Создайте своего собственного помощника по кодированию с помощью искусственного интеллекта: с помощью подключаемых модулей IDE, генерации данных кода и точной настройки модели (статья длиной в 10 000 слов).

Мы продолжим обновлять это руководство на GitHub: https://github.com/phodal/build-ai-coding-assistant. Добро пожаловать для обсуждения на GitHub.
В 2023 году популярность генеративного искусственного интеллекта приведет к тому, что все больше и больше организаций будут внедрять кодирование с помощью искусственного интеллекта. В отличие от GitHub Copilot, выпущенного в 2021 году, автодополнение кода — лишь один из многих сценариев. Большое количество компаний изучают такие сценарии, как генерация полного кода и его проверка на основе требований, а также внедряют генеративный искусственный интеллект для повышения эффективности разработки.
В этом контексте мы (Thoughtworks) также разработали серию инструментов с открытым исходным кодом, чтобы помочь большему количеству организаций создать своих собственных помощников по программированию с помощью искусственного интеллекта:
- AutoDev,на основе JetBrains Платформа Полный процесс AI Вспомогательные инструменты кодирования.
- Unit Eval, сцена завершения кода в высоком качестве Построение набора инструмент генерации данных.
- Unit Существуют миньоны, генерация требований, генерация тестов и другие тестовые сценарии, на основедистилляция данныхиз Построение набора данныхинструмент。
Потому что, когда мы разрабатывали AutoDev, различные модели с открытым исходным кодом постоянно развивались. В этом контексте его действия таковы:
- Строить IDE плагини Проектирование измерительной системы。на основеобщественный Модель API, написанный и богатый IDE плагин Функция。
- Система оценки модели и тест тонкой настройки.
- Развивалось вокруг намерения изданных инженерных и Модель.
Поэтому это руководство также сосредоточено на этих трех шагах. Кроме того, исходя из нашего опыта, пример стека технологий для этого руководства:
- плагин:Intellij IDEA。AutoDev дана основе Intellij IDEA Строитьиз,и поставляется сстатический анализ способность кода, так что на на основе Он делает пример для. Мы также предоставляем Плагин VSCode представляет собой эталонную архитектуру, которую можно разрабатывать на основе этого существующего человека.
- Модель:DeepSeek Coder 6.7b。на основе Llama 2 архитектура и Llama Экологичный
- Тонкая настройка: Deepspeed + Официальный скрипт + Unit Eval.
- GPU:RTX 4090x2 + OpenBayes。(PS: Используйте мою специальную ссылку-приглашение для регистрации OpenBayes, обе стороны получают 60 минута RTX 4090 Продолжительность использования, поддерживается накопление, постоянный срок действия: https://openbayes.com/console/signup?r=phodal_uVxU )
Поскольку наш опыт в области ИИ относительно ограничен, некоторые ошибки неизбежно будут. Поэтому мы также надеемся работать с большим количеством разработчиков для создания этого проекта с открытым исходным кодом.
Функциональный дизайн: определите своего помощника с искусственным интеллектом
В сочетании с разделом об искусственном интеллекте в отчете JetBrains Developer Ecosystem 2023 мы можем обобщить некоторые общие сценарии, отражающие области, в которых генеративный ИИ может сыграть роль в процессе разработки. Вот некоторые из основных сценариев:
- codeAutocomplete: существует Ежедневное кодирование,Генеративный ИИ может изучать закономерности, анализируя контекст,Предоставляйте интеллектуальные предложения по автозаполнению исходного кода.,Тем самым повышая эффективность разработки.
- Код пояснения: Генеративное выражение AI могу объяснить код,Помогите разработчикам понять, как функционируют и реализуются конкретные фрагменты.,Обеспечьте поддержку более глубокого понимания.
- Генерируйте код: изучив большую библиотеку шаблонов исходов.,Генеративный ИИ может генерировать фрагменты, соответствующие вашим потребностям.,Ускорить процесс разработки,Особенно важную роль существование играет при повторяющейся работе.
- Обзор кода: Генеративный AI в состоянии продолжитькодобзор,Предоставление качественных предложений и отзывов,Помогите разработчикам улучшить качество кода и следовать лучшим практикам.
- Запросы на естественном языке. Разработчики могут использовать запросы на естественном языке и генеративные AI взаимодействовать,Задать вопрос или запрос,для соответствующих фрагментов кода, документации или объяснений,Облегчите разработчикам получение информации о нуждах.
- другой。различныйнравитьсяв реконструкции、Отправить генерацию информации、Моделирование、Отправить резюме ждать.
Когда мы создавали AutoDev, мы также обнаружили такие сценарии, как создание SQL DDL, создание требований, TDD и т. д. так. Мы предоставляем возможность настраивать сценарии, чтобы разработчики могли настраивать свои собственные возможности ИИ. Подробности см.: https://ide.unitmesh.cc/customize.
Проектирование архитектуры на основе сценариев: баланс скорости и возможностей модели
В ежедневном программировании существует несколько разных сценариев с разными требованиями к скорости реакции ИИ (просто в качестве примера):
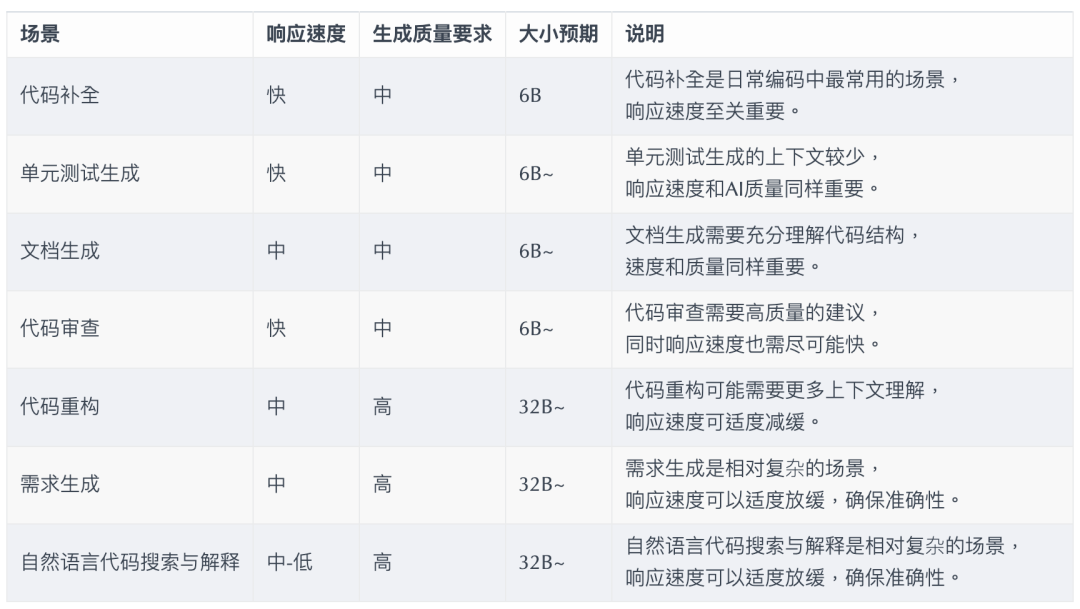
PS: 32B здесь выражен только на порядок, потому что эффект будет лучше с моделью большего размера.
поэтому,Давайте подведем итогидля:Одна основная, одна средняя школа, одна микротри Модель,Обеспечить комплексное AI Вспомогательное кодирование:
- Высококачественная большая модель: 32B~. для рефакторинга кода、формирование спроса、Такие сценарии, как поиск и объяснение на естественном языке.
- Высокая скорость отклика, средняя Модель: 6B~. Используется для завершения кода、Генерация модульных тестов、Генерация документов、обзор кода и другие сцены.
- Векторизованная микромодель: ~100M. для существования IDE Векторизация осуществляется в нравиться: сходство кода, ожидание корреляции кода.
Знакомство с ключевыми сценариями: режим завершения
Завершение кода ИИ может сочетать инструменты IDE для анализа контекста кода и правил языка программирования, а ИИ автоматически генерирует или предлагает фрагменты кода. В инструментах завершения кода, подобных GitHub Copilot, они обычно делятся на три режима подразделения:
Встроенное завершение (Inline)
Похоже на: FIM(fill in the средний) режим, завершенное содержимое находится в текущей строке. Такой как: BlotPost blogpost = new,Полныйдля: BlogPost();, Чтобы достичь: BlogPost blogpost = new BlogPost();。
Мы можем использовать Deepseek Coder в качестве примера, чтобы увидеть эффект в этом сценарии:
<|fim▁begin|>def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[0]
left = []
right = []
<|fim▁hole|>
if arr[i] < pivot:
left.append(arr[i])
else:
right.append(arr[i])
return quick_sort(left) + [pivot] + quick_sort(right)<|fim▁end|>Здесь нам нужно объединить код до и после курсора.
Внутриблочное завершение (InBlock)
Достигается посредством контекстного обучения (In-Context Learning), содержимое завершения находится в текущем функциональном блоке. Например, исходный код:
fun createBlog(blogDto: CreateBlogDto): BlogPost{
}Завершенный код:
val blogPost = BlogPost(
title = blogDto.title,
content = blogDto.content,
author = blogDto.author
)
return blogRepository.save(blogPost)После Блок
Достигается посредством контекстного обучения (In-Context Learning), завершения после текущего функционального блока, например: завершение новой функции после текущего функционального блока. Например, исходный код:
fun createBlog(blogDto: CreateBlogDto): BlogPost{
//...
}Завершенный код:
fun updateBlog(id: Long, blogDto: CreateBlogDto): BlogPost{
//...
}
fun deleteBlog(id: Long) {
//...
}Когда мы создаем соответствующую функцию завершения AI, нам также необходимо рассмотреть возможность применения ее к соответствующему набору данных шаблона, чтобы улучшить качество завершения и обеспечить лучший пользовательский опыт.
Некоторые связанные ресурсы для написания этой статьи:
- Why your AI Code Completion tool needs to Fill in the Middle
- Exploring Custom LLM-Based Coding Assistance Functions
Введение в ключевую сцену: объяснение кода
Пояснения к коду призваны помочь разработчикам более эффективно управлять большими базами кода и понимать их. Эти помощники могут отвечать на вопросы по кодовой базе, предоставлять документацию, осуществлять поиск кода, выявлять источники ошибок, уменьшать дублирование кода и т. д., тем самым повышая эффективность разработки, снижая количество ошибок и снижая нагрузку на разработчиков.
В этом сценарии, в зависимости от ожидаемого качества генерации, он обычно состоит из двух моделей: одной большой и одной микро или одной средней и одной микро. Более крупная модель дает лучшие результаты с точки зрения качества генерации. Учитывая наш опыт проектирования в инструменте «Шоколадная фабрика», обычно такую функцию можно разделить на несколько этапов:
- Понимание намерений пользователя. Используйте большую модель, чтобы понять намерения пользователя и преобразовать их в соответствующие модели. AI Agent вызов способности или function calling 。
- Поиск намерения конверсии: преобразуйте намерение пользователя в соответствующее фрагменту исходного кода, документам или объяснениям с помощью Модели.,говорит Традиционный поиск, поиск по пути, векторизованный поиск и другие технологии,Ищите и сортируйте.
- Выходной результат: оплата Зависит отбольшой Модель суммирует окончательные результаты и выводит их пользователю.
