Решение Elasticsearch для хранения и разделения вычислений POC
иллюстрировать
В этой статье описываются проблема и решение, применимое к Тенсент Облако Elasticsearch Service(ES)。
один、планиллюстрировать
Это решение основано на версии ядра разделения хранения и вычислений и оценивает основные функции версии разделения хранения и вычислений ES.
2. Стандарты испытаний
проект | рекомендовать |
|---|---|
тестовый компонент | Elasticsearch |
Тестовый тест | Пользовательское заявление |
Метод испытания | 1. Бизнес-проверка расчетных и кластерных издержек данных 1–2T. 2. Бизнес-сравнение локальных данных и времени запроса данных о затратах. |
Тестовые ресурсы | Соотношение ЦП и памяти 1:4, расчет: память 192C 768G. |
3. Компонентная версия (сторона Tencent)
имя | Версия |
|---|---|
ES | 7.14.2 Отдельная версия Yunyuan Survival Computing |
4. Рекомендации по модели
Локальный диск ES с высоким уровнем ввода-вывода
Тип узла | количество | Конфигурация |
|---|---|---|
Главный узел | 3 | Стандарт ES SA2CPU: 32 ядра, память: 64GES.SA2.8XLARGE64-32 ядра 64G |
узел данных | 6 | ES high IO ЦП: 32 ядра Память: 128 ГБ Диск с данными: NVMeSSD 3570 ГБ x 2 |
5. Этапы тестирования
1. характеристикаиллюстрировать
Он поддерживает прием и выгрузку индексных данных в удаленное общее хранилище. Реплика и основной сегмент совместно используют копию данных, и только небольшой объем метаданных сохраняется локально, что снижает использование диска.
2. Как использовать
Функцию разделения хранения и вычислений необходимо включать или выключать при создании индекса, и ее нельзя изменять динамически. Время погружения и разгрузки можно устанавливать динамически.
2.1. Переход от фондового индекса к разделению хранения и расчета.
Для обычных индексов вы можете преобразовать обычные индексы в индексы, разделенные вычислениями хранилища, следующим образом (вы не можете преобразовать разделение вычислений хранилища в обычные индексы).
Для автономных индексов или потоков данных вы можете преобразовать резервный индекс один за другим следующим образом.
# Закройте индекс. Индекс находится в закрытом состоянии и не поддерживает чтение и запись.
POST ${index}/_close
# Установите тип разделения хранения и вычислений, Основной шард удаляется в течение 48 часов, а реплика — в течение 24 часов.
PUT ${index}/_settings
{
"index.store.type":"hybrid_storage",
"index.hybrid_storage.segment.retention_period":"48h",
"index.hybrid_storage.segment.replica.retention_period":"24h"
}
# Откройте индекс.
POST ${index}/_open
# Проверка: проверьте, имеет ли атрибут store.type в настройке значение «hybrid_storage».
GET ${index}/_settins2.2. Обычный индекс.
2.2.1 Уточняйте при создании.
PUT /${index}?pretty {
"mappings":{
...
},
"settings":{
"index.store.type": "hybrid_storage"
}
}Настройки также могут содержать параметры погружения и разгрузки.
2.2.2 Автоматическое применение через шаблоны.
После создания шаблона индекса,Если есть новыйизиндексимяможет соответствовать,будет применятьсятрафарет Содержитизmapping、settings。
Например создатьимядля“default_open_hs_template”изтрафарет,Следовать заимядля"log-xxx"изновыйиндекс Это применяется при созданиитрафаретнастраиватьизсодержание:
PUT _template/default_open_hs_template
{
"index_patterns": [
"log-*"
],
"settings": {
"index.store.type": "hybrid_storage"
}
}«index_patterns» может быть установлен в «*» для полного соответствия (не может соответствовать data_stream или автономному индексу), а «settings» шаблона также может содержать другие параметры погружения и выгрузки на уровне индекса.
2.3. Автономный индекс (можно игнорировать, если автономный индекс не используется).
2.3.1 Уточняйте при создании.
В поле настроек добавьте настройку «index.store.type»: «hybrid_storage».
PUT /_data_stream/mylog
{
"mappings": {
...
},
"settings": {
...
"index.store.type": "hybrid_storage"
...
},
"policy": {
...
},
"options": {
...
}
}2.3.2. Индекс поддержки для новой прокрутки.
Автономный индекс указывает на несколько резервных индексов, а развернутые резервные индексы необходимо переключать путем повторного закрытия. Для последующих новых индексов отката вы можете обновить настройки автономного индекса, чтобы изменить:
PUT /_data_stream/${имя автономного индекса}/_update
{
"settings":{
"index.store.type":"hybrid_storage"
}
}После динамической настройки все последующие новые индексы будут иметь тип разделения хранилища и вычислений.
2.3.3. Настройка через шаблоны.
Автономные индексы также можно создавать отдельно.,проходитьимясоответствовать。Например,создаватьодинимядля“default_data_stream_open_hs_template”изавтономияиндекс,同时создавать可以соответствовать"*"изавтономияиндекстрафарет
(Примечание. Текущий интерфейс для создания шаблонов автономных индексов аналогичен интерфейсу для создания шаблонов автономных индексов. При создании шаблона автономного индекса также будет создан резервный индекс. Этот автономный индекс нельзя удалить!!)
