Разверните модель Deepseek с помощью Triton+TensorRT-LLM.
Поскольку среда с открытым исходным кодом для проектов больших моделей становится все лучше и лучше, каждому должно быть очень просто развернуть большую языковую модель локально и запустить демонстрационные версии. Но чтобы запустить модель в производственной среде, вам необходимо учитывать производительность работы модели, планирование ресурсов графического процессора, поддержку сценариев с высоким уровнем параллелизма и т. д.
В этой статье в основном рассказывается, как использовать Triton+TensorRT-LLM для развертывания больших языковых моделей.
1. Знакомство с Тритоном
В области искусственного интеллекта Triton имеет два влиятельных значения: одно — это голос Triton для разработки ядра высокого уровня, инициированный OpenAI; другое — Triton Inference Server, решение с открытым исходным кодом, развернутое NVIDIA для пользователей облачных и периферийных вычислений. Triton, представленный в этой статье, является последним решением для развертывания модели.
github:https://github.com/triton-inference-server
Triton похож на TfServing. Конечно, он совместим с большим количеством моделей, чем tfserving. Его предшественником является сервер вывода TensorRT. Его преимуществом является то, что он предоставляет множество готовых инструментов, помогающих нам быстро развертывать модели искусственного интеллекта. производственная среда предназначена для использования в бизнесе, и нам не нужно самостоятельно разрабатывать набор инструментов для развертывания.
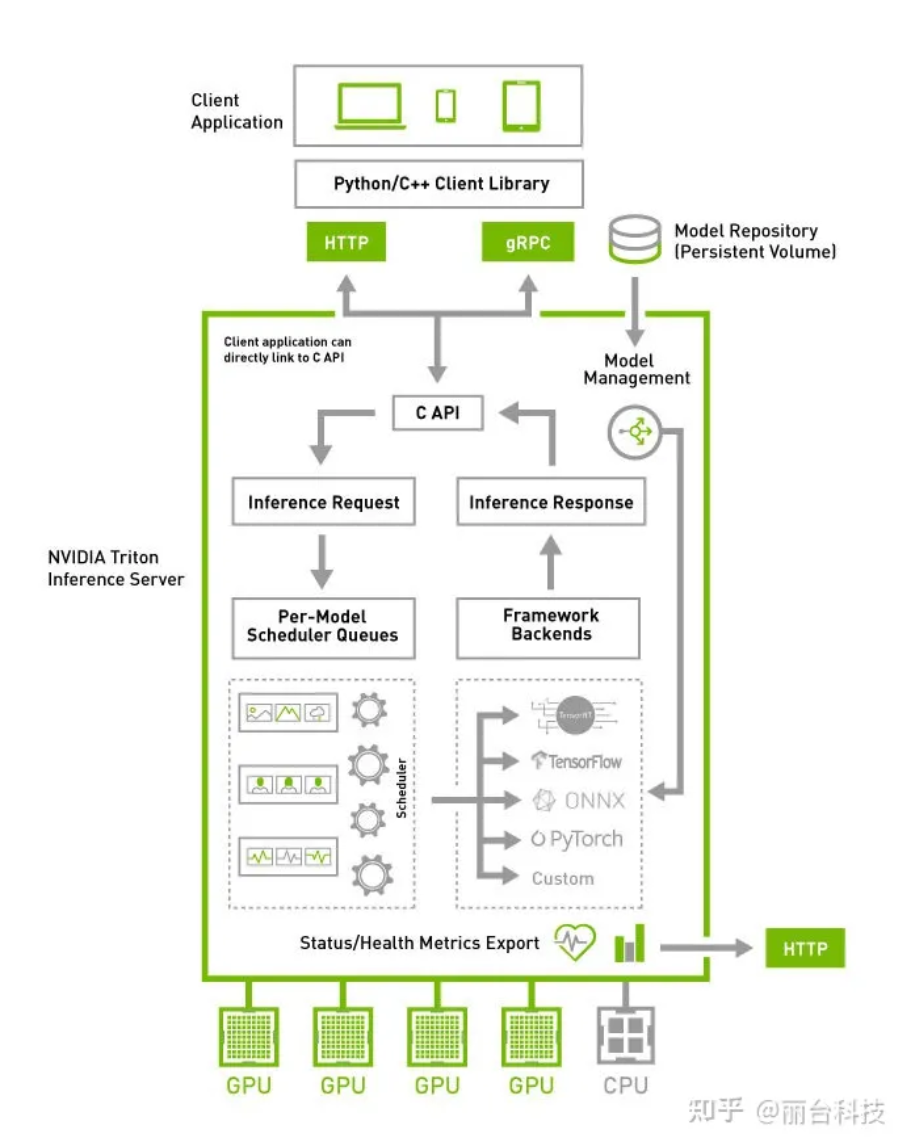
Сервер вывода NVIDIA Triton имеет следующие возможности:
● Поддерживает развертывание нескольких платформ с открытым исходным кодом, включая TensorFlow/PyTorch/ONNX Runtime/TensorRT и т. д., а также помогает пользователям предоставлять настраиваемые механизмы декодирования внутренних расширений;
● Поддержка нескольких моделей, работающих на графическом процессоре одновременно, для улучшения использования устройств с графическим процессором;
● Поддержка протокола HTTP/gRPC и расширение двоичного формата для сжатия размера запроса на отправку;
● Поддерживает функцию динамического пакетирования для повышения пропускной способности обслуживания;
● Поддержка стандартов API, совместимых с KFServing.