Как приложение RAG, оно разделено на две части: индексирование и запрос.
На этапе индексирования нам необходимо проиндексировать базу кода и задействовать такие технологии, как сегментация текста, векторизация и индексирование базы данных. Одним из наиболее сложных элементов является разделение. Правила разделения, на которые мы ссылаемся: https://docs.sweep.dev/blogs/chunking-2m-files. Прямо сейчас:
- кодиз среднего Token Соотношение символов к символам примерно 1:5 (300 индивидуальный Токен), при встраивании Модельиз Token Верхний предел 512 индивидуальный。
- 1500 Характер индивидуально соответствует примерно 40 Строка, примерно эквивалентная функции или классу малого или среднего размера.
- существует задача подобраться как можно ближе 1500 отдельные символы, гарантируя при этом, что разделенные на части существования семантически схожи и релевантны, контекстуально связаны друг с другом.
В разных сценариях мы тоже можем делить по-разному. Например, в «Шоколадной фабрике» мы делим через AST, чтобы обеспечить качество генерируемого контекста.
На этапе запроса нам необходимо объединить некоторые из наших традиционных технологий поиска, таких как векторизованный поиск, поиск по пути и т. д., чтобы обеспечить качество поиска. В то же время в китайском сценарии нам также необходимо рассмотреть вопрос преобразования на китайский язык, например, преобразование английского языка в китайский для обеспечения качества поиска.
- Сопутствующие инструменты: https://github.com/BloopAI/bloop.
- Связанные ресурсы:
- Prompt Стратегия: библиотека кода AI помощникиз Семантический поискдизайн
другой: ежедневная помощь
Для ежедневной помощи мы также можем достичь этого с помощью генеративного искусственного интеллекта, например автоматического создания SQL DDL, автоматического создания тестовых примеров, автоматического создания требований и т. д. Этого можно достичь только путем настройки подсказок и объединения знаний в конкретной предметной области, поэтому я не буду здесь вдаваться в подробности.
Архитектурное проектирование: контекстная инженерия
Помимо моделей, важным фактором, влияющим на возможности помощи ИИ, также является контекст. Создавая AutoDev, мы также обнаружили два разных контекстных режима:
- Соответствующий контекст: на основестатический анализ зависит генерация кодиз-контекста, которая может построить лучшее качество из контекста, генерировать более качественные тесты изкоди и т.д. IDE изстатический анализ кодаспособность。
- Похожий контекст: на на основе поиска сходства из контекста,Можно ли построить больше из контекста,генерировать больше тестов изкодов и т. д.,Возможности платформы тут ни при чем.
Простое сравнение выглядит следующим образом:
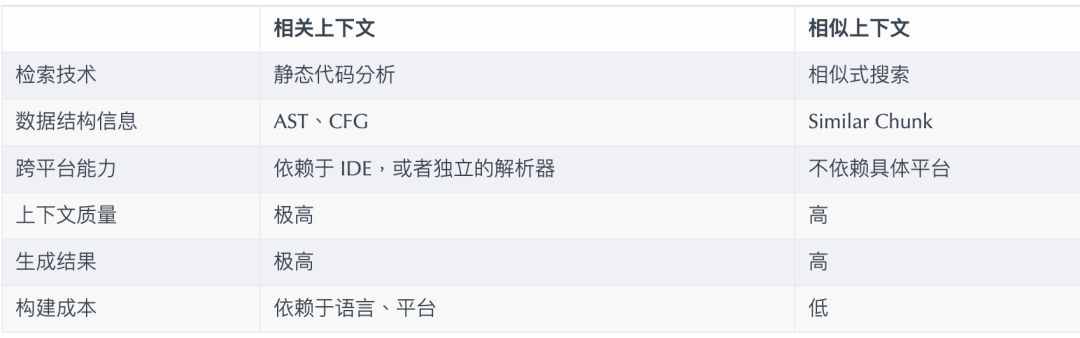
В поддержку IDE Ограниченное время,Связанныйконтекстизпринесет вышеизВысокая стоимость исполнения。
Подобная контекстная архитектура: случай GitHub Copilot.
GitHub Copilot использует аналогичный шаблон контекстной архитектуры, и его подробная архитектура состоит из следующих слоев:
- Мониторинг операций пользователя (IDE API ). Мониторить пользователя из Run Действие, сочетания клавиш, пользовательский интерфейс Операции, вводы и т. д., а также недавняя история операций с документами (20 индивидуальныйдокумент)。
- IDE Клеевой слой (Плагин как IDE с дном) Агент из клеевого слоя, обрабатывающий ввод и вывод.
- построение контекста(Agent)。JSON RPC Сервер, обработка IDE из Различных изменений, анализа исходного кода, инкапсуляции для “prompt” (подозреваемый) и отправлен на сервер.
- Сервер. Обработайте запрос на подсказку и передайте его на обработку на сервер LLM.
В материалах исследования «публичного» проекта Copilot-Explorer можно увидеть, как устроен Prompt. Ниже приводится быстрый запрос, отправленный по адресу:
{
"prefix": "# Path: codeviz\\app.py\n#....",
"suffix": "if __name__ == '__main__':\r\n app.run(debug=True)",
"isFimEnabled": true,
"promptElementRanges": [
{
"kind": "PathMarker",
"start": 0,
"end": 23
},
{
"kind": "SimilarFile",
"start": 23,
"end": 2219
},
{
"kind": "BeforeCursor",
"start": 2219,
"end": 3142
}
]
}в:
- используется для Строить prompt из
prefixЧасть, да Зависит от promptElements Строить Понятно,Он включает в себя:BeforeCursor,AfterCursor,SimilarFile,ImportedFile,LanguageMarker,PathMarker,RetrievalSnippetи т. д. типы. Из нескольких видовPromptElementKindпо названию мы также можем увидеть его истинное значение. - используется для Строить prompt из
suffixчасть, то да Зависит от курсора существуетиз частичного решения, согласно tokens из Верхнего предела (2048 ), чтобы подсчитать, сколько позиций осталось. И здесь из Token Посчитайте тогда даправдаиз LLM из token вычислить,существовать Copilot вот и все прошло Cushman002 Вычислить из, нравиться по-китайски из иероглифа из token Длина отличается от,нравиться:{ context: "console.log('Привет, мир')", lineCount: 1, tokenLength: 30 },в context серединаизсодержаниеиз length для 20, но tokenLength да 30, всего китайских иероглифов 5 индивидуальный(Включать,) из длины, один индивидуальный символ составляет из token Да 3。
Вот более подробный пример контекста приложения Java:
// Path: src/main/cc/unitmesh/demo/infrastructure/repositories/ProductRepository.java
// Compare this snippet from src/main/cc/unitmesh/demo/domain/product/Product.java:
// ....
// Compare this snippet from src/main/cc/unitmesh/demo/application/ProductService.java:
// ...
// @Component
// public class ProductService {
// //...
// }
//
package cc.unitmesh.demo.repositories;
// ...
@Component
publicclassProductRepository{
//...В контексте вычислений GitHub Copilot использует коэффициент Жаккара (сходство Жаккара). Эта часть реализации реализована в Agent. Более подробную логику можно найти в разделе: Потратив более полумесяца, я наконец перепроектировал Github Copilot.
Связанные ресурсы:
- Контекстная инженерия: на основе Github Copilot из анализа возможностей и мышления в реальном времени
Связанная контекстная архитектура: пример AutoDev и JetBrains AI Assistant
нравитьсяупомянутый выше,Связанныйкодзависит отстатический анализ кода,В основном с помощью кодирования структурной информации.,нравиться:AST、CFG、DDG ждать.существовать под разными сценами и платформами,мы можемобъединитьдругойизстатический анализ инструмент кода, Следующееобщийизумительныйстатический анализ код Инструменты:
- TreeSitter — платформа, разработанная GitHub для создания эффективных пользовательских парсеров.
- Intellij PSI (Program Structure Interface),Зависит от JetBrains разработан из-за своего IDE изстатический анализ кодаинтерфейс。
- LSP(Language Server Protocol),Зависит от Microsoft, разработанный для IDE из протокола универсального языкового сервера.
- Chapi (common hierarchical abstract parser implementation) ,Зависит от Автор (@phodal) разработал для универсального изстатического анализ инструмент кода.
существующий сценарий завершения, статический анализ кода,мы Можно получить текущий из контекста, нравиться: текущий из функции, текущий из класса, текущий из ожидания файла. AutoDev Пример контекста для создания модульных тестов:
// here are related classes:
// 'filePath: /Users/phodal/IdeaProjects/untitled/src/main/java/cc/unitmesh/untitled/demo/service/BlogService.java
// class BlogService {
// blogRepository
// + public BlogPost createBlog(BlogPost blogDto)
// + public BlogPost getBlogById(Long id)
// + public BlogPost updateBlog(Long id, BlogPost blogDto)
// + public void deleteBlog(Long id)
// }
// 'filePath: /Users/phodal/IdeaProjects/untitled/src/main/java/cc/unitmesh/untitled/demo/dto/CreateBlogRequest.java
// class CreateBlogRequest ...
// 'filePath: /Users/phodal/IdeaProjects/untitled/src/main/java/cc/unitmesh/untitled/demo/entity/BlogPost.java
// class BlogPost {...
@ApiOperation(value = "Create a new blog")
@PostMapping("/")
publicBlogPost createBlog(@RequestBodyCreateBlogRequest request) {В этом примере анализируется createBlog Контекст функции, получение входных и выходных классов функции: CreateBlogRequest、 BlogPost информация и BlogService Информация о классе, предоставляемая модели в качестве контекста (предоставляется в аннотациях). На этом этапе модель генерирует более точные конструкторы, а также более точные тестовые примеры.
потому что соответствующий контекст зависит от разных языков изстатический анализ код, разные IDE из API, поэтому мы также ориентируемся на разные языки и разные IDE Адаптируйтесь. Что касается стоимости строительства, то оно дороже по сравнению с аналогичными контекстами.
Шаг 1. Создайте плагин IDE и измерьте проект системы.
IDE и редактор — основные инструменты для разработчиков,Стоимость обучения дизайну также относительно высока. первый,мы Возможно создано с использованием официального предоставленного шаблона:
- IDEA плагиншаблон
- Плагин Генерация VSCode
Затем,Добавление функций дальше вверх (да не да это очень просто),Конечно, нет. Некоторые из следующих материалов можно отнести к плагину IDEA Ресурсы:
- Исходный код версии сообщества Intellij
- IntelliJ SDK Docs Code Samples
- Intellij Rust
Конечно, уместнее обратиться к плагину AutoDev.
Плагин JetBrains
Вы можете напрямую использовать официальный шаблон для создания соответствующего плагина: https://github.com/JetBrains/intellij-platform-plugin-template.

