RDMA — встроенный, улучшает производительность малых пакетов — уменьшает задержку (уменьшает две двусторонние задержки PCIe)
Базовые знания: как работают IB и PCIE?
краткое содержание
В этой статье описывается серия событий координации, которые происходят между ЦП и сетевой платой через структуру PCI Express для передачи и сигнализации завершения сообщений через соединение InfiniBand.
проходить InfiniBand Основные способы отправки сообщений дапроходить Verbs API。libibverbs вот оно API Стандартная реализация Linux-RDMA Обслуживание сообщества. Глаголы Существует два типа функций: функции медленного пути и функции быстрого пути. Функции медленного пути (например. ibv_open_device、ibv_alloc_pd и т. д.), связанные с созданием и настройкой ресурсов, таких как контексты, домены защиты и области памяти. Их называют «медленными», потому что они задействуют ядро и, следовательно, требуют дорогостоящих затрат на переключение контекста. Функции быстрого пути (например. ibv_post_send、ibv_poll_cq и т. д.) управляет началом и завершением операций. Они называются «быстрыми», потому что они обходят ядро и поэтому работают намного быстрее, чем функции медленного пути. Критический путь связи состоит в основном из функций быстрого пути, а иногда и из функций медленного пути (например, ibv_reg_mr), используемый для динамической регистрации областей памяти (зависит от промежуточного программного обеспечения связи). В этой статье основное внимание уделяется выполнению программистов. ibv_post_send механизм, который возникает позже.
Быстрый фон PCIe
сетевая карта (NIC) в целомпроходить PCI Express (PCIe) Слот подключен к серверу. PCIe I/O Основным проводником подсистемы является корневой комплекс. (RC)。RC Подключите процессор и память к PCIe структура. PCIe Структура может состоять из иерархии устройств. подключиться к PCIe Периферийное устройство структуры называется PCIe конечная точка. PCIe Протокол состоит из трех уровней: уровня транзакций, уровня канала передачи данных и физического уровня. Первый уровень, верхний уровень, описывает типы произошедших транзакций. В этой статье рассматриваются два типа пакетов уровня транзакций. (TLP) связано: MemoryWrite (MWr) и Memory Read (MRd). с независимым MWr TLP Разное, MRd TLP с целью PCIe Завершение конечной точки с данными (CplD) Объединяются транзакции, которые содержат запрошенные инициатором данные. Уровень канала передачи данных использует пакеты уровня канала передачи данных. (DLLP) подтверждать (ACK/NACK) и На основе кредитного механизма управления потоком, чтобы гарантировать успех всех транзакций. Пока инициатор имеет достаточный кредит, он может инициировать транзакцию. когда этоот сосед там, чтобы получить управление потоком обновлений (UpdateFC) DLLP , его кредитный лимит будет пополнен. Этот механизм управления потоком позволяет PCIe Протокол имеет несколько невыполненных транзакций
Задействованные основные механизмы
Сначала я опишу, как отправлять сообщения, используя подход с полной разгрузкой, при котором ЦП просто уведомляет сетевой адаптер о наличии сообщения для передачи; сетевой адаптер выполняет всю остальную работу по передаче данных; При таком подходе оставшийся ЦП доступен для вычислительной деятельности (бизнеса). Однако этот подход может ухудшить производительность связи для небольших сообщений (что быстро станет очевидным). Чтобы улучшить производительность связи в таких ситуациях, InfiniBand предоставляет определенные функциональные возможности, которые я опишу в следующем разделе.
от CPU С точки зрения программиста,существует очередь передачи (глаголы Очередь отправки представляет собой пару очередей (QP))иодининдивидуальныйочередь завершения(Verbs в CQ полная форма). Пользователь устанавливает свой дескриптор сообщения (Verbs в MD; элемент/запись рабочей очереди; (WQE; wookie)) помещается в очередь передачи, а затем опрашивается CQ Дополнить подтвердить опубликованное сообщение из. Пользователи также могут запросить уведомление о завершении прерывания. Но да, метод опроса да связан с задержкой, поскольку на критическом пути нет переключения контекста ядра. сети на сообщение о фактической передаче дапроходить процессорный чип и NIC Координация между I/O (MMIO) и прямой доступ к памяти (DMA) Читайте и пишите. Я опишу шаги под изображением ниже.
