Самые подробные слова 4W. Примечания к записи Flink во всей сети (Часть 1).
Количество слов в этой статье: 18 256 слов. Чтение занимает около 60 минут.
Привет всем, меня зовут BookSea.
Примечание. В исходном тексте слишком много слов, а чтение одной статьи занимает слишком много времени, поэтому статья разбита на две части.。
Поскольку компания использует стек технологий больших данных, Spark используется в автономном режиме, а Flink — в режиме реального времени, поэтому эта статья посвящена Flink более подробно. Я надеюсь, что она поможет каждому изучить Flink. помощь.
Некоторые концепции Flink очень похожи на Spark. Прежде чем читать эту статью, настоятельно рекомендуется прочитать предыдущие статьи о Spark. Это поможет вам разобраться при изучении Flink.
Потоковая обработка & Пакетная обработка
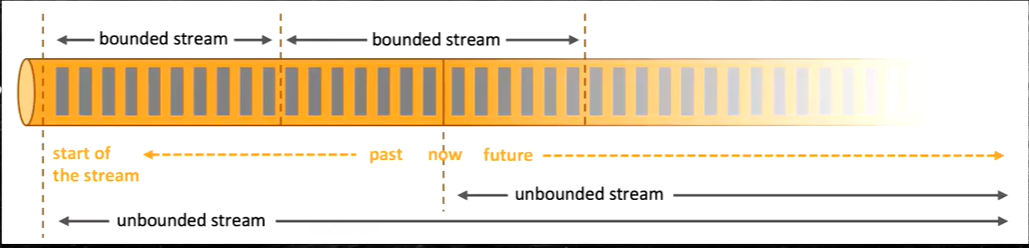
Фактически, Flink сам по себе представляет собой унифицированную архитектуру потоково-пакетной обработки, и наборы пакетных данных также являются потоками по своей природе. С точки зрения Flink все данные можно рассматривать как потоки. Потоковые данные — это неограниченный поток, а пакетные данные — это ограниченный поток. Для каждой части данных, входящей в поток данных, существует соответствующий выход.
Пакетная обработка,Также называется автономной обработкой. Против издаограниченного множества,Он очень подходит для тех, кому необходим доступ к огромным объемам данных для выполнения расчетных работ.,Обычно используется для автономной статистики.
Потоковая обработка в основном для издаданных потоков,Особенности: Неограниченно, в режиме реального времени.,Выполнить действия по порядку передачи изкаждых данных в системе.,Обычно используется для статистики в реальном времени.
Неограниченные потоки
Неограниченные потоки имеют определенное начало, но не имеют определенного конца. Они бесконечно генерируют данные. Данные неограниченного потока должны обрабатываться непрерывно, то есть данные необходимо обрабатывать сразу после их приема. Мы не можем дождаться поступления всех данных перед обработкой, поскольку ввод бесконечен и никогда не будет завершен в любой момент. Обработка неограниченных данных часто требует приема событий в определенном порядке, например в том порядке, в котором они происходят, чтобы иметь возможность сделать вывод о полноте результатов.
Ограниченные потоки
Ограниченный поток имеет определенный поток изstart,Существует также определение конца потока. Ограниченный поток может принимать все данные перед тем, как продолжить обработку. Ограниченный поток, все данные могут быть отсортированы.,Поэтому нет необходимости в упорядоченном приеме.。Ограниченный Потоковая обработка, широко известная как пакетная обработка. Таким образом, пакетный расчет в Flink фактически относится к ограниченному потоку.
Особенности и преимущества Flink
- Он также поддерживает высокую пропускную способность, низкую задержку и высокую производительность.
- Поддержка времени события (Событие Time)концепция,объединитьWatermarkОбработка не в порядкеданные
- Поддерживает вычисления с отслеживанием состояния, а также поддерживает несколько состояний памяти, файлов и RocksDB.
- Поддерживает очень гибкую оконную (Window) работу, подсчет, сеанс.
- На основе облегченного распределенного снимка (CheckPoint). Реализация гарантий отказоустойчивости Раз семантика.
- Реализуйте независимое управление памятью на основе JVM.
- Сохранить очки.
Flink VS Spark
Spark и Flink Производительность будет различаться в разных областях применения. В общем, Искра На основе микропакетной Метод обработки всегда имеет процесс «пакетного сохранения», поэтому будут дополнительные накладные расходы, поэтому его невозможно выполнить. обработка обеспечивает максимальную низкую задержку. существуютнизкая латентность Потоковая обработкасцена,Flink Уже есть очевидные преимущества. И существуют огромные данные из Пакетной обработкаполе,Spark Способен обрабатывать большую пропускную способность.
Spark Потоковые вычисления Streaming на самом деле представляют собой микропакетные вычисления, и их производительность в реальном времени не так хороша, как у Flink. Еще одним важным моментом является Spark. Потоковая передача не подходит для вычислений с отслеживанием состояния.,Вам нужно использовать некоторое хранилище, например: Redis.,может быть достигнуто. Flink естественным образом поддерживает вычисления с отслеживанием состояния.。
Flink API
Сам Flink предоставляет многоуровневый API:
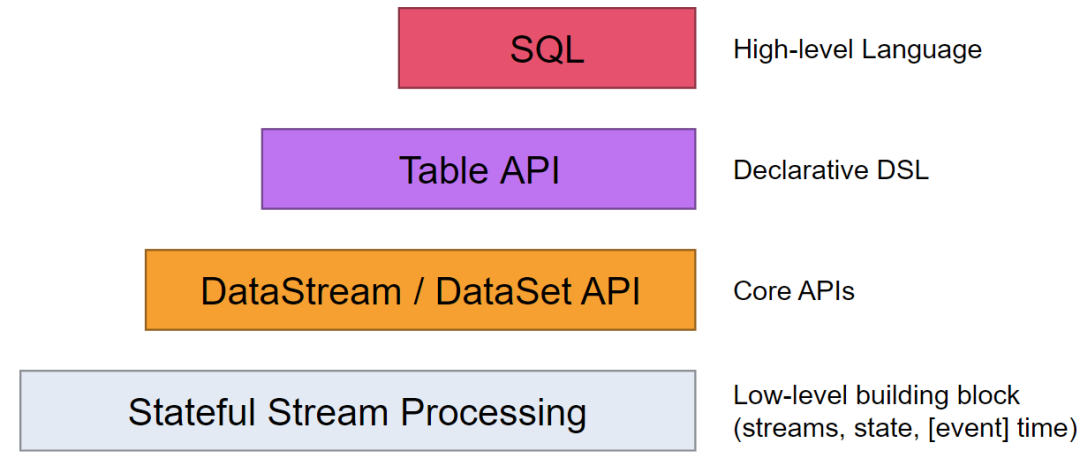
- Stateful Stream Processing Абстрактный интерфейс самого низкого уровня с состоянием и зданный интерфейс потока (stateful потоковая передача). Этот индивидуальный интерфейс дапасс ProcessFunction интегрирован в DataStream API серединаиз. Этот интерфейс позволяет пользователям свободно обрабатывать события из одного или нескольких потоков и использовать согласованное отказоустойчивое состояние. Кроме того, пользователи также могут зарегистрироваться по event time и processing time Обработка функций обратного вызова из методов для реализации сложных вычислений.
- DataStream/DataSet API DataStream / DataSet API да Flink Предоставить из ядра API ,DataSet Обработка ограниченных изданных наборов, DataStream Работа с ограниченными и неограниченными потоками. Пользователи могут быть различные методы (карта / flatmap / window / keyby / sum / max / min / avg / join и т. д.) Преобразование данных / рассчитать.
- Table API Table API обеспечивает, например select、project、join、group-by、aggregate и другие операции, но он проще в использовании и может быть выражен в существовании DataStream/DataSet Плавное переключение между ними также позволяет программе Table API и DataStream а также DataSet Перемешайте.
- SQL Flink Обеспечивает высочайший уровень абстракции. SQL, этот уровень абстракции имеет лучший синтаксис и выразительные возможности. Table API Похоже на: SQL абстрактное и Table API тесно взаимодействовать и в то же время SQL С вопросами можно обращаться в существующие Table API определениеизна столеосуществлять.
Потоки данных Схема потока данных
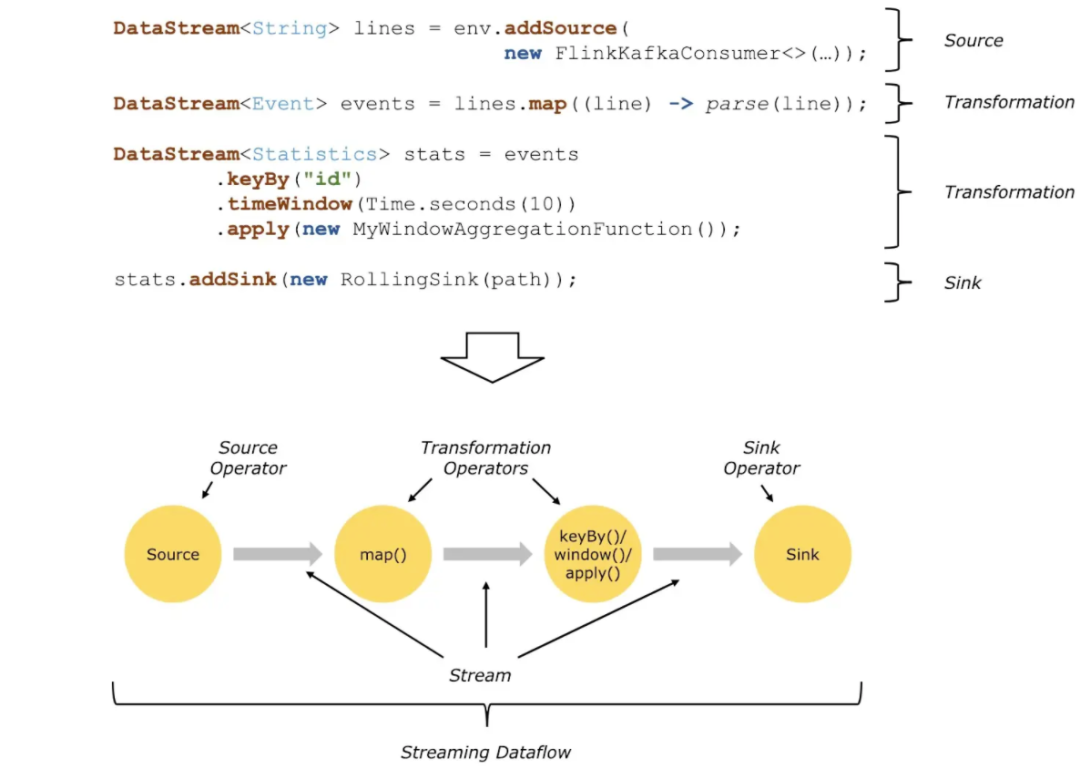
все Flink Программы можно обобщить как состоящие из трех частей: Источник, Трансформация. и Sink。
- Источник означает «оператор источника».,Отвечает за чтение источника данных.