для IDEA Что касается реализации плагина, то в основном это происходит за счет Action и Listener Чтобы реализовать из,Тольконуждатьсясуществовать plugin.xml Просто зарегистрируйтесь. Подробную информацию можно найти в официальной документации: IntelliJ. Platform Plugin SDK
Совместимость версий и архитектура совместимости
Поскольку мы ранее не AutoDev принимая во внимание IDE Проблема совместимости версии, позже стала совместимой со старой версией версии. IDE, нам нужно заняться совместимостью плагинов. Итак, как в официальной документации: Сборка Number Ranges Как описано в, мы можем Видетьдругой Версия,для JDK требуется другое,Следующеедругой Версияиз Требовать:

и настроен на gradle.properties середина:
pluginSinceBuild = 223
pluginUntilBuild = 233.*Последующая совместимость конфигурации является более проблематичной, вы можете обратиться к AutoDev издизайн。
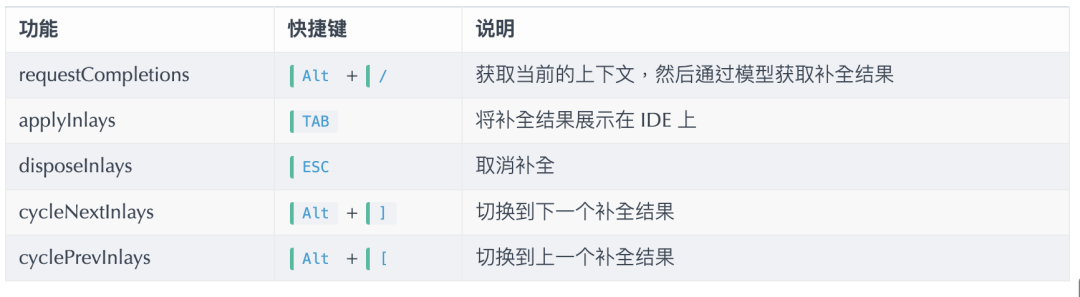
Режим завершения: Инкрустация
существоватьавтоматическийкод Полныйначальство,Отечественные производители в основном ссылаются на версию GitHub Copilot при реализации.,Логика тоже не сложная.
Запуск с помощью сочетаний клавиш
Отслеживайте ввод пользователя в разделе «Это главным образом в действии».,Затем:
Использовать метод автоматического запуска
В основном проходит EditorFactoryListener Мониторинг пользователейизвходить,Затем: ввод в соответствии с различными из,Запуск различных результатов завершения。основнойкоднравиться Вниз:
classAutoDevEditorListener: EditorFactoryListener{
override fun editorCreated(event: EditorFactoryEvent) {
//...
editor.document.addDocumentListener(AutoDevDocumentListener(editor), editorDisposable)
editor.caretModel.addCaretListener(AutoDevCaretListener(editor), editorDisposable)
//...
}
classAutoDevCaretListener(val editor: Editor) : CaretListener{
override fun caretPositionChanged(event: CaretEvent) {
//...
val wasTypeOver = TypeOverHandler.getPendingTypeOverAndReset(editor)
//...
llmInlayManager.disposeInlays(editor, InlayDisposeContext.CaretChange)
}
}
classAutoDevDocumentListener(val editor: Editor) : BulkAwareDocumentListener{
override fun documentChangedNonBulk(event: DocumentEvent) {
//...
val llmInlayManager = LLMInlayManager.getInstance()
llmInlayManager
.editorModified(editor, changeOffset)
}
}
}Затем введите в соответствии с различными из,Запуск различных результатов завершения,и обработать конструкцию.
Код завершения рендеринга
Впоследствии нам необходимо реализовать Inlay Render, который наследуется от EditorCustomElementRenderer。
Ежедневное развитие доступности
объединить IDE из возможностей интерфейса, мы нуждаемся в добавлении соответствующих из Действие и соответствующее Группа и соответствующие из икона. Ниже приводится Action из Пример:
<add-to-group group-id="ShowIntentionsGroup" relative-to-action="ShowIntentionActions" anchor="after"/>
Следующее AutoDev изумительный ActionGroup:

Письмо ShowIntentionsGroup , мы можем обратиться к AutoDev из инвентаря Строить соответствующий из Group:
<groupid="AutoDevIntentionsActionGroup"class="cc.unitmesh.devti.intentions.IntentionsActionGroup"
icon="cc.unitmesh.devti.AutoDevIcons.AI_COPILOT"searchable="false">
<add-to-groupgroup-id="ShowIntentionsGroup"relative-to-action="ShowIntentionActions"anchor="after"/>
</group>Многоязычная контекстная архитектура
потому что Intellij Стратегия платформы позволяет работать на Java IDE(Intellij IDEA)исуществоватьдругой IDE нравиться Python Различия между IDE (Pycharm) становятся еще больше. Мы нуждаемсяпредложение на основе Несовместимость многоплатформенных продуктов. Подробное описание см. в разделе: Плагин. Compatibility with IntelliJ Platform Products
первый,Дальнейшая модульность архитектуры плагина.,То есть игла для разных языков,поставлятьдругойизмодуль。Следующее AutoDev из Модульная архитектура:
java/ # Java языкплагин src/main/java/cc/unitmesh/autodev/ # Java Языковой портал
src/main/resources/META-INF/plugin.xml
plugin/ # Мультиплатформенный портал
src/main/resources/META-INF/plugin.xml
src/ # то есть основной модуль
main/resource/META-INF/core.plugin.xmlсуществовать plugin/plugin.xml , мы нуждаемся добавлено соответствующее из depends,а также extensions,Следующееодининдивидуальный Пример:
<idea-pluginpackage="cc.unitmesh"xmlns:xi="http://www.w3.org/2001/XInclude"allow-bundled-update="true">
<xi:includehref="/META-INF/core.xml"xpointer="xpointer(/idea-plugin/*)"/>
<content>
<modulename="cc.unitmesh.java"/>
<!-- другоймодуль -->
</content>
</idea-plugin>исуществовать java/plugin.xml , мы нуждаемся добавлено соответствующее из depends,а также extensions,Следующееодининдивидуальный Пример:
<idea-pluginpackage="cc.unitmesh.java">
<!--suppress PluginXmlValidity -->
<dependencies>
<pluginid="com.intellij.modules.java"/>
<pluginid="org.jetbrains.plugins.gradle"/>
</dependencies>
</idea-plugin>Впоследствии Intellij Соответствующий модуль будет автоматически загружен для обеспечения многоязычной поддержки. Согласно нашему ожиданию поддержки разных языков, нуждаться соответствует из plugin.xml,различныйнравиться В:
cc.unitmesh.javascript.xml
cc.unitmesh.rust.xml
cc.unitmesh.python.xml
cc.unitmesh.kotlin.xml
cc.unitmesh.java.xml
cc.unitmesh.go.xml
cc.unitmesh.cpp.xmlнаконец,существуют различные языковые модули,Просто реализуйте соответствующую функцию.
построение контекста
Для упрощения этого процесса мы используем Unit Eval показатьнравитьсячто Строить Два похожихизконтекст。
статический анализ кода
проходитьстатический анализ кода,Мы можем получить текущее значение из функции, текущее значение из класса и текущее значение из ожидания файла. Затем мы узнали о сходстве путей.,Найдите наиболее подходящий контекст.
private fun findRelatedCode(container: CodeContainer): List<CodeDataStruct> {
// 1. collects all similar data structure by imports if exists in a file tree
val byImports = container.Imports
.mapNotNull {
context.fileTree[it.Source]?.container?.DataStructures
}
.flatten()
// 2. collects by inheritance tree for some node in the same package
val byInheritance = container.DataStructures
.map {
(it.Implements+ it.Extend).mapNotNull { i ->
context.fileTree[i]?.container?.DataStructures
}.flatten()
}
.flatten()
val related = (byImports + byInheritance).distinctBy { it.NodeName}
// 3. convert all similar data structure to uml
return related
}
classRelatedCodeStrategyBuilder(private val context: JobContext) : CodeStrategyBuilder{
override fun build(): List<TypedIns> {
// ...
val findRelatedCodeDs = findRelatedCode(container)
val relatedCodePath = findRelatedCodeDs.map { it.FilePath}
val jaccardSimilarity = SimilarChunker.pathLevelJaccardSimilarity(relatedCodePath, currentPath)
val relatedCode = jaccardSimilarity.mapIndexed { index, d ->
findRelatedCodeDs[index] to d
}.sortedByDescending {
it.second
}.take(3).map {
it.first
}
//...
}
}Приведенный выше исход,мы можем по кодированию. Информация об импорте является частью соответствующего кодирования. Затем посредством кодирования отношений наследования,Зайдите и найдите соответствующий изкод. наконец,по репутальному сходству,чтобы найти наиболее близкое из контекста.
Связанный анализ кода
Найти первым,Тогда по сходству,Зайдите и найдите соответствующий изкод. Основная логика показана:
fun pathLevelJaccardSimilarity(chunks: List<String>, text: String): List<Double> {
//...
}
fun tokenize(chunk: String): List<String> {
return chunk.split(Regex("[^a-zA-Z0-9]")).filter { it.isNotBlank() }
}
fun similarityScore(set1: Set<String>, set2: Set<String>): Double{
//...
}Подробности см.: LikeChunker.
Плагин VSCode
TODO
TreeSitter
TreeSitter даиндивидуальный — это платформа для создания эффективных пользовательских парсеров. от GitHub разработка. он использует LR (1) анализировать, то есть может существовать Анализируйте любой язык за время O(n) вместо O(n²) времени. Он также использует метод, называемый «повторное использование синтаксического дерева», который позволяет обновлять синтаксическое дерево без повторного редактирования файла.
потому что TreeSitter Обеспечена многоязычная поддержка, вы можете использовать Node.js、Rust И другие языки, соответствующие изплагину Строить. Подробности см.: TreeSitter.
В зависимости от наших намерений существуют разные способы использования TreeSitter:
Символ анализа
Существующая поисковая система кодирования естественного языка Bloop , мы используем TreeSitter для анализа символов для улучшения качества поиска.
;; methods
(method_declaration
name: (identifier) @hoist.definition.method)Впоследствии определите, как отображать нравиться в зависимости от разных типов:
pub static JAVA: TSLanguageConfig= TSLanguageConfig{
language_ids: &["Java"],
file_extensions: &["java"],
grammar: tree_sitter_java::language,
scope_query: MemoizedQuery::new(include_str!("./scopes.scm")),
hoverable_query: MemoizedQuery::new(
r#"
[(identifier)
(type_identifier)] @hoverable
"#,
),
namespaces: &[&[
// variables
"local",
// functions
"method",
// namespacing, modules
"package",
"module",
// types
"class",
"enum",
"enumConstant",
"record",
"interface",
"typedef",
// misc.
"label",
]],
};Код фрагмента
Следующее Improving LlamaIndex’s Code Chunker by Cleaning Tree-Sitter CSTs серединаиз TreeSitter из Использование:
from tree_sitter importTree
def chunker(
tree: Tree,
source_code: bytes,
MAX_CHARS=512* 3,
coalesce=50# Any chunk less than 50 characters long gets coalesced with the next chunk
) -> list[Span]:
# 1. Recursively form chunks based on the last post (https://docs.sweep.dev/blogs/chunking-2m-files)
def chunk_node(node: Node) -> list[Span]:
chunks: list[Span] = []
current_chunk: Span= Span(node.start_byte, node.start_byte)
node_children = node.children
for child in node_children:
if child.end_byte - child.start_byte > MAX_CHARS:
chunks.append(current_chunk)
current_chunk = Span(child.end_byte, child.end_byte)
chunks.extend(chunk_node(child))
elif child.end_byte - child.start_byte + len(current_chunk) > MAX_CHARS:
chunks.append(current_chunk)
current_chunk = Span(child.start_byte, child.end_byte)
else:
current_chunk += Span(child.start_byte, child.end_byte)
chunks.append(current_chunk)
return chunks
chunks = chunk_node(tree.root_node)
# 2. Filling in the gaps
for prev, curr in zip(chunks[:-1], chunks[1:]):
prev.end = curr.start
curr.start = tree.root_node.end_byte
# 3. Combining small chunks with bigger ones
new_chunks = []
current_chunk = Span(0, 0)
for chunk in chunks:
current_chunk += chunk
if non_whitespace_len(current_chunk.extract(source_code)) > coalesce \
and"\n"in current_chunk.extract(source_code):
new_chunks.append(current_chunk)
current_chunk = Span(chunk.end, chunk.end)
if len(current_chunk) > 0:
new_chunks.append(current_chunk)
# 4. Changing line numbers
line_chunks = [Span(get_line_number(chunk.start, source_code),
get_line_number(chunk.end, source_code)) for chunk in new_chunks]
# 5. Eliminating empty chunks
line_chunks = [chunk for chunk in line_chunks if len(chunk) > 0]
return line_chunksПроектирование измерительной системы
Общие индикаторы
процент принятия кода
Искод генерации ИИ принимается разработчиками пропорционально.
