Разберитесь, как работает Трансформер, в одной статье! !
Предисловие
Эта статья начнется сПринцип работы с одной головкой Внимание、Как работает многоголовое внимание?、полностью подключенная сеть Работапринциптри аспекта,выполнить Разбираемся в одной статьеКак работает Трансформер。

Как работает Трансформер
1. Принцип работы одноголового внимания
Одноголовое внимание: Одноголовое внимание — это механизм внимания, который привлекает внимание только один раз. В этом процессе внимание обращается на один и тот же запрос (Q), ключ (K) и значение (V) один раз, и получается результат. Этот механизм позволяет модели сосредоточиться на информации в разных местах из разных подпространств представления.
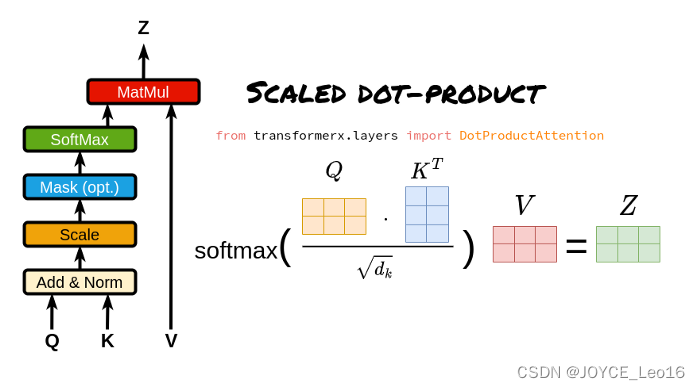
Scaled Dot-Product (операция масштабированного скалярного произведения)
- Матрица запроса, ключа и значения:
Матрица запроса (Q):Указывает текущийсосредоточиться на точку или информационное требование, используемое для сопоставления с Ключевой матрицей.
Ключевая матрица (К):Содержит идентификационную информацию для каждой позиции во входной последовательности.,Используется для сопоставления с запросом матрицы запросов.
Матрица значений (V):хранится сKeyФактическое значение или информационное содержание, соответствующее матрице,Когда запрос соответствует ключу,Соответствующее значение будет использоваться для расчета выходных данных.
- Расчет скалярного произведения:
Путем вычисления скалярного произведения между матрицей запроса и матрицей ключей (то есть соответствующие элементы умножаются, а затем суммируются) измеряется степень сходства или совпадения между запросом и каждым ключом.
- Коэффициент масштабирования:
