Серия обзоров векторных функций ES8 (1): Предварительное исследование и улучшение функции гибридного поиска.
Введение
Elasticsearch 8.x предоставляет мощные возможности векторного поиска, делая возможным эффективный поиск по k-ближайшим соседям (kNN) в крупномасштабных наборах данных. Векторный поиск очень важен во многих сценариях применения, таких как RAG, рекомендательные системы, поиск изображений и т. д. Целью этой статьи является простой и углубленный анализ функций поиска kNN и гибридного поиска Elasticsearch 8.x, а также представление принципов его реализации и ключевых технических моментов. В то же время мы также будем интерпретировать соответствующий вклад, внесенный Tencent Cloud ES в сообщество, и поможем читателям лучше понять и применить функцию векторного поиска Elasticsearch посредством интерпретации на уровне исходного кода.
1. Анализ процесса запроса kNN
1.1 Тип запроса
Друзья, знакомые с Elasticsearch, должны быть знакомы с несколькими этапами запроса: этапом запроса и этапом выборки.
эти двоеPhaseдаquery_then_fetch(по умолчаниюsearch_type)Будет два этапа。И ещеsearch_type,dfs_query_then_fetch,Как следует из названия,Его этапы разделены на три: Фаза DFS.,DFS Query Фаза и выборка Phase。
Давайте сначала сделаем интересную попытку,При выполнении оператора, содержащего запрос kNN,Добавить параметрыsearch_type=query_then_fetch,Посмотрим, что произойдет.
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "cannot set [search_type] when using [knn] search, since the search type is determined automatically"
}
],
"type": "illegal_argument_exception",
"reason": "cannot set [search_type] when using [knn] search, since the search type is determined automatically"
},
"status": 400
}Вы можете увидеть подсказкуkNNПоиск исправленsearch_type。существоватьElasticsearchВы можете увидеть это в исходном кодеkNNЗапрос будет назначенDFS_QUERY_THEN_FETCHрежим запроса。org.elasticsearch.action.search.TransportSearchAction#adjustSearchType
static void adjustSearchType(SearchRequest searchRequest, boolean singleShard) {
// if there's a kNN search, always use DFS_QUERY_THEN_FETCH
if (searchRequest.hasKnnSearch()) {
searchRequest.searchType(DFS_QUERY_THEN_FETCH);
return;
}
...
}1.2 Анализ этапа
При традиционном поиске BM25 на этапе статистики распределенной частоты (DFS) система собирает дополнительную информацию со всех сегментов перед фактическим выполнением запроса. Цель этого этапа — повысить точность оценки. Поскольку каждый шард независим, они знают только свои локальные данные и не имеют глобального представления. Оценка документа может зависеть от факторов внутри сегмента (таких как обратная частота документа, называемая IDF). Осколок не может точно рассчитать IDF, что может привести к несогласованности оценок между сегментами. На этапе DFS можно собрать эту статистику по конкретным сегментам, чтобы можно было более объективно сравнивать оценки из разных сегментов на последующих этапах запроса, чтобы обеспечить точность и согласованность оценок.
В запросах kNN цель этапа DFS немного другая. Поскольку поиск kNN основан на вычислениях расстояний в векторном пространстве, а не на текстовой статистике частоты слов, роль этапа DFS здесь заключается в сборе лучших результатов k кандидатов из каждого сегмента. Затем эти результаты кандидатов объединяются для определения k лучших результатов в мире. Эти глобально лучшие k совпадений затем передаются на этап запроса DFS.
DFS_QUERY_THEN_FETCHрежим запросабудет выполнен первымDFS Phase,проходитьKnnVectorQueryBuilderПостроение векторного запроса。org.elasticsearch.search.dfs.DfsPhase#executeKnnVectorQuery
private void executeKnnVectorQuery(SearchContext context) throws IOException {
...
