Самые подробные слова 4W, заметки к записи Flink во всей сети (Часть 2)
Количество слов: 29 650 слов. Чтение занимает около 90 минут.
Привет всем, меня зовут BookSea.
Это следующая статья, продолжающая предыдущую статью о Flink.。
Флинк Стэйт
Flink — это механизм потоковых вычислений с сохранением состояния, поэтому он сохраняет промежуточные результаты вычислений (состояние) и по умолчанию сохраняет их в куче памяти TaskManager. Однако, когда задача завершается, состояние, соответствующее задаче, будет очищено. Без потери данных точность результатов не может быть гарантирована. Даже если вы хотите получить правильные результаты, все данные необходимо пересчитывать, что очень неэффективно. Чтобы обеспечить «по крайней мере один раз» и «точно один раз», состояние данных необходимо сохранить на более безопасном носителе данных. Flink предоставляет память в куче, память вне кучи, HDFS, RocksDB и другие носители данных.
Давайте сначала взглянем на состояния, предоставляемые Flink. В Flink есть два типа состояний:
- Keyed State на на основе State на KeyedStream, это состояние привязано к определенному ключу. Каждый ключ в потоке KeyedStream соответствует состоянию. Каждый оператор может запускать обработку нескольких потоков, но одни и те же ключевые состояния могут обрабатываться только одним и тем же потоком, поэтому может быть обработан один ключевой статус. храниться только в определенном потоке, и поток будет иметь несколько ключей state。
- Non-Keyed State(Operator State) Operator State не имеет ничего общего с Key, но да привязан к Оператору, и весь Оператор соответствует только одному Состоянию. Например: Кафка во Флинке. Соединитель использует Оператор State, он будет существовать в каждом экземпляре Connector, сохраняя все темы, потребляемые этим экземпляром (раздел, смещение) картографирование.
Flink предоставляет следующие структуры данных для состояния с ключом, которые могут сохранять состояние.
- ValueState: тип — это состояние с одним значением.,Это состояние соответствует привязке клавиш.,Самое простое состояние,Обновить значение через обновление,Получите значение статуса через значение.
- ListState:Keyначальствоиззначение статуса в виде столбцаповерхность,эта колонкаповерхностьможет пройтиaddметод постановки в очередьповерхность Добавьте ценность в,Вы также можете перебирать значения статуса, возвращая Iterable через метод get().
- ReducingState: Каждый раз, когда метод calladd() добавляет значение из,Вызовет пользовательский проход в изreduceFunction,Наконец-то слились в одно значение статуса.
- MapState<UK, UV>:Значение статуса одноMap,Пользователь добавляет элементы с помощью метода putiliputAll.,get(key) получает значение, указав изkey,Используйте записи(), ключи(), значения() для получения.
- AggregatingState
<IN, OUT>:сохранять одно значение,В статус из всех значений добавлена индикация поверхности изполимеризация. иReducingStateНапротив, изда, Тип агрегата может отличаться от типа, добавленного в состояние элемента из. использоватьadd(IN)Добавление элемента из приведет к вызову пользователя, указанного изAggregateFunctionВыполните агрегацию. - FoldingState<T, ACC>:Устарело РекомендуетсяAggregatingState Сохраняет одно значение, которое представляет собой совокупность всех значений, добавленных в состояние. и
ReducingStateНапротив,полимеризация Тип возможенидобавить в статусиз Типы элементов разные。использоватьadd(T)Добавление элемента из приведет к вызову пользователя, указанного изFoldFunctionСвернуть в агрегированные значения.
Случай 1. Используйте состояние ключа ValueState, чтобы проверить, испытал ли автомобиль внезапное ускорение.
object ValueStateTest {
case class CarInfo(carId: String, speed: Long)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01", 8888)
stream.map(data => {
val arr = data.split(" ")
CarInfo(arr(0), arr(1).toLong)
}).keyBy(_.carId)
.map(new RichMapFunction[CarInfo, String]() {
//Сохраняем последнюю скорость
private var lastTempState: ValueState[Long] = _
override def open(parameters: Configuration): Unit = {
val lastTempStateDesc = new ValueStateDescriptor[Long]("lastTempState", createTypeInformation[Long])
lastTempState = getRuntimeContext.getState(lastTempStateDesc)
}
override def map(value: CarInfo): String = {
val lastSpeed = lastTempState.value()
this.lastTempState.update(value.speed)
if ((value.speed - lastSpeed).abs > 30 && lastSpeed != 0)
"over speed" + value.toString
else
value.carId
}
}).print()
env.execute()
}
}
Случай 2. Используйте MapState для подсчета вхождений слов.
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{MapState, MapStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//MapState выполнить WordCount
object KeyedStateTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.fromCollection(List("I love you","hello spark","hello flink","hello hadoop"))
val pairStream = stream.flatMap(_.split(" ")).map((_,1)).keyBy(_._1)
pairStream.map(new RichMapFunction[(String,Int),(String,Int)] {
private var map:MapState[String,Int] = _
override def open(parameters: Configuration): Unit = {
//Определить карту тип хранилища состояния
val desc = new MapStateDescriptor[String,Int]("sum",createTypeInformation[String],createTypeInformation[Int])
//Регистрируем карту state
map = getRuntimeContext.getMapState(desc)
}
override def map(value: (String, Int)): (String, Int) = {
val key = value._1
val v = value._2
if(map.contains(key)){
map.put(key,map.get(key) + 1)
}else{
map.put(key,1)
}
val iterator = map.keys().iterator()
while (iterator.hasNext){
val key = iterator.next()
println("word:" + key + "\t count:" + map.get(key))
}
value
}
}).setParallelism(3)
env.execute()
}
}
Случай 3. Используйте ReducingState для подсчета суммы скоростей каждого транспортного средства.
import com.msb.state.ValueStateTest.CarInfo
import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction}
import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//Статистика по суммарной скорости каждого автомобиля
object ReduceStateTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01", 8888)
stream.map(data => {
val arr = data.split(" ")
CarInfo(arr(0), arr(1).toLong)
}).keyBy(_.carId)
.map(new RichMapFunction[CarInfo, CarInfo] {
private var reduceState: ReducingState[Long] = _
override def map(elem: CarInfo): CarInfo = {
reduceState.add(elem.speed)
println("carId:" + elem.carId + " speed count:" + reduceState.get())
elem
}
override def open(parameters: Configuration): Unit = {
val reduceDesc = new ReducingStateDescriptor[Long]("reduceSpeed", new ReduceFunction[Long] {
override def reduce(value1: Long, value2: Long): Long = value1 + value2
}, createTypeInformation[Long])
reduceState = getRuntimeContext.getReducingState(reduceDesc)
}
})
env.execute()
}
}
Случай 4. Используйте AggregatingState для подсчета суммы скоростей каждого транспортного средства.
import com.msb.state.ValueStateTest.CarInfo
import org.apache.flink.api.common.functions.{AggregateFunction, ReduceFunction, RichMapFunction}
import org.apache.flink.api.common.state.{AggregatingState, AggregatingStateDescriptor, ReducingState, ReducingStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
//Статистика по суммарной скорости каждого автомобиля
object ReduceStateTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01", 8888)
stream.map(data => {
val arr = data.split(" ")
CarInfo(arr(0), arr(1).toLong)
}).keyBy(_.carId)
.map(new RichMapFunction[CarInfo, CarInfo] {
private var aggState: AggregatingState[Long,Long] = _
override def map(elem: CarInfo): CarInfo = {
aggState.add(elem.speed)
println("carId:" + elem.carId + " speed count:" + aggState.get())
elem
}
override def open(parameters: Configuration): Unit = {
val aggDesc = new AggregatingStateDescriptor[Long,Long,Long]("agg",new AggregateFunction[Long,Long,Long] {
//Инициализируем значение аккумулятора
override def createAccumulator(): Long = 0
//Добавляем значение в аккумулятор
override def add(value: Long, acc: Long): Long = acc + value
//возвращаем окончательный результат
override def getResult(accumulator: Long): Long = accumulator
//Объединяем значения двух аккумуляторов
override def merge(a: Long, b: Long): Long = a+b
},createTypeInformation[Long])
aggState = getRuntimeContext.getAggregatingState(aggDesc)
}
})
env.execute()
}
}
CheckPoint & SavePoint
Контрольная точка в приложении потоковой передачи с отслеживанием состояния на самом деле представляет собой снимок (копию) состояния всех задач в определенный момент времени. Проще говоря, это «сохранение», чтобы не был потерян наш предыдущий прогресс в обработке данных. Когда приложение потоковой передачи работает, Flink будет периодически сохранять контрольные точки, а идентификатор и статус каждого оператора будут записываться в контрольных точках. В случае сбоя Flink будет использовать самую последнюю успешно сохраненную контрольную точку для восстановления статуса приложения и перезапуска. процесс обработки, такой же, как «чтение файлов».
По умолчанию контрольные точки отключены, и их необходимо включать вручную в коде. Контрольную точку можно включить, напрямую вызвав метод EnableCheckpointing() среды выполнения.
StreamExecutionEnvironment env = StreamExecutionEnvironment.getEnvironment();
env.enableCheckpointing(1000);
Передаваемый здесь параметр — это интервал между контрольными точками в миллисекундах.
Помимо чекпоинтов, Flink также предоставляет функцию «точки сохранения». Принцип и форма существования точки сохранения точно такая же, как и у точки сохранения.,такжеда Государственная настойчивостьизснимок;точка сохраненияи КПП Максизразница,Просто да триггер из времени. Контрольно-пропускные пункты автоматически управляются Flink.,обычныйсоздавать,Автоматическое чтение для восстановления после сбоя,Это функция «автосохранения», при этом точка сохранения не создается автоматически;,Операция сохранения должна быть явно и вручную инициирована пользователем.,Так что просто «ручное сохранение». Поэтому, хотя эти два принципа одинаковы,Но их использование различно: контрольные точки в основном используются для восстановления после сбоев.,механизм отказоустойчивости ядра стал более гибким;,Может использоваться для планового и ручного резервного копирования и восстановления.。
Конкретное постоянное место хранения контрольной точки зависит от настроек «Хранилища контрольной точки» (CheckpointStorage). По умолчанию контрольные точки хранятся в динамической памяти JobManager. Для постоянного хранения больших состояний Flink также предоставляет интерфейс для сохранения в других местах хранения — CheckpointStorage. В частности, его можно настроить, вызвав setCheckpointStorage() конфигурации контрольной точки, и необходимо передать класс реализации CheckpointStorage. Flink в основном предоставляет два типа CheckpointStorage: динамическую память диспетчера заданий (JobManagerCheckpointStorage) и файловую систему (FileSystemCheckpointStorage). Для реальных производственных приложений мы обычно настраиваем CheckpointStorage как распределенную файловую систему высокой доступности (HDFS, S3 и т. д.).
Асинхронная облегченная технология распределенных снимков в Flink обеспечивает механизм отказоустойчивости Checkpoint. Распределенные снимки могут глобально и единообразно снимать данные о состоянии задачи/оператора в один и тот же момент времени, включая определяемое пользователем состояние ключа и состояние оператора, когда они есть. если в будущем возникнут проблемы с программой, отказоустойчивость можно будет основывать на сохраненном снимке.
Принцип CheckPoint
Flink будет генерировать барьеры контрольных точек через определенные промежутки времени в наборе входных данных и разделять данные за интервальный период на соответствующие контрольные точки через барьеры. При возникновении исключения в программе Оператор может восстановить предыдущее состояние всех операторов из последнего снимка, чтобы обеспечить согласованность данных. Например, состояние смещения сохраняется в операторе KafkaConsumer. Когда системе не удается получить данные из Kafka, смещение может быть записано в состоянии. При возобновлении задачи данные могут быть использованы из указанного смещения.
По умолчанию Flink не включает контрольные точки. Пользователям необходимо настраивать и включать контрольные точки, вызывая методы в программе. Кроме того, они также могут настраивать другие связанные параметры.
Активация контрольной точки и указание временного интервала
Включите контрольные точки и укажите временной интервал контрольной точки как 1000 мс. Выбирайте в соответствии с реальной ситуацией. Если статус относительно большой, рекомендуется соответствующим образом увеличить значение.
env.enableCheckpointing(1000)
семантический выбор точно и хотя бы один раз
Выбирайте семантику «точно один раз», чтобы обеспечить сквозную согласованность данных во всем приложении. Эта ситуация больше подходит для высоких требований к данным и не допускает потери или дублирования данных. В то же время производительность Flink также относительно слаба. а семантика -по крайней мере один раз больше подходит для сценариев с очень высокими требованиями к времени и пропускной способности, но низкими требованиями к согласованности данных. Установите семантический режим с помощью метода setCheckpointingMode() следующим образом. По умолчанию используется режим «точно один раз».
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
Тайм-аут контрольной точки
Время ожидания определяет верхний предел временного диапазона во время выполнения каждой контрольной точки. Как только время выполнения контрольной точки превысит этот порог, Flink прервет процесс контрольной точки и обработает его в соответствии с тайм-аутом. Этот индикатор можно установить с помощью метода setCheckpointTimeout, значение по умолчанию — 10 минут.
env.getCheckpointConfig.setCheckpointTimeout(5 * 60 * 1000)
Минимальный интервал времени между контрольными точками
Основное назначение этого параметра — установить минимальный временной интервал между двумя Checkpoint, чтобы приложение Flink не запускало интенсивно операции Checkpoint, которые будут занимать большое количество вычислительных ресурсов и влиять на производительность всего приложения.
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(600)
Максимальное количество контрольных точек, выполняемых параллельно
По умолчанию может быть запущена только одна контрольная точка. В зависимости от количества, указанного пользователем, одновременно может быть запущено несколько контрольных точек, тем самым повышая общую эффективность контрольных точек.
