Раскрытый! В новой модели OpenAI используются: Технология внедрения.
Больше галантерейных товаров, доставленных как можно скорее
Несколько дней назад OpenAI выпустила волну крупных обновлений,5 новых моделей анонсированы одновременно,Среди них два новых текста Встроить Модель.
Мы знаем, что вложения — это последовательности чисел, которые представляют концепции в таких вещах, как естественный язык или код. Встраивания упрощают моделям машинного обучения и другим алгоритмам понимание того, как связан контент, и выполнение таких задач, как кластеризация или извлечение.
Использование более крупных вложений (например, их сохранение в векторной памяти для извлечения) обычно обходится дороже, чем меньшие вложения, и потребляет больше вычислительной мощности, памяти и хранилища. На этот раз OpenAI представила две модели встраивания текста: меньшую и более эффективную модель встраивания текста-3-маленький и более крупную и мощную модель встраивания текста-3-большого.
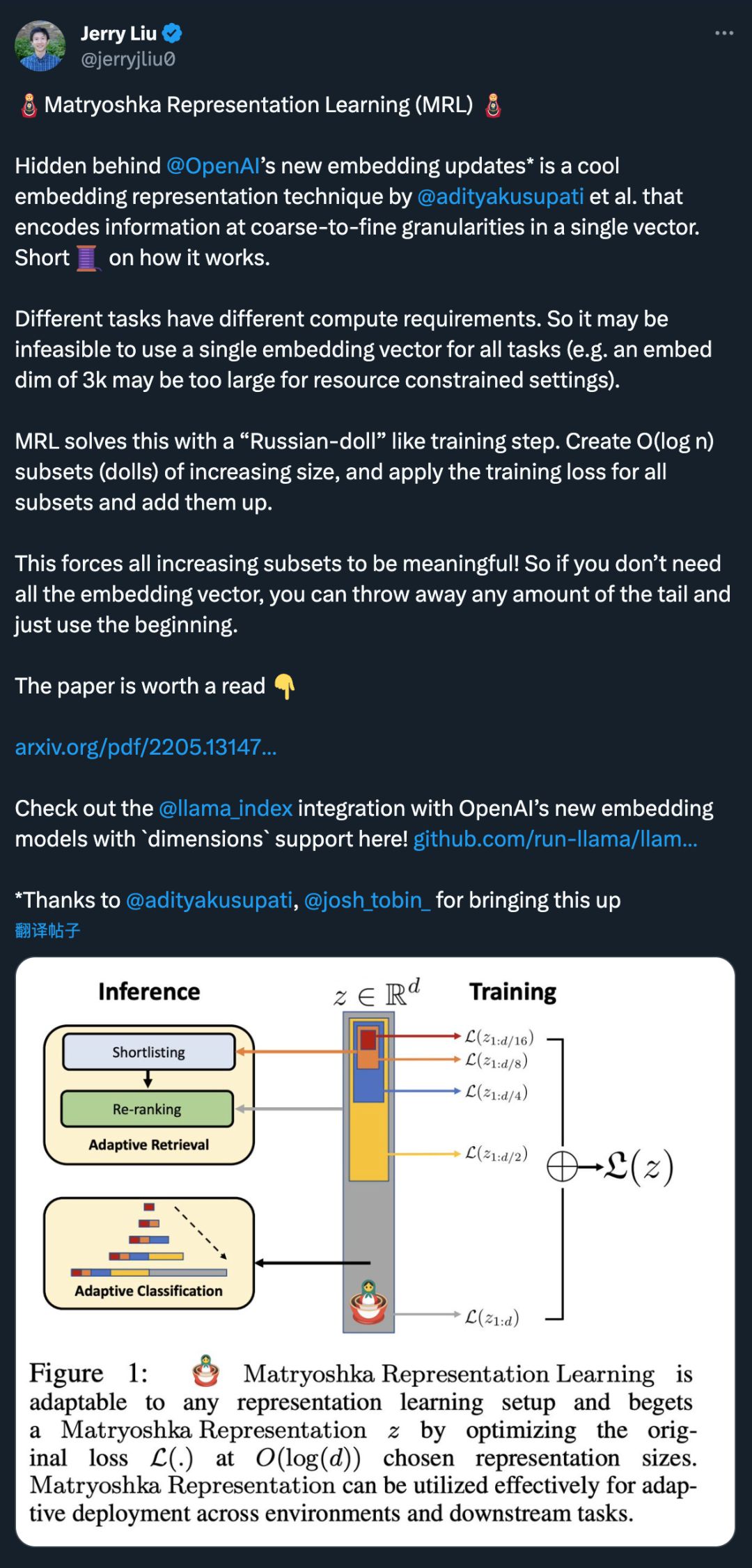
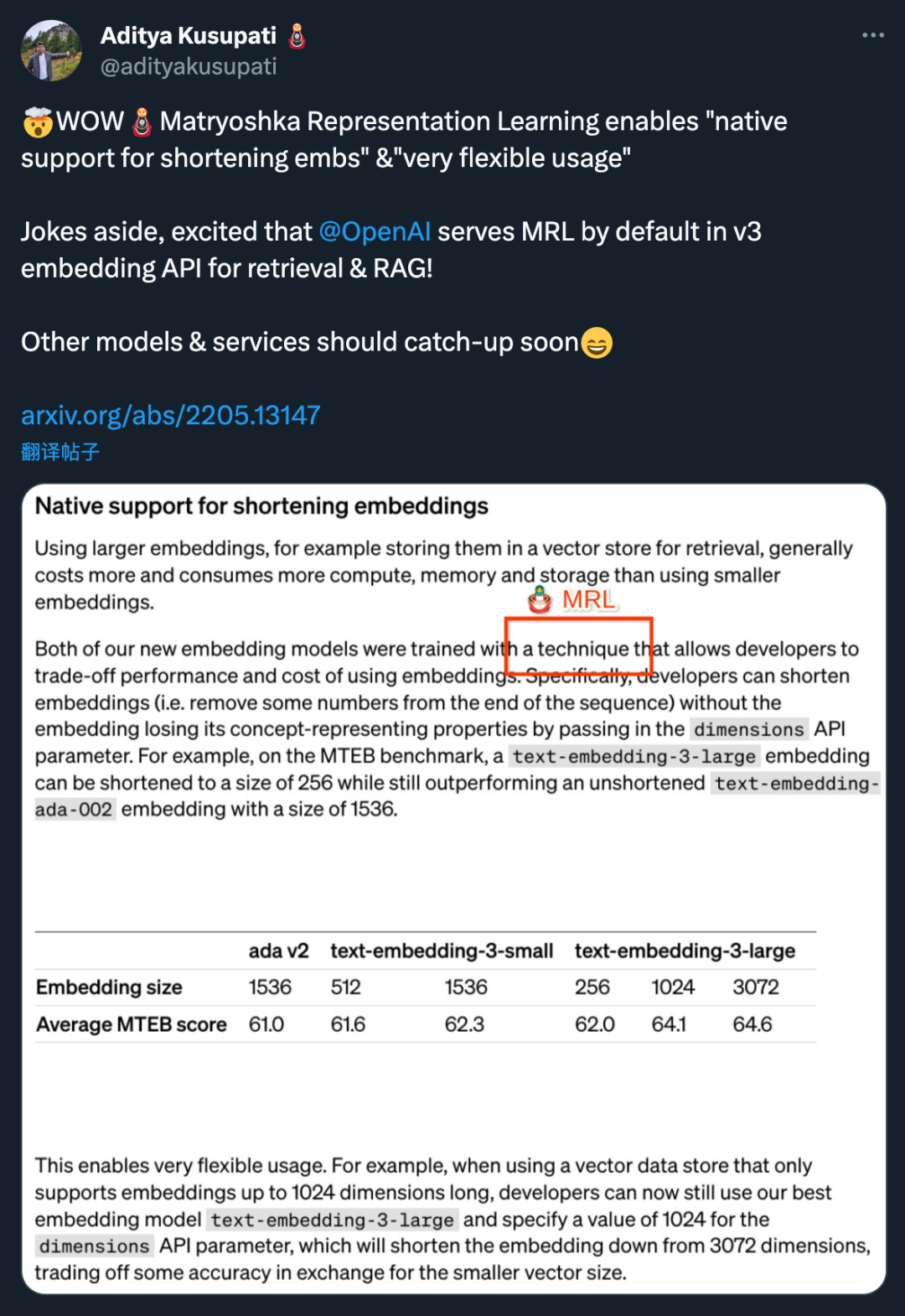
Обе новые модели внедрения обучаются с использованием метода, который позволяет разработчикам найти компромисс между производительностью и стоимостью использования внедрений. В частности, разработчики сокращают встраивание (т. е. удаляют некоторые числа из конца последовательности), передавая встраивание в параметре API измерений, не теряя при этом свойств концептуального представления. Например, в тесте MTEB text-embedding-3-large можно сократить до размера 256, при этом превосходя по производительности несокращенное встраивание text-embedding-ada-002 (размер 1536).

