Сравнение основных OLAP-инфраструктур больших данных
Что такое ОЛАП?

Благодаря постоянному развитию таких технологий, как Интернет, Интернет вещей, 5G, искусственный интеллект и облачные вычисления, в Интернете генерируется все больше и больше данных, и работа Интернета стала более совершенной. данные, анализ данных и цифровой маркетинг. Это стало предметом внимания каждой интернет-компании. OLAP и OLTP — это технологии, с которыми мы обязательно столкнемся при анализе данных. Прежде чем перейти к выбору технологии механизма OLAP, давайте сначала посмотрим, что означают эти две технологии.
OLTP (онлайн-обработка транзакций OnlineTransactionProcessing),да Традицияреляционная база данныхизприкладная технология,Обеспечить ежедневную и базовую обработку транзакций,Например, онлайн-транзакции и т. д.。OLAP (онлайн-аналитическая обработка),дабольшие данныеанализироватьизприкладная технология,Обеспечьте комплексные аналитические операции и сосредоточьтесь на поддержке принятия решений. Текущие основные движки isOLAP включают Hive, Presto, Druid, Clickhouse, Kylin, Sparksql, Greeplum.,Каждый двигатель имеет свои особенности
OLAP (On-line Analytical Processing) — совокупность различных ориентированных на анализ операций, реализованных на основе многомерной модели хранилища данных. Вы можете сравнить его с традиционной OLTP (онлайн-обработкой транзакций), чтобы увидеть его характеристики:

OLAP-классификация
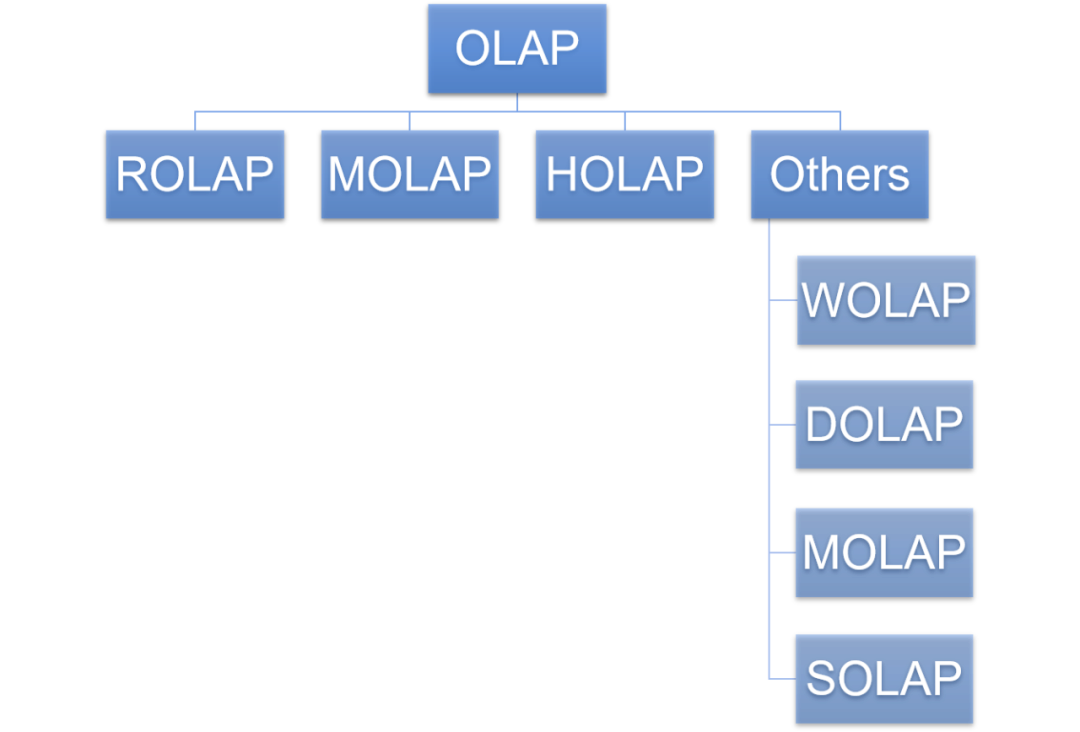
OLAP — это метод вычислений, который позволяет пользователям удобно и быстро анализировать данные с разных точек зрения. Основной поток OLAP можно разделить на три категории:
1. Многомерная OLAP (Многомерная OLAP)、
2. Реляционная OLAP
3. Гибридный OLAP Три основные категории.
1. Многомерная OLAP (Многомерная OLAP)
MOLAP основан на собственной логической модели, которая напрямую поддерживает многомерные данные и операции. Данные физически хранятся в многомерных массивах, и для доступа к ним используются методы позиционирования.
MOLAPАрхитектура СодержитСлужба базы данныхустройство、Сервер MOLAP и интерфейсный инструмент, три компонента.

Типичными представителями МОЛАП являются: Друид и Кайлин. MOLAP обычно генерирует предварительно агрегированные данные при записи данных на основе определяемых пользователем измерений и показателей (также называемых индикаторами). Когда приходит запрос Query, он фактически запрашивает предварительно агрегированные данные вместо исходных подробных данных. относительно фиксированных сценариях такое ускорение оптимизации очевидно.
MOLAP Преимущества и недостатки связаны с предварительной обработкой данных. ( pre-processing ) связь。Предварительная обработка данных,Исходные данные агрегируются и заранее рассчитываются по заданным правилам расчета.,Это позволяет избежать выполнения большого количества вычислений в процессе запроса.,Улучшена производительность запросов.
