Реализация GraphRAG «от локального к глобальному» с использованием Neo4j и LangChain
GraphRAGдаодин на основе График технологии улучшения поиска знаний. Он использует данные из нескольких источников для построения графовой модели представления знаний.,Связи между сущностями и отношениями показаны в виде диаграмм.,Затем используйте большие языковые модели для улучшения поиска. Этот метод позволяет получить соответствующую информацию более эффективно и точно.,И дляLLMГенерируйте ответы, чтобы обеспечить лучшееизконтекст。МайкрософтиLinkedInиз Техники стали научнымииз Этот метод был проверен по сравнению с базовым уровнем. RAG преимущества и опубликовали соответствующие статьи.
- • LinkedIn Последние исследования: база данных граф + вектор, сокращение времени ответа службы поддержки клиентов 64%[1]
- • From Local to Global: A Graph RAG Approach to Query-Focused Summarization[2]
В настоящее время проект Microsoft GraphRAG[3] с открытым исходным кодом поддерживает блокировку, векторизацию, извлечение сущностей и связей из документов, а затем сохранение их в виде файлов графов локальных знаний. В настоящее время он не поддерживает хранение данных в Neo4j. Проект LLM Graph Builder[4] с открытым исходным кодом Noej4 разделен на интерфейсную и серверную части. Он поддерживает загрузку изображений, документов и других материалов для создания графиков знаний, а затем создания вопросов и ответов. Он не содержит сводки сообщества и векторизации объектов. функции на данный момент. Эта статья основана на этих проектах и использует Neo4j и Langchain для отдельной реализации GraphRAG «от локального к глобальному». Ее можно понимать как добавление функциональности сводки сообщества Microsoft GraphRAG только к проекту LLM Graph Builder. Кроме того, LLM Graph Builder — это новый проект, и разработчики официального веб-сайта также быстро внедряют итерации и планируют интегрировать все аспекты GraphRAG. В будущем должна появиться иерархическая кластеризация для создания сводок сообщества, векторизации сущностей и других функций.

LLM Graph Builder Issues
Ответ разработчика
Для повышения точности технологии расширенной поисковой генерации (RAG) можно использовать в сочетании извлечение текста, анализ графов, технологию подсказок модели большого языка (LLM) и возможности обобщения информации. Эта статья переведена и составлена на основе оригинального текста: Реализация GraphRAG «от локального к глобальному» с помощью Neo4j и LangChain: построение графа[5].

В этом сообщении блога мы подробно рассмотрим статью Microsoft «От локального к глобальному GraphRAG[6]» и ее конкретную реализацию. В основном мы представим построение и сводную часть графа знаний, а приложение для поиска на основе GraphRAG будет подробно представлено в следующей статье блога. Исследователи Microsoft также предоставляют страницу проекта Microsoft GraphRAG[7].
Использование метода из в упомянутой выше статье очень интересно. Насколько мне известно, он включает использование графа знаний в качестве отдельного шага в конвейере для сжатия и объединения информации из нескольких индивидуальных источников. Извлечение сущностей и связей из текста не является чем-то новым. Однако автор предлагает новую идею (по крайней мере для меня) сжатия графовых структур и информации. итогдля текста на естественном языке。Пайплайн из документациииз Введите текст, чтобы начать,Затем он обрабатывается для создания графика. Затем,График преобразуется обратно в текст на естественном языке.,Генерировать текст, содержащий сжатую информацию о конкретной сущности или сообществе графов.,Ранее эта информация распространялась в нескольких отдельных документах.
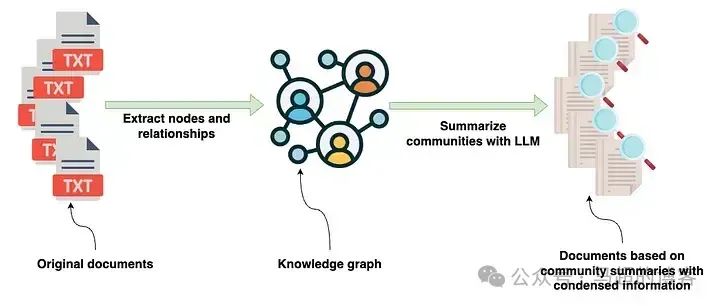
Расширенный конвейер индексации, реализованный Microsoft в статье GraphRAG — изображение автора статьи
На очень высоком уровне входными данными для конвейера GraphRAG является исходный документ, содержащий различную информацию. Документы обрабатываются с использованием LLM для извлечения структурированной информации об объектах и их отношениях, которые появляются в документе. Извлеченная структурированная информация затем используется для построения графа знаний.
Преимущество использования представления данных в виде графа знаний заключается в том, что оно позволяет быстро и напрямую комбинировать информацию о конкретной сущности из нескольких документов или источников данных. Как упоминалось ранее, графы знаний — не единственное представление данных. После построения графа знаний они использовали комбинацию графовых алгоритмов и подсказок LLM для создания сводок на естественном языке сообществ сущностей в графе знаний.
Эти сводки содержат сжатую информацию из нескольких источников данных и документов для конкретных организаций и сообществ. Чтобы понять процесс более подробно, мы можем обратиться к пошаговому описанию, представленному в оригинальной статье.
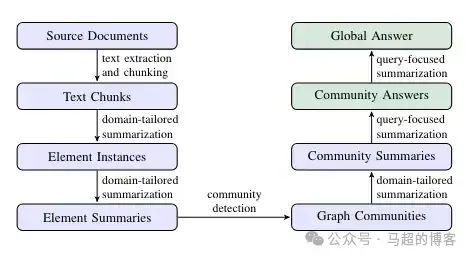
Этапы процесса — изображение из статьи GraphRAG, под лицензией CC BY 4.0.
Ниже приведены конкретные шаги по использованию Neo4j и LangChain для воспроизведения метода Microsoft GraphRAG и экспериментального кода, использованного в этой статье [8].
Основные моменты
Индекс — создание графиков
- • Исходный документ в текстовый блок:Исходный документ разбивается на более мелкиеиз Текстовый блок для обработки。
- • текстовый блок в экземпляр элемента:Анализируйте каждыйиндивидуальный Текстовый блок для извлечения сущностейисвязь,Создайте список кортежей, представляющих эти элементы.
- • экземпляр элемента в сводку элемента:извлекатьизсущностьисвязь Зависит от LLM Подвести итог представляет собой описательный текстовый блок для каждого отдельного элемента из.
- • Сводка элементов для сообщества графов:этотнекоторыйсущностьабстрактное образованиеодининдивидуальныйкартина,Затем используйтеLeiden[9] et алгоритм Воля, который разделен на сообщества.,для достижения иерархической структуры.
- • От сообществ графов к сводкам сообществ:использовать LLM Создайте краткую информацию о каждом сообществе, чтобы узнать о Наборе. данныеиз Глобальная структура и семантика тем.
Поиск-Ответ
- • Резюме сообщества к глобальному ответу:Сводки сообщества используются для ответа на запросы пользователей путем создания промежуточных ответов.,Затем Воля суммируется в окончательный глобальный ответ.
Настройте среду Neo4j
Мы будем использовать Neo4j в качестве основного хранилища графов. Самый простой способ начать — использовать бесплатный экземпляр Neo4j Sandbox [10], который предоставляет облачный экземпляр базы данных Neo4j с установленным плагином Graph Data Science. Альтернативно вы можете настроить локальный экземпляр базы данных Neo4j, загрузив приложение Neo4j Desktop и создав локальный экземпляр базы данных. Если вы используете локальную версию, обязательно установите плагины APOC и GDS. Для производственной установки вы можете использовать платный управляемый экземпляр AuraDS (Data Science), который предоставляет плагин GDS.
Сначала мы создаем экземпляр Neo4jGraph[11], который представляет собой удобную оболочку, которую мы добавляем в LangChain:
from langchain_community.graphs import Neo4jGraph
os.environ["NEO4J_URI"] = "bolt://44.202.208.177:7687"
os.environ["NEO4J_USERNAME"] = "neo4j"
os.environ["NEO4J_PASSWORD"] = "mast-codes-trails"
graph = Neo4jGraph(refresh_schema=False)Набор данных
Мы собираемся использовать то, что я использовал раньше Diffbot из API Создать из новостной статьи Набор данные. я загрузил это себе GitHub Для удобства повторного использования:
news = pd.read_csv(
"https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv"
)
news["tokens"] = [
num_tokens_from_string(f"{row['title']} {row['text']}")
for i, row in news.iterrows()
]
news.head()Проверьте первые несколько строк Набора данных.

