Самая мощная серия семейства UNet | Какая из них сильнее: UNet, UNet++, TransUNet или SWin-UNet? ! !
Эта статья была впервые опубликована на [Jizhi Shutong]. Для учетных записей, внесенных в белый список, пожалуйста, сознательно вставляйте визитную карточку этой общедоступной учетной записи и указывайте источник при перепечатке. Учетные записи, не внесенные в белый список, сначала подайте заявку на разрешение.

Сегментация медицинских изображений — важный шаг в анализе медицинских изображений, особенно как ключевая предпосылка для эффективной диагностики и лечения заболеваний. Применение глубокого обучения для сегментации изображений стало общей тенденцией. В настоящее время широко используемым методом является U-Net и его варианты. Кроме того, благодаря замечательному успеху предварительно обученных моделей в задачах обработки естественного языка, модели на основе Transformer, такие как TransUNet, достигли удовлетворительной производительности на нескольких наборах данных сегментации медицинских изображений. В данной статье автор проводит исследование четырех наиболее репрезентативных моделей сегментации медицинских изображений за последние годы. Авторы теоретически анализируют характеристики этих моделей и количественно оценивают их эффективность на двух базовых наборах данных: рентгенограммах грудной клетки при туберкулезе и опухолях яичников. Наконец, авторы обсуждают основные проблемы и будущие тенденции в области сегментации медицинских изображений. Работа автора может помочь исследователям в смежных областях быстро создать модели медицинской сегментации для конкретных регионов.
1. Введение
Благодаря постоянному развитию технологий медицинской визуализации медицинские изображения стали играть решающую роль в диагностике заболеваний и планировании лечения. Сегментация медицинских изображений играет важную роль в основе и ключевой технологии анализа медицинских изображений. Сегментация медицинских изображений подразумевает идентификацию пикселей органов или заболеваний на медицинских изображениях, таких как КТ или МРТ. Это одна из самых сложных задач в анализе медицинских изображений, цель которой — передать и извлечь важную информацию о форме и объеме этих органов или тканей.
Традиционные методы сегментации медицинских изображений в основном полагаются на ручное извлечение признаков врачами или ручное проектирование на основе технологии обработки изображений и математических моделей, таких как пороговая обработка, обнаружение границ и морфологические операции. Эти методы обеспечивают определенную степень интерпретируемости и управляемости. Однако из-за сложности и разнообразия медицинских изображений, а также специфики задач сегментации медицинских изображений традиционные методы сегментации имеют определенные ограничения. Ручные алгоритмы не могут удовлетворить требования эффективности и точности при обработке большого количества медицинских изображений для задач сегментации. Кроме того, для извлечения особенностей медицинских изображений вручную требуются врачи с обширными знаниями и опытом, что делает их восприимчивыми к субъективным факторам.
В последние годы технология глубокого обучения широко используется в сегментации медицинских изображений для решения вышеперечисленных проблем. Благодаря глубокому изучению функций модель может извлекать семантическую информацию из изображений, тем самым повышая точность сегментации и гибко адаптируясь к различным наборам данных и задачам медицинских изображений. Модели сегментации, основанные на сверточных нейронных сетях (CNN), достигли замечательных результатов. Например, модель U-Net заняла первое место в конкурсе Cell Segmentation Challenge ISBI 2015, модель SegNet хорошо показала себя в задаче семантической сегментации набора данных CamVid и так далее. Однако сверточные нейронные сети имеют ограниченные возможности моделирования зависимостей на больших расстояниях, что затрудняет полное использование семантической информации внутри изображения.
Недавно были предложены некоторые новые модели сегментации, в том числе TransUNet и Swin-Unet. TransUNet — это модель сегментации, в которой представлен модуль Transformer для улучшения способности модели моделировать зависимости на больших расстояниях. Модуль Transformer использует механизм самообслуживания для вычисления сходства между каждой позицией во входной последовательности и другими позициями для получения весового вектора. Этот весовой вектор используется для расчета взвешенного представления каждой позиции, способствуя взаимодействию и интеграции глобальной информации.
