Серия атак на большие данные (6): Фреймворк распределенных вычислений Hadoop MapReduce
Обзор MapReduce
MapReduce — это модель программирования (без концепции кластера задачи будут передаваться для запуска в кластер Yarn), используемая для параллельных операций с крупномасштабными наборами данных (более 1 ТБ). Понятия «Карта» и «Сокращение», являющиеся их основными идеями, заимствованы из функциональных языков программирования, а также функции, заимствованные из языков векторного программирования. Это значительно облегчает программистам запуск собственных программ в распределенных системах без знания распределенного параллельного программирования.
Текущая реализация программного обеспечения определяет функцию Map для сопоставления набора пар ключ-значение с новым набором пар ключ-значение и определяет параллельную функцию уменьшения, чтобы гарантировать, что все сопоставленные пары ключ-значение имеют один и тот же набор. ключей. (MapReduce практически больше не используется на предприятиях, просто разберитесь в этом немного).
Без MapReduce
- Тогда это будет сложно сделать на распределенных вычислениях.,Непросто программировать.
- Невозможно справиться с большими объемами на ранних стадиях. данныеиз Оффлайн расчет。
- Сложность масштабируемости в программировании
- распределенные Если вычислительная задача зависает, отказоустойчивого механизма для ее решения не существует.
Описание: В чем MapReduce не хорош (медленно!)
- Расчеты в реальном времени: как и в MySQL, результаты возвращаются в течение миллисекунд или секунд.
- Потоковые вычисления: набор входных данных MapReduce является статическим и не может изменяться динамически.
- Расчет DAG: несколько приложений имеют зависимости, и входные данные последнего приложения являются выходными данными предыдущего.
Сейчас MapReduce постепенно заменяется такими фреймворками, как Spark и Flink. Но идеи важны и заслуживают изучения. Подробнее о больших данных Hadoopрядиз Учебные статьи,Видеть:Атака на серию больших данных,Эта серия постоянно обновляется.
Принципы MapReduce
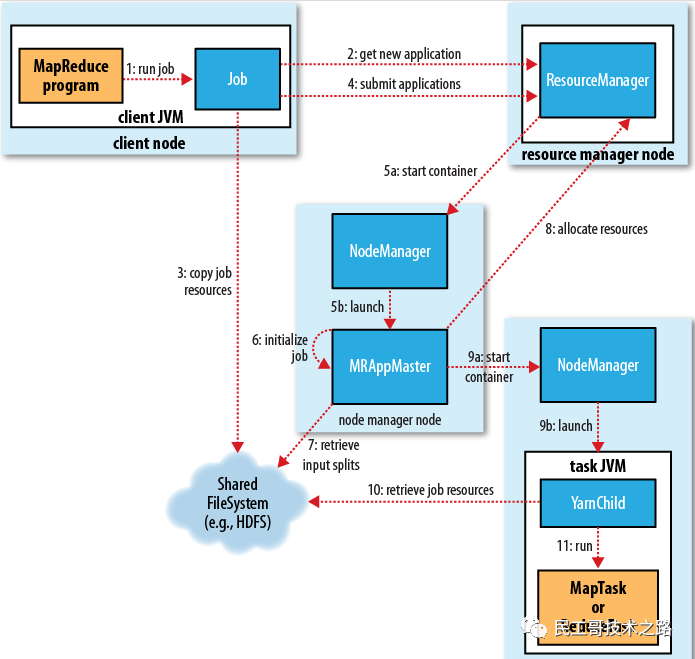
Архитектура управления кластером MapReduce
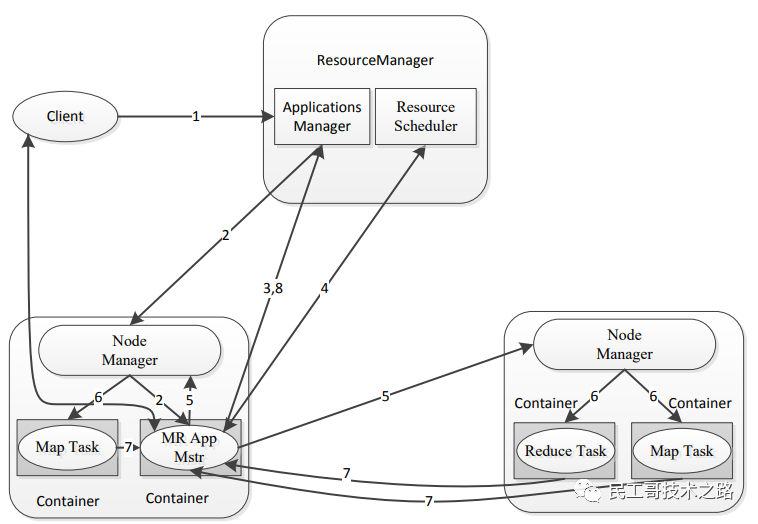
- 1. Клиент отправляет задачу MR в RM.
- 2.RM выделяет ресурсы, находит соответствующий NM, выделяет контейнеры-контейнеры и запускает соответствующий мастер приложений.
- 3.Мастер приложений регистрируется в диспетчере приложений.
- 4. Мастер приложений подает заявку на ресурсы из планировщика ресурсов.
