Spark: расчет индикатора мониторинга в реальном времени в течение 30 секунд от 0
Предисловие
Говоря о Spark, каждый, естественно, вспомнит о Flink и неосознанно сравнит эти две основные технологии обработки больших данных в реальном времени. Затем мы наконец пришли к выводу: производительность Flink в реальном времени выше, чем у Spark.
действительно,Расчет данных в Flink управляется событиями.,Таким образом, часть данных вызовет расчет,Spark рассчитывает на основе набора данных RDD.,Минимальный интервал генерации RDD составляет 50 миллисекунд.,такSparkопределяется какВычисления в субреальном времени。
Окно
СДР здесь является «естественным окном». Мы устанавливаем временной интервал для генерации СДР равным 1 минуте, тогда это СДР можно понимать как «1минутное окно». Так что, если вам нужен расчет окна, я все равно предпочитаю Spark.
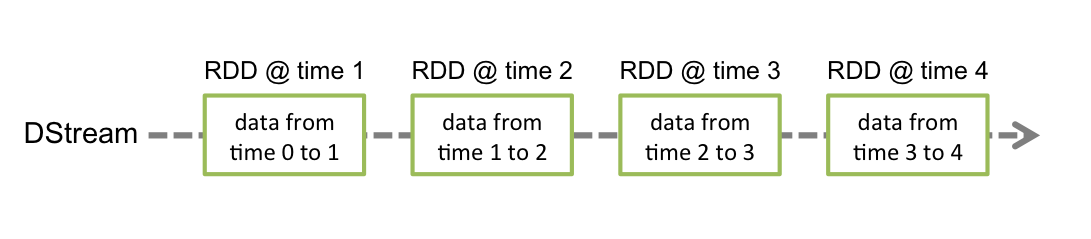
Но когда нам нужно вычислить непосредственное временное окно,Необходимо использоватьраздвижное окнооператор для реализации。что скоро?
Например, описание временного диапазона — «в течение 3 минут». Расчет этого временного диапазона требует расчета исторических данных. Например, 1~3 - это 3 минуты, 2~4 - тоже 3 минуты, здесь повторно используются данные 2 и 3 и так далее, 3~5 - тоже 3 минуты, а 3 и 4 тоже используются повторно.
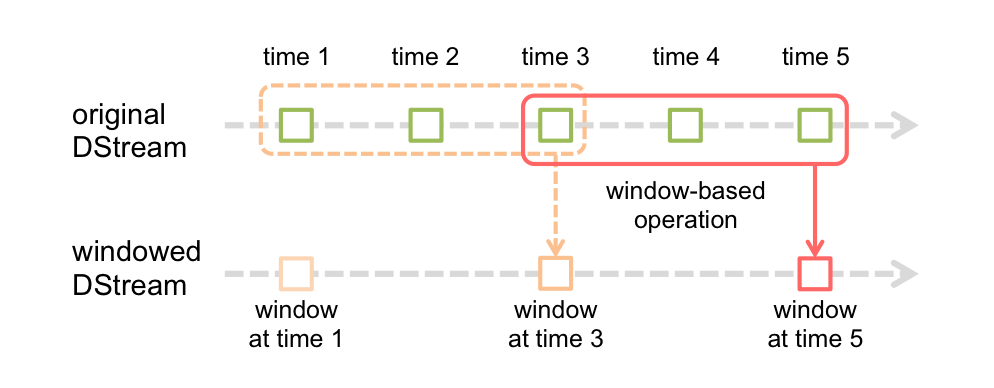
Если вы используете обычное окно, вы не можете соблюдать концепцию времени «в течение последних 3 минут».
Как показано на рисунке ниже, многие окна потеряли время близости. Например, время близости третьего СДР на самом деле является вторым СДР, но их нельзя рассчитать вместе. Вот почему обычные окна не используются.
