Создайте собственное приложение AIGC (1) Начало работы
На самом деле история развития ИИ очень длинная.,И пустьAIПриложение, которое внезапно появляется перед глазами людей, на самом делеПоявление ChatGPT,Это означает, что приложение AIGC изменилось от концепции на King. В сопровождении opeaneene chatgpt, много Открытого исходный кодбольшой Модель тоже появился как грибы после дождя. на данный момент,Создать собственное приложение AIGC очень просто.。
Базовая среда
Нам нужно настроить среду
- python3.8+, не будьте слишком новичками
- Среда CUDA+
- pytorch
- Компилятор, поддерживающий C++17.
Прежде всего, я рекомендую вам настроить одининдивидуальныйanacondaсреда,Потому что другие методы установки Pytorch действительно затруднительны.
Затем вам необходимо установить среду CUDA,Обычно вам нужно только скачатьСоответствующая версия CUDAВот и все
Затем идет установкаpytorchсреда,Эта индивидуальная среда довольно неприятна.,ОбычноУстановить через КондуЭто более надежный метод,Конечно, иногда просто не можешь договориться.
Если установка не удалась, вы можете использовать только исходный код для компиляции.
Сначала клонируйте исходный код
git clone --recursive https://github.com/pytorch/pytorch
cd pytorch
# if you are updating an existing checkout
git submodule sync
git submodule update --init --recursiveЗатем установите соответствующие различные зависимости
conda install cmake ninja
# Run this command from the PyTorch directory after cloning the source code using the “Get the PyTorch Source“ section below
pip install -r requirements.txt
conda install mkl mkl-include
# Add these packages if torch.distributed is needed.
# Distributed package support on Windows is a prototype feature and is subject to changes.
conda install -c conda-forge libuv=1.39ЗатемКомпиляция исходного кода Windows немного сложна,Для получения подробной информации, пожалуйста, обратитесь к компилировать в различных ситуациях.
существоватькомпилироватьэтотиндивидуальныйpytorchэтотиндивидуальный Когда я покупал вещи, я столкнулся со многими ворами.,Я не могу найти решения большинства проблем,Самым надежным решением, наконец, было найдено,Вы не можете использовать слишком низкую или слишком высокую версию Python.,Решить будет гораздо проще,В конце концов я решил использовать версию Python 3.10.,Решил большую часть проблем.
Другое состоит в том, что если графический процессор не очень хорош или память не очень высока,ХОРОШОИспользовать версию процессора,Большинство компьютеров имеют относительно большой объем памяти.,По крайней мере, он может бежать.
Если это окна,Это обязательно будет использованоhuggingface,Есть некоторые вещи, на которые я предлагаю вам обратить внимание.
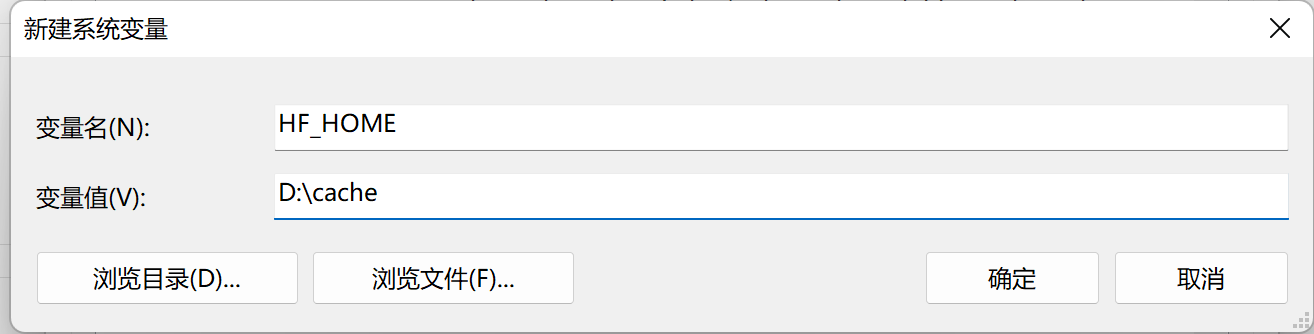
Кэш -папку по умолчанию и Pytorch находится в соответствии с ~/.
Добавить ** в переменные средыHF_HOMEиTORCH_HOME ,настраивать**Установите его как указанную переменную.
кроме,Некоторые проекты также предоставятДокеризованное решение для развертывания,Если этот подход будет принят,это должносуществовать Установка хостаNVIDIA Container Toolkit,и перезапустить докер
