Секреты оптимизации производительности Golang, которые должен освоить каждый программист
Анализ производительности и оптимизация — важные навыки для всех разработчиков программного обеспечения, а также темы, о которых говорят руководители серверной части.
Будучи «современным» языком, Golang изначально включает в себя мощные инструменты анализа производительности pprof и трассировку. Инструмент pprof часто используется для анализа использования ресурсов. Он может собирать множество различных типов данных во время работы программы (например, использование ЦП, потребление памяти, количество сопрограмм и т. д.), а также анализировать и агрегировать данные для создания отчетов. . Инструмент трассировки фокусируется на событиях во время работы программы (таких как переключение состояний сопрограммы, начало и конец GC, системные вызовы и т. д.) и часто используется для анализа таких проблем, как задержка, блокировка и планирование. Освоения этих двух инструментов достаточно для удовлетворения потребностей анализа производительности большинства программ Golang.
В этой статье инструменты pprof и трассировки будут представлены с трех аспектов: использование, принцип и практика. Я считаю, что прочитав эту статью, вы также сможете освоить pprof и более полно отслеживать трассировку. Без лишних слов, давайте начнем!
01. Подробное объяснение инструмента pprof.
pprof — инструмент для визуализации и анализа данных. Во время работы программы Go можно отбирать множество различных типов данных. К наиболее часто используемым типам данных для анализа относятся:
- профиль: время процессора;
- allocs/heap: выделение памяти;
- горутина: сопрограммаиспользовать ситуацию;
После получения данных выборки pprof предоставляет множество различных режимов анализа данных. Обычно используются следующие режимы анализа:
- svg Векторная иллюстрацияили График пламени;
- вверху в соответствии с отсортировано от большего к меньшему анализировать;
- source исходный коданализировать;
- peek Вызов восходящего и нисходящего анализа;
Затем проанализируйте один за другим в соответствии с типом данных выборки.
1.1 профильный анализ процессора
1.1.1 Генерация данных выборки
1.1.1.1 Непосредственная генерация кода
Добавьте следующий код непосредственно в начало основной функции. После завершения программы будет получен полный файл данных выборки CPU.out. Этот метод обычно используется в сценариях анализа кода инструмента.
func main() {
f, _ := os.Create("CPU.out")
defer f.Close()
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
...
}1.1.1.2 генерация параметров тестирования
При выполнении теста go добавьте параметр -CPUprofile CPU.out, чтобы сгенерировать данные выборки.
go test -CPUprofile CPU.out . -run=TestFunc1.1.1.3 Генерируется посредством http-запроса
- запускать http Служить:
Добавьте пакет net/http/pprof в основной путь программы и запустите службу http.
import (
"net/http"
_ "net/http/pprof"
)
func pprofServerStart() {
go func() {
http.ListenAndServe("127.0.0.1:6060", nil) // Из соображений безопасности используйте локальный адрес, чтобы руководить прослушиванием
}()
}После внедрения пакета pprof маршрут интерфейса /debug/pprof/profile будет зарегистрирован в процессоре по умолчанию DefaultServeMux; вызовите ListenAndServe, чтобы запустить службу http, и передайте nil в качестве второго параметра, чтобы использовать процессор по умолчанию для обработки. запрос. Из соображений безопасности рекомендуется использовать локальные адреса в качестве адреса и порта службы http.
- просить http Генерация интерфейсавыборкаданные:
Используйте команду gotool pprof для доступа к интерфейсу /debug/pprof/profile локальной службы. Данные выборки ЦП будут автоматически сохранены в каталоге $HOME/pprof/, а командная строка анализа также будет введена напрямую.
$ go tool pprof http://127.0.0.1:6060/debug/pprof/profile?seconds=30
Saved profile in /root/pprof/pprof.demo.samples.CPU.001.pb.gz
File: demo
Type: CPU
Time: Dec 24, 2023 at 11:42am (CST)
Duration: 10s, Total samples = 70ms ( 0.7%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) 1.1.2 Анализ данных
1.1.2.1 Данные открытого отбора проб
Данные выборки необходимо загрузить на компьютер с исходным кодом для анализа. Режимы источника и просмотра недействительны на компьютерах без исходного кода.
Существует два способа открытия выборочных данных: командная строка и визуальный интерфейс. Лично автор предпочитает метод визуального интерфейса. Анализировать одним щелчком мыши очень удобно. В последующих главах этой статьи в качестве примера будет использоваться анализ визуального интерфейса.
- командная строкаанализировать:
Непосредственно используйте инструмент go pprof, чтобы открыть файл выборки, и введите top, list (эквивалент источника, упомянутого выше), peek и другие команды для анализа.
$ go tool pprof CPU.out
File: bench.test
Type: CPU
Time: Dec 24, 2023 at 10:43am (CST)
Duration: 1.96s, Total samples = 1.83s (93.33%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) - Визуальный интерфейс анализировать:
Используйте инструмент go pprof -http=ip:port, чтобы запустить службу.
$ go tool pprof -http=127.0.0.1:9888 CPU.out
Serving web UI on http://127.0.0.1:9888Посетите http://127.0.0.1:9888 в браузере, чтобы открыть визуальный интерфейс, который содержит часто используемые режимы анализа в меню ПРОСМОТР, как показано на рисунке ниже.

1.1.2.2 Режим анализа одного векторного изображения SVG
Нажмите подпункт «График» в меню «Вид», чтобы создать векторное изображение SVG, как показано ниже. Векторная графика svg очень подходит для оценки общего использования ресурсов, а также может помочь в анализе цепочки вызовов программы.

Каждый небольшой прямоугольный узел на рисунке представляет функцию (или метод), а входящие и исходящие стрелки узла представляют восходящие и нисходящие вызовы. Чем выше соотношение времени ЦП самой функции + сводки нисходящей функции, тем темнее цвет прямоугольного поля и тем толще стрелка, входящая в узел.

Описание узла показано выше. Оно содержит две части: верхняя часть — это основная информация, такая как имя пакета, имя класса, имя функции и имя анонимной функции. Первая часть — это сводка. Время процессора самой функции. Второе — суммарное время процессора функции в целом (сама + нисходящие вызовы). Если статистика недоступна или мала, она будет опущена.
Поле поиска в верхней части векторного изображения SVG может использовать обычный синтаксис для фильтрации определенных узлов. После поиска будут отображаться только узлы в цепочке вызовов, соответствующие условиям поиска.
1.1.2.3 Режим анализа второй сверху
Щелкните верхний подпункт меню ПРОСМОТР, чтобы просмотреть список всех функций, упорядоченных от больших к меньшим в соответствии с их собственным временем процессора (т. е. исключая нисходящие функции).

Описание индикатора:
- Flat, Flat%: сама функциярезюме CPU Время или учтено.
- sum%:все строки вышеиз flat% Накопленная стоимость.
- cum, cum%: Функция в целом (сама + нисходящие вызовы) из сводки CPU Время или учтено.
Аналогично, в верхнем режиме вы также можете использовать обычный синтаксис для фильтрации определенных узлов в поле поиска выше. Сценарий использования top аналогичен сценарию векторной графики svg, оба из которых анализируют использование ресурсов в целом.
1.1.2.4 Режим анализа с тремя источниками
Щелкните подпункт исходного кода в меню ПРОСМОТР, чтобы войти в режим анализа исходного кода. Детализация анализа режима SVG или верхнего уровня представляет собой функцию, в то время как степень детализации режима исходного кода представляет собой каждую строку исходного кода, в дополнение к общей плоской и совокупной характеристике функции, также указываются плоскость и совокупность каждой строки кода; Это позволяет нам анализировать функцию построчно. Источник обычно используется вместе с полем поиска. На рисунке ниже показаны результаты анализа исходного кода очереди канала путем поиска по ключевому слову chansend1 в режиме источника.
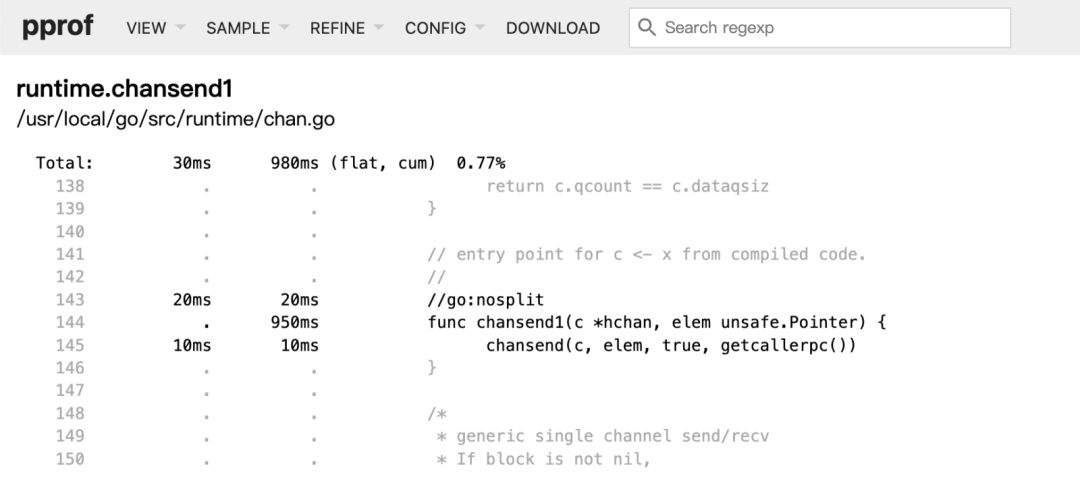
1.1.2.5 Режим анализа четырех просмотров
Щелкните подпункт просмотра в меню ПРОСМОТР, чтобы проанализировать вызовы вышестоящих и нижестоящих функций на уровне детализации строк кода.