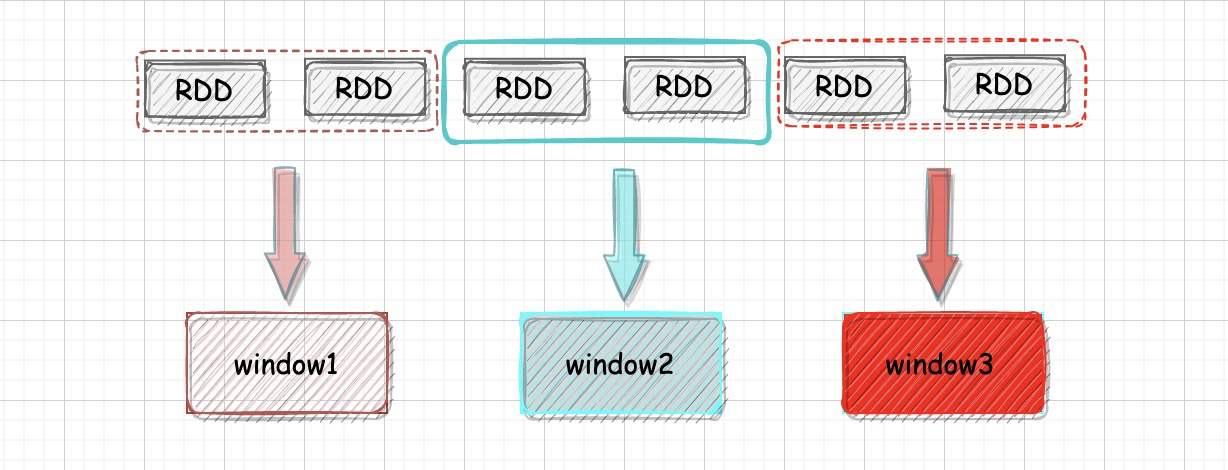
раздвижное окно
раздвижное окно Три элемента: время генерации RDD、длина окна、Размер скользящего шага.
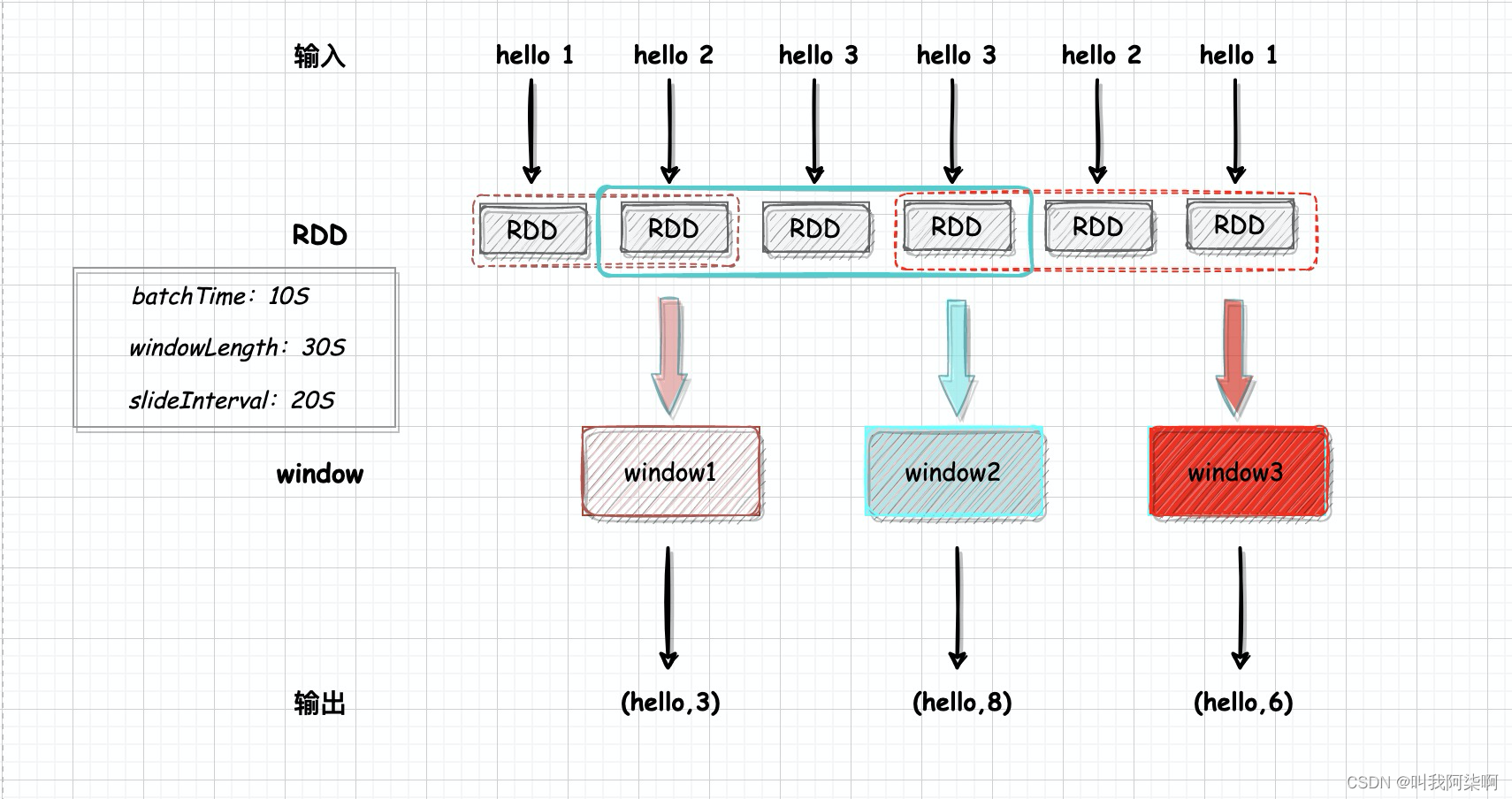
В этой практике я установил временной интервал RDD на 10 с, длину окна на 30 с и шаг скольжения на 10 с. То есть каждые 10 секунд будет генерироваться окно для расчета данных за последние 30 секунд. Каждое окно состоит из 3 RDD.
Создание источника данных
1. Спецификация данных
Предположим, что мы собираем индикаторную информацию об устройстве. Здесь мы фокусируемся только на пропускной способности и времени ответа. Перед сбором мы определяем поля данных и спецификации [пропускная способность, время ответа], которые определяются как тип int. определяется как миллисекунды мс.
В реальных ситуациях мы не можем собрать только одно устройство. Если мы хотим получить мониторинг индикаторов каждого устройства или каждого типа устройства, мы должны добавить уникальный идентификатор или TypeID к каждому устройству при сборе данных.
Моя идея здесь состоит в том, чтобы проанализировать показатели каждого устройства, поэтому я добавил уникальный идентификатор для каждого устройства, а конечные поля — [id, пропускная способность, время ответа], поэтому мы следуем этому формату данных и строим данные в части чтения источника SparkStreaming.
2. Читайте Кафку
val conf = new SparkConf().setAppName("aqi").setMaster("local[1]")
val ssc = new StreamingContext(conf, Seconds(10))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "121.91.168.193:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "aqi",
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> (true: java.lang.Boolean)
)
val topics = Array("evt_monitor")
val stream: DStream[String] = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
).map(_.value)Здесь мы устанавливаем временной интервал RDD равным 10 с.,Потому что я работаю на ноутбуке,так Здесь нам нужноMasterустановлен наlocal,Указывает локальный режим работы,1 означает использование 1 потока.
Мы используем Kafka в качестве источника данных,При чтении необходимо построить конфиг Потребителя.,картинаbootstrap.serversОб этих базовых конфигурациях особо нечего сказать.,Ключauto.offset.resetиenable.auto.commit,
Эти два параметра управляют чтением политик потребления тем и отправкой смещений. Самый ранний здесь начнет использовать самые ранние существующие данные в теме, а самый последний начнет использовать самую последнюю позицию.