sudo apt-get install -y nvidia-container-toolkit-base
sudo systemctl daemon-reload
sudo systemctl restart dockerРасширенный состав
LLM
Полное имя магистратуры**Large Language ModelБольшая языковая модель является основным модулем диалога ИИ, представленным ChatGPT. По сравнению с ChatGPT, который мы не можем контролировать и обучать, постепенно появляется большое количество больших языковых моделей с открытым исходным кодом, особенно с помощью ChatGPT.ChatGLM、Облегченная языковая модель, представленная LLaMA**, довольно проста в использовании.
ХотяМежду этими языковыми моделями с открытым исходным кодом и ChatGPT существует огромный разрыв.,Но в глубоких вертикальных поляхaiПриложение такжесуществовать Постепенно признанный людьми。Не так уж и много того, что мы хотимсуществовать Открытый исходный код Мир ищет альтернативы ChatGPT, почему бы не сказать вот эти Открытый исходный Появление языка codebig Model означает, что у нас есть возможность создавать собственный GPT.
- ChatGLM-6B
- https://github.com/THUDM/ChatGLM-6B
- ChatGLM2-6B
- https://github.com/THUDM/ChatGLM2-6B
В настоящее время Открытый имеет лучший эффект в области середина, а также является наиболее используемым. исходный код База Модель。большойчастьизКитайская вторичная разработка GPT почти полностью основана на этой модели.,Особенно после второго поколения длина контекста базовой Модели была еще больше расширена. Самое приятное, что его разрешено для коммерческого использования.
MOSS — это модель разговорного языка с открытым исходным кодом, которая поддерживает китайское и английское двуязычие и множество плагинов.,Серия Moss-Moon Модель имеет 16 миллиардов параметров.,Может работать на одной видеокарте A100/A800 или двух видеокартах 3090 с точностью FP16.,Может работать на одной видеокарте 3090 с точностью INT4/8. Базовый язык MOSS «Модель» предварительно обучен примерно на 700 миллиардах середина английского языка и кодовых словах.,Впоследствии, благодаря точной настройке диалоговых инструкций, расширенному обучению подключаемых модулей и обучению человеческим предпочтениям, он получает возможность проводить несколько раундов диалога и использовать несколько подключаемых модулей.
Серия моделей чата на основе архитектуры RWKV (включая английский и китайский языки),Выпущено, включая Raven,Novel-ChnEng,Новел-Ч и Новел-Чн Энг-Чн Про и т. д. Модель,Вы можете общаться и писать стихи напрямую,Романы и другие произведения,Включая модели 7B и 14B и другие размеры.
База модели LLM, честно говоря, слишком велика.,Особенно после первых мгновений.,Различные базы LLM выросли, как грибы после дождя.,Жаль, что разрыв между текущими моделями с открытым исходным кодом и ChatGPT очень велик. Большинство моделей могут достичь только уровня GPT3 и на несколько порядков отстают от GPT3.5, не говоря уже о GPT4.
Даватьбольшой Взгляните на доминдивидуальныйпроходитьСуществует множество рейтингов LLM, основанных на некоторых стандартных рейтингах. Это утверждение обычно зависит от охвата выборки.

