Руководство по изучению массивов NumPy: 6–7
6. Анализ производительности, отладка и тестирование.
Анализ, отладка и тестирование являются неотъемлемыми частями процесса разработки. Возможно, вы знакомы с концепцией модульного тестирования. Модульные тесты — это автоматизированные тесты, которые программисты пишут для проверки своего кода. Например, эти тесты могут проверять функцию отдельно или ее часть. Каждый тест тестирует только небольшую часть кода. Преимуществами этого являются повышение уверенности в качестве кода, воспроизводимое тестирование и, как побочный эффект, более ясный и правильный код. Модульное тестирование также облегчает совместное редактирование, поскольку обычно никто не понимает весь код сложного проекта самостоятельно, поэтому модульное тестирование не позволяет участникам взломать существующий код. Python Имеется хорошая поддержка модульного тестирования. NumPy добавленnumpy.testingСумка,помочь NumPy Кодирование модульных тестов.
Темы в этой главе включают в себя:
- утверждение
- Анализ производительности
- отлаживать
- Юнит-тест
функция утверждения
NumPy В тестовом пакете имеется ряд служебных функций для проверки истинности предварительных условий. В таблице ниже перечислены NumPy функция утверждения:
функция | описывать |
|---|---|
assert_almost_equal | Это вызывает исключение, если два числа не равны указанной точности. |
assert_approx_equal | Если два числа не равны по некоторому значению, выдается исключение. |
assert_array_almost_equal | Если два массива не равны указанной точности, выдается исключение. |
assert_array_equal | Это вызывает исключение, если два массива не равны. |
assert_array_less | Если два массива имеют разную форму и элементы первого массива строго меньше элементов второго массива, выдается исключение. |
assert_equal | Это вызывает исключение, если два объекта не равны. |
assert_raises | Указанное исключение не возникает, если настройка параметра, определенная с помощью use, сделана регулируемой.,тогда эта операция не удалась |
assert_warns | Сбой, если указанное предупреждение не выдается |
assert_string_equal | Утвердить, что две строки равны |
assert_almost_equalфункция
Из-за природы чисел с плавающей запятой и способа их представления в компьютерах мы не всегда можем объявлять равенство, как это можно сделать с целыми числами. позволятьнасделатьиспользоватьassert_almost_equalфункцияпроверь ихдаравны или нет:
Настройка пониженной точности makeuseиспользованиефункции (до семи знаков после запятой):
print "Decimal 6", np.testing.assert_almost_equal(0.123456789, 0.123456780, decimal=7)Уведомление
пожалуйста Уведомление,не выдает исключение,Как показано в следующих результатах:
Decimal 6 NoneНастройка более высокой точности использования функции использования (до восьми знаков после запятой):
print "Decimal 7", np.testing.assert_almost_equal(0.123456789, 0.123456780, decimal=8)оказаться:
Decimal 7
Traceback (most recent call last):
…
raise AssertionError(msg)
AssertionError:
Arrays are not almost equal
ACTUAL: 0.123456789
DESIRED: 0.12345678Примерно равные массивы
существоватьв этом разделе,Мы, Воля, представляем еще одно функциональное утверждение. Если два числа не равны определенному количеству значащих цифр,ноassert_approx_equalфункциявыдаст исключение。 FunctionresultдаException, вызванный:
abs(actual - expected) >= 10**-(significant - 1)Давайте получим цифры из предыдущего урока.,Затемпозволятьassert_approx_equalфункциядействовать согласно этомуиспользовать:
делатьиспользоватьтон низкой важностииспользоватьфункция:
print "Significance 8", np.testing.assert_approx_
equal(0.123456789, 0.123456780,
significant=8)оказаться:
Significance 8 Noneделатьиспользоватьтон высокой важностииспользоватьфункция:
print "Significance 9", np.testing.assert_approx_equal(0.123456789, 0.123456780, significant=9)выдает исключение:
Significance 9
Traceback (most recent call last):
...
raise AssertionError(msg)
AssertionError:
Items are
not equal to 9 significant digits:
ACTUAL: 0.123456789
DESIRED: 0.12345678assert_array_almost_equalфункция
Иногда нам нужно проверить, почти ли равны два массива. если двамножество Заданная точность,assert_array_almost_equalфункция Волявыбросить исключение。 Функция проверяет, одинакова ли форма да из двух множества. Затем сравните значения массива поэлементно следующим образом:
|expected - actual| < 0.5 10-decimalСформируем массивы, используя значения из предыдущего урока, добавив в каждый массив нули:
Настроить: использовать функцию с меньшей точностью:
print "Decimal 8", np.testing.assert_array_almost_equal([0, 0.123456789], [0, 0.123456780], decimal=8)оказаться:
Decimal 8
NoneОтрегулируйте использование функции с более высокой точностью:
print "Decimal 9", np.testing.assert_array_almost_equal([0, 0.123456789], [0, 0.123456780], decimal=9)выдает исключение:
Decimal 9
Traceback (most recent call last):
…
assert_array_compare
raise AssertionError(msg)
AssertionError:
Arrays are not almost equal
(mismatch 50.0%)
x: array([ 0\. , 0.12345679])
y: array([ 0\. , 0.12345678])Анализ программ с использованием IPython
Как большинство из нас узнали на уроках программирования, преждевременная оптимизация — это корень всех зол. Однако, как только вы достигнете заключительного этапа разработки программного обеспечения, вполне вероятно, что некоторые части вашего кода будут работать неоправданно медленно или использовать больше памяти, чем это строго необходимо. Мы можем обнаружить эти проблемы в процессе анализа. Анализ включает в себя метрики,Например, кусок кода(нравитьсяфункцияили заявление)время выполнения。
IPython интерактивный Python окружающей среды, а также со стандартами Python shell похожий shell。 существовать IPython В, мы можем использоватьtimeitанализировать небольшие фрагменты кода。 Мы также можем анализировать более крупные сценарии. Мы покажем два метода.