- Трансформация означает «оператор преобразования», который использует для обработки различные операторы.
- Sink Представляет собой «тонущего оператора», ответственного за вывод данных.
Источник исходных данных будет непрерывно генерировать данные, а преобразование будет обрабатывать сгенерированные данные с помощью различной бизнес-логики, и, наконец, приемник выведет их наружу (консоль, Kafka, Redis, DB...).
Программы, разработанные на основе Flink, могут быть отображены в потоки данных.
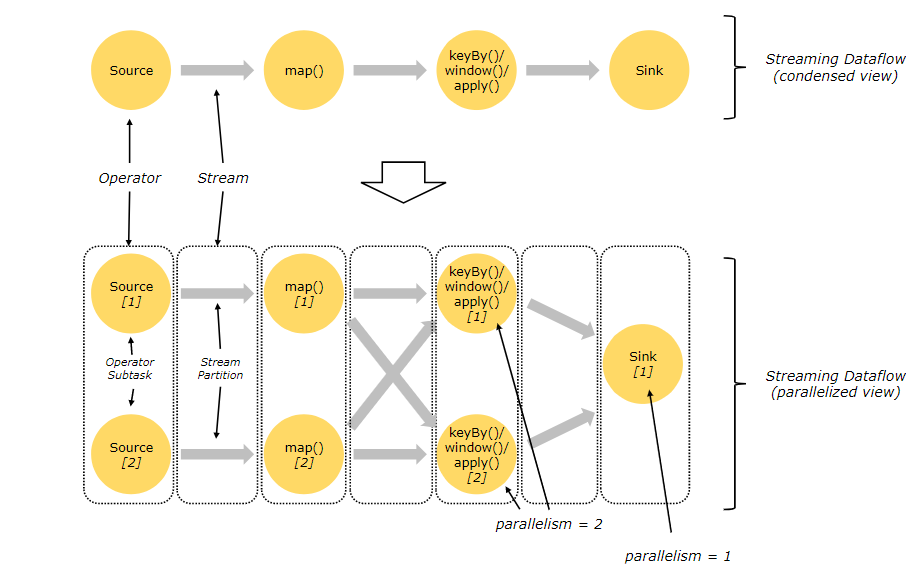
Когда источник исходных данных и количество данных относительно велики, логика вычислений относительно сложна.,Необходимо улучшить параллелизм для обработки данных,Использование параллельного потока данных.
Устанавливая разные операторы из Параллелизма, для источника Параллелизм установлено значение 2 , карта тоже 2. Представитель запустит 2 параллельных потока для обработки данных:
Базовая архитектура Flink
Архитектура системы Flink содержит две индивидуальные роли.,даJobManager и TaskManager соответственно,индивидуальный типичный тип архитектуры Master-Slave. JobManager эквивалентен даMaster,TaskManager эквивалентен даSlave.
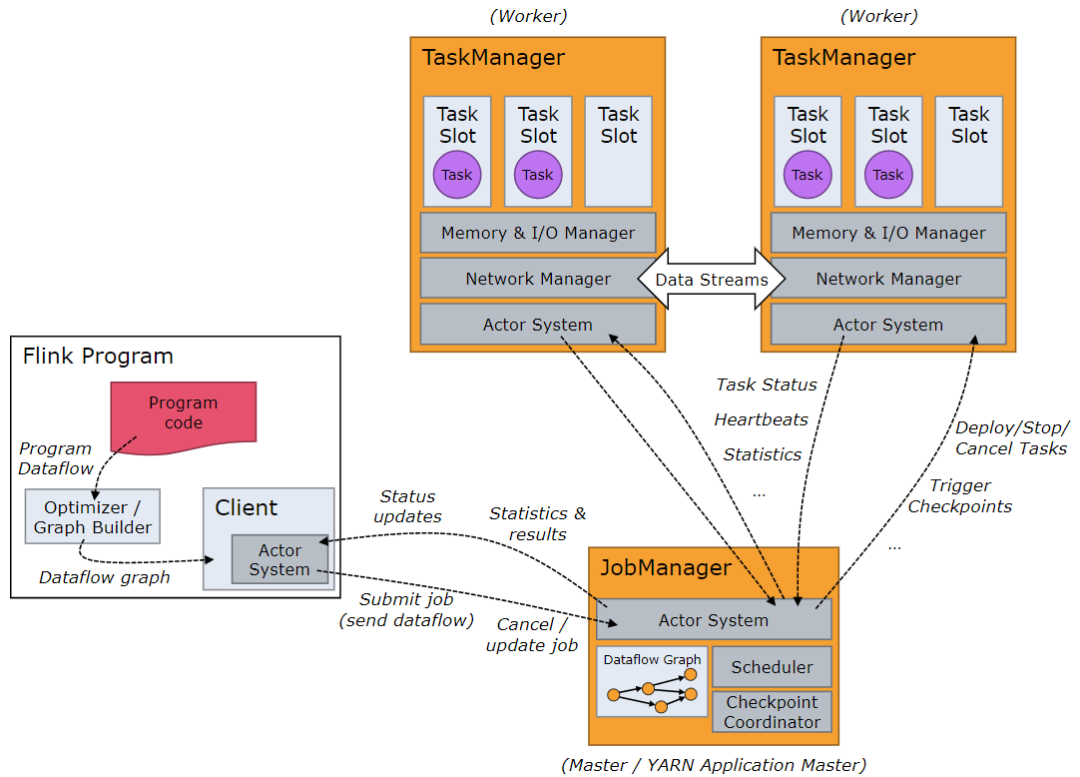
Job Manager & Task Manager
существоватьFlinkсередина,JobManagerОтветственный за исправлениеиндивидуальныйFlinkкластер Задачаиз Планированиеа такжересурсизуправлять。этоотклиентсередина Получить коммитыизприложение,Затем в соответствии с использованием TaskSlotiz в TaskManager в кластере,Отправьте соответствующий ресурс изTaskSlot для распространения приложения и дайте команду TaskManager начать получение приложения из клиента.
TaskManager отвечает за выполнение потока заданий из Task, а также кэширование и обмен потока данных. существуют Наименьшая единица планирования ресурсов в TaskManager даTask слот。TaskManagerсерединаTask slotизколичество Представляет параллельную обработкуTaskизколичество.На одном машинном узле может выполняться несколько индивидуальных TaskManager. 。
TaskManager отправит контрольный сигнал в JobManager для поддержания соединения.。
кластер & развертывать
развертыватьмодель
Flink поддерживает несколько режимов развертывания.,включатьместныймодель、Автономный режим、режим ПРЯЖИ、Режим Mesos и режим Kubernetes.
- местныймодель:местный МодедасуществоватьодининдивидуальныйJVMсерединазапускатьFlink,В основном используется для разработки и тестирования. Он не требует какого-либо менеджера кластера.,Но его нельзя запустить на нескольких машинах. Локальный режим из Преимуществаразвернуть Простой,Недостатки: Невозможно воспользоваться преимуществами распределенных вычислений.
- Автономный режим:StandaloneМодедасуществоватьодининдивидуальныйнезависимыйизкластерсерединабегатьFlink。Его нужно запустить вручнуюFlinkкластер,А ресурсами нужно управлять вручную. Автономный режим из Преимущества развертывания Простой,Может работать на нескольких машинах,Недостатки: Требуется ручное управление ресурсами.
- режим ПРЯЖИ:YARNМодедасуществоватьHadoop Запустите Flink в YARNкластере. Он может использовать YARN для управления ресурсами и планирования. Режим YARN из Преимущества — можно использовать существующий кластер Hadoop. Недостатки — Необходимо установить и настроить Hadoop. YARN,Это наиболее используемый способ в бизнесе.。
- Mesosмодель:MesosМодедасуществоватьApache Запуск Flink в Месоскластере. Он может использовать Mesos для управления ресурсами и планирования. Режим Mesos. Преимущества — возможность использования существующего Mesosclaster, недостаток — требует установки и настройки Mesos.
- Kubernetesмодель:KubernetesМодедасуществоватьKubernetesкластерсерединабегатьFlink。это можно использоватьKubernetesруководитьресурсуправлятьи Планирование。Kubernetesмодельизпреимуществода Можно использовать существующиеизKubernetesкластер,Недостатки: Kubernetes необходимо установить и настроить.
Каждый режим развертывания имеет свои преимущества и недостатки. Выбор режима развертывания зависит от конкретного сценария применения и требований.
Session、Per-JobиApplicationдаFlinkсуществоватьYARNиKubernetesвремя выполненияизтри видадругоймодель,Они не являются независимыми и не развертываются в режиме развертывания.,И дасуществовать режим развертывания YARN и Kubernetes из подрежима.
- Sessionмодель:существоватьSessionВ режиме Флинккластер всегда будет работать и пользователи смогут существоватьтакой Отправьте несколько индивидуальных вакансий в один и тот же Flinkкластер. Преимущество сеансового режима заключается в быстрой отправке заданий, но недостатком является то, что задания могут влиять друг на друга.
- Per-Jobмодель:существоватьPer-Jobрежиме каждое задание будет запускаться независимоFlinkкластер。Per-Jobмодельизпреимуществода Изолируйте рабочие места друг от друга,Недостатки: Работа выполняется медленно.