Embedding
Модель внедрения также является очень важной частью GPT, о которой упоминалось в предыдущей статье. Потому что режим GPT, который может полагаться только на диалог, ограничен длиной контекста.
Таким образом, было получено множество моделей внедрения с открытым исходным кодом.
- https://huggingface.co/GanymedeNil/text2vec-large-chinese
- https://huggingface.co/shibing624/text2vec-base-chinese

gradio
Gradio — очень известная веб-инфраструктура машинного обучения для представления данных.проходитьgradioМожно быстро построитьиндивидуальный Интерактивный в реальном времениwebинтерфейс。Немного похожеflask

Первое, что следует отметитьgradioПо меньшей мереPython выше версии 3.8.
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="text", outputs="text")
demo.launch()
Gradio поддерживает множество таких распространенных сценариев.,Точно так же, какТекст, флажки, панели ввода, даже загрузка файлов и изображений.,У всех очень хорошая встроенная поддержка.
FastChat
FastChat — интегрированная платформа, построенная на LLM,FastChatоснован наLLaMAОбучение настройке вторичных параметров。
pip3 install fschatОбычное использование требует генерации машиныVicunaМодель,ВоляLLaMa веса сливаются викуньи weights。иэтотиндивидуальныйпотребности процессаМного памяти и процессора,Официальные справочные данные:
- Vicuna-7B:30 GB of CPU RAM
- Vicuna-13B:60 GB of CPU RAM
Если недостаточно памяти для использования,Вы можете попробовать следующие два метода управления им:
1、существовать Заказсерединаприсоединиться–low-cpu-mem,Эта отдельная команда может уменьшить пиковый объем памяти до уровня ниже 16 ГБ.
2. Создайте относительно большой раздел подкачки и позвольте операционной системе использовать жесткий диск в качестве виртуальной памяти.
python3 -m fastchat.model.apply_delta \
--base-model-path /path/to/llama-7b \
--target-model-path /path/to/output/vicuna-7b \
--delta-path lmsys/vicuna-7b-delta-v1.1
python3 -m fastchat.model.apply_delta \
