Руководство по оптимизации производительности Wanzi Spark (Коллекционное издание)
Введение:Нашел хорошую статью,Поделитесь этим со всеми. Полный текст разделен на четыре части.,В основном охватывает все точки оптимизации Spark.,Необходим для собеседований и практической работы. Полный текст длиннее,Рекомендуется собрать его и просмотреть на ПК или устранить неполадки на работе.
《Оптимизация производительности Spark: разработка и настройка》
《Оптимизация производительности Spark: настройка ресурсов》
《Оптимизация производительности Spark: настройка искажения данных Глава》
«Оптимизация производительности Spark: настройка в случайном порядке»
Оптимизация производительности Spark: разработка и настройка
В области вычислений больших данных Spark становится одной из все более популярных и популярных вычислительных платформ. Функции Spark охватывают различные типы вычислительных операций, такие как автономная пакетная обработка, обработка на основе SQL, потоковые вычисления/вычисления в реальном времени, машинное обучение, графовые вычисления и т. д. в области больших данных, а сфера применения и перспективы его применения очень широки. .
Однако разработать высокопроизводительные задачи по обработке больших данных с помощью Spark не так просто. Если задание Spark не настроено должным образом, скорость выполнения задания Spark может быть очень низкой, что совершенно не отражает преимуществ Spark как быстрого механизма вычислений для больших данных. Поэтому, если вы хотите эффективно использовать Spark, вам необходимо провести разумную оптимизацию его производительности.
Настройка производительности Spark на самом деле состоит из множества частей. Невозможно сразу улучшить производительность работы, отрегулировав несколько параметров. Нам необходимо провести комплексный анализ заданий Spark на основе различных бизнес-сценариев и условий данных, а затем настроить и оптимизировать несколько аспектов для достижения наилучшей производительности.
Основываясь на предыдущем опыте разработки заданий Spark и накопленном практическом опыте, автор суммировал набор решений по оптимизации производительности заданий Spark. Все решение в основном разделено на настройку разработки, настройку ресурсов, настройку наклона данных и настройку перемешивания. Настройка разработки и настройка ресурсов — это некоторые основные принципы, на которые необходимо обращать внимание и которым необходимо следовать во всех заданиях Spark. Они лежат в основе высокопроизводительных заданий Spark. Настройка искажения данных в основном объясняет полный набор решений для устранения искажения данных заданий Spark. Решение : настройка в случайном порядке предназначена для учащихся, которые глубоко понимают и исследуют принципы Spark. В ней в основном объясняется, как настроить процесс выполнения в случайном порядке, а также детали заданий Spark.
Эта статья является основной частью руководства по оптимизации производительности Spark и в основном объясняет настройку разработки и настройку ресурсов.
Разработка и настройка Первый шаг в оптимизации производительности Spark — обратить внимание и применить некоторые базовые принципы оптимизации производительности в процессе разработки заданий Spark. Разработка и настройка призваны дать возможность каждому понять следующие основные принципы разработки Spark, в том числе: проектирование линии RDD, рациональное использование операторов, оптимизацию специальных операций и т. д. В процессе разработки вам следует всегда обращать внимание на вышеуказанные принципы и гибко применять эти принципы к своим собственным заданиям Spark на основе конкретных бизнес-сценариев и реальных приложений.
Принцип 1. Избегайте создания дубликатов RDD
Вообще говоря, когда мы разрабатываем задание Spark, мы сначала создаем исходный RDD на основе определенного источника данных (например, таблицы Hive или файла HDFS), затем выполняем определенную операцию оператора над этим RDD, а затем получаем следующий RDD; И так по повторяющемуся циклу, пока не вычислим нужный нам конечный результат. В этом процессе несколько RDD будут связаны друг с другом с помощью различных операторских операций (таких как сопоставление, сокращение и т. д.). Эта «строка RDD» представляет собой родословную RDD, которая представляет собой «цепочку кровного родства RDD». В процессе разработки следует обратить внимание: для одних и тех же данных следует создавать только один RDD, а несколько RDD не могут быть созданы для представления одних и тех же данных. Когда некоторые новички Spark впервые начинают разрабатывать задания Spark или опытные инженеры разрабатывают задания Spark с чрезвычайно длинной линией RDD, они могут забыть, что они уже создали RDD ранее для определенного фрагмента данных, в результате чего для одних и тех же данных создается несколько RDD. . Это означает, что наше задание Spark будет выполнять несколько повторяющихся вычислений для создания нескольких RDD, представляющих одни и те же данные, тем самым увеличивая затраты на производительность задания.
простой пример
Необходимо выполнить операцию сопоставления с файлом HDFS с именем «hello.txt», а затем выполнить операцию сокращения.
//Другими словами, над копией данных необходимо выполнить две операторские операции.
//Неправильный подход: создавать несколько RDD при выполнении нескольких операторских операций с одними и теми же данными.
//Метод textFile здесь выполняется дважды, и для одного и того же файла HDFS создаются два RDD.
//Затем над каждым СДР выполняется операторская операция.
//В этом случае Spark необходимо дважды загрузить содержимое файла hello.txt из HDFS и создать два отдельных RDD;
//Затраты на производительность при загрузке файлов HDFS и создании RDD во второй раз явно напрасны.
val rdd1 = sc.textFile("[hdfs://192.168.0.1:9000/hello.txt](hdfs://192.168.0.1:9000/hello.txt)")
rdd1.map(...)
val rdd2 = sc.textFile("[hdfs://192.168.0.1:9000/hello.txt](hdfs://192.168.0.1:9000/hello.txt)")
rdd2.reduce(...)
//Правильное использование: при выполнении нескольких операций оператора над данными используйте только один RDD.
//Этот способ записи, очевидно, намного лучше предыдущего, поскольку мы создаем только один RDD для одних и тех же данных,
//Затем над этим RDD выполняется несколько операторских операций.
//Но следует отметить, что оптимизация еще не закончена. Поскольку rdd1 выполнялся дважды, операция оператора выполняется дважды. Когда операция сокращения выполняется во второй раз.
//Данные rdd1 также будут пересчитаны из источника снова, поэтому при повторных вычислениях все равно возникнут издержки производительности.
//Чтобы полностью решить эту проблему, мы должны объединить "Принцип 3: Сохранение СДР, используемых многократно”,
//Только для того, чтобы гарантировать, что RDD вычисляется только один раз при многократном использовании.
val rdd1 = sc.textFile("[hdfs://192.168.0.1:9000/hello.txt](hdfs://192.168.0.1:9000/hello.txt)")
rdd1.map(...)
rdd1.reduce(...)
Принцип 2. Как можно чаще используйте один и тот же RDD.
Помимо того, чтобы избежать создания нескольких СДР для одних и тех же данных в процессе разработки, также необходимо как можно чаще повторно использовать СДР при выполнении операторских операций над разными данными. Например, формат данных одного RDD имеет тип «ключ-значение», а другой — тип «одиночное значение». Данные значений этих двух RDD абсолютно одинаковы. Тогда в это время мы можем использовать только RDD типа «ключ-значение», поскольку он уже содержит данные другого типа. В подобных ситуациях, когда данные из нескольких RDD перекрываются или содержат друг друга, мы должны попытаться повторно использовать один RDD, что может максимально сократить количество RDD и тем самым максимально сократить количество выполнений операторов.
простой пример
// Неправильный подход.
// есть один<long , String>ОтформатированныйRDD,Прямо сейчасrdd1。
// Затем в связи с потребностями бизнеса была выполнена операция сопоставления с rdd1 и был создан rdd2.
//Данные в rdd2 — это просто значение в rdd1, то есть rdd2 — это подмножество rdd1.
JavaPairRDD</long><long , String> rdd1 = ...
JavaRDD<string> rdd2 = rdd1.map(...)
// Различные операторские операции выполняются над rdd1 и rdd2 соответственно.
rdd1.reduceByKey(...)
rdd2.map(...)
// Правильный поступок.
// В приведенном выше случае, по сути, разница между rdd1 и rdd2 — это не что иное, как разный формат данных.
//Данные rdd2 полностью являются подмножеством rdd1, но создаются два rdd и над обоими rdd выполняется операция оператора.
// В это время, поскольку оператор карты выполняется на rdd1 для создания rdd2, будет выполнена еще одна операторная операция, тем самым увеличивая издержки производительности.
// Фактически, в этом случае один и тот же RDD можно использовать повторно.
// Мы можем использовать rdd1 для выполнения как операций уменьшения по ключу, так и операций отображения.
// При выполнении второй операции сопоставления используйте только кортеж._2 каждой информации, который является значением в rdd1.
JavaPairRDD<long , String> rdd1 = ...
rdd1.reduceByKey(...)
rdd1.map(tuple._2...)
// По сравнению с первым методом второй метод явно снижает накладные расходы на вычисления rdd2.
// Но пока оптимизация еще не закончена. Мы по-прежнему выполняем две операторные операции над rdd1, и rdd1 фактически будет рассчитан дважды.
// Поэтому с «Принципом» тоже необходимо сотрудничать. 3: Сохранение СДР, используемых многократно" использовать,
//Только для того, чтобы гарантировать, что RDD вычисляется только один раз при многократном использовании.
Принцип 3: Сохранение СДР, используемых многократно
После того как вы несколько раз выполнили операторские операции над RDD в коде Spark, поздравляем, вы достигли первого шага по оптимизации задания Spark, а именно повторного использования RDD в максимально возможной степени. В настоящее время на этой основе пришло время выполнить второй этап оптимизации, который заключается в том, чтобы при выполнении нескольких операторских операций над СДР сам СДР вычислялся только один раз.
Принцип по умолчанию выполнения нескольких операторов на RDD в Spark заключается в следующем: каждый раз, когда вы выполняете операторскую операцию на RDD, она снова вычисляется из источника, вычисляется RDD, а затем выполняется на RDD. Ваши операторские операции. . Эффективность этого метода очень низкая.
Поэтому в этой ситуации мы предлагаем: сохранить RDD, который используется несколько раз. В это время Spark сохранит данные из RDD в памяти или на диске в соответствии с вашей стратегией сохранения. Каждый раз, когда в дальнейшем над этим СДР будет выполняться оператор, постоянные данные СДР будут извлекаться непосредственно из памяти или диска, а затем оператор будет выполняться, вместо пересчета СДР из источника и последующего выполнения операции оператора.
Пример кода для сохранения RDD, используемого несколько раз
/ Если вы хотите сохранить RDD, просто вызовите функции cache() и persist() на RDD.
// Правильный поступок.
// Метод кэша() означает: Используйте метод несериализации, чтобы попытаться сохранить все данные из RDD в данные.
// В настоящее время, когда над rdd1 выполняются две операторские операции, этот rdd1 будет рассчитываться из источника только тогда, когда оператор карты выполняется в первый раз.
// Когда оператор сокращения выполняется во второй раз, данные будут напрямую извлечены из Память для расчета, и RDD не будет рассчитываться повторно.
val rdd1 = sc.textFile("[hdfs://192.168.0.1:9000/hello.txt](hdfs://192.168.0.1:9000/hello.txt)").cache()
rdd1.map(...)
rdd1.reduce(...)
// Метод persist() означает: вручную выбрать уровень сохранения и использовать указанный метод для сохранения.
// Например, StorageLevel.MEMORY_AND_DISK_SER указывает, что когда Память будет достаточно, она сначала будет сохранена в Память.
//Когда Памяти недостаточно, сохраните его в файл на диске.
// А суффикс _SER указывает, что RDD сохраняется с использованием сериализации. В это время каждый раздел в RDD сохраняется.
//Он будет сериализован в большой байтовый массив, а затем сохранен в Память или диск.
// Метод сериализации может уменьшить объем Память/диска, занимаемого постоянными данными, тем самым предотвращая слишком большую занятость Память постоянными данными.
//Таким образом, происходит частый сбор мусора.
val rdd1 = sc.textFile("[hdfs://192.168.0.1:9000/hello.txt](hdfs://192.168.0.1:9000/hello.txt)")
.persist(StorageLevel.MEMORY_AND_DISK_SER)
rdd1.map(...)
rdd1.reduce(...)
Для метода persist() мы можем выбирать разные уровни сохраняемости в соответствии с разными бизнес-сценариями.
Уровень стойкости искры

Как выбрать наиболее подходящую стратегию персистентности
1. По умолчанию самая высокая производительность, конечно, MEMORY_ONLY, но предполагается, что ваша память должна быть достаточно большой, чтобы хранить все данные всего RDD. Поскольку операции сериализации и десериализации не выполняются, эта часть затрат на производительность исключается; все последующие операции оператора на этом RDD основаны на чистых данных в памяти, и нет необходимости считывать данные из дисковых файлов. очень высокий нет необходимости копировать копию данных и передавать ее удаленно на другие узлы; Но здесь следует отметить, что в реальной производственной среде сценарии, в которых эта стратегия может использоваться напрямую, по-прежнему ограничены. Если в RDD много данных (например, миллиарды), непосредственное использование этого уровня устойчивости приведет к возникновению причин. Исключение переполнения памяти OOM для JVM.
