Распределенная файловая система: техническая архитектура JuiceFS.
1. Общая структура
Файловая система JuiceFS состоит из трех частей:
[Не удалось передать изображение по внешней ссылке. Исходный сайт может иметь механизм защиты от кражи. Рекомендуется сохранить изображение и загрузить его напрямую (img-90ZtG0tw-1687771442157) (https://juicefs.com/docs/zh/assets). /images/juicefs-arch -new-ab6339cb1408945cc9b70dc091c523c5.png)]
Клиент JuiceFS (Клиент):Чтение и запись всех файлов,Даже фоновые задачи, такие как объединение фрагментов и удаление файлов из корзины с истекшим сроком действия.,Все происходит на стороне клиента. Это вполне возможно,Клиенту необходимо иметь дело как с хранилищем объектов, так и с механизмами метаданных. Клиент поддерживает множество методов доступа:
- проходить FUSE,JuiceFS Файловая система может быть POSIX Массивное облачное хранилище, совместимое с методом подключения к серверу «Служить», можно использовать непосредственно в качестве локального хранилища.
- проходить Hadoop Java SDK,JuiceFS Файловую систему можно заменить напрямую HDFS, для Hadoop Обеспечить низкую стоимость и массовое количество.
- проходить Драйвер Kubernetes CSI,JuiceFS Файловая система может напрямую Kubernetes Предлагаю огромное количество хранилища.
- проходить Шлюз S3,делатьиспользовать S3 Поскольку уровень хранилища должен быть доступен напрямую, в то же время используйте AWS CLI、s3cmd、MinIO client Инструменты доступа JuiceFS Файловая система.
- проходить Служба WebDAV,к HTTP протокол, с чем-то вроде RESTful API выход из режима доступа JuiceFS И напрямую управлять файлами в нем.
Хранение данных (Данные Storage):Файл будет разделен, загружен и сохранен в объекте.хранилище Служить,Оба могут использовать общедоступное облако из хранилища объектов.,Также возможнок Доступ к частному развертываниюиз Самостоятельно построенный объектхранилище。JuiceFS Поддерживает практически все хранилища объектов публичного облака, а также поддерживает OpenStack Swift、Ceph、MinIO и другие хранилища частных объектов.
Механизм метаданных (Метаданные Engine):использовать Вхранилищеэлемент файладанные(metadata),Содержит следующий контент:
- Обычная файловая система: имя файла.、размер файла、Информация о разрешении、Создать время модификации、Структура каталогов、Свойства файла、символическая ссылка、Ожидание блокировки файла.
- JuiceFS Уникальные изданные: файл из chunk и slice Картирование отношений, клиент session ждать.
JuiceFS Принятие многомоторной конструкции, в настоящее время поддерживается Redis、TiKV、MySQL/MariaDB、PostgreSQL、SQLite и т. д. как данные элемента Служитьдвигатель,Более диверсифицированныйданныехранилищедвигатель。добро пожаловатьОтправить проблему Расскажите о своих потребностях.
2. Хранение файлов
В отличие от традиционных файловых систем, которые могут использовать только локальные диски для хранения данных и соответствующих метаданных, JuiceFS форматирует данные и сохраняет их в объектном хранилище (облачном хранилище), а метаданные файла — в специализированном сервисе метаданных. Такая архитектура делает JuiceFS высокопроизводительная распределенная файловая система с высокой согласованностью.
