Серия развертывания модели: повышение скорости в 10 раз, разреженность модели обнаружения Yolov8 - более 500 кадров в секунду на процессоре
Разработанный компанией Ultralytics, авторами популярных моделей YOLOv3 и YOLOv5, YOLOv8 выводит обнаружение объектов на новый уровень благодаря конструкции без привязки. YOLOv8 разработан для реальных развертываний с упором на скорость, задержку и экономичность.
[1] Подробную информацию см. MarkAI Blog [2] Пожалуйста, обратите внимание на дополнительную информацию и проекты MarkAI Github [3] Пожалуйста, начните интервью с алгоритмом восприятия таможенного оформления Краткое изложение вопросов для собеседования по алгоритму Цяньдао в 2024 году
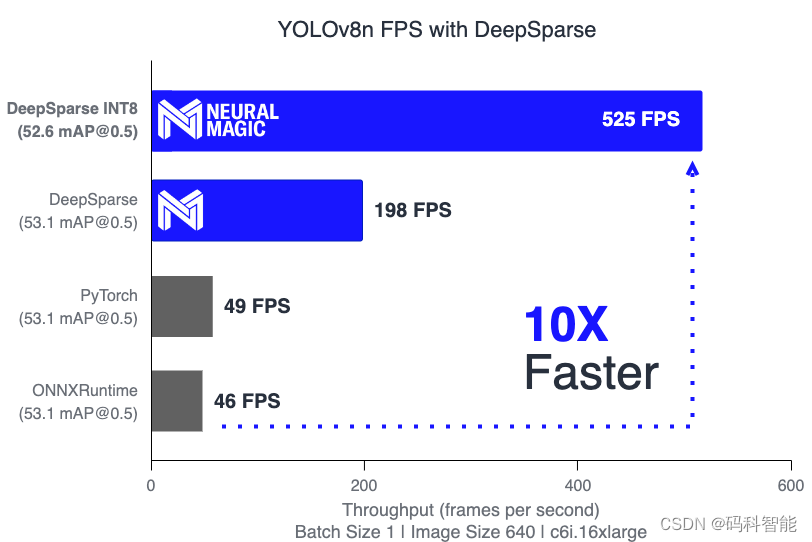
В этой статье вы узнаете о последней версии YOLO и о том, как развернуть ее с помощью DeepSparse, чтобы добиться максимальной производительности вашего процессора. Мы проиллюстрируем это, развернув нашу модель на AWS, достигнув 209 кадров в секунду на YOLOv8 (маленькая версия) и 525 кадров в секунду на YOLOv8n (нано-версия), что в 10 раз быстрее по сравнению со средами выполнения PyTorch и ONNX!
связанный DeepSparse Подробное руководство о том, как добиться ускорения за счет разреженности, см. YOLOv5 with Neural Magic’s DeepSparse。
Использование YOLOv8
новыйультралитикиможет легкоиспользовать Обучение пользовательским данным YOLO модель и преобразовать ее в ONNX формат для развертывания.
Ниже приведен пример API Python:
from ultralytics import YOLO
# Load a model
model = YOLO("yolov8n.yaml") # build a new model from scratch
model = YOLO("yolov8n.pt") # load a pretrained model (recommended for training)
# Use the model
results = model.train(data="coco128.yaml", epochs=3) # train the model
results = model.val() # evaluate model performance on the validation set
results = model("https://ultralytics.com/images/bus.jpg") # predict on an image
success = YOLO("yolov8n.pt").export(format="onnx") # export a model to ONNX formatВот пример через CLI:
yolo task=detect mode=predict model=yolov8n.pt
source="https://ultralytics.com/images/bus.jpg"Разверните YOLOv8 с помощью DeepSparse.
Для производственных развертываний в реальных приложениях скорость вывода имеет решающее значение для определения общей стоимости и скорости реагирования системы. DeepSparse — это среда выполнения вывода, ориентированная на быстрое выполнение моделей глубокого обучения, таких как YOLOv8, на ЦП. DeepSparse достигает оптимальной производительности с помощью разреженных моделей, оптимизированных для вывода, а также может эффективно запускать стандартные готовые модели.
Давайте экспортируем стандартную модель YOLOv8 в ONNX и проведем несколько тестов процессора.