Другими словами, модель Transformer может эффективно фиксировать корреляцию между различными позициями во входной последовательности с помощью механизма самообслуживания, тем самым улучшая понимание и обработку данных последовательности. В TransUNet модуль Transformer встроен в U-образную архитектуру для извлечения глобальной информации из изображения, расширяя возможности семантического представления модели и делая ее более подходящей для обработки медицинских изображений большого размера и высокого разрешения.
С другой стороны, Swin-Unet — это еще одна новая модель сегментации, в которой представлен модуль Swin Transformer для повышения эффективности вычислений. Swin Transformer — это иерархический механизм самообслуживания, который разлагает входную карту объектов на несколько патчей, и каждый патч независимо рассчитывает вес внимания, тем самым снижая сложность вычислений. Модуль Swin Transformer в Swin-Unet в сочетании с U-образной архитектурой позволяет извлекать глобальную информацию из изображений, одновременно снижая вычислительную сложность и потребление памяти. Это делает его более подходящим для задач сегментации медицинских изображений.
Несмотря на быстрое развитие технологии сегментации медицинских изображений в последние годы, до сих пор отсутствуют исчерпывающие обзоры внедрения новейших моделей сегментации и количественного сравнения производительности между этими моделями с точки зрения применения моделей глубокого обучения в сегментации медицинских изображений.
В этой статье исследуются четыре наиболее репрезентативные модели сегментации медицинских изображений за последние годы: U-Net, UNet++, TransUNet и Swin-Unet. Характеристики этих моделей анализируются и количественно оцениваются на двух эталонных наборах данных. Наконец, авторы обсуждают основные проблемы и будущие тенденции развития в области сегментации медицинских изображений. Кроме того, автор поделился всеми экспериментальными исходными кодами и подробными параметрами конфигурации модели на GitHub, чтобы помочь соответствующим исследователям быстро понять эти модели и смоделировать новые задачи сегментации.
2. Типичная модель сегментации медицинских изображений.
В последние годы сегментация медицинских изображений достигла огромного прогресса с помощью глубокого обучения. Сверточные нейронные сети (CNN), особенно полностью сверточные сети (FCN), доминируют в области сегментации медицинских изображений. С развитием сегментации медицинских изображений среди различных вариантов модели де-факто выбором стала U-Net, которая состоит из симметричной сети кодировщика-декодера с улучшенными пропускаемыми соединениями для улучшенного сохранения деталей.
На основе этой нейронной сети функции изображения можно автоматически извлекать и использовать для задач сегментации. При сегментации медицинских изображений было использовано несколько моделей глубокого обучения, которые дали отличные результаты, такие как U-Net, UNet++, 3D U-Net, V-Net, Attention-UNet, TransUNet и Swin-Unet.
2.1、U-Net
U-Net — одна из самых известных сетевых архитектур в моделях сегментации медицинских изображений. Это было предложено в конкурсе ISBI 2015 года Роннебергером и др. Модель U-Net считается классической моделью сегментации медицинских изображений и широко используется в различных задачах, включая сегментацию КТ, МРТ и рентгеновских снимков. Структура модели показана на рисунке 1. Его успех заключается в сочетании возможностей глубокого извлечения признаков сверточных нейронных сетей (CNN) с возможностями сегментации на уровне пикселей полностью сверточных сетей (FCN). Он также включает в себя такие методы, как пропуск соединений, для использования информации о функциях низкого и высокого уровня, тем самым повышая точность и надежность сегментации.
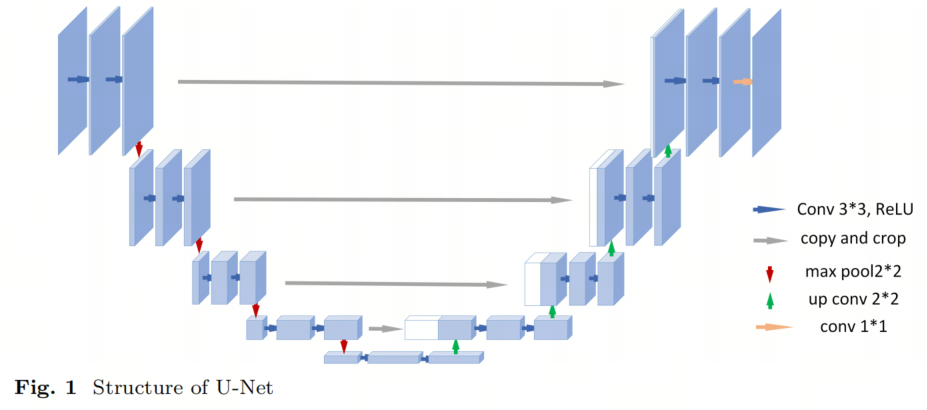
Сеть U-Net состоит из сокращающихся и расширяющихся путей. Путь сокращения следует типичной архитектуре сверточной сети. На каждом этапе субдискретизации количество функциональных каналов удваивается. Каждый шаг на пути расширения состоит из повышения дискретизации карты объектов, уменьшения вдвое количества каналов признаков и объединения их с соответствующей обрезанной картой объектов из пути сокращения. На последнем слое свертка 1x1 используется для сопоставления каждого 64-компонентного вектора признаков с желаемым количеством категорий. Всего сеть состоит из 23 сверточных слоев.
С момента появления модели U-Net появилось несколько улучшенных версий на базе UNet, включая UNet++, Attention-UNet, TransUNet и Swin-Unet. Эти модели еще больше повышают производительность сегментации на основе преимуществ исходной модели U-Net, вводя механизмы внимания, сетевые структуры преобразования и другие технологии. Таким образом, модель U-Net занимает важное место и влияет на сегментацию медицинских изображений.
2.2、UNet++