2. Если при использовании уровня MEMORY_ONLY происходит переполнение памяти, рекомендуется попробовать использовать уровень MEMORY_ONLY_SER. Этот уровень будет сериализовать данные RDD, а затем сохранять их в памяти. На данный момент каждый раздел представляет собой просто массив байтов, что значительно уменьшает количество объектов и снижает использование памяти. Дополнительные издержки производительности на этом уровне по сравнению с MEMORY_ONLY — это, главным образом, накладные расходы на сериализацию и десериализацию. Однако последующие операторы могут работать на основе чистой памяти, поэтому общая производительность относительно высока. Кроме того, возможные проблемы такие же, как указано выше. Если объем данных в RDD слишком велик, это все равно может вызвать исключение переполнения памяти OOM.
3. Если использовать чистые уровни памяти невозможно, рекомендуется использовать стратегию MEMORY_AND_DISK_SER вместо стратегии MEMORY_AND_DISK. Потому что теперь, когда мы дошли до этого шага, это означает, что объем данных в RDD очень велик и память невозможно полностью освободить. Сериализованные данные относительно малы, что позволяет сэкономить память и дисковое пространство. В то же время эта стратегия будет отдавать приоритет попыткам кэширования данных в памяти. Если кэшировать память невозможно, они будут записаны на диск.
4. Вообще не рекомендуется использовать DISK_ONLY и уровень с суффиксом _2: поскольку чтение и запись данных, полностью основанных на файлах диска, приведет к резкому снижению производительности, иногда лучше пересчитать все RDD один раз. На уровне с суффиксом _2 все данные необходимо скопировать и отправить на другие узлы. Копирование данных и передача по сети вызовут большие потери производительности. Если не требуется высокая доступность задания, это не рекомендуется.
Принцип 4: Старайтесь избегать использования операторов перемешивания
Если возможно, старайтесь избегать использования операторов перемешивания. Потому что при выполнении задания Spark наиболее ресурсоемкой частью является процесс перемешивания. Проще говоря, процесс перемешивания заключается в переносе одного и того же ключа, распределенного на нескольких узлах кластера, на один и тот же узел для операций агрегации или соединения. Такие операторы, как сокращениеByKey и join, запускают операции перемешивания.
Во время процесса перемешивания один и тот же ключ на каждом узле сначала будет записан в файл локального диска, а затем другим узлам необходимо извлечь тот же ключ из файла диска на каждом узле посредством передачи по сети. Более того, когда одни и те же ключи переносятся на один и тот же узел для операций агрегирования, на одном узле может быть обработано слишком много ключей, что приводит к нехватке памяти для хранения, а затем переполняется в файл на диске. Таким образом, во время процесса тасования может произойти большое количество операций ввода-вывода и записи дискового файла, а также операций передачи данных по сети. Дисковый ввод-вывод и передача данных по сети также являются основными причинами низкой производительности перемешивания.
Поэтому в нашем процессе разработки нам следует избегать использования операторов сокращения, объединения, разделения, перераспределения и других операторов перемешивания, насколько это возможно, и стараться использовать операторы, не допускающие перемешивания, класса карты. В этом случае задания Spark без операций перемешивания или с меньшим количеством операций перемешивания могут значительно снизить затраты на производительность.
Пример кода соединения трансляции и карты
// Традиционные операции соединения приведут к операциям перемешивания.
// Потому что в двух RDD один и тот же ключ необходимо передать узлу через сеть, и задача выполнит операцию соединения.
val rdd3 = rdd1.join(rdd2)
// Операция соединения Broadcast+map не приведет к операции перемешивания.
// Используйте Broadcast, чтобы использовать небольшой RDD в качестве широковещательной переменной.
val rdd2Data = rdd2.collect()
val rdd2DataBroadcast = sc.broadcast(rdd2Data)
// В операторе rdd1.map все данные rdd2 можно получить из rdd2DataBroadcast.
// Затем пройдите, если обнаружено, что ключ определенных данных в rdd2 совпадает с ключом текущих данных в rdd1,
//Затем определяется, что соединение может быть выполнено.
// В это время вы можете соединить текущие данные в rdd1 с данными, которые можно подключить в rdd2, в соответствии с нужным вам методом.
//Соединяем вместе (строку или кортеж).
val rdd3 = rdd1.map(rdd2DataBroadcast...)
// Обратите внимание, что описанная выше операция рекомендуется только в том случае, если размер rdd2 относительно невелик (например, несколько сотен M или один или два G).
// Потому что Память каждого Исполнителя будет иметь полную копию данных rdd2.
Принцип 5. Используйте операцию перемешивания перед агрегированием на стороне карты.
Если операция перемешивания должна использоваться из-за потребностей бизнеса и не может быть заменена операторами карты, попробуйте использовать операторы, которые можно предварительно агрегировать на стороне карты.
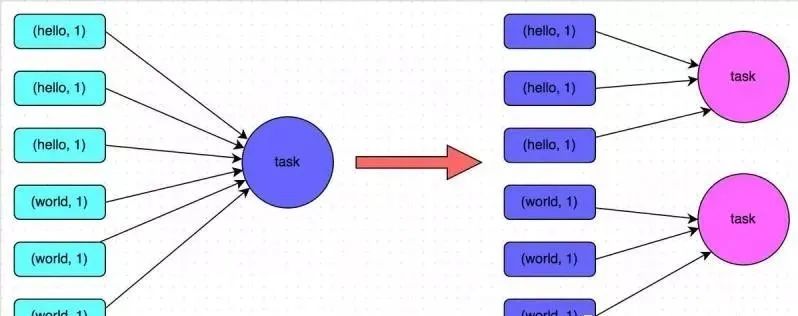
Так называемая предварительная агрегация на стороне карты означает выполнение операции агрегации с одним и тем же ключом локально на каждом узле, аналогично локальному объединителю в MapReduce. После предварительного агрегирования на стороне карты каждый узел будет иметь только один идентичный ключ локально, поскольку было агрегировано несколько идентичных ключей. Когда другие узлы используют один и тот же ключ на всех узлах, объем данных, которые необходимо получить, значительно уменьшается, тем самым уменьшая дисковый ввод-вывод и накладные расходы на передачу по сети. Вообще говоря, когда это возможно, рекомендуется использовать оператор сокращениеByKey илиагрегатByKey для замены оператора groupByKey. Потому что операторы сокращениеByKey иагрегатByKey будут использовать определяемые пользователем функции для предварительного агрегирования одного и того же ключа локально на каждом узле. Оператор groupByKey не выполняет предварительную агрегацию. Полный объем данных будет распределяться и передаваться между различными узлами кластера, а производительность будет относительно низкой.
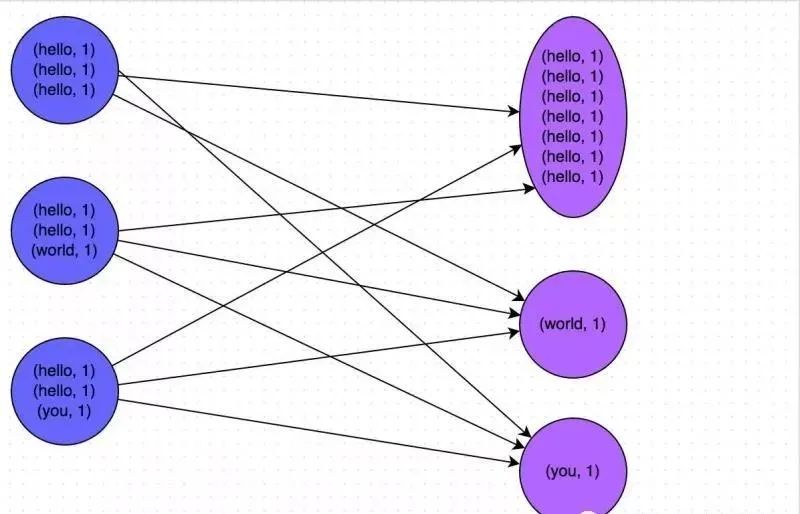
Например, на рисунке ниже показан типичный пример подсчета слов на основе уменьшенияByKey и groupByKey соответственно. Первое изображение — это схематическая диаграмма groupByKey. Вы можете видеть, что, когда локальная агрегация не выполняется, все данные будут передаваться между узлами кластера. Второе изображение — это схематическая диаграмма уменьшения по ключу. Вы можете видеть, что каждый узел локально имеет один и тот же ключ. данные предварительно агрегируются перед передачей на другие узлы для глобального агрегирования.
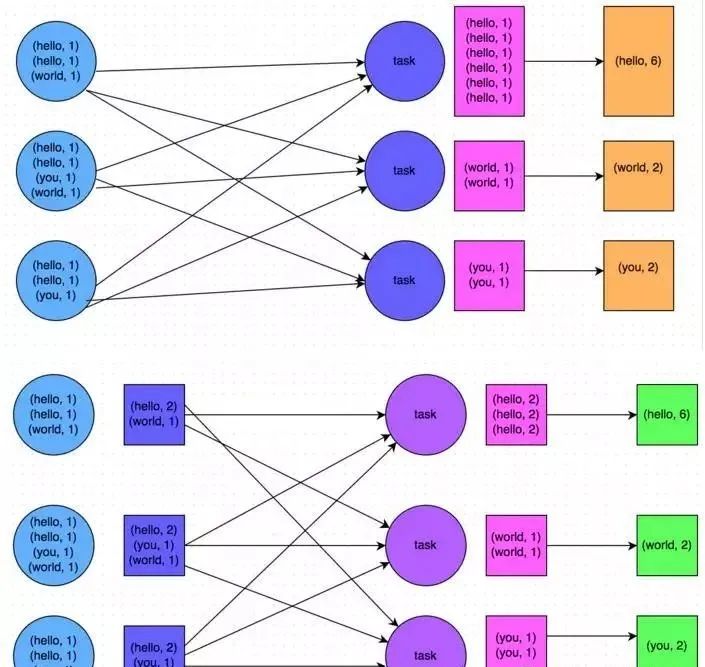
Принцип 6: Используйте высокопроизводительные операторы
В дополнение к принципам оптимизации для операторов, связанных с перетасовкой, соответствующие принципы оптимизации есть и у других операторов.
Используйте сокращениеByKey/aggregateByKey вместо groupByKey.
Подробности см.“Принцип 5. Используйте операцию перемешивания перед агрегированием на стороне карты.”。
Используйте mapPartitions вместо обычной карты.
Операторы класса mapPartitions будут обрабатывать все данные раздела за один вызов функции вместо обработки одного фрагмента данных за один вызов функции, и производительность будет относительно выше. Но иногда при использовании MapPartitions возникают проблемы OOM (нехватка памяти). Поскольку один вызов функции должен обработать все данные раздела, при недостаточности памяти слишком много объектов не могут быть переработаны во время сборки мусора, и может возникнуть исключение OOM. Поэтому будьте осторожны при использовании этого типа операций!
Используйте foreachPartitions вместо foreach
Принцип аналогичен принципу «использовать MapPartitions вместо карты». Один вызов функции обрабатывает все данные раздела вместо одного вызова функции, обрабатывающего один фрагмент данных. На практике было обнаружено, что оператор класса foreachPartitions очень помогает повысить производительность. Например, в функции foreach все данные в RDD записываются в MySQL. Если это обычный оператор foreach, данные будут записываться один за другим. Каждый вызов функции может создавать соединение с базой данных, что неизбежно будет происходить часто. Производительность создания и разрушения соединений с базой данных очень низкая, но если вы используете оператор foreachPartitions для обработки данных одного раздела за раз, то для каждого раздела вам нужно только создать соединение с базой данных, а затем выполнить операции пакетной вставки; В настоящее время производительность относительно высока. На практике установлено, что при написании MySQL примерно для 10 000 фрагментов данных производительность можно повысить более чем на 30%.
Выполните операцию объединения после использования фильтра
Обычно после выполнения оператора фильтра на СДР для фильтрации большего количества данных в СДР (например, более 30% данных) рекомендуется использовать оператор объединения, чтобы вручную уменьшить количество разделов в СДР и сжать файлы. данные в RDD разбиваются на меньшее количество разделов. Потому что после фильтрации в каждом разделе СДР будет отфильтровано много данных. Если последующие вычисления выполнять как обычно, объем данных в разделе, обрабатываемом каждой задачей, на самом деле не очень велик, что немного. Более того, в это время чем больше задач обрабатывается, тем медленнее может быть скорость. Таким образом, объединение используется для уменьшения количества разделов и сжатия данных в RDD в меньшее количество разделов. Все разделы можно обрабатывать с меньшим количеством задач. В некоторых сценариях будет полезно повысить производительность.
Используйте repartitionAndSortWithinPartitions, чтобы заменить операции перераспределения и сортировки.
repartitionAndSortWithinPartitions — это оператор, рекомендованный официальным сайтом Spark. Официальная рекомендация заключается в том, что если вам нужно выполнить сортировку после перераспределения, рекомендуется использовать оператор repartitionAndSortWithinPartitions напрямую. Потому что этот оператор может одновременно выполнять операции перераспределения и сортировки. Две операции перемешивания и сортировки выполняются одновременно. Производительность может быть выше, чем сначала перемешивание, а затем сортировка.
Принцип седьмой: трансляция больших переменных
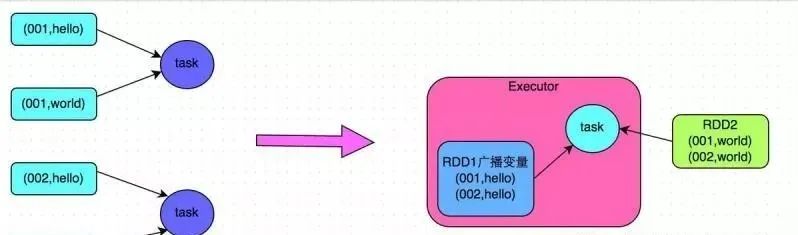
Иногда в процессе разработки вы можете столкнуться со сценариями, в которых вам необходимо использовать внешние переменные в функциях оператора (особенно большие переменные, такие как большие коллекции размером более 100 МБ). В это время вам следует использовать функцию трансляции Spark для повышения производительности.
