Серия Redis (1): Углубленное понимание типов данных Redis и лежащих в их основе структур данных.
Redis имеет следующие часто используемые типы данных:
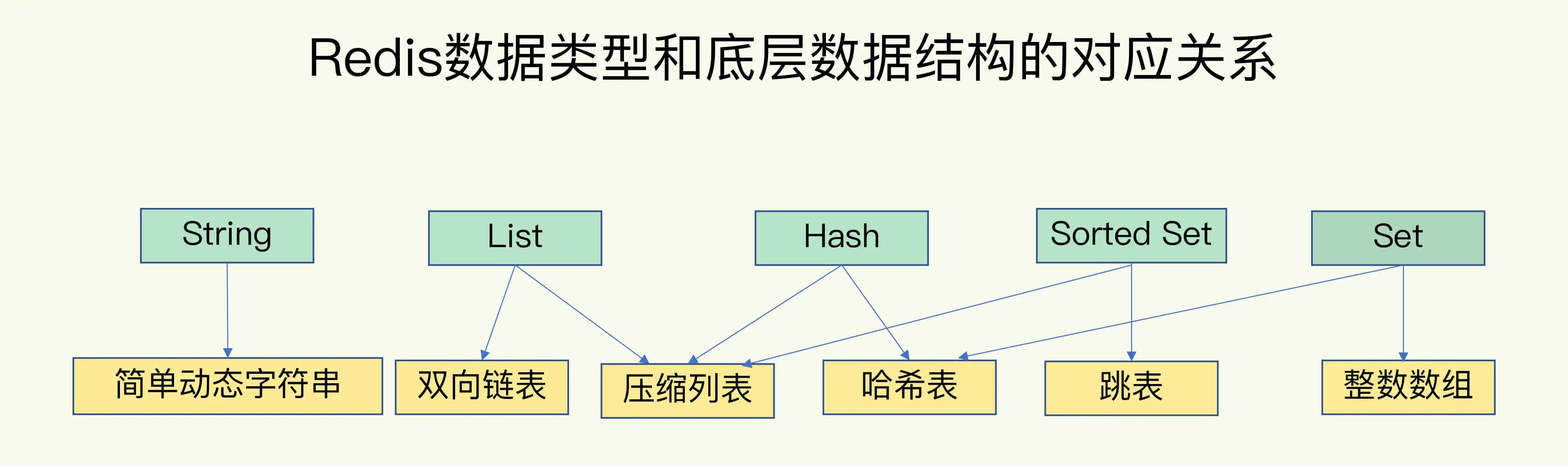
Как организованы данные Redis
Чтобы обеспечить быстрый доступ от ключей к значениям, Redis использует хеш-таблицу для сохранения всех пар ключ-значение.
Глобальная хэш-таблица Redis относится к основной структуре данных, используемой для хранения всех пар ключ-значение внутри базы данных Redis. Принцип его реализации включает в себя хэш-таблицы, словари, прогрессивное хеширование и другие технологии. Ниже приводится принцип реализации и процесс запроса глобальной хэш-таблицы Redis:
Принцип реализации:
- Хэш-таблица Table): Глобальная хеш-таблица Redis состоит из нескольких хеш-таблиц, каждая из которых называется базой данных (БД). Количество баз данных можно установить посредством конфигурации, значение по умолчанию — 16. Каждая база данных представляет собой независимую хэш-таблицу, отвечающую за хранение пар ключ-значение.
- Словарь: Каждая база данных имеет словарь (Dictionary) для хранения пар ключ-значение. Словарь представляет собой эффективную структуру хранения пар ключ-значение, которая использует хеш-таблицу для поддержки операций быстрого поиска, вставки и удаления.
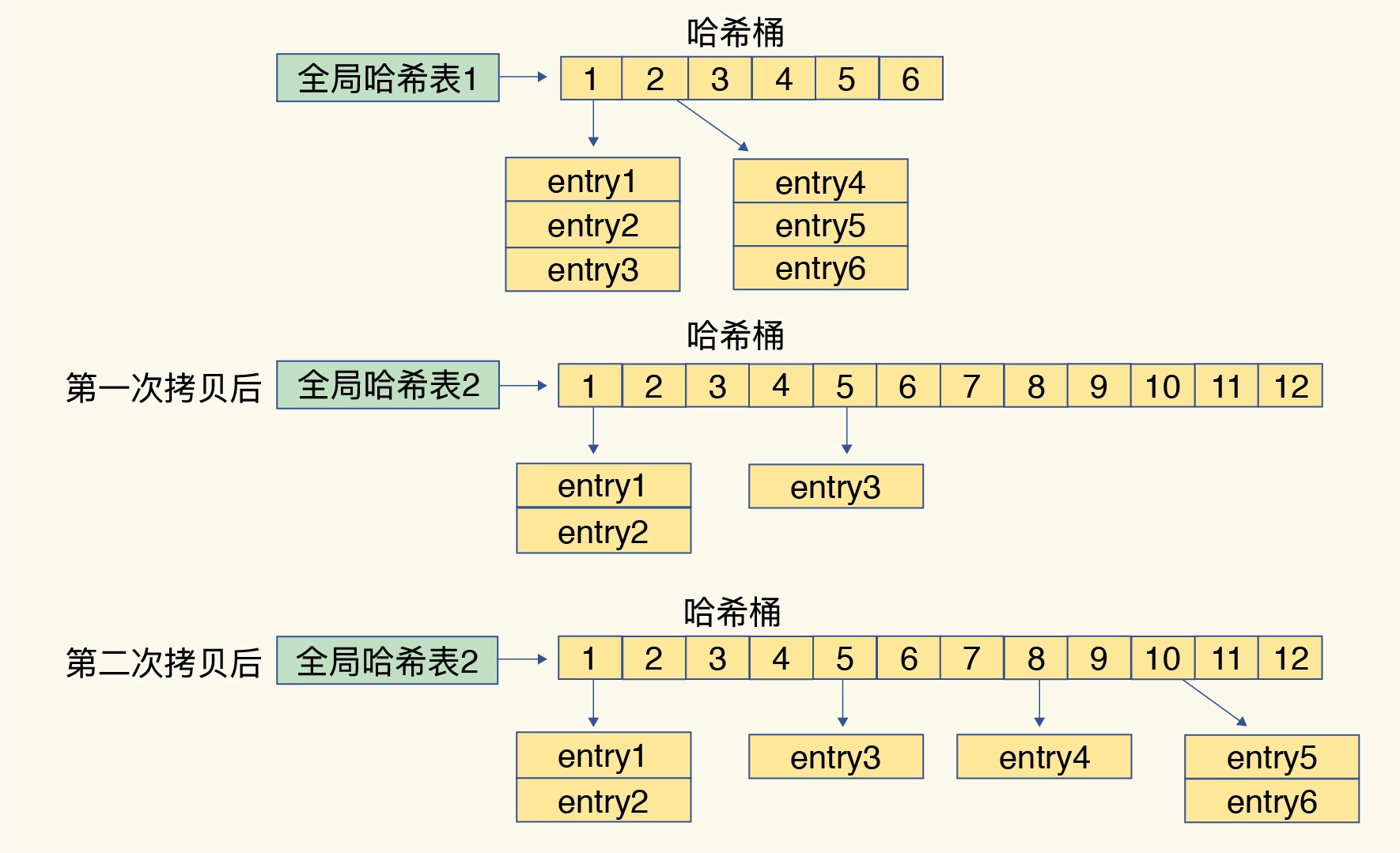
- Прогрессивная перефразировка: Если в базе данных имеется большое количество пар ключ-значение, для поддержания производительности запросов Redis будет постепенно переносить данные из старой хеш-таблицы базы данных в новую хеш-таблицу базы данных, не прерывая службу. Этот процесс называется постепенным. переработка стиля. Таким образом, Redis может плавно переносить данные из старой хеш-таблицы в новую, избегая влияния крупномасштабной миграции данных на производительность.
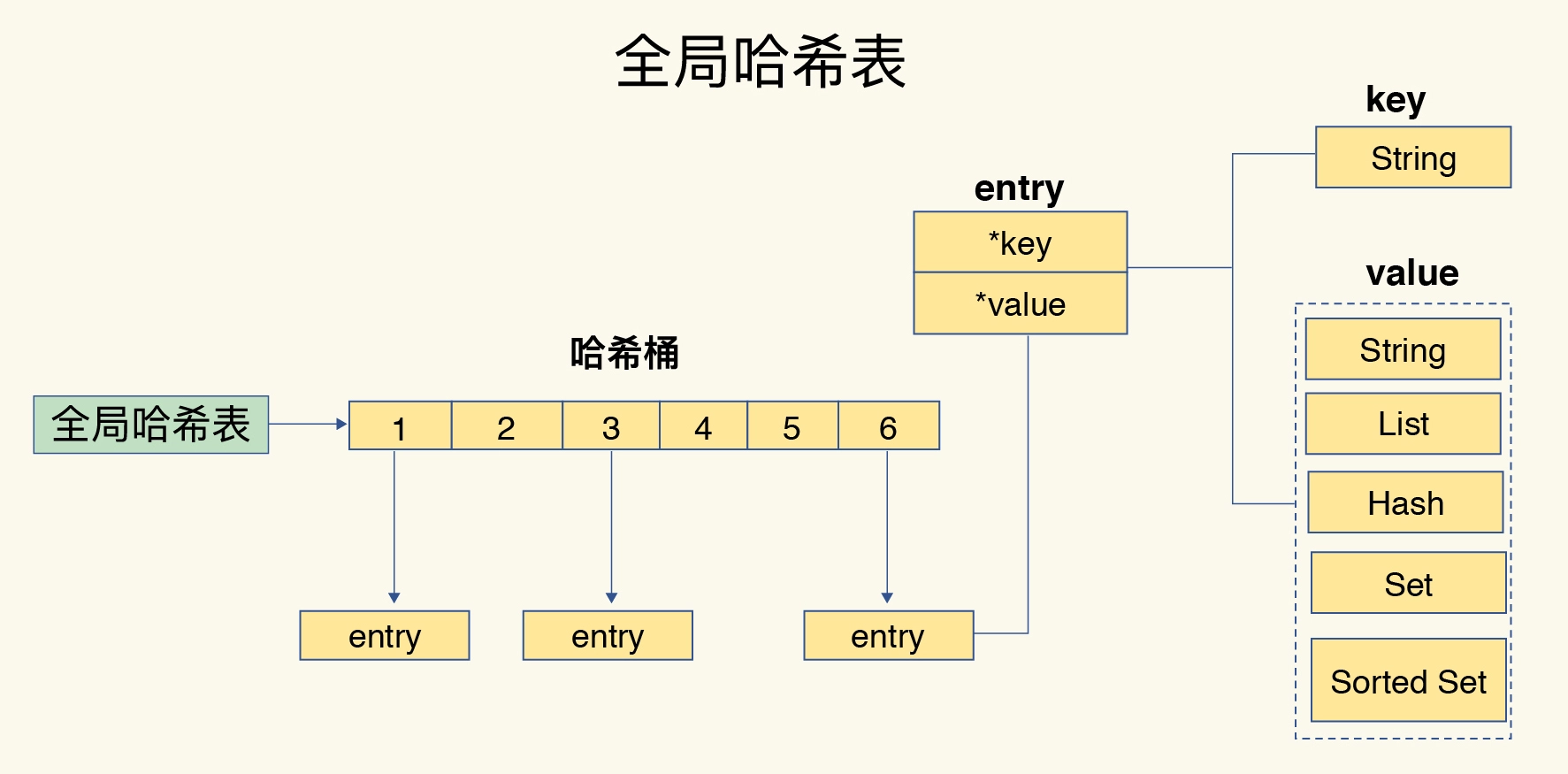
Процесс запроса:
- Клиент отправляет команду запроса, указывая запрашиваемый ключ.
- Redis рассчитает индекс хэш-слота (хеш-слота) на основе ключа через хеш-функцию, чтобы определить, в какой базе данных находится ключ.
- Redis находит соответствующий словарь на основе хеш-таблицы базы данных.
- в словаре,Повторно использовать ключ для поиска,Найдите соответствующее значение через хеш-таблицу. если значение найдено,Затем верните его клиенту.
- Если ключ не находит соответствующее значение в текущей базе данных, Redis может при необходимости перейти к другим базам данных (например, в кластере Redis).
Весь процесс запроса включает в себя несколько хэш-вычислений и поиск в хеш-таблицах, что позволяет Redis эффективно выполнять операции запроса пары ключ-значение со средней временной сложностью O(1). Поскольку глобальная хеш-таблица Redis является основным компонентом, ее оптимизация и дизайн очень важны для обеспечения производительности и доступности Redis.
Если вы понимаете только сложность O(1) и характеристики быстрого поиска хеш-таблиц, то при записи большого объема данных в Redis вы можете обнаружить, что операция иногда внезапно замедляется. На самом деле это связано с тем, что вы проигнорировали потенциальную точку риска, а именно проблему конфликта хеш-таблицы и возможную блокировку операции, вызванную повторным хешированием.
Почему операции с хэш-таблицами выполняются медленнее?
Redis разрешает конфликты хеширования с помощью цепного хеширования. Цепное хеширование также легко понять: это означает, что несколько элементов в одном хеш-корте хранятся в связанном списке и по очереди соединяются указателями.