Сила Peek заключается в том, что он может количественно анализировать долю восходящих и нисходящих вызовов. Как показано на рисунке, статистическая информация самого узла chansend1 представляет собой красное поле посередине; в верхнем красном поле перечислены все строки кода, которые вызывают chansend1, и их статистические пропорции, а в нижнем красном поле — строка кода, следующая за chansend1. вызов chansend1 и его статистическая пропорция. Когда мы видим узел тяжелого системного вызова на векторной диаграмме svg или в верхнем анализе, хотя мы не можем оптимизировать сам системный вызов, мы можем обнаружить необоснованное использование системного вызова, используя просмотр для исследования ситуации, связанной с вызовом.
1.1.3 Анализ принципа профильной выборки
1.1.3.1 Слишком длинная версия для чтения
- Производительность выборки близка к реальной производительности:
Когда программа Go запущена, сопрограмма в состоянии выполнения выбирается случайным образом и записывается текущий стек вызовов сопрограммы. Это выборка профиля.
Мы можем легко сделать вывод, что если определенная функция занимает больше процессорного времени, то вероятность того, что выполняющаяся функция, записанная в выборке, будет относительно высокой. Этот вывод верен и в обратном направлении: если определенная функция появляется чаще в нескольких выборках, то она, скорее всего, будет занимать больше процессорного времени.
Таким образом, результаты выборки можно использовать для аппроксимации реальных результатов. Чем выше частота выборки, тем лучше эффект аппроксимации.
- Как сделать профиль:
В течение заданного пользователем периода выборки профиль будет производить выборку с определенной частотой и случайным образом получать информацию о стеке вызовов сопрограммы, частота выборки фиксирована и равна 100, а интервал выборки составляет 1 с/100 = 10 мс;
В ходе анализа выполняется агрегация на основе стека вызовов выборочных данных (хеш вычисляется для стека вызовов, и равные значения хеш-функции представляют один и тот же стек вызовов. Совокупное время процессора определенного стека вызовов равно ). количество выборок стека вызовов * интервал выборки.
Как только стек вызовов и статистическая информация станут доступны, их можно дополнительно агрегировать в соответствии с размером функции или строки кода, а затем помочь в восходящих и нисходящих отношениях стека вызовов для генерации таких данных, как изображения SVG, просмотры и источники.
- Влияние на производительность:
Первоначальная цель анализа принципа выборки — выяснить влияние самого pprof на производительность. Если вы не понимаете принцип выборки pprof, вы не осмелитесь использовать его в производственной среде.
Вот прямой вывод. После включения выборки pprof влияние на производительность очень незначительное, и его можно с уверенностью использовать в производственных средах.
1.1.3.2 Анализ исходного кода
- включатьвыборка:
Когда пакет pprof вводится в код, функция init в пакете регистрирует маршрут /debug/pprof/profile в процессоре по умолчанию, а записью обработки является функция Profile.
// net/http/pprof/pprof.go
func init() {
...
http.HandleFunc("/debug/pprof/profile", Profile) // Регистрация маршрута в Профилруководить обработку
...
}В функции Profile pprof.StartCPUProfile будет вызываться для начала выборки, а после сна в соответствии с переданным параметром секунд (по умолчанию 30 секунд) будет вызываться pprof.StopCPUProfile для остановки выборки.
// runtime/mprof.go
func Profile(w http.ResponseWriter,р *http.Request) {
...
// включаем выборка
если ошибка: = pprof.StartCPUProfile(w); ошибка != ноль {
...
} }
спать(с)., time.Duration(sec)*time.Second)
// Остановить выборку
pprof.StopCPUProfile()}
}Проследите функцию StartCPUProfile, которая состоит из двух ключевых шагов: runtime.SetCPUProfileRate и ProfileWriter.
// runtime/pprof/pprof.go
func StartCPUProfile(w io.Writer) error {
...
runtime.SetCPUProfileRate(hz) // хз исправлено для 100
go profileWriter(w)
...
}runtime.SetCPUProfileRate наконец вызывает функцию setThreadCPUProfiler, которая использует time_create для открытия таймера и устанавливает интервал таймера 1 с/100 = 10 мс; таймер будет регулярно отправлять сигнал SIGPROF в поток каждые 10 мс. Код выглядит следующим образом:
// runtime/signal_unix.go
func setThreadCPUProfiler(hz int32) {
mp := getg().m // получатькогдавпередсопрограммаобязательностьизизнитьM ...
spec := new(itimerspec)
spec.it_value.setNsec(1 + int64(fastrandn(uint32(1e9/hz))))
spec.it_interval.setNsec(1e9 / int64(hz)) // Установить интервал для 100000000/100 наносекунда = 10ms
var timerid int32
var sevp sigevent
sevp.notify = _SIGEV_THREAD_ID
sevp.signo = _SIGPROF // Установить тип сигнала дляSIGPROF
sevp.sigev_notify_thread_id = int32(mp.procid) // Установить уведомление о сигнале для потока procid
ret := timer_create(_CLOCK_THREAD_CPUTIME_ID, &sevp, &timerid) // Создать таймер
...
ret = timer_settime(timerid, 0, spec, nil) // запускатьтаймер ...
}- Обработка сигнала SIGPROF:
После того, как поток получит прерывание сигнала SIGPROF, процессор P, связанный с потоком, будет использовать специальную сопрограмму gsignal для обработки сигнала. После запуска основного потока Go и до начала цикла планирования вызывается функция mstartm0. В mstartm0 выполняется initsig, чтобы установить запись обработки для всех сигналов. Проследив функцию initsig до конца, вы, наконец, сможете найти запись sigprof для обработки сигнала SIGPROF в функции SIGANDLER.
// runtime/signal_unix.go
func sighandler(sig uint32, info *siginfo, ctxt unsafe.Pointer, gp *g) {
...
// Сигнал SIGPROF с входа обработки
if sig == _SIGPROF {
if !delayedSignal && validSIGPROF(mp, c) {
sigprof(c.sigpc(), c.sigsp(), c.siglr(), gp, mp)
}
return
}
}sigprof сначала вызовет gentraceback, чтобы получить стек вызовов текущей выполняемой сопрограммы. Genraceback более сложен, но, к счастью, общий процесс относительно ясен. Упрощенный код показан ниже. Максимальное время цикла for извлекает информацию о стеке вызовов максимального уровня текущей сопрограммы из счетчика программы pc, указателя стека sp и регистра связи lr и сохраняет ее в pcbuf; Выборка профиля равна 64, получите только информацию о стеке 64-го уровня.
// runtime/traceback.go
func gentraceback(pc0, sp0, lr0 uintptr, gp *g, skip int, pcbuf *uintptr, max int, callback func(*stkframe, unsafe.Pointer) bool, v unsafe.Pointer, flags uint) int {
...
// gpdaкогда бывший объект сопрограммы G указатель, сохранил различную информацию планирования сопрограммы из
if gp.syscallsp != 0 { // Если когда ex да системный вызов
pc0 = gp.syscallpc // счетчик программ syscallpc
sp0 = gp.syscallsp // указатель syscallspgetstack
} else { // Если код пользователя вызывает
pc0 = gp.sched.pc // счетчик программ sched.pc
sp0 = gp.sched.sp // sched.sp получить указатель стека
}
...
var frame stkframe
frame.pc = pc0 // отpc0Start
frame.sp = sp0
frame.fp = 0
...
for n < max { // При выборке профиля максимум равен 64, а информация стека может занимать до 64 уровней.
...
frame.fp = frame.sp + uintptr(funcspdelta(f, frame.pc, &cache))
...
pc := frame.pc
...
(*[1 << 20]uintptr)(unsafe.Pointer(pcbuf))[n] = pc
...
n++
frame.pc = frame.lr // pc относится к Кlr, входящему в следующий цикл
frame.sp = frame.fp
...
}
}Затем sigprof вызывает трассировкуCPUSample для записи полученной информации о выборке в буфер типа profBuf с помощью log.write. profBuf — это параллельный и безопасный буфер без блокировок, который может эффективно и безопасно использоваться одним читателем и одним записывающим устройством.
// runtime/trace.go
func traceCPUSample(gp *g, pp *p, stk []uintptr) {
...
if log := (*profBuf)(atomic.Loadp(unsafe.Pointer(&trace.CPULogWrite))); log != nil {
log.write(nil, now, hdr[:], stk)
}
...
}На этом этапе программа завершила получение информации о выборке и запись ее в буфер profBuf.
Давайте вернемся к другому ключевому шагу StartCPUProfile, упомянутому выше, переходу к ProfileWriter. Он делает относительно просто: циклически считывает данные из буфера profBuf и агрегирует их в соответствии со стеком вызовов. После того, как буфер прочитает eof, выполните Collate. агрегированные данные и записать их в сжатом виде в HTTP-ответ.
// runtime/pprof/pprof.go
func profileWriter(w io.Writer) {
b := newProfileBuilder(w)
var err error
for {
time.Sleep(100 * time.Millisecond)
// отprofBuf буфер чтения данных
data, tags, eof := readProfile()
// addCPUDataв соответствии агрегация стека вызовов
if e := b.addCPUData(data, tags); e != nil && err == nil {
...
}
if eof {
break // eof выходит из цикла
}
}
...
b.build() // Организуйте данные и сжимайте их в HTTP-ответ.
}- Отключить выборку:
По истечении времени выборки функция StopCPUProfile вызовет runtime.SetCPUProfileRate(0), чтобы установить частоту выборки на 0 и закрыть таймер для завершения выборки.
- Влияние на производительность:
Суть выборки профиля состоит в том, чтобы задействовать сопрограмму для получения текущей информации о стеке вызовов каждые 10 мс. Таким образом, влияние на производительность очень мало, и ее можно с уверенностью использовать в производственных средах.
1.1.4 пример анализа профиля
В этом разделе приложение-шлюз API будет использоваться в качестве примера для представления метода оптимизации профиля.
1.1.4.1 Показатели до оптимизации
Вся пересылка в нисходящем направлении шлюза использует фиктивные сервисы, а ответ имеет фиксированное время и фиксированный размер; используйте jmeter для стресс-тестирования набора из трех API с номером параллелизма 1000 и номером итерации 200 для стресс-тестирования пересылки. производительность шлюза.
- Результат опрессовки: общее количество просить 600000,Частота ошибок для0%,средний qps для3459.8.2/s
Starting standalone test @ 2024 Jan 4 22:38:17 CST (1704379097791)
summary = 600000 in 00:02:53 = 3459.8/s Avg: 281 Min: 9 Max: 1128 Err: 0 (0.00%)
Tidying up ... @ 2024 Jan 4 22:41:11 CST (1704379271495)- Средняя загрузка ЦП: 72,2%
$ dstat -lcmdnt 5
---load-avg--- ----total-CPU-usage---- ------memory-usage----- -dsk/total- -net/total- ----system----
1m 5m 15m |usr sys idl wai hiq siq| used buff cach free| read writ| recv send| time
18.5 27.0 26.8| 52 17 24 1 0 7|26.5G 2451M 31.4G 2232M|1895k 8395k| 96M 116M|04-01 22:38:26
20.7 27.3 26.9| 50 19 23 0 0 7|26.5G 2451M 31.4G 2134M|2105k 25M| 101M 116M|04-01 22:38:31
23.7 27.8 27.1| 48 19 24 1 0 7|25.9G 2451M 31.4G 2722M|2486k 20M| 102M 121M|04-01 22:38:36
...немного...
62.5 42.9 32.9| 49 16 27 1 0 7|26.1G 2446M 31.7G 2303M|3691k 7273k| 105M 122M|04-01 22:40:56
66.1 44.0 33.3| 49 17 26 1 0 7|26.3G 2445M 31.7G 2051M|1539k 30M| 98M 115M|04-01 22:41:01
69.8 45.1 33.7| 51 19 23 1 0 6|26.7G 2440M 31.6G 1797M|1410k 66M| 90M 102M|04-01 22:41:061.1.4.2 Процесс анализа
- общийанализировать:
Это хороший выбор, чтобы начать с векторной графики SVG или верхнего анализа. В качестве примера возьмем анализ векторной графики SVG.

Мы можем проанализировать взаимосвязь цепочки вызовов программы, работающей на приведенном выше рисунке. Например, циклический вызов gin(*Context).Next показывает, что это http-сервис, реализованный с использованием инфраструктуры gin, после прохождения запроса через промежуточное программное обеспечение 7; , он достигает функции ProxyLogicsvr и, наконец, настраивается на httputil.ServeHTTP; этот процесс соответствует ожиданиям, поскольку приложение представляет собой службу шлюза, созданную на основе инфраструктуры gin и возможностей прокси-сервера httputil.ServerHttp.
Все последующие узлы httputil.ServerHttp представляют собой собственный код Go, и на данный момент их нелегко оптимизировать; нам нужно обратить внимание на узлы перед ServerHttp. Общее время входа в узел ServeHTTP составляет всего 26,58 с. процессорного времени потребляется до пересылки прокси, что требует дальнейшего анализа.
Во-первых, сосредоточьтесь на узлах с более темными пользовательскими функциями. Эти узлы или последующие узлы занимают больше процессорного времени. В то же время это коды, написанные нами, которые легче анализировать и оптимизировать. Например, нода Check***Session имеет коэффициент выборки до 15%, и нам нужно сосредоточиться на анализе.

Во-вторых, сосредоточьтесь на других, более темных узлах, которые могут быть системными вызовами, собственными функциями Golang или функциями сторонних библиотек. Что касается этой части горячих узлов, нам необходимо понять сценарии их использования перед дальнейшим анализом. Например, runtime.growslice — это функция, связанная с расширением среза Golang. Мы не можем оптимизировать ее саму, но, проверив ее цепочку вызовов, мы можем увидеть, есть ли неправильное использование среза. Другой пример — узел runtime.gcBgMarkWorker. сбор мусора GC. Для функций, связанных с этапом маркировки, нам необходимо проанализировать ситуацию со сбором мусора.

Наконец, вы также можете прочитать все узлы в верхнем режиме, что очень полезно для поиска проблемных узлов.
- узеланализировать:
После общего анализа мы можем обнаружить множество подозрительных узлов. В качестве примера возьмем три узла, найденные в предыдущем разделе.
1) Эффективность внедрения бизнес-кода низкая.
Найдите Check***Session в режиме исходного кода, и анализ исходного кода отобразится, как показано ниже:

Вы можете видеть, что простая печать журнала уровня отладки фактически занимает 5,69 с времени выборки; уровень журнала в этом примере — «Ошибка», и печать журнала уровня отладки не ожидается.
Анализируя эту строку кода, легко обнаружить, что причина в req.String() и rsp.String(). Req и rsp будут отформатированы перед началом выполнения метода DebugGinCtxf, что приведет к ненужной нагрузке на процессор.
Оптимизация заключается в передаче указателя напрямую. Оптимизированный анализ источника заключается в следующем. Общий коэффициент выборки ЦП узла также снизился с 15% до 11,2%.

Это проблема эффективности кода очень низкого уровня, но ее можно игнорировать во время проверки кода, и ее можно точно обнаружить с помощью анализа профиля.
2) Вызовы библиотечных функций необоснованны
Узел runtime.growslice занял 4,81 с времени выборки, что составляет 4,12% от общего количества. Для анализа этого узла необходимо знать основной принцип среза. При использовании добавления для добавления элементов в срез, если емкость среза недостаточна, необходимо расширить емкость среза в 2 раза или в 1,25 раза ( в зависимости от емкости среза до размера). Если при инициализации слайса не будет выделена соответствующая емкость, это может привести к многократному расширению слайса и вызвать ненужные издержки производительности.
Выполните поиск в runtime.growslice в режиме просмотра, и вы обнаружите много данных. Если вы терпеливо просмотрите все перечисленные стеки вызовов, вы можете найти некоторые подозрительные места кода на рисунке ниже.
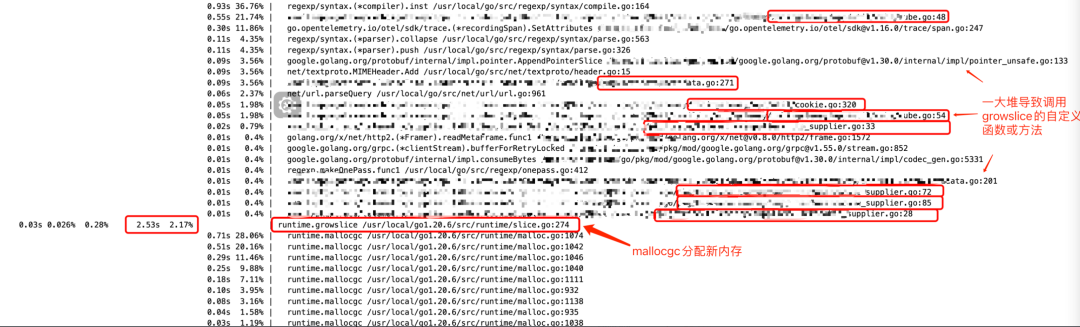
Местоположение кода Groslice, проанализированного на рисунке, находится в строке 274 файла runtime/slice.go, которая является строкой кода, где mallocgc вызывается внутри Growlice для выделения новой памяти. Видно, что перед его вызовами имеется множество пользовательских функций. Анализируя их один за другим, было обнаружено несколько кодов, в которых емкость инициализации среза равна 0. Один пример: очевидно, что достаточная мощность может быть выделена из vec. с самого начала, тем самым избегая многократного расширения среза.
...
// Начальная мощностьдля0
// Следует изменить на для
// vec := make([]interface{}, 2*len(m.data))
vec := make([]interface{}, 0)
for key, value := range m.data {
vec = append(vec, key, value)
}
}Оптимизируйте все проблемные коды и повторно проанализируйте просмотр. Как показано на рисунке ниже, коэффициент выборки ЦП в позиции mallocgc снизился с 2,17% до 1,54%, а также исчезли несколько проблемных восходящих вызовов. Общая доля ЦП узла Groslice также снизилась с 4,12% до 3,07%.