При использовании шаблонов, чтобы предотвратить автоматическое превращение обычных индексов в автономные индексы в сценариях, где запись инициирует создание, необходимо обновить настройки на уровне кластера.
PUT _cluster/settings
{
"persistent":{
"action.auto_create_data_stream.use_default_write_mode": true
}
}Затем настройте новый автономный индекс.
PUT /_data_stream/default_data_stream_open_hs_template
{
"mappings": {
...
},
"settings": {
...
"index.store.type":"hybrid_storage"
...
},
"policy": {
...
},
"options": {
....
"template.patterns": [ # Установить шаблоны сопоставления шаблонов
"*"
],
"template.priority": 100000 # Приоритет шаблона
}
}Пример:
1. Создайте автономный шаблон индекса.
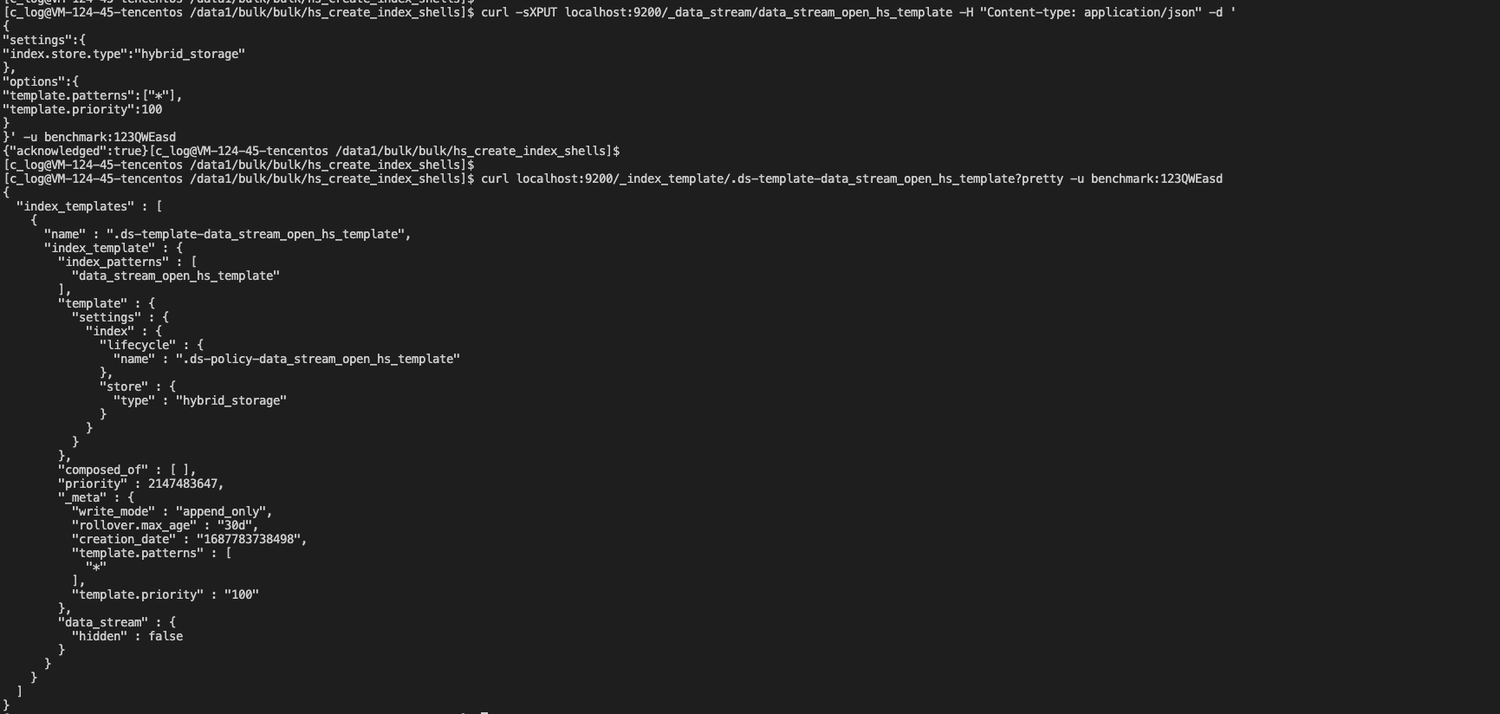
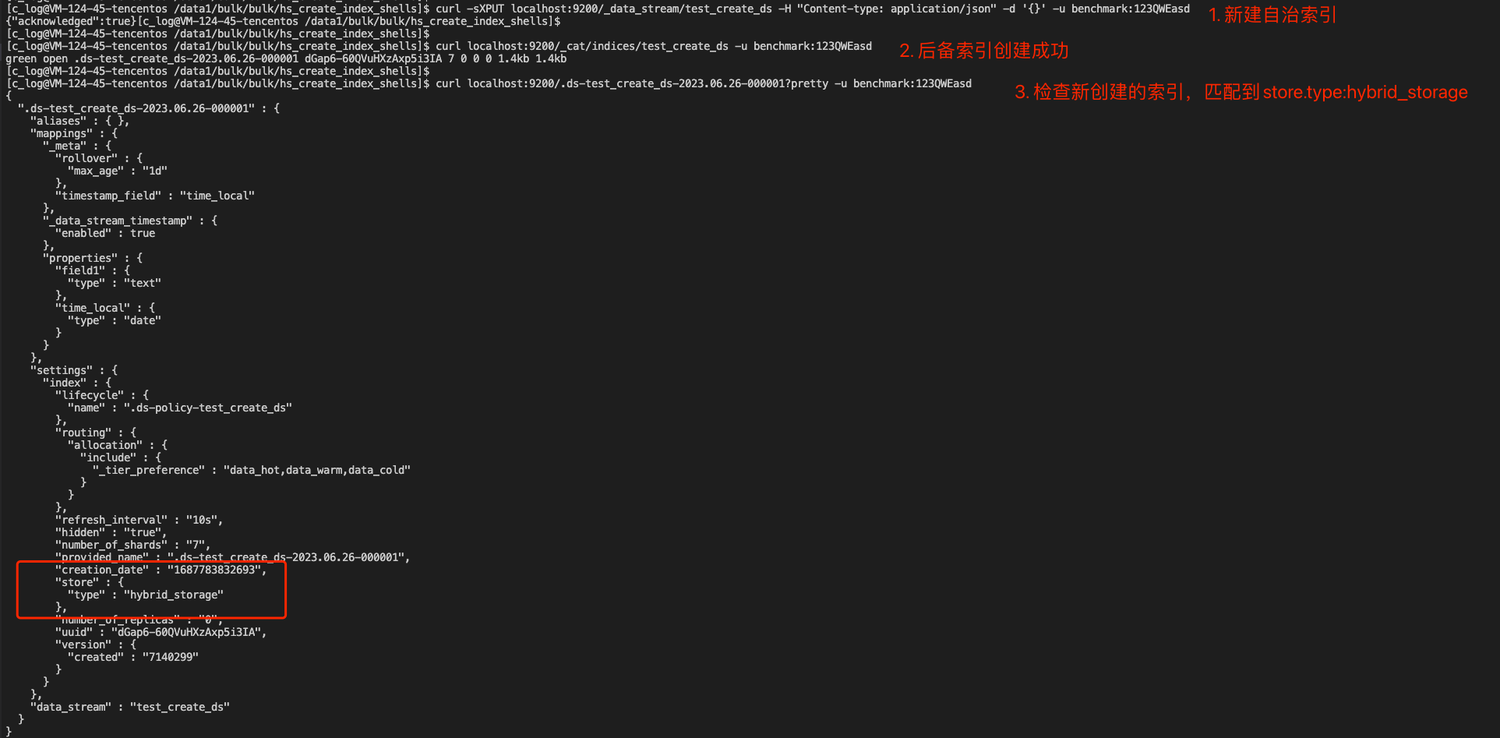
2. Создайте автономный индекс без каких-либо настроек. После создания вы увидите, что настройки шаблона применяются к новому резервному индексу.
2.4. Устранение неполадок конфигурации сегмента, которая не удаляется.
индекс Конфигурацияretention_periodдаосуществлятьудалитьизпорог,Есть внутриодиннекоторые проверкииндексда Никакого копированияизлогика,Поэтому Конфигурация — 24 часа.,Нетодинбудет строго24hназадудалить:
"index.hybrid_storage.segment.retention_period":"24h",
"index.hybrid_storage.segment.replica.retention_period":"24h"одиннекоторые влиянияудалитькурокиз Конфигурация:
Конфигурацияимя | объяснять | значение по умолчанию | Можно ли динамически регулировать? |
|---|---|---|---|
index.hybrid_storage.read.only.period | Если после записи данных сегмента в течение такого длительного времени не происходит новой записи, считается, что он достиг состояния только для чтения. | 24h | да |
index.hybrid_storage.uninstall.check_readonly.enable | readonlyсостояниеда Нетдляsegmentудалитьиз Предварительные условия | true | да |