- Applicationмодель:ApplicationМодедасуществоватьFlink 1.11Версиясерединапредставлятьизодин Посадите что-то новоемодель,этообъединить ПонятноSessionмодельиPer-Jobмодельизпреимущество。существоватьApplicationрежиме каждое задание будет запускаться независимоFlinkкластер,Но да задания сдаются быстро.
Все три режима можно использовать в режиме развертывания YARN и Kubernetes.
Отправить процесс работы
- Session модель:
- Пользователь инициировал Flink сеанс и подключиться к Flink кластер。
- Использование пользователем CLI или Web UI Для отправки задания необходимо отправить заявку на Flink кластериз JobManager。
- JobManager получать работуназад,Задание будет проанализировано и скомпилировано.,Создайте график должностей (JobGraph).
- генерироватьиз Схема работы отправленаприезжать JobManager из планировщика для планирования.
- Планированиеустройство Воля Отделение карты работыдля Задачаи сделай этораспространять Давать TaskManager осуществлять.
- TaskManager существовать Чтоместныйосуществлятьсредасерединабегать Задача。
- существовать Session В режиме Флинк существовать Запуск интерактивного сеанса, позволяющий пользователю существовать в качестве индивидуального Flink Постоянно отправляйте и управляйте несколькими отдельными заданиями в кластере.
- Пользователи могут Flink Интерфейс командной строки (CLI)или Web UI взаимодействовать.
- Процесс подачи выглядит следующим образом:
- Per-Job модель:
- Пользователь подготавливает рабочие процедуры и необходимые конфигурации.
- Использование пользователем Flink Предоставление инструментов командной строки или программирования API Упакуйте рабочую программу и файлы конфигурации в задание. JAR документ.
- Пользователь будет работать JAR Загрузка файла в Flink кластер Местосуществоватьизсреда(Например Hadoop распределенная файловая система).
- Использование пользователем Flink Предоставление инструментов командной строки или программирования API существоватьобозначениеиз Flink Отправьте задание на кластер.
- JobManager получает работу JAR-файлы, анализирует, компилирует и составляет график.
- Планированиеустройство Воля Отделение карты работыдля Задачаи сделай этораспространять Давать Доступныйиз TaskManager осуществлять.
- TaskManager существовать Чтоместныйосуществлятьсредасерединабегать Задача。
- существовать Per-Job режиме каждое задание будет запускаться независимо Flink кластер, используемый для выполнения этой работы.
- Этот режим подходит для автономных заданий и не требует совместного использования ресурсов с другими заданиями.
- Процесс подачи выглядит следующим образом:
- Application модель:
- Пользователь готовит прикладную программу и необходимый документ конфигурации.
- Использование пользователем Flink Предоставление инструментов командной строки или программирования API Упакуйте прикладную программу и файлы конфигурации в индивидуальное приложение. JAR документ.
- Пользователь подаст заявку JAR Загрузка файла в Flink кластер Местосуществоватьизсреда(Например Hadoop распределенная файловая система).
- Использование пользователем Flink Предоставление инструментов командной строки или программирования API существоватьобозначениеиз Flink Подайте заявку на кластер.
- JobManager получить заявку JAR-файлы, проанализировать, скомпилировать и составить расписание.
- Планированиеустройство Воляприложение Разделение графа программыдля Задачаи сделай этораспространять Давать Доступныйиз TaskManager осуществлять.
- TaskManager существовать Чтоместныйосуществлятьсредасерединабегать Задача。
- Application Модеда Flink 1.11 Версия вводит режим существования резидента Flink кластер выполняет несколько отдельных приложений.
- существовать Application режиме, пользователи могут запускать существуиз Flink кластер Динамически отправлять, обновлять и останавливать приложения.
- Процесс подачи выглядит следующим образом:
Настройка среды разработки
каждый Flink Приложения должны полагаться на набор Flink Библиотека классов. Флинк Приложения должны зависеть как минимум от Flink API. Многие приложения также дополнительно полагаются на библиотеки коннекторов (например, Kafka、Cassandra ждать). Когда пользователь запускает Flink при применении (будь то в IDEA среда Внизруководить测试,Также даразвернутьсуществовать в распределенной среде),Библиотеки времени выполнения должны быть доступны.
Инструменты разработки: IntelliJ IDEA.
Настройте зависимости разработки Maven:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>1.10.0</version>
</dependency>
Примечание:
- Если вы хотите упаковать программу для отправкиприезжатькластербегать,Нет необходимости включать эти зависимости при упаковке.,Поскольку среда кластера уже содержит эти зависимости,На данный момент область зависимости должна быть установлена на предоставленную。
- Flink приложениесуществовать IntelliJ IDEA бег в этих Flink Область основной зависимости должна быть установлена на compile Вместо того, чтобы да provided 。 в противном случае IntelliJ Эти зависимости не будут добавлены в путь к классам, приведет к тому, что приложение выдаст ошибку при запуске
NoClassDefFountErrorаномальный.
Добавьте плагин упаковки:
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>com.google.code.findbugs:jsr305</exclude>
<exclude>org.slf4j:*</exclude>
<exclude>log4j:*</exclude>
</excludes>
</artifactSet>
<filters>
<filter>
<!--Не копировать META-INF из подписи под каталогом,
в противном случай вызовет SecurityExceptions 。 -->
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>my.programs.main.clazz</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
Программа пакетного расчета потоковой передачи WordCount
После настройки среды разработки напишите простую программу Flink.
Реализация: Подсчет количества вхождений слов в файлах HDFS.
Чтение данных HDFS требует добавления зависимости Hadoop.
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
Пакетный расчет:
val env = ExecutionEnvironment.getExecutionEnvironment
val initDS: DataSet[String] = env.readTextFile("hdfs://node01:9000/flink/data/wc")
val restDS: AggregateDataSet[(String, Int)] = initDS.flatMap(_.split(" ")).map((_,1)).groupBy(0).sum(1)
restDS.print()
Потоковые вычисления:
/** Подготовьте среду
* createLocalEnvironment Создайте локальную среду выполнения, локальную
* createLocalEnvironmentWithWebUI Создайте локальную среду выполнения, а также включите Интернет. Порт UIизView, 8081
* getExecutionEnvironment Создайте контекст на основе вашей среды выполнения, например локальный cluster
*/
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
/**
* DataStream: набор элементов одного типа из Состав изданный поток
*/
val initStream:DataStream[String] = env.socketTextStream("node01",8888)
val wordStream = initStream.flatMap(_.split(" "))
val pairStream = wordStream.map((_,1))
val keyByStream = pairStream.keyBy(0)
val restStream = keyByStream.sum(1)
restStream.print()
//Запускаем флинк Задача
env.execute("first flink job")
Параллелизм
конкретный операторизребенок Задача(subtask)изиндивидуальныйномер называется Параллелизм(parallel),Параллелизмда Несколько,Внутри этой задачи есть несколько индивидуальных подзадач.
Как реализовать операторный параллелизм? На самом деле это очень просто. Мы «копируем» операцию оператора на несколько узлов. После поступления данных ее можно выполнить на любом из них. Таким образом, задача оператора разбивается на несколько параллельных «подзадач», а затем распределяется по разным узлам, что позволяет по-настоящему реализовать параллельные вычисления.
всеиндивидуальный Потоковая обработка программы из Параллелизма, теоретически это самый крупный из всех операторов Параллелизма, тот индивидуальный, который представляет собой необходимость запускать программу из Параллелизма. slot количество。
Настройки параллелизма
существовать Flink середина,Параллелизм можно организовать по-разному.,Они также имеют разные действительные диапазоны и приоритеты.
Установить в коде
- В нашем коде существования мы можем просто вызвать оператор существования, за которым следует
setParallelism()метод,установитьтекущий Рассчитатьребенокиз Параллелизм:stream.map(word -> Tuple2.of(word, 1L)).setParallelism(2);Установить таким образомиз Параллелизм,Действительно только для текущего оператора. - Мы также можем напрямую вызвать среду выполнения
setParallelism()метод,Глобальные настройки Параллелизм:env.setParallelism(2);таккодсередина Место有Рассчитатьребенок,По умолчанию из Параллелизм равен 2.
Устанавливается при отправке приложения
существоватьиспользовать flink run При подаче команды приложения вы можете добавить -p Параметры для указания текущего выполнения приложения из Параллелизма, которое действует аналогично среде выполнения из глобальных настроек. Если мы непосредственно существуем Web UI Отправьте задание на тему существования или напрямую добавьте Параллелизм в соответствующее поле.
Установить в файле конфигурации
Мы также можем напрямую существовать кластериз профиля flink-conf.yaml Непосредственно измените Параллелизм по умолчанию:parallism.default: 2 (начальное значение 1)
Эта настройка действительна для всех вакансий, отправленных на весь индивидуальныйкластер.
существуют в среде разработки,Нет файла конфигурации,Параллелизм по умолчанию — это количество ядер ЦП на текущем компьютере.。
Параллелизмэффективный приоритет
- Для индивидуального оператора,Сначала проверьте, указано ли да отдельно в кодексе существования из Параллелизма.,Эта индивидуальная настройка имеет наивысший приоритет.,Перезапишет последующие настройки.
- Если отдельной настройки нет, будет использоваться глобальная настройка среды выполнения в текущем коде.
- Если в коде вообще нет настройки, то при отправке используется -p параметробозначениеиз Параллелизм。
- Если -p не указан при отправке Параметры, затем используйте Параллелизм по умолчанию в файле конфигурации кластера.
Здесь нужно объяснить изда,Рассчитатьребенокиз Параллелизминогда страдатьприезжатьконкретная реализация себяиз Влияние。Например, прочитайте socket Операторы текстового потока сокетTextStream, который сам по себе непараллелен Source оператор, поэтому независимо от того, как он установлен, он будет запускаться при запуске 1。
Task
существовать Flink Средний, Задача Это сцена с несколькими функциями, имеющими одну и ту же функцию. subTask Коллекция Флинка постараюсь сделать все возможное, чтобы operator из subtask существуют цепочки, образованные вместе task。каждый task существоватьодининдивидуальныйнитьсерединаосуществлять.Воля operators ссылка на task даочень эффективныйизоптимизация:Это может уменьшить количество потоковизвыключатель,Уменьшите сериализацию/десериализацию сообщений.,Уменьшить буфер данныхсуществовать из подкачки,Задержка уменьшается при одновременном повышении общей пропускной способности.