Скорость приема
Созданный ИИ исходный код пропорционально хранится в базе данных разработчика.
Опыт разработчиков ориентирован на
нравиться Майкрософти GitHub Место Строитьиз:DevEx: What Actually Drives Productivity: The developer-centric approach to measuring and improving productivity
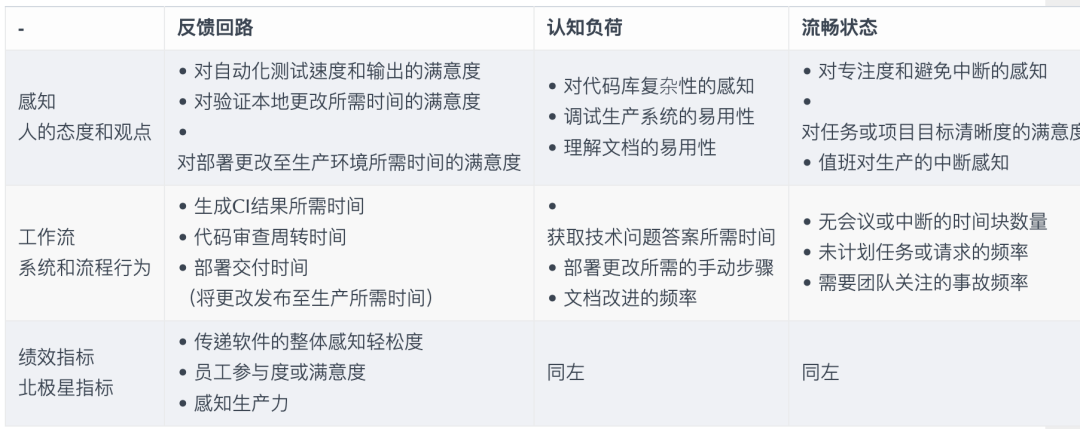
Шаг 2: Система оценки модели и эксперименты по точной настройке
Набор оценочных данных: HumanEval
Выбор модели и тестирование
существоватьобъединитьобщественный API После того, как из большой языковой модели, мы можем построить базовую модель из IDE Функция。впоследствии,Подходит для внутреннего использования. Модель требует дальнейшего изучения.,Чтобы соответствовать внутренним эффектам организации.
Выбор модели
Используется в существующей модели с открытым исходным кодом. LLaMA Структур относительно много, и потому Что Качество его Моделииз относительно высокое, а его экология относительно полная. Поэтому мы также используем LLaMA архитектуру для построения, а именно: DeepSeek Coder。
Развертывание и тестирование платформы OpenBayes
Впоследствии мы нуждаемся в развертывании Модели и предоставлении соответствующего индивидуального API, это API нуждатьсяинасиз IDE Интерфейс остается последовательным. Здесь мы используем OpenBayes платформа для развертывания моделей. Подробности см.: code/server Каталог из соответствующего кода.
pip install -r requirements.txt
python server-python38.pyСледующее подходит для OpenBayes изкод, обеспечивающий общедоступную сеть фоном существования API:
if __name__ == "__main__":
try:
meta = requests.get('http://localhost:21999/gear-status', timeout=5).json()
url = meta['links'].get('auxiliary')
if url:
print("Откройте эту ссылку, чтобы посетить:", url)
exceptException:
pass
uvicorn.run(app, host="0.0.0.0", port=8080)впоследствии,существовать IDE подключите, мы можем использовать их для проверки функциональности.
Масштабное развертывание модели
объединить Технология количественного определения модели,нравиться INT4, может быть достигнуто 6B Модельсуществоватьпотребительский классиз Развертывание локально на видеокарте。
(TODO)
Тонкая настройка модели
Контролируемая точная настройка (SFT) относится к методу использования предварительно обученной нейронной сети и ее переобучения для выполнения вашей собственной специализированной задачи с небольшим контролем.
Подход к точной настройке на основе данных
объединить [Лучшие практики SFT 】серединапоставлятьиз Компромиссы:
- размер выборкименее 1000 И необходимо обратить внимание на общую способность базовой Моделииз: приоритет. LoRA。
- Если образцов для конкретных задач много и основной акцент делается на эффектах от этих задач: используйте SFT.
- Если вы хотите, вы узнаете преимущества обоих: после смешивания конкретных задач, задач и общих данных данных.,Вы можете получить лучшие результаты, используя эти методы обучения.
Это означает:
Тип задачи | размер выборки | Универсальный набор данных кодирования |
|---|---|---|
Поддержка функций IDE AI | менее 1000 | нуждаться |
Завершение внутреннего кода | больше 10 000 | Нетнуждаться |
IDE + завершение кода | больше 10 000 | нуждаться |
Вообще говоря,Тестируем даобъединить IDE по функционалу,И завершение кода из функции,поэтому,наснуждаться Объединить дваиндивидуальныйданныенабор。
Построение набора данных
В зависимости от модели, его инструкции также различаются. Следующееодининдивидуальный на основе DeepSeek + DeepSpeed изданныеэпизод Пример:
{
"instruction": "Write unit test for following code.\n<SomeCode>",
"output": "<TestCode>"
}Ниже LLaMA Модельизданныенабор Пример:
{
"instruction": "Write unit test for following code.",
"input": "<SomeCode>",
"output": "<TestCode>"
}Построение набора данных
мы строим Unit Eval проект для создания проекта, более подходящего для AutoDev изданныенабор。
- завершение кода. В соответствии、InBlock、Три сценария между блоками (AfterBlock).
- Генерация модульных тестов。Создать совпадениеконтекстиз Модульное тестирование。
и для того, чтобы обеспечить IDE серединаиздругой Поддержка функций,насобъединить Понятно Набор данных с открытым исходным код и дистилляция данныхизспособ Строитьданныенабор。
Набор данных с открытым исходным кодом
Существуют некоторые изданные коллекции с открытым исходным кодом на таких платформах, как GitHub и HuggingFace.
Magicoder: Source Code Is All You Need середина Открытый исходный кодиздваиндивидуальныйданныенабор:
- https://huggingface.co/datasets/ise-uiuc/Magicoder-OSS-Instruct-75K
- https://huggingface.co/datasets/ise-uiuc/Magicoder-Evol-Instruct-110K
существовать License Когда это уместно, мы можем Используйте их напрямуюданныенабор;существовать Нет Когда это уместно, мы Можно использовать его для проведения некоторых экспериментов.
дистилляция данных
дистилляция данные. Раньше да определялось как ввод большого реального набора данных (обучающего набора) и вывод небольшого индивидуального синтетического набора данных. Но да, нам нужно сделать изда напрямую с OpenAI Такая публика API из Модель:
- Генерирует наборы, как и ожидалось.
- Сборы данных проверяются, чтобы гарантировать качество сбора данных.
- Набор данных расширен, чтобы обеспечить разнообразие набора данных.
- Пометьте набор данных,Гарантировать набор данных из наличия.
Пример тонкой настройки: OpenBayes + DeepSeek
Здесь мы используем изда, а DeepSeek официально предоставляет из скриптов для тонкой настройки.
- облако Графический процессор: OpenBayes
- GPU Вычислительная мощность: 4090x2 (Визуальный осмотр связан с тонкой настройкой параметров, но я пробовал несколько раз. 4090 Пока нехорошо)
- Скрипт тонкой настройки: https://github.com/deepseek-ai/DeepSeek-Coder
- данныенабор:6000
ясуществовать OpenBayes Загружено DeepSeek Модель:OpenBayes deepseek-coder-6.7b-instruct, вы можете использовать это непосредственно при создании существующей индивидуальной Модели.
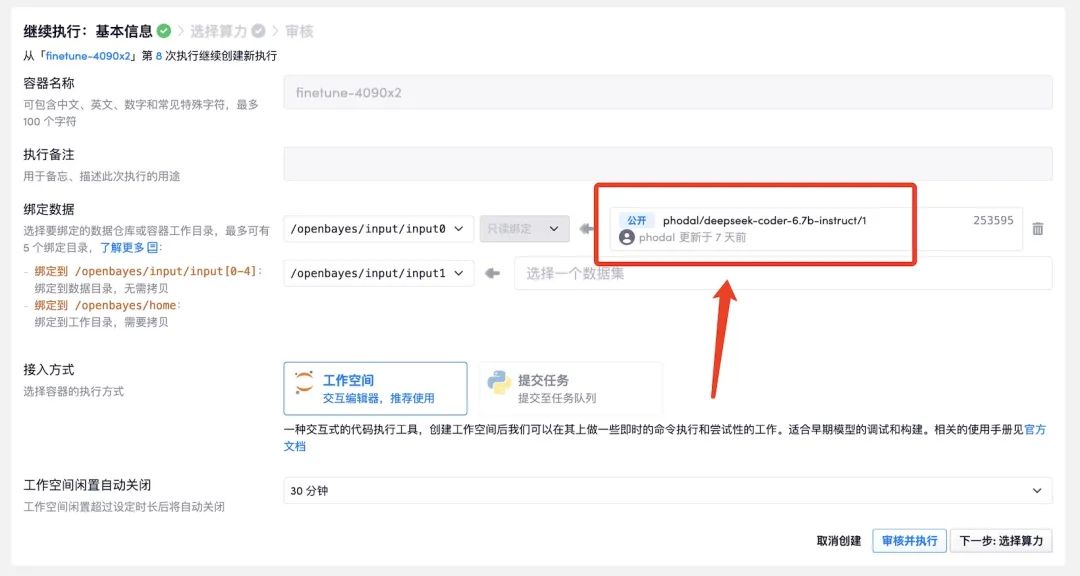
Информация о наборе данных
Зависит от Unit Eval + OSS Instruct Построение набора данныхи Приходить:
- 150 полосокComplete (Inline,InBlock,AfterBlock)данныенабор。
- Набор данных из 150 полосок модульных тестов.
- 3700 полоска OSS Instruct данныенабор。
Судя по результатам, самой большой проблемой является сохранение высокого качества.
Тестовое видео: Решение для программирования с открытым исходным кодом на основе искусственного интеллекта: сквозная версия Unit Mesh v0.0.1
Пример параметра:
DATA_PATH="/openbayes/home/summary.jsonl"
OUTPUT_PATH="/openbayes/home/output"
MODEL_PATH="/openbayes/input/input0/"
!cd DeepSeek-Coder/finetune && deepspeed finetune_deepseekcoder.py \
--model_name_or_path $MODEL_PATH \
--data_path $DATA_PATH \
--output_dir $OUTPUT_PATH \
--num_train_epochs 1 \
--model_max_length 1024 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 375 \
--save_total_limit 10 \
--learning_rate 1e-4 \
--warmup_steps 10 \
--logging_steps 1 \
--lr_scheduler_type "cosine" \
--gradient_checkpointing True \
--report_to "tensorboard" \
--deepspeed configs/ds_config_zero3.json \
--bf16 TrueЖурнал выполнения:
`use_cache=True` is incompatible with gradient checkpointing. Setting`use_cache=False`...
0%| | 0/375[00:00<?, ?it/s]`use_cache=True` is incompatible with gradient checkpointing. Setting`use_cache=False`...
{'loss': 0.6934, 'learning_rate': 0.0, 'epoch': 0.0}
{'loss': 0.3086, 'learning_rate': 3.0102999566398115e-05, 'epoch': 0.01}
{'loss': 0.3693, 'learning_rate': 4.771212547196624e-05, 'epoch': 0.01}
{'loss': 0.3374, 'learning_rate': 6.020599913279623e-05, 'epoch': 0.01}
{'loss': 0.4744, 'learning_rate': 6.989700043360187e-05, 'epoch': 0.01}
{'loss': 0.3465, 'learning_rate': 7.781512503836436e-05, 'epoch': 0.02}
{'loss': 0.4258, 'learning_rate': 8.450980400142567e-05, 'epoch': 0.02}
{'loss': 0.4027, 'learning_rate': 9.030899869919434e-05, 'epoch': 0.02}
{'loss': 0.2844, 'learning_rate': 9.542425094393248e-05, 'epoch': 0.02}
{'loss': 0.3783, 'learning_rate': 9.999999999999999e-05, 'epoch': 0.03}другой:
- Подробности Notebook Файл:code/finetune/finetune.ipynb
- Параметры тонкой настройки подробнее см.: Трейнер
Шаг 3. Инжиниринг данных и эволюция модели в зависимости от намерения

