Stable Video 3D представляет собой шокирующий дебют: создание 3D-видео без слепых зон из одного изображения и открытие веса модели.
Отчет о сердце машины
Монтажер: Ду Вэй
В области создания 3D-изображений появился новый «плеер SOTA», поддерживающий как коммерческое, так и некоммерческое использование.
В большом семействе моделей Stability AI появился новый член.
Вчера, после запуска Stable Diffusion и Stable Video Diffusion, Stability AI представила сообществу большую модель создания 3D-видео «Stable Video 3D» (сокращенно SV3D).
Эта модель основана на Stable Video Diffusion, которая может значительно улучшить качество и согласованность нескольких представлений при генерации 3D. Эффект лучше, чем у Stable Zero123, ранее выпущенного Stability AI, и Zero123-XL, исходный код которого совместно открыт Исследовательским институтом Toyota и Toyota. Колумбийский университет.
В настоящее время Stable Video 3D поддерживает как коммерческое использование, для которого требуется членство в Stability AI Membership, так и некоммерческое использование, когда пользователи могут загружать веса моделей на Hugging Face.

Сгенерированный эффект Stable Video 3D показан на видео ниже.
Stability AI предоставляет два варианта модели: SV3D_u и SV3D_p. Среди них SV3D_u генерирует орбитальное видео на основе одного входного изображения и не требует настройки камеры. SV3D_p расширяет возможности генерации, адаптируя одно изображение и орбитальную перспективу, позволяя создавать 3D-видео вдоль заданного пути камеры.
В настоящее время опубликована исследовательская работа по Stable Video 3D, в которой участвуют три основных автора.

- бумагаадрес:https://stability.ai/s/SV3D_report.pdf
- Адрес блога: https://stability.ai/news/introducing-stable-video-3d
- Адрес Huggingface: https://huggingface.co/stabilityai/sv3d
Обзор технологий
Stable Video 3D обеспечивает значительные преимущества в создании 3D-изображений, особенно в синтезе новых изображений (NVS).
В то время как предыдущие подходы часто решали проблему ограниченных углов обзора и непоследовательных входных данных, Stable Video 3D способен обеспечить целостное изображение под любым заданным углом и хорошо обобщать. В результате модель не только повышает управляемость позой, но и обеспечивает единообразный внешний вид объекта в нескольких видах, что еще больше улучшает ключевые проблемы, влияющие на реалистичное и точное создание 3D-изображений.
Как показано на рисунке ниже, по сравнению со Stable Zero123 и Zero-XL, Stable Video 3D способен создавать новые мультипросмотры, которые более детализированы, более точно соответствуют входному изображению и более согласованы в разных ракурсах.

Кроме того, Stable Video 3D использует согласованность нескольких представлений для оптимизации трехмерных полей нейронного излучения (NeRF) для улучшения качества трехмерных сеток, создаваемых непосредственно из новых представлений.
С этой целью компания Stability AI разработала замаскированные потери выборки при фракционной перегонке, которые еще больше улучшают трехмерное качество невидимых областей в прогнозируемом виде. Кроме того, чтобы устранить проблемы с запеченным освещением, Stable Video 3D использует разделенную модель освещения, оптимизированную с помощью трехмерных форм и текстур.
На изображении ниже показан пример улучшенного создания 3D-сетки за счет 3D-оптимизации при использовании 3D-модели Stable Video и ее выходных данных.

На рисунке ниже показано сравнение результатов 3D-сетки, созданных с помощью Stable Video 3D, с результатами, созданными EscherNet и Stable Zero123.