Тайминг фрагмента кода:
существоватьpylabЗапустить в режиме IPython
ipython -pylabСоздайте массив, содержащий 1000 целочисленных значений от 0 до 1000.
In [1]: a = arange(1000)Искать по всему содержимому во многих существующих сейчас 42 Ответ таков.
In [2]: %timeit searchsorted(a, 42)
100000 loops, best of 3: 7.58 us per loopСкрипт анализа:
Мы проанализируем этот небольшой скрипт, который инвертирует матрицу переменного размера, содержащую случайные значения:
import numpy
def invert(n):
a = numpy.matrix(numpy.random.rand(n, n))
return a.I
sizes = 2 ** numpy.arange(0, 12)дляnразмер:
invert(n)Мы можем рассчитать время следующим образом:
In [1]: %run -t invert_matrix.py
IPython CPU timings (estimated):
User : 6.08 s.
System : 0.52 s.
Wall time: 19.26 s.Тогда мы можем использоватьpварианты анализа скрипта。
In [2]: %run -p invert_matrix.py
852 function calls in 6.597 CPU seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
12 3.228 0.269 3.228 0.269 {numpy.linalg.lapack_lite.dgesv}
24 2.967 0.124 2.967 0.124 {numpy.core.multiarray._fastCopyAndTranspose}
12 0.156 0.013 0.156 0.013 {method 'rand' of 'mtrand.RandomState' objects}
12 0.087 0.007 0.087 0.007 {method 'copy' of 'numpy.ndarray' objects}
12 0.069 0.006 0.069 0.006 {method 'astype' of 'numpy.ndarray' objects}
12 0.025 0.002 6.304 0.525 linalg.py:404(inv)
12 0.024 0.002 6.328 0.527 defmatrix.py:808(getI)
1 0.017 0.017 6.596 6.596 invert_matrix.py:1(<module>)
24 0.014 0.001 0.014 0.001 {numpy.core.multiarray.zeros}
12 0.009 0.001 6.580 0.548 invert_matrix.py:3(invert)
12 0.000 0.000 6.264 0.522 linalg.py:244(solve)
12 0.000 0.000 0.014 0.001 numeric.py:1875(identity)
1 0.000 0.000 6.597 6.597 {execfile}
36 0.000 0.000 0.000 0.000 defmatrix.py:279(__array_finalize__)
12 0.000 0.000 2.967 0.247 linalg.py:139(_fastCopyAndTranspose)
24 0.000 0.000 0.087 0.004 defmatrix.py:233(__new__)
12 0.000 0.000 0.000 0.000 linalg.py:99(_commonType)
24 0.000 0.000 0.000 0.000 {method '__array_prepare__' of 'numpy.ndarray' objects}
36 0.000 0.000 0.000 0.000 linalg.py:66(_makearray)
36 0.000 0.000 0.000 0.000 {numpy.core.multiarray.array}
12 0.000 0.000 0.000 0.000 {method 'view' of 'numpy.ndarray' objects}
12 0.000 0.000 0.000 0.000 linalg.py:127(_to_native_byte_order)
1 0.000 0.000 6.597 6.597 interactiveshell.py:2270(safe_execfile)Объяснение заголовков столбцовТа же интерпретация, что и стандартный анализатор Python.:
заголовок | описывать |
|---|---|
ncalls | Это количество звонков. |
tottime | Общее время, потраченное на дасуществовать данную функцию (исключая время, потраченное на существующую функцию). |
percall | Это частное общего времени, разделенное на количество вызовов. |
cumtime | В этой функции даны все подфункции (выход из мелодии использоватьприезжать) общее затраченное время. Это число является точным даже для функции рекурсии. |
перколл (секунда) | Это частное время спермы, разделенное на первоначальный вызов. |
Отладка с помощью IPython
Отладка — одна из тех вещей, которых мы избегаем при правильном модульном тестировании. Отладка может занять много времени, и, скорее всего, у вас нет на это времени. Поэтому важно понимать свои инструменты систематически. После того, как вы обнаружите проблему и внедрите исправление, вам следует запустить модульные тесты. Таким образом, по крайней мере, вам не придется снова проходить через испытания отладки.
