Синтез речи Microsoft NaturalSpeech запускает третье поколение, пользователи сети воскликнули: «Сверхъестественное!» Заслуженно
Колонна «Машинное сердце»
Редакция «Машинное сердце»
Эффект синтеза речи SOTA.
Синтез текста в речь (Text to Speech, TTS), как важная тема генеративного искусственного интеллекта (Generative AI или AIGC), в последние годы достиг быстрого развития. В эпоху больших моделей (LLM) технология синтеза речи может расширить возможности речевого взаимодействия больших моделей и получила широкое внимание.
На протяжении многих лет Microsoft продолжала концентрироваться на технологических исследованиях и разработке продуктов в области речи. Для того чтобы синтезировать качественную и естественную человеческую речь, был создан исследовательский проект NaturalSpeech (https://aka.ms/speechresearch). существование.
Чтобы реализовать эту амбициозную концепцию, проект NaturalSpeech разбил свои цели на несколько этапов:
1) Первый этап — добиться человеческого качества речи на одном динамике. С этой целью исследовательская группа 2022 Запущен в NaturalSpeech 1,существовать LJSpeech Набор данных синтеза речи достиг качества звука, сравнимого с человеческими записями.。
2) Второй этап — эффективно добиться синтеза речи, столь же разнообразной, как и люди, включая разных говорящих, просодию, эмоции, стиль и т. д. С этой целью исследовательская группа 2023 Запущен в NaturalSpeech 2,Использование модели диффузии для реализации синтеза речи Zero-Shot。
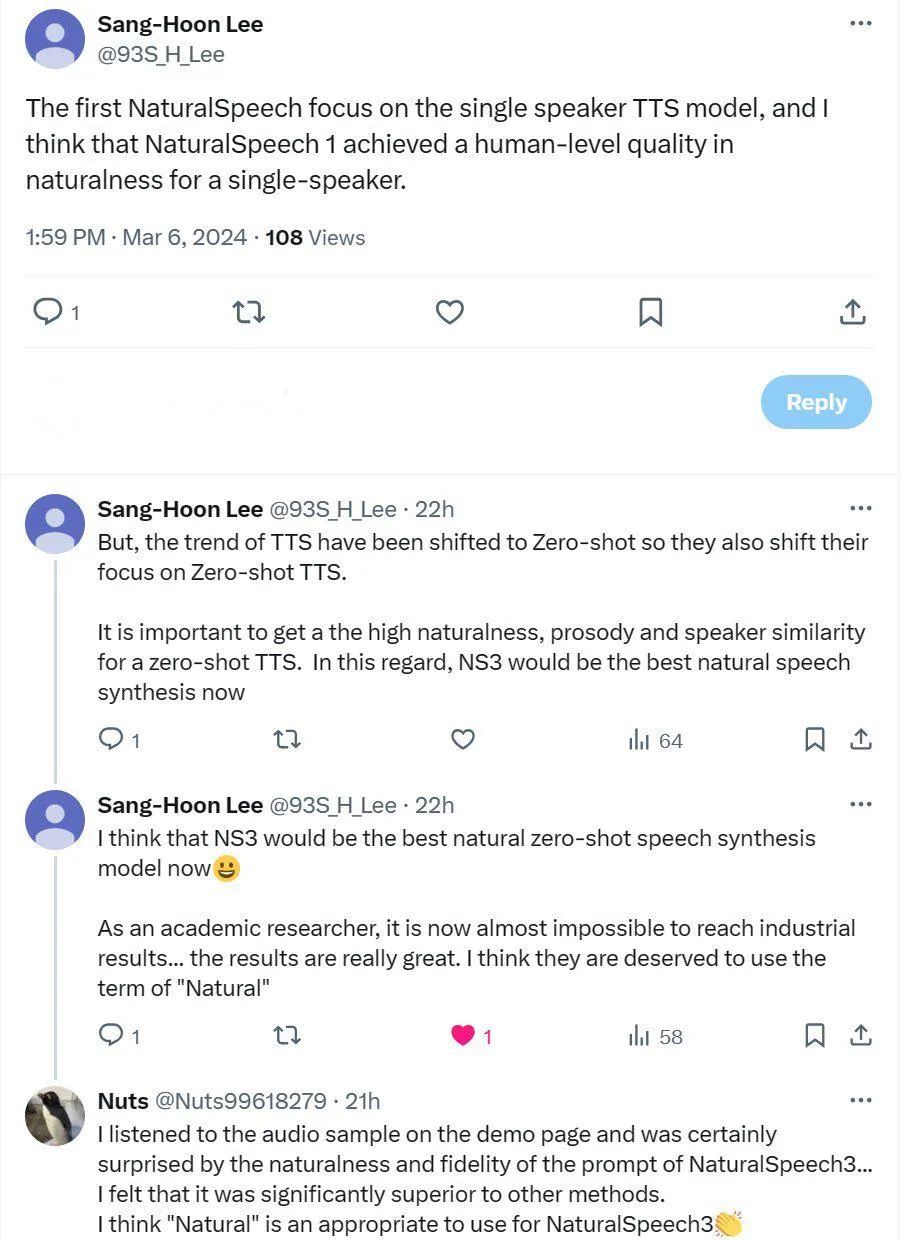
В 2024 году исследовательская группа объединила усилия с Университетом науки и технологий Китая.、CUHK(Шэньчжэнь)、Чжэцзянский университет и другие учреждения совместно выпустили новыйсистема:NaturalSpeech 3,это начинается сголосданныеиз "выражать" и «Моделирование» Начиная с двух точек зрения, используя инновационную диффузию декомпозиции атрибутов Модели декомпозиции атрибутов голосового нейронного кодека FACodec, через Data/Model Масштабирование позволило добиться важного прорыва в синтезе речи с нулевой выборкой и значительно продвинулось к цели второго этапа.