Когда в операторной функции используется внешняя переменная, Spark по умолчанию создает несколько копий переменной и передает их задаче через сеть. В это время каждая задача имеет копию переменной. Если сама переменная относительно велика (например, 100 МБ или даже 1 ГБ), то это приведет к снижению производительности при передаче большого количества копий переменной в сети, а также частому сбору мусора, вызванному занятием слишком большого количества памяти в Исполнителе каждого узла. , сильно повлияет на производительность.
Поэтому в описанной выше ситуации, если используемая внешняя переменная относительно велика, рекомендуется использовать функцию трансляции Spark для трансляции переменной. Широковещательные переменные гарантируют, что только одна копия переменной будет находиться в памяти каждого Исполнителя, и задачи в Исполнителе будут совместно использовать эту копию переменной в Исполнителе при выполнении. Таким образом, количество копий переменных может быть значительно уменьшено, тем самым снижая накладные расходы на производительность сетевой передачи, уменьшая накладные расходы на занятость памяти исполнителя и уменьшая частоту GC.
Пример кода для трансляции больших переменных
// Следующий код использует внешние переменные в операторной функции.
// В настоящее время никаких специальных операций не выполняется, каждая задача будет иметь копию списка list1.
val list1 = ...
rdd1.map(list1...)
// Следующий код инкапсулирует list1 в широковещательную переменную типа Broadcast.
// В операторной функции при использовании широковещательных переменных сначала будет оцениваться, есть ли копия переменной в Исполнителе, где находится текущая задача.
// Если он есть, используйте его напрямую; если нет, извлеките копию удаленно из Драйвера или другого узла Исполнителя и поместите ее в локальный Память Исполнителя.
// В каждой Память Executor находится только одна копия широковещательной переменной.
val list1 = ...
val list1Broadcast = sc.broadcast(list1)
rdd1.map(list1Broadcast...)
Принцип 8. Используйте Kryo для оптимизации производительности сериализации.
В Spark есть три основных места, где используется сериализация:
1. При использовании внешних переменных в операторной функции,Переменная будет сериализована для передачи по сети (см. объяснение в «Принципе седьмой: трансляция больших запросов»). 2. При использовании пользовательского типа в качестве универсального типа RDD (например, JavaRDD,Студент - это нестандартный тип),Все объекты пользовательского типа,Все будет сериализовано. Так что в этом случае,Также требуется, чтобы пользовательский класс реализовывал интерфейс Serializable. 3. При использовании сериализуемой стратегии сохранения (например, MEMORY_ONLY_SER),Spark сериализует каждый раздел в RDD в большой массив байтов.
Для этих трех мест, где происходит сериализация, мы можем оптимизировать производительность сериализации и десериализации с помощью библиотеки классов сериализации Kryo. По умолчанию Spark использует механизм сериализации Java, который представляет собой API ObjectOutputStream/ObjectInputStream для сериализации и десериализации. Однако Spark также поддерживает использование библиотеки сериализации Kryo. Производительность библиотеки классов сериализации Kryo намного выше, чем у библиотеки классов сериализации Java. Согласно официальному описанию, механизм сериализации Kryo примерно в 10 раз более производительен, чем механизм сериализации Java. Причина, по которой Spark не использует Kryo в качестве библиотеки классов сериализации по умолчанию, заключается в том, что Kryo требует регистрации всех пользовательских типов, которые необходимо сериализовать. Поэтому этот метод является более проблематичным для разработчиков.
Ниже приведен пример кода с использованием Kryo. Нам нужно только установить класс сериализации и зарегистрировать пользовательский тип для сериализации (например, тип внешней переменной, используемый в функции оператора, пользовательский тип как универсальный тип RDD и т. д.). :
// Создайте объект SparkConf.
val conf = new SparkConf().setMaster(...).setAppName(...)
// Установите сериализатор KryoSerializer.
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// Зарегистрируйте пользовательский тип для сериализации.
conf.registerKryoClasses(Array(classOf[MyClass1], classOf[MyClass2]))Принцип 9: Оптимизируйте структуры данных
В Java есть три типа, которые потребляют больше памяти:
1. Объекты. Каждый объект Java имеет дополнительную информацию, такую как заголовки объектов и ссылки, поэтому он занимает больше места в памяти. 2. Строка. Каждая строка имеет массив символов и дополнительную информацию, например длину. 3. Типы коллекций, такие как HashMap, LinkedList и т. д., поскольку типы коллекций обычно используют некоторые внутренние классы для инкапсуляции элементов коллекции, например Map.Entry.
Поэтому Spark официально рекомендует при реализации кодирования Spark, особенно для кода в операторных функциях, стараться не использовать три вышеуказанные структуры данных, стараться использовать строки вместо объектов и использовать примитивные типы (такие как Int, Long) вместо строк. Используйте массивы вместо типов коллекций, чтобы максимально сократить использование памяти, тем самым уменьшая частоту сборки мусора и повышая производительность.
Однако в авторской практике кодирования я обнаружил, что добиться этого принципа непросто. Потому что мы также должны учитывать удобство сопровождения кода. Если код вообще не имеет никакой абстракции объектов и представляет собой конкатенацию строк, то это, несомненно, станет огромной катастрофой для последующего обслуживания и модификации кода. Точно так же, если все операции будут реализованы на основе массивов без использования типов коллекций, таких как HashMap и LinkedList, это также станет серьезной проблемой для наших сложностей с кодированием и удобства сопровождения кода. Поэтому автор рекомендует использовать структуры данных, которые занимают меньше памяти, когда это возможно и целесообразно, но при этом предполагается обеспечить удобство сопровождения кода.
Оптимизация производительности Spark: настройка ресурсов
После разработки задания Spark пришло время настроить соответствующие ресурсы для задания. Параметры ресурса Spark в основном могут быть установлены как параметры в команде spark-submit. Многие новички в Spark обычно не знают, какие необходимые параметры задавать и как эти параметры задавать. В итоге они могут устанавливать их только случайным образом или даже не задавать вообще. Если параметры ресурса установлены необоснованно, ресурсы кластера могут быть использованы не полностью, и задание будет выполняться крайне медленно, или если ресурсы установлены слишком большими, в очереди может не хватить ресурсов для их предоставления, что может привести к различным отклонениям в работе; . Короче говоря, независимо от ситуации, задание Spark будет выполняться неэффективно или даже не запустится вообще. Поэтому мы должны иметь четкое представление о принципах использования ресурсов заданиями Spark, а также знать, какие параметры ресурсов можно установить во время выполнения заданий Spark и как установить соответствующие значения параметров.
1. Основные принципы работы Spark-заданий
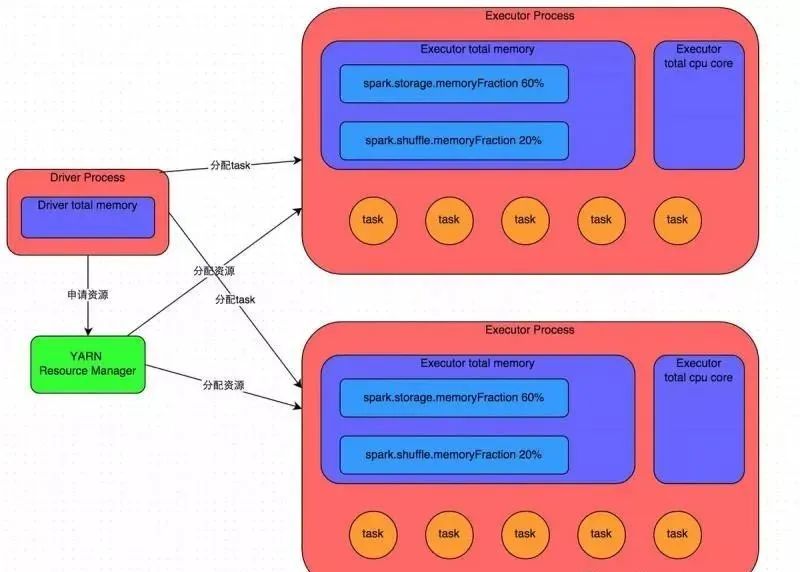
Подробные принципы смотрите на рисунке выше. После того, как мы используем Spark-submit для отправки задания Spark, задание запустит соответствующий процесс драйвера. В зависимости от используемого вами режима развертывания (deploy-mode) процесс Драйвера может быть запущен локально или на рабочем узле кластера. Сам процесс Драйвера будет занимать определенный объем памяти и ядра ЦП в соответствии с заданными нами параметрами. Первое, что должен сделать процесс Драйвера, — это обратиться к диспетчеру кластера (который может быть автономным кластером Spark или другими кластерами управления ресурсами. Meituan и Dianping используют YARN в качестве кластера управления ресурсами) для запуска задания Spark. необходимо использовать, ресурсы здесь относятся к процессу Исполнителя. Менеджер кластера YARN запустит определенное количество процессов Executor на каждом рабочем узле в зависимости от параметров ресурсов, которые мы установили для задания Spark. Каждый процесс Executor занимает определенный объем памяти и ядер ЦП.
После подачи заявки на ресурсы, необходимые для выполнения задания, процесс Драйвера начнет планировать и выполнять написанный нами код задания. Процесс Driver разделит написанный нами код задания Spark на несколько этапов. Каждый этап выполняет часть фрагмента кода, создает пакет задач для каждого этапа, а затем распределяет эти задачи для каждого процесса Executor. Задача — это наименьшая вычислительная единица, отвечающая за выполнение одной и той же вычислительной логики (то есть определенного фрагмента кода, написанного нами же), но данные, обрабатываемые каждой задачей, различны. После выполнения всех задач этапа промежуточные результаты вычислений будут записаны в файлы локального диска каждого узла, а затем Драйвер запланирует запуск следующего этапа. Входными данными задачи следующего этапа является промежуточный результат, выдаваемый предыдущим этапом. Этот цикл продолжается до тех пор, пока вся написанная нами логика кода не будет выполнена, все данные не вычислены и не будут получены нужные нам результаты.
Spark делит этапы на основе операторов перемешивания. Если в нашем коде выполняется оператор перемешивания (например, сокращениеByKey, join и т. д.), граница этапа будет разделена на этом операторе. Грубо говоря, можно понять, что код перед выполнением оператора перемешивания будет разделен на один этап, а код после выполнения оператора перемешивания будет разделен на следующий этап. Поэтому, когда этап впервые начинает выполняться, каждая из его задач может вытягивать все ключи, которые необходимо обработать, посредством сетевой передачи из узла, где находится задача предыдущего этапа, а затем использовать Операторную функцию, которую мы написали сами, выполняет агрегацию операции (например, функция, полученная оператором уменьшитьByKey()). Этот процесс является перемешиванием.
Когда мы выполняем операции персистентности, такие как кэширование/сохранение в коде, в зависимости от выбранного нами уровня персистентности данные, рассчитанные каждой задачей, также будут сохраняться в памяти процесса Исполнителя или в дисковом файле узла, где они расположены. .
Поэтому память Исполнителя в основном делится на три части: первая часть используется, когда задача выполняет написанный нами код, а по умолчанию — 20% от общего объема памяти Исполнителя; вторая часть используется задачей; для протягивания предыдущего этапа через процесс перемешивания. После вывода задачи он используется при выполнении таких операций, как агрегация. По умолчанию он также занимает 20% от общего объема памяти Исполнителя. Третий блок используется при создании RDD. постоянный и по умолчанию занимает 60% всей памяти Исполнителя.
Скорость выполнения задачи напрямую связана с количеством ядер ЦП в каждом процессе-исполнителе. Ядро ЦП может одновременно выполнять только один поток. Несколько задач, назначенных каждому процессу-исполнителю, выполняются одновременно несколькими потоками, по одному потоку на задачу. Если количество ядер ЦП достаточно и количество назначенных задач разумно, то, вообще говоря, эти потоки задач могут выполняться относительно быстро и эффективно.
Выше приведено объяснение основных принципов работы заданий Spark. Вы можете понять это с помощью рисунка выше. Понимание основных принципов работы является основной предпосылкой для нас при настройке параметров ресурсов.
2. Настройка параметров ресурса
Поняв основные принципы работы заданий Spark, легко понять параметры, связанные с ресурсами. Так называемая настройка параметров ресурсов Spark на самом деле предназначена для оптимизации эффективности использования ресурсов путем настройки различных параметров, в которых ресурсы используются во время работы Spark, тем самым улучшая производительность выполнения заданий Spark. Следующие параметры являются основными параметрами ресурсов в Spark. Каждый параметр соответствует определенной части принципа выполнения задания. Мы также предоставляем справочное значение для настройки.
num-executors
Описание параметра: этот параметр используется для установки общего количества процессов Executor, которые будут использоваться для выполнения задания Spark. Когда Драйвер подает заявку на ресурсы от менеджера кластера YARN, менеджер кластера YARN сделает все возможное, чтобы запустить соответствующее количество процессов-исполнителей на каждом рабочем узле кластера в соответствии с вашими настройками. Этот параметр очень важен. Если он не установлен, по умолчанию будет запускаться только небольшое количество процессов Executor. В это время ваше задание Spark будет выполняться очень медленно.