List<KnnSearchBuilder> knnSearch = context.request().source().knnSearch();
List<KnnVectorQueryBuilder> knnVectorQueryBuilders = knnSearch.stream().map(KnnSearchBuilder::toQueryBuilder).toList();
...
List<DfsKnnResults> knnResults = new ArrayList<>(knnVectorQueryBuilders.size());
for (int i = 0; i < knnSearch.size(); i++) {
...
// Создание и выполнение векторных запросов
Query knnQuery = searchExecutionContext.toQuery(knnVectorQueryBuilders.get(i)).query();
knnResults.add(singleKnnSearch(knnQuery, knnSearch.get(i).k(), context.getProfilers(), context.searcher(), knnNestedPath));
}
context.dfsResult().knnResults(knnResults);
}На этапе DFS объединенные результаты кандидатов будут переданы на следующий этап: этап запроса DFS. org.elasticsearch.action.search.SearchDfsQueryThenFetchAsyncAction#getNextPhase`
@Override
protected SearchPhase getNextPhase(final SearchPhaseResults<DfsSearchResult> results, SearchPhaseContext context) {
final List<DfsSearchResult> dfsSearchResults = results.getAtomicArray().asList();
final AggregatedDfs aggregatedDfs = SearchPhaseController.aggregateDfs(dfsSearchResults);
// Объединить k лучших результатов кандидатов, собранных для каждого осколка
final List<DfsKnnResults> mergedKnnResults = SearchPhaseController.mergeKnnResults(getRequest(), dfsSearchResults);
return new DfsQueryPhase(
dfsSearchResults,
aggregatedDfs,
mergedKnnResults,
queryPhaseResultConsumer,
(queryResults) -> new FetchSearchPhase(queryResults, aggregatedDfs, context),
context
);
}DFS Query PhaseволяпроходитьKnnScoreDocQueryBuilderСоздайте оценочный запрос для результатов кандидатов。
org.elasticsearch.action.search.DfsQueryPhase#rewriteShardSearchRequest
ShardSearchRequest rewriteShardSearchRequest(ShardSearchRequest request) {
...
for (DfsKnnResults dfsKnnResults : knnResults) {
List<ScoreDoc> scoreDocs = new ArrayList<>();
// Разделить объединенные результаты этапа DFS
for (ScoreDoc scoreDoc : dfsKnnResults.scoreDocs()) {
if (scoreDoc.shardIndex == request.shardRequestIndex()) {
scoreDocs.add(scoreDoc);
}
}
...
// Перенос результатов этапа DFS для построения оценочного запроса
QueryBuilder query = new KnnScoreDocQueryBuilder(scoreDocs.toArray(new ScoreDoc[0]))
.boost(source.knnSearch().get(i).boost()).queryName(source.knnSearch().get(i).queryName());
...
subSearchSourceBuilders.add(new SubSearchSourceBuilder(query));
i++;
}
source = source.shallowCopy().subSearches(subSearchSourceBuilders).knnSearch(List.of());
request.source(source);
return request;
}1.3 Краткое описание процесса
Хотя первоначальной целью разработки этапа DFS является сбор информации о частоте слов, поиск kNN на самом деле не имеет этой концепции, которая немного «устарела». Но основная идея этапа DFS — сбор и объединение глобальной информации, и у поиска kNN тоже есть такая необходимость. Поэтому Elasticsearch предпочитает выполнять глобальный сбор векторной информации и операции слияния поиска kNN на этапе DFS.
В настоящее время мы понимаем, что поиск kNN будет осуществляться в:
- DFS Phase:использовать
KnnVectorQueryBuilderСоздание векторных запросов на уровне сегментов,Используйте алгоритм HNSW, чтобы быстро найти вектор документа, ближайший к вектору запроса.,Наконец, объедините их глобально. Алгоритм HNSW не будет анализироваться в этой статье. - DFS Query Phase:использовать
KnnScoreDocQueryBuilderСоздайте запрос рейтинга на уровне сегмента,для сортировки документов в конечном наборе результатов.