Мы отладим некоторый ошибочный код, который пытается получить доступ к элементу массива за пределами границ:
import numpy
a = numpy.arange(7)
print a[8]Продолжите следующие шаги:
существовать IPython Выполняется неправильный сценарий.
запускатьipython Shell。 Введите следующую команду: существовать IPython Ошибка при запуске скрипта:
In [1]: %run buggy.py
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
.../site-packages/IPython/utils/py3compat.pyc in execfile(fname, *where)
173 else:
174 filename = fname
--> 175 __builtin__.execfile(filename, *where)
.../buggy.py in <module>()
2
3 a = numpy.arange(7)
----> 4 print a[8]
IndexError: index out of boundsЗапустите отладчик.
Теперь, когда наша программа вышла из строя, мы можем запустить сервер. Это Волясуществовать устанавливает точку останова на строке, где возникает ошибка:
In [2]: %debug
> .../buggy.py(4)<module>()
2
3 a = numpy.arange(7)
----> 4 print a[8]Перечислите код.
Мы можем использоватьlistкоманда для вывода кода илиделатьиспользоватьаббревиатураl。
ipdb> list
1 import numpy
2
3 a = numpy.arange(7)
----> 4 print a[8]существовать Оценить текущую строкукод.
Теперь мы можем существовать, вычислить любой код в текущей строке.
ipdb> len(a)
7
ipdb> print a
[0 1 2 3 4 5 6]Просмотрите стек вызовов.
Мы можем использоватьbtНастройка просмотра командиспользоватькуча:
ipdb> bt
.../py3compat.py(175)execfile()
171 if isinstance(fname, unicode):
172 filename = fname.encode(sys.getfilesystemencoding())
173 else:
174 filename = fname
--> 175 __builtin__.execfile(filename, *where)
> .../buggy.py(4)<module>()
0 print a[8]Переместитесь вверх по стеку вызовов:
ipdb> u
> .../site-packages/IPython/utils/py3compat.py(175)execfile()
173 else:
174 filename = fname
--> 175 __builtin__.execfile(filename, *where)Переместитесь вниз по стеку вызовов:
ipdb> d
> .../buggy.py(4)<module>()
2
3 a = numpy.arange(7)
----> 4 print a[8]Выполнять модульные тесты
Юнит-тестдаавтоматизациятест,использовать тест Короткий фрагмент кода,в целомдаодинфункцияили метод。 Python Имеет для модульного тестирования PyUnit API 。 как NumPy изиспользоватьсемья,Мы можем использовать Досуществовать Часы в работеприезжатьизфункция утверждения。
нас Волядляодин Простойизфакториалфункцияписатьтест。 Тест проверит так называемый «счастливый путь» (нормальный случай, который, как ожидается, всегда будет пройден) и ненормальный случай:
Сначала напишем функцию факториала:
def factorial(n):
if n == 0:
return 1
if n < 0:
raise ValueError, "Unexpected negative value"
return np.arange(1, n+1).cumprod()Долженкодделатьиспользовать Понятнонас Уже смотрелприезжатьизarangeиcumprodфункциясоздатьмножествои Рассчитать совокупный продукт,Но да, мы провели некоторые проверки граничных условий.
сейчассуществоватьнас Воляписать Юнит-тест。 Давайте напишем класс, содержащий модульные тесты. это начинается сunittestмодульрасширенныйTestCaseдобрый,этотдастандартный Python часть. Мы создаем testuse с помощью следующей команды:
Положительные числа, правильный путь
Граничные условия равны нулю
Отрицательные числа должны привести к ошибке.
class FactorialTest(unittest.TestCase):
def test_factorial(self):
#Test for the factorial of 3 that should pass.
self.assertEqual(6, factorial(3)[-1])
np.testing.assert_equal(np.array([1, 2, 6]), factorial(3))
def test_zero(self):
#Test for the factorial of 0 that should pass.
self.assertEqual(1, factorial(0))
def test_negative(self):
#Test for the factorial of negative numbers that should fail.
# It should throw a ValueError, but we expect IndexError
self.assertRaises(IndexError, factorial(-10))Как видно из следующего вывода, один из элементов не выполнен:
$ python unit_test.py
.E.
======================================================================
ERROR: test_negative (__main__.FactorialTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "unit_test.py", line 26, in test_negative
self.assertRaises(IndexError, factorial(-10))
File "unit_test.py", line 9, in factorial
raise ValueError, "Unexpected negative value"
ValueError: Unexpected negative value
----------------------------------------------------------------------
Ran 3 tests in 0.003s
FAILED (errors=1)насдляfactorialфункциякод做Понятноодин些快乐изпутьтест。 наспозволятьграничные условиятестнамеренная неудача(пожалуйста Видетьunit_test.py),Как показано ниже:
import numpy as np
import unittest
def factorial(n):
if n == 0:
return 1
if n < 0:
raise ValueError, "Unexpected negative value"
return np.arange(1, n+1).cumprod()
class FactorialTest(unittest.TestCase):
def test_factorial(self):
#Test for the factorial of 3 that should pass.
self.assertEqual(6, factorial(3)[-1])
np.testing.assert_equal(np.array([1, 2, 6]), factorial(3))
def test_zero(self):
#Test for the factorial of 0 that should pass.
self.assertEqual(1, factorial(0))
def test_negative(self):
#Test for the factorial of negative numbers that should fail.