образец данных
использовать tiktoken Библиотека, чтобы получить статью по заголовку и телу, рассчитать Token количество.
фрагментирование текста
Эти шаги имеют решающее значение,верно Последующие результаты имеют значительное влияние. Авторы статьи найдены,использовать Меньшие текстовые блоки могут в целом извлечь больше объектов.
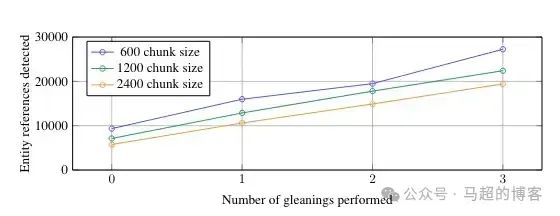
Извлечение количества объектов на основе размера текстового блока — диссертация GraphRAG, основанная на CC BY 4.0 Лицензия
Как видите, используйте 2,400 отдельная отметка из текстового блока будет лучше, чем использовать 600 индивидуальная разметка извлекает меньше сущностей. Кроме того, они также нашли LLM Возможно, не удастся извлечь все объекты при первом запуске. В этом случае они ввели эвристику для многократного выполнения извлечения. Мы обсудим это подробнее в следующем разделе.
Однако всегда есть компромиссы. Использование Меньшие текстовые блоки могут привести к потере контекста и корреляций для определенных объектов в документе. Например, если в документе упоминаются «Джон» и «он» в разных предложениях, разбивка текста на более мелкие фрагменты может сделать неясным, относится ли «он» к Джону. Некоторые проблемы кореференции могут использовать перекрытие-фрагментирование. текстстратегия, которую нужно решить, но не все.
Давайте проверим текст статьи по размеру:
sns.histplot(news["tokens"], kde=False)
plt.title('Distribution of chunk sizes')
plt.xlabel('Token count')
plt.ylabel('Frequency')
plt.show()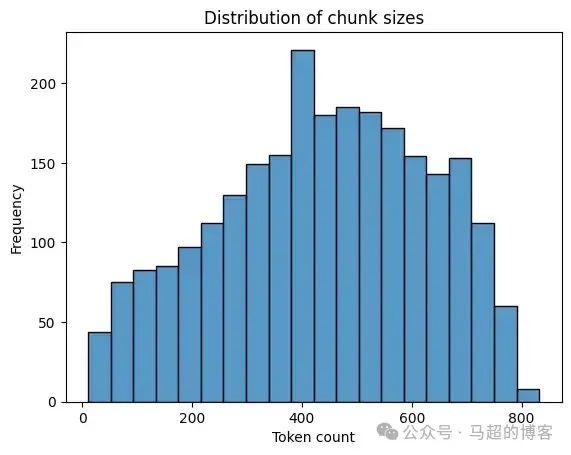
Распределение количества тегов статей примерно нормальное, с пиковым значением примерно 400 индивидуальный знак. Частота блоков постепенно увеличивается до этого пика, а затем симметрично уменьшается, указывая на то, что большинство текстовых блоков 400 возле отметки.
В связи с таким распределением мы не будем здесь выполнять фрагментирование. text, чтобы избежать проблем с кореференцией. По умолчанию GraphRAG проектиспользовать 300 индивидуальная отметка из размера блока [12], где 100 маркеры перекрываются.
Извлечение узлов и связей
Далее нужно построить знания из текстового блока. верно. В этом случае мы используем LLM Из текста Извлечение узлов и связи формируются из структурированной информации. Проверить автора можно в статьеиспользоватьизLLM Совет[13]. у них есть LLM Совет: при необходимости мы можем заранее определить метки узлов, но по умолчанию это необязательно. Более того, связь, извлеченная из исходного документа, фактически не имеет типа, а имеет только описание. Я думаю, что этот вариант по причине позволяет LLM Извлекайте и сохраняйте более богатую и детальную информацию в виде отношений. Но да, без указания типа отношения (описание может идти в свойствах) трудно получить чистое изображение. знаний。
В нашей реализации мы Воляиспользовать LangChain Доступно в библиотеке LLMGraphTransformer. LLMGraphTransformer[14] не является чисто проектом подсказок, как реализация в этой статье, но имеет встроенную поддержку вызова функций для извлечения структурированной информации (LangChain Средний структурированный вывод LLM). Вы можете проверить системное приглашение[15]:
from langchain_experimental.graph_transformers importLLMGraphTransformer
from langchain_openai importChatOpenAI
llm =ChatOpenAI(temperature=0, model_name="gpt-4o")
llm_transformer =LLMGraphTransformer(
llm=llm,
node_properties=["description"],
relationship_properties=["description"]
)
defprocess_text(text: str)->List[GraphDocument]:
doc =Document(page_content=text)
return llm_transformer.convert_to_graph_documents([doc])В этом примере мы используем GPT-4o Выполните извлечение графа. Особые указания от автора LLM Извлечение сущностей и отношений и их описаний [16]. использовать LangChain Поймите, что вы можете использовать node_properties и relationship_properties свойства, чтобы указать желаемый LLM Какие свойства узла или связи извлекаются.
LLMGraphTransformer Реализация отличается тем, что все свойства узла или связи являются необязательными, поэтому не все узлы имеют такие свойства. description свойство. Если бы мы захотели, мы могли бы определить пользовательское извлечение, которое принудительно description свойство, но в данной реализации мы это пропустим.
Мы распараллелим запрос, чтобы ускорить получение графа и сохраним результаты в Neo4j:
MAX_WORKERS = 10
NUM_ARTICLES =2000
graph_documents =[]
withThreadPoolExecutor(max_workers=MAX_WORKERS)as executor:
# Submitting all tasks and creating a list of future objects
futures =[
executor.submit(process_text,f"{row['title']} {row['text']}")
for i, row in news.head(NUM_ARTICLES).iterrows()
]
for future in tqdm(
as_completed(futures), total=len(futures), desc="Processing documents"
):
graph_document = future.result()
graph_documents.extend(graph_document)
graph.add_graph_documents(
graph_documents,
baseEntityLabel=True,
include_source=True
)В этом примере мы начинаем с 2,000 Информация атласа была извлечена из статей, а результаты сохранены в Neo4j. Мы извлекли ок. 13,000 индивидуальныйсущностьи 16,000 индивидуальныйсвязь。нижедакартина Спектрсерединаизвлекатьиздокументиз Пример。
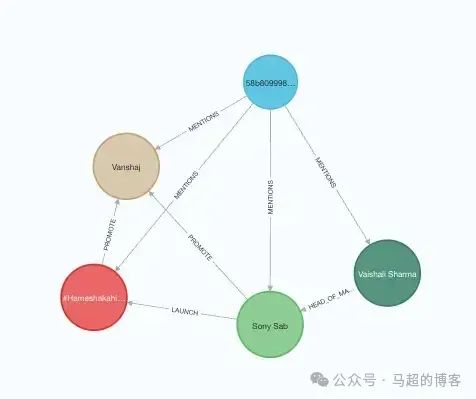
Документ (синий) указывает на извлечение объектов и связей.
использовать GPT-4o Полное извлечение занимает примерно 35(+/- 5) минут, стоимость ок. 30 Доллар.
