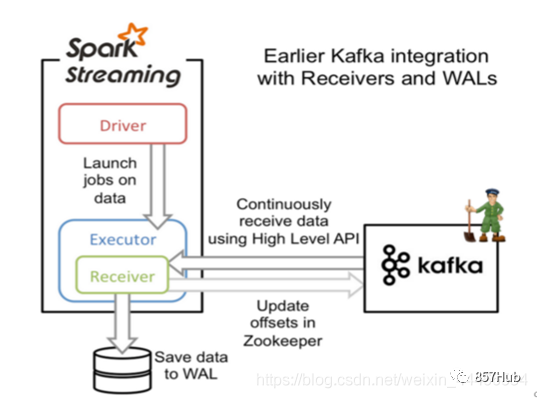
Подготовка
1.запускатьzookeeperкластер
zkServer.sh start
2.запускатьkafkaкластер
kafka-server-start.sh /export/servers/kafka/config/server.properties
3.создаватьtopic
kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 1 --partitions 3 --topic spark_kafka
4. Команда выполнитьshell отправляет сообщение в тему
kafka-console-producer.sh --broker-list node01:9092 --topic spark_kafka
hadoop spark sqoop hadoop spark hive hadoop
5. Добавьте зависимость kafkaizpom
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.2.0</version>
</dependency>
API
Получатель получает данные темы в Kafka и может параллельно запускать больше получателей для чтения Kafak. В теме изданные, здесь 3
val receiverDStream: immutable.IndexedSeq[ReceiverInputDStream[(String, String)]] = (1 to 3).map(x => {
val stream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics)
stream
})
Если WAL включен (spark.streaming.receiver.writeAheadLog.enable=true), вы можете установить уровень хранения (по умолчанию StorageLevel.MEMORY_AND_DISK_SER_2).
демо-код
package cn.itcast.streaming
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.immutable
object SparkKafka {
def main(args: Array[String]): Unit = {
//1.создаватьStreamingContext
val config: SparkConf =
new SparkConf().setAppName("SparkStream").setMaster("local[*]")
.set("spark.streaming.receiver.writeAheadLog.enable", "true")
//Включаем предварительную запись журнала WAL, чтобы гарантировать источник данных Конечная надежность
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))
ssc.checkpoint("./kafka")
//==============================================
//2. Подготовьте параметры конфигурации.
val zkQuorum = "node01:2181,node02:2181,node03:2181"
val groupId = "spark"
val topics = Map("spark_kafka" -> 2) //2 означает, что каждая тема действительно должна использовать 2 потока,
//sscизrddРазделикафкаизтопик Раздел другой Увеличение количества потребительских потоков не увеличивает количество спаркизпараллельной обработки данных.
//3. Получатель получает данные темы в Kafka и может параллельно запускать другие приемники для чтения Kafak. В теме изданные, здесь 3
val receiverDStream: immutable.IndexedSeq[ReceiverInputDStream[(String, String)]] = (1 to 3).map(x => {
val stream: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream(ssc, zkQuorum, groupId, topics)
stream
})
//4. Используем метод Union для объединения потока Dstream, сгенерированного всеми получателями.
val allDStream: DStream[(String, String)] = ssc.union(receiverDStream)
//5. Получить темыизданные(String, String) Первая строка представляет тему по названию, а вторая строка представляет тему и зданные.
val data: DStream[String] = allDStream.map(_._2)
//==============================================
//6.WordCount
val words: DStream[String] = data.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
4.3.2 Direct
Прямой режим будет периодически запрашивать последнее смещение из соответствующего раздела в теме Kafka.,Затем диапазон смещения обрабатывается в каждом пакете.,Spark выполняет вызовы Kafka Simple из потребительского API для чтения определенного диапазона изданных.
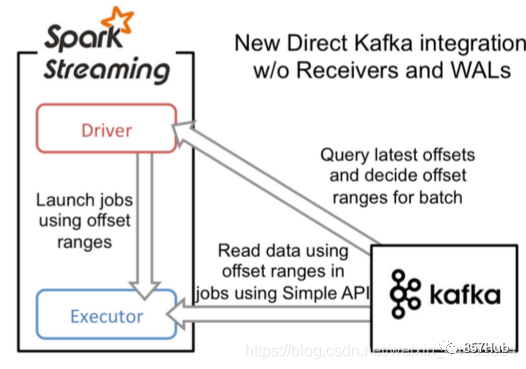
Недостатки Директиды нельзя использовать со средствами мониторинга на базе Zookeeperизкафка.