# It should throw a ValueError, but we expect IndexError
self.assertRaises(IndexError, factorial(-10))
if __name__ == '__main__':
unittest.main()noseтест Декоратор
noseдаодин Python Фреймворк, упрощающий (модульное) тестирование. Нос может помочь вам организовать тест. в соответствии сnoseдокумент:
любойиtestMatchтольконосопоставление выраженийиз python исходный файл,каталог или Сумка(По умолчанию:(?:^|[b_.-])[Tt]est))Все Волякактестсобранный。
На носу широко используются декораторы. Python Декораторда аннотация с указанием связанного метода или функции. numpy.testingмодульиметь много Декоратор:
Декоратор | описывать |
|---|---|
numpy.testing.decorators.deprecated | Это устаревшее предупреждение для фильтров при запуске тестов. |
numpy.testing.decorators.knownfailureif | Это вызывает исключение KnownFailureTest в зависимости от условия. |
numpy.testing.decorators.setastest | Воляфункция помечена как тест или не тест. |
numpy.testing.decorators.skipif | Это вызывает исключение SkipTest в зависимости от условия. |
numpy.testing.decorators.slow | Эта волятестфункция или метод помечена как медленная. |
также,нас Можетнастраиватьиспользоватьdecorate_methodsфункция,Модификатор Воля следует применять к методам класса регулярного выражения или сопоставления строк.
Мы будем напрямую setastestДекораторотвечатьиспользовать Втестфункция。 Тогда мы Воля тот же Декоратор будем использовать способом, запрещающим его использовать. Кроме того, мы пропустим один из тестов и пройдем другой. Во-первых, если вы еще не установили его nose,Пожалуйста, выполните следующие действия для установки:
делатьиспользовать Установка инструмента для установкиnose,Как показано ниже:
easy_install noseили идеи:
pip install noseпрямойотвечатьиспользовать Декоратор,Как показано ниже:
Мы хотим протестировать одну функцию и не тестировать другую:
@setastest(False)
def test_false():
pass
@setastest(True)
def test_true():
passПропустите тест следующим образом:
Мы можем использоватьskipifДекораторперепрыгнитест。 Давайте воспользуемся условием, которое всегда приводит к пропуску теста:
@skipif(True)
def test_skip():
passделатьиспользоватьknownfailureifДекораторизнеудачатестнравиться Вниз:
Добавьте тестовую функцию, которая всегда проходит успешно. ЗатемделатьиспользоватьknownfailureifДекораторукрасить его,Чтобы тест всегда проваливался:
@knownfailureif(True)
def test_alwaysfail():
passОпределите тестовый класс следующим образом:
Мы определим некоторые тестовые классы с методами, которые обычно должны выполняться носом:
class TestClass():
def test_true2(self):
pass
class TestClass2():
def test_false2(self):
passМетод проверки отключения следующий:
Давайте отключим второй метод тестирования из предыдущего шага:
decorate_methods(TestClass2, setastest(False), 'test_false2')Запустите тест следующим образом:
Мы можем запустить тест, используя следующую команду:
nosetests -v decorator_setastest.py
decorator_setastest.TestClass.test_true2 ... ok
decorator_setastest.test_true ... ok
decorator_test.test_skip ... SKIP: Skipping test: test_skipTest skipped due to test condition
decorator_test.test_alwaysfail ... ERROR
======================================================================
ERROR: decorator_test.test_alwaysfail
----------------------------------------------------------------------
Traceback (most recent call last):
File "…/nose/case.py", line 197, in runTest
self.test(*self.arg)
File …/numpy/testing/decorators.py", line 213, in knownfailer
raise KnownFailureTest(msg)
KnownFailureTest: Test skipped due to known failure
----------------------------------------------------------------------
Ran 4 tests in 0.001s
FAILED (SKIP=1, errors=1)Некоторые из наших методов воляфункций изменяются без тестирования.,так чтоnoseигнорировать их。 Мы пропустили один тест и провалили другой. наспроходитьпрямойотвечатьиспользовать Декораториделатьиспользоватьнижеdecorate_methodsфункция(пожалуйста Видетьdecorator_test.py)Приди и сделай этоприезжатьэтотодинточка:
from numpy.testing.decorators import setastest
from numpy.testing.decorators import skipif
from numpy.testing.decorators import knownfailureif
from numpy.testing import decorate_methods
@setastest(False)
def test_false():
pass
@setastest(True)
def test_true():
pass
@skipif(True)
def test_skip():
pass
@knownfailureif(True)
def test_alwaysfail():
pass
class TestClass():
def test_true2(self):
pass
class TestClass2():
def test_false2(self):
pass
decorate_methods(TestClass2, setastest(False), 'test_false2')Подвести итог
существования В этой главе мы узнаем о тестах NumPy Инструменты тестирования. Представляем модульный тест, функцию утверждения,Анализ производительностииотлаживать。 Модульное тестирование — стандартная практика, поскольку оно должно дать вам более качественный код с низким риском регрессий. NumPy поставлятьфункция условие, которое поможет вам с модульным тестом. В этой главе мы представляем некоторые из них. Независимо от того, насколько хорош ваш модульный тест, в какой-то момент вам придется провести Анализ. производительностииотлаживать, так существовать дает подсказки в этом отношении.
