Результаты обзора докладов ICLR 2024 уже опубликованы! Более 7000 высокодоходных бумаг установили новый рекорд, причем наибольшая доля приходится на диффузионные модели.
Шин Джиген
【Введение】ICLR Наконец-то стали известны результаты обзора статей 2024 года. В этом году было подано более 7000 статей, что стало новым рекордом в истории.
Объявлены результаты проверки ICLR 2024!
ICLR — одна из важных научных конференций в области машинного обучения, которая проводится ежегодно. 2024 — двенадцатая по счету выставка, которая пройдет в Вене, Австрия, с 7 по 11 мая.
Согласно официальным результатам, опубликованным OpenReview, в этом году всего было подано 7135 работ.

Кроме того, другой отечественный разработчик, Вэй Гоцян, собрал полную статистику по своему сканеру. Было подано 7215 статей со средним баллом 4,88.
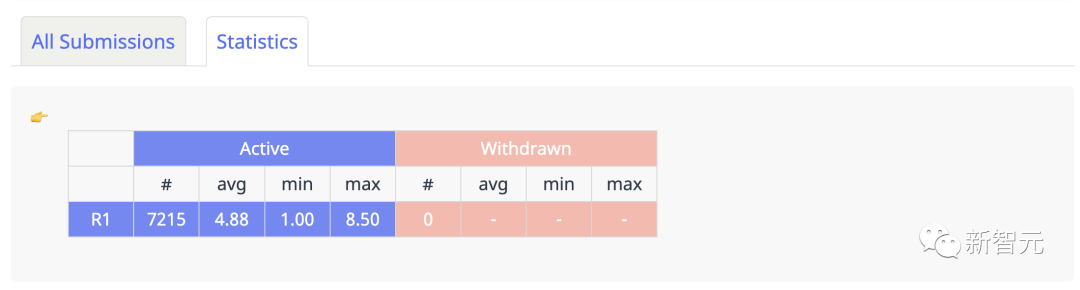
https://guoqiangwei.xyz/iclr2024_stats/iclr2024_submissions.html
Если посмотреть на конкретное распределение баллов, то имеется 1086 статей со средним баллом 4,2, 1163 статьи со средним баллом 4,9 и 1015 статей со средним баллом 5,7. Это баллы статей со средним баллом 1000+.
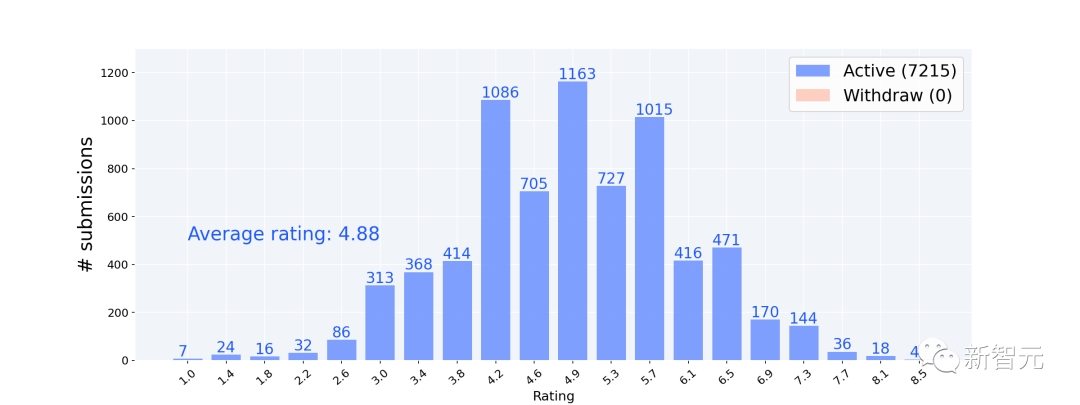
Инженеры Amazon насчитали 7304 отправленных статьи со средним баллом 4,9.