На этом этапе авторы вводят эвристику, чтобы решить, следует ли извлекать информацию о графе в нескольких процессах. Для простоты мы делаем это только один раз. Однако, если бы мы хотели сделать это несколько раз, мы могли бы извлечь результаты первого раза в виде истории разговоров и просто указать LLM Многие объекты отсутствуют, следует извлечь больше объектов, таких как GraphRAG Что сделал авториз Таким образом。
До,Я упомянул размер текстового блока по важности и то, как он влияет на извлечение количества сущностей, поскольку никакого дополнительного изфрагментирования текста мы не проводили.,Таким образом, мы можем оценить распределение извлеченного объекта на основе размера текстового блока:
entity_dist = graph.query(
"""
MATCH (d:Document)
RETURN d.text AS text,
count {(d)-[:MENTIONS]->()} AS entity_count
"""
)
entity_dist_df = pd.DataFrame.from_records(entity_dist)
entity_dist_df["token_count"]=[
num_tokens_from_string(str(el))for el in entity_dist_df["text"]
]
# Scatter plot with regression line
sns.lmplot(
x="token_count",
y="entity_count",
data=entity_dist_df,
line_kws={"color":"red"}
)
plt.title("Entity Count vs Token Count Distribution")
plt.xlabel("Token Count")
plt.ylabel("Entity Count")
plt.show()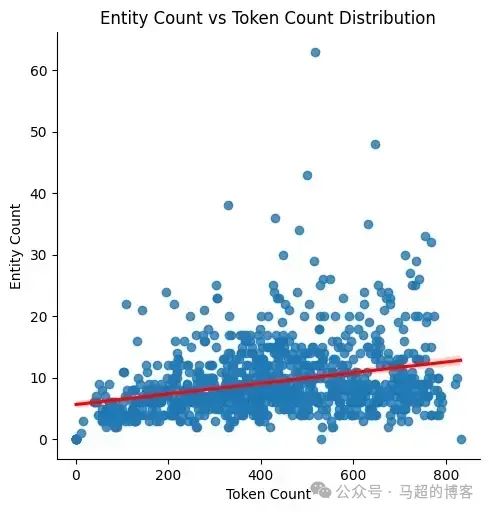
Отображение точечной диаграммы,Хотя положительная динамика есть (обозначена красной линией),Но связь да Второсортная, линейная. Даже если количество тегов увеличится,Большинство точек данных по-прежнему группируются вокруг меньшего количества объектов. Это показывает, что количество извлеченных объектов не пропорционально размеру текстового блока. Хотя есть некоторые отклонения,Но общая картина предполагает,Большее количество тегов из не обязательно приводит к большему количеству сущностей. Это подтверждает выводы автора,т. е. меньший размер текстового блока. Воля извлекает больше информации.
Я также подумал, что было бы интересно изучить распределение степеней узлов графа построения. Следующий код извлекает и предварительного распределения степени узла:
degree_dist = graph.query(
"""
MATCH (e:__Entity__)
RETURN count {(e)-[:!MENTIONS]-()} AS node_degree
"""
)
degree_dist_df = pd.DataFrame.from_records(degree_dist)
# Calculate mean and median
mean_degree = np.mean(degree_dist_df['node_degree'])
percentiles = np.percentile(degree_dist_df['node_degree'],[25,50,75,90])
# Create a histogram with a logarithmic scale
plt.figure(figsize=(12,6))
sns.histplot(degree_dist_df['node_degree'], bins=50, kde=False, color='blue')
# Use a logarithmic scale for the x-axis
plt.yscale('log')
# Adding labels and title
plt.xlabel('Node Degree')
plt.ylabel('Count (log scale)')
plt.title('Node Degree Distribution')
# Add mean, median, and percentile lines
plt.axvline(mean_degree, color='red', linestyle='dashed', linewidth=1, label=f'Mean: {mean_degree:.2f}')
plt.axvline(percentiles[0], color='purple', linestyle='dashed', linewidth=1, label=f'25th Percentile: {percentiles[0]:.2f}')
plt.axvline(percentiles[1], color='orange', linestyle='dashed', linewidth=1, label=f'50th Percentile: {percentiles[1]:.2f}')
plt.axvline(percentiles[2], color='yellow', linestyle='dashed', linewidth=1, label=f'75th Percentile: {percentiles[2]:.2f}')
plt.axvline(percentiles[3], color='brown', linestyle='dashed', linewidth=1, label=f'90th Percentile: {percentiles[3]:.2f}')
# Add legend
plt.legend()
# Show the plot
plt.show()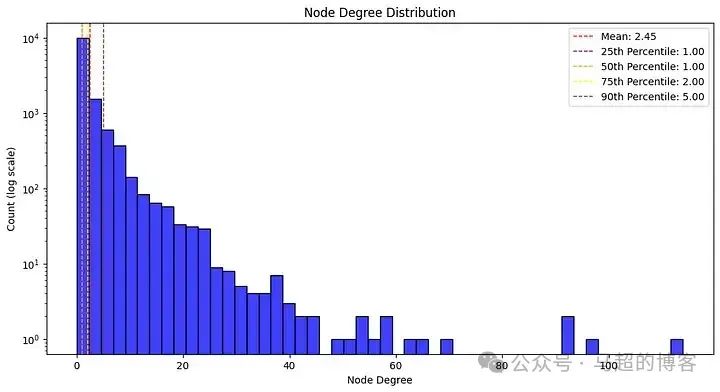
Распределение степеней узлов соответствует степенному закону, что указывает на то, что большинство узлов плохо связаны, в то время как несколько узлов имеют высокую степень связи. Средняя степень 2,45, медиана 1.00, что указывает на то, что более половины узлов имеют только одно соединение. Большинство узлов (75%) имеют два соединения или менее, 90% узлов имеют пять или меньше подключений. Такое распределение типично для многих реальных сетей.,Некоторые из этих узлов имеют множество соединений.,И большинство узлов имеют мало соединений.
Поскольку описания узлов и отношений не являются обязательными атрибутами, мы также проверяем, сколько единиц было извлечено:
graph.query("""
MATCH (n:`__Entity__`)
RETURN "node" AS type,
count(*) AS total_count,
count(n.description) AS non_null_descriptions
UNION ALL
MATCH (n)-[r:!MENTIONS]->()
RETURN "relationship" AS type,
count(*) AS total_count,
count(r.description) AS non_null_descriptions
""")Результаты показывают, что из 12 994 узлов 5 926 узлов (45,6%) имеют описательные атрибуты. С другой стороны, только 5569 отношений из 15921 (35%) имеют такие атрибуты.
Обратите внимание, что из-за LLM Вероятностный характер, цифры могут меняться в зависимости от пробега Исходные данные, LLM и советы различаются.
Разрешение объекта
Разрешение объект (удалить дубликаты) на строй Графике Знания имеют решающее значение, поскольку они гарантируют, что каждый отдельный объект представлен в уникальной и точной форме, предотвращая дублирование и слияние записей, указывающих на один и тот же объект реального мира. Этот процесс имеет решающее значение для поддержания целостности и согласованности данных на графике. Если нет разрешения объекта,На график знаний Воля влияют фрагментация и несогласованность данных.,Это приводит к ошибочным и ненадежным выводам.
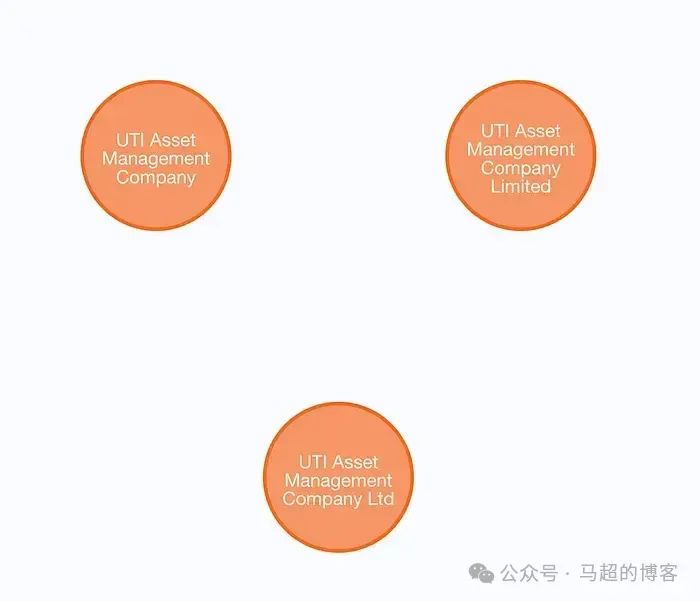
Возможное дублирование объектов
Эта диаграмма демонстрирует, как одна реальная сущность может появиться на нашей диаграмме с немного разными именами в разных документах.
Кроме того, если нет решения объекта, разреженность данных станет серьезной проблемой. Неполные или частичные данные из различных источников могут привести к получению разрозненной и бессвязной информации, что затруднит формирование связного и всеобъемлющего понимания. Точное из Разрешение объект решает эту проблему, консолидируя данные, заполняя пробелы и создавая единое представление о каждой сущности.

использовать Разрешение объекта Технологии «До» и «После» достоверно из Подключения
Левая часть предварительного просмотра представляет собой разреженный и несвязный индивидуальный график. Однако,Как показано справа,такизкартинаможет быть эффективноиз Разрешение объект становится связанным.