2. Функциональный анализ kNN
2.1 Запрос kNN верхнего уровня
Как следует из названия, запрос kNN верхнего уровня (Top-level kNN search)Воляknnпункт написатьсуществовать ЗапросDSLверхний уровень,Форма как:
GET hybird_test/_search
{
"query": {...},
"knn": {
"field": "vector",
"num_candidates": 5,
"k": 5,
"query_vector": [...]
}
}Процесс, который мы представили выше, представляет собой общий процесс запроса kNN верхнего уровня. Он был представлен в ES 8.x и является наиболее часто используемым синтаксисом запросов, специально разработанным для гибридного и векторного поиска.
Официальная документация по запросу kNN верхнего уровня
существоватьSearchSourceBuilderопределяется следующим образом,Определение List означает, что он может выполнять несколько поисков kNN одновременно.,Очки с нескольких дорожек суммируются.
private List<KnnSearchBuilder> knnSearch = new ArrayList<>();После введения предложения kNN на том же уровне, что и предложение запроса, запрос DSL будет «разделен на несколько путей». Это то, что мы называем гибридным поиском. Версия Elasticsearch 8.x поддерживает собственный гибридный поиск. большое количество векторов вне досягаемости баз данных. Гибридный поиск сочетает в себе соответствующие преимущества BM25 и векторного поиска, обеспечивая более семантический отзыв, чем поиск BM25, и более точный, чем векторный поиск.
2.2 Запрос kNN в Query
В дополнение к запросу kNN верхнего уровня, представленному в ES 8.x, запрос kNN в Query (kNN Query) также представлен в версии ES 8.12. Его использование происходит следующим образом:
GET hybird_test/_search
{
"size": 5,
"query": {
"bool": {
"must": [
{
"match": {...}
},
{
"knn": {
"field": "vector",
"num_candidates": 5,
"query_vector": [...]
}
}
]
}
}
}запрос kNN в запросе предназначен для удовлетворения большего числа потребностей экспертов.,Потому что предложения запроса Воляк НН обрабатываются как традиционные предложения класса BM25.,В сочетании с традиционным использованием расширенных запросов, таких какbool、dis_max、function_scoreи т. д. Совместимость。ОднакоBM25Рейтинг на основеTF/IDF,Оценка kNN основана на расстоянии вектора (косинус, скалярное произведение, методы расчета евклидова расстояния).,Принципы и методы очень разные.,Оценка сложных запросов требует от пользователей очень точного понимания и контроля над методом расчета окончательной оценки.
Запрос kNN в Query больше не использует этап DFS для поиска ближайшего соседа и сбора глобальной информации.
Официальная документация по запросу kNN в Query
Предпочтительный способ выполнить поиск kNN — использовать запрос kNN верхнего уровня. Запрос kNN в Query — это возможность, поддерживаемая ES. Она представлена только без расширения. Tencent Cloud ES только что выпустила версию 8.13.3, которая, естественно, поддерживает эту функцию экспертного уровня.
3. Анализ RRF
3.1 Введение в алгоритм слияния
Ранжированное поисковое объединение (RRF) — это алгоритм объединения, используемый для объединения нескольких результатов запроса с целью повышения точности результатов поиска. Основной принцип RRF заключается в сортировке каждого результата запроса и присвоении веса в соответствии с ранжированием. Наконец, вес каждого результата запроса накапливается для создания объединенного результата.
Математическая формула RRF выглядит следующим образом:
в, \text{rank}_i(d) Представлять документ d В первом i ранжирование в результатах запроса, k — константа, используемая для сглаживания рейтинга.
3.2 Как использовать
в гибридном поиске,проходитьобозначениеrankпараметры для включенияRRF
GET hybird_test/_search
{
"query": {...},
"knn": {...},
"rank": {
"rrf": {
"window_size": 100,
"rank_constant": 60
}
}
}3.3 Функциональный дефект: сохраняется только ранг, стирается оценка.