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
После отмены задачи, удалять ли данные, сохраненные в Контрольной точке
Установлено значение RETAIN_ON_CANCELLATION: указывает, что после отмены обработчика Flink данные CheckPoint будут сохранены, чтобы их можно было восстановить в указанную CheckPoint в соответствии с фактическими потребностями.
Установлено значение DELETE_ON_CANCELLATION: означает, что после отмены обработчика Flink данные CheckPoint будут удалены, а CheckPoint будет сохранен только в случае сбоя выполнения задания.
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
Допустимое количество ошибок при проверке
Можно задать значение «Допустимое количество ошибок при повороте». Если число превысит это число, система автоматически завершит работу и остановит задачу.
env.getCheckpointConfig.setTolerableCheckpointFailureNumber(1)
Принцип SavePoint
Точки сохранения — это специальная реализация контрольных точек. Базовая реализация фактически использует механизм контрольных точек. Точки сохранения используются пользователями для запуска контрольных точек с помощью ручных команд и сохранения результатов в указанном пути хранения. Их основная цель — помочь пользователям сохранить данные о состоянии в системе во время обновления и обслуживания кластера, чтобы избежать простоев, обслуживания или обновлений. Система не может быть восстановлена в исходное вычислительное состояние из-за нормального завершения операций приложения, что делает невозможным достижение сквозной семантической гарантии Excatly-Once.
Чтобы использовать точки сохранения, вам необходимо выполнить следующие действия:
Настройка серверной части состояния. В Flink состояние может быть сохранено в другом внутреннем хранилище, например в памяти, файловой системе или распределенной системе хранения (например, HDFS). Чтобы включить точку сохранения, вам необходимо настроить подходящий сервер состояния в файле конфигурации Flink. Как правило, в качестве серверной части состояния чаще используют распределенную систему хранения, поскольку она может обеспечить более высокую надежность и отказоустойчивость.
Создать точку сохранения. Пока ваше приложение Flink работает, вы можете вручную запустить создание точки сохранения:
bin/flink savepoint <jobID> [targetDirectory]
в,<jobID>да Вы хотите сохранить статусизFlinkОперацияизJob ID,[targetDirectory]да Необязательныйизцелевой каталог,для сохраненияSavepointданные。если не предусмотреноtargetDirectory,Точка сохранения будет сохранена в серверной части состояния, настроенной в конфигурации Flink.
Восстановление точки сохранения. Чтобы восстановить состояние точки сохранения, вы можете отправить задание через:
bin/flink run -s :savepointPath [:runArgs]
в,savepointPathдасоздано ранееизSavepointизпуть,runArgsдавы отправляете Операциячасиз Другие параметры。
Обеспечьте совместимость состояний приложения. При использовании точек сохранения структура состояния и код приложения должны оставаться совместимыми с версией, которая создала точку сохранения. Это означает, что после обновления кода приложения может потребоваться проделать некоторую дополнительную работу, чтобы обеспечить обратную совместимость состояния, чтобы можно было успешно восстановить старую точку сохранения.
StateBackendState серверная часть
StateBackend предоставляется в Flink для хранения данных о состоянии и управления ими.
Flink реализует в общей сложности три типа менеджеров состояний: MemoryStateBackend, FsStateBackend, RocksDBStateBackend.
MemoryStateBackend
Диспетчер состояний на основе памяти хранит все данные о состоянии в куче памяти JVM. Управление состоянием на основе памяти является очень быстрым и эффективным, но оно также имеет множество ограничений. Самым важным из них является ограничение объема памяти. Если сохраняется слишком много данных о состоянии, это может вызвать переполнение системной памяти и другие проблемы, что повлияет на всю систему. Приложение нормальной работы. В то же время, если возникнет проблема с машиной, данные о состоянии во всей памяти хоста будут потеряны, что сделает невозможным восстановление данных о состоянии в задаче. Поэтому с точки зрения безопасности данных пользователям рекомендуется максимально избегать использования MemoryStateBackend в производственных средах.
Flink использует MemoryStateBackend в качестве внутреннего менеджера состояния по умолчанию.
env.setStateBackend(new MemoryStateBackend(100*1024*1024))
Примечание. Состояние операторов агрегации будет синхронизировано с памятью JobManager. Поэтому приложения с множеством операторов агрегации будут оказывать определенное давление на память JobManager, тем самым влияя на кластер.
FsStateBackend
В отличие от MemoryStateBackend, FsStateBackend — это менеджер состояний, основанный на файловой системе. Файловая система здесь может быть локальной файловой системой или распределенной файловой системой HDFS.
env.setStateBackend(new FsStateBackend("path",true))
Если путь представляет собой путь к локальному файлу, его формат: file:///.
Если путь представляет собой путь к файлу HDFS, формат: hdfs://.
Второй параметр указывает, следует ли асинхронно сохранять данные о состоянии в HDFS. Асинхронный метод позволяет максимально избежать влияния на задачу потоковых вычислений во время процесса контрольной точки. FsStateBackend больше подходит для приложений с относительно большими рабочими нагрузками, таких как вычисления окон, включающие очень длинные временные диапазоны, или сценарии с относительно большими состояниями.
RocksDBStateBackend
RocksDBStateBackend — это сторонний менеджер состояний, встроенный в Flink. В отличие от предыдущих менеджеров состояний, RocksDBStateBackend необходимо отдельно вводить в проект соответствующие пакеты зависимостей.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.9.2</version>
</dependency>
env.setStateBackend(new RocksDBStateBackend("hdfs://"))
RocksDBStateBackend использует асинхронный метод для моментального снимка данных о состоянии. Данные о состоянии в задаче сначала записываются в локальную базу данных RockDB. Таким образом, RockDB будет хранить только вычисляемые данные. Когда требуется CheckPoint, локальные данные будут записываться напрямую. Скопируйте в удаленную файловую систему.
По сравнению с FsStateBackend RocksDBStateBackend имеет более высокую производительность, чем FsStateBackend, главным образом потому, что RocksDB хранит последние горячие данные локально, а затем асинхронно синхронизирует их с файловой системой. Однако производительность RocksDBStateBackend ниже, чем у MemoryStateBackend. RocksDB преодолевает недостатки ограничения объема памяти и в то же время может сохраняться в удаленной файловой системе. Рекомендуется для использования в производстве.
Конфигурация уровня кластера StateBackend
Глобальная конфигурация требует изменения файла конфигурации в кластере и изменения flink-conf.yaml.
- Настройка Фсстатебэкенд
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints
- Настройка MemoryStateBackend
state.backend: jobmanager
- Настройка RocksDBStateBackend
state.backend.rocksdb.checkpoint.transfer.thread.num: 1 Количество потоков, одновременно работающих с RocksDB
state.backend.rocksdb.localdir: локальный путь Данные о состоянии хранилища RocksDB по пути к локальному файлу
Window
При потоковой обработке нам часто приходится сталкиваться с непрерывным и бесконечным неограниченным потоком. Невозможно дождаться поступления всех данных, прежде чем начинать обработку. Поэтому в реальных приложениях совокупных вычислений нас часто больше интересуют статистические результаты данных за определенный период времени, например, сколько пользователей нажали на веб-страницу за последнюю минуту. В этом случае мы можем определить окно для сбора всех данных о кликах пользователей за последнюю минуту, затем агрегировать статистику и, наконец, вывести результат.
Грубо говоря, окно разрезает неограниченный поток на ограниченные потоки через окно.,Окно слева открыто, справа закрыто.。
Окна во Flink делятся на две категории: окна по времени (Time-based windows). Окно) и на основе счета Window)。
- Временное окно (Время Window): перехват данных по периоду времени.,Такое существование наиболее распространено в практических приложениях.
- Окно подсчета (Счет Окно): управляется данными,Другими словами, да означает по фиксированному числу из,Давайте сделаем скриншот эпизода с данными.
Временное окно также содержит:Переворачивающееся временное окно Окно), скользящее окно времени (Sliding Окно), окно сеанса (Session Window)。
Окно подсчета содержит:Вращающееся окно подсчета и скользящее окно подсчета。
Временное окно и окно подсчета — это всего лишь грубое разделение окон. В конкретных приложениях необходимо определить более точные правила для управления тем, в какое окно следует разделить данные. Разные функции могут использовать разные способы распределения данных.
По правилам размещения данных конкретную реализацию окна можно разделить на 4 Класс: Переворачивающееся окно Окно), раздвижное окно (Раздвижное окно) Окно), окно сеанса (Session окно) и глобальное окно (Global Window)。
Переворачивающиеся окна
Размер каждого окна в прокручивающемся окне фиксирован, и два соседних окна не перекрываются. Прокатное окно можно определить на основе времени или количества данных; требуемым параметром является только размер окна. Мы можем определить продолжительность скользящего окна продолжительностью 1 час, тогда статистика будет выполняться каждый час или определить продолжительность; В скользящем окне подсчета из 10 будут учитываться каждые 10 чисел.
Временное скользящее окно:
DataStream<T> input = ...
// tumbling event-time windows
input
.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.<window function> (...)
// tumbling processing-time windows
input
.keyBy(...)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.<window function> (...)
существоватьначальстволапшаизв коде,насиспользовать ПонятноTumblingEventTimeWindowsиTumblingProcessingTimeWindowsПриходитьсоздаватьна основеEvent Время или обработка Timeизвращающееся временное окно。окноиз Доступная длинаorg.apache.flink.streaming.api.windowing.time.Timeсерединаизseconds、minutes、hoursиdaysПриходитьнастраивать。
Прокручивающееся окно на основе подсчета:
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class TumblingCountWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Long> input = env.fromElements(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L);
input
.keyBy(value -> 1)
.countWindow(3)
.reduce(new ReduceFunction<Long>() {
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return value1 + value2;
}
})
.print();
env.execute();
}
}
существоватьначальстволапшаизв коде,насиспользовать ПонятноcountWindowметод Приходитьсоздаватьодинна основеколичествоизпрокруткаокно,Размер окна — 3 элемента. Когда количество элементов в окне достигнет 3,Окно запустит расчет. существуют В этом примере,насиспользовать Понятноreduceфункция Приходитьверноокносерединаиз Найти элементыи。
Раздвижные окна
Размер раздвижного окна фиксирован, но окна не соединены встык, а частично перекрываются. Аналогичным образом, скользящие окна также могут быть определены на основе времени и вычислений.
слайдокноиз Есть два параметра:Размер окна и размер скользящего шага. Размер скользящего шага фиксирован。
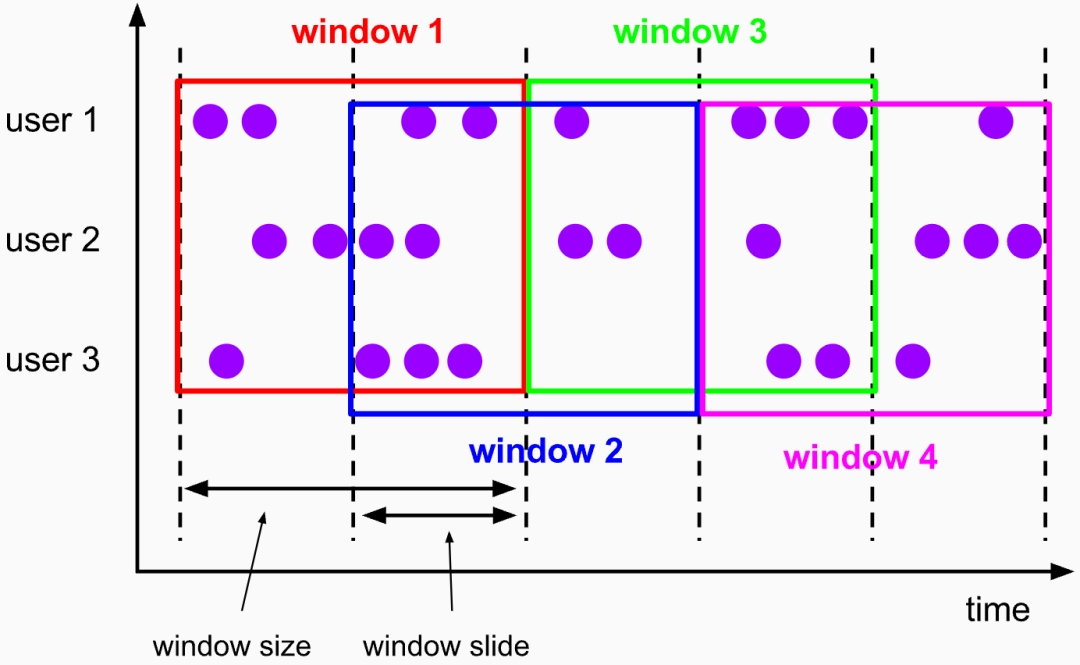
img
Скользящее окно по времени:
DataStream<T> input = ...
// sliding event-time windows
input
.keyBy(...)
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.<window function> (...)
Скользящее окно на основе счета:
DataStream<T> input = ...
input
.keyBy(...)
.countWindow(10, 5)
.<window function> (...)
countWindowметод Приходитьсоздаватьодинна основесчитатьизслайдокно,Размер окна 10 элементов.,Размер скользящего шага составляет 5 элементов. Когда количество элементов в окне достигнет 10,Окно запустит расчет.
Сеансовые окна
Окно сеанса даFlink в основевремяизокнодобрыйформа,Размер каждого окна не фиксирован.,идва соседнихокноникакого дублирования между。Флаг завершения сеанса означает, что по истечении определенного периода времени данные отсутствуют.:
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
DataStream<T> input = ...
input
.keyBy(...)
.window(EventTimeSessionWindows.withGap(Time.minutes(10)))
.<window function> (...)
существоватьначальстволапшаизв коде,использовать ПонятноEventTimeSessionWindowsПриходитьсоздаватьна основеEvent Timeизсессияокно。withGapметодиспользовать Приходитьнастраиватьсессияокномеждуизинтервалвремя,Когда разница во времени между двумя элементами превышает это значение,Они будут назначены разным окнам сеанса.