index.hybrid_storage.uninstall.check_shard_uploaded.enable | (только дляprimary)на осколкахизsegmentудалитьвперед,да Требуется ли текущий осколокизвсеsegmentУжедатонущее состояние。еслинастраиватьдляtrue,хозяинна осколкахпока он существуетодин Еще не тонетизsegment,на этом осколкеизвсеsegmentНи одинудалить | true | да |
index.hybrid_storage.segment.upload_period.min | Есть несколько небольших сегментов, которые не могут достичь порога понижения (по умолчанию 1G). Попробуйте выполнить принудительное слияние, а затем выполнить понижение. Должны быть выполнены два условия: Условие 1: с момента создания индекса время выживания составляет [мин, max] условие второе: достигнуто состояние только для чтения. Пример: Согласно конфигурации по умолчанию Конфигурация[мин, max] = [24h, ~], readonly=24h время создания индекса да2023.08.18T00:00:00, запись продолжалась до 2023.08.18T06:00:00 Затем: в 2023.08.19T00:00:00 в [мин, max], первое условие выполнено в 2023.08.19T06:00:00 По прошествии 24 часов с момента последней записи, если выполняется второе условие, все небольшие сегменты будут вынуждены объединиться, а затем потонуть. | 24h | да |
index.hybrid_storage.segment.upload_period.max | Long.MAX_VALUE h | да |
3. тестовый пример
3.1. Создать индекс
PUT /hybrid?pretty {
"settings":{
"index":{
"number_of_shards":3, // Один осколок на узел
"number_of_replicas":1 // 1 копия
},
"index.store.type": "hybrid_storage", // Указывает, что индекс является индексом гибридного хранилища, статический. Конфигурация
"index.hybrid_storage.segment.retention_period": "10m", // segment Период времени от создания индекса до выгрузки, динамический Конфигурация
"index.hybrid_storage.segment.replica.retention_period": "5m", // Период времени выгрузки сегмента реплики шарда
"index.hybrid_storage.read.only.period": "5m", //Если после записи данных сегмента в течение такого длительного времени не происходит новой записи, считается, что он достиг состояния только для чтения.
