Redis: Расскажи мне, как выдержать давление 20 миллионов запросов в секунду
Предисловие
За многие годы разработки обработки больших потоков данных SparkStreaming, помимо Kafka, наиболее часто используемым компонентом был Redis. В настоящее время в производстве находится несколько кластеров Redis. Самый крупный кластер Codis из 32 узлов достиг 4 миллиардов ключей и максимального количества запросов в секунду 20 миллионов.
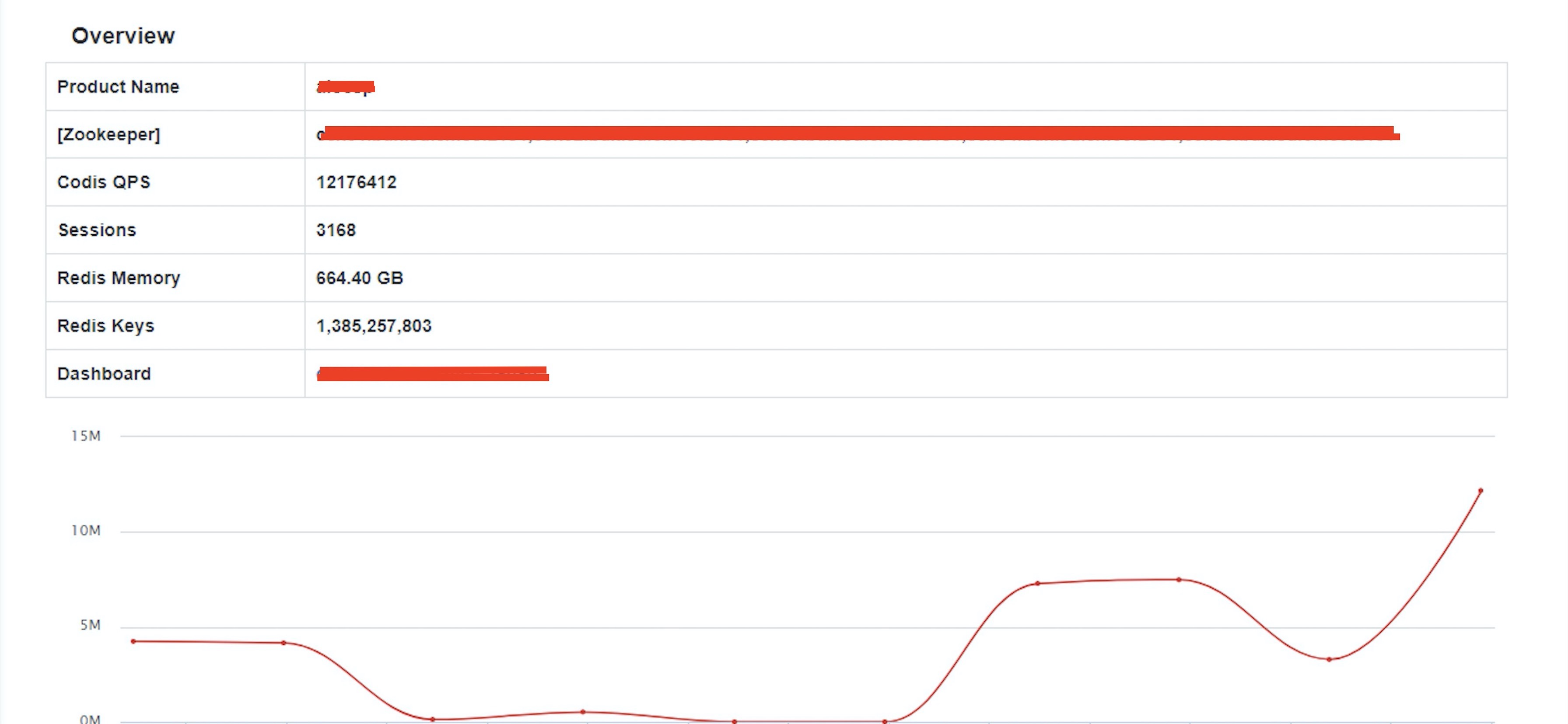
Как показано на рисунке выше, пиковое количество запросов в секунду для codis все еще может достигать около 12 миллионов, когда он находится в режиме ожидания. В настоящее время многие компании перешли с кластера Codis на Redis. С какими проблемами они столкнутся при обновлении архитектуры и как их решить? Именно это в основном и хочет выразить эта статья.
Redis в потоковых вычислениях
Redis имеет два сценария применения при разработке потоковой обработки:
- Данные таблицы измерений обновляются в автономном режиме и используются для увеличения информации об измерениях потоковых данных.
- Применяйте обновляемые данные о статусе в режиме реального времени
Независимо от сценария приложения, в конечном итоге SparkStreaming должен взаимодействовать с Redis для выполнения операций получения и установки. Если временной интервал RDD в SparkStreaming составляет 1 минуту, то данные в этом окне будут считаться «без задержки» при расчете. выполняется в течение 1 минуты. При возникновении задержки вычислений, если вы не взаимодействуете с Redis, увеличение вычислительных ресурсов ядра и памяти или увеличение степени параллелизма решит проблему.
В предыдущей разработке приложения SparkStreaming с объемом данных 100 млн/мин было обнаружено, что причиной задержки вычислений может быть то, что на взаимодействие с Redis уходит слишком много времени. В это время увеличиваются вычислительные ресурсы и улучшаются. параллелизм не даст особого эффекта, поэтому необходимо на данный момент оптимизировать взаимодействие между приложениями и Redis.
Оптимизация производительности Redis
Во многих случаях мы не можем оптимизировать развернутый сервис Redis. Даже если некоторые параметры по умолчанию необоснованны, мы не можем изменить параметры по своему усмотрению и перезапустить кластер, что влияет на производство. Таким образом, мы можем оптимизировать код только со стороны кода приложения.
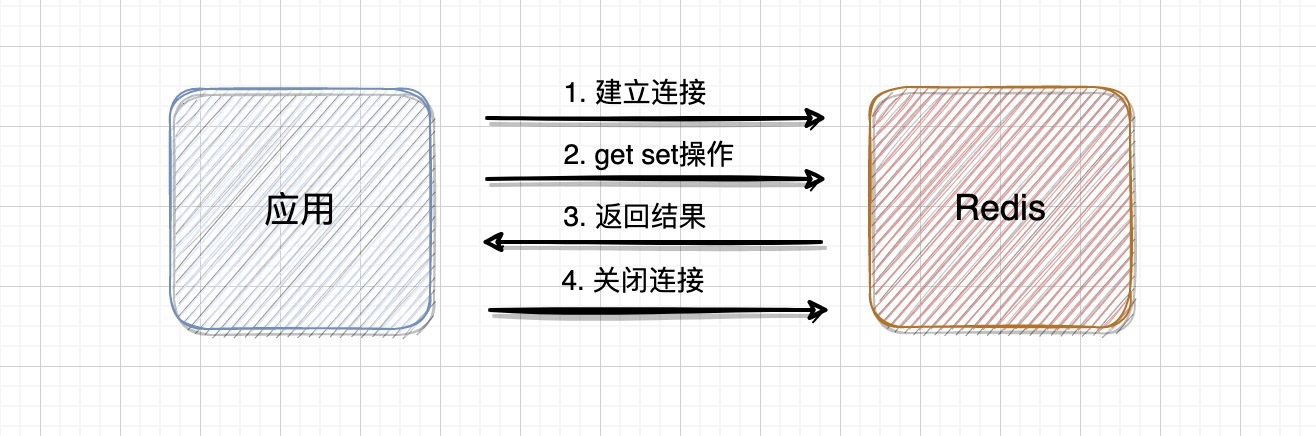
Процесс взаимодействия данных между приложениями и сервисами Redis примерно следующий:
пул соединений
на Яве,Применение иRedisКласс соединения для взаимодействияJedis。Если вам нужно создать по одному для каждого соединенияJedisслова,Затем каждый раз, когда трехстороннее рукопожатие TCP устанавливает соединение,При закрытии помахайте руками четыре раза, чтобы отключиться.,Хотя скорость в интранете достаточно быстрая,Но он не может обрабатывать большой объем данных.,Поэтому нам необходимо поддерживать длительную связь.
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(10);
poolConfig.setMinIdle(5);
poolConfig.setMaxIdle(8);
JedisPool jedisPool = new JedisPool(poolConfig, "localhost", 6379);
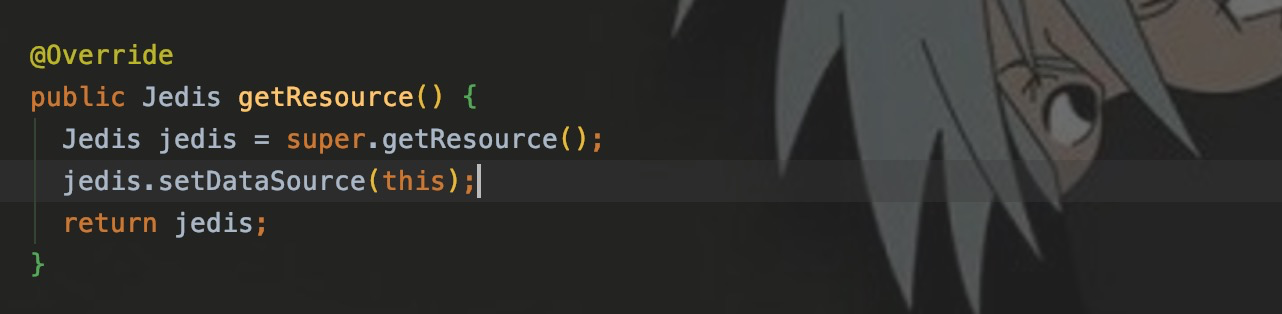
Jedis jedis = jedisPool.getResource()так,JedisPool для завершения инициализации Jedis,Нам просто нужно позвонитьgetResource() Вы можете получить джедаев,и будетJedisPoolОбъект назначенJedisизdataSourceсвойство,Используется для указания того, получен ли объект Jedis из JedisPool.