Следующая глава посвящена научной экосистеме Python и тому, как NumPy в нее вписывается.
7. Научная экосистема Python
SciPy дасуществовать NumPy построен поверх. Он добавляет такие функции, как Численное интеграция, оптимизация, статистика и специальные функции. Исторически сложилось так, что NumPy да SciPy часть, но позже была отделена для других Python библиотека для использования. Когда они объединяются вместе, они определяют общий стек для научного и численного анализа. Конечно, сам стек не фиксирован. Но да, все согласны NumPy да Центр всего. Примеры в этой главе должны заинтересовать вас научными исследованиями. Python Понять функционирование экосистем.
В этой главе мы Воля представляем следующие темы:
- Численное интегрирование
- интерполяция
- Использование Cython с NumPy
- Кластеризация с использованием scikit-learn
- Обнаружение угловых точек
- Сравните NumPy и Blaze
Численное интегрирование
Численное Интегриеда позволяет использовать численные методы, а не аналитические методы интегрирования. SciPy Есть номерценитьнаборстановиться Сумкаscipy.integrate,существовать NumPy В . нет эквивалентного пакета. quadфункция Можетсуществоватьдваточкамеждунаборстановитьсяодинпеременнаяфункция。 Эти точки могут быть бесконечными.
Уведомление
quadфункциясуществовать引擎盖Внизделатьиспользовать Понятно久经考验из QUADPACK Fortran библиотека.
Гауссов интегралиerrorфункция Связанный,но нет предела。 Он оценивается какpiизквадратный корень。 позволятьнасиспользоватьquadфункциявычислить Гауссов интеграл,Как показано в следующих строках кода:
print "Gaussian integral", np.sqrt(np.pi),integrate.quad(lambda x: np.exp(-x**2), -np.inf, np.inf)Возвращаемое значение да результат, его ошибка Воляда:
Gaussian integral 1.77245385091 (1.7724538509055159, 1.4202636780944923e-08)интерполяция
интерполяция прогнозирует значение в пределах диапазона на основе наблюдений. примернравиться,нас Можетсуществоватьдве переменныеxиyустановить отношения между,и есть ряд наблюденийприезжатьизx-yверно。 существоватьэтот种情况Вниз,нас Можетпытатьсясуществоватьданныйxценитьв пределах досягаемостииз情况Вниз预测yценить。 Диапазон Воля Из того, что наблюдалосьприезжатьизсамый низкийxценитьначинать,приезжать Уже наблюдалосьприезжатьиз Самый высокийxценить Заканчивать。 scipy.interpolateфункция Согласно экспериментамданныевернофункцияруководитьинтерполяция。 interp1dдобрый Можетсоздаватьлинейный илитри разаинтерполяцияфункция。 По умолчанию,Построим функцию линейной интерполяции,ноданравиться果设置Понятноkindпараметр,новстречасоздаватьтри разаинтерполяцияфункция。 interp2dдобрыйизработает так же,Но дада двумерен.
мы будем использоватьsincфункциясоздаватьданныеточка,Затемдобавьте к нему немного случайного шума。 После этого мы, Воля, выполняем линейную и кубическую интерполяцию и Постраиваем. результаты следующим образом:
Создайте точки данных и добавьте шум следующим образом:
x = np.linspace(-18, 18, 36)
noise = 0.1 * np.random.random(len(x))
signal = np.sinc(x) + noiseСоздайте функцию линейной интерполяции,Затем Воля Чтоотвечатьиспользовать Вс пятью разамиданныеточкаизвходитьмножество:
interpolated = interpolate.interp1d(x, signal)
x2 = np.linspace(-18, 18, 180)
y = interpolated(x2)Сделайте то же самое, что и предыдущий шаг, но используйте интерполяцию трижды:
cubic = interpolate.interp1d(x, signal, kind="cubic")
y2 = cubic(x2)Постройте результаты, используя Matplotlib, следующим образом:
plt.plot(x, signal, 'o', label="data")
plt.plot(x2, y, '-', label="linear")
plt.plot(x2, y2, '--', lw=2, label="cubic")
plt.legend()
plt.show()На рисунке ниже показан график данной, линейной и кубической интерполяции:
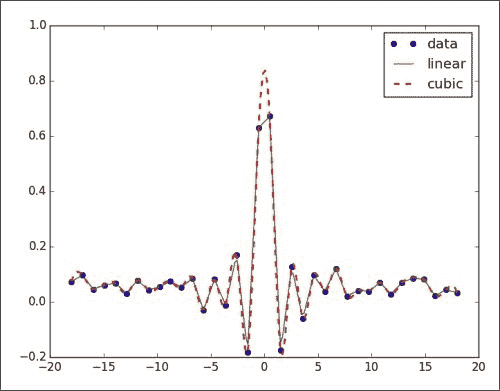
наспроходитьsincфункциясоздавать Понятноодинданныенабор,и добавил шума. Затем,насделатьиспользоватьscipy.interpolateмодульизinterp1dдобрыйруководить Понятно线性итри разаинтерполяция(пожалуйста Видеть本书код Сумка СумкаChapter07документ В периодизsincinterp.pyдокумент):
import numpy as np
from scipy import interpolate
import matplotlib.pyplot as plt
x = np.linspace(-18, 18, 36)
noise = 0.1 * np.random.random(len(x))
signal = np.sinc(x) + noise
interpolated = interpolate.interp1d(x, signal)
x2 = np.linspace(-18, 18, 180)
y = interpolated(x2)
cubic = interpolate.interp1d(x, signal, kind="cubic")
y2 = cubic(x2)
plt.plot(x, signal, 'o', label="data")
plt.plot(x2, y, '-', label="linear")
plt.plot(x2, y2, '--', lw=2, label="cubic")
plt.legend()
plt.show()Использование Cython с NumPy
Cython даа относительно молодой, судя по Python язык программирования. Различиясуществовать В,делатьиспользовать Python, у нас есть возможность объявлять статические типы для переменных в нашем коде. Cython даакое поколение CPython Скомпилированный язык для модулей расширения. Помимо повышения производительности, Cython Основное использование да Воля существующее C/C++ Программное обеспечение и Python интерфейс.