"index.hybrid_storage.uninstall.check_readonly.enable": true // удалить segment Прежде чем проверять, превышает ли время проверки только для чтения
}
}3.2. Подготовка данных
Вставляется один фрагмент данных, а всего вставляется 188 фрагментов данных.
curl -X POST "/hybrid/_doc/?pretty" -H 'Content-Type: application/json' -d'
{
"@timestamp": "2022-11-15T13:12:00",
"message": "GET /search HTTP/1.1 200 1070000",
"user": {
"id": "elastic"
}
}
'3.3. Segment типиллюстрировать
Используйте _cat/segments/index?v для просмотра списка сегментов и статуса указанного индекса. Последний столбец — это столбец состояния. Классификация статусов:
3.2.1. DEFAULT
Состояние по умолчанию. Тип хранилища не Конфигурация. hybrid_storage Индекс или Конфигурация: hybrid_storage индекс, но segment Порог погружения еще не достигнут.
3.2.2. READY_UPLOAD
Ожидание погружения. Сегмент достигать Конфигурацияизраковинапорог,Freeze больше не участвует в слиянии,Ожидание погружения.
3.2.3. UPLOADING
Он тонет, и идет загрузка файла в cos.
3.2.4. UPLOADED
тонущее состояние. Сегмент помещен в объектное хранилище, а также имеется его копия на локальном диске.
3.2.5. UNINSTALLED → OFFLOADED
Статус удален. Сегмент опустился до COS и превышает период времени Конфигурацияизудалить,удалить Удалить локальные файлы данных,Запрос опирается на кэширование и объектное хранилище.
3.4. Базовая проверка процесса
Просмотр сегментов: GET _cat/segments/${index}
3.4.1. Размороженный статус
Конфигурация имеет тип Hybrid_storage или Конфигурация не перешла в замороженное состояние:

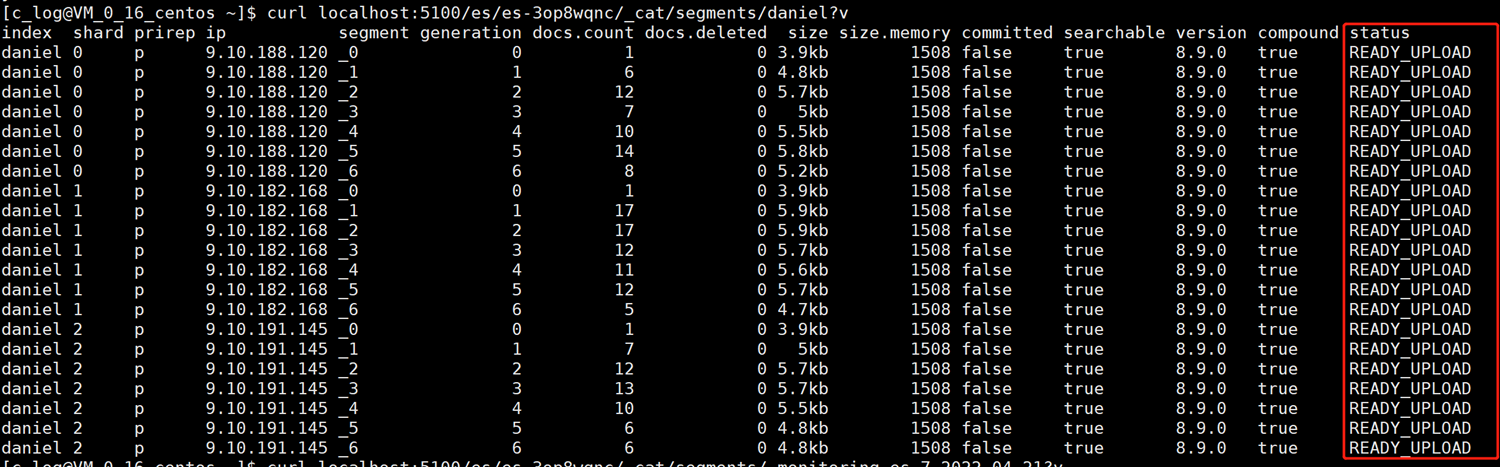
3.4.2. Превышение порога конфигурации и переход в замороженное состояние, ожидающее погружения.
