Руководство по созданию конвейеров потока данных с помощью Kafka, Spark, Airflow и Docker.
В этом руководстве мы подробно рассмотрим создание мощного конвейера данных с использованием Kafka для потоковой передачи, Spark для обработки, Airflow для оркестрации, Docker для контейнеризации, S3 для хранения и Python в качестве основного языка сценариев.
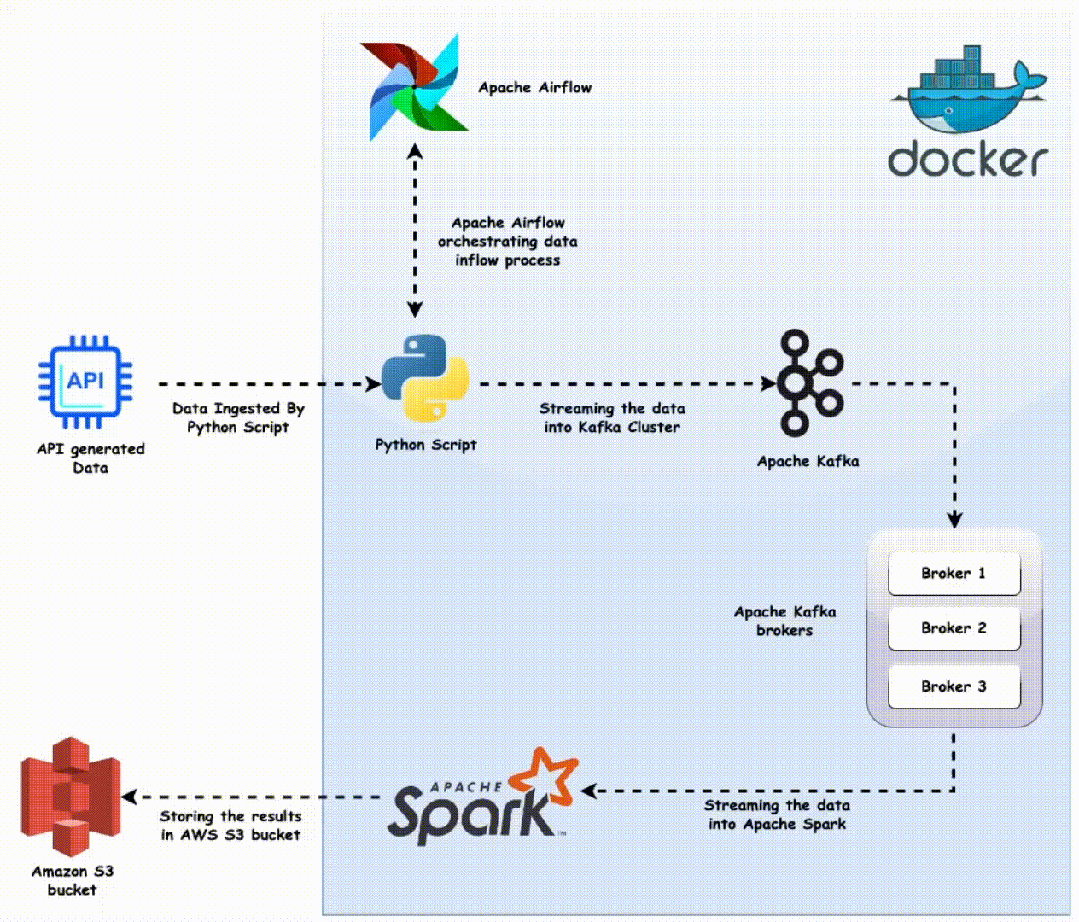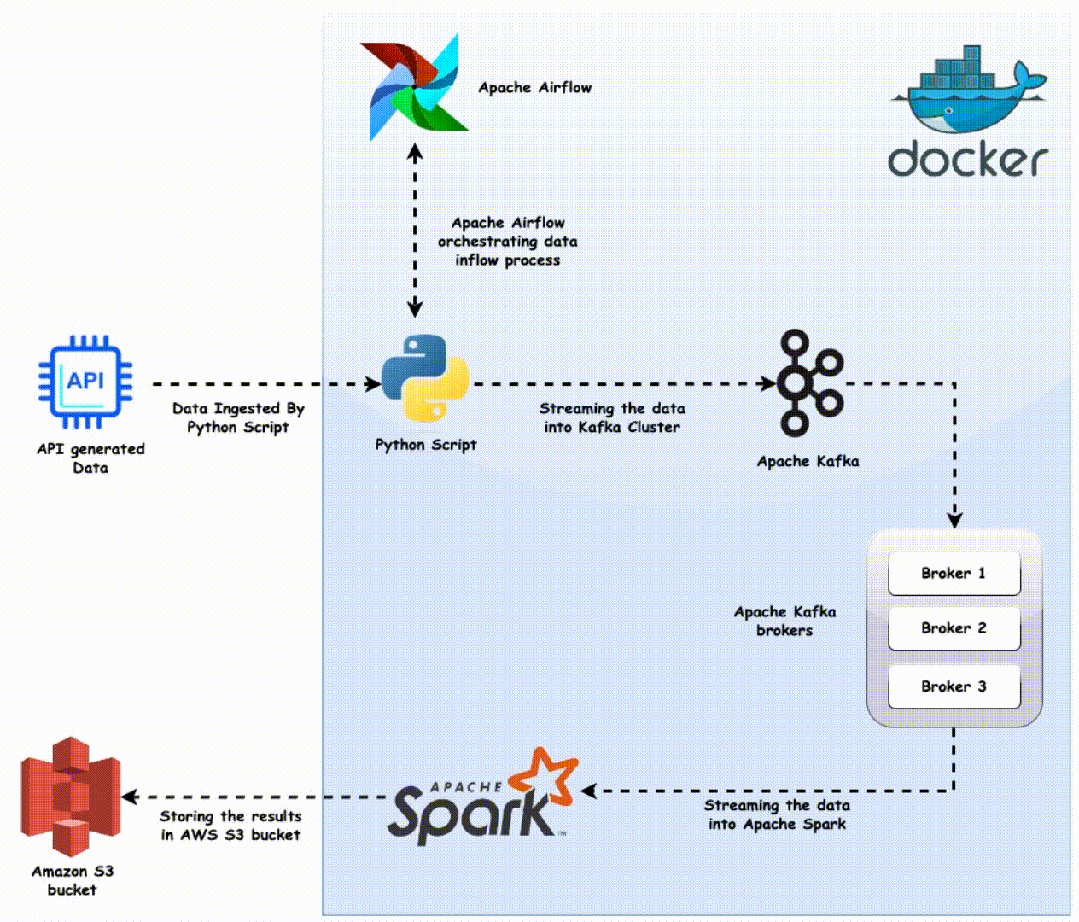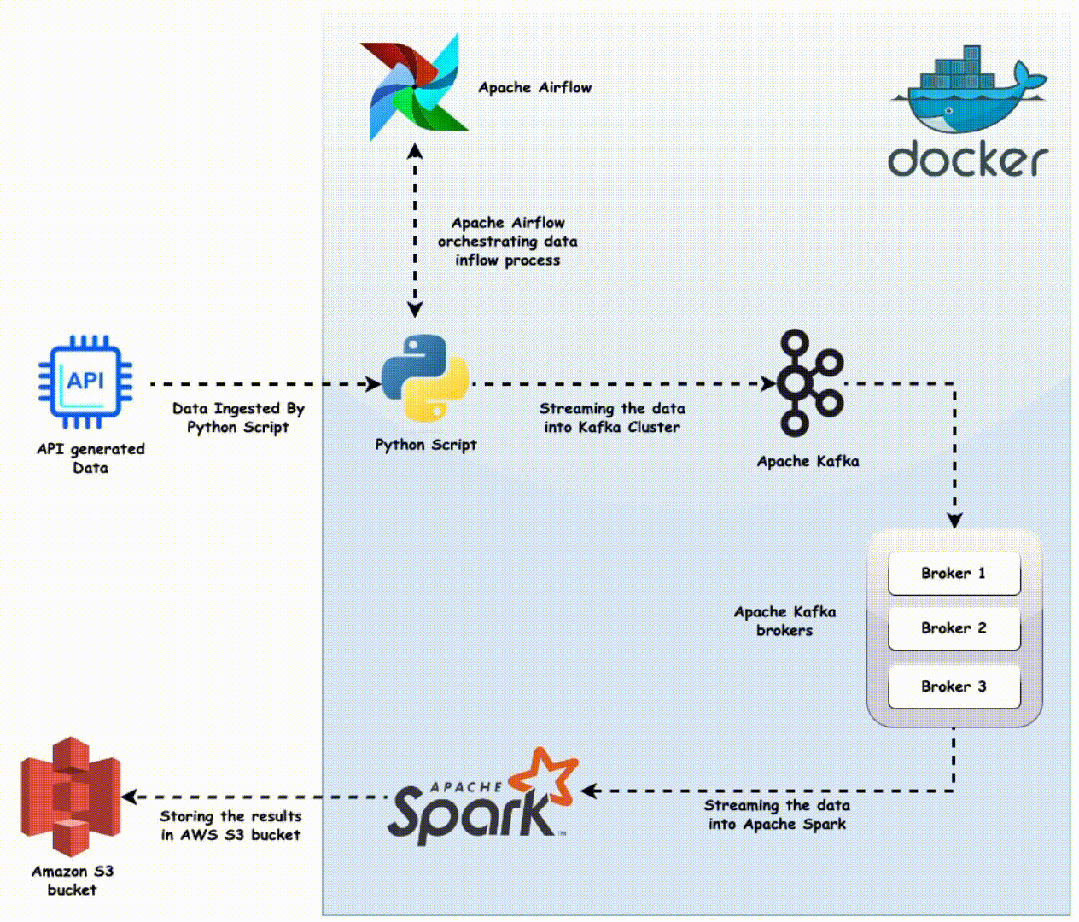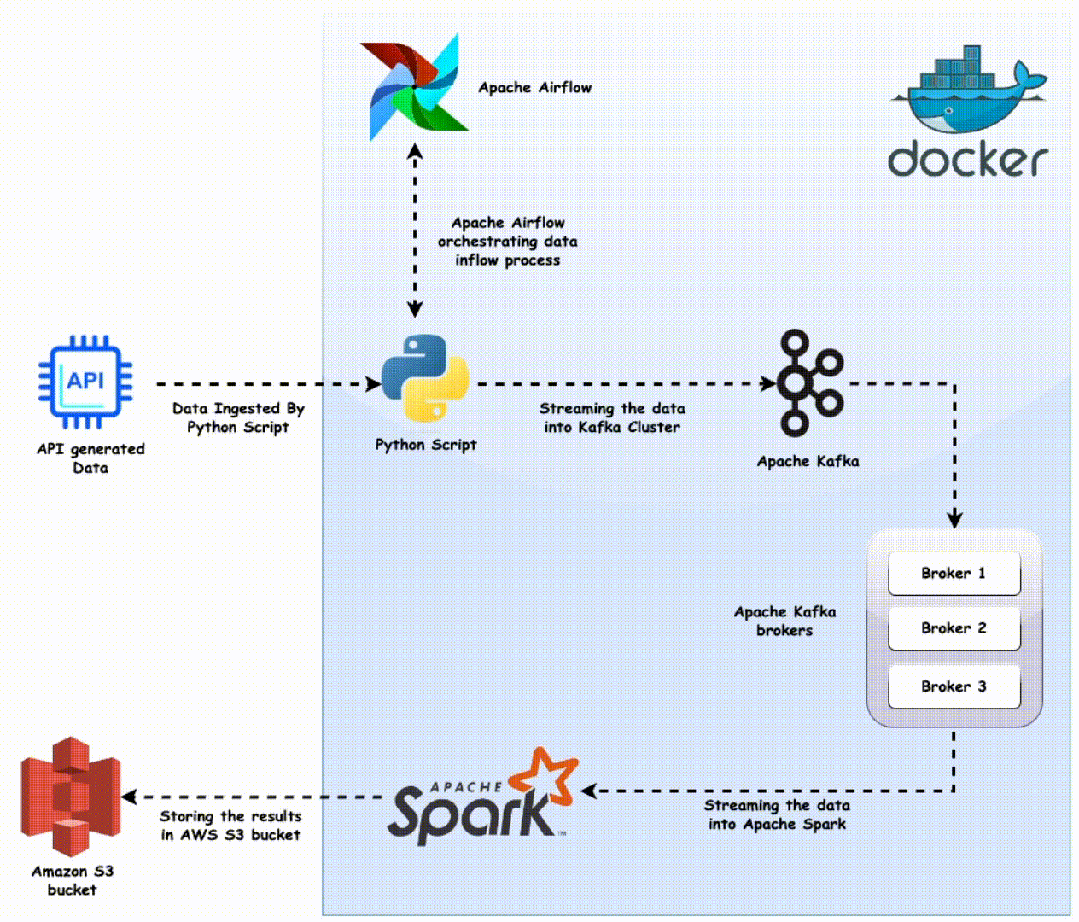
Чтобы проиллюстрировать этот процесс, мы будем использовать API случайных имен — универсальный инструмент, который генерирует новые случайные данные при каждом запуске. Он обеспечивает практическое представление данных в реальном времени, с которыми многие предприятия сталкиваются ежедневно. Наш первый шаг включает в себя скрипт Python, тщательно разработанный для