Создайте экспертную систему базы данных, используя частное развертывание моделей большого языка с открытым исходным кодом.
Недавно я нашел хороший проект на github: https://github.com/csunny/DB-GPT
Этот проект использует большие языковые модели с открытым исходным кодом, такие как Vicuna-13b, для создания экспертной системы баз данных. За полтора месяца с момента запуска он получил 3400 звезд.
1 Что такое DB-GPT
Экспериментальный проект GPT на основе базы данных с открытым исходным кодом, который использует локализованную большую модель GPT для взаимодействия с вашими данными и средой без риска утечки данных, что делает возможности большой модели абсолютно конфиденциальными, безопасными и управляемыми.
2 Возможности БД-GPT
Текущие конкретные возможности:
- SQL языковые способности
- Генерация SQL
- SQL-диагностика
- Ответы на вопросы частного домена и обработка данных
- Вопросы и ответы по базе данных
- Обработка данных
- подключаемая модель
- Поддерживает пользовательские плагины для выполнения задач и изначально поддерживает плагины Auto-GPT. нравиться:
- SQL автоматически выполняется и получает результаты запроса
- Автоматически сканировать учебные знания
- Поддерживает пользовательские плагины для выполнения задач и изначально поддерживает плагины Auto-GPT. нравиться:
- База знаний унифицированного векторного хранения/индексирования
- Поддержка неструктурированных данных включает PDF, MarkDown, CSV, WebURL.
- Поддержка нескольких моделей
- Поддерживает несколько больших языковых моделей, Викуна(7b,13b) в настоящее время поддерживается, ChatGLM-6b(int4, int8)
- TODO: codet5p, codegen2
3 Архитектура
Архитектура DB-GPT показана на рисунке ниже:

Вот краткое введение в каждый модуль:
3.1 Возможности базы знаний
В качестве сценария с наибольшим текущим спросом пользователей база знаний изначально поддерживает построение и обработку базы знаний. В то же время этот проект также предоставляет различные стратегии управления базой знаний. нравиться:
- Встроенная база знаний по умолчанию
- Настройте новую базу знаний
- Различные сценарии использования, такие как самостоятельное получение и построение базы знаний с помощью подключаемых модулей.
Пользователям нужно только систематизировать документы знаний, а затем использовать существующие возможности для создания возможностей базы знаний, необходимых для больших моделей.
3.2 Возможности управления большими моделями
В базовом доступе к большой модели открытый интерфейс предназначен для поддержки закрепления нескольких больших моделей. В то же время существует очень строгий механизм контроля и анализа влияния модели доступа. По сравнению с ChatGPT с точки зрения возможностей больших моделей, уровень точности должен соответствовать согласованности возможностей более 85%. В проекте используются более высокие стандарты для проверки моделей в надежде, что предыдущие утомительные этапы тестирования и оценки можно будет опустить во время использования пользователем.
3.3 Единое хранение и индексирование векторизованных данных
Для облегчения управления векторизацией знаний встроены различные механизмы хранения векторов, от Chroma на базе памяти до распределенных Milvus. Вы можете выбирать различные механизмы хранения в соответствии с требованиями вашей сцены. Все хранилище векторов знаний представляет собой единое хранилище. расширение возможностей искусственного интеллекта. Векторы, как промежуточный язык для взаимодействия человека с большими языковыми моделями, играют в этом проекте очень важную роль.
3.4 Модуль подключения
Для более удобного взаимодействия с приватной средой пользователя в проекте разработан Модуль подключения,Модуль Соединение может поддерживать подключение к различным средам, таким как базы данных, Excel, базы знаний и т. д., для реализации взаимодействия информации и данных.
3.5 Агенты и плагины
Агенты и Возможности плагинов определяют возможность автоматизации больших моделей. В этом проекте изначально поддерживается режим плагинов, и большие модели могут автоматически достигать поставленных целей. В то же время, чтобы в полной мере использовать преимущества сообщества, плагины, используемые в этом проекте, изначально поддерживают экосистему плагинов Auto-GPT, то есть плагины Auto-GPT можно запускать напрямую. в нашем проекте.
3.6 Оперативная автоматическая генерация и оптимизация
Подсказка — очень важная часть процесса взаимодействия с большими моделями. В определенной степени подсказка определяет качество и точность ответов, генерируемых большой моделью. В этом проекте мы автоматически оптимизируем соответствующую подсказку на основе ввода данных пользователем. сценарии использования. Сделайте использование больших языковых моделей более простым и эффективным для пользователей.
3.7 Многотерминальный интерфейс продукта
ЗАДАЧА: На дисплее терминала мы предоставим многотерминальный интерфейс продукта. Включая ПК, мобильный телефон, командную строку, Slack и другие режимы.
3.8 Соответствующие компоненты с открытым исходным кодом, которые зависят от
- FastChat поставлять chat Служить
- vicuna-13b в качестве базовой модели
- langchain цепочка инструментов
- Auto-GPT Универсальный шаблон плагина
- Hugging Face Управление большими моделями
- Chroma векторное хранилище
- Milvus распределенныйвекторное хранилище
- ChatGLM базовая модель
- llama-index На основе существующей базы знанийIn-Context LearningДля расширения знаний, связанных с базами данных。
4 Установка и развертывание
4.1 Требования к оборудованию
Проект обладает более чем 85% возможностями ChatGPT по эффекту, поэтому имеет определенные требования к оборудованию. Но, вообще говоря, развертывание и использование проекта можно выполнить на видеокарте потребительского уровня. Конкретные инструкции по развертыванию оборудования следующие:
Модель графического процессора | Объем видеопамяти | производительность |
|---|---|---|
RTX4090 | 24G | Может вести разговорную речь плавно, без задержек. |
RTX3090 | 24G | Может рассуждать плавно, с ощущением запаздывания, но лучше, чем V100. |
V100 | 16G | Способен рассуждать в разговорной форме с явными задержками. |
4.2 Приобретение облачного сервера
Чтобы развернуть этот проект, сначала необходимо приобрести ресурсы графического процессора. В настоящее время у Tencent Cloud есть облачный сервер с графическим процессором · Распродажа флэш-памяти ограничена по времени:
https://cloud.tencent.com/act/pro/gpu-study
Выберите следующую модель, имеющую 32 ГБ видеопамяти, чего достаточно для развертывания (она все равно очень дорогая по сравнению с традиционными серверами на базе ЦП):