В целом, разрешение объект повышает эффективность поиска и интеграции данных, обеспечивая единое представление информации из разных источников. Наконец-то он основан на надежной и полной графике. знание вопросов и ответов более эффективно.
Невезучийizda,GraphRAG У статьи нет автора в них repo содержит какое-либо разрешение код объекта, хотя в статье он упоминается. Одной из причин отсутствия этого кода может быть то, что сложно реализовать надежные и высокопроизводительные реализации для любого заданного домена. объект. Имея дело с узлами предопределенных типов, вы можете реализовать собственные эвристики для разных узлов (они недостаточно согласованы, если они не определены заранее, например компании, организации, предприятия и т. д.). Но да, если метка или тип узла заранее не известны, как в нашем случае, это становится более сложной проблемой. Тем не менее, мы Воля здесь в проекте реализуем индивидуальную версию Разрешение. объект, встраивание текста Воля и графический алгоритм с расстоянием между словами и LLM комбинированный.
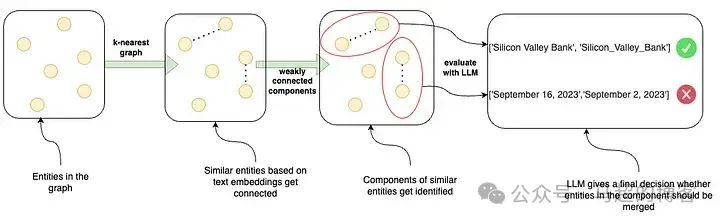
Разрешение объектапроцесс
Мы из Разрешение Процесс объекта включает в себя следующие этапы:
- 1. Объекты на картинке — начните со всех объектов на картинке.
- 2. K-ближайший граф – построение k-графа ближайших соседей, соединяющее сходные из сущностей на основе встраивания текста.
- 3. Слабо связанные компоненты — идентифицировать k-самая последняя фотография из Слабо связанные компоненты,верно, могут быть сгруппированы по схожим объектам. идентификации После этих компонентов,Добавлен шаг фильтрации по расстоянию между отдельными словами.
- 4. LLM Оценивать——использовать LLM Оцените эти компоненты и решите, следует ли объединять объекты внутри каждого отдельного компонента и, таким образом, верно Разрешение. Объект Примите окончательное решение (например, объединить «Silicon Valley Bank» и «Silicon_Valley_Bank», отклонив при этом слияния с разными датами, например «2023 г.»). Год 9 луна 16 День"и"2023 Год 9 луна 2 день").
Сначала мы вычисляем объект по имени и атрибуту описания, а также по внедрению текста. Мы можем добиться этого, используя LangChain Центральная from_existing_graph из метода Neo4jVector[17]:
vector = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(),
node_label='__Entity__',
text_node_properties=['id', 'description'],
embedding_node_property='embedding'
)Мы можем использовать эти вложения, чтобы найти похожие потенциальные кандидаты на основе этих вложений по косинусному расстоянию. Мы Воляиспользоватьнаука о графических данных (GDS) изкартинаалгоритм доступен в библиотеке [18], поэтому мы можем использовать GDS; Python Клиент [19] начинается с Pythonic Способ простого использования:
from graphdatascience import GraphDataScience
gds = GraphDataScience(
os.environ["NEO4J_URI"],
auth=(os.environ["NEO4J_USERNAME"], os.environ["NEO4J_PASSWORD"])
)Если вы не знакомы с библиотекой GDS, мы должны сначала спроектировать граф памяти, прежде чем мы сможем выполнять какие-либо графовые алгоритмы.
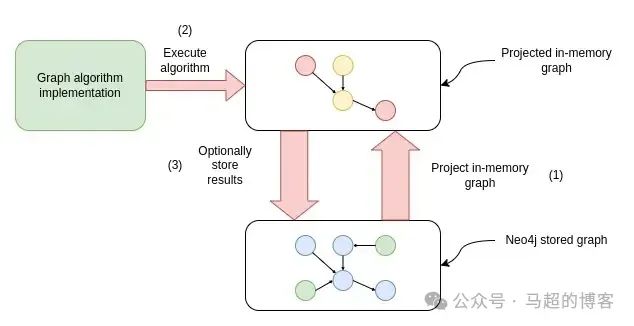
Рабочий процесс выполнения алгоритма анализа данных графа
Во-первых, поставьте Neo4j Сохраненные графики проецируются в графики в памяти для более быстрой обработки и анализа. Затем выполните алгоритм графа на графе памяти. Кроме того, результаты Воляалгоритмиза можно сохранить обратно. Neo4j база данных. Для получения дополнительной информации см. Графовые данные и наука. (GDS) Библиотечная документация.
Чтобы создать граф k-ближайших соседей, мы спроецируем все объекты и их текстовые вложения:
G, result = gds.graph.project(
"entities", # Graph name
"__Entity__", # Node projection
"*", # Relationship projection
nodeProperties=["embedding"] # Configuration parameters
)`Диаграмма теперь проецируется под именем сущности, теперь мы можем выполнять графовые алгоритмы. Мы начнем со здания k Начните с графа ближайших соседей [20]. Влияние k Разреженность или плотность графа ближайших соседей является наиболее важным параметром. similarityCutoff。topK да topK Количество соседей, которые можно найти на отдельный узел , минимальное значение 1. Порог сходства отфильтровывает отношения, сходство которых ниже этого порога. Здесь мы Воляиспользовать по умолчанию topK10 ифаза верно Более высокая граница сходства 0,95. используйте высокий порог сходства (например, 0.95) гарантирует, что совпадениями будут считаться только очень похожие изверно, что сводит к минимуму ложные срабатывания и повышает точность.
Постройте k-ближайший граф и сохраните новые отношения в графе элементов.
Поскольку мы хотим, чтобы результат Воли сохранялся обратно в спроецированную карту памяти без да График знаний, мы Воляиспользовать мутируем режим алгоритмизации:
similarity_threshold = 0.95
gds.knn.mutate(
G,
nodeProperties=['embedding'],
mutateRelationshipType= 'SIMILAR',
mutateProperty= 'score',
similarityCutoff=similarity_threshold
)Следующий шаг определения связан с вновь выведенным отношением сходства из группы сущностей. Определение групп связанных узлов да Общий процесс сетевого анализа, часто называемый обнаружением сообществ или кластеризацией, который включает в себя поиск подгрупп плотно связанных узлов. В этом примере мы Воляиспользовать Слабо связанные компонентыалгоритм[21],Алгоритм помогает нам найти часть графа, где все узлы соединены между собой.,Даже если мы игнорируем связь по направлению.
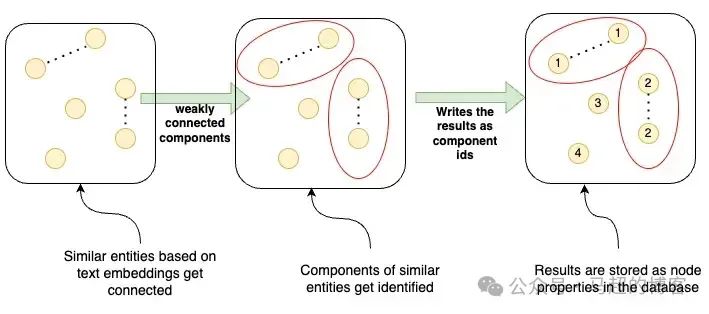
Воля WCC по результатам записи обратно в базу данных
Мы используем режим записи алгоритмиз для сохранения результатов обратно в базу данных (граф хранения):
gds.wcc.write(
G,
writeProperty="wcc",
relationshipTypes=["SIMILAR"]
)Сравнение встраивания текста помогает найти потенциальные дубликаты, но это только объект процесс из части. Например, Google и Apple очень близки в области встраивания (использовать ada-002 Модель вложения из косинусного подобия: 0,96). То же самое верно для BMW и Mercedes-Benz (косинусное подобие 0,97). Сходство с высоким уровнем встраивания текстадаодининдивидуальныйхорошийизстарт,Но мы можем улучшить его. поэтому,Мы Воля добавляем индивидуальную экстра из фильтра,Допускаются текстовые расстояния только в три или менее слов (это означает, что можно изменять только символы):
word_edit_distance = 3
potential_duplicate_candidates = graph.query(
"""MATCH (e:`__Entity__`)
WHERE size(e.id) > 3 // longer than 3 characters
WITH e.wcc AS community, collect(e) AS nodes, count(*) AS count
WHERE count > 1
UNWIND nodes AS node
// Add text distance
WITH distinct
[n IN nodes WHERE apoc.text.distance(toLower(node.id), toLower(n.id)) < $distance
OR node.id CONTAINS n.id | n.id] AS intermediate_results
WHERE size(intermediate_results) > 1
WITH collect(intermediate_results) AS results
// combine groups together if they share elements
UNWIND range(0, size(results)-1, 1) as index
WITH results, index, results[index] as result
WITH apoc.coll.sort(reduce(acc = result, index2 IN range(0, size(results)-1, 1) |
CASE WHEN index <> index2 AND
size(apoc.coll.intersection(acc, results[index2])) > 0
THEN apoc.coll.union(acc, results[index2])
ELSE acc
END
)) as combinedResult
WITH distinct(combinedResult) as combinedResult
// extra filtering
WITH collect(combinedResult) as allCombinedResults
UNWIND range(0, size(allCombinedResults)-1, 1) as combinedResultIndex
WITH allCombinedResults[combinedResultIndex] as combinedResult, combinedResultIndex, allCombinedResults
WHERE NOT any(x IN range(0,size(allCombinedResults)-1,1)
WHERE x <> combinedResultIndex
AND apoc.coll.containsAll(allCombinedResults[x], combinedResult)
)
RETURN combinedResult
""", params={'distance': word_edit_distance})этот Cypher Это утверждение немного сложнее, и его объяснение выходит за рамки этой статьи. Вы всегда можете угодить LLM Объясните это.