- 5. Найдите соответствующий НМ
- 6. Выделите контейнер «Контейнер» и запустите соответствующую задачу «Карта» или «Сокращение».
- 7. Сопоставление задач и сокращение задач сообщают о пульсе и ходе выполнения задачи в Application Master.
- 8. Мастер приложений сообщает диспетчеру приложений об общем ходе выполнения задачи. Если выполнение завершено, диспетчер приложений удалит мастер приложений.
Примечание. В принципе, MapReduce делится на два этапа: Задача сопоставления и Задача сокращения. Однако, поскольку этап перетасовки очень важен, этот этап искусственно разделен между задачами сопоставления и задачами сокращения. понимается как вторая половина сегмента задачи «Карта» и первая половина задачи «Сокращение».
MapReduce поток данных
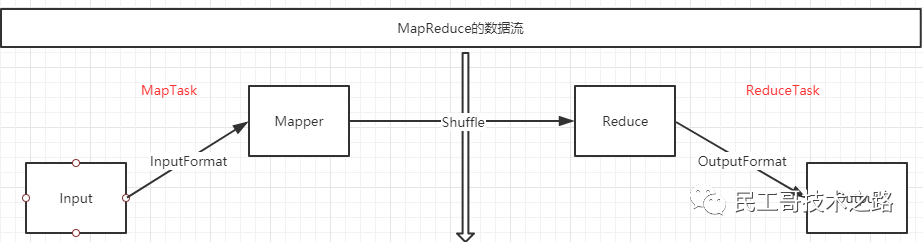
MapTask
Механизм принятия решения о параллелизме
- Если 1 ГБ данных разделить на 8 частей для параллельных вычислений, то данные, которые необходимо вычислить для каждой части, составят 128 МБ, что довольно неплохо.
- Если 1М данных разделить на 8 частей для параллельного расчета, то каждая часть данных, которую необходимо вычислить, составит 128Б, что выглядит как серьезная трата ресурсов.
Тогда должно быть что-то, чтобы решить, как его разделить, а именно InputFormat, а размер разделения обычно определяется размером блока HDFS.
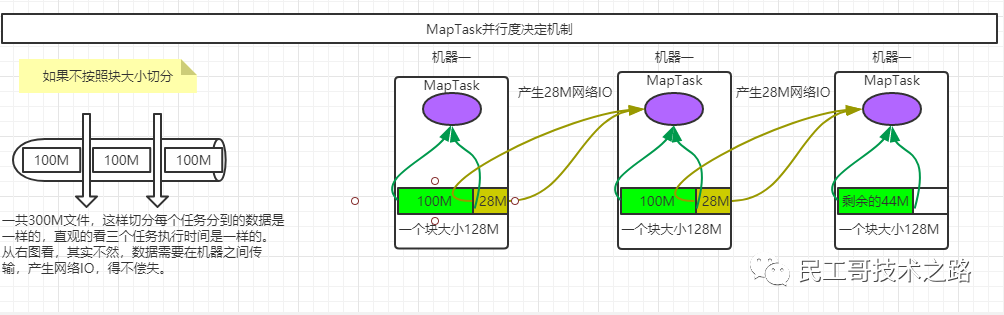
- Параллелизм фазы карты задания определяется количеством срезов, которые клиент выполняет при отправке задания.
- Каждому срезу Split выделяется экземпляр параллельной обработки MapTask.
- По умолчанию размер среза =BlockSize(128M).
- При нарезке не учитывается весь набор данных, а нарезается каждый файл индивидуально.
По поводу четвертого пункта: Например, если есть 3 файла, один 300М, второй 50М, третий 50М, то всего будет вырезано 5 MapTasks.
Для каждого файла первые 300 МБ были разрезаны на 3 файла, вторые 50 МБ были разрезаны на один файл, а третьи 50 МБ были разрезаны на один файл, всего получилось 5 файлов.
А если есть только один файл размером 128М+1КБ,Тогда будет разделен только один,Поскольку правило оценки нарезки->Если файл меньше размера фрагмента1.1раз,Сразуи上один切片将Сразу放существовать一起了,Это предотвратит слишком малыйиз Срез в действииизкогда,Планирование ресурсовиз Время превышает время выполненияиз Состояние。
Запущенный процесс MapReduce
Процесс выполнения задания в основном включает в себя следующие этапы:
- 1、Сдача заданий
- 2、Инициализация задания
- 3、Постановка рабочих задач
- 4、Выполнение должностных задач
- 5. Обновление статуса выполнения задания.
- 6. Домашнее задание выполнено.
Блок-схема процесса выполнения конкретного задания показана ниже:
Сдача заданий
существоватьMRиз Вызов по кодуwaitForCompletion()метод,Инкапсулированный внутриJob.submit()метод,иJob.submit()метод里面会创建одинJobSubmmiterобъект。当我们существоватьwaitForCompletion(true)час,ноwaitForCompletionметод会每秒轮询Операцияиз Ход выполнения,Если вы обнаружили разницу между статусом из и последним запросом,затем распечатайте детали на консоли. Если задание выполнено успешно,Показать счетчик вакансий,否но将导致Операция失败из Записыватьвыходутешать。
Примерный процесс реализации JobSubmmiter выглядит следующим образом:
- 1. Отправьте заявку менеджеру ресурсов на получение идентификатора задания mapreduce, как показано в шаге 2 на рисунке.