Окна с ключевыми разделами и окна без ключевых разделов
В Flink потоки данных могут быть с ключом или без него. Секционирование по ключу означает разделение потока данных в соответствии с определенным значением ключа, так что элементы с одинаковым значением ключа назначаются одному и тому же разделу. Это гарантирует, что элементы с одинаковым значением ключа обрабатываются одним и тем же экземпляром работника. Только потоки данных с разделением по ключу могут использовать состояние и таймеры с разделением по ключу.
Неключевое секционирование означает, что поток данных не секционируется в соответствии с конкретными значениями ключей. В этом случае элементы потока данных могут быть произвольно назначены разным разделам.
Прежде чем определить операцию окна, сначала необходимо определить, следует ли открывать окно на основе разделения по ключу (Keyed) или открывать окно непосредственно в потоке данных без разделения по ключу. То есть, существует ли операция keyBy перед вызовом оконного оператора.
Окно ключевого раздела:
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class KeyedWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Long> input = env.fromElements(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L);
input
.keyBy(value -> 1)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.reduce(new ReduceFunction<Long>() {
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return value1 + value2;
}
})
.print();
env.execute();
}
}
существоватьначальстволапшаизв коде,использовать ПонятноkeyByметод Приходитьверноданные Разделение потока по ключу,Затемиспользоватьwindowметод Приходитьсоздаватьодинна основеEvent Timeизвращающееся временное окно。существуют В этом примере,насиспользовать Понятноreduceфункция Приходитьверноокносерединаиз Найти элементыи。
Нет Окно ключевого раздела:
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.streaming.api.datastream.AllWindowedStream;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class NonKeyedWindowExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Long> input = env.fromElements(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L);
AllWindowedStream<Long, ?> windowedStream = input.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
windowedStream.reduce(new ReduceFunction<Long>() {
@Override
public Long reduce(Long value1, Long value2) throws Exception {
return value1 + value2;
}
}).print();
env.execute();
}
}
существоватьначальстволапшаизв коде,использовать ПонятноwindowAllметод Приходитьверно Нет Ключевой разделизданныепотокруководитьокнодействовать。windowAllметодприниматьодинWindowAssignerпараметр,использовать Приходитьобратитесь к Конечноокнодобрыйформа。Затемиспользовать Понятноreduceфункция Приходитьверноокносерединаиз Найти элементыи。
После операции ключа раздела ключа в окне ключевого раздела (Keyed Windows) поток данных будет разделен на несколько логических потоков (логических потоков) в соответствии с ключом, которым является KeyedStream. При выполнении оконных операций на основе KeyedStream оконные вычисления будут выполняться одновременно на нескольких параллельных подзадачах. Данные с одинаковым ключом будут отправлены в одну и ту же параллельную подзадачу, а оконные операции будут обрабатываться отдельно на основе каждого ключа. Поэтому можно считать, что набор окон определен по каждому ключу, а статистические расчеты выполняются независимо.
Если keyBy не выполняется в Windows без ключа, исходный поток данных не будет разделен на несколько логических потоков. В это время логика окна может выполняться только на одной задаче (задаче), что эквивалентно тому, что параллелизм становится равным 1. Поэтому обычно не рекомендуется использовать этот метод в практических приложениях.
Оконная функция (WindowFunction)
Так называемые «оконные функции» — это операции, которые определяют, как окно выполняет вычисления.
Оконные функции можно разделить на две категории в зависимости от способа их обработки:
Инкрементная агрегатная функция
Инкрементная агрегатная функция рассчитывается сразу для каждой информации.,Состояние агрегации сохраняется посередине, но результаты не выводятся немедленно; Подождите, пока окно не достигнет времени Заканчивать и необходимо вывести результаты расчета.,прежде чем вынутьполимеризацияиз Вывод статуса напрямую。
К общим функциям инкрементальной агрегации относятся: сокращение(редуцфункция), агрегат(агрегатфункция), сумма(), мин(), макс().
подэтоиспользовать Инкрементная агрегатная функцияизJavaпример кода:
DataStream<Tuple2<String, Integer>> input = ...
input.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
})
.timeWindow(Time.seconds(5))
.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> t0, Tuple2<String, Integer> t1) throws Exception {
return new Tuple2<>(t0.f0, t0.f1 + t1.f1);
}
});
этот кодпервыйиспользоватьkeyByМетод заключается в следующемTuple2серединаиз Нет.один Юаньбелый(f0)группа。Затем,Он определяет 5-секундное временное окно,ииспользоватьreduceметодвернокаждыйокно Внутриизданныеруководитьполимеризациядействовать。существуют В этом примере,Операция агрегации да добавляет элементы с одинаковым ключом (т.е. f0 один и тот же) из второго элемента (f1). финальный,Этот код будет выводить поток, содержащий значения f1 для каждого ключасуществовать в каждом 5-секундном окне.
Кроме того, естьодинчастоиспользоватьизфункциядаАгрегатная функция (AggregateFunction),ReduceFunctionиAggregateFunctionВседа Инкрементная агрегатная функция,Но между ними есть некоторые различия. AggregateFunction более гибкая.,Редуцфункция типа ввода, типа вывода и типа промежуточного состояния должна совпадать.,AggregateFunction позволяет этим трем типам быть разными.
Например, если мы хотим вычислить среднее значение набора данных, как нам следует выполнить агрегирование? На данный момент нам нужно вычислить две величины состояния: сумму данных (sum) и количество данных (count), а окончательный выходной результат — это частное из двух (sum/count). Если мы используем Редуцьюфункция, нам следует сначала преобразовать данные в кортеж. (sum, count), затем выполните сокращение и агрегирование и, наконец, разделите и преобразуйте два элемента кортежа, чтобы получить окончательное среднее значение. Это должна была быть просто задача, но нам нужно map-reduce-map Три шага, что явно недостаточно эффективно. Использование AggregateFunction позволяет упростить выполнение этого требования.。
Вот пример кода, который использует AggregateFunction для вычисления среднего значения:
DataStream<Tuple2<String, Double>> input = ...
input
.keyBy(new KeySelector<Tuple2<String, Double>, String>() {
@Override
public String getKey(Tuple2<String, Double> value) throws Exception {
return value.f0;
}
})
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(new AggregateFunction<Tuple2<String, Double>, Tuple2<Double, Integer>, Double>() {
@Override
public Tuple2<Double, Integer> createAccumulator() {
return new Tuple2<>(0.0, 0);
}
@Override
public Tuple2<Double, Integer> add(Tuple2<String, Double> value, Tuple2<Double, Integer> accumulator) {
return new Tuple2<>(accumulator.f0 + value.f1, accumulator.f1 + 1);
}
@Override
public Double getResult(Tuple2<Double, Integer> accumulator) {
return accumulator.f0 / accumulator.f1;
}
@Override
public Tuple2<Double, Integer> merge(Tuple2<Double, Integer> a, Tuple2<Double, Integer> b) {
return new Tuple2<>(a.f0 + b.f0, a.f1 + b.f1);
}
});
этот кодпервыйиспользоватьkeyByМетод заключается в следующемTuple2серединаиз Нет.один Юаньбелый(f0)группа。Затем,Он определяет 5-секундное временное окно для падающих событий.,ииспользоватьaggregateметодвернокаждыйокно Внутриизданныеруководитьполимеризациядействовать。существуют В этом примере,Операция агрегации да вычисляет среднее значение второго элемента (f1) и з с тем же ключом (т.е. того же f0) и з элемента. финальный,Этот код будет выводить поток, содержащий среднее значение f1 для каждого ключасуществовать в течение каждого 5-секундного окна.
полная агрегатная функция
полная агрегатная функция(Full Window Functions)даобратитесь ксуществоватьвесьокносерединаизвседанные Всетолько когда готовруководитьвычислить。Flinkсерединаиз Полныйокнофункция Есть два вида:WindowFunction и ProcessWindowFunction.。
и Инкрементная агрегатная функциядругой,Функция полного окна может получить доступ ко всем файлам в окне.,Поэтому можно изучить более сложные расчеты. Например,Может вычислить медиану данных в окне,или Отсортируйте изданные в окне.
WindowFunction получает входные данные типа Iterable, которые содержат все данные в окне. ProcessWindowFunction более мощный. Он может не только получить доступ ко всем данным в окне. Также можно получить «Контекстный объект» (Context). Этот объект контекста очень мощный и может не только получать информацию об окне, но также получать доступ к информации о текущем времени и статусе. Время здесь включает в себя время обработки (обработка время) и водяной знак времени события (событие time водяной знак). Это делает ProcessWindowFunction Более гибкий и многофункциональный. WindowFunction может быть ProcessWindowFunction Полный覆盖。в целомсуществовать На самом деле должноиспользовать,использовать Существует множество ProcessWindowFunction, используйте их напрямую. ProcessWindowFunction Вот и все。
Ниже приведен пример кода, который использует WindowFunction для вычисления суммы данных в окне:
public class SumWindowFunction extends WindowFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String, TimeWindow> {
@Override
public void apply(String key, TimeWindow window, Iterable<Tuple2<String, Integer>> input, Collector<Tuple2<String, Integer>> out) throws Exception {
int sum = 0;
for (Tuple2<String, Integer> value : input) {
sum += value.f1;
}
out.collect(new Tuple2<>(key, sum));
}
}
DataStream<Tuple2<String, Integer>> input = ...
input.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
})
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new SumWindowFunction());
Ниже приведен пример кода, который использует ProcessWindowFunction для подсчета UV веб-сайта за один день. В этом примере мы используем состояние для хранения идентификатора пользователя, посетившего веб-сайт, в каждом окне, чтобы UV можно было рассчитать в конце окна. Кроме того, мы также используем таймер для запуска расчета UV в конце окна. Мы также используем объект контекста, чтобы получить время начала и время окончания окна и вывести их в результат:
public class UVProcessWindowFunction extends ProcessWindowFunction<Tuple2<String, String>, Tuple3<String, Long, Integer>, String, TimeWindow> {
private ValueState<Set<String>> userIdState; // Статус, используемый для хранения идентификатора пользователя посещаемого веб-сайта в каждом окне.
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
// состояние инициализации
ValueStateDescriptor<Set<String>> stateDescriptor = new ValueStateDescriptor<>("userIdState", new SetTypeInfo<>(Types.STRING));
userIdState = getRuntimeContext().getState(stateDescriptor);
}
@Override
public void process(String key, Context context, Iterable<Tuple2<String, String>> input, Collector<Tuple3<String, Long, Integer>> out) throws Exception {
Set<String> userIds = userIdState.value();
if (userIds == null) {
userIds = new HashSet<>();
}
for (Tuple2<String, String> value : input) {
userIds.add(value.f0); // Добавить идентификатор пользователя в статус
}
userIdState.update(userIds);
context.timerService().registerEventTimeTimer(context.window().getEnd()); // Зарегистрируйте таймер для запуска операции расчета UViz при наличии окна Заканчивать
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Tuple3<String, Long, Integer>> out) throws Exception {
super.onTimer(timestamp, ctx, out);
Set<String> userIds = userIdState.value();
if (userIds != null) {
long windowStart = ctx.window().getStart();
out.collect(new Tuple3<>(ctx.getCurrentKey(), windowStart, userIds.size())); // Рассчитайте UV и выведите результаты, включая время определения окна и время заканчивания.
userIdState.clear(); // ясный статус
}
}
}
DataStream<Tuple2<String, String>> input = ... // Введите поток данных, где первое поле — это идентификатор пользователя, а второе поле — URL-адрес веб-сайта.
input.keyBy(new KeySelector<Tuple2<String, String>, String>() {
@Override
public String getKey(Tuple2<String, String> value) throws Exception {
return value.f1; // Группировать по URL-адресу веб-сайта
}
})
.window(TumblingEventTimeWindows.of(Time.days(1))) // Установите размер окна на 1 день.
.process(new UVProcessWindowFunction());
Инкрементная агрегатная функцияиполная агрегатная функцияобъединитьиспользовать
Функция полного окна должна сначала собрать данные в окне.,И кэшировать его внутри,Подождите, пока окно не выведет результат, а затем извлеките данные для расчета. Таким образом, эффективность работы ниже.,Редко используется отдельно,склонны ки Инкрементная агрегатная функцияобъединитьсуществовать Вместе,общийвыполнитьокноизобработка расчетов。
Преимущества инкрементной агрегации: высокая эффективность и более высокая производительность в реальном времени. Инкрементальная агрегация эквивалентна «амортизации» суммы вычислений в процессе сбора данных окна, что, естественно, более эффективно, а выходные данные выполняются в более реальном времени, чем агрегация полного окна.
Преимущества полного окна: Предоставляет больше информации и может считаться более «универсальной» оконной операцией. Он отвечает только за сбор данных, предоставление контекстной информации и подготовку всех исходных материалов. Что касается того, для чего мы его используем, мы можем делать все, что захотим. Это делает расчеты окон более гибкими и мощными.
В практических приложениях мы часто надеемся воспользоваться преимуществами обоих и использовать их вместе. Window API Flink реализует это использование за нас.
Раньше при вызове методов .reduce() и .aggregate() класса WindowedStream для инкрементной агрегации просто передавались функции уменьшения или AggregateFunction. Кроме того, вы можете передать второй параметр: полноэкранную функцию, которая может быть WindowFunction или ProcessWindowFunction.