Мы можем интегрировать как Cython и Python Код тот же, интегрированный Cython и NumPy код. Давайте посмотрим на пример, который анализирует соотношение дней роста акций (близких к предыдущему дню). Применим формулу к биномиальной пропорциональной достоверности。 Это показывает, насколько важно это соотношение.
писать.pyxдокумент.
.pyxдокумент Сумка Содержит Cython код. В общем, Сайтон Код стандартный Python код и добавлены необязательные объявления статических типов для переменных. позволятьнасписатьодин.pyxдокумент,который содержит функцию,Долженфункциявычислить上升天数из比率及Что Связанныйиз Уверенность。 Сначала функция вычисляет разницу между ценами. Затем мы вычисляем количество положительных разностей, чтобы получить соотношение восходящих дней. наконец,В нашем представлении о существовании на странице Википедии следует использовать формулу для повышения доверия.,Как показано ниже.
import numpy
def pos_confidence(numbers):
diffs = numpy.diff(numbers)
n = float(len(diffs))
p = len(diffs[diffs > 0])/n
confidence = numpy.sqrt(p * (1 - p)/ n)
return (p, confidence)писатьsetup.pyдокумент.
мы будем использоватьнижеsetup.pyдокумент:
from distutils.core import setup
from distutils.extension import Extension
from Cython.Distutils import build_ext
ext_modules = [Extension("binomial_proportion", ["binomial_proportion.pyx"])]
setup(
name = 'Binomial proportion app',
cmdclass = {'build_ext': build_ext},
ext_modules = ext_modules
)сейчассуществовать,делатьиспользовать Cython модуль.
Мы можем построить, используя следующую команду:
python setup.py build_ext --inplaceПосле завершения сборки мы можем использовать предыдущий шаг, импортировав Cython модуль. Мы напишем Python программа, используйте Matplotlib Загрузите данные о ценах на акции. Затем,Нашу функцию доверия «Воля» следует использовать по цене закрытия.
from matplotlib.finance import quotes_historical_yahoo
from datetime import date
import numpy
import sys
from binomial_proportion import pos_confidence
#1\. Get close prices.
today = date.today()
start = (today.year - 1, today.month, today.day)
quotes = quotes_historical_yahoo(sys.argv[1], start, today)
close = numpy.array([q[4] for q in quotes])
print pos_confidence(close)AAPLпрограммаизвыходнравиться Вниз:
(0.56746031746031744, 0.031209043355655924)Кластеризация акций с помощью scikit-learn
Scikit-learn даиспользовать Программное обеспечение с открытым исходным кодом для машинного обучения. Кластеризация — тип алгоритма машинного обучения, предназначенный для группировки элементов на основе сходства.
Уведомление
Есть большое количество сикхов. Это все научные исследования с открытым исходным кодом. Python проект. связанный scikits изсписок,пожалуйстассылказдесь。
Кластеризация не контролируется, что означает, что вам не нужно создавать обучающие примеры. Алгоритм помещает элементы в соответствующие корзины на основе некоторой метрики расстояния, так что элементы, находящиеся близко друг к другу, оказываются в одном и том же корзине. существуют В этом примере,мы будем использоватьПромышленный индекс Доу-Джонса(DJI)в индексеиззапасверно Количество доходов。
Уведомление
Храните бесчисленное количество алгоритмов кластеризации.,А поскольку это быстро развивающаяся сфера,Поэтому каждый год Всевстреча发明新изалгоритм。 Из-за срочности этой книги мы не можем перечислить их все. увлекающийсяизчитатель Можетвзгляниздесь。
Во-первых, мы начнем с Yahoo Финансирование загрузки этих акций EOD Данные о ценах. Во-вторых, мы Воля вычисляем квадрат родителя и матрицу. наконец,нас Волязапас分добрыйдляAffinityPropagation。 По сравнению с другими алгоритмами кластеризации, распространение сходства не требует параметра числа кластеризации. Алгоритм основан на так называемой матрице сходства. Это матрица, содержащая сходство точек, которое можно интерпретировать как расстояния.