Однако такая предварительная обработка требует предварительного определения измерений, что ограничивает гибкость последующих запросов данных, если запрос включает новые показатели, процесс предварительной обработки необходимо добавлять снова, что приводит к потере гибкости и высокой эффективности; затраты на хранение; в то же время этот метод не поддерживает подробный запрос данных и подходит только для агрегированных запросов (таких как сумма, среднее значение, количество).
Таким образом, MOLAP подходит для сценариев, в которых сценарий запроса относительно фиксирован и имеет очень высокие требования к производительности запроса. Например, анализ отчетов о доставке рекламы часто используется рекламодателями.
2. Реляционная OLAP
Реляционная OLAP (ROLAP) — это промежуточные серверы, которые находятся между реляционными внутренними серверами и пользовательскими интерфейсными инструментами, которые используют реляционную или расширенную реляционную СУБД для сохранения и обработки данных хранилища, а также используют промежуточное программное обеспечение OLAP для предоставления недостающих данных.
Архитектура ROLAP показана ниже и включает в себя сервер базы данных, сервер ROLAP и интерфейсные инструменты.

Типичными представителями ROLAP являются: Presto, Impala, GreenPlum, Clickhouse, Elasticsearch, Hive, Spark SQL, Flink SQL.
Преимущества ROLAP заключаются в следующих двух аспектах:
Во-первых, при записи данных ROLAP не использует технологию предварительного агрегирования, такую как MOLAP. Когда ROLAP получает запрос запроса, он сначала анализирует запрос, генерирует план выполнения, сканирует данные, выполняет реляционные операторы и выполняет фильтрацию (Where), агрегацию (Sum, Avg, Count), ассоциацию (Join) и группировку. по исходным данным (Группировать по), сортировать (Упорядочить по) и т. д. и, наконец, возвращать результаты расчета пользователю. Весь процесс рассчитывается в реальном времени, и для оптимизации запроса нет предварительно агрегированных данных. Все, что имеет значение, — это размер ресурсов и вычислительная мощность.
Во-вторых, ROLAP не требует предварительной обработки данных (предобработки), поэтому запрос является гибким и имеет хорошую масштабируемость. Механизм этого типа использует архитектуру MPP (крупномасштабную архитектуру параллельной обработки, аналогичную Hadoop, которая позволяет увеличить вычислительные ресурсы за счет расширения параллелизма) и может эффективно обрабатывать большие объемы данных.
Однако у ROLAP есть и недостатки: когда объем данных велик или запрос сложен, производительность запроса не может быть такой стабильной, как MOLAP. Все вычисления запускаются немедленно (без предварительной обработки), поэтому они потребляют больше вычислительных ресурсов и приводят к возможным повторным вычислениям.
Таким образом, ROLAP подходит для сценариев, в которых режим запроса не фиксирован и гибкость запросов высока. Например, продукты анализа данных, обычно используемые аналитиками данных, часто выполняют различные заранее определенные анализы данных, поэтому они требуют более высокой гибкости запросов.
3. Гибридный OLAP
Гибридный OLAP представляет собой сочетание MOLAP и ROLAP. При запросе агрегированных данных используйте технологию MOLAP; при запросе подробных данных используйте технологию ROLAP; В соответствии с заданными сценариями использования, чтобы добиться оптимизации производительности запросов. Техническая архитектура гибридного OLAP выглядит следующим образом:

Преимущество гибридного OLAP в том, что он сочетает в себе преимущества MOLAP и ROLAP и обеспечивает быстрый доступ ко всем уровням агрегации. А еще потому, что он хранит только совокупную информацию на сервере OLAP, а подробные записи хранятся в реляционной базе данных. Таким образом, дубликаты подробных записей не сохраняются, что позволяет сбалансировать требования к дисковому пространству.
Недостаток гибридного OLAP заключается в том, что он объединяет MOLAP и ROLAP, поэтому ему необходимо поддерживать как MOLAP, так и ROLAP, а его архитектура также очень сложна.
4.Others
В дополнение к этому включены некоторые другие классификации, в том числе OLAP с поддержкой Интернета (WOLAP), настольная OLAP (DOLAP), мобильная OLAP (MOLAP) и пространственная OLAP (SOLAP). Но в целом он не очень популярен, поэтому больше вводить его не будет.
OLAP-архитектура
Концептуальная записка
- Serde:сериализациядесериализация,serialize/deSerialize
- MPP:Технология массово-параллельной обработки (Massively Parallel Processor)
- В зависимости от типа запроса OLAP Обычно делится на Специальный запроси Солидный запрос,
- Специальный запрос:по почерку sql Выполните некоторые временные требования к анализу данных, такие как sql Форма изменяема, логика сложная, жестких требований к времени запроса нет.
- Солидный запрос:обратитесь кизда Некоторые затвердевшиеиз Получить номер、Посмотрите на спрос,Предоставляется пользователям в виде информационных продуктов.,тем самым улучшаяданныеанализироватьиоперацииизэффективность。Этот типиз sql Фиксированный режим предъявляет более высокие требования ко времени отклика.
В соответствии с реализацией архитектуры основные механизмы OLAP в основном делятся на следующие три категории:
- MPP Архитектурасистема(Presto/Impala/SparkSQL/Drill ждать). Этот тип архитектуры в основном начинается с механизма запросов и использует механизм распределенных запросов вместо использования hive+mapreduce Архитектура, повышение эффективности запросов.
- Поисковая система(es,solr и т.д.), конвертировать данные в инвертированный индекс при входе в базу данных, используя Scatter-Gather Вычислительная модель жертвует гибкостью ради хорошей производительности и может обеспечить ответ на поисковые запросы за доли секунды. Однако для агрегирования сканирования в качестве основного запроса по мере увеличения объема обрабатываемых данных время ответа также будет снижаться до минутного уровня.