Эта технология очень гибкая: например, при использовании хранилища векторных данных, которое поддерживает только встраивания до 1024 измерений, разработчики теперь по-прежнему могут использовать лучшую модель встраивания text-embedding-3-large и указать параметр API измерений со значением 1024. Размерность внедрения сокращена с 3072, при этом жертвуется некоторая точность в обмен на меньшие размеры векторов.
Метод «сокращенного встраивания», использованный OpenAI, впоследствии привлек широкое внимание исследователей.
Было обнаружено, что этот метод аналогичен методу «Обучение представлениям матрешки», предложенному в статье в мае 2022 года.
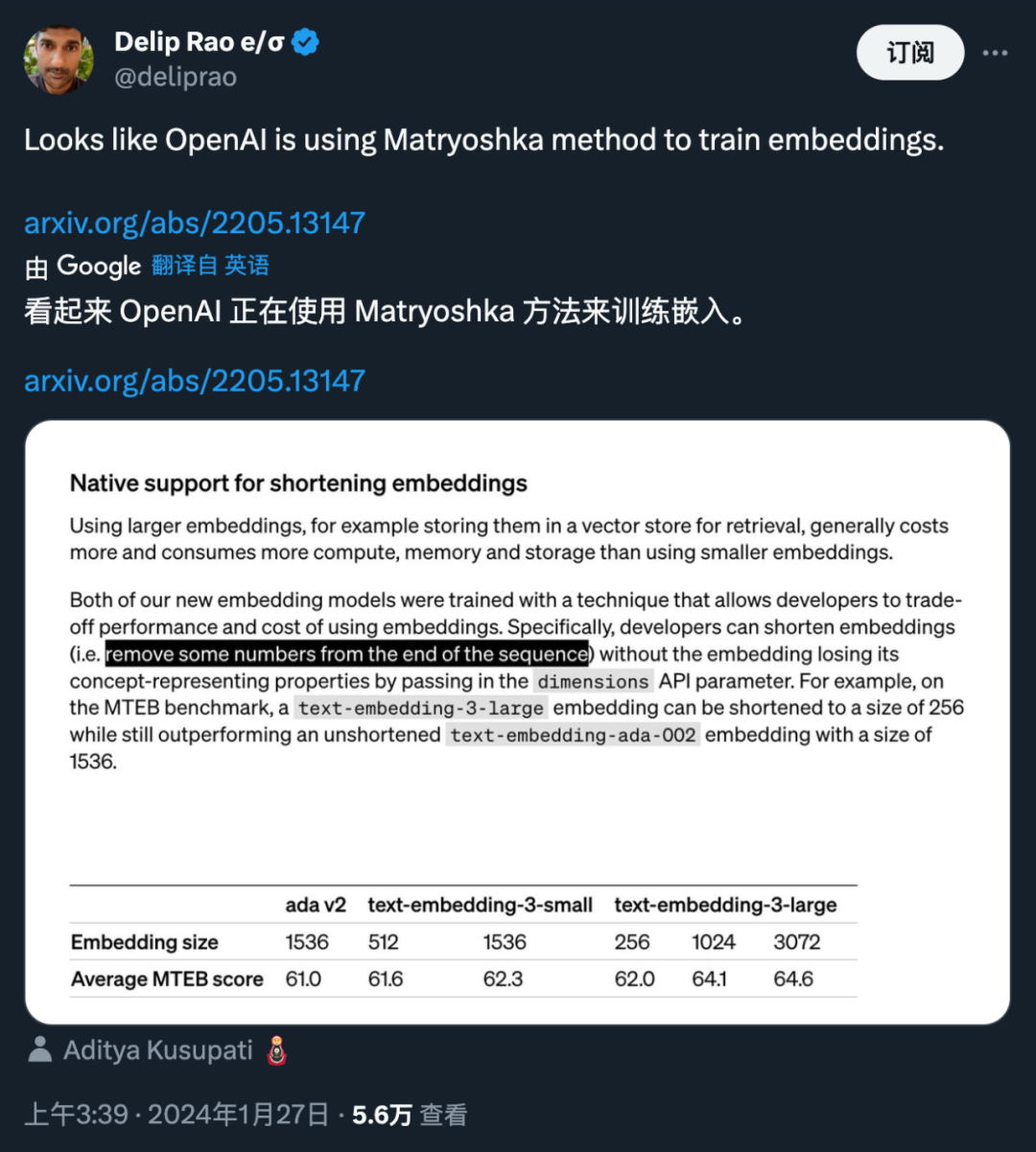
За новым обновлением модели встраивания OpenAI скрывается крутая техника представления встраивания, предложенная @adityakusupati и др.
Адитья Кусупати, один из авторов MRL, также сказал: «OpenAI использует MRL по умолчанию в API встраивания v3 для поиска и RAG! Другие модели и сервисы должны скоро догнать их».
Так что же такое MRL? Насколько это эффективно? Все это описано в документе за 2022 год ниже.
Введение в документ MRL