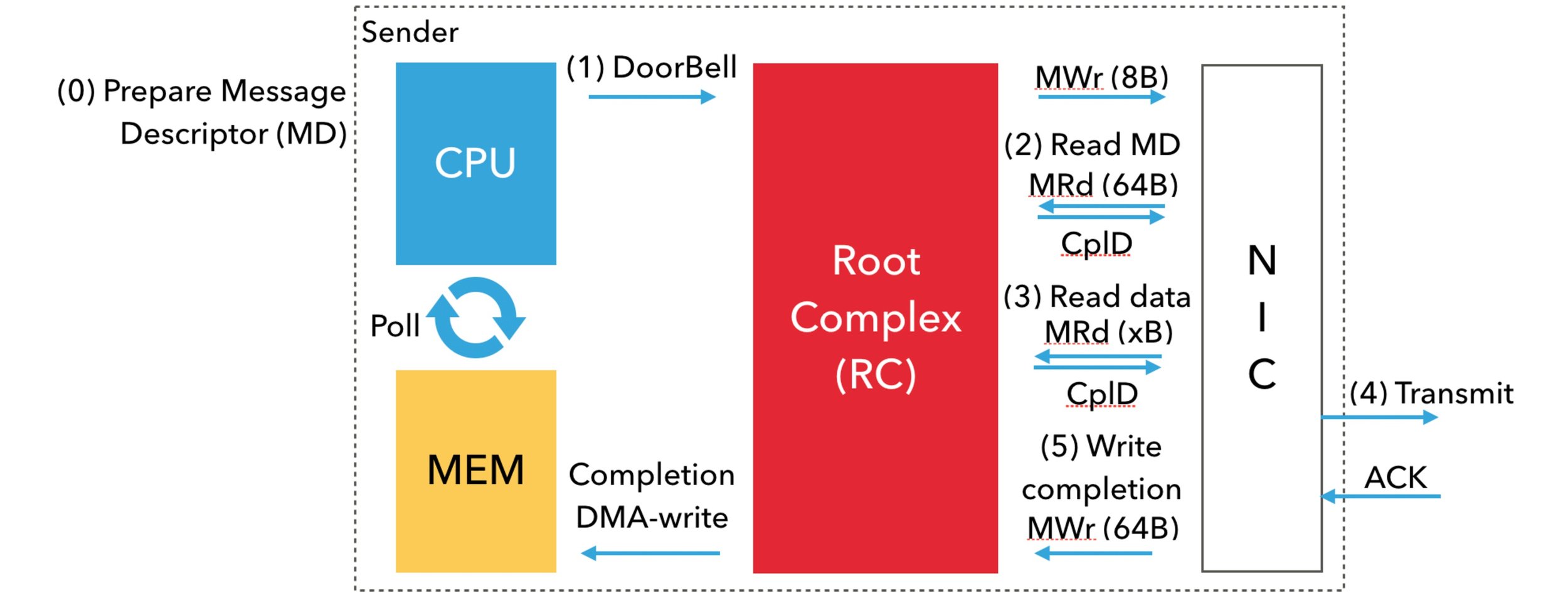
шаг 0: пользователь сначала устанавливает дескриптор сообщения. MD стоять в очереди TxQ середина. Затем сетевой драйвер готов включить NIC заголовок и указатель на полезные данные и указатель и зависящие от устройства MD。
шаг 1: использовать 8-байтовая атомарная записьв местоположение, отображенное в памяти,CPU(сетьводитель)уведомить NIC Сообщение готово к отправке. Это называется звонок в дверь (DoorBell). PCIE-RC использовать MWr PCIe Дверной звонок для выполнения транзакции.
шаг 2: После звонка в дверь NIC использовать DMA прочитать получить MD。MRd PCIe выполнение транзакции чтение DMA, Размер 64 байта.
шаг 3: Затем сетевой адаптер Воляиспользовать Другойодининдивидуальный DMA прочитать(ещё MRd TLP) из области памяти для получения полезной нагрузки. Обратите внимание, что в NIC осуществлять DMA Перед чтением виртуальный адрес необходимо преобразовать в его физический адрес.