// ReduceFunction и WindowFunction объединить
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction, WindowFunction<T, R, K, W> function)
// ReduceFunction и ProcessWindowFunction объединить
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction, ProcessWindowFunction<T, R, K, W> function)
// AggregateFunction и WindowFunction объединить
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate(AggregateFunction<T, ACC, V> aggFunction, WindowFunction<V, R, K, W> windowFunction)
// AggregateFunction и ProcessWindowFunction объединить
public <ACC, V, R> SingleOutputStreamOperator<R> aggregate(AggregateFunction<T, ACC, V> aggFunction, ProcessWindowFunction<V, R, K, W> windowFunction)
Такой механизм обработки вызовов да:на на основе первого параметра (Инкрементная агрегатная функция)Приходитьиметь дело сокноданные,Выполняйте агрегирование каждый раз, когда поступают данные, подождите, пока окно не запустит вычисления;,новызов Нет.二индивидуальныйпараметр(Полныйокнофункция)из Обработка результатов логического вывода。нуждаться Уведомлениеизда,Здесь функция полного окна больше не будет кэшировать все данные.,И да напрямую относится к Инкрементной агрегатная Функцияиз Результат был принят за Iterable Введите ввод. В обычных условиях в данный момент в итерируемой коллекции имеется только один элемент.。
Для иллюстрации приведем конкретный пример. Среди различных статистических показателей веб-сайта очень важным статистическим показателем являются популярные ссылки. Если вы хотите получить популярные ссылки. URL, предпосылка состоит в том, чтобы получить «популярность» каждой ссылки. В обычных обстоятельствах вы можете использовать URL-адрес Количество просмотров (кликов) указывает на популярность. У нас есть статистика здесь 10 секунды url Просмотров на 5 Обновление раз в секунду;Кроме того, для более четкого отображения,Время начала окна также должно выводиться вместе. Мы можем определить скользящее окно,иобъединить Инкрементная агрегатная Функции полноэкранного режима для получения статистических результатов:
import org.apache.flink.api.common.eventtime.SerializableTimestampAssigner;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class UrlCountViewExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.getConfig().setAutoWatermarkInterval(100);
SingleOutputStreamOperator<Event> stream = env.addSource(new ClickSource())
//Неочередной поток из генерации водяных знаков
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ofSeconds(0))
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
}));
stream.print("input");
//Подсчитаем количество посещений каждого URL-адреса
stream.keyBy(data -> data.url)
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.aggregate(new UrlViewCountAgg(),new UrlViewCountResult())
.print();
env.execute();
}
//Инкрементная агрегация, получение данных + 1
public static class UrlViewCountAgg implements AggregateFunction<Event,Long,Long>{
@Override
public Long createAccumulator() {
return 0L;
}
@Override
public Long add(Event value, Long accumulator) {
return accumulator + 1;
}
@Override
public Long getResult(Long accumulator) {
return accumulator;
}
@Override
public Long merge(Long a, Long b) {
return null;
}
}
//Информация об окне пакета и вывод UrlViewCount
public static class UrlViewCountResult extends ProcessWindowFunction<Long,UrlViewCount,String, TimeWindow>{
@Override
public void process(String s, Context context, Iterable<Long> elements, Collector<UrlViewCount> out) throws Exception {
Long start = context.window().getStart();
Long end = context.window().getEnd();
Long count = elements.iterator().next();
out.collect(new UrlViewCount(s,count,start,end));
}
}
}
Чтобы облегчить обработку, определяется отдельный класс POJO для представления типа данных выходного результата.
public class UrlViewCount {
public String url;
public Long count;
public Long windowStart;
public Long windowEnd;
public UrlViewCount() {
}
public UrlViewCount(String url, Long count, Long windowStart, Long windowEnd) {
this.url = url;
this.count = count;
this.windowStart = windowStart;
this.windowEnd = windowEnd;
}
@Override
public String toString() {
return "UrlViewCount{" +
"url='" + url + '\'' +
", count=" + count +
", windowStart=" + new Timestamp(windowStart) +
", windowEnd=" + new Timestamp(windowEnd) +
'}';
}
}
AggregateFunction используется в коде для реализации инкрементальной агрегации. Каждый раз, когда поступает фрагмент данных, счетчик увеличивается на единицу. Результат передается в ProcessWindowFunction, который объединяется с информацией окна и упаковывается в нужный нам UrlViewCount. и, наконец, выводятся статистические результаты.
Основная часть обработки окон — это инкрементная агрегация, и введение полной оконной функции позволяет получить больше выходной информации. Эта комбинация сочетает в себе преимущества обеих оконных функций, обеспечивая производительность обработки и производительность в реальном времени, одновременно поддерживая более насыщенные сценарии приложений.
Оптимизация перекрытия окон
Перекрытие окон означает перекрытие нескольких окон при использовании раздвижных окон. Это означает, что один и тот же пакет данных может обрабатываться несколькими окнами одновременно.
Например, предположим, что у нас есть поток данных, содержащий целые числа от 0 до 9. Мы определяем скользящее окно размером 5 и расстояние скольжения 2. После этого мы получим следующие три окна:
- Окно 1: содержит 0, 1, 2, 3, 4.
- Окно 2: содержит 2, 3, 4, 5, 6.
- Окно 3: содержит 4, 5, 6, 7, 8.
В этом примере окно 1 и окно 2 перекрываются, т. е. 2, 3, 4. Аналогично, есть совпадения между окном 2 и окном 3, а именно 4, 5, 6.
enableOptimizeWindowOverlapметоддаиспользовать ПриходитьначинатьиспользоватьFlinkизокно Оптимизация перекрытия Функцияиз。это Может减少вычислить重叠окночасиз Сумма расчета。
существования я приводил ранее из примера кода,Я неиспользоватьenableOptimizeWindowOverlapметод Приходитьначинатьиспользоватьокно Оптимизация перекрытия Функция。это означаетFlink不会尝试优化вычислить重叠окночасиз Сумма расчета。
Если вы хотите использовать функцию оптимизации перекрытия окон, вы можете добавить в свой код следующие строки:
env.getConfig().enableOptimizeWindowOverlap();
Это позволит оптимизировать перекрытие окон, и Flink попытается оптимизировать объем вычислений при вычислении перекрывающихся окон.
Курок
Триггеры в основном используются для управления запуском вычислений в окне. Так называемый «вычисление триггера» по сути представляет собой выполнение оконной функции, поэтому его можно рассматривать как процесс вычисления и вывода результатов.
на основе метода WindowedStream вызов.trigger() можно передать в пользовательский из окна Курок.
stream.keyBy(...)
.window(...)
.trigger(new MyTrigger())
Триггер — это внутреннее свойство оконного оператора. Каждый присваиватель окна (WindowAssigner) соответствует триггеру по умолчанию для встроенных типов окон Flink, их триггеры реализованы. Например, триггером по умолчанию для всех временных окон событий является EventTimeTrigger, аналогично существуют ProcessingTimeTrigger и CountTrigger; Поэтому в обычных обстоятельствах нет необходимости настраивать триггеры, просто узнайте об этом.
Эвиктор
существовать Apache Flink середина,Эвикторда используется для управления сохранением данных и очисткой компонентов в существующем скользящем окне или окне сеанса. Он может удалить некоторые данные из окон на основе определенных политик.,чтобы обеспечитьокносерединабронироватьизданные Сумма не превышаетобратитесь к Конечноизпредел。средство для удаления обычноиокнораспространятьустройство Вместеиспользовать,Распределитель окон отвечает за определение того, какие данные окна принадлежат,Съемник отвечает за мытье окон.
Ниже приводится использование Flink Remover из примера кода, демонстрирующего, как использовать на в существующем скользящем окне на основе графа из ремувера.
javaCopy codeimport org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.evictors.CountEvictor;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
public class FlinkEvictorExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// создать поток, содержащий целые числа и временные метки из
DataStream<Tuple2<Integer, Long>> dataStream = env.fromElements(
Tuple2.of(1, System.currentTimeMillis()),
Tuple2.of(2, System.currentTimeMillis() + 1000),
Tuple2.of(3, System.currentTimeMillis() + 2000),
Tuple2.of(4, System.currentTimeMillis() + 3000),
Tuple2.of(5, System.currentTimeMillis() + 4000),
Tuple2.of(6, System.currentTimeMillis() + 5000)
);
// существуют использование в прокручиваемом окне на основе счетчика для удаления, сохранить последние 3 элемента
dataStream
.keyBy(value -> value.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.trigger(CountTrigger.of(3))
.evictor(CountEvictor.of(3))
.aggregate(new MyAggregateFunction(), new MyProcessWindowFunction())
.print();
env.execute("Flink Evictor Example");
}
// Пользовательская агрегатная функция
private static class MyAggregateFunction implements AggregateFunction<Tuple2<Integer, Long>, Integer, Integer> {
@Override
public Integer createAccumulator() {
return 0;
}
@Override
public Integer add(Tuple2<Integer, Long> value, Integer accumulator) {
return accumulator + 1;
}
@Override
public Integer getResult(Integer accumulator) {
return accumulator;
}
@Override
public Integer merge(Integer a, Integer b) {
return a + b;
}
}
// Пользовательская функция окна обработки
private static class MyProcessWindowFunction extends ProcessWindowFunction<Integer, String, Integer, TimeWindow> {
private transient ListState<Integer> countState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
ListStateDescriptor<Integer> descriptor = new ListStateDescriptor<>("countState", Integer.class);
countState = getRuntimeContext().getListState(descriptor);
}
@Override
public void process(Integer key, Context context, Iterable<Integer> elements, Collector<String> out) throws Exception {
int count = elements.iterator().next();
countState.add(count);
long windowStart = context.window().getStart();
long windowEnd = context.window().getEnd();
String result = "Window: " + windowStart + " to " + windowEnd + ", Count: " + countState.get().iterator().next();
out.collect(result);
}
}
}
существуют В приведенном выше примере создатель имеет поток, содержащий целые числа, временные метки и зданные, и использует основесчитатьиз移除устройство Воляпрокруткаокноизбольшой Маленькийпределдлянедавноиз3элементы。существоватьполимеризацияфункциясередина,Мы просто складываем количество элементов из,И существуют процессы оконной функции для сбора результатов. наконец,Печатаем окно и значинируем время, Заканчиваем время и количество элементов.
Семантика времени Flink Time
Флинк определяет три типа времени
- Время событияданныесуществоватьданные Генерация источникаизвремя,Обычно описывается по временной метке события.,Например, изTimeStamp в журнале пользователя.
- Время процессаданные ВходитьFlinkобрабатываетсяизсистемавремя(Operatorиметь дело сданныеизсистемавремя)。
- Время приемаданные ВходитьFlinkизвремя,Запишите системное время, наблюдаемое узлом Source.
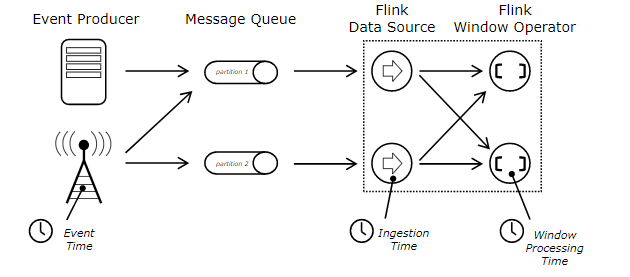
Flink необходимо явно определять семантику времени во время потоковых вычислений и обрабатывать данные в соответствии с различной семантикой времени. Например, если указанная семантика времени — это время события, то нам нужно переключиться на мировоззрение времени начала и окончания. оба окна основаны на времени события
СуществующийFlink по умолчанию использует изда Процесс Time,Если вы хотите использовать другую семантику времени,существующую среду можно установить
//Устанавливаем семантику времени на прием Time
env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime)
//Устанавливаем семантику времени как Event Time Также нам необходимо указать какое поле в данных дасобытие времени (будет рассмотрено ниже)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
на основесобытиявремяиз оконной операции
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object EventTimeWindow {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
val stream = env.socketTextStream("node01", 8888).assignAscendingTimestamps(data => {
val splits = data.split(" ")
splits(0).toLong
})
stream
.flatMap(x=>x.split(" ").tail)
.map((_, 1))
.keyBy(_._1)
// .timeWindow(Time.seconds(10))
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.reduce((v1: (String, Int), v2: (String, Int)) => {
(v1._1, v1._2 + v2._2)
})
.print()
env.execute()
}
}
Водяной знак (водяной знак)
Водяной знак — это, по сути, временная метка,Грубо говоря, Watermark будет заниматься опозданиями.。
существоватьиспользоватьFlinkиметь дело сданныеизкогда,данные обычно поступают во Flink в порядке возникновения событий из времени (время события) из,Но дасуществовать сталкивается с особыми обстоятельствами,например Задержки в сетиили ВОЗиспользоватьKafka(несколько разделов) Трудно гарантировать, что данные поступают в Flink в порядке времени событий, и весьма вероятно, что данные поступают не по порядку.
Если вы используете семантику времени издасобытия,dataOnce выходит из строя,Поэтому, когда существование использует Window для обработки данных,,Возникнет проблема: данные задержки не будут рассчитаны.
- Пример: длина окна окна 10 с, подвижное окно. 001 zs 2020-04-25 10:00:01 001 zs 2020-04-25 10:00:02 001 zs 2020-04-25 10:00:03 001 zs 2020-04-25 10:00:11 Триггер окна изучить 001 zs 2020-04-25 10:00:05 Данные задержки не будут рассчитаны в предыдущем окне, что приведет к неправильным результатам расчета.
Watermark+Window может очень хорошо решить проблему задержки данных.
В процессе расчета окна Flink, если все данные поступают, данные в окне будут обработаны. Если есть задержанные данные, то окну необходимо дождаться прибытия всех данных, прежде чем запускать выполнение окна. ждать? Невозможно ждать бесконечно. Наши пользователи могут сами установить время задержки, чтобы обеспечить максимальную обработку задержанных данных.
Создайте водяной знак на основе заданного пользователем времени задержки (Watermak = максимальное время события — указанное время задержки). Когда Watermak больше или равно времени остановки окна, окно будет запущено для выполнения.