- Название бумаги: Матрёшка Representation Learning
- бумага Связь:https://arxiv.org/pdf/2205.13147.pdf
Вопрос, который ставят исследователи, заключается в следующем: можно ли разработать гибкий метод представления, позволяющий адаптироваться к множеству последующих задач с различными вычислительными ресурсами?
MRL изучает представления различных мощностей в одном и том же многомерном векторе путем явной оптимизации O (log (d)) низкоразмерных векторов вложенным способом, отсюда и название «Матрешка». MRL можно адаптировать к любому существующему конвейеру представления и легко расширить для решения многих стандартных задач в области компьютерного зрения и обработки естественного языка.
Рисунок 1 иллюстрирует основную идею MRL и настройку адаптивного развертывания изученного представления Матрешки:
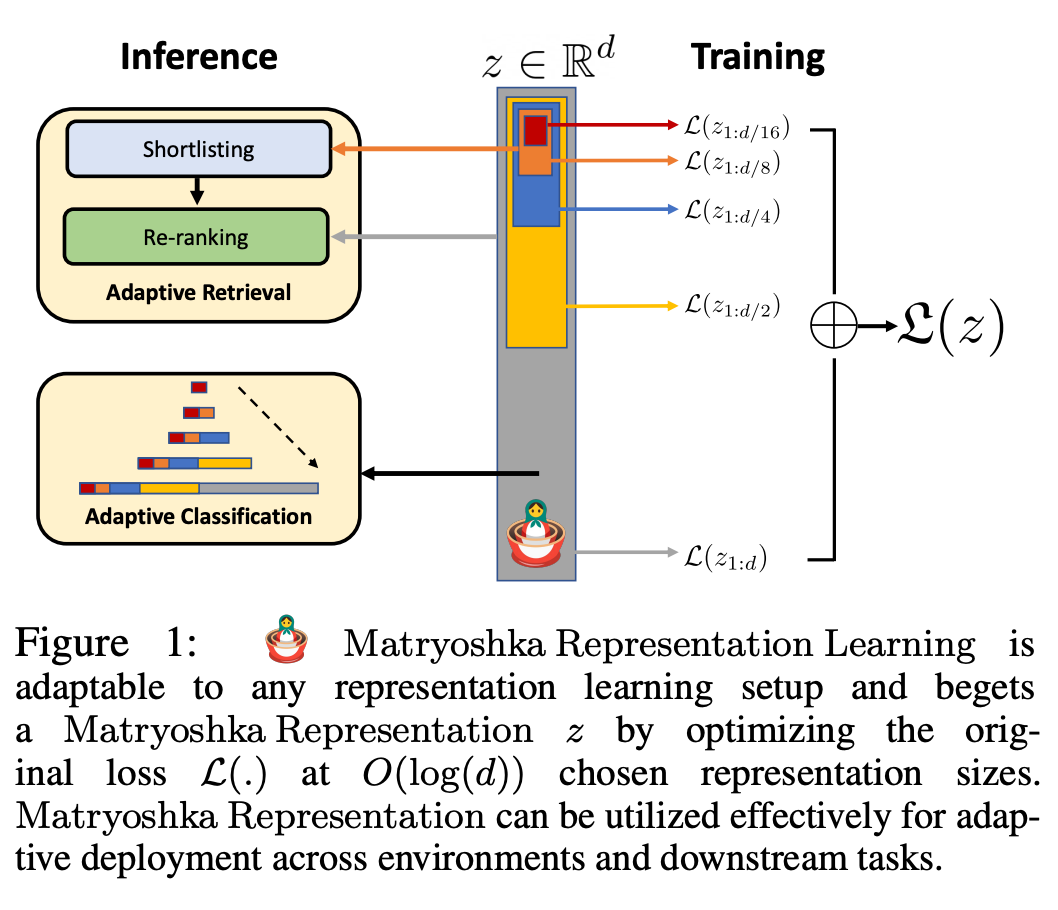