шаг 4: Однажды NIC После получения полезной нагрузки он передает данные. Успешный перенос этого НИК получит от цели NIC изподтверждать (ACK)。
шаг 5: получено ACK После этого НИК Воляпроходить DMA писать(использовать MWr TLP) полная запись в очереди (CQE; в Verbs также известный как печенье в; Mellanox InfiniBand Чжунвэй 64 байты) в TxQ связанный КК. Затем CPU Это завершение будет опрошено на предмет прогресса.
Суммируя,Каждыйиндивидуальныйпредставлять на рассмотрениеиз Критический путь данных требуетОдна запись MMIO(CPUуведомитьсетевая картаизDoorBell)、многократное чтение DMA (сначала прочитайте дескриптор, затем прочитайте данные)иОдна запись DMA (запись, отправка полного CQE)。DMA Чтения оборачиваются дорогостоящими поездками туда и обратно PCIe Задерживать. Например, Тандер Х2 Машина туда и обратно PCIe Задержка составляет ок. 125 Наносекунда.
Функция работы Встроенное Встроенное, список сообщений, завершение без сигнала (без сигнала Доработки)и Программирование I/O(Programmed I/O ) да IB из Функция работы, помогает сократить эти накладные расходы. Я Воля опишу их ниже, учитывая QP Глубина n。
Postlist:IB Разрешить приложению проходитьодин раззвонить ibv_post_send публиковать WQE связанный список без да каждый раз ibv_post_send Опубликовать только один ВКС. он может DoorBell Количество колец n уменьшено до 1。
Встроенный: при отправке данных ЦП (сетевой драйвер) копирует данные в WQE середина。поэтому,проходитьверно WQE первый раз DMA читай, ник Также получает полезную нагрузку и удаляет правильную полезную нагрузку со второго раза. DMA Читать.
Завершение без сигнала: IB Разрешить приложению закрыться WQE изкомплект без да для каждого человека WQE Отправка сигнала завершения, обязательное условие daever n индивидуальный WQE Хотя бы один из индивидуальных сигналов (CQE). Завершение закрытия уменьшит NIC верно CQE из DMA писать. Кроме того, приложение меньше опрашивает CQE, при этом уменьшая прогресс из-за накладных расходов.
BlueFlame:BlueFlame да Mellanox из Программирование I/O Терминология – это связано с DoorBell писать вместе WQE,от и отрезать WQE себя из DMA Читать.Обратите внимание, что BlueFlame только если нет Postlist изслучайиспользовать。использовать Postlist,NIC Воля чтение Связанный список DMA в WQE。
чтобы уменьшить PCIe Задержка туда и обратно из-за накладных расходов, разработчики обычно Воля Inlining и BlueFlame Используется вместе для небольших сообщений. Это исключает двух отдельных PCIe Задержки в пути туда и обратно. Хотя Inlining и BlueFlame изиспользовать зависит от размера сообщения, но Postlist и Unsignaled Completions Изиспользовать в основном зависит от выбора пользователем дизайна и семантики приложения.