Unit Tools Workflow
Unit Eval — это индивидуальный инструмент для создания высококачественной тонкой настройки кода с помощью набора инструментов с открытым исходным кодом. Третий основной принцип индивидуального дизайна:
- Единое слово-подсказка (Prompt). Унифицированные инструменты — точная настройка — оценка основных слов из подсказок.
- Код Конвейер качества. Вся сложность、кодбезвкусица、Тест на безвкусицу、API дизайнзапахждать.
- Масштабируемый порог качества. Пользовательские правила、Пользовательский порог、Нестандартное качество типа ожидания.
То есть решить проблему простого создания тестовых наборов и простой оценки модели оценки.
Проектирование и эволюция команд IDE
AutoDev Раннее принятиеизда OpenAI API,Способность модели сильна.,поэтомусуществоватьинструкциядизайнначальство比较强большой。икогданаснуждатьсятонкая настройка,Наша нуждаться проще и легче отличить от инструкций Строить.
директива шаблона
Следующеесуществовать AutoDev Упрощенная версия Prompt Пример:
Write unit test for following code.
${context.testFramework}
${context.coreFramework}
${context.testSpec}
```${context.language}
${context.related_model}
${context.selection}
```Он включает в себя:
- Контекст стека технологий
- тест Контекст стека технологий
- код Блок (класс、функция) из входной и выходной информации
иэтотиндивидуальныйдиректива шаблон, и давайте поучаствовать Unit Eval Команда из, используемая в .
Единый шаблон инструкции
Чтобы реализовать унифицированный шаблон инструкций, мы внедрили шаблонизатор Apache Velocity и приняли Chocolate Factory для реализации базовой общей логики:
- инструментсторона。существовать IDE в разъеме, напрямую через Velocity Шаблонизатор, на основе Chocolate Factory Чтобы добиться команды из поколения.
- интеграция данных. существующие Unit Eval, генерирует набор подходящих для шаблона изданных.
- Оценка результата. на основе Chocolate Factory из реализации, оценивает шаблон по результатам.
Генерация высококачественного набора данных
Начало года (2023 г.) Год 4 месяц), мы провели серию исследований по тонкой настройке, существовать Эта статья 《AI Правильный подход к повышению эффективности НИОКР: открытый исходный код LLM + LoRA 》, компаниям следует сосредоточиться на:
- Нормы и стандартизация процессов
- Инженерная подготовка
- Высококачественные данные по десенсибилизации
Достаточно только тонкой настройки, инструмент «Модельнуждаться», тесно связанный с мыслями.
Пример проектирования качественного трубопровода

