Распределенное хранилище и распределенные вычисления так легко понять!

Что такое распределенное хранилище и распределенные вычисления?
Эта статья объяснит вам это подробно~~
Оказывается, их так легко понять!
01
Распределенное хранилище больших данных
Файловая система Google GFS — это типичная распределенная файловая система и конкретная реализация распределенного хранилища. Сетевой диск, используемый в повседневной работе и жизни, также представляет собой типичную распределенную файловую систему.
На рисунке ниже показана базовая архитектура GFS.

Хранение данных в распределенной файловой системе требует решения двух проблем — как хранить огромные объемы данных и как обеспечить безопасность данных. Если эти две проблемы технически решены, можно реализовать распределенную файловую систему для хранения больших данных и обеспечения безопасности данных.
Решением является использование распределенного кластера, который использует несколько узлов для формирования распределенной среды.
Подробности реализации обсуждаются ниже, чтобы представить базовую архитектуру и принципы реализации распределенной файловой системы HDFS Hadoop.
1. Как хранить огромные объемы данных
Поскольку необходимо хранить огромные объемы больших данных, традиционный автономный режим хранения не может использоваться.
Решение также очень простое. Поскольку один узел или один сервер не могут хранить данные, используйте несколько узлов или несколько серверов для совместного хранения, то есть распределенного хранилища, а затем разработайте распределенную файловую систему для обеспечения распределенного хранения данных.
Основная логика распределенной файловой системы для хранения данных показана на рисунке ниже.
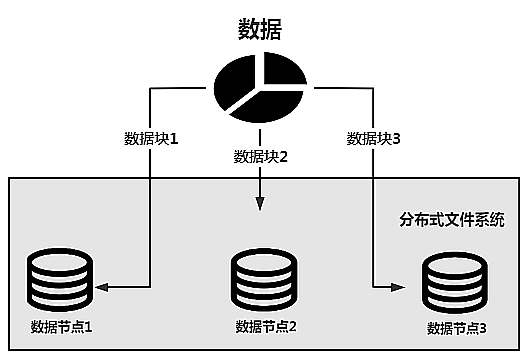
Данные будут разделены и храниться на разных узлах данных, чтобы обеспечить хранение больших объемов данных. Если предположить, что размер данных составляет 20 ГБ, а пространство для хранения каждого узла данных составляет всего 8 ГБ, данные не могут храниться на одном узле.
Но теперь таких узлов 3. Если предположить, что объем памяти каждого узла по-прежнему составляет 8 ГБ, то общий размер составит 24 ГБ. Данные объемом 20 ГБ могут храниться в распределенной файловой системе, состоящей из этих трех узлов.
Если эти три узла данных заполнены, вы можете добавить в файловую систему новые узлы данных, например узел данных 4, узел данных 5..., чтобы добиться горизонтального расширения узлов данных.
Теоретически такое расширение может быть расширено до бесконечности, что позволит хранить огромные объемы данных. Если архитектура на приведенном выше рисунке сопоставлена с распределенной файловой системой Hadoop HDFS, узлом данных является DataNode.
Здесь есть еще одна проблема — когда данные хранятся в распределенной файловой системе, они хранятся в блоках данных. Например, начиная с версии Hadoop 2.x, размер блока данных HDFS по умолчанию составляет 128 МБ.
намекать:
Блок данных представляет собой логическую единицу, а не физическую единицу. То есть 128 МБ блока данных не соответствуют фактическому физическому размеру данных.
Вот простой пример.
Предположим, что объем данных, подлежащих хранению, составляет 300 МБ, а для отдельного хранения используются блоки данных по 128 МБ. Данные будут разделены на 3 блока. Размер первых двух блоков составляет 128 МБ, что соответствует размеру блока данных HDFS по умолчанию, тогда как фактический размер третьего блока составляет 44 МБ, то есть занимаемое физическое пространство составляет 44 МБ. Однако логическое пространство, занимаемое третьим устройством, по-прежнему равно размеру блока данных. Если оно находится в HDFS, оно по-прежнему равно 128 МБ. Другими словами, третий блок данных не заполнен.
2. Как обеспечить безопасность данных
Данные хранятся на узлах данных в виде блоков данных. Если узел данных имеет проблему или не работает, блоки данных, хранящиеся на этом узле, не могут быть доступны нормально. Как обеспечить безопасность блоков данных?
GFS Google использует идею избыточности для решения этой проблемы. Проще говоря, избыточность блока данных заключается в хранении нескольких копий одного и того же блока данных и их хранении на разных узлах данных, чтобы даже в случае возникновения проблемы на узле данных блок данных можно было получить из других узлов, как показано. ниже.