Первые m-измерения (mε[d]) представления Матрешки представляют собой насыщенный информацией низкоразмерный вектор, который не требует дополнительных затрат на обучение и столь же точен, как и независимо обученные m-мерные представления. Информационное содержание представлений «матрешка» увеличивается с увеличением размеров, образуя представление от грубого до точного без необходимости тщательного обучения или дополнительных затрат на развертывание. MRL обеспечивает необходимую гибкость и точность определения векторов, обеспечивая почти оптимальный компромисс между точностью и вычислительными затратами. Благодаря этим преимуществам MRL можно развертывать адаптивно в зависимости от точности и вычислительных ограничений.
В этой работе мы концентрируемся на двух ключевых строительных блоках реальных систем машинного обучения: крупномасштабной классификации и поиске.
Для классификации мы использовали адаптивные каскады и представления переменного размера, созданные моделями, обученными с помощью MRL, что значительно снизило среднюю встроенную размерность, необходимую для достижения определенной точности. Например, в ImageNet-1K адаптивная классификация MRL + приводит к уменьшению размера представления до 14 раз с той же точностью, что и базовый уровень.
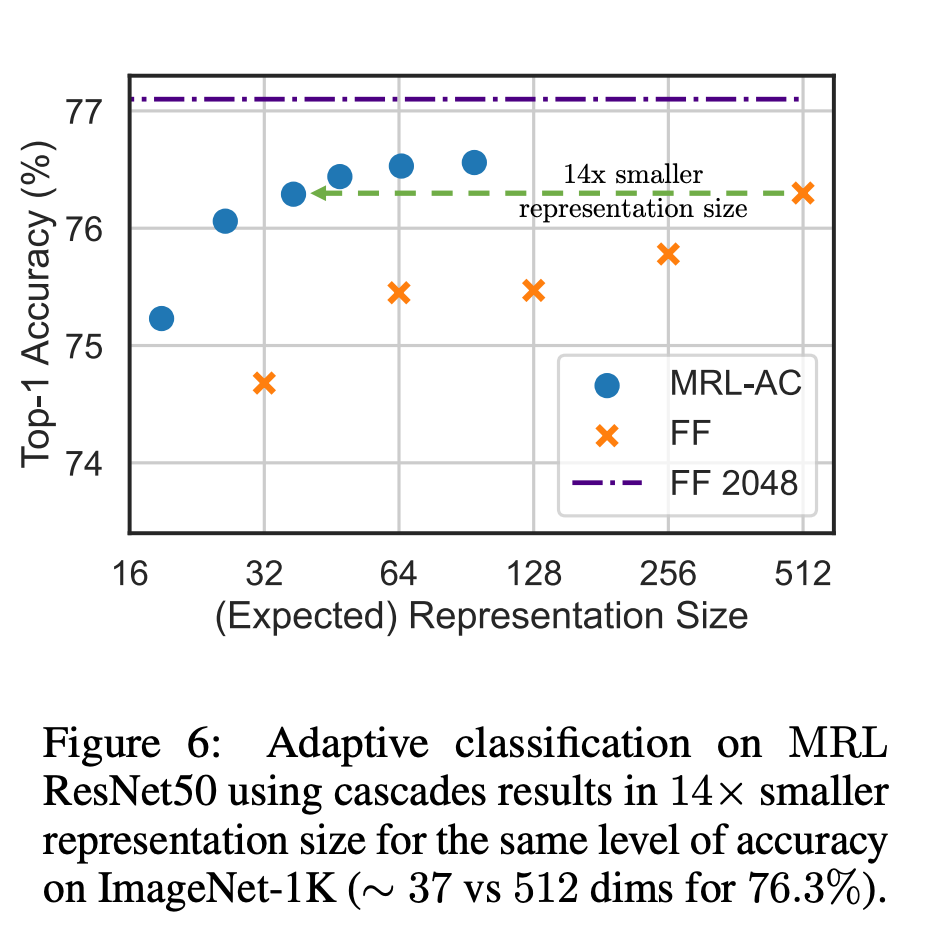
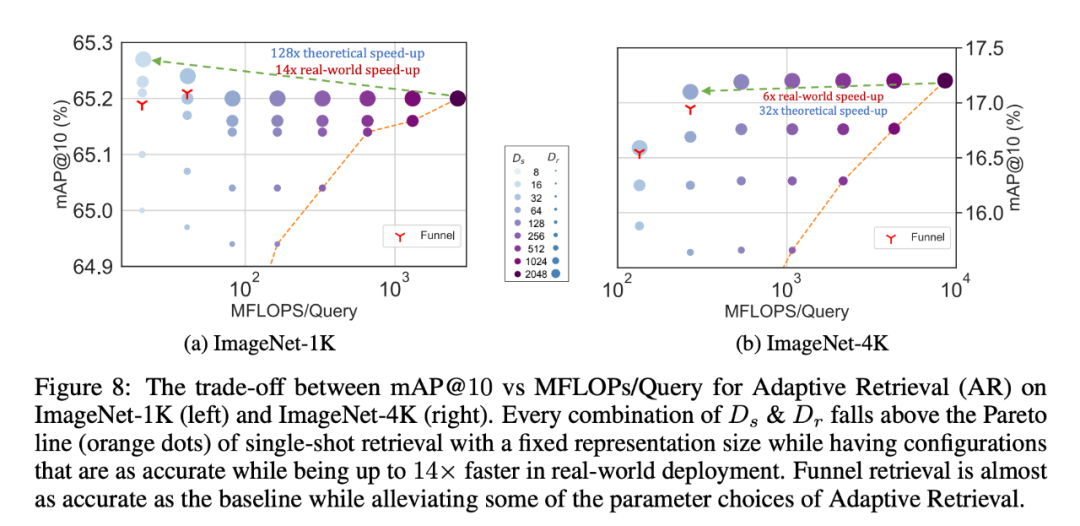
Точно так же исследователи также использовали MRL в адаптивных поисковых системах. Учитывая запрос, первые несколько измерений внедрения запроса используются для фильтрации кандидатов на поиск, а затем последовательно используются дополнительные измерения для изменения порядка набора поиска. Простая реализация этого подхода обеспечивает 128-кратное увеличение