получения данных из API. Чтобы имитировать потоковую передачу данных, мы будем периодически выполнять этот скрипт. Этот скрипт также будет служить нашим мостом к Kafka, записывая полученные данные непосредственно в тему Kafka.
По мере того, как мы идем глубже, ключевую роль играет направленный ациклический граф (DAG) Airflow. Сценарий Airflow DAG организует наш процесс, гарантируя, что наши сценарии Python работают как часы, непрерывно передавая данные в наш конвейер. Как только наши данные достигают производителя Kafka, эстафету берет на себя Spark Structured Streaming. Используйте эти данные, обработайте их, а затем легко запишите измененные данные в S3, гарантируя их готовность к последующему процессу анализа.
Важным аспектом проекта является его модульная архитектура. Благодаря контейнерам Docker каждый сервис, будь то Kafka, Spark или Airflow, работает в изолированной среде. Не только обеспечивает плавное взаимодействие, но также упрощает масштабируемость и отладку.
Начало работы: необходимые условия и настройка
В этом проекте мы использовали репозиторий GitHub для размещения всей нашей установки, что позволило каждому легко начать работу.
А. Docker: Docker станет нашим основным инструментом для организации и запуска различных сервисов.
- Установить:доступ Docker Официальный сайт, скачайте и установите подходящую для вашей операционной системы версию. Docker Desktop。
- Проверьте: откройте терминал или командную строку и выполните docker --version, чтобы убедиться, что установка прошла успешно.
Б. S3: AWS S3 — наш лучший выбор для хранения данных.
- Настройки: Войти AWS Консоль управления, перейдите к S3 Служить,Затем создайте новое ведро,Убедитесь, что вы настроили его в соответствии с вашими предпочтениями по хранению данных.
