Руководство по началу работы с проектом Prompt: основные принципы и практика (4) — Подсказка в рамках стратегии извлечения расширенной генерации (RAG)
Предисловие
Эта статья уже четвертая в этой серии, а это значит, что мы вошли в глубоководную зону проекта Prompt. Освоенные нами знания и технологии постоянно совершенствуются. Навыки и стратегии Prompt не могут ограничиваться местными. Приложение, но должно быть адаптировано. Общая структура большой модели LLM улучшена и реструктурирована. Более распространенная структура модели LLM может быть основана на цепочке мышления (CoT), дереве мышления (ToT) и расширенном поиске (RAG). Среди них структуру RAG можно рассматривать как одно из клише в исследованиях и разработках платформ ИИ, поскольку как отдельные лица, так и компании хотят развивать ИИ, профессиональный в своей области. Однако сопутствующие проблемы не ограничиваются галлюцинациями, отсутствием интерпретируемости сгенерированного текста, плохим пониманием профессиональных знаний и ограниченным пониманием новейших знаний.
По сравнению с дорогими решениями «Post Train» или «SFT» лучшим техническим решением является проектирование на основе структуры RAG. Ядро структуры RAG похоже на встроенную интеллектуальную поисковую систему, которая может точно находить контент базы знаний или. история разговоров, которая наиболее соответствует запросу пользователя. Эта способность позволяет RAG не только отвечать на вопросы, но и направлять модель для получения более точных и насыщенных информацией результатов путем создания подсказок. Как обеспечить эффективность модели, одновременно повысив ее точность и надежность в конкретных областях? Как избежать чрезмерной зависимости от поискового контента и обеспечить, чтобы создаваемый текст был одновременно новым и креативным? Изучая структуру RAG и ее элегантную стратегию быстрого реагирования, мы можем не только раскрыть новый потенциал больших языковых моделей, но и указать путь для будущих исследований и приложений ИИ. По мере развития этой статьи мы будем изучать принцип работы, лежащий в основе структуры RAG, и соответствующую стратегию Prompt, как она станет ключевой технологией, позволяющей преодолеть разрыв между потребностями пользователей и большими объемами данных, и как она может достичь потрясающей производительности в практических приложениях.
В каждой статье я буду стараться изо всех сил упростить профессиональные знания, связанные с вертикальной областью, и превратить их в простые для понимания знания, которые могут быть прочитаны и поняты массами. Я разберу сложные этапы создания программ один за другим. и постепенно превращайте сложное в простое. Постепенно осваивая и практикуя, все учащиеся могут подписаться на блоггера, который продолжит создавать передовые статьи о практических технологиях.
Обзор структуры RAG
Представьте себе, что, когда вы пишете статью или решаете задачу, если вы столкнетесь с трудной проблемой, что вы будете делать? Вы можете обратиться к поисковой системе, чтобы найти информацию, а затем построить свой ответ на основе найденной информации. Этот процесс на самом деле очень похож на то, что делает структура RAG. Чтобы упростить сложное, давайте сначала разберемся, что такое RAG. Начнем со значения букв: РАГ — Поиск. Augmented Generation,как следует из названия,это своего родаПоиск(Retrieval)игенерировать(Generation)комбинированные технологии。Все начинается с использования огромной базы знаний.ПоискПредоставьте наиболее актуальную информацию по заданному вопросу.,а затем на основе этой информациигенерироватьотвечать。Преимущество этого заключается в том, что,Это позволяет модели полагаться не только на существующие знания.,Внешние данные также можно использовать в режиме реального времени для предоставления более точных и полных ответов.
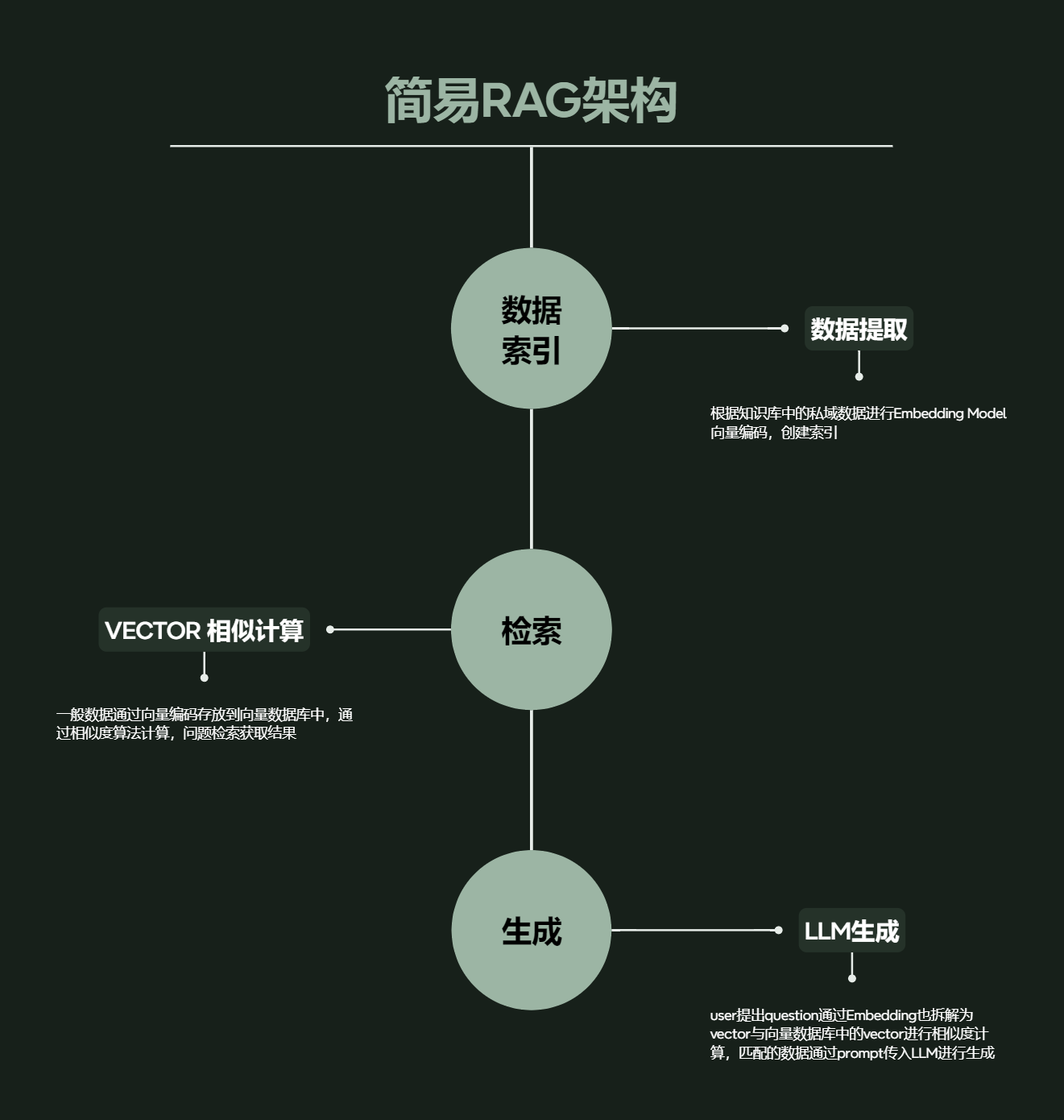
В целом его можно разделить на три структуры: индекс данных - Получение. данных——поколение LLM,Общая структура аналогична описанной выше.,Давайте сначала посмотрим на процесс RGA с общей точки зрения, как показано на рисунке выше. С точки зрения непрофессионала
- Этап поиска:когда пользователь задает вопрос,RAG сначала рассматривает этот вопрос как запрос.,Выполняйте поиск в обширной заранее созданной базе данных или базе знаний.,Найдите самую актуальную информацию. Это похоже на то, когда вы вводите запрос в Google,Система возвращает результаты, которые лучше всего соответствуют вашему запросу.
- генерироватьэтап:Как только вы найдете наиболее актуальную информацию,RAG будет использовать эту информацию в качестве подсказок (или подсказок).,Ответ строится через модель языка. Этот процесс подобен написанию отчета или ответу на вопрос на основе информации, которую вы получаете из поисковой системы.
Теперь давайте разберем работу, проделанную на каждом этапе RGA.
Рамочный процесс RGA
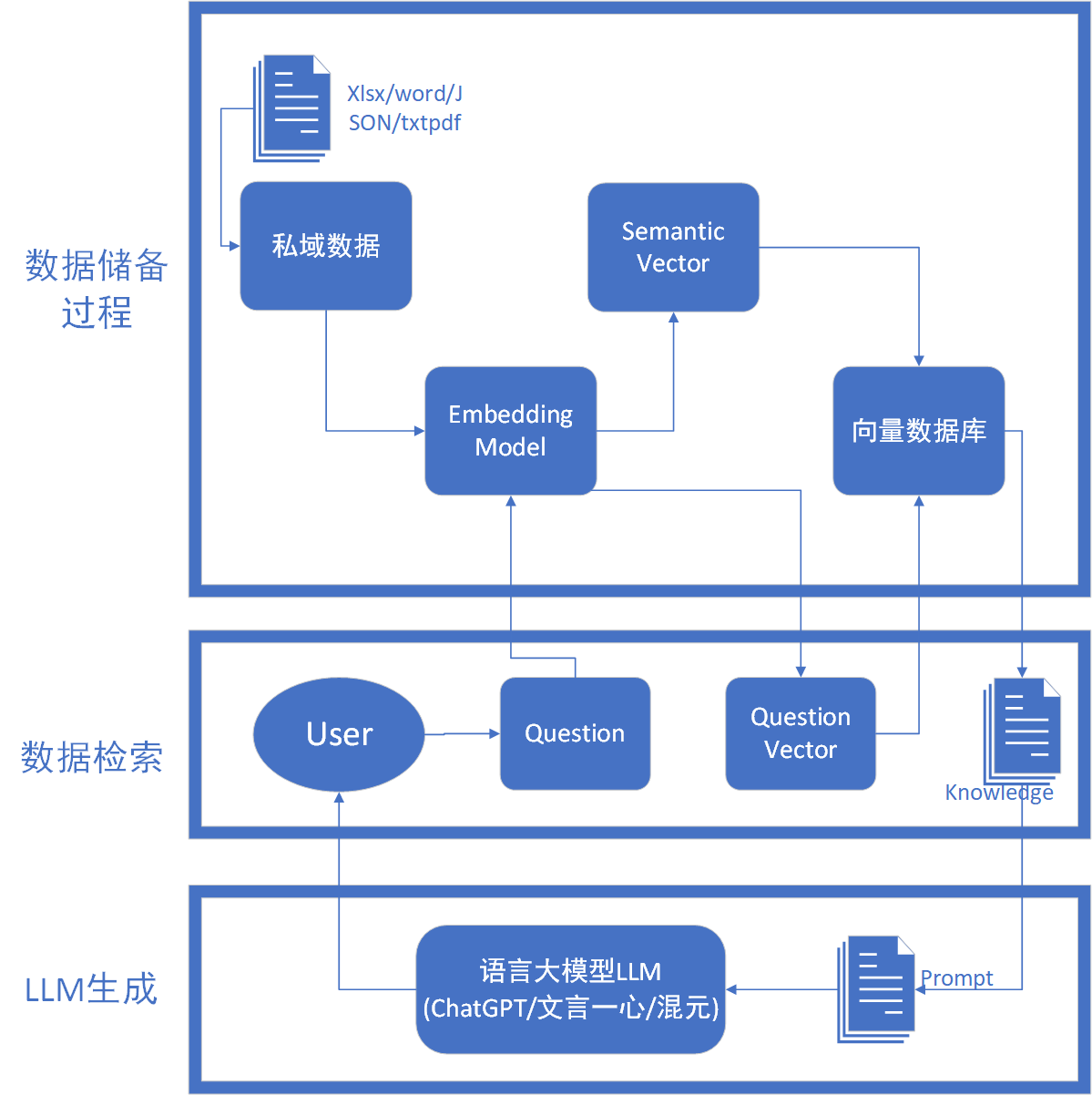
Резерв данных
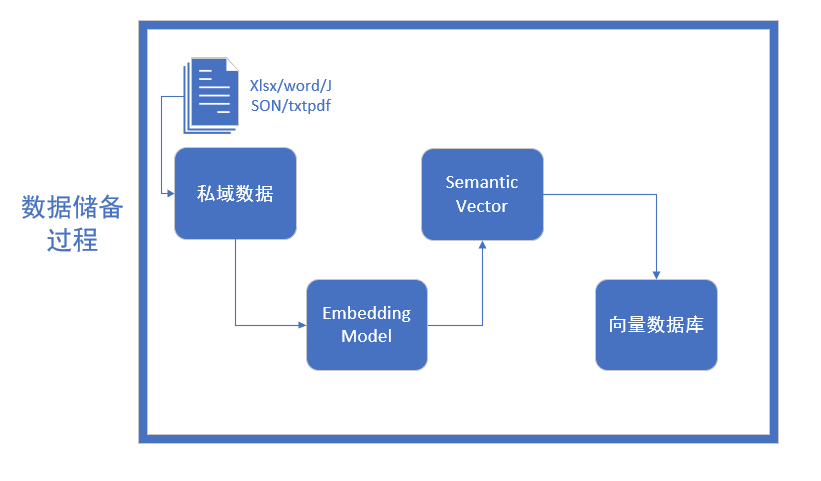
Весь резерв Процесс данных можно разделить на четыре этапа, первый — выполнить Очистку. данных。
Очистка данных
Его необходимо преобразовать в формат, который может быть обработан моделью внедрения. Источники знаний, с которыми мы сталкиваемся, могут включать в себя несколько форматов, таких как документы Word, файлы TXT, таблицы данных CSV, таблицы Excel и даже файлы PDF, изображения и видео. и т. д., все из которых должны быть преобразованы в простые текстовые данные, понятные большим языковым моделям. Кроме того, длинные статьи также нуждаются в сегментации текста, и необходимо учитывать два фактора: 1) ограничения модели внедрения по токенам 2) влияние семантической целостности на общий эффект поиска;
- Сегментация предложения: сегментируйте по степени детализации «предложения», чтобы сохранить полную семантику предложения. К распространенным разделителям относятся: точки, восклицательные знаки, вопросительные знаки, разрывы строк и т. д.
- Сегментация фиксированной длины. В соответствии с ограничением длины токена модели внедрения текст сегментируется на токены фиксированной длины (например, 256/512 токенов). При этом методе сегментации теряется много семантической информации, что обычно устраняется добавлением . определенное количество избыточности в начале и в хвосте.
Векторизация (встраивание)
Ранее я написал статью о проектировании рекомендательной системы на основе векторных баз данных, в которой подробно описан процесс векторизации. В современную эпоху глубокого обучения векторы являются неизбежным понятием, то есть все можно преобразовать искусственно. Например, нам имеет смысл использовать красный, желтый и зеленый цвета при проектировании событий дорожных пробок. Элементы можно сопоставить с одной и той же широтой с помощью модели внедрения:
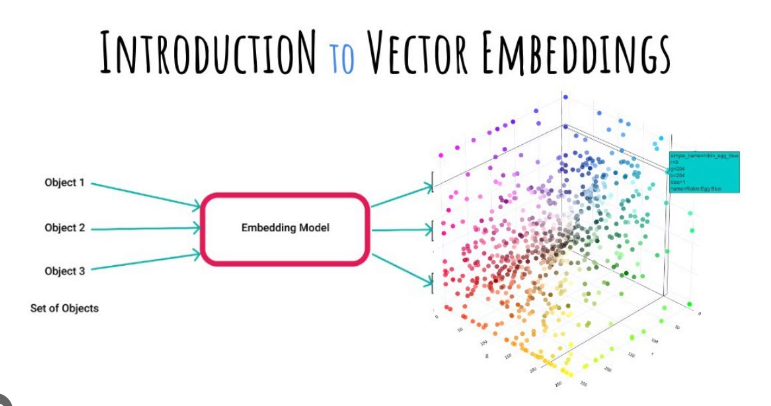
Затем сохраните и вычислите сходство для последующего использования в рекомендациях. На рынке уже существует множество моделей встраивания:
Название модели | описывать | Получить адрес |
|---|---|---|
ChatGPT-Embedding | ChatGPT-Embedding предоставляется OpenAI и вызывается в виде интерфейса. | |
ERNIE-Embedding V1 | ERNIE-Embedding V1 предоставляется Baidu, который опирается на возможности больших моделей Wenxin и вызывается в виде интерфейса. | |
M3E | M3E — это мощная модель внедрения с открытым исходным кодом, включая m3e-small, m3e-base, m3e-large и другие версии, поддерживающие тонкую настройку и локальное развертывание. | |
BGE | BGE был выпущен Пекинским научно-исследовательским институтом искусственного интеллекта Чжиюань. Это также мощная модель внедрения с открытым исходным кодом, включающая несколько версий, поддерживающих китайский и английский языки, а также тонкую настройку и локальное развертывание. |
Процесс построения индекса после векторизации данных и записи их в базу данных можно резюмировать как процесс хранения данных. Базы данных, подходящие для сценариев RAG, включают: FAISS, Chromadb, ES, milvus и т. д.
Получение данных
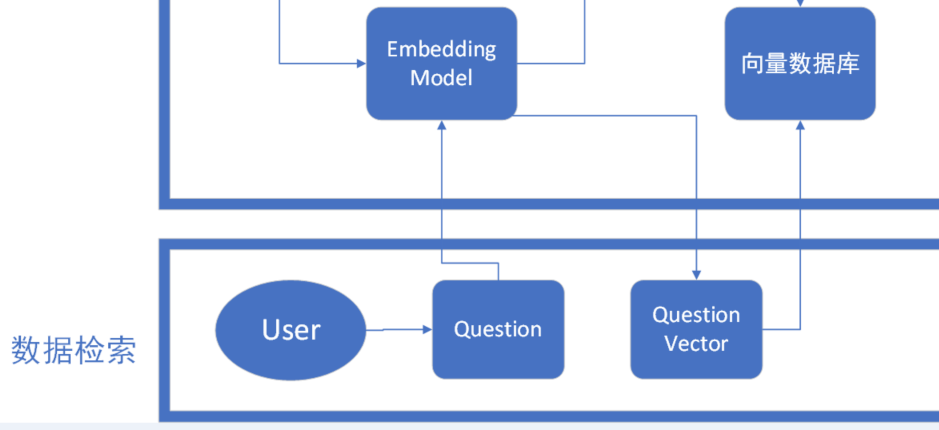
Нам также необходимо векторно закодировать вопросы, заданные пользователем, что соответствует дизайну системы рекомендаций. Фактически, модели поведения при рекомендации продуктов и рекомендации ответов пользователям согласованы. Системы рекомендаций по существу работают, когда потребности пользователей неясны. Технические средства для поиска интересующей пользователей информации из огромных массивов информации. В статье о системе построения портрета пользователя, написанной блоггером, было написано, что система рекомендаций используется в качестве нижестоящего сервиса. Интегрируя информацию о пользователе, информацию о предметах и историческое поведение пользователей, система рекомендаций использует технологию машинного обучения для построения. персонализированная модель интересов пользователей. Схема поведения поиска ответов у пользователей одинакова. Вопросы, заданные пользователями, преобразуются в векторы и вводятся в векторную базу данных для обработки. данных。
Обычное получение К методам данных относятся: поиск по сходству, полнотекстовый поиск и т. д. В соответствии с эффектом поиска вы обычно можете интегрировать несколько методов поиска, чтобы улучшить скорость отзыва. При получении запроса пользователя (например, вопроса или ключевого слова) структура RAG сначала преобразует этот запрос в векторную форму. Этот шаг обычно выполняется с помощью предварительно обученных языковых моделей (таких как BERT, GPT и т. д.).,Чтобы гарантировать, что вектор запроса может эффективно отражать семантику запроса.
Получив вектор запроса, RAG использует алгоритм поиска ближайшего соседа, чтобы найти вектор документа, ближайший к вектору запроса, в предварительно построенном индексе. Эти ближайшие векторы представляют собой наиболее релевантную информацию в базе знаний для запроса. Алгоритмов поиска довольно много.
- Поиск по сходству: вычисляет оценку сходства между вектором запроса и всеми сохраненными векторами.,Возвращайте рекорды с высокими баллами。Общие методы расчета сходства включают::косинусное подобие、Евклидово расстояние、Манхэттенское расстояние и т. д.
- Полнотекстовый поиск: Полнотекстовый поиск — более классический способ поиска.,Когда данные сохраняются,Постройте инвертированный индекс по ключевому слову при поиске;,Полный текст Поиск по ключевому слову,Найдите соответствующую запись.
При реализации структуры RAG общие технологии и инструменты включают Elasticsearch, FAISS (Facebook AI Similarity Search)、Annoy(Approximate Nearest Neighbors Oh Ага) и т. д., эти инструменты предназначены для масштабного получения. данные и дизайн поиска ближайшего соседа могут эффективно поддерживать структуру Поиск спроса в РАГ.
поколение LLM
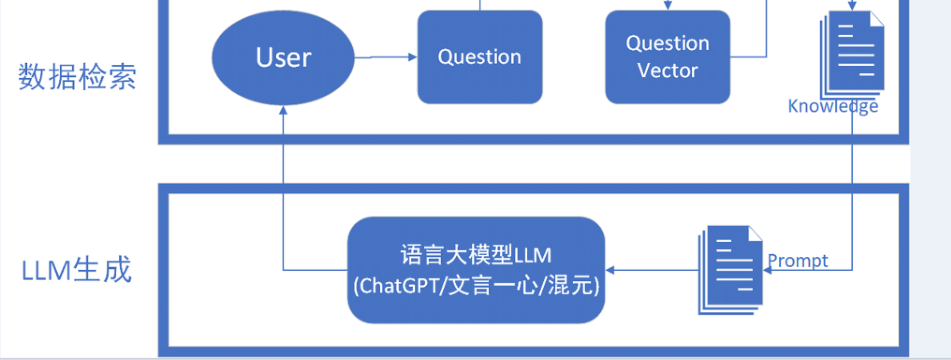
Дошло до поколения LLMЭтот шаг относительно прост,Поскольку данные с наивысшим баллом получены с помощью индекса сходства,Далее нам нужно лишь выдавать поэтапные подсказки через возвращенные Знаниягенерировать,Затем вернитесь к языковой модели LLM.,Пусть LLM подведет итоги, а затем вернет их пользователю. Для дальнейшего повышения релевантности поиска и точности текста.,В некоторых моделях RAG реализована технология динамической подсказки. Этот метод анализирует предварительные результаты путем,Автонастройка или ограничение новое Подсказка,Оптимизировать последующий процесс Поиска и оценки. Этот цикл обратной связи может значительно улучшить производительность модели. Более того, модель RAG позволяет пользователям оценивать или изменять предварительное предложение,Результаты поиска и оценки дополнительно оптимизируются на основе отзывов пользователей.
РАГ и тонкая настройка
Поймите вышеизложенноеструктура После RAG, имея определенную основу НЛП или языка больших моделей, у нас появится новая идея: RAG. и тонкая настройка Какое решение является лучшим? Ответ на этот вопрос не высечен в камне. Он зависит от многих факторов, в том числе от конкретного сценария применения и доступности. ресурсы и конкретные требования к производительности модели.
Различия в сценариях применения
- структура RAGОсобенно подходит для тех, кому необходимо объединить широкую базу знаний длягенерировать Сценарий ответа или контента。оно проходит Поиск Информация, тесно связанная с проблемой,и ответьте на основании этой информации,Он особенно подходит для обработки информации, систем вопросов и ответов, рекомендаций по контенту и других областей. Сила RAG заключается в ее способности использовать новейшие внешние источники информации.,Дайте новые и более точные ответы.
- тонкая настройкаОн подходит для ситуаций, когда имеется большой объем размеченных данных.,Предварительно обученные модели можно персонализировать под конкретные задачи. Это работает для различных задач НЛП.,Такие как классификация текста, анализ настроений、Распознавание названного объекта и т. д. тонкая Преимуществом настройки является возможность добиться высокой точности на конкретных задачах, особенно при предварительно обученных моделях и тонкая настройка Когда задача весьма актуальна.
доступность ресурсов
- структура RAGТребуется возможность доступа и обработки больших объемов внешней информации.。这意味着它对计算资源и数据存储的要求相对较高。в то же время,Внедрение эффективного механизма управления информацией также является ключом к успешному применению RAG.
- тонкая настройкаХотя это тоже требует определённых вычислительных ресурсов,Но обычно,Требования к ресурсам ниже, чем у RAG.,Потому что сразу модель тонкая настройка, нет необходимости во внешней информации в режиме реального времени. Однако, тонкая настройка требует большого количества размеченных данных для обучения модели,В некоторых сценариях это может быть ограничивающим фактором.
Провести детальную оценку посредством экспериментов(выбиратьMetaПоследние статьи):Использование трех популярных наборов данных тонкой настройки: SQL, functional representation and GSM8K и обнаружил, что когда образец был RAG В сочетании с точной настройкой нулевых выборок точность всех трех наборов данных улучшилась на несколько процентных пунктов.
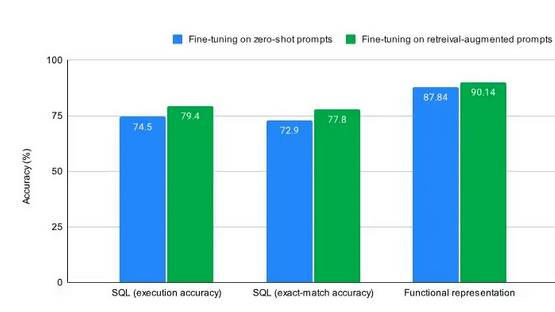
Синий цвет — при точной настройке для вывода с нулевым результатом, зеленый — при точной настройке для сигналов улучшения поиска (с примерами улучшения поиска из обучающего набора). Для любой задачи тонкой настройки, независимо от того, является ли она наукоемкой или нет, разрешение модели использовать контекстное обучение и тонкую настройку приведет к повышению производительности, чем просто точная настройка вывода с нулевым выстрелом. В некоторых случаях сочетание RAG и тонкой настройки может оказаться лучшей стратегией.
Краткое содержание
В связи с быстрым развитием области искусственного интеллекта мы ожидаем появления в будущем более инновационных технологий, которые еще больше улучшат возможности обработки задач НЛП и предоставят больше возможностей для решения сложных задач обработки языка. В то же время это также означает, что инженерам и исследователям искусственного интеллекта необходимо постоянно изучать новые модели, технологии и методы, чтобы оставаться конкурентоспособными в этой динамично развивающейся области. Я призываю читателей продолжать обращать внимание на RAG, тонкую настройку и другие передовые технологии НЛП и технологии искусственного интеллекта и посредством экспериментов и исследований находить решение, которое лучше всего соответствует их потребностям. Будь то академические исследования или разработка практических приложений, постоянные инновации и эксперименты станут важной движущей силой прогресса.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