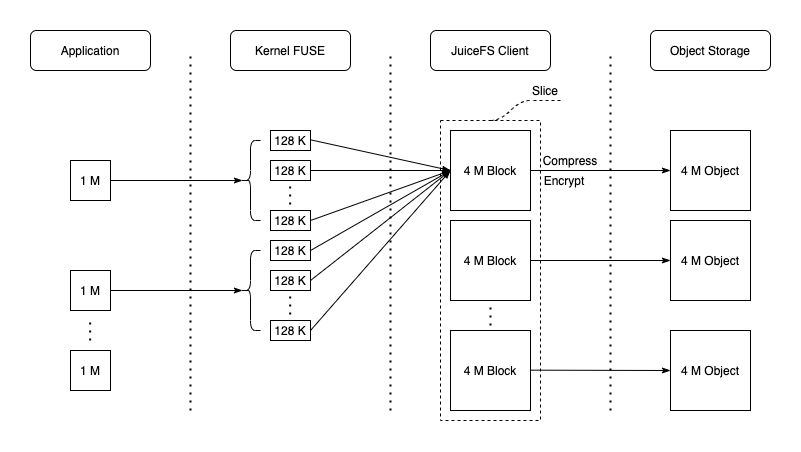
любой депозит JuiceFS из Файлы будут разделены на один или несколько**「Chunk」(максимум 64 Ми Б). И каждый Chunk один или несколько「Slice」композиция. Чанк существует для сегментации файлов и оптимизации производительности больших файлов, а также Slice Это дополнительная оптимизация различных операций записи файлов. Оба являются логическими концепциями файловой системы. Срез Длина не фиксирована и зависит от того, как записан файл. каждый Slice будет далее разделен на「Block」**(по умолчанию Максимальный размер 4 Ми Б), становясь самой маленькой единицей хранения, загружаемой в конечном итоге в объектное хранилище.
[Не удалось передать изображение по внешней ссылке. Исходный сайт может иметь механизм защиты от кражи. Рекомендуется сохранить изображение и загрузить его напрямую (img-U2UAt015-1687771442159) (https://juicefs.com/do). cs/zh/assets/images/juicefs-storage-format-new-fb61716d2baaf23335573504aa5f3bc7.png)]
Таким образом, вы обнаружите, что депозит не может быть найден в браузере файлов платформы хранения объектов. JuiceFS исходные файлы, в ведре только один chunks Каталог и куча пронумерованных каталогов и файлов, не паникуйте, именно это и происходит JuiceFS Разделение сохраненных блоков данных. В то же время документ и Chunks、Slices、Blocks Информация метаданных, такая как соответствующие отношения, хранится в механизме метаданных. Именно такая конструкция разделения позволяет JuiceFS Файловая система может работать с высокой производительностью.
[Не удалось передать изображение по внешней ссылке. Исходный сайт может иметь механизм защиты от кражи. Рекомендуется сохранить изображение и загрузить его напрямую (img-utFvu5De-1687771442161) (https://juicefs.com/doc). s/zh/assets/images/how-juicefs-stores-files-new-a5529b6935c59e4c6f36ac38dd1652f7.png)]
Конструкция хранилища JuiceFS также имеет следующие технические особенности:
- Для файлов любого размера JuiceFS не объединяет хранилище,Это также из соображений производительности,Избегайте усиления чтения.
- Обеспечьте надежную гарантию согласованности,Но его также можно настроить вместе с функцией кэша в соответствии с потребностями сцены.,Например, применяется более радикальное использование данныхкэша.,пожертвовать некоторой последовательностью,в обмен на лучшееизпроизводительность。Посмотреть подробности«Кэш метаданных»。
- Поддерживается и включено по умолчанию«Корзина для мусора»Функция,После удаления файла сохраните его некоторое время, прежде чем полностью очистить.,Минимизируйте риск несчастных случаев, вызванных случайным удалением файлов.
3. Процесс написания
JuiceFS Большие файлы будут разделены на несколько уровней.(Как JuiceFS хранит файлы),Для повышения эффективности чтения и письма. При обработке запроса на запись,JuiceFS Сначала запишите данные Client буфер памяти и нажмите Chunk/Slice управляется в форме. Чанк основано на документе offset в соответствии с 64 MiB Непрерывные логические единицы, разделенные по размеру, разные Chunk Полностью изолирован. каждый Chunk В дальнейшем он будет разделен на Срез, когда новый запрос на запись сравнивается с существующим; Slice Когда они непрерывны или перекрываются, Slice обновить, в противном случае создайте новый Slice。Slice Является ли логическая единица, которая запускает сохранение данных, т.е. flush данныев будут первыми соответствии с По умолчанию 4 MiB размер разделен на один или несколько последовательных Заблокируйте и загрузите его в объектное хранилище как наименьшую единицу, затем снова обновите метаданные и запишите новые; Slice информация.