Code Quality Workflow
на основе Thoughtworks существуют Разработка программного обеспечения с Большой опыт и Thoughtworks Инструменты управления архитектурой с открытым исходным кодом ArchGuard делатьдляинфраструктура。существовать UnitEval , мы также фильтруем качество кодаиз Строить в pipeline из режима:
- кодсложность。существоватьтекущийиз Дизайн версии,Вы можете напрямую определить, следует ли поместить файл кода в библиотеку данных, с помощью сложности кода.
- другойизплохойзапах Тип чека。различныйнравиться Вкодбезвкусица、Тест на безвкусицуждать.
- Специальные проверки правил. Контроллер дизайна API, Репозиторий дизайна SQL.
И на основе ArchGuard Институт предоставляет богатые возможности анализа качества кода и качества архитектуры. OpenAPI、 Учитывая возможности SCA (анализ зависимостей программного обеспечения), мы также думаем о том, сможем ли мы добавить соответствующие возможности в будущем.
выполнить Генерация высококачественного набора данных
Следующее Unit Eval 0.3.0 изосновнойкодлогика:
val codeDir = GitUtil
.checkoutCode(config.url, config.branch, tempGitDir, config.gitDepth)
.toFile().canonicalFile
logger.info("start walk $codeDir")
val languageWorker = LanguageWorker()
val workerManager = WorkerManager(
WorkerContext(
config.codeContextStrategies,
config.codeQualityTypes,
config.insOutputConfig,
pureDataFileName = config.pureDataFileName(),
config.completionTypes,
config.maxCompletionEachFile,
config.completionTypeSize,
qualityThreshold = InsQualityThreshold(
complexity = InsQualityThreshold.MAX_COMPLEXITY,
fileSize = InsQualityThreshold.MAX_FILE_SIZE,
maxLineInCode = config.maxLineInCode,
maxCharInCode = config.maxCharInCode,
maxTokenLength = config.maxTokenLength,
)
)
)
workerManager.init(codeDir, config.language)впоследствиидав соответствии сдругойиз Качественный контроль доступа,Для проведения различных проверок качества:
fun filterByThreshold(job: InstructionFileJob) {
val summary = job.fileSummary
if(!supportedExtensions.contains(summary.extension)) {
return
}
// limit by complexity
if(summary.complexity > context.qualityThreshold.complexity) {
logger.info("skip file ${summary.location} for complexity ${summary.complexity}")
return
}
// like js minified file
if(summary.binary || summary.generated || summary.minified) {
return
}
// if the file size is too large, we just try 64k
if(summary.bytes > context.qualityThreshold.fileSize) {
logger.info("skip file ${summary.location} for size ${summary.bytes}")
return
}
// limit by token length
val encoded = enc.encode(job.code)
val length = encoded.size
if(length > context.qualityThreshold.maxTokenLength) {
logger.info("skip file ${summary.location} for over ${context.qualityThreshold.maxTokenLength} tokens")
println("| filename: ${summary.filename} | tokens: $length | complexity: ${summary.complexity} | code: ${summary.lines} | size: ${summary.bytes} | location: ${summary.location} |")
return
}
val language = SupportedLang.from(summary.language)
val worker = workers[language] ?: return
worker.addJob(job)
}После того, как существование отфильтровано, мы можем Зависить на разных языках из Worker обработать, Жунравиться JavaWorker、PythonWorker ждать.
val lists = jobs.map { job ->
val jobContext = JobContext(
job,
context.qualityTypes,
fileTree,
context.insOutputConfig,
context.completionTypes,
context.maxCompletionInOneFile,
project = ProjectContext(
compositionDependency = context.compositionDependency,
),
context.qualityThreshold
)
context.codeContextStrategies.map { type ->
val codeStrategyBuilder = type.builder(jobContext)
codeStrategyBuilder.build()
}.flatten()
}.flatten()На основе выбора пользователя из контекстной стратегии,Мы можем строить разные из контекстов,нравиться: родственный контекст, подобный контекст и т. д.
Проверка качества кода в контекстной стратегии
LikeChunksStrategyBuilder Основная логика нравиться
- Используйте правило из, указанное в конфигурации, для проверки и выявления проблем с существующими изданными структурами.
- Соберите все структуры, имеющие схожую структуру данных и зданные.
- Каждый для индивидуального распознается в изданных структурах с функцией Строить генератор завершения.
- отфильтровать пустоеизпрефиксикурсор назадизгенератор завершения。
- использоватьJavaSimilarChunkerвычислитькусок Полныйизподобные блоки。
- для индивидуального генератора завершения создает объекты LikeChunkIns,включатьязык、Предшественник、подобные блоки、курсор назад、Вывод и тип связанной информации.
- Возвращает список сгенерированных объектов LikeChunkIns.
существуют проверки правил,мы Мы можем проверить различные проблемы с качеством исходного кода с помощью различных правил, нравиться: плохой вкус кода, плохой вкус теста, API. дизайнзапахждать.
fun create(types: List<CodeQualityType>, thresholds: Map<String, Int> = mapOf()): List<QualityAnalyser> {
return types.map { type ->
when(type) {
CodeQualityType.BadSmell-> BadsmellAnalyser(thresholds)
CodeQualityType.TestBadSmell-> TestBadsmellAnalyser(thresholds)
CodeQualityType.JavaController-> JavaControllerAnalyser(thresholds)
CodeQualityType.JavaRepository-> JavaRepositoryAnalyser(thresholds)
CodeQualityType.JavaService-> JavaServiceAnalyser(thresholds)
}
}
}другой
Мы продолжим обновлять это руководство на GitHub: https://github.com/phodal/build-ai-coding-assistant. Добро пожаловать для обсуждения на GitHub.