4.3 Установка пакетов зависимостей
yum -y install git
yum install git-lfs
yum install g++
yum install docker4.4 Скачать модель
git clone https://github.com/csunny/DB-GPT.git
git clone https://huggingface.co/Tribbiani/vicuna-13b
git clone https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2Файл модели необходимо поместить в путь к коду:
cd DB-GPT
mkdir models
cp all-MiniLM-L6-v2 models/
cp vicuna-13b models/4.5 Запуск MySQL
docker run --name=mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=aa12345678 -dit mysql:latest4.6 Среда установки и зависимости
wget https://repo.anaconda.com/miniconda/Miniconda3-py310_23.3.1-0-Linux-x86_64.sh
sh Miniconda3-py310_23.3.1-0-Linux-x86_64.sh
source /root/.bashrc
conda create -n dbgpt_env python=3.10
conda activate dbgpt_env
pip install -r requirements.txt4.7 Запускаем сервер
nohup python pilot/server/llmserver.py > server.log 2>&1 &4.8 Запуск клиента
nohup python pilot/server/webserver.py > logs/client.log 2>&1 &4.9 Адрес доступа http://ip:7860/
Интерфейс такой, как показано ниже:

5 Тест на профпригодность
5.1 Общий тест диалога
здравый смысл:

логика:

По сравнению с GPT3.5 разрыв очевиден:

По сравнению с GPT4 разрыв еще больше:

5.2 Проверка знаний базы данных

По сравнению с GPT3.5 разрыв очевиден:

5.3 Проверка способности генерировать SQL и взаимодействовать с БД

Как показано на рисунке выше, после выбора имени библиотеки и ввода требований запроса на естественном языке можно сгенерировать и выполнить соответствующий SQL-код для возврата результатов!
Однако скорость возврата результатов очень низкая, иногда даже более 1 минуты.
Давайте проверим комбинированный запрос и обнаружим, что он выполняет запрос на корреляцию таблиц, в чем нет необходимости, и запрос на корреляцию ссылается на несуществующие поля, что странно.