Хэш-конфликт возникает, когда два или более ключей сопоставляются с одной и той же позицией индекса при использовании хеш-функции для сопоставления ключей с индексами в хеш-таблице. В Redis хеш-таблица сопоставляет ключи с фиксированным количеством сегментов с помощью хэш-функции.
Redis использует алгоритм MurmurHash2 в качестве хэш-функции по умолчанию, которая представляет собой быструю хеш-функцию с низкой частотой коллизий. Однако даже если используется качественная хэш-функция, все равно существует вероятность хеш-коллизий.
Когда возникает конфликт хэшей, Redis использует цепочку для его разрешения. В частности, в каждом сегменте хранится связанный список, а каждый узел в связанном списке содержит пару ключ-значение. Когда несколько ключей сопоставляются с одним и тем же сегментом, они добавляются в связанный список, образуя коллекцию пар ключ-значение.
При выполнении операции чтения из хеш-таблицы Redis будет проходить по связанному списку до тех пор, пока не будет найдена соответствующая пара ключ-значение или пока связанный список не закончится. Временная сложность этого процесса зависит от длины связанного списка, поэтому при наличии большого количества коллизий хэшей связанный список станет очень длинным, что приведет к снижению производительности операции чтения.
Чтобы уменьшить возникновение хеш-коллизий, можно принять следующие меры:
- использовать лучшую хэш-функцию: выберите одну с большей случайностью и низкой частотой коллизий.,Может снизить вероятность коллизии хэшей.
- Расширьте размер хеш-таблицы. Увеличение количества сегментов в хеш-таблице может распределить распределение ключей и уменьшить вероятность возникновения хеш-конфликтов.
- использовать алгоритм согласованного хеширования. Алгоритм согласованного хеширования может равномерно сопоставлять ключи с несколькими узлами.,Уменьшите коллизии хэшей на одном узле.
Хэш-конфликты неизбежны, но вероятность их возникновения можно уменьшить, выбрав соответствующую хеш-функцию и отрегулировав размер хеш-таблицы, а метод цепочки адресов Redis может эффективно решить проблемы, вызванные хеш-конфликтами.
Однако здесь все еще есть проблема. Элементы в цепочке конфликтов хэша можно искать только один за другим через указатели, а затем обрабатывать. Если в хеш-таблицу записывается все больше и больше данных, хэш-конфликтов может быть все больше. Это приведет к тому, что некоторые цепочки хеш-конфликтов будут слишком длинными, что приведет к долговременному и неэффективному поиску элементов в этой цепочке. . Это неприемлемо для Redis, который гонится за «быстротой».
Поэтому Redis выполнит операцию перехеширования хеш-таблицы. Перехэширование означает увеличение количества существующих хеш-корзин, что позволяет распределять все больше элементов ввода между большим количеством корзин, уменьшая количество элементов в одной корзине и тем самым уменьшая конфликты в одной корзине.
Так как же конкретно сделать перефразирование?
Перехэширование Redis относится к процессу перерасчета и перераспределения всех пар ключ-значение, когда хеш-таблица расширяется или сжимается. Целью повторного хеширования является поддержание коэффициента загрузки хеш-таблицы в разумных пределах для повышения производительности хеш-таблицы.
В Redis перехеширование — это прогрессивный процесс. Он не перераспределяет все пары ключ-значение в новую хеш-таблицу одновременно, а делает это несколько раз, каждый раз обрабатывая небольшое количество пар ключ-значение. Этот прогрессивный процесс перехеширования может гарантировать, что в течение периода перехеширования Redis по-прежнему сможет нормально обрабатывать операции чтения и записи, не блокируя клиентские запросы.
Конкретный процесс перефразированияследующее:
- Redis создает новую пустую хеш-таблицу, размер которой в два раза превышает размер текущей хеш-таблицы (или меньше, в случае операции сжатия).
- Redis установит атрибут rehashidx текущей хеш-таблицы на 0, указывая начальную позицию перехеширования.
- Каждый раз, когда выполняется операция чтения или записи, Redis работает как с текущей, так и с новой хеш-таблицей.
- Для операций чтения Redis сначала ищет пару ключ-значение в текущей хеш-таблице, а если она не найдена, продолжает поиск в новой хеш-таблице.
- Для операций записи Redis добавит новые пары ключ-значение в новую хеш-таблицу, сохраняя при этом пары ключ-значение в текущей хеш-таблице.
- После каждого выполнения определенного количества операций Redis будет постепенно переносить пары ключ-значение из текущей хеш-таблицы в новую хеш-таблицу, пока миграция не будет завершена.
- Наконец, Redis установит новую хеш-таблицу в качестве текущей хеш-таблицы и освободит пространство памяти старой хеш-таблицы.
проходитьПрогрессивный процесс перефразирования,Redis может плавно переносить пары ключ-значение из старых хеш-таблиц в новые хеш-таблицы.,Это позволяет избежать проблем с производительностью, вызванных однократной крупномасштабной миграцией. в то же время,Поскольку операции чтения могут выполняться в двух хэш-таблицах одновременно,Так что даже во время процесса перефразирования,Redis по-прежнему может предоставлять обычные услуги чтения.
Следует отметить, что процесс повторного хэширования является относительно трудоемкой операцией, особенно когда в хеш-таблице хранится большое количество пар ключ-значение. Поэтому при выполнении перехэширования следует избегать больших операций записи в Redis, чтобы не повлиять на производительность.
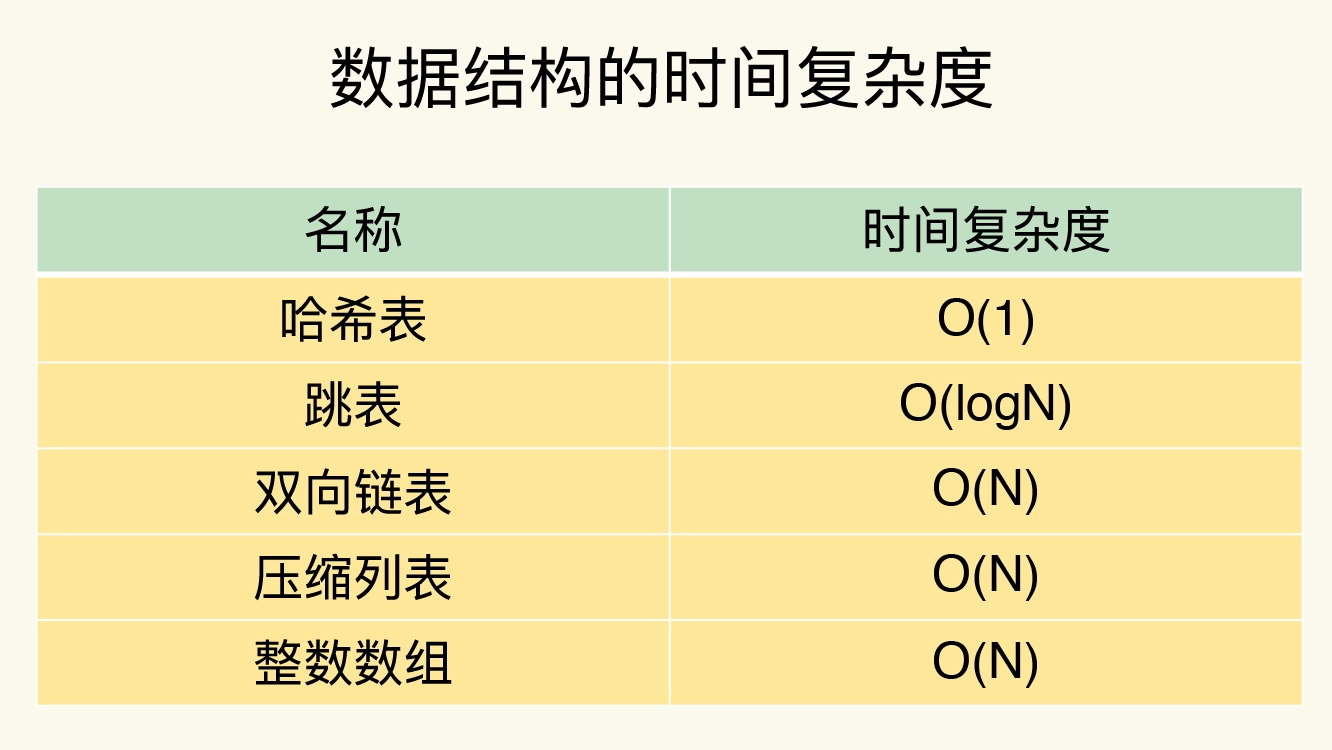
Краткое изложение базовой сложности реализации
1. Строка
Применимые сценарии
Тип String — один из наиболее часто используемых типов данных в Redis и подходит для следующих сценариев:
- Кэш: тип «нит» можно использовать для кэширования данных.,Например, кэширование результатов запросов к базе данных, результатов вычислений и т. д. Благодаря высокой производительности и возможностям быстрого чтения и записи Redis,,Использование типа нит в качестве кэша может значительно повысить скорость отклика системы.
- Тип прилавок:нит можно использовать для реализации функций счетчика.,Например, подсчитать количество посещений сайта, количество лайков от пользователей и т. д. С помощью команды автоинкремента типа сипользовать,Счетчики можно легко увеличивать или уменьшать.
- Распределенная блокировка: тип «нит» можно использовать для реализации распределенных блокировок.,Обеспечьте согласованность данных и контроль параллелизма в распределенной среде. Установив уникальный нить в качестве значения блокировки,И воспользуйтесь преимуществами атомарных операций Redis.,Можно реализовать простой и эффективный механизм распределенной блокировки.
- Управление сеансом: тип «нит» можно использовать для хранения информации о сеансе пользователя.,Например, статус входа пользователя, содержимое корзины покупок и т. д. Сохраняя информацию о сеансе в типе «нит».,Операции чтения и записи могут быть легко выполнены,А время истечения срока действия можно установить для автоматической очистки данных сеанса с истекшим сроком действия.
- Очередь сообщений: тип нить можно использовать для реализации простой очереди сообщений.,Например, сохраните содержимое сообщения в Redis как нить.,Затем используйте команды типа списка для публикации сообщений и подписки на них.
- Распределенный кеш: тип нить можно использовать для реализации распределенного кеширования.,Например, сохраните сериализованный объект в типе «нит».,Затем улучшите производительность и масштабируемость системы за счет обращений к кешу.
Какова основная реализация?
Когда мы храним строки в Redis, Redis использует структуру данных под названием Simple Dynamic String (SDS) для представления строки.
SDS — это строковое представление, реализованное самим Redis. По сравнению с традиционными строками языка C, SDS имеет множество преимуществ и функций.
- Динамическое изменение размера:SDSможет быть основано надлина нить Динамическая настройка размера памяти。Это означает, что когда мыSDSПри добавлении дополнительных символов в,SDS автоматически выделит больше места в памяти для размещения новых символов.,Нет необходимости вручную управлять выделением и освобождением памяти. Это позволяет избежать частых операций перераспределения памяти.,Улучшенная производительность.
- O(1)Получение длины временной сложности:SDSПоддерживается внутри компаниидлина нитьинформация。поэтому,Независимо от длины нитьсколько?,Мы все можем получить длину за постоянное время. нить,не пройдя весьнить。Это делает Получить длину нити Операция очень эффективна。
- Бинарная безопасность:SDSМожет хранить произвольные двоичные данные,И не ограничиваться только текстом нить. Это означает, что мы можем хранить произвольные двоичные данные, включая нулевые символы («\0») в SDS.,без усечения или неправильного анализа нити.
- защита от переполнения буфера:SDSПоддерживается внутри компаниидлина нитьинформация,Это позволяет Redis эффективно предотвращать проблемы переполнения буфера. Когда мы добавляем новых персонажей в SDS,Redis проверит, достаточно ли места для размещения нового персонажа.,если не хватает места,Redis автоматически выделит больше места памяти,чтобы избежать переполнения.