Удельные пропорции составляют 4,9-5,0 и 5,2-5,3 соответственно, что составляет 9% от общего количества статей.
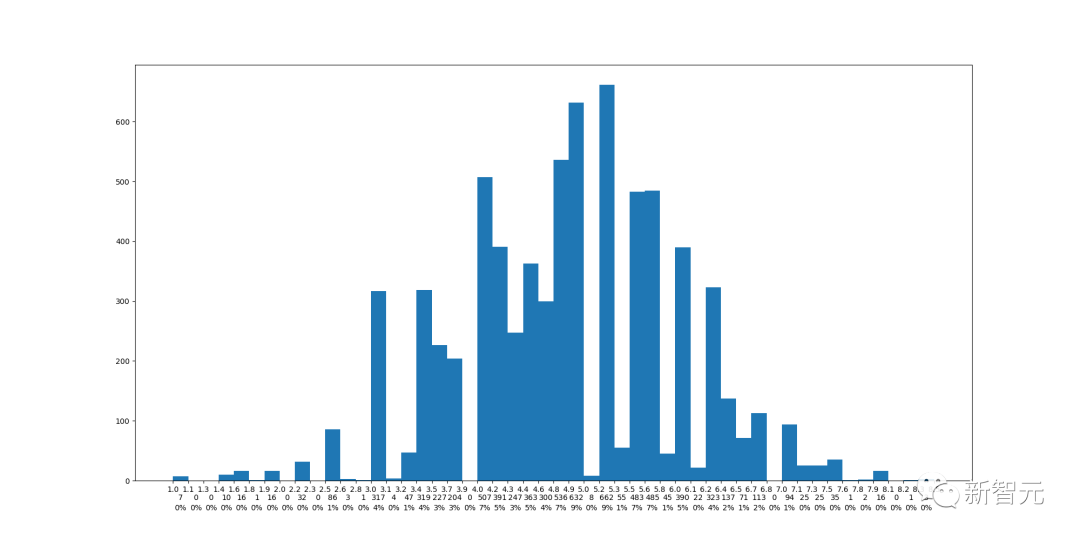
https://github.com/maxxu05/openreview_summarizereviews/tree/main
Количество поданных статей выросло более чем на 7000, достигнув рекордного уровня
Самое примечательное, что независимо от конкретного количества заявок, общее количество заявок на ICLR 2024 достигло рекордного уровня.
Этот огромный контраст можно увидеть из статистических данных за последние годы.
В ICLR 2017 было всего 490 статей, а в ICLR 2023 — 4955 статей. ICLR 24 добавил более 2000 статей.