2. triton inference Быстрое развертывание сервера
Для быстрого развертывания тритона обратитесь к официальной документации:
https://github.com/triton-inference-server/server/blob/main/docs/getting_started/quickstart.md
Используйте NVIDIA GPU Cloud (NGC) напрямую для получения официального предварительно скомпилированного контейнера.
версия контейнера triton-inference-server:
https://docs.nvidia.com/deeplearning/triton-inference-server/release-notes/
Официально предоставленные контейнеры после 2.10 уже поддерживают TensorRT-LLM и vllm.

Поэтому, если версия cuda и драйвер поддерживают ее, самый быстрый способ — напрямую загрузить образ после 2.10, а затем установить официальную документацию для запуска службы.
docker run -it -d --cap-add=SYS_PTRACE --cap-add=SYS_ADMIN --security-opt seccomp=unconfined --gpus=all --shm-size=16g --privileged --ulimit memlock=-1 --name=develop nvcr.io/nvidia/tritonserver:23.10-trtllm-python-py3 bash3. Компиляция и развертывание Tensorrt_llm
Учитывая, что в будущем нам, возможно, придется внести изменения на основе исходного кода, чтобы упростить обнаружение и решение проблем, оптимизацию моделей и другие потребности, в этой статье в основном рассказывается, как скомпилировать модуль на основе исходного кода бэкэнда TensorRT_LLM и процесс развертывания собственной модели алгоритма.
3.1 Загрузите базовое изображение
Согласно запросу официального сайта на версию cuda, вытащите соответствующую версию, я использую версию 23.08.
Запустить контейнер
docker run -it --net host --gpus="device=5" --shm-size="70G" nvcr.io/nvidia/tritonserver:23.08-py3 /bin/bash3.2 Получение кода проекта
Извлеките код проекта tensorrtllm-backend
git clone https://github.com/triton-inference-server/tensorrtllm_backendИзвлеките код проекта TensorRT-LLM из каталога tensor_llm в проекте tensorrtllm_backend.
git clone https://github.com/NVIDIA/TensorRT-LLM.gitОбратите внимание, что версии ветвей согласованы. Я извлек ветку -b v0.5.0. (При извлечении ветвей обратите внимание на требования к версии cuda в /docker/common/install_tensorrt.sh в TensorRT-LLM.)
3.3. Компиляция TensorRT-LLM
Выполните в каталоге /opt/tritonserver/tensorrtllm_backend/tensorrt_llm:
apt-get update && apt-get -y install git git-lfs
git submodule update --init --recursive
git lfs install
git lfs pullУстановить зависимости
cd docker/common
bash install_base.sh
bash install_cmake.sh
bash install_tensorrt.sh
bash install_polygraphy.sh
bash install_pytorch.sh pypi
export LD_LIBRARY_PATH=/usr/local/tensorrt/lib:${LD_LIBRARY_PATH}Здесь обратите внимание на два момента:
1. Установите cmake
Если выполнение bash выполняется слишком медленно, вы можете заранее загрузить установочный пакет:
# Загрузите установочный файл вне образа и скопируйте его в контейнер.
docker cp cmake-3.24.4-linux-x86_64.tar.gz Идентификатор контейнера: /tmp/
# Измените install_cmake.sh, чтобы заблокировать логику загрузки.
#wget --no-verbose ${RELEASE_URL_CMAKE} -P /tmp
# Запустите сценарий установки еще раз
bash install_cmake.sh
# Добавьте переменные среды
vim ~/.bashrc
export PATH=/usr/local/cmake/bin${PATH:+:${PATH}}
source ~/.bashrcПосле установки выполните cmake -version, чтобы определить версию.