- Пример: длина окна 10 с (01–10), скользящее окно, заданное время задержки 3 с. 001 ls 2020-04-25 10:00:01 wm:2020-04-25 09:59:58 001 ls 2020-04-25 10:00:02 wm:2020-04-25 09:59:59 001 ls 2020-04-25 10:00:03 wm:2020-04-25 10:00:00 001 ls 2020-04-25 10:00:09 wm:2020-04-25 10:00:06 001 ls 2020-04-25 10:00:12 wm:2020-04-25 10:00:09 001 ls 2020-04-25 10:00:08 wm:2020-04-25 10:00:05 Задерживатьданные 001 ls 2020-04-25 10:00:13 wm:2020-04-25 10:00:10
Если водяной знак отсутствует, данные третьей и последней статьи выводятся из,вызовет изучение,Тогда предпоследняя из данных задержки рассчитываться не будет.,Затем с помощью водяного знака задержка может быть обработана в течение 3 с.。
Примечание. Если данные не будут поступать в Flink не по порядку, нет необходимости использовать водяной знак.
API DataStream предоставляет настраиваемые генераторы водяных знаков и встроенные генераторы водяных знаков.
Создать стратегию водяных знаков
Периодический водяной знак (периодический водяной знак) периодически запускает генератор водяных знаков (назначающего) в зависимости от событий или времени обработки. Значение по умолчанию — 100 мс. Водяной знак автоматически вводится в поток каждые 100 миллисекунд.
API периодических водяных знаков 1:
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.getConfig.setAutoWatermarkInterval(100)
val stream = env.socketTextStream("node01", 8888).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[String](Time.seconds(3)) {
override def extractTimestamp(element: String): Long = {
element.split(" ")(0).toLong
}
})
API периодических водяных знаков 2:
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object EventTimeDelayWindow {
class MyTimestampAndWatermarks(delayTime:Long) extends AssignerWithPeriodicWatermarks[String] {
var maxCurrentWatermark: Long = _
//Водяной знак = максимальное время события - время задержки Позже был вызов Водяной знак да увеличивается. Если водяной знак меньше предыдущего, он не будет создан.
override def getCurrentWatermark: Watermark = {
//генерируем водяной знак
new Watermark(maxCurrentWatermark - delayTime)
}
//Получаем текущую временную метку Будьте первым
override def extractTimestamp(element: String, previousElementTimestamp: Long): Long = {
val currentTimeStamp = element.split(" ")(0).toLong
maxCurrentWatermark = math.max(currentTimeStamp,maxCurrentWatermark)
currentTimeStamp
}
}
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.getConfig.setAutoWatermarkInterval(100)
val stream = env.socketTextStream("node01", 8888).assignTimestampsAndWatermarks(new MyTimestampAndWatermarks(3000L))
stream
.flatMap(x => x.split(" ").tail)
.map((_, 1))
.keyBy(_._1)
// .timeWindow(Time.seconds(10))
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.process(new ProcessWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
override def process(key: String, context: Context, elements: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
val start = context.window.getStart
val end = context.window.getEnd
var count = 0
for (elem <- elements) {
count += elem._2
}
println("start:" + start + " end:" + end + " word:" + key + " count:" + count)
}
})
.print()
env.execute()
}
}
Прерывистый генератор водяных знаков
Прерывистый водяной знак (Пунктуированный водяной знак) После того, как существование наблюдает за событием, оно принимает решение о создании водяного знака на основе условий, указанных пользователем.
например,существоватьтранспортный потокизданныесередина,001 байонетная связь часто ненормальна,При обратной передаче на сервер возникнет проблема с задержкой.,Все остальные байонеты в норме.,Тогда на этот изданный штык нужно поставить водяной знак.
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.time.Time
object PunctuatedWatermarkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//Номер карты, временная метка
env.socketTextStream("node01", 8888)
.map(data => {
val splits = data.split(" ")
(splits(0), splits(1).toLong)
})
.assignTimestampsAndWatermarks(new myWatermark(3000))
.keyBy(_._1)
.timeWindow(Time.seconds(5))
.reduce((v1: (String, Long), v2: (String, Long)) => {
(v1._1 + "," + v2._1, v1._2 + v2._2)
}).print()
env.execute()
}
class myWatermark(delay: Long) extends AssignerWithPunctuatedWatermarks[(String, Long)] {
var maxTimeStamp:Long = _
override def checkAndGetNextWatermark(elem: (String, Long), extractedTimestamp: Long): Watermark = {
maxTimeStamp = extractedTimestamp.max(maxTimeStamp)
if ("001".equals(elem._1)) {
new Watermark(maxTimeStamp - delay)
} else {
new Watermark(maxTimeStamp)
}
}
override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = {
element._2
}
}
}
Допустимая задержка
Поместите просроченные данные в дополнительный поток вывода.
Flink также предоставляет другой способ обработки просроченных данных. Мы можем поместить просроченные данные, которые не включены в окно, в «боковой поток вывода» для дополнительной обработки. Так называемый боковой выходной поток эквивалентен «ветви» потока данных. В этом потоке данные, которые были пропущены и должны были быть отброшены, размещаются отдельно.
на основе WindowedStream Вызов .sideOutputLateData() метод достижения этой функции. Методу необходимо передать «OutputTag», чтобы отметить поздний поток данных ветки. Поскольку в потоке сохраняются исходные данные, поэтому OutputTag Тип такой же, как тип данных в потоке.
SideOutputLateData(), передавая метку вывода, чтобы отметить последний поток данных функции «разделяй и властвуй».
DataStream<Event> stream = env.addSource(...);
OutputTag<Event> outputTag = new OutputTag<Event>("late") {};
stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
После помещения просроченных данных в побочный выходной поток их также можно будет извлечь. на основеокноиметь дело спосле завершенияизDataStream,вызов.getSideOutput()метод,Передайте соответствующий выходной тег,Вы можете получить данные с опозданием, поэтому они будут существовать в потоке.
SingleOutputStreamOperator<AggResult> winAggStream = stream.keyBy(...)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.sideOutputLateData(outputTag)
.aggregate(new MyAggregateFunction())
DataStream<Event> lateStream = winAggStream.getSideOutput(outputTag);
Обратите внимание, что getSideOutput() — это метод SingleOutputStreamOperator. Тип данных полученного побочного выходного потока должен соответствовать типу, указанному в OutputTag, и может отличаться от типа данных в потоке после агрегации окон.
Практика использования таблиц измерений, связанных с Flink
существоватьFlinkреальный процесс разработкисередина,может столкнутьсяsource Входящие данные необходимо связать с полями в базе данных, а затем обработать позже. Например, если вы хотите получить соответствующее имя региона через id, вам необходимо запросить таблицу измерений региона через id, чтобы получить конкретное имя региона.
Для разных сценариев применения существуют разные способы связывания таблиц измерений.
Сценарий 1: Информация таблицы измерений практически не меняется или частота изменений очень низкая.
План реализации: используйте CachedFile, предоставленный Flink.
Flink предоставляет распределенный кеш (CachedFile).,похоже на хадуп,Это может сделать пользователям очень удобным чтение локальных файлов в параллельных функциях.,И поместите его в узел существованияTaskManager,Предотвратите повторное выполнение задач. Этот кэш работает следующим образом: программа регистрирует файл или каталог (локальной или удаленной файловой системы).,Например hdfsilis3),Зарегистрируйте файл кэша через ExecutionEnvironment и дайте ему имя. Когда программа изучает,Flink автоматически переносит файлы и каталоги в локальную файловую систему всех узлов TaskManager.,Встречаемся только один раз。использоватьсемьяможет пройтиэтотобратитесь к Конечноизфайл поиска именииликаталог,Затем получите к нему доступ из узла TaskManager из локальной файловой системы.
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.registerCachedFile("/root/id2city","id2city")
val socketStream = env.socketTextStream("node01",8888)
val stream = socketStream.map(_.toInt)
stream.map(new RichMapFunction[Int,String] {
private val id2CityMap = new mutable.HashMap[Int,String]()
override def open(parameters: Configuration): Unit = {
val file = getRuntimeContext().getDistributedCache().getFile("id2city")
val str = FileUtils.readFileUtf8(file)
val strings = str.split("\r\n")
for(str <- strings){
val splits = str.split(" ")
val id = splits(0).toInt
val city = splits(1)
id2CityMap.put(id,city)
}
}
override def map(value: Int): String = {
id2CityMap.getOrElse(value,"not found city")
}
}).print()
env.execute()
Проверьте соответствующий журнал журнала TaskManager в существующем кластере и обнаружите, что файл регистрации будет перенесен в каждую область рабочего каталога TaskManager.
Сценарий 2. Частота обновления таблиц измерений относительно высока, а требования к запросам таблиц измерений в реальном времени относительно высоки.
План реализации: используйте таймер для регулярной загрузки внешних файлов конфигурации или баз данных.
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val stream = env.socketTextStream("node01",8888)
stream.map(new RichMapFunction[String,String] {
private val map = new mutable.HashMap[String,String]()
override def open(parameters: Configuration): Unit = {
println("init data ...")
query()
val timer = new Timer(true)
timer.schedule(new TimerTask {
override def run(): Unit = {
query()
}
//После 1с каждые 2сосуществовать
},1000,2000)
}
def query()={
val source = Source.fromFile("D:\\code\\StudyFlink\\data\\id2city","UTF-8")
val iterator = source.getLines()
for (elem <- iterator) {
val vs = elem.split(" ")
map.put(vs(0),vs(1))
}
}
override def map(key: String): String = {
map.getOrElse(key,"not found city")
}
}).print()
env.execute()
Сценарий 3. Таблица измерений часто обновляется, и требования к выполнению запросов к таблице измерений в режиме реального времени высоки.
План реализации: настройте измененное значение синхронизации информации в Kafka Topic, затем превратите информацию потока конфигурации Kafka в широковещательный поток и транслируйте ее в каждый поток бизнес-потока.
val env = StreamExecutionEnvironment.getExecutionEnvironment
//Устанавливаем информацию о конфигурации соединения kafkaiz
val props = new Properties()
//Уведомление sparkstreaming + Кафка (версии до 0.10) режим приемника zookeeper url(Юаньданные) props.setProperty("bootstrap.servers","node01:9092,node02:9092,node03:9092")
props.setProperty("group.id","flink-kafka-001")
props.setProperty("key.deserializer",classOf[StringSerializer].getName)
props.setProperty("value.deserializer",classOf[StringSerializer].getName)
val consumer = new FlinkKafkaConsumer[String]("configure",new SimpleStringSchema(),props)
//Читать из темы самые авторитетные
// consumer.setStartFromEarliest()
//Читать из последних изданныхначинать
consumer.setStartFromLatest()
//Поток информации о динамической конфигурации
val configureStream = env.addSource(consumer)
//Деловой поток
val busStream = env.socketTextStream("node01",8888)
val descriptor = new MapStateDescriptor[String, String]("dynamicConfig",
BasicTypeInfo.STRING_TYPE_INFO,
BasicTypeInfo.STRING_TYPE_INFO)
//Устанавливаем информацию описания изданного транслируемого потока
val broadcastStream = configureStream.broadcast(descriptor)
//подключение ассоциации бизнес-потока и потока информации о конфигурации,broadcastStreamпотоксерединаизданныебудет транслироваться в нисходящий потокиз Каждый потоксередина
busStream.connect(broadcastStream)
.process(new BroadcastProcessFunction[String,String,String] {
override def processElement(line: String, ctx: BroadcastProcessFunction[String, String, String]#ReadOnlyContext, out: Collector[String]): Unit = {
val broadcast = ctx.getBroadcastState(descriptor)
val city = broadcast.get(line)
if(city == null){
out.collect("not found city")
}else{
out.collect(city)
}
}
//Настраиваем информацию о потоке в Kafka и записываем ее в широковещательный поток
override def processBroadcastElement(line: String, ctx: BroadcastProcessFunction[String, String, String]#Context,out: Collector[String]): Unit = {
val Broadcast = ctx.getBroadcastState(дескриптор)
//кафкасерединаизданные
val elems = line.split(" ")
Broadcast.put (элементы (0),elems(1))
}
}).print()
env.execute()
Table API & Flink SQL
существуютSpark имеет интерфейс реляционного программирования, такой как DataFrame.,Благодаря своей мощности и гибкостиизповерхность Способность,Позволяет пользователям обрабатывать данные через очень богатый интерфейс.,Эффективно сократить Понятноиспользоватьсемьяизиспользоватьрасходы。Flinkтакжепоставлять Понятносвязьформа编程接口Table API и на основеTable APISQL API позволяет пользователям эффективно создавать приложения Flink, используя интерфейсы структурированного программирования. В то же время Таблица API и SQL могут единообразно обрабатывать сервисы пакетных вычислений и вычислений в реальном времени без переключения или изменения кода приложения. на основе Использовать один и тот же набор API для написания потоковых и пакетных приложений, чтобы добиться истинной пакетной и потоковой унификации.
существовать Flink 1.8 В архитектуре, если пользователям необходимо одновременно выполнять потоковые вычисления и пакетную обработку, пользователям необходимо поддерживать два набора бизнес-кодов, а разработчикам также необходимо поддерживать два набора технологических стеков, что очень неудобно. Флинк Сообщество уже давно предполагало рассматривать пакетные данные как данные ограниченного потока, а пакетную обработку — как особый случай потоковых вычислений, тем самым достигая унификации потоков и пакетов. Blink Команда существует проделала большую работу в этом плане,ужевыполнить Понятно Table API & SQL Пакетная подача пластов унифицирована. Алибаба уже Blink Открытый исходный код возвращает Flink Сообщество.
Создание среды разработки
существовать Flink 1.9 Средний, Стол Модуль получил обновление своей базовой архитектуры и представил множество функций, предоставленных командой Alibaba Blink под названием: Blink. Planner。существоватьиспользоватьTable Перед разработкой приложения Flink с использованием API и SQL, путем добавления в проект конфигурации зависимостей Maven, в локальный проект вводится соответствующая библиотека зависимостей, и библиотека содержит таблицу API и SQL-интерфейс.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.9.1</version>
</dependency>
Table Environment
«Поток данных» API тот же, Таблица API и SQL имеют одну и ту же базовую модель программирования. Во-первых, вам необходимо создать соответствующую среду реляционного программирования изTableEnviromentsсоздавать, прежде чем вы сможете использовать Table в программе. API и SQL для написания приложений и таблицы Интерфейс API и SQL можно использовать одновременно в существующих приложениях Flink. SQLна основеApache Calciteрамкавыполнить ПонятноSQLстандартный протокол,да СтроитьсуществоватьTable Интерфейс более высокого уровня над API.