Архитектурные детали
Архитектура модели Stable Video 3D показана на рисунке 2 ниже. Она построена на основе архитектуры Stable Video Diffusion и содержит UNet с несколькими уровнями. Каждый уровень содержит последовательность остаточных блоков со слоем Conv3D и два блока A. со слоями внимания (пространственным и временным).
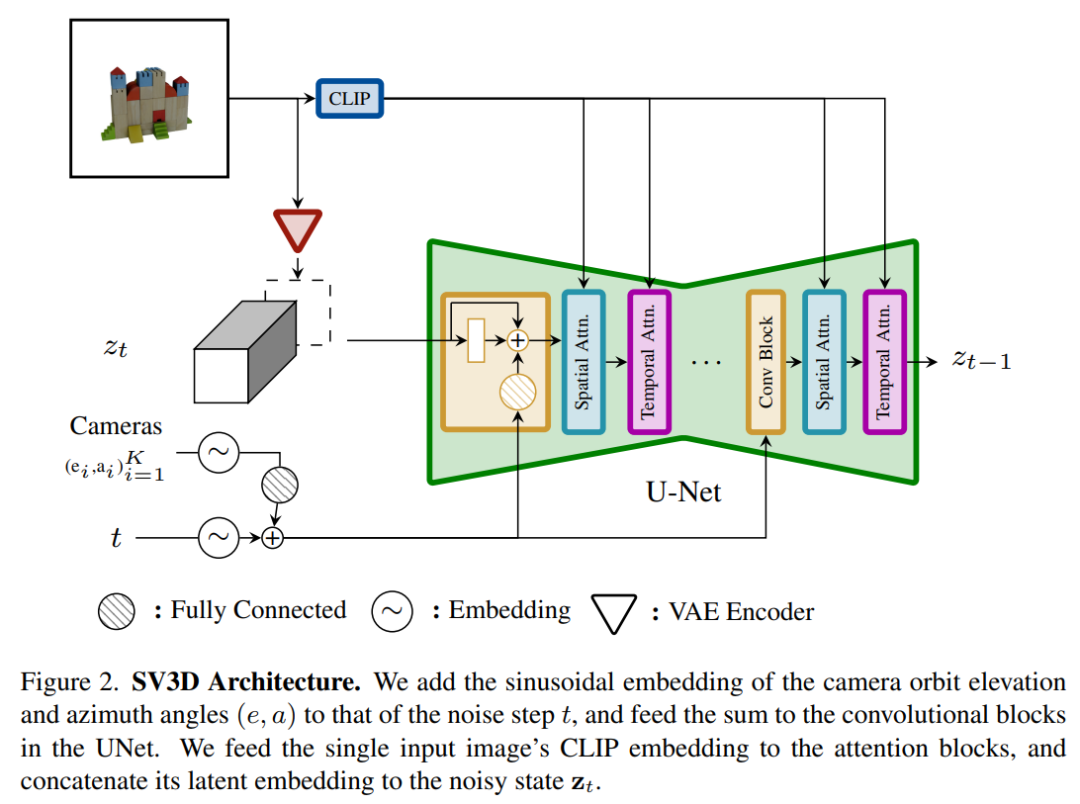
Конкретный процесс заключается в следующем:
(i) Удалить векторные условия «идентификатор кадра в секунду» и «идентификатор сегмента движения», поскольку они не связаны со Stable Video 3D;
(ii) условное изображение внедряется в скрытое пространство через кодировщик VAE Stable Video Diffusion, а затем подключается к входу zt скрытого состояния с шумом на шумном временном шаге t, ведущем к UNet;
(iii) матрица внедрения CLIP условного изображения предоставляется на уровень перекрестного внимания каждого блока преобразователя в качестве ключей и значений, и запрос становится признаком соответствующего уровня;
(iv) Траектория камеры подается в остаточный блок вдоль временного шага диффузионного шума. Углы положения камеры ei и ai и временной шаг шума t сначала встраиваются в представление синусоидального положения, затем представления положения камеры объединяются вместе для линейного преобразования и добавляются к внедрению временного шага шума и, наконец, вводятся в каждый остаточный блок и добавляется к входным объектам блока.