Уровень принятия был выше 30% в течение последних двух лет, и в этом году он не будет ниже.
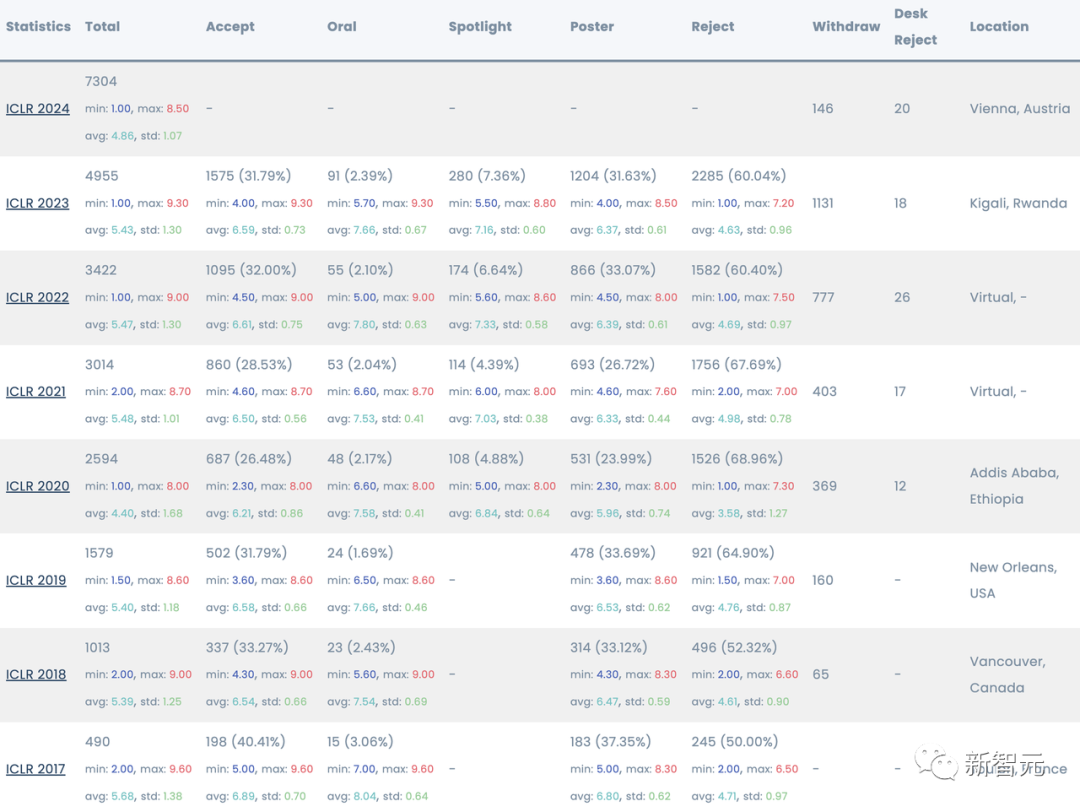
Беспрецедентное количество поданных статей неотделимо от огромного вклада ChatGPT.
На прошлой неделе платформа arXiv объявила общее количество статей, отправленных на платформу в октябре. Всего за месяц было отправлено 20 710 статей, что также установило новый рекорд.
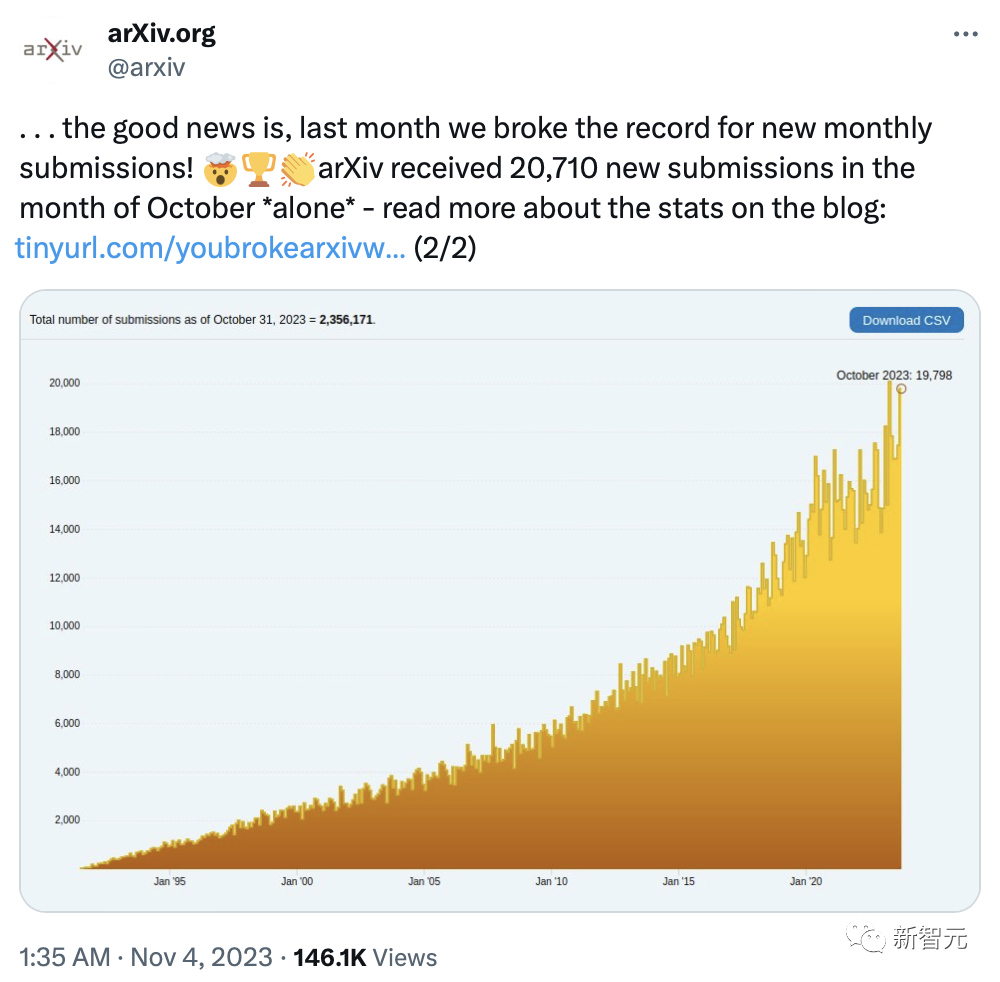
Среди них около половины статей относятся к области CS, а 3500 препринтов относятся к областям CV и ML.