При перезапуске программы эти два режима потребления контролируются параметром Enable.auto.commit. Если установлено значение true для отправки смещения, самый ранний и последний режимы больше не действуют и используются из смещения, записанного группой потребителей. Установите значение false, и смещение не будет отправлено. Самые ранние данные по-прежнему будут использоваться из самых ранних существующих данных в теме, а самые последние будут использоваться из самых последних данных.
Последний шаг — задать тему для чтения и создать поток данных DStream Kafka. На этом чтение всего источника данных завершено. Далее идет разработка логики обработки данных.
3. Расчет агрегирования показателей
stream.map(x => {
val s = x.split(",")
(s(0), (s(2).toInt, 1))
}).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))
.reduceByKeyAndWindow((x: (Int, Int), y: (Int, Int)) => (x._1 + y._1, x._2 + y._2), Seconds(30), Seconds(10))
.foreachRDD(rdd => {
rdd.foreach(x => {
val id = x._1
val responseTimes = x._2._1
val num = x._2._2
val responseTime_avg = responseTimes / num
println(id, responseTime_avg)
})
})Мы исходим из собственных потребностей,задумать разработку логики программы. С точки зрения спроса,Ключевые слова – это не что иное, какЗа последний период в среднем。Хотите получить данные за определенный период времени,Просто используйте раздвижное окно,На основе текущего времени,Обведите временные рамки вперед.
И средний,Это не что иное, как размещение временного диапазона,То есть сумма всех времен отклика окна,Затем разделите на количество элементов данных. Хотите суммировать все время ответа,используется здесьreduceByKey() Добавьте время устройства с тем же идентификатором в окно и добавьте количество элементов данных.
Поэтому, когда я разделяю данные на первом этапе, я разделяю данные на кортежи KV. У V есть два поля: первое — это время ответа, а второе — 1, представляющее фрагмент данных. Функция «reduceByKey» разделена на два этапа. Первый — это «reducByKey» в RDD, который также рассматривается как предварительная обработка данных. Данные RDD будут рассчитываться только один раз. Когда этот RDD используется несколькими окнами, он не будет рассчитываться повторно. Вторым шагом является агрегирование данных всех RDD в окне на основе значения «reducByKey» окна и, наконец, получение выходных данных в foreachRDD.
4. Результаты проверки
Мы желаемkafkaизevt_monitorэтотtopicзаписать данные в。

Примечание. (Последние 11 идентификаторов — это проблема с отображением терминала, на самом деле это 1), а затем можно вывести среднее значение.
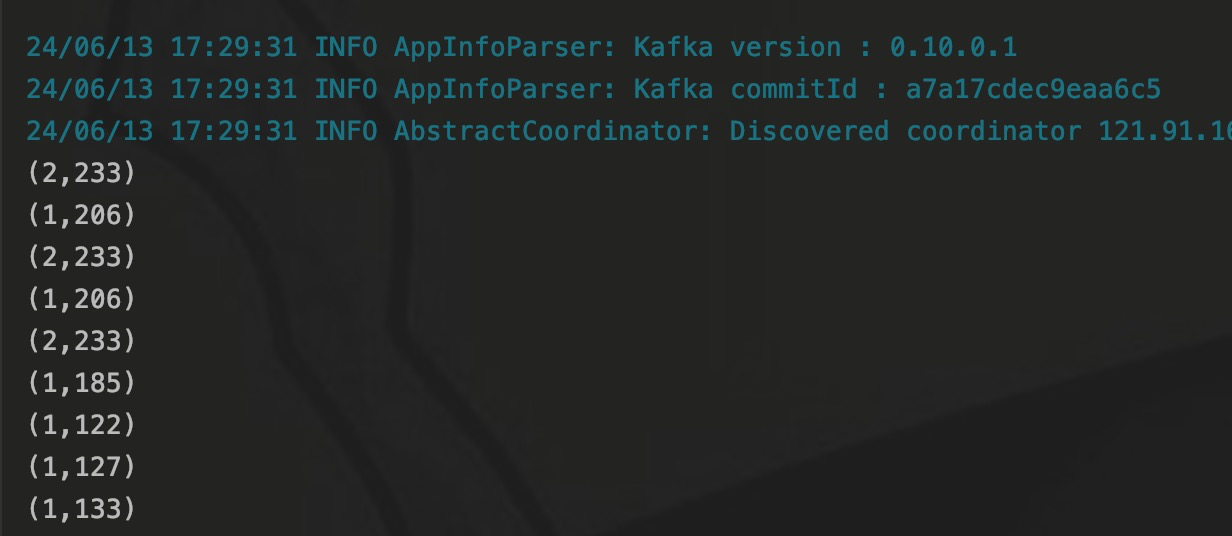
С результатами проверки проблем нет. С другой стороны, мы также можем посмотреть на это со стороны DAG.