C. Элементы настройки:
- Клонировать репозиторий. Сначала вам необходимо клонировать проект из репозитория GitHub, используя следующую команду:
git clone <https://github.com/simardeep1792/Data-Engineering-Streaming-Project.git>- Перейдите в каталог проекта:
cd Data-Engineering-Streaming-ProjectИспользуйте развертывание службы docker-compose следующим образом: В каталоге проекта вы Воля находите
документ docker-compose.yml. Должендокумент описывает все услуги.
docker network create docker_streaming
docker-compose -f docker-compose.yml up -d
Должен командная координация Docker Все необходимые услуги по иззапуску контейнера, напр. Kafka、Spark、Airflow ждать.Разбить файлы проекта
1、docker-compose.yml
version: '3.7'
services:
# Airflow PostgreSQL Database
airflow_db:
image: postgres:16.0
environment:
- POSTGRES_USER=${POSTGRES_USER}
- POSTGRES_PASSWORD=${POSTGRES_PASSWORD}
- POSTGRES_DB=${POSTGRES_DB}
logging:
options:
max-size: 10m
max-file: "3"
# Apache Airflow Webserver
airflow_webserver:
command: bash -c "airflow db init && airflow webserver && airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin"
image: apache/airflow:latest
restart: always
depends_on:
- airflow_db
environment:
- LOAD_EX=${LOAD_EX}
- EXECUTOR=${EXECUTOR}
- AIRFLOW__CORE__SQL_ALCHEMY_CONN=postgresql+psycopg2://${POSTGRES_USER}:${POSTGRES_PASSWORD}@airflow_db:5432/${POSTGRES_DB}
logging:
options:
max-size: 10m
max-file: "3"
volumes:
- ./dags:/opt/airflow/dags
- ./requirements.txt:/opt/airflow/requirements.txt
ports:
- "8080:8080"
healthcheck:
test: ["CMD-SHELL", "[ -f /usr/local/airflow/airflow-webserver.pid ]"]
interval: 30s
timeout: 30s
retries: 3
# Zookeeper for Kafka
kafka_zookeeper:
image: confluentinc/cp-zookeeper:latest
ports:
- "2181:2181"
environment:
- ZOOKEEPER_CLIENT_PORT=${ZOOKEEPER_CLIENT_PORT}
- ZOOKEEPER_SERVER_ID=${ZOOKEEPER_SERVER_ID}
- ZOOKEEPER_SERVERS=kafka_zookeeper:2888:3888
networks:
- kafka_network
- default
# Kafka Broker Instances
kafka_broker_1:
extends:
service: kafka_base
environment:
- KAFKA_BROKER_ID=1
- KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka_broker_1:19092,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092,DOCKER://host.docker.internal:29092
kafka_broker_2:
extends:
service: kafka_base
environment:
- KAFKA_BROKER_ID=2
- KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka_broker_2:19093,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9093,DOCKER://host.docker.internal:29093
kafka_broker_3:
extends:
service: kafka_base
environment:
- KAFKA_BROKER_ID=3
- KAFKA_ADVERTISED_LISTENERS=INTERNAL://kafka_broker_3:19094,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9094,DOCKER://host.docker.internal:29094
kafka_base:
image: confluentinc/cp-kafka:latest
environment:
- KAFKA_LISTENER_SECURITY_PROTOCOL_MAP=${KAFKA_LISTENER_SECURITY_PROTOCOL_MAP}
- KAFKA_INTER_BROKER_LISTENER_NAME=${KAFKA_INTER_BROKER_LISTENER_NAME}
- KAFKA_ZOOKEEPER_CONNECT=kafka_zookeeper:2181
- KAFKA_LOG4J_LOGGERS=${KAFKA_LOG4J_LOGGERS}
- KAFKA_AUTHORIZER_CLASS_NAME=${KAFKA_AUTHORIZER_CLASS_NAME}
- KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND=${KAFKA_ALLOW_EVERYONE_IF_NO_ACL_FOUND}
networks:
- kafka_network
- default
# Kafka Connect
kafka_connect:
image: confluentinc/cp-kafka-connect:latest
ports:
- "8083:8083"
environment:
- CONNECT_BOOTSTRAP_SERVERS=${CONNECT_BOOTSTRAP_SERVERS}
- CONNECT_REST_PORT=${CONNECT_REST_PORT}
- CONNECT_GROUP_ID=${CONNECT_GROUP_ID}
- CONNECT_CONFIG_STORAGE_TOPIC=${CONNECT_CONFIG_STORAGE_TOPIC}
- CONNECT_OFFSET_STORAGE_TOPIC=${CONNECT_OFFSET_STORAGE_TOPIC}
- CONNECT_STATUS_STORAGE_TOPIC=${CONNECT_STATUS_STORAGE_TOPIC}
- CONNECT_KEY_CONVERTER=${CONNECT_KEY_CONVERTER}
- CONNECT_VALUE_CONVERTER=${CONNECT_VALUE_CONVERTER}
- CONNECT_INTERNAL_KEY_CONVERTER=${CONNECT_INTERNAL_KEY_CONVERTER}
- CONNECT_INTERNAL_VALUE_CONVERTER=${CONNECT_INTERNAL_VALUE_CONVERTER}
- CONNECT_REST_ADVERTISED_HOST_NAME=${CONNECT_REST_ADVERTISED_HOST_NAME}
- CONNECT_LOG4J_ROOT_LOGLEVEL=${CONNECT_LOG4J_ROOT_LOGLEVEL}
- CONNECT_LOG4J_LOGGERS=${CONNECT_LOG4J_LOGGERS}
- CONNECT_PLUGIN_PATH=${CONNECT_PLUGIN_PATH}
networks:
- kafka_network
- default
# Kafka Schema Registry
kafka_schema_registry:
image: confluentinc/cp-schema-registry:latest
ports:
- "8081:8081"
environment:
- SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS=${SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS}
- SCHEMA_REGISTRY_HOST_NAME=${SCHEMA_REGISTRY_HOST_NAME}
- SCHEMA_REGISTRY_LISTENERS=${SCHEMA_REGISTRY_LISTENERS}
networks:
- kafka_network
