Redis против локального кэширования: зачем вам оба?

введение
в интервью,Интервьюер спросил меня о моем опыте использования локального кэша.,Первое, что пришло мне в голову, былоRedis,Однако после некоторых раздумий,Это не совсем правильно. после колебания,Мне пришлось ответить, что у меня нет соответствующего опыта. После возвращения домой,Я сразу проверил соответствующую информацию,Только тогда я обнаружил,Оказывается, это поле есть в локальном кэше.,Здесь так много скрытых тайн.
1. Введение в Redis
The open source, in-memory data store used by millions of developers as a database, cache, streaming engine, and message broker.
Простой перевод: программное обеспечение для хранения данных в памяти с открытым исходным кодом, используемое миллионами разработчиков в качестве базы данных, кэша, механизма потоковой передачи и брокера сообщений.
1.1 Что такое Редис
Судя по официальному представлению, помимо функции кэширования, он также имеет множество привлекательных функций. Однако сегодня мы сосредоточимся исключительно на функциональности кэширования. Когда я впервые узнал об этом, я сравнил его с MySQL, которая привлекла большое внимание как база данных NoSQL в памяти. Учитывая узкое место базы данных с точки зрения ввода-вывода и тот факт, что большинство операций связаны только с чтением данных, мы рассмотрели возможность введения промежуточного уровня для кэширования части данных и предоставления их клиенту.
В истории вычислений всегда существовало мнение, что любую проблему в области вычислений можно решить, добавив промежуточный слой.
Как правило, разница между уникальной скоростью записи диска и памяти составляет более 10 раз.
Redis родился по похожему сценарию. На заре существования веб-сайта из-за небольшого количества посещений было возможно использовать JavaScript для подсчета и мониторинга различных данных. Однако по мере роста объема данных рабочая нагрузка по обслуживанию продолжает увеличиваться, и диск становится узким местом. Поэтому автор Redis написал эту базу данных в памяти на языке C.
Причина, по которой Redis называется Redis, заключается в том, что весь его процесс представляет собой службу REmote DIctionary Service, которая интерпретируется как служба удаленного словаря. (Это также соответствует местному).

Функции
- Храните неструктурированные данные Поскольку это словарная служба, по сути, это служба, хранящая неструктурированные типы данных (ключ:значение).
- Большой объем памяти и высокая скорость одновременной записи На уровне хранилища Redis предоставляет множество специальных структур данных для различных предприятий. Кроме того, Redis, являясь базой данных в памяти, обеспечивает высокую производительность чтения и записи.
- распределенный Распределенная реализация Redis в основном опирается на две основные концепции Redis Sentinel и Redis Cluster.
1.2 Основные функции Redis
Согласно официальному описанию, его основные функции разделены на четыре части: база данных, кеш, механизм потоковой передачи и брокер сообщений.
ⅠВ качестве базы данных
Поскольку это база данных, хранящаяся в памяти, потеря данных может легко произойти после отключения питания или сбоя. Затем он также разрабатывает стратегию. Это персистентность, разделенная на RDB и AOF.
- RDB записывает данные на жесткий диск в течение определенного практического интервала.
- AOF записывает каждую полученную команду на жесткий диск.
Так какой из них лучше? Ответ: я хочу их всех. Хорошо это или нет, во многом зависит от вашего сценария использования. Что подходит, то и лучше.

Ⅱ Кэш
Обычно это основная функция, которую мы используем Redis. Пока у нее нет конкурентов в базах данных NoSQL.
Ⅲ Стриминговый движок
Тогда мне интересно, что такое потоковой двигатель?
Механизмы потоковой передачи — это способ обработки постоянных потоков данных, управляемых событиями. В потоке данных каждое событие соответствует элементу данных, и каждый элемент добавляется, изменяется или удаляется в течение определенного интервала времени. Механизмы потоковой передачи обычно используются в сценариях обработки данных в реальном времени, таких как очереди сообщений, архитектура, управляемая событиями, анализ данных в реальном времени и т. д.