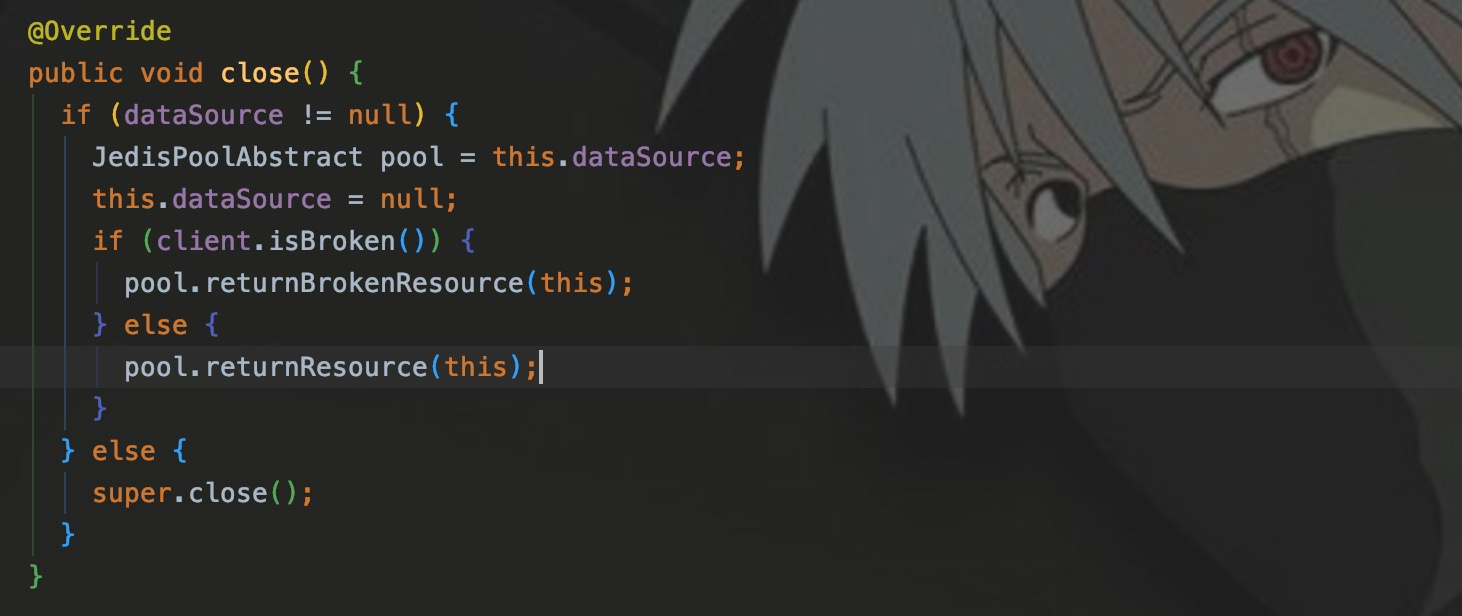
Когда мы звонимclose() При закрытии соединения будет оцениваться источник данных. Если он равен нулю, соединение Redis будет отключено напрямую. действий, то этот джедай будет помещен в пул джедаев.
batch.size
часто и сильно данныеиметь дело сиз Слово каждому знакомо:batch.size。обычно относится кизда Два компонента взаимодействуютчас,Попробуйте обработать пакет данных за одно взаимодействие.,Повысьте эффективность обработки за счет сокращения количества коммуникаций.
kafka
Например, в KafkaProduer параметр пакетный.размер используется для управления количеством данных, отправляемых в Kafka за один раз.
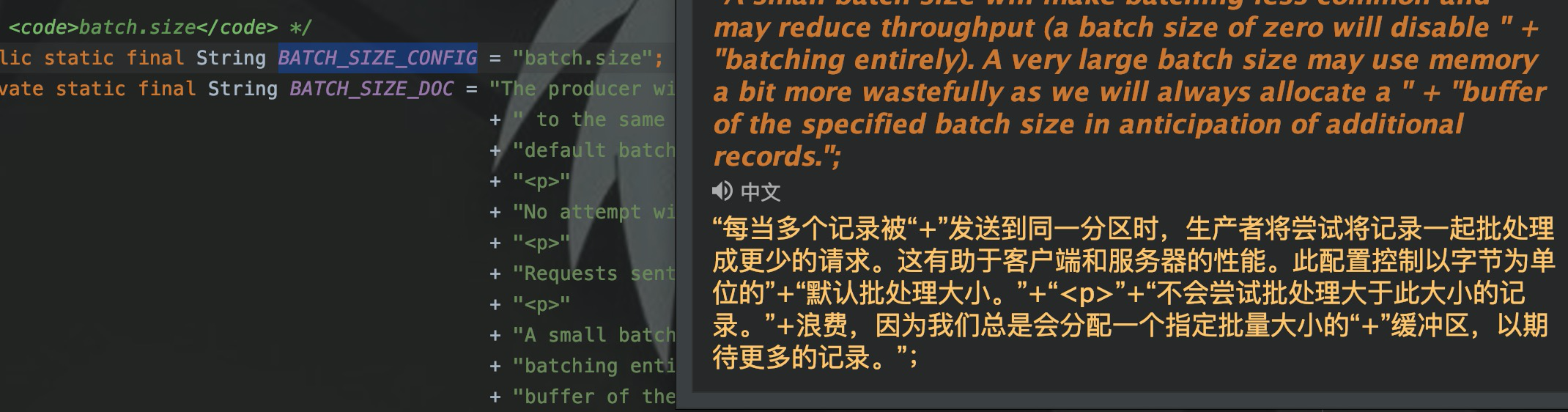
Но проблема возникает снова,Если пакетный размер установлен на 100,Есть только 99 фрагментов данных,Тогда просто не отправлять? Поэтому, чтобы обеспечить производительность данных в режиме реального времени в пакетных ситуациях,,Итак, это было определено еще разlinger.msконтролировать время ожидания,Batch.size и linger.ms должны удовлетворять только одному,Просто отправьте данные в Кафку.
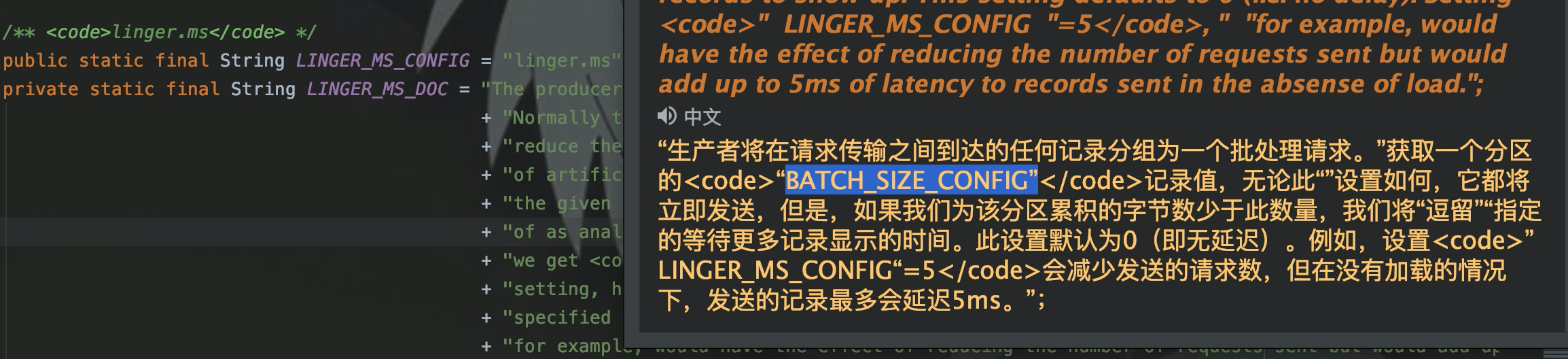
Flume
Аналогичным образом, в файле конфигурации Flume мы часто видим параметр размера пакета, который обычно контролирует количество данных, которые источник отправляет в канал или приемник извлекает из канала.

Итак, можем ли мы также упаковать несколько наборов и получить операции в пакеты и отправить несколько команд операций одновременно?
pipeline
Jedis обеспечивает режим работы конвейера,Позволяет одновременно выполнять несколько рабочих команд,Затем выполните его вручную с помощьюsyncотправить вRedis,Вернуть результат запроса. Далее, пул соединения реализует код конвейера.
Jedis jedis = jedisPool.getResource()
Pipeline pipeline = jedis.pipelined();
Response<String> res1 = pipeline.get("aa");
Response<String> res2 = pipeline.get("bb");
// Здесь вы также можете выполнять set, hmget и другие операции.
pipeline.sync();
String s1 = res1.get();
String s2 = res2.get();отjedis.pipelined() Между созданием конвейера и выполнением синхронизации для отправки Redis,Вы можете выполнить несколько разных команд Redis. Выполнять операции получения через Jedis,Возвращается строка. И используйте выполнение конвейера,возвращатьсяизда ДженерикиStringизResponse。
Заполнение данных ответа
Это похоже на Future в NIO. Как вы можете видеть из приведенного выше кода, после того, как конвейер выполняет get(key), он не отправляется в redis немедленно, поэтому в это время он может только вернуть объект Response и зарезервировать поле. для получения возвращаемого значения. После выполнения sync() для отправки запроса в redis возвращаемые результаты один за другим заполняются в соответствующие поля ответа.