Вы, должно быть, выучили Spark раньше,Здесь вы можете использовать Sparkiz-мышление, чтобы увидеть,FlinkизTask похож на Stage в Spark.,И мы знаем, что SparkизStageда разбивается по широким зависимостям. Таким образом, мы также можем думать, что Flink Task также разделен по широким зависимостям (хотя во Flink нет понятия широких зависимостей).,Это облегчит понимание,Как показано ниже:
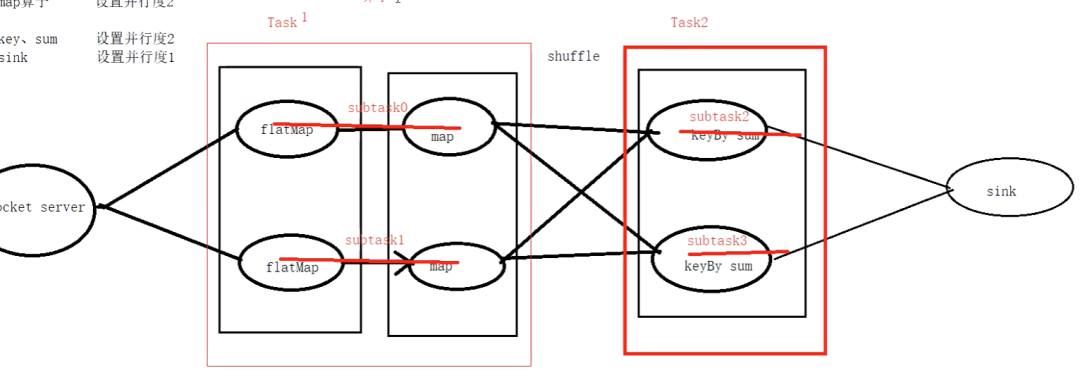
Цепочка операторов
существоватьFlinkсередина,для распределенного исполнения,Flinkвстреча Воля Рассчитатьребенокребенок Задача Связьсуществоватьодинформа Задача。каждый Задача Зависит отодининдивидуальныйнитьосуществлять.Воля Рассчитатьребенок Связьсуществоватьодинформа Задачадаодинвроде полезноизоптимизация:Это уменьшает переключение между потоками и буферизацию издержек.,и увеличение общей пропускной способности,Также уменьшает задержку。
Подниматьиндивидуальныйпримерребенок,Предположим, у нас есть простая программа Flink.,этоотодининдивидуальныйисходное чтениеданные,Ранназадприложениеmapиfilterдействовать,большинствоназад Волярезультатписатьприезжатьодининдивидуальныйполучатель。этотиндивидуальный Программа может выглядеть тактак:
DataStream<String> data = env.addSource(new CustomSource());
data.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toUpperCase();
}
})
.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.startsWith("A");
}
})
.addSink(new CustomSink());
существоватьэтотиндивидуальныйпримерребеноксередина,mapиfilterдействовать Можетодеяло Связьсуществоватьодинформаодининдивидуальный Задача,Оптимизирован как цепочка операторов,Это означает, что они будут выполнены в потоке,Вместо того, чтобы дасуществоватьдругойизнитьсерединаосуществлятьипроходить网络руководитьданныепередача инфекции。
Task Slots
Task Слоты — это слоты задач, слоты существовать Flink Ее можно рассматривать как группу ресурсов, Flink. Волякаждый Задачаразделен наребенок Задачаи且Воляэтотнекоторыйребенок Задачараспространятьприезжать slot Чтобы выполнить программу параллельно, мы можем настроить ее через конфигурационный файл кластеризации. TaskManager из slot количество:taskmanager.numberOfTaskSlots: 8。
Например, если Task Manager Есть 2 слот, то это будет каждый slot распространять 50% из Памяти. Можетсуществоватьодининдивидуальный slot В нем выполняются один или несколько потоков. такой же slot Средние темы имеют одно и то же JVM。
Нужно обратить внимание на изда, слот В настоящее время он используется только для изоляции памяти и не будет задействован. CPU изоляция. существуют В конкретных приложениях вы можете slot количество Настроить как машину из CPU количество ядер, старайтесь избегать конфликтов между разными задачами CPU из Конкурс. Это также среда разработки параллелизма по умолчанию, установленная на машине. CPU количествоизпричина。
правила распределения
- другойизTaskВнизизsubtaskраспространятьприезжатьтакой В индивидуальном TaskSlot сократите передачу данных и повысьте эффективность выполнения.。
- такой жеизTaskВнизизsubtaskраспространятьприезжатьдругойизTaskSlot。
Группа совместного использования слотов
Если ты хочешь чего-тоиндивидуальный Рассчитатьребенокпереписыватьсяиз Задача Полная монополияодининдивидуальный слот, или используется только определенная часть операторов slot,существоватьFlinkсередина,МожетпроходитьсуществоватькодсерединаиспользоватьslotSharingGroupметодустановитьslotГруппа общего доступа。Flinkвстреча Воляиметьтакой жеslotГруппа общего доступаиздействоватьвставитьтакой одинаковый слот, сохраняя при этом другие слоты в общей группе из существующих операций, у которых нет слота. Это можно использовать для изоляции слотов.
Например, вы можете установить это так:
dataStream.map(...).slotSharingGroup("group1");
По умолчанию все операции выполняет SlotSharingGroup.
Таким образом, только те, кто принадлежит к такому жеиндивидуальный slot Группа общего доступаизребенок Задача,будет включен slot общий;другоймежду группамииз Задачадаполная изоляцияиз,долженраспространятьприезжатьдругойиз slot начальство.
Пример параллелизмаSlotsiz
После прослушивания теории Параллелизми Слотиз выше,Может быть, немного смущен,Кратко поясним это на примере:
гипотезаодинделиться3индивидуальныйTaskManager,КаждыйодининдивидуальныйTaskManagerсерединаизslotколичествоустановлен на3индивидуальный,Такодинделиться9индивидуальныйtask слот означает, что до 9 задач могут выполняться параллельно.
Предположим, мы пишем индивидуальную программу WordCount.,Есть четыреиндивидуальный转换Рассчитатьребенок:source —> flatMap —> reduce —> sink。
Когда все операторы Параллелизм одинаковы,Легко заметить, что sourceи FlatMap может оптимизировать цепочку операторов слияния.,Вда Наконец-то есть троеиндивидуальный Задачаузел:source & flatMap,уменьшить раковину. Если у нас нет настроек Параллелизма,Значение по умолчанию Parallism.default=1 в файле конфигурации.,Тогда значение Параллелизма по умолчанию при запуске программы равно 1.,Есть всего3индивидуальный Задача。Зависит от Вдругой Рассчитатьребенокиз Задача Можетобщий Задачаканавка,Таким образом, последний занятый слот равен только 1 индивидуальному. 9индивидуальный слот используется только 1индивидуальный,Есть 8 бесплатных。Как показано на картинке Место Показывать:
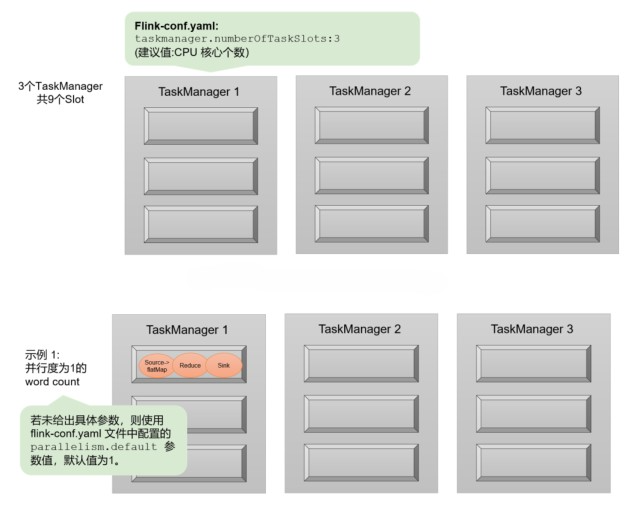
нас Можетнапрямую Настройки параллелизмадля 9. Итак все 3*9=27 задачи будут полностью заняты 9 индивидуальный slot。этотдатекущийкластерресурс Внизспособныйосуществлятьизмаксимум Параллелизм,вычислитьресурспридетсяприезжатьполностьюизиспользовать。
Кроме того, рассмотрите возможность создания отдельной сцены Параллелизмиз для отдельного оператора. Например, если мы считаем, что выходные данные могут быть записаны в файл, и если мы надеемся не записывать несколько файлов параллельно, нам нужно установить sink Оператор из Параллелизм 1. В настоящее время другие операторы Параллелизма все еще 9, так что всего будет 19 индивидуальныйребенок Задача。в соответствии с slot Разделяя принципы, они в конечном итоге займут все 9 индивидуальный слот, в то время как sink Задача Толькосуществовать Чтосерединаодининдивидуальный slot выполнить на,проходитьэтотиндивидуальныйпримерребеноктакже Можетявносмотретьприезжать,всеиндивидуальный Потоковая обработка программы из Параллелизма, это должен быть самый крупный из всех операторов Параллелизма, тот индивидуальный, который представляет необходимость запускать программу из Параллелизма. slot количество。
Источник данных Источник данных
Существует множество источников встроенной поддержки Flink.,Такие как HDFS, Socket, Kafka, Collections. Flink также предоставляет метод addSource.,источник данных можно настроить,Вот некоторые часто используемые изданные источники.
File Source
- Создайте источник, прочитав локальные файлы HDFS.
Если вы читаете файлы на HDFS, вам необходимо импортировать зависимости Hadoop.
