Расшифровка подсказок. Серия 21. Агент LLM снова говорит о плотности отзывной информации и качестве RAG.
Продолжая вышеизложенную оптимизацию разнообразия отзыва,Схема отзыва с несколькими индексами может предоставить больше потенциального контента-кандидата. Но чем больше кандидатов,Как фильтровать и сортировать этот контент становится все более важным。В этой главе мы вспоминаем плотность и качество информации.。Также обратитесь кКлассическая система поиска и рекомендаций,Эта глава соответствуетСортировка+Изменить порядоксвязь,Учитывая различие между грубой сортировкой и тонкой сортировкой, сортировка в основном предназначена для инженерной оптимизации с малой задержкой.,Никакого дальнейшего различия здесь делаться не будет.,Считайте равномерно Сортировочный модуль. Давайте сначала сравним перестановку и Сортировочный. Сходства и различия модуля в классическом фреймворке и RAG
- Сортировочный модуль
- классическая рамка:Поточечное моделирование, максимизирующее ценность отдельного локального объекта.,Значением здесь может быть рейтинг кликов контента в поисковых рекомендациях.,Или ecpm в рекламе,Значение определяется последующими пользователями.
- RAG: та же базовая и классическая структура.,Однако ценность — это степень, в которой большая модель может ответить на вопрос, используя вышеизложенное. Определение ценности сначала дается лежащей в ее основе большой моделью.,Остается сделать еще один шаг, чтобы охватить пользователей. Более конкретное определение,Сортировочный модульмедведьФункции, которые максимизируют плотность информации,То есть отфильтровать как можно больше высококачественного контента в меньшем количестве Топ К.,и отфильтровывать шумную информацию.
- переставить модуль
- классическая рамка:Списковое моделирование максимизирует глобальную ценность за счет упорядочения и комбинирования элементов.,В свою очередь, общее впечатление от нескольких действий пользователя будет лучше. Здесь все может быть страницей со списком поиска.,Информационный поток рекомендаций на одном экране,Это также может быть более продолжительный общий показатель пользовательского опыта в течение всего сеанса.,и ценность бизнеса, стоящая за этим. Распространенный подход – расстаться.,Улучшение разнообразия в последовательном контенте,и логическая связность содержания до и после,Но расставание - это всего лишь средство,Глобальная ценность – конечная цель
- ТРЯПКА: аналогичная концепция,Оптимизируйте эффективность использования общего контекста путем перестановки модели.。Оптимизируйте использование вышеизложенного в модели, улучшите согласованность и разнообразие информации, а также сведите к минимуму информационные несоответствия и конфликты.。Однако текущий метод диалогового взаимодействия больших моделей сложнее получить сигналы обратной связи о пользовательском опыте.,Оптимизировать пользовательский опыт сложнее.
Ниже мы поговорим о решениях реализации этих двух модулей соответственно.
1. Сортировочный модуль
В предыдущей главе упоминалось использование перезаписи запросов, многоканальной индексации, включая дискретный индекс bm25, и многократного внедрения непрерывных индексов для многоканального вызова контента. Этот подход обеспечит кандидатов с более богатым содержанием, но также значительно увеличит длину приведенного выше текста. Во многих статьях было оценено, что слишком длинные тексты и большая доля шумовой информации в слишком длинных текстах повлияют на эффект вывода модели следующим образом.
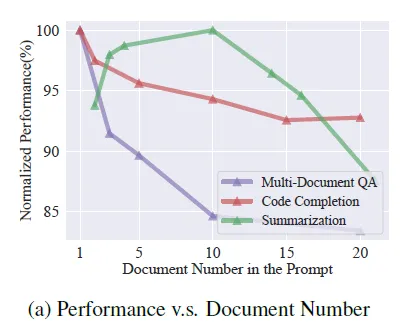
Так как же отсортировать и отфильтровать контент более высокого качества из отозванного контента?,Фильтрация зашумленной информации — это то, что должен делать Сортировочный модуль. Учтите, что оценки сходства между различными индексами несопоставимы друг с другом.,Не будет добавлено,Таким образом, для ранжирования контента-кандидата необходим единый параметр оценки.,Доступно здесьДве неконтролируемые гибридные схемы ранжирования и оценки
1.1 Смешанная схема RRF
https://learn.microsoft.com/en-us/azure/search/hybrid-search-ranking https://python.langchain.com/docs/modules/data_connection/retrievers/ensemble
Наиболее распространенным гибридным рейтингом многоканального отзыва является Reciprocal Rank Fusion (RRF), который преобразует все параметры оценки в рейтинги. Окончательная оценка каждого документа является обратной величиной суммы многоканальных рейтингов. Разница в масштабе между разными оценками устраняется посредством ранжирования. Формула выглядит следующим образом, где r(d) — рейтинг документа по одному измерению оценки, K — константа, играющая сглаживающую роль, а значение, данное Microsoft после эксперимента, равно 60.