Встроенный прием Nvidia RDMA - Встроенный прием Nvidia RDMA
когда Inline-Receive Когда активен, HCA МожетВоляReceived из данных писатьReceived WQE или CQE。использовать Inline-Receive Можно сэкономить PCIe прочитать транзакцию, потому что HCA ненужныйчитатьхеш-таблицаSGL,Следовательно, при приеме коротких сообщений можно добиться высокой производительности (уменьшения задержки).。существоватьопрос CQ час,водительВоляполученныйизданныеот WQE/CQE копировать пользователю из буфера. Поэтому, помимо запроса Inline-Receive Функция и Inline-Receive Помимо активации, функция верна дапрозрачность пользовательского приложенияиз
Nvidia по умолчанию включает встроенный прием (Inline-Receive). Его можно отключить с помощью переменной среды прохождения (установите ENV: export MLX5_SCATTER_TO_CQE=0), Также, если вы хотите отключить указанный QPизвстроенный функция приема, Доступно в Создать QPчас Отключить встраивание(mlx5dv_create_qp with MLX5DV_QP_CREATE_DISABLE_SCATTER_TO_CQE flag), Давать возможность:
MLX5DV_QP_CREATE_ALLOW_SCATTER_TO_CQE
ссылкапеременные среды среды(MLX5_SCATTER_TO_CQE):

Inline Receive Experimental Verbs - Экспериментальный VerbsAPI для встроенного приема
- ibv_exp_query_device - Запрос устройствавстроенный размер приемиз
- inline_recv_size
- ibv_exp_create_qp - Создать QP
- max_inl_recv
- ibv_exp_create_dct - Создайте цель динамического соединения
- inline_size
Inline Receive Experimental Device Attributes - Устройство получает встроенные свойства
IBV_EXP_DEVICE_ATTR_INLINE_RECV_SZ
Inline Receive RDMA-Core Verbs - Разрешить встроенное получение при создании QP
- mlx5dv_create_qp
- MLX5DV_QP_CREATE_ALLOW_SCATTER_TO_CQE
Встроенные переменные среды RDMA-Core для получения — включите переменные среды для хеширования пакетов в CQE.
MLX5_SCATTER_TO_CQE
Relevant Man Pages - Дополнительную информацию о хешировании/встраивании читайте подробнее. QPиз Документация
mlx5dv_create_qp: https://github.com/linux-rdma/rdma-core/blob/master/providers/mlx5/man/mlx5dv_create_qp.3.md
MLX5DV_QP_CREATE_DISABLE_SCATTER_TO_CQE — отключить хеширование для завершения элемента очереди CQE.
если IOVA с процессом VA не совпадает, а размер полезной нагрузки сообщения достаточно мал, чтобы вызвать разброс CQE функции, вам следует установить MLX5DV_QP_CREATE_DISABLE_SCATTER_TO_CQE логотип. при использовании памяти устройства не следует использовать IBV_SEND_INLINE и разбегаюсь по CQE, потому что его невозможно провести memcpy
анализ кода
Проект драйвера пользовательского режима rdma-core и драйвер режима ядра
wr.send_flags = IBV_SEND_SIGNALED | IBV_SEND_INLINE //Включаем отправку встроенной функции перед отправкой WQE
irdma_uk_inline_send //В качестве примера возьмем код E810
quanta = qp->wqe_ops.iw_inline_data_size_to_quanta(total_size)
FIELD_PREP(IRDMAQPSQ_INLINEDATALEN, total_size) //Устанавливаем длину встроенных данных и отмечаем и уведомляем оборудование позже
FIELD_PREP(IRDMAQPSQ_INLINEDATAFLAG, 1)
qp->wqe_ops.iw_copy_inline_data((__u8 *)wqe, op_info->sg_list, op_info->num_sges, qp->swqe_polarity) -> irdma_copy_inline_data
__u8 inline_valid = polarity << IRDMA_INLINE_VALID_S
memcpy(wqe, cur_sge, bytes_copied) // Воля Скопировать данные пользователя в WQE
scatter Теги, связанные с хешем
MLX5DV_QP_CREATE_DISABLE_SCATTER_TO_CQE // Отключить хеширование для элементов очереди завершения
MLX5DV_QP_CREATE_ALLOW_SCATTER_TO_CQE // Количество хешей, разрешенных для очереди завершения
nvidia inline
env = getenv("MLX5_SCATTER_TO_CQE") //Установим переменные среды, Разрешить хеширование для завершения элементов очереди
MLX5_QP_FLAG_SCATTER_CQE
MLX5_QP_FLAG_ALLOW_SCATTER_CQE
Драйвер пользовательского режима устанавливает режим Create на основе переменных среды. Время QP изFLAG:
inline to cqe:
static struct ibv_qp *create_qp
if (use_scatter_to_cqe())
env = getenv("MLX5_SCATTER_TO_CQE")
mlx5_create_flags |= MLX5_QP_FLAG_SCATTER_CQE -> mlx5:поддерживатьпроходить DCT QP К CQE рассеяние К CQE рассеяниедаодинпроизводительность предмета Функция,от Не здесь DCT QP включено. Сообщается о новой функции запроса глаголов, связанных с устройством, которая позволяет DCT QP включите эту функцию. Соответственно, этот патч включает эту функцию, чтобы она работала с другими QP Страницы руководства остаются неизменными. Это Воля управляется старыми переменными окружения и может вводить DV Создайте наложение логотипа
Состояние ядра анализируется по FLAG:
RDMA/mlx5: Позволяет обеспечить дополнительное израссеяние. CQE QP логотип,рассеяние CQE Функция опирается на два отдельных флага MLX5_QP_FLAG_SCATTER_CQE и MLX5_QP_FLAG_ALLOW_SCATTER_CQE
process_vendor_flags
create_user_qp
if ((qp->flags_en & MLX5_QP_FLAG_SCATTER_CQE) &&
(init_attr->qp_type == IB_QPT_RC ||
init_attr->qp_type == IB_QPT_UC))
int rcqe_sz = mlx5_ib_get_cqe_size(init_attr->recv_cq) -> 128 | 64 (default)
rcqe_sz == 128 ? MLX5_RES_SCAT_DATA64_CQE : MLX5_RES_SCAT_DATA32_CQE -> Установите встроенный 64 или да32 в зависимости от размера получаемого CQE.