Похоже, что он действительно похож на Message Queuing (MQ), и его удобнее использовать с операцией персистентности Redis. В практических сценариях применения его можно использовать в качестве промежуточного потока сообщений для обмена мгновенными сообщениями, анализа веб-данных, системных журналов и т. д.
Ⅳ Брокер сообщений
Эта функция в основном используется, чтобы позволить Redis выполнять асинхронную связь и приложения, управляемые событиями, в реальном времени между несколькими узлами.
Поскольку Redis поддерживает модель публикации/подписки, это очень важное средство.
Конечно, это также может служить промежуточным прокси-сервером для микросервисов.
1.3 Сценарии применения Redis
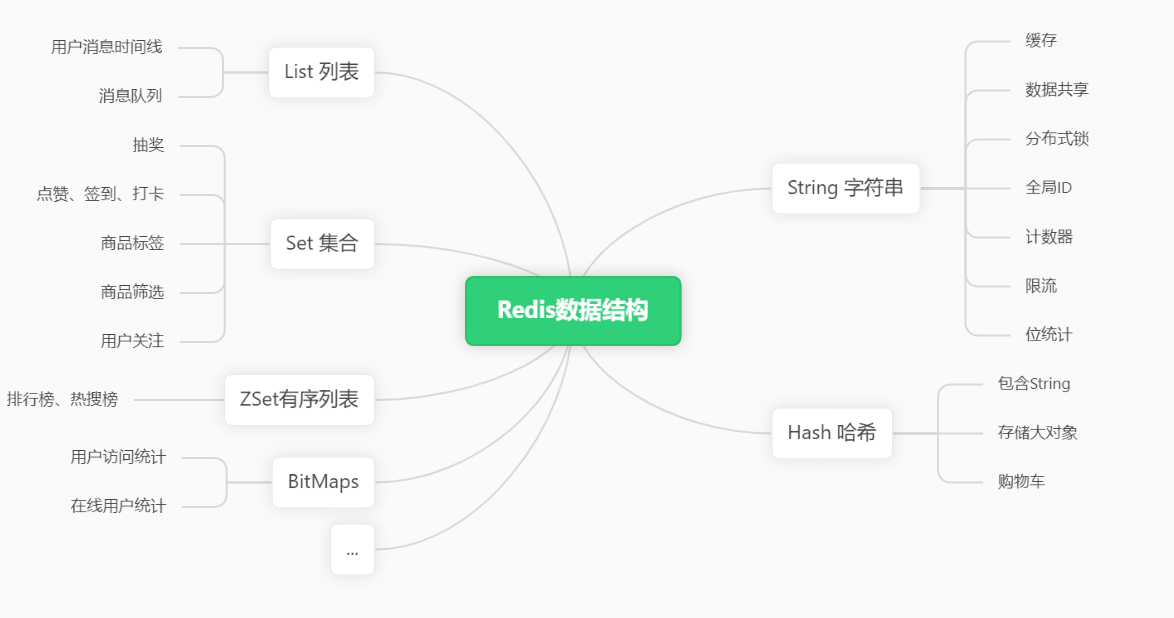
Если вы просто задумаетесь о том, какие ресурсы может сэкономить кэширование, вы, возможно, какое-то время не сможете ответить на этот вопрос. Но начиная со структуры данных Redis, будет много вдохновения.
- ① Строка Распределенная блокировка, глобальный идентификатор
- ② Хэш Храните объекты и информацию о корзине.
- ③ Список списка Очередь сообщений, временная шкала сообщений пользователя
- ④ набор набор Лотерея, типа, войдите, вбейте, Тег продукта пользовательсосредоточиться на: взаимныйсосредоточиться на?пересечение ясосредоточиться налюди такжесосредоточиться на него? пересечение Кто-то, кого вы можете знать? набор различий
Здесь есть еще много случаев, и все они основаны на богатых структурах данных.
2. Знакомство с локальным кешем
Прежде чем обращаться к удаленному кешу, многие кеши фактически используются неявно в процессе, например, кеш ORM и строковый кеш JDK (постоянный пул).
Понимание этого в Java на самом деле представляет собой большую карту.
2.1 Локальный кеш
Если мы хотим реализовать кэш самостоятельно, что нам нужно учитывать?