Рекомендации по настройке параметров. Обычно более целесообразно устанавливать от 50 до 100 процессов-исполнителей для каждого задания Spark. Установка слишком малого или слишком большого количества процессов-исполнителей не является хорошим решением. Если установлено слишком малое значение, ресурсы кластера не могут быть полностью использованы; если оно установлено слишком большим, большинство очередей могут оказаться не в состоянии предоставить достаточные ресурсы;
executor-memory
Описание параметра: Этот параметр используется для установки памяти каждого процесса-исполнителя. Размер памяти Executor часто напрямую определяет производительность заданий Spark, а также напрямую связан с распространенными исключениями OOM JVM.
Рекомендации по настройке параметров: целесообразнее установить настройку памяти 4G-8G для каждого процесса-исполнителя. Однако это лишь справочное значение, и конкретные настройки необходимо определять в соответствии с очередями ресурсов разных отделов. Вы можете проверить максимальный лимит памяти для очереди ресурсов вашей команды. Умножьте количество исполнителей на память исполнителя, что представляет собой общий объем памяти, запрошенный вашим заданием Spark (то есть общий объем памяти всех процессов-исполнителей). максимальный объем памяти очереди не может быть превышен. Кроме того, если вы делитесь этой очередью ресурсов с другими людьми в команде, то общий объем запрошенной памяти не должен превышать 1/3–1/2 от максимального общего объема памяти очереди ресурсов, чтобы предотвратить занятие вашего собственного задания Spark. вся память в очереди, из-за чего домашние задания других учащихся не могут быть выполнены.
executor-cores
Описание параметра: Этот параметр используется для установки количества ядер ЦП для каждого процесса-исполнителя. Этот параметр определяет способность каждого процесса-исполнителя параллельно выполнять потоки задач. Поскольку каждое ядро ЦП может одновременно выполнять только один поток задач, чем больше ядер ЦП имеет каждый процесс-исполнитель, тем быстрее он может выполнять все назначенные ему потоки задач.
Рекомендации по настройке параметров: Более целесообразно установить количество ядер ЦП Исполнителя на 2–4. Это также зависит от очередей ресурсов различных отделов. Вы можете посмотреть максимальный предел ядер ЦП вашей собственной очереди ресурсов, а затем определить, сколько ядер ЦП может быть выделено каждому процессу-исполнителю на основе количества установленных исполнителей. Также рекомендуется, если вы разделяете эту очередь с другими, более целесообразно, чтобы количество ядер-исполнителей * ядер-исполнителей не превышало примерно от 1/3 до 1/2 от общего числа ядер ЦП в очереди, чтобы избежать влияния выполнение работы других студентов.
driver-memory
Описание параметра: Этот параметр используется для установки памяти процесса драйвера.
Предложения по настройке параметров: Вообще говоря, память драйвера не установлена, или установки ее примерно на 1 ГБ должно быть достаточно. Единственное, что требует внимания, это то, что если вам нужно использовать оператор сбора для передачи всех данных RDD в Драйвер для обработки, вы должны убедиться, что память Драйвера достаточно велика, иначе произойдет переполнение памяти OOM.
spark.default.parallelism
Описание параметра: Этот параметр используется для установки количества задач по умолчанию для каждого этапа. Этот параметр чрезвычайно важен. Если он не установлен, он может напрямую повлиять на производительность вашего задания Spark.
Предложения по настройке параметров: Число задач по умолчанию для заданий Spark составляет 500–1000, что является более подходящим. Распространенная ошибка, которую допускают многие студенты, — не задать этот параметр, в результате чего Spark будет устанавливать количество задач на основе количества базовых блоков HDFS. По умолчанию один блок HDFS соответствует одной задаче. Вообще говоря, количество настроек Spark по умолчанию слишком мало (например, всего несколько десятков задач). Если количество задач слишком мало, все предыдущие установленные вами параметры Executor будут потрачены впустую. Только представьте, сколько бы у вас ни было процессов-исполнителей, насколько велики память и процессор, а задач всего 1 или 10, то у 90% процессов-исполнителей может вообще не выполняться ни одной задачи, а это пустая трата времени. ресурсы! Таким образом, принцип настройки, рекомендованный официальным сайтом Spark, заключается в том, что более целесообразно установить для этого параметра значение, равное 2–3 раза количеству исполнителей * ядер исполнителя. Например, если общее количество ядер ЦП Исполнителя составляет 300. , тогда можно задать 1000 задач. В это время вы можете полностью использовать ресурсы кластера Spark.
spark.storage.memoryFraction
Описание параметра: Этот параметр используется для установки доли постоянных данных RDD в памяти исполнителя. Значение по умолчанию — 0,6. Другими словами, 60% памяти Executor по умолчанию может использоваться для сохранения постоянных данных RDD. В зависимости от выбранной вами стратегии сохранения, если памяти недостаточно, данные могут не сохраниться или данные могут быть записаны на диск.
Рекомендации по настройке параметров: если в задании Spark выполняется много операций сохранения RDD, значение этого параметра можно соответствующим образом увеличить, чтобы гарантировать возможность размещения постоянных данных в памяти. Чтобы избежать нехватки памяти для кэширования всех данных, данные можно записывать только на диск, что снижает производительность. Однако если в задании Spark много операций перемешивания и мало операций сохранения, то целесообразнее соответствующим образом снизить значение этого параметра. Кроме того, если обнаружено, что задание выполняется медленно из-за частого выполнения gc (затраты времени gc задания можно наблюдать через веб-интерфейс искры), что означает, что задаче не хватает памяти для выполнения пользовательского кода, то это также рекомендуется снизить значение этого параметра.
spark.shuffle.memoryFraction
Описание параметра: этот параметр используется для установки доли памяти Исполнителя, которая может использоваться для операций агрегирования после того, как задача извлекает выходные данные задачи предыдущего этапа во время процесса перемешивания. Значение по умолчанию — 0,2. Другими словами, по умолчанию у Executor для этой операции используется только 20% памяти. Если во время операции перемешивания обнаруживается, что используемая память превышает предел в 20 %, лишние данные переполняются в файл на диске, что значительно снижает производительность.
Рекомендации по настройке параметров: Если в задании Spark мало операций сохранения RDD и много операций перемешивания, рекомендуется уменьшить коэффициент памяти для операции сохранения и увеличить коэффициент памяти для операции перемешивания, чтобы избежать нехватки памяти при наличии слишком много данных в процессе перемешивания. Если они используются, их необходимо перезаписать на диск, что снижает производительность. Кроме того, если обнаружено, что задание выполняется медленно из-за частого выполнения gc, что означает, что задаче не хватает памяти для выполнения пользовательского кода, то также рекомендуется снизить значение этого параметра. Не существует фиксированного значения для настройки параметров ресурса. Учащимся необходимо основывать на нем свою фактическую ситуацию (включая количество операций перемешивания в задании Spark, количество операций сохранения RDD и состояние gc задания, отображаемое в веб-интерфейсе Spark). В то же время обратитесь к этому. Установите вышеуказанные параметры разумно в соответствии с принципами и предложениями по настройке, изложенными в этой статье.
3. Справочные примеры параметров ресурса
Ниже приведен пример команды spark-submit. Вы можете обратиться к нему и настроить его в соответствии с вашей реальной ситуацией:
./bin/spark-submit \
--master yarn-cluster \
--num-executors 100 \
--executor-memory 6G \
--executor-cores 4 \
--driver-memory 1G \
--conf spark.default.parallelism=1000 \
--conf spark.storage.memoryFraction=0.5 \
--conf spark.shuffle.memoryFraction=0.3 \Оптимизация производительности Spark: настройка искажения данных
1. Предисловие
следовать《Оптимизация производительности Spark: разработка и настройка》и《Оптимизация производительности Spark: настройка ресурсов» объясняет Разработка, с которой должен быть знаком каждый разработчик Spark. и После настройки и настройки ресурса данная статья публикуется как "Оптимизация Spark". производительностигид》изпередовой Глава,Проведет углубленный анализ настройки наклона данных и настройки перемешивания.,для решения более сложных проблем с производительностью.
2. Настройка наклона данных
2.1. Обзор настройки Иногда мы можем столкнуться с одной из самых сложных проблем при обработке больших данных — неравномерностью данных. В это время производительность заданий Spark будет намного хуже, чем ожидалось. Настройка перекоса данных заключается в использовании различных технических решений для решения различных типов проблем перекоса данных, чтобы обеспечить производительность заданий Spark.
2.2. Феномен, когда возникает асимметрия данных 1. Большинство задач выполняются очень быстро, но отдельные задачи выполняются крайне медленно. Например, всего задач 1000, и все 997 задач выполняются в течение одной минуты, а оставшиеся две или три задачи занимают час или два. Эта ситуация очень распространена.
2. Задание Spark, которое изначально выполнялось нормально, однажды внезапно сообщило об исключении OOM (нехватка памяти). Судя по стеку исключений, оно было вызвано написанным нами бизнес-кодом. Такая ситуация относительно редка.
2.3. Принцип перекоса данных Принцип перекоса данных очень прост: при выполнении тасования один и тот же ключ на каждом узле необходимо подтягивать к задаче на определенном узле для обработки, например агрегации или объединения по ключу. действовать. При этом, если объем данных, соответствующих определенному ключу, особенно велик, произойдет перекос данных. Например, большинство ключей соответствуют 10 фрагментам данных, но некоторые ключи соответствуют 1 миллиону фрагментов данных. Тогда большинство задач можно распределить только по 10 фрагментам данных, а затем выполнить их за 1 секунду, но некоторые задачи могут быть распределены; для 1 миллиона фрагментов данных требуется час или два. Таким образом, ход выполнения всего задания Spark определяется задачей с наибольшим временем выполнения.
Таким образом, при возникновении неравномерности данных задание Spark будет выполняться очень медленно и может даже вызвать переполнение памяти, поскольку объем данных, обрабатываемых определенной задачей, слишком велик.
На рисунке ниже показан очень наглядный пример: ключ hello соответствует в общей сложности 7 фрагментам данных на трех узлах. Эти данные будут переданы в одну и ту же задачу для обработки; два ключа соответствуют друг другу соответственно 1. фрагмент данных, поэтому двум другим задачам необходимо обрабатывать только один фрагмент данных соответственно. В это время время выполнения первой задачи может быть в 7 раз больше, чем у двух других задач, а скорость работы всего этапа также определяется самой медленной задачей.
2.4. Как определить код, вызывающий искажение данных? Вот некоторые часто используемые операторы, которые могут запускать операции перемешивания: Different, groupByKey, уменьшитьByKey,агрегатByKey, join, cogroup, перераспределение и т. д. Неравномерность данных может быть вызвана использованием одного из этих операторов в вашем коде.
2.5. Когда определенная задача выполняется очень медленно, первое, на что следует обратить внимание, — на каком этапе происходит искажение данных.
Если вы отправляете заявку в режиме Yarn-cluster, вы можете напрямую просмотреть журнал локально и узнать, какой этап в данный момент выполняется в журнале. Если вы отправляете в режиме Yarn-cluster, вы можете просмотреть текущий этап через веб-интерфейс Spark; .Какой этап достигнут. Кроме того, независимо от того, используется ли режим пряжи-клиента или режим пряжи-кластера, мы можем подробно изучить объем данных, выделенных для каждой задачи на текущем этапе веб-интерфейса Spark, чтобы дополнительно определить, является ли неравномерное распределение данных задач вызвало наклон данных.
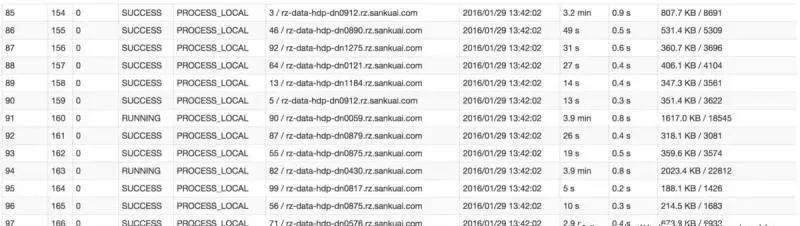
Например, на рисунке ниже в предпоследнем столбце показано время выполнения каждой задачи. Хорошо видно, что некоторые задачи выполняются очень быстро и занимают всего несколько секунд; в то время как некоторые задачи выполняются очень медленно и занимают несколько минут. В этом случае это можно определить только по времени выполнения. перекошенный. Кроме того, в предпоследнем столбце показан объем данных, обработанных каждой задачей. Хорошо видно, что задаче с особенно коротким временем выполнения требуется обработать всего несколько сотен КБ данных, а задаче с особенно длительным временем выполнения. необходимо обработать несколько тысяч КБ данных, объем обрабатываемых данных в 10 раз хуже. На данный момент более вероятно, что произошел перекос данных.
Зная, на каком этапе происходит перекос данных, нам нужно вычислить, какая часть кода соответствует этапу, на котором происходит перекос, исходя из принципа разделения этапов. В этой части кода обязательно будет оператор перемешивания. Точное вычисление соответствующих взаимосвязей между этапами и кодами требует глубокого понимания исходного кода Spark. Здесь мы можем представить относительно простой и практичный метод расчета: до тех пор, пока вы видите оператор перемешивания или SQL-код Spark, появляющийся в коде Spark. Если в операторе появляется оператор, который вызовет перемешивание (например, группировка за оператором), то можно определить, что два этапа разделены на два этапа на основе этого места в качестве границы.