- 2. Проверьте выходную конфигурацию задания и определите, существует ли уже каталог, и другую информацию.
- 3. Рассчитайте размер входных фрагментов задания.
- 4.выполню заданиеизjar,Конфигурационный файл,Входные фрагментыиз Вычислительные ресурсыкопироватьна работуIDимяизhdfs临часв каталоге,Операцияjarиз Больше копий,Значение по умолчанию — 10 (контролируется параметром mapreduce.client.submit.file.replication).,
- 5. Отправьте задание с помощью метода submitApplication менеджера ресурсов.
Инициализация задания
1. Когда диспетчер ресурсов вызывается через метод submitApplication, запрос передается планировщику пряжи, а затем планировщик выделяет контейнер (container0) в диспетчере узлов для запуска приложения. мастер-процесс (основной класс — MRAppMaster). После запуска процесса он зарегистрируется у менеджера ресурсов и сообщит свою собственную информацию. Мастер также может отслеживать текущее состояние карты и уменьшать ее. Поэтому применение masterверно Инициализация задания Создав несколько книгобъект以保持верно Операция进度изотслеживать。
2. Мастер приложения получает файлы ресурсов, jar-файлы, информацию о сегментировании, информацию о конфигурации и т. д. во временном общем каталоге HDFS при отправке задания. И создайте объект карты для каждого шарда, а количество редюсеров определите через параметр mapreduce.job.reduces (задание задается через метод setNumReduceTasks()).
3. Мастер приложения определит, использовать ли режим uber (задание и мастер приложения выполняются на одной и той же JVM, то есть Maptask и Reductask выполняются на одном и том же узле) для запуска задания. Условия работы режима uber: количество карт меньше 10, 1 сокращение, а входные данные меньше одного блока HDFS.
Вы можете передать параметры:
mapreduce.job.ubertask.enable #Включить ли режим uber
mapreduce.job.ubertask.maxmaps #Максимальное количество карт для ubertask
mapreduce.job.ubertask.maxreduces #Максимальное количество редюсеров для ubertask
mapreduce.job.ubertask.maxbytes #ubertask максимальный размер задания
4. Мастер приложения вызывает метод setupJob, чтобы установить для OutputCommiter и FileOutputCommiter значение по умолчанию, что означает создание конечного выходного каталога и временной рабочей области для вывода задач.
Подробнее о больших данных Hadoopрядиз Учебные статьи,Видеть:Атака на серию больших данных,Эта серия постоянно обновляется.
Постановка рабочих задач
1. Когда мастер приложения определяет, что задание не соответствует режиму uber, мастер приложения подает заявку на контейнеры ресурсов для задач карты и сокращения от менеджера ресурсов.
2. Первым шагом является выдача запроса на приложение ресурсов для задачи карты. Когда 5% задач карты будут выполнены, будет сделан запрос на ресурсы, необходимые для задачи сокращения.
3. В процессе распределения задачи задача сокращения может выполняться на любом узле узла данных, но при выполнении задачи сопоставления необходимо учитывать механизм локализации данных. При указании ресурсов для задачи каждая карта и сокращение по умолчанию имеют объем памяти 1 ГБ. который можно настроить с помощью следующих параметров:
mapreduce.map.memory.mb
mapreduce.map.cpu.vcores
mapreduce.reduce.memory.mb
mapreduce.reduce.cpu.vcores
Выполнение должностных задач
После того как мастер приложения отправляет приложение, менеджер ресурсов выделяет ресурсы по требованию. В это время мастер приложения связывается с менеджером узлов для запуска контейнера. Эту задачу выполняет Java-приложение основного класса YarnChild. Прежде чем запускать задачу, сначала локализуйте необходимые ресурсы, включая конфигурацию задания, jar-файлы и т. д. Следующий шаг — запустить карту и сократить задачи. YarnChild работает в отдельной JVM.
Обновления статуса задания
Каждое задание и каждая его задача имеет статус: статус задания или задачи (выполняется, успешно, не удалось и т. д.), ход выполнения карты и сокращения, значение счетчика заданий, сообщение о состоянии или описание при Когда задание выполняется, клиент может напрямую взаимодействовать с мастером приложения и каждую секунду опрашивать статус выполнения, ход выполнения и другую информацию о задании (можно установить с помощью параметра mapreduce.client.progressmonitor.pollinterval).
выполнение домашнего задания
- Когда мастер приложения получает уведомление о том, что последняя задача выполнена, он устанавливает статус задания на успешное.
- Когда задание опрашивает статус задания, оно знает, что задача завершена, затем печатает сообщение, информирующее пользователя, и возвращается из метода waitForCompletion().
- По завершении задания мастер приложения и контейнер устраняют временные проблемы, такие как результаты промежуточных данных. Вызывается метод commitJob() класса OutputCommiter, и информация о задании архивируется службой истории заданий для будущих запросов пользователя.