Алгоритм RRF использует только рейтинги, полученные каждым каналом, и не обращает внимания на оценки. Запрос с включенным RRF сотрет всю информацию о оценках в процессе, и в конечном итоге будут сохранены только объединенные рейтинги.
Не зная конкретной оценки каждого документа в результате объединения, невозможно узнать, из какого отзыва получен результат объединения. Процесс запроса будет «черным ящиком», и анализ запроса будет сильно затруднен. Пример результата запроса RRF:
{
...
"hits": {
...
"hits": [
{
"_index": "hybird_test",
"_id": "999006",
"_score": null,
"_rank": 1
},
{
"_index": "hybird_test",
"_id": "999005",
"_score": null,
"_rank": 2
}
]
}
}4. Улучшение функции RRF
4.1 Восстановить стертые источники и партитуры
авторпроходитьпредставлять на рассмотрениеissueОбсудить с сообществом,Кратчайший путь преобразования получается:проходить“именованный запрос”(Named запросы). С точки зрения непрофессионала, именованный запрос позволяет вам называть предложения запроса DSL, чтобы получить информацию о совпадении именованных предложений из окончательных результатов, включая совпадения и конкретные оценки предложений.
Официальная документация запроса именования
После реализации функции,Эффект от включения гибридного поиска RRF следующий:,Можетсуществоватьmatched_queriesВы можете интуитивно увидеть путь поиска, откуда берутся отозванные документы.:
{
...
"hits": {
...
"hits": [
{
"_index": "hybird_test",
"_id": "999006",
"_score": null,
"_rank": 1,
"matched_queries": [
"query",
"knn"
]
},
{
"_index": "hybird_test",
"_id": "999005",
"_score": null,
"_rank": 2,
"matched_queries": [
"knn"
]
}
]
}
}проходить_searchуказано вinclude_named_queries_score=trueпараметр,Вы также можете получить конкретные оценки для каждого поиска:
{
...
"hits": {
...
"hits": [
{
"_index": "hybird_test",
"_id": "999006",
"_score": null,
"_rank": 1,
"matched_queries": {
"query": 1,
"knn": 0.9124442
}
},
{
"_index": "hybird_test",
"_id": "999005",
"_score": null,
"_rank": 2,
"matched_queries": {
"knn": 1
}
}
]
}
}4.2 Подробности модификации исходного кода
Из-за запроса kNN в запросеи традицииDSLпункты имеют то же самоеизиспользовать Способ,существовать Также в исходном кодеданепосредственно унаследовал традициюDSLпунктизименованный запросизспособность:org.elasticsearch.index.query.AbstractQueryBuilder#queryName(java.lang.String)。
Таким образом, задача функционального преобразования упрощается до: нужно лишь реализовать Топ-запрос. kNNизqueryNameФункция,То есть на этапе DFS и этапе запроса DFS.,позволятьkNNПоддержка запросов и эффективная доставкаqueryName。
Благодаря отличному дизайну и возможности повторного использования исходного кода Elasticsearch это преобразование в конечном итоге упростилось до трёх пунктов:
- Воля
_nameполя добавлены вKnnSearchBuilderсередина. - Измените сериализацию, чтобы включить
_name。 - убеждаться
_nameОбрабатывается во время выполнения межэтапного запроса и включается в ответ середина.
Автор завершил разработку и проверку тестирования согласно вышеизложенным идеям.,ПоданныйPR,В конце концов эта функция была принята сообществом.
4.3 Повышение эффективности функций
На рисунке ниже показан окончательный эффект этой функции.