Поскольку результат операции скалярного произведения может быть очень большим, особенно если входная размерность высока, это может привести к тому, что функция softmax войдет в зону насыщения при вычислении весов внимания. Чтобы избежать этой проблемы, внимание к масштабированному скалярному произведению вводит коэффициент масштабирования, обычно квадратный корень из входного измерения. Разделив результат скалярного произведения на этот коэффициент масштабирования, можно сохранить входные данные функции softmax в разумных пределах.
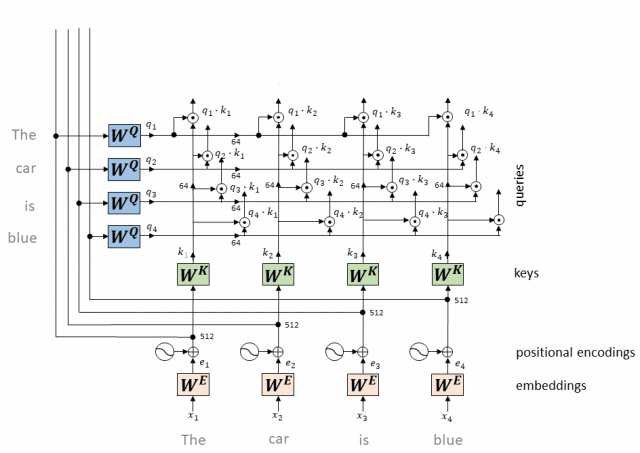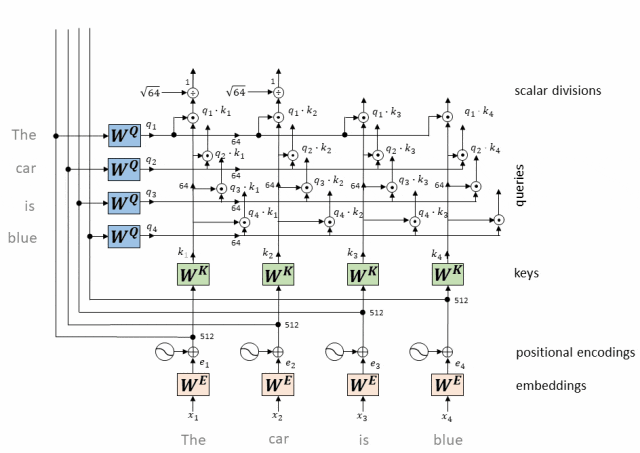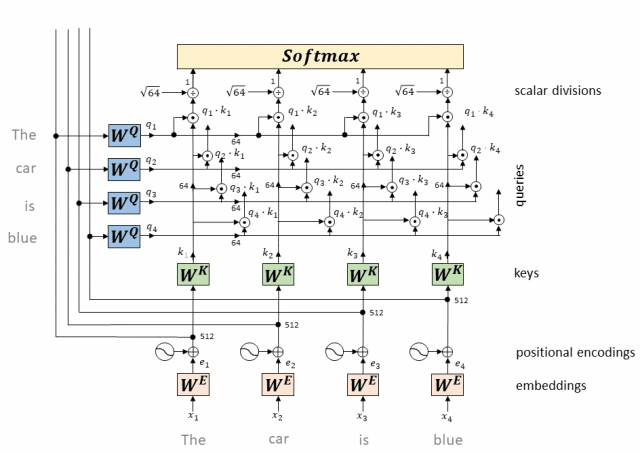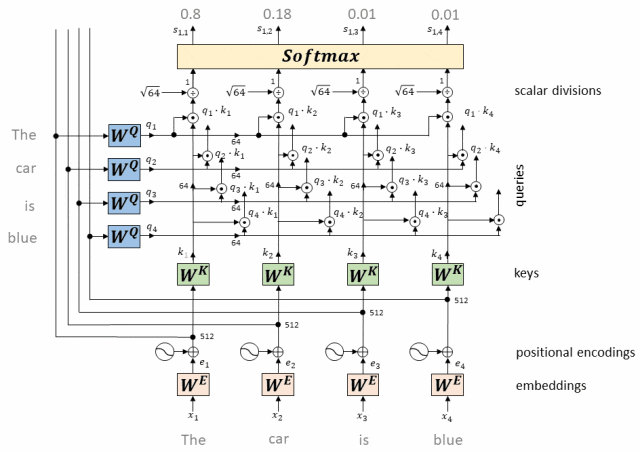
- Функция Софтмакс:
Введите масштабированный результат скалярного произведения в функцию softmax, чтобы вычислить вес внимания каждого ключа относительно запроса. Функция Softmax преобразует исходный балл в такое распределение вероятностей, что сумма весов внимания всех ключей равна 2.
Принцип работы: внимание с одной головкой вычисляет скалярное произведение вектора запроса каждого токена и ключевых векторов всех токенов, получает веса внимания посредством нормализации softmax, а затем применяет эти веса к векторам значений для взвешенного суммирования, тем самым генерируя Выходное представление каждого токена с самообслуживанием.
- Вектор запроса, соответствующий каждому токену, представляет собой скалярное произведение с вектором ключа, соответствующим каждому токену.
Для каждого токена во входной последовательности у нас есть соответствующий вектор запроса (вектор запроса, Q) и вектор ключа (вектор ключа, K).
Мы вычисляем скалярное произведение каждого вектора запроса со всеми ключевыми векторами.
Этот шаг заключается в установлении связи между всеми токенами, указывающей степень «внимания» каждого токена к другим токенам.