В среднем каждый день загружается 668 статей, что действительно немного возмутительно.


Область исследований ICLR 2024, наибольшая доля приходится на диффузионную модель.
Итак, какие области охватываются темами докладов, представленных на ICLR 2024? Некоторые пользователи сети также подвели итоги?
- 451 наименование содержит "Diffusion" - 208 наименований содержат "LLM" - 6 заголовков содержат "ChatGPT" - 25 наименований содержат "NeRF" - 41 заголовок содержит слово "ГАН" - 15 наименований содержат «Все, что вам нужно» - 22 названия содержат "Мечта" - 6 названий содержат «Магию»
эссе на высокий балл
Первая статья «Обобщение в моделях диффузии возникает из геометрически адаптивного гармонического представления» представляет собой исследование моделей диффузии с оценками 8,8,10,8.
В настоящее время алгоритм обратной диффузии на основе оценок способен генерировать высококачественные выборки, и это открытие демонстрирует, что глубокие нейронные сети (DNN), обученные шумоподавлению, могут изучать распределения плотности данных, несмотря на проклятие размерности.
Однако в последнее время было много дискуссий о том, что модель просто запоминает обучающие данные и на самом деле не изучает существенное распределение данных.
В связи с этим исследователи обучили две модели DNN с шумоподавлением на разных подмножествах данных и обнаружили, что их оценочные функции и распределения плотности были очень близки, а объем данных обучающего изображения был на удивление небольшим.
Эта сильная способность к обобщению доказывает, что в архитектуре DNN и алгоритме обучения существует сильная индуктивная предвзятость.
Далее исследователи проанализировали причину существования этого индуктивного смещения и доказали, что модель шумоподавления выполняет операции сжатия, основанные на адаптации к основному изображению.
Модель все равно изучит это гармоническое представление, даже если она обучена на некоторых данных изображения, которые не подходят для этой основы. Таким образом, можно продемонстрировать, что модель шумоподавления смещена в сторону этого адаптивного гармонического представления.
Кроме того, мы показываем, что сеть достигает почти оптимальной производительности шумоподавления при обучении на обычных классах изображений, где оптимальной основой, как известно, является геометрическая адаптация и гармонизация.