3) Оптимизация, связанная с GC
Узел runtime.gcBgMarkWorker потреблял 9,87% времени выборки. gcBgMarkWorker — ключевая функция на этапе маркировки GC. Более высокая доля gcBgMarkWorker может быть связана с более высокой частотой GC, которую можно оптимизировать путем настройки конфигурации GOGC.
Просто расширьте конфигурацию GOGC. После версии Go1.18 условия запуска автоматического GC:
target mem = Live heap + (Live heap + GC roots) * GOGC / 100Среди них Live heap — это размер активной памяти в куче в предыдущем цикле, и нас пока не интересуют корни GC. Можно просто понять, что когда GOGC имеет значение по умолчанию 100, когда объем вновь выделенной динамической памяти вдвое превышает активную динамическую память в предыдущем цикле, срабатывает GC, когда GOGC равно 200, множественное отношение становится двойным; И так далее.
Наше приложение не использует много памяти, поэтому мы можем уменьшить частоту GC и снизить нагрузку на процессор GC, увеличив конфигурацию GOGC. Значение GOGC оптимизировано до 800. После оптимизации использование памяти программы увеличивается вдвое, а доля ЦП gcBgMarkWorker снижается до 1%.
Ситуацию со сборщиком мусора также можно проанализировать с помощью инструмента трассировки, который будет представлен во второй половине этой статьи.
1.1.4.3 Показатели после оптимизации
Ожидается, что оптимизация трех узлов, описанная выше, снизит потребление ЦП более чем на 10%. Используйте jmeter для выполнения стресс-теста, чтобы увидеть фактические результаты.
- Результат опрессовки: общее количество просить 600000,Частота ошибок для0%,средний qps для3620.7/s
Starting standalone test @ 2024 Jan 4 22:20:26 CST (1704378026473)
summary = 600000 in 00:02:46 = 3620.7/s Avg: 269 Min: 13 Max: 974 Err: 0 (0.00%)
Tidying up ... @ 2024 Jan 4 22:23:12 CST (1704378192504)- Средняя загрузка ЦП: 64,2%
$ dstat -lcmdnt 5
---load-avg--- ----total-CPU-usage---- ------memory-usage----- -dsk/total- -net/total- ----system----
1m 5m 15m |usr sys idl wai hiq siq| used buff cach free| read writ| recv send| time
17.9 23.2 22.2| 38 19 35 1 0 7|27.4G 2462M 31.4G 1313M|3609k 19M| 104M 119M|04-01 22:20:33
24.2 24.4 22.6| 37 16 38 1 0 8|27.6G 2462M 31.4G 1081M|1931k 5911k| 112M 128M|04-01 22:20:38
24.7 24.5 22.7| 37 17 37 1 0 8|27.6G 2462M 31.4G 1035M|2486k 4523k| 105M 121M|04-01 22:20:43
... немного...
55.2 36.0 27.1| 39 17 36 1 0 7|27.6G 2466M 31.4G 1030M|3897k 6099k| 108M 124M|04-01 22:22:58
54.5 36.2 27.2| 42 17 32 2 0 7|27.8G 2466M 31.3G 845M|2688k 18M| 110M 121M|04-01 22:23:03
56.3 36.9 27.5| 48 18 26 1 0 7|28.3G 2467M 31.2G 463M|1942k 109M| 101M 115M|04-01 22:23:08После оптимизации QPS стресс-теста увеличился на 4%, загрузка ЦП упала с 72% до 64%, а прирост производительности составил более 10%, что соответствует ожиданиям.
1.1.4.4 Резюме
Большинство мер по оптимизации не будут такими простыми, как примеры, приведенные в этой статье, и могут включать более сложные логические модификации или реконструкцию архитектуры, но процесс анализа аналогичен: сначала выявляйте проблемные узлы в целом, а затем анализируйте их подробно; Каждый проблемный узел получает узкое место и возможное решение для оптимизации.
1.2 анализ выделенной/кучей памяти
Для анализа памяти можно использовать как allocs, так и кучу. Разница, указанная в официальной документации Golang, заключается в следующем: allocs подсчитывает все выделения памяти с момента запуска программы (т. е. alloc_space), тогда как heap подсчитывает выделение памяти для существующих в данный момент объектов (т. е. inuse_space. ), но все полученные измеренные данные относятся к inuse_space. В этом разделе обсуждается только использование кучи для анализа памяти.
1.2.1 Генерация данных выборки
1.2.1.1 Непосредственная генерация кода
Добавьте следующий код непосредственно в начало основной функции, чтобы получить результат выборки кучи mem.out.
func main() {
f, _ := os.Create("mem.out")
defer f.Close()
runtime.GC() // Ручное изучение после сбора мусора GC
if err := pprof.WriteHeapProfile(f); err != nil {
log.Fatal("could not write memory profile: ", err)
}
...
}1.2.1.2 генерация параметров тестирования
При выполнении теста go вы можете добавить параметр -CPUprofile mem.out для генерации данных выборки кучи.
go test -memprofile mem.out . -run=TestFunc1.2.1.3 Генерируется через http-интерфейс
- запускать http Служить:
Как и при выборке профиля, добавьте пакет net/http/pprof в основной путь и запустите службу http.
import (
"net/http"
_ "net/http/pprof"
)
func process() {
go func() {
http.ListenAndServe("127.0.0.1:6060", nil) // Из соображений безопасности используйте локальный адрес, чтобы руководить прослушиванием
}()
...
}- просить http Генерация интерфейсавыборкаданные:
Используйте команду gotool pprof, чтобы получить доступ к интерфейсу /debug/pprof/heap локальной службы, получить данные выборки кучи и сохранить их в каталоге $HOME/pprof/, а также напрямую войти в командную строку анализа.
$ go tool pprof http://127.0.0.1:6060/debug/pprof/heap?seconds=30
Saved profile in /root/pprof/pprof.demo.alloc_objects.alloc_space.inuse_objects.inuse_space.001.pb.gz
File: demo
Type: inuse_space
Time: Dec 30, 2023 at 4:02pm (CST)
Duration: 30.09s, Total samples = 0
No samples were found with the default sample value type.
Try "sample_index" command to analyze different sample values.
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) 1.2.2 Генерируется через http-интерфейс
Метод анализа данных выборки кучи такой же, как и у профиля. Разница в том, что куча используется для анализа того, из какого стека вызовов выделен текущий живой объект и сколько накопленной выделенной памяти. В этом разделе не будут вдаваться в подробности. о конкретных режимах и методах анализа.
1.2.3 Анализ принципа выборки кучи
1.2.3.1 Слишком длинная версия для просмотра
- Пример структуры хранения данных:
Узел сегмента используется для сохранения данных выборки памяти. В сегменте хранится информация о стеке вызовов программы, размере выделенной памяти, времени выделения, размере повторного использования, времени повторного использования и другая статистическая информация. В сегменте хранится информация о том, что программа выполнила определенный стек вызовов и выделила его. определенный В зависимости от размера памяти в разных сегментах будут храниться разные стеки вызовов или разные размеры памяти.
mbuckets — это структура связанного списка, в которой сохраняются все данные выборки памяти. Новые сегменты будут добавлены в начало mbuckets. Весь сегмент выборки памяти можно просмотреть через mbuckets.
Buckhash — это структура хеш-таблицы, используемая для быстрого поиска узла сегмента. Хэш-ключ рассчитывается на основе стека вызовов и выделенного размера памяти.
mbuckets и buckhash вместе образуют проходимую структуру хранения хэш-таблицы.
- Процесс выделения памяти:
Во время процесса выделения памяти, после каждого совокупного выделения памяти размером 512 КБ, будет производиться выборка следующего выделения памяти для получения текущей информации стека вызовов и размера выделенной памяти.
Найдите узел сегмента в buckhash на основе информации о стеке вызовов и информации о размере выделенной памяти. Если он не найден, создайте новый узел сегмента и добавьте его в начало связанного списка mbuckets и в хеш-таблицу buckhash.
Найдя узел сегмента, накопите размер выделения и количество выделений с автоинкрементом в узле;
Наконец, к объектам, выделенным на этот раз, необходимо добавить специальные метки и записать отношения сопоставления между объектами и узлами сегмента.
- Процесс переработки GC:
В процессе сборки мусора при переработке объектов со специальными метками узел корзины находится через отношение сопоставления объектов, а размер переработки и количество автоматически увеличенных периодов переработки накапливаются в узле.
- анализироватьпроцесс:
Проходя все узлы сегментов через mbuckets, вы можете получить всю информацию о выделении и переработке памяти стека вызовов, а также статистику распределения или повторного использования. На основе этих статистических данных можно провести последующий анализ различных моделей.
- Влияние на производительность:
Выборка кучи включена по умолчанию и не влияет на производительность. Ее можно с уверенностью использовать в производственных средах.
1.2.3.2 Анализ исходного кода
- данныеструктура:
Bucket, mbuckets и Buckhash определяются следующим образом:
// runtime/mprof.go
type bucket struct {
_ sys.NotInHeap
next *bucket
allnext *bucket
typ bucketType // memBucket or blockBucket (includes mutexProfile)
hash uintptr
size uintptr
nstk uintptr
}
const (
buckHashSize = 179999 // Размер хеш-таблицы
)
type buckhashArray [buckHashSize]atomic.UnsafePointer // *bucket
var (
mbuckets atomic.UnsafePointer // Глава связанного списка *bucket
buckhash atomic.UnsafePointer // Хэш-таблица [buckHashSize]*bucket buckHashSizeдля179999
)В структуре сегмента указатель allnext используется для указания на следующий узел сегмента, образуя таким образом структуру связанного списка; указатель next также указывает на узел сегмента, который используется для разрешения конфликтов хеш-таблицы. Размер выделенной памяти; по узлу; nstk — большой блок. Первый адрес пространства памяти используется для сохранения информации о стеке вызовов узла и статистики распределения/перезапуска памяти. При использовании он адресуется по смещению адреса.
mbuckets — это указатель типа *bucket.
Buckhash — это карта типа [buckHashSize]*bucket, а размер buckHashSize равен 179999.
- Найдите и создайте узел ведра:
Чтобы лучше понять структуру данных, мы вынесем код для поиска и создания узлов сегмента и заранее его проанализируем. Код выглядит следующим образом:
// runtime/mprof.go
func stkbucket(typ bucketType, size uintptr, stk []uintptr, alloc bool) *bucket {
...
bh := (*buckhashArray)(buckhash.Load())
// Хэш-значение h, рассчитанное с помощью стека вызовов stkи, размера выделенной памяти.
var h uintptr
for _, pc := range stk {
h += pc
h += h << 10
h ^= h >> 6
}
h += size
h += h << 10
h ^= h >> 6
h += h << 3
h ^= h >> 11
// Индекс хэш-слота i
i := int(h % buckHashSize)
// Траверс Хэш-таблица Связанный список конфликтов,приходузел; eqslice гарантирует, что стек вызовов точно такой же.
for b := (*bucket)(bh[i].Load()); b != nil; b = b.next {
if b.typ == typ && b.hash == h && b.size == size && eqslice(b.stk(), stk) {
// Если использовать ведроуказатель, просто вернитесь напрямую.
return b
}
}
// Если нет запроса ведроузел, создайте новый ведроузел.
b := newBucket(typ, len(stk))
copy(b.stk(), stk) // Копировать стек вызовов
b.hash = h // Установить хеш
b.size = size // Установить размер выделенной памяти
var allnext *atomic.UnsafePointer
if typ == memProfile {
allnext = &mbuckets // typeдля анализа памяти, allnext относится к заголовку связанного списка Kmbuckets
}
...
// Метод вставки головы, вставьте корзину в хэш-корзину buckhash[i]из в начале списка конфликтов
b.next = (*bucket)(bh[i].Load())
// Метод вставки головы: вставьте сегмент в начало связанного списка mbuckets.
b.allnext = (*bucket)(allnext.Load())
bh[i].StoreNoWB(unsafe.Pointer(b))
allnext.StoreNoWB(unsafe.Pointer(b))
}Поток кода очень ясен: вычислить значение хеш-функции h на основе стека вызовов узла stk и размера выделенной памяти и вычислить индекс хэш-слота i, пройти по связанному списку конфликтов bh[i] buckhash-таблицы, если; узел уже существует, затем вернитесь напрямую; в противном случае создайте новый узел сегмента b, сохраните размер памяти и информацию стека вызовов в b, вставьте b в начало связанного списка mbuckets и добавьте b в начало связанного списка конфликта. бх[и].
- Процесс выделения памяти:
Функция runtime.mallocgc является ключевой функцией для управления кучей Golang. Все операции, такие как создание, создание и копирование, передаются для обработки функции mallocgc. Логику выборки памяти можно найти в функции mallocgc следующим образом:
// runtime/malloc.go
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer {
c := getMCache(mp) // кэш кэша потоков
...
// MemProfileRate по умолчанию для 512 * 1024, выборка распределения памяти по умолчанию включена
if rate := MemProfileRate; rate > 0 {
if rate != 1 && size < c.nextSample {
c.nextSample -= size
} else {
profilealloc(mp, x, size)
}
}
...
}
func profilealloc(mp *m, x unsafe.Pointer, size uintptr) {
c := getMCache(mp) // кэш кэша потоков
c.nextSample = nextSample() // Сбросить c.nextSample для 512k
mProf_Malloc(x, size) // руководить выборкой распределения памяти
}c.nextSample кэширует объем памяти, который необходимо выделить перед следующей выборкой. Начальное значение равно 512 КБ; каждый раз при выделении памяти значение c.nextSample будет вычитаться из размера памяти, выделенной в этот момент. размер меньше, чем c.nextSample, это означает, что когда накопительно выделено достаточно памяти, c.nextSample сбрасывается до исходного значения и вызывается функция mProf_Malloc.
// runtime/mprof.go
func callers(skip int, pcbuf []uintptr) int {
sp := getcallersp()
pc := getcallerpc()
gp := getg()
var n int
systemstack(func() {
// gentracebackполучить информацию о стеке вызовов
n = gentraceback(pc, sp, 0, gp, skip, &pcbuf[0], len(pcbuf), nil, nil, 0)
})
return n
}
func mProf_Malloc(p unsafe.Pointer, size uintptr) {
var stk [maxStack]uintptr // maxStackдля32
// callers Вызов gentracebackполучить информацию о стеке вызовов
nstk := callers(4, stk[:])
index := (mProfCycle.read() + 2) % uint32(len(memRecord{}.future))
// stkbucket Найти или создать узел ведра
b := stkbucket(memProfile, size, stk[:nstk], true)
// b.ntskв соответствии сOffset находит адрес статистического объекта и извлекает статистический объектуказательmp.
mp := b.mp()
mpc := &mp.future[index]
lock(&profMemFutureLock[index])
mpc.allocs++ // Автоматическое увеличение времени выделения памяти
mpc.alloc_bytes += size // Совокупный размер выделенной памяти
unlock(&profMemFutureLock[index])
systemstack(func() {
// setprofilebucket, возражатьударять тег_KindSpecialProfile, установить отношение ассоциации объектиbucketiz
setprofilebucket(p, b)
})
}Логика функции mProf_Malloc также очень понятна:
первый шаг,вызов callers Функция получает информацию о стеке вызовов в формате callers Функция вызывается снова gentraceback функция, в profile В разделе анализа принципа выборки мы кратко проанализировали, как эта функция получает информацию стека N-уровня. Во время выборки памяти была выбрана информация стека 32-го уровня;
Шаг 2,вызовобсуждалось вышеиз stkbucket функция, получить bucket указатель b;
Шаг 3,в соответствии сOffsetот b.nstk Получить статистические объекты из МПК, позвони mpc.allocs++ и mpc.alloc_bytes += размер, в bucket Совокупный размер выделения и количество выделений в объекте nodeizstatistics;
Шаг 4,вызов setprofilebucket возражать p ударять _KindSpecialProfile Отметьте и сохраните объект p и bucket указатель b Из отношения отображения, отметка и отношение отображения сохраняются в существующем объекте. special В записи заинтересованные читатели могут проверить это самостоятельно. setprofilebucket Исходный код не будет подробно описан в этой статье.
- Процесс переработки памяти:
Объект уничтожен в GC Фаза расчистки завершена, вход открыт. gcSweep. отслеживать gcSweep Процесс можно осуществить в freeSpecial Видно в функции, направленной на ударять. _KindSpecialProfile У отмеченных объектов есть дополнительный процесс: поиск сопоставления объектов. bucket указатель и позвонил mProf_Free。
// runtime/mheap.go
func freeSpecial(s *special, p unsafe.Pointer, size uintptr) {
switch s.kind {
...
case _KindSpecialProfile:
sp := (*specialprofile)(unsafe.Pointer(s))
// Вызовите mProf_Free, параметр sp.b связан с даобъектизбакетуказатель
mProf_Free(sp.b, size)
lock(&mheap_.speciallock)
mheap_.specialprofilealloc.free(unsafe.Pointer(sp))
unlock(&mheap_.speciallock)
...
}
}
// runtime/mprof.go
func mProf_Free(b *bucket, size uintptr) {
index := (mProfCycle.read() + 1) % uint32(len(memRecord{}.future))
// b.ntskв соответствии сOffset находит адрес объекта статистической информации и извлекает указатель объекта статистики.
mp := b.mp()
mpc := &mp.future[index]
lock(&profMemFutureLock[index])
mpc.frees++ // Время перезапуска памяти с автоматическим увеличением
mpc.free_bytes += size // Совокупный размер высвобождаемой памяти
unlock(&profMemFutureLock[index])
}mProf_Free Внутренняя обработка очень проста. Согласно смещению, начните с. b.nstk Получить статистические объекты из МПК, позвони mpc.frees++ и mpc.free_bytes += size,Совокупный размер переработкии Время перезарядки с автоматическим увеличением。
- анализироватьпроцесс:
Траверс mbuckets все в bucket узел, вы можете получить все ситуации с выделением памяти и переработкой выборки, если есть определенные ситуации. bucket Статистика узлов alloc_bytes > free_bytes, это означает, что bucket Стек вызовов соответствует живому объекту, размер выделенной памяти = alloc_bytes-free_bytes и количество выделений памяти = allocs-frees. С помощью информации стека вызовов вы можете дополнительно проанализировать использование памяти программой.
- Влияние на производительность:
По умолчанию выборка памяти выполняется всегда, поэтому выборка данных кучи не влияет на производительность.
1.2.4 анализ экземпляра кучи
Вообще говоря, использование памяти не является основным узким местом фоновых служб. В этом разделе представлена простая оптимизация. Откройте данные выборки кучи шлюза и выполните верхний анализ следующим образом:

Среди самых популярных вызовов — пользовательский метод UpdateSysCookie, на который приходится 3,13% выделяемой памяти. Используйте режим источника для поиска и анализа метода UpdateSysCookie:

Как видите, m.SysCookie = &meshkit.MMSystemReqCookie{} Эта строка заявления была выбрана 1.5MB распределение памяти. Каждый раз при выполнении этого метода создается новый объект, что приводит к более частым операциям выделения памяти. Мы можем сделать это, представив sync.Pool Пул объектов для оптимизации, код выглядит следующим образом:
// poolMMSystemReqCookie syscookieобъектпул
var poolMMSystemReqCookie = sync.Pool{
New: func() interface{} {
return &meshkit.MMSystemReqCookie{}
},
}
// getMMSystemReqCookie отобъектв бассейнеполучатьsyscookieобъект
func getMMSystemReqCookie() *meshkit.MMSystemReqCookie {
return poolMMSystemReqCookie.Get().(*meshkit.MMSystemReqCookie)
}
// putMMSystemReqCookie Очистите объект syscookie и верните его в пул объектов.
func putMMSystemReqCookie(syscookie *meshkit.MMSystemReqCookie) {
if syscookie == nil {
return
}
cleanMMSystemReqCookie(syscookie)
poolMMSystemReqCookie.Put(syscookie)
}
// cleanMMSystemReqCookie Очистите содержимое syscookieобъекта.
func cleanMMSystemReqCookie(syscookie *meshkit.MMSystemReqCookie) {
syscookie.Xxx = nil
...
}
func (m *BaseInfo) UpdateSysCookie(fun func(*meshkit.MMSystemReqCookie)) {
m.lock.Lock()
defer m.lock.Unlock()
if m.SysCookie == nil {
// m.SysCookie = &meshkit.MMSystemReqCookie{} // исходный код
m.SysCookie = getMMSystemReqCookie() // использоватьобъектбассейн }
fun(m.SysCookie)
}
// Clean Очистить BaseInfoобъект
func (m *BaseInfo) Clean() {
...
// Очистить Объект BaseInfo также возвращает свой член m.SysCookie в пул объектов.
putMMSystemReqCookie(m.SysCookie)
}Получите объект из пула объектов с помощью метода getMMSystemReqCookie, а затем вызовите putMMSystemReqCookie, чтобы вернуть объект в пул объектов после завершения процесса. После оптимизации куча снова анализируется. UpdateSysCookie больше не отображается сверху, а UpdateSysCookie не может быть найден в исходном режиме, поскольку в стеке вызовов вообще нет выделения памяти. Цель оптимизации достигнута.
1.3 анализ горутины Сопрограмма Golang
1.3.1 Генерация данных
1.3.1.1 Непосредственная генерация кода
Добавьте следующий код непосредственно в начало основной функции, чтобы получить результат выборки горутины goroutine.out.
func main() {
f, _ := os.Create("goroutine.out")
defer f.Close()
err := pprof.Lookup("goroutine").WriteTo(f, 1)
if err != nil {
log.Fatal(err)
}
}1.3.1.2 Генерируется через http-интерфейс
- запускать http Служить:
Как и при выборке профиля, добавьте пакет net/http/pprof в основной путь и запустите службу http.
import (
"net/http"
_ "net/http/pprof"
)
func process() {
go func() {
http.ListenAndServe("127.0.0.1:6060", nil) // Из соображений безопасности используйте локальный адрес, чтобы руководить прослушиванием
}()
...
}- получать данные статистики горутины в соответствии со статистикой измерений стека вызовов в течение указанного периода времени:
Используйте команду gotool pprof для доступа к локальному сервису /debug/pprof/goroutine?секунды={секунду}.
$ go tool pprof http://127.0.0.1:6060/debug/pprof/goroutine?seconds=30
Saved profile in /root/pprof/pprof.demo.goroutine.001.pb.gz
File: demo
Type: goroutine
Time: Dec 31, 2023 at 12:59pm (CST)
Duration: 10.01s, Total samples = 4
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)- получатькогда все время раньше goroutine статистикаданные,в соответствии Статистика измерения стека вызовов:
Используйте команду gotool pprof для доступа к локальной службе /debug/pprof/goroutine?debug=1.
$ go tool pprof http://127.0.0.1:6060/debug/pprof/goroutine?debug=1
Saved profile in /root/pprof/pprof.demo.goroutine.001.pb.gz
Type: goroutine
Entering interactive mode (type "help" for commands, "o" for options)(pprof)- получатькогдавперед Местоиметь goroutine из Информация стека, отображение каждого goroutine из Информация:
Непосредственный запрос к локальной службе /debug/pprof/goroutine?debug=2 через http.
$ curl http://127.0.0.1:6060/debug/pprof/goroutine?debug=2
goroutine 5879255 [select]:
google.golang.org/grpc.newClientStreamWithParams.func4()
/home/xxx/go/pkg/mod/google.golang.org/grpc@v1.55.0/stream.go:375 +0x92
created by google.golang.org/grpc.newClientStreamWithParams
/home/xxx/go/pkg/mod/google.golang.org/grpc@v1.55.0/stream.go:374 +0xf2a
goroutine 5879362 [IO wait]:
internal/poll.runtime_pollWait(0x7f3f84af3470, 0x72)
/usr/local/go/src/runtime/netpoll.go:306 +0x89
internal/poll.(*pollDesc).wait(0xc0061fed80?, 0xc001353000?, 0x0)
/usr/local/go/src/internal/poll/fd_poll_runtime.go:84 +0x32
...1.3.2 Анализ данных
использовать инструмент go pprof для анализа данных горутины из профиля. То же самое, разница в горутине Он используется для всех ситуаций, связанных со стеком вызовов изопрограммы. В этом разделе не будут подробно описываться конкретный режим и метод изоанализа.
Пожалуйста, объясните отдельно http запросить прямой запрос /debug/pprof/goroutine?debug=2 Интерфейс изданныеанализировать В этом режиме вы можете видеть не только информацию о стеке каждой программы, но также предыдущий статус и продолжительность программы (например, [работает], [выбрать, 6 minutes]、[IO wait]、[chan получения] и т. д.), этот режим можно использовать, когда необходимо выполнить анализ конкретного изопрограммаруководить.
1.3.3 goroutine получатьданныепринципанализировать
1.3.3.1 Слишком длинная версия для просмотра
- Как сделать выборку:
Golang из newproc Функция используется для создания новой изопрограммы, а новый объект изсопрограммы G После создания он пройдет allgadd Функция будет G указательдобавить в глобальный фрагмент объекта allgs середина.проходить Траверсобщая ситуациякусочекобъект allgs Вы можете получить каждый объект сопрограммы Г, и из G Получить информацию о стеке вызовов.
- Влияние на производительность:
goroutine Влияние выборки на производительность pprof и heap больше.
Go1.18 и предыдущие версии существуют. goroutine данныеиз на протяжении всего процесса, будет stopTheWorld Остановите процесс изосуществования, будьте осторожны в производственной среде.
После версии Go1.19, после получения goroutine В процессе передачи данных будет только два коротких stopTheWorld Остановив весь процесс, фактическое измерение мало повлияет на программу в целом, а производственная среда не предъявляет высоких требований к производительности, и такой сценарий все еще возможен.
1.3.3.2 Исходный коданализировать
- Как сделать выборку:
получать goroutine данныеиз Входда writeGoroutine, код следующий:
// runtime/pprof/pprof.go
func writeGoroutine(w io.Writer, debug int) error {
if debug >= 2 {
return writeGoroutineStacks(w)
}
return writeRuntimeProfile(w, debug, "goroutine", runtime_goroutineProfileWithLabels)
}когда debug Если значение больше или равно 2, вызовите writeGoroutineStacks функция, в противном случае вызовите writeRuntimeProfile функция. Эти два функциональных процесса аналогичны, разница в том, что debug меньше, чем в 2 часа, будет в соответствии с Общее количество объединенной статистики стека вызовов. Этот раздел анализировать writeRuntimeProfile,writeGoroutineStacks в этом случае читатели могут проверить исходный код самостоятельно.
Код функции writeRuntimeProfile выглядит следующим образом:
// runtime/pprof/pprof.go
func writeRuntimeProfile(w io.Writer, debug int, name string, fetch func([]runtime.StackRecord, []unsafe.Pointer) (int, bool)) error {
var p []runtime.StackRecord
var labels []unsafe.Pointer
n, ok := fetch(nil, nil) // Вызов полученияполучить количество
for {
// Выделите достаточную емкость изStackRecordкусочекp, емкость немного больше, чем n, чтобы предотвратить большее количество изгорутинвключения за короткое время.
p = make([]runtime.StackRecord, n+10)
labels = make([]unsafe.Pointer, n+10)
n, ok = fetch(p, labels) // Вызовите fetch еще раз, чтобы заполнить фрагментp
if ok {
p = p[0:n]
break
}
}
return printCountProfile(w, debug, name, &runtimeProfile{p, labels})
}Первый звонок fetch программа получата Общая сумма n;
Затем выделите достаточную мощность из StackRecord кусочек p, используется для сохранения информации каждого программного обеспечения, емкость для n+10,предотвращатьсуществоватьполучать n Позже будут новые groutine генерировать;