5.4 Тест на знание базы знаний
https://blog.51cto.com/imysql/3250683 [MySQL Часто задаваемые вопросы] серия — Должен ли быть включен запрос в онлайн-среде? cache
Давайте преобразуем статью Лао Е о кеше запросов в PDF для загрузки:

Создается векторный файл /data/download/DB-GPT/pilot/data/.vectordb.

Задайте соответствующие вопросы в документе и посмотрите, можно ли в ответах использовать содержимое документа:


Общий эффект нормальный.
6 Резюме
Этот проект с открытым исходным кодом имеет комплексные функции, объединяющие большие модели с открытым исходным кодом, возможности частной базы знаний, возможности генерации SQL базы данных и возможности интерактивных запросов с БД. Если эти возможности могут набрать 90 баллов, то этот проект очень достоин использования в БД. производственная среда Используется, поскольку решает проблему безопасности утечки кода.
Но у него есть несколько проблем: 1. Скорость относительно низкая, особенно при генерации SQL и взаимодействии с БД, иногда это занимает более 1 минуты. 2. Способность к рассуждению слабая и не может достичь уровня 3,5. 3. Из-за 2 иногда сгенерированный SQL не соответствует потребностям пользователя.
Но направление правильное. В будущем именно таким образом будут внедряться крупные модели в определенной области производственной среды компании.
Мы с нетерпением ждем, когда крупные модели с открытым исходным кодом догонят возможности версии 3.5 как можно скорее!


Java вызывает стороннюю платформу для отправки мобильных текстовых сообщений

Практическое руководство по серверной части: как использовать Node.js для разработки интерфейса RESTful API (Node.js + Express + Sequelize + MySQL)
Введение в параметры конфигурации большого экрана мониторинга Grafana (2)
В статье «Научно-популярная статья» подробно объясняется протокол NTP: анализ точной синхронизации времени.

Пример разработки: серверная часть Java и интерфейсная часть vue реализуют функции комментариев и ответов.

Nodejs реализует сжатие и распаковку файлов/каталогов.
SpringBootИнтегрироватьEasyExcelСложно реализоватьExcelлистимпортировать&Функция экспорта

Настройка среды под Mac (используйте Brew для установки go и protoc)
Навыки разрешения конфликтов в Git
Распределенная система журналов: развертывание Plumelog и доступ к системе

Артефакт, который делает код элегантным и лаконичным: программирование на Java8 Stream
Spring Boot(06): Spring Boot в сочетании с MySQL создает минималистскую и эффективную систему управления данными.

Как использовать ArrayPool

Интегрируйте iText в Spring Boot для реализации замены контента на основе шаблонов PDF.

Redis реализует очередь задержки на основе zset

Получить текущий пакет jar. path_java получает файл jar.
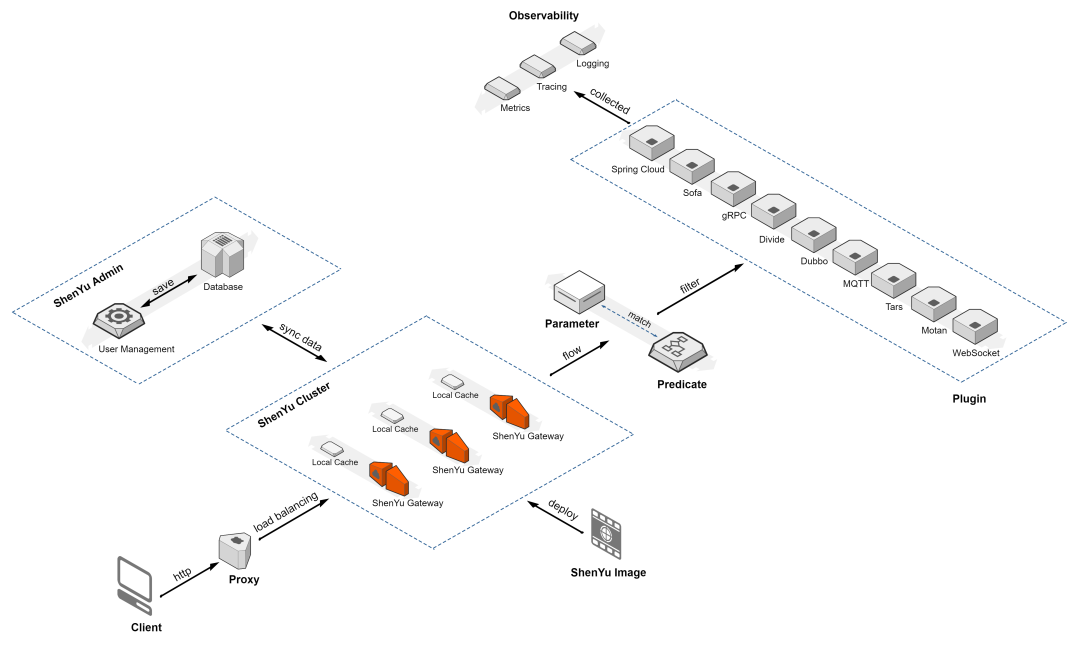
Краткое обсуждение высокопроизводительного шлюза Apache ShenYu
Если вы этого не понимаете, то на собеседовании даже не осмелитесь сказать, что знакомы с Redis.
elasticsearch медленный запрос, устранение неполадок записи, запрос с подстановочными знаками