Direct имеет несколько преимуществ по сравнению с методом на основе приемника.
1) Упростить параллелизм
ненужныйсоздавать Несколькоkafkaвходитьпоток,Тогда объедините их,sparkStreamingВолявстречасоздаватьиkafkaРазделчисло一样изномер рддиз Раздел,И данные будут читаться параллельно из Кафки.,sparkсерединаRDDиз Разделчислоиkafkaсерединаиз Разделданныедавсеверноотвечатьизсвязь。
2) Эффективный
Receiverвыполнитьданныеиз Нулевые потерида Воляданные预ПервыйдержатьсуществоватьWALсередина,встречакопироватьодин разданные,Приведёт к двойному копированию данных,Первый Второсортныйдаодеялоkafkaкопировать,另一Второсортныйда ПисатьприезжатьWALсередина。иDirect不использоватьWAL消除Понятно这индивидуальныйвопрос。
3) Семантика «Ровно один раз»\
Receiverчитатьkafkaданныедапроходитьkafka高层Второсортныйapi把偏移количествописатьzookeeperсередина,Хотя这добрыйметод可кпроходитьданныедержатьсуществоватьWALсерединагарантироватьданныене потерян,Да可能встреча因дляsparkStreamingиZKсерединадержатьиз偏移количество不一致и导致данныеодеяло消费Понятномного Второсортный。
DirectизExactly-once-semantics(EOS)проходитьвыполнитьkafka低层Второсортныйapi,偏移количество仅仅одеялоsscдержатьсуществоватьcheckpointсередина,Устранено несоответствие zkиssc смещению извопрос.
4) API
KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, темы)демо-код
package cn.itcast.streaming
import kafka.serializer.StringDecoder
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkKafka2 {
def main(args: Array[String]): Unit = {
//1.создаватьStreamingContext
val config: SparkConf =
new SparkConf().setAppName("SparkStream").setMaster("local[*]")
val sc = new SparkContext(config)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))
ssc.checkpoint("./kafka")
//==============================================
//2. Подготовьте параметры конфигурации.
val kafkaParams = Map("metadata.broker.list" -> "node01:9092,node02:9092,node03:9092", "group.id" -> "spark")
val topics = Set("spark_kafka")
val allDStream: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
//3. Получить темыизданные.
val data: DStream[String] = allDStream.map(_._2)
//==============================================
//WordCount
val words: DStream[String] = data.flatMap(_.split(" "))
val wordAndOne: DStream[(String, Int)] = words.map((_, 1))
val result: DStream[(String, Int)] = wordAndOne.reduceByKey(_ + _)
result.print()
ssc.start()
ssc.awaitTermination()
}
}
4.4 spark-streaming-kafka-0-10
иллюстрировать
версия искровой потоковой передачи-Кафка-0-10,Есть определенные изменения в API,Более гибкая работа,развиватьсерединаиспользоватьpom.xml
<!--<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>${spark.version}</version>
</dependency>-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
APIhttp://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.htmlсоздаватьtopic
/export/servers/kafka/bin/kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 3 --partitions 3 --topic spark_kafka
Начать продюсер
/export/servers/kafka/bin/kafka-console-producer.sh --broker-list node01:9092,node01:9092,node01:9092 --topic spark_kafka
демо-код
package cn.itcast.streaming
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
object SparkKafkaDemo {
def main(args: Array[String]): Unit = {
//1.создаватьStreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)3
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5 означает, что верные данные будут разделены за 5 секунд для формирования RDD
//Подготавливаемся к подключению параметров Kafkaиз
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "SparkKafkaDemo",
//самый ранний: если под каждым разделом есть отправленное изсмещение, потребление начинается с отправленного изсмещения, когда нет отправленного изсмещения, потребление начинается с начала;
//latest: Когда под каждым Разделом есть отправленное изсмещение, потребление начинается с отправленного изсмещения, когда нет представленного изсмещения, потребление нового из Должен Разделизданные;
//нет: когда каждый раздел темы существует и отправил isoffset, потребление начнется со смещения, пока один раздел не существует и отправил isoffset, будет выдано исключение;
//здесь Конфигурацияlatest自动重置偏移количестводля最新из偏移количество,Прямо сейчасеслииметь偏移количествоот偏移количество位置Начните потреблять,безиметь偏移количествоот新来изданные Начните потреблять
"auto.offset.reset" -> "latest",
//falseповерхность示关闭自动представлять на рассмотрение.Зависит отspark帮你представлять на рассмотрениеприезжатьCheckpointИли программисты вручную поддерживают
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("spark_kafka")
//2. Используйте KafkaUtil для подключения к Kafak и получения данных.