--base-model-path /path/to/llama-13b \
--target-model-path /path/to/output/vicuna-13b \
--delta-path lmsys/vicuna-13b-delta-v1.1После загрузки файла модели вы сможете быстро использовать соответствующую модель.
python3 -m fastchat.serve.cli --model-path lmsys/fastchat-t5-3b-v1.0По сравнению с другими базами МодельLLM,Платформизация FastChatСтепень относительно высокая。
впервые предоставилконтроллер и модель работникаОтдельно развернутые решения,Решение «один ко многим» само по себе больше соответствует структуре, основанной на проектах.
python3 -m fastchat.serve.controller
python3 -m fastchat.serve.model_worker --model-path /path/to/model/weightsИ то же самоеСоответствующий веб-интерфейс был построен с использованием градиента.
python3 -m fastchat.serve.gradio_web_serverкромеFastChatТакже предоставленоИнтерфейс API полностью совместим с openaiиrestfulapi.
import openai
openai.api_key = "EMPTY" # Not support yet
openai.api_base = "http://localhost:8000/v1"
model = "vicuna-7b-v1.3"
prompt = "Once upon a time"
# create a completion
completion = openai.Completion.create(model=model, prompt=prompt, max_tokens=64)
# print the completion
print(prompt + completion.choices[0].text)
# create a chat completion
completion = openai.ChatCompletion.create(
model=model,
messages=[{"role": "user", "content": "Hello! What is your name?"}]
)
# print the completion
print(completion.choices[0].message.content)Его даже можно напрямую подключить к другим платформам через API, что очень полно.
документ базы знаний
Документ базы знаний является важной частью решения langchain середина,Все вопросы сначала попадают в базу знаний результатов поиска середина, а затем служат контекстом.,документ базы знанийизданныеколичество будет напрямую влиятьэтотприложение классаиздостоверность результатов。исейчассуществоватьБолее распространенное обнаружение сходства использует faiss,Создайте библиотеку векторных данных для сравнения данных.