3) Текущий,Объединенная исследовательская группа изучает более естественный синтез речь, наконец, достигнув естественной и непринужденной вокализации, как у людей.
Хотите присоединиться к исследовательской группе, занимающейся передовыми исследованиями речи, аудио и видео? В конце статьи есть информация о наборе сотрудников.

Ссылка на статью NaturalSpeech 3: https://arxiv.org/abs/2403.03100
Демо-версия NaturalSpeech 3: https://speechresearch.github.io/naturalspeech3
NaturalSpeech 3 Как только статья была опубликована, она вызвала бурные дискуссии в социальных сетях в стране и за рубежом. Пользователи Twitter похвалили: NaturalSpeech. 3 На данный момент это лучший нулевой образец TTS Модель «Натуральная» в названии можно сказать вполне заслуженная.
Советы по использованию NaturalSpeech 3 Можно просто пройти 3s Аудиосуществовать, чтобы добиться потрясающих эффектов клонирования звука на динамиках, которых вы никогда раньше не видели, как показано в примере ниже:
NaturalSpeech 3 может не только создавать реалистичные модели тембра, но и очень хорошо восстанавливать ритм, эмоции и другие характеристики. Давайте послушаем следующий пример:
Вы можете это почувствовать, NaturalSpeech 3 сгенерировал результат, существующий с точки зрения качества звука и тембра, почти нет отличий от реального Аудио, и он очень хорошо воспроизводит эмоции и другую голосовую информацию, содержащуюся в подсказке Аудио.
NaturalSpeech 3 также может использовать разные подсказки для разных атрибутов, чтобы обеспечить более управляемую генерацию. Например, вы можете использовать голос человека, который говорит быстрее, в качестве подсказки о продолжительности, чтобы сгенерированные результаты также имели более высокую скорость речи. Например, следующий пример:
Можно обнаружить, что NaturalSpeech 3 Тембр сохраняется и другие атрибуты prompt Будьте последовательны, но следуйте duration prompt Более высокая скорость речи.