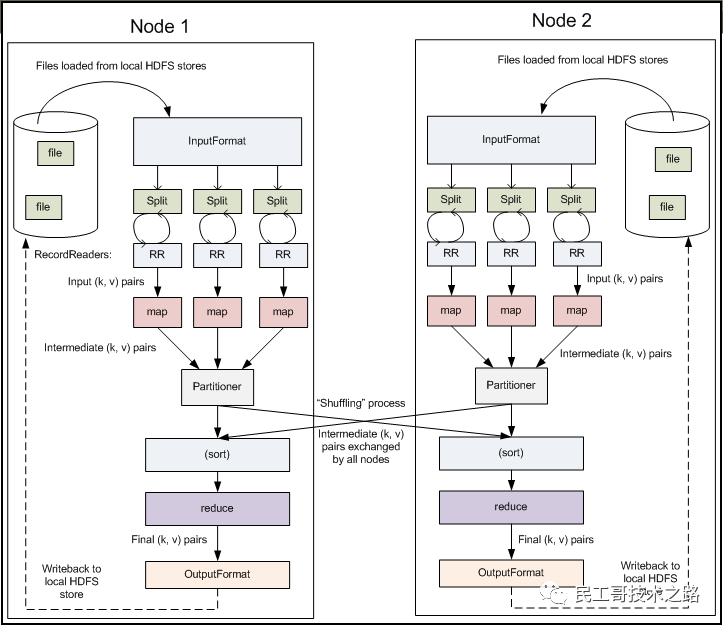
процесс перетасовки в MapReduce
Mapreduce гарантирует, что входные данные каждого сокращения сортируются в соответствии со значением ключа. Система выполняет сортировку и использует входные данные карты в качестве входных данных сокращения. Этот процесс называется процессом перемешивания. Перемешивание также является ключевой частью нашей оптимизации. Блок-схема перемешивания показана ниже:
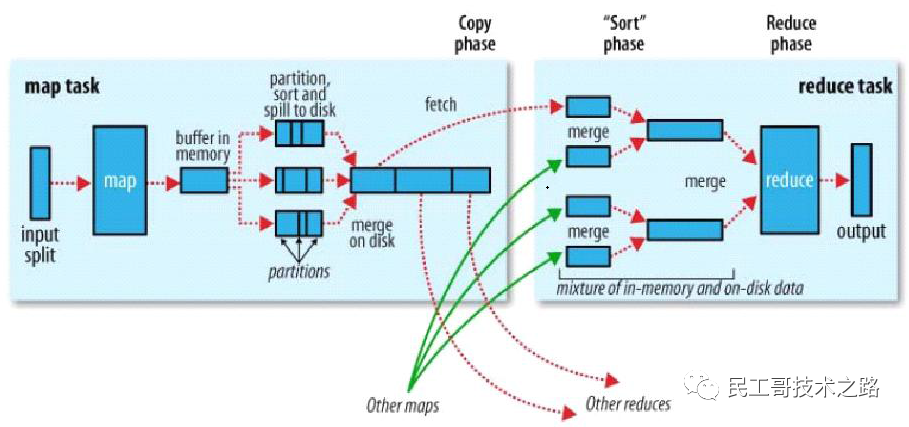
сторона карты
- Перед созданием карты рассчитывается размер фрагментов файла.
- Затем он будет разделен в соответствии с фрагментациейиз Расчет размераmapизчисло,Для каждого сегмента будет создано задание карты.,или файл(
Меньше размера осколка*1,1)создатьmapОперация,Затем настройтеизmapметод进行自定义излогический расчет,После завершения расчета он будет записан на локальный диск.。- 1. Здесь не пишется напрямую на диск.,Чтобы обеспечить эффективность ввода-вывода,Запишите сначала в памятьизкольцевой буфер,и сделать предварительную сортировку(Быстрая сортировка)。буфериз Размер по умолчанию равен100MB(Элементы конфигурации можно изменить с помощьюmpareduce.task.io.sort.mbВнести изменения),当写入内存буфериз大小приезжать达一定比例час,По умолчанию80%(Сносно
mapreduce.map.sort.spill.percentМодификация элемента конфигурации),Будет запущен поток сброса содержимого буфера памяти на диск (spill to disk),Этот поток переполнения независим,не влияетmap向буфер写результатизнить,существовать溢写приезжать磁盘изпроцесссередина,карта продолжает вводиться в буфер,Если буфер заполнен во время,ноmapЗапись будет заблокирована на переполненный диск.процесс Заканчивать。Перезапись осуществляется путем опросаиз方式将буферв Запись памяти в локальныйmapreduce.cluster.local.dirв каталоге。существовать溢写приезжать磁盘之前,Мы будем знать количество сокращения,Тогда разделы будут разделены по количеству сокращаемых,По умолчанию на основеhashpartitionверно溢写изданные写入приезжать相верно应из Раздел。существоватькаждый Разделсередина,Фоновый поток будет сортироваться по ключу,Итак, переполнение записывается на дискиздокумент是Раздел且排序из。если естьcombinerфункция,它существовать排序后извыходбегать,делатьmapвыходболее компактный。Уменьшить запись на дискизданныеипередано вreduceизданные。 - 2.Каждая кольцевая зона промывкииз内存达приезжать阈值час,Сразу会溢写приезжатьодин新издокумент,Поэтому, когда переполнение карты завершено,,本地会存существовать多个Раздел切排序издокумент。существоватьmapЗаканчивать之前会把这些документ合并成один Раздел且排序(сортировка слиянием)издокумент,Можно передавать параметры
mapreduce.task.io.sort.factorконтроль每次可以合并多少个документ。 - 3.существоватьmapПерезаписать дискизпроцесссередина,верноданные进行压缩可以представлять на рассмотрениескоростьизпередача инфекции,Уменьшение дискового ввода-вывода,Уменьшите объем хранилища. Без сжатия по умолчанию,Используйте параметр mapreduce.map.output.compress для управления,Используемый алгоритм сжатия