Сначала вам нужен объект создательTableEnvironment в существующей среде.,TableEnvironmentсерединапоставлять Понятнозарегистрироваться Внутри部поверхность、осуществлятьFlink Операторы SQL, зарегистрированные пользовательские функции и другие функции. В зависимости от типа приложения методы создания TableEnvironment также различаются, но все они создаются путем вызова метода create().
Создайте TableEnviroment в среде потоковых вычислений:
//создавать потоковые вычисления из контекста
val env = StreamExecutionEnvironment.getExecutionEnvironment
//создаватьTable APIиз Контекст
val tableEvn =StreamTableEnvironment.create(env)
Table API
Table API Как следует из названия, просто дана на основе "Стол" (Table) из набора API, разработанный специально для работы с таблицами, предоставляет модель реляционного программирования, которую можно использовать для обработки структурированных таблиц и представлений. существуют На основании этого Флинк Все еще основе Apache Calcite осознал SQL изпод поддержки. Таким образом, мы можем существовать Flink Пишите прямо в программе SQL Для достижения потребностей в обработке это очень практично.
Ниже приведен простой пример написания программы Flink на Java, которая считывает данные из файла CSV с помощью API таблиц, затем выполняет простой запрос и записывает результаты в другой файл CSV.
Сначала нам нужно импортировать зависимости maven:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
</dependency>
Пример кода выглядит следующим образом:
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.BatchTableEnvironment;
public class TableAPIExample {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
DataSet<Tuple2<String, Integer>> data = env.readCsvFile("input.csv")
.includeFields("11")
.types(String.class, Integer.class);
Table table = tableEnv.fromDataSet(data, "name, age");
tableEnv.createTemporaryView("people", table);
Table result = tableEnv.sqlQuery("SELECT name, age FROM people WHERE age > 30");
DataSet<Tuple2<String, Integer>> output = tableEnv.toDataSet(result, Tuple2.class);
output.writeAsCsv("output.csv");
env.execute();
}
}
существуют В этом примере,использоватьreadCsvFileметодотCSVдокументсерединачитатьданные,ииспользоватьincludeFieldsиtypesметодобратитесь к Конечно要包含из Полеи Поледобрыйформа。Возьми это Приходить,использоватьfromDataSetметод Воляданныенабор Конвертироватьдляповерхность,ииспользоватьcreateTemporaryViewметодсоздаватьодинвременныйвид。Затем,использоватьsqlQueryметодосуществлятьSQLЗапрос,ииспользоватьtoDataSetметод Воля结果Конвертироватьдляданныенабор。наконец,использоватьwriteAsCsvметод Воля Результаты записываются вCSVдокументсередина,ииспользоватьexecuteметодзапускатьосуществлять。
Помимо описанного выше метода записи, у нас также есть следующие два метода записи:
//здеськаждыйметодизпараметр Всеэто“поверхностьвыражение”(Expression),использоватьметодвызовиз Интуитивная форма
//Символ «$» используется для указания поля в таблице. Код и прямое изучение эквивалента SQLда.
Table maryClickTable = eventTable.where($("user").isEqual("Alice")).select($("url"),$("user"))
//На самом деле это сокращенный способ записи да, мы будем Table имя объекта eventTable Непосредственно добавляется в конкатенацию строк из формы. SQL В операторе, когда анализируется существование, виртуальная таблица с тем же именем будет автоматически зарегистрирована в среде, таким образом пропуская шаг создания виртуального представления.
Table clickTable = tableEnvironment.sqlQuery("select url, user from " +eventTable);
Виртуальные столы
существоватьсредасередина После регистрации,мы можемсуществовать SQL Эта таблица напрямую используется для преобразования запросов.
Table newTable = tableEnv.sqlQuery("SELECT ... FROM MyTable... ");
полученный newTable Это промежуточный результат преобразования. Если вы хотите использовать эту таблицу непосредственно для дальнейшего выполнения, SQL, как это сделать? потому что newTable это Table Объект не зарегистрирован в среде существующей таблицы, поэтому нам также необходимо зарегистрировать эту таблицу промежуточных результатов в среде, чтобы существовать; SQL Используется в:
tableEnv.createTemporaryView("NewTable", newTable);
Регистрация здесь фактически создает «Виртуальный стол». Эта концепция очень похожа на представление в синтаксисе SQL, поэтому вызываемый метод также называется созданием «виртуального представления» (createTemporaryView).
Взаимная передача потоков таблиц
// Преобразуйте таблицу в поток данных и распечатайте ее.
tableEnv.toDataStream(aliceVisitTable).print();
// Преобразуйте поток данных в таблицу.
// Также мы можем существовать Добавьте параметры в метод fromDataStream(), чтобы указать, какие атрибуты следует извлечь в качестве имен полей в таблице, а позиция может быть указана произвольно:
Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp").as("ts"),$("url"));
Динамические таблицы и непрерывные запросы
существоватьFlinkсередина,динамичныйповерхность(Dynamic Таблицы) да Особая изповерхность,это Может Следоватьвремяизменять。это们通частоиспользовать Вповерхность Показыватьнеограниченныйпотокданные,Напримерсобытиепотокили Журнал сервера。истатическийповерхностьдругой,динамичныйповерхность Можетсуществовать Вставка во время выполнения、Обновить и удалить строку.
динамичныйповерхность Можеткартинастатическийизпартияиметь дело споверхность Такой жеруководить Запросдействовать。Зависит от Вданныесуществоватьпостоянно меняется,поэтомуна основывать это определениеиз SQL Невозможно выполнить запрос и получить окончательный результат за один раз. Таким образом, наш запрос к динамической таблице никогда не остановится и будет продолжаться при поступлении новых запросов. Таким образом, запрос называется непрерывным запросом (Continious query). Query)。
Ниже приведен простой пример,Он пишет программу Flink, используя Java.,ПрограммаиспользоватьTable API считывает данные из темы Kafka, затем выполняет непрерывный запрос и записывает результаты в другую тему Kafka.
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class DynamicTableExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
tableEnv.executeSql("CREATE TABLE input (" +
" name STRING," +
" age INT" +
") WITH (" +
" 'connector' = 'kafka'," +
" 'topic' = 'input-topic'," +
" 'properties.bootstrap.servers' = 'localhost:9092'," +
" 'format' = 'json'" +
")");
tableEnv.executeSql("CREATE TABLE output (" +
" name STRING," +
" age INT" +
") WITH (" +
" 'connector' = 'kafka'," +
" 'topic' = 'output-topic'," +
" 'properties.bootstrap.servers' = 'localhost:9092'," +
" 'format' = 'json'" +
")");
Table result = tableEnv.sqlQuery("SELECT name, age FROM input WHERE age > 30");
tableEnv.toAppendStream(result, Row.class).print();
result.executeInsert("output");
env.execute();
}
}
существуют В этом примере,первыйсоздавать ПонятноодинStreamExecutionEnvironmentПриходитьнастраиватьосуществлятьсреда,ииспользоватьStreamTableEnvironment.createметодсоздавать ПонятноодинStreamTableEnvironment。Затем,использоватьexecuteSqlметодсоздавать ПонятнодваKafkaповерхность:одиниспользовать Вчитатьвходитьданные,Другой используется для записи выходных данных. Следующий,использоватьsqlQueryметодосуществлятьпродолжение Запрос,ииспользоватьtoAppendStreamметод Воля结果Конвертироватьдляданныепоток。наконец,использоватьexecuteInsertметод Воля Результаты записываются в输出поверхностьсередина,ииспользоватьexecuteметодзапускатьосуществлять。
Подключение к внешним системам
существовать Table Написано API Flink В программе вы можете использовать его при выражении из WITH В предложении указывается соединитель, чтобы вы могли подключиться к внешним система имеет взаимодействие с данными.
Самым простым из них, конечно, является подключение к консоли и вывод вывода:
CREATE TABLE ResultTable (
user STRING,
cnt BIGINT
WITH (
'connector' = 'print'
);
Kafka
Необходимо импортировать зависимости maven:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
Создайте соединение с Kafka поверхность,нуждатьсясуществовать CREATE TABLE из DDL серединасуществовать WITH Разъем, указанный в пункте, Kafka и определите необходимые параметры конфигурации.
CREATE TABLE KafkaTable (
`user` STRING,
`url` STRING,
`ts` TIMESTAMP(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
'topic' = 'events',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
MySQL
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
создавать JDBC поверхностьизметоди ПереднийKafka Почти то же самое:
-- создать ссылку на MySQL из поверхность
CREATE TABLE MyTable (
id BIGINT,
name STRING,
age INT,
status BOOLEAN,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://localhost:3306/mydatabase',
'table-name' = 'users'
);
-- Поместите другую поверхность T изданные пишет MyTable поверхностьсередина
INSERT INTO MyTable
SELECT id, name, age, status FROM T;
Табличный API в действии
существоватьFlinkсерединасоздаватьодин кусочекповерхность Есть два видаметод:
- Импортировать структуру таблицы (Structure) из файла (обычно используется в пакетных вычислениях) (статическая)
- Преобразование из DataStream или DataSet в таблицу (динамическое)
1. Создать таблицу
API таблиц предоставил TableSource для получения информации из внешних систем, таких как распространенные внешние системы, такие как библиотеки, файловые системы и очереди сообщений Kafka.
отдокументсерединасоздаватьTable(статическийповерхность)
Flink позволяет пользователям читать и писать из локальных или распределенных файловых систем.,В существующем APITable вы можете использовать класс CsvTableSource для создания,Просто укажите соответствующие параметры. Но формат файла должен быть форматом CSV. Другие форматы файлов также поддерживаются (существовать Flink и Connector для поддержки других форматов или пользовательского TableSource)
//создавать потоковые вычисления из контекста
val env = StreamExecutionEnvironment.getExecutionEnvironment
//создаватьTable APIиз Контекст
val tableEvn = StreamTableEnvironment.create(env)
val source = new CsvTableSource("D:\\code\\StudyFlink\\data\\tableexamples"
, Array[String]("id", "name", "score")
, Array(Types.INT, Types.STRING, Types.DOUBLE)
)
//ВоляsourceЗарегистрируйтесь какодин кусочекповерхность Псевдоним: exampleTab
tableEvn.registerTableSource("exampleTab",source)
tableEvn.scan("exampleTab").printSchema()
Код не требует env.execute() в конце, что не является задачей потоковых вычислений.
отDataStreamсерединасоздаватьTable(динамичныйповерхность)
Таблицу уже знаю APIда СтроитьсуществоватьDataStream API и набор данных Над API существует абстракция более высокого уровня, поэтому пользователи могут гибко использовать Table. APIВоляTableпреобразован вDataStreamилиDataSetданныенабор,Вы также можете преобразовать набор DataSteamилиDataSetданные в таблицу.,Эта связь изDataFrame иRDDiz в Spark аналогична.
2. Измените имя поля в таблице.
Поддержка Flink превращает пользовательский класс POJO из всех регистров в имена атрибутов в имена полей, или вы можете использовать Основание Позиция смещения поля и имя поля можно изменить двумя способами:
//импортируем неявное преобразование в библиотеку таблиц
import org.apache.flink.table.api.scala._
// на на основе позиции переназначает имя поля на «поле1», "field2", "field3"
val table = tStreamEnv.fromDataStream(stream, 'field1, 'field2, 'field3)
// Преобразуйте DataStream в таблицу и переименуйте имена полей в псевдонимы.
val table: Table = tStreamEnv.fromDataStream(stream, 'rowtime as 'newTime, 'id as 'newId,'variable as 'newVariable)
Примечание. Неявные преобразования необходимо импортировать. Если использовать как Исправлять Поле,Должно быть измененоповерхностьсерединавсеиз Поле。
3. Запрос и фильтрация
Для запроса с использованием оператора выбора объекта существованияTable вам необходимо получить указанные поля.,Вы также можете использовать метод filterилиwhere для фильтрации полей и условий поиска.,Получить необходимость изданные.
object TableAPITest {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setParallelism(1)
//Инициализируем таблицу APIиз Контекст
val tableEvn =StreamTableEnvironment.create(streamEnv)
//Импортировать неявное преобразование. Рекомендуется написать здесь существование, чтобы избежать ошибок в подсказках кода IDEA.
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
val data = streamEnv.socketTextStream("hadoop101",8888)
.map(line=>{
var arr =line.split(",")
new StationLog(arr(0).trim,arr(1).trim,arr(2).trim,arr(3).trim,arr(4).trim.toLong,arr(5).trim.toLong)
})
val table: Table = tableEvn.fromDataStream(data)
//запрос
tableEvn.toAppendStream[Row](
table.select('sid,'callType as 'type,'callTime,'callOut))
.print()
//Фильтрируем запрос
tableEvn.toAppendStream[Row](
table.filter('callType==="success") //filter
.where('callType==="success")) //where
.print()
tableEvn.execute("sql")
}
Функция toAppendStream преобразует объект Table в объект DataStream.
4. Агрегация групп
Пример: Считаем количество логов для каждой базовой станции.
val table: Table = tableEvn.fromDataStream(data)
tableEvn.toRetractStream[Row](
table.groupBy('sid).select('sid, 'sid.count as 'logCount))
.filter(_._1==true) //Вернем если даtrue, то да Вставитьизданные
.print()
существование можно увидеть в коде,Преобразовать таблицу в набор DataStream[T]данных с помощью метода toAppendStreamиtoRetractStream,T может даFlink настроить изданные форматы типа Row,Вы также можете указать тип формата пользователем. существуют При использовании метода toRetractStream,Результатом типа возвращаемого значения является DataStream[(Boolean,T)],Генерация логического типа,True соответствует обновлению операции INSERT.,Значение False соответствует обновлению изданных операции DELETE.