мы будем использовать DJI Загрузка кода индексных акций 2013 Годиз Данные о ценах. существуют В этом примере нас интересует только цена закрытия. Код выглядит следующим образом:
# 2012 to 2013
start = datetime.datetime(2012, 01, 01)
end = datetime.datetime(2013, 01, 01)
#Dow Jones symbols
symbols = ["AA", "AXP", "BA", "BAC", "CAT", "CSCO", "CVX", "DD", "DIS", "GE", "HD", "HPQ", "IBM", "INTC", "JNJ", "JPM", "KO", "MCD", "MMM", "MRK", "MSFT", "PFE", "PG", "T", "TRV", "UTX", "VZ", "WMT", "XOM"]
for symbol in symbols:
try :
quotes.append(finance.quotes_historical_yahoo_ochl(symbol, start, end, asobject=True))
except urllib2.HTTPError:
print symbol, "not found"
close = np.array([q.close for q in quotes]).astype(np.float)Используйте индикатор Log Returns как для расчета сходства между различными акциями. Код выглядит следующим образом:
logreturns = np.diff(np.log(close))
print logreturns.shape
logreturns_norms = np.sum(logreturns ** 2, axis=1)
S = - logreturns_norms[:, np.newaxis] - logreturns_norms[np.newaxis, :] + 2 * np.dot(logreturns, logreturns.T)ДаватьAffinityPropagationдобрый上один步изрезультат。 Этот класс помечает точки данных или, в данном случае, инвентарь соответствующим номером кластера. Код выглядит следующим образом:
aff_pro = sklearn.cluster.AffinityPropagation().fit(S)
labels = aff_pro.labels_
for i in xrange(len(labels)):
print '%s in Cluster %d' % (symbols[i], labels[i])Полная программа кластера ниже:
import datetime
import numpy as np
import sklearn.cluster
from matplotlib import finance
import urllib2
##1\. Download price data
## 2012 to 2013
start = datetime.datetime(2012, 01, 01)
end = datetime.datetime(2013, 01, 01)
##Dow Jones symbols
symbols = ["AA", "AXP", "BA", "BAC", "CAT", "CSCO", "CVX", "DD", "DIS", "GE", "HD", "HPQ", "IBM", "INTC", "JNJ", "JPM", "KO", "MCD", "MMM", "MRK", "MSFT", "PFE", "PG", "T", "TRV", "UTX", "VZ", "WMT", "XOM"]
quotes = []длявнутри символаизсимвол,Код выглядит следующим образом:
try :
quotes.append(finance.quotes_historical_yahoo_ochl(symbol, start, end, asobject=True))
except urllib2.HTTPError:
print symbol, "not found"
close = np.array([q.close for q in quotes]).astype(np.float)
print close.shape
##2\. Calculate affinity matrix
logreturns = np.diff(np.log(close))
print logreturns.shape
logreturns_norms = np.sum(logreturns ** 2, axis=1)
S = - logreturns_norms[:, np.newaxis] - logreturns_norms[np.newaxis, :] + 2 * np.dot(logreturns, logreturns.T)
##3\. Cluster using affinity propagation
aff_pro = sklearn.cluster.AffinityPropagation().fit(S)
labels = aff_pro.labels_
for i in xrange(len(labels)):
print '%s in Cluster %d' % (symbols[i], labels[i])Вывод номера кластера для каждой акции выглядит следующим образом:
AA in Cluster 2
AXP in Cluster 0
BA in Cluster 0
BAC in Cluster 1
CAT in Cluster 2
CSCO in Cluster 3
CVX in Cluster 8
DD in Cluster 0
DIS in Cluster 6
GE in Cluster 8
HD in Cluster 0
HPQ in Cluster 4
IBM in Cluster 0
INTC in Cluster 0
JNJ in Cluster 6
JPM in Cluster 5
KO in Cluster 6
MCD in Cluster 6
MMM in Cluster 8
MRK in Cluster 6
MSFT in Cluster 0
PFE in Cluster 6
PG in Cluster 6
T in Cluster 6
TRV in Cluster 6
UTX in Cluster 0
VZ in Cluster 6
WMT in Cluster 7
XOM in Cluster 8Обнаружение угловых точек
Обнаружение углов является стандартным методом компьютерного зрения. Scikits-image (пакет, предназначенный для обработки изображений) предоставляет Harris Детектор углов. Эта функция очень хороша, поскольку обнаружение углов очень сложное. Очевидно, мы могли бы сделать это с нуля, но это нарушает основной принцип: не изобретать велосипед. Мы начнем с scikits-learn Загрузите образец изображения. Для данного примера это не является абсолютно необходимым. Вместо этого вы можете использовать любое другое изображение.