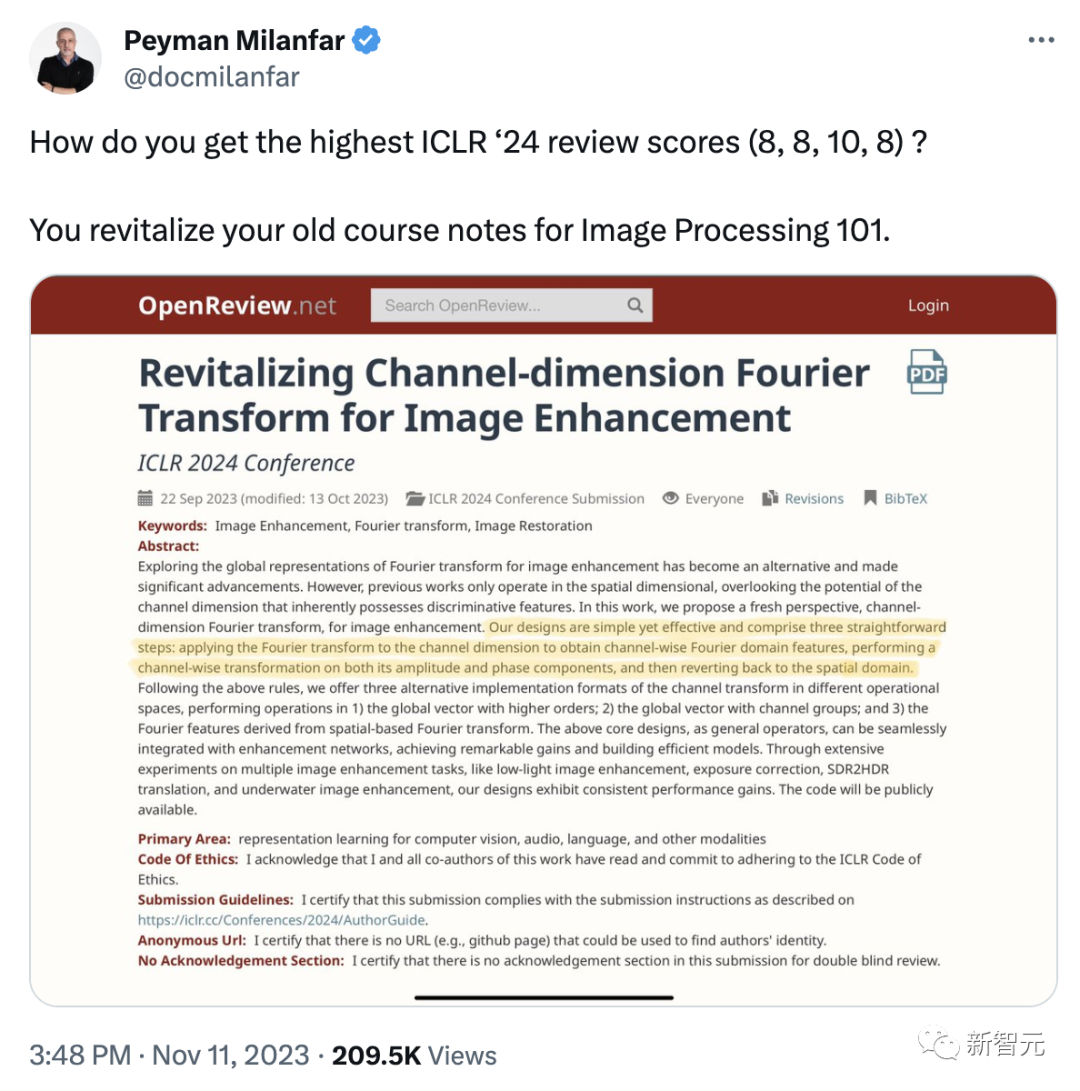
Вторая статья, «Восстановление преобразования Фурье размерности канала для улучшения изображения», посвящена улучшению изображения и преобразованию Фурье с оценками 8,10,8,8.
Исследование глобальных представлений преобразований Фурье для улучшения изображений стало альтернативным подходом, и был достигнут значительный прогресс.
Однако предыдущие исследования проводились только в пространственном измерении и игнорировали потенциал канального измерения, которое само по себе имеет идентификационные характеристики.
В этой работе авторы предлагают совершенно новое перспективное канально-размерное преобразование Фурье для улучшения изображений.
Процесс проектирования прост и эффективен, включая 3 простых шага: преобразование Фурье размерности канала для получения характеристик области Фурье канала, преобразование канала его амплитудной и фазовой составляющих, а затем возврат в пространственную область.
В соответствии с приведенными выше правилами автор предлагает 3 альтернативных формата реализации преобразования каналов в разных операционных пространствах соответственно: 1) глобальный вектор высокого порядка, 2) глобальный вектор с группой каналов и 3) пространственный. Операция выполняется над Фурье; признаки, полученные преобразованием Фурье.
В качестве оператора общего назначения описанная выше базовая конструкция может быть легко интегрирована с расширенной сетью для достижения значительных выгод и построения эффективных моделей.
Благодаря обширным экспериментам по множеству задач улучшения изображения, таких как улучшение изображения при слабом освещении, коррекция экспозиции, преобразование SDR2HDR и улучшение подводного изображения, изученная архитектура проекта демонстрирует последовательное улучшение производительности.