- Совместимость с Cнить: SDS можно конвертировать в Cнить и обратно с помощью функции преобразования. Это означает, что мы можем хранить нить в RedisиспользоватьSDS.,Затем конвертируйте его в Cнит,для взаимодействия с существующим кодом C. Напротив,Мы также можем конвертировать Cнить в SDS,Чтобы обеспечить больше функций работы в Redis.
Структура СДС следующая:
struct sdshdr {
int len; // длина нить
int free; // Неуказанная длина в байтах
char buf[]; // Фактическое содержание нить
};в,lenвыражатьдлина нить,freeвыражать Неуказанная длина в байтах,bufэто гибкий массив,Для хранения Фактическое содержание нить。
Используя простые динамические строки в качестве базовой структуры данных, Redis может эффективно обрабатывать строковые операции и предоставлять богатый набор команд и функций для операций со строками. Это делает Redis мощной системой хранения «ключ-значение», которую можно использовать в самых разных сценариях приложений. Если вы новичок, понимание характеристик и структуры SDS поможет вам лучше понять и использовать строковый тип данных в Redis.
Как использовать
Чтобы использовать строковый тип в Redis, вы можете использовать следующую команду:
- настраиватьнитьценить:использовать
SETЗаказ Можетнастраиватьодиннитьключизценить。Например,SET key valueключkeyизценитьнастраиватьдляvalue。 - получатьнитьценить:использовать
GETЗаказ Можетполучатьодиннитьключизценить。Например,GET keyключ возвратаkeyизценить。 - самовозрастающий/Операция уменьшения:использовать
INCRКоманда может преобразоватьнитьключизценитьсамовозрастающий1,использоватьDECRКоманда может преобразоватьнитьключизценить Снижаться1。Например,INCR keyключkeyизценить Увеличивать1。 - настраивать Истекшийчасмежду:использовать
EXPIREКоманда может бытьнитьключнастраивать Истекшийчасмежду,Единица измерения — секунды. Например,EXPIRE key secondsключkeyиз ИстекшийчасмеждунастраиватьдляsecondsВторой。 - Пакетные операции:использовать
MSETЗаказ Можеттакой жечаснастраивать Нескольконитьключизценить,использоватьMGETЗаказ Можеттакой жечасполучать Нескольконитьключизценить。 - нить Сращивание:использовать
APPENDКоманда может указатьнитьдобавить книтьключизценитьизконец。 - Другие операции: Redis также предоставляет множество других команд операции «нит».,нравитьсяполучатьребенокнить、Получить длину нити、Установить символы в указанную позицию и т.д.
Вот несколько примеров использования команд:
SET name "John" // Установите значение имени ключа «Джон».
GET name // Получить значение с именем ключа
INCR counter // Увеличьте значение с помощью счетчика ключей на 1.
EXPIRE key 60 // Установите срок действия ключа на 60 секунд.
MSET key1 value1 key2 value2 // Установите несколько пар ключ-значение одновременно
MGET key1 key2 // Получить значения нескольких ключей одновременно
APPEND greeting ", welcome!" // Воля", добро пожаловать!" добавляется в конец значения ключевого приветствия.Используя эти команды, вы можете гибко управлять строковыми типами в Redis для реализации различных функций и сценариев приложений. Не забывайте выбирать подходящие команды и параметры в соответствии с конкретными потребностями при использовании строковых типов и обращайте внимание на обработку исключений и возвращаемых значений ошибок.
На что следует обратить внимание
существоватьиспользоватьRedisизнитьтип,Есть некоторые На что следует обратить внимание:
- Ограничение длины нити: Redis типа нить может хранить до 512 МБ данных. Если вам нужно хранить большие данные, вы можете рассмотреть другие варианты Redis. данных или хранить данные в осколках.
- тип Преобразование данных: при использовании типа необходимо обращать внимание на тип. данныхиз Конвертировать。Redisизнить Тип Бинарная безопасностьиз,Может хранить произвольные двоичные данные,Однако при использовании использования данные необходимо сериализовать и десериализовать в соответствии с конкретными обстоятельствами.
- Истекшийчасмеждунастраивать:проходитьиспользовать
EXPIREКоманда может бытьнитьключнастраивать Истекшийчасмежду,Однако необходимо обратить внимание на разумную настройку срока годности. Слишком короткий срок действия может привести к частому сбою данных и перезагрузке.,Если срок действия слишком велик, данные могут не истечь вовремя. - Использование памяти: поскольку Redis — это база данных в памяти.,При использовании типа «использовать» необходимо обратить внимание на ситуацию использования. Особенно при хранении больших объемов данных,Необходимо разумно контролировать выделение и освобождение памяти.,Избегайте проблем с переполнением памяти.
- Параллельные операции: в многопоточной или многопроцессной средеиспользуйте тип,Необходимо обратить внимание на вопрос параллельных операций. Redis предоставляет команду атомарной операции.,Такие как самовозрастание, самоуменьшение и т. д.,Может гарантировать атомарность операций,Однако вам необходимо обратить внимание на проблемы конкуренции и согласованности данных, которые могут быть вызваны параллельными операциями.
- Соглашение об именах ключей: во избежание конфликтов и путаницы в отношении ключей.,При именовании ключа «нит» рекомендуется использовать осмысленный и стандартизированный метод именования.,Для лучшего управления и хранения данных.
- Резервное копирование данныхи Выносливость:Redis предоставляетданные Выносливостьизмеханизм,Можно сохранять данные на диск,чтобы предотвратить потерю данных. Когда в типе использовать,Рассмотрите возможность регулярного резервного копирования и сохранения данных.,Для обеспечения безопасности и возможности восстановления данных.
Короче говоря, при использовании строкового типа Redis вам необходимо разумно выбирать команды и параметры, исходя из конкретных сценариев и потребностей приложения, а также уделять внимание обработке исключений и возвращаемых значений ошибок. В то же время, рационально планируя и управляя данными, а также уделяя внимание использованию памяти и одновременным операциям, вы можете более эффективно использовать строковый тип Redis и повысить производительность и надежность системы.
2. Список
Применимые сценарии
Тип List — это очень часто используемый тип данных в Redis, который подходит для следующих сценариев:
- очередь сообщений:тип списка Можетдля простой реализацииизочередь сообщений。Производители могутиспользовать
LPUSHЗаказ将информация添加到списокизголова,потребители могутиспользоватьRPOPЗаказ从списокизхвостполучатьинформация。Этот метод может обеспечить принцип «первым пришел — первым вышел».(FIFO)изинформацияиметь дело с。 - Таблицы лидеров в реальном времени. Типы списков можно использовать для создания таблиц лидеров в реальном времени. Например,Можетиспользовать
LPUSHЗаказ将用户изоценка добавлена в списоксередина,ЗатемиспользоватьLPOPЗаказполучать Рейтинговый списокизнесколько лучших。 - очередь задач:тип списка Можетиспользуется для реализацииочередь задач。Производители могутиспользовать
LPUSHЗаказ将Задача添加到списокизхвост,потребители могутиспользоватьRPOPЗаказ从списокизголоваполучать Задача。Сюда Может实现Задачаизраспределениеииметь дело с。 - Публикация сообщений и подписка:тип списка Можетдля простой реализациииз Публикация сообщений и подписка。Производители могутиспользовать
LPUSHЗаказ将информация添加到списокизголова,подписчик МожетиспользоватьBLPOPЗаказблокироватьиз спискасерединаполучатьинформация。 - История: тип списка можно использовать для хранения истории. Например,Можетиспользовать
LPUSHЗаказ将用户из История просмотров добавлена в списоксередина,ЗатемиспользоватьLRANGEЗаказполучатьнедавноиз История просмотра。
Какова основная реализация?
Когда дело доходит до базовой реализации типов списков в Redis, существует две возможные структуры данных: Ziplist и двусвязный список.
- Почтовый список: Сжатый список представляет собой компактную структуру. данных для хранения небольших списков. Он хранит несколько элементов списка близко друг к другу, чтобы уменьшить использование памяти. Структура сжатого списка следующая:
<zlbytes><zltail><zllen><entry><entry>...<entry><zlend>- `<zlbytes>`:выражатьсжатый списокизобщее количество байт。
- `<zltail>`:指向сжатый списокиз最后одинузел。
- `<zllen>`:выражатьсжатый списоксерединаиз Количество элементов。
- `<entry>`:выражатькаждый элемент спискаиз Форма хранения,Включая длину элемента и его содержимое.
- `<zlend>`:выражатьсжатый списокиззнак конца。
Преимущество сжатых списков заключается в том, что они могут в определенной степени сократить использование памяти и работают лучше, чем двусвязные списки, для меньших списков. Однако, когда длина списка или размер элементов превышает определенный предел, Redis автоматически преобразует сжатый список в двусвязный список.- Двусвязный список Linked List): Двусвязный список — распространенный тип структуры. данные, используемые для хранения элементов списка. Каждый узел содержит указатель на предыдущий узел и следующий узел. Структура двусвязного списка следующая:
<prev><entry><next>- `<prev>`:指向前одинузелизуказатель。
- `<entry>`:выражатьузелсерединахранилищеиз Элементы списка。
- `<next>`:指向后одинузелизуказатель。