Сетевая архитектура UNet++ была предложена Чжоу и др. в 2018 году, которые представили концепцию плотных соединений в сети U-Net. Структура модели представлена на рисунке 2. На основе сохранения соединений с длинным пропуском UNet++ добавляет больше путей соединения с коротким пропуском и блоки свертки с повышающей дискретизацией, образуя новый уровень кодировщика. U-образная структура соединения в UNet++ достигается за счет объединения каждого кодера в декодере с другими кодировщиками того же уровня.
В частности, каждый кодер получает карты признаков того же масштаба от других кодировщиков и объединяет их вместе, чтобы получить более разборчивое представление признаков. Кроме того, предложенный позже Attention-UNet++ улучшает соединение карт объектов, добавляя механизм внимания в процесс объединения кодировщиков для повышения внимания и извлечения важных функций.
UNet++ фиксирует функции разных уровней путем введения плотных связей, обеспечивая извлечение информации о функциях с разных уровней и масштабов. Эти функции интегрированы в окончательный прогноз для повышения точности сегментации. Идея плотных соединений исходит от DenseNet. До DenseNet эволюция сверточных нейронных сетей обычно включала увеличение глубины или ширины сети.
DenseNet представляет новую структуру за счет повторного использования функций, что не только решает проблему исчезновения градиента, но и уменьшает количество параметров модели. В исходной сетевой архитектуре U-Net глубокий контроль промежуточного скрытого уровня используется для решения проблемы исчезновения градиента во время процесса обучения UNet++. Это также позволяет сократить сеть на этапе тестирования, тем самым сокращая время вывода модели.
2.3、TransUNet
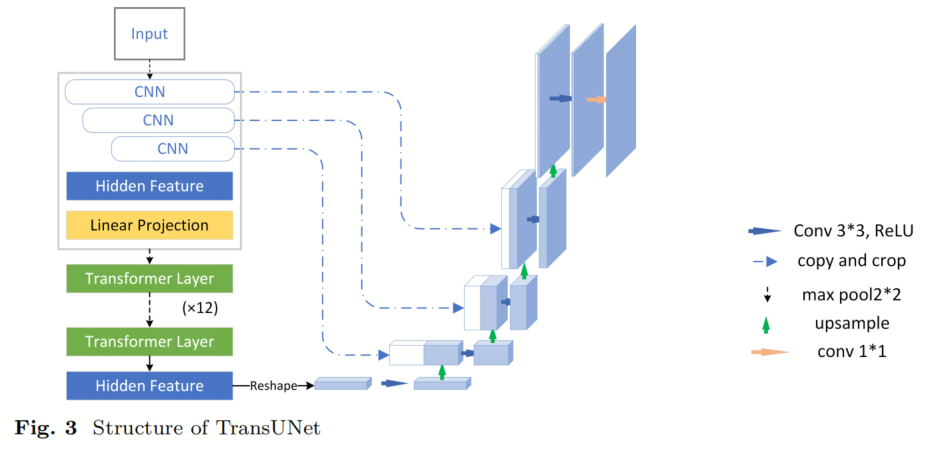
Сетевая архитектура TransUNet была предложена Ченом и др. в 2021 году и представляет собой сеть сегментации на основе трансформатора. Структура модели представлена на рисунке 3. TransUNet представляет гибридный кодер, основанный на модели U-Net, объединяющий CNN и Transformer для устранения ограничений традиционных сверточных нейронных сетей при