- Предварительная вычислительная система(Druid/Kylin и т. д.), данные предварительно агрегируются при вводе в базу данных, что еще больше жертвует гибкостью ради производительности для достижения супер-больших результатов. dataSET из Второй ответ. Существующий метод реализации отслеживания данных с точки зрения потребностей бизнеса заключается в следующем: запрашивать и перечислять данные по заданному запросу в каждом отчетном периоде, а также анализировать причины неурегулированного расчета, который смещен в сторону Солидного. запросить способ. Однако существующий способ реализации заключается в том, чтобы сначала запросить данные основной таблицы в соответствии со значением столбца запроса, а затем получить вспомогательную таблицу запроса на основе связанных полей вспомогательной таблицы основной таблицы. sql,sql Для динамического сращивания этот метод более ориентирован на Специальный. запросить реализацию.
Выбор структуры необходимо рассматривать с учетом следующих трех аспектов: хранение и создание данных, установка и строительство, а также затраты на разработку.
Преимущества OLAP основаны на предметно-ориентированном, интегрированном, историческом и неизменяемом хранилище данных, а также на многомерной модели, многоперспективной и многоуровневой организации данных. Без этих двух пунктов OLAP. уже не будет и не будет. Есть о каких преимуществах можно говорить.
Общие операции механизма OLAP
Несколько операций OLAP, описанных ниже, предназначены для схем Кимбалла «Звезда» и «Снежинка». В модели Кимбалла определены факты и измерения.
Свертывание/агрегирование: выберите определенные измерения и агрегируйте факты на основе этих измерений, если они выражены в SQL, выберите dim_a, aggs_func(fact_b) из группы fact_table с помощью детализации dim_a: свертывание детализации — это противоположная операция. Он выбирает определенные измерения, разбирает их на более мелкие измерения (например, годы на месяцы, провинции на города), а затем объединяет факты. Нарезка (Slicing, Dicing): выберите определенные измерения, отфильтруйте значения этих измерений в соответствии с конкретными значениями и разрежьте исходный большой куб на маленькие кубики. Например, dim_a в («CN», «США»). Поворот (Pivot/Rotate): смена позиций размеров. На рисунке ниже приведен конкретный пример:
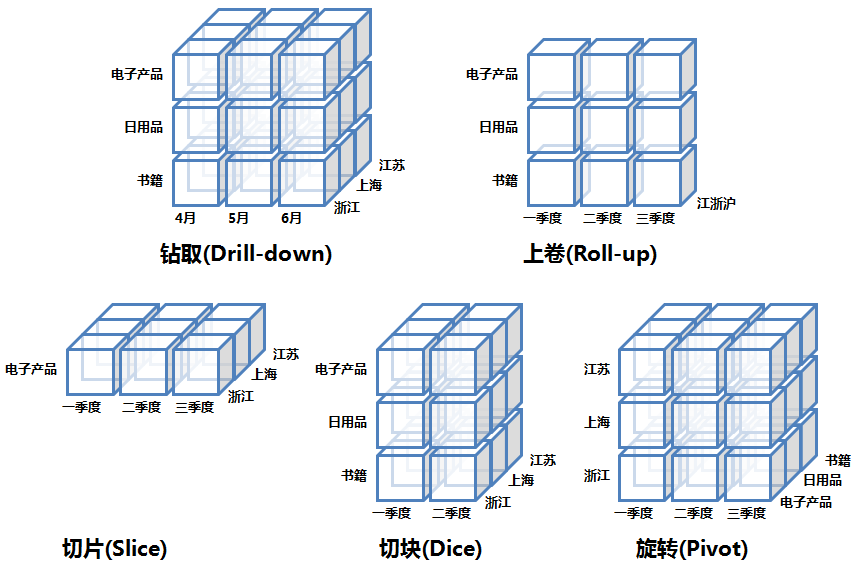
Выполнить сравнение моделей
- Модель выполнения Scatter-Gather: эквивалент одного обращения к MapReduce в MapReduce.,Никаких множественных итераций,А промежуточные результаты вычислений часто сохраняются в памяти.,Обмен напрямую по сети. Elasticsearch, Druid и Kylin используют эту модель.
- MapReduce: Hiveданная модель
- MPP: научное название MPP для массовых параллельных вычислений.,На самом деле трудно дать ему точное определение. Если я скажу «из» немного шире,,Presto、Impala、Doris、Clickhouse、Spark SQL、Flink SQL все имеет значение. Некоторые люди говорят, что Искра SQLиFlink SQL относится к модели DAG. Поразмыслив над этим, мы считаем, что DAG — это не отдельная модель. Это всего лишь способ создания планов выполнения.