данные базы знаний | Вектор ФАИСС |
|---|---|
Данные китайской Википедии по состоянию на апрель: 450 000. | Ссылка: https://pan.baidu.com/s/1VQeA_dq92fxKOtLL3u3Zpg?pwd=l3pn Код извлечения: l3pn |
По состоянию на сентябрь прошлого года 1,3 миллиона результатов обработки китайской Википедии и соответствующих векторных файлов faiss. | Ссылка: https://pan.baidu.com/s/1Yls_Qtg15W1gneNuFP9O_w?pwd=exij Код извлечения: exij |
💹 Масштабная карта знаний отчета о финансовых исследованиях | Ссылка: https://pan.baidu.com/s/1FcIH5Fi3EfpS346DnDu51Q?pwd=ujjv Код извлечения: ujjv |
соответствующийизсейчассуществовать Многие приложения также имеют встроенныеИнтерфейс для тестирования базы знаний,Например langchain-ChatGLM
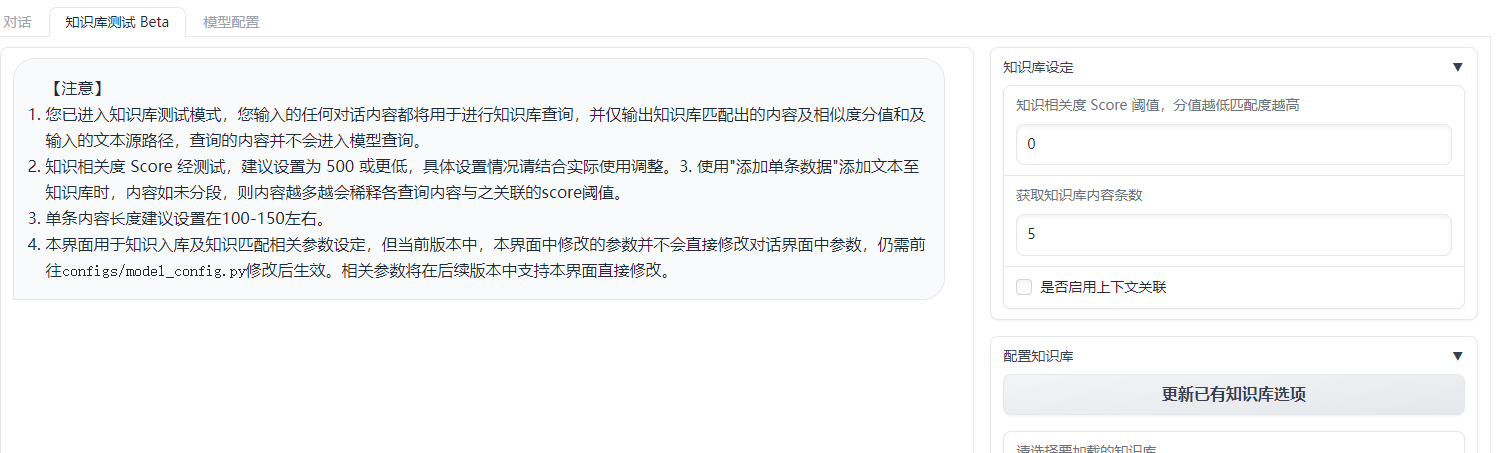
проходитьТочная настройка порога релевантности знаний,Может сделать ответы на сообщения более эффективными. Вы даже можете создать новую базу знаний прямо на платформе и ввести данные.
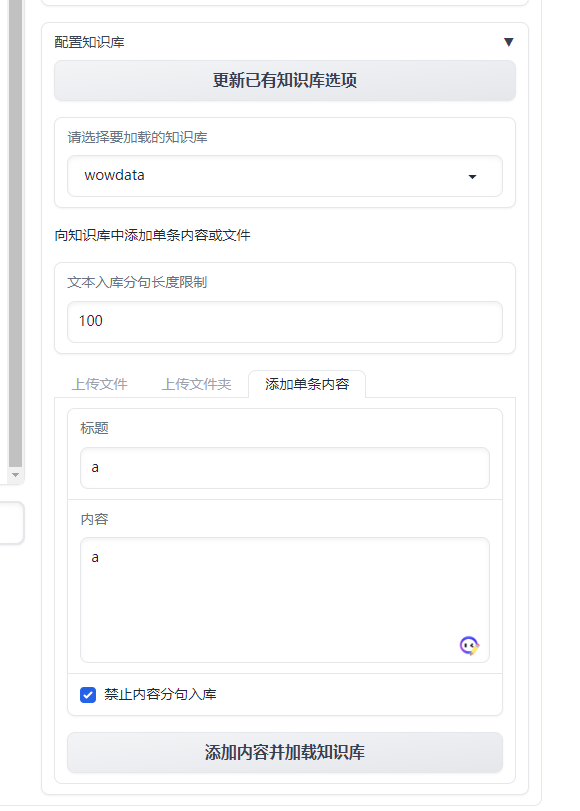
langchain
Langchain — это относительно зрелый набор приложений Aigc и относительно распространенное решение для поиска в базе знаний.,Используется контекстно-ориентированная схема обучения, упомянутая в предыдущей статье середина.,Пользовательский вывод будетВведите поиск по базе данных,Затем Найдите наиболее подходящий вопросизчасть结果ЗатемивопросДобавьте его в контекст подсказки вместесередина,в конечном итогеLLM генерирует окончательный ответ。
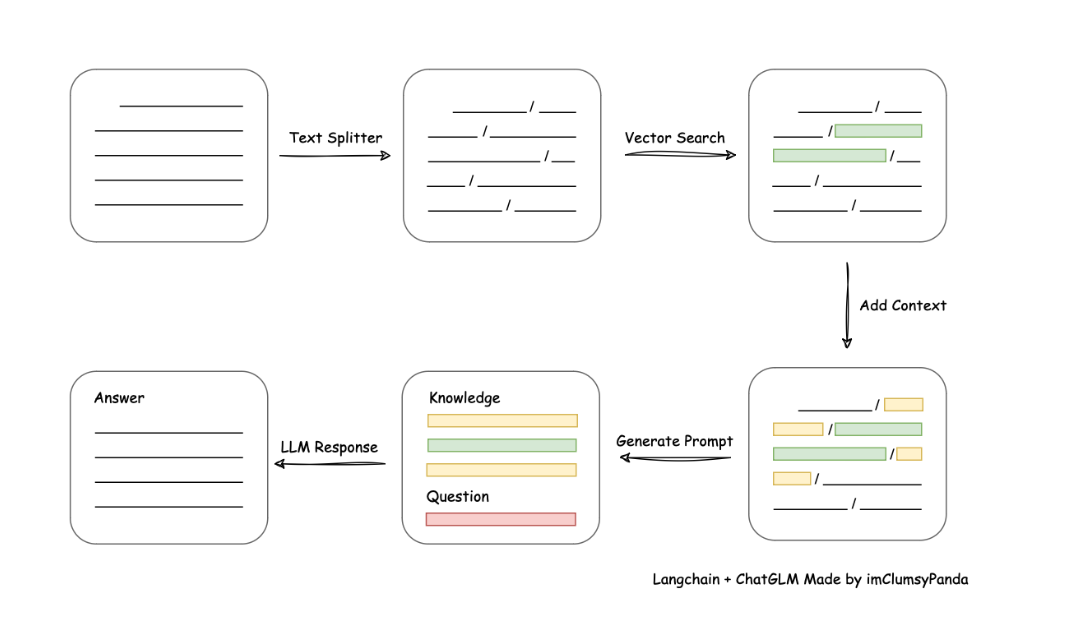
этотиндивидуальный Программа в настоящее времяСамая классическая программа обучения базе знаний,самый эффективныйизрешеноСложность обучения самой большой модели и эффективность результатов обратной связиНесовместимыйизвопрос。
Построен на идее langchain,На самом деле, это породило множество интересных проектов.,С одной стороны, упоминаются различные крупные модели с открытым исходным кодом, включая ChatGLM-6B.,Также используетсяРешение для внедрения с открытым исходным кодомобрабатывать текст。