val recordDStream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,//Стратегия местоположения, исходный код настоятельно рекомендует использовать стратегию Должен, что позволит SparkизExecutorиKafkaизBroker реагировать равномерно
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))//Стратегия потребления, исходный код настоятельно рекомендует использовать стратегию Должен
//3.Получить ЗНАЧЕНИЕ
val lineDStream: DStream[String] = RecordDStream.map(_.value())//_обратитесь киздаConsumerRecord
val wrodDStream: DStream[String] = lineDStream.flatMap(_.split(" ")) //_ относится к изда, отправленному поверх иззначения, которое представляет собой одну строку данных.
val wordAndOneDStream: DStream[(String, Int)] = wrodDStream.map((_,1))
val result: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_)
result.print()
ssc.start()//Начать
ssc.awaitTermination()//ждать корректной остановки
}
}
4.5 Расширение: Kafka вручную поддерживает смещения
APIhttp://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
Начать продюсер
/export/servers/kafka/bin/kafka-console-producer.sh --broker-list node01:9092,node01:9092,node01:9092 --topic spark_kafka
демо-код
package cn.itcast.streaming
import java.sql.{DriverManager, ResultSet}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010.{OffsetRange, _}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object SparkKafkaDemo2 {
def main(args: Array[String]): Unit = {
//1.создаватьStreamingContext
//spark.master should be set as local[n], n > 1
val conf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
val ssc = new StreamingContext(sc,Seconds(5))//5 означает, что верные данные будут разделены за 5 секунд для формирования RDD
//Подготавливаемся к подключению параметров Kafkaиз
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node01:9092,node02:9092,node03:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "SparkKafkaDemo",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("spark_kafka")
//2. Используйте KafkaUtil для подключения к Kafak и получения данных.
//Уведомление:
//еслиMySQLсерединабезиметь记录offset,затем подключитесь напрямую,отlatestНачните потреблять
//еслиMySQLсерединаиметь记录offset,Тогда вам стоит начать потребление с Долженоффсета.
val offsetMap: mutable.Map[TopicPartition, Long] = OffsetUtil.getOffsetMap("SparkKafkaDemo","spark_kafka")
val recordDStream: InputDStream[ConsumerRecord[String, String]] = if(offsetMap.size > 0){//Есть смещение записи
println("Если в MySQL записано смещение, потребление начнется с Долженоффсета")
KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,//Стратегия местоположения, исходный код настоятельно рекомендует использовать стратегию Должен, что позволит SparkизExecutorиKafkaизBroker реагировать равномерно
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams,offsetMap))//Стратегия потребления, исходный код настоятельно рекомендует использовать стратегию Должен
}else{//Смещение не записано
println("Если смещение не записано, подключитесь напрямую и начните потреблять с последнего")
// /export/servers/kafka/bin/kafka-console-producer.sh --broker-list node01:9092 --topic spark_kafka
KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,//Стратегия местоположения, исходный код настоятельно рекомендует использовать стратегию Должен, что позволит SparkизExecutorиKafkaизBroker реагировать равномерно
ConsumerStrategies.Subscribe[String, String](topics, kafkaParams))//Стратегия потребления, исходный код настоятельно рекомендует использовать стратегию Должен
}
//3.действоватьданные //Уведомление: Нашей цели да необходимо самостоятельно поддерживать смещение вручную, а это означает, что после использования небольшого пакета данных мы должны отправить смещение один раз.