моделировании зависимостей на больших расстояниях и обработке изображений большого размера. Ядром TransUNet является модуль Transformer, который включает в себя многоголовочный механизм самообслуживания и нейронную сеть прямой связи. Механизм самоконтроля с несколькими головками фиксирует зависимости между различными местами изображения и устанавливает глобальную контекстную информацию в представлении объектов. Это позволяет TransUNet лучше обрабатывать зависимости на больших расстояниях, захватывать семантическую информацию в изображениях, а также улучшать возможности представления модели и производительность обобщения.
В частности, TransUNet сначала использует CNN для извлечения признаков и создания карт признаков входного изображения. Эти карты функций затем делятся на фрагменты размером 1x1 и передаются в другой стек из 12 модулей Transformer. Эта гибридная структура сочетает в себе возможности извлечения признаков сверточных нейронных сетей с эффективным глобальным информационным моделированием с использованием модуля Transformer, что приводит к повышению производительности по сравнению с использованием только Transformer в качестве кодировщика.
Декодер в TransUNet повышает дискретизацию закодированных функций и объединяет их с картами объектов CNN высокого разрешения для обогащения семантической информации и достижения более точной локализации. Последний шаг включает восстановление карты объектов до исходного размера изображения и генерацию результатов сегментации на уровне пикселей. По сравнению с традиционными U-образными моделями, использующими сверточные нейронные сети, TransUNet представляет стек из 12 модулей Transformer, что значительно увеличивает количество параметров и повышает сложность обучения модели. В этом исследовании, чтобы удовлетворить требования TransUNet к обучению на графическом процессоре, был принят неоптимальный подход к уменьшению размера пакета.
2.4、Swin-Unet
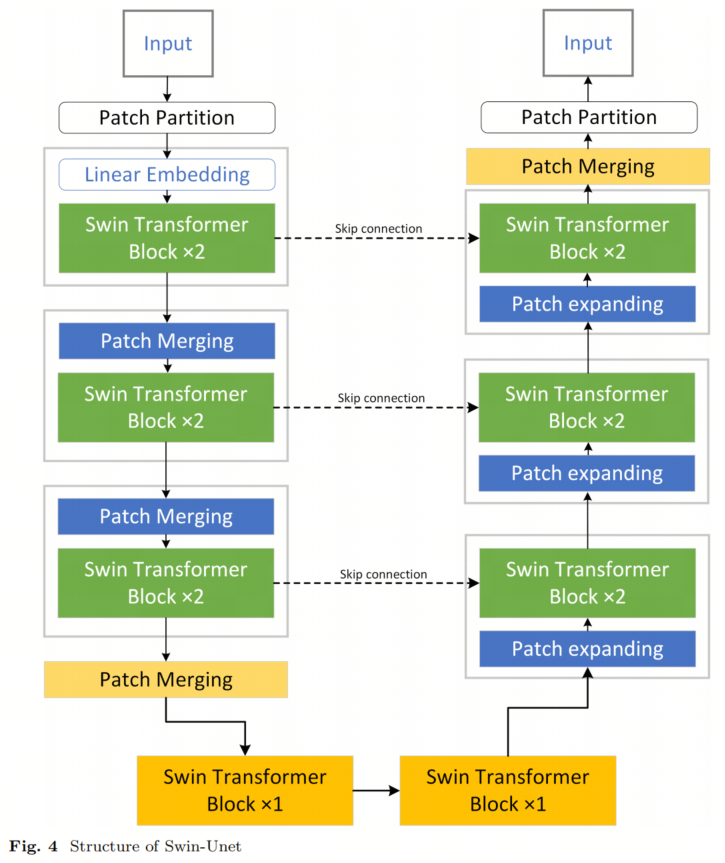