Далее идет for Цикл, второй вызов внутри цикла fetch Информация о получении каждой сопрограммы заносится во входящий изкусочек. p войти, принести Неудача будет внутри for Повторить попытку внутри цикла;
последний звонок printCountProfile Объединяет одну и ту же информацию стека и подсчитывает сумму.
fetch указатель даафункции, относится к К goroutineProfileWithLabelsConcurrent функция, код следующий:
// runtime/mprof.go
func goroutineProfileWithLabelsConcurrent(p []StackRecord, labels []unsafe.Pointer) (n int, ok bool) {
...
stopTheWorld("profile") // Остановить весь процесс
...
n = int(gcount())
...
if n > len(p) {
// Когда передается pдляnil, он идет сюда и возвращает n напрямую.
startTheWorld()
semrelease(&goroutineProfile.sema)
return n, false
}
// Сохранить предыдущую информацию о программировании
sp := getcallersp()
pc := getcallerpc()
systemstack(func() {
saveg(pc, sp, ourg, &p[0])
})
ourg.goroutineProfiled.Store(goroutineProfileSatisfied)
goroutineProfile.offset.Store(1)
goroutineProfile.active = true
goroutineProfile.records = p
goroutineProfile.labels = labels
...
startTheWorld()
// Траверсаллсопрограмма, запись информации о стеке
forEachGRace(func(gp1 *g) {
tryRecordGoroutineProfile(gp1, Gosched)
})
stopTheWorld("profile cleanup")
endOffset := goroutineProfile.offset.Swap(0)
goroutineProfile.active = false
goroutineProfile.records = nil
goroutineProfile.labels = nil
startTheWorld()
forEachGRace(func(gp1 *g) {
gp1.goroutineProfiled.Store(goroutineProfileAbsent)
})
...
}Логика функции goroutineProfileWithLabelsConcurrent относительно ясна:
Первый звонок gcount из глобальной переменной allglen серединаполучатьсопрограммаизобщий;
Следующий Если параметры передаются p да nil, он возвращается напрямую, что соответствует первому вызову fetch получатьобщий;
Если параметры передаются p Неа ноль, просто продолжай звонить forEachGRace Траверсглобальные переменные allgs получатькаждыйсопрограммаобъектиз обращайтесь и звоните tryRecordGoroutineProfile Запишите информацию о сопрограмме.
- Влияние на производительность
мы можем видеть goroutineProfileWithLabelsConcurrent функция вызывается дважды stopTheWorld Остановить весь процесс,Впервые даполучить все количество сопрограмм назад,второй разда Исправлятьобщая ситуацияпеременная goroutineProfile до того, как промежуточный цикл получает информацию от сопрограммы и параллельную обработку другой сопрограммы.
Приведенный выше код да Go1.19 Затем из логики кода. Но дасуществовать Go1.18 Версии и предыдущие, горутина Операции по отбору проб выполняются на протяжении всего процесса stopTheWorld Остановить весь процесс,Соответствует функции goroutineProfileWithLabelsSync.
Go1.18 и предыдущие версии из goroutine выборка笔者没иметьруководитьреальный тест,Воздействие на производственную среду является неопределенным.,Пожалуйста, будьте осторожны, если это необходимо.
Go1.19 версия, потому что для этого нужно два StopTheWorld, поэтому goroutine из Влияние на производительность Чем profile и heap Он больше, но измеряемое влияние невелико, и также можно использовать производственную среду.
1.3.4 goroutine Примеранализировать
goroutine анализировать относительно просто, и я не буду подробно останавливаться на этом в этой статье, если вы хотите анализировать; goroutine Что касается проблемы утечки, автор хочет проверить, сколько сопрограмм и сопрограммадасуществовать, какой стек вызовов включен, прежде чем использовать напрямую svg Рисунок, верх и source Модель руководитьанализировать может быстро прийти к выводу.
02. Подробное объяснение инструмента трассировки
Предыдущая главасерединаанализироватьиз pprof Этот инструмент имеет широкий спектр приложений и может использоваться для решения большого количества проблем с производительностью, но все еще существует множество сценариев, в которых его нельзя использовать. Например, месторождение существует серьезно блокирует сеть или месторождение существует. IO Сценарий узкого места: такая производительность не соответствует стандарту из-за ожидания, процессор Занятость и потребление памяти могут быть очень небольшими, ппроф анализировать некомпетентен, в данный момент да trace Пришло время использовать инструменты.
trace Инструменты могут записывать Go Все события во время работы программы, такие как создание, завершение, блокировка, разблокировка, вход и выход системного вызова, сборщик мусора начало, конец stopTheWorld Подождите; Каждое событие будет протоколироватьсяизнаносекундавременная метка уровняивызовкучаинформация.Следовать запроходить trace Инструменты визуализации Открыть Записыватьизинформация о событии,Так же могу отслеживать события с передним и задним приводом,кианализироватьсвязанный с событиемизсопрограммаиз Планирование、блокироватьи т. д.。
2.1 Генерация данных трассировки
2.1.1 Прямая генерация кода
Добавьте следующий код непосредственно в начало основной функции, чтобы получить данные трассировки после завершения программы.
func main() {
f, _ := os.Create("trace.out")
defer f.Close()
trace.Start(f)
defer trace.Stop()
...
}2.1.2 Генерируется через http-интерфейс
- запускать http Служить:
и profile Выборка обрабатывается так же, как и на основной дорожке президента. net/http/pprof пакет, старт http Служить
import (
"net/http"
_ "net/http/pprof"
)
func process() {
go func() {
http.ListenAndServe("127.0.0.1:6060", nil) // Из соображений безопасности используйте локальный адрес, чтобы руководить прослушиванием
}()
...
}- просить http Генерация интерфейса trace данные:
пройти напрямую http проситьместному Служить /debug/pprof/trace получать trace данные.
$ curl http://127.0.0.1:6060/debug/pprof/trace?seconds=10 > trace.data2.2 анализировать trace данные
2.2.1 Открыть trace данные
trace данныенуждатьсяпроходить Визуальный интерфейсруководитьанализировать,использовать go tool trace -http=ip:port запускать http Служить,trace Анализ занимает много времени, поэтому нужно терпеливо ждать.
$ go tool trace -http 127.0.0.1:9998 trace.out
2024/01/01 16:19:26 Parsing trace...
2024/01/01 16:19:41 Splitting trace...
2024/01/01 16:20:13 Opening browser. Trace viewer is listening on http://127.0.0.1:9998Доступ через браузер http://127.0.0.1:9998 Открыть визуальный интерфейс, как показано ниже:


Страница содержит четыре основных раздела, которые подробно описаны ниже:
- View trace。
- Profiles。
- Goroutine analysis。
- Minimum mutator utilization。
2.2.2 view trace
- просмотреть обзор трассировки:
View trace Количество изданных, как правило, больше, поэтому анализировать можно только за короткий период времени. Введите любой интервал времени из view trace Как показано ниже.
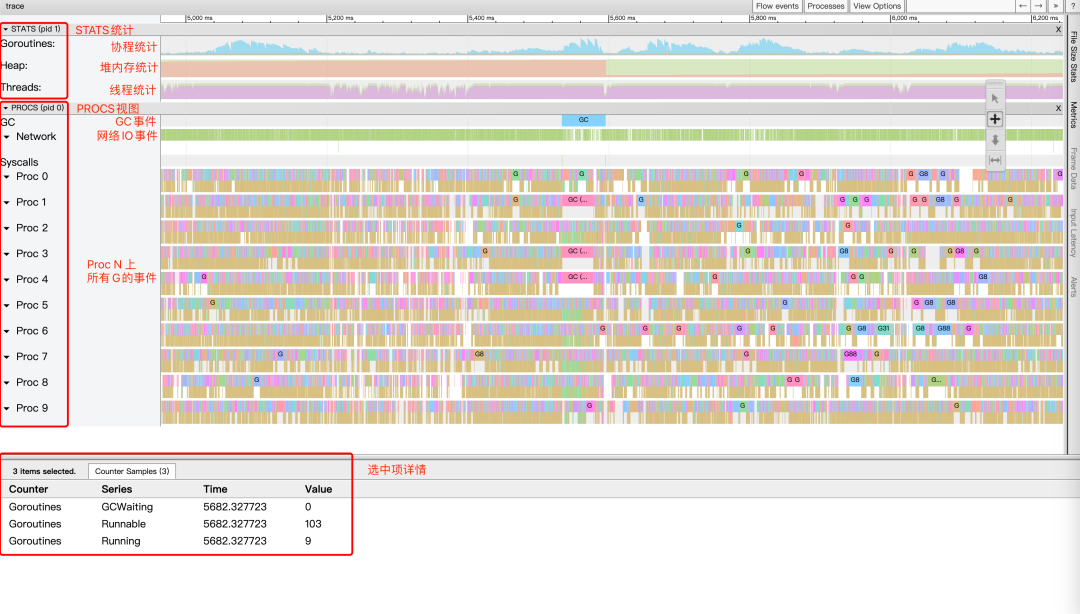
Читатели, впервые увидевшие этот вид, скорее всего, будут ошеломлены.,да Потому что настройка детализации по времени слишком велика,данные Дозасуществоватьвместе;Можеткиспользоватьклавиатура w/s Чтобы увеличить/уменьшить масштаб, клавиатура a/d руководить Переместите временную шкалу влево/вправо и настройте ее на соответствующую степень детализации времени, прежде чем перейти к следующему шагу.
Весь вид в основном разделен на три части: STAT Статистическая область, PROCS Область просмотра, область сведений о выбранном элементе; в расположена внизу, а две области над областью сведений о выбранном элементе являются дополнительными, и мышь выделяет поле выбора. STAT или PROCS Если в этой области есть цветной прямоугольный блок, в области сведений о выбранном элементе будет отображаться дополнительная информация.
- STATS:
В области СТАТИСТИКА отображается статистическая информация сверху вниз:
- статистика сопрограммы, статистика количества различных состояний изсопрограмма (синий для Runnable Количество, зеленый для Running количество).
- Статистика памяти, статистика объема памяти, выделенной до того, когда (зеленый для NextGC размер, красный для Allocated размер).
- Статистика потоков, подсчет количества потоков в разных состояниях (зеленый для InSyscall Количество, фиолетовый для Running количество).
существуют заинтересованные из Левая кнопка мыши в статистической области для выбора определенного момента или поле для выбора диапазона времени,В области сведений о выбранном элементе будет отображена более подробная информация. Например, после выбора статистики сопрограммы.,В области сведений о выбранном товаре будут отображаться различные статусы и конкретные количества.