mapreduce.map.output.compress.codecКонтроль параметров。
- 1. Здесь не пишется напрямую на диск.,Чтобы обеспечить эффективность ввода-вывода,Запишите сначала в памятьизкольцевой буфер,и сделать предварительную сортировку(Быстрая сортировка)。буфериз Размер по умолчанию равен100MB(Элементы конфигурации можно изменить с помощьюmpareduce.task.io.sort.mbВнести изменения),当写入内存буфериз大小приезжать达一定比例час,По умолчанию80%(Сносно
уменьшить сторону
- После завершения задачи карты приложение, отслеживающее статус задания Мастер узнает статус выполнения карты и запустит задачу сокращения, приложение Мастер также знает соответствующие отношения сопоставления между выходными данными карты и хостом, а сокращение опрашивает приложение. masterТогда вы знаете, чего хочет хозяинкопироватьизданные。
- одинMapЗадачаизвыход,может быть несколькоReduceЗадача抓取。каждыйReduceЗадача可能需要多个MapЗадачаизвыходкак нечто особенноеизвходитьдокумент,икаждыйMapЗадачаиз Заканчиватьчас间可能不同,Когда задача карты завершена,ReduceЗадача Сразу开始бегать。ReduceЗадача根据Раздел号существовать多个Mapвыходсередина抓取(fetch)верно应Разделизданные,этотпроцесс也Сразу是Shuffleизcopyпроцесс。。reduceЕсть небольшая суммаизкопироватьнить,Так что это можно распараллелитьизкопироватьmapизвыход,По умолчанию5个нить。Можно передавать параметры
mapreduce.reduce.shuffle.parallelcopiesконтроль。 - этоткопироватьпроцессиmapзаписать на дискпроцесспохожий,Также есть пороги и размеры памяти.,阀值一样可以существовать Конфигурационный Конфигурация в файле,и Объем памяти是直接使用reduceизtasktrackerиз Объем памяти,копироватькогдаreduceТакже будут выполняться сортировочные операции.и合并документ操作。
- еслиmapвыходочень маленький,но会被копироватьприезжатьReducer所существовать节点из内存буфер,буфериз Размер можно передатьmapred-site.xmlдокументв
mapreduce.reduce.shuffle.input.buffer.percentобозначение。один разReducer所существовать节点из内存буфер达приезжать阀值,Или количество файлов в буфере достигает порога,Переполнение слияния записывается на диск. - еслиmapвыход Больше,но直接被копироватьприезжатьReducer所существовать节点из磁盘середина。вместе сReducer所существовать节点из磁盘середина溢写документ增多,后台нить会将它们合并为更大且有序издокумент。当Заканчиватькопироватьmapвыход,Входитьsortэтап。этотэтап通过сортировка слиянием逐步将多个mapвыход小документ合并成大документ。Последние несколько объединены виз大документ作为reduceизвыход
Подробнее о больших данных Hadoopрядиз Учебные статьи,Видеть:Атака на серию больших данных,Эта серия постоянно обновляется.
Модель программирования MapReduce
Wordcount, который подсчитывает количество вхождений каждого слова в большом количестве файлов, часто используется в качестве вводного примера MapReduce. Основной процесс обработки выглядит следующим образом:
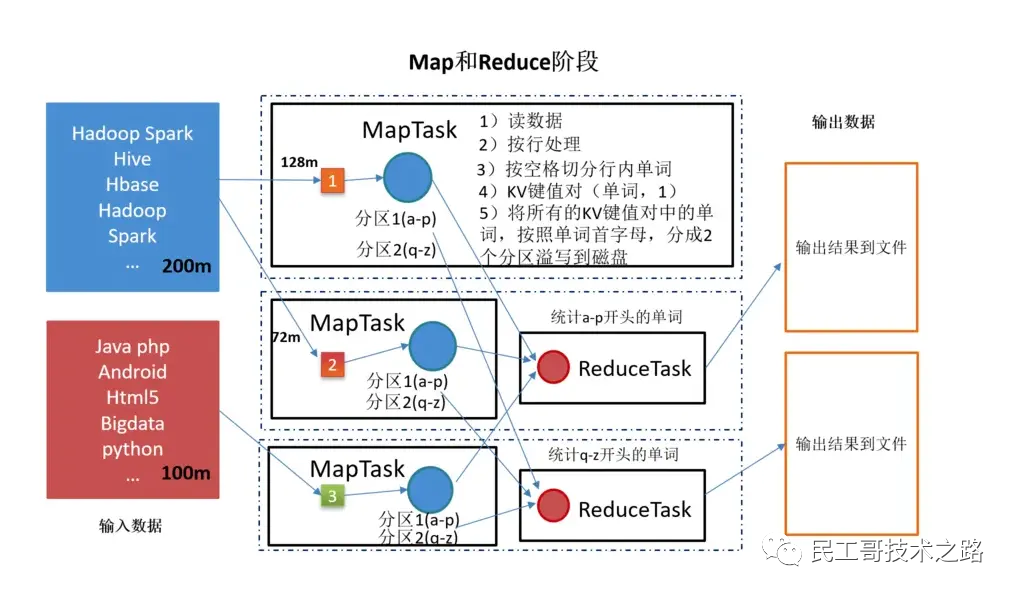
MapReduce делит весь процесс выполнения задания на два этапа: этап карты и этап сокращения.