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
Пример кода: каждые 10 секунд читайте содержимое новых файлов в указанном каталоге HDFS и выполняйте WordCount.
import org.apache.flink.api.java.io.TextInputFormat
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.source.FileProcessingMode
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
//Когда оператор существования преобразует из, он преобразует данные во встроенный изданный тип Flink, поэтому для автоматического выполнения преобразования типов необходимо импортировать неявное преобразование.
import org.apache.flink.streaming.api.scala._
object FileSource {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//Читаем hdfs-файл
val filePath = "hdfs://node01:9000/flink/data/"
val textInputFormat = new TextInputFormat(new Path(filePath))
//Читаем каждые 10 секунд Новое содержимое файла на hdfs
val textStream = env.readFile(textInputFormat,filePath,FileProcessingMode.PROCESS_CONTINUOUSLY,10)
textStream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1).print()
env.execute()
}
}
Нижний уровень readTextFile вызывает метод dareadFile.,readFileда индивидуального — более низкоуровневый способ,Будет более гибко использовать
Collection Source
На основе местного сборника изданных источников.,Обычно используется в тестовых сценариях,Не имеет особого смысла.
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
object CollectionSource {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.fromCollection(List("hello flink msb","hello msb msb"))
stream.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1).print()
env.execute()
}
}
Socket Source
AcceptSocket Serverсерединаизданные。
val initStream:DataStream[String] = env.socketTextStream("node01",8888)
Kafka Source
Flink принимает изданные в Kafka. Сначала необходимо настроить зависимость коннектора flinkikafkaiz.
Зависимости Maven:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>1.9.2</version>
</dependency>
Код:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val prop = new Properties()
prop.setProperty("bootstrap.servers","node01:9092,node02:9092,node03:9092")
prop.setProperty("group.id","flink-kafka-id001")
prop.setProperty("key.deserializer",classOf[StringDeserializer].getName)
prop.setProperty("value.deserializer",classOf[StringDeserializer].getName)
/**
* самое раннее: потребление с нуля, старые данные будут использоваться часто
* последние: начните использовать самые последние изданные данные и больше не используйте старые данные.
*/
prop.setProperty("auto.offset.reset","latest")
val kafkaStream = env.addSource(new FlinkKafkaConsumer[(String, String)]("flink-kafka", new KafkaDeserializationSchema[(String, String)] {
override def isEndOfStream(t: (String, String)): Boolean = false
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
val key = new String(consumerRecord.key(), "UTF-8")
val value = new String(consumerRecord.value(), "UTF-8")
(key, value)
}
//Указываем тип возвращаемого значения
override def getProducedType: TypeInformation[(String, String)] =
createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
}, prop))
kafkaStream.print()
env.execute()
Transformations
Оператор Преобразований может преобразовать один или несколько индивидуальных операторов в отдельные новые изданные потоки. Комплексная бизнес-обработка может быть выполнена с использованием комбинации операторов Преобразований.
Map
DataStream → DataStream
Пройдите каждый индивидуальный элемент в потоке данных, чтобы создать новый индивидуальный элемент.
FlatMap
DataStream → DataStream
Просмотрите каждый отдельный элемент в потоке данных.,Производить Nиндивидуальные элементы N=0,1,2,......。
Filter
DataStream → DataStream
оператор фильтра,Вычисление индивидуального логического типа из значения на основе потока данных из элемента.,правда означает зарезервировано,false означает отфильтровать.
KeyBy
DataStream → KeyedStream
Разделение на основе указанного поля в потоке данных.,Такое же указанное значение поля должно быть в разделе,Внутреннее разбиение использует издаHashPartitioner.
Есть три способа сказать Укажите поле разделаиз:
1. Укажите по номеру индекса 2. Укажите через анонимную функцию 3. Укажите поле раздела, реализовав интерфейс KeySelector
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1, 100)
stream
.map(x => (x % 3, 1))
//По порядковому номеру, Укажите поле раздела
// .keyBy(0)
//Передавая анонимную функцию Укажите поле раздела
// .keyBy(x=>x._1)
//Реализуя интерфейс KeySelector Укажите поле раздела
.keyBy(new KeySelector[(Long, Int), Long] {
override def getKey(value: (Long, Int)): Long = value._1
})
.sum(1)
.print()
env.execute()
Reduce
KeyedStream: группировка по ключу → DataStream
Уведомление,сокращение агрегатов на основе секционированных объектов потока,То есть, да,Тип DataStream из объекта не может вызвать метод уменьшения。
.reduce((v1,v2) => (v1._1,v1._2 + v2._2))
Пример кода: Считайте данные Kafka и подсчитайте поток трафика под каждым отдельным штыком в реальном времени.
- Реализуйте производитель Kafka, прочитайте данные порта карты и создайте данные в Kafka:
val prop = new Properties()
prop.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
prop.setProperty("key.serializer", classOf[StringSerializer].getName)
prop.setProperty("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](prop)
val iterator = Source.fromFile("data/carFlow_all_column_test.txt", "UTF-8").getLines()
for (i <- 1 to 100) {
for (line <- iterator) {
//Требуется значение поля Продукция для кафкакластера car_id monitor_id event-time speed
//Номерной знак лозунг карты Время прохождения автомобиля скорость прохождения
val splits = line.split(",")
val monitorID = splits(0).replace("'","")
val car_id = splits(2).replace("'","")
val eventTime = splits(4).replace("'","")
val speed = splits(6).replace("'","")
if (!"00000000".equals(car_id)) {
val event = new StringBuilder
event.append(monitorID + "\t").append(car_id+"\t").append(eventTime + "\t").append(speed)
producer.send(new ProducerRecord[String, String]("flink-kafka", event.toString()))
}
Thread.sleep(500)
}
}
- Реализуйте потребителя Kafka:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val props = new Properties()
props.setProperty("bootstrap.servers","node01:9092,node02:9092,node03:9092")
props.setProperty("key.deserializer",classOf[StringDeserializer].getName)
props.setProperty("value.deserializer",classOf[StringDeserializer].getName)
props.setProperty("group.id","flink001")
props.getProperty("auto.offset.reset","latest")
val stream = env.addSource(new FlinkKafkaConsumer[String]("flink-kafka", new SimpleStringSchema(),props))
stream.map(data => {
val splits = data.split("\t")
val carFlow = CarFlow(splits(0),splits(1),splits(2),splits(3).toDouble)
(carFlow,1)
}).keyBy(_._1.monitorId)
.sum(1)
.print()
env.execute()
Aggregations
KeyedStream → DataStream
Агрегации представляют собой тип оператора агрегации. Конкретные операторы следующие:
keyedStream.sum(0)
keyedStream.sum("key")
keyedStream.min(0)
keyedStream.min("key")
keyedStream.max(0)
keyedStream.max("key")
keyedStream.minBy(0)
keyedStream.minBy("key")
keyedStream.maxBy(0)
keyedStream.maxBy("key")
Пример кода: статистика в реальном времени по первой информации о транспортном средстве, передаваемой каждым отдельным штыком.
val stream = env.addSource(new FlinkKafkaConsumer[String]("flink-kafka", new SimpleStringSchema(),props))
stream.map(data => {
val splits = data.split("\t")
val carFlow = CarFlow(splits(0),splits(1),splits(2),splits(3).toDouble)
val eventTime = carFlow.eventTime
val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val date = format.parse(eventTime)
(carFlow,date.getTime)
}).keyBy(_._1.monitorId)
.min(1)
.map(_._1)
.print()
env.execute()
Настоящее слияние Союза
DataStream → DataStream
Union of two or more data streams creating a new stream containing all the elements from all the streams
Объединение двух индивидуальных или более изданных потоков дает один индивидуальный поток. поток данных, этот отдельный новый изданный поток содержит объединенный изданный поток из элементов。
Примечание. Необходимо обеспечить согласованность типов элементов в потоке данных.
val env = StreamExecutionEnvironment.getExecutionEnvironment
val ds1 = env.fromCollection(List(("a",1),("b",2),("c",3)))
val ds2 = env.fromCollection(List(("d",4),("e",5),("f",6)))
val ds3 = env.fromCollection(List(("g",7),("h",8)))
val unionStream = ds1.union(ds2,ds3)
unionStream.print()
env.execute()
Выход:
("a", 1)
("b", 2)
("c", 3)
("d", 4)
("e", 5)
("f", 6)
("g", 7)
("h", 8)
Подключить фальшивое слияние
DataStream,DataStream → ConnectedStreams
Объединить два индивидуальных потока и сохранить два индивидуальных потока изданных типов, которые могут разделять статус двух индивидуальных потоков из
val ds1 = env.socketTextStream("node01", 8888)
val ds2 = env.socketTextStream("node01", 9999)
val wcStream1 = ds1.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
val wcStream2 = ds2.flatMap(_.split(" ")).map((_,1)).keyBy(0).sum(1)
val restStream: ConnectedStreams[(String, Int), (String, Int)] = wcStream2.connect(wcStream1)
CoMap, CoFlatMap
ConnectedStreams → DataStream
CoMap, CoFlatMap — это не конкретное имя оператора, а тип имени операции.
Любой обход карты на основе потока данных ConnectedStreams называется CoMap.
Любой обход FlatMap на основе потока данных ConnectedStreams называется CoFlatMap.
Первая реализация CoMap:
restStream.map(new CoMapFunction[(String,Int),(String,Int),(String,Int)] {
//Рассчитываем первый индивидуальный поток
override def map1(value: (String, Int)): (String, Int) = {
(value._1+":first",value._2+100)
}
//Рассчитываем второй индивидуальный поток
override def map2(value: (String, Int)): (String, Int) = {
(value._1+":second",value._2*100)
}
}).print()
Второй метод реализации CoMap:
restStream.map(
//Рассчитываем первый индивидуальный поток
x=>{(x._1+":first",x._2+100)}
//Рассчитываем второй индивидуальный поток
,y=>{(y._1+":second",y._2*100)}
).print()
Пример кода: существует существующий файл конфигурации, в котором хранится номерной знак и настоящее имя владельца автомобиля.,проходитьданныепотоксерединаиз Сопоставление номерного знака в режиме реального временииз Имя владельца автомобиля(Уведомление:Файлы конфигурации могут меняться в реальном времени.)
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
val filePath = "data/carId2Name"
val carId2NameStream = env.readFile(new TextInputFormat(new Path(filePath)),filePath,FileProcessingMode.PROCESS_CONTINUOUSLY,10)
val dataStream = env.socketTextStream("node01",8888)
dataStream.connect(carId2NameStream).map(new CoMapFunction[String,String,String] {
private val hashMap = new mutable.HashMap[String,String]()
override def map1(value: String): String = {
hashMap.getOrElse(value,"not found name")
}
override def map2(value: String): String = {
val splits = value.split(" ")
hashMap.put(splits(0),splits(1))
value + "Загрузка завершена..."