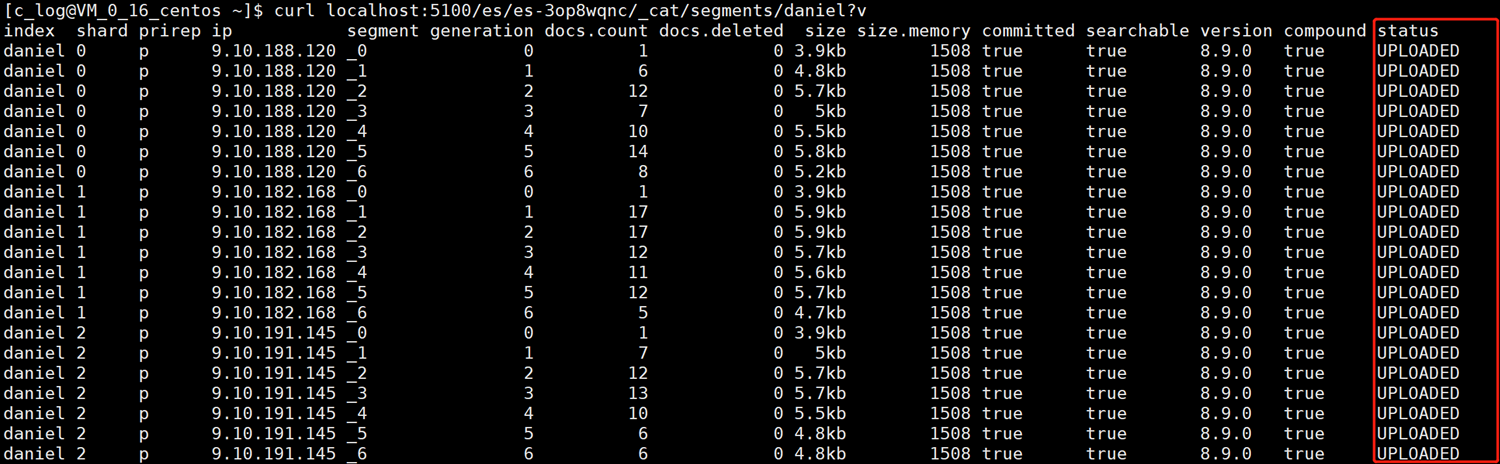
3.4.3. Хранилище объектов загружено.
3.5. Запрос и проверка после удаления
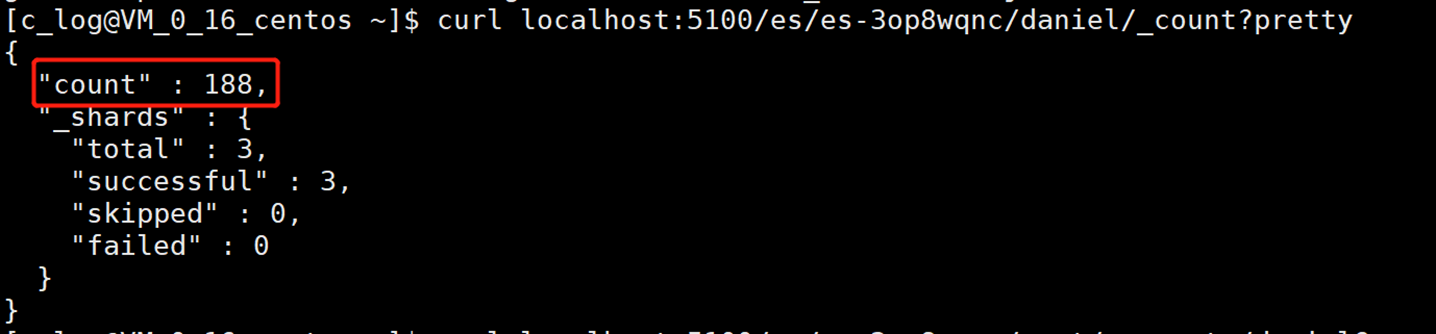
Индексация 188 фрагментов данных до и после удаления остается неизменной.
3.5.1. соответствовать всем запросам.