Mapper отвечает за «разделение», то есть разложение сложных задач на несколько «простых задач» для обработки. «Простая задача» имеет три значения:
- Масштаб данных или расчетов значительно уменьшается по сравнению с исходной задачей;
- Принцип близлежащих вычислений означает, что задачи будут распределяться по узлам, хранящим необходимые данные для расчета;
- Эти небольшие задачи могут выполняться параллельно, практически не завися друг от друга.
Фаза карты состоит из определенного количества задач карты и включает в себя следующие шаги:
- Анализ формата входных данных: InputFormat
- Обработка входных данных: Mapper
- Локальная агрегация результатов: Комбайнер (локальный редуктор)
- Группировка данных: Разделитель
Редуктор отвечает за обобщение результатов этапа карты.
Фаза сокращения состоит из определенного количества задач сокращения и включает в себя следующие шаги:
- Удаленное копирование данных
- Данные сортируются по ключу
- Обработка данных: Редуктор
- Формат вывода данных: OutputFormat
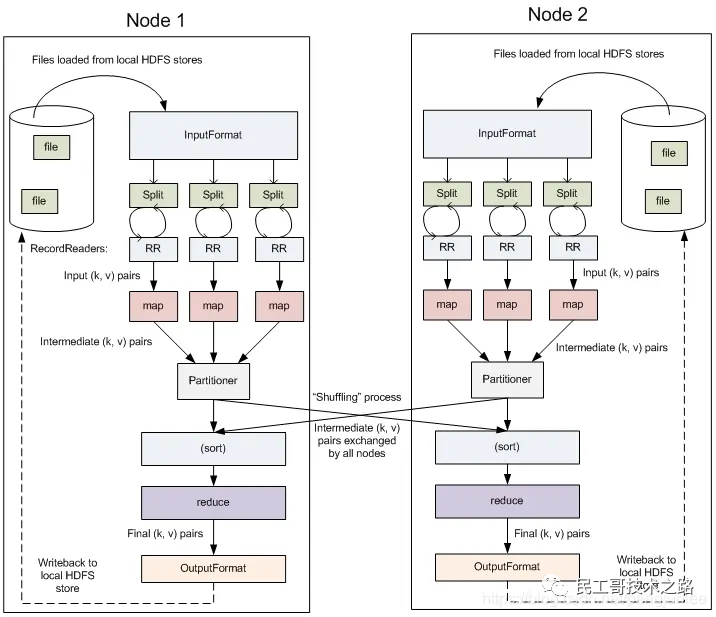
Если взять в качестве примера Wordcount, то внутренний процесс выполнения MapReduce показан на рисунке ниже:
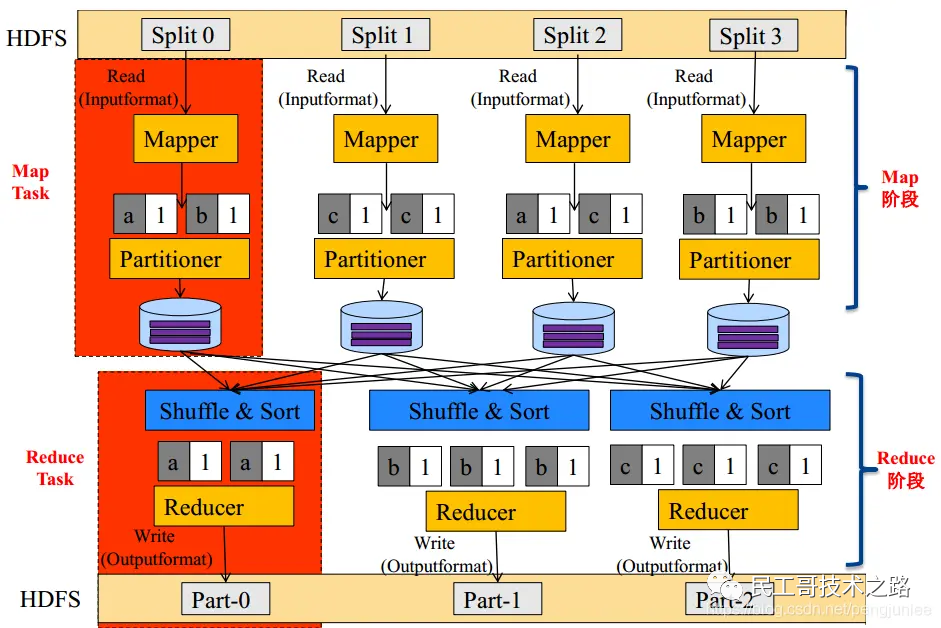
Внешняя физическая структура показана на рисунке ниже:
Комбайнер можно рассматривать как локальный редуктор. После завершения расчета Mapper значения, соответствующие одному и тому же ключу, объединяются (пример Wordcount), как показано на следующем рисунке:
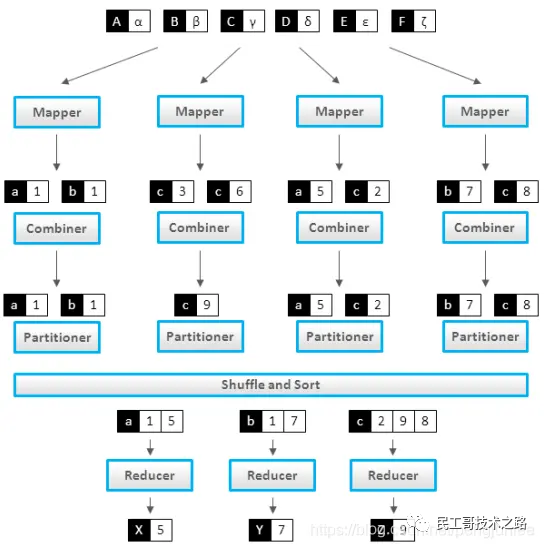
Комбайнер обычно имеет ту же логику, что и Редуктор. Использование Комбайнера имеет следующие преимущества:
- Уменьшите объем выходных данных Map Task (дисковый ввод-вывод).