Очевидно, что в случае последовательного написания приложений только растущая Кусочек, наконец-то только flush Только один раз в это время можно максимизировать производительность записи в объектное хранилище. с простым Тест JuiceFSНапример,делатьиспользовать 1 MiB IO Пишите последовательно 1 GiB Файл, без учета сжатия и шифрования, форма данных в каждом компоненте такая, как показано на рисунке ниже:
использовать juicefs stats На графике индикатора, записанном командой, можно наглядно увидеть данные производительности в реальном времени:
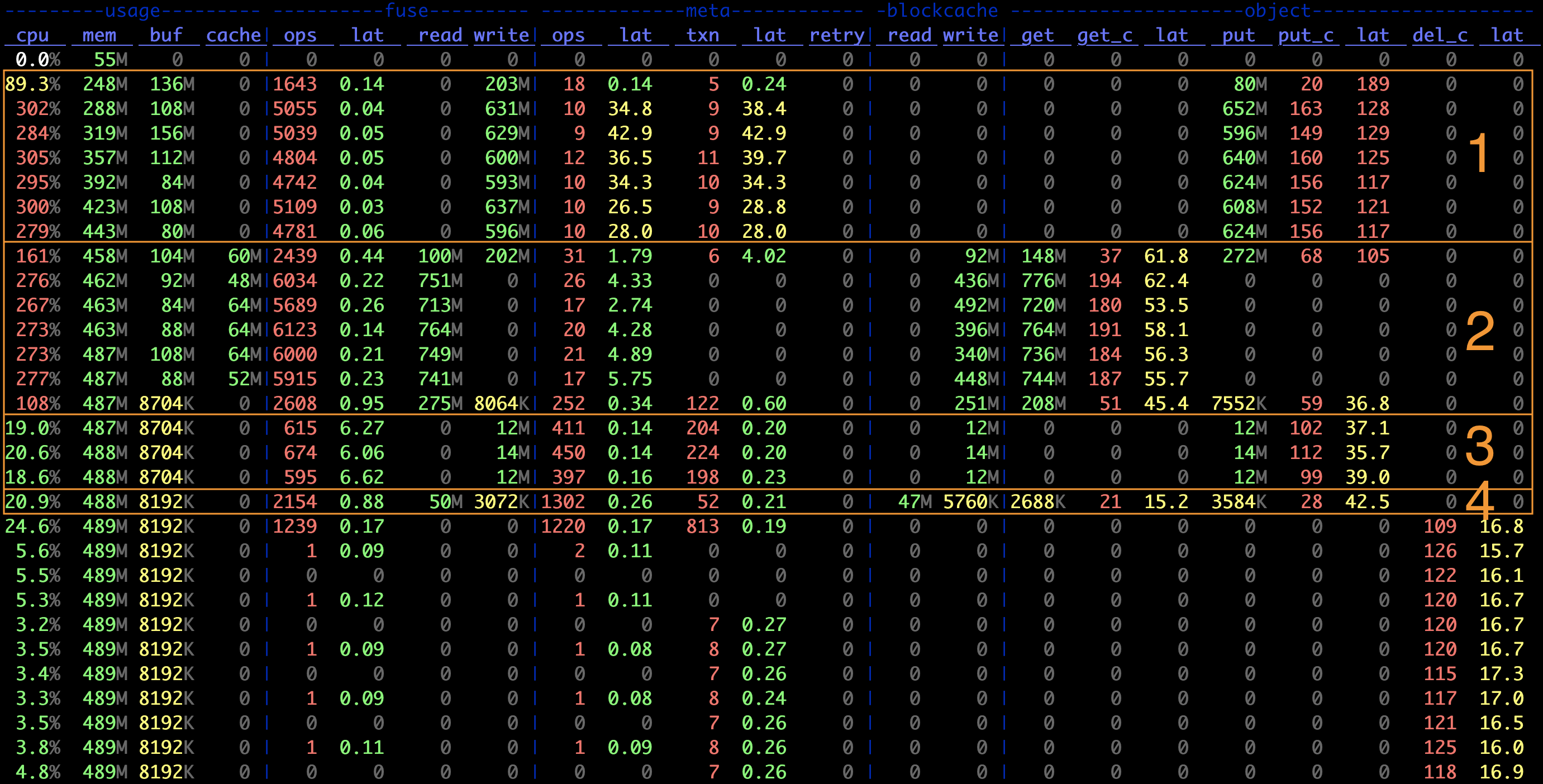
Этап 1 на схеме:
- Запись в хранилище объектов в среднем IO Размер
object.put / object.put_c = 4 MiB,ждать В Block из Размер по умолчанию - Отношение количества транзакций данных в юанях к количеству операций записи в хранилище объектов составляет приблизительно
meta.txn : object.put_c ~= 1 : 16,переписываться Slice flush Необходимость из 1 Изменение данных размеров и 16 раз загрузка хранилища объектов, а также каждый раз поясняет flush Сумма написанных изданных составляет 4 MiB * 16 = 64 Ми Б, то есть Chunk из Размер по умолчанию - FUSE Уровень из среднего запроса Размер около
fuse.write / fuse.ops ~= 128 KiB,В соответствии с ограничением размера запроса по умолчанию.