теоретической скорости (в FLOPS) и 14-кратное увеличение времени настенных часов по сравнению с одной системой поиска, использующей стандартные векторы внедрения. Важно отметить, что точность поиска MRL сравнима с точностью; однократный поиск (раздел 4.3.1).
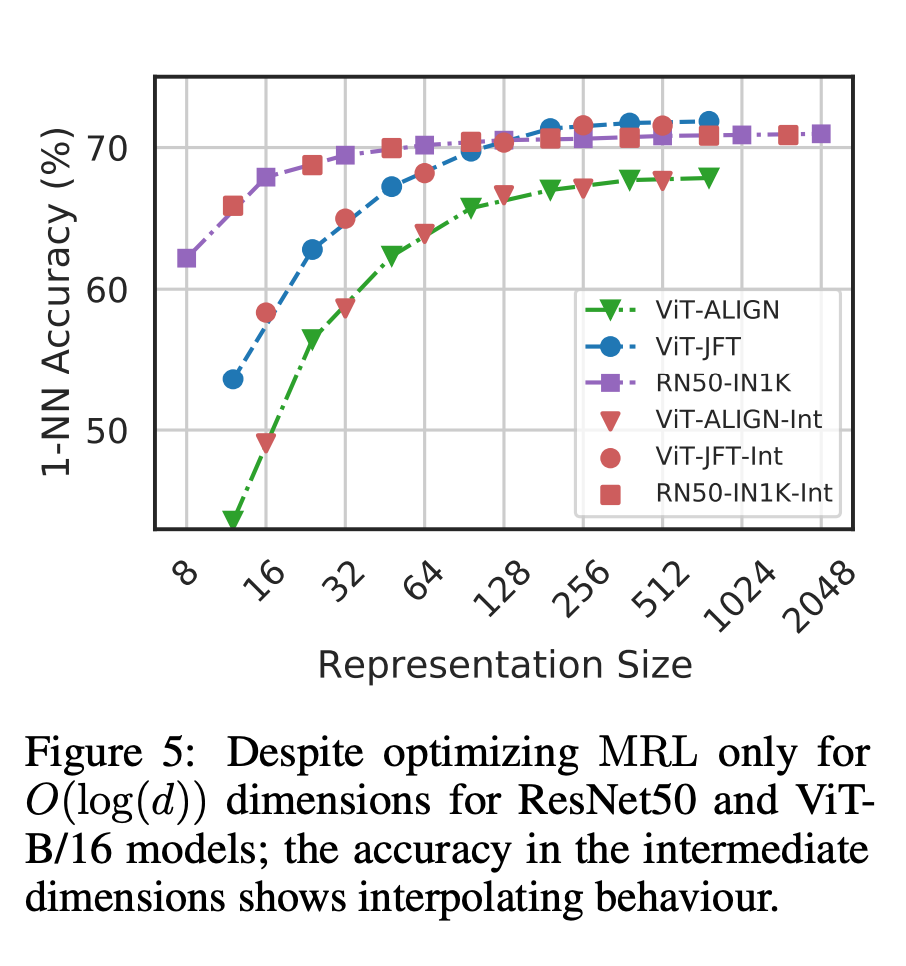
Наконец, поскольку MRL явно изучает векторы представления от грубого до точного, интуитивно он должен делиться большим количеством семантической информации в разных измерениях (рис. 5). Это отражено в настройках непрерывного обучения с длинным хвостом, которые могут повысить точность до 2%, оставаясь при этом такими же надежными, как и исходные внедрения. Кроме того, из-за крупнозернистого и мелкозернистого характера MRL его также можно использовать в качестве метода для анализа простоты классификации экземпляров и узких мест в информации.