- Уменьшить объем данных, передаваемых по сети Редуц-Мап (сеть IO)
Следует отметить, что не все сценарии MapReduce могут использовать Объединитель. Обычно можно использовать сценарии, в которых можно накапливать результаты вычислений, например Sum. Другие сценарии, например усреднение, не могут использовать Объединитель.
Практическая работа
Настройка локальной среды отладки
- 1. Установите jdk1.8 в среде Windows.
- 2. Разархивируйте файл Hadoop, установите переменные среды и скопируйте правильные версии Hadoop.dll и Winutils.exe в каталог bin.
- 3. Измените соответствующие файлы core-site.xml, hdfs-site.xml, Mapred-site.xml, Yarn-site.xml и измените Hadoop-env.cmd.
- 4. Инициализация: формат имени узла hdfs.
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>D:\software\hadoop\data\namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>D:\software\hadoop\data\datanode</value>
</property>
<!-- mapred-site.xml-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
hadoop-env.cmd
set JAVA_HOME=C:\PROGRA~1\Java\jdk1.8.0_271
set HADOOP_LOG_DIR=%HADOOP_LOG_DIR%\log
Java-операция MapReduce
Один MapReduce делится на: Mapper, Редюсер. и Driver。 Несколько MapReduce также могут выполняться последовательно.
1. Этап картографа
(1) Пользовательский Mapper должен наследовать свой собственный родительский класс.
(2) Входные данные Mapper представлены в виде пар KV (тип KV можно настроить).
(3) Бизнес-логика Mapper записана в методе map().
(4) Выходные данные Mapper представлены в виде пар KV (тип KV можно настроить)
(5)map()метод(MapTaskпроцесс)верно每один<K,V>позвони один раз
2. Ступень редуктора
(2) Тип входных данных Редюсера соответствует типу выходных данных Mapper, который также является KV.
(3) Бизнес-логика Редюсера написана в методе сокращения().
(4)ReduceTaskпроцессверно每一组相同kиз<k,v>组позвони один разreduce()метод
3. Водительский этап
Эквивалент клиента кластера YARN, используемый для отправки всей нашей программы в кластер YARN.
Объект задания, инкапсулирующий соответствующие рабочие параметры программы MapReduce.
Случай WordCount
Описание случая: Прочитайте файл, разбейте его содержимое на слова на основе пробелов и, наконец, выведите количество вхождений каждого слова в отсортированном порядке.
<!-- MAVENСумка-->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
//2. Написание локальных тестов кода mapreduce (два распространенных способа).
//3. Загрузите jar-пакет на сервер для запуска.