NaturalSpeech 3 Секрет успеха кроется в декомпозиции атрибутов. Codec+Diffusion парадигмы моделирования и Data/Model Масштабирование. Традиция TTS система Из-за ограниченного обучающего набора сложно поддерживать высококачественный синтез с нулевой выборкой речь. А недавние исследования расширили корпус,Хотя некоторый прогресс был достигнут,носуществоватькачество звука、сходствоиритмеще не достиг идеального уровня с точки зрения。
NaturalSpeech 3 Предлагаемая инновационная диффузия декомпозиции атрибутов Модели декомпозиции атрибутов нейронного голосового кодера FACodec, через разлагает голос на подпространства с разными атрибутами и генерирует их соответственно в соответствии с разными подсказками, что эффективно снижает сложность моделирования голоса, тем самым значительно повышая эффективность синтеза. качество и естественность речи.
Тем временем NaturalSpeech 3 Распространив обучающие данные на 20 10 000 часов (самый большой объем данных, использованных в опубликованных исследованиях на сегодняшний день) и увеличение размера модели до 1B(2B Еще большая модельпозитив существует в обучении), дальнейшее улучшение синтеза. качество и естественность речи.
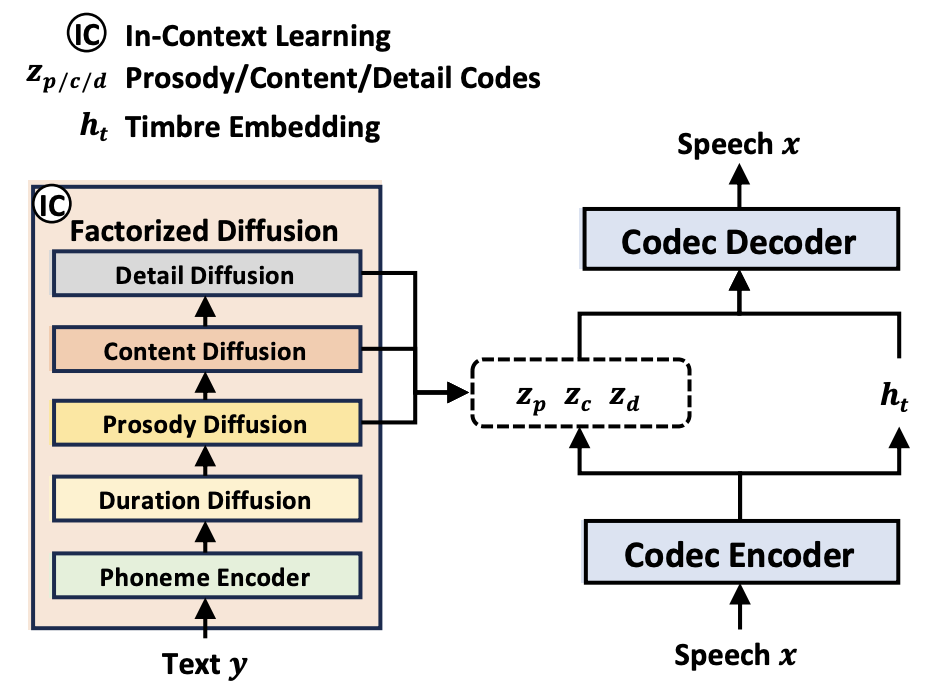
Факторизованный по атрибутам кодек нейронной речи (FACodec): NaturalSpeech 3 предложить инновациюизсвойство Разлагать нервыголоскодек(Codec)Ответственный за комплексизголоссигналы преобразуются для представления различныхголоссвойство(содержание、ритм、тониакустические детали)изотделенное подпространство,И восстанавливайте высококачественные голосовые сигналы на основе этих свойств.
FACodec Этот процесс достигается с помощью кодера голоса, экстрактора тембра, трех векторных квантователей разложения (один для содержания, просодии и акустических деталей), декодера голоса и комбинации методов обучения. Такая конструкция способствует разделению голосовых атрибутов и упрощает TTS Процесс моделирования речевых представлений.