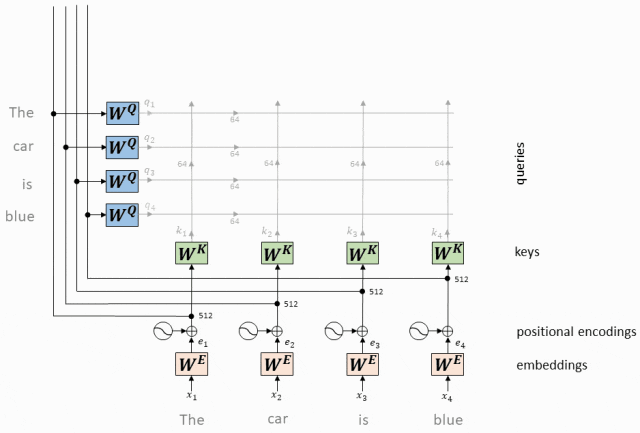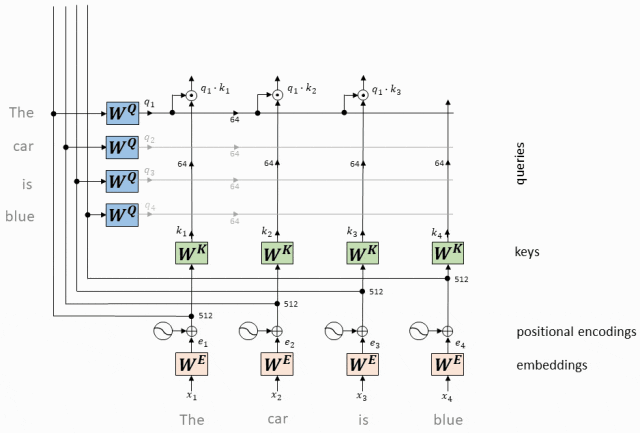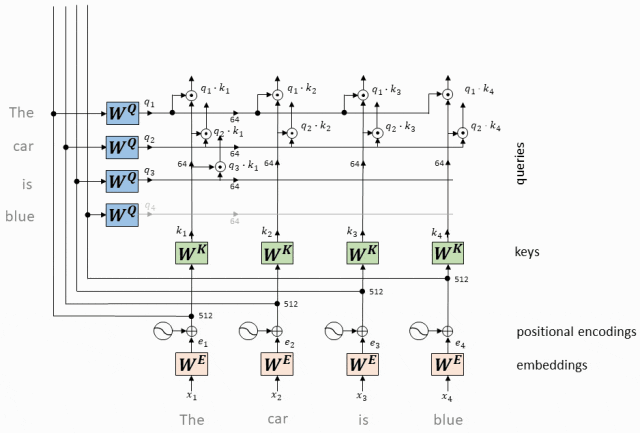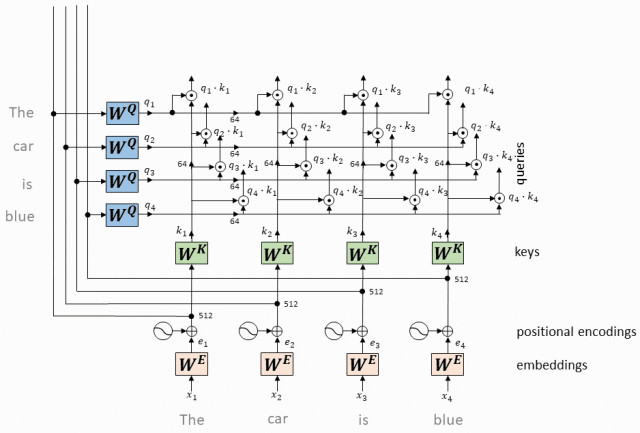
Операция скалярного произведения вектора QK
- Возьмите softmax вышеуказанного скалярного произведения (получено значение от 0 до 1, которое является весом внимания)
Результат скалярного произведения должен пройти через функцию softmax, чтобы гарантировать, что сумма весов внимания всех токенов равна 1. Функция softmax преобразует результаты скалярного произведения в значения от 0 до 1, которые представляют вес внимания каждого токена относительно всех остальных токенов.
Рассчитать вес внимания
- Рассчитайте вес внимания каждого токена относительно всех остальных токенов (в конечном итоге формируя матрицу внимания).
Веса внимания после обработки softmax формируют матрицу внимания.
Каждая строка этой матрицы соответствует токену, а каждый столбец также соответствует токену. Каждый элемент в матрице представляет вес внимания соответствующего токена строки к токену столбца.

Составьте матрицу внимания
- Вектор значений, соответствующий каждому токену, умножается на вес внимания и суммируется, чтобы получить вектор значения самовнимания текущего токена.
Используйте эту матрицу внимания, чтобы взвесить вектор значений (V) во входной последовательности.
В частности, для каждого токена мы умножаем соответствующий ему вектор значений на все веса строки токена в матрице внимания и складываем результаты.
Результатом этого взвешенного суммирования является выходное представление токена после обработки механизмом самообслуживания.