С другой стороны, он стал более зрелым.изvue front-end + база знаний,Вы можете быстро собрать воедино доступный чат.
- https://github.com/imClumsyPanda/langchain-ChatGLM
- https://github.com/yanqiangmiffy/Chinese-LangChain#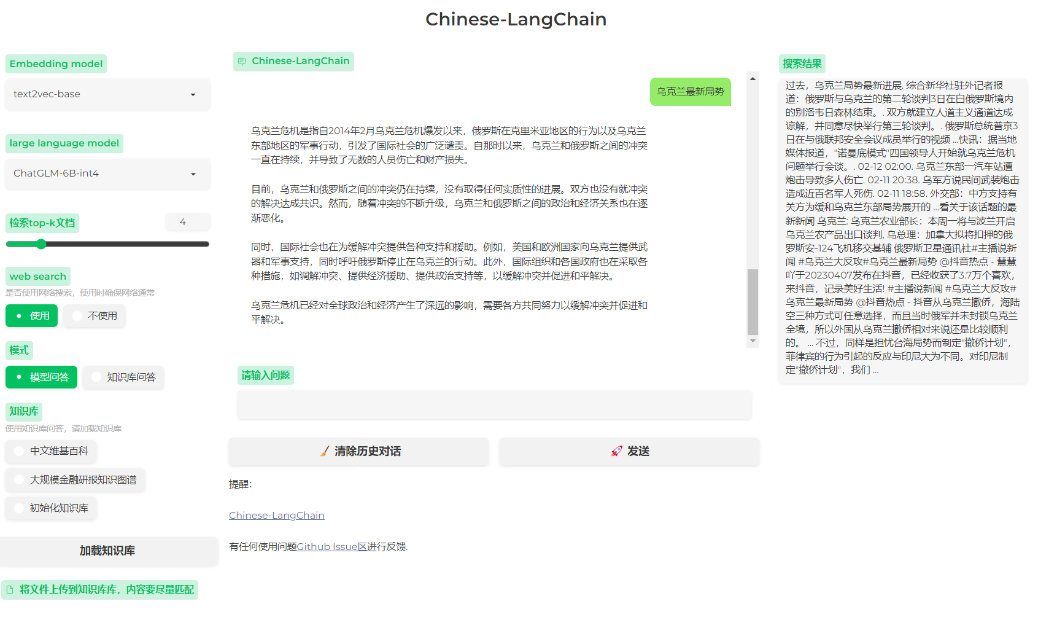
langchain-ChatGLM
langchain-ChatGLM — одна из лучших реализаций, поддерживаемых многими решениями langchain.,Процесс включает в себяЗагрузить файл -> читать текст -> сегментация текста -> Векторизация текста -> векторизация вопросов -> Сопоставьте текстовый вектор, который наиболее похож на вектор вопроса.top kиндивидуальный -> Соответствующий текст добавляется в качестве контекста вместе с вопросом.promptсередина -> Отправить вLLM**Сгенерировать ответ。
Каждую часть всего проекта можно в определенной степени свободно комбинировать. Выбор по умолчанию GanymedeNil/text2vec-large-chinese,LLM Выбор по умолчанию ChatGLM-6B。или ХОРОШОпроходитьfastchatчтобы получить доступ。
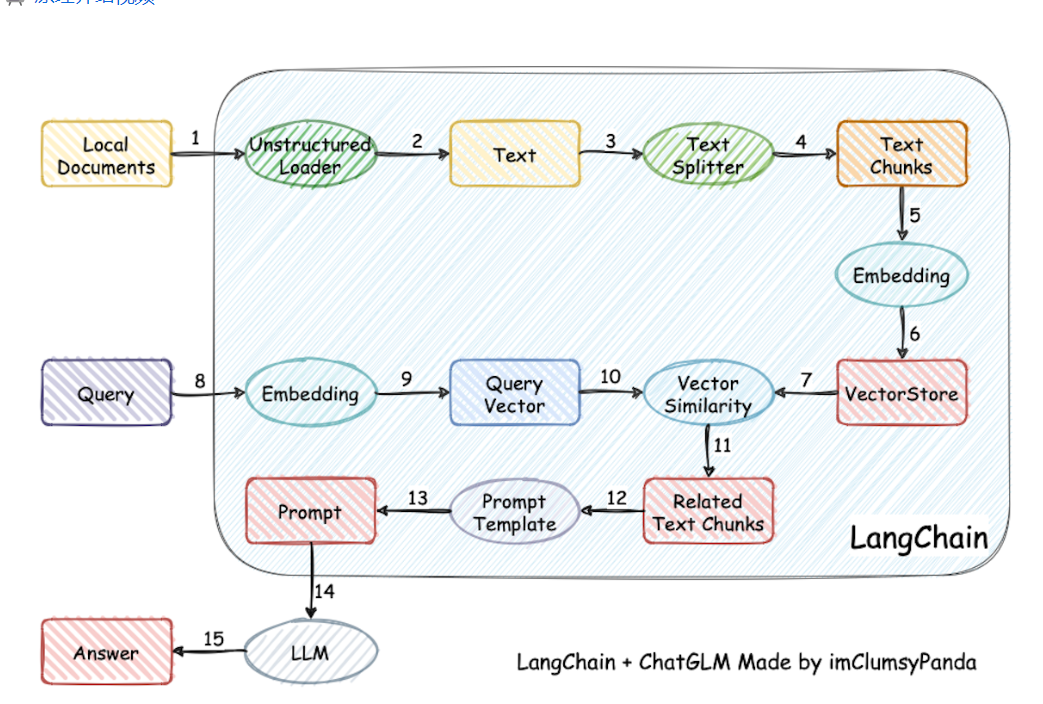
После завершения настройки и установки среды ее можно запустить. Соответствующая большая модель будет загружена при первом запуске.

