«PytorchConference2023 Translation Series» 7. Углубленное исследование CUTLASS: как в полной мере использовать тензорные ядра
Подробные моменты
1. Общие сведения
- Cutlass — это библиотека глубокого обучения NVIDIA с открытым исходным кодом.
- Для программирования на тензорных ядрах
- Первоначально использовался в Вольте, теперь широко используется в экосистеме.
2. Принцип работы
- Построен на 5 уровнях абстракции для обеспечения гибкости.
- Cute упрощает сопоставление данных потоков
- CollectiveиTiled ОП обрабатывает расчеты Ядро
3. Применение Cutlass в экосистеме PyTorch
- В качестве бэкэнда Inductor в PyTorch
- AItemplateиXformer использует возможности Cutlass
- Геометрическое приложение PyTorch Cutlass для создания групповых драгоценных камней
4. Новейшие функции
- Интерфейс Python снижает сложность шаблонов C++.
- Конфигурация дерева посетителей Эпилога сложна. Эпилог
- Gemm смешанного ввода поддерживает разные типы данных.
5. Тестирование производительности
- Уровень использования достигает более 90%
- Постоянное улучшение производительности при оптимизации версий
6. Планы дальнейшего развития
- Больше оптимизаций, таких как низкое выравнивание гемм.
- Поддержка нового оборудования, такого как Hopper и Ada.
- Улучшение документации для облегчения разработки
Эй, мы собираемся начать. Меня зовут Мэтью Нисли. Я являюсь менеджером по компилятору глубокого обучения NVIDIA, и сегодня я представлю некоторые методы использования тензорных ядер NVIDIA. Сначала я хочу поговорить о Cutlass. Я дам вам некоторую предысторию и обзор того, почему вы можете ее использовать, некоторые из последних и будущих функций, а затем я дам вам обзор открытой платформы Triton. Если вы только что посетили последнюю лекцию, вы уже это знаете.

Хорошо, Cutlass — это наша библиотека с открытым исходным кодом на GitHub для программирования на Tensor Core. Первоначально он был выпущен в 2017 году для улучшения программируемых возможностей Volta. С тех пор его применение постепенно расширялось. Он превратился из исследовательского инструмента, используемого специалистами по глубокому обучению, в широко используемый производственный актив во всей экосистеме.
Cutlass состоит из строительных блоков с использованием гемм, свертков и т. д. в зависимости от ваших потребностей, либо из готовых блоков, либо из ядра вашей собственной разработки. Мы поддерживаем несколько режимов эпилога, а также NVIDIA. GPUВсе типы расчета данных найдены на。Недавно мы выпустилиPythonинтерфейс,Я расскажу об этом подробнее позже. кроме того,У нас также есть профилировщик производительности,Вы можете использовать это, чтобы найти лучшую конфигурацию для вашего варианта использования. Cutlass имеет решающее значение для экосистемы NVIDIA,Вы найдете его во многих библиотеках.,Напримерcublas、CUSPARSE、cuTENSORиDALIи т. д.。Так,Как это работает?