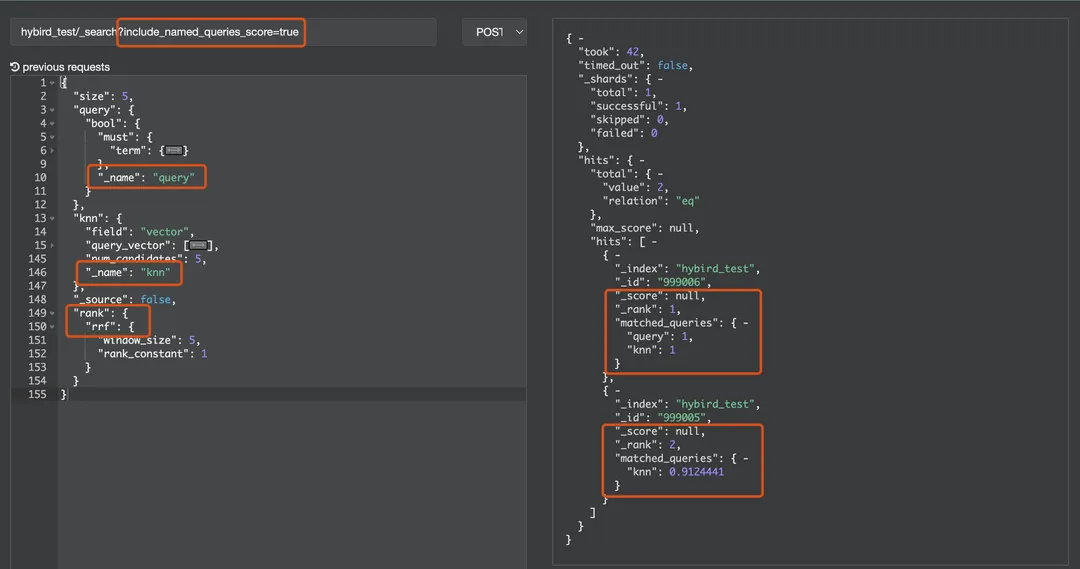
4.4 Вклад Tencent Cloud ES
Эта функция была предложена сообществу, и согласно официальному плану Elasticsearch, эта функция будет выпущена в версии 8.15.
Tencent Cloud ES спонтанно завершила предложение и реализацию этой функции. Эту функцию можно заранее использовать в недавно выпущенной версии ES 8.13.3 Tencent Cloud ES и новой версии ядра 8.11.3.
Tencent Cloud ES также взяла на себя инициативу по предоставлению этой функции клиентам на внутренней платформе WeChat, быстро поддерживая плавный запуск бизнеса клиентов.
5. Резюме
5.1 Обзор контента
В этой статье первоначально рассматривается функция поиска kNN Elasticsearch 8.x, включая ее процесс запроса, реализацию функции и алгоритм объединения RRF. Благодаря анализу исходного кода он помогает читателям глубже понять функцию векторного поиска Elasticsearch. В то же время он знакомит сообщество с значимым вкладом Tencent Cloud ES в направление векторного поиска и обеспечивает функциональные улучшения гибридного поиска RRF.
5.2 Обзор серии
Автор надеется, что эта серия статей сможет обеспечить предварительный анализ и исследование всех аспектов векторных функций, представленных ES8, чтобы достичь целей популярной науки и общего прогресса. Мы также надеемся, что больше пользователей, которым нужен векторный/гибридный поиск, смогут попробовать использовать Tencent Cloud ES 8.x. Если у вас также есть уникальные потребности или идеи, вы можете связаться с командой Tencent Cloud ES, и мы сделаем все возможное, чтобы изучить их вместе с вами. . решать. В настоящее время последняя версия Tencent Cloud ES внимательно следит за развитием сообщества и выпустила версию 8.13.3. В то же время мы постоянно добавляем собственные функции и оптимизации. Дополнительный анализ будет представлен позже. Из-за ограниченного уровня, если в статье есть какие-либо ошибки, пожалуйста, простите меня. Автор очень готов обсудить и внести исправления, если у вас есть какие-либо функции вектора ES, которые вас интересуют, вы можете оставить сообщение; и автор также учтет их при выборе тем последующих циклов статей.
Анонс следующего выпуска: «Серия обзоров векторных функций ES8 (2): Хранение и оптимизация векторных данных»



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