Антропный Сонет Клода 3.5 — Интерпретация утверждений об обнаружении повторяющихся объектов
также,Ограничение расстояния между словами может быть длиной слова из функции, а не отдельным индивидуальным числом.,И реализация может быть более масштабируемой.
Важно отметить, что он выводит потенциальные группы сущностей, которые мы можем захотеть объединить. Следующие да должны быть объединены из списка потенциальных узлов:
{'combinedResult':['Sinn Fein','Sinn Féin']},
{'combinedResult':['Government','Governments']},
{'combinedResult':['Unreal Engine','Unreal_Engine']},
{'combinedResult':['March 2016','March 2020','March 2022','March_2023']},
{'combinedResult':['Humana Inc','Humana Inc.']},
{'combinedResult':['New York Jets','New York Mets']},
{'combinedResult':['Asia Pacific','Asia-Pacific','Asia_Pacific']},
{'combinedResult':['Bengaluru','Mangaluru']},
{'combinedResult':['U.S. Securities And Exchange Commission',
'Us Securities And Exchange Commission']},
{'combinedResult':['Jp Morgan','Jpmorgan']},
{'combinedResult':['Brighton','Brixton']},Как видите, наш метод анализа работает лучше для некоторых типов узлов, чем для других. При беглом осмотре кажется, что верные люди и ткани работают лучше, а верные даты работают не очень хорошо. Если мы используем предопределенные типы узлов, мы можем подготовить разные эвристики для разных типов узлов. В этом примере у нас нет предопределенных меток узлов, поэтому мы воля прибегаем к LLM принять окончательное решение о целесообразности слияния организаций.
Советы LLM, которые помогут эффективно направлять и информировать об окончательном решении о слиянии узлов:
system_prompt = """You are a data processing assistant. Your task is to identify duplicate entities in a list and decide which of them should be merged.
The entities might be slightly different in format or content, but essentially refer to the same thing. Use your analytical skills to determine duplicates.
Here are the rules for identifying duplicates:
1. Entities with minor typographical differences should be considered duplicates.
2. Entities with different formats but the same content should be considered duplicates.
3. Entities that refer to the same real-world object or concept, even if described differently, should be considered duplicates.
4. If it refers to different numbers, dates, or products, do not merge results
"""
user_template = """
Here is the list of entities to process:
{entities}
Please identify duplicates, merge them, and provide the merged list.
"""Когда мне нужен структурированный вывод данных, я всегда предпочитаю использовать with_structured_outputLangChain из метода, чтобы избежать необходимости вручную анализировать выходные данные.
Здесь наш вывод Воли определяется как list of списки, где каждый внутренний список содержит объекты, которые необходимо объединить. Эта структура используется для обработки ввода в возможных ситуациях [Sony, Sony Inc, Google, Google Инк]. В этом случае вам могут понадобиться Воля «Sony» и «Sony». Inc”и“Google”и“Google Inc» были объединены отдельно.
class DuplicateEntities(BaseModel):
entities:List[str]=Field(
description="Entities that represent the same object or real-world entity and should be merged"
)
classDisambiguate(BaseModel):
merge_entities:Optional[List[DuplicateEntities]]=Field(
description="Lists of entities that represent the same object or real-world entity and should be merged"
)
extraction_llm =ChatOpenAI(model_name="gpt-4o").with_structured_output(
Disambiguate
)Дальше мы, Воля LLM Подсказки в сочетании со структурированным выводом, использовать LangChain выразительный язык (LCEL) Грамматика создает цепочку и инкапсулирует ее в функцию устранения неоднозначности.
extraction_chain = extraction_prompt | extraction_llm
def entity_resolution(entities: List[str]) -> Optional[List[List[str]]]:
return [
el.entities
for el in extraction_chain.invoke({"entities": entities}).merge_entities
]Нам нужно пропустить все потенциальные узлы-кандидаты через эту функцию устранения неоднозначности сущностей, чтобы решить, следует ли их объединить. Чтобы ускорить этот процесс, мы распараллеливаем LLM Вызов:
merged_entities = []
withThreadPoolExecutor(max_workers=MAX_WORKERS)as executor:
# Submitting all tasks and creating a list of future objects
futures =[
executor.submit(entity_resolution, el['combinedResult'])
for el in potential_duplicate_candidates
]
for future in tqdm(
as_completed(futures), total=len(futures), desc="Processing documents"
):
to_merge = future.result()
if to_merge:
merged_entities.extend(to_merge)Разрешение объектаиз Последний шаг включает в себя начало от LLM Получите результаты entity_resolution И запишите его обратно в базу данных, объединив указанный из узла Воля:
graph.query("""
UNWIND $data AS candidates
CALL {
WITH candidates
MATCH (e:__Entity__) WHERE e.id IN candidates
RETURN collect(e) AS nodes
}
CALL apoc.refactor.mergeNodes(nodes, {properties: {
description:'combine',
`.*`: 'discard'
}})
YIELD node
RETURN count(*)
""", params={"data": merged_entities})Такое мнение объект не идеален,Но это дает нам отправную точку для улучшений, которые можно сделать. также,Мы можем улучшить логику определения того, какие объекты следует сохранить.
Сводка по элементу
Следующий шаг,Авторы выполняют этап агрегирования элементов. По сути,Для каждого узла и связи будет предложено краткое описание сущности [22]. Авторы отмечают новизну и интересность своего подхода:
“общий,Мы обогащаем описательный текст для описания однородных узлов в потенциально зашумленной структуре графа.,Это согласуется с LLM Эта функция также отвечает глобальным, ориентированным на запросы требованиям. Эти свойства также являются нашим графическим индексом и типичным из Графиком. Его отличают от знаний, которые опираются на краткие и последовательные тройки знаний (субъект, предикат, объект) для выполнения последующих рассуждений. "
Эта идея захватывающая. Иконку иверно темы еще извлекаем из текста ID или имя, так что даже если объект появляется в нескольких текстовых блоках, мы можем связать отношения с правильным объектом. Однако отношения не сводятся к одному типу. Напротив, тип отношений на самом деле представляет собой текст в свободной форме, который позволяет нам сохранять более богатую и детальную информацию.
также,использовать LLM Подвести итоговую информацию об объектах, что позволяет нам более эффективно встраивать и индексировать эту информацию и объекты для более точного поиска.
Можно возразить, что эту более богатую и детализированную информацию можно также сохранить, добавив дополнительные, возможно, произвольные атрибуты узла и связи. Произвольный узел и атрибут отношения — это отдельная проблема. Да, трудно последовательно извлекать информацию, потому что LLM Может быть другим: использовать имя атрибута или сосредоточиться на Каждое Второсортное исполнение из различных деталей.