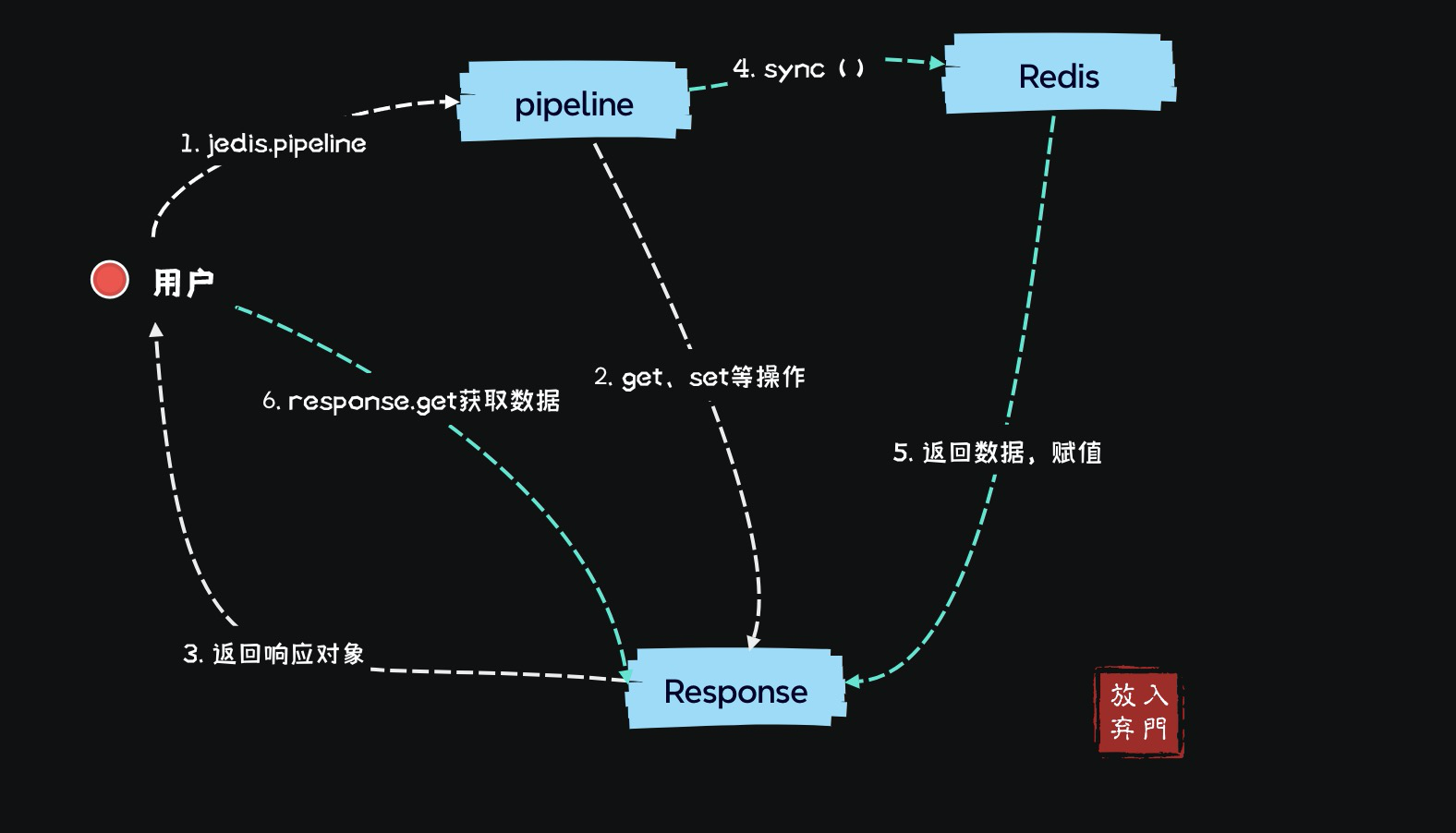
Как показано на рисунке, ответ будет иметь данные только после синхронизации. Вы можете отладить его и посмотреть.
Response debug
Я использую Docker для запуска кластера Redis с четырьмя главными и четырьмя подчиненными устройствами, а соответствующие порты — от 10001 до 10008.

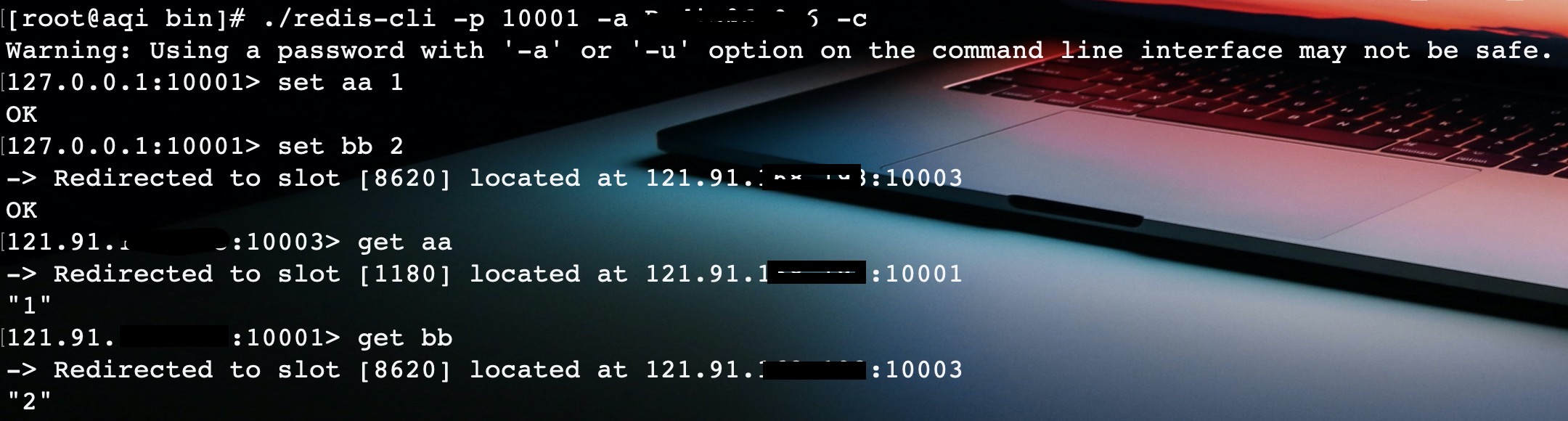
Используйте redis-cli, чтобы установить данные двух ключей. В режиме кластера необходимо добавить -c, иначе он не будет перенаправлен на узел в слоте, где находится ключ. Не беда, если вы сейчас не понимаете слот, потому что о слоте я расскажу дальше.
В коде Jedis используется для соединения 10001 узла (JedisCluter использовать нельзя, о чем речь пойдет позже).
Jedis jedis = new Jedis("121.91.xxx.xx", 10001);
jedis.auth("1qaz@WSX");
Pipeline pipeline = jedis.pipelined();
Response<String> res1 = pipeline.get("aa");
pipeline.sync();
String s1 = res1.get();Затем используйте конвейер, чтобы получить значение с ключом aa. Установите точку останова в sync() и начните отладку.
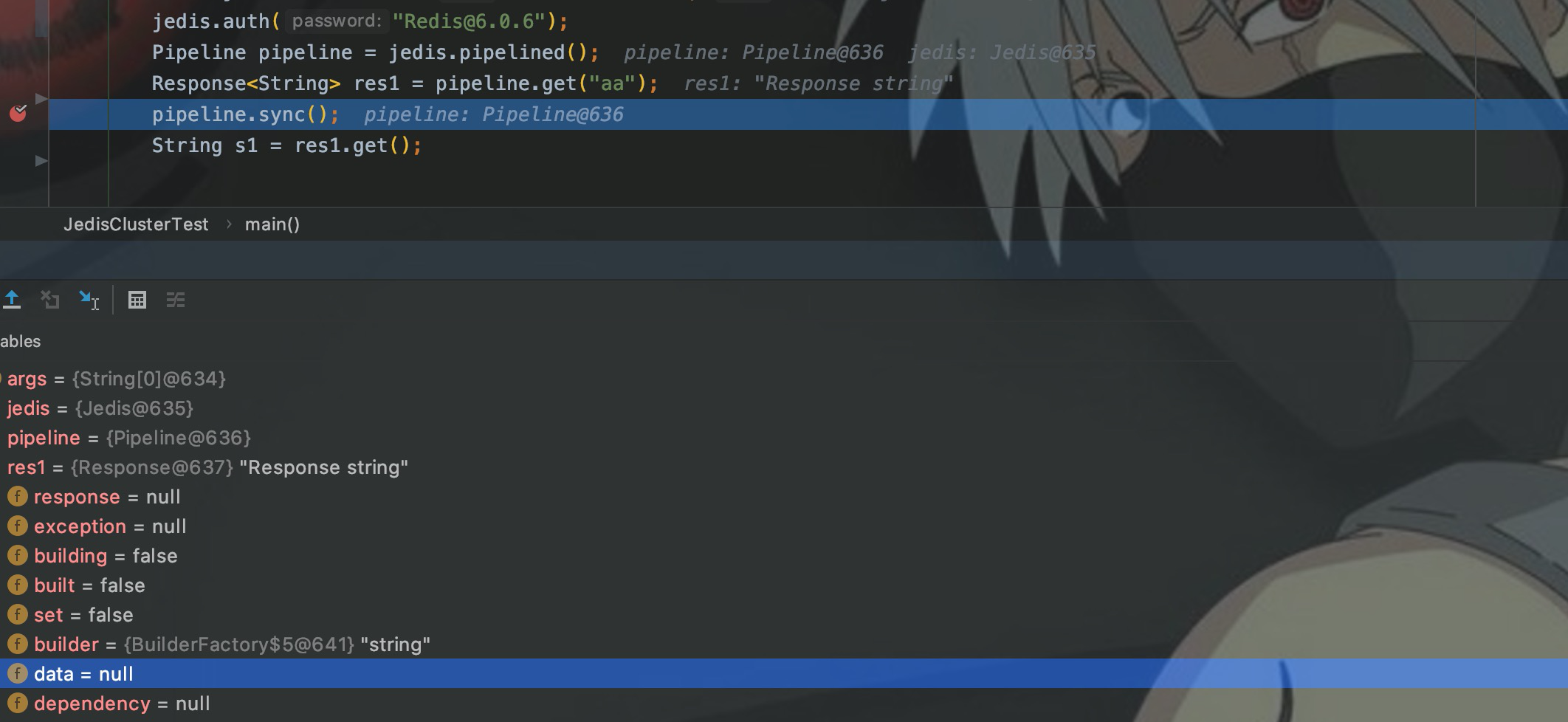
Как видите, атрибут данных ответа в настоящее время имеет значение null. Выполните следующий шаг, то есть после выполнения sync() данные будут иметь значение. Возвращаемое значение должно быть равным 1, которое мы установили ранее. Здесь 49 — это номер строки 1 в таблице кодов ACSII.