- default
# Kafka User Interface
kafka_ui:
container_name: kafka-ui-1
image: provectuslabs/kafka-ui:latest
ports:
- 8888:8080
depends_on:
- kafka_broker_1
- kafka_broker_2
- kafka_broker_3
- kafka_schema_registry
- kafka_connect
environment:
- KAFKA_CLUSTERS_0_NAME=${KAFKA_CLUSTERS_0_NAME}
- KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS=${KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS}
- KAFKA_CLUSTERS_0_SCHEMAREGISTRY=${KAFKA_CLUSTERS_0_SCHEMAREGISTRY}
- KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME=${KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME}
- KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS=${KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS}
- DYNAMIC_CONFIG_ENABLED=${DYNAMIC_CONFIG_ENABLED}
networks:
- kafka_network
- default
# Apache Spark Master Node
spark_master:
image: bitnami/spark:3
container_name: spark_master
ports:
- 8085:8080
environment:
- SPARK_UI_PORT=${SPARK_UI_PORT}
- SPARK_MODE=${SPARK_MODE}
- SPARK_RPC_AUTHENTICATION_ENABLED=${SPARK_RPC_AUTHENTICATION_ENABLED}
- SPARK_RPC_ENCRYPTION_ENABLED=${SPARK_RPC_ENCRYPTION_ENABLED}
volumes:
- ./:/home
- spark_data:/opt/bitnami/spark/data
networks:
- default
- kafka_network
#volumes for data
volumes:
spark_data:
#network for Kafka
networks:
kafka_network:
driver: bridge
default:
external:
name: docker_streamingЯдром настройки проекта является файл docker-compose.yml. Он координирует наши услуги и обеспечивает бесперебойную связь и инициализацию. Вот разбивка:
1) Версия
Используйте формат файла Docker Compose версии «3.7», чтобы обеспечить совместимость со службой.
2) Сервис
Проект включает в себя несколько сервисов:
- Airflow:
- База данных (airflow_db): использует PostgreSQL 1.
- Web сервер ( airflow_webserver):запускатьбаза данныхинастраиватьадминистраторпользователь。
- Kafka:
- Zookeeper (kafka_zookeeper): управляет метаданными брокера.
- Брокеры: три экземпляра (kafka_broker_1, 2 и 3).
- Базовый Конфигурация ( kafka_base): Общие настройки брокера.
- Kafka Connect (kafka_connect): облегчает обработку потоков.
- Реестр схемы (kafka_schema_registry): управляет схемой Kafka.
- пользовательинтерфейс ( kafka_ui):Kafka визуальный интерфейс.
- spark:
- Главный узел (spark_master): центральный узел управления Apache Spark.
3) Объем
Используйте постоянный том spark_data, чтобы обеспечить согласованность данных Spark.
4) Сеть
У сервиса есть две сети:
- Сеть Kafka (kafka_network): исключительно для Kafka.
- Сеть по умолчанию (по умолчанию): внешнее имя docker_streaming.
2、kafka_stream_dag.py
# Importing required modules
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from kafka_streaming_service import initiate_stream
# Configuration for the DAG's start date
DAG_START_DATE = datetime(2018, 12, 21, 12, 12)
# Default arguments for the DAG
DAG_DEFAULT_ARGS = {
'owner': 'airflow',
'start_date': DAG_START_DATE,
'retries': 1,
'retry_delay': timedelta(seconds=5)
}
# Creating the DAG with its configuration
with DAG(
'name_stream_dag', # Renamed for uniqueness
default_args=DAG_DEFAULT_ARGS,
schedule_interval='0 1 * * *',
catchup=False,
description='Stream random names to Kafka topic',
max_active_runs=1
) as dag:
# Defining the data streaming task using PythonOperator
kafka_stream_task = PythonOperator(
task_id='stream_to_kafka_task',
python_callable=initiate_stream,
dag=dag
)
kafka_stream_taskЭтот файл в основном определяет ациклический граф Airflow Directed (DAG) для обработки потока данных в темы Kafka.
1) Импорт
Импортируйте базовые модули и функции, в частности Airflow DAG и PythonOperator, и инициализируйте_поток из kafka_streaming_service.
2) Конфигурация
- Дата начала группы обеспечения доступности баз данных (DAG_START_DATE): установите время начала выполнения группы обеспечения доступности баз данных.
- Параметры по умолчанию ( DAG_DEFAULT_ARGS):Конфигурация DAG Основные параметры, такие как владелец, дата начала и настройки повтора.
3) Определение группы обеспечения доступности баз данных
Новая группа обеспечения доступности баз данных с именем name_stream_dag будет создана и настроена для запуска каждый день в 1 час ночи. Он разработан таким образом, чтобы не запускаться в пропущенных интервалах (с catchup=False) и разрешать одновременное выполнение только одного действия.
4) Задача
Одна задача kafka_stream_task определяется с помощью PythonOperator. Эта задача вызывает функцию ignore_stream, которая эффективно передает данные в Kafka во время работы группы обеспечения доступности баз данных.