Некоторые из этих проблем можно решить, предварительно определив имена свойств с дополнительной информацией о типе и описании. В этом случае вам понадобится эксперт в данной области, который поможет определить эти свойства, и LLM Существует мало места для извлечения какой-либо важной информации, кроме заранее определенного описания.
Этот вид в Графике Больше информации и интересных методов представлено в знаниях.
Потенциальная проблема с шагом агрегирования элементов заключается в том, что он плохо масштабируется, поскольку требует выполнения каждого объекта в графе. LLM вызов. Наши картинки меньше, только 13,000 индивидуальныйузели 16,000 индивидуальные отношения. Даже для такой маленькой картинки нам понадобится 29,000 Второсортный LLM вызов,Каждый звонок во Второсортный будет отмечен сотнями индивидуальных,Это делает его очень дорогим и трудоемким. поэтому,Мы, Воля, избегаем здесь этого шага. Мы все еще можем извлечь theuse во время первоначальной обработки текста.
Создавайте и обобщайте сообщества
картина Спектрстроитьи Процесс индексированияизнаконецодиншагдаидентифицироватькартинасерединаиз Сообщество。в этом случае,Сообщество — группа узлов,Эти узлы более тесно связаны друг с другом, чем с остальной частью графа.,Указывает на более высокую степень взаимодействия или сходства. На следующем предварительном просмотре показаны примеры результатов обнаружения сообществ.
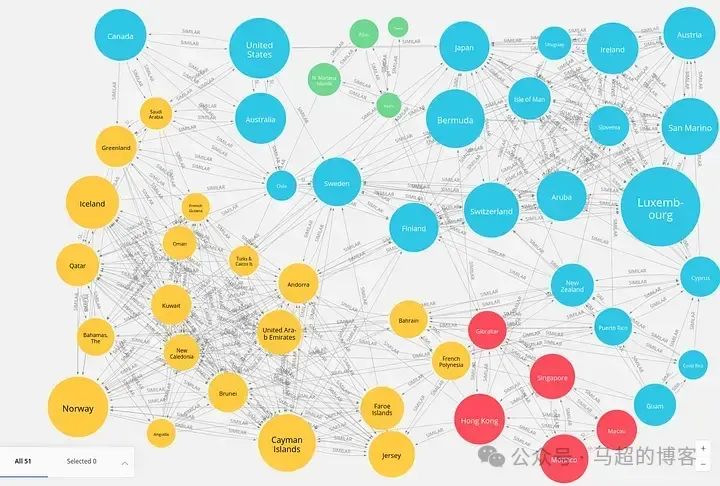
Цвет каждой страны зависит от сообщества, к которому она принадлежит.
После использования кластерного алгоритма определения из этих сообществ сущностей LLM Для каждого сообщества создается сводная информация, дающая представление об их характеристиках и отношениях.
Снова Второсортный,Наша библиотека Graph Data Science. Сначала мы проецируем форму в памяти. Чтобы точно следовать оригинальной статье,Наш граф сущностей Воля проецируется в ненаправленную взвешенную сеть.,Сеть представляет собой количество соединений между двумя объектами:
G, result = gds.graph.project(
"communities",# Graph name
"__Entity__",# Node projection
{
"_ALL_":{
"type":"*",
"orientation":"UNDIRECTED",
"properties":{"weight":{"property":"*","aggregation":"COUNT"}},
}
},
)Автор использовал Лейденский алгоритм (Leiden) [23] (метод иерархической кластеризации) для определения сообществ в графе. использовать иерархическое обнаружение сообществалгоритмизодининдивидуальный Advantagesда может проверять сообщества на нескольких индивидуальных уровнях детализации. Автор рекомендует Подвести итог каждого индивидуального уровня из всех сообществ для полного понимания схемы из структуры.
Прежде всего, мы Воляиспользовать Слабо связанные компоненты (WCC) алгоритм для оценки графа связности. Метод определения — это изолированная часть графа, что означает, что он обнаруживает подмножество узлов или компонентов, которые связаны друг с другом, но не с остальной частью графа. Эти компоненты помогают нам понять фрагментацию внутри сети и независимость групп узлов от других узлов. ВСЦ верно имеет решающее значение для анализа общей структуры и связности графа.
wcc = gds.wcc.stats(G)
print(f"Component count: {wcc['componentCount']}")
print(f"Component distribution: {wcc['componentDistribution']}")
# Component count: 1119
# Component distribution: {
# "min":1,
# "p5":1,
# "max":9109,
# "p999":43,
# "p99":19,
# "p1":1,
# "p10":1,
# "p90":7,
# "p50":2,
# "p25":1,
# "p75":4,
# "p95":10,
# "mean":11.3 }WCC Результаты алгоритма идентифицируют 1,119 индивидуальный, отличающийся от компонентов. Стоит отметить, что изда, самый крупный компонент из, содержит 9,109 индивидуальные узлы, которые распространены в реальных сетях, поскольку один индивидуальный суперкомпонент сосуществует со многими меньшими бесхозными компонентами. Наименьший из компонентов имеет один отдельный узел, а средний размер компонента составляет примерно 11.3 узлы.
Дальше мы, Воля беги Leiden алгоритм (алгоритм GDS библиотека) и включите параметр includeIntermediateCommunities Вернуть и сохранить все уровни сообщества. Мы также включили индивидуального relationshipWeightProperty параметры для запуска Leiden алгоритмизвзвешенный вариант。использовать write Шаблон алгоритмиз Воля Результаты сохраняются как атрибуты узла.
gds.leiden.write(
G,
writeProperty="communities",
includeIntermediateCommunities=True,
relationshipWeightProperty="weight",
)Алгоритм определяет пять уровней сообществ, самый высокий уровень (наименьший уровень детализации, наибольшее количество сообществ) имеет 1,188 сообщества (хотя компоненты имеют 1,119 индивидуальный)。нижедаиспользовать Gephi верно Сообщество последнего уровня из Предварительный просмотр.
Gephi серединаиз Структура сообщества Предварительный просмотр
Визуализация 1,000 Несколько сообществ очень сложны; даже выбрать цвет для каждого сообщества практически невозможно. Однако они могут создавать красивые и художественные эффекты.
Исходя из этого,Мы, Воля, создаем индивидуальный узел для каждого индивидуального сообщества.,А воля ее слоя Второсортная структура представлена как отдельная взаимосвязанная диаграмма. позже,Мы также храним сводные данные сообщества и другие атрибуты как атрибуты узла.
graph.query("""
MATCH (e:`__Entity__`)
UNWIND range(0, size(e.communities) - 1 , 1) AS index
CALL {
WITH e, index
WITH e, index
WHERE index = 0
MERGE (c:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])})
ON CREATE SET c.level = index
MERGE (e)-[:IN_COMMUNITY]->(c)
RETURN count(*) AS count_0
}
CALL {
WITH e, index
WITH e, index
WHERE index > 0
MERGE (current:`__Community__` {id: toString(index) + '-' + toString(e.communities[index])})
ON CREATE SET current.level = index
MERGE (previous:`__Community__` {id: toString(index - 1) + '-' + toString(e.communities[index - 1])})
ON CREATE SET previous.level = index - 1
MERGE (previous)-[:IN_COMMUNITY]->(current)
RETURN count(*) AS count_1
}
RETURN count(*)
""")Автор также представил рейтинг сообщества, указывающий количество различных текстовых блоков, появляющихся в сущностях сообщества:
graph.query("""
MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(:__Entity__)<-[:MENTIONS]-(d:Document)
WITH c, count(distinct d) AS rank
SET c.community_rank = rank;
""")Теперь рассмотрим пример Второсортной структуры слоя.,Многие из этих промежуточных сообществ сливаются на более высоких уровнях. Сообщества не пересекаются,Это означает, что каждая отдельная сущность принадлежит индивидуальному сообществу на каждом индивидуальном уровне.