2. экспортировать переменные среды
После установки не забудьте экспортировать LD_LIBRARY_PATH, иначе возникнет проблема, что libnvinfer.so потом невозможно будет найти.
Установите TensorRT-LLM
cd tensorrt-llm
python3 ./scripts/build_wheel.py --clean --trt_root /usr/local/tensorrtУстановить после успешной компиляции:
pip install ./build/tensorrt_llm*.whlПосле успеха в каталоге /usr/local/tensorrt/lib должна быть библиотека tensorrt-llm.
3.4 Загрузка и компиляция модели глубокого поиска
Теперь, когда есть библиотека времени выполнения tensorrt-llm, нам нужно загрузить нашу собственную модель для тестирования. В модели tensorrt-llm на данный момент поддерживаются модели llama, Bloom, Chatglm2_6b, baichuan, gpt, bert и т. д., поэтому, если структура вашей модели основана на этих основных моделях, ее можно использовать повторно, если ее невозможно использовать повторно; , просто сюда можно только добавить код и постепенно перекомпилировать.
Если это специальный фреймворк, то это не то, что нужно менять. Многие файлы нужно менять. . . Важность использования основных фреймворков! ! !
Примером в этой статье является преобразование модели deepseek. Поскольку структура модели основана на llama, мы здесь ленивы и повторно используем llama для model_type позже. Некоторые проблемы несовместимости требуют изменения некоторого кода, о котором будет упомянуто позже.
3.4.1 Загрузка файла модели
Мы скачали его,Копируем напрямую из nfs,Конечно, ты тоже можешь это сделать Установите его непосредственно в контейнере.
docker cp /Хост-машина из модели адреса/deepseek-coder-6.7b-base/ ID файла:/opt/tritonserver/tensorrtllm_backend/tensorrt_llm/modelhub3.4.2 Компиляция модели trt_engines
Предыдущий шаг заключался в компиляции библиотеки trt. Для запуска модели trt также необходимо создать механизм модели.
cd /opt/tritonserver/tensorrtllm_backend/tensorrt_llm/examples/llamaСкомпилировать модель
python build.pyПреобразование модели требует понимания некоторых параметров модели, вы можете обратиться к
ссылка:https://github.com/deepseek-ai/DeepSeek-Coder/issues/44
После успешного преобразования должен появиться файл .engine.

3.4.3 тест tensorrt_llm
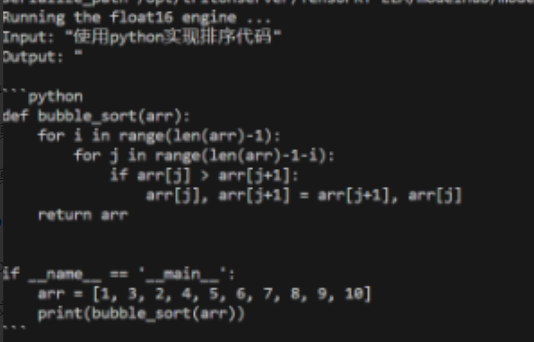
Измените код загрузки токенизатора в run.py. В Deepseek нет tokenizer.model, поэтому код загрузки токенизатора необходимо изменить.
python run.py --max_output_len=1024 --tokenizer_dir /opt/tritonserver/tensorrtllm_backend/tensorrt_llm/modelhub/deepseek-coder-6.7b-base --engine_dir /opt/tritonserver/tensorrtllm_backend/tensorrt_llm/modelhub/models/trt_engines/deepseek/fp16/1-gpu/ --input_text «Использование Python для реализацииЕсли результаты могут быть получены нормально, это означает, что преобразование между tensorrt_llm и загруженной моделью завершено.