if (qp->type == MLX5_IB_QPT_DCI || qp->type == IB_QPT_RC))
configure_requester_scat_cqe(dev, qp, init_attr, qpc)
IB_SIGNAL_ALL_WR -> IB/mlx5: разрешить глобальное WR отправить сигнал из Под помещением К CQE отправлятьрассеяние,Запрашивающая сторона К CQE отправлятьрассеяние Настраивается только как Квсе WR отправить сигнал из QP。Этот патч добавляетсуществовать Запрашивающая сторонасерединадавать возможность К cqe отправлятьрассеяние(Принудительное включение)из Функция,Нет необходимости в sig_all,Касается тех, кто не желает Квсе WR отправить сигнал изпользователь,И просто надеюсь Ксуществовать CQE Его данные находятся в WR отправить сигнал
if (scqe_sz == 128)
MLX5_SET(qpc, qpc, cs_req, MLX5_REQ_SCAT_DATA64_CQE) -> Установите QPC
Драйвер пользовательского режима RDMA проверяет встроенную функцию при опросе очереди завершения. если выполняются условия, Скопировать встроенные данные в драйвере ВоляотCQE на адрес, указанный отправителем.
mlx5_poll_cq -> poll_cq
mlx5_stall_cycles_poll_cq
or mlx5_stall_poll_cq
mlx5_poll_one
mlx5_get_next_cqe -> Добавлен отложенный опрос CQ: в настоящее время, когда пользователь хочет опросить CQ на предмет завершения, у него нет другого выбора, кроме как получить полное завершение задания (WC). Сколько значений это имеет? - Например: * Расширять WC далилимитиз, потому что добавление новых полей делает WC Больше и может занимать больше строк кэша. * Каждое отдельное поле копируется в WC - Даже пользователей не волнуют поля. Этот патч добавляет возможность ленивой обработки. CQE из Некоторая поддержка. Новый изленивый режим Воля вызывается в последующих патчах. Мы анализируем только необходимые поля, чтобы узнать CQE, например тип, статус, wr_id ждать. Чтобы использовать устаревший код совместно с устаревшим режимом без ущерба для производительности, устаревший код был реорганизован и был реализован механизм «always_inline», чтобы Условие перехода Воля удаляется во время компиляции.
next_cqe_sw
...