Кроме того, Stability AI разработал статические и динамические орбиты для изучения влияния корректировок позы камеры, как показано на рисунке 3 ниже.
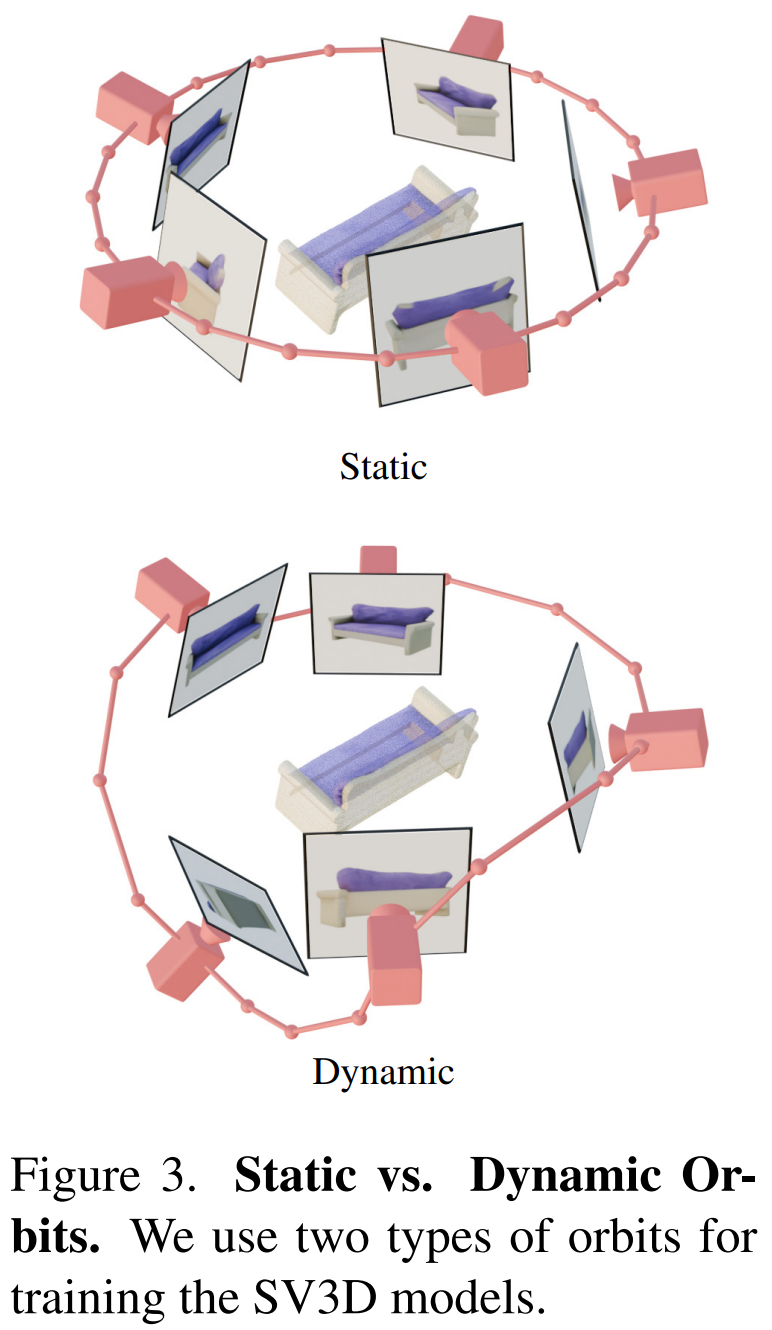
На статической орбите камера вращается вокруг объекта под равноотстоящими углами по азимуту, используя тот же угол возвышения, что и условное изображение. Недостаток этого подхода в том, что на основе скорректированного угла возвышения вы не сможете получить никакой информации о верхней или нижней части объекта. На динамической орбите углы азимута могут быть неодинаковыми, а углы места каждого обзора также могут быть разными.
Чтобы построить динамическую орбиту, Stability AI производит выборку статической орбиты, добавляет небольшой случайный шум к ее азимуту и случайно взвешенную комбинацию синусоид разных частот к ее углу места. Это обеспечивает временную плавность и гарантирует, что траектория камеры заканчивается по той же петле азимута и угла места, что и условное изображение.
Результаты эксперимента
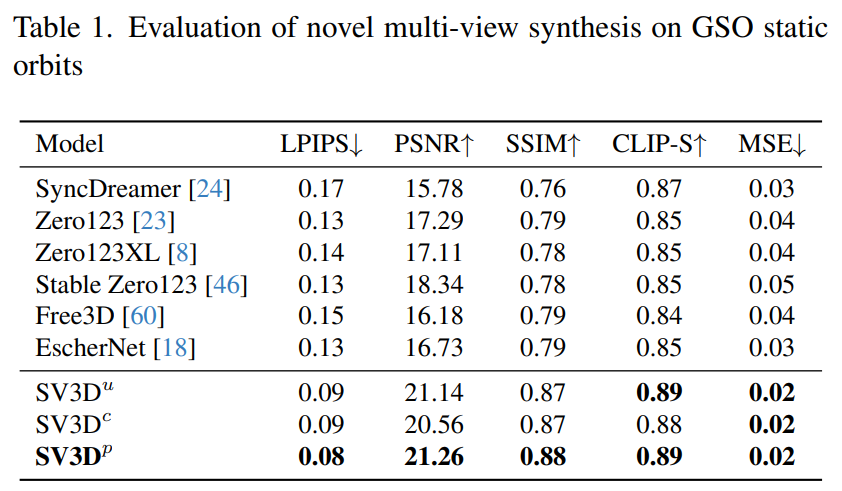
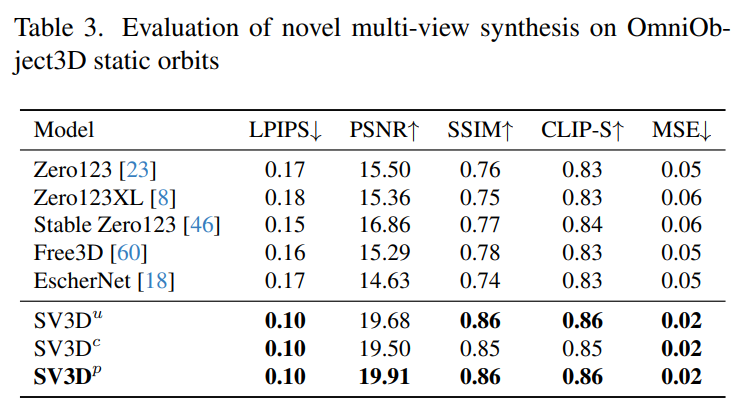
Stability AI оценивает составные многовидовые эффекты Stable Video 3D на статических и динамических орбитах на невидимых наборах данных GSO и OmniObject3D. Результаты, показанные в таблицах 1–4 ниже, показывают, что Stable Video 3D достигает самых современных характеристик при новом многоракурсном синтезе.