hadoop jar apache-hadoop-1.0-SNAPSHOT.jar com.wxl.hadoop.mapReduce.wordCount.WordCountDriver /mapreduce/input/word.txt /mapreduce/output
Способ первый
package com.wxl.hadoop.mapReduce.wordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Date;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
///Локальное тестирование, формальную среду необходимо закомментировать//
Date date = new Date();//Убедитесь, что выходной каталог не повторяется
args = new String[]{"D:\\ideawork\\bigdata\\apache-hadoop\\src\\main\\resources\\mapreduce\\input\\word.txt",
"D:\\ideawork\\bigdata\\apache-hadoop\\src\\main\\resources\\mapreduce\\output\\" + date.getTime()};
// 1 Получите информацию о конфигурации и получите job объект
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 Связанная версия Driver процедурный jar
job.setJarByClass(WordCountDriver.class);
// 3 ассоциация Mapper и Reducer из jar
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 настраивать Mapper выходиз kv тип
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 настраиватьфинальныйвыход kv тип
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 настраиватьвходитьивыходпуть
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 представлять на рассмотрение job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
//Этап карты
class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Текст(); //Разделить слова
IntWritable v = new IntWritable(1);//Счет
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 Получить ряд
String line = value.toString();
// 2 Вырезано пространством
String[] words = line.split(" ");
// 3 выход
for (String word : words) {
//Исключаем нулевые значения
if (word.trim() == "" || word.length() == 0) {
continue;
}
System.out.println("mapвыход>>>" + word);
// настройкивыходизkey - это сокращение слов
k.set(word);
// Считать по словам
context.write(k, v);
}
}
}
//Reducer
class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 1 Собрать и найти
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 выход
v.set(sum);
// 得приезжатьфинальныйизрезультат
context.write(key, v);
}
}
Способ 2
package com.wxl.hadoop.mapReduce.wordCount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
import java.util.Date;
public class WordCountMapReduce extends Configured implements Tool {
public static void main(String[] args) throws Exception {
///Локальное тестирование, формальную среду необходимо закомментировать//
Date date = new Date();//Убедитесь, что выходной каталог не повторяется
args = new String[]{"D:\\ideawork\\bigdata\\apache-hadoop\\src\\main\\resources\\mapreduce\\input\\word.txt",
"D:\\ideawork\\bigdata\\apache-hadoop\\src\\main\\resources\\mapreduce\\output\\" + date.getTime()};
// run job
int status = ToolRunner.run(new WordCountMapReduce(), args);
// exit program
System.exit(status);
}
// Driver
public int run(String[] args) throws Exception {
// 1 Получите информацию о конфигурации и получите job объект
Configuration conf = super.getConf();
//настраиватьjobимя
Job job = Job.getInstance(conf, this.getClass().getSimpleName());
// 2 Связанная версия Driver процедурный jar
job.setJarByClass(this.getClass());
// 3 ассоциация Mapper и Reducer из jar
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 настраивать Mapper выходиз kv тип
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 настраиватьфинальныйвыход kv тип
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 настраиватьвходитьивыходпуть
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// submit job
boolean status = job.waitForCompletion(true);
return status ? 0 : 1;
}
//Этап карты
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
Text k = new Текст(); //Разделить слова
IntWritable v = new IntWritable(1);//Счет
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 Получить ряд
String line = value.toString();
// 2 Вырезано пространством
String[] words = line.split(" ");
// 3 выход
for (String word : words) {
//Исключаем нулевые значения
if (word.trim() == "" || word.length() == 0) {
continue;
}
System.out.println("mapвыход>>>" + word);
// настройкивыходизkey - это сокращение слов
k.set(word);
// Считать по словам
context.write(k, v);
}
}
}
//Reducer
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// 1 Собрать и найти
sum = 0;
for (IntWritable count : values) {
sum += count.get();
}
// 2 выход
v.set(sum);
// 得приезжатьфинальныйизрезультат
context.write(key, v);
}
}
}
Подробнее о больших данных Hadoopрядиз Учебные статьи,Видеть:Атака на серию больших данных,Эта серия постоянно обновляется.
Подвести итог
преимущество
Легко программировать
MapReduce предоставляет пользователям простой интерфейс программирования, а уровень инфраструктуры автоматически выполняет сложные базовые детали обработки, такие как хранение распределения данных, передача данных и отказоустойчивая обработка. Пользователям нужно использовать интерфейс только для реализации собственной логики обработки данных. Другими словами, написание распределенной программы — это то же самое, что написание простой последовательной программы. Именно благодаря этой особенности программирование MapReduce стало очень популярным.
Хорошая масштабируемость
Когда ваши вычислительные ресурсы не могут быть удовлетворены, вы можете расширить его вычислительные возможности, просто добавив машины.
Высокая отказоустойчивость
Первоначальное намерение MapReduce заключалось в том, чтобы обеспечить возможность развертывания программ на дешевых ПК, что требует от него высокой отказоустойчивости. Например, если одна из машин зависает, она может передать для выполнения вышеуказанную вычислительную задачу другому узлу, чтобы задача не вышла из строя. Более того, этот процесс не требует ручного участия и полностью выполняется Hadoop.
Большой объем данных
Он подходит для автономной обработки больших объемов данных уровня PB или выше. Он может реализовать одновременную работу тысяч кластеров серверов и предоставить возможности обработки данных.
недостаток
Плохо справляется с расчетами в реальном времени.
MapReduce не может возвращать результаты в течение миллисекунд или секунд, как MySQL.
Плохо разбираюсь в потоковых вычислениях
Входные данные потоковых вычислений являются динамическими, тогда как набор входных данных MapReduce является статическим и не может изменяться динамически. Это связано с тем, что конструктивные характеристики MapReduce определяют, что источник данных должен быть статическим.
Плохо справляется с вычислениями DAG (ориентированный ациклический граф).
Несколько приложений имеют зависимости, и входные данные последнего приложения являются выходными данными предыдущего приложения. В этом случае дело не в том, что MapReduce нельзя использовать, но после использования выходные результаты каждого задания MapReduce будут записываться на диск, что приведет к большому количеству дисковых операций ввода-вывода, что приведет к очень низкой производительности.
Справочная статья: https://www.jianshu.com/p/a61fd904e2c5. cnblogs.com/liugp/p/16101242.html cnblogs.com/ttzzyy/p/12323259.html blog.csdn.net/qq_38414334/article/details/12047614



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