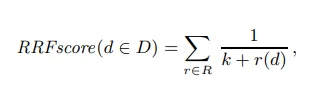
Ниже приведена схематическая диаграмма использования класса RRF для объединения текстового и векторного поиска в Microsoft Search. RRF используется для гибридной сортировки содержимого многоканального вызова текстового и векторного поиска соответственно.
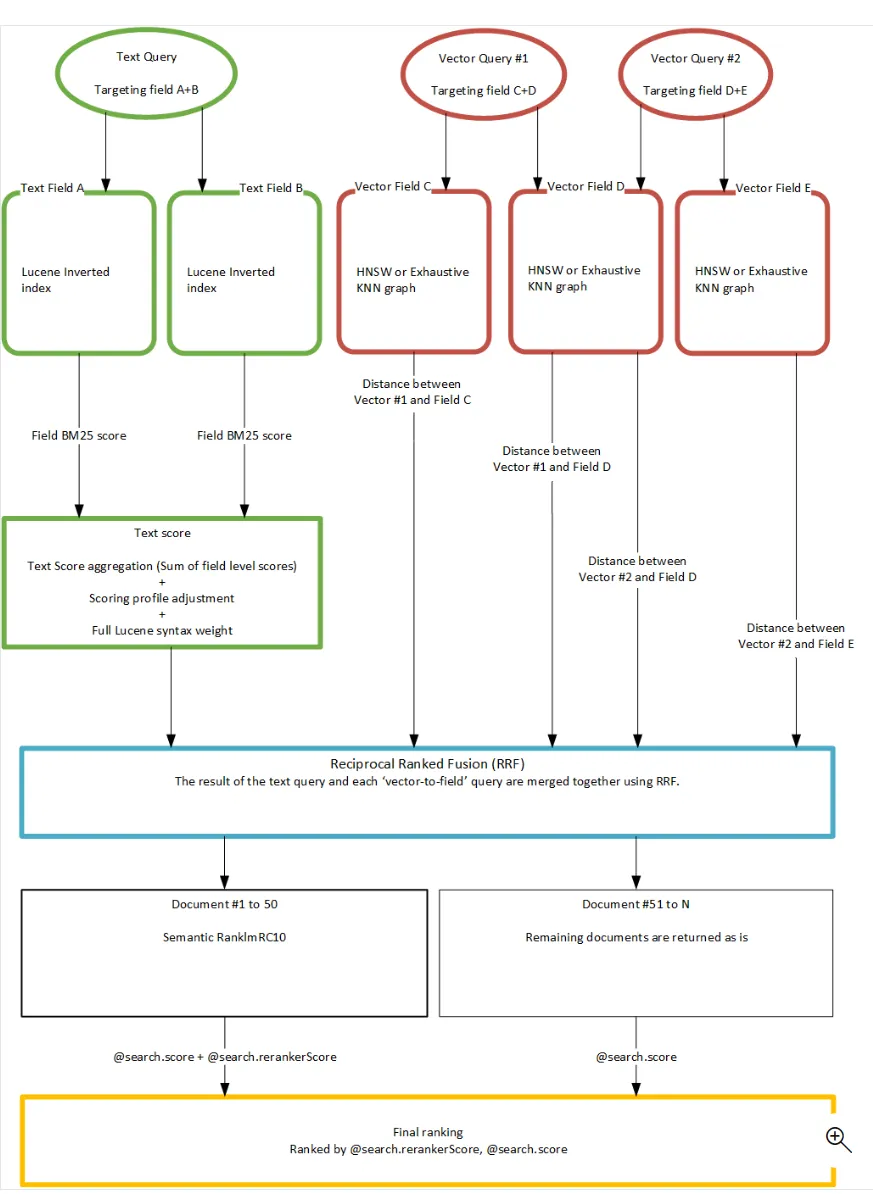
1.2 Оценка информационной энтропии
Помимо использования рейтингов для нормализации качества контента, вспоминаемого различными каналами, вы также можете использовать унифицированную модель оценки для измерения качества контента. Например, вы можете использовать Bert. Cross-Encoder BGE-RerankerОценка и сортировка всех документов кандидатов,Перекрестная модель является более точной, чем модель внедрения, и позволяет дополнительно фильтровать вызываемый контент.