В таблицах 1 и 3 показаны результаты Stable Video 3D по сравнению с другими моделями на статических орбитах, показывая, что даже модель SV3D_u без корректировки позы работает лучше, чем все предыдущие методы.
Результаты анализа абляции показывают, что SV3D_c и SV3D_p превосходят SV3D_u в генерации статических траекторий, хотя последний обучается исключительно на статических траекториях.
В таблицах 2 и 4 ниже показаны результаты генерации динамических траекторий, включая модели корректировки позы SV3D_c и SV3D_p, причем последняя достигает SOTA по всем показателям.
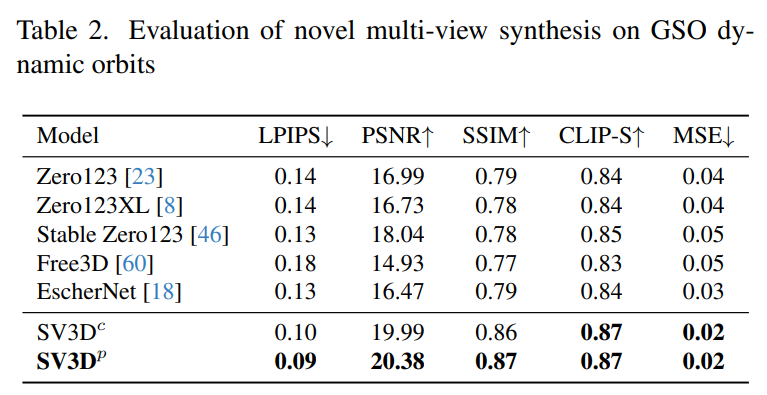
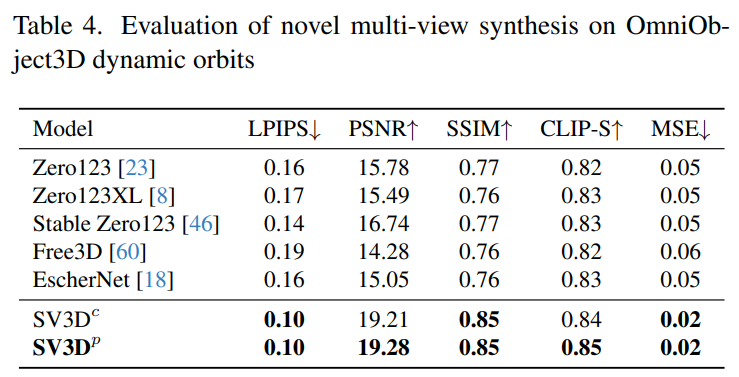
Результаты визуального сравнения на рисунке 6 ниже также демонстрируют, что Stable Video 3D генерирует изображения, которые более детализированы, более близки к условным изображениям и более согласованы при различных углах обзора, чем предыдущая работа.

Более подробную техническую информацию о результатах эксперимента можно найти в оригинальной статье.
© THE END
Пожалуйста, свяжитесь с этим общедоступным аккаунтом, чтобы получить разрешение на перепечатку.
Публикуйте статьи или ищите освещение: content@jiqizhixin.com



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