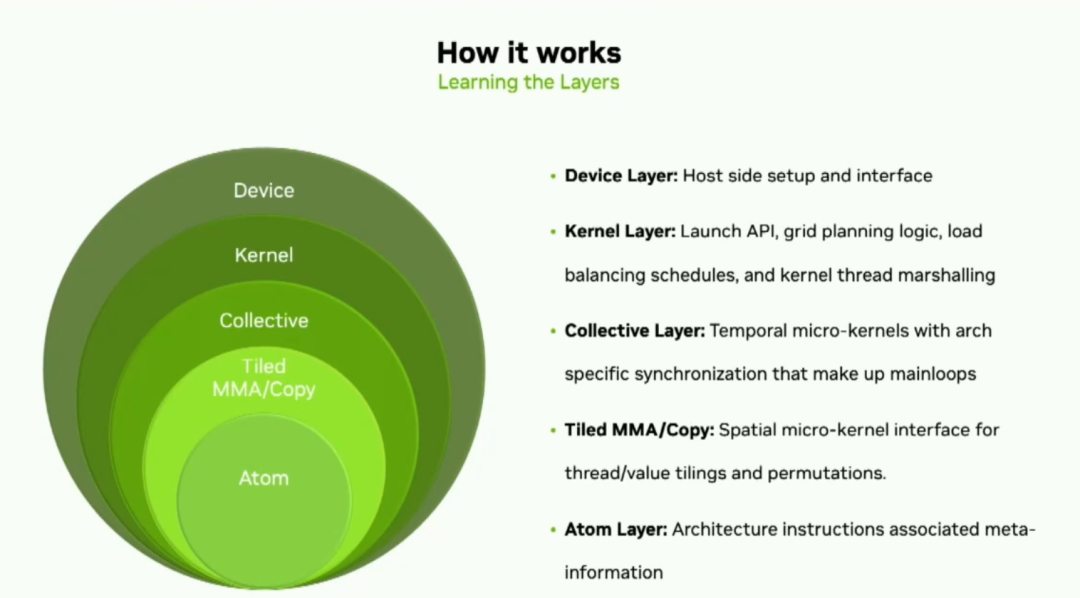
Cutlass состоит из пяти слоев абстракции.,Цель состоит в том, чтобы максимизировать гибкость. первый,Мы выпустили версию 3 несколько месяцев назад,У него новый бэкэнд под названием Cute.,Значительно упрощает сопоставление данных потоков.,и позволяет основным разработчикам сосредоточиться на тензорахи Логическое описание алгоритма。(CuTe is a collection of C++ CUDA template abstractions for defining and operating on hierarchically multidimensional layouts of threads and данные.) Итак, если разбить эти уровни абстракции, нижний уровень — это атомы, включая PTX. MMA и копия плитки, после слоя коллектива следует слой ядра, куда можно добавить коллектив; mainloop and a collective эпилог вместе. Наконец, на уровне устройства вы найдете конфигурацию ядра, инструменты загрузки и гарантии переносимости на уровне устройства.
(⭐Жалоба переводчика: если вы не прочитаете официальную документацию, вы не сможете понять многие из представленных здесь концепций... Поэтому я вкраплю еще кое-что, чтобы не было слишком резко. Если вы не хотите его читать, можете пропустить. Перепечатано из официальной документации https://github.com/NVIDIA/cutlass/blob/main/media/docs/cutlass_3x_backwards_compatibility.md.
Коллективный основной цикл и эпилог являются ключевыми компонентами CUTLASS для выполнения коллективных матричных операций умножения-накопления (MMA).
Коллективный основной цикл — это структура цикла, используемая для выполнения операций MMA в нескольких потоках. Он отвечает за разбиение входной матрицы на небольшие части и координацию операций передачи данных и вычислений между несколькими потоками. Основной цикл использует инструкции MMA для выполнения операций умножения и накопления матриц над этими небольшими блоками, используя преимущества параллелизма и локальности оборудования для ускорения вычислений. Основной цикл также управляет синхронизацией потоков и связью, чтобы обеспечить правильные зависимости данных и согласованность результатов.
Эпилог — это серия операций после основного цикла, используемая для обработки выходных результатов основного цикла. Он может выполнять различные операции, такие как коррекция, масштабирование, округление и т. д. с результатами. Цель Epilogue — преобразовать выходные данные основного цикла в окончательный матричный результат умножения-накопления. CUTLASS предоставляет различные типы эпилогов, и вы можете выбрать подходящий тип эпилога в соответствии с вашими конкретными потребностями.
Объединив коллективный основной цикл и эпилог, CUTLASS может эффективно выполнять коллективные операции MMA, используя преимущества параллелизма и локальности оборудования для повышения эффективности вычислений. Гибкость этой комбинации позволяет CUTLASS адаптироваться к различным аппаратным архитектурам и требованиям приложений и обеспечивать высокопроизводительные матричные функции умножения-накопления.
Здесь мы предполагаем, что в качестве примера используется описание gemm:
// cutlass::gemm::kernel::GemmUniversal: ClusterTileM and ClusterTileN loops
// are either rasterized by the hardware or scheduled by the kernel in persistent kernels.