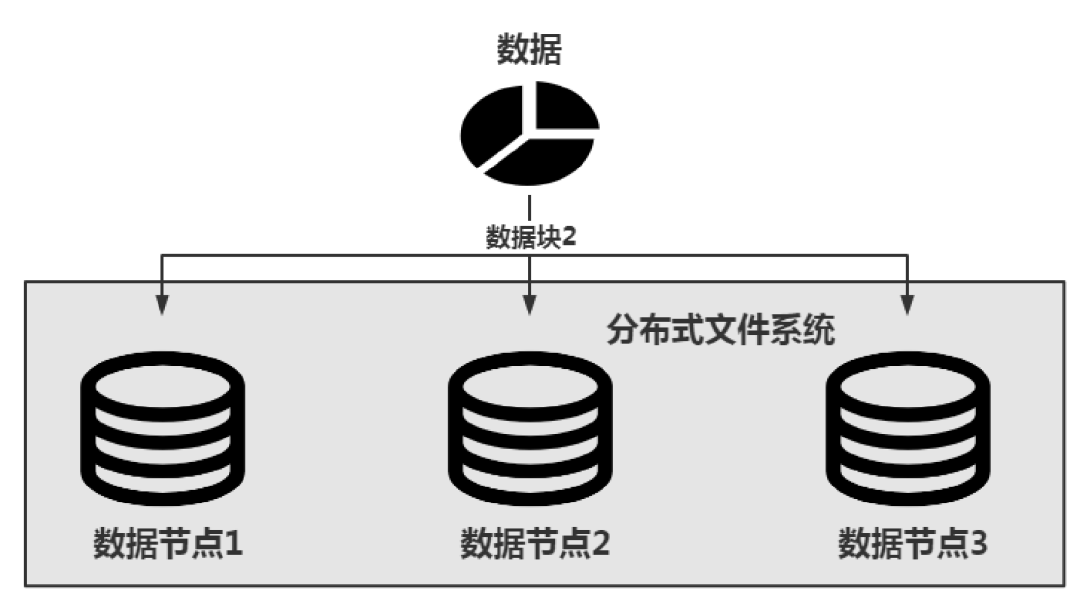
На приведенном выше рисунке блок данных 2 хранится на 3 узлах данных одновременно, то есть избыточность равна 3, так что информацию блока данных можно получить из любого узла данных.
намекать:
Внедрение идеи избыточности данных решает проблему безопасности данных в распределенных файловых системах, но приведет к бесполезной трате места хранения.
В архитектуре HDFS помимо упомянутого ранее узла данных DataNode существуют NameNode и SecondaryNameNode.
HDFS — это архитектура «главный-подчиненный», главный узел — NameNode, а подчиненный узел — DataNode. Базовая архитектура HDFS показана на рисунке ниже.

02
Распределенные вычисления для больших данных
Большие данные могут храниться с использованием распределенной файловой системы, так как же решить проблему вычислений больших данных?
Подобно идее хранения больших данных, из-за огромного объема данных невозможно использовать автономную среду для выполнения вычислительных задач.
Поскольку одна машинная среда не может выполнять вычислительные задачи,Просто используйте несколько серверов для совместного выполнения вычислительных задач.,образуя таким образомраспределенные расчет кластера для завершения большого данныевычислительные задачи。Основываясь на этой идее, Google предложила вычислительную модель MapReduce.
намекать:
MapReduce, предложенная Google, представляет собой вычислительную модель обработки больших данных и не имеет ничего общего с конкретными языками программирования.
Вычислительная модель MapReduce реализована в системе Hadoop. Hadoop — это платформа, реализованная на языке Java, поэтому программа MapReduce, разработанная на Hadoop, также является программой Java.
Как мы все знаем, MongoDB также поддерживает вычислительную модель MapReduce, а языком программирования в MongoDB является JavaScript, поэтому разработка программ MapReduce в MongoDB требует использования языка JavaScript.
Почему Google предложил вычислительную модель MapReduce? Его основная цель — решить проблему PageRank, то есть проблему ранжирования веб-страниц. Поэтому, прежде чем внедрять вычислительную модель MapReduce, необходимо ввести PageRank. Как поисковая система Google обладает мощными поисковыми возможностями.
Каждый результат поиска представляет собой веб-страницу HTML, а именно Page. Так как же определить порядок веб-страниц? Для этого необходимо присвоить каждой веб-странице оценку, то есть значение рейтинга. Чем больше значение рейтинга, тем выше соответствующая страница находится в результатах поиска. Простой пример PageRank показан ниже.