Сравнение движка OLAP с открытым исходным кодом

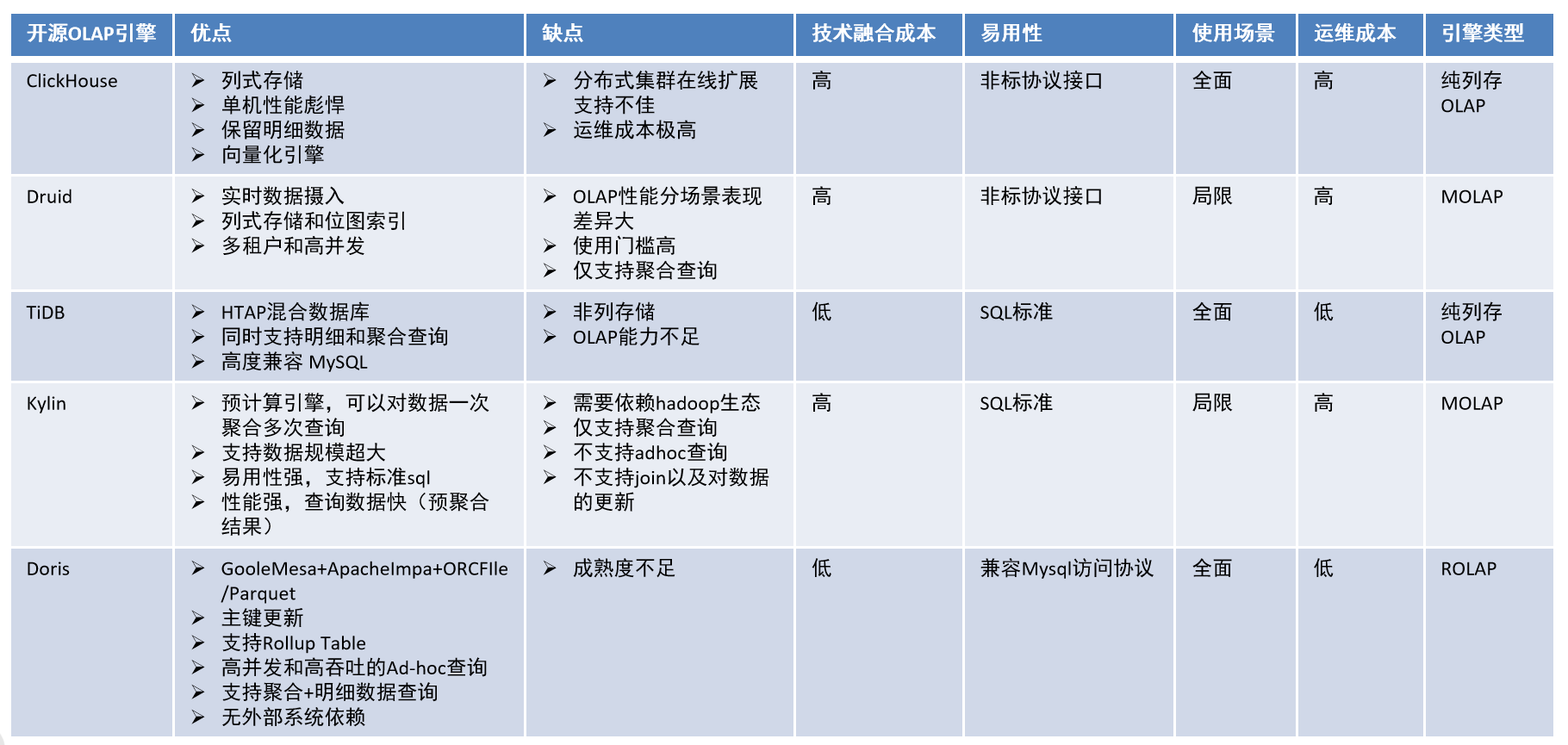
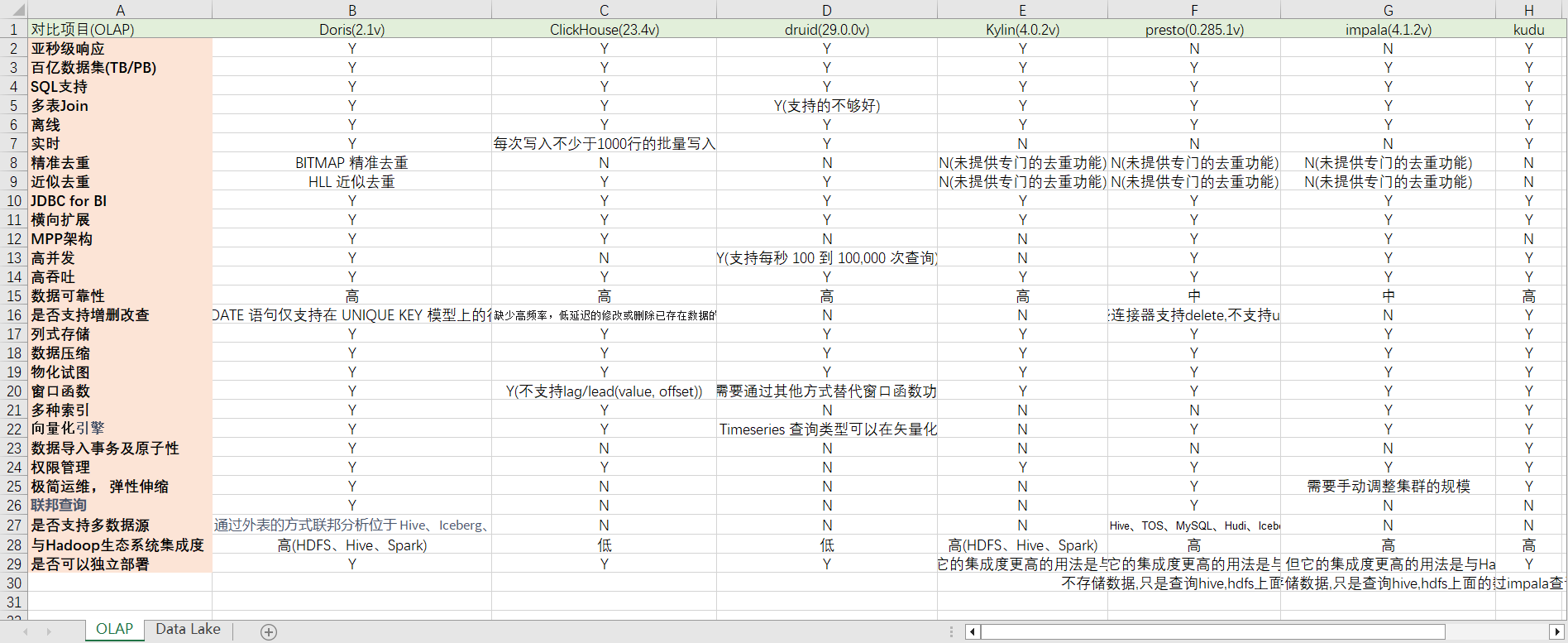
Для нескольких механизмов OLAP с открытым исходным кодом, которые очень популярны в индустрии больших данных: Hive, SparkSQL, FlinkSQL, Clickhouse, Elasticsearch, Druid, Kylin, Doris, Presto и Impala, мы выбрали несколько сценариев для сравнения. Ни один механизм не может этого сделать. Чтобы достичь совершенства в объеме данных, гибкости и производительности, пользователям необходимо выбирать, исходя из своих собственных потребностей.