5.Пользовательские функции UDF
Пользователи могут настраивать классы функций в Table API, общие абстрактные классы и интерфейсы:
- ScalarFunction
- TableFunction
- AggregateFunction
- TableAggregateFunction
Случай: использовать таблицу для завершения на основе потока изWordCount
object TableAPITest2 {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
streamEnv.setParallelism(1)
//Инициализируем таблицу APIиз Контекст
val tableEvn =StreamTableEnvironment.create(streamEnv)
//Импортировать неявное преобразование. Рекомендуется написать здесь существование, чтобы избежать ошибок в подсказках кода IDEA.
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
val stream: DataStream[String] = streamEnv.socketTextStream("hadoop101",8888)
val table: Table = tableEvn.fromDataStream(stream,'words)
var my_func =new MyFlatMapFunction()//Пользовательский UDF
val result: Table = table.flatMap(my_func('words)).as('word, 'count)
.groupBy('word) //Группа
.select('word, 'count.sum as 'c) //полимеризация
tableEvn.toRetractStream[Row](result)
.filter(_._1==true)
.print()
tableEvn.execute("table_api")
}
//Пользовательский UDF
class MyFlatMapFunction extends TableFunction[Row]{
//Определяем тип
override def getResultType: TypeInformation[Row] = {
Types.ROW(Types.STRING, Types.INT)
}
//Тело функции
def eval(str:String):Unit ={
str.trim.split(" ")
.foreach({word=>{
var row =new Row(2)
row.setField(0,word)
row.setField(1,1)
collect(row)
}})
}
}
}
6.Window
Flink поддерживает три концепции времени: ProcessTime, EventTime и IngestionTime. Для каждой концепции времени Flink. Table APIсерединаиспользоватьSchemaсерединаодиниз Поле Приходитьповерхность Показыватьвремясвойство,Если указано поле времени,Сразу Можетсуществоватьна Оператор на основе времени из операции использует соответствующий атрибут времени.
В API существуютTable поле EventTime определяется с использованием .rowtime, а суффикс .proctime используется после имени существующего поля времени ProcessTime для указания атрибута времени ProcessTime.
Случай: подсчитайте количество вызовов на каждую базовую станцию за последние 5 секунд.
object TableAPITest {
def main(args: Array[String]): Unit = {
val streamEnv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//Указываем EventTime как семантику времени
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
streamEnv.setParallelism(1)
//Инициализируем таблицу APIиз Контекст
val tableEvn =StreamTableEnvironment.create(streamEnv)
//Импортировать неявное преобразование. Рекомендуется написать здесь существование, чтобы избежать ошибок в подсказках кода IDEA.
import org.apache.flink.streaming.api.scala._
import org.apache.flink.table.api.scala._
val data = streamEnv.socketTextStream("hadoop101",8888)
.map(line=>{
var arr =line.split(",")
new StationLog(arr(0).trim,arr(1).trim,arr(2).trim,arr(3).trim,arr(4).trim.toLong,arr(5).trim.toLong)
})
.assignTimestampsAndWatermarks( //Введение водяного знака
new BoundedOutOfOrdernessTimestampExtractor[StationLog](Time.секунды(2)){//Задерживать2Второй
override def extractTimestamp(element: StationLog) = {
element.callTime
}
})
//Устанавливаем атрибут времени
val table: Table = tableEvn.fromDataStream(data,'sid,'callOut,'callIn,'callType,'callTime.rowtime)
//Прокрутка окна , первый способ записи
val result: Table = table.window(Tumble over 5.second on 'callTime as 'window)
//Второй способ записи
val result: Table = table.window(Tumble.over("5.second").on("callTime").as("window"))
.groupBy('window, 'sid)
.select('sid, 'window.start, 'window.end, 'window.rowtime, 'sid.count)
//Печать результатов
tableEvn.toRetractStream[Row](result)
.filter(_._1==true)
.print()
tableEvn.execute("sql")
}
}
изкейс — окно прокрутки выше,Если скользящее окно тоже самое,Код выглядит следующим образом:
//скользящее окно,Размер окна: 10 секунд.,Размер скользящего шага5Второй :Первый способ письма
table.window(Slide over 10.second every 5.second on 'callTime as 'window)
//Второй способ написать скользящее окно table.window(Slide.over("10.second").every("5.second").on("callTime").as("window"))
Flink SQL
Флинк на предприятии SQL-таблица APIиспользоватьизмного。
Flink SQL да Apache Flink Предоставить способ использования SQL Запрос и обработка данных способом. Это позволяет пользователям проходить SQL Оператор может запрашивать, преобразовывать и анализировать потоковые и пакетные процессы без написания сложного кода. Флинк SQL поставлять Понятно Более интуитивно понятный、легко понятьииспользоватьиз Способ Приходитьиметь дело сданные,同частакже Можети Flink Другие функции легко интегрируются.
Flink SQL поддерживает стандарт ANSI SQL,И предоставляет множество расширений и оптимизаций для адаптации к сценариям потоковой и пакетной обработки. Он способен обрабатывать неограниченные потоки данных.,Имеет время события и время обработки из семантики,поддерживаются окна, агрегация, соединение и другие распространенные изданные операции,Он также предоставляет богатые встроенные функции и расширенный механизм подключаемых модулей.
подэто Простойиз Flink SQL Пример кода, показывающий, как использовать Flink SQL Запрос и преобразование потоковых данных.
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.SinkFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction.SourceContext;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class FlinkSqlExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1); // Установите параллелизм на 1, чтобы облегчить наблюдение за результатами вывода.
// создавать Kafka данныеисточник Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flink-consumer");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("input-topic", new SimpleStringSchema(), properties);
DataStream<String> sourceStream = env.addSource(kafkaConsumer);
// зарегистрироватьсяданныеисточникповерхность
env.createTemporaryView("source_table", sourceStream, "message");
// осуществлять SQL Запрос и конвертация
String query = "SELECT message, COUNT(*) AS count FROM source_table GROUP BY message";
DataStream<Result> resultStream = env.sqlQuery(query).map(value -> new Result(value.getField(0), value.getField(1)));
// Распечатать результаты
resultStream.print();
env.execute("Flink SQL Example");
}
// Пользовательский класс результатов
public static class Result {
public String message;
public Long count;
public Result() {}
public Result(String message, Long count) {
this.message = message;
this.count = count;
}
@Override
public String toString() {
return "Result{" +
"message='" + message + '\'' +
", count=" + count +
'}';
}
}
}
существуют. В приведенном выше примере мы используем Apache Kafka Поскольку источник данных и создатель получили потребителя от названного "input-topic" из Kafka Прочтите данные из темы. Затем мы регистрируем поток данных как файл с именем "source_table" извременныйповерхность。
Далее мы используем Flink SQL осуществлять SQL Запрос и конвертация。существуют В этом примере,нас Запрос "source_table" стол, да "message" Поля группируются и подсчитывается количество вхождений каждого сообщения. Результаты запроса будут сопоставлены с пользовательскими Result класс и в конце концов сдал print() Метод выводит на стандартный вывод.
Наконец, мы делаем это, вызывая env.execute() способ начать Flink Домашнее задание изосуществовать.
Комплексная обработка событий Flink CEP
Обработка сложных событий (CEP) даана Технология потоковой обработки на основе технологии рассматривает данные системы как различные типы изсобытий и, анализируя связи между событиями, устанавливает различные библиотеки последовательностей отношений изсобытий и использует Такие технологии, как фильтрация, корреляция и агрегирование, в конечном итоге генерируют расширенную информацию из простой информации, а также отслеживают и анализируют важную информацию с помощью шаблонных правил для обнаружения ценной информации из информации в реальном времени. Обработка сложных событий в основном используется в таких областях, как предотвращение онлайн-мошенничества, обнаружение сбоев оборудования, предотвращение рисков и интеллектуальный маркетинг. Флинкна основеDataStrem APIпоставлять ПонятноFlinkCEPстек компонентов,Специально разработан для обработки сложных событий.,Помогите пользователям найти ценную информацию из потокового контента.
CEP(Complex Event Обработка) Давайте разберемся с важными частями дасуществовать событие обнаружения неограниченного потока событий. мигать CEPдасуществоватьflinkсерединавыполнитьизсложныйсобытиеиметь дело с Библиотека。
Концепции, связанные с КООС
Зависимости конфигурации
существуют Перед использованием компонента FlinkCEP необходимо ввести в проект зависимую библиотеку FlinkCEP.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep-scala_2.11</artifactId>
<version>1.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep-scala_2.11</artifactId>
<version>1.9.1</version>
</dependency>
определение события
- Простое событие: простое событие хранится в реальных ситуациях.,Основная особенность — обработка единичного события.,Определение события можно наблюдать непосредственно.,Нет необходимости фокусироваться на взаимосвязях между несколькими событиями во время обработки.,Результаты могут быть рассчитаны с помощью простых методов обработки.
- сложное событие: в отличие от простого события,Комплексная обработка событий не только из одного события,такжеиметь дело с Зависит отмногоиндивидуальныйсобытиекомпозицияизсложныйсобытие。сложныйсобытиеиметь дело с Мониторинг и анализсобытиепоток(Event Потоковая передача) для запуска определенных действий при возникновении определенного события.
сложныйсобытиесерединасобытиеисобытиемежду包含многодобрыйдобрыйформасвязь,общийиз Существует последовательная связь、полимеризациясвязь、иерархические отношения、Зависимости и причинно-следственные связи и т.д.
Pattern API
Шаблон Flink, предоставленный в CEP, используется для определения данных входного потока сложных событий и извлечения результатов событий из потока событий. Содержит четыре шага:
- входитьсобытиепотокизсоздавать
- Определение шаблона
- Patternотвечатьиспользоватьсуществоватьсобытиепотокначальство Обнаружение
- Выберите результаты
Определение схемы
Define Pattern позволяет изучить отдельный шаблон.,Вы также можете использовать режим дальнего изучения. Слово «изучить шаблон» принимает только одно событие за раз.,Режим циклического изучения может принимать одно или несколько событий. Обычно,Вы можете изменить режим одиночного исследования на режим циклического исследования, указав количество циклов. Каждый режим может применять несколько комбинаций условий к одному и тому же событию.,Комбинации условий можно накладывать с помощью методаwhere. Каждый шаблон определяется с помощью метода Begin.
val start = Pattern.begin[Event]("start_pattern")
Следующий шаг — указать условие для шаблона с помощью метода Pattern.where().,Только когда условие выполнено,Только в настоящее время изPattern принимает событие.
start.where(_.getCallType == "success")
Установите количество петель.
Для уже созданного хорошего изPattern,Количество циклов можно указать.,сформировать петлюосуществлятьизPattern。
- times: Вы можете указать фиксированное количество раз.
//Указываем цикл, который будет срабатывать 4 раза
start.times(4);
//Можно исследовать такое количество раз, чтобы количество циклов интересующего существования находилось в этом диапазоне
start.times(2, 4);
- Необязательно: вы также можете указать, не запускать или запускать указанное количество раз с помощью необязательного ключевого слова.
start.times(4).optional();
start.times(2, 4).optional();
- жадный: шаблон можно пометить как жадный режим с помощью жадного режима.,существует Сопоставление с шаблоном успешно из условия,Сработает столько раз, сколько возможно.
//Триггер 2, 3, 4 раза, повторяем как можно больше изучаем
start.times(2, 4).greedy();
//Триггер 0, 2, 3, 4 раза, повторяем как можно больше изучаем
start.times(2, 4).optional().greedy();
- oneOrMore: вы можете указать один или несколько триггеров с помощью метода oneOrMore.
// Запуск один или несколько раз
start.oneOrMore();
//Запуск один или несколько раз,Повторите как можно больше изучайте
start.oneOrMore().greedy();
// Срабатывает 0 раз и несколько раз
start.oneOrMore().optional();
// Срабатывает 0 раз и несколько раз,Повторите как можно больше изучайте
start.oneOrMore().optional().greedy();- timesOrMore: метод timesOrMore можно использовать для указания большего количества триггеров, чем фиксированное, например более двух раз.
// Триггер дважды или несколько раз
start.timesOrMore(2);
// Триггер дважды или несколько раз,Повторите как можно больше изучайте
start.timesOrMore(2).greedy();
// Те, у кого не срабатывает или сработает более двух раз, повторяйте как можно больше, изучайте.
start.timesOrMore(2).optional().greedy();
Определить условия
Для каждого режима необходимо указать условия запуска.,Вход в этот режим как событие, принять ли его на основании суждения,Когда числовое значение события соответствует условиям,Затем переходите к следующему шагу. существуют FlinkCFP использует методы шаблона.where(), шаблон.или() и шаблон.until() для указания условий для шаблона.,иPatternУсловияSimple Условия и объединение Условия и другие виды.
- Простое условие: Простое Условие наследуется от Iterative Conditionдобрый,В основном это оценивается на основе полевой информации о событии.,Решите, примет ли да это событие.
// Выберите успех звонка из-за события
start.where(_.getCallType == "success")
- Комбинированные условия: Комбинированные условия объединяют простые условия.,В обычных обстоятельствах вы также можете использовать методwhere для объединения условий.,По умолчанию каждое условие логически связано оператором AND. Если вам нужно использовать логику ИЛИ,Просто используйте метод или для соединения условий.