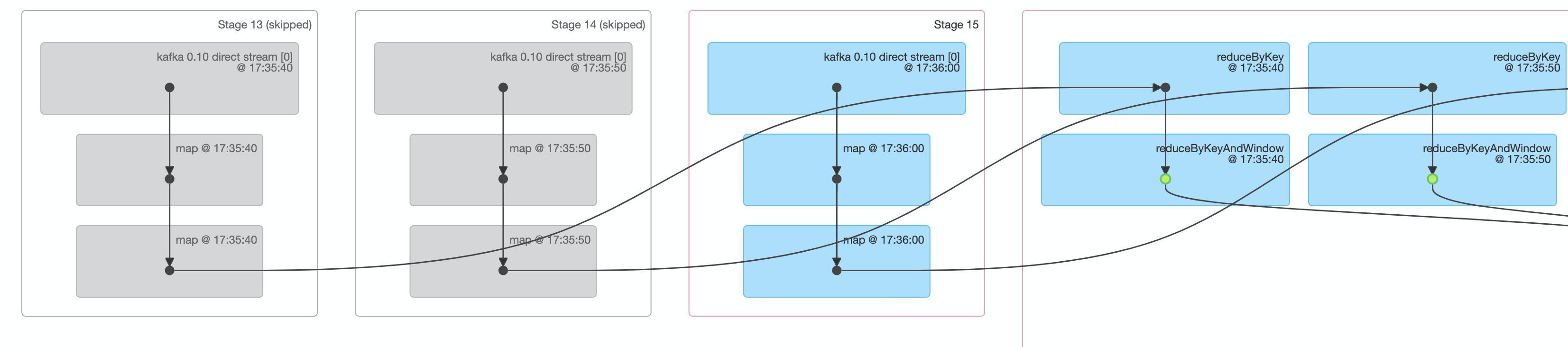
В этом окне рассчитано всего 3 СДР. Два слева имеют серый цвет с пропущенными логотипами, что означает, что два СДР были рассчитаны в предыдущем окне. В этом окне необходимо рассчитать только текущий СДР. а затем вместе выполните расчет окна для данных результатов RDD.
Заключение
В этой статье в основном используется раздвижное приложение Spark. окно, сделал сценарий приложения для расчета среднего времени ответа, используя Kafka в качестве источника данных, через раздвижное окноиreduceByKeyоператор реализован。в то же время,При разработке Spark настоятельно рекомендуется использовать Scala.,Вся программа не выглядит лишней.
Наконец, есть мое личное мнение по поводу выбора Spark и Flink. Spark действительно хуже Flink с точки зрения производительности в реальном времени, но у Spark все же есть преимущества для оконных вычислений. Поэтому по каждой технологии вам не нужно следовать тому, что говорят другие, лучше всего подходит та, которая вам подходит.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