Здесь мы возьмем в качестве примера самую базовую вводную программу Spark — подсчет слов и то, как использовать простейший метод для грубого расчета кода, соответствующего этапу. Как показано в следующем примере, во всем коде есть только один оператор сокращениеByKey, который будет вызывать перемешивание. Поэтому можно считать, что, используя этот оператор в качестве границы, будут разделены два этапа до и после.
1. Stage0 в основном выполняет операции с текстовым файлом на карту и выполняет операции записи в случайном порядке. Операцию произвольной записи можно просто понимать как разбиение данных на пары RDD. В данных, обрабатываемых каждой задачей, один и тот же ключ будет записан в один и тот же файл на диске.
2. Стадия 1 в основном выполняет операции уменьшения по ключу для сбора. Как только каждая задача стадии 1 запускается, она сначала выполняет операцию чтения в случайном порядке. Задача, выполняющая операцию чтения в случайном порядке, будет извлекать обрабатываемые ею ключи из узлов, где находится каждая задача на этапе 0, а затем выполнять глобальные операции агрегации или объединения для одного и того же ключа. Здесь значение ключа накапливается. После того, как стадия 1 выполняет оператор уменьшенияByKey, она вычисляет окончательный RDD wordCounts, а затем выполняет оператор сбора, чтобы передать все данные в драйвер, чтобы мы могли их просмотреть и распечатать.
val conf = new SparkConf()
val sc = new SparkContext(conf)
val lines = sc.textFile("[hdfs://...](hdfs://...)")
val words = lines.flatMap(_.split(" "))
val pairs = words.map((_, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.collect().foreach(println(_))
Я надеюсь, что посредством анализа программы подсчета слов каждый сможет понять самый основной принцип разделения этапов и то, как выполняется операция перемешивания на границе двух этапов после разделения этапов. Тогда мы знаем, как быстро определить, какая часть кода соответствует этапу, на котором происходит перекос данных. Например, в веб-интерфейсе Spark или в локальном журнале мы обнаружили, что некоторые задачи этапа 1 выполнялись очень медленно, и мы определили, что на этапе 1 имеется неравномерность данных. Затем мы могли вернуться к коду и обнаружить, что этап 1 в основном включает в себя оператор перемешивания уменьшитьByKey. На этом этапе можно в принципе определить, что проблема с искажением данных вызвана оператором сокращениеByKey. Например, если определенное слово встречается 1 миллион раз, а другие слова встречаются только 10 раз, то задача на этапе 1 обработает 1 миллион данных, и эта задача замедлит скорость всего этапа.
2.6. Определенная задача необъяснимым образом переполняет память. В этом случае легче найти проблемный код. Мы рекомендуем напрямую просматривать стек исключений в локальном журнале в режиме клиента Yarn или просматривать стек исключений в журнале в режиме кластера пряжи через YARN. Вообще говоря, информацию стека исключений можно использовать для определения того, какая строка вашего кода имеет переполнение памяти. Затем просмотрите эту строку кода. Обычно там присутствует оператор перемешивания. Вероятно, этот оператор вызывает искажение данных.
Однако всем следует отметить, что асимметрию данных нельзя определить просто по случайному переполнению памяти. Из-за ошибок в написанном вами коде и случайных аномалий данных также может произойти переполнение памяти. Таким образом, вам все равно необходимо следовать методу, упомянутому выше, и проверять время выполнения каждой задачи и объем выделенных данных на этапе, когда об ошибке сообщалось через веб-интерфейс Spark, чтобы определить, вызвано ли переполнение памяти неравномерностью данных.
2.7. Проверьте распределение данных по ключам, вызывающим неточность данных. Узнав, где происходит неточность данных, обычно необходимо проанализировать таблицу RDD/Hive, которая выполнила операцию перемешивания и вызвала неточность данных, и проверить распределение ключей. . В основном это необходимо для того, чтобы обеспечить основу для выбора технического решения в дальнейшем. В различных ситуациях, когда комбинируются разные распределения ключей и разные операторы тасования, для решения проблемы может потребоваться выбор разных технических решений.
На данный момент, в зависимости от ситуации, в которой вы выполняете операцию, существует множество способов просмотра распределения ключей:
1. Если данные искажены из-за операторов group by и join в Spark SQL, проверьте распределение ключей таблицы, используемой в SQL.
2. Если неточность данных вызвана выполнением оператора перемешивания в Spark RDD, вы можете добавить код для просмотра распределения ключей в задании Spark, например RDD.countByKey(). Затем соберите/отнесите клиенту подсчитанное количество вхождений каждого ключа и распечатайте его, и вы сможете увидеть распределение ключей.
Например, для упомянутой выше программы подсчета слов, если определено, что оператор уменьшитьByKey на этапе 1 вызывает искажение данных, вам следует посмотреть распределение ключей в RDD, где выполняется операция уменьшенияByKey. В этом примере она относится к. пары. В следующем примере мы можем сначала выбрать 10% выборочных данных для пар, затем использовать оператор countByKey для подсчета количества вхождений каждого ключа и, наконец, просмотреть и распечатать количество вхождений каждого ключа в выборочных данных на клиент.
val sampledPairs = pairs.sample(false, 0.1)
val sampledWordCounts = sampledPairs.countByKey()
sampledWordCounts.foreach(println(_))3. Решения проблемы искажения данных
Решение 1. Используйте Hive ETL для предварительной обработки данных.
Применимый сценарий решения: именно таблица Hive вызывает искажение данных. Если данные в самой таблице Hive очень неравномерны (например, один ключ соответствует 1 миллиону фрагментов данных, а другие ключи соответствуют только 10 фрагментам данных), а бизнес-сценарий требует частого использования Spark для выполнения определенных операции анализа на таблице Hive, затем сравнение. Подходит для данного технического решения.
Идея реализации решения: на данный момент вы можете оценить, можно ли выполнить предварительную обработку данных через Hive (то есть предварительное агрегирование данных по ключу через Hive ETL или предварительное объединение с другими таблицами), а затем нацелить данные в Задание Spark. Источником является не исходная таблица Hive, а предварительно обработанная таблица Hive. В настоящее время, поскольку данные были агрегированы или объединены заранее, нет необходимости использовать исходный оператор перемешивания для выполнения таких операций в задании Spark.
Принцип реализации схемы. Эта схема устраняет основную причину неравномерности данных, поскольку она полностью позволяет избежать выполнения операторов перемешивания в Spark, поэтому проблем с неравномерностью данных точно не возникнет. Но здесь также следует напомнить всем, что этот метод лечит симптомы, а не первопричину. В конце концов, сами данные имеют проблемы с неравномерным распределением, поэтому при выполнении операций перемешивания, таких как группировка или объединение в Hive ETL, перекос данных все равно будет происходить, что приводит к очень медленной работе Hive ETL. Мы просто сообщаем о возникновении неравномерности данных в Hive ETL, чтобы избежать неравномерности данных в программе Spark.
Преимущества решения: его просто и удобно реализовать, эффект очень хороший, полностью исключается искажение данных, а производительность заданий Spark значительно повышается.
Недостатки решения: оно устраняет только симптомы, но не основную причину. В Hive ETL по-прежнему будет происходить искажение данных.
Практический опыт решения: в некоторых проектах, где системы Java сочетаются со Spark, возникнут сценарии, в которых код Java часто вызывает задания Spark, а производительность выполнения заданий Spark очень высока, поэтому это решение является более подходящим. Hive ETL, который перенаправляет данные в восходящий поток, выполняется только один раз в день, и только этот раз выполняется относительно медленно. После этого каждый раз, когда Java вызывает задание Spark, скорость выполнения будет очень высокой, что может обеспечить высокую скорость выполнения. лучший пользовательский опыт.
Практический опыт проекта: это решение используется в интерактивной системе анализа поведения пользователей Meituan·Dianping. Система в основном позволяет пользователям отправлять задачи анализа данных и статистики через веб-систему Java, а серверная часть отправляет задания Spark через Java для анализа и анализа данных. статистика. Задания Spark должны выполняться быстро и стараться выполнять их в течение 10 минут. В противном случае скорость будет слишком низкой, и взаимодействие с пользователем будет плохим. Поэтому мы усовершенствовали операции перемешивания некоторых заданий Spark в Hive ETL, что позволило Spark напрямую использовать предварительно обработанные промежуточные таблицы Hive, максимально сократив операции перемешивания Spark, значительно повысив производительность и улучшив производительность некоторых заданий более чем на 6 раз. раз.
Решение 2. Отфильтруйте несколько ключей, вызывающих перекос
Применимый сценарий решения: если обнаружено, что существует всего несколько ключей, вызывающих перекос, и влияние на сам расчет невелико, то это решение очень подходит для использования. Например, 99% ключей соответствуют 10 фрагментам данных, но только один ключ соответствует 1 миллиону фрагментов данных, что приводит к искажению данных.
Идея реализации решения: если мы посчитаем, что несколько ключей с большим объемом данных не особенно важны для выполнения и результатов вычислений задания, то мы можем просто отфильтровать эти несколько ключей. Например, вы можете использовать предложениеwhere для фильтрации этих ключей в Spark SQL или выполнить оператор фильтра для RDD в Spark Core, чтобы отфильтровать эти ключи. Если вам нужно динамически определять, какие ключи содержат наибольший объем данных каждый раз при выполнении задания, а затем фильтровать его, вы можете использовать оператор выборки для выборки RDD, затем вычислить количество каждого ключа и отфильтровать ключ с помощью самый большой объем данных.
Принцип реализации решения: после фильтрации ключей, вызывающих перекос данных, эти ключи не будут участвовать в вычислении, и генерировать перекос данных, естественно, невозможно.
Преимущества решения: его просто реализовать, эффект очень хороший, можно полностью избежать искажения данных.
Недостатки решения: Не так много применимых сценариев. В большинстве случаев существует множество ключей, а не несколько.
Практический опыт решения: мы также использовали это решение для устранения неравномерности данных в проектах. Однажды я обнаружил, что задание Spark внезапно вышло из строя во время выполнения в определенный день. Проследив его, я обнаружил, что для определенного ключа в таблице Hive в тот день были ненормальные данные, что привело к резкому увеличению объема данных. Поэтому перед каждым выполнением выполняется выборка, и после вычисления ключей с наибольшим объемом данных в выборке эти ключи отфильтровываются непосредственно в программе.
Решение 3. Улучшите параллелизм операций перемешивания
Применимый сценарий решения: если нам придется столкнуться с проблемой неравномерности данных, рекомендуется отдать приоритет этому решению, поскольку это самое простое решение для борьбы с неравномерностью данных.
Идея реализации решения: при выполнении оператора перемешивания на RDD передайте параметр оператору перемешивания, например, сокращениеByKey(1000). Этот параметр задает количество задач чтения в случайном порядке при выполнении оператора перемешивания. Для операторов перемешивания в Spark SQL, таких как группировка, объединение и т. д., необходимо установить параметр, а именно spark.sql.shuffle.partitions. Этот параметр представляет параллелизм задачи чтения в случайном порядке. Значение по умолчанию — 200. который подходит для многих сценариев. Он слишком мал.
Принцип реализации решения: увеличение количества задач чтения в случайном порядке позволяет нескольким ключам, изначально назначенным одной задаче, назначаться нескольким задачам, позволяя каждой задаче обрабатывать меньше данных, чем раньше. Например, если изначально имеется 5 ключей, каждый ключ соответствует 10 фрагментам данных, и эти 5 ключей назначены задаче, то эта задача будет обрабатывать 50 фрагментов данных. После добавления задачи чтения в случайном порядке каждой задаче назначается ключ, то есть каждая задача обрабатывает 10 фрагментов данных, поэтому, естественно, время выполнения каждой задачи будет сокращено. Конкретный принцип показан на рисунке ниже.
Преимущества решения: его относительно просто реализовать, и оно позволяет эффективно смягчить и уменьшить влияние неравномерности данных.
Недостатки решения: Оно лишь уменьшает неравномерность данных, но не устраняет проблему полностью. Согласно практическому опыту, его эффект ограничен.
Практический опыт решения: Это решение обычно не может полностью решить проблему перекоса данных, поскольку если возникают какие-то экстремальные ситуации, например, объем данных, соответствующих определенному ключу, равен 1 миллиону, то независимо от того, насколько увеличивается количество ваших задач. , этот ключ соответствует 1 миллиону данных. Он обязательно все равно будет назначен задаче для обработки, поэтому неизбежен перекос данных. Таким образом, можно сказать, что это решение является первым методом, который будет использоваться при обнаружении асимметрии данных. Это просто попытка уменьшить асимметрию данных с помощью простых методов или его можно использовать в сочетании с другими решениями.
Решение 4. Двухэтапная агрегация (локальная агрегация + глобальная агрегация)
Применимые сценарии решения. Это решение больше подходит при выполнении агрегатных операторов перемешивания, таких как сокращениеByKey в RDD, или использовании оператора group by в Spark SQL для группового агрегирования.