Особенности компонента и введение
Hive
https://hive.apache.org/
Hive — это инструмент хранилища данных, основанный на Hadoop. Он может отображать файлы структурированных данных в таблицу базы данных и предоставлять полные функции SQL-запросов. Он может преобразовывать операторы SQL в задачи MapReduce для запуска. Его преимущество заключается в низкой стоимости обучения, простой статистике MapReduce можно быстро реализовать с помощью SQL-подобных операторов, и нет необходимости разрабатывать специальные приложения MapReduce. Он очень подходит для статистического анализа хранилищ данных.

Для hive он в основном ориентирован на приложенияOLAP.,его первый этаждаhdfsРаспределенная файловая система,Hive обычно используется только для анализа запросов и статистики.,И не может быть общей операции изCUD,Hive необходимо синхронизировать существующую базу данных и войти в файловую систему hdfs.,В настоящее время очень сложно добиться поэтапной синхронизации в реальном времени.
Преимущества Hive — полная поддержка SQL, чрезвычайно низкие затраты на обучение, настраиваемые форматы данных, чрезвычайно высокая масштабируемость, которую можно легко расширить до тысяч узлов и т. д.
Однако Hive не выполняет никакой обработки данных в процессе загрузки и даже не сканирует данные, поэтому некоторые ключи в данных не индексируются. Когда Hive хочет получить доступ к определенным значениям в данных, которые соответствуют условиям, ему необходимо перебором просканировать всю базу данных, поэтому задержка доступа высока.
Улей действительно слишком медленный. Для больших расчетов по агрегации данных или запросов к совместным таблицам времязатратность Hive зачастую может исчисляться часами. В определенный момент мне даже хотелось исключить его из «национальности» OLAP, но приходится признать, что Hive по-прежнему остается самым распространенным. использовалась система на базе механизма Hadoop.
Spark SQL、Flink SQL

В большинстве сценариев вычисления Hive по-прежнему слишком медленны. Не говоря уже о том, что они не могут удовлетворить потребности внешних онлайн-сервисов, которым требуется высокое количество запросов в секунду и низкая задержка запросов. Даже внутренние аналитики продуктов, операций и данных предприятия часто жалуются на Hive. Выполнение специальных запросов происходит слишком медленно. Эти болевые точки способствовали рождению и развитию итераций памяти MPP и вычислительных моделей DAG, таких как Spark. SQL、Flink Такие технологии, как SQL и Presto, также очень популярны на предприятиях. Искра SQL、Flink Скорость выполнения SQLиз быстреебыстрый,Богатый программный API,Поддержите обаПотоковые вычисленияс пакетной обработкой,И есть тенденция унификации партий,делатьбольшие Приложение данных еще проще. Примечание. Упомянутые выше онлайн-сервисы относятся к бизнес-консультантам по приложениям данных, открытым Alibaba для миллионов владельцев магазинов Taobao, а также к анализу рекламы в провинции Гуандиантун, разработанному Tencent для сотен тысяч рекламодателей.
Presto
Это официальное введение в Presto. Presto — это механизм распределенных SQL-запросов для больших данных с открытым исходным кодом от Facebook. Он подходит для запросов интерактивного анализа и может поддерживать множество источников данных, включая HDFS, RDBMS, KAFKA и т. д., а также обеспечивает очень удобный интерфейс для разработки соединителей источников данных.
Presto поддерживает стандарт ANSI SQL, включая сложные запросы, агрегацию, соединения и оконные функции. В качестве замены Hive и Pig (как Hive, так и Pig выполняют запрос данных HDFS через поток конвейера MapReduce), Presto не хранит данные сами, но может получать доступ к нескольким источникам данных и поддерживает каскадирование между источниками данных.
Presto не использует MapReduce, это делается с помощью специального механизма запросов и выполнения. Вся обработка запросов находится в памяти, что является одной из основных причин его высокой производительности. Presto имеет большое сходство со Spark SQL, что является наиболее фундаментальным отличием между ним и Hive.
Однако Presto основан на памяти, а hive читает и записывает на диск, поэтому presto намного быстрее, чем hive. Однако, поскольку это вычисления на основе памяти, ошибки переполнения памяти могут легко возникнуть, когда несколько больших таблиц связаны друг с другом.


Presto, Impala и GreenPlum основаны на архитектуре MPP по сравнению с простыми моделями Scatter-Gather, такими как Elasticsearch, Druid и Kylin, они более универсальны в поддержке вычислений SQL и больше подходят для сценариев специальных запросов. системы общего назначения часто лучше, чем специализированные системы. Оптимизировать производительность сложнее, поэтому они не подходят для запроса QPS (эталонное значение QPS). > 1000), требования к задержке относительно высоки (поиск опорного значения latency < 500мс)из Онлайн сервис,Он больше подходит для внутренних служб запросов компании и ускоренных служб запросов Hive. У Presto также есть отличная функция: он использует SQL стандарта ANSI.,и поддерживает более30+изисточник данныхConnector。Здесь мы даемУ читателей возникает вопрос: в чем причина большой разницы в производительности между моделью MPP, представленной Presto, и моделью MapReduce, представленной Hive?