3、kafka_streaming_service.py
# Importing necessary libraries and modules
import requests
import json
import time
import hashlib
from confluent_kafka import Producer
# Constants and configuration
API_ENDPOINT = "https://randomuser.me/api/?results=1"
KAFKA_BOOTSTRAP_SERVERS = ['kafka_broker_1:19092','kafka_broker_2:19093','kafka_broker_3:19094']
KAFKA_TOPIC = "names_topic"
PAUSE_INTERVAL = 10
STREAMING_DURATION = 120
def retrieve_user_data(url=API_ENDPOINT) -> dict:
"""Fetches random user data from the provided API endpoint."""
response = requests.get(url)
return response.json()["results"][0]
def transform_user_data(data: dict) -> dict:
"""Formats the fetched user data for Kafka streaming."""
return {
"name": f"{data['name']['title']}. {data['name']['first']} {data['name']['last']}",
"gender": data["gender"],
"address": f"{data['location']['street']['number']}, {data['location']['street']['name']}",
"city": data['location']['city'],
"nation": data['location']['country'],
"zip": encrypt_zip(data['location']['postcode']),
"latitude": float(data['location']['coordinates']['latitude']),
"longitude": float(data['location']['coordinates']['longitude']),
"email": data["email"]
}
def encrypt_zip(zip_code):
"""Hashes the zip code using MD5 and returns its integer representation."""
zip_str = str(zip_code)
return int(hashlib.md5(zip_str.encode()).hexdigest(), 16)
def configure_kafka(servers=KAFKA_BOOTSTRAP_SERVERS):
"""Creates and returns a Kafka producer instance."""
settings = {
'bootstrap.servers': ','.join(servers),
'client.id': 'producer_instance'
}
return Producer(settings)
def publish_to_kafka(producer, topic, data):
"""Sends data to a Kafka topic."""
producer.produce(topic, value=json.dumps(data).encode('utf-8'), callback=delivery_status)
producer.flush()
def delivery_status(err, msg):
"""Reports the delivery status of the message to Kafka."""
if err is not None:
print('Message delivery failed:', err)
else:
print('Message delivered to', msg.topic(), '[Partition: {}]'.format(msg.partition()))
def initiate_stream():
"""Initiates the process to stream user data to Kafka."""
kafka_producer = configure_kafka()
for _ in range(STREAMING_DURATION // PAUSE_INTERVAL):
raw_data = retrieve_user_data()
kafka_formatted_data = transform_user_data(raw_data)
publish_to_kafka(kafka_producer, KAFKA_TOPIC, kafka_formatted_data)
time.sleep(PAUSE_INTERVAL)
if __name__ == "__main__":
initiate_stream()1) Импортировать и настроить
Импортируйте базовую библиотеку и установите константы, такие как конечные точки API, сервер начальной загрузки Kafka, имя темы и сведения об интервале потока.
2) Получение пользовательских данных
Функция return_user_data извлекает случайные данные пользователя из указанной конечной точки API.
3) Преобразование данных
Функция Transform_user_data форматирует необработанные пользовательские данные для потока Kafka, а функция encrypt_zip хеширует почтовый индекс для обеспечения конфиденциальности пользователя.
4) Конфигурация и выпуск Kafka
- configure_kafka настраивает производителя Kafka.
- publish_to_kafka После конвертации данные Воляизпользователя отправляются в Kafka тема.
- Delivery_status предоставляет информацию о том, были ли данные успешно отправлены в Kafka.
5) Основные функции потоковой передачи
ignore_stream управляет всем процессом, периодически извлекая, преобразовывая и публикуя пользовательские данные в Kafka.
6) Исполнение
При непосредственном запуске сценария ignore_stream выполнит функцию и передаст данные в течение указанного времени STREAMING_DURATION.
4、spark_processing.py
import logging
from pyspark.sql import SparkSession
from pyspark.sql.functions import from_json, col
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
# Initialize logging
logging.basicConfig(level=logging.INFO,
format='%(asctime)s:%(funcName)s:%(levelname)s:%(message)s')
logger = logging.getLogger("spark_structured_streaming")
def initialize_spark_session(app_name, access_key, secret_key):
"""
Initialize the Spark Session with provided configurations.
:param app_name: Name of the spark application.
:param access_key: Access key for S3.
:param secret_key: Secret key for S3.
:return: Spark session object or None if there's an error.
"""
try:
spark = SparkSession \
.builder \
.appName(app_name) \
.config("spark.hadoop.fs.s3a.access.key", access_key) \
.config("spark.hadoop.fs.s3a.secret.key", secret_key) \
.config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \
.getOrCreate()
spark.sparkContext.setLogLevel("ERROR")
logger.info('Spark session initialized successfully')
return spark
except Exception as e:
logger.error(f"Spark session initialization failed. Error: {e}")
return None
def get_streaming_dataframe(spark, brokers, topic):
"""
Get a streaming dataframe from Kafka.
:param spark: Initialized Spark session.
:param brokers: Comma-separated list of Kafka brokers.
:param topic: Kafka topic to subscribe to.
:return: Dataframe object or None if there's an error.
"""
try:
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", brokers) \
.option("subscribe", topic) \
.option("delimiter", ",") \
.option("startingOffsets", "earliest") \
.load()
logger.info("Streaming dataframe fetched successfully")
return df
except Exception as e:
logger.warning(f"Failed to fetch streaming dataframe. Error: {e}")
return None
def transform_streaming_data(df):
"""
Transform the initial dataframe to get the final structure.