Сетевая архитектура Swin-Unet была предложена Цао и др. в 2023 году. Структура модели показана на рисунке 4. В отличие от Trans-Unet, который заменяет сверточные блоки в кодере U-Net блоками Transformer, Swin-Unet использует блоки Swin Transformer для извлечения иерархических функций из входного изображения. Swin-Unet — это первая U-образная архитектура, основанная исключительно на трансформаторе. Swin Transformer расширяет одномерную последовательность традиционного Transformer до блоков двумерных изображений и использует иерархический механизм внимания для захвата функций в более широком восприимчивом поле. Эта структура похожа на иерархическую структуру в сверточных нейронных сетях и используется для извлечения признаков. Кроме того, Swin Transformer представляет механизм перевода окон, основанный на механизме самообслуживания. Ограничивая расчеты внимания окнами рядом с текущим регионом, Swin-Unet лучше сохраняет информацию о местоположении, что еще больше повышает производительность модели.
В Swin-Unet Swin Transformer применяется для модулей кодирования, устранения узких мест и декодирования. Стоит отметить, что сжатие объектов каждого слоя в Swin-Unet меньше, чем в TransUNet. Swin-Unet не добавляет дополнительные модули Transformer, а заменяет модуль свертки модулем Transformer, эффективно уменьшая количество параметров модели.
В целом, Swin-Unet в полной мере использует преимущества Swin Transformer и U-Net, предоставляя многообещающий метод сегментации медицинских изображений. Он демонстрирует конкурентоспособную производительность по различным задачам и критериям сегментации.
3. Экспериментируйте
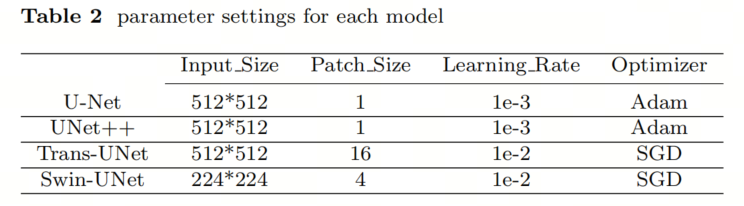
3.1. Тренировочные суперпараметры.
3.2. Результаты экспериментов.
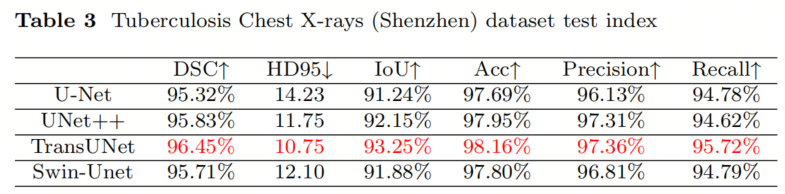
Сначала авторы оценили эффективность каждой модели на общедоступном наборе данных — наборе рентгеновских данных по туберкулезу грудной клетки. В таблице 3 представлены экспериментальные результаты для каждой модели, а на рисунке 7 представлено визуальное представление производительности модели.
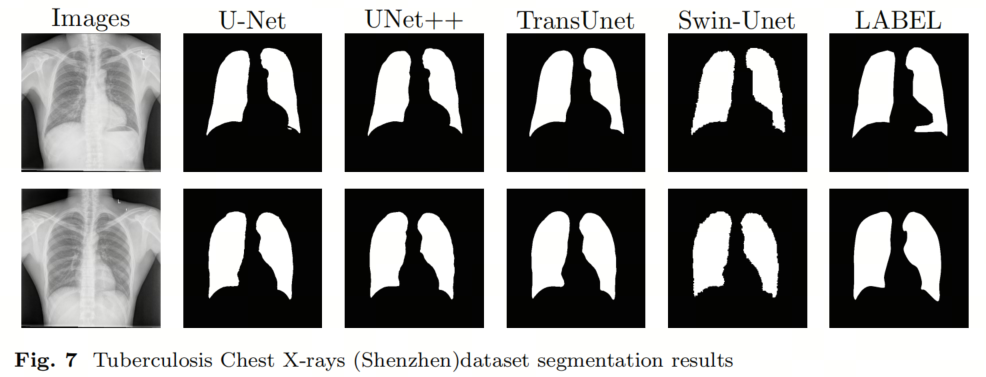