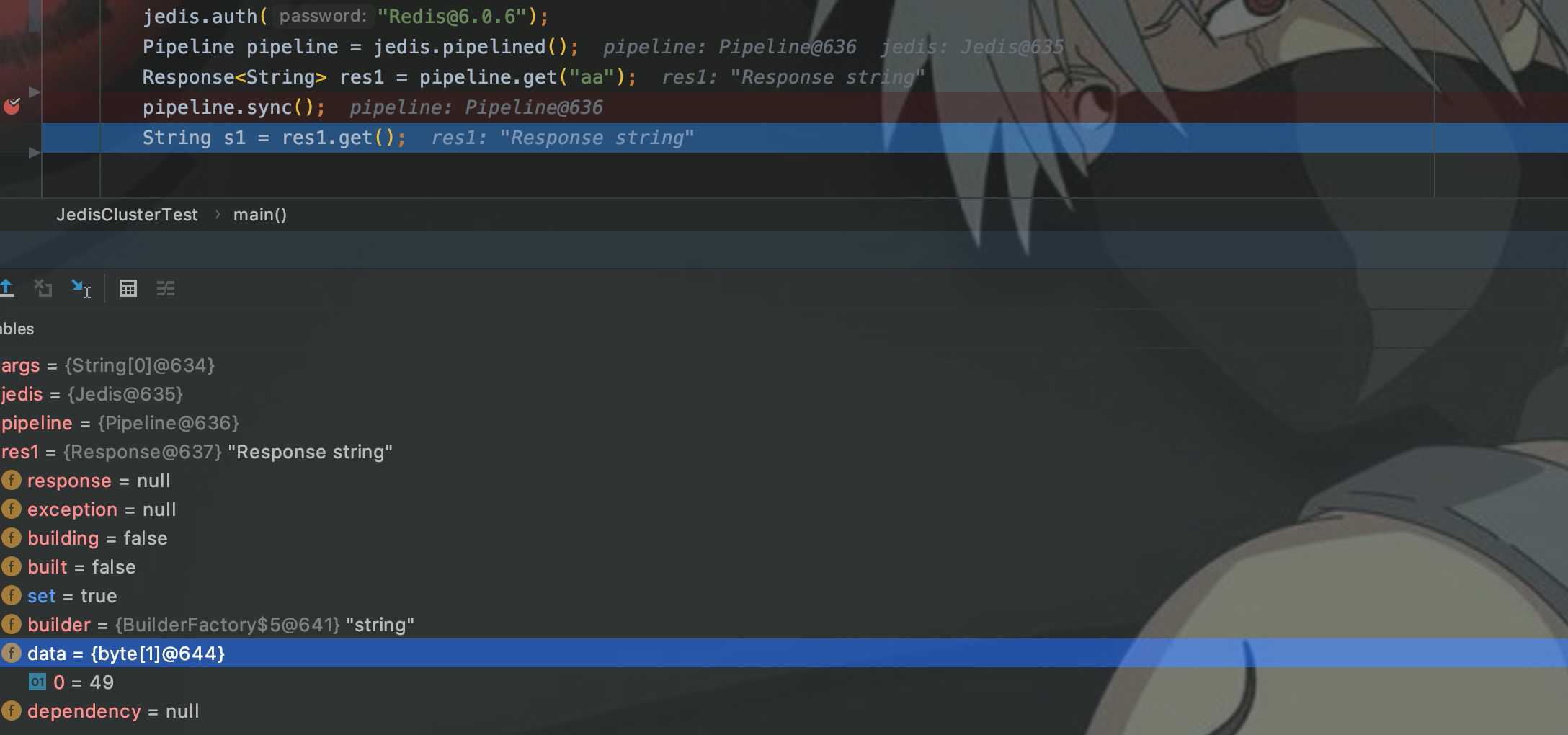
Поэтому после выполнения пакета команд в конвейере обычно выполняется sync() для отправки всех команд в redis. Во время разработки SparkStreaming я обычно устанавливаю пакет на 256 или 512, то есть выполняю 256 или 512 за раз. время.
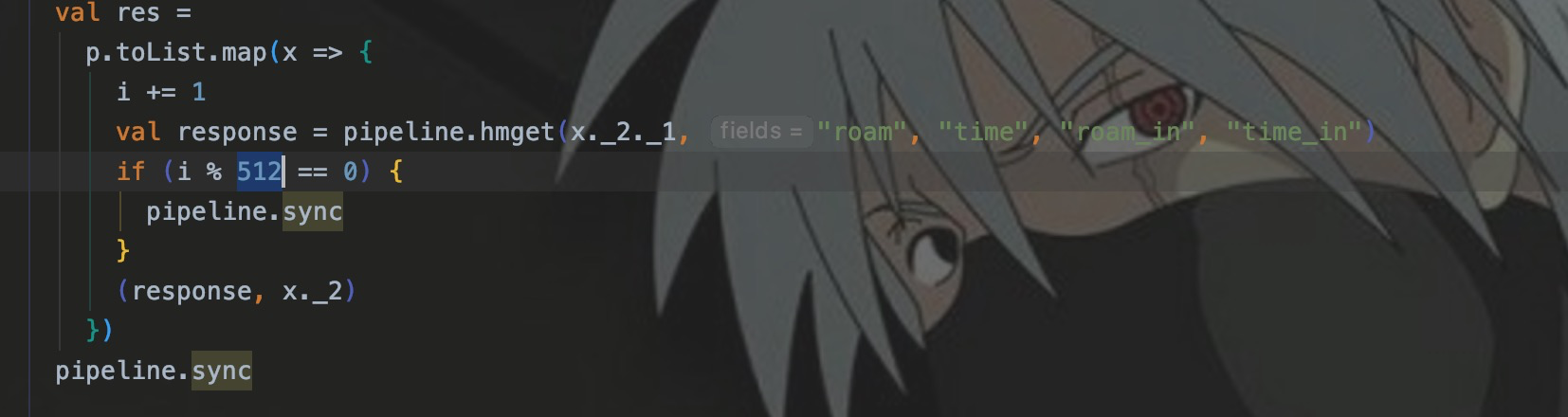
Что касается 256 или 512, его можно оценить на основе размера возвращаемого значения или типа запроса. На этом этапе оптимизация Redis на двух уровнях приложения завершена.
ноПоскольку конвейер эквивалентен созданию канала с помощью Redis и последующей пакетной отправке данных, конвейер есть только у Jedis.。Что это означает конкретно?,Нам все еще нужно начать с общей архитектуры Redis.
Общая архитектура Redis
Redis имеет несколько режимов работы,Одна точка, дозорный, кластер. В настоящее время в производстве,Кластерный режим является наиболее часто используемым. Что касается режима кластера, Redis по умолчанию поддерживает режим кластера. Но в течение многих лет в разработке обработки потоков больших данных,Я думаю, что лучше всего использоватьизclusterвозвращатьсяда Вандуцзя с открытым исходным кодомизCodis,К сожалению, обновления и обслуживание давно прекращены.
Мы упомянули вышетрубопровод только для джедаев,В чем причина?,Нам нужно начать с архитектуры хранения данных Redis.
В Redis всего поделено 16384 слота, и каждый ключ распределен в одном из слотов.
Режим одной точки
Для режима одной точки,16384 слота находятся на одном узле,Неважно, какой ключ будет на этом узле,Мы можем установить связь с этим узлом через джедаев.