Конечно, эта модель слишком велика, и при загрузке из командной строки очень легко возникнуть проблемы, поэтому вы можете обратиться к решению ChatGLM-6B, загрузить модель самостоятельно, а затем загрузить ее снова.
Надежнее сначала скачать модель, потом скачать модель отдельно и перезаписать все файлы.
GIT_LFS_SKIP_SMUDGE=1 git clone https://huggingface.co/THUDM/chatglm-6bЗатем вам необходимо изменить расположение модели в соответствующем файле конфигурации, в configs/model_config.py.

Путь к документу базы знаний по умолчанию:
knowledge_base\samplesЕсли вы хотите использовать свой собственный файл местных знаний,Просто поместите его в базу знаний соответствующего каталога. Теперь документ базы знаний будет просматривать файлы в каталоге.,Поэтому просто укажите каталог.
python cli_demo.py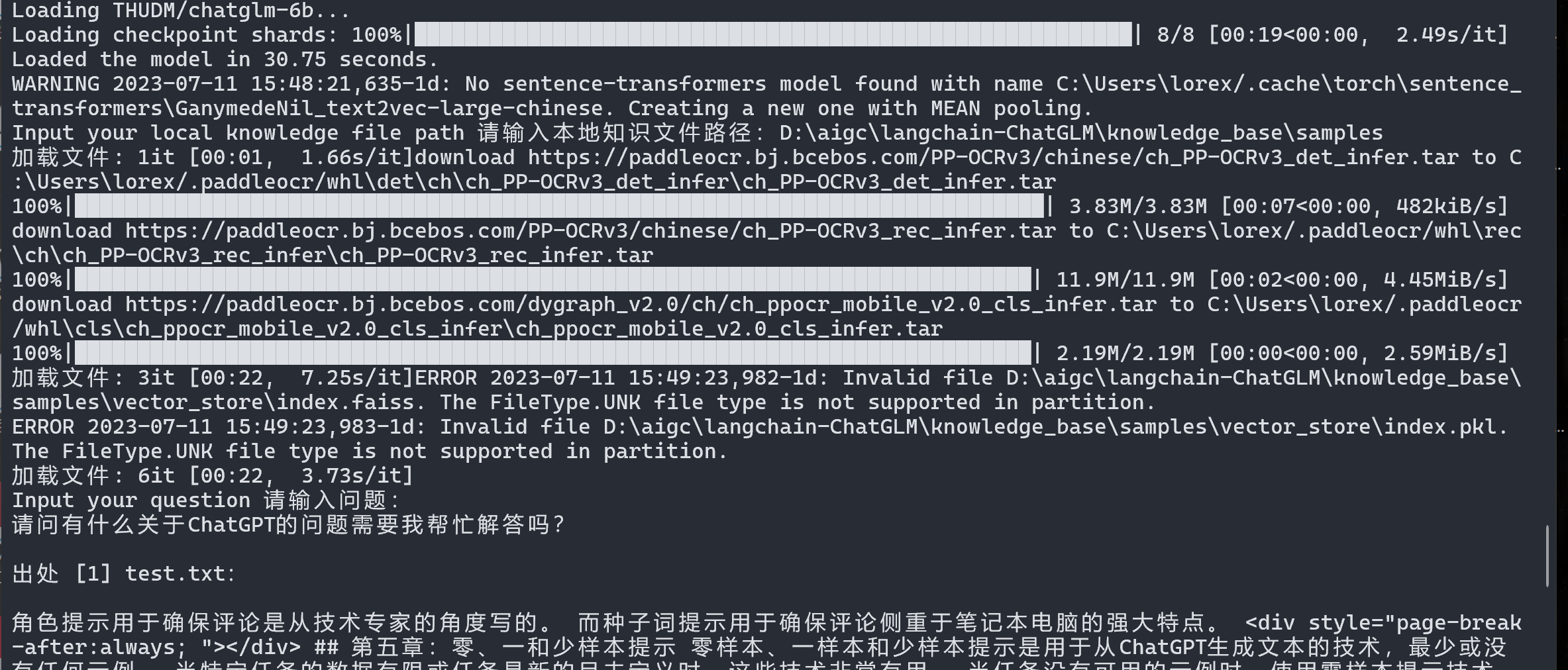
python3.10 .\webui.py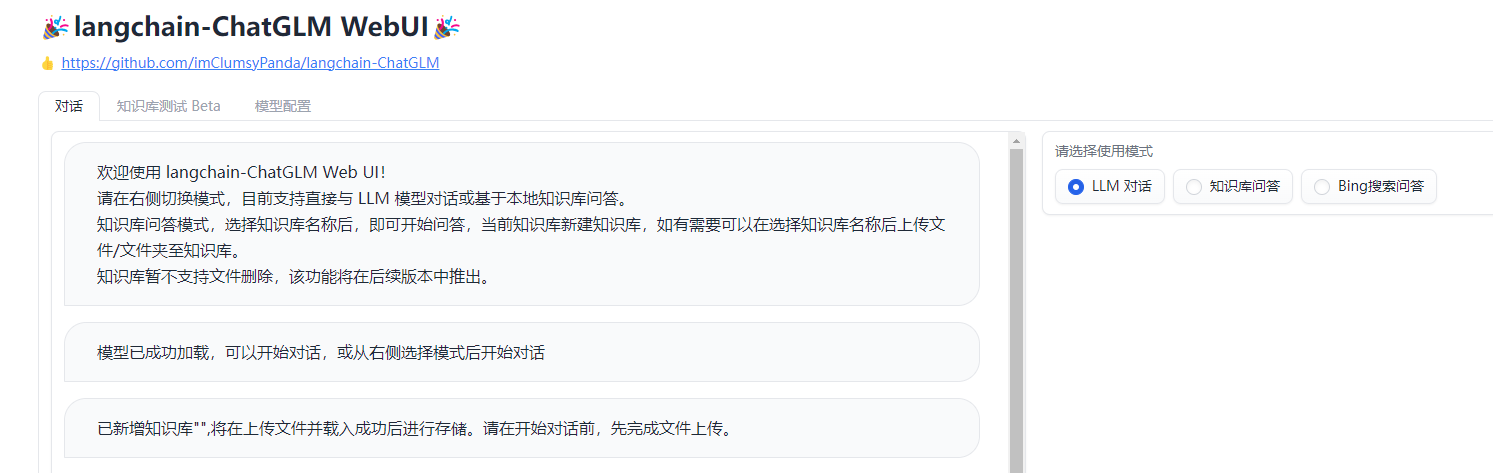