// Parallelism over thread block clusters
for (int cluster_m = 0; cluster_m < GemmM; cluster_m += ClusterTileM) {
for (int cluster_n = 0; cluster_n < GemmN; cluster_n += ClusterTileN) {
// cutlass::gemm::collective::CollectiveMma: mainloop that iterates over all k-tiles
// No loop unrolling is performed at this stage
for (int k_tile = 0; k_tile < size<2>(gmem_tensor_A); k_tile++) {
// loops inside cute::gemm(tiled_mma, a, b, c); Dispatch 5: (V,M,K) x (V,N,K) => (V,M,N)
// TiledMma uses the hardware instruction provided through its Mma_Atom
// TiledMma's atom layout, value layout, and permutations define the iteration order
for (int tiled_mma_k = 0; tiled_mma_k < size<2>(A); tiled_mma_k++) {
for (int tiled_mma_m = 0; tiled_mma_m < size<1>(A); tiled_mma_m++) {
for (int tiled_mma_n = 0; tiled_mma_n < size<1>(B); tiled_mma_n++) {
// TiledMma's vector mode dispatches to the underlying instruction.
mma.call(d, a, b, c);
} // tiled_mma_n
} // tiled_mma_m
} // tiled_mma_k
} // k_tile mainloop
} // cluster_m
} // cluster_n
CUTLASS представляет собой описанное выше вложение циклов (гемм выше) с использованием следующих компонентов, которые специализируются на типах данных, макете и математических инструкциях.
API level | API Class and/or function names |
|---|---|
Device | cutlass::gemm::device::GemmUniversalAdapter |
Kernel | cutlass::gemm::kernel::GemmUniversal |
Collective | cutlass::gemm::collective::CollectiveMma cutlass::epilogue::collective::DefaultEpilogue cutlass::epilogue::collective::Epilogue |
Tiled (MMA and Copy) | cute::TiledMma and cute::TiledCopy cute::gemm() and cute::copy() |
Atom | cute::Mma_Atom and cute::Copy_Atom |
В CUTLASS 3.0 мы делаем это, сначала объединяя коллективный основной цикл (cutlass::gemm::collective::CollectiveMma: mainloop, который перебирает все k-тайлы) и коллективный эпилог на уровне ядра, а затем используя хост-сторону конвертер, чтобы обернуть их в дескриптор ядра GEMM.
В следующих разделах описываются компоненты, необходимые для сборки ядра, в том порядке, в котором пользователь создает их экземпляры:
- Соберите необходимый коллективный основной цикл и эпилоги.
- Объедините их вместе, чтобы построить тип Ядро.
- Используйте конвертер слоев устройства Ядро.
Коллектив — «ммма атомы и копировать атомы. Самый большой набор нитей, которые расщепляются на». То есть,Это сетка с максимальным количеством потоков,Сотрудничайте, используя аппаратные функции для ускорения связи и синхронизации.Эти аппаратные функции включают в себя:
- Асинхронный массив копировать (например,из глобальной памяти в общую память);
- Инструкции MMA для небольших блоков, расположенных в общей памяти;
- для кластеризации、Блокировка потока и/или операция синхронизации warp и/или;
Аппаратное ускорение (например, барьеры) для обеспечения зависимости данных между асинхронными операциями.
Collective использует API-интерфейсы TiledMma и TiledCopy для доступа к операциям копирования и MMA на фрагментах.
Класс Cutlass::gemm::collective::CollectiveMma является основным интерфейсом основного цикла коллективного матричного умножения и накопления (MMA). «Основной цикл» здесь относится к циклу «кластерной плитки k» в псевдокоде в начале этой статьи. Именно здесь возникает ситуация, когда алгоритму может потребоваться перебрать несколько блоков.
Пожалуйста, проверьте документацию самостоятельно для получения дополнительной информации.
(⭐Возврат отсюда к основной лекции)

Зачем использовать Cutlass? Наверное, это самый частый вопрос. cublas получит лучший опыт распаковки. У него будет более быстрый выход на рынок. Он обеспечивает гарантии переносимости между различными архитектурами. Он имеет набор эвристик, которые выбирают лучшее ядро на основе ваших параметров. Поэтому я говорю многим своим клиентам: если Cublas соответствует вашим потребностям, используйте его.