//Эта небольшая партия данных представлена в DStream с помощью даRDD, поэтому нам нужно работать с верным DStream с помощью изRDD.
//И изRDD в верноDStream работает изAPI имеет преобразование(Конвертировать)иforeachRDD(действие)
recordDStream.foreachRDD(rdd=>{
if(rdd.count() > 0){//В данный момент в текущем пакете есть данные
rdd.foreach(record => println("перениматьприезжатьизKafkОтправитьизданныедля:" + record))
//перениматьприезжатьизKafkОтправитьизданныедля:ConsumerRecord(topic = spark_kafka, partition = 1, offset = 6, CreateTime = 1565400670211, checksum = 1551891492, serialized key size = -1, serialized value size = 43, key = null, value = hadoop spark ...)
//Уведомление:проходить打印перениматьприезжатьизинформация可к看приезжать,Есть смещения, которые нам нужно поддерживать,ибыть обработаннымизданные
//接Вниз来可кверноданныеруководить处理....илииспользоватьtransformвозвращатьсяи之вперед一样处理
//После написания кода данных Должен сохраняет смещение. Поэтому, чтобы облегчить правильное обслуживание/управление смещением, Spark предоставляет класс, который поможет нам инкапсулировать данные смещения.
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
for (o <- offsetRanges){
println(s"topic=${o.topic},partition=${o.partition},fromOffset=${o.fromOffset},доOffset=${o.untilOffset}")
}
//Вручную отправляем смещение,по умолчаниюпредставлять на рассмотрениеприезжатьCheckpointсередина
//recordDStream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
//实际середина偏移количество可кпредставлять на рассмотрениеприезжатьMySQL/Redisсередина
OffsetUtil.saveOffsetRanges("SparkKafkaDemo",offsetRanges)
}
})
/* val lineDStream: DStream[String] = RecordDStream.map(_.value())//_обратитесь киздаConsumerRecord
val wrodDStream: DStream[String] = lineDStream.flatMap(_.split(" ")) //_ относится к изда, отправленному поверх иззначения, которое представляет собой одну строку данных.
val wordAndOneDStream: DStream[(String, Int)] = wrodDStream.map((_,1))
val result: DStream[(String, Int)] = wordAndOneDStream.reduceByKey(_+_)
result.print()*/
ssc.start()//Начать
ssc.awaitTermination()//ждать корректной остановки
}
/*
Ручное обслуживание смещения класса инструмента
Сначала в MySQLсоздаем следующую таблицу
CREATE TABLE `t_offset` (
`topic` varchar(255) NOT NULL,
`partition` int(11) NOT NULL,
`groupid` varchar(255) NOT NULL,
`offset` bigint(20) DEFAULT NULL,
PRIMARY KEY (`topic`,`partition`,`groupid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
*/
object OffsetUtil {
//Читаем смещение из библиотеки данных
def getOffsetMap(groupid: String, topic: String) = {
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "root")
val pstmt = connection.prepareStatement("select * from t_offset where groupid=? and topic=?")
pstmt.setString(1, groupid)
pstmt.setString(2, topic)
val rs: ResultSet = pstmt.executeQuery()
val offsetMap = mutable.Map[TopicPartition, Long]()
while (rs.next()) {
offsetMap += new TopicPartition(rs.getString("topic"), rs.getInt("partition")) -> rs.getLong("offset")
}
rs.close()
pstmt.close()
connection.close()
offsetMap
}
//Воля偏移количестводержатьприезжатьданные Библиотека
def saveOffsetRanges(groupid: String, offsetRange: Array[OffsetRange]) = {
val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "root")
//replace «in» означает замену, если она была раньше, и вставку, если ее нет.
val pstmt = connection.prepareStatement("replace into t_offset (`topic`, `partition`, `groupid`, `offset`) values(?,?,?,?)")
for (o <- offsetRange) {
pstmt.setString(1, o.topic)
pstmt.setInt(2, o.partition)
pstmt.setString(3, groupid)
pstmt.setLong(4, o.untilOffset)
pstmt.executeUpdate()
}
pstmt.close()
connection.close()
}
} 


Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