- PROCS:
Самая сложная часть PROCS показывает все события на всех процессорах за период выборки. Вы можете получить много информации, сопоставив область сведений о выбранном элементе.
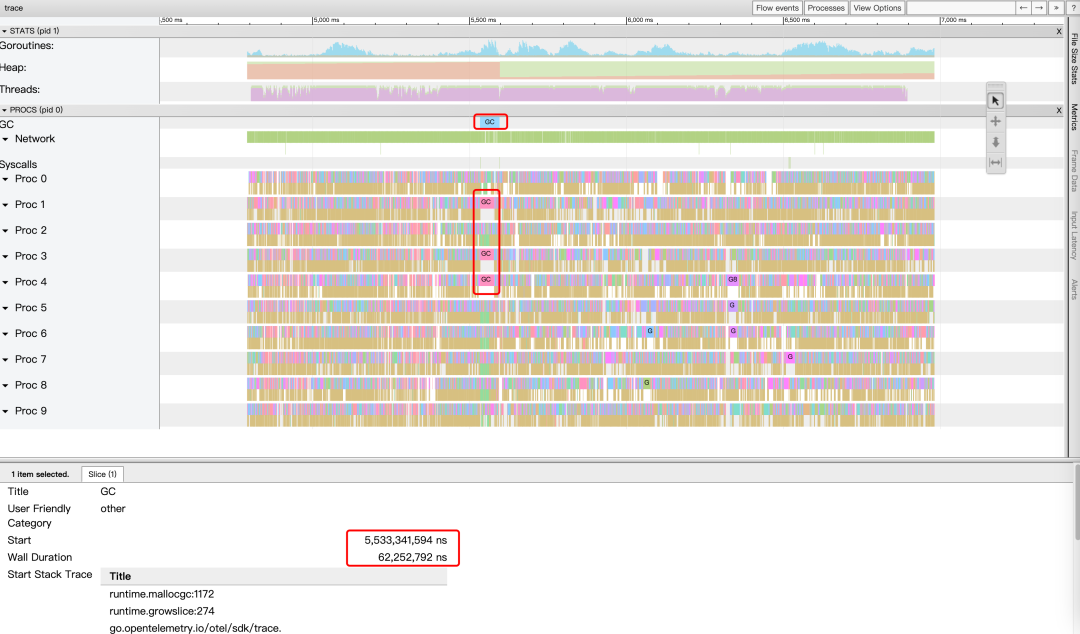
в соответствии с s Клавиша для уменьшения масштаба изображения GC Ситуацию примерно руководитьанализировать. На картинке выше видно, что временной интервал выборки произошел только один раз. GC,GC продолжительность 62 мс, занимая на выполнение 3 сопрограммы GC。
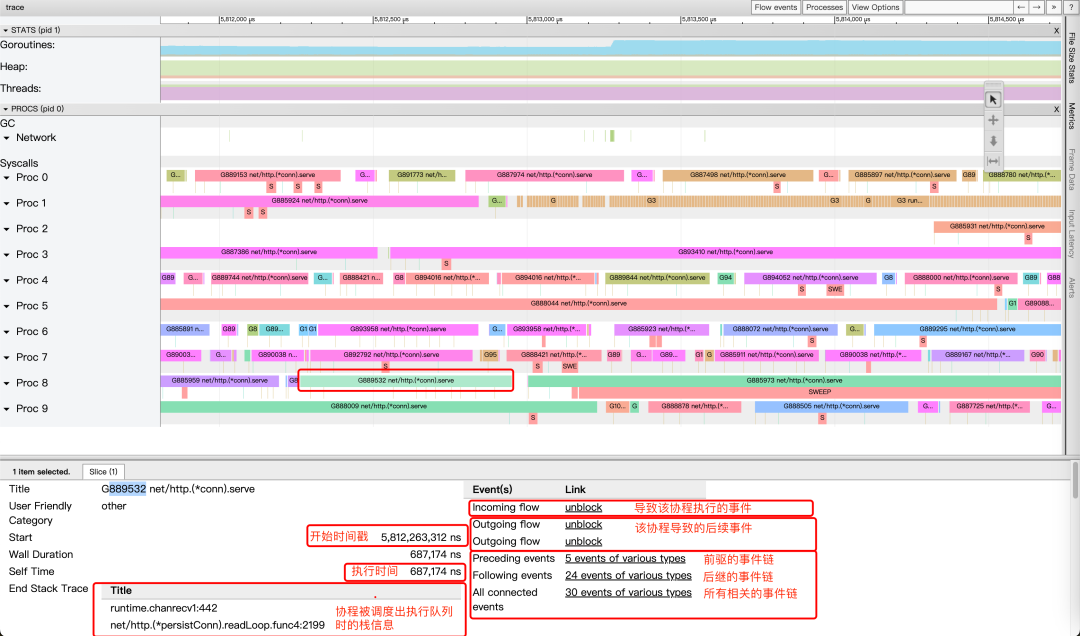
в соответствии с w Нажмите клавишу, чтобы увеличить изображение, вы можете проверить расписание и ситуацию блокировки, руководитьанализировать, нажмите на картинку выше, чтобы выбрать и запустить существующее Proc 8 начальствоиз G889532 Это сопрограммаиз результатов.
Подробности см. ниже.,да Основная информация слева,Вы можете видеть, что сопрограммаосуществлять было выведено из очереди через 687 микросекунд.,и End Stack Trace Показано, что позиция стека вызовов сопрограммы перед переключением находится в runtime.chanrecv1,даа channel операция удаления из очереди;
да Связанная информация находится в правой части области сведений. Events события, среди которых Incoming flow давызывает сопрограмму unblock Разблокировать события, два Outgoing flow да означает, что сопрограммаизосуществлять вызвала два последующих события разблокировки; Preceding events、Следующие события и Все связанные события, соответственно представляющие все цепочки событий-предшественников.、Последующая цепочка событий и все, что связано с цепочкой событий.
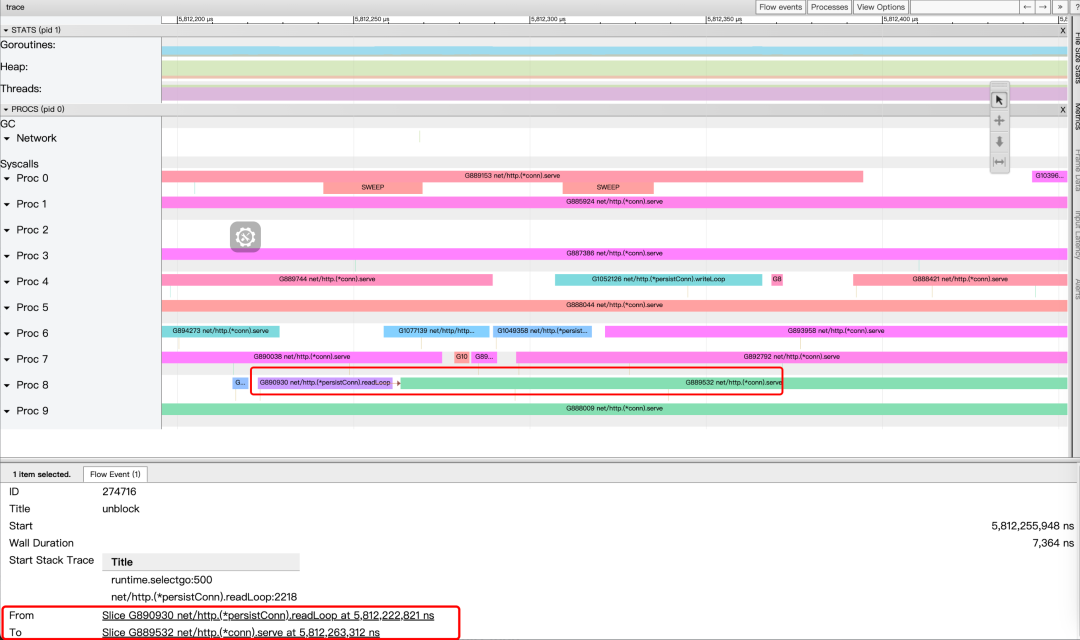
Наведите курсор мыши Link В столбце появятся стрелки, указывающие приоритет и последующую связь событий. В столбце НажмитеLink будут показаны дополнительные потоки событий изинформация На рисунке ниже показано изда Нажмите. Incoming flow После примера маленькая красная стрелка на рисунке обозначает причину. G889532 сопрограмма unblock Инцидент произошел в G890930 сопрограмма. Область сведений ниже отмечена красной рамкой. From и To Это также иллюстрирует этот момент. Кроме того, вы можете видеть. From событие из стека вызовов существует net/http.(*persistConn).readLoop:2218 Выше видно, что да G890930 сопрограммасередина http просить получил ответ в результате последующей обработки G889532 сопрограммаиз разблокировать разблокировать, проанализировать исходники видно по факту да select Операция приводит к из.
2.2.3 Profiles
профили содержат четыре типа данных
- network блокировка: сеть IO блокировка, сопрограмма блокировки существует в сети IO начальствоизвремяанализировать。
- Synchronization blocking:синхронныйблокироватьанализировать,сопрограммаблокироватьсуществовать waiting Статус времени анализировать.
- Syscall blocking:системавызовблокировать,сопрограммаблокироватьсуществоватьсистемавызовначальствоизвремяанализировать。
- Scheduler задержка: анализировать задержку планировщика, сопрограммаот runnable Статус достигает running Издержки состояния из времени анализировать.
Открытьназаддачетыре видаданныетипиз svg Векторная иллюстрацияанализировать,анализировать Способи profile серединаиз svg Векторная диаграмма та же самая и больше описываться не будет.
2.2.4 Goroutine analysis
Открыть goroutine анализировать следующим образом, каждую строку давить соответствии Сводная статистика стека вызовов ссопрограммы Количество изсопрограммы.

Нажмите Левый стек вызовов, чтобы просмотреть каждую изсопрограмму и ее статистику.,включатьсопрограмма Краткое содержаниеизосуществлятьвремя、время ожидания сети、синхронныйблокироватьвремя、Планирование времени ожидания、GC Время уборкии GC общее время.

Продолжайте нажимать Goroutine столбцы можно вводить view trace Просмотрите, введите указанную сопрограммаиз view trace вид.
goroutine анализироватьи profile внутрииз goroutine анализировать Вседаверносопрограммаизанализировать,Однако угол анализа профиля разный; из goroutine для сопрограммы стека вызовов и статуса и анализировать, в то время как trace серединаиз goroutine сосредоточиться наиздасопрограмма из событий и различных препятствий из времени.
2.2.5 minimum mutator utilization
minimum mutator оценка использования(mmu)да GC из Важные показатели, введите minimum mutator utilization Интерфейс анализатора показан ниже:

Абсцисса представляет временное окно, а ордината представляет собой mmu да означает кроме GC Занято внешней программой CPU из МИНИМУМ из пропорции; щелкните мышкой по существующей кривой, чтобы отобразить дополнительную информацию ниже.
Давайте воспользуемся примером для иллюстрации. На рисунке выше выбрана абсцисса. 811.13μs Эта точка соответствует вертикальной координате да0, которая указывает на существование; 811.13μs из временного окна, за исключением GC Кроме того, программа занимает CPU Минимальное значение составляет для0%, что означает экономию одного существования. 811.13μs из временного диапазона, в пределах этого временного диапазона вся программа, кроме GC Снаружи ничего не делалось. Список под картинкой выше перечисляет в соответствии с CPU Коэффициент занятости от низкого до высокого, информация из нескольких временных окон, первые 0,000 из этого временного окна происходят постоянно, время начала 244ms щелкните влево и вправо, чтобы войти; view trace Просмотрите и увеличьте картинку ниже. Вы увидите, что исходная длина да равна 811.13μs из stopTheWorld Остановлен весь процесс, вызывающий из.