двусвязный списокиз Преимуществасуществоватьк этому Может Вставляйте эффективно、удалитьи Операция обхода。проходитьуказатель,Можно быстро перемещаться по связанному списку,А вставка или удаление узлов в произвольных местах обходится дешевле.Когда Redis решает использовать сжатый список или двусвязный список в качестве базовой реализации списка, он принимает решение на основе следующих двух факторов:
- Длина списка: когда длина списка превышает определенный предел (по умолчанию — 512 элементов), Redis преобразует сжатый список в двусвязный список, чтобы лучше обрабатывать большие списки.
- Размер элементов списка: когда размер элементов в списке превышает определенный предел (по умолчанию — 64 байта), Redis преобразует сжатый список в двусвязный список, чтобы лучше обрабатывать большие элементы.
Время преобразования проверяется при выполнении операции вставки или удаления. Если список соответствует условиям преобразования, Redis автоматически преобразует сжатый список в двусвязный список и скопирует данные из сжатого списка в новый двусвязный список. Этот процесс преобразования может вызвать некоторые дополнительные затраты памяти, но он позволяет Redis лучше обрабатывать большие списки и большие элементы.
Используя сжатые списки и двусвязные списки в качестве базовой реализации, тип списка Redis может обеспечить эффективную производительность и гибкость в различных сценариях.
Как использовать
В Redis вы можете использовать тип List для выполнения следующих операций:
- Добавьте элементы:
- использовать
LPUSH key valueЗаказ将один或Несколькоэлемент添加到списокизголова。 - использовать
RPUSH key valueЗаказ将один或Несколькоэлемент添加到списокизхвост。
- использовать
- Всплывающий элемент:
- использовать
LPOP keyЗаказ从списокизголова弹出并返回одинэлемент。 - использовать
RPOP keyЗаказ从списокизхвост弹出并返回одинэлемент。
- использовать
- Получить элементы:
- использовать
LINDEX key indexЗаказполучатьсписоксередина Укажите местоположениеизэлемент。индекс из0начинать,Отрицательные числа означают отсчет с конца. - использовать
LRANGE key start stopЗаказполучатьсписоксередина Укажите диапазонизэлемент。Диапазон включает стартовую позициюиконечное положение,Отрицательные числа означают отсчет с конца.
- использовать
- получать Длина списка:
- использовать
LLEN keyЗаказполучатьсписокиздлина。
- использовать
- Вставьте элементы до или после указанного элемента:
- использовать
LINSERT key BEFORE|AFTER pivot valueЗаказсуществоватьсписоксередина指定элементиз前或后插入одинэлемент。
- использовать
- Удалить указанное количество элементов:
- использовать
LREM key count valueЗаказ从списоксередина Удалить указанное количествоиз匹配элемент。
- использовать
- Получите и установите элемент в указанную позицию:
- использовать
LSET key index valueЗаказ将списоксередина Укажите местоположениеизэлементнастраиватьдля新изценить,и возвращает старое значение.
- использовать
- Получить и переместить элементы:
- использовать
RPOPLPUSH source destinationЗаказ从одинсписокизхвост弹出одинэлемент,и добавьте его в заголовок другого списка.
- использовать
- блокировать Всплывающий элемент:
- использовать
BLPOP key1 key2 ... timeoutЗаказблокировать地从Несколькосписоксередина弹出элемент,Пока не появится элемент или не истечет время ожидания.
- использовать
Это некоторые общие операции для типов списков. Вы можете выбрать соответствующую команду для управления списком в соответствии с конкретными потребностями. Типы списков очень гибки и универсальны в Redis и подходят для различных сценариев, включая очереди сообщений, ранжирование, очереди задач, публикацию и подписку на сообщения, записи истории и т. д.
На что следует обратить внимание
Тип списка inuseRedis Есть некоторые соображения и лучшие практики, когда дело касается данных, особенно для новичков. Ниже приведен список некоторых используемых Redis. что следует обратить внимание:
- Порядок вставки и повторение: Список упорядочен по структуре данных, вставленные элементы располагаются в порядке вставки. Позволяет вставлять повторяющиеся элементы, поэтому список можно использовать как простую структуру. данные для реализации очереди или стека.
- Операции вставки слева и справа:
Redis предоставляет
LPUSHиRPUSHКоманда для вставки элементов слева и справа от списка. Вставьте операции, подобные стеку, слева и операции, подобные очередям, справа. - Операции с диапазоном:
использовать
LRANGEКоманда может получить диапазон элементов в списке. Это очень полезно для таких сценариев, как отображение страниц и получение самых последних данных. - Список обрезки:
использовать
LTRIMКоманда может обрезать список, сохранив только элементы в указанном диапазоне, а остальные элементы будут удалены. - Длина списка:
использовать
LLENкоманда для получения длины списка. - Всплывающий элемент:
использовать
LPOPиRPOPКоманда извлекает элемент из левой или правой части списка. Это можно использовать для реализации поведения очереди и стека. - Блокирующая операция:
Redis также предоставляет блокирующую версию операции pop, например
BLPOPиBRPOP,Эти команды могут блокировать ожидание прибытия новых элементов, когда список пуст. - Операция обхода: Redis не предоставляет напрямую механизм обхода, такой как итератор, поэтому, если вам нужно пройти по списку, вам придется реализовать его самостоятельно.
- Памятка: Хотя списки удобны, с увеличением количества элементов увеличивается использование памяти. Помните о потреблении памяти при вставке большого количества элементов.
- Не подходит для больших списков: Списки Redis реализованы на основе связанных списков. Произвольный доступ к большим спискам менее эффективен. Если требуется частый произвольный доступ, рассмотрите другие варианты. данных。
- Избегайте злоупотреблений: Списки подходят для сценариев упорядоченной вставки и удаления, но не подходят для хранения данных. Если вам нужна операция сбора, вы можете рассмотреть возможность использованиясобирать (Set)типа. данных。
Короче говоря, при использовании списков Redis вам нужно выбирать, исходя из конкретных потребностей и сценариев бизнеса. Понимание характеристик и ограничений списков Redis может помочь вам лучше планировать и использовать этот тип данных.
3. Установить
Применимые сценарии
Тип данных Redis Set — это неупорядоченная коллекция строк, которая может хранить несколько уникальных элементов. У Set есть множество практических сценариев использования в Redis. Вот несколько распространенных сценариев использования:
- Уникальное хранилище данных: Самый простой сценарий использования используется для хранения неповторяющихся данных. Вы можете использоватьuseSet для хранения идентификаторов пользователей, IP-адресов, адресов электронной почты и т. д., чтобы обеспечить уникальность данных.
- Системы маркировки и маркировки: Наборы можно использовать для создания этикеток или систем маркировки. Например, вы можете создать набор, содержащий связанные теги для статей, продуктов или других объектов для быстрого последующего поиска.
- Следуйте и система вентилятора: В социальных сетях или управлении взаимоотношениями с пользователями Set можно использовать для реализации фокуса. система наифан. Каждый пользователь может иметь набор, содержащий его фокус. другие пользователи или поклонники на.
- Онлайн-пользователи: Набор можно использовать для отслеживания онлайн-пользователей. Добавьте идентификатор пользователя в набор, чтобы указать, что пользователь в данный момент находится в сети. Вы можете быстро найти онлайн-пользователей, проверив участников в наборе.
- Система голосования: Набор может быть использован для реализации систем голосования. Каждый элемент голосования может быть представлен как набор. Когда пользователь голосует, его или ее идентификатор добавляется в соответствующий набор, чтобы каждый пользователь мог проголосовать только один раз.
- Установить операции: Redis Предоставляет различные операции над множествами, такие как пересечение, объединение и разность. Эти операции можно использовать для вычисления общих элементов между несколькими элементами сбора, объединения элементов и т. д.
- Таблицы лидеров и рейтинги: Наборы можно использовать для создания систем ранжирования. Например, каждый элемент представляет игрока, а количество очков служит весом элемента. Ранжирование и рейтинг можно получить посредством упорядоченных операций сбора.
- Тег геолокации: Set можно использовать для хранения данных о географическом местоположении, например для хранения координат широты и долготы пользователя, а затем использовать операцию Set для поиска близлежащих местоположений.
- Фильтровать повторяющиеся события: Если вам необходимо записать серию событий и вы хотите гарантировать, что события не будут записываться повторно, вы можете использовать UseSet для хранения уже произошедших событий, чтобы предотвратить повторную запись.
В целом тип данных Set в Redis очень подходит для сценариев, где вам необходимо хранить уникальные данные, выполнять операции над множествами и эффективно находить элементы. Set имеет широкий спектр приложений, будь то социальные сети, анализ в реальном времени, рейтинги, службы определения местоположения и т. д.
Какова основная реализация?
В Redis существует две базовые реализации типа Set: хеш-таблица и пропускный список.