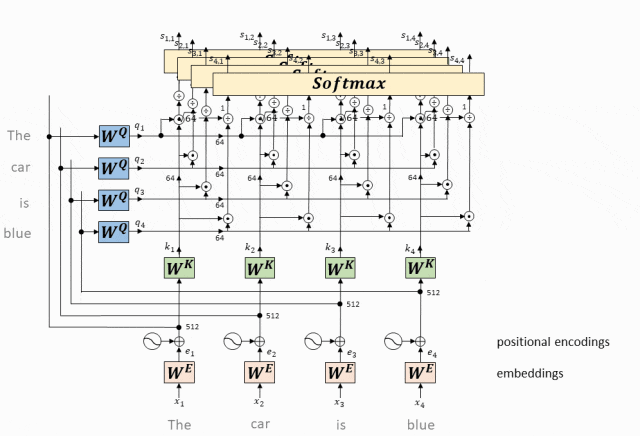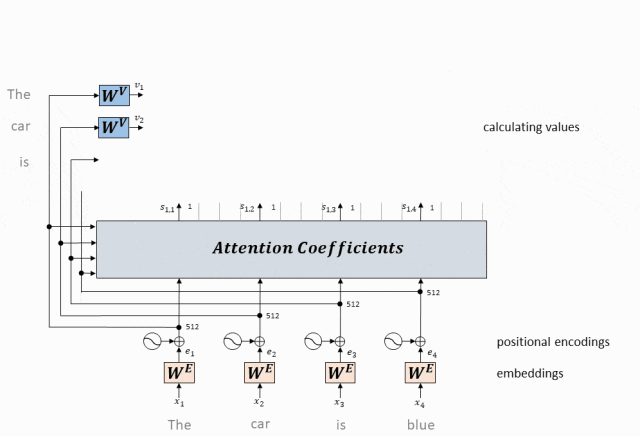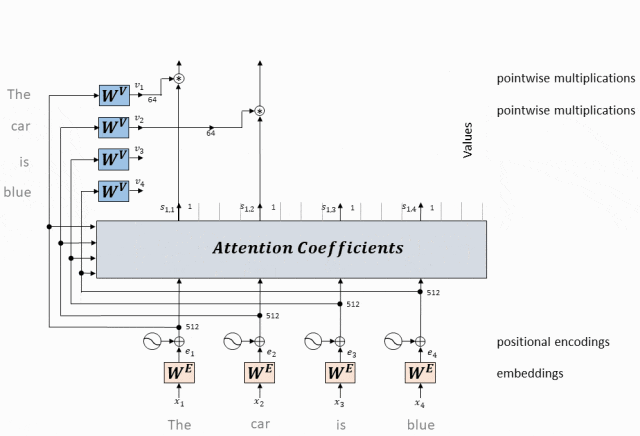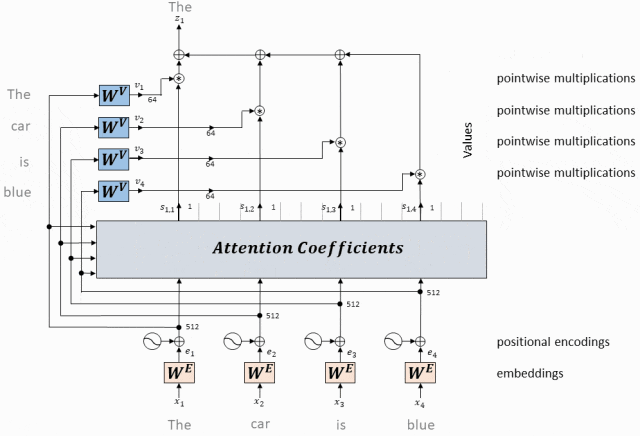
Вектор значения взвешенной суммы
- Преобразуйте приведенные выше операции в Применяется к каждому токену
Приведенные выше операции будут применены к каждому токену в входной последовательности, чтобы получить выход, выраженный каждым токеном с помощью механизма самообслуживания.
Эти выходные представления обычно отправляются на следующий уровень модели для дальнейшей обработки.