Jedis jedis = new Jedis("ip", 10001);
Pipeline pipeline = jedis.pipelined();
Response<String> res1 = pipeline.get("aa");
Response<String> res2 = pipeline.get("bb");
pipeline.sync();Здесь нужно помнить только одну вещь:Jedis может подключаться только к одному сервису Redis.。
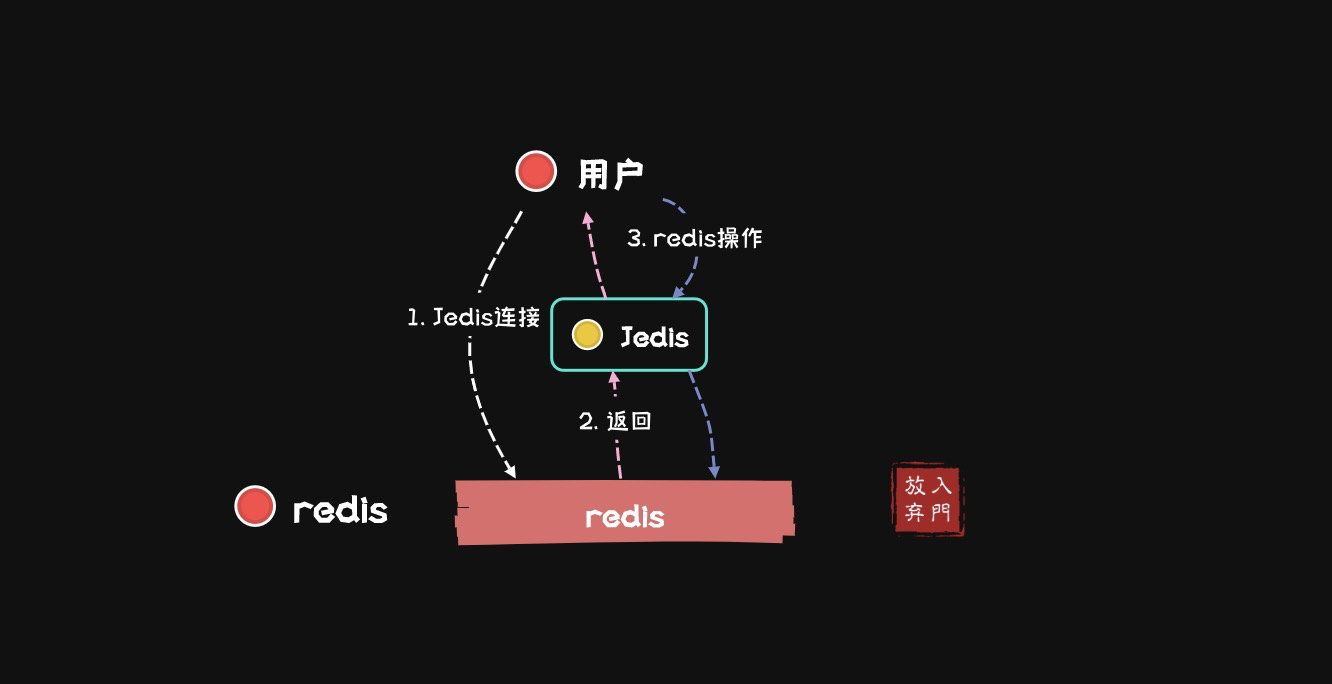
Для режима кластера,Каждый узел кластера поровну разделен на слоты,Когда мы храним ключ,рассмотреть:В каком слоте ключ? На каком узле находится этот слот? Следовательно, это проблема, возникающая при использовании конвейера в режиме кластера.
codis
В архитектуре кодиса,разделен науровень прокси-сервера Codisиserverуровень обслуживания。 codis Proyx делает весь кодис похожим на «большой одноточечный Redis», а прокси реализует протокол Redis, поэтому пользователи могут использовать Jedis для подключения к Codis (большой одноточечный Redis).
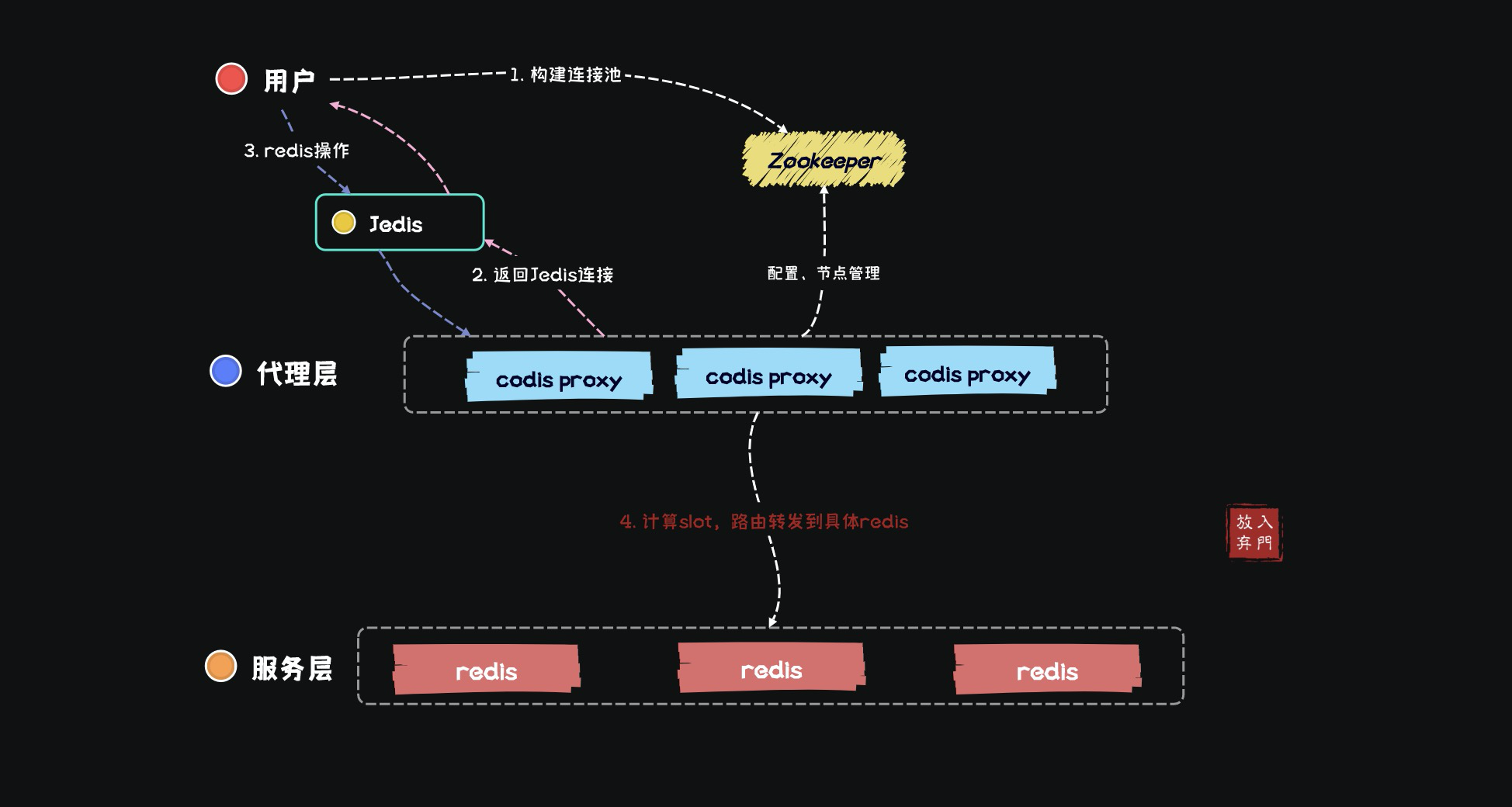
С другой стороны, уровень серверного обслуживания состоит из нескольких экземпляров Redis, и 16384 слота равномерно распределены по каждому экземпляру Redis. Однако уровень сервера находится под прокси-сервером и является прозрачным и невидимым для пользователей. То, к чему пользователи на самом деле подключаются через Jedis, — это уровень прокси, и прокси-сервер рассчитает соответствующий слот на основе каждого ключа, затем найдет узел Redis, соответствующий слоту, а затем выполнит различные операции.
Основная работа выполняется прокси-сервером codis. Нам нужно только подключиться к прокси-серверу codis, а затем по умолчанию на прокси-сервере codis находится 16384 слота. Не нужно беспокоиться о том, в каком Redis находится базовый слот.
val poolConfig = new JedisPoolConfig
val poolx: JedisResourcePool = RoundRobinJedisPool.create()
.curatorClient(redisHost, 30000)
.zkProxyDir("/jodis/" + database)
.poolConfig(poolConfig)
.timeoutMs(60000)
.build()
val jedis: Jedis = poolx.getResourceПоэтому codis тоже подключается на базе Jedis, но подключается к прокси-серверу codis, а не к конкретному redis.
redis cluster
Как и в случае с codis, кластер Redis также состоит из нескольких экземпляров Redis, и 16384 слота равномерно распределены по каждому экземпляру Redis. Разница в том, что в кластере Redis нет уровня прокси, а уровень сервера доступен непосредственно пользователям. Как мы уже говорили выше, Jedis может подключаться только к одному узлу.
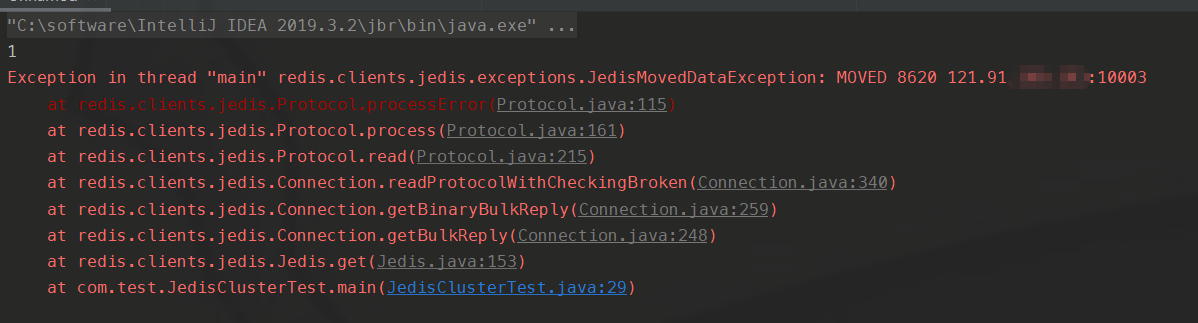
Если вы используете Jedis для подключения к узлу в кластере Redis, то этот Jedis может работать только с ключом слота, распространяемого этим узлом. Например, в redis-cli, когда я нажимаю клавишу bb, я вижу, что перенаправление перенаправляется на узел 10003. Когда я нажимаю клавишу aa, оно перенаправляется на узел 10001.