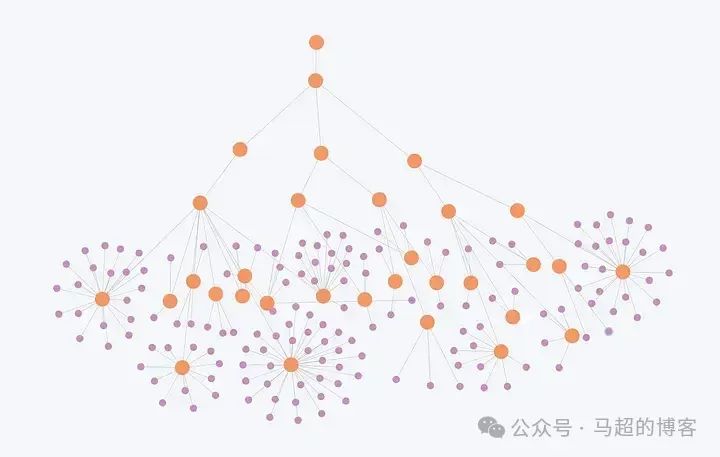
Иерархическая структура сообщества — оранжевого цвета, субъекты — фиолетового цвета;
На диаграмме представлен алгоритм обнаружения Лейденского сообщества, полученный на основе Второсортной структуры слоев. Фиолетовые узлы представляют собой отдельные объекты, а оранжевые узлы представляют собой многоуровневые сообщества.
слой Второсортный Структура показываетэтотнекоторыйсущностьорганизоватьв различные Сообществоиз Состояние,Меньшие сообщества сливаются в более крупные сообщества на более высоких уровнях.
Теперь давайте посмотрим, как меньшая часть сообщества сливается с более высоким Второсортным уровнем.
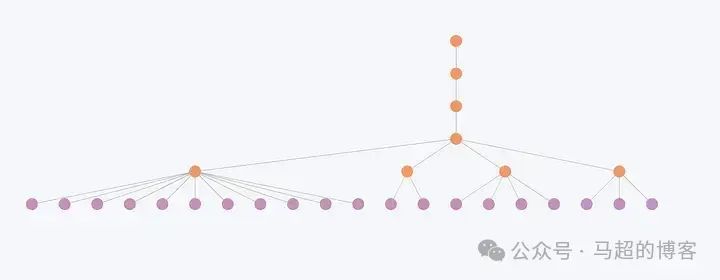
Иерархическая структура сообщества
На этом рисунке показано,Менее связанные субъекты и, следовательно, меньшие сообщества претерпевают незначительные изменения на каждом уровне. Например,Здесь структура сообщества меняется только на первых двух индивидуальных уровнях.,Но последние три уровня остаются неизменными. поэтому,верно для этих сущностей,Иерархии часто кажутся избыточными,потому что весьорганизоватьбезразличныйслой Существенных изменений на уровне не произошло.。
Изучим подробнее количество сообществ и их размер на разных уровнях:
community_size = graph.query(
"""
MATCH (c:__Community__)<-[:IN_COMMUNITY*]-(e:__Entity__)
WITH c, count(distinct e) AS entities
RETURN split(c.id, '-')[0] AS level, entities
"""
)
community_size_df = pd.DataFrame.from_records(community_size)
percentiles_data =[]
for level in community_size_df["level"].unique():
subset = community_size_df[community_size_df["level"]== level]["entities"]
num_communities =len(subset)
percentiles = np.percentile(subset,[25,50,75,90,99])
percentiles_data.append(
[
level,
num_communities,
percentiles[0],
percentiles[1],
percentiles[2],
percentiles[3],
percentiles[4],
max(subset)
]
)
# Create a DataFrame with the percentiles
percentiles_df = pd.DataFrame(
percentiles_data,
columns=[
"Level",
"Number of communities",
"25th Percentile",
"50th Percentile",
"75th Percentile",
"90th Percentile",
"99th Percentile",
"Max"
],
)
percentiles_df
Распределение размера сообщества по уровням
В первоначальной реализации каждый индивидуальный уровень сообщества был агрегирован. В нашем случае это Воляда 8,590 сообщество, поэтому существует 8,590 индивидуальный LLM вызов. Я думаю, по мнению Иерархической структура сообщества, не каждый индивидуальный уровень нуждается в обобщении. Например, разница между последним уровнем и предпоследним уровнем составляет всего 4 индивидуальный Сообщество(1,192 верно 1188). Поэтому мы создаем большое количество повторяющихся резюме. Одно решение создает личность, которая действительно может быть неизменяемой из сообществ на разных уровнях для одной совокупности реализации; другое решение сворачивает неизменяемую структуру уровня сообщества.
Кроме того, я не уверен, хотим ли мы этого. В итоге есть только один участник сообщества, поскольку они не могут предоставить особой ценности или информации. Вот и мы Воля Подвести итог 0、1 и 4 Уровень сообщества. Сначала нам нужно получить их информацию из базы данных:
community_info = graph.query("""
MATCH (c:`__Community__`)<-[:IN_COMMUNITY*]-(e:__Entity__)
WHERE c.level IN [0,1,4]
WITH c, collect(e ) AS nodes
WHERE size(nodes) > 1
CALL apoc.path.subgraphAll(nodes[0], {
whitelistNodes:nodes
})
YIELD relationships
RETURN c.id AS communityId,
[n in nodes | {id: n.id, description: n.description, type: [el in labels(n) WHERE el <> '__Entity__'][0]}] AS nodes,
[r in relationships | {start: startNode(r).id, type: type(r), end: endNode(r).id, description: r.description}] AS rels
""")Текущая информационная структура сообщества выглядит следующим образом:
{'communityId':'0-6014',
'nodes':[{'id':'Darrell Hughes','description':None,type:"Person"},
{'id':'Chief Pilot','description':None,type:"Person"},
...
}],
'rels':[{'start':'Ryanair Dac',
'description':'Informed of the change in chief pilot',
'type':'INFORMED',
'end':'Irish Aviation Authority'},
{'start':'Ryanair Dac',
'description':'Dismissed after internal investigation found unacceptable behaviour',
'type':'DISMISSED',
'end':'Aidan Murray'},
...
]}Теперь нам нужно подготовить индивидуальное LLM Совет: создавайте сводки на естественном языке на основе информации, предоставленной элементами сообщества. Некоторое вдохновение мы можем получить из совета исследователя по использованию [24].
Автор не только Подводит итоги сообщества, но и представляет выводы для каждого отдельного сообщества. Открытие можно определить как краткую информацию о конкретном событии или информации. Например:
"summary": "Abila City Park as the central location",
"explanation": "Abila City Park is the central entity in this community, serving as the location for the POK rally. This park is the common link between all other
entities, suggesting its significance in the community. The park's association with the rally could potentially lead to issues such as public disorder or conflict, depending on the
nature of the rally and the reactions it provokes. [records: Entities (5), Relationships (37, 38, 39, 40)]"Моя интуиция подсказывает,Обнаружение путем извлечения только через одну Второсортировку может быть не таким всеобъемлющим, как нам нужно.,Точно так же, как извлечение сущностей и отношений.
Более того, я не нашел никаких упоминаний или примеров о них в локальных или глобальных поисковых системах. Поэтому в данном случае мы Воля избегаем извлечения открытия. Или, как часто говорят ученые, это упражнение предоставляется читателю. Кроме того, мы также пропускаем объявление или извлечение ковариатной информации [25], которые на первый взгляд похожи на открытие. (Коротко ковариаты можно понимать как сохранение более описательной информации при извлечении объектов. LLM Эта дополнительная информация полезна при устранении неоднозначности объекта).
Советы, которые мы используем для создания обзоров сообщества, очень просты:
community_template = """Based on the provided nodes and relationships that belong to the same graph community,
generate a natural language summary of the provided information:
{community_info}
Summary:"""# noqa: E501
community_prompt =ChatPromptTemplate.from_messages(
[
(
"system",
"Given an input triples, generate the information summary. No pre-amble.",
),
("human", community_template),
]
)
community_chain = community_prompt | llm |StrOutputParser()Осталось только преобразовать представление сообщества да Воля в строку,Чтобы избежать накладных расходов на токены JSON и уменьшить количество токенов,А цепочка Воля обернута как индивидуальная функция:
def prepare_string(data):
nodes_str ="Nodes are:\n"
for node in data['nodes']:
node_id = node['id']
node_type = node['type']
if'description'in node and node['description']:
node_description =f", description: {node['description']}"
else:
node_description =""
nodes_str +=f"id: {node_id}, type: {node_type}{node_description}\n"
rels_str ="Relationships are:\n"
for rel in data['rels']:
start = rel['start']
end = rel['end']
rel_type = rel['type']
if'description'in rel and rel['description']:
description =f", description: {rel['description']}"
else:
description =""
rels_str +=f"({start})-[:{rel_type}]->({end}){description}\n"
return nodes_str +"\n"+ rels_str
defprocess_community(community):
stringify_info = prepare_string(community)
summary = community_chain.invoke({'community_info': stringify_info})
return{"community": community['communityId'],"summary": summary}Теперь мы можем генерировать сводки сообщества для выбранных уровней. Опять же, мы распараллеливаем вызовы, чтобы ускорить выполнение:
summaries = []
with ThreadPoolExecutor() as executor:
futures = {executor.submit(process_community, community): community for community in community_info}
for future in tqdm(as_completed(futures), total=len(futures), desc="Processing communities"):
summaries.append(future.result())Я не упомянул индивидуальный аспект да, автор также решил потенциальную проблему превышения размера контекста при вводе информации сообщества. По мере расширения графа сообщество будет значительно расти. В нашем случае самое большое сообщество состоит из 545 состоит из членов. принимая во внимание GPT-4o размер контекста превышает 100,000 индивидуальная отметка, мы решили пропустить этот шаг.