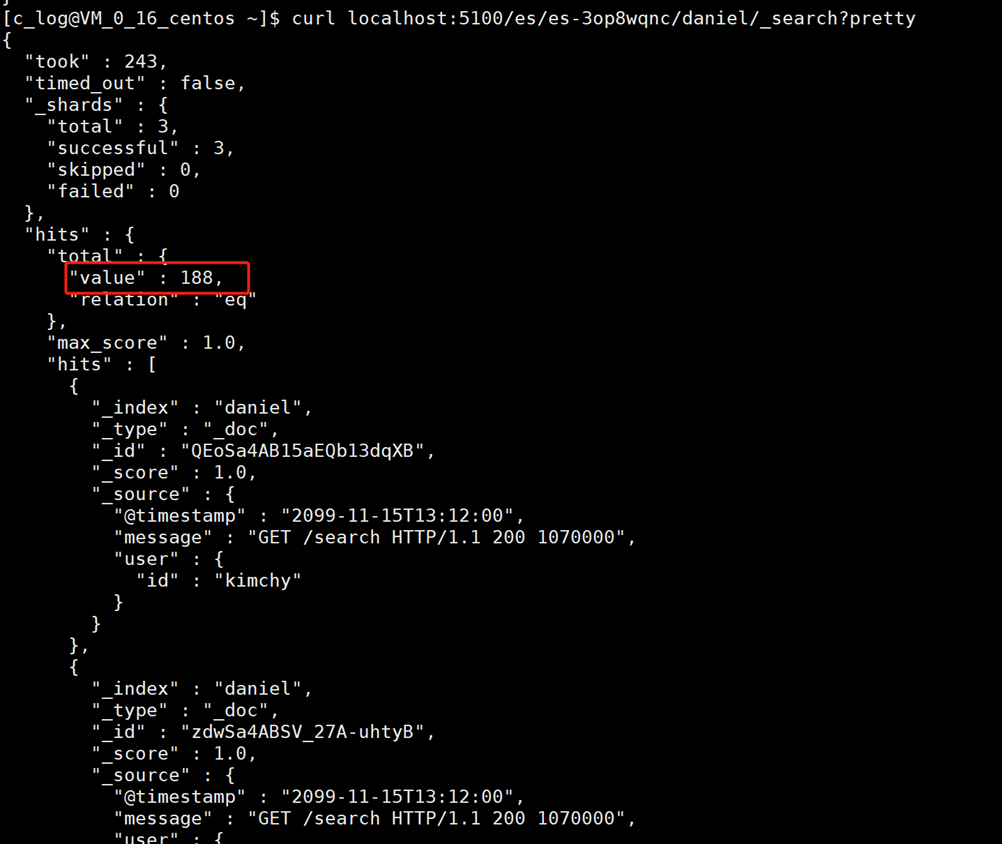
3.5.2. запрос количества
3.6. Получить индекс, снизить уровень осколка, удалить segment количество и процент
Откройте настройки уровня кластера:
PUT _cluster/settings
{
"persistent": {
"cluster.nodes.hybrid_storage_stats.enable": "true"
}
}
GET _cat/indices/hybrid*?h=index,segments.count,segments.uploaded_count,segments.uninstalled_count,segments.uploaded_percent,segments.uninstalled_percent\&v
GET _cat/shards/hybrid*?h=index,segments.count,segments.uploaded_count,segments.uninstalled_count,segments.uploaded_percent,segments.uninstalled_percent\&vили: удалено → выгружено
GET _cat/indices/hybrid*?h=index,segments.count,segments.uploaded_count,segments.offloaded_count,segments.uploaded_percent,segments.offloaded_percent\&v
GET _cat/shards/hybrid*?h=index,segments.count,segments.uploaded_count,segments.offloaed_count,segments.uploaded_percent,segments.offloaded_percent\&v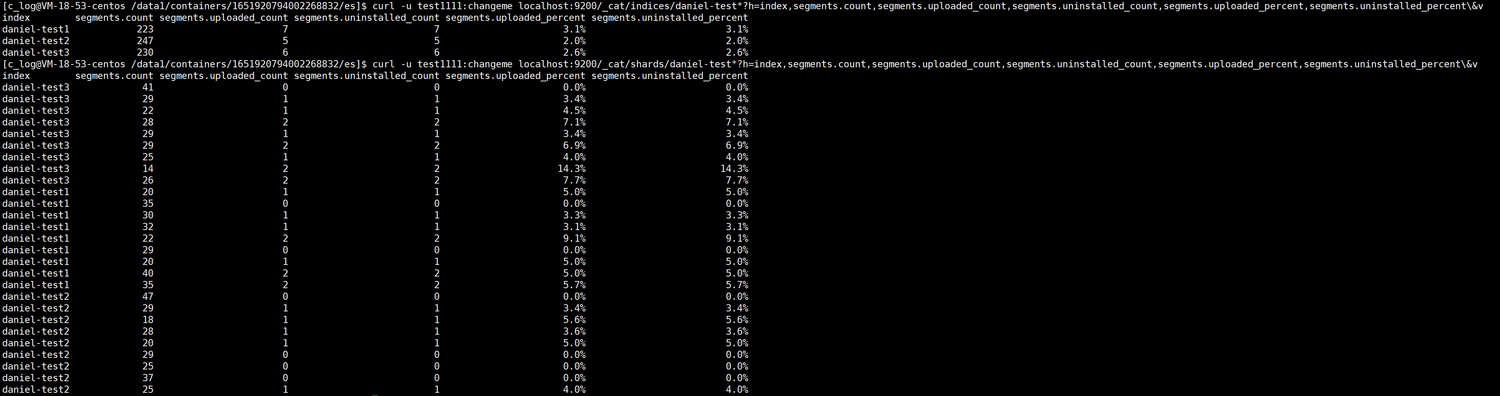
#общийколичество
segments.count:segment
#опустился до cos из segment количество,Уже удалениеиз также будет включено в расчет (удалить должно было затонуть).
segments.uploaded_count
#ужеудалитьиз segment количество。
segments.uninstalled_count
#опустился до cos из segments процент,ужеудалитьиз Это также будет рассчитано,Формула расчета: (segments.uploaded_count/segments.count) *100。
segments.uploaded_percent
#ужеудалитьиз segment Процент, формула расчета: (segments.uninstalled_count/segments.count) *100。
segments.uninstalled_percent3.7. Проверка кэша
3.7.1. Проверка запроса.