Таким образом, aa распределяется в слоте узла 10001, а bb хранится в слоте узла 10003. Вы можете использовать Jedis для проверки:
Jedis jedis = new Jedis("121.91.xx.xxx", 10001);
jedis.auth("1qaz@WSX");
System.out.println(jedis.get("aa"));
System.out.println(jedis.get("bb"));Поскольку bb находится в слоте узла 10003, а мой Jedis подключен к узлу 10001, ошибка выдается непосредственно при получении bb.
Потому что джедаи могут управлять слотом только одного узла.,Вот почему он инкапсулированJedisClusterдействоватьredis Все разделы кластера.
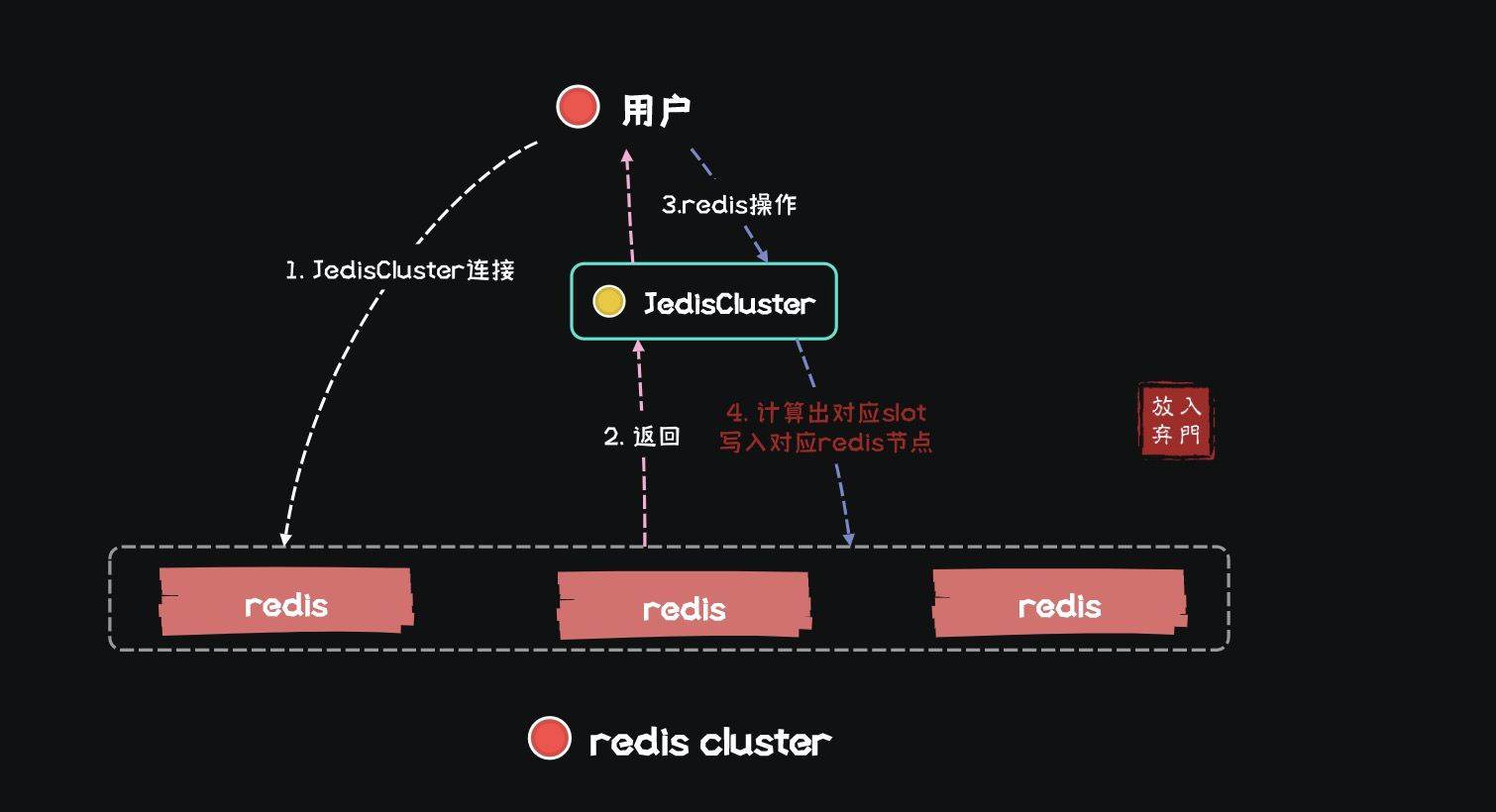
Подключитесь ко всему кластеру Redis через JedisCluster, а затем выполните set, get и другие команды.
HashSet<HostAndPort> jedisClusterNodes = new java.util.HashSet();
jedisClusterNodes.add(new HostAndPort("121.91.xx.xxx", 10001));
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(-1);
config.setMaxIdle(-1);
config.setMaxWaitMillis(1000);
JedisCluster cluster = new JedisCluster(jedisClusterNodes, 1000, 1000, 10, "1qaz@WSX", config);
cluster.get("aa");
cluster.get("bb");Но будь то кластер codis или redis, конечная цель — подключиться к нескольким базовым сервисам Redis. Поэтому JedisCluster также реализует функцию прокси-сервера codis, чтобы данные можно было размещать в соответствующем Redis.
1. соединение Redis
Когда JedisCluter сохраняет данные, Jedis по-прежнему используется на нижнем уровне.
При инициализации JedisCluster,ЧтоconnectionHandlerсвойствоизcacheсвойство,JedisPool будет автоматически создан для всех узлов Redis.,хранится вnodesсередина,и вslotsсвойствосередина,Сформируйте отношение сопоставления между 16384 слотами и JedisPool Redis. Как показано ниже:
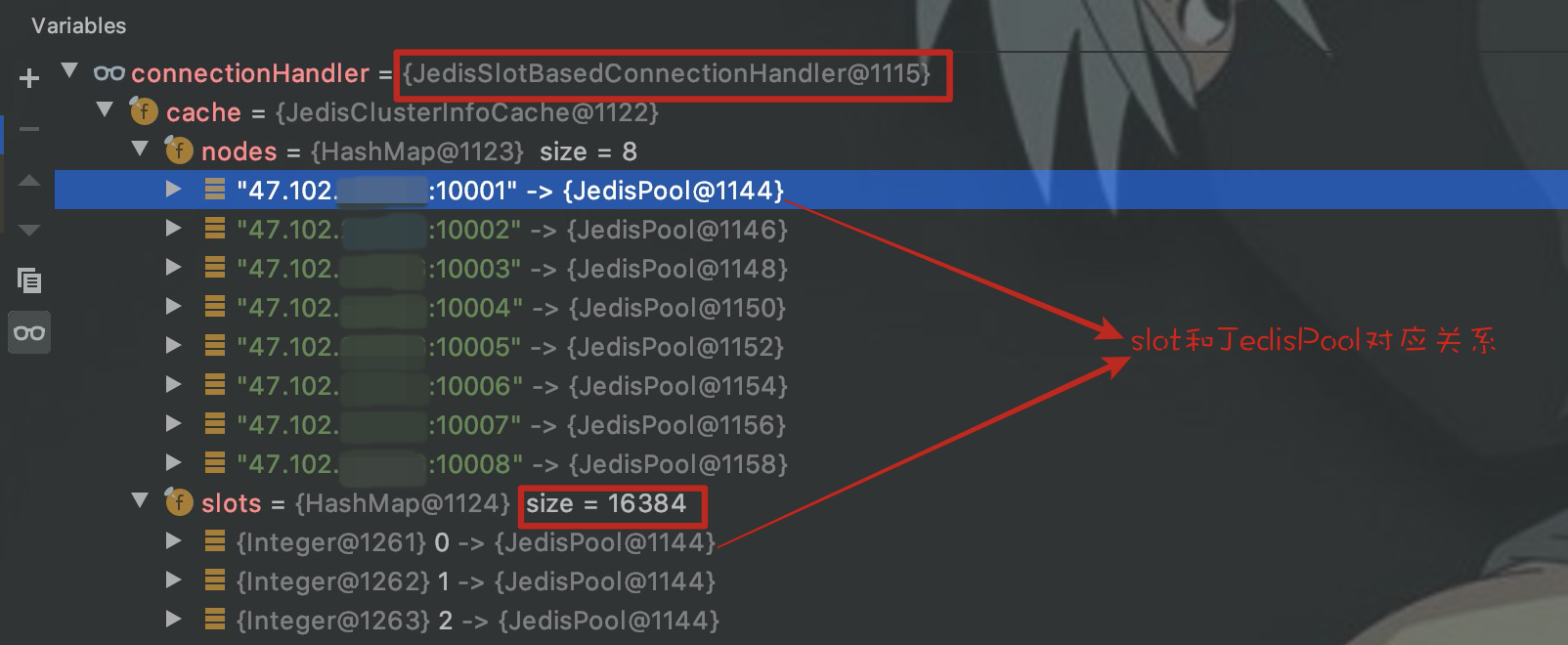
такJedisClusterТолько что понялСвязь между каждым слотом, Redis и JedisPool.,Далее JedisCluster знает, какой ключ в какой слот следует поместить.,Вы можете напрямую получить соединение Jedis с Redis, соответствующим слоту.,Поместите ключ в Redis.
2. Расчет ключа
Каждый раз, когда JedisClustr выполняет такие операции, как установка и получение,,пройдетJedisClusterCRC16изgetSlot() , вычислив слот, в котором находится ключ.