# Install packages for DeepSparse and YOLOv8
pip install deepsparse[yolov8] ultralytics
# Export YOLOv8n and YOLOv8s ONNX models
yolo task=detect mode=export model=yolov8n.pt format=onnx opset=13
yolo task=detect mode=export model=yolov8s.pt format=onnx opset=13
# Benchmark with DeepSparse!
deepsparse.benchmark yolov8n.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 198.3282
> Latency Mean (ms/batch): 5.0366
deepsparse.benchmark yolov8s.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 68.3909
> Latency Mean (ms/batch): 14.6101DeepSparse также предоставляет несколько удобных утилит для интеграции моделей в ваши приложения. Например, вы можете использовать YOLOv8 для аннотирования изображений или видео. Файлы с аннотациями сохраняются в папке annotation-results:
deepsparse.yolov8.annotate --source basilica.jpg --model_filepath "yolov8n.onnx # or "yolov8n_quant.onnx"
Оптимизируя модель вывода, можно внести дальнейшие улучшения. DeepSparse производительность. Дип Спарс был создан, чтобы использовать преимущества моделей, оптимизированных за счет сокращения веса и квантования, методов, которые могут значительно сократить объем необходимых вычислений без ущерба для точности. через нашу One-Shot Методы оптимизации (будут представлены в ближайшем будущем). Sparsify предусмотренные в продукте), мы сгенерировали YOLOv8s и YOLOv8n ONNX модели, которые были количественно определены как INT8, сохраняя при этом не менее 99% оригинал FP32 mAP@0.5 . Это используется только 1024 Этого можно добиться с помощью нескольких выборок без обратного распространения ошибки.。ты можешьСкачать здесь Количественная модель.
Выполните следующие команды для проверки производительности:
deepsparse.benchmark yolov8n_quant.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 525.0226
> Latency Mean (ms/batch): 1.9047
deepsparse.benchmark yolov8s_quant.onnx --scenario=sync --input_shapes="[1,3,640,640]"
> Throughput (items/sec): 209.9472
> Latency Mean (ms/batch): 4.7631DeepSparse в 4 раза быстрее в FP32 и в 10 раз быстрее в INT8.
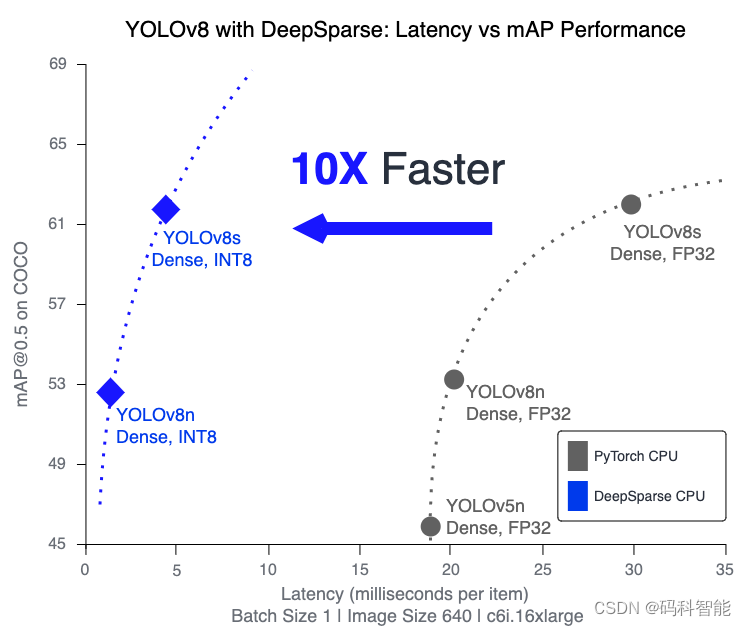
Model | Size | mAPval (50-95) | mAPval (50) | Precision | Engine | Speed CPU b1(ms) | FPS CPU |
|---|---|---|---|---|---|---|---|
YOLOv8n | 640 | 37.2 | 53.1 | FP32 | PyTorch | 20.5 | 48.78 |
YOLOv8n | 640 | 37.2 | 53.1 | FP32 | ONNXRuntime | 21.74 | 46.00 |
YOLOv8n | 640 | 37.2 | 53.1 | FP32 | DeepSparse | 5.74 | 198.33 |
YOLOv8n INT8 | 640 | 36.7 | 52.6 | INT8 | DeepSparse | 1.90 | 525.02 |
YOLOv8s | 640 | 44.6 | 62.0 | FP32 | PyTorch | 31.30 | 31.95 |
YOLOv8s | 640 | 44.6 | 62.0 | FP32 | ONNXRuntime | 32.43 | 30.83 |
YOLOv8s | 640 | 44.6 | 62.0 | FP32 | DeepSparse | 14.66 | 68.23 |
YOLOv8s INT8 | 640 | 44.2 | 61.6 | INT8 | DeepSparse | 4.76 | 209.95 |



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