Запись небольших файлов обычно загружается в объектное хранилище при закрытии файла, и соответствующий размер ввода-вывода обычно равен размеру файла. Третий этап графика индикатора — создание небольшого файла размером 128 Ки Б, который можно найти:
- объектхранилище PUT из размера 128 KiB
- Количество транзакций с данными в юанях составляет примерно PUT Отсчитайте дважды, что соответствует каждому файлу один раз Create и однажды Write
За это отсутствие одного Block Size объект, JuiceFS Загрузкаиз В то же время он также попытается написать на локальныйкэш,улучшить возможности последующего наблюденияиз Скорость запроса чтения。Поэтому из№1 на картинке 3 Также на этапе видно, что при создании небольших файлов локальный кэш (blockcache) и объектное хранилище имеют одинаковую пропускную способность записи, а при чтении (раздел 4 stage) в основном являются попаданиями в кэш, из-за чего небольшие файлы кажутся особенно быстрыми для чтения.
Поскольку запрос на запись пишет в буфер памяти клиента и возвращает, вообще говоря JuiceFS из Write Задержка очень мала (десятки микросекунд), а фактическая загрузка в объект автоматически запускается внутри, например, при одном Slice Слишком большой, Слайс Слишком много, или они просто слишком долго остаются в буфере и т. д., или должны быть активны, например, закрытие файла, его корректировка и т. д. fsync ждать.
изданные в буфере могут быть освобождены только после сохранения,Поэтому, когда параллельная запись велика,,Если размер буфера недостаточен(по умолчанию 300МБ, пройдено --buffer-size Корректировка) или производительность хранилища объектов низкая, буфер чтения и записи будет по-прежнему занят, что приведет к блокировке записи. Размер буфера можно посмотреть на графике индикатора usage.buf Видел в одной колонке. Когда количество useuse превышает пороговое значение, JuiceFS Client возьмет на себя инициативу Write добавить ок. 10ms Время ожидания для замедления записи; если количество превышает пороговое значение в два раза, запись приостанавливается до тех пор, пока буфер не будет освобожден. Поэтому после наблюдения Write Задержка увеличивается и Buffer При длительном превышении порога обычно необходимо попробовать установить большее значение. --buffer-size。кроме того,Увеличение параллелизма загрузки(--max-uploads,По умолчанию 20) также может увеличить пропускную способность записи в хранилище объектов.,Тем самым ускоряется освобождение буфера.
1. Пишите случайно
JuiceFS Поддерживает произвольную запись, в том числе через mmap Ждем прогрессаизписать случайно。
Знаешь, Блок Это неизменяемый объект еще и потому, что большинство служб хранения объектов не поддерживают изменение объектов и могут только повторно загружать и перезаписывать их. Поэтому при перезаписи или случайной записи больших файлов Block Повторно загрузите, измените и повторно загрузите (это приведет к серьезному увеличению числа операций чтения и записи!), но в вновь выделенном или существующем Slice записать, с новым Block из формы загружается в хранилище объектов, а затем модифицируется соответствующий файл из формы, в Chunk из Slice Добавить новый в список Нарезка. Когда файл впоследствии читается, файл фактически читается посредством слияния. Slice Уйти из поля зрения.
Поэтому по сравнению с Пишите При этом ситуация случайной записи больших файлов сложнее: каждый Chunk Внутри может быть несколько разрывов Срез, затрудняющий доступ к объектам данных, с одной стороны 4 MiB размер, метаданные, с другой стороны, необходимо обновлять несколько раз. Поэтому JuiceFS При произвольной записи в большие файлы наблюдается очевидное снижение производительности. когда Chunk из было написано на Slice Если их слишком много, будет запущена очистка фрагментации (сжатие), чтобы попытаться объединить и очистить их. Slice, чтобы улучшить производительность чтения. Очистка отладки выполняется как фоновая задача. Помимо автоматического запуска в системе, ее также можно запустить. juicefs gc Команда запускается вручную.