Здесь я хочу поговорить о другом аспекте оценки качества контента, помимо релевантности. - Information-Entropy。Information-EntropyОн оценивает и проверяет достоверность и качество контента с точки зрения энтропии текстовой информации.,Существует несколько различных способов измерения информационной энтропии:
1.2.1 Selective-Context
Unlocking Context Constraints of LLMs: Enhancing Context Efficiency of LLMs with Self-Information-Based Content Filtering
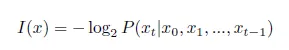
Selective-Contextиспользоватьинформация о себеОцените качество контента。Последний раз, когда я встретилинформация о себе, все еще работаю над новым алгоритмом интеллектуального анализа слов. То же самое справедливо и в отношении проверки качества контента. Чем ниже значение энтропии (тем ниже неопределенность), информация. о себе НижнийtokenКоличество информации, вносимой в языковую модель, меньше.,Например стоп-слова,Синонимы и т. д.。Таким образом, информация о себе, нижний контент сам по себе стоит меньше.。ноинформация о Расчет себе ведется на уровне детализации токена,хочу соединить фразы,предложение,Подсчет абзацев можно аппроксимировать суммированием токенов.,То естьПредположим, что токены независимы друг от друга。但是越大Гранулированный信息合并,Простая сумма информации о себе Чем больше ошибка, потому что токен не является по-настоящему независимым. Так что просто используйте информацию о содержании о себе的计算方式更适合短语Гранулированный上文Сжатие контента,Кажется, не совсем подходит для оценки содержания отрывков, вспоминаемых RAG.,Но не волнуйтесь и оглянитесь назад~
Ниже приводится эффект выборочного сжатия контекста посредством самоинформации. Что касается амплитуды сжатия и влияния на рассуждения модели после сжатия, мы сравним их в конце.

1.2.2 LLMLingua
LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models
LLMLingua также использует значение энтропии токена для оценки качества контента, но еще больше ослабляет предположение о независимости токенов. Формула расчета следующая: Сначала разделите весь контекст на сегменты. В документе используется 100 токенов как один сегмент. Следующее $S_{j,i}$ — это i-е слово в j-м абзаце, а $\tilde{S}_j$ — это сжатое содержимое всех абзацев перед j-м абзацем. То есть при вычислении значения энтропии каждого слова в текущем абзаце ранее сжатый контент будет склеен спереди, что сделает оценку значения энтропии абзацев с большей детализацией более точной.
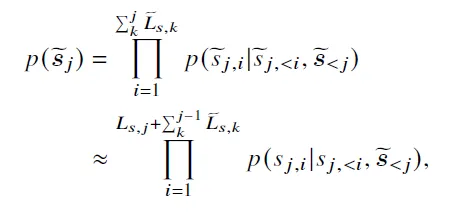
1.2.3 LongLLMLingua
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression
LongLLMLingua дополнительно оптимизирует информационную энтропию, полностью основанную на контенте, в условную энтропию для ответов на вопросы, основанные на контенте, которая более идеально адаптируется к требованиям модуля сортировки в структуре RAG для общей оценки отозванного контента.
Вышеупомянутые LLMLinugua и Selective-Context просто вычисляют значение энтропии вышеуказанного контента, но весьма вероятно, что, хотя контент с высоким значением энтропии содержит много информации, он не имеет никакого отношения к проблеме и является просто чистым информационным шумом. . Таким образом, LongLLMLingua вводит проблемы в расчете энтропии, которые представляют собой не что иное, как две схемы расчета: либо для расчета значения энтропии контента с учетом проблемы, либо для расчета значения энтропии проблемы с учетом контента. В статье считается, что контент может представлять собой смесь эффективной информации и шумовой информации, поэтому выбирается последняя. То есть, учитывая каждую часть содержимого воспоминания, рассчитывается значение энтропии вопроса.
Здесь в документе также добавлена инструкция перед вопросом: «$X^{restrict}=$мы можем получить ответ на этот вопрос в данных документах», чтобы оптимизировать расчет условной энтропии за счет повышения релевантности контента для вопрос.