Модели шумоподавления и диффузии под руководством Монте-Карло для байесовских линейных обратных задач представляют собой исследование моделей шумоподавления диффузии с оценками 6,10,8,10.
Трудноразрешимые линейные обратные задачи часто возникают в самых разных приложениях, от вычислительной фотографии до медицинских изображений. Недавние направления исследований заключаются в использовании байесовского вывода и априорной информации для решения таких проблем.
Среди этих предварительных условий недавно были успешно применены генеративные модели на основе оценок (SGM) для решения нескольких различных обратных задач.
В этом исследовании автор использует специальную структуру априоров, определенную SGM, для определения серии промежуточных линейных обратных задач. По мере снижения уровня шума апостериорные задачи этих обратных задач становятся все ближе и ближе к целевой апостериорной части исходной обратной задачи.
Для выборки из этой серии апостериорных данных исследователи использовали последовательный метод Монте-Карло (SMC) и предложили алгоритм \algo.
Исследования доказали, что этот алгоритм превосходит другие аналогичные алгоритмы при решении обратных задач с неоднозначными задачами в байесовской среде.

Нам наиболее знакома модель SDXL, имеющая баллы 8,8,8,8.
Авторы представляют модель скрытой диффузии для синтеза текста в изображение — SDXL. По сравнению с предыдущей версией модели SD магистральная сеть UNet, используемая SDXL, расширена в 3 раза, что достигается за счет значительного увеличения количества блоков внимания и добавления второго кодировщика текста.
Кроме того, исследователи также разработали множество новых схем настройки и обучили SDXL использованию нескольких соотношений сторон.
Чтобы обеспечить результаты высочайшего качества, они также представили модель уточнения для улучшения визуальной точности образцов, сгенерированных SDXL, с использованием методов апостериорного преобразования изображения в изображение.
Исследования показывают, что SDXL представляет собой значительное улучшение по сравнению с предыдущими версиями Stable Diffusion, а результаты сравнимы с результатами передовых генераторов изображений, таких как Midjourney.

Что касается того, как получить эссе на высокий балл 8,8,10,8, вам нужно всего лишь просмотреть курсы обработки изображений, которые вы изучали в бакалавриате.
Остальное эссе на высокий балл,Интересует детская обувь.,Вы можете проверить это сами.
Адрес: https://guoqiangwei.xyz/iclr2024_stats/iclr2024_submissions.html
Наконец, я молюсь, чтобы каждый смог победить.
Рекомендуем к прочтению
[1]октябрь 2023 г. Краткое изложение популярных статей, всего 12
[2]Microsoft предлагает модель генерации кода всего с 75 миллионами параметров!
[2] Когда большая модель сталкивается с новыми знаниями, может ли она дать правильный ответ?
[3]Мета предложила BSM, Лама-чат сравним с GPT-4!
[4]EMNLP2023 | Поделитесь 10 статьями, которые стоит прочитать

[Серия Foolish Old Man] Ноябрь 2023 г. Специальная тема Winform Control Элемент управления DataGridView Подробное объяснение