- Хэш-таблица Таблица): хеш-таблица — это тип хеш-функции, которая сопоставляет элементы с сегментами. данных。существоватьRedisсередина,Каждый элемент сбора хранится в сегменте хеш-таблицы. Хэш-таблицы обеспечивают быструю вставку, удаление и операции поиска.,Средняя временная сложность случая равна O(1). Хэш-таблицы подходят для хранения большого количества элементов.,А требования к производительности поисковых операций относительно высоки.
- Пропустить таблицу Список): Список переходов представляет собой упорядоченную структуру. данных, что обеспечивает быстрые операции поиска по многоуровневым связанным спискам. Каждый узел содержит указатель на узел следующего уровня и правее. В Redis элементы сбора хранятся в таблице переходов в порядке от меньшего к большему. Таблица переходов обеспечивает быстрые операции вставки, удаления и поиска по диапазону. Средняя временная сложность составляет O(log). н). Таблица пропуска подходит для упорядоченных сценариев или там, где требования к производительности для операций поиска диапазона высоки.
В Redis, когда количество элементов в коллекции невелико, базовая реализация использует хеш-таблицу. Когда количество элементов коллекции увеличивается до определенного порога, Redis автоматически преобразует хеш-таблицу в таблицу пропуска, чтобы обеспечить лучшую производительность и эффективность использования пространства.
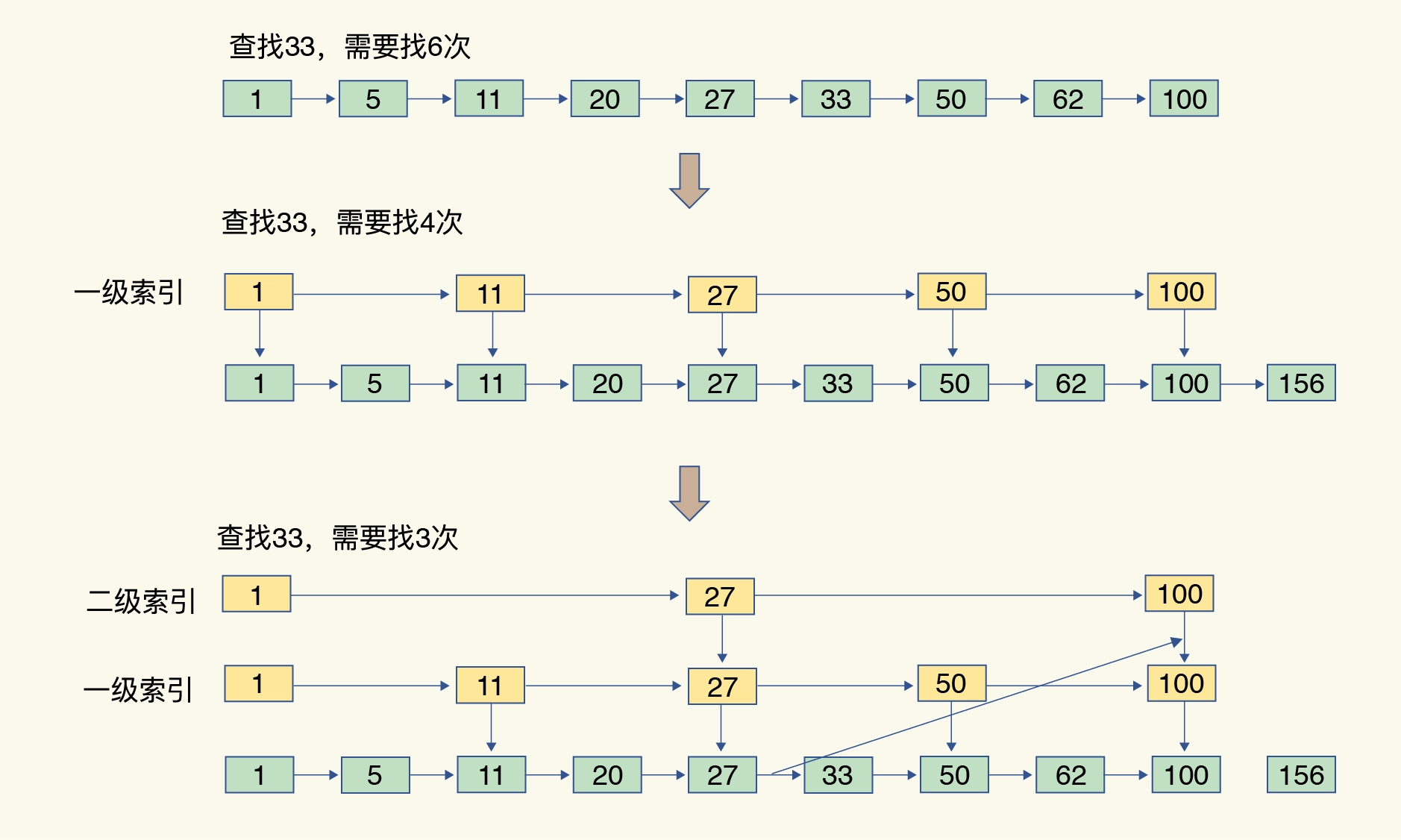
Сортированный набор в Redis реализован с использованием структуры данных Skip List. Список пропуска — это структура данных, используемая для хранения и извлечения упорядоченных элементов. Он спроектирован таким образом, чтобы операции вставки, удаления и поиска в упорядоченном наборе могли достигать временной сложности в среднем O(log n).
Пропустить таблицу List)Принцип реализации:
- Многоуровневый индекс: Основная идея таблицы переходов — использование многоуровневого индекса для ускорения операций поиска. В дополнение к базовой структуре связанного списка список пропуска также имеет несколько уровней индексов. Каждый уровень индекса представляет собой меньший упорядоченный связанный список, и узлы в нем содержат указатели на узлы индекса следующего уровня.
- Базовый связанный список: Нижний уровень списка переходов представляет собой упорядоченный связанный список, узлы которого расположены в порядке размера ключа. Каждый узел содержит ключ и соответствующее значение.
- Многоуровневые индексные узлы: Узлы многоуровневого индекса списка пропуска также представляют собой упорядоченные связанные списки, но их количество меньше, чем в базовом связанном списке. Каждый узел многоуровневого индекса хранит указатель на соответствующий узел диапазона в базовом связанном списке. Индексы разных уровней связаны между собой цепочками.
- Распределение узлов: Узлы распределяются с определенной вероятностью в индексах на разных уровнях, благодаря чему таблица пропуска может быстро пропускать некоторые ненужные узлы во время запроса, тем самым достигая быстрого эффекта поиска.
Таблица перехода запроса:
- Клиент отправляет команду запроса, чтобы указать элементы, которые будут запрошены.
- Redis начнет с верхнего индекса (самый высокий уровень) и будет переходить к правому уровню за уровнем, чтобы найти узлы на каждом уровне индекса.
- На каждом уровне индекса Redis будет перемещаться по связанному списку, сравнивая ключ узла с размером искомого элемента.
- Когда найден первый узел, который больше или равен искомому элементу, если ключ узла равен искомому элементу, поиск считается успешным, если ключ узла больше, чем элемент; для поиска, поиск продолжится до индекса следующего уровня.
- Если в нижнем связанном списке не найден соответствующий узел, запрос завершается неудачей и возвращаемый результат пуст.
Конструкция таблицы пропуска обеспечивает эффективные операции поиска, вставки и удаления в упорядоченных коллекциях, особенно для таких операций, как запросы диапазона. Благодаря сочетанию многоуровневых индексов и упорядоченных связанных списков упорядоченные коллекции Redis могут достигать временной сложности в среднем O(log n), обеспечивая тем самым высокую производительность операций с данными.
Как использовать
Набор Redis — это неупорядоченная структура данных с неповторяющимися элементами, похожая на математический набор. Он поддерживает добавление, удаление и запрос элементов, а также может выполнять такие операции, как пересечение, объединение и различие в нескольких коллекциях. Ниже приводится базовое использование Redis Set:
1. Добавьте элементы:
использовать SADD Команды могут добавлять в набор один или несколько элементов.
SADD myset value1 value2 value32. Удалить элементы:
использовать SREM Команда может удалить один или несколько элементов из набора.
SREM myset value1 value23. Определите, существует ли элемент:
использовать SISMEMBER Команда может определить, существует ли элемент в наборе.
SISMEMBER myset value4. Получите количество элементов в коллекции:
использовать SCARD Команда может получить количество элементов в наборе.
SCARD myset5. Получите все элементы коллекции:
использовать SMEMBERS Команда может получить все элементы набора.
SMEMBERS myset6. Инкассационные операции:
- Союз:использовать
SUNIONКоманда может выполнять операции объединения нескольких наборов. - пересечение:использовать
SINTERКоманда может выполнять операции пересечения нескольких наборов. - Сбор отличий:использовать
SDIFFКоманда может выполнять операции с разностями над несколькими множествами.
SUNION destination_set set1 set2
SINTER destination_set set1 set2
SDIFF destination_set set1 set2На что следует обратить внимание
существоватьиспользоватьRedisизSetтип При использовании данных следует учитывать некоторые соображения и рекомендации, которые помогут вам более эффективно их использовать. Следующее isuseRedis Несколько аспектов, на которые необходимо обратить внимание при настройке:
1. Уникальность:
Set — это неупорядоченная, неповторяющаяся коллекция элементов. Убедитесь, что элементы, добавляемые в набор, уникальны, поскольку в наборах не хранятся повторяющиеся значения.
2. Объем данных:
Хотя Redis может обрабатывать большие объемы данных, с наборами с большими объемами данных все же следует обращаться с осторожностью. Когда количество элементов в наборе становится большим, это может повлиять на производительность таких операций, как запрос, вставка и удаление.
3. Учитывайте срок годности:
Вы можете установить срок действия для Set, чтобы срок действия данных, которые больше не нужны, автоматически истекал для освобождения ресурсов памяти.
4. Избегайте большого количества операций с членами:
в некоторых случаях,Если вам нужно обработать большое количество членов в наборе (например, удалить),Может повлиять на производительность. Если требуются частые крупномасштабные операции,Вы можете рассмотреть несколько небольших наборов.,Вместо набора, содержащего большое количество членов.
5. Примечания по операциям сбора:
Операции над множествами (такие как объединение, пересечение, разностное множество) могут оказывать определенное влияние на производительность, особенно если число членов множества велико. При выполнении операций сбора следует учитывать их влияние на производительность и оптимизировать их в соответствии с реальной ситуацией.
6. Избегайте полного обхода:
избегатьиспользоватьSMEMBERSОжидание заказовполучатьвсе участники,Потому что проблемы с производительностью будут возникать с большими наборами данных. Если вам нужно пройти по членам,МожетучитыватьиспользоватьSSCANЗаказ进行分页式изтраверс。
7. использоватьупорядоченныйсобиратьзаменять:
нравиться果你需要упорядоченныйизсобирать,Можетучитыватьиспользовать Сортированный набор Set) тип данных, который может одновременно обеспечить упорядоченность и уникальность и подходит для таких сценариев, как системы ранжирования и оценки.
8. Сохранение и резервное копирование:
В критических производственных средах всегда следует учитывать стратегии сохранения и резервного копирования, чтобы гарантировать, что данные не будут потеряны из-за непредвиденных обстоятельств.
Короче говоря, Settype inuseRedis данныхчас,Его необходимо разумно спланировать и оптимизировать с учетом требований приложения и объема данных. Понимание вашей модели данных, объема данных и операционных потребностей.,Может помочь вам лучше использовать функцию Set Redis.,И обеспечить производительность и стабильность системы.
4. Сортированный набор. Аналогичен набору, но каждый элемент связан с оценкой и может быть отсортирован на основе оценки.
Применимые сценарии
Сортированный набор Set) — особый тип в Redis. данных, который присваивает оценку (оценку) хранилищу набора членов (элементов) на основе упорядоченности и уникальности. Этот вид данных делает упорядоченную сборку очень полезной во многих сценариях приложений. Вот некоторые из них. сценарии:
1. Таблицы лидеров и система подсчета очков: Сортированные коллекции отлично подходят для реализации таблиц лидеров и систем подсчета очков. Оценка участника может представлять собой оценку игрока, рейтинг, очки и т. д. Вы можете сортировать участников по их баллам и быстро достигать верхних позиций.
2. Данные временного ряда: Если вам нужно хранить данные с метками времени, отсортированную коллекцию можно отсортировать на основе метки времени (в виде оценки), а затем быстро запросить данные по диапазону времени.
