Руководство по началу работы для инженеров по разработке данных и хранилищ данных (1) Концептуальная архитектура хранилища данных
Предисловие
Автор впервые начал работать над разработкой больших данных и созданием хранилищ данных после окончания учебы и попутно работал инженером по искусственному интеллекту и компьютерному зрению. Неожиданно он в конце концов вернулся к своей первоначальной работе в качестве инженера по разработке данных. Но о их собственной работе написано немного технических материалов.
В прошлом большинство статей автора были посвящены моделированию алгоритмов, и большинство из них были посвящены расширению возможностей вычислений, которым все уделяли много внимания. Однако по мере изменения общей среды компании уделяют больше внимания сбалансированному развитию множества. области, то есть, по сравнению с исходной рабочей средой, таланты должны быть диверсифицированы, и им необходимо овладевать многомерными знаниями, а не сосредотачиваться на одной области. Грубо говоря, это сложнее, поэтому можно сказать, что необходимо овладеть некоторыми знаниями, неотделимыми от построения систем данных. Например, построение хранилища данных компании и базовые знания архитектуры системы хранилища данных. Поэтому я хотел бы воспользоваться этой возможностью, чтобы поделиться с вами построением хранилища данных корпоративного уровня и самой передовой технологией анализа данных.
Авторские технологии применения искусственного интеллекта и практические проекты будут по-прежнему обновляться, но скорость не такая быстрая, как обычно. Спасибо за вашу поддержку!
1. Концепция хранилища данных
Прежде всего, мы можем представить себе концепцию пересадочной станции. Например, если вы едете по дороге и хотите проехать с национальной автомагистрали на скоростную автомагистраль, вы должны ехать быстрее и получать больше удовольствия от поездки. Автострада. Тогда вы думаете о хранилище данных как о высокоскоростной перегрузочной станции, которая объединяется с национальной автомагистрали на автомагистраль. Она отвечает за сбор данных из различных местных источников, их обобщение и сортировку, а затем размещение на трассе. использования, достигая эффекта эффективной передачи данных.
Целью хранилища данных является объединение всех полезных данных в коллекции, создание интегрированной среды данных для анализа и предоставление предприятию поддержки принятия решений посредством окончательных результатов анализа данных. Для всего хранилища данных ему не нужно создавать или потреблять данные. Вместо этого он предоставляет результаты наружу посредством серии операций обработки в хранилище данных.
1. Архитектура хранилища данных
Давайте возьмем общую архитектуру в качестве примера, чтобы понять:
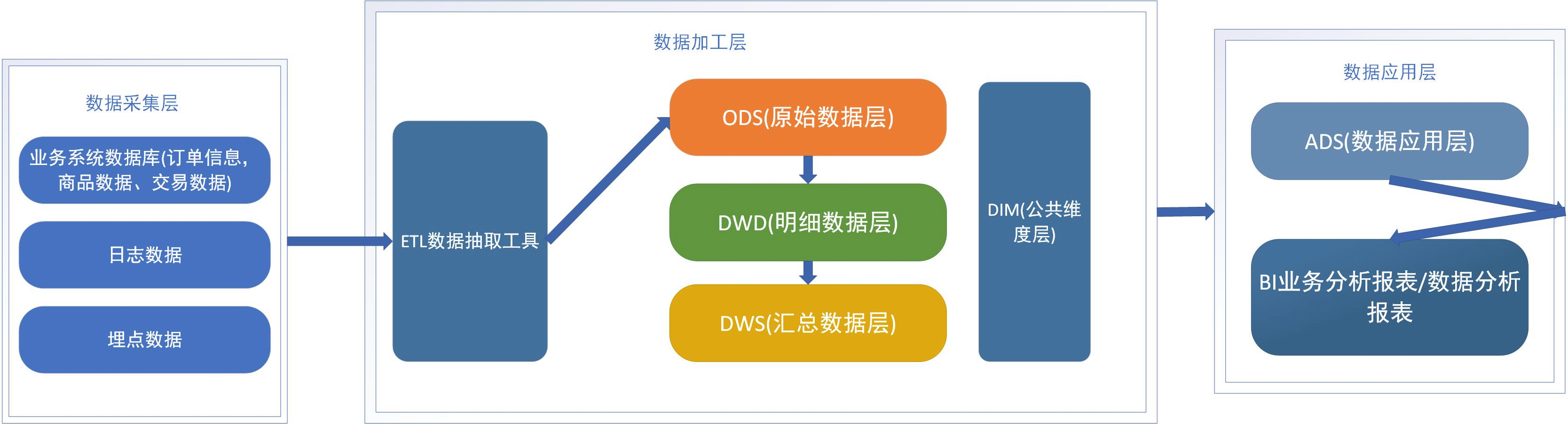
1.1 Уровень сбора данных
Прежде всего, нам необходимо хранить соответствующие бизнес-данные. Существует множество источников этих данных, не только тех, которые я нарисовал на картинке выше, но и за счет интеграции внешних исходных данных. Поскольку источники данных различаются, а данные в несовместимых форматах могут быть данными формата журнала или данными формата журнала и данными формата JSON, нам необходимо преобразовать данные через ETL и поместить их в наше хранилище данных в унифицированном формате.
1.2. Уровень обработки данных.
Уровень обработки данных — это основная функция хранилища данных. Он должен преобразовать все обобщенные данные в данные, которые мы можем проанализировать. Мы не хотим потерять исходную информацию, поэтому нам нужно построить как можно больше таблиц правил. для сохранения данных, которые мы собираем. Информация и данные являются активами.
В соответствии с этой концепцией мы вывели множество иерархических концепций хранилища данных. Обычно мы делим хранилище данных на три уровня, снизу вверх, и извлекаем и уточняем слой за слоем. Начиная с извлечения, это: уровень введения данных (ODS, хранилище операционных данных), общий уровень данных (CDM, общая модель данных) и уровень приложений данных (ADS, служба данных приложений).

Мы по-прежнему анализируем на основе архитектуры процессов хранения данных:
1.2.1 Уровень введения данных ODS (хранилище операционных данных)
Вообще говоря, можно сказать, что ODS представляет собой таблицу сопоставления исходной таблицы данных, которая хранит необработанные исходные данные в системе хранилища данных. Она структурно соответствует исходной информации данных. Это также область кэша подготовки данных. хранилище данных. Оно может сохранять записи исторических данных и добавлять поля. Сохраненные исторические данные доступны только для чтения.

В автономном хранилище данных бизнес-данные регулярно импортируются в ODS посредством процесса ETL. Существует два метода импорта: полный объем и инкрементальный.
- Полный импорт: выберите этот метод при первом импорте данных.
- Инкрементальный импорт: данные не импортируются в первый раз.,Каждый раз необходимо импортировать только вновь добавленные и измененные данные.,Рекомендуется использовать внешние соединения.&Полное покрытие
1.2.2 CDM общего уровня данных (общая модель данных)
CDM общего уровня данных (общая модель данных, также известная как уровень общей модели данных), включая таблицу измерений DIM, DWD и DWS, обрабатывается из данных уровня ODS. В основном он завершает обработку и интеграцию данных, устанавливает согласованные измерения, создает многоразовые подробные таблицы фактов для анализа и статистики, а также суммирует показатели общедоступной детализации.
Среди них трехслойная таблица размеров DIM строится в CDM. Процесс DWD и DWS:
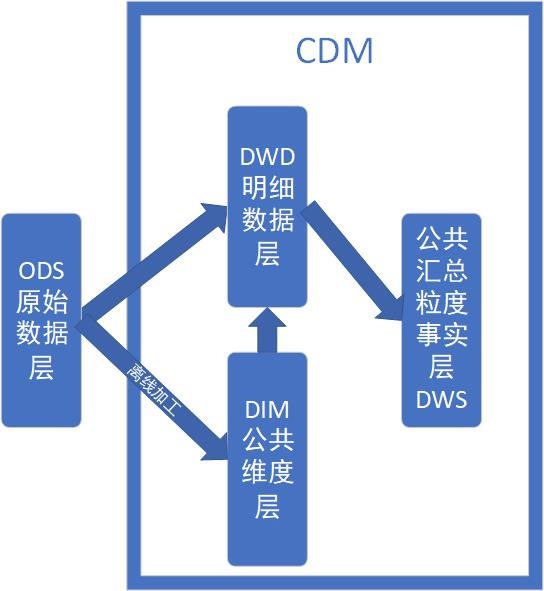
Прежде всего, мы в конечном итоге будем обслуживать уровень ADS, поэтому сначала нам нужно извлечь две абстрактные вещи: темы бизнеса и анализа, которые необходимо унифицировать.
1.2.2.1 Слой сводки общедоступного измерения DIM (Измерение)
Уровень сводки общедоступных измерений (DIM) в основном состоит из таблиц измерений (таблиц измерений). Измерение — это логическая концепция, точка зрения, с которой можно измерять и наблюдать за бизнесом. Таблицы измерений — это физические таблицы, построенные на платформе данных на основе измерений и их атрибутов с использованием принципа проектирования широких таблиц. Таким образом, общий уровень сводки измерений (DIM) сначала должен определить измерения и установить согласованные измерения по всему предприятию. Уменьшите риск несогласованности калибров и алгоритмов расчета данных.
Если нам нужно создать сводный уровень общедоступного измерения DIM и таблицу измерений для бизнеса, занимающегося назначением ставок, сначала необходимо подробно понять потребности бизнеса, занимающегося назначением ставок, и определить основные измерения, которые необходимо проанализировать и запросить. При проведении торгов могут потребоваться следующие аспекты:
- Тендерный проект
- тендерная компания
- Категория тендера
- географическая зона
- Время Размеры (год、четверть、луна、день)
- Руководитель проекта
- Статус ставки
На данный момент мы не будем подробно останавливаться на этом. Процесс моделирования будет подробно описан в подробном процессе моделирования данных хранилища данных в будущем.
1.2.2.2 Подробный уровень детальных фактов DWD (детали хранилища данных)
В архитектуре хранилища данных DWD (уровень подробных данных) является очень важным звеном. Он очищает и преобразует исходные данные на уровне ODS, предоставляет детализированные подробные данные и поддерживает дальнейший анализ и применение данных. Принимая бизнес-процесс в качестве движущей силы моделирования, наиболее детальная таблица фактов на уровне детализации строится на основе характеристик каждого конкретного бизнес-процесса. Вы можете объединить характеристики использования данных предприятия, чтобы сделать некоторые важные поля атрибутов измерения подробной таблицы фактов соответствующим образом избыточными, то есть обработку широкой таблицы. Таблицы на детальном уровне фактов часто также называют логическими таблицами фактов.
Если мы по-прежнему используем бизнес-торговлю для моделирования данных, подробная таблица фактов должна содержать все подробные данные, которые необходимо проанализировать.
Подробная структура таблицы фактов:
- DWD_Детали тендера:
- Тендерный проектID
- Название тендерного проекта
- Категория тендераID
- Идентификатор региона
- Руководитель проектаID
- тендерная компанияID
- Сумма ставки
- Дата тендера
- Статус ставки(Например, торги、Неудачная ставка、выигрышная ставка и т. д.)
- Количество ставок
- Другие связанные поля (например, оценки по отзывам, комментарии по отзывам и т. д.)
1.2.2.3 Уровень фактов детализации общедоступного сводного отчета DWS (сводка хранилища данных)
Создание общего уровня фактов сводной детализации (DWS) — важный шаг в хранилище данных, целью которого является суммирование подробных данных и обеспечение более эффективной поддержки запросов и анализа. Используйте бизнес-процессы в качестве драйверов моделирования. Используя предметный объект анализа в качестве драйвера моделирования, на основе требований к индикатору приложения верхнего уровня и продукта строится таблица фактов сводного индикатора с общедоступной степенью детализации, и модель физизируется с помощью широких таблиц. Создавайте статистические индикаторы со стандартизированными названиями и единообразным калибром, предоставляйте общедоступные индикаторы для верхнего уровня, а также создайте сводные широкие таблицы и подробные таблицы фактов.
Таблицы общедоступного уровня детализации сводных данных также часто называются сводными логическими таблицами и используются для хранения данных производных показателей.
Во-первых, определите данные, которые необходимо обобщить, а также параметры и показатели, которые необходимо обобщить. Для проведения тендерных операций может потребоваться следующее резюме:
- Сводка по времени (год, квартал, месяц)
- Сводка по регионам
- в соответствии стендерная компанияобменобщий
- в соответствии с Категория тендераобменобщий
- в соответствии с Руководитель резюме проекта
Спроектируйте структуру таблицы фактов с суммарной степенью детализации и выберите соответствующие меры и измерения. Например:
- Суммарная мера:
- общий Сумма ставки
- Сумма выигрышной ставки
- Количество ставок
- Количество выигравших ставок
- Размеры:
- время Размеры
- область Размеры
- тендерная компания Размеры
- Категория тендера Размеры
- Руководитель проекта Размеры
Создайте таблицу фактов со сводной детализацией на основе определенных измерений и мер:
-- Создать сводную таблицу фактов DWS
CREATE TABLE Сводка DWS_Тендера (
Идентификатор времени INT,
Идентификатор региона INT,
тендерная компанияID INT,
Категория тендераID INT,
Руководитель проектаID INT,общий Сумма ставки DECIMAL(18, 2),
Сумма выигрышной ставки DECIMAL(18, 2),
Количество ставок INT,
Количество выигравших ставок INT,
PRIMARY KEY (Идентификатор времени, Идентификатор региона, тендерная компанияID, Категория тендераID, Руководитель проектаID)
);Подробные данные уровня DWD суммируются и загружаются на уровень DWS посредством процесса ETL. Для агрегирования данных можно использовать агрегатные функции SQL.
-- 插入обменобщийданные поступают Сводка DWS_Тендераповерхность
INSERT INTO Сводка DWS_Тендера (Идентификатор времени, Идентификатор региона, тендерная компанияID, Категория тендераID, Руководитель проектаID,общий Сумма ставки, Сумма выигрышной ставки, Количество ставок, Количество выигравших ставок)
SELECT
Идентификатор времени,
Идентификатор региона,
тендерная компанияID,
Категория тендераID,
Руководитель проектаID,
SUM(Сумма ставки) ASобщий Сумма ставки,
SUM(CASE WHEN Статус ставки = «выигравшая ставка» THEN Сумма ставки ELSE 0 END) AS Сумма выигрышной ставки,
COUNT(*) AS Количество ставок,
SUM(CASE WHEN Статус ставки = «выигравшая ставка» THEN 1 ELSE 0 END) AS Количество выигравших ставок
FROM
FACT_Тендер
GROUP BY
Идентификатор времени,
Идентификатор региона,
тендерная компанияID,
Категория тендераID,
Руководитель проектаID;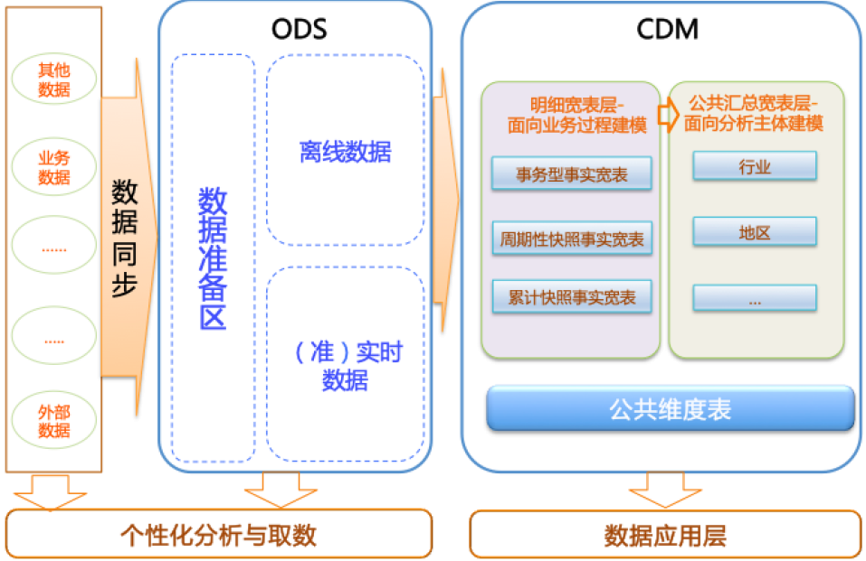
Вышеизложенное является основной концепцией всей архитектуры разработки хранилища данных.
3. Уровень приложений данных
Прикладной уровень данных обычно хранит персонализированные статистические показатели информационных продуктов. Генерируется в соответствии с обработкой на уровне CDM и ODS. Он в основном используется для продуктов данных и анализа данных. Обычно он хранится в ES, PostgreSql, Redis и других системах для использования онлайн-системами. Он также может храниться в Hive или Druid для анализа и интеллектуального анализа данных.
Вообще говоря, это отчет данных BI:
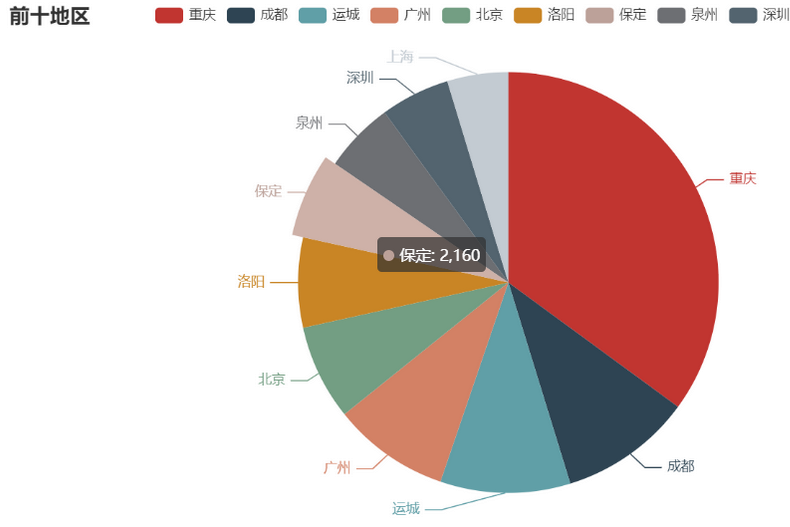
Хранилища данных хороши для анализа данных. Если они напрямую откроют интерфейс бизнес-запросов, это увеличит их нагрузку.。



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