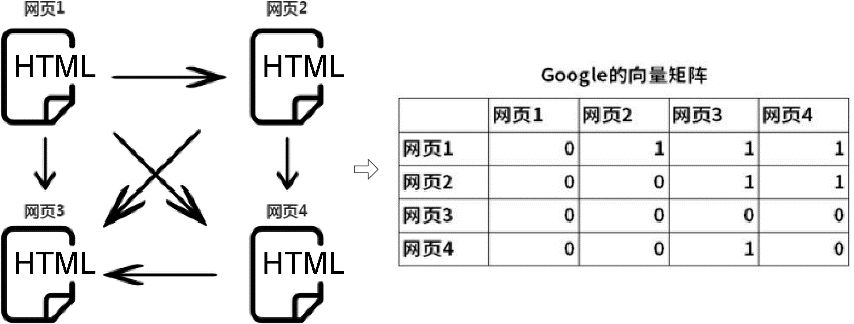
Этот пример начинается с4индивидуальныйHTMLвеб-страницы для отображения。Между веб-страницами вы можете передавать<a>пометить гиперссылку изиндивидуальный Веб-страница переходит на другуюиндивидуальныйвеб-страница。
Предположим, что ссылка веб-страницы 1 переходит на веб-страницу 2, веб-страницу 3 и веб-страницу 4; ссылка веб-страницы 2 переходит на веб-страницу 3, а ссылка веб-страницы 3 переходит на другие веб-страницы; .
Если 1 используется для указания того, что между веб-страницами существует связь перехода по ссылке, а 0 используется для обозначения отсутствия связи перехода по ссылке, а в строковых единицах может быть установлена векторная матрица Google для представления связи перехода между веб-страницами. страницы. Полученная здесь векторная матрица будет матрицей 4×4. Путем расчета этой матрицы можно получить значение веса каждой веб-страницы, и это значение веса является значением ранга, тем самым ранжируя результаты веб-поиска.
Но в реальных ситуациях полученная векторная матрица Google очень огромна. Например, веб-сканеры извлекли 100 миллионов веб-страниц с веб-сайтов по всему миру и сохранили их в распределенной файловой системе, при этом между веб-страницами происходит переход по ссылкам. Созданная в это время векторная матрица Google будет огромной матрицей размером 100 миллионов × 100 миллионов. Такую огромную матрицу невозможно рассчитать на одном компьютере. Как решить проблему расчета этой огромной матрицы, будет ключом к PageRank. В контексте подобных проблем Google предложила вычислительную модель MapReduce.
Основная идея MapReduce на самом деле — всего 6 слов, то есть сначала разделить, а потом объединить. Таким образом, вычисления могут выполняться независимо от того, насколько велика результирующая векторная матрица. Процесс разделения называется «Карта», а процесс слияния — «Сокращение». Основной процесс обработки данных MapReduce показан на рисунке ниже.
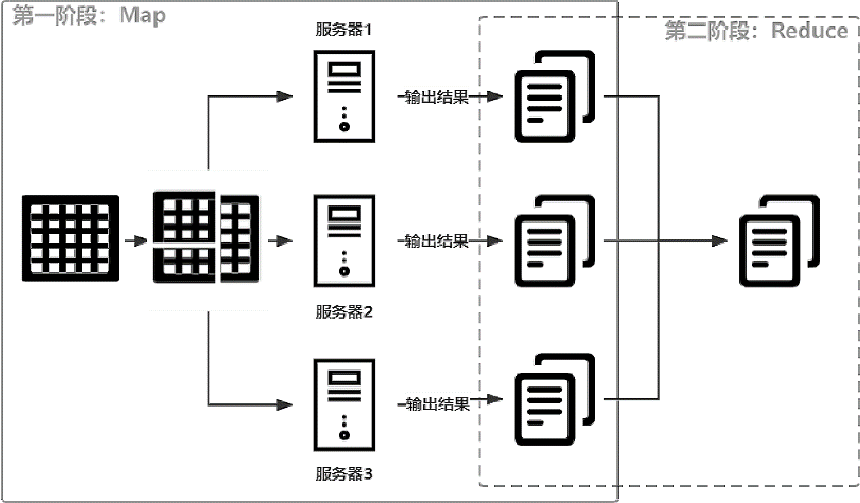
В приведенном выше примере предположим, что необходимо вычислить огромную матрицу. Поскольку ее невозможно выполнить на одном компьютере, матрица сначала разбивается на 4 небольшие матрицы. , просто дайте компьютеру завершить расчет.
- Каждый компьютер вычисляет одну из небольших матриц и получает частичные результаты. Этот процесс называется «Карта», как показано сплошной линией на рисунке выше.
- Выходной результат Map вычисляется дважды, чтобы получить результат большой матрицы. Этот процесс называется сокращением, как показано в пунктирном прямоугольнике на рисунке выше.
С помощью Map и уменьшить, независимо от того, насколько велика векторная матрица Google, можно вычислить окончательный результат. Этот метод расчета реализован в Hadoop с использованием языка Java, также эта идея позаимствована у Spark и Flink. Например, основной моделью данных в Spark является RDD, состоящая из разделов. Каждый раздел обрабатывается подчиненным узлом Spark Worker, тем самым реализуя распределенные вычисления.
Выходная информация журнала выполнения задач MapReduce в Hadoop показана на рисунке ниже.

Из выходного журнала видно, что задача MapReduce Hadoop разделена на два этапа, а именно этап Map и этап сокращения. После завершения выполнения карты выполняется сокращение, и данные, обработанные картой, будут использоваться в качестве входных данных для сокращения.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