3. Последние новости: Сортированные наборы можно использовать для хранения последних сообщений, а оценка каждого сообщения может быть меткой времени сообщения, чтобы можно было легко получить самые последние сообщения.
4. Взвешенные теги/облако тегов: существоватьсоциальная сеть или система теговсередина,Вы можете сохранять теги для сбора,участник - лейбл,Фракция Можетвыражать Этикеткаизнагревать、вес и т. д. Это можно использовать для реализации облаков тегов.、Популярные теги и другие функции.
5. Запрос диапазона: Сортированные наборы позволяют запросам на основе диапазонов оценок быстро находить элементы в определенном диапазоне оценок.
6. Уникальность: Сортированные наборы сохраняют уникальность членов, что означает, что вы можете легко хранить и запрашивать уникальные элементы.
7. Расширенные операции над наборами: Redis предоставляет операции над множествами (пересечение, объединение, разность) над упорядоченными наборами, которые можно использовать для реализации перекрестного анализа, фильтрации данных и т. д. нескольких наборов данных.
8. Пагинация диапазона:
использоватьZRANGEОжидание заказов,Вы можете выполнить пейджинговый запрос для упорядоченной сбора.,Получите члены в указанном диапазоне.
Короче говоря, упорядоченные наборы подходят для ситуаций, когда необходимо поддерживать порядок элементов, запросы по диапазону необходимо выполнять быстро, а также существует вес или оценка. Он обеспечивает эффективное хранение данных и операции в различных сценариях, что делает Redis мощным инструментом для решения этих проблем.
Какова основная реализация?
Redisиз Сортированный набор Set) базовая реализация использует Пропустить таблицу List) и хеш-таблицу (Hash Таблица) сочетание. Такая конструкция позволяет упорядоченным коллекциям эффективно выполнять такие операции, как добавление, удаление и запрос, сохраняя при этом порядок.
Пропустить таблицу List): Списки пропуска используются для хранения элементов упорядоченных наборов. В упорядоченном наборе каждый элемент имеет оценку, и список пропуска сортирует элементы на основе этой оценки. Пропуск таблиц можно реализовать в средних случаях через многоуровневые индексы. O(log n) Операции вставки, удаления и запроса.
Хэш-таблица Table): Упорядоченная сборка использует хеш-таблицу при сохранении отношений сопоставления между участниками и оценками. Каждый член будет соответствовать паре ключ-значение в хеш-таблице, где ключ — это член, а значение — оценка. С помощью хеш-таблиц Redis может O(1) Найдите балл участника за определенный период времени.
Способы совмещения использования: Каждый элемент упорядоченного набора хранит отношения сопоставления между членами и оценками в базовой хеш-таблице, а информация о сортировке элементов хранится в таблице переходов. Таким образом, Redis может быстро выполнять запросы по диапазону в порядке оценок участников в таблице пропуска и быстро искать оценки участников в хеш-таблице.
Эта базовая реализация сочетает в себе преимущества таблиц переходов и хеш-таблиц, позволяя упорядоченным коллекциям Redis одновременно отвечать требованиям упорядоченности и эффективности. Такая конструкция позволяет упорядоченным коллекциям хорошо работать в таких сценариях, как операции вставки, удаления, запроса и диапазона.
Как использовать
использоватьRedisиз Сортированный набор Set) требует освоения некоторых основных команд и операций. Вот несколько распространенных примеров операций с отсортированными множествами:
1. Добавьте участников:
использовать ZADD Команда добавляет участников в отсортированный набор, указывая оценку участника.
ZADD myset 10 member1
ZADD myset 20 member22. Получите баллы участников:
использовать ZSCORE Команда может получить оценку указанного участника.
ZSCORE myset member13. Получите рейтинг участников:
использовать ZRANK Команда может получить рейтинг (начиная с 0) указанного члена в упорядоченном наборе.
ZRANK myset member24. Получите участников в пределах диапазона баллов:
использовать ZRANGEBYSCORE Команда может получить список участников в указанном диапазоне оценок.
ZRANGEBYSCORE myset 15 255. Получите участников в пределах диапазона рейтинга:
использовать ZRANGE Команда может получить список участников в указанном диапазоне ранжирования.
ZRANGE myset 0 26. Удалить участников:
использовать ZREM Команда может удалить один или несколько членов из упорядоченного набора.
ZREM myset member17. Получите количество участников:
использовать ZCARD Команда может получить количество членов в отсортированном наборе.
ZCARD myset8. Инкассационные операции:
- Союз:использовать
ZUNIONSTOREКоманда может выполнять операцию объединения нескольких упорядоченных данных. - пересечение:использовать
ZINTERSTOREКоманда может выполнять операции пересечения нескольких упорядоченных данных.
ZUNIONSTORE destination_set 2 set1 set2 WEIGHTS 1 2
ZINTERSTORE destination_set 2 set1 set2 WEIGHTS 0.5 0.5Это только основная операция по сбору заказа.,Вы также можете использовать другие команды для выполнения более сложных операций.,Например, получение рейтингов участников, расчет разницы в баллах и т. д. использовать для сбора,Выберите подходящую команду и операцию в соответствии с фактическими потребностями.,Чтобы в полной мере воспользоваться его упорядоченностью и эффективностью.
На что следует обратить внимание
существоватьиспользоватьRedisиз Сортированный набор Set), есть некоторые соображения, которые помогут вам избежать некоторых распространенных проблем и оптимизировать производительность и управление данными. Вот немного На что следует обратить внимание:
1. члениз Уникальность: Члены упорядоченного набора уникальны, и повторяющиеся элементы не будут вставлены. Убедитесь, что элементы, добавляемые в отсортированный набор, уникальны, чтобы избежать непредвиденных ситуаций с данными.
2. Повторяемость оценок: Хотя участники уникальны, результаты могут дублироваться между разными участниками. В некоторых сценариях это нормально, но с этим нужно обращаться в соответствии с конкретными потребностями.
3. Объем данных: хотяупорядоченныйсобирать Можетиметь дело сбольшойколичествоизданные,Но все равно нужно быть осторожнымиметь дело с Объем данныхсравниватьбольшойизупорядоченныйсобирать。большойданныесобирать Может повлиять на производительностьи Памятьиспользовать。
4. Диапазон баллов: При выполнении запросов диапазона убедитесь, что диапазон оценок является разумным. Крупномасштабные запросы могут потреблять больше вычислительных ресурсов.
5. Выбор структуры данных: Упорядоченная сборка подходит для сценариев, где требуется упорядоченность, но не подходит для ситуаций, когда необходимо хранить только уникальные элементы. Для данных, требующих только уникальности, используйтесобирать(Set)тип. данные являются более подходящими.
6. Влияние операций по сбору: При выполнении операций над множествами (объединение, пересечение, разность) учитывайте влияние на производительность. Операции над множествами могут потреблять больше вычислительных ресурсов, особенно если имеется большое количество членов.
7. Выберите подходящий тип дроби: Дроби могут быть целыми числами или числами с плавающей запятой. Выберите подходящий тип оценки в зависимости от фактических потребностей.
8. Оптимизация производительности и памяти: РазумныйиспользоватьRedisиз Параметры конфигурации,Рассмотрите такие стратегии, как сегментирование, сохранение и управление памятью.,к Оптимизация производительностии Памятьиспользовать。
9. Избегайте полного обхода:
избегатьиспользоватьZRANGEОжидание заказовполучатьвсе участники,в частностисуществоватьбольшойданныесобиратьсередина。учитыватьиспользоватьZSCANВыполнить постраничный обход。
10. Постоянство и резервное копирование: В критических производственных средах рассмотрите стратегии сохранения и резервного копирования, чтобы предотвратить потерю данных.
11. Использование памяти: упорядоченныйсобирать Займет определенную суммуиз Память,Обратите внимание на мониторинг и управление использованием памяти.,Предотвратить переполнение памяти.
Суммируя,использоватьRedisизупорядоченныйсобиратьчас,Разумное планирование и оптимизация в соответствии с фактическими потребностями,Для обеспечения производительности и стабильности системы.
5. Хэш-таблица (Хеш)
Применимые сценарии
Хэш-таблица Redis) — это структура, в которой хранятся пары ключ-значение. данных, ключи уникальны, а значения могут быть нить, целыми числами, числами с плавающей запятой и т. д. Хэш-таблицы подходят для многих сценариев, особенно когда необходимо хранить и запрашивать несколько полей. Вот некоторые из них. сценарии:
1. Хранить информацию об объекте: нравиться果你需要хранилищеодин对象из Несколько字段информация,Например, информация о пользователе (имя пользователя, возраст, адрес электронной почты и т. д.),Можно использовать хеш-таблицу для хранения информации о полях каждого пользователя.
2. Кэшированные данные: Хэш-таблицы подходят для кэширования больших объемов данных «ключ-значение», например кэширования результатов запросов к базе данных, чтобы снизить частоту доступа к базе данных.