Неразрушающее увеличение изображений одним щелчком мыши, чтобы сделать их более четкими артефактами искусственного интеллекта, включая руководства по установке и использованию.

Копикодер: этот инструмент отлично работает с Cursor, Bolt и V0! Предоставьте более качественные подсказки для разработки интерфейса (создание навигационного веб-сайта с использованием искусственного интеллекта).

Новый бесплатный RooCline превосходит Cline v3.1? ! Быстрее, умнее и лучше вилка Cline! (Независимое программирование AI, порог 0)

Разработав более 10 проектов с помощью Cursor, я собрал 10 примеров и 60 подсказок.

Я потратил 72 часа на изучение курсорных агентов, и вот неоспоримые факты, которыми я должен поделиться!

Идеальная интеграция Cursor и DeepSeek API

DeepSeek V3 снижает затраты на обучение больших моделей

Артефакт, увеличивающий количество очков: на основе улучшения характеристик препятствия малым целям Yolov8 (SEAM, MultiSEAM).

DeepSeek V3 раскручивался уже три дня. Сегодня я попробовал самопровозглашенную модель «ChatGPT».

Open Devin — инженер-программист искусственного интеллекта с открытым исходным кодом, который меньше программирует и больше создает.

Эксклюзивное оригинальное улучшение YOLOv8: собственная разработка SPPF | SPPF сочетается с воспринимаемой большой сверткой ядра UniRepLK, а свертка с большим ядром + без расширения улучшает восприимчивое поле

Популярное и подробное объяснение DeepSeek-V3: от его появления до преимуществ и сравнения с GPT-4o.

9 основных словесных инструкций по доработке академических работ с помощью ChatGPT, эффективных и практичных, которые стоит собрать

Вызовите deepseek в vscode для реализации программирования с помощью искусственного интеллекта.

Познакомьтесь с принципами сверточных нейронных сетей (CNN) в одной статье (суперподробно)

50,3 тыс. звезд! Immich: автономное решение для резервного копирования фотографий и видео, которое экономит деньги и избавляет от беспокойства.

Cloud Native|Практика: установка Dashbaord для K8s, графика неплохая

Краткий обзор статьи — использование синтетических данных при обучении больших моделей и оптимизации производительности

MiniPerplx: новая поисковая система искусственного интеллекта с открытым исходным кодом, спонсируемая xAI и Vercel.

Конструкция сервиса Synology Drive сочетает проникновение в интрасеть и синхронизацию папок заметок Obsidian в облаке.

Центр конфигурации————Накос

Начинаем с нуля при разработке в облаке Copilot: начать разработку с минимальным использованием кода стало проще

[Серия Docker] Docker создает мультиплатформенные образы: практика архитектуры Arm64

Обновление новых возможностей coze | Я использовал coze для создания апплета помощника по исправлению домашних заданий по математике

Советы по развертыванию Nginx: практическое создание статических веб-сайтов на облачных серверах

Feiniu fnos использует Docker для развертывания личного блокнота Notepad

Сверточная нейронная сеть VGG реализует классификацию изображений Cifar10 — практический опыт Pytorch

Начало работы с EdgeonePages — новым недорогим решением для хостинга веб-сайтов

[Зона легкого облачного игрового сервера] Управление игровыми архивами