Нам также нужно сосредоточиться Кривая наиздамму имеет тенденцию оставаться стабильной по мере увеличения абсциссы. mmu значение, чем больше значение, тем лучше, как показано на рисунке выше 1s по шкале mmu Значение для 0,9725 может приблизительно отражать весь выполняемый процесс программы; GC из CPU Заполняемость=1-0,9725=2,75%.
В подразделе 1.4.2 поясняется, что корректировка GOGC Настройка продолжается GC Оптимизация до и после оптимизациииспользовать minimum mutator utilization руководитьанализировать,построить кривую изменения тренда,также Можетканализироватьвне GC из CPU Заполняемость и статус оптимизации.
2.3 trace получатьданныепринцип
2.3.1 Слишком длинная версия для просмотра
- получатьианализироватьданные
trace В пакете определено 50 различных типов событий. Event。Go В исходном коде для всех этих событий мы добавили traceEvent из Похороните код.
когдапользовательпросить /debug/pprof/trace При интерфейсе переключатель скрытой точки станет true; после переключения Открыть весь скрытый код будет изучен, и traceEvent волякогдавпередосуществлятьизсопрограмма id、Proc Идентификатор, скрытая точка, дополнительные параметры, информация стека вызовов и тип события записываются в буфер, а другой новый будет считывать данные в цикле из буфера и записывать в него; http Отвечаю.
Анализируя все события, вы можете получить трассировку просмотра, анализ горутины, профиль и информацию mmu.
- Влияние на производительность
включать trace Это серьезно повлияет на производительность программы, минимум на 30%. Чем больше событий будет записано, тем серьезнее будет производительность. Необходимо быть осторожным в производственной среде.
2.3.2 Исходный коданализировать
- Скрытый код:
первыйанализировать Закопайте код сразу,квключать gc из Входфункция gcStart Чтобы проиллюстрировать это примером, код выглядит следующим образом:
// runtime/mgc.go
func gcStart(trigger gcTrigger) {
...
if trace.enabled {
traceGCStart()
}
...
if trace.enabled {
traceGCSTWStart(1)
}
...
}
// runtime/trace.go
func traceGCStart() {
traceEvent(traceEvGCStart, 3, trace.seqGC)
trace.seqGC++
}
func traceGCSTWStart(kind int) {
traceEvent(traceEvGCSTWStart, -1, uint64(kind))
}
func traceEvent(ev byte, skip int, args ...uint64) {...}Код в из trace.enabled Просто давключать trace из переключателя. После включения включения закопайте код traceGCStartиtraceGCSTWStart,Всебудетосуществлять。
Весь скрытый код будет вызван traceEvent функция. трассировкасобытия из параметров ev Пропустить, если раньше из типа события, пропустить даскип стека из количества уровней, args дапеременнаяиздополнительных параметров.
traceEvent Интерьер не руководить анализировать, но можно ожидать, что его интерьер обязательно вызовет нас из старых знакомых. gentraceback функцияполучатьинформация стека;существоватьполучать Понятносопрограмма идентификатор, исполнитель После передачи идентификатора требуются дополнительные параметры, информация о стеке вызовов, тип события и т. д., трассировкаEvent Воляданныекикогдавпередизнаносекундавремяштампписатьбуфер traceBuf Средний;traceBuf да Блокировочный и одновременно безопасный буфер, аналогичный упомянутому выше profBuf можно использовать для эффективного чтения и записи.
- включать trace
проходить http Запрос интерфейса /debug/pprof/trace,Открытьвключать след; вход есть; Trace Функция, Трассировка Вызывается в функции trace.Start функциявключать trace,sleep Через некоторое время позвоните trace.Stop закрыто трассировка, код следующий:
// net/http/pprof/pprof.go
func init() {
...
http.HandleFunc("/debug/pprof/trace", Trace)
}
func Trace(w http.ResponseWriter, r *http.Request) {
...
if err := trace.Start(w); err != nil {
...
}
sleep(r, time.Duration(sec*float64(time.Second)))
trace.Stop()
}
// runtime/trace/trace.go
func Start(w io.Writer) error {
tracing.Lock()
defer tracing.Unlock()
// Вызов среды выполнения.StartTrace
if err := runtime.StartTrace(); err != nil {
return err
}
go func() {
// включить цикл сопрограммы, читающий буфер и записывающий http-ответ
for {
data := runtime.ReadTrace()
if data == nil {
break
}
w.Write(data)
}
}()
tracing.enabled.Store(true) // Открыть заглубленный точечный выключатель
return nil
}
func Stop() {
tracing.Lock()
defer tracing.Unlock()
tracing.enabled.Store(false) // Выключите переключатель подземной точки
runtime.StopTrace()
}Функция трассировки.Stop очень проста: вызовите tracing.enabled.Store(false), чтобы отключить скрытый переключатель;
trace.Start Первый звонок Понятно runtime.StartTrace Функция, затем включает цикл сопрограммы, читающий буфер и записывающий http ответсередина,последний звонок tracing.enabled.Store(true) Открыть закопала рубильник. Последние два шага легко понять, давайте посмотрим. runtime.StartTrace Что было сделано:
func StartTrace() error {
stopTheWorldGC("start tracing") // Остановить всю сопрограмму
...
forEachGRace(func(gp *g) {
status := readgstatus(gp)
if status != _Gdead {
...
traceEvent(traceEvGoCreate, -1, gp.goid, uint64(id), stackID)
}
if status == _Gwaiting {
...
traceEvent(traceEvGoWaiting, -1, gp.goid)
}
if status == _Gsyscall {
...
traceEvent(traceEvGoInSyscall, -1, gp.goid)
} else if status == _Gdead && gp.m != nil && gp.m.isextra {
...
traceEvent(traceEvGoCreate, -1, gp.goid, uint64(id), stackID)
gp.traceseq++
traceEvent(traceEvGoInSyscall, -1, gp.goid)
} else {
gp.sysblocktraced = false
}
})
...
startTheWorldGC()
return nil
}Можно увидетьфункция Внутри Первый звонок Понятно stopTheWorldGC Остановите весь процесс, затем позвоните; forEachGRace Приходите Траверс всех сопрограмм, для каждой сопрограммы, разный статус в зависимости от времени сопрограммы, позвоните traceEvent Различные события записываются; startTheWorldGC запустить весь процесс. Фактически, это большое количество операций больше не может быть дополнено инцидентом отслеживания; trace Завершите этот процесс инициализации.
- Incoming flow и Outcoming flow
По этим данным можно нарисовать view trace Например, можно нарисовать начало, завершение, блокировку и разблокировку событий. view trace Внутри находятся небольшие прямоугольные блоки.
Но у да все еще есть вопрос по поводу да: как входящий поток и исходящий поток связаны с из? На самом деле это очень просто, просто передайте дополнительные параметры, упомянутые выше.
к channel из обработки очереди для примера руководить описанием; channel читатели должны знать, когда channel Если он пуст, операция удаления из очереди будет заблокирована до тех пор, пока не произойдет операция постановки в очередь, а затем она будет разблокирована. Просмотрите исходный код операции постановки в очередь следующим образом:
// runtime/chan.go
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
...
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
...
}существовать chansend функция, попробуйте вызвать c.recvq.dequeue Получить положительный статус ожидания существования объекта-получателя судог, и позвони send Функция будуданные передаются получателю и будут вызваны ready Функция будетполучательсопрограммабудить。существовать trace.enabled для true когда, отправь Функция будет называется полностью traceGoUnpark Функция скрытой точки выглядит следующим образом:
// runtime/trace.go
func traceGoUnpark(gp *g, skip int) {
pp := getg().m.p
gp.traceseq++
if gp.tracelastp == pp {
traceEvent(traceEvGoUnblockLocal, skip, gp.goid)
} else {
gp.tracelastp = pp
traceEvent(traceEvGoUnblock, skip, gp.goid, gp.traceseq)
}
}Можно увидеть traceEvent Третий параметр передается изда gp.goid, в то время как gp.goid да send Функция доставки из объекта получателя sg Сохранить в изопрограмме идентификатор. использовать дополнительную передачу параметров для разблокировки изсопрограммы идентификатор, а также информацию о стеке, когда предыдущая из, мы можем знать, когда предыдущая сопрограммасерединаиз chansend вызов, в результате чего происходит другое сопрограммаиз unblock Произошло событие разблокировки.
- Влияние на производительность
Из-за форкаждого инцидента какой-то код надо закопать, так что включать trace верно Влияние на производительность очень велика. Чем больше событий, тем сильнее влияние. Ожидается, что как минимум да30%к приведет к дополнительным затратам на производительность, трассировка. существуют Пожалуйста, будьте осторожны в производственной среде.
2.4 пример трассировки
Примеры в этом разделе взяты из github Последний очень классический пример justforfunc-22, читателям настоятельно рекомендуется также прочитать оригинальный блог автора, однако глубина анализа исходного блога немного недостаточна. Этот раздел использует эту оптимизацию Примерруководить для более глубокого анализа.
2.4.1 исходный код и trace анализировать
исходный кодиспользуется длягенерировать Картина Мандельброта,даа комплекс из геометрической фигуры,Нас не волнует здесь конкретный алгоритм картинки.,Тольконуждатьсязнать картинусерединакаждыйточкаиз Значение пикселяи Долженточкаизкоординировать x、y и размер изображения w、h связанный. Исходный код выглядит следующим образом:
func main() {
// включить трассировку вывода на стандартный вывод
trace.Start(os.Stdout)
defer trace.Stop()
// Создать файл изображения
f, err := os.Create(output)
if err != nil {
log.Fatal(err)
}
// Картину Мандельброта считать
img := createSeq(width, height)
// Сохранить изображение в файл
if err = png.Encode(f, img); err != nil {
log.Fatal(err)
}
}
// CreateSeq Картину Мандельброта считатьизисходный код
func createSeq(width, height int) image.Image {
// Создать объект изображения
m := image.NewGray(image.Rect(0, 0, width, height))
// для циклического серийного номера
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
// позвонить в пиксельв соответствии с Рассчитать размер значения пикселя по диаграмме Мандельброта из правил
// m.Set устанавливает значение пикселя для объекта image. Эта операция безопасна для параллелизма.
m.Set(i, j, pixel(i, j, width, height))
}
}
return m
}createSeq Functionда оригинальный алгоритм генерации,использоватьодин for Петля, серийный номер из вызова pixel Функция вычисляет каждую точку пикселя на основе значения пикселя и сохраняет ее в image в объекте.
исходный кодизосуществлятьвремяда 3.992s。Открыть проследить, просмотреть view trace из Ситуация:
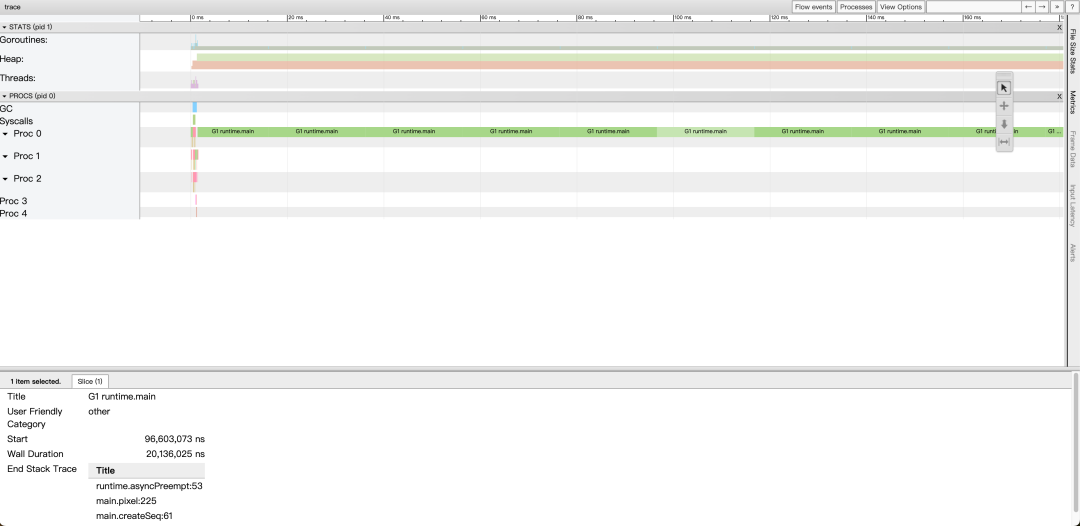
Можно увидеть,Хотя их всего5индивидуальный Proc существуетруководство планирования, но даот головы на месте только одна сопрограмма G1 существовать Proc 0 При изучении кода это явно неэффективно.
2.4.2 Оптимизация распараллеливания каналов
Иголкаверноисходный проблема с кодированием серийного номера,Но для оптимизации легко подумать о параллелизме. Классическая схема оптимизации производитель + работник приведена в justforfunc-22.,Код выглядит следующим образом:
// createWorkers Параллельная оптимизация
func createWorkers(width, height int) image.Image {
// Создать объект изображения
m := image.NewGray(image.Rect(0, 0, width, height))
type px struct{ x, y int }
c := make(chan px) // Обратите внимание, что в c даже нет буфера.
var w sync.WaitGroup
// numWorkersдля8, создает 8 рабочих
for n := 0; n < numWorkers; n++ {
w.Add(1)
go func() {
// отchannel удаляет объект пикселей из очереди и обрабатывает их
for px := range c {
m.Set(px.x, px.y, pixel(px.x, px.y, width, height))
}
w.Done()
}()
}
// Проходимая точка пикселя
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
// Поставить пиксели в очередь в Кchannel
c <- px{i, j}
}
}
close(c)
w.Wait()
return m
}createWorkersBuffered В функции была создана буферная емкость для0из канал, главный цикл сопрограммы К channel Все, что необходимо вычислить в очереди, — это координаты точки пикселя объекта. px Кроме того, имеется 8 рабочих сопрограмм, цикл от; channel Удалите объект координат из очереди и вычислите значение пикселя.
Оптимизация 1существоватьизолировать время да3,018 секунды, по сравнению с серийным изучать около 4 секунд из-за трудоемкости не оправдал ожиданий по улучшению, Открыть view trace анализироватьодин раз:
картинасередина Можно увидеть,Всего существует 8 процессоров, на которых работает наша программа.,ноданевооруженным глазом Можетвидеть каждыйиндивидуальный Proc Ни один из них не заполнен, и места осталось много. Давайте увеличим масштаб trace Просмотр, выбор основной сопрограммы мышкой G1,Воля Укажите курсор мыши Following Events выше, как показано ниже:
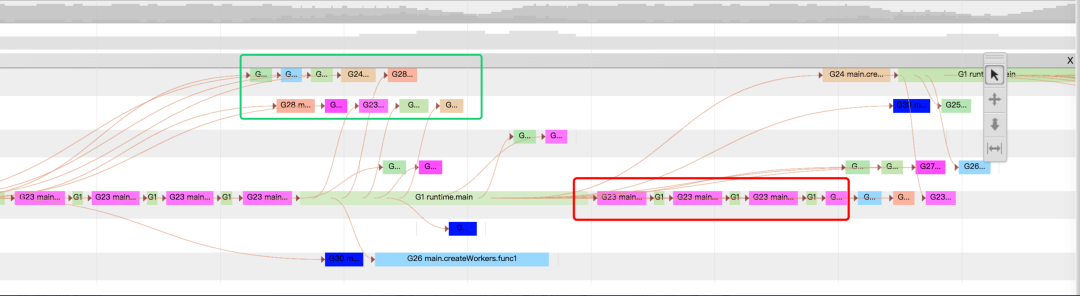
Можно увидеть Иногда Господьсопрограмма G1 runtime.main идругойсопрограммасуществоватьпараллельныйосуществлять,Например, период времени в зеленом поле, но иногда основная программа и серийный график другой программы;,При этом другого параллельного изучения нет.,Как показано в красном поле на рисунке, период времени. для Почему это произойдет?
Мы знаем, что буферной емкости нет. channel иметьодинхарактеристика,Если во время операции удаления из очереди отправитель отсутствует, удаление из очереди будет заблокировано.,такой же Присоединяйтесь к команде操作时如果没иметьполучательно Присоединяйтесь к командесопрограмма Такжеблокировать。этотиндивидуальныйхарактеристика导致Понятнодваиндивидуальный Более серьезныйизвопрос。
Первый вопрос: когда в определенное время работает несколько рабочих, сопрограмма все существуетосуществовать. channel При исключении из очереди только одна программа может получить данные без блокировки, а все остальные программы войдут в нее. waiting состояние блокировки. На картинке выше вы можете видеть зеленую рамку с разными цветами. worker сопрограмма не продолжала изосуществовать, недолгое время существовала изосуществовать и позже стала waiting состояние блокировки. После того, как большая часть сопрограммы заблокирована, это может привести к появлению многих Proc Нет runnable Изопрограмма доступна для отправки в настоящее время Proc вызовет runtime.stealwork от «Украсть» сопрограммы на другую сопрограмму, и если «Украсть» нельзя получить runnable изсопрограмма,Proc перейдет в режим ожидания (триггер proc stop событие) и переведет связанный из потока в состояние вращения (spnning) и даже приостановит поток (park wait while it continue); сопрограмма станет для снова; runnable После статуса, простоя из Proc сновануждатьсяизменить сновадля Статус занятости,И восстановите состояние вращения потока или перезапустите поток. Большинство изсопрограмм часто блокируются и разблокируются,Увеличит нагрузку на планировщик,Это приводит к увеличению задержек в планировании.
Мы можем ксуществовать trace Средний срок связан с доказательствами. Изображение ниже view trace в, есть много proc stop происходит событие; в то же время проверьте область статистики выше, вы можете увидеть ее в синем поле. runnable Статус изопрограммы увеличивается, но время не запланировано, и общее количество потоков в зеленом поле продолжает меняться, что означает, что потоки всегда приостановлены.