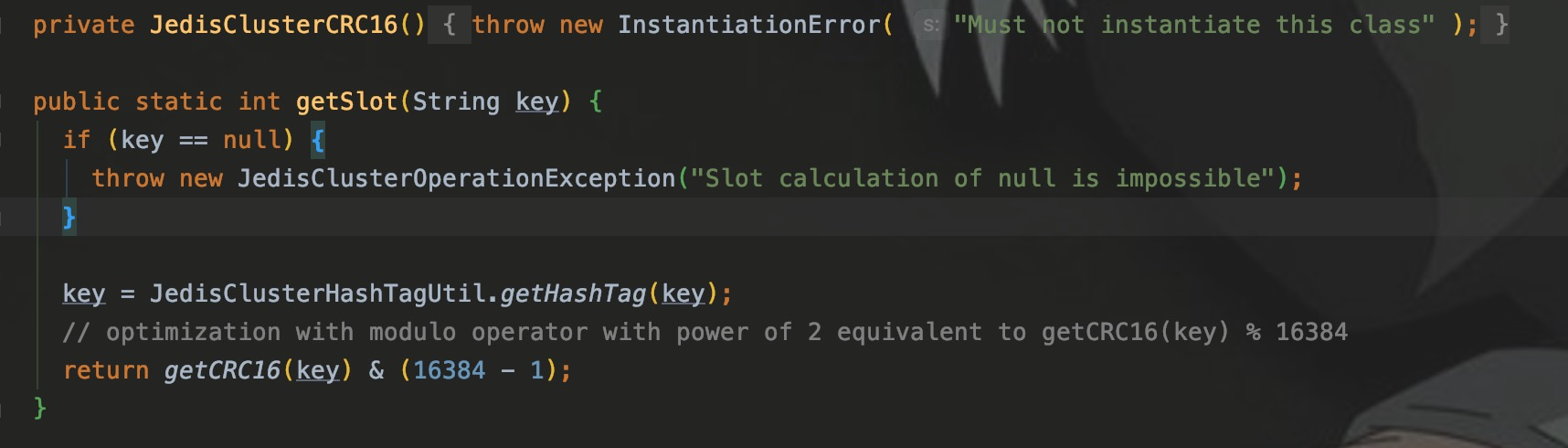
позвони еще разgetConnectionFromSlot() , используйте вычисленный слот для получения JedisPool, соответствующего этому слоту, из кэша.
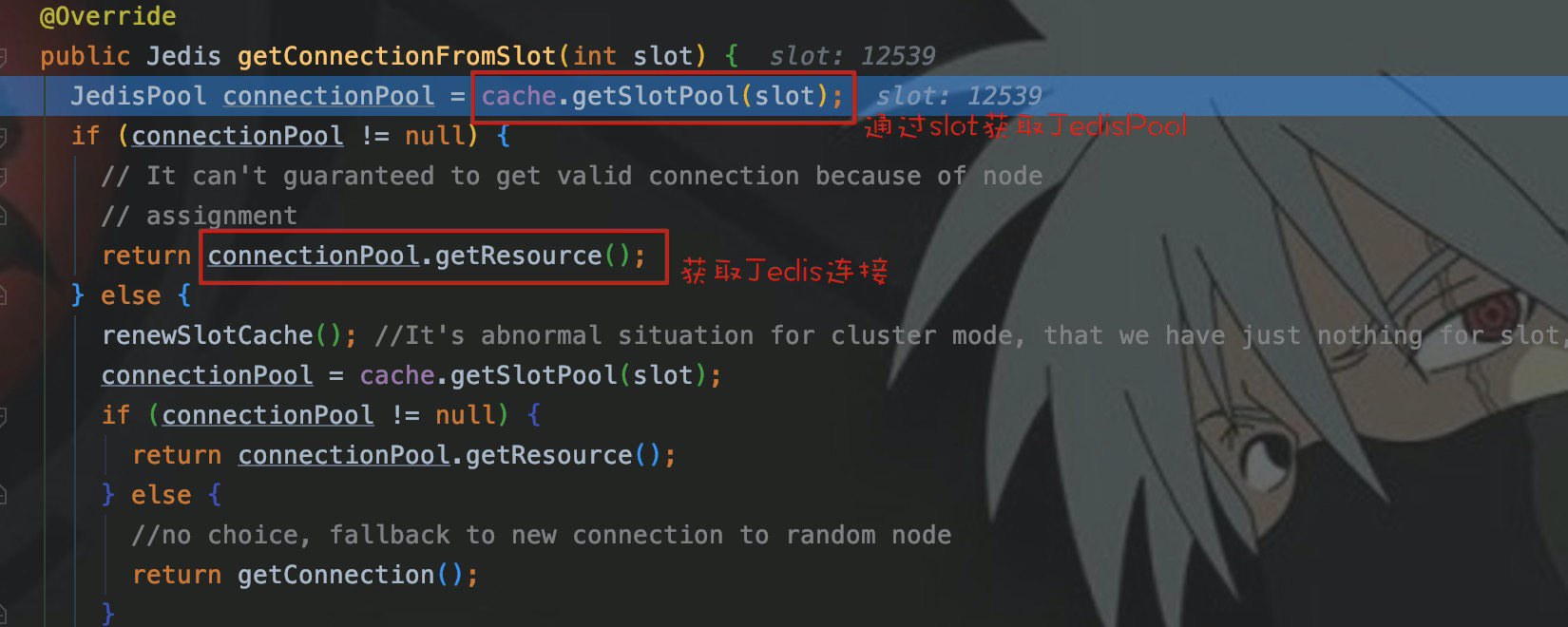
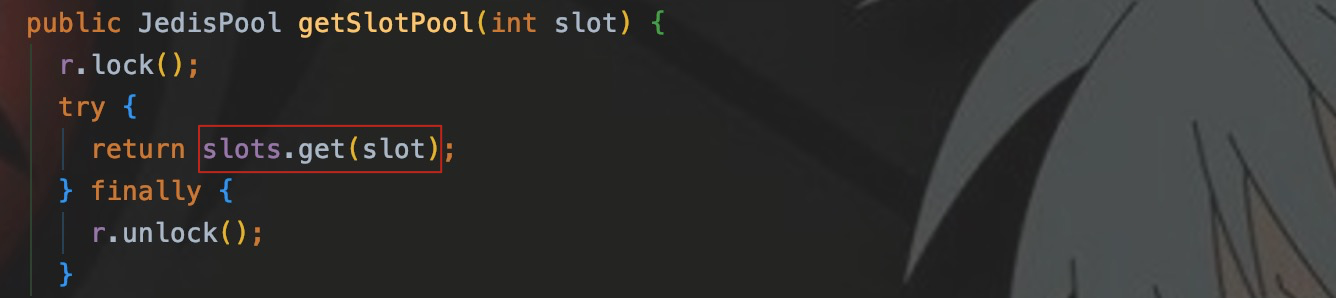
вызовиздаcacheизgetSlotPool() ,от1серединагенерироватьизslotsсвойствосередина,Получите соответствующий JedisPool.
Последний ключ поэтапно помещается в соответствующий слот Redis через интерфейс JedisCluster.
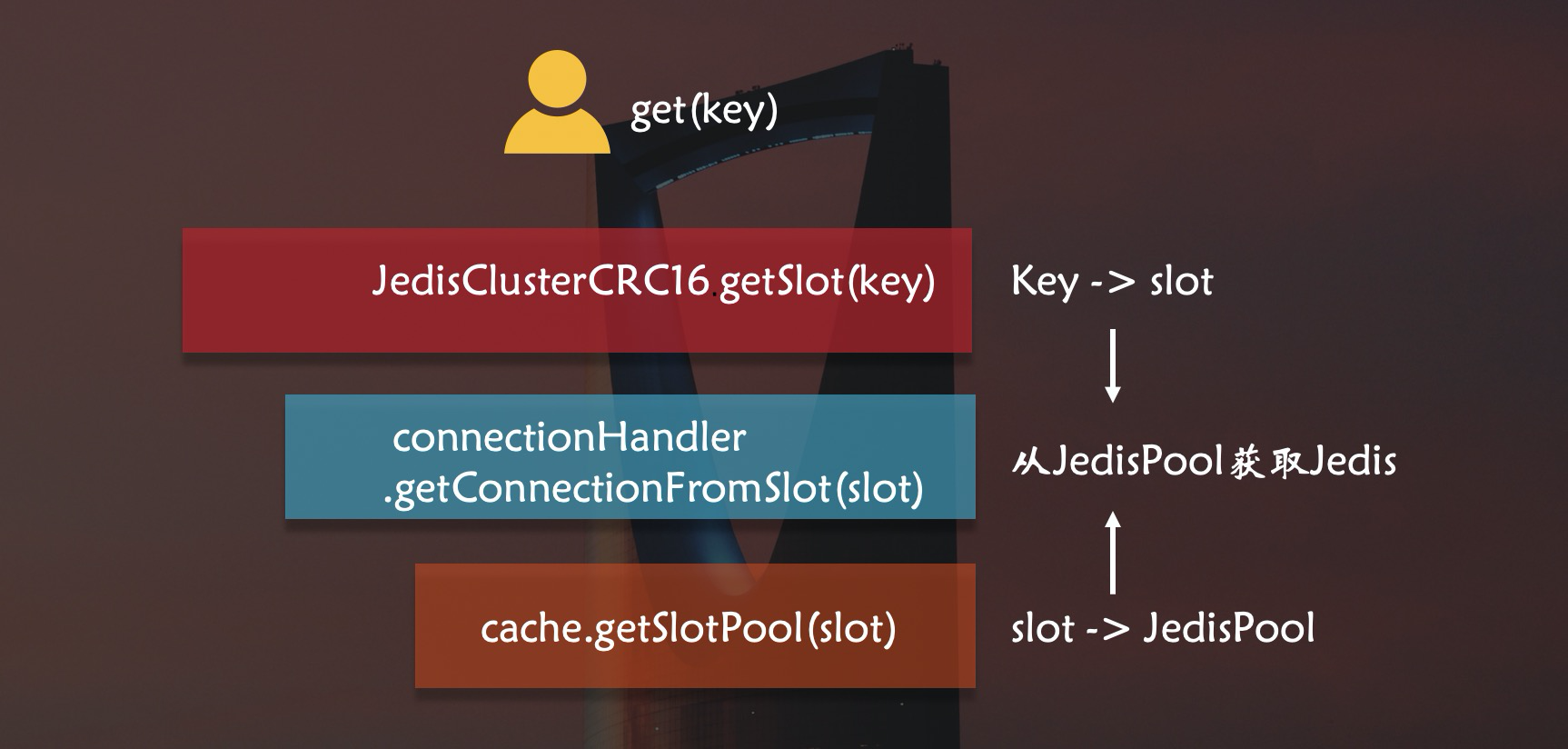
Нижний уровень JedisCluster — это весь Redis в кластере.,Оба создают JedisPool. Но если посмотреть на весь JedisCluster,Никакие объекты Jedis не доступны пользователям.,Другими словами, JedisCluster обращается ко всем узлам кластера.,скорее, чем Чтосерединаопределенный узел。такJedisClusterнепригоден для использованияpipelineиз。
Конвейер кластера Redis
В SparkStreaming, когда я использую кластер Redis для обработки данных со скоростью 100 миллионов в минуту, данные будут задерживаться из-за чрезмерного взаимодействия с кластером Redis. По этой причине я пробовал много методов, когда только что переключился с кластера Codis на кластер Redis.