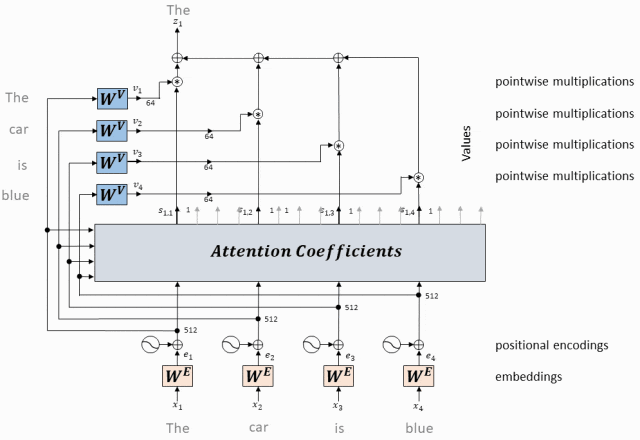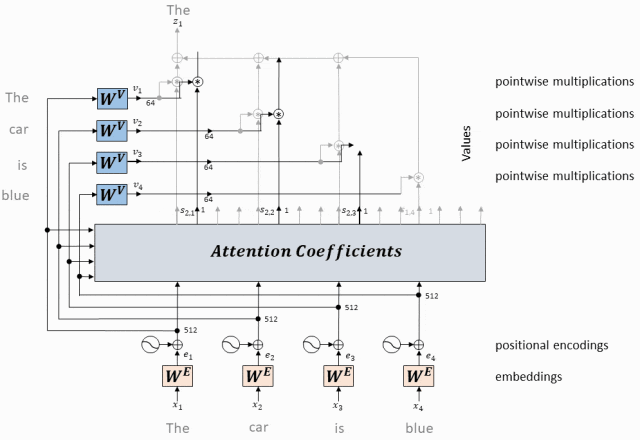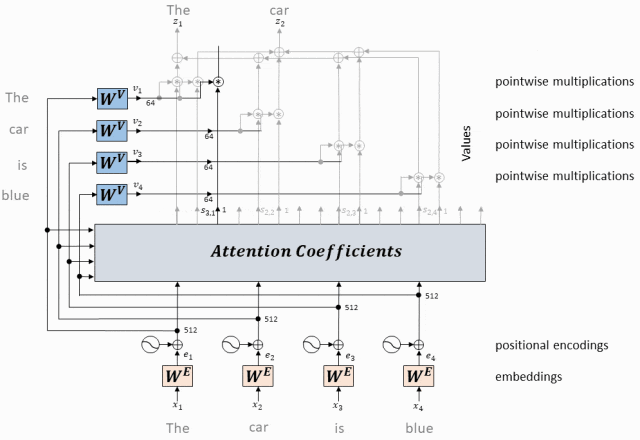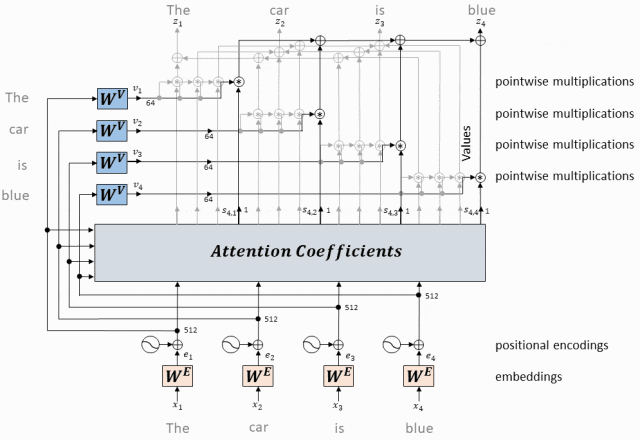
Применяется к каждому токену
2. Принцип работы мультиголовочного внимания
Многоголовое внимание: механизм многоголового внимания может одновременно захватывать информацию входной последовательности в разных подпространствах, параллельно запуская несколько слоев самообслуживания и синтезируя результаты, тем самым улучшая выразительные способности модели.
- Многоголовое внимание на самом деле представляет собой несколько параллельных слоев самообслуживания, и каждая «голова» независимо изучает разные веса внимания.
- Выходные данные этих «голов» затем объединяются (обычно объединяются и пропускаются через линейный уровень) для получения окончательного выходного представления.
- Таким образом, Multi-Head Attentionспособен одновременнососредоточиться —Информация из разных подпространств входной последовательности.
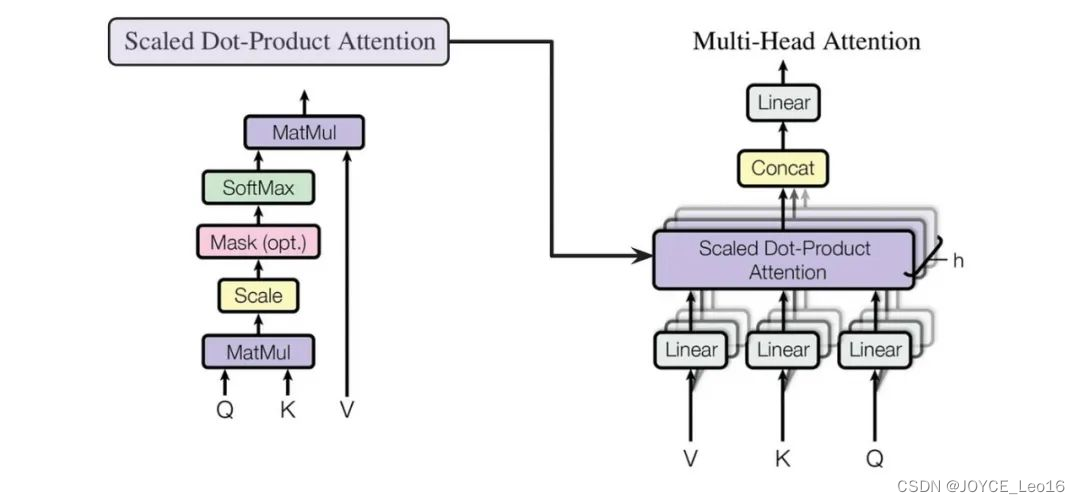
Multi-Head Attention
Принцип работы: Multi-Head Attention объединяет векторы, полученные каждой головой, и, наконец, умножает линейную матрицу для получения выходных данных Multi-Head Attention.