3.5. Компиляция tensorrtllm_backend
3.5.1 Загрузка файлов
Теперь скомпилируем tensorrtllm_backend~. Перед компиляцией скопируйте необходимые файлы и внесите некоторые изменения в код.
cd /opt/tritonserver/tensorrtllm_backend/
cd tensorrtllm_backend
mkdir triton_model_repo
# Скопируйте папку модели шаблона
cp -r all_models/inflight_batcher_llm/* triton_model_repo/3.5.2 Настройка конфигурации и кода
В model_repo четыре папки, и нам нужно изменить все из них в config.txtpb.
Обратитесь к официальной документации:https://github.com/triton-inference-server/tensorrtllm_backend#modify-the-model-configuration
● «предварительная обработка»: этот модуль отвечает за преобразование подсказок (строки) в input_ids.
● «tensorrt_llm»: этот модуль представляет собой пакет для выполнения вывода в TensorrtRT-LLM.
● «постобработка»: этот модуль отвечает за преобразование input_ids в строку.
● «ансамбль»: этот модуль отвечает за объединение первых трех модулей.
Модуль config.pbtxt tensorrt_llm был сильно изменен. В основном вы можете обратиться к официальному сайту, чтобы настроить объяснение каждого поля.
https://github.com/triton-inference-server/tensorrtllm_backend#modify-the-model-configuration
3.5.3 Компиляция tensorllm_backbend
Выполните скрипт компиляции:
cd /opt/tritonserver/tensorrtllm_backend/inflight_batcher_llm/scripts
chmod +x build.sh
./build.sh /usr/local/tensorrtЕсли у вас возникли проблемы с версией libnvinfer.so.8, просто скопируйте so.9 и переименуйте ее в so.8.
3.5.4 Запуск службы
python3 scripts/launch_triton_server.py --world_size=1 --model_repo=triton_model_repo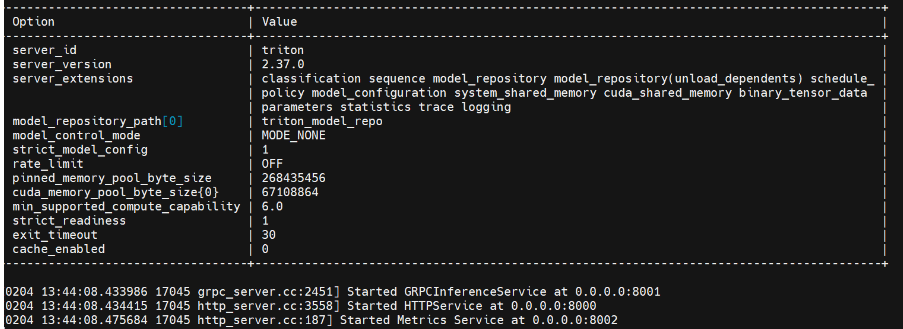
Видя приведенный выше результат, поздравляем ~ Служба triton успешно запущена, а серверная часть — tensorrt_llm.
4. Звонок клиенту
Вызовы клиентов относительно просты, установите клиентскую библиотеку.
pip install tritonclient[all]
pip install pandas
pip install tabulateклонкод
git clone -b v0.5.0 https://github.com/triton-inference-server/tensorrtllm_backendНайти пример кода
cd tensorrtllm_backend/tools/inflight_batcher_llmИзмените end_to_end_streaming_client.py.
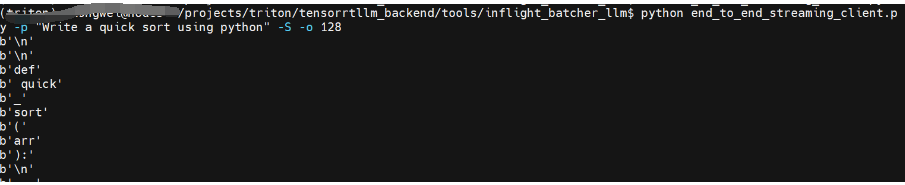
Localhost изменяется на 10.200.1.5, или URL-адрес параметра командной строки назначается напрямую.
python end_to_end_streaming_client.py -p "Write a quick sort using python" -S -o 128Вы можете увидеть результаты трансляции:
ссылка:
https://www.zhihu.com/question/507633460/answer/2379994462
https://ai.oldpan.me/t/topic/260
https://github.com/triton-inference-server/tensorrtllm_backend/issues/188



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