Presto и Hive представляют две разные архитектуры обработки данных, а именно MPP (массовая параллельная обработка) и MapReduce. Разница в производительности в основном вызвана следующими факторами:
- Параллелизм: MPP Архитектура Внизиз Presto Поддерживает параллельную обработку и может выполнять задачи запросов на нескольких узлах одновременно, тем самым улучшая параллелизм запросов и производительность. Напротив, Улей из MapReduce Задача будет зависеть от диска при выполнении IO, обработка данных происходит медленнее.
- Управление памятью: Престо Использование памяти в качестве основного вычислительного ресурса позволяет более эффективно использовать память для обработки данных и вычислений. Hive в исполнении MapReduce Эта задача требует частых операций чтения и записи диска, что приводит к относительно низкой производительности.
- Оптимизация запросов: Престо Предоставляет дополнительные функции оптимизации запросов, включая динамическое сокращение разделов, перемещение предикатов, динамическую фильтрацию и т. д., что позволяет выполнять запросы более разумно и сократить ненужное сканирование и вычисления данных, в то же время Hive Возможности оптимизации относительно слабы.
Impala

Impala да Cloudera получение Google из Dremel Вдохновлен разработкой интерактивного SQL в реальном времени. инструмент запроса данных, даCDH Предпочтительная платформа PB сортбольшие Механизм анализа запросов данных в реальном времени. Он обладает той же масштабируемостью, что и Hadoop, предоставляет синтаксис, подобный SQL (Hsql), а также может иметь высокую скорость ответа и пропускную способность в многопользовательских сценариях. Он реализуется на Java и C++. Java обеспечивает взаимодействие запросов, а C++ реализует часть механизма запросов. Кроме того, Impala также может совместно использовать Hive. Metastore, вы даже можете напрямую использовать HiveизJDBC. jarиbeeline и т. д. напрямую опрашивают Impala и поддерживают широкие форматы хранения данных (Parquet, Avro и т. д.). Кроме того, Импала Больше никакого использования медленного из Hive+MapReduce пакетную обработку и использование механизма распределенных запросов, аналогичного тому, который используется в коммерческих параллельных реляционных базах данных (управляемый Query Planner、Query Coordinator и Query Exec Engine состоит из трёх частей), которые можно получить непосредственно из HDFS или HBase Китайское использование SELECT、JOIN Статистические функции запрашивают данные, что значительно снижает задержку. Impala часто предоставляет услуги вместе с механизмом хранения Kudu. Самым большим преимуществом этого является то, что перечисление происходит быстрее и поддерживает обновление и удаление данных. Примечание:Часть контента взята изhttps://zhuanlan.zhihu.com/p/55197560
Особенности Импалы включают в себя:
- Поддерживает несколько форматов файлов, таких как Parquet, Avro, Text, RCFile, SequenceFile и т. д.
- Поддерживает хранилище в HDFS, HBase, Amazon. S3начальствоиз Операции с данными
- Поддерживает несколько методов кодирования сжатия: Snappy, Gzip, Deflate, Bzip2, LZO.
- Поддержка UDFиUDAF
- Автоматически выполнять соединения таблиц в наиболее эффективном порядке.
- Позволяет определять политики очередей с приоритетом запросов.
- Поддержка многопользовательских одновременных запросов
- Поддержка кэширования данных
- Предоставление статистики вычислений (COMPUTE STATS)
- Предоставьте оконные функции (агрегирование OVER PARTITION, RANK, LEAD, LAG, NTILE и т. д.) для поддержки функций расширенного анализа.
- Поддерживает использование дисков для подключения и агрегации. Когда операция использует переполнение памяти, она преобразуется в дисковые операции.
- Разрешить подзапросы в предложенииwhere
- Разрешить дополнительную статистику — выполнять статистические расчеты только для новых и измененных данных.
- Поддерживает сложные вложенные запросы к картам, структурам и массивам.
- HBase можно обновить с помощью вставки Impala или
Druid
https://druid.apache.org/
https://blog.csdn.net/warren288/article/details/80629909
Druid Он может обеспечить запросы уровня менее секунды и хранение данных для исторических данных и данных в реальном времени. Друид Поддержка приема данных с низкой задержкой,Гибкое исследование и анализ данных,Высокопроизводительная агрегация данных,Легко расширяется по горизонтали. Подходит для больших объемов данных,К системам аналитических запросов предъявляются высокие требования к масштабируемости.
Druidрешатьиз Вопросы включают в себя:данныеизбыстрыйбыстрый приемиданныеизбыстрый Быстрый запрос。 так что поймиDruid,Это нужно понимать как две системы.,То есть система ввода и система запросов.
Друидиз Архитектура выглядит следующим образом:


Возможности Друидиз включают в себя:
- Потребление данных Druid в режиме реального времени,Получение данных в реальном времени и результаты запросов в реальном времени
- Druid поддерживает данные уровня PB, быструю обработку сотен миллиардов событий и поддерживает тысячи одновременных запросов в секунду.
- Друид ИзCoreВременные серии,Храните данные пакетами в соответствии с временными рядами,Очень подходит для статистического анализа на основе временных сценариев.
- Druid делит столбцы данных на три категории: временные метки, столбцы измерений и столбцы индикаторов.
- Druid поддерживает соединения с несколькими столами, нодаподдерживатьизнедостаточно хорошо
- Данные в Druid обычно используют другие вычислительные платформы (Spark и т. д.) для предварительного вычисления статистических данных низкого уровня.
- Druid не подходит для обработки сложных и изменяемых сценариев запросов перспективных измерений.