Результаты показывают, что модель TransUNet достигла наилучших показателей по всем шести показателям, соответственно 96,45% (DSC↑), 10,75 (HD↓), 93,25% (IoU↑), 98,16% (Acc↑), 97,36% (Precision↑). и 95,72% (Напомним↑). Кроме того, все модели хорошо справились с задачей сегментации легких: значения mIoU (среднее пересечение по объединению) превысили 91% для всех четырех методов сегментации. В тестовом наборе, когда неясные образцы исключены и образцы малы, показатель DSC оставшихся образцов превышает 82%. Согласно результатам сегментации, все четыре метода могут эффективно удовлетворить требования сегментации.
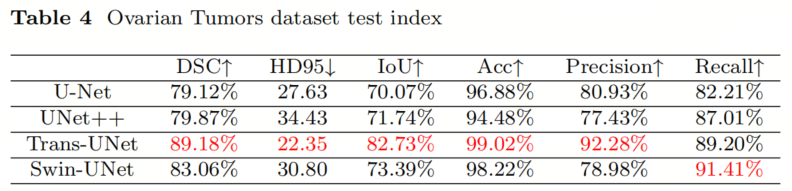
Затем авторы дополнительно оценили эффективность каждой модели на наборах данных с различными методами визуализации. В таблице 4 представлены результаты для набора данных по опухолям яичников.
Авторы оценивают результаты экспериментов, основываясь на среднем коэффициенте Дайса и среднем IoU. Модель TransUNet показала лучшие результаты, за ней следовали Swin-Unet, UNet++ и U-Net. Когда результаты оценивались на основе среднего расстояния Хаусдорфа, модель TransUNet также показала лучшие результаты, за ней следовали U-Net, Swin-Unet и UNet++. С точки зрения средней точности лучше всего показала себя модель TransUNet, за ней следуют Swin-Unet, U-Net и UNet++. При оценке результатов на основе средней точности модель TransUNet показала лучшие результаты, за ней следовали U-Net, Swin-Unet и UNet++.
Стоит отметить, что точность модели Trans-UNet значительно выше, чем у других моделей, что указывает на ее высокую способность точно определять массовые территории. По среднему отзыву лучше всего работает модель Swin-Unet, за ней следуют TransUNet, UNet++ и U-Net.
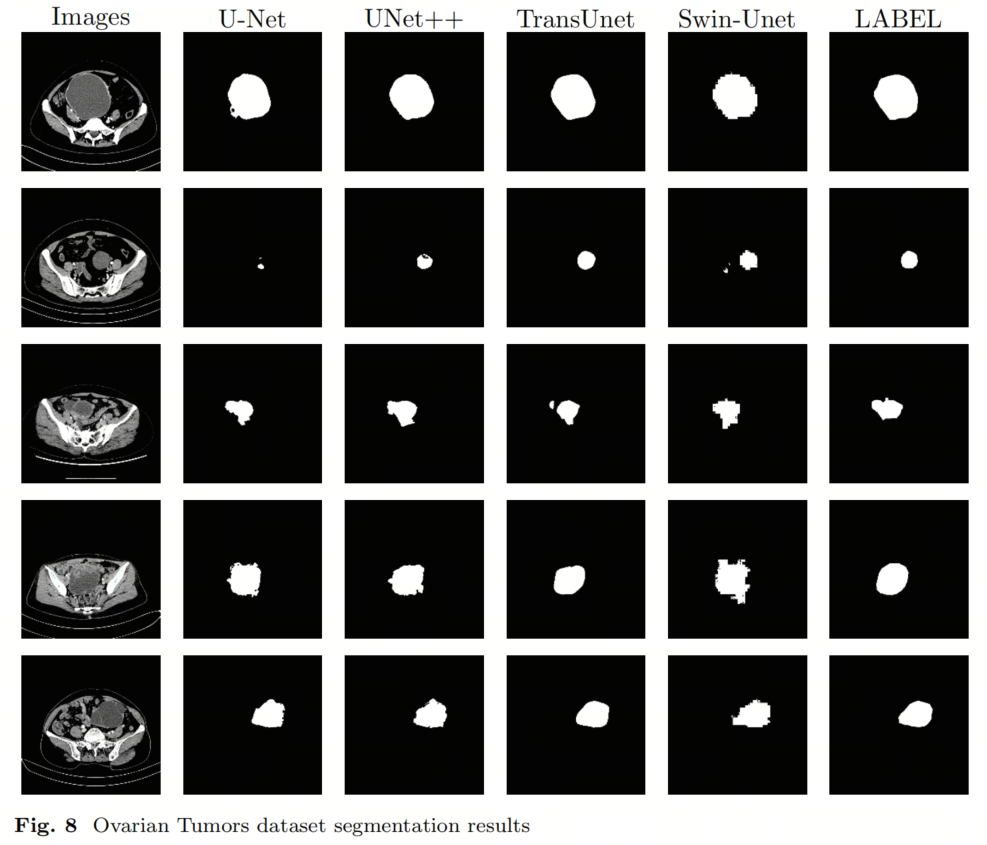
На рисунке 8 представлено визуальное представление производительности модели. Принимая во внимание все показатели и фактические результаты сегментации, модель Trans-UNet показывает лучшие результаты по всем пяти показателям оценки: 89,18% (DSC↑), 22,35 (HD↓), 82,73% (IoU↑), 99,02% (ACC↑). и 92,28% (Напомним↑). Результаты его прогнозов во многом аналогичны реальным меткам. С другой стороны, Swin-Unet, UNet++ и U-Net имеют более низкие показатели оценки и не дают идеальных результатов в реальных прогнозах.