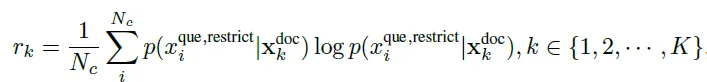
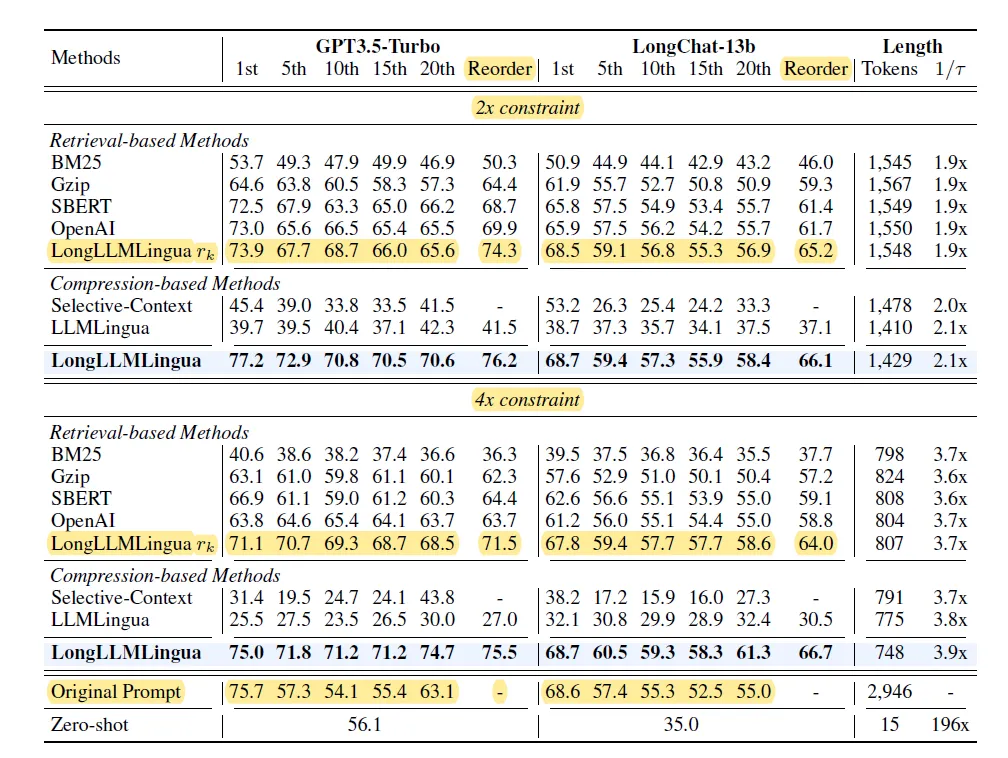
В статье сравниваются различные схемы оценки и сортировки, включая BM25, различные векторные вложения и LLMLingua. Среди них LongLLMLinuga значительно лучше по скорости отзыва документов TopK, как показано на рисунке ниже. Конкретная степень сжатия и сравнение эффектов вывода будут обсуждаться вместе с модулем перестановки позже.

LongLLMLingua выходит за рамки приведенных выше абзацев.,Он также добавляет сжатие контента на уровне токена внутри абзацев. То есть сначала отфильтруйте абзацы TopN,Затем отфильтруйте внутри абзаца, чтобы быть эффективным.Token。но看论文效果感觉段落排序的重要性>>Сжатие контента,Я не буду вдаваться в подробности этой части.,Если вам интересно, пожалуйста, прочтите статью~
2. Переставить модули
против Сортировочный Кандидаты Топ К, отобранные по модулю, переставить модуль необходимо дополнительно систематизировать и объединить по содержанию,Максимизируйте общий эффект рассуждения модели.。и Сортировочный модуль Самым большим отличием является его целостность.,Больше никакой независимой оценки для каждого документа,Вместо этого оптимизируйте весьContextЭффект от вышеперечисленного。В основном существуют два направления оптимизации::Один из них — это оптимизация местоположения документов, а другой — оптимизация корреляции между документами.
2.1 Местоположение документа
LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression Lost in the Middle: How Language Models Use Long Contexts https://api.python.langchain.com/en/latest/document_transformers/langchain.document_transformers.long_context_reorder.LongContextReorder.html#
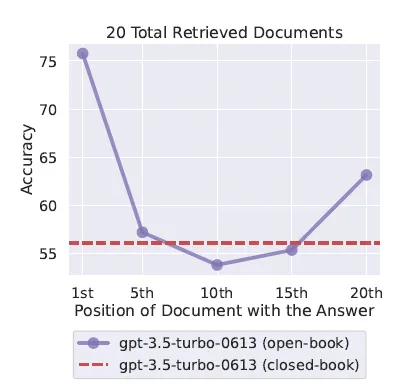
Оптимизация местоположения документа — «Потерянные посередине» (на фото выше), с которой, я думаю, каждый может быть знаком. Проще говоря, когда большие модели используют приведенные выше рассуждения, они склонны использовать первый и последний контент, игнорируя при этом средний контент. Таким образом, в зависимости от качества контента важный контент может быть размещен перед контекстом и позади него.