.NET Как загрузить файлы через HttpWebRequest

[Веселый проект Docker] Обновленная версия 2023 года! Создайте эксклюзивный инструмент управления паролями за 10 минут — Vaultwarden
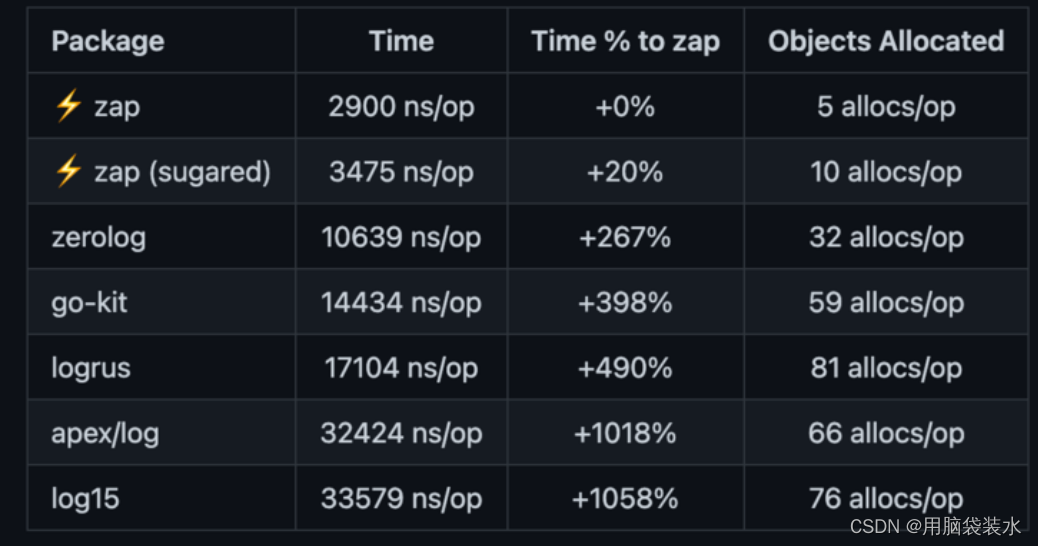
Высокопроизводительная библиотека бревен Golang zap + компонент для резки бревен лесоруба подробное объяснение

Концепция и использование Springboot ConstraintValidator

Новые функции Go 1.23: точная настройка основных библиотек, таких как срезы и синхронизация, значительно улучшающая процесс разработки.

[Весна] Введение и базовое использование AOP в Spring, SpringBoot использует AOP.

Чтобы начать работу с рабочим процессом Flowable, этой статьи достаточно.

Байтовое интервью: как решить проблему с задержкой сообщений MQ?
ASP.NET Core использует функциональные переключатели для управления реализацией доступа по маршрутизации.
[Проблема] Решение Невозможно подключиться к Redis; вложенное исключение — io.lettuce.core.RedisConnectionException.
От теории к практике: проектирование чистой архитектуры в проектах Go
Решение проблемы искажения китайских символов при чтении файлов Net Core.
Реализация легких независимых конвейеров с использованием Brighter

Как удалить и вернуть указанную пару ключ-значение из ассоциативного массива в PHP
Feiniu fnos использует Docker для развертывания учебного пособия по AList
Принципы и практика использования многопоточности в различных версиях .NET.
Как использовать PaddleOCRSharp в рамках .NET

CRUD используется уже два или три года. Как читать исходный код Spring?

Устраните проблему совместимости между версией Spring Boot и Gradle Java: возникла проблема при настройке корневого проекта «demo1» > Не удалось.

Научите вас шаг за шагом, как настроить Nginx.
Это руководство — все, что вам нужно для руководства по автономному развертыванию сервера для проектов Python уровня няни (рекомендуемый сборник).

Не удалось запустить docker.service — Подробное объяснение идеального решения ️

Настройка файлового сервера Samba в системе Linux Centos. Анализ NetBIOS (супер подробно)
Как настроить метод ssh в Git, как получить и отправить код через метод ssh

RasaGpt — платформа чат-ботов на основе Rasa и LLM.

Nomic Embed: воспроизводимая модель внедрения SOTA с открытым исходным кодом.

Улучшение YOLOv8: EMA основана на эффективном многомасштабном внимании, основанном на межпространственном обучении, и эффект лучше, чем у ECA, CBAM и CA. Малые цели имеют очевидные преимущества | ICASSP2023

Урок 1 серии Libtorch: Тензорная библиотека Silky C++
