Руководство по выбору озера данных | Hudi и Iceberg. Углубленное сравнение возможностей обновления данных.
озеро данныхКак новое поколение инфраструктуры больших данных,продолжает оставаться популярным в последние годы,Многие передовые студенты обсуждают озеро Как следует строить данные Многие компании также строят или планируют построить собственное озеро? данных。На основании этого,естественно, породило множество опасений по поводуозеро данных Выборизобсуждатьи Исследовать。Но после поиска мы нашли,Большая часть того, что существует в Интернете, основана на более ранней информации из открытых источников.,На ранних стадиях исследования предприятия легко создать ошибочные впечатления и представления.
Итак, с этим вопросом,Планируем запустить серию статей по выбору озера данных.,На основе последней информации из открытых источников,отМодернизация архитектуры озера данныхНесколько важных широт, которые помогут вам провести более глубокие сравнения。Я надеюсь, что это может вдохновить других,Заставьте всех думать и резонировать,Учащиеся могут обсудить это вместе.
На практике мы обнаружили,Среди клиентов, планирующих обновить архитектуру озера данных,Поддержка транзакционных обновлений данныхОбычно это первый основной запрос каждого.。поэтому,В первой статье этой серии мы начнем с истории возникновения спроса.,и другое озеро Сравнение возможностей архитектуры данных при транзакциях данных, два аспекта помогают каждому в озере данных Принимайте более обоснованные решения на пути к выбору.
Фон спроса
В традиционной архитектуре автономного хранилища данных Hive стоимость обновления данных очень высока. Обновление части данных требует перезаписи всего раздела или даже всей таблицы. Поэтому в реальных бизнес-сценариях из-за таких соображений, как затраты на разработку и риски данных, никто не будет обновлять данные в хранилище данных Hive.
Однако с запуском Hive 3.0 таблицы Hive сделали большой шаг вперед в возможностях транзакций. При запуске 3.0 чиновник также сосредоточился на продвижении своих транзакционных возможностей. Однако в практическом применении все еще существуют очень большие ограничения, и очень немногие пользователи действительно внедрили его в производство. (Поддерживаются только внутренние таблицы транзакций ORC, а это означает, что вычислительные механизмы, такие как Spark, не могут напрямую выполнять разработку ETL/ELT для таблиц транзакций Hive. Такие компании, как CDH и Kangaroo Cloud, вложили средства в совместимость со Spark, но эффект не очень хороший. Отлично, намного меньше, чем ожидаются от приложений производственного уровня)
поэтому,В процессе отбора данных озера,Возможность эффективного одновременного обновлениястановится особенно важным。Это может изменить нашу Hive Хранилище данных сталкивается с проблемой высоких затрат на обновление данных и поддерживает обновление и удаление огромных объемов автономных данных.
Выбор реализации обновления данных
В настоящее время на рынке представлено несколько основных продуктов озера данных с открытым исходным кодом: Apache Iceberg, Apache Hudi и Delta.
В этой статье основное внимание будет уделено производительности Hudi и Iceberg при реализации обновления данных.
Реализация обновления данных Hudi
Hudi (Hadoop Update Delete Incremental), как видно из названия, был рожден для решения проблем обновления данных и инкрементных запросов в системе Hadoop. Чтобы понять, как Hudi реализует операции быстрого обновления в файловых системах, таких как HDFS, нам необходимо сначала понять несколько особенностей Hudi:
· Форма организации файлов таблицы Hudi: В каждом разделе (Partition) файлы данных разделены и организованы в группы файлов (FileGroup), и каждая группа файлов уникально идентифицируется FileID.
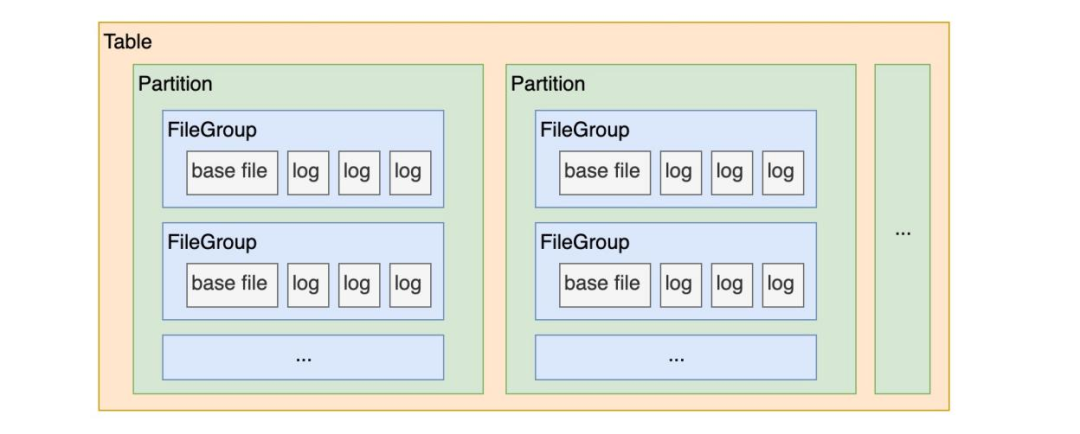
· Hudi Есть столДизайн индексаиз。
Объединив приведенные выше три характеристики, можно сделать вывод, что индекс таблицы Hudi может помочь нам быстро найти определенный фрагмент данных, существующий в определенной файловой группе определенного раздела, а затем выполнить над ним операцию обновления, т.е. , перепишите эту часть файловой группы.