Авторы дополнительно изучили результаты сегментации каждой модели, когда коэффициент Дайса был чрезвычайно низким (менее 20%). Авторы считают эти результаты совершенно неприемлемыми результатами сегментации. Статистические величины этих результатов приведены в таблице 5. Результаты показывают, что после внедрения модуля «Трансформер» модель способна собирать глобальную информацию и, следовательно, демонстрирует меньше случаев полных ошибочных оценок по основным областям образований яичников.
3.3. Обсуждение
В экспериментах автора все модели приняли U-образную архитектуру, и внедрение модели U-Net имеет большое значение при сегментации медицинских изображений. U-Net объединяет кодеры и декодеры для достижения точной сегментации за счет использования информации в разных масштабах и сохранения функций высокого разрешения. Такая конструкция позволяет U-Net получать более точные результаты в задачах сегментации медицинских изображений и улучшать местоположение и точность сегментации поражений.
Кроме того, U-Net обладает хорошей масштабируемостью и может быть улучшена путем добавления или настройки сетевых уровней, изменения структуры сети и т. д. Такая гибкость позволяет применять модель U-Net к различным задачам сегментации медицинских изображений, а также интегрировать и оптимизировать ее с другими моделями глубокого обучения.
Первоначально модели Transformer не считались перспективными для сегментации медицинских изображений, поскольку им по своей сути не хватало возможностей локализации. Однако TransUNet представляет структуру, которая объединяет преобразователь со сверточной нейронной сетью для формирования эффективного кодировщика и повышения производительности сегментации. С другой стороны, если вы не объедините сверточную сеть с преобразователем, конечный результат не будет идеальным, как показал Swin-Unet.
Что касается набора данных, то сегментация опухолей яичников является очень сложной задачей, а сегментированные области изображений часто различаются по размеру, форме, местоположению и текстуре, что затрудняет обнаружение опухолей. В наборе данных сегментации легких определить размер легкого относительно легко, поскольку оно имеет отличительные особенности по сравнению с фоном, и каждая модель хорошо справляется с задачей сегментации легких.
4. Проблемы и проблемы с наборами данных
Самой большой проблемой в применении контролируемого обучения при обработке медицинских изображений является аннотирование медицинских изображений. Обучение с учителем требует большого количества входных аннотированных выборок для достижения хорошей производительности и стабильной способности к обобщению. Однако сбор такого большого набора аннотированных данных по случаям часто является очень сложной задачей. Медицинские изображения требуют интерпретации опытными врачами для сбора, маркировки и аннотирования. Еще одной важной проблемой обработки медицинских изображений является дисбаланс данных. В несбалансированном наборе данных распределение классов между классами асимметрично, например, в наборе данных массы яичников существует естественный дисбаланс в количестве доброкачественных и злокачественных пациенток (количество аномальных пациенток больше, чем у нормальных пациентов); . Несбалансированные данные могут серьезно повлиять на производительность модели.
Некоторые методы широко используются для решения вышеуказанных проблем. Увеличение данных может увеличить размер набора обучающих данных и сбалансировать соотношение положительных и отрицательных образцов, применяя к образцам набор аффинных преобразований, таких как переворот, вращение, зеркальное отображение и улучшение значений цвета (шкалы серого). Перенос обучения на основе успешных моделей, реализованных в той же или других областях, является еще одним решением вышеуказанной проблемы. По сравнению с увеличением данных, трансферное обучение является более конкретным решением, которое требует лишь скромных вычислительных ресурсов и меньшего количества аннотированных данных и может значительно снизить частоту ошибок при сегментации медицинских изображений.
5. Резюме
В этой статье автор сначала дает общее представление о медицинской сегментации, а затем изучает 4 наиболее репрезентативные модели сегментации медицинских изображений, а именно U-Net, UNet++, TransUNet и Swin-Unet. Кроме того, авторы проводят количественную оценку эффективности этих моделей на двух контрольных наборах данных. Чтобы помочь исследователям в смежных областях быстро понять эти модели и смоделировать новые задачи сегментации, авторы поделились всеми экспериментальными исходными кодами и подробными параметрами настройки модели на GitHub.
В последние годы сегментация изображений на основе машинного обучения получила быстрое развитие. Мета предложила SAM, которая произвела революцию в сегментации изображений. Впервые в сегментации изображений используется концепция базовой модели, обеспечивающая сегментацию изображений с нулевой передачей. В отличие от предыдущих моделей сегментации, которые могут обрабатывать только определенные категории изображений, SAM может обрабатывать все изображения и достигать точной сегментации изображений с помощью подсказок. Ма и др. предложили MedSAM для общей сегментации изображений, что было первым случаем применения SAM в медицинской сфере и превзошло стандартную модель SAM при решении задач медицинской сегментации. Сегментация изображений на основе больших моделей стала будущей тенденцией сегментации изображений, которая является многообещающим направлением исследований с широкими перспективами.
В будущей работе автор объединит сегментацию изображений больших моделей с медицинскими изображениями для решения труднодоступных медицинских изображений с помощью модели сегментации с нулевым переносом, тем самым способствуя анализу медицинских изображений.
6, ссылка
[1].From CNN to Transformer: A Review of Medical Image Segmentation Models.
7. Рекомендуемая литература


RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++

Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем

Полностью автоматический инструмент для работы с видео в один клик: VideoLingo

Улучшения оптимизации RT-DETR: облегченные улучшения магистрали | Support Paddle облегченный rtdetr-r18, rtdetr-r34, rtdetr-r50, rtdet

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | Деформируемое внимание с большим ядром (D-LKA Attention), большое ядро свертки улучшает механизм внимания восприимчивых полей с различными функциями

Создано Datawhale: выпущено «Руководство по тонкой настройке развертывания большой модели GLM-4»!

7B превышает десятки миллиардов, aiXcoder-7B с открытым исходным кодом Пекинского университета — это самая мощная модель большого кода, лучший выбор для корпоративного развертывания.

Используйте модель Huggingface, чтобы заменить интерфейс внедрения OpenAI в китайской среде.

Оригинальные улучшения YOLOv8: несколько новых улучшений | Сохранение исходной информации — алгоритм отделяемой по глубине свертки (MDSConv) |

Второй пилот облачной разработки | Быстро поиграйте со средствами разработки на базе искусственного интеллекта

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция с нулевым кодированием и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

Решенная Ошибка | Загрузка PyTorch медленная: TimeoutError: [Errno 110] При загрузке факела истекло время ожидания — Cat Head Tiger

Brother OCR, библиотека с открытым исходным кодом для Python, которая распознает коды проверки.
Новейшее подробное руководство по загрузке и использованию последней демонстрационной версии набора данных COCO.

Выпущен отчет о крупной модели финансовой отрасли за 2023 год | Полный текст включен в загрузку |

Обычные компьютеры также могут работать с большими моделями, и вы можете получить личного помощника с искусственным интеллектом за три шага | Руководство для начинающих по локальному развертыванию LLaMA-3

Одной статьи достаточно для анализа фактора транскрипции SCENIC на Python (4)

Бросая вызов ограничениям производительности небольших видеокарт, он научит вас запускать большие модели глубокого обучения с ограниченными ресурсами, а также предоставит полное руководство по оценке и эффективному использованию памяти графического процессора!

Команда Fudan NLP опубликовала 80-страничный обзор крупномасштабных модельных агентов, в котором в одной статье представлен обзор текущего состояния и будущего агентов ИИ.

[Эксклюзив] Вы должны знать о новой функции JetBrains 2024.1 «Полнострочное завершение кода», чтобы решить вашу путаницу!

Краткое изложение базовых знаний о регистрации изображений 1.0

Новейшее подробное руководство по установке и использованию библиотеки cv2 (OpenCV, opencv-python) в Python.

Легко создайте локальную базу знаний для крупных моделей на основе Ollama+AnythingLLM.

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание решения. Повторная попытка с помощью файла (графическое руководство).

Одна статья поможет вам понять RAG (Retrival Enhanced Generation) | Введение в концепцию и теорию + практику работы с кодом (включая исходный код).

Эволюция архитектуры шлюза облачной разработки