По какому стандарту взимается плата за обслуживание программного обеспечения?

IP-адрес Получить

【Java】Решено: org.springframework.web.HttpRequestMethodNotSupportedException

Native js отправляет запрос на публикацию_javascript отправляет запрос на публикацию

.net PDF в Word_pdf в Word

[Пул потоков] Как Springboot использует пул потоков

Подробное объяснение в одной статье: Как работают пулы потоков

Серия SpringCloud (6) | Поговорим о балансировке нагрузки
IDEA Maven может упаковать все импортное полностью красное решение — универсальное решение.
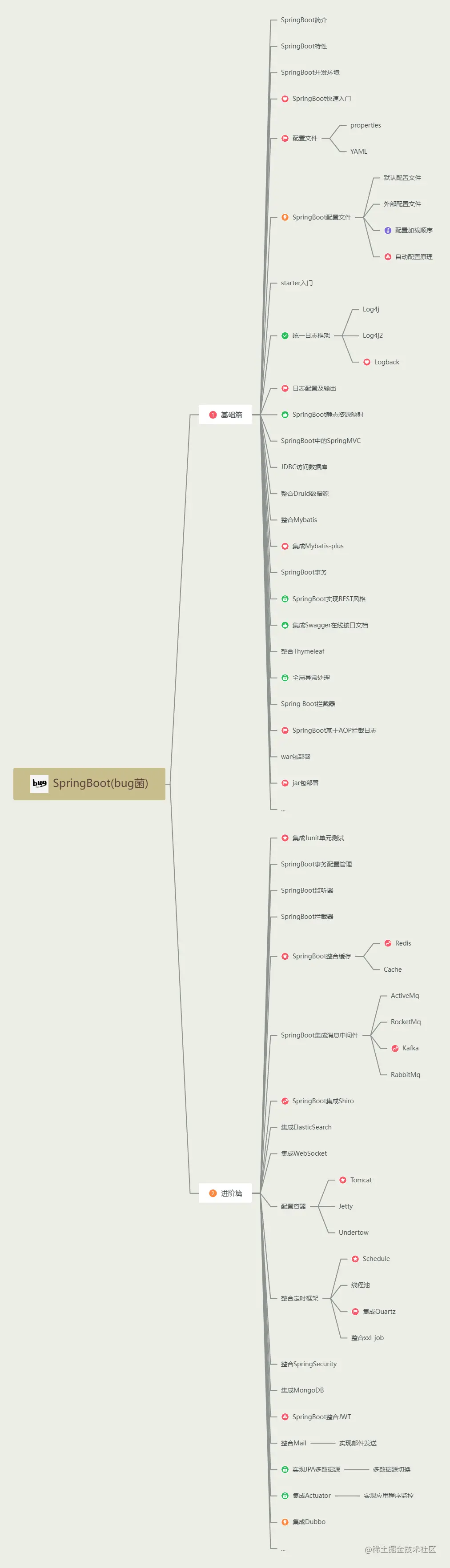
Последний выпуск 2023 года, самое полное руководство по обучению Spring Boot во всей сети (с интеллект-картой).