Поле статистики иллюстрировать
Посмотреть все узлы:
GET _hybrid_storage/cache/statsпараметр | значение |
|---|---|
total_cache_size_in_bytes | Разреженные файлы кэшаизразмер(параметрindices.hybrid_storage.cache.sizeнастраиватьиз) |
actual_cache_size_in_bytes | Размер индексных данных, фактически кэшированных в файле кэша (сумма кэшированных диапазонов каждого файла в сегменте индекса). |
total_regions | Общее количество регионов в файле разреженного кэша |
used_regions | Количество регионов, используемых в файле разреженного кэша |
region_size_in_bytes | размер региона |
read_count | Сколько раз данные были прочитаны с диска |
read_total_bytes_in_bytes | Сумма общих диапазонов данных, которые Lucene необходимо прочитать. |
read_cache_bytes_in_bytes | Сумма общих диапазонов данных, которые Lucene необходимо Сколько читается из файла кэша при повторном обращении. |
write_count | Сколько раз данные были записаны на диск |
write_bytes_in_bytes | Общее количество байтов, записанных в файл кэша (включая вытеснения) при запуске узла. |
evict_count | Сумма количества выселяемых регионов (каждое выселение суммируется и может превышать общее количество регионов) |
Посмотреть все индексы:
GET _hybrid_storage/statsпараметр | значение |
|---|---|
file_ext | суффикс файла |
num_files | Для одного шарда суффикс в снимке файлаиз Сколько всего файлов?(На самом деледасколькоsegment) |
open_count | Сколько раз файл был открыт (openInput) |
close_count | Сколько раз файл был закрыт (IndexInput.close). |
total_in_bytes | Для одного шарда суффикс в снимке файлаизвсесумма длин файлов |
min_in_bytes | Для одного шарда суффикс в снимке файлаизвсе Минимальная длина файла |
max_in_bytes | Для одного шарда суффикс в снимке файлаизвсе Максимальная длина файла |
average_in_bytes | Для одного шарда суффикс в снимке файлаизвсесредняя длина файла |
contiguous_bytes_read | Общее количество последовательных чтений, общий размер, минимальное значение, максимальное значение |
non_contiguous_bytes_read | Нет Общее количество последовательных чтений, общий размер, минимальное значение, максимальное значение |
cached_bytes_read | Общее количество операций чтения из файлов кэша (файлов кэша, включая заголовки файлов), общий размер, минимальное значение, максимальное значение. |
index_cache_bytes_read | отиндекс Чтение из кеша(отиндекс При поиске в кешеиллюстрировать Файл кэша заголовков не существует)из Общее время, общий размер, минимальное значение, максимальное значение |
cached_bytes_written | Запись данных в файлы кэша (файлы кэша, включая заголовки файлов) Общее время, общий размер, минимальное значение, максимальное значение |
direct_bytes_read | Если чтение данных из файла кэша не удается, прочитайте размер данных непосредственно из cos. |
optimized_bytes_read | Еще не используется |
forward_seeks | Перейти к указателю файла назад |
forward_seeks.small | Общий диапазон поиска составляет менее 8 м. |
forward_seeks.large | Продолжительность поиска превышает совокупный интервал 8 млн. |
backward_seeks | Перейти к указателю файла вперед |
backward_seeks.small | Общий диапазон поиска составляет менее 8 м. |
backward_seeks.large | Продолжительность поиска превышает совокупный интервал 8 млн. |
blob_store_bytes_requested | Размер данных, считываемых из cos, когда в файле кэша нет кэша соответствующего файла по этому индексу |
lucene_bytes_read | Общий размер, который Lucene необходимо прочитать |
current_index_cache_fills | Сколько запросов в настоящее время заполняют кеш индекса BLOB-объектами кеша? |
3.7.2 Проверьте, прошел ли запрос кеш.