- Введите линейное преобразование:Для вводаQuery(Запрос)、Key(ключ)иValue(ценить)вектор,Во-первых, они отображаются в разные подпространства посредством линейного преобразования. Эти параметры линейного преобразования — это то, что модель должна изучить.
- Разделение длинной позиции:После линейного преобразования,Векторы запроса, ключа и значения разбиваются на несколько заголовков. Каждая голова производит расчеты внимания самостоятельно.
- Масштабирование внимания к скалярному произведению:внутри каждого заголовка,Используйте масштабированное скалярное произведение внимания, чтобы вычислить оценку внимания между запросом и ключом. Эта оценка определяет при создании выходных данных,Модель должнасосредоточиться — Часть вектора значений.
- Внимание: приложение веса:Примените рассчитанные веса внимания кValueвектор,Получите взвешенный промежуточный результат. Этот процесс можно понимать как фильтрацию и фокусировку входной информации на основе весов внимания.
- Сплайсинг и линейное преобразование:Объедините взвешенные выходные данные всех головок.,Затем окончательный вывод внимания Multi-Head получается посредством линейного преобразования.
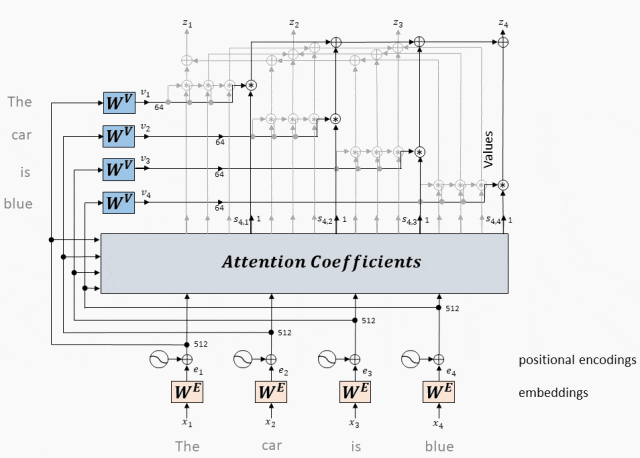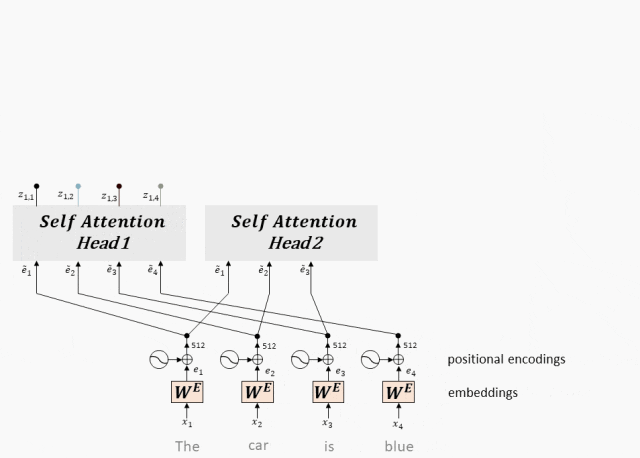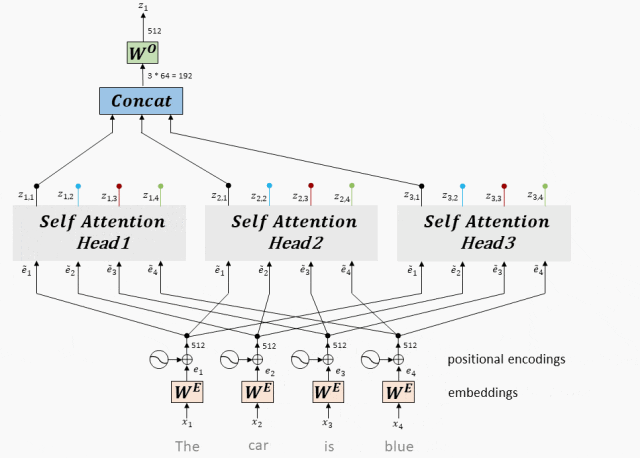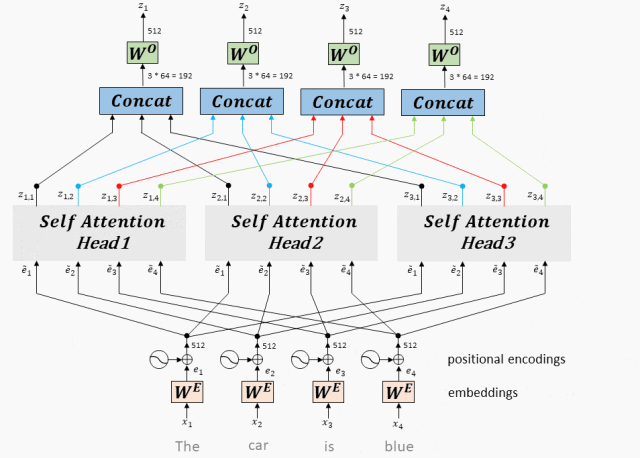
Сплайсинг и линейное преобразование
3. Принцип работы полностью подключенной сети.