- Друид хорошо справляется с запросами одного типа, некоторыми часто используемыми SQL (groupby и т. д.). Операторы выполняются на средней скорости в друиде.
- Поддержка друидов с низкой задержкой при вставке данных、Новее, но лучше, чем hbase、Традиционные базы данных работают намного медленнее
Аналогично другим базам данных временных рядов,У Druid могут возникнуть проблемы с производительностью, когда условия запроса затрагивают большой объем данных.,Более того, такие способности, как сортировка и агрегирование, как правило, не очень хороши.,Недостаточная гибкость и масштабируемость,Например, отсутствие Join, подзапроса и т. д.
Мое личное понимание Друидизма заключается в,Druid обеспечивает запись данных в реальном времени.,Подходит для ввода очищенных записей в режиме реального времени.,Затем быстро запросите результаты, содержащие историческую информацию.,Никакого практического применения в нашем нынешнем бизнесе это не имеет.
Информацию о приложениях Druid см. в разделе «Сценарии использования Druid и практика применения» https://blog.csdn.net/weixin_34273481/article/details/89238947.
Kylin
http://kylin.apache.org/cn/ https://www.infoq.cn/article/kylin-apache-in-meituan-olap-scenarios-practice/
Когда дело доходит до Кайлина, нам приходится говорить о ROLAP и MOLAP.
- Традиционный OLAP делится на ROLAP (реляционный olap) и MOLAP (многомерное olap)
- ROLAP хранит данные, которые в основном используются для анализа, в реляционной модели.,Преимущество в том, что объем хранилища небольшой.,Гибкие методы запросов,Однако очевидны и недостатки,Каждый запрос требует агрегированного расчета данных.,Чтобы исправить недостатки,ROLAPделать Используемое хранилище столбцов、Параллельный запрос、Оптимизация запросов、Растровый индекс и другие технологии.
- MOLAP физически хранит данные, используемые для анализа, в виде многомерных массивов.,Сформируйте структуру CUBE. Значение атрибута измерения отображается в многомерный массив из индекса или диапазона индексов.,Факты хранятся в ячейках массива в виде многомерных массивов и значений.,Преимущества: быстрый запрос,Недостатки: объем данных нелегко контролировать.,Могут возникнуть проблемы с взрывом размеров.
Kylin сам по себе является системой MOLAP. Конструкция многомерного куба (MOLAP Cube) позволяет пользователям определять модели данных для более чем 10 миллиардов наборов данных в Kylin и создавать кубы для предварительного агрегирования данных.
Apache Kylin™ — это механизм распределенного анализа с открытым исходным кодом, который предоставляет интерфейс SQL-запросов и возможности многомерного анализа (OLAP) поверх Hadoop/Spark для поддержки сверхбольших данных. Первоначально он был разработан eBay. Inc. Развивайте и вносите вклад в сообщество открытого исходного кода. Он может запрашивать огромные таблицы Hive за доли секунды.

К преимуществам Килиниз можно отнести:
- Обеспечить интерфейс ANSI-SQL
- Возможности интерактивных запросов
- MOLAP Cube из концепции
- Бесшовная интеграция с инструментами BI
Итак, подходящие сцены для Килиниз включают в себя:
- Пользовательские данные существуют в Hadoop HDFS. Hive используется для доступа к данным файлов HDFS в режиме реляционных данных. Объем данных огромен, более 500 ГБ.
- Каждый день поэтапно импортируются несколько гигабайт или даже десятки гигабайт данных.
- Существует менее 10 относительно фиксированных измерений анализа.
Проще говоря,Идея куба данных в Kylin заключается в обмене пространства на время.,Определив ряд из широт,Каждая комбинация широт заранее рассчитывается и сохраняется. Есть N широт,Комбинаций будет 2изN. Поэтому лучше всего контролировать широту и количество,Потому что емкость хранилища будет взрываться по мере увеличения широты.,привести к катастрофическим последствиям.
ClickHouse
https://clickhouse.yandex/
https://clickhouse.yandex/docs/zh/development/architecture/
http://www.clickhouse.com.cn/
https://www.jianshu.com/p/a5bf490247ea
На официальном сайте ClickHouse представлены:
ClickHouse is an open source column-oriented database management system capable of real time generation of analytical data reports using SQL queries.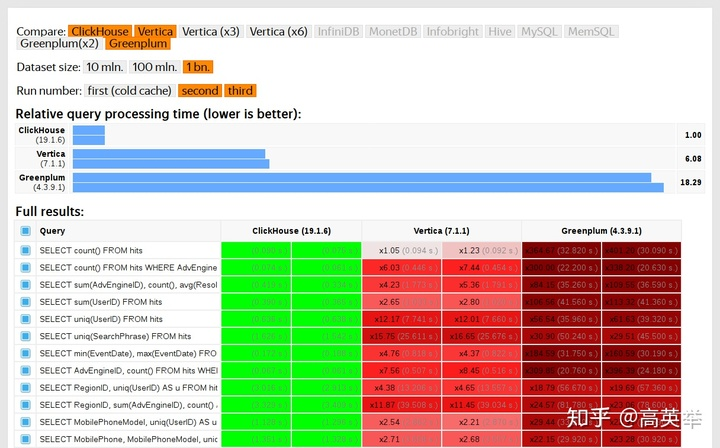
ClickHouseмаксимумиз Характеристикадабыстрый,быстрый,быстрый,Важно сказать это трижды!