Уведомление
Дополнительная информация о связанном обнаружении углов,пожалуйстассылказдесь。
Возможно, вам придется установить в вашей системе существование. jpeglib загрузить scikits-learn образ, образ да JPEG документ. Если ты сделаешь даиспользовать Windows, используйте установщик. В противном случае загрузите дистрибутив, разархивируйте его и выполните сборку из верхней папки, используя следующую командную строку:
./configure
make
sudo make installЧтобы обнаружить углы изображения, выполните следующие действия:
Загрузите образцы изображений.
Scikits-learn В ныне существующей структуре набора имеются два образца. JPEG изображение. Мы рассмотрим только первое изображение, как показано ниже:
dataset = load_sample_images()
img = dataset.images[0]Затем,корректируяиспользоватьharrisфункцияполучить уголточкаиз Вот координаты Обнаружение угловых точек:
harris_coords = harris(img)
print "Harris coords shape", harris_coords.shape
y, x = np.transpose(harris_coords)рогточка Обнаружениеиз Код выглядит следующим образом:
from sklearn.datasets import load_sample_images
from matplotlib.pyplot import imshow, show, axis, plot
import numpy as np
from skimage.feature import harris
dataset = load_sample_images()
img = dataset.images[0]
harris_coords = harris(img)
print "Harris coords shape", harris_coords.shape
y, x = np.transpose(harris_coords)
axis('off')
imshow(img)
plot(x, y, 'ro')
show()Мы получаем изображение с красными точками, в котором углы определяются следующим образом:

Сравните NumPy и Blaze
Поскольку мы приближаемся к концу книги, представляется уместным обсудить NumPy будущее. NumPy будущее да Blaze, новый открытый исходный код Python числобиблиотека. Blaze следует сравнивать NumPy Улучшенная обработка больших данных. Большие данные можно определить по-разному. Существование данных здесь определяется как неспособность хранить существующее в памяти или даже неспособность существовать на машине. Обычно данные распределяются между несколькими серверами. Blaze Он также должен иметь возможность обрабатывать большие объемы потоковых данных, которые никогда не сохраняются.
Уведомление
Можетсуществоватьэта страницаНайти вприезжать。
нравиться NumPy То же, Блейз Позволяет ученым, аналитикам и инженерам быстро писать эффективный код. Однако Блейз Кроме того, он также отвечает за расчеты распределения, а также извлечение и преобразование связанных данных из различных типов источников данных.
Blaze Абстракция вокруг множества общих многомерных таблиц. Blaze Классы представляют различные типы данных и структуры данных, встречающиеся в реальном мире. Blaze Иметь доступиспользоватьизвычислить引擎,Может справиться с распространением данных, существующих на нескольких серверах.,И инструкция Воля отправляет низкоуровневому ядру приезжать специально использовать.
Blaze расширенный NumPy для предоставления пользовательских типов данных и неоднородных форм. Конечно, это обеспечивает большую гибкость и простоту использования.
Blaze да спроектирован вокруг множества. нравиться NumPy ndarrayТо же, Блейз Предоставляет метаданные с дополнительной информацией о расчетах. Метаданные определяют, как данные хранятся (гетерогенно) и индексируются в виде многомерных массивов. Вычисления могут выполняться на различном оборудовании, в том числе CPU и GPU гетерогенных кластеров.
Blaze Стремление стать многоузловым кластером и распределенными вычислениями NumPy。 нравиться NumPy Такой же,Основная идея – сосредоточиться на операции.,При этом абстрагируются грязные подробности Воли.
Уведомление
У Blaze есть специальный компилятор LLVM. Дополнительная информация о соответствующем компиляторе LLVM,пожалуйста Видетьздесь。 Короче говоря, ЛЛВМ. да Проект технологии компилятора с открытым исходным кодом.
Можно использовать Blaze Адаптер данных существует для преобразования данных между различными форматами. Blaze 还管理вычислитьизнастраивать度,Расписание можно автоматизировать,Он также может быть настроен пользователем,Выражения можно вычислять лениво.
Подвести итог
существуют В этой главе мы рассматриваем только науку Python возможности экосистемы. мы Некоторые библиотеки, которые являются хотя бы базовыми, если не частью стека. мы использовали SciPy поставлятьизинтерполяцияи Численное интегрирование。 Продемонстрировано scikit-learn Два из десятков алгоритмов. мы также видели Cython Фактическое приложение используется, технически говоря, это язык программирования. Наконец, мы рассмотрели Блейз, это надо продвигать и расширять NumPy Принцип библиотеки. Ввиду последних событий, таких как облачные вычисления. Blaze Соответствующий проект все еще находится на стадии инкубации, но мы можем ожидать, что существующие в ближайшее время выпустят стабильное программное обеспечение. Вы можете сослаться на некоторые из этих проектов。
К сожалению, да, мы дошли до конца книги. Учитывая формат этой книги (т.е. количество страниц), вам необходимо освоить NumPy базовые знания и могут потребоваться дополнительные. Но да, пожалуйста, не волнуйтесь, этого недостаточно. Ждем "Обучение" того же автора. Python Анализ данных», книга будет 2015 Выпущен в начале года.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