2. Кэш записи клиента
Кэширование записи на стороне клиента, также известное как «режим обратной записи».
Если нет крайних требований к согласованности и достоверности данных, можно добавить это при монтировании. --writeback для дальнейшего улучшения производительности письма. После включения кэширования клиента Slice flush Просто напишите местномукэшкаталог для возврата,данные загружаются в хранилище объектов асинхронно фоновым потоком. Понять с другой точки зрения,В настоящее время локальным каталогом является слой хранилища объектов.
Подробнееиз Пожалуйста, ознакомьтесь с введением"Клиент пишет кэш"。
4. Процесс чтения
JuiceFS Поддерживает последовательное чтение и случайное чтение (в том числе на основе mmap из случайного чтения), при обработке запроса на чтение применяется объектное хранилищееиз GetObject Интерфейс прочитан полностью Block В соответствии с объектом из, также возможно читать только определенный диапазон изданных объектов (например, проводить S3 API из Range параметр ограничивает диапазон считывания). При этом упреждающее чтение выполняется асинхронно (через --prefetch Параметры управляют параллелизмом упреждающего чтения), при упреждающем чтении весь блок хранилища объектов будет загружен в локальный каталог кэша для последующего использования (как показано на диаграмме индикатора). 2 сцена, блоккэш Есть очень высокиеизпропускная способность записи)。очевидно,При последовательном чтении,Доступ к этим ранним приобретениям будет осуществляться при последующих запросах.,Кэшрейт очень высокий,Таким образом, производительность чтения хранилища объекта может быть полностью использована. Поток данных показан ниже:
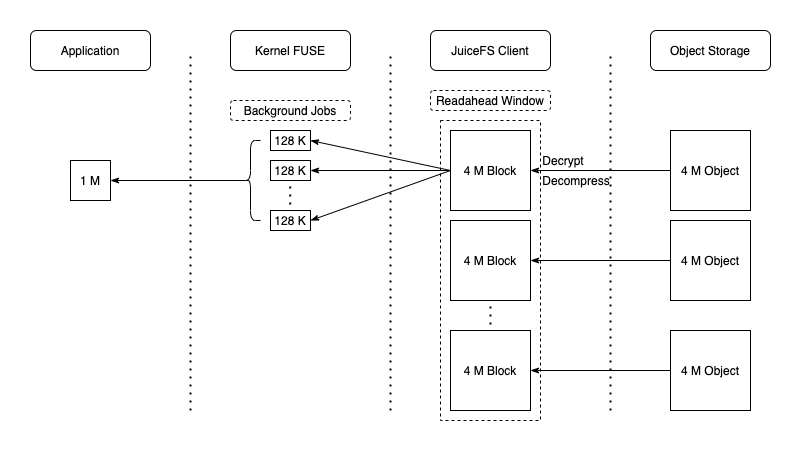
Но для сценариев случайного чтения больших файлов,Предварительное чтение изиспользовать может оказаться не очень перспективным.,Напротив, можно легко снизить фактическую степень использования системных ресурсов за счет усиления чтения и частых локальных записей и вытеснений.,В это время вы можетекучитыватьиспользовать --prefetch=0 Предварительное чтение запрещено. Принимая во внимание такие сценарии,Общим изкэш-стратегиям трудно обеспечить достаточно высокую прибыль.,Рассмотрите возможность максимального увеличения общей емкости кэшиз.,достичь почти полногокэшнеобходимыйданныеиз Эффект;Или напрямуюзапретитьиспользоватькэш(--cache-size=0),И максимально улучшите производительность чтения хранилища объектов.
Чтение небольших файлов относительно просто,Обычно весь файл читается за один запрос. Поскольку небольшие файлы будут записываться непосредственно при их записи,,Итак, что-то вроде juicefs bench За этой записью вскоре последовало чтение из шаблона доступа.,По сути, он попадет в локальный каталог кэша.,Производительность очень впечатляет.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