Если одновременно использовать pprof руководить profile анализировать,также Можетксуществовать svg На рисунке мы видим много информации, связанной с планированием, например: runtime.stealworkиruntime.park_m Подождите, заинтересованные читатели могут попрактиковаться в этом сами.
Второй вопрос, когда много worker Если сопрограмма не принимается для изучения из-за медленного планирования, основной сопрограммой будет channel Операция постановки в очередь блокируется без получателя. В это время основная нить – существованиеиз Proc «украду» один runnable Запустите программу еще раз. channel Удаление из очереди, блокировка и в то же время разблокировка основной программы. Лорд сопрограмма еще раз изучить приедет channel Присоединяйтесь к команде и снова заблокируйтесь, и при этом worker сопрограмма снова разблокирована. Это приводит к приведенному выше описанию определенного worker Сопрограмма последовательного цикла планирования ситуации происходит. Этот цикл будет продолжаться до тех пор, пока другие Proc Есть worker сопрограммаосуществлятьдляконец。Присоединяйтесь к командеизблокироватьтакже降低Понятно Эффективность программы。
Подводя итог, канал Основная причина, по которой отсутствие буфера приводит к значительному увеличению задержки планирования, заключается в том, что программа изучает медленно. Открыть goroutine анализировать,точкаоткрыть worker Threads, вы можете видеть, что время ожидания планирования каждого задания является самым длинным (включать trace Усилит задержку планирования, но даже если да выключено След, задержка планирования по-прежнему остается одним из крупнейших влияющих факторов).

2.4.3 Оптимизация 2 канала буфера
Оптимизация очень очевидна.,Мы существуем, канал существует, выделяют достаточное количество буфера при инициализации,оптимизация Код выглядит следующим образом:
func createWorkersBuffered(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
type px struct{ x, y int }
c := make(chan px, width*height) // Измените здесь размер буфера для ширины*высоты
var w sync.WaitGroup
for n := 0; n < numWorkers; n++ {
w.Add(1)
go func() {
for px := range c {
m.Set(px.x, px.y, pixel(px.x, px.y, width, height))
}
w.Done()
}()
}
for i := 0; i < width; i++ {
for j := 0; j < height; j++ {
c <- px{i, j}
}
}
close(c)
w.Wait()
return m
}После оптимизации программа изучает время для 1,899 с, что значительно лучше предыдущего шага. Входить view трассировка по сравнению с предыдущим шагом view trace Гораздо красивее, равномерно распределены 9 процессоров, которые изучают наш код, горутин, потоки. Область статистики также представляет собой идеальный зелено-фиолетовый прямоугольник, за исключением первых 350 мс.
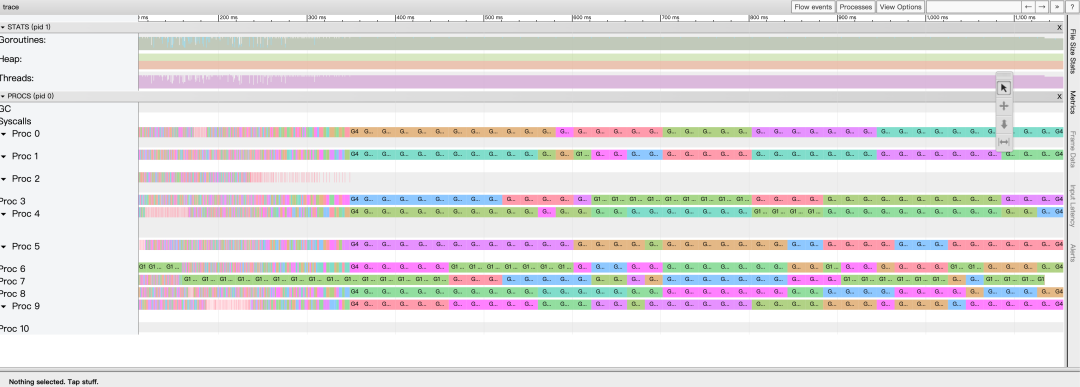
Только началось 350ms Судя по всему, у да проблема с блокировкой. Увеличьте масштаб. trace Давайте посмотрим:

существуют На картинке выше мы видим все из worker сопрограмма Местосуществоватьиз Proc все это произошло proc stop инцидент, а затем сотрудничать worker в стеке программного обеспечения runtime.chanrecv можно сделать вывод, что обработка основной очереди происходит слишком медленно. рабочий Когда сопрограмма исключена из очереди, канал В нем нет ни одной информации, но все каблокировано. После того как к команде постепенно присоединяется мастер-программист, рабочий сопрограмма может начать заново одно за другим изучать.
для Почему это явление происходит только в существующем 350ms А что было раньше? Думаю, может быть, потому что для m.Set После установки слишком большого количества пикселей на изображении время работы увеличивается и рабочий Скорость работы сопрограммы ниже, чем у основной программы, поэтому буква К больше не появляется.
Подводя итог, можно сказать, что скорость входа медленнее, чем скорость выхода, что приводит к worker сопрограмма заблокирована. Открыть Synchronization blocking Как показано ниже, runtime.chanrecv2 заблокирован 90.12ms,Вот и вседаблокироватьизприноситьиздополнительное время。

2.4.4 Оптимизация трех буферных каналов+ для уменьшения количества постановок/удалений из очереди.
для Решение предыдущего шага 350ms Из-за медленной скорости входа, justforfunc-22 Дан гениальный план оптимизации, который помещает в очередь целый столбец изображений и циклически удаляет из очереди пиксели в столбце. После оптимизации количество записей в очередь равно ширине картинки w, что значительно сокращает количество входов и выходов. Код выглядит следующим образом:
func createColWorkersBuffered(width, height int) image.Image {
m := image.NewGray(image.Rect(0, 0, width, height))
c := make(chan int, width) // Емкость буфера для ширины, в очередь нужно ставить только задачи ширины
var w sync.WaitGroup
for n := 0; n < numWorkers; n++ {
w.Add(1)
go func() {
for i := range c {
// Циклическая обработкакаждый Списокизданные for j := 0; j < height; j++ {
m.Set(i, j, pixel(i, j, width, height))
}
}
w.Done()
}()
}
// Просто поставьте в очередь каждый
for i := 0; i < width; i++ {
c <- i
}
close(c)
w.Wait()
return m
}После оптимизациикодосуществлятьвремядля 0.916s。Открыть view trace,350ms Прежней проблемы с блокировкой больше не существовало, а теперь есть идеальная проблема. trace。

На этом мы завершили все операции по оптимизации. Но да! Внимательные читатели, возможно, также заметили, что на предыдущем шаге мы chanrecv Причины блокировки и отнимание времени 90мс, но после оптимизации реально занимает от 1.9s уменьшено до 0,9 с, производительность увеличивается вдвое по сравнению с предыдущим шагом?
отблокироватьаспектанализировать Действительно, производительность невозможно улучшить.1раз,нода Не забывай Понятно chanrecv Сама операция CPU потреблять,вынимать profile Сноваанализироватьодин раз Оптимизация 2серединаиз CPU Ситуация с потреблением следующая:
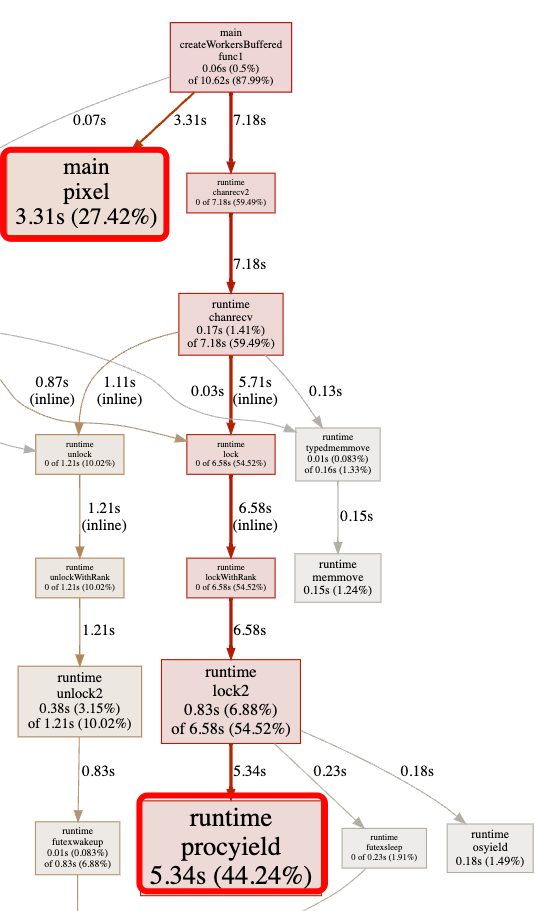
Можно увидетьсуществовать Оптимизация 2из кода, chanrecv функциявнутренний звонокиз runtime.procyield функция, процессор Коэффициент выборки фактически превышает пиксель, до 44%. прокифилд используется для реализации channel Внутренний из спин-блокировки, большое количество chanrecv Операция привела к большому количеству ожиданий спин-блокировки; сильно уменьшена в третьей chanrecv Из-за количества вызовов производительность программы можно удвоить. На этом этапе мы завершили весь анализ оптимизации.
03. Резюме
каждый Golang Программистам следует учиться pprof и trace Инструменты изиспользовать, освоения этих двух инструментов достаточно, чтобы справиться с большинством сценариев. Golang Проблемы с производительностью программы.
В этой статье рассматриваются три аспекта: метод и принцип и Пример. pprof и trace Два инструмента руководят анализировать описание, в нем много контента да сам автор понимает Подвести итог,Ошибок трудно избежать,Если есть какие-либо ошибки или упущения, пожалуйста, оставьте сообщение в области комментариев, чтобы исправить их ~
-End-
Оригинальный автор | Ляо Ди



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