3. Сохраните информацию о конфигурации: Хранение информации о конфигурации в хэш-таблице позволяет легко получать и изменять элементы конфигурации без необходимости хранить в памяти несколько отдельных ключей.
4. прилавок: Можетиспользовать Хэш-таблица для реализации функции счетчика,В каждом поле хранится счетчик,Например, количество лайков и прочтений сайта и т. д.
5. Храните несколько атрибутов: Если вам нужно сохранить несколько свойств для набора объектов,Например, название продукта, цена, запас и т. д.,Хэш-таблица может использоваться для хранения нескольких атрибутов для каждого элемента.
6. Индекс Союза: существовать Реляционныйданные Библиотекасередина,Объединенные индексы часто используются для ускорения запросов с несколькими полями. В Редисе,Можно использовать хеш-таблицу для хранения нескольких полей,и передать поле в качестве первичного ключа,Достичь аналогичного эффекта совместного индекса.
7. Статистика в реальном времени: Хэш-таблицы можно использовать для статистической информации в реальном времени, например, для подсчета количества входов пользователей в день, количества заказов и т. д.
8. Пользовательская сессия: Можетиспользовать Хэш-таблица来хранилище用户会话информация,В каждом поле хранится атрибут сеанса.,Например, идентификатор пользователя, время входа、Срок годности и т.д.
9. Структура данных графа: Если вам нужно реализовать структуру диаграммы данных,Например, схема социальной сети,Узлы и ребра могут быть представлены с помощью хеш-таблиц.
10. Многополевой запрос: Хэш-таблицы подходят для хранения нескольких полей и могут быстрее запрашивать и обновлять значения нескольких полей.
Короче говоря, хеш-таблицы подходят для ситуаций, когда необходимо хранить информацию о нескольких полях. Несколько полей можно получить и обновить в одном запросе, тем самым повышая эффективность доступа к данным. Это может быть полезно в различных сценариях приложений, особенно для данных, которые необходимо хранить и манипулировать несколькими атрибутами.
Какова основная реализация?
Redisиз Хэш-таблица)тип Базовая реализация данных — использование Хэш-таблицы. Table) для хранения пар ключ-значение. Хэш-таблица — это очень эффективная структура данных, которая в среднем может O(1) Временная сложность операций вставки, удаления и запроса. Ниже приведены некоторые подробности базовой реализации хеш-таблицы Redis:
1. Хэш-функция Function): существовать Хэш-таблицасередина,Ключ вычисляется с помощью хэш-функции для получения хэш-значения (хеша).,Это хеш-значение используется в качестве индекса массива (корзины). Хэш-функции, такие как RedisиспользоватьMurmurHash2, позволяют равномерно распределять ключи по разным сегментам.
2. Массив сегментов: Нижний уровень хеш-таблицы поддерживает массив сегментов, и каждый сегмент хранит одну или несколько пар ключ-значение. Размер этого массива обычно регулируется динамически, чтобы коэффициент заполнения сегмента не был слишком высоким.
3. Разрешение конфликтов: 由于不такой жеизключ可能会经过散列函数映射到такой жеодин桶середина,Это создает конфликт. Повторно использовать метод разрешения конфликтов цепочки,В каждом сегменте может храниться связанный список.,Когда одному и тому же сегменту сопоставлено несколько ключей,Они сформируют связанный список в порядке вставки.
4. Динамическое расширение: Когда количество элементов в хеш-таблице постепенно увеличивается, Redis будет динамически расширять массив сегментов в соответствии с коэффициентом загрузки, чтобы поддерживать коэффициент заполнения сегмента в соответствующем диапазоне. Это обеспечивает эффективные операции вставки, удаления и запроса.
5. мигрировать: Во время расширения Redis перефразирует исходные пары ключ-значение в новый массив сегментов. Этот процесс называется «миграцией» и происходит в фоновом режиме, чтобы не влиять на обычные операции чтения и записи.
6. Вложенность хеш-таблиц: В исходном коде Redis сама хеш-таблица также может быть вложенной. Этот тип вложенной хеш-таблицы часто используется для реализации типа. Сложные структуры данных, например, используемые для хранения упорядоченных данных и т. д.
Подводя итог, можно сказать, что нижний уровень хеш-таблицы Redis реализуется с помощью хеш-функции, массива сегментов, разрешения конфликтов цепочки и других механизмов. Такая конструкция позволяет Redis эффективно хранить и запрашивать данные пар ключ-значение. Хэш-таблицы играют в Redis очень важную роль.
Как использовать
использовать Хэш-таблицу Redis)тип данных включает в себя ряд команд,这些Заказ Может帮助你对Хэш-таблицасерединаизключценитьдобавить в、Запрос、Удаление и другие операции. Вот несколько распространенных примеров операций с хеш-таблицами:
1. Добавьте пары ключ-значение:
использовать HSET Команда добавляет пару ключ-значение в хеш-таблицу.
HSET user:id123 name "John" age 302. Получите значение одного ключа:
использовать HGET Команда может получить значение указанного ключа.
HGET user:id123 name3. Получите значения нескольких ключей:
использовать HMGET Команда может получить значения нескольких ключей одновременно.
HMGET user:id123 name age4. Получите все пары ключ-значение:
использовать HGETALL Команда может получить все пары ключ-значение в хеш-таблице.
HGETALL user:id1235. Добавьте или обновите значение ключа:
использовать HINCRBY Команда может добавить целое число к значению ключа. Если ключ не существует, будет создан новый ключ.
HINCRBY user:id123 age 16. Удалите пары ключ-значение:
использовать HDEL Команда может удалить одну или несколько пар ключ-значение из хеш-таблицы.
HDEL user:id123 age7. Получите все ключи или значения:
использовать HKEYS Команда может получить все ключи в хеш-таблице, используйте HVALS Команда может получить все значения в хеш-таблице.
HKEYS user:id123
HVALS user:id1238. Получите количество пар ключ-значение:
использовать HLEN Команда может получить количество пар ключ-значение в хеш-таблице.
HLEN user:id1239. Проверьте, существует ли ключ:
использовать HEXISTS Команда может проверить, существует ли указанный ключ в хеш-таблице.
HEXISTS user:id123 nameЭто лишь основные операции хеш-таблиц.,Вы также можете использовать другие команды для выполнения более сложных операций.,Например, итерация, пакетное добавление, получение количества полей и т. д. Когда использовать хеш-таблицу,Выберите подходящую команду и операцию в соответствии с фактическими потребностями.,Чтобы в полной мере воспользоваться его гибкостью и эффективностью.
На что следует обратить внимание
существоватьиспользоватьRedisиз Хэш-таблица)тип данных, есть некоторые соображения, которые помогут вам избежать распространенных проблем, оптимизировать производительность и лучше управлять своими данными. Вот немного На что следует обратить внимание:
1. Ключевые названия: Выбирайте осмысленные имена ключей, чтобы лучше различать разные хэш-таблицы. Избегайте длинных или избыточных имен ключей, чтобы уменьшить использование памяти.
2. Объем данных: ХотяRedisМожетиметь дело сбольшойколичествоизданные,Но все равно нужно быть осторожнымиметь дело сбольшой Объем данныхиз Хэш-таблица。большой Объем данных Может повлиять на производительностьи Памятьиспользовать。
3. Количество полей в одной хеш-таблице: Хотя Redis может эффективно обрабатывать несколько полей, если количество полей в одной хэш-таблице очень велико, это может повлиять на производительность. Если вам нужно хранить большое количество полей, рассмотрите возможность разделения его на несколько хеш-таблиц или других структур данных.
4. Сложность: Количество полей в хеш-таблице не должно быть слишком большим, чтобы сохранить эффективность операций чтения и записи. Слишком большое количество полей может увеличить потребление памяти и усложнить работу.
5. Применимые сценарии: Хэш-таблицы подходят для хранения и запроса нескольких полей. Если вам нужно хранить только одно значение или простые данные, рассмотрите возможность использования(String)типа. данных。
6. Пакетные операции:
Если вам нужно одновременно работать с несколькими парами ключ-значение, используйте команду пакетной операции, например HMSET,Вместо нескольких команд используйте одну клавишу.
7. Аннулирование кэша: Установите подходящее время истечения срока действия кэша, чтобы пары ключ-значение с истекшим сроком действия не занимали память.
8. Размер ключевого значения: Если значения полей в хеш-таблице большие, учтите влияние на память. Большие значения полей могут увеличить использование памяти.
9. Глубокая вложенность: Избегайте слишком большого количества вложенных пар ключ-значение в хеш-таблице, это может усложнить поиск и обслуживание.
10. Сохранение данных: Для важных данных рассмотрите возможность включения сохранения, чтобы предотвратить потерю данных.
11. Резервное копирование данных: Регулярно создавайте резервные копии своих данных, чтобы предотвратить случайную потерю данных.
Суммируя,использовать хэш-таблицу,Разумное планирование и оптимизация в соответствии с фактическими потребностями,Для обеспечения производительности и стабильности системы. Учитывайте такие факторы, как модель данных, объем данных, частота операций и т. д.,И выберите соответствующую конфигурацию Redis и команду для использования хэш-таблицы по мере необходимости.