ClickHouse стал популярен в последние годы наиз Столбчатая база данных с открытым исходным кодом, в основном используется в области анализа данных (OLAP). В настоящее время отечественное сообщество находится на подъеме, и крупные производители последовали его примеру и использовали его в больших масштабах:
- Сегодняшние заголовки ClickHouse используется внутри компании для анализа поведения пользователей. Внутри компании имеются тысячи узлов ClickHouse, максимум 1200 узлов в одном кластере. Общий объем данных составляет десятки ПБ, а исходные данные увеличиваются примерно на 300 ТБ каждый день.
- ТенсентДля внутреннего использованияClickHouseиграть в игрыданныеанализировать,Для него создан полный набор систем мониторинга, эксплуатации и обслуживания.
- Cтрипвнутренне из18Год7Начать пробный доступ через месяц,В настоящее время 80% бизнеса работает на ClickHouse. Объем данных увеличивается более чем на один миллиард каждый день,Почти миллион запросов.
- быстрый работникТакже внутриделатьиспользоватьClickHouse,Общий объем хранилища составляет примерно 10 ПБ., 200ТБ добавляются каждый день, 90% запросов занимают менее 3 секунд.
За рубежом в Яндексе существуют сотни узлов, используемых для анализа поведения пользователей по кликам, их также используют ведущие компании, такие как CloudFlare и Spotify. Исходя из потребностей сценариев OLAP, ClickHouse настроил и разработал новый набор высокоэффективных механизмов столбчатого хранения, а также реализовал богатые функции, такие как упорядоченное хранилище данных, индекс первичного ключа, разреженный индекс, сегментирование данных, секционирование данных, TTL, первичный и разреженный индекс. резервную копию копировать. Вышеупомянутые функции вместе закладывают основу для чрезвычайно быстрого выполнения анализа ClickHouse. Примечание:Контент поступает изhttps://zhuanlan.zhihu.com/p/98135840 Развертывание Архитектуры ClickHouse просто и удобно в использовании и не зависит от системы Hadoop (HDFS+YARN). Лучше на месте да, чем на большом dataQuantity из Агрегационный запрос по одной таблице. Clickhouse реализован на C++, а базовая реализация имеет векторизованное выполнение. Выполнение), сокращение ветвей и другие возможности оптимизации.,Он имеет высокую производительность запросов. В настоящее время широко используется в интернет-компаниях.,Больше подходит для внутренних приложений BI-отчетности.,Может обеспечить низкую задержку (уровень мс) и скорость отклика.,То естьда Скажем, один запрос оченьбыстрый。нодаClickhouseтакже есть этоизограничение,При выборе технологии OLAP,Его следует избегать, так как запрос на соединение нескольких таблиц (JOIN) из движка,Вам также следует избегать его использования в сценариях, где вы ожидаете поддержки высококонкурентных запросов к данным.,В сценарии анализа OLAP,Обычно считается, что QPS достигает 1000+, что считается высоким параллелизмом.,В отличие от бизнес-сценариев, таких как электронная коммерция и захват красных конвертов,,10 Вт или более считается высоким уровнем параллелизма.,Ведь сценарии анализа данных,Массивные данные,Расчет сложный,Достичь 1000 QPS непросто. Например Кликхаус,Если объем данных соответствует уровню даTB,Агрегационные расчеты немного сложнее.,Как правило, для одного кластера очень сложно достичь показателя QPS 100.,Поэтому он больше подходит для внутренних приложений отчетов BI предприятия.,Он не подходит для отчетов о приложениях, связанных с сотнями тысяч рекламодателей или миллионами владельцев магазинов Taobao. Модель выполнения Clickhouse определяет, что она сделает все возможное для выполнения запроса.,Вместо одновременного выполнения множества запросов.
По сравнению с гигантскими компонентами, такими как Hadoop и Spark, ClickHouse очень легкий и имеет следующие функции:
- База данных столбцового хранения, сжатие данных
- Реляционный, поддерживает SQL
- Распределенные параллельные вычисления доводят производительность одной машины до предела
- Высокая доступность
- Масштаб данных находится на уровне PB
- Обновления данных в режиме реального времени
- индекс
Использование ClickHouse также имеет свои ограничения, в том числе:
- отсутствие высоких частот,Низкая задержка и возможность изменять и удалять существующие данные. Его можно использовать только для пакетного удаления и изменения данных.
- Нет полной поддержки транзакций
- Индекс второго уровня не поддерживается.
- Ограниченная поддержка SQL, реализация соединения другая.
- Степень параллелизма невысока и больше подходит для внутренних приложений отчетов BI предприятия.
Doris


Я думал,Здесь мы знакомимся и анализируем каждый механизм OLAP.,Не обязательно на 100% разумно и точно,Просто ссылка. Только люди с реальным онлайн-опытом OLAP,В конкретных бизнес-сценариях и определенных объемах данных,Эксперты, имеющие опыт глубокой оптимизации одного или нескольких механизмов OLAP, представленных выше.,Только тогда мы сможем иметь право говорить и давать предложения по техническому отбору. Но поскольку для этих механизмов OLAP слишком много технических решений,,Ни один специалист не может знать их все. Возьмите меня лично в качестве примера,Прошлый опыт работы позволил мне лучше понять Hive, SparkSQL, FlinkSQL, Presto и Elasticsearch.,Остальные движки не осмеливаются сказать, что понимают это.,Это не является рекомендацией по техническому выбору. Поэтому, вероятно, то, что говорит каждый эксперт, является неточным и неполным.,Мы призываем всех обсуждать и комментировать здесь,Задавайте больше вопросов,Станьте экспертом в различных механизмах OLAP.
Ссылки
https://cloud.tencent.com/developer/article/1797949
https://doris.apache.org/zh-CN/docs/get-starting/quick-start
https://cloud.tencent.com/developer/article/1899164?areaId=106001
https://cloud.tencent.com/developer/article/1506296?areaId=106001



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