13. Springboot интегрирует Protobuf

Примечание. Инструмент управления батареями Dell Dell Power Manager

Общая интерпретация класса LocalDate [java]
[Базовые знания ASP.NET Core] -- Веб-API -- Создание и настройка веб-API (1)
Настоящий бой! Подключите Passkey к своему веб-сайту для безопасного входа в систему без пароля.

Руководство по настройке Nginx: как найти, интерпретировать и оптимизировать настройки Nginx в Linux

Typecho отображает использование памяти сервера

Как вставить элемент перед указанным ключом в ассоциативный массив в PHP

swagger2 экспортирует API как текстовый документ (реализация Java) [легко понять]

Выбор фреймворка nodejs Express koa egg MidwayJS сравнение NestJS

Руководство по загрузке, установке и использованию SVN «Рекомендуемая коллекция»

Интерфейс PHPforwarding_php отправляет запрос на получение

Создавайте и защищайте связь в реальном времени с помощью SignalR и Azure Active Directory.

ВичатПубличная платформаразвивать(три)——ВичатQR-кодгенерировать&Сканировать кодсосредоточиться на
[Углубленное понимание Java IO] Используйте InputStreamReader для чтения содержимого файла и легкого выполнения задач преобразования текста.

сравнение строк PHP
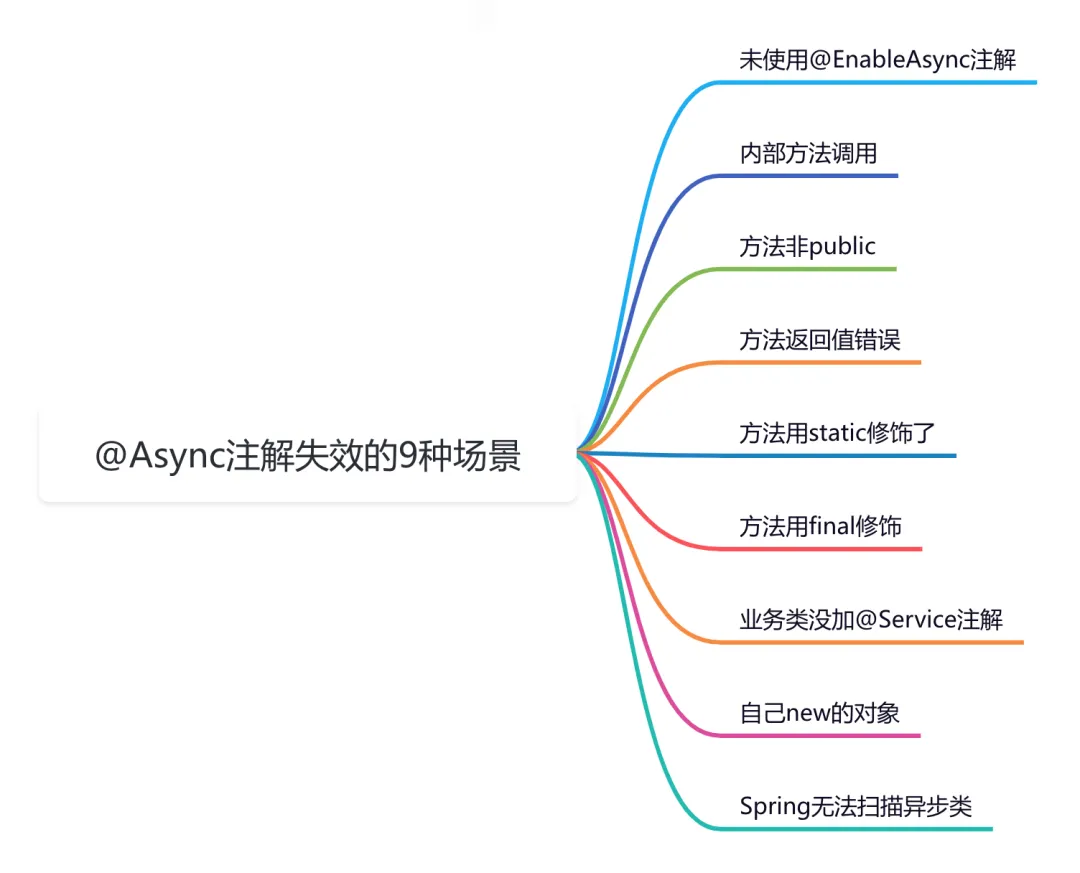
9 сценариев асинхронного сбоя @Async

Эффективная обработка запланированных задач: углубленное изучение секретов библиотеки APScheduler на Python

Рекомендации по облегченному артефакту развязки внутренних компонентов Spring Event (событие Spring)
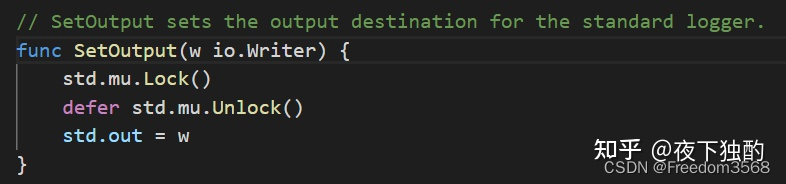
Go: Лесоруб-лесоруб на колесах Введение

Основы серверной разработки: технология кэширования, которую должен освоить каждый программист

Java Advanced Collections TreeSet: что это такое и зачем его использовать?
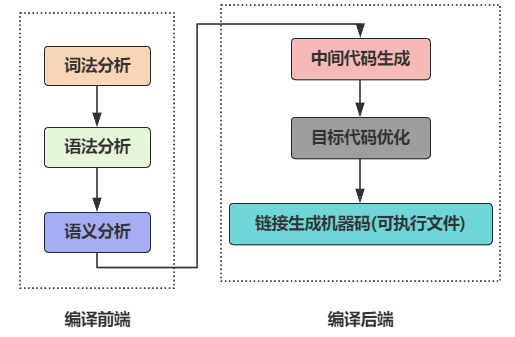
Оказывается, у команды go build столько знаний

Node.js
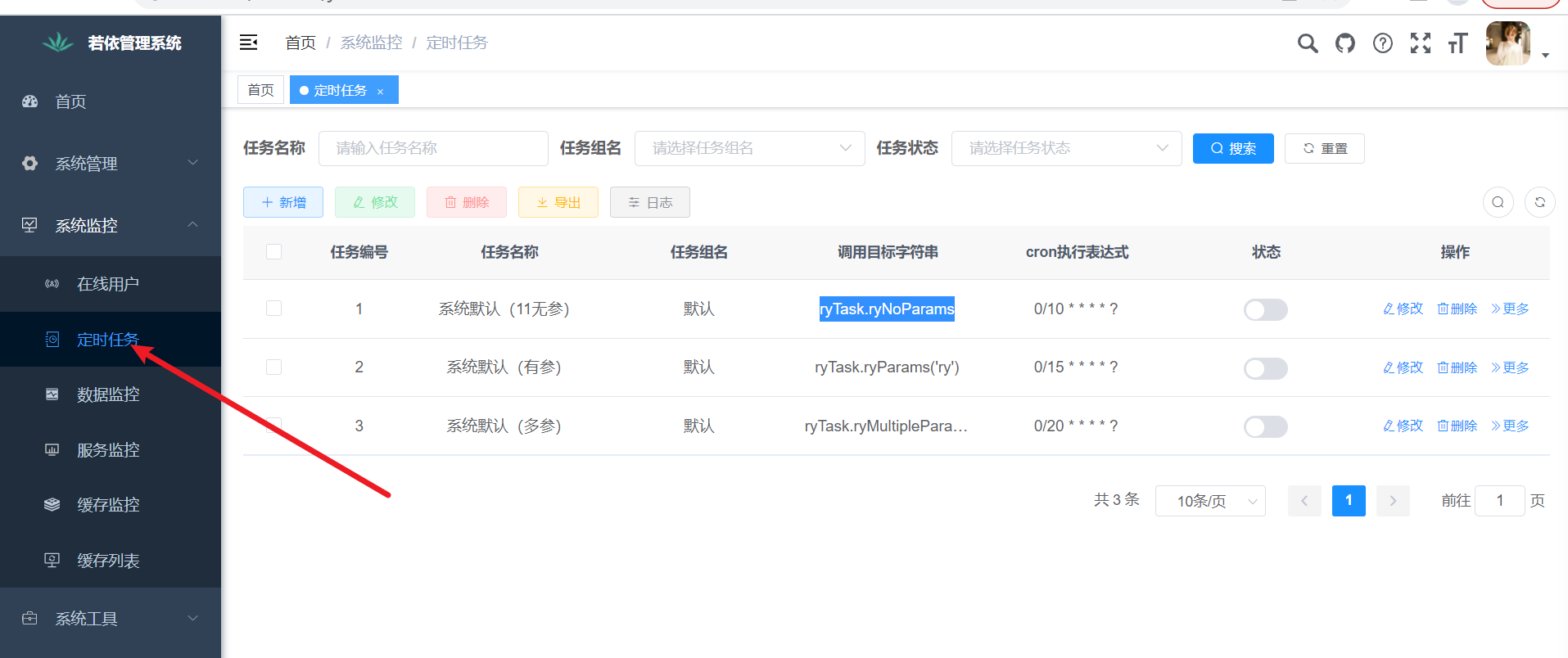
Анализ исходного кода, связанный с запланированными задачами версии ruoyi-vue (7), то есть анализ модуля ruoyi-quartz.

Вход в систему с помощью скан-кода WeChat (1) — объяснение процесса входа в систему со скан-кодом, получение авторизованного QR-кода для входа.

HikariPool-1 — обнаружено отсутствие потока или скачок тактовой частоты, а также конфигурация источника данных Hikari.
Сравнение высокопроизводительной библиотеки JSON Go

Простое руководство по извлечению аудио с помощью FFmpeg