Идея реализации схемы: Основная идея реализации этой схемы заключается в выполнении двухэтапной агрегации. В первый раз происходит локальное агрегирование. Сначала каждому ключу присваивается случайное число, например случайное число в пределах 10. В этот раз исходный тот же ключ становится другим, например (привет, 1) (привет, 1) (привет, 1) (привет, 1) (привет, 1) (привет, 1) (привет, 1) (привет, 1) (привет, 1) (привет, 1) (привет, 1) (привет, 1) , 1) (привет, 1) станет (1_привет, 1) (1_привет, 1) (2_привет, 1) (2_привет, 1). Затем выполните операции агрегации, такие как сокращение по ключу, для данных после добавления случайных чисел для выполнения локальной агрегации. Тогда результат локальной агрегации станет (1_hello, 2) (2_hello, 2). Затем удалите префикс каждого ключа, и он станет (привет, 2) (привет, 2). Выполните операцию глобальной агрегации еще раз, чтобы получить окончательный результат, например (привет, 4).
Принцип реализации схемы: добавляя случайные префиксы к исходному одному и тому же ключу, его можно преобразовать во множество разных ключей, так что данные, первоначально обработанные одной задачей, можно распределить по нескольким задачам для локальной агрегации, тем самым решая проблему единой задачи. обработка данных. Проблема слишком многого. Затем удалите случайный префикс и снова выполните глобальную агрегацию, чтобы получить окончательный результат. Конкретный принцип смотрите на рисунке ниже.
Преимущества решения: Очень хороший эффект при перекосе данных, вызванном операцией перемешивания класса агрегации. Неравномерность данных обычно можно устранить или, по крайней мере, значительно уменьшить, повысив производительность заданий Spark более чем в несколько раз.
Недостатки решения: оно применимо только для операций перемешивания агрегатных классов, а сфера его применения относительно узка. Если это операция перемешивания типа соединения, необходимо использовать другие решения.
// Первым шагом является присвоение каждому ключу в RDD случайного префикса.
JavaPairRDD<String, Long> randomPrefixRdd = rdd.mapToPair(
new PairFunction<Tuple2<Long,Long>, String, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(10);
return new Tuple2<String, Long>(prefix + "_" + tuple._1, tuple._2);
}
});
// Второй шаг — выполнить частичную агрегацию ключей со случайными префиксами.
JavaPairRDD<String, Long> localAggrRdd = randomPrefixRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
// Третий шаг — удалить случайный префикс каждого ключа в RDD.
JavaPairRDD<Long, Long> removedRandomPrefixRdd = localAggrRdd.mapToPair(
new PairFunction<Tuple2<String,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<String, Long> tuple)
throws Exception {
long originalKey = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Long>(originalKey, tuple._2);
}
});
// Четвертый шаг — выполнить глобальную агрегацию на RDD с удалением случайных префиксов.
JavaPairRDD<Long, Long> globalAggrRdd = removedRandomPrefixRdd.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
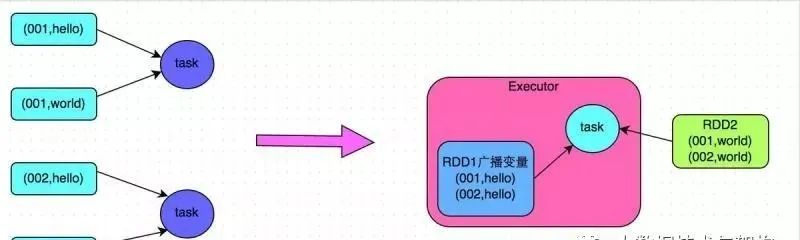
Решение 5. Преобразование соединения с сокращением в соединение по карте
Применимые сценарии решения: при использовании операций соединения в RDD или при использовании операторов соединения в Spark SQL, а объем данных в RDD или таблице в операции соединения относительно невелик (например, несколько сотен M или один или два г), больше подходит эта программа.
Идея реализации решения: вместо использования операторов соединения для операций соединения используйте широковещательные переменные и операторы отображения для реализации операций соединения, тем самым полностью избегая операций перемешивания и полностью избегая возникновения и появления перекоса данных. Извлеките данные из меньшего RDD непосредственно в память драйвера через оператор сбора, а затем создайте для него переменную Broadcast, затем выполните оператор карты на другом RDD и внутри функции оператора из переменной Broadcast. Получите полные данные; меньший СДР и сравнить его с каждым фрагментом данных в текущем СДР по ключу подключения. Если ключи подключения совпадают, то соединить данные двух СДР нужным вам способом.
Принцип реализации решения: обычные соединения будут проходить процесс перемешивания, и после перемешивания это эквивалентно извлечению данных с тем же ключом в задачу чтения в случайном порядке, а затем объединению, которое представляет собой соединение с сокращением. Однако, если RDD относительно небольшой, вы можете использовать широковещательный оператор полных данных + карты малого RDD для достижения того же эффекта, что и соединение, то есть объединения по карте. В этот момент операция перемешивания не будет выполняться, и она будет. нет искажения данных. Конкретный принцип показан на рисунке ниже.
Преимущества решения: Эффект очень хорош для асимметрии данных, вызванной операцией соединения, поскольку перемешивание не произойдет вообще, и, следовательно, асимметрия данных не произойдет вообще.
Недостатки решения: Существует мало применимых сценариев, поскольку это решение подходит только для одной большой таблицы и одной маленькой таблицы. Ведь нам нужно транслировать небольшую таблицу, которая будет потреблять больше ресурсов памяти. У драйвера и каждого Исполнителя в памяти будет полная копия небольшого RDD. Если передаваемые нами данные RDD относительно велики, например, более 10 ГБ, может произойти переполнение памяти. Поэтому он не подходит для ситуаций, когда обе таблицы большие.
// Сначала соберите данные относительно небольшого RDD в драйвер.
List<Tuple2<Long, Row>> rdd1Data = rdd1.collect()
// Затем используйте функцию трансляции Spark, чтобы преобразовать данные небольшого RDD в широковещательную переменную, чтобы у каждого Исполнителя была только одна копия данных RDD.
// Вы можете максимально сэкономить место и снизить накладные расходы на производительность передачи по сети.
final Broadcast<List<Tuple2<Long, Row>>> rdd1DataBroadcast = sc.broadcast(rdd1Data);
// Выполните операцию сопоставления с другим RDD вместо операции соединения.
JavaPairRDD<String, Tuple2<String, Row>> joinedRdd = rdd2.mapToPair(
new PairFunction<Tuple2<Long,String>, String, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, Tuple2<String, Row>> call(Tuple2<Long, String> tuple)
throws Exception {
// В операторной функции rdd1данные в локальном Исполнителе получаются путем широковещательной передачи переменной.
List<Tuple2<Long, Row>> rdd1Data = rdd1DataBroadcast.value();
// Данные rdd1 можно преобразовать в карту для облегчения последующих операций соединения.
Map<Long, Row> rdd1DataMap = new HashMap<Long, Row>();
for(Tuple2<Long, Row> data : rdd1Data) {
rdd1DataMap.put(data._1, data._2);
}
// Получите ключ и значение текущих RDDданных.
String key = tuple._1;
String value = tuple._2;
// Из rdd1данныеMap получите данные, которые можно объединить на основе ключа.
Row rdd1Value = rdd1DataMap.get(key);
return new Tuple2<String, String>(key, new Tuple2<String, Row>(value, rdd1Value));
}
});
// Вот напоминание.
// Вышеупомянутый подход применим только к сценарию, где ключи в rdd1 не повторяются и все уникальны.
// Если в rdd1 имеется несколько одинаковых ключей, вам необходимо использовать операцию класса FlatMap. Вы не можете использовать карту при объединении. Вместо этого вам нужно пройти по всем ключам в rdd1, чтобы присоединиться.
// Каждая информация в rdd2 может возвращать несколько данных после присоединения.
Решение 6. Выборка искаженного ключа и разделение операции соединения
Применимый сценарий решения: при объединении двух таблиц RDD/Hive, если объем данных относительно велик и «пятое решение» невозможно использовать, вы можете взглянуть на распределение ключей в двух таблицах RDD/Hive. Если неравномерность данных возникает из-за того, что объем данных нескольких ключей в одной таблице RDD/Hive слишком велик, а все ключи в другой таблице RDD/Hive распределены равномерно, то это решение является более подходящим.
Идеи реализации решения:
1. Для СДР, который содержит несколько ключей с чрезмерным объемом данных, используйте оператор выборки для выборки, затем подсчитайте количество каждого ключа и вычислите, какие ключи имеют наибольший объем данных. 2. Затем отделите данные, соответствующие этим ключам, от исходного СДР, чтобы сформировать отдельный СДР, и присвойте каждому ключу случайное число в пределах n, не вызывая искажения большинства ключей. Сформируйте другой СДР. 3. Затем в другом СДР, который необходимо соединить, отфильтруйте данные, соответствующие перекошенным ключам, и сформируйте отдельный СДР. Разверните каждый фрагмент данных на n фрагментов данных. К этим n фрагментам данных добавляется символ 0~. По порядку префикс n не приведет к искажению большинства ключей и образованию другого RDD. 4. Затем присоедините независимый RDD со случайным префиксом, прикрепленным к другому независимому RDD, расширенному n раз. В это время исходный тот же ключ можно разбить на n частей и распределить по нескольким задачам для объединения. 5. Два других обычных RDD можно соединить как обычно. 6. Наконец, используйте оператор объединения, чтобы объединить результаты двух соединений, что является окончательным результатом соединения.
Принцип реализации решения: в случае неравномерности данных, вызванной объединением, если причиной неравномерности являются только несколько ключей, несколько ключей можно разделить на независимые RDD и добавить случайные префиксы, чтобы разбить их на n частей для объединения. , эти несколько ключей могут быть разделены на независимые RDD. Данные, соответствующие каждому ключу, не будут сосредоточены на нескольких задачах, а будут распределены по нескольким задачам для объединения. Конкретный принцип смотрите на рисунке ниже.
Преимущества решения: в случае неравномерности данных, вызванной объединением, если причиной неравномерности являются только несколько ключей, этот метод можно использовать для разделения ключей наиболее эффективным способом для объединения. Более того, его нужно расширить только n раз для данных, соответствующих нескольким ключам перекоса, и нет необходимости расширять все данные. Не занимайте слишком много памяти.
Недостатки решения: Если слишком много ключей, вызывающих перекос, например, тысячи ключей вызовут перекос данных, то этот метод не подходит.

// Сначала выберите 10% выборок данных из rdd1, которые содержат несколько ключей, вызывающих наклон данных.
JavaPairRDD<Long, String> sampledRDD = rdd1.sample(false, 0.1);
// Подсчитайте количество вхождений каждого ключа в образце данныхRDD и отсортируйте их в порядке убывания количества вхождений.
// Для данных, отсортированных по убыванию, удалите верхнюю часть 1 или топ Данные со значением 100 — это первые n данных с наибольшим количеством ключей.
// Каждый сам решает, сколько ключей с наибольшим количеством ключей извлечь. Мы возьмем один здесь в качестве демонстрации.
JavaPairRDD<Long, Long> mappedSampledRDD = sampledRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, String> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._1, 1L);
}
});
JavaPairRDD<Long, Long> countedSampledRDD = mappedSampledRDD.reduceByKey(
new Function2<Long, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Long call(Long v1, Long v2) throws Exception {
return v1 + v2;
}
});
JavaPairRDD<Long, Long> reversedSampledRDD = countedSampledRDD.mapToPair(
new PairFunction<Tuple2<Long,Long>, Long, Long>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Long> call(Tuple2<Long, Long> tuple)
throws Exception {
return new Tuple2<Long, Long>(tuple._2, tuple._1);
}
});
final Long skewedUserid = reversedSampledRDD.sortByKey(false).take(1).get(0)._2;
// Разделите ключ, вызывающий искажение данных, от rdd1, чтобы сформировать независимый RDD.
JavaPairRDD<Long, String> skewedRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
});
// Разделите обычные ключи, которые не приводят к отклонению данных от rdd1, для формирования независимого RDD.
JavaPairRDD<Long, String> commonRDD = rdd1.filter(
new Function<Tuple2<Long,String>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, String> tuple) throws Exception {
return !tuple._1.equals(skewedUserid);
}
});
// Rdd2 — это RDD, в котором все ключи распределены относительно равномерно.
// Здесь данные, соответствующие ранее полученному ключу в rdd2, отфильтровываются, разбиваются на отдельные rdd, а оператор FlatMap используется для расширения данных в rdd в 100 раз.
// Каждая строка расширения имеет префикс числа от 0 до 100.
JavaPairRDD<String, Row> skewedRdd2 = rdd2.filter(
new Function<Tuple2<Long,Row>, Boolean>() {
private static final long serialVersionUID = 1L;
@Override
public Boolean call(Tuple2<Long, Row> tuple) throws Exception {
return tuple._1.equals(skewedUserid);
}
}).flatMapToPair(new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(
Tuple2<Long, Row> tuple) throws Exception {
Random random = new Random();
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(i + "_" + tuple._1, tuple._2));
}
return list;
}
});
// Разделите независимый rdd, который вызывает искажение ключа, из rdd1 и добавьте случайный префикс в пределах 100 к каждой информации.
// Затем соедините независимое разделение rdd из rdd1 с независимым разделением rdd из rdd2 выше.
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD1 = skewedRDD.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
})
.join(skewedUserid2infoRDD)
.mapToPair(new PairFunction<Tuple2<String,Tuple2<String,Row>>, Long, Tuple2<String, Row>>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<Long, Tuple2<String, Row>> call(
Tuple2<String, Tuple2<String, Row>> tuple)
throws Exception {
long key = Long.valueOf(tuple._1.split("_")[1]);
return new Tuple2<Long, Tuple2<String, Row>>(key, tuple._2);
}
});
// Разделите независимый rdd, содержащий обычные ключи, из rdd1 и напрямую соедините его с rdd2.
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD2 = commonRDD.join(rdd2);
// наклонит ключ Результат после соединения такой же, как и при использовании обычного ключа. Результат после соединения — uinon.
// Это окончательный результат соединения.
JavaPairRDD<Long, Tuple2<String, Row>> joinedRDD = joinedRDD1.union(joinedRDD2);Решение 7. Используйте случайные префиксы и расширенный RDD для присоединения.
Применимые сценарии решения:если продолжаетсяjoinВо время работы,В RDD имеется большое количество ключей, что приводит к искажению данных.,Тогда нет смысла разбивать ключ.,На этом этапе последнее решение можно использовать только для решения проблемы.
Идеи реализации решения:
1. Идея реализации этого решения в основном аналогична «Решению 6». Сначала проверьте распределение данных в таблице RDD/Hive и найдите таблицу RDD/Hive, которая вызывает перекос данных. Например, существует несколько ключей. соответствует более чем 10 000 фрагментам данных. 2. Затем добавьте случайный префикс в пределах n к каждому фрагменту данных в RDD. 3. В то же время разверните другой обычный RDD, разверните каждый фрагмент данных на n фрагментов данных, и каждый фрагмент расширенных данных будет иметь префикс 0~n по очереди. 4. Наконец, соедините два обработанных RDD.
Принцип реализации решения:сделать то же самое, что и раньшеkeyСтаньте другим, добавив случайный префиксkey,Затем вы можете распределить эти обработанные «разные ключи» по нескольким задачам обработки.,Вместо того, чтобы одна задача обрабатывала большое количество одинаковых ключей. Разница между этим решением и «Решением шестым» заключается в том, что,Предыдущее решение — попытаться выполнить специальную обработку только данных, соответствующих нескольким клавишам наклона.,Поскольку процесс обработки должен расширить СДР,Таким образом, предыдущее решение не занимает большого объема Память после расширения RDD, и это решение предназначено для ситуаций, когда имеется большое количество искаженных ключей;,Невозможно выделить некоторые ключи для отдельной обработки.,Поэтому весь СДР можно расширить только за счет данных.,Требования к ресурсам Память очень высоки.
Преимущества программы:верноjoinтипданные С наклоном в принципе можно справиться,И эффект относительно значительный,Улучшение производительности очень хорошее.
Недостатки решения:Программа скорее облегчениеданныенаклон,Вместо того, чтобы полностью избегать искажения данных. И весь РДД надо расширять,Требования к ресурсам Память очень высоки.
Практический опыт программы:однажды разработалданные Когда необходимо,Было обнаружено соединение, вызвавшее наклон данных. До оптимизации,Время выполнения задания после оптимизации с использованием данного решения составляет около 60 минут;,Время выполнения сокращено примерно до 10 минут.,Производительность улучшилась в 6 раз.
// Сначала один из RDD с относительно равномерным распределением ключей расширяется в 100 раз.
JavaPairRDD<String, Row> expandedRDD = rdd1.flatMapToPair(
new PairFlatMapFunction<Tuple2<Long,Row>, String, Row>() {
private static final long serialVersionUID = 1L;
@Override
public Iterable<Tuple2<String, Row>> call(Tuple2<Long, Row> tuple)
throws Exception {
List<Tuple2<String, Row>> list = new ArrayList<Tuple2<String, Row>>();
for(int i = 0; i < 100; i++) {
list.add(new Tuple2<String, Row>(0 + "_" + tuple._1, tuple._2));
}
return list;
}
});
// Во-вторых, добавьте еще один RDD с клавишей наклона данных и добавьте случайный префикс в пределах 100 к каждой информации.
JavaPairRDD<String, String> mappedRDD = rdd2.mapToPair(
new PairFunction<Tuple2<Long,String>, String, String>() {
private static final long serialVersionUID = 1L;
@Override
public Tuple2<String, String> call(Tuple2<Long, String> tuple)
throws Exception {
Random random = new Random();
int prefix = random.nextInt(100);
return new Tuple2<String, String>(prefix + "_" + tuple._1, tuple._2);
}
});
// Просто соедините два обработанных RDD.
JavaPairRDD<String, Tuple2<String, Row>> joinedRDD = mappedRDD.join(expandedRDD);Решение 8. Используйте комбинацию нескольких решений
На практике обнаруживается, что во многих случаях, если вы имеете дело только с относительно простыми сценариями искажения данных, вы можете решить его, используя одно из вышеперечисленных решений. Однако если вы хотите иметь дело с более сложным сценарием отклонения данных, вам может потребоваться объединить несколько решений. Например, для заданий Spark с несколькими неравномерными связями данных мы можем сначала использовать решения первое и второе для предварительной обработки части данных и фильтрации части данных для ее устранения, во-вторых, мы можем улучшить параллелизм некоторых операций перемешивания и оптимизировать их; Производительность; наконец, вы можете выбрать решение для оптимизации производительности для различных операций агрегации или соединения. Каждому необходимо хорошо понимать идеи и принципы этих решений, а затем гибко использовать различные решения для решения собственных проблем перекоса данных в соответствии с различными практическими ситуациями.
Оптимизация производительности Spark: настройка в случайном порядке
1. Обзор настройки
Производительность большинства заданий Spark в основном потребляется в случайном порядке, поскольку этот канал включает в себя большое количество дисковых операций ввода-вывода, сериализации, передачи данных по сети и других операций. Поэтому, если вы хотите повысить производительность работы, необходимо настроить процесс перемешивания. Однако мы также должны напомнить всем, что факторы, влияющие на производительность задания Spark, — это, главным образом, разработка кода, параметры ресурсов и неравномерность данных. Настройка Shuffle может составлять лишь небольшую часть всей настройки производительности Spark. Поэтому каждый должен усвоить основные принципы настройки и никогда не жертвовать хорошим ради слабого. Далее мы подробно объясним принцип перемешивания, а также опишем связанные параметры, а также предоставим рекомендации по настройке каждого параметра.
2. Обзор разработки ShuffleManager
В исходном коде Spark компонентом, ответственным за выполнение, расчет и обработку процесса перемешивания, в основном является ShuffleManager, также известный как менеджер перемешивания. С развитием версии Spark ShuffleManager также постоянно совершенствуется и становится все более совершенным.
До версии Spark 1.2 механизмом расчета перемешивания по умолчанию был HashShuffleManager. У ShuffleManager и HashShuffleManager есть очень серьезный недостаток, заключающийся в том, что они будут генерировать большое количество промежуточных дисковых файлов, что, в свою очередь, влияет на производительность из-за большого количества дисковых операций ввода-вывода.
Поэтому в Spark 1.2 и более поздних версиях ShuffleManager по умолчанию меняется на SortShuffleManager. SortShuffleManager имеет определенные улучшения по сравнению с HashShuffleManager. Главное, что когда каждая Задача выполняет операцию перемешивания, хотя она и генерирует больше временных файлов на диске, все временные файлы в конечном итоге будут объединены в один файл на диске, поэтому каждая Задача имеет только один файл на диске. Когда задача случайного чтения следующего этапа извлекает свои собственные данные, ей нужно прочитать только часть данных в каждом файле диска в соответствии с индексом.
Давайте подробно разберем принципы работы HashShuffleManager и SortShuffleManager.
2.1. Принцип работы HashShuffleManager.
2.1.1. Неоптимизированный HashShuffleManager.
На следующем рисунке показан принцип неоптимизированного HashShuffleManager. Здесь мы сначала уточним предположение: каждый Исполнитель имеет только 1 ядро ЦП. То есть, независимо от того, сколько потоков задач выделено этому Исполнителю, одновременно может выполняться только один поток задач.
Начнем с произвольной записи. Этап записи в случайном порядке предназначен в основном для «классификации» данных, обрабатываемых каждой задачей, по ключу, чтобы следующий этап мог выполнять операторы перемешивания (например, сокращениеByKey) после вычисления одного этапа. Так называемая «классификация» заключается в выполнении алгоритма хеширования на одном и том же ключе, так что один и тот же ключ записывается в один и тот же файл на диске, и каждый файл на диске принадлежит только одной задаче последующего этапа. Перед записью данных на диск данные будут записаны в буфер памяти. Когда буфер памяти заполнится, они будут перезаписаны в файл на диске.
Итак, сколько файлов на диске должно быть создано для каждой задачи, выполняющей запись в случайном порядке, для следующего этапа? Все очень просто. Сколько файлов на диске создается для каждой задачи текущего этапа, столько же задач на следующем этапе. Например, если на следующем этапе всего 100 задач, то каждая задача текущего этапа создаст 100 дисковых файлов. Если на текущем этапе 50 задач, всего 10 Исполнителей и каждый Исполнитель выполняет 5 Заданий, то всего на каждом Исполнителе будет создано 500 дисковых файлов, а на всех Исполнителях будет создано 5000 дисковых файлов. Видно, что количество дисковых файлов, созданных в результате неоптимизированных операций произвольной записи, крайне тревожно.
Далее поговорим о случайном чтении. Чтение в случайном порядке — это обычно то, что делается в начале этапа. При этом каждой задаче этого этапа необходимо перетянуть все те же ключи, что и в результатах вычислений предыдущего этапа, от каждого узла к своему узлу через сеть, а затем выполнить такие операции, как агрегирование ключей или соединение. Поскольку в процессе произвольной записи задача создает дисковый файл для каждой задачи на нисходящем этапе, поэтому в процессе перемешивания чтения каждой задаче нужно только вытащить свой собственный из узлов, где расположены все задачи на восходящем этапе. Файла с диска достаточно.
Процесс извлечения при случайном чтении является агрегированием во время извлечения. Каждая задача чтения в случайном порядке будет иметь свой собственный буфер. Она может каждый раз извлекать данные только того же размера, что и буфер, а затем выполнять агрегацию и другие операции через карту в памяти. После агрегирования пакета данных следующий пакет данных извлекается и помещается в буфер для операции агрегирования. И так далее, пока все данные не будут извлечены и не получен окончательный результат.
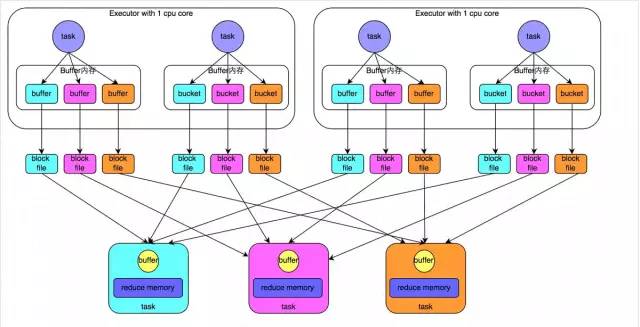
2.1.2 Оптимизированный HashShuffleManager.
На следующем рисунке показан принцип оптимизированного HashShuffleManager. Упомянутая здесь оптимизация означает, что мы можем установить параметр spark.shuffle.consolidateFiles. Значение этого параметра по умолчанию — false. Установите для него значение true, чтобы включить механизм оптимизации. Вообще говоря, если мы используем HashShuffleManager, рекомендуется включить эту опцию.
После включения механизма консолидации во время процесса записи в случайном порядке задача не создает файл на диске для каждой задачи на нисходящем этапе. В это время появится концепция shuffleFileGroup. Каждая shuffleFileGroup будет соответствовать пакету дисковых файлов. Количество дисковых файлов соответствует количеству задач на следующем этапе. Количество ядер ЦП в Executor определяет, сколько задач может выполняться параллельно. Каждая задача, выполняемая параллельно в первом пакете, создает shuffleFileGroup и записывает данные в соответствующий файл на диске.
Когда ядро ЦП Исполнителя завершает выполнение пакета задач, а затем выполняет следующий пакет задач, следующий пакет задач будет повторно использовать существующую группу shuffleFileGroup, включая входящие в нее дисковые файлы. Другими словами, в это время задача будет записывать данные в существующий файл на диске, а не в новый файл на диске. Таким образом, механизм консолидации позволяет различным задачам повторно использовать один и тот же пакет дисковых файлов, так что дисковые файлы нескольких задач могут быть эффективно объединены в определенной степени, тем самым значительно уменьшая количество дисковых файлов и тем самым повышая производительность произвольной записи. .
Предположим, что на втором этапе 100 задач, а на первом этапе 50 задач. Всего Исполнителей по-прежнему 10, и каждый Исполнитель выполняет 5 задач. Затем, когда изначально использовался неоптимизированный HashShuffleManager, каждый Исполнитель создавал 500 дисковых файлов, а все Исполнители создавали 5000 дисковых файлов. Но после оптимизации в это время формула расчета количества дисковых файлов, создаваемых каждым Исполнителем, выглядит так: количество ядер ЦП * количество задач на следующем этапе. Другими словами, каждый Исполнитель в это время создаст только 100 дисковых файлов, а все Исполнители создадут только 1000 дисковых файлов.
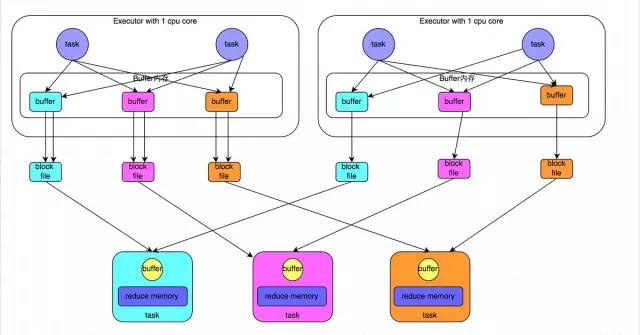
2.2. Принцип работы SortShuffleManager.
Рабочий механизм SortShuffleManager в основном делится на два типа: один — обычный рабочий механизм, а другой — обходной рабочий механизм. Когда количество задач чтения в случайном порядке меньше или равно значению параметра spark.shuffle.sort.bypassMergeThreshold (по умолчанию — 200), механизм обхода будет включен.
2.2.1. Обычный рабочий механизм.
На следующем рисунке показан принцип обычного SortShuffleManager. В этом режиме данные сначала будут записаны в структуру данных памяти. При этом могут быть выбраны разные структуры данных на основе разных операторов тасования. Если это оператор перемешивания типа агрегации, такой как сокращениеByKey, то будет использоваться структура данных Map, а агрегация через Map будет выполняться во время записи в память, если это обычный оператор перемешивания, такой как join, то структура данных Array; будет выбран и записан непосредственно в память. Затем каждый раз, когда фрагмент данных записывается в структуру данных памяти, будет оцениваться, достиг ли он определенного критического порога. Если критический порог достигнут, то будет предпринята попытка переполнить данные в структуре данных памяти на диск, а затем очистить структуру данных памяти.
Перед переполнением в файл на диске существующие данные в структуре данных памяти будут отсортированы по ключу. После сортировки данные будут пакетно записываться в файл на диске. Номер пакета по умолчанию — 10 000, что означает, что отсортированные данные будут записываться в файл диска пакетами по 10 000 данных в каждом пакете. Запись в файлы на диске осуществляется через Java BufferedOutputStream. BufferedOutputStream — это буферизованный выходной поток Java. Он сначала буферизует данные в памяти, а затем снова записывает их в файл на диске, когда буфер памяти заполнен. Это может уменьшить количество дисковых операций ввода-вывода и повысить производительность.
В процессе выполнения задачи, записывающей все данные в структуру данных памяти, произойдет несколько операций переполнения диска и будет создано несколько временных файлов. Наконец, все предыдущие временные файлы диска будут объединены. Это процесс объединения. В этот момент данные всех предыдущих временных файлов диска будут считаны, а затем последовательно записаны в окончательный файл диска. Кроме того, поскольку задача соответствует только одному дисковому файлу, это означает, что данные, подготовленные этой задачей для задач последующего этапа, все находятся в этом файле, поэтому будет записан отдельный индексный файл, который идентифицирует данные каждого нисходящая задача Начальное и конечное смещение данных в файле.
SortShuffleManager значительно уменьшает количество файлов, поскольку имеет процесс объединения файлов на диске. Например, на первом этапе 50 задач, всего 10 Исполнителей, каждый Исполнитель выполняет 5 задач, а на втором этапе 100 задач. Поскольку каждая задача заканчивается только одним дисковым файлом, в настоящее время на каждом Исполнителе имеется только 5 дисковых файлов, а для всех Исполнителей — только 50 дисковых файлов.
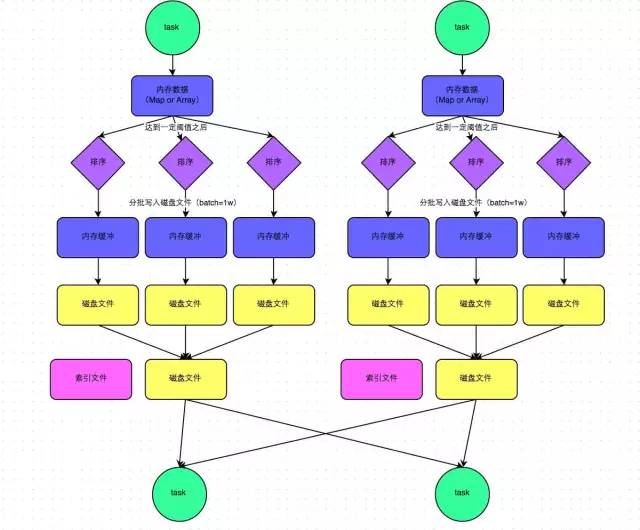
2.2.2. Механизм обхода.
На следующем рисунке показан принцип обхода SortShuffleManager. Условия срабатывания механизма обхода следующие:
1. Количество задач карты перемешивания меньше значения параметра spark.shuffle.sort.bypassMergeThreshold. 2. Оператор перемешивания, не являющийся классом агрегации (например, сокращениеByKey).
В это время задача создаст временный файл на диске для каждой последующей задачи, хеширует данные по ключу, а затем запишет ключ в соответствующий файл на диске в соответствии с хеш-значением ключа. Конечно, при записи в файл на диске он также сначала записывается в буфер памяти, а затем переполняется в файл на диске после заполнения буфера. Наконец, все временные файлы диска также объединяются в один файл диска и создается отдельный индексный файл.
Механизм записи на диск в этом процессе на самом деле точно такой же, как и в неоптимизированном HashShuffleManager, поскольку создается поразительное количество дисковых файлов, за исключением того, что дисковый файл объединяется в конце. Таким образом, небольшое количество конечных файлов на диске также повышает производительность произвольного чтения этого механизма по сравнению с неоптимизированным HashShuffleManager.
Отличие этого механизма от обычного рабочего механизма SortShuffleManager заключается в следующем: во-первых, механизм записи на диск отличается, во-вторых, сортировка выполняться не будет; Другими словами, самое большое преимущество включения этого механизма заключается в том, что во время процесса записи в случайном порядке нет необходимости сортировать данные, что экономит эту часть затрат на производительность.
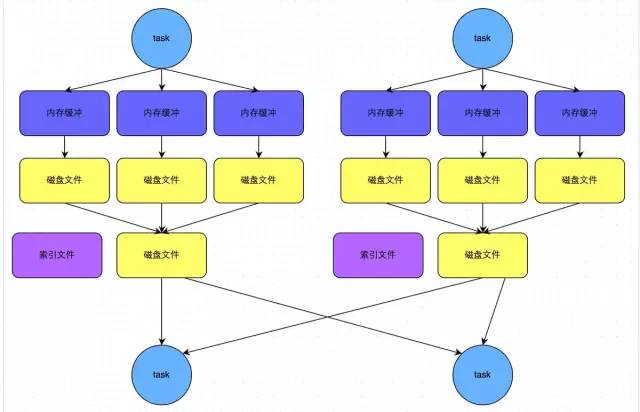
3. Настройка параметров, связанных с перемешиванием
Ниже приведены некоторые основные параметры процесса Shffule. Функции, значения по умолчанию и предложения по настройке, основанные на практическом опыте, подробно объясняются для каждого параметра.
spark.shuffle.file.buffer
значение по умолчанию:32k Описание параметра:Этот параметр используется для установкиshuffle write Размер буфера BufferedOutputStream задачи. Прежде чем записывать данные в файл диска, они сначала будут записаны в буфер. После заполнения буфера они будут перезаписаны на диск. Рекомендации по настройке:Если вакансия доступна Память Если ресурсов достаточно,Вы можете соответствующим образом увеличить размер этого параметра (например, 64 КБ).,тем самым уменьшая перемешивание Количество раз, когда файл на диске перезаписывается во время процесса записи, может уменьшить количество операций ввода-вывода на диске и тем самым повысить производительность. На практике было обнаружено, что при правильной настройке этого параметра производительность улучшится на 1–5%.
spark.reducer.maxSizeInFlight
значение по умолчанию:48m Описание параметра:Этот параметр используется для установкиshuffle read Размер буфера задачи, и этот буфер определяет, сколько данных можно извлечь каждый раз. Рекомендации по настройке:Если вакансия доступна Память Если ресурсов достаточно,Вы можете соответствующим образом увеличить размер этого параметра (например, 96 м).,Тем самым уменьшая количество запросов на получение данных.,Это также уменьшает количество сетевых передач.,тем самым улучшая производительность. нашел на практике,Отрегулируйте этот параметр соответствующим образом,Производительность будет улучшена на 1%~5%.
spark.shuffle.io.maxRetries
значение по умолчанию:3 Описание параметра:shuffle read задача из перетасовки write Когда узел, на котором расположена задача, извлекает свои собственные данные, если извлечение не удается из-за сбоев в сети, он автоматически повторяет попытку. Этот параметр представляет максимальное количество повторов. Если получение завершится неудачей в течение указанного количества раз, выполнение задания может завершиться неудачей. Рекомендации по настройке:верно Для тех, которые включают специальное потреблениечасизshuffleОперативные задачи,Рекомендуется увеличить максимальное количество повторов (например, 60 раз).,избегать из-заJVMизfull Не удалось получить данные из-за таких факторов, как gc или нестабильность сети. На практике было обнаружено, что настройка этого параметра может значительно повысить стабильность процесса перемешивания для чрезвычайно больших объемов данных (от миллиардов до десятков миллиардов).
spark.shuffle.io.retryWait
значение по умолчанию:5s Описание параметра:Конкретное объяснение такое же, как указано выше.,Этот параметр представляет интервал ожидания для каждой повторной попытки получения данных.,По умолчанию — 5 с. Рекомендации по настройке:Рекомендуется увеличить интервал времени.(например60s),Для повышения стабильности работы в случайном порядке.
spark.shuffle.memoryFraction
значение по умолчанию:0.2 Описание параметра:Этот параметр представляетExecutorПамятьсередина,назначено перетасовать read Доля памяти задачи для операций агрегирования. Значение по умолчанию — 20%. Рекомендации по настройке:существовать Настройка параметров Этот параметр был объяснен в ресурсе. Если Память достаточно и операции сохранения используются редко, рекомендуется увеличить это соотношение и перетасовать Операция агрегирования чтения требует больше памяти, чтобы избежать частого чтения и записи с диска во время процесса агрегации из-за нехватки памяти. На практике установлено, что разумная регулировка этого параметра может улучшить производительность примерно на 10%.
spark.shuffle.manager
значение по умолчанию:sort Описание параметра:Этот параметр используется для установкиShuffleManagerизтип。Spark После 1,5 есть три варианта: хэш, сортировка и сортировка вольфрамом. HashShuffleManager — это Spark Вариант по умолчанию до версии 1.2, но Spark Версии 1.2 и более поздние используют SortShuffleManager по умолчанию. tungsten-sort похож на sort, но использует механизм управления памятью вне кучи в плане вольфрама, что делает использование памяти более эффективным. Рекомендации по настройке:потому чтоSortShuffleManagerПо умолчанию будетверноданные Сортировать,Итак, если вам нужен этот механизм сортировки в вашей бизнес-логике,Затем вы можете использовать SortShuffleManager по умолчанию, если ваша бизнес-логика не требует сортировки данных;,Тогда для настройки рекомендуется обратиться к следующим параметрам.,Избегайте операций сортировки с помощью механизма обхода или оптимизированного HashShuffleManager.,В то же время это обеспечивает лучшую производительность чтения и записи дисков. Здесь следует отметить, что,вольфрамовую сортировку следует использовать с осторожностью,Потому что некоторые соответствующие ошибки были обнаружены раньше.
spark.shuffle.sort.bypassMergeThreshold
значение по умолчанию:200 Описание параметра:когдаShuffleManagerдляSortShuffleManagerчас,еслиshuffle read Количество задач меньше этого порога (по умолчанию — 200), затем перетасуйте В процессе записи не будет операции сортировки, а данные будут записываться напрямую по неоптимизированному методу HashShuffleManager. Однако в итоге все временные файлы диска, сгенерированные каждой задачей, будут объединены в один файл, и отдельный индекс. файл будет создан. Рекомендации по настройке:когдаты используешьSortShuffleManagerчас,Если действительно нет необходимости в операциях сортировки,Тогда рекомендуется увеличить этот параметр,больше, чемshuffle read Количество задач. Тогда механизм обхода будет автоматически включен в это время, и сортировка на стороне карты не будет, что снижает затраты на производительность сортировки. Однако этот метод все равно будет генерировать большое количество файлов на диске, поэтому перетасуйте Необходимо улучшить производительность записи.
spark.shuffle.consolidateFiles
значение по умолчанию:false Описание параметра:если Усе Хаш Шуффл Менеджер,Этот параметр действителен. если установлено значение true,После этого будет включен механизм консолидации.,Shuffle будет сильно объединен Выходной файл записи для перемешивания read Когда количество задач особенно велико, этот метод может значительно снизить нагрузку на дисковые операции ввода-вывода и повысить производительность. Рекомендации по настройке:еслииз Действительно не нуженSortShuffleManagerизмеханизм сортировки,Тогда в дополнение к использованию механизма обхода,Вы также можете попробовать вручную указать параметр spark.shffle.manager в виде хеша.,Усе Хаш Шуффл Менеджер,При этом включается механизм консолидации. попробовал на практике,Обнаружено, что его производительность на 10–30 % выше, чем у SortShuffleManager с включенным механизмом обхода.
Последние написанные слова
В этой статье объясняются принципы оптимизации в процессе разработки, оптимизация настройки параметров ресурсов перед работой, решения проблем с искажениями данных во время работы и оптимизация перемешивания для достижения совершенства. Я надеюсь, что после прочтения этой статьи вы сможете запомнить эти принципы и решения по настройке производительности и попробовать больше во время разработки, тестирования и эксплуатации заданий Spark. Только таким образом мы сможем разрабатывать лучшие задания Spark и постоянно улучшать их производительность.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