- Область вызова. Если вы полагаетесь на Spring Boot, вы можете зарегистрировать его в классе запуска и использовать глобально (немного опасно).
- Срок годности Если память занята в течение длительного времени, это неизбежно приведет к сбою программы, поэтому подумайте об истечении срока действия и удалении.
- последовательность Это очень распространенная проблема в кэшировании. Ключ заключается в том, должен ли бизнес полностью доверять ей и применять разные стратегии.
- Параллелизм и блокировки JDK предоставляет пакет JUC, и коллекции в нем очень полезны.
- Масштабируемость Можно ли повторно расширить приложение плагина?
Принимая все во внимание, это на самом деле большая проблема. К счастью, экосистема Java достаточно сильна.
2.2 Зрелая структура
Guava Cache
Guava Cache — это локальная библиотека инструментов кэширования с открытым исходным кодом, разработанная Google. Ее дизайн вдохновлен ConcurrentHashMap. Она использует мелкозернистые блокировки в нескольких сегментах для обеспечения безопасности потоков, одновременно поддерживая требования к сценариям с высоким уровнем параллелизма и поддерживая несколько типов стратегий очистки кэша. Очистка на основе емкости, очистка на основе времени, очистка на основе ссылок и т. д.
Важным контейнером пакета JUC является ConcurrentHashMap, созданный на его основе и имеющий более мелкую детализацию блокировок. В сочетании с полной реализацией в мышлении и родилась такая основа. Судя по Google, существует определенная гарантия прочности. Вначале он стал встроенным кешем Spring.
Caffeine
Caffeine — это библиотека кэширования Java с открытым исходным кодом, которая обеспечивает высокую частоту попаданий и отличные возможности параллелизма. Caffeine поддерживает параллелизм и доступ к данным временной сложности O(1), аналогично структуре данных ConcurrentMap, но предоставляет стратегию автоматического удаления «редко используемых» данных для поддержания разумного использования памяти. В Caffeine данные можно кэшировать из локальной памяти приложения Java, чтобы повысить производительность и скорость реагирования приложения. Caffeine предоставляет четыре стратегии добавления кэша, включая ручную загрузку, автоматическую загрузку, ручную асинхронную загрузку и автоматическую асинхронную загрузку.
Усовершенствованный Guava и ставший первым выбором платформы кэширования в Spring 5, это Caffeine, и его название очень похоже на Java.
Ява, остров Ява, богат кофе. Итак, иконка Java — это форма кофе. Кофеин: кофеин

2.2 Основные сценарии локального кэша
Помимо вышеперечисленных фреймворков, локальное кэширование действительно прошло длительный период развития. Так что же с ними сделали разработчики?
- Кэш базы данных Это похоже на идею удаленного кэширования. В рамках ORM такая возможность кэширования доступна. Например, кэш третьего уровня MyBatis. Конечно, если кеш этого не понимает, данные очень легко прочитать или изменить, что приведет к путанице.
- Кэширование сетевых запросов Кэширование сетевых запросов также является важной частью одного из нескольких сценариев ввода-вывода.
3. Почему вам нужно иметь и то, и другое
После сравнения преимуществ и недостатков этих двух вариантов, я думаю, у вас уже есть ответ. Но здесь я кратко изложу свою точку зрения.
- Адаптируйтесь к потребностям различных сценариев Даже в распределенной системе фреймворк реализовал для нас необходимость локального кэша, нам все равно нужно сосредоточиться и оптимизировать его. Локальный кеш: больше ориентирован на одну службу/приложение, что позволяет сократить количество операций ввода-вывода и повысить производительность. Распределенный кеш: подходит для комплексных приложений в более крупных сценариях, глобальный кеш.
- Компромисс затрат и выгод Хотя внедрение новых технологий может принести высокую прибыль, оно также сопряжено с высокими рисками. Поэтому предприятиям следует сосредоточиться на экономии затрат на технологии, а также затрат на эксплуатацию и техническое обслуживание в процессе разработки, даже если новая технология действительно очень полезна.
в заключение
Независимо от технологии, лучшим выбором будет та технология, которая лучше всего соответствует потребностям вашего бизнеса.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