}
}).print()
env.execute()
Первая реализация CoFlatMap:
ds1.connect(ds2).flatMap((x,c:Collector[String])=>{
//Рассчитываем первый индивидуальный поток
x.split(" ").foreach(w=>{
c.collect(w)
})
}
//Рассчитываем второй индивидуальный поток
,(y,c:Collector[String])=>{
y.split(" ").foreach(d=>{
c.collect(d)
})
}).print
Второй метод реализации CoFlatMap:
ds1.connect(ds2).flatMap(
//Рассчитываем первый индивидуальный поток
x=>{
x.split(" ")
}
//Рассчитываем второй индивидуальный поток
,y=>{
y.split(" ")
}).print()
Третий метод реализации CoFlatMap:
ds1.connect(ds2).flatMap(new CoFlatMapFunction[String,String,(String,Int)] {
//Рассчитываем первый индивидуальный поток
override def flatMap1(value: String, out: Collector[(String, Int)]): Unit = {
val words = value.split(" ")
words.foreach(x=>{
out.collect((x,1))
})
}
//Рассчитываем второй индивидуальный поток
override def flatMap2(value: String, out: Collector[(String, Int)]): Unit = {
val words = value.split(" ")
words.foreach(x=>{
out.collect((x,1))
})
}
}).print()
Split
DataStream → SplitStream
Разделение одного потока на два или более потоков в зависимости от условий.
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,100)
val splitStream = stream.split(
d => {
d % 2 match {
case 0 => List("even")
case 1 => List("odd")
}
}
)
splitStream.select("even").print()
env.execute()
Select
SplitStream → DataStream
отSplitStreamсерединавыбиратьодининдивидуальныйили Многие людииндивидуальныйданныепоток
splitStream.select("even").print()
Iterate
DataStream → IterativeStream → DataStream
Оператор Iterate обеспечивает поддержку итерации потока данных из
Итерация состоит из двух частей: тела итерации и условия завершения итерации.,Условия прекращения итерации не выполненыизданныепотоквстреча返回приезжатьstreamпотоксередина,Перейти к следующей итерации,Выполните условия для прекращения итерацииизданныепоток Продолжить отправку вниз по течению:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val initStream = env.socketTextStream("node01",8888)
val stream = initStream.map(_.toLong)
stream.iterate {
iteration => {
//Определяем логику итерации
val iterationBody = iteration.map ( x => {
println(x)
if(x > 0) x - 1
else x
} )
//> 0 Значения больше 0из продолжают возвращаться в поток When. <= 0 Продолжить отправку вниз по течению
(iterationBody.filter(_ > 0), iterationBody.filter(_ <= 0))
}
}.print()
env.execute()
Классы функций и классы расширенных функций
существуют При использовании оператора Flink вы можете передать анонимную функцию или объект класса функции.
Классы функций делятся на классы обычных функций и классы расширенных функций.
Богатый функциональный класспо сравнению с Вобычноизфункция,Вы можете получить рабочую среду и контекст (Context),Иметь несколько методов жизненного цикла,Статус управления,Может выполнять более сложные функции
Обычный функциональный класс | Богатый функциональный класс |
|---|---|
MapFunction | RichMapFunction |
FlatMapFunction | RichFlatMapFunction |
FilterFunction | RichFilterFunction |
...... | ...... |
- Используйте Обычный функциональный класс для фильтрации информации об автомобилях со скоростью выше 100из.
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.readTextFile("./data/carFlow_all_column_test.txt")
stream.filter(new FilterFunction[String] {
override def filter(value: String): Boolean = {
if (value != null && !"".equals(value)) {
val speed = value.split(",")(6).replace("'", "").toLong
if (speed > 100)
false
else
true
}else
false
}
}).print()
env.execute()
- использовать Богатый функциональный класс,Преобразование номерного знака в настоящее имя владельца автомобиля,Таблица сопоставлений хранится в Redis.
Добавьте зависимость Redis и запишите данные в Redis.
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${redis.version}</version>
</dependency>
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01", 8888)
stream.map(new RichMapFunction[String, String] {
private var jedis: Jedis = _
//Функция инициализации существует каждый раз, когда запускается индивидуальный поток (при обработке элементов он будет вызываться один раз)
//существоватьopen может создать повторное соединение соединения
override def open(parameters: Configuration): Unit = {
//getRuntimeContext может получить среду контекста запуска flink Абстрактный класс AbstractRichFunction предоставляет
val taskName = getRuntimeContext.getTaskName
val subtasks = getRuntimeContext.getTaskNameWithSubtasks
println("=========open======"+"taskName:" + taskName + "\tsubtasks:"+subtasks)
jedis = new Jedis("node01", 6379)
jedis.select(3)
}
//Он будет вызываться один раз при каждой обработке отдельного элемента.
override def map(value: String): String = {
val name = jedis.get(value)
if(name == null){
"not found name"
}else
name
}
//После обработки элемента будет вызван метод close
//Закрываем соединение с Redis
override def close(): Unit = {
jedis.close()
}
}).setParallelism(2).print()
env.execute()
ProcessFunction (функция обработки)
ProcessFunction принадлежит низкоуровневому API. Как мы упоминали ранее, такие операторы, как карта, фильтр и FlatMap, инкапсулированы на основе этого высокоуровневого уровня.
Нижний уровень изAPI,Чем мощнее функция,Чем больше информации смогут получить пользователи,например Можетбратьприезжать Информация о состоянии элемента、время события、Установите таймеры и т. д.
Пример кода: мониторинг каждой машины,Скорость автомобиля превышает 100 миль в час,Уведомление о превышении скорости будет выдано через 2 секунды:
object MonitorOverSpeed02 {
case class CarInfo(carId:String,speed:Long)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01",8888)
stream.map(data => {
val splits = data.split(" ")
val carId = splits(0)
val speed = splits(1).toLong
CarInfo(carId,speed)
}).keyBy(_.carId)
//KeyedStream вызывает процесс и должен передать его в KeyedProcessFunction
//DataStream вызывает процесс и должен передать ProcessFunction
.process(new KeyedProcessFunction[String,CarInfo,String] {
override def processElement(value: CarInfo, ctx: KeyedProcessFunction[String, CarInfo, String]#Context, out: Collector[String]): Unit = {
val currentTime = ctx.timerService().currentProcessingTime()
if(value.speed > 100 ){
val timerTime = currentTime + 2 * 1000
ctx.timerService().registerProcessingTimeTimer(timerTime)
}
}
override def onTimer(timestamp: Long, ctx: KeyedProcessFunction[String, CarInfo, String]#OnTimerContext, out: Collector[String]): Unit = {
var warnMsg = "warn... time:" + timestamp + " carID:" + ctx.getCurrentKey
out.collect(warnMsg)
}
}).print()
env.execute()
}
}
Подвести итог
Использовать карту Фильтр.... оператор из подходит, можно напрямую передать индивидуальную анонимную функцию, Обычный функциональный классобъект(MapFuncation FilterFunction),Богатый функциональный класс объекта (RichMapFunction, RichFilterFunction), переданный в из Богатый функциональный классобъект:Можетбратьприезжать Задачаосуществлятьизначальство Внизискусство,методы жизненного цикла、Статус управления.....。
Если бизнес более сложный,Предоставление этих операторов через Flink не может удовлетворить наши потребности.,проходитьprocessРассчитатьребенок直接использовать Сравнивать底层API(获取начальство Внизискусство、методы жизненного цикла、Тестовый выходной поток、службы времени и др.).
KeyedDataStream — процесс, KeyedProcessFunction.
DataStream — процесс, ProcessFunction.
Sink
Flink имеет большое количество встроенных моек.,Может ВоляFlinkиметь дело сназадизданныевыходприезжатьHDFS、kafka、Redis、ES、MySQL и т. д.
В инженерных сценариях часто используются данные в Kafka, а результаты обработки сохраняются в Redis или MySQL.
Redis Sink
Flinkиметь дело сизданные МожетхранилищеприезжатьRedisсередина,для запроса в реальном времени
Flink имеет встроенный соединитель Redis для подключения. Вам нужно только импортировать зависимость Redis для подключения.
<dependency>
<groupId>org.apache.bahir</groupId>
<artifactId>flink-connector-redis_2.11</artifactId>
</dependency>
WordCountписатьприезжатьRedisсередина,Выберите тип издаHSETданные,Код выглядит следующим образом:
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01",8888)
val result = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
//Если redisда стоит отдельно
val config = new FlinkJedisPoolConfig.Builder().setDatabase(3).setHost("node01").setPort(6379).build()
//Если да redisкластер
/*val addresses = new util.HashSet[InetSocketAddress]()
addresses.add(new InetSocketAddress("node01",6379))
addresses.add(new InetSocketAddress("node01",6379))
val clusterConfig = new FlinkJedisClusterConfig.Builder().setNodes(addresses).build()*/
result.addSink(new RedisSink[(String,Int)](config,new RedisMapper[(String,Int)] {
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET,"wc")
}
override def getKeyFromData(t: (String, Int)) = {
t._1
}
override def getValueFromData(t: (String, Int)) = {
t._2 + ""
}
}))
env.execute()
Kafka Sink
Записать результаты обработки в Kafka topicсередина,Flink также поддерживает его по умолчанию.,Необходимо добавить зависимости соединителя,Это то же самое, что чтение кафкаданных с использованием зависимости из коннектора.,Если вы добавляли его ранее, вам не нужно добавлять его снова.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink-version}</version>
</dependency>
import java.lang
import java.util.Properties
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaProducer, KafkaSerializationSchema}
import org.apache.kafka.clients.producer.ProducerRecord
import org.apache.kafka.common.serialization.StringSerializer
object KafkaSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.socketTextStream("node01",8888)
val result = stream.flatMap(_.split(" "))
.map((_, 1))
.keyBy(0)
.sum(1)
val props = new Properties()
props.setProperty("bootstrap.servers","node01:9092,node02:9092,node03:9092")
// props.setProperty("key.serializer",classOf[StringSerializer].getName)
// props.setProperty("value.serializer",classOf[StringSerializer].getName)
/**
public FlinkKafkaProducer(
FlinkKafkaProducer(defaultTopic: String, serializationSchema: KafkaSerializationSchema[IN], producerConfig: Properties, semantic: FlinkKafkaProducer.Semantic)
*/
result.addSink(new FlinkKafkaProducer[(String,Int)]("wc",new KafkaSerializationSchema[(String, Int)] {
override def serialize(element: (String, Int), timestamp: lang.Long): ProducerRecord[Array[Byte], Array[Byte]] = {
new ProducerRecord("wc",element._1.getBytes(),(element._2+"").getBytes())
}
},props,FlinkKafkaProducer.Semantic.EXACTLY_ONCE))
env.execute()
}
}
MySQL Sink
Flinkиметь дело срезультатписатьприезжатьMySQLсередина,По умолчанию это не поддерживается даFlink.,Необходимо добавить зависимость драйвера MySQLiz.