lettuce
кластер Redis, кроме JedisCluster,Также есть открытый исходный кодизlettuce,Чтосерединаизасинхронный асинхронныйдобрыйpipelineдействовать。
RedisURI uri = RedisURI.builder()
.withHost("47.102.xxx.xxx")
.withPassword("1qaz@WSX".toCharArray())
.withPort(10001)
.build();
RedisClusterClient client = RedisClusterClient.create(uri);
StatefulRedisClusterConnection<String, String> connect = client.connect();
RedisAdvancedClusterAsyncCommands<String, String> async = connect.async();
async.set("key1", "v1");
async.set("key2", "v2");
async.flushCommands();
Thread.sleep(1000 * 3);
connect.close();
client.shutdown();Но после реального испытания,Эффективность по-прежнему невозможно повысить,увлекающийсяиз Друзья могут попробовать сами。Есть еще одинRedissonклиент,Результаты испытаний также не идеальны. Позже я реализовал конвейерный клиент на основе JedisCluster.,Сейчас в производстве,Эффективность по-прежнему очень быстрая.
Пользовательский конвейер
Упоминалось выше,JedisClusterизconnectionHandlerсвойствоизcacheсвойствоизslotsсвойство,Установлена связь между слотом и JedisPool.,Однако в JedisCluster нет внешнего кеша.
К счастью,cacheдаprotected,а не частный.
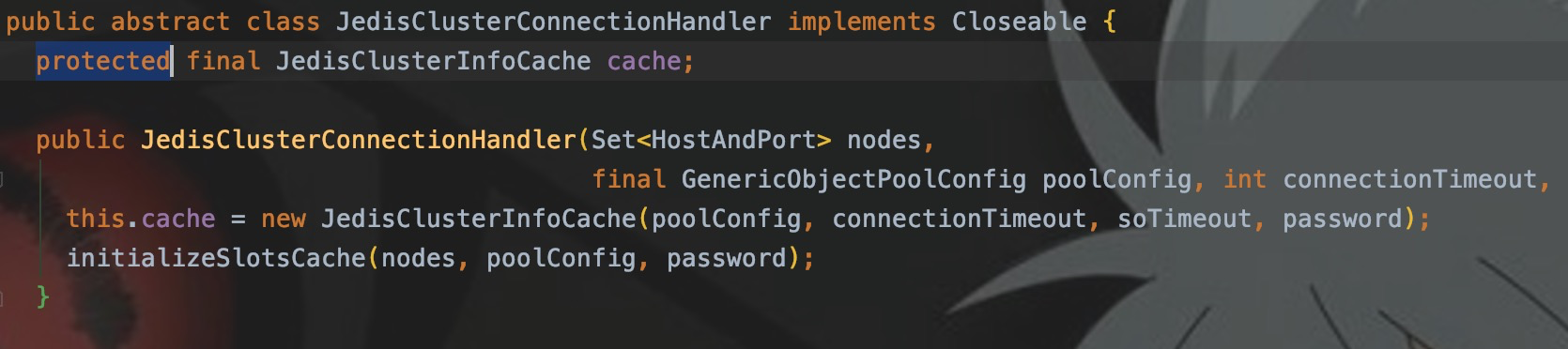
Другими словами, подклассы JedisClusterConnectionHandler могут получать кеш, поэтому реализуйте подклассы для получения слотов.
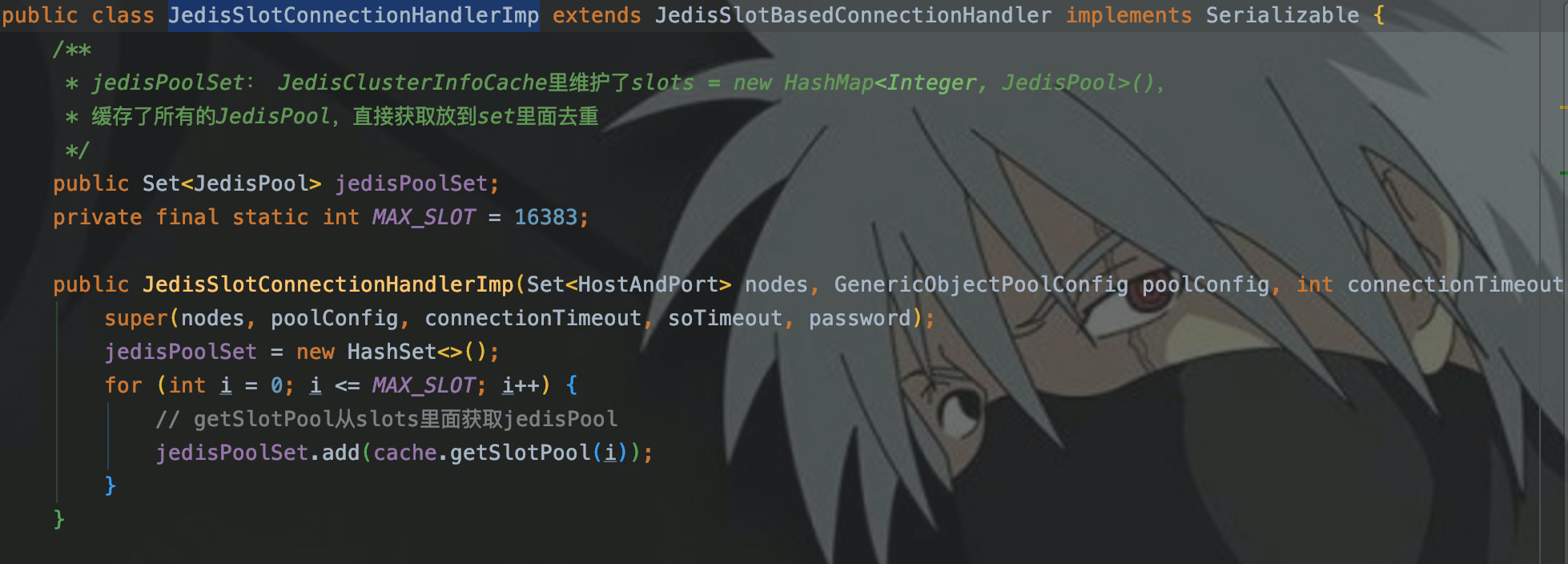
Используйте взаимосвязи слотов,Мы также создаем несколько карт,Для достижения каждого узла Redis,Мы все можем получить джедая,Чтобы запустить конвейер。
- <JedisPool, Jedis>: Вводkeyчас,Вычислить слот, соответствующий ключу,Затем получите соответствующий JedisPool из слотов.,Удалить джедая из JedisPool,создать<JedisPool, Jedis>изкартографирование,Если следующий ключ также находится в этом слоте,Просто используйте этого джедая напрямую. Убедитесь, что в экземпляре Redis есть только один джедай.,такpipelineЭто имеет смысл。
- <Jedis, Pipeline>:через это отображение,Убедитесь, что джедай открывает трубопровод только один раз.,И ключами на том же Redis можно управлять через этот конвейер.
- <Pipeline, num>:этотдаиспользуется для установкиsyncизпорог,num — количество раз, когда эта операция конвейера используется для записи,Траверс,Выполнить синхронизацию при достижении установленного порога.,Отправьте команды конвейера в Redis.
Конкретные идеи реализации см. в предыдущем разделе.изстатья:JedisCluster Идеи реализации конвейера
На этой теоретической основе, а затем исходя из моих реальных потребностей в разработке, я использовал Java + scala для разработки конвейера JedisCluster в дополнение к версии SparkStreaming.
Заключение
Это мой личный опыт использования Redis при разработке больших данных. Я чувствую, что о Redis есть что написать, помимо вышеупомянутых методов оптимизации, таких как разумное проектирование K/V в хэш-структуре и ряд других методов.
Недавно было объявлено, что codis, который работает с ним уже семь лет, отключен от сети, поскольку уязвимость не удалось устранить с помощью обновлений. Хотя я очень рано начал переходить от кластера codis к кластеру redis, в этот момент я не могу не вздохнуть: «Издревле красавицы оплакивают свою старость, а героям не дают стареть».



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