LongLLMLingua также предприняла аналогичную попытку и посчитала, что передняя позиция более важна, чем задняя, поэтому она напрямую использовала указанный выше модуль сортировки для оценки абзацев, переупорядочила содержимое-кандидат, оставшееся после сортировки, и упорядочила от высокого к меньшему в соответствии с переставить счет.
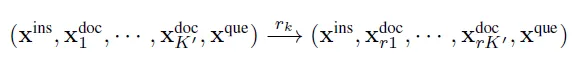
Наконец, давайте посмотрим на эффекты. В статье LongLLMLingua сравнивается влияние различных схем сортировки по сходству на сохранение документов TopN и использование этой схемы сортировки для дальнейшей реорганизации контента. Эффект LongLLMLingua, очевидно, является лучшим при степени сжатия в 2 и 4 раза. Однако можно обнаружить, что эффект от использования только LongLLMLingua для сортировки (методы базы поиска) и изменения порядка (столбец изменения порядка) на самом деле неплох. . , а сжатие токенов внутри абзаца — еще одна вишенка на торте.
2.2 Актуальность документа
https://python.langchain.com/docs/integrations/retrievers/merger_retriever MetaInsight: Automatic Discovery of Structured Knowledge for Exploratory Data Analysis
Логика вышеуказанной сортировки и перестановки учитывает корреляцию между вопросами и вспоминаемым содержанием, но не вводит корреляцию между различным вспоминаемым содержанием в контексте.
LOTR (Merger Retriever) компании Langchain реализует некоторые аналогичные функции, в том числе использование встраивания для дедупликации контента многоканальных вызовов, кластеризацию контента и выбор части контента, ближайшей к центру, в каждом кластере. Этот шаг можно выполнить во время сортировки или в модуле перестановки после сортировки.
ДоРасшифровка подсказки Серия 19. Применение LLM Agent в области анализа данныхMicrosoft упоминается в главеMetaInsightАналогичная логика распада также представлена.。в
- Общая ценность контента = сумма ценности каждого фрагмента контента – значение перекрытия между контентом.
- Значение перекрытия двух частей контента = минимальная оценка двух частей контента * степень перекрытия контента.
Если вы поместите это в структуру RAG, вы сможете использовать указанную выше информационную энтропию в качестве оценки, а сходство — в качестве степени совпадения.
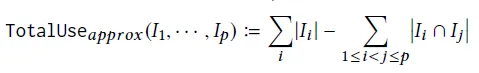
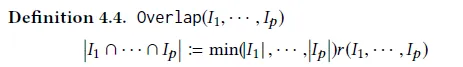
Мы также пробуем эту область, поэтому окончательных результатов нет. Любой, кто пробовал этот эффект, может ответить в области комментариев.
- Согласованность информации: не лучше ли расположить несколько отзывов с похожим содержанием подряд, а не разбрасывать их по контексту?
- Разнообразие информации. Кластеризация отозванного контента, дедупликация нескольких отозваний с похожим контентом или использование только самого последнего контента или контента TopN из центра кластера в каждом кластере улучшит эффект вывода?
- Последовательность информации: какое влияние оказывают многочисленные воспоминания о противоречивых точках зрения или содержании на рассуждения?
Если вы хотите увидеть более полный обзор статей, связанных с большими моделями, данными и платформами точной настройки и предварительного обучения, а также приложениями AIGC, перейдите на Github. >> DecryPrompt
Reference
- Рекомендуемая система [4]: Тонкое ранжирование - подробный алгоритм ранжирования LTR (Learning to Rank)_ поточечные, попарные, списочные индикаторы оценки, сверхподробное руководство по знаниям.
- Практика мультибизнес-моделирования в поисковом рейтинге Meituan
- Каковы сходства и различия в идеях моделирования между изменением порядка поиска и изменением порядка списка рекомендаций?
- Практика Трансформера в поисковом рейтинге Meituan
- Как обычно создается приблизительная модель в отрасли (рекомендация по поиску)?
- Эволюция модели поискового ранжирования Zhihu



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