(Переводчик: Если вы не понимаете, вот объяснение GPT:
CUTLASS и CUBLAS — две библиотеки для матричных операций на графических процессорах NVIDIA. Они имеют следующие различия:
- Разработчик: CUTLASS — проект с открытым исходным кодом, разработанный и поддерживаемый NVIDIA.,CUBLAS — это библиотека с закрытым исходным кодом, официально предоставляемая NVIDIA.
- Гибкость и настраиваемость: CUTLASS обеспечивает более высокий уровень гибкости и настраиваемости.,Позволяет пользователям настраивать детали матричных операций. Он предоставляет базовые примитивы матричных операций и реализацию алгоритмов.,Разрешение пользователям настраивать иоптимизацию под конкретные нужды. CUBLAS обеспечивает более высокий уровень абстракции и простоту использования.,Подходит для общих задач работы с матрицей.
- Оптимизация производительности: CUTLASS фокусируется на оптимизации производительности и использовании аппаратных функций. Он предоставляет больше возможностей конфигурации и стратегии оптимизации.,Позволяет пользователям настраивать производительность на основе конкретной аппаратной архитектуры и требований приложения. CUTLASS также обеспечивает специальную оптимизацию для задач глубокого обучения.,Например, вычисление с плавающей запятой половинной точности (FP16) и ускорение Tensor Core. CUBLAS также выполнил некоторые оптимизации производительности.,Но он больше ориентирован на обеспечение простоты использования и универсальности.
- Поддерживаемые функции: CUTLASS предоставляет больше функций и вариантов алгоритмов.,Включая матричное умножение и накопление (MMA), свертку и т. д. CUBLAS предоставляет набор предопределенных функций работы с матрицами.,Такие как умножение матрицы, умножение матрицы на вектор и т. д.
- Открытый исходный код: CUTLASS имеет открытый исходный код.,Пользователи могут получить доступ к исходному коду и участвовать в обсуждениях и вкладах сообщества. CUBLAS имеет закрытый исходный код,Его базовая реализация недоступна для пользователей. )
Если вам нужна максимальная гибкость, например, настройка эпилогов, которых нет в кубласах, используйте Cutlass. Хотя для начала работы требуется некоторое время, у вас есть максимальный контроль над передачей данных и операциями.
Где вы можете найти Cutlass в экосистеме PyTorch? На высоком уровне вы обнаружите несколько плотных и разреженных операций в активном режиме, и в настоящее время ведется работа по добавлению Cutlass в качестве альтернативы Inductor. AItemplate (серверный инструмент для создания кода Torch от Meta) использует некоторые функции каждого уровня в процессе разработки. Эффективное использование памяти в Xformer было разработано в Cutlass. Наконец, PyTorch геометрический — один из первых, кто внедрил нашу группу Gemm.
Ранее я упоминал интерфейс Python. Одна из самых больших проблем Cutlass — шаблоны C++. Благодаря нашему интерфейсу Python мы значительно сократили количество настроек по умолчанию, необходимых для начала работы. Вот базовый пример gemm, вы можете видеть, что это, вероятно, более трети необходимых параметров.
using Gemm = typename gemm::kernel::DefaultGemmUniversal<
half, layout::RowMajor, ComplexTransform::kNone,
half, layout::RowMajor, ComplexTransform::kNone,
half, layout::RowMajor,
arch::OpClassTensorOp, arch::Sm8e,
gemm::GemmShape<256, 128, 64>,
gemm::GemmShape<64, 64, 64>,
gemm::GemmShape<16, 8, 16>,
epilogue::thread::LinearCombination<half, a, half, half>
gemm::threadblock::GemmIdentityThreadblockSwizzle<1>,
arch::OpMultiplyAdd>::GemmKernel;
# СоздатьGEMM plan
plan = cutlass.op.Gemm(element=torch.float16, layout=cutlass.LayoutType.RowMajor)
# Изменить свистлинг functor
plan.swizzling_functor = cutlass.swizzle.ThreadblockSwizzlestreamk
# добавить слитый ReLU
plan.activation = cutlass.epilogue.relu
Другая цель интерфейса Python — улучшить интеