Руководство по локальному развертыванию Stable Diffusion: подробные шаги и анализ распространенных проблем
Недавно я провел углубленное исследование процесса локального развертывания модели стабильной диффузии. В этом руководстве я подробно опишу каждый шаг от подготовки среды до запуска модели и предоставлю решения распространенных проблем развертывания, которые помогут вам успешно начать локальное создание Stable Diffusion.

1. Экологическая подготовка
1. Установите основные зависимости
В вашей системе установлен Python версии 3.8 или выше, CUDA 11.3+ и соответствующая библиотека cuDNN. Кроме того, вам необходимо установить драйвер NVIDIA.、PyTorch(>=1.10)иtorchvision:
bash
pip install torch torchvision2. Получите код и модель стабильной диффузии.
Клонируйте репозиторий Stable Diffusion:
bash
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusionЗагрузите предварительно обученную модель (требуется регистрация и ключ API):
bash
python scripts/download.py --model-type v1 --prompt-engine dango --api-key <your_api_key>2. Конфигурация и работа модели.
1. Настройте рабочие параметры
Отредактируйте скрипты/run_diffusion.py и настройте путь к модели, параметры выборки, выходной каталог и т. д. в соответствии с вашими потребностями:
python
# Example configuration
model_path = "models/stable-diffusion-v1-4/ldm/stable-diffusion-v1-4.ckpt"
prompt_engine = "dango"
output_dir = "./outputs"
# Sampling parameters
num_samples = 1
image_width = 512
image_height = 512
guidance_scale = 7.52. Запустите модель для создания изображений.
Выполните следующую команду, чтобы начать создание изображений:
bash
python scripts/run_diffusion.pyСгенерированное изображение будет сохранено в указанном выходном_каталоге.
3. Часто задаваемые вопросы и решения
1. Несоответствие версий CUDA/CuDNN.
Убедитесь, что установленные версии CUDA и cuDNN соответствуют требованиям PyTorch. Информацию о версии можно проверить с помощью nvcc --version и cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2.
2. Недостаточно видеопамяти.
Если из-за нехватки видеопамяти программа выходит из строя, попробуйте уменьшить image_width и image_height или уменьшить num_samples. Также убедитесь, что не запущены другие процессы, занимающие видеопамять.
3. Ключ API недействителен или загрузка не удалась.
Проверьте, верен ли предоставленный ключ API и стабильно ли сетевое соединение. Если у вас возникли проблемы, попробуйте получить ключ еще раз или измените сетевое окружение и повторите попытку.
4. Не удалось загрузить модель.
Убедитесь, что путь к файлу модели правильный и файл не поврежден. Если вы получаете модель из других источников, убедитесь, что она совместима с кодом Stable Diffusion.
5. Низкое качество получаемых результатов.
Отрегулируйте параметрguide_scale. Чем больше значение, тем выше точность модели в отношении подсказок, но можно пожертвовать инновациями. Попробуйте использовать разные слова подсказки и комбинации параметров, чтобы получить удовлетворительные результаты.
4. Расширенные операции
1. Используйте собственные слова-подсказки
В run_diffusion.py измените переменную приглашения на необходимое текстовое приглашение:
python
prompt = "A highly detailed painting of a serene mountain landscape, oil on canvas, by Claude Monet"2. Пакетная генерация
Измените параметр num_samples, чтобы генерировать несколько изображений одновременно. Убедитесь, что вашей видеопамяти достаточно для покрытия дополнительных затрат памяти, необходимых для пакетной генерации.
С помощью этого руководства вы должны успешно развернуть и запустить локально модель Stable Diffusion. Несмотря на то, что в процессе развертывания вы можете столкнуться с некоторыми проблемами, если вы будете следовать приведенным выше шагам и решениям один за другим, вы сможете плавно начать свой путь создания произведений искусства с использованием ИИ. В будущем я продолжу делиться более продвинутыми методами использования и методами стабильной диффузии, так что следите за обновлениями.


API-интерфейс Jitu Express для электронных счетов-Express Bird [просто для понимания]

Каковы архитектуры микросервисов Java. Серверная часть плавающей области обслуживания

Описание трех режимов жизненного цикла службы внедрения зависимостей Asp.net Core.

Java реализует пользовательские аннотации для доступа к интерфейсу без проверки токена.

Серверная часть Unity добавляет поддержку .net 8. Я еще думал об этом два дня назад, и это сбылось.
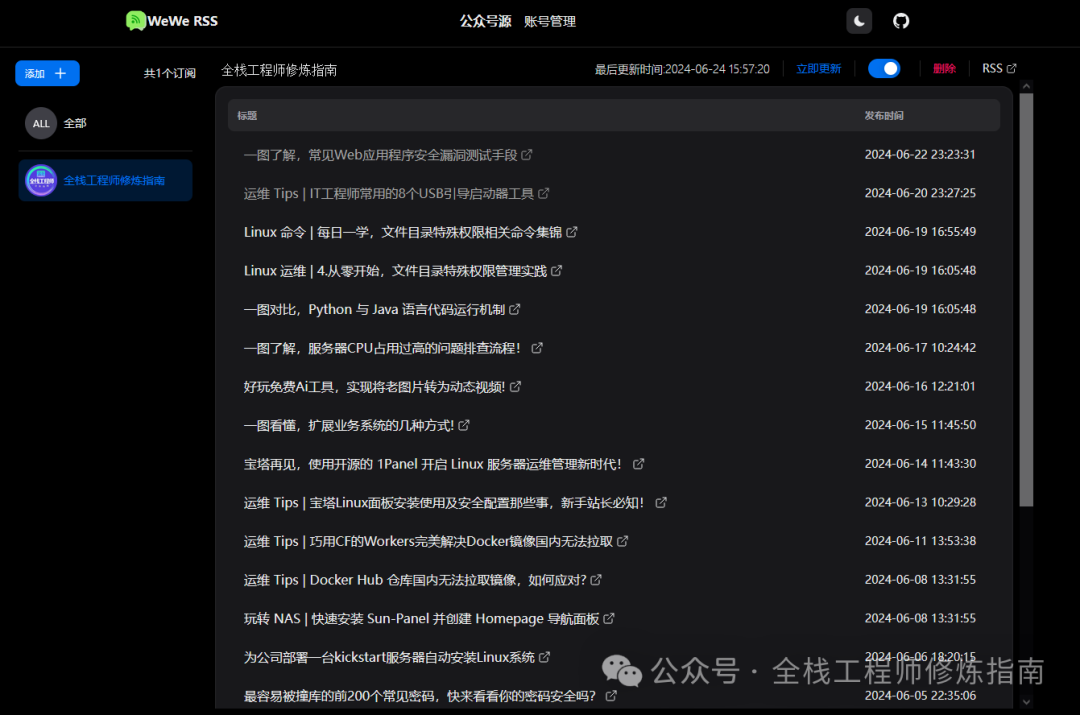
Проект с открытым исходным кодом | Самый элегантный метод подписки на публичные аккаунты WeChat на данный момент
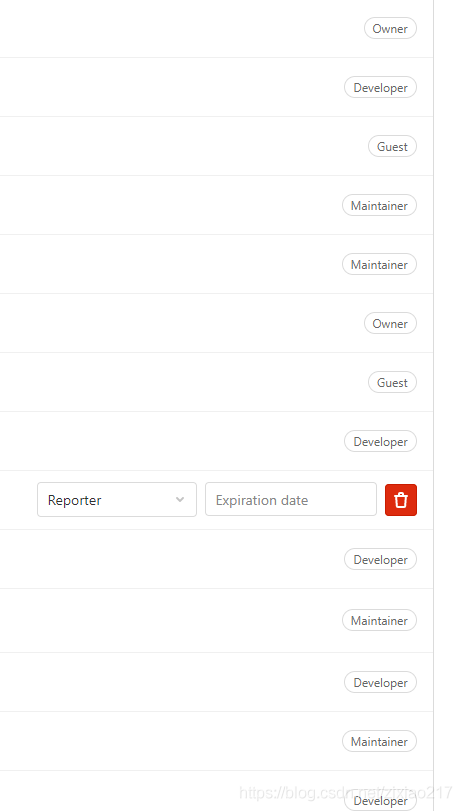
Разрешения роли пользователя Gitlab Гость, Репортер, Разработчик, Мастер, Владелец

Spring Security 6.x подробно объясняет механизм управления аутентификацией сеанса в этой статье.

[Основные знания ASP.NET] — Аутентификация и авторизация — Использование удостоверений для аутентификации.

Соединение JDBC с базой данных MySQL в jsp [легко понять]

[Уровень няни] Полный процесс развертывания проекта Python (веб-страницы Flask) в Docker.
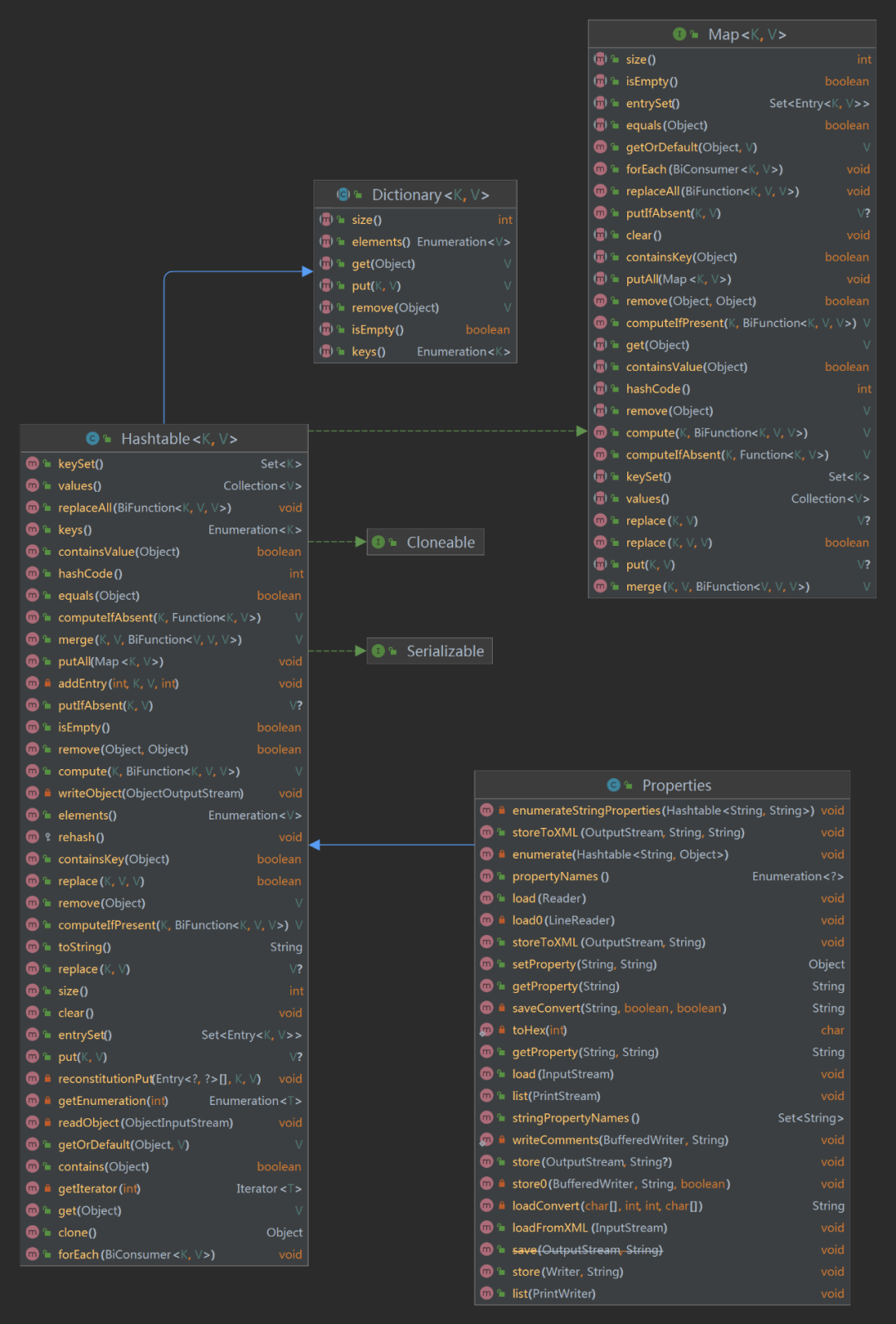
6 способов чтения файлов свойств, рекомендуем собрать!
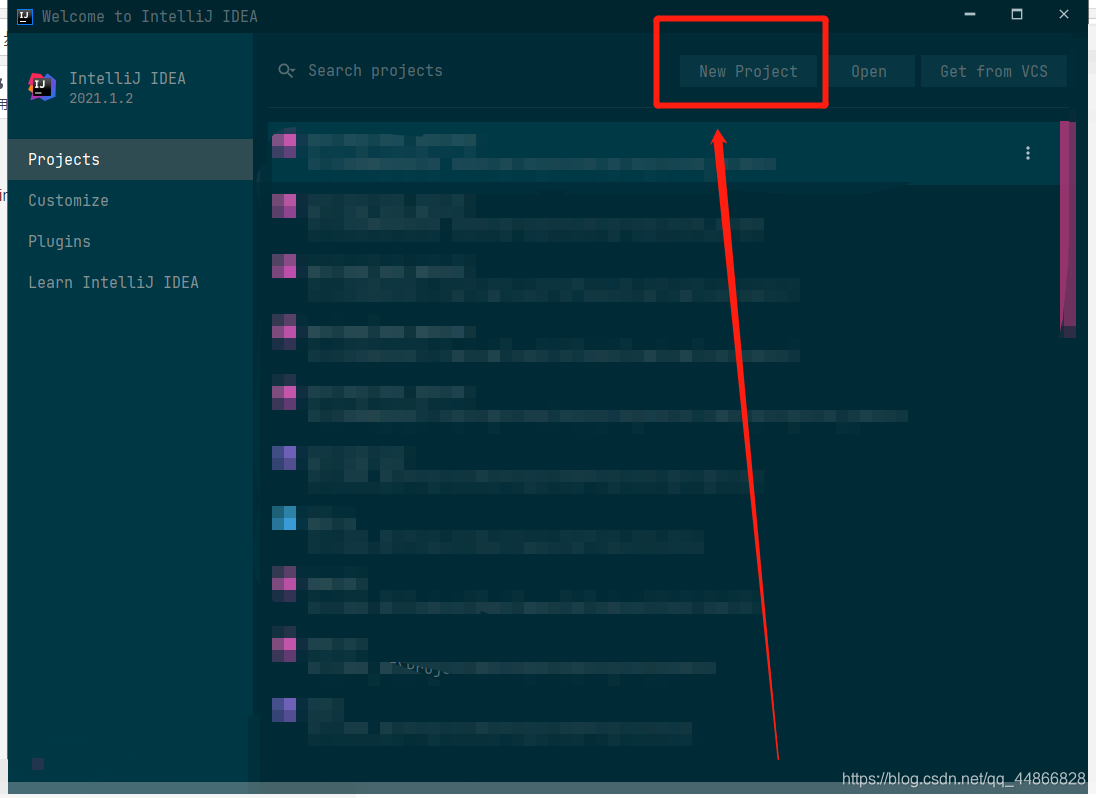
Графическое объяснение этапа строительства проекта IDEA 2021 Spring Cloud (базовая версия)

Подробное объяснение технологии междоменного запроса данных JSONP.

Учебное пособие по SpringBoot (14) | SpringBoot интегрирует Redis (наиболее полный во всей сети)
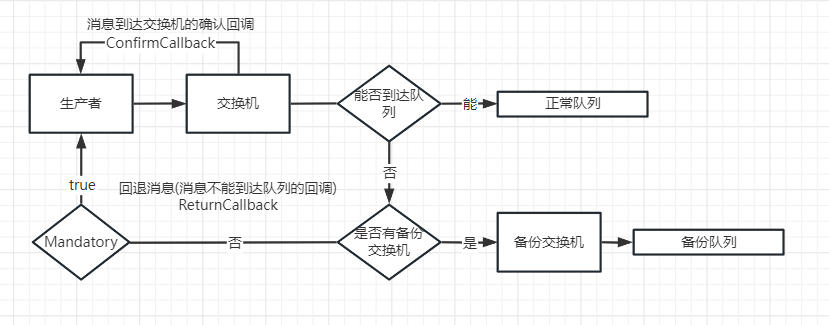
Подробное объяснение механизма подтверждения выпуска сообщений RabbitMQ.

На этот раз полностью поймите протокол ZooKeeper.

Реализуйте загрузку файлов с использованием минимального WEB API.

Демо1 Laravel5.2 — генерация и хранение URL-адресов
Spring boot интегрирует Kafka и реализует отправку и потребление информации (действительно при личном тестировании)
Мысли о решениях по внутренней реализации сортировки методом перетаскивания

Междоменный доступ к конфигурации nginx не может вступить в силу. Междоменный доступ к странице_Page

Как написать текстовый контент на php

PHP добавляет текстовый водяной знак или водяной знак изображения к изображениям – метод инкапсуляции
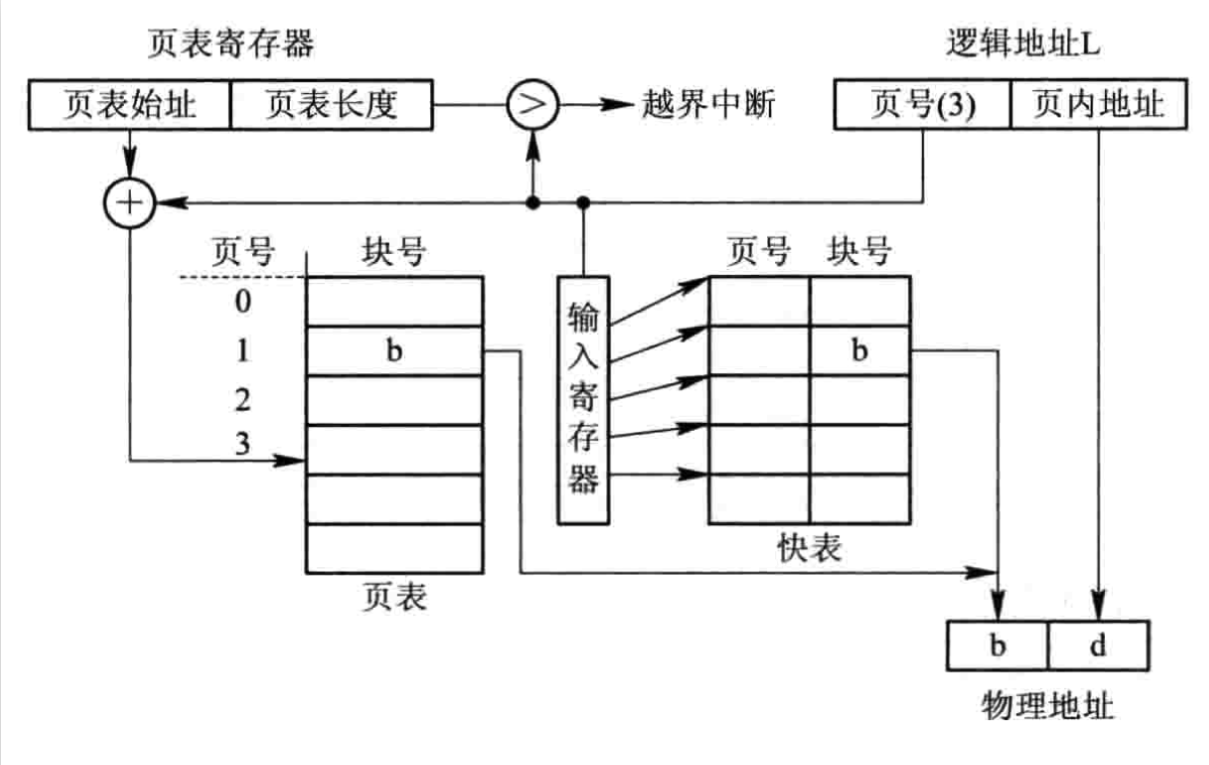
Интерпретация быстрой таблицы (TLB)

Интерфейс WeChat API (полный) — оплата WeChat/красный конверт WeChat/купон WeChat/магазин WeChat/JSAPI

Преобразование Java-объекта в json string_complex json-строки в объект

Примените сегментацию слов jieba (версия Java) и предоставьте пакет jar

matinal: Самый подробный анализ управления разрешениями во всей сети SAP. Все управление разрешениями находится здесь.