Расшифровка подсказки. Серия 20. Агент LLM снова обсуждает оптимизацию разнообразия отзыва RAG.
Мы говорили несколько месяцев назадRAGклассическая схемаРасшифровка подсказок. Серия 14. Дизайн поискового приложения LLM Agent。Буквально на днях закончил смотретьopenAIсуществоватьDevDayПредставлено на закрытом заседанииRAGСоответствующий опыт,Некоторые новые идеи,Воспользуйтесь этой возможностью, чтобы разобраться во всем еще разRAGСопутствующие решения по оптимизации。Рекомендуется смотреть оригинальное видео напрямую.(Нужно посещать зарубежные сайты)A Survey of Techniques for Maximizing LLM Performance
На самом деле наиболее важной частью RAG является не LLM, а запоминание связанного контента. Как указано выше для рассуждений о большой модели, отличное запоминание контента должно соответствовать следующим условиям:
- разнообразие и запоминаемость:Отозванный контент должен отвечать на вопрос,И содержательное богатство,Включите несколько точек зрения на одну и ту же проблему,несколько углов
- Актуальность и точность:Содержание отзыва связано с проблемой,Вы не можете вспомнить только 2 из 100 статей, посвященных проблеме.
- Последовательность и низкий уровень конфликтов:Согласованность мнений среди вспоминаемого контента высокая.
- Более высокие требования: высокий период времени, власть, целостность взгляда, повторение контента.
Здесь мы могли бы также поучиться на предыдущем опыте,ссылкаОсновная структура поиска: понимание и расширение запросов -> Многократный отзыв -> сортировка слиянием -> Переставить и разбить。последние несколько месяцевRAGВ статье также, похоже, сочетаются традиционные поисковые решения.,использоватьLLMОбновление парадигмы происходило по очереди。В этой главе мы сначала сосредоточимся наРазнообразие содержания воспоминанийВсего несколько слов。
Непосредственное использование пользовательского запроса для векторного поиска часто приводит к невысокой скорости отзыва по следующим причинам:
- Запрос короткий, а сама информация ограничена.
- Эффект встраивания короткого текста плохой
- Существуют различия в пространственном представлении между вектором короткого текста запроса и вектором длинного текста документа.
- Пользователи не совсем понимают, о чем они хотят спросить
- Для ответа на запрос пользователя может потребоваться агрегирование информации из нескольких направлений.
Вышеупомянутые проблемы на самом деле касаются двух моментов: разнообразия информации, содержащейся в самом Query, и разнообразия поисковых индексов. Ниже мы представим их соответственно на основе новых и старых статей, а также некоторых новых функций langchain~
1. Разнообразие запросов
2019 Query Expansion Techniques for Information Retrieval: a Survey
Расширение традиционного поискового запроса,Существуют похожие запросы, основанные на анализе журнала поиска пользователей.,Существуют похожие запросы, основанные на одной и той же ассоциации документов отзыва.,Еще есть Queryпереписать на базе SMT план。Это лучше соответствует эпохе больших моделей.из Конечнопереписать план,Поддержка LLM значительно снижает сложность переписывания запроса.,Это также предоставляет больше возможностей для перезаписи.
1.1 Подобное семантическое переписывание
Learning to Rewrite Запросы, Yahoo (2016) webcpm: Interactive Web Search for Chinese Long-form Question Отвечаю, Цинхуа (2023)
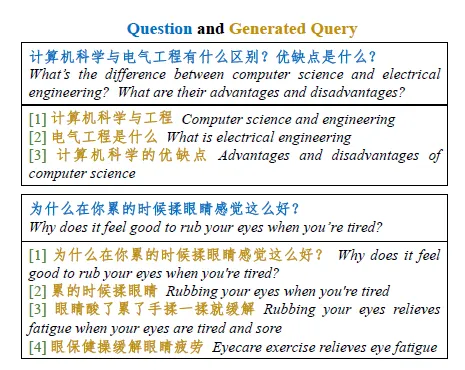
Еще в 2016 году Yahoo исследовала возможность переписывания запросов.,В то время это еще былseq2seqизLSTM。Затем следует вступление.изwebcpmСуществует такжеиспользоватьбольшая модельqueryПерепишите, чтобы улучшить запоминаемость контента。НедавноlangchainТакже интегрированMultiQueryRetrieverиз Похожие функции。Логика заключается в том, чтобы поместить пользователяизQueryПереписано на несколько семантически схожихизQuery,Используйте несколько запросов вместе для отзыва,следующее
1.2 Двунаправленная перезапись
Query2doc: Query Expansion with Large Language Модели, Microsoft (2023) Query Expansion by Prompting Large Language Models, Гугл (2023 г.)
Кроме того, существует альтернативное решение по переписыванию запроса, которое заключается в переписывании запроса в документ, как указано в Query2doc. В документе используется подсказка из 4 шагов, позволяющая LLM сначала сгенерировать псевдодокумент на основе запроса, а затем использовать сгенерированный ответ для вызова соответствующего контента. Эта адаптация имеет некоторые существенные преимущества.
- Устранить проблему плохого эффекта векторизации короткого текстового запроса.
- Устранение проблемы пространственных различий между векторами длинного текста документа и векторами короткого текста запроса.
- Улучшите эффект извлечения дискретных индексов, таких как BM25. В конце концов, эффективные ключевые слова легче извлечь, если текст длиннее.
Конечно, недостатки также существенны. Один из них заключается в том, что в псевдодокументах может возникнуть семантический дрейф. В ответах-галлюцинациях будут вводиться неправильные ключевые слова, что снизит точность запоминания, и декодирование займет много времени ~

Здесь Query2Doc написан наоборот,Doc2Query — еще одно направление оптимизации.,Он заключается в создании N связанных запросов (псевдозапросов) для каждого документа.,Используйте вектор внедрения связанного запроса для представления документа.,и настоящийQueryВыполните расчеты сходства。langchainизMultiVector RetrieverТакже интегрированпохожийиз Функция。
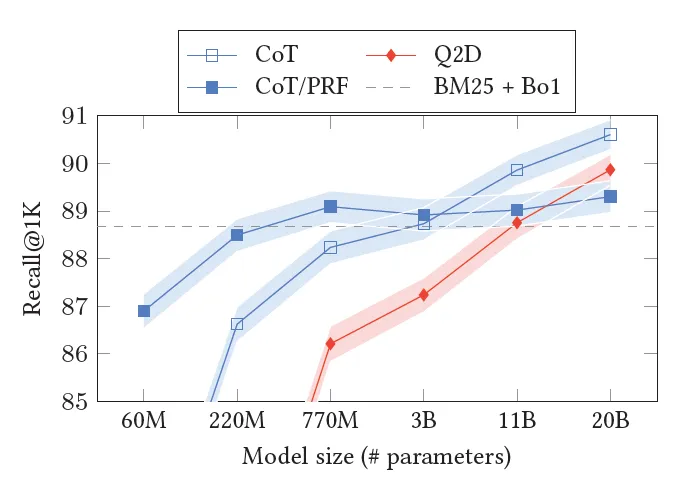
Google также предпринял аналогичную попытку. Мы сравнили несколько схем перезаписи Query2Doc (Q2D), Query2Keyword (Q2E) и Query2COT, а также эффекты использования различных инструкций подсказок, таких как «нулевой», «несколько шагов» и улучшение документа отзыва. Среди них Query2Doc использует ту же инструкцию приглашения, что и Microsoft, описанную выше. Другие инструкции следующие.

Результаты показывают, что когда размер модели достаточно велик, Query2COT показывает значительно лучшие результаты. Даже за пределами схемы COT/PRF, которая включает соответствующую документацию выше. С одной стороны, COT выполнит многоэтапный демонтаж Query. С другой стороны, процесс мышления будет генерировать более эффективные ключевые слова, и отказ от использования связанных документов может более эффективно раскрыть способность воспоминания и креативность самой модели.
1.3 Адаптация обучения с подкреплением
ASK THE RIGHT QUESTIONS: ACTIVE QUESTION REFORMULATION WITH REINFORCEMENT ОБУЧЕНИЕ, Google (2018) Query Rewriting for Retrieval-Augmented Large Language Модели, Microsoft (2023)
Вышеупомянутый план переписывания был упомянут на закрытой встрече Openai. Он действительно может в определенной степени улучшить эффект RAG и может быть использован для первоначальных попыток. Однако этот вид переписывания является неконтролируемым, то есть он переписывается на основе аналогичной семантики, и нет никакой гарантии, что эффект поиска переписанного запроса будет лучше. Тогда мы могли бы также поставить цель целенаправленно оптимизировать эффект перезаписи.
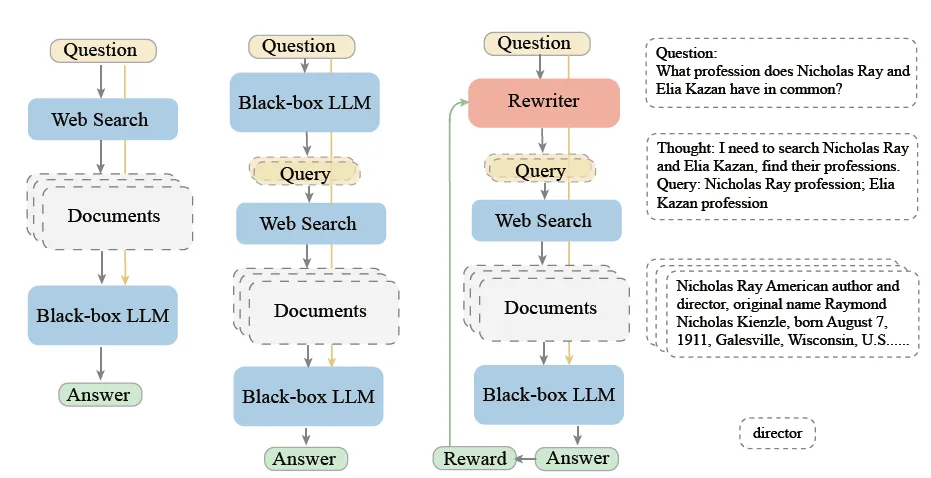
В 2018 году Google попыталась использовать обучение с подкреплением для оптимизации модели переписывания, рассматривая поисковую систему как среду, а модель seq2seq сгенерировала несколько кандидатов на перезапись запросов в качестве действий. Содержимое отзыва исходного запроса и содержимое отзыва переписанного запроса отправляются в последующий модуль сортировки. Скорость возврата содержимого переписанного запроса в содержимом TopK модуля сортировки используется в качестве оценки вознаграждения для постепенного обновления. модель перезаписи. Максимальное преобразование скорости отзыва перезаписи. В конце концов, каким бы необычным ни было ваше переписывание, оно может эффективно улучшить запоминаемость контента. Более высокий уровень запоминаемости эксклюзивного контента — действительно полезная модель переписывания.
В эпоху больших моделей модуль переписывания был обновлен до LLM. В рамках перезаписывания переписывания, предложенная Microsoft, используя большие модели в качестве переписывания, Bing Search в качестве ретривера, Chatgpt в качестве читателя, попробуйте использовать PPO, чтобы точно настроить модель переписывания в задаче QA. и реальные ответы. Тем не менее, в реальной сцене этот вид стандартного ответа QA Q & A на самом деле очень маленький, и более открытый Q & A. Таким образом, на самом деле, традиционная схема вышеуказанной компиляции может использоваться для использования эталонной скорости рассуждений крупной модели в качестве целевого рисунка. В конце концов, какой из входов больших моделей разумный, принцип аналогичен принципам ** сущности **.
2. Расширение индекса
После разговора о расширении запросов давайте посмотрим на расширение индекса. В настоящее время большинство индексов отзыва RAG по-прежнему основаны на одной векторной модели внедрения, но один вектор в качестве индекса отзыва имеет следующие общие проблемы:
- Существуют различные типы сходства текста: семантическое сходство, сходство грамматической структуры, сходство ключевых слов сущности и неотличимость по одному измерению.
- Сходство текста имеет разную степень детализации: в некоторых сценариях требуется вспомнить точное совпадение содержимого, в то время как в других требуется нечеткое сопоставление, а большинство векторных моделей имеют ограниченную распознаваемость.
- Подобные определения различаются в разных областях: В области утилизации существует проблема низкой пригодности векторной модели.
- Подобные проблемы между длинным и коротким текстом: длинный и короткий текстовый вектор может быть не в векторном пространстве
Давайте посмотрим, какие еще типы индексов можно использовать в качестве дополнения к одному вектору.
2.1 Расширение дискретного индекса
Query Expansion by Prompting Large Language Models, Гугл (2023 г.) ChatLaw: Open-Source Legal Large Language Model with Integrated External Knowledge Bases
В традиционном поиске часто используется большое количество дискретных индексов, и они часто оказывают хорошее дополнение к векторному вызову при вызове контента во многих вертикальных полях. Точность восстановления некоторых дискретных индексов, таких как объекты, может быть значительно выше, чем векторных. отзывать. Некоторые общие представления Query о создании дискретных индексов включают:
- Извлечение: сегментация слов, распознавание нграмм новых слов, распознавание частей речи, извлечение объектов, извлечение ключевых слов и т. д.
- Классификация: классификация намерений, классификация тем, классификация концепций, классификация местоположения и т. д.
- Многошаговый режим: связывание сущностей, расширение синонимов, запрос KG и т. д.
Первое, что приходит на ум, — это использование больших моделей для улучшения парадигм.,Все единодушно сосредоточили свое внимание насуществовать Понятнорасширение ключевого слова。
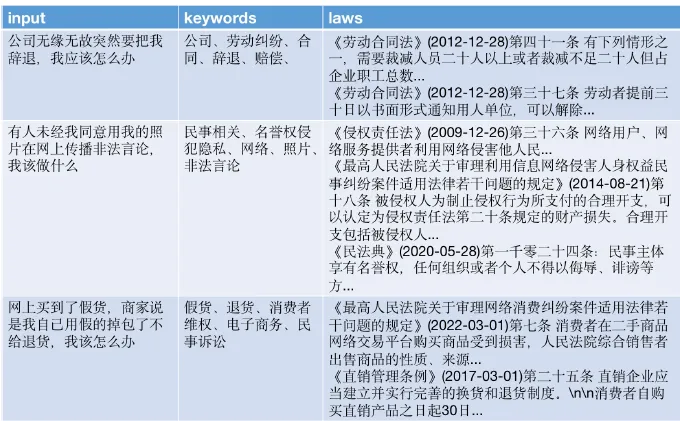
Хотя эффект query2Keyword, опробованный в статье Google выше, не превзошел query2Doc и Query2COT. Но сама генерация ключевых слов не требует больших усилий и требует много времени.,И на самом деле он дает очень хорошие результаты в некоторых вертикальных областях. Например, ChatLaw — крупная модель в юридической сфере.,Просто используй этоLLM выполняет ассоциацию ключевых слов правовых положений。бумагаиспользоватьLLMОриентирован на пользователейQueryСоздайте ключевые слова, связанные с юридическими вопросами,ииспользоватьключевые словаизEnsemble Встраивание для напоминания соответствующих юридических терминов. Конечно, вы также можете использовать ключевые слова для прямого вызова. Этот дизайн на самом деле разработан для юридической сферы, где ключевые слова домена часто имеют значительно лучший эффект запоминаемости.
2.2 Постоянное расширение индекса
https://github.com/FlagOpen/FlagEmbedding https://github.com/shibing624/text2vec https://github.com/Embedding/Chinese-Word-Vectors AUGMENTED EMBEDDINGS FOR CUSTOM RETRIEVALS, Майкрософт 2023
При расширении векторных индексов первое, что приходит на ум, — это одновременное использование нескольких различных непрерывных векторных индексов, в том числе
- Наивный режим: различные модели внедрения, наиболее распространенными из которых являются серии Ada от OpenAI, BGE от Zhiyuan и Text2vec, используют многоканальные модели внедрения для одновременного вызова или используют решения взвешенного отзыва, чтобы учиться на сильных сторонах друг друга.
- Простой режим: используйте ключевые слова, извлеченные выше, и взвешивание вектора слов для запоминания. По сравнению с векторами текста, векторы слов, как правило, имеют более высокую скорость запоминания и дают хорошие результаты в некоторых вертикальных полях. Конечно, обратное состоит в том, что точность векторов слов может быть низкой, но этап вспоминания по своей сути заключается в забрасывании широкой сети, чтобы поймать больше рыбы.
- Сложный режим: Встраивание обучающего поля. Стоимость самая высокая, и ее можно будет опробовать в конце. Дело, упомянутое на openai devday, заключается в том, что модель предметной области имеет ограниченные улучшения по сравнению с общей моделью, а стоимость высока.
Однако недавно Microsoft предложила более легкое решение, чем модель внедрения, в области тонкой настройки. Она аналогична идее тонкой настройки Лора. Мы не перемещаем базовую модель, а настраиваем ее. адаптер на нем, чтобы оптимизировать эффект сопоставления запроса и документа.
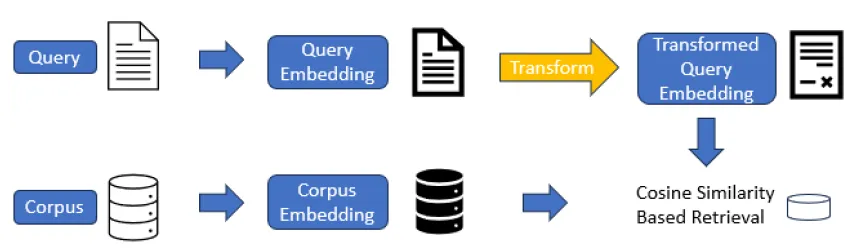
Для адаптера изменения вектора в статье используется сложение векторов, которое заключается в добавлении остатка на основе выходных данных D-мерного встраивания исходной модели. Расчет остатка представляет собой ключ-значение. Функция поиска содержит две переменные K и v одинаковой формы. Например, векторный вывод для openai — D = 1536 размеров,residualвыберуh<<Dтрансформировать,Значение h находится между 16 и 128.,Тогда K и V — h*D-мерные матрицы соответственно.,То есть адаптерной части нужны только параметры обновления градиента порядка 2hD.,следующее
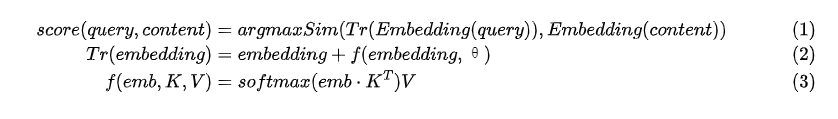
Функция точной настройки потерь использует Globa контрастного обучения. lNegative Loss,То есть каждый (запрос,содержание) пара — положительный образец,Все содержимое остальных образцов является отрицательными образцами.,Целями обучения являютсяqueryКазумаса Тономотоиз Сходство>和其余所有负样本Сходствоизмаксимальное значение。Кажется, он очень легкийизплан,Если будет возможность, попробую~
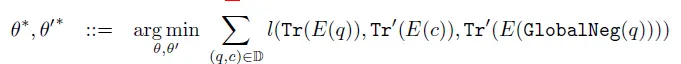
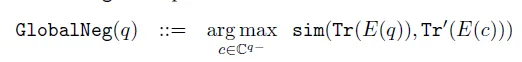
2.3 Отзыв гибридного индекса
https://learn.microsoft.com/en-us/azure/search/hybrid-search-ranking
Смешайте вызов дискретного индекса, например BM25, и непрерывный вызов индекса, например векторы внедрения, для гибридного вызова.,langchainизEnsemble RetrieverЭта функция интегрирована。Однако смешанный отзыв является крупнейшимиз Проблема в разных отзывахиз Рейтинг сложно отсортировать。Поэтому, когда содержимое многоканального смешанного отзыва велико,,Необходимо ввести модуль сортировки для дальнейшей фильтрации контента.,Мы поговорим об этом позже~
reference
- Применение понимания запроса и семантического отзыва в поиске Zhihu
- Понимание и запоминание поиска Meituan
- Приложение для понимания запросов в поиске Meituan
- Поиск электронной коммерции QP: запрос переписан
- Технология расширения запросов в поиске Dingxiangyuan
- Исследование и практика технологии переписывания запросов в Meituan Search
Я участвую в третьем этапе специального тренировочного лагеря Tencent Technology Creation 2023 с эссе, получившими приз, и сформирую команду, которая разделит приз!



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