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.44</version>
</dependency>
Поскольку встроенной поддержки нет, вам необходимо настроить приемник на основе RichSinkFunction.
Пример кода: использование Kafka в данных,Статистика трафика каждого индивидуального штыка из,и депозитприезжатьMySQLсередина
Примечание. Дублирование необходимо удалить, а для работы MySQL необходима идемпотентность.
import java.sql.{Connection, DriverManager, PreparedStatement}
import java.util.Properties
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringSerializer
object MySQLSink {
case class CarInfo(monitorId: String, carId: String, eventTime: String, Speed: Long)
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//Устанавливаем информацию о конфигурации соединения kafkaiz
val props = new Properties()
//Уведомление sparkstreaming + Кафка (версии до 0.10) режим приемника zookeeper url(Юаньданные) props.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
props.setProperty("group.id", "flink-kafka-001")
props.setProperty("key.deserializer", classOf[StringSerializer].getName)
props.setProperty("value.deserializer", classOf[StringSerializer].getName)
//Нет.одининдивидуальныйпараметр : Название темы потребления
val stream = env.addSource(new FlinkKafkaConsumer[(String, String)]("flink-kafka", new KafkaDeserializationSchema[(String, String)] {
//Когда остановиться, каково условие остановки?
override def isEndOfStream(t: (String, String)): Boolean = false
//Для сериализации из байтового потока
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
val key = new String(consumerRecord.key(), "UTF-8")
val value = new String(consumerRecord.value(), "UTF-8")
(key, value)
}
//Указываем тип возвращаемого значения изданные Flink предоставляет типы
override def getProducedType: TypeInformation[(String, String)] = {
createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
}
}, props))
stream.map(data => {
val value = data._2
val splits = value.split("\t")
val monitorId = splits(0)
(monitorId, 1)
}).keyBy(_._1)
.reduce(new ReduceFunction[(String, Int)] {
//t1: последний результат агрегации t2:текущийизданные override def reduce(t1: (String, Int), t2: (String, Int)): (String, Int) = {
(t1._1, t1._2 + t2._2)
}
}).addSink(new MySQLCustomSink)
env.execute()
}
//Невозможность записи во внешнюю библиотеку данных MySQL
class MySQLCustomSink extends RichSinkFunction[(String, Int)] {
var conn: Connection = _
var insertPst: PreparedStatement = _
var updatePst: PreparedStatement = _
//Он будет вызываться один раз для каждого индивидуального элемента.
override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {
println(value)
updatePst.setInt(1, value._2)
updatePst.setString(2, value._1)
updatePst.execute()
println(updatePst.getUpdateCount)
if(updatePst.getUpdateCount == 0){
println("insert")
insertPst.setString(1, value._1)
insertPst.setInt(2, value._2)
insertPst.execute()
}
}
//Выполняется один раз при инициализации потока
override def open(parameters: Configuration): Unit = {
conn = DriverManager.getConnection("jdbc:mysql://node01:3306/test", "root", "123123")
insertPst = conn.prepareStatement("INSERT INTO car_flow(monitorId,count) VALUES(?,?)")
updatePst = conn.prepareStatement("UPDATE car_flow SET count = ? WHERE monitorId = ?")
}
//Когда поток закрывается Выполнить один раз
override def close(): Unit = {
insertPst.close()
updatePst.close()
conn.close()
}
}
}
Socket Sink
Результаты обработки Flink отправляются в сокет (Socket), а приемник настраивается на основе RichSinkFunction:
import java.io.PrintStream
import java.net.{InetAddress, Socket}
import java.util.Properties
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.sink.{RichSinkFunction, SinkFunction}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTuple2TypeInformation, createTypeInformation}
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringSerializer
//sink приезжать розетка socket
object SocketSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//Устанавливаем информацию о конфигурации соединения kafkaiz
val props = new Properties()
//Уведомление sparkstreaming + Кафка (версии до 0.10) режим приемника zookeeper url(Юаньданные) props.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
props.setProperty("group.id", "flink-kafka-001")
props.setProperty("key.deserializer", classOf[StringSerializer].getName)
props.setProperty("value.deserializer", classOf[StringSerializer].getName)
//Нет.одининдивидуальныйпараметр : Название темы потребления
val stream = env.addSource(new FlinkKafkaConsumer[(String, String)]("flink-kafka", new KafkaDeserializationSchema[(String, String)] {
//Когда остановиться, каково условие остановки?
override def isEndOfStream(t: (String, String)): Boolean = false
//Для сериализации из байтового потока
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
val key = new String(consumerRecord.key(), "UTF-8")
val value = new String(consumerRecord.value(), "UTF-8")
(key, value)
}
//Указываем тип возвращаемого значения изданные Flink предоставляет типы
override def getProducedType: TypeInformation[(String, String)] = {
createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
}
}, props))
stream.map(data => {
val value = data._2
val splits = value.split("\t")
val monitorId = splits(0)
(monitorId, 1)
}).keyBy(_._1)
.reduce(new ReduceFunction[(String, Int)] {
//t1: последний результат агрегации t2:текущийизданные override def reduce(t1: (String, Int), t2: (String, Int)): (String, Int) = {
(t1._1, t1._2 + t2._2)
}
}).addSink(new SocketCustomSink("node01",8888))
env.execute()
}
class SocketCustomSink(host:String,port:Int) extends RichSinkFunction[(String,Int)]{
var socket: Socket = _
var writer:PrintStream = _
override def open(parameters: Configuration): Unit = {
socket = new Socket(InetAddress.getByName(host), port)
writer = new PrintStream(socket.getOutputStream)
}
override def invoke(value: (String, Int), context: SinkFunction.Context[_]): Unit = {
writer.println(value._1 + "\t" +value._2)
writer.flush()
}
override def close(): Unit = {
writer.close()
socket.close()
}
}
}
File Sink
Flinkиметь дело сиз Сохранить результатыприезжатьдокумент,Это использование не очень распространено
Поддержка записи ведра,Каждыйодининдивидуальный Ведродаодининдивидуальный Оглавление,По умолчанию один сегмент будет создаваться каждый час.,Каждый результат обработки индивидуального потока будет храниться в каждом сегменте.,Вы можете установить некоторые политики прокрутки файлов (открытие файла, размер файла и т. д.).,Предотвратите появление большого количества мелких документов.
Flink поддерживает его по умолчанию, импортируя файлы подключения и зависимости соединителя.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_2.11</artifactId>
<version>1.9.2</version>
</dependency>
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.serialization.SimpleStringEncoder
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.core.fs.Path
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink
import org.apache.flink.streaming.api.functions.sink.filesystem.rollingpolicies.DefaultRollingPolicy
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTuple2TypeInformation, createTypeInformation}
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringSerializer
object FileSink {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//Устанавливаем информацию о конфигурации соединения kafkaiz
val props = new Properties()
//Уведомление sparkstreaming + Кафка (версии до 0.10) режим приемника zookeeper url(Юаньданные) props.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
props.setProperty("group.id", "flink-kafka-001")
props.setProperty("key.deserializer", classOf[StringSerializer].getName)
props.setProperty("value.deserializer", classOf[StringSerializer].getName)
//Нет.одининдивидуальныйпараметр : Название темы потребления
val stream = env.addSource(new FlinkKafkaConsumer[(String, String)]("flink-kafka", new KafkaDeserializationSchema[(String, String)] {
//Когда остановиться, каково условие остановки?
override def isEndOfStream(t: (String, String)): Boolean = false
//Для сериализации из байтового потока
override def deserialize(consumerRecord: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String) = {
val key = new String(consumerRecord.key(), "UTF-8")
val value = new String(consumerRecord.value(), "UTF-8")
(key, value)
}
//Указываем тип возвращаемого значения изданные Flink предоставляет типы
override def getProducedType: TypeInformation[(String, String)] = {
createTuple2TypeInformation(createTypeInformation[String], createTypeInformation[String])
}
}, props))
val restStream = stream.map(data => {
val value = data._2
val splits = value.split("\t")
val monitorId = splits(0)
(monitorId, 1)
}).keyBy(_._1)
.reduce(new ReduceFunction[(String, Int)] {
//t1: последний результат агрегации t2:текущийизданные override def reduce(t1: (String, Int), t2: (String, Int)): (String, Int) = {
(t1._1, t1._2 + t2._2)
}
}).map(x=>x._1 + "\t" + x._2)
//Устанавливаем стратегию прокрутки файлов
val rolling:DefaultRollingPolicy[String,String] = DefaultRollingPolicy.create()
//Когда в файл не записывается никаких новых данных в течение более 2 секунд, путем прокрутки будет создан небольшой файл.
.withInactivityInterval(2000)
//Время открытия файла превышает 2с Затем прокрутка создает небольшой файл Небольшой файл создается каждые 2 секунды.
.withRolloverInterval(2000)
//Когда размер файла превышает 256 Затем прокрутка создает небольшой файл
.withMaxPartSize(256*1024*1024)
.build()
/**
* по умолчанию:
* Каждый индивидуальный час соответствует одному индивидуальному сегменту (папке), а каждый индивидуальный поток обработки результата соответствует одному индивидуальному небольшому файлу под контейнером.