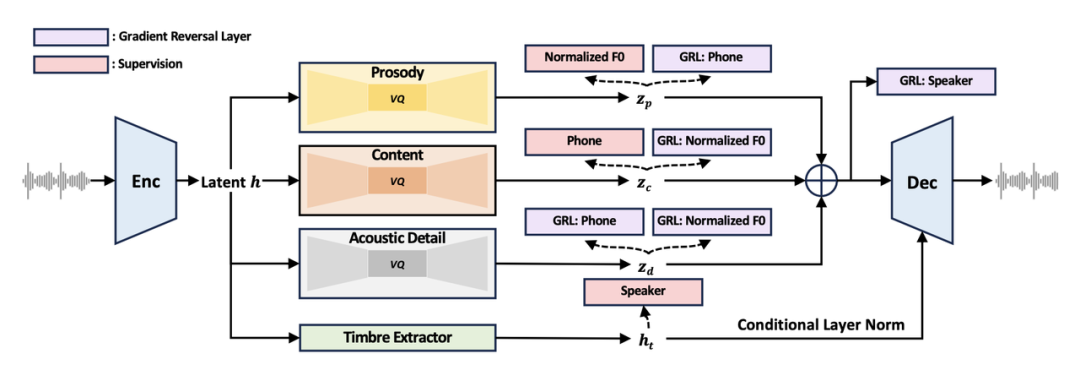
NaturalSpeech Атрибутная декомпозиция 3-х нейронных речевых кодеков FACodec
Текущие голосовые проекты с открытым исходным кодом Amphion Уже поддерживается NaturalSpeech 3 основные компоненты Были выпущены FACodec и предварительно обученные модели. Факодек как NaturalSpeech 3 изосновной,Возможность преобразования сложных голосовых сигналов в отдельные представления, представляющие такие атрибуты, как содержание, ритм, тембр и акустические детали.,И восстанавливайте высококачественные голосовые сигналы на основе этих свойств.
Эта технология может значительно снизить сложность моделирования голоса.,Исследователи могут использовать FACodec Повторение NaturalSpeech 3 Или применяться для различных последующих задач генерации, таких как синтез речи и преобразование речи.。
Предварительно обученная модель FACodec: https://huggingface.co/spaces/amphion/naturalspeech3_facodec
Код FACodec: https://github.com/open-mmlab/Amphion/tree/main/models/codec/ns3_codec
Расширенная модель декомпозиции атрибутов:NaturalSpeech 3 Несколько модулей модели диффузии предназначены для моделирования длительности, ритма, содержания и акустических деталей фонемы соответственно (ритм, содержание и акустические детали совместно используют модель диффузии). Нет необходимости моделировать тембр отдельно, поскольку характеристики тембра могут быть заданы напрямую. от prompt извлечено из. Более того, каждая диффузионная модель prompt Это связано только с голосовым фактором этого модуля, обеспечивая контролируемую генерацию каждого модуля.