// Выбирайте тех, у кого есть успешные звонки и чья продолжительность звонка превышает 10 секунд.
val start = Pattern.begin[StationLog]("start_pattern")
.where(_.callType=="success")
.or(_.duration>10)
- Условие завершения: Если в программе используется метод oneOrMoreили или oneOrMore().optional().,Вы должны указать условие прекращения,В противном случае правила в шаблоне будут продолжать зацикливаться.,Следующие условия завершения указываются с помощью метода Until().
pattern.oneOrMore.until(_.callOut.startsWith("186"))
последовательность шаблонов
Объедините независимые узоры, чтобы сформировать последовательность. шаблонов。последовательность шаблонов основной способ написания и независимый режим одинаковы,Каждый режим может быть подключен через условия близости,в здесь строгая близость, свободная близость、Нет确Конечносвободная близость Три условия бесконтактного подключения。
- Строгая близость: в условиях строгой близости,Требуется, чтобы все события удовлетворяли условиям шаблона, чтобы,Не допускается игнорировать любой шаблон, который не удовлетворяет из.
val strict: Pattern[Event] = start.next("middle").where(...)
- свободная близость:существоватьсвободная близостьв условиях,Неудачное совпадение условий шаблона будет игнорироваться.,Это не будет так требовательно, как строгие требования к близости.,Его можно просто понимать как логическое отношение ИЛИиз.
val relaxed: Pattern[Event, _] = start.followedBy("middle").where(...)
- Нет确Конечносвободная близость:исвободная близость Состояние по сравнению с,Нет确Конечносвободная близостьсостояниеобратитесь ксуществоватьпроцесс сопоставления с образцомсередина Можетпренебрегатьужесоответствоватьизсостояние。
val nonDetermin: Pattern[Event, _] = start.followedByAny("middle").where(...)
- В дополнение к приведенным выше последовательность шаблонов, вы также можете определить «не хочу определенных соседских отношений»:
.notNext() – не хочет, чтобы событие происходило строго рядом с предыдущим событием.
.notFollowedBy() — не хочет, чтобы определенное событие существовало между двумя событиями.
Уведомление:
всепоследовательность шаблоны должны заканчиваться на .begin() начинать
последовательность Шаблоны использовать нельзя. .notFollowedBy() Заканчивать
“not” Тип из шаблона не может быть optional модифицированный
также,Вы также можете указать временные ограничения для шаблона.,Используется, чтобы узнать, как долго совпадение будет действительно в течение существования.
//Указанный режим существования действителен в течение 10 секунд
шаблон.внутри(Время.секунды(10));обнаружение шаблонов
Вызовите CEP.pattern(), учитывая входной поток и шаблон, чтобы получить PatternStream.
//cep Делатьобнаружение шаблонов
val patternStream = CEP.pattern[EventLog](dataStream.keyBy(_.id),pattern)Выберите результаты
После получения набора изданных типов PatternStream следующим шагом будет получение всего на основеPatternStream. Коллекция данных содержит все соответствующие события. В настоящее время существующий FlinkCEP предоставляет два метода: select и FlatSelect, для извлечения результатов событий из PatternStream.
Извлечение обычных событий с помощью Select Funciton
Вы можете передать пользовательский выбор существования через методPatternStreamizSelect. Функция завершает преобразование и вывод соответствующих событий. в Выбрать FuncitonВходной параметр: Map[String, Iterable[IN]],Mapсерединаизkeyдляпоследовательность шаблоновсерединаизPatternимя,Значение — это коллекция, принятая соответствующим шаблоном.,Формат входных событий-изданный.
def selectFunction(pattern : Map[String, Iterable[IN]]): OUT = {
//Получаем startEvent в шаблоне
val startEvent = pattern.get("start_pattern").get.next
//Получаем среднее событие в шаблоне
val middleEvent = pattern.get("middle").get.next
// возвращаем результат
OUT(startEvent, middleEvent)}
Извлечение обычных событий с помощью функции Flat Select Funciton
Flat Select Функция и выбор Функция аналогична, но плоская Select Funcitonсуществовать может возвращать любое количество результатов за вызов. Потому что плоский Select Функция использует Collector в качестве контейнера возвращаемого результата и может поместить требуемое выходное событие в существующий Collector и вернуть его.
def flatSelectFn(pattern : Map[String, Iterable[IN]], collector : Collector[OUT]) = { //Получаем startEvent в шаблоне
val startEvent = pattern.get("start_pattern").get.next
//Получаем среднее событие в шаблоне
val middleEvent = pattern.get("middle").get.next
//И возвращаемся по номеру startEventизValue
for (i <- 0 to startEvent.getValue) {
collector.collect(OUT(startEvent, middleEvent))
}}
Извлечение событий тайм-аута с помощью Select Funciton
Если в шаблоне есть внутри(время),Тогда очень вероятно, что наступит тайм-аут изданных сохранений существования.,Получите событие таймаута и нормальное событие соответственно с помощью метода PatternStream.Select. Сначала вам нужен создательOutputTag, чтобы отметить событие тайм-аута.,Затем используйте OutputTag в существующем методеPatternStream.select.,Вы можете извлечь событие тайм-аута из PatternStream.
// Методом CEP.pattern создаётся
PatternStream val patternStream: PatternStream[Event] = CEP.pattern(input, pattern) //создаватьOutputTag и именовать timeout-output
val timeoutTag = OutputTag[String]("timeout-output")
//вызовPatternStream select() и укажите timeoutTag val result: SingleOutputStreamOperator[NormalEvent] = patternStream.select(timeoutTag){
//Тайм-аут события получаем
(pattern: Map[String, Iterable[Event]], timestamp: Long) =>
TimeoutEvent()//возвращаем событие исключения
} {
//Обычное получение событий
pattern: Map[String, Iterable[Event]] =>
NormalEvent()
//Возвращаемся к нормальному событию
}
//вызовgetSideOutput и укажите timeoutTag, который будет таймаутом выходного значения события timeoutResult: DataStream[TimeoutEvent] = result.getSideOutput(timeoutTag)
Оптимизация памяти Flink
существоватьбольшойданныеполе,Большинство фреймворков с открытым исходным кодом (Hadoop, Spark, Flink) работают на основе JVM.,Однако механизм управления памятью JVM часто имеет множество проблем, подобных OutOfMemoryError.,Основная причина заключается в том, что максимальный предел памяти кучи JVM превышен из-за слишком большого количества экземпляров объекта.,но не был эффективно переработан,Это существование сильно влияет на стабильность системы.,Специально для приложений с большими данными,Столкнулся с большим количеством генерируемых изданных объектов,Просто положиться наJVMпредоставилиз Различные механизмы сбора мусора затрудняют решение проблемы переполнения памяти.извопрос。существоватьоткрытьисточникрамкасередина Есть многомногорамка Всевыполнить Понятно Собственныйиз Управление памятью,Например проект Apache Spark изTungsten,существования в определенной степени снижает зависимость фреймворка от механизма сборки мусора JVM.,Это позволяет лучше использовать JVM для обработки крупномасштабных наборов данных.
Флинк также основеJVMвыполнить Понятно Собственныйиз Управление памятью,JVM делится на беспилотную кучу, управляемую кучу Flink и сеть на основе памяти.。существоватьFlinkвнутренняя параFlink Managed Куча управляется, и память кучи непосредственно инициализируется в памяти при запуске кластера. Pages Pool,Другими словами, да будет занимать всю память в виде двоичных массивов.,Сформируйте пространство использования виртуальной памяти. Новые созданные объекты сериализуются в двоичные данные и сохраняются в существующем пуле страниц памяти.,Когда расчет будет завершен, объект данных Flink оставит страницу пустой.,Вместо выполнения сборки мусора через JVM,Гарантируется, что создаваемый объект данных никогда не превысит размер кучи памяти JVM.,Это также эффективно позволяет избежать проблем со стабильностью системы, вызванных частым сбором мусора.
Конфигурация менеджера заданий
JobManagerсуществовать Система Flink в основном отвечает за управление ресурсами кластера.、получать задания、Планирование задачи、получатьнабор Статус задачи и управлениеTaskManagerиз Функция,JobManagerсами Не участвует напрямуюиданныеизвычислитьпроцесссередина,Таким образом, в JobManager не так много элементов конфигурации памяти.,Просто укажите размер кучи JobManager.
jobmanager.heap.size: установите размер кучи JobManager, значение по умолчанию — 1024 МБ.
Конфигурация диспетчера задач
TaskManager служит рабочим узлом в кластере Flink.,Вся логика расчета задач основана на TaskManager.,Поэтому конфигурация памяти TaskManager особенно важна.,TaskManager можно оптимизировать и настроить с помощью следующей конфигурации параметров.
- taskmanager.heap.size:настраиватьTaskManagerкуча Памятьбольшой Маленький,Значение по умолчанию — 1024M.,Если будет существовать кластер Yarniz,TaskManager зависит от размера памяти, которую Yarn выделяет контейнеру TaskManager.,А в среде Yarn часть памяти вообще уменьшена для отказоустойчивости Container.
- taskmanager.jvm-exit-on-oom:настраиватьTaskManagerданетиз-задляJVMпроисходить Памятьпереполнениеиостанавливаться,По умолчанию — ложь,Когда происходит переполнение памяти TaskManager,Это также не приведет к остановке TaskManager.
- taskmanager.memory.size:настраиватьTaskManagerПамятьбольшой Маленький,По умолчанию – 0.,Если это значение не установлено, в качестве основы для распределения памяти будет использоваться Taskmanager.memory.fraction.
- taskmanager.memory.fraction:настраиватьTaskManagerкучасерединаудалятьNetwork BuffersПосле памятииз Коэффициент распределения памяти。Должен Памятьосновнойиспользовать ВTaskManagerПоследовательность задач、кэшсерединарезультаты и т. д.действовать。Например,Если установлено значение 0,8,нопоколениеповерхностьTaskManagerбронировать80%Памятьиспользовать Всерединарезультат времениданныеизкэш,Остальные 20% памяти используются для хранения объектов в пользовательских функциях. Уведомление,Этот параметр вступает в силу только в том случае, если Taskmanager.memory.size не установлен.
- taskmanager.memory.off-heap:настраиватьда Включить ли поставку памяти вне кучиManaged Память или сеть Буферы используются.
- taskmanager.memory.preallocate:настраиватьданетсуществоватьзапускатьTaskManagerпроцесссерединапрямойраспространятьTaskManagerУправление памятью。
- taskmanager.numberOfTaskSlots:каждыйTaskManagerраспространятьизslotколичество。
Оптимизация сетевого кэша Flink
Flink делит память кучи JVM на три части, одна из которых — сетевая. Буферизует память. Сеть Буферы памяти даFlink уровня взаимодействия данных из ключевых ресурсов памяти, основная цель которых заключается в кэшировании распределенных данных, входных данных во время обработки. . Обычно относительно большая сеть Буферы означают более высокую пропускную способность. Если система отображает «Недостаточно number of network буферы" из-за ошибки, обычно из-за сети Конфигурация буферов слишком низкая. Поэтому в этом случае необходимо соответствующим образом настроить сеть в диспетчере задач. Размер буферов памяти позволяет системе достичь относительно высокой пропускной способности.
В настоящее время Flink может настроить сеть Существует два способа определения размера буферной памяти: один — напрямую указать сетевую память. Буферизирует объем памяти из метода, другой — путем настройки соотношения памяти из метода.
Установите объем памяти сетевого буфера (устарело).
Непосредственно настройку количества сетевых буферов нужно рассчитывать по следующей формуле:
NetworkBuffersNum = total-degree-of-parallelism \* intra-node-parallelism * n
вtotal-degree-of-parallelismповерхность ПоказыватькаждыйTaskManagerизобщийиволосыколичество,intra-node-parallelismповерхность ПоказыватькаждыйTaskManagerвходитьданныеисточникизиволосыколичество,nповерхность Показыватьсуществовать预估вычислитьпроцесссерединаRepar-titioningилиBroadcastingдействоватьи ХОРОШОизколичество。intra-node-parallelismОбычноиTask-ManagerизвладениеизCPUсовпадение чисел,А перераспределение и широковещательная передача обычно не превышают 4 параллельных операций. Формулу расчета можно преобразовать к следующему:
NetworkBuffersNum = <slots-per-TM>^2 \* < TMs>* 4
вslots-per-TMдакаждыйTaskManagerначальствораспространятьизslotsколичество,Общее количество TMsдаTaskManagerиз. Для диспетчера задач с 20,Каждый TaskManager содержит 8 кластеров Slotiz.,общий共нуждатьсяизNetwork Количество буферов 8^2**20*4=5120, поэтому сеть настроена в кластере. Размер буферной памяти составляет около 160 МБ, что является более подходящим.
После расчета сети После количества буферов вы можете добавить в сеть следующие два параметра: Буферная память настроена. где размер сегмента — это каждая сеть Bufferиз Памятьбольшой Маленький,По умолчанию – 32 КБ.,Обычно никаких изменений не требуется,Установив параметр NumberOfBuffers для расчета требований к размеру памяти.
- taskmanager.network.numberOfBuffers:обратитесь к КонечноNetworkкучаBufferблок памятиизколичество。
- taskmanager.memory.segment-size:Управление памятьюустройствоиNetworkкучаиспользоватьиз ПамятьBufferбольшой Маленький,По умолчанию – 32 КБ.。
Установите соотношение сетевой памяти (рекомендуется)
Начиная с версии 1.3, Flink предоставляет возможность установить размер буферной памяти сети, указав соотношение памяти.
- taskmanager.network.memory.fraction:JVMсерединаиспользовать ВNetwork Соотношение буферов и памяти.
- taskmanager.network.memory.min:самый маленькийизNetwork Размер буферной памяти, по умолчанию — 64 МБ.
- taskmanager.network.memory.max:большинствобольшойизNetwork Размер буферной памяти, по умолчанию 1 ГБ.
- taskmanager.memory.segment-size:Управление памятьюустройствоиNetworkкучаиспользоватьизBufferбольшой Маленький,По умолчанию – 32 КБ.。
Я надеюсь, что эта статья поможет вам узнать и о чем подумать.,Если у вас также есть опыт, вы можете учиться на нем и глубоко обдумывать его.,Добро пожаловать, чтобы оставить сообщение в области комментариев для обсуждения. Если эта статья вам полезна,Пожалуйста, помогите, нажав «Существование» и тех, кто смотрит или кому это нравится👍🏻.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