:param df: Initial dataframe with raw data.
:return: Transformed dataframe.
"""
schema = StructType([
StructField("full_name", StringType(), False),
StructField("gender", StringType(), False),
StructField("location", StringType(), False),
StructField("city", StringType(), False),
StructField("country", StringType(), False),
StructField("postcode", IntegerType(), False),
StructField("latitude", FloatType(), False),
StructField("longitude", FloatType(), False),
StructField("email", StringType(), False)
])
transformed_df = df.selectExpr("CAST(value AS STRING)") \
.select(from_json(col("value"), schema).alias("data")) \
.select("data.*")
return transformed_df
def initiate_streaming_to_bucket(df, path, checkpoint_location):
"""
Start streaming the transformed data to the specified S3 bucket in parquet format.
:param df: Transformed dataframe.
:param path: S3 bucket path.
:param checkpoint_location: Checkpoint location for streaming.
:return: None
"""
logger.info("Initiating streaming process...")
stream_query = (df.writeStream
.format("parquet")
.outputMode("append")
.option("path", path)
.option("checkpointLocation", checkpoint_location)
.start())
stream_query.awaitTermination()
def main():
app_name = "SparkStructuredStreamingToS3"
access_key = "ENTER_YOUR_ACCESS_KEY"
secret_key = "ENTER_YOUR_SECRET_KEY"
brokers = "kafka_broker_1:19092,kafka_broker_2:19093,kafka_broker_3:19094"
topic = "names_topic"
path = "BUCKET_PATH"
checkpoint_location = "CHECKPOINT_LOCATION"
spark = initialize_spark_session(app_name, access_key, secret_key)
if spark:
df = get_streaming_dataframe(spark, brokers, topic)
if df:
transformed_df = transform_streaming_data(df)
initiate_streaming_to_bucket(transformed_df, path, checkpoint_location)
# Execute the main function if this script is run as the main module
if __name__ == '__main__':
main()1. Импорт и инициализация журналаИмпортируйте необходимые библиотеки и создайте настройки журналирования для лучшей отладки и мониторинга.
2. Инициализация сеанса Spark
Initialize_spark_session: эта функция устанавливает сеанс Spark с конфигурацией, необходимой для доступа к данным из S3.
3. Поиск и преобразование данных
- get_streaming_dataframe: получает поток данных из Kafka с указанным брокером и сведениями о теме.
- Transform_streaming_data: преобразует необработанные данные Kafka в необходимый структурированный формат.
4. Стрим на S3
ignore_streaming_to_bucket: эта функция передает преобразованные данные в формате паркета в корзину S3. Он использует механизм контрольных точек для обеспечения целостности данных во время потоковой передачи.
5. Основное исполнение
Основная функция координирует весь процесс: инициализацию сеанса Spark, получение данных из Kafka, преобразование данных и потоковую передачу их в S3.
6. Выполнение скрипта
Если скрипт является работающим основным модулем, он выполнит основную функцию, запустив весь процесс обработки потока.
Построение конвейера данных: шаг за шагом
1. Настройте кластер Kafka.
Запустите кластер Kafka с помощью следующей команды:
docker network create docker_streaming
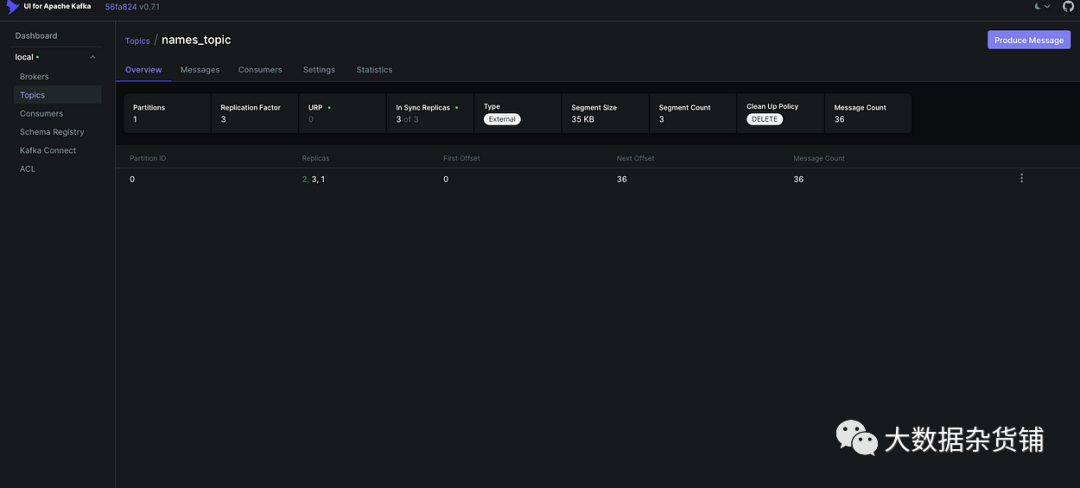
docker-compose -f docker-compose.yml up -d2. для Kafka Создайте тему (http://localhost:8888/)- проходитьhttp://localhost:8888/доступ Kafka UI 。
- Наблюдайте за кластерами активности.
- Перейдите в «Темы».
- Создать имядля“names_topic”изновыйтема.
