Разница между искрообразованием и искрой
Spark Streaming и Spark — два важных компонента экосистемы Apache Spark. Они принципиально различаются по способу и целям обработки данных. Ниже приводится подробное сравнение этих двух компонентов и объяснение того, как их использовать для обработки данных.
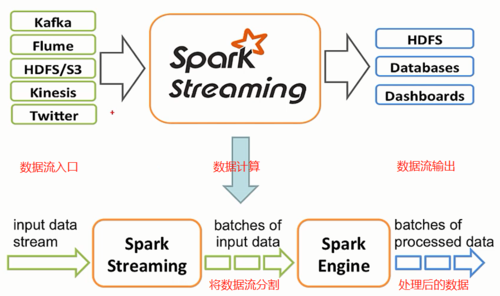
(Источник изображения из Интернета, удален в связи с нарушением авторских прав)
1. Основные понятия Spark Streaming и Spark.
Spark Streaming
Spark Streaming — это платформа потоковой обработки, которая позволяет пользователям обрабатывать потоки данных в реальном времени с высокой пропускной способностью. Spark Streaming может обрабатывать данные из нескольких источников данных (таких как Kafka, Flume, Kinesis и т. д.) и преобразовывать непрерывные потоки данных. Разделить на ряд дискретных пакетов данных. Эти пакеты называются DStreams (Дискретизированные потоки), и каждый пакет данных может обрабатываться в механизме Spark, аналогично заданию пакетной обработки.
Spark
Spark Это платформа обработки больших данных, предоставляющая мощный интерфейс для выполнения задач пакетной обработки Spark. Spark поддерживает различные операции обработки данных, включая преобразования и действия, и может эффективно обрабатывать крупномасштабные наборы данных в памяти. Основная концепция заключается в RDD(ResiLIent Distributed DaTAset),Это неизменяемая коллекция распределенных объектов.,Возможна параллельная обработка.
Исходная ссылка: https://www.mfdjyx.com/om/34522.html.
2. Разница между Spark Streaming и Spark
Методы обработки данных
Spark Streaming:Обработка Непрерывнаяизпоток данных,Разделите данные на небольшие пакеты,и обрабатывается для каждой партии.
Spark:Работа со статическими наборами данных,Обычно обработка больших объемов данных, хранящихся в файловой системе или базе данных.
в реальном времени
Spark Streaming:Обеспечить возможности обработки практически в реальном времени,Вы можете установить интервал пакетной обработки в соответствии с вашими потребностями (например, обработка данных каждые 1 секунду).
Spark:Не подходит для обработки в реальном времени.,Потому что он предназначен для пакетной обработки.
модель данных
Spark Streaming:использовать DStreams для представления непрерывного потока данных.
Spark:использовать RDDs для представления статических наборов данных.
механизм отказоустойчивости
Spark Streaming:Сохранив данные в Spark из RDD в, наследство Spark измеханизм отказоустойчивости。
Spark:проходитьRDDизродословная карта(lineage)для достижения отказоустойчивости,Нет необходимости пересчитывать недостающие данные.
3. Техническое обучение
Использование потоковой передачи Spark
Для начала Использование потоковой передачи Спарк, тебе нужно настроить Spark Streaming контекст, а затем создайте его из источника данных DStreams, определяют операции преобразования и вывода. Ниже приведен простой пример, показывающий, как использовать потоковой передачи Spark Считайте данные из источника текстового файла и посчитайте каждое слово.
import org.apache.spark._
import org.apache.spark.streaming._
// создавать SparkConf и StreamingContext
val conf = new SparkConf().setAppName("WordCount")
val ssc = new StreamingContext(conf, Seconds(1))
// Из источника текстового файла создателя DStream
val lines = ssc.textFileStream("hdfs://...")
// Разделите каждую строку на слова
val words = lines.flatMap(_.split(" "))
// Посчитайте каждое слово
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
// Распечатать результаты
wordCounts.print()
// Начните получать данные и обрабатывать их
ssc.start()
ssc.awaitTermination()
Использование Искры
Использование Искры Выполнение обработки данных обычно включает загрузку набора данных, выполнение серии преобразований, а затем запуск вычислений, таких как Искры Выполните подсчет слов по простому примеру.
import org.apache.spark._
import org.apache.spark.rdd.RDD
// создавать SparkConf и SparkContext
val conf = new SparkConf().setAppName("WordCount")
val sc = new SparkContext(conf)
// Загрузите текстовый файл в RDD
val textFile = sc.textFile("hdfs://...")
// Разделите каждую строку на слова
val words = textFile.flatMap(_.split(" "))
// Посчитайте каждое слово
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
// Соберите результаты и распечатайте
val result = wordCounts.collect()
result.foreach(println)
// останавливаться SparkContext
sc.stop()
4. Заключение
Spark Streaming и Spark Оба являются мощными инструментами обработки данных, но подходят для разных сценариев. Streaming Подходит для сценариев, требующих быстрой обработки потоков данных в реальном времени, и Spark Больше подходит для пакетной обработки больших объемов статических данных.,При выборе того, какой фреймворк использовать,Решение должно приниматься на основе конкретных потребностей бизнеса и технических требований.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