Сеть прямой связи: в модели Transformer сеть прямой связи используется для сопоставления вектора входного слова с вектором выходного слова для извлечения более богатой семантической информации. Сети прямой связи обычно включают в себя несколько линейных преобразований и нелинейных функций активации, а также остаточную связь и операцию нормализации слоев.
- Кодировщик:
Часть кодера в Transformer состоит из N идентичных слоев кодера.
Каждый уровень кодера имеет два подуровня, а именно уровень многоголового внимания и сеть прямой связи.
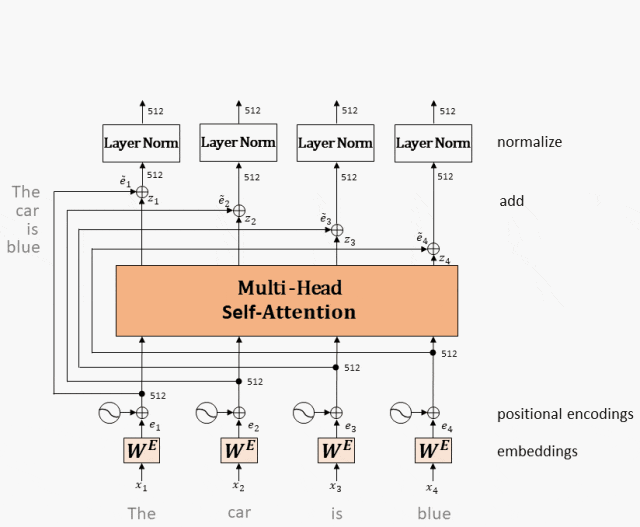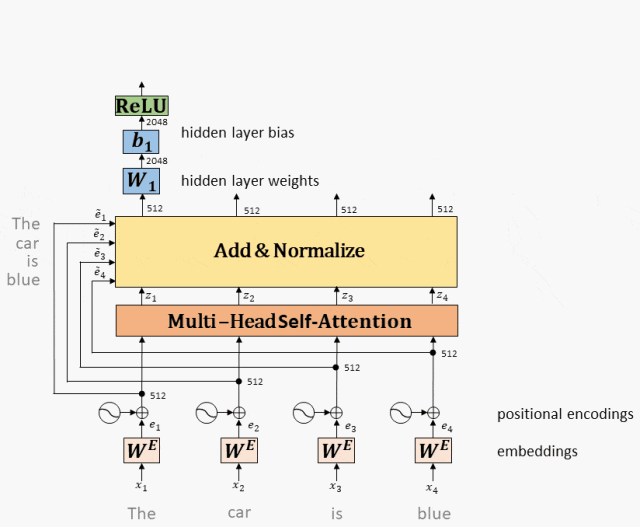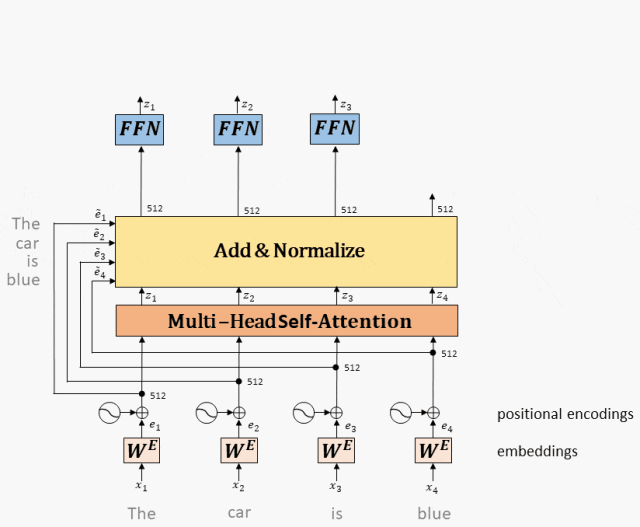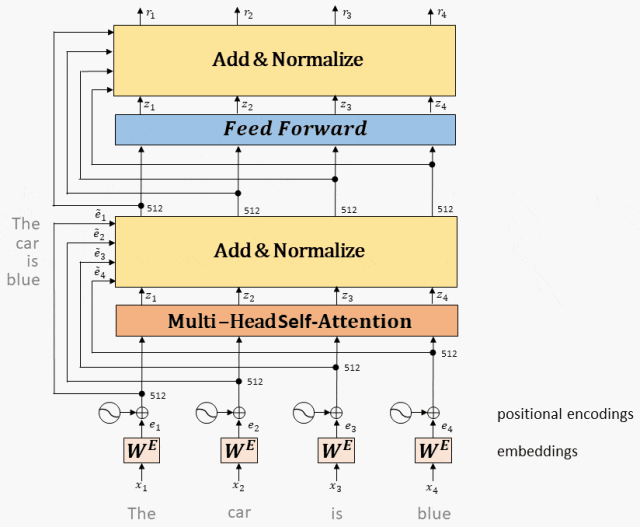
За каждым подслоем расположены операции остаточного соединения (пунктирная линия на рисунке) и нормализации слоя (LayerNorm).,Эти двое вместе называютсяAdd&Normдействовать。