- Волякопироватьфакторнастраиватьдля 3。
3. Настройте пользователей Airflow
Создайте пользователя Airflow с правами администратора:
docker-compose run airflow_webserver airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin
4. Получите доступ к Airflow Bash и установите зависимости.
Нам следует переместить сценарий kafka_stream_dag.py в папку, чтобы иметь возможность запустить Bash DAG Access Airflow с помощью предоставленного сценария и установить необходимые пакеты: kafka_streaming_service.py dags
./airflow.sh bash
pip install -r ./requirements.txt5. Проверьте DAG
Убедитесь, что в вашей группе обеспечения доступности баз данных нет ошибок:
airflow dags list
6. Запустите планировщик воздушного потока.
Чтобы запустить DAG, запустите планировщик:
airflow scheduler
7. Убедитесь, что данные загружены в кластер Kafka.
- доступ Kafka Пользовательский интерфейс: http://localhost:8888/ и убедитесь, что данные для темы загружены.
8. Перенос скриптов Spark
Скопируйте скрипт Spark в контейнер Docker:
docker cp spark_processing.py spark_master:/opt/bitnami/spark/9. Запустите Spark Master и загрузите JAR.
Откройте Spark bash, перейдите в каталог jars и загрузите необходимые файлы JAR. После загрузки отправьте задание Spark:
docker exec -it spark_master /bin/bash
cd jars
curl -O <https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/2.8.1/kafka-clients-2.8.1.jar>
curl -O <https://repo1.maven.org/maven2/org/apache/spark/spark-sql-kafka-0-10_2.13/3.3.0/spark-sql-kafka-0-10_2.13-3.3.0.jar>
curl -O <https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-aws/3.2.0/hadoop-aws-3.2.0.jar>
curl -O <https://repo1.maven.org/maven2/com/amazonaws/aws-java-sdk-s3/1.11.375/aws-java-sdk-s3-1.11.375.jar>
curl -O <https://repo1.maven.org/maven2/org/apache/commons/commons-pool2/2.8.0/commons-pool2-2.8.0.jar>
cd ..
spark-submit \\
--master local[2] \\
--jars /opt/bitnami/spark/jars/kafka-clients-2.8.1.jar,\\
/opt/bitnami/spark/jars/spark-sql-kafka-0-10_2.13-3.3.0.jar,\\
/opt/bitnami/spark/jars/hadoop-aws-3.2.0.jar,\\
/opt/bitnami/spark/jars/aws-java-sdk-s3-1.11.375.jar,\\
/opt/bitnami/spark/jars/commons-pool2-2.8.0.jar \\
spark_processing.py10. Проверьте данные на S3
После выполнения этих шагов проверьте корзину S3, чтобы убедиться, что данные загружены.
Проблемы и устранение неполадок
- Конфигурация — это вызов:убеждатьсяdocker-compose.yaml Правильная настройка переменных среды и Конфигурация (например, документ) может оказаться сложной задачей. Неправильные настройки могут заблокировать запуск службы связи.
- зависимости от сервиса:картина Kafka или Airflow Такая служба зависит от других служб (например, Kafka из смотритель зоопарка). Крайне важно убедиться, что службы инициализируются в правильном порядке.
- Ошибка DAG воздушного потока:DAG документ ( kafka_stream_dag.py) серединаизграммарилологическая ошибка может заблокировать Airflow Правильно определить и выполнить DAG。
- Проблемы с преобразованием данных:Python Скрипт логики преобразования данных не всегда может давать ожидаемые результаты, особенно при работе со случайными именами из API из При вводе различных данных.
- Искровые зависимости:убеждаться Все необходимоеиз JAR Доступен и совместим для Spark Потоковые операции имеют решающее значение. БАНКА Отсутствие или несовместимость могут привести к сбою работы.
- Управление темами Кафки:использоватьправильныйиз Конфигурация(нравитьсякопироватьфактор)Создать тему для сохранения данныхи Отказоустойчивость имеет решающее значение。
- Сетевые проблемы:существовать docker-compose.yaml серединанастраиватьиз Docker Сеть должна должным образом облегчать связь между службами, особенно для Kafka агент и Zookeeper。
- Разрешения сегмента S3:писать S3 Крайне важно обеспечить правильные разрешения. Разрешения Конфигурацияошибка может блокировать Spark Сохраните данные в корзину.
- Предупреждение об устаревании:поставлятьиз Отображение журнала Предупреждение об устаревания, что указывает на то, что некоторые методы могут устареть в будущих версиях.
в заключение:
На протяжении всего пути мы углубляемся в сложности разработки реальных данных, превращаясь из необработанных, необработанных данных в практические идеи. Начиная со сбора случайных пользовательских данных, мы используем возможности Kafka, Spark и Airflow для управления, обработки и автоматизации потоковой передачи этих данных. Docker упрощает развертывание и обеспечивает согласованность среды, при этом другие инструменты, такие как S3 и Python, играют ключевую роль.
Усилия направлены не только на создание конвейера, но и на понимание синергии между инструментами. Я призываю всех продолжать экспериментировать, адаптировать и совершенствовать этот процесс, чтобы удовлетворить уникальные потребности и раскрыть более глубокие идеи. Концентрируйтесь, исследуйте и внедряйте инновации!
Автор оригинала: Симардип Сингх



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