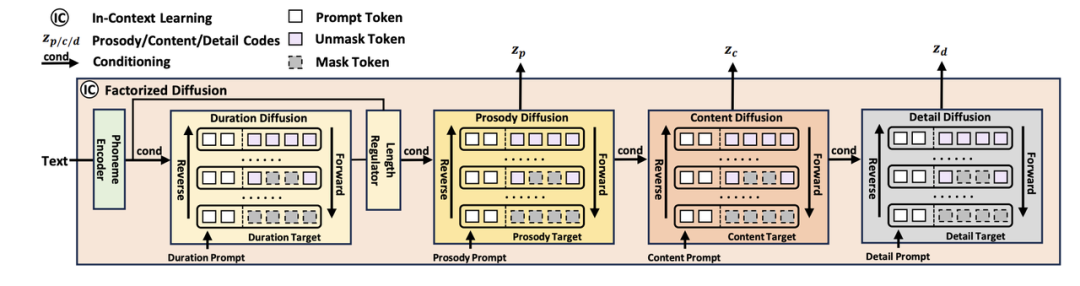
Диффузионная модель разложения атрибутов NaturalSpeech 3
Эффект синтеза речи SOTA:После многихиз Экспериментальная проверка,NaturalSpeech 3 Существующий голос превосходит существующее современное состояние по качеству, сходству, ритму и разборчивости. TTS система。в частности,существовать LibriSpeech На тестовом наборе в сравнении с реальной речью NaturalSpeech 3 существовать CMOS Рейтинги сопоставимы или даже лучше.изголоскачество;существоватьголос Сходство,Реализован новыйизлучший уровень;существоватьритм Моделирование также показало значительныеизулучшать。
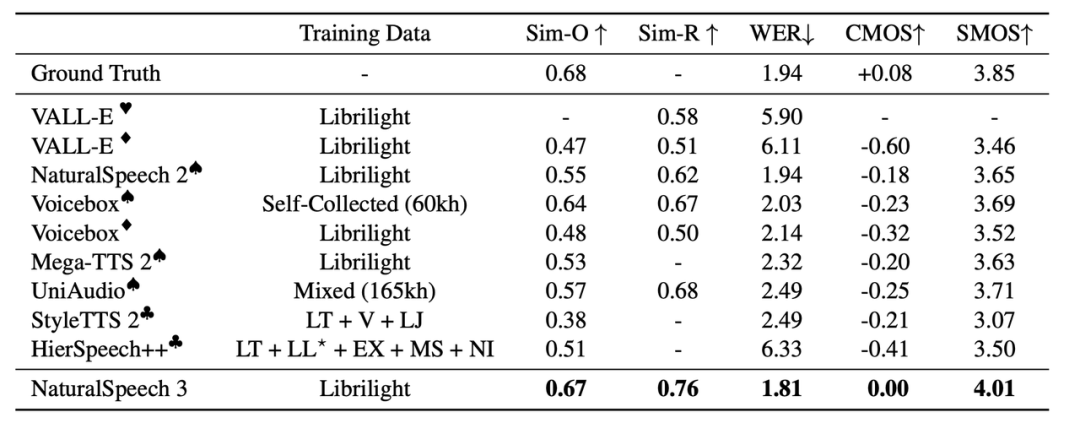
Natural Speech 3и Другая система TTSСравнение
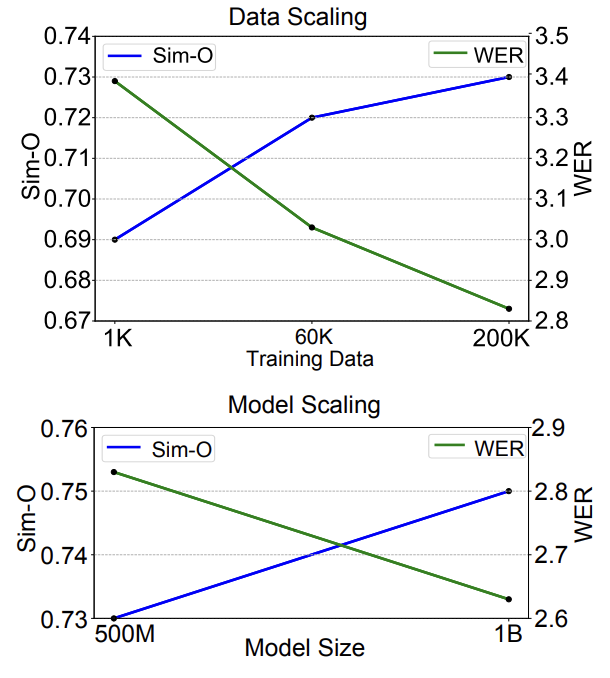
NaturalSpeech 3существовать Сравнение разных размеров Модели иданные



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