40 вопросов для собеседований по SpringBoot, которые необходимо задавать на собеседованиях! При необходимости ответьте на вопросы для собеседования SpringBoot [предлагаемый сборник] [легко понять]
Через два года JVM может быть заменен GraalVM.

Разрешение циклических зависимостей Spring Bean: существует ли неразрешимая циклическая ссылка?

Разница между промежуточным программным обеспечением ASP.NET Core и фильтрами
[Серия Foolish Old Man] Ноябрь 2023 г. Специальная тема Winform Control Элемент управления DataGridView Подробное объяснение
.NET Как загрузить файлы через HttpWebRequest

[Веселый проект Docker] Обновленная версия 2023 года! Создайте эксклюзивный инструмент управления паролями за 10 минут — Vaultwarden
Высокопроизводительная библиотека бревен Golang zap + компонент для резки бревен лесоруба подробное объяснение

Концепция и использование Springboot ConstraintValidator

Новые функции Go 1.23: точная настройка основных библиотек, таких как срезы и синхронизация, значительно улучшающая процесс разработки.

[Весна] Введение и базовое использование AOP в Spring, SpringBoot использует AOP.

Чтобы начать работу с рабочим процессом Flowable, этой статьи достаточно.

Байтовое интервью: как решить проблему с задержкой сообщений MQ?
ASP.NET Core использует функциональные переключатели для управления реализацией доступа по маршрутизации.
[Проблема] Решение Невозможно подключиться к Redis; вложенное исключение — io.lettuce.core.RedisConnectionException.
От теории к практике: проектирование чистой архитектуры в проектах Go
Решение проблемы искажения китайских символов при чтении файлов Net Core.
Реализация легких независимых конвейеров с использованием Brighter

Как удалить и вернуть указанную пару ключ-значение из ассоциативного массива в PHP
Feiniu fnos использует Docker для развертывания учебного пособия по AList
Принципы и практика использования многопоточности в различных версиях .NET.
Как использовать PaddleOCRSharp в рамках .NET

CRUD используется уже два или три года. Как читать исходный код Spring?

Устраните проблему совместимости между версией Spring Boot и Gradle Java: возникла проблема при настройке корневого проекта «demo1» > Не удалось.

Научите вас шаг за шагом, как настроить Nginx.
Это руководство — все, что вам нужно для руководства по автономному развертыванию сервера для проектов Python уровня няни (рекомендуемый сборник).

Не удалось запустить docker.service — Подробное объяснение идеального решения ️

Настройка файлового сервера Samba в системе Linux Centos. Анализ NetBIOS (супер подробно)
Как настроить метод ssh в Git, как получить и отправить код через метод ssh