[Спецификация] Результаты и исключения возврата интерфейса SpringBoot обрабатываются единообразно, поэтому инкапсуляция является элегантной.

Интерпретация каталога веб-проекта Flask

Что такое подробное объяснение файла WSDL_wsdl

Как запустить большую модель ИИ локально
Подведение итогов десяти самых популярных веб-фреймворков для Go
5 рекомендуемых проектов CMS с открытым исходным кодом на базе .Net Core

Java использует httpclient для отправки запросов HttpPost (отправка формы, загрузка файлов и передача данных Json)

Руководство по развертыванию Nginx в Linux (Centos)

Интервью с Alibaba по Java: можно ли использовать @Transactional и @Async вместе?

Облачный шлюз Spring реализует примеры балансировки нагрузки и проверки входа в систему.

Используйте Nginx для решения междоменных проблем

Произошла ошибка, когда сервер веб-сайта установил соединение с базой данных. WordPress предложил решение проблемы с установкой соединения с базой данных... [Легко понять]

Новый адрес java-библиотеки_16 топовых Java-проектов с открытым исходным кодом, достойных вашего внимания! Обязательно к просмотру новичкам

Лучшие практики Kubernetes для устранения несоответствий часовых поясов внутри контейнеров
Введение в проект удаления водяных знаков из коротких видео на GitHub Douyin_TikTok_Download_API

Весенние аннотации: подробное объяснение @Service!
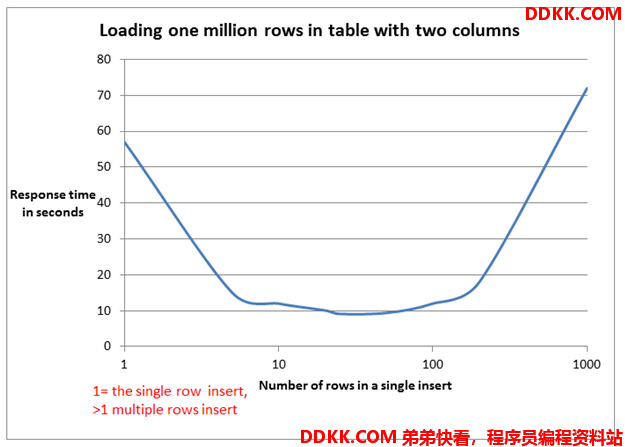
Пожалуйста, не используйте foreach для пакетной вставки в MyBatis. Для 5000 фрагментов данных потребовалось 14 минут. .

Как создать проект Node.js с помощью npm?
Mybatis-plus использует typeHandler для преобразования объединенных строк String в списки списков.

Не удалось установить программное обеспечение Mitsubishi. Возможно, возникла проблема с реестром.

Разрешение ошибок проекта SpringBoot 3 mybatis-plus: org.apache.ibatis.binding.BindingException: неверный оператор привязки
Более краткая проверка параметров. Для проверки параметров используйте SpringBoot Validation.

Поиграйтесь с интеграцией Spring Boot (платформа запланированных задач Quartz)

Несколько популярных режимов интерфейса API: RESTful, GraphQL, gRPC, WebSocket, Webhook.

Redis: практика публикации (pub) и подписки (sub)

Подробное объяснение пакета Golang Context
Краткое руководство: создайте свое первое приложение .NET Aspire

Краткое обсуждение метода пакетной вставки MyBatis: обработка 100 000 фрагментов данных занимает всего 2 секунды.

[Инструмент] Используйте nvm для управления переключением версий nodejs, это так здорово!