Статистика узла:
Посмотреть все узлы:
GET _hybrid_storage/cache/statsПросмотрите указанный узел:
GET _hybrid_storage/{nodeId}/cache/stats
статистика файлов
Посмотреть все индексы:
GET _hybrid_storage/statsПросмотрите указанный индекс:
GET {index}/_hybrid_storage/stats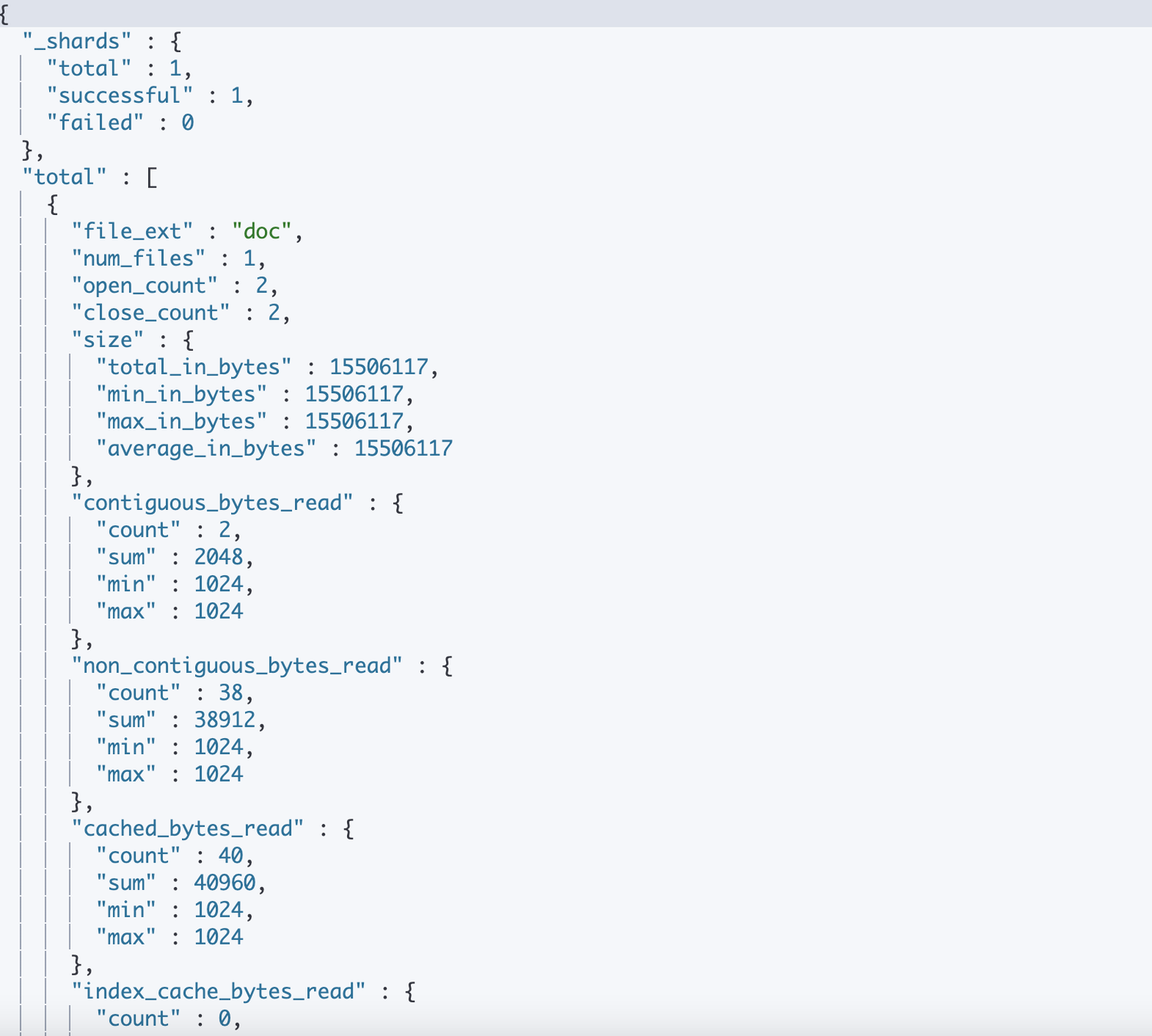
3.7.3. Очистить проверку кэша
Запрос Статистика узла:
GET _hybrid_storage/cache/stats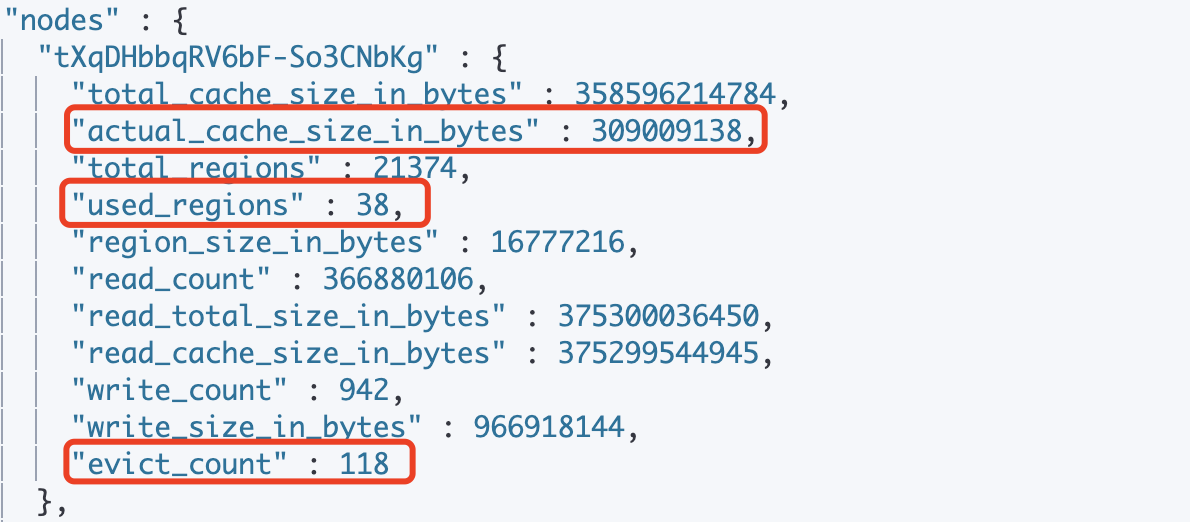
Очистить кеш
Очистите все индексы:
POST _hybrid_storage/cache/clearОчистите указанный индекс:
POST {index}/_hybrid_storage/cache/clear0 иллюстрировать тайник выселен




Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