Реализация обновления данных Iceberg
Iceberg из Официальное позиционирование такое.「Эффективный формат хранения для сценариев анализа больших объемов данных.」。Так что это не похоже на Hudi Он также имитирует шаблон проектирования бизнес-базы данных (первичный ключ + индекс) для обновления данных, но разрабатывает более мощную форму организации файлов для обновления данных. update Подробности эксплуатации см. на рисунке ниже:
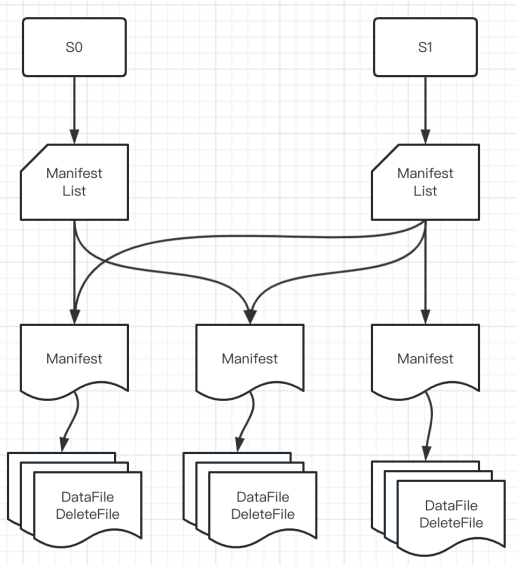
• Снимок: каждая фиксация пользователя создает новый снимок.
• Список манифестов: сохраняет все манифесты в текущем снимке.
• Манифест: сохраняет все файлы данных и удаляет файлы в текущем манифесте.
• Файл данных: файл, в котором хранятся данные.
• Удалить файл: файл, в котором хранятся «удаленные данные».
Основываясь на приведенной выше организации файлов, мы видим, что общая логика реализации обновления Iceberg такова:
· Сначала запишите удаляемые данные в «Удалить файл»;
· Затем «Файл данных» JOIN «Удалить файл» используется для сравнения данных для обновления данных.
Конечно, существует множество технических деталей для реализации этих двух шагов: например, использование порядкового номера для обеспечения порядка транзакций; «Удалить файл» определяет, следует ли использовать логику удаления позиции или удаления по равенству, на основе статуса файла на момент удаления; введение концепции равенства_идов для имитации первичных ключей и т. д.
Как выбрать
Просто посмотрим на это с точки зрения возможностей обновления данных:
· Hudi использует шаблон проектирования группа файлов + индекс + первичный ключ.,способен быть эффективнымУменьшите количество избыточных обновлений файлов данных.,Повысьте эффективность обновления данных.
· Iceberg также может добиться эффекта обновления данных за счет проектирования файловой организации, но при каждой фиксации будут создаваться новые файлы. Если запись/обновление происходит часто, проблема небольших файлов будет более серьезной. (Хотя официальный пакет также предоставляет небольшие возможности управления файлами, потребление ресурсов и сложность управления этой частью относительно выше, чем у Hudi)
Как применить это на практике
После того, как мы определимся с выбором озера данных, следующим вопросом становится то, как реализовать практическое применение в производственной среде.
Здесь нужно заранее разобраться с понятием типа таблицы,такой же видозеро данных表格式也有不同из Разница типов,Применимо к различным сценариям:
• COW (Копирование при записи): копирование таблицы при записи. Когда данные записываются/обновляются, исходный файл данных немедленно перезаписывается и создается новый файл данных.
• MOR (объединить при чтении): объединить таблицы при чтении. Когда данные записываются/обновляются, исходный файл не изменяется, записывается новый журнал/файл, а когда данные читаются позже, файл данных перезаписывается.
Исходя из разницы характеристик этих двух типов столов, мы даем следующие предложения:
· Если ваша таблица Lake нечасто записывается/обновляется и в основном используется для поддержки сценариев запроса/анализа данных, рекомендуется использовать таблицу COW.
· Если ваша таблица Lake часто записывается/обновляется (даже для сценариев разработки в реальном времени), рекомендуется использовать таблицу MOR.
Подвести итог
Не существует лучшей технической архитектуры, есть только наиболее подходящая техническая архитектура для текущего бизнеса.
Конечно, выбор озера данных нельзя судить только по одному параметру — возможности обновления данных. В будущем мы продолжим проводить сравнения различных архитектур озер данных по большему количеству измерений, таких как управление схемами, ускорение запросов и интеграция пакетных потоков. Приглашаем всех обсудить и пообщаться с нами.
Адрес для скачивания «Белой книги по отраслевой практике управления данными»:https://fs80.cn/380a4b
Адрес проекта:https://github.com/DTStack



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