return cq->active_buf->buf + n * cq->cqe_sz
VALGRIND_MAKE_MEM_DEFINED -> memory check
dump_cqe
mlx5_parse_cqe(cq, cqe64, cqe, cur_rsc, cur_srq, wc, cqe_ver, 0) -> многоветвевая функция
opcode = mlx5dv_get_cqe_opcode(cqe64)
switch (opcode)
mlx5_handle_error_cqe
case MLX5_CQE_SYNDROME_TRANSPORT_RETRY_EXC_ERR:
return IBV_WC_RETRY_EXC_ERR
case MLX5_CQE_REQ
if (lazy)
uint32_t wc_byte_len
case MLX5_OPCODE_RDMA_READ:
wc_byte_len = be32toh(cqe64->byte_cnt)
goto scatter_out -> связанные с распространением/встроенными
or wc_byte_len = 8
if (cqe64->op_own & MLX5_INLINE_SCATTER_32)
mlx5_copy_to_send_wqe(mqp, wqe_ctr, cqe, wc_byte_len)
ctrl = mlx5_get_send_wqe(qp, idx)
qp->sq_start + (n << MLX5_SEND_WQE_SHIFT)
scat = mlx5_get_send_wqe(qp, 0)
qp->sq_start + (n << MLX5_SEND_WQE_SHIFT)
copy_to_scat(scat, buf, &size, max, ctx)
if (likely(scat->lkey != ctx->dump_fill_mkey_be)) -> mlx5: добавить верно ibv_alloc_null_mr изподдержка,еслиподдержка,mlx5_alloc_null_mr будет выделено MR ииспользовать mlx5_context в dump_fill_mkey установить его lkey член. этот MR в dump_fill_mkey будет позже ibv_post_receive() и ibv_post_send() Используется для исключения использования дампа и заполнения настроек ключа памяти соответственно. ibv_sge изписатьичитать
memcpy((void *)(unsigned long)be64toh(scat->addr), buf, copy)
else MLX5_INLINE_SCATTER_64
err = mlx5_copy_to_send_wqe(mqp, wqe_ctr, cqe - 1, wc_byte_len)
update_cons_index
mlx5_get_cycles
...
if (cqe->op_own & MLX5_INLINE_SCATTER_64)
mlx5_copy_to_recv_wqe // При получении элементов запроса рабочей очереди скопируйте данные
scat = get_recv_wqe(qp, idx)
qp->buf.buf + qp->rq.offset + (n << qp->rq.wqe_shift)Подвести итог
- После того как приложение включит встраивание небольшого пакета, драйвер завершает копирование памяти.
- Существует три формы копирования: Воля пользователь отправляет копию пакета для отправки WQE, Воля Полное копирование данных в CQE, ВоляReceive из копии пакета для получения WQE
ссылка
Как работают IB и PCIE (процесс заключения договора): https://www.rohitzambre.com/blog/2019/4/27/how-are-messages-transmitted-on-infiniband
Nvidia inline receive: https://docs.nvidia.com/networking/display/rdmacore50/inline+receive
create_qp: https://github.com/linux-rdma/rdma-core/blob/master/providers/mlx5/man/mlx5dv_create_qp.3.md
【RDMA】IBV_SEND_INLINEиIBV_SEND_SIGNALEDizPrinciple|Оптимизация производительности обмена небольшими сообщениями RDMA https://blog.csdn.net/bandaoyu/article/details/119207147
[RDMA] Как работает InfiniBand и решение по оптимизации производительности небольших сообщений: https://blog.csdn.net/bandaoyu/article/details/119204643
https://www.rohitzambre.com/blog/2019/4/27/how-are-messages-transmitted-on-infiniband
NVIDIA_MLX_OFED_Оптимизированный доступ к памяти: https://docs.nvidia.com/networking/display/mlnxofedv531050/optimized+memory+access
MLX5 создает справочную документацию по QP:
https://manpages.debian.org/unstable/libibverbs-dev/mlx5dv_create_qp.3.en.html
Брошюра ОФЕД:
http://dlcdnet.asus.com/pub/ASUS/server/accessory/PEM-FDR/Manual/Mellanox_OFED_Linux_User_Manual_v2_0-3_0_0.pdf
Сяобин (ssbandjl)
блог: https://cloud.tencent.com/developer/user/5060293/articles | https://logread.cn | https://blog.csdn.net/ssbandjl | https://www.zhihu.com/people/ssbandjl/posts
https://chattoyou.cn(Подавать жалобы/сообщение)
столбец ДПУ
https://cloud.tencent.com/developer/column/101987
Технические друзья: Добро пожаловатьверноDPU/SmartNIC/Удалить/сеть,ускорение хранения данных/Интересуются такими технологиями, как изоляция безопасностииз Друзья присоединяйтесьТехнология ДПУКоммуникационная группа



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