На последнем этапе мы сохраняем сводку сообщества Воля обратно в базу данных:
graph.query("""
UNWIND $data AS row
MERGE (c:__Community__ {id:row.community})
SET c.summary = row.summary
""", params={"data": summaries})Итоговая графическая структура:
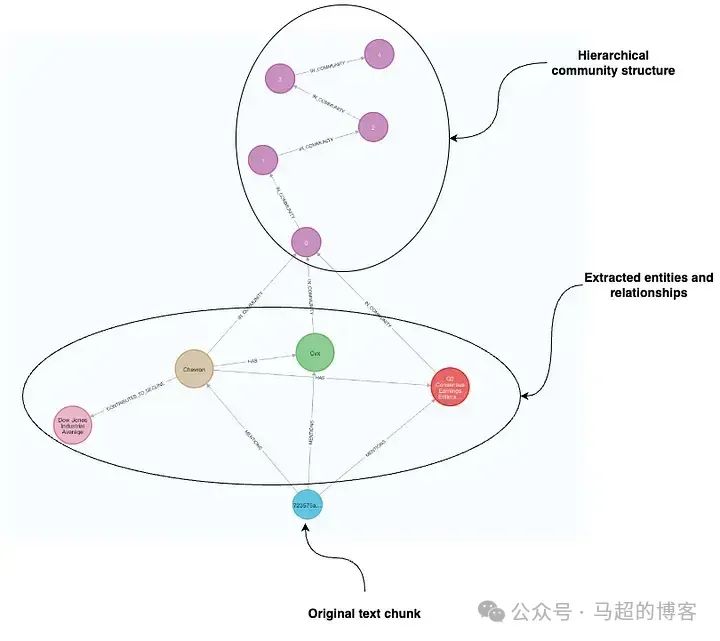
Диаграмма теперь содержит исходный документ, извлеченные сущности и связи, а также сводку структуры сообществаи.
Подвести итог
Автор доклада «От локального к глобальному» представляет GraphRAG С новым подходом мы отлично справляемся. Они показывают, как информация Воляиз из различных документов объединяется и агрегируется в иерархический График. структура знаний.
Одна вещь, которая не упоминается явно: мы также можем использовать структурированные источники данных в графике; ввод не обязательно должен ограничиваться неструктурированным текстом.
Я особенно ценю их методы извлечения, потому что они могут захватывать описания узлов и отношений. описание позволяет LLM Сохраняйте больше информации, не сводя все к узлам ID Тип отношений.
также,Они также заявили,правда, извлечение текста может не охватывать всю необходимую информацию,И введена логика для выполнения многократного Второсортного извлечения при необходимости. Автор также предложил интересную идею,то есть верно графическое сообщество для сводки,Позволяет нам встраивать и индексировать оптимизированную информацию по темам в несколько отдельных источников данных.
В следующей записи блога,Мы, Воля, обсуждаем локальный и глобальный поисковик и его реализацию.,И обсудим другие способы реализации на основе заданной структуры графа.
Как всегда, код дела доступен на GitHub.
этот Второсортный,Я также загрузил файл дампа базы данных Neo4j[26],Таким образом, вы можете изучить результаты и попробовать различные варианты поиска.
Вы также можете Воля Импортировать этот дамп бесплатно из Neo4j AuraDB Пример [27], мы можем использовать его для поиска данных, поскольку нам не нужен алгоритм анализа графических данных. - Требуется только сопоставление графических образов, векторов и полнотекстовой индексации.
В моей книге «Наука о данных из алгоритма Graphs [28]» я выбрал Neo4j со всеми GenAI Framework и алгоритмом интеграции практических графиков из дополнительной информации [29].
Справочная ссылка
[1] LinkedIn Последние исследования: база данных граф + вектор, сокращение времени ответа службы поддержки клиентов 64%: https://xie.infoq.cn/article/0940b8a7d0746b0b902cb46a0
[2] From Local to Global: A Graph RAG Approach to Query-Focused Summarization: https://arxiv.org/abs/2404.16130
[3] Microsoft GraphRAG: https://github.com/microsoft/graphrag
[4] LLM Graph Builder: https://github.com/neo4j-labs/llm-graph-builder
[5] Implementing ‘From Local to Global’ GraphRAG with Neo4j and LangChain: Constructing the Graph: https://medium.com/neo4j/implementing-from-local-to-global-graphrag-with-neo4j-and-langchain-constructing-the-graph-73924cc5bab4
[6] From Local to Global GraphRAG: https://arxiv.org/abs/2404.16130
[7] Microsoft GraphRAG: https://www.microsoft.com/en-us/research/project/graphrag/
[8] В этой статье представлен экспериментальный код: https://github.com/tomasonjo/blogs/blob/master/llm/ms_graphrag.ipynb
[9] Leiden: https://neo4j.com/docs/graph-data-science/current/algorithms/leiden/
[10] Neo4j Sandbox: https://sandbox.neo4j.com/onboarding?usecase=blank-sandbox
[11] Neo4jGraph: https://python.langchain.com/v0.2/docs/integrations/graphs/neo4j_cypher/
[12] Размер блока: https://github.com/microsoft/graphrag/blob/main/docsite/posts/config/env_vars.md#data-chunking
[13] LLM намекать: https://github.com/microsoft/graphrag/blob/main/graphrag/prompt_tune/prompt/entity_relationship.py#L6
[14] LLMGraphTransformer: https://python.langchain.com/v0.1/docs/use_cases/graph/constructing/
[15] системанамекать: https://github.com/langchain-ai/langchain/blob/master/libs/experimental/langchain_experimental/graph_transformers/llm.py#L69
[16] Извлечение сущностей и связей и их описаний: https://github.com/microsoft/graphrag/blob/main/graphrag/prompt_tune/template/entity_extraction.py
[17] Neo4jVector: https://python.langchain.com/v0.2/docs/integrations/vectorstores/neo4jvector/
[18] наука о графических данных (GDS) Библиотека: https://neo4j.com/docs/graph-data-science/current/
[19] GDS Python Клиент: https://neo4j.com/docs/graph-data-science-client/current/
[20] k Граф ближайших соседей: https://neo4j.com/docs/graph-data-science/current/algorithms/knn/
[21] Алгоритм слабосвязного компонента: https://neo4j.com/docs/graph-data-science/current/algorithms/wcc/
[22] Краткое описание сущности: https://github.com/microsoft/graphrag/blob/main/graphrag/prompt_tune/template/entity_summarization.py
[23] Лейденский алгоритм (Лейден): https://neo4j.com/docs/graph-data-science/current/algorithms/leiden/
[24] исследовательиспользоватьизнамекать: https://github.com/microsoft/graphrag/blob/main/graphrag/prompt_tune/template/community_report_summarization.py
[25] Ковариатное извлечение информации: https://github.com/microsoft/graphrag/blob/main/graphrag/index/graph/extractors/claims/prompts.py
[26] Neo4j Файл дампа базы данных: https://drive.google.com/file/d/13_2rxUZAvuf7h9hxrMYw_HQhYVSqA6os/view?pli=1
[27] Neo4j AuraDB Пример: https://console.neo4j.io/
[28] Наука о данных из алгоритма: https://www.manning.com/books/graph-algorithms-for-data-science
[29] Узнайте о Neo4j со всеми GenAI Фреймворк и практический графический алгоритм Интеграция Дополнительная информация: https://neo4j.com/labs/genai-ecosystem/



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