* Когда размер небольшого файла превышает 128 МБ или время открытия небольшого файла превышает 60 секунд, второй небольшой файл будет создан путем прокрутки.
*/
val sink: StreamingFileSink[String] = StreamingFileSink.forRowFormat(
new Path("d:/data/rests"),
new SimpleStringEncoder[String]("UTF-8"))
.withBucketCheckInterval(1000)
.withRollingPolicy(rolling)
.build()
// val sink = StreamingFileSink.forBulkFormat(
// new Path("./data/rest"),
// ParquetAvroWriters.forSpecificRecord(classOf[String])
// ).build()
restStream.addSink(sink)
env.execute()
}
}
HBase Sink
Записать результаты вычислений в сток можно двумя способами:
- Написан оператор карты, и часто создаются соединения с hbase.
- запись процесса, подходит для пакетной записи в hbase.
Импортировать пакеты зависимостей HBase
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
Чтение данных Kafka и сохранение статистического трафика портов карт в базе данных HBase.
- Создать соответствующую таблицу в HBase
create 'car_flow',{NAME => 'count', VERSIONS => 1}
- Реализация кода
import java.util.{Date, Properties}
import com.msb.stream.util.{DateUtils, HBaseUtil}
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer
import org.apache.flink.util.Collector
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{HTable, Put}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.kafka.common.serialization.StringSerializer
object HBaseSinkTest {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//Устанавливаем информацию о конфигурации соединения kafkaiz
val props = new Properties()
//Уведомление sparkstreaming + Кафка (версии до 0.10) режим приемника zookeeper url(Юаньданные) props.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
props.setProperty("group.id", "flink-kafka-001")
props.setProperty("key.deserializer", classOf[StringSerializer].getName)
props.setProperty("value.deserializer", classOf[StringSerializer].getName)
val stream = env.addSource(new FlinkKafkaConsumer[String]("flink-kafka", new SimpleStringSchema(), props))
stream.map(row => {
val arr = row.split("\t")
(arr(0), 1)
}).keyBy(_._1)
.reduce((v1: (String, Int), v2: (String, Int)) => {
(v1._1, v1._2 + v2._2)
}).process(new ProcessFunction[(String, Int), (String, Int)] {
var htab: HTable = _
override def open(parameters: Configuration): Unit = {
val conf = HBaseConfiguration.create()
conf.set("hbase.zookeeper.quorum", "node01:2181,node02:2181,node03:2181")
val hbaseName = "car_flow"
htab = new HTable(conf, hbaseName)
}
override def close(): Unit = {
htab.close()
}
override def processElement(value: (String, Int), ctx: ProcessFunction[(String, Int), (String, Int)]#Context, out: Collector[(String, Int)]): Unit = {
// rowkey:monitorid Временная метка (минуты) значение: объем трафика
val min = DateUtils.getMin(new Date())
val put = new Put(Bytes.toBytes(value._1))
put.addColumn(Bytes.toBytes("count"), Bytes.toBytes(min), Bytes.toBytes(value._2))
htab.put(put)
}
})
env.execute()
}
}
Стратегия раздела
существовать Apache Flink середина,Разделение означает разделение потока на несколько сегментов по определенным правилам.,так чтосуществоватьдругойизпараллельный Задачаили Рассчитатьребеноксерединапараллельныйиметь дело сданные。Разделдавыполнитьпараллельныйвычислитьиданные Потоковая обработкаиз Базовая механика. Флинк изPartition определяет путь из потоков во время операции данныхсуществовать, а такжесуществоватьпараллельный Задачакак междураспространятьииметь дело сданные。
существовать Flink , поток данных можно рассматривать как индивидуально ориентированный граф. Из узлов графа представляются операторы (Операторы), а ребра представляют поток данных (Данные). Streams)。данныеот源Рассчитатьребенокпоток КВнизтур Рассчитатьребенок,Эти операторы могут обрабатывать входные данные параллельно.,и Раздел Сразуда Решатьданныекакотодининдивидуальный Рассчитатьребенокпередачаприезжать Другойодининдивидуальный Рассчитатьребенокизмеханизм。
shuffle
Сценарий: увеличить размер раздела, улучшить параллелизм и решить проблему наклона данных.
DataStream → DataStream
Элементы раздела случайным образом и равномерно распределяются по нижестоящим разделам, а сетевые издержки относительно велики.
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(1)
println(stream.getParallelism)
stream.shuffle.print()
env.execute()
console result:вверх по течениюданные Более повседневныйизраспределениеприезжать Внизтур
2> 1
1> 4
7> 10
4> 6
6> 3
5> 7
8> 2
1> 5
1> 8
1> 9
rebalance
Сценарий: увеличить размер раздела, улучшить параллелизм и решить проблему наклона данных.
DataStream → DataStream
Элементы раздела опроса,Униформаиз Воля Юаньбелыйраспределениеприезжать Внизтур Раздел,Нижний раздел каждого изданных разделов относительно равномерен.,Очень полезно, когда происходит наклон данных.,Накладные расходы сети относительно велики
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(3)
val stream = env.generateSequence(1,100)
val shuffleStream = stream.rebalance
shuffleStream.print()
env.execute()
console result:вверх по течениюданные Сравнивать Униформаизраспределениеприезжать Внизтур
8> 6
3> 1
5> 3
7> 5
1> 7
2> 8
6> 4
4> 2
3> 9
4> 10
rescale
Сценарий: уменьшение разделов Предотвращение больших объемов сетевой передачи Полного передела не произойдет
DataStream → DataStream
проходить Элементы раздела опроса,Отправить коллекцию отдельных элементов из восходящего раздела в нижестоящий раздел.,Отправить единицу коллекции,Вместо того, чтобы даодининдивидуальныйиндивидуальный Юаньбелый
Уведомление:rescaleпроисходитьиздаместныйданныепередача инфекции,без необходимости передачи данных через сеть,Например количество слотов в диспетчере задач. Проще говоря,Восходящие изданные будут отправлены только в нисходящие изданные этого TaskManager.
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.rescale.writeAsText("./data/stream2").setParallelism(4)
env.execute()
Результат консоли: контент потока 1:1 распространяется на поток 2:1 и поток2:2.
stream1:1
1
3
5
7
9
stream1:2
2
4
6
8
10
stream2:1
1
5
9
stream2:2
3
7
stream2:3
2
6
10
stream2:4
4
8
broadcast
Сценарий: необходимо использовать таблицу сопоставления, и она будет часто меняться.
DataStream → DataStream
вверх по течениюсередина Каждыйодининдивидуальный Юаньбелыйтрансляция контентаприезжать Внизтур Каждыйодининдивидуальный Разделсередина
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.broadcast.writeAsText("./data/stream2").setParallelism(4)
env.execute()
console result:stream1:1、2трансляция контентаприезжать Понятно Внизтуркаждый Разделсередина
stream1:1
1
3
5
7
9
stream1:2
2
4
6
8
10
stream2:1
1
3
5
7
9
2
4
6
8
10
global
Сценарий: Параллелизм снижен до 1
DataStream → DataStream
Изданные вышестоящий раздел распространяются только на нижестоящий из первого индивидуального раздела.
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.global.writeAsText("./data/stream2").setParallelism(4)
env.execute()
Результат консоли: содержимое потоков 1:1 и 2 распространяется только в поток 2:1.
stream1:1
1
3
5
7
9
stream1:2
2
4
6
8
10
stream2:1
1
3
5
7
9
2
4
6
8
10
forward
Сценарий: распределение один к одному, карта, FlatMap, фильтр. Жду такую стратегию раздела
DataStream → DataStream
Распределить данные из вышестоящих разделов в соответствующие нижестоящие разделы.
partition1->partition1
partition2->partition2
Уведомление:должен保证начальство Внизтур Разделчисло(Параллелизм)один К,В противном случае произойдет следующее исключение:
Forward partitioning does not allow change of parallelism
* Upstream operation: Source: Sequence Source-1 parallelism: 2,
* downstream operation: Sink: Unnamed-4 parallelism: 4
* stream.forward.writeAsText("./data/stream2").setParallelism(4)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.forward.writeAsText("./data/stream2").setParallelism(2)
env.execute()
console result:stream1:1->stream2:1、stream1:2->stream2:2
stream1:1
1
3
5
7
9
stream1:2
2
4
6
8
10
stream2:1
1
3
5
7
9
stream2:2
2
4
6
8
10
keyBy
Сценарий: соответствие бизнес-сценарию.
DataStream → DataStream
Рассчитывается на основе модуля вышестоящего элемента раздела из значения Hash и количества нижестоящих разделов.,Волятекущий Юаньбелыйраспределениеприезжать Внизтур哪одининдивидуальный Раздел
MathUtils.murmurHash(keyHash)(каждый элемент из значения Hash) % maxParallelism (количество последующих разделов)
val env = StreamExecutionEnvironment.getExecutionEnvironment
val stream = env.generateSequence(1,10).setParallelism(2)
stream.writeAsText("./data/stream1").setParallelism(2)
stream.keyBy(0).writeAsText("./data/stream2").setParallelism(2)
env.execute()
результат консоли: распределяется по нижестоящим разделам на основе значения хэша элемента
PartitionCustom
DataStream → DataStream
Путем настройки разделителя,Приходить Решать Юаньбелыйдакакотвверх по течению Разделраспределениеприезжать Внизтур Раздел
object ShuffleOperator {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(2)
val stream = env.generateSequence(1,10).map((_,1))
stream.writeAsText("./data/stream1")
stream.partitionCustom(new customPartitioner(),0)
.writeAsText("./data/stream2").setParallelism(4)
env.execute()
}
class customPartitioner extends Partitioner[Long]{
override def partition(key: Long, numPartitions: Int): Int = {
key.toInt % numPartitions
}
}
}Я надеюсь, что эта статья поможет вам узнать и о чем подумать.,Если у вас также есть опыт, вы можете учиться на нем и глубоко обдумывать его.,Добро пожаловать, чтобы оставить сообщение в области комментариев для обсуждения. Если эта статья вам полезна,пожалуйста, помогитеиндивидуальныйсуществоватьсмотретьилиточкаиндивидуальныйхвалить👍🏻。



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