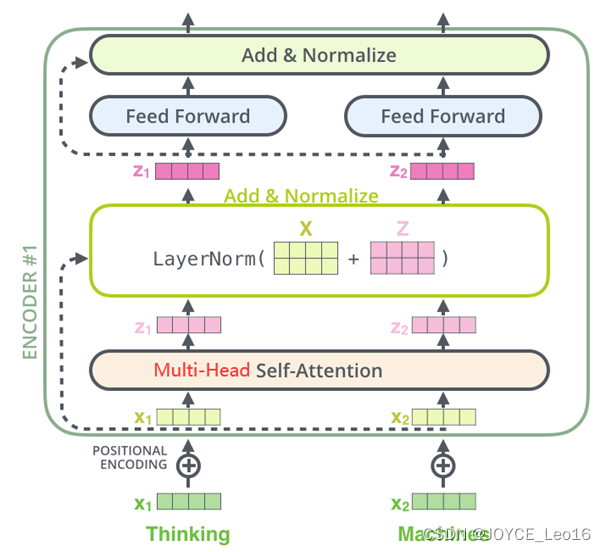
Архитектура кодировщика
- Декодер декодер:
Часть декодера в Transformer также состоит из N идентичных слоев декодера.
Каждый уровень декодера имеет три подуровня: уровень маскированного самообслуживания, уровень внимания кодировщика-декодера и сеть прямой связи.
такой же,За каждым подслоем расположены операции остаточного соединения (пунктирная линия на рисунке) и нормализации слоя (LayerNorm).,Эти двое вместе называютсяAdd&Normдействовать。
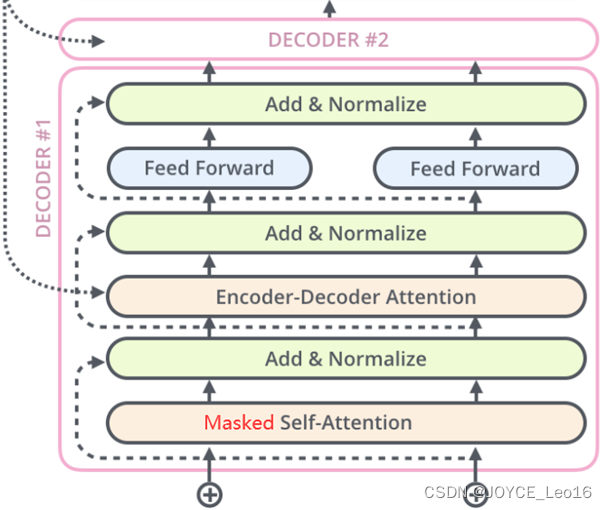
Структура декодера
Принцип работы: Выход Multi-Head Attention входит в двухслойную полностью подключенную сеть после остатка и нормы.
полностью подключенная сеть
Ссылка: Architect предлагает вам поиграть с ИИ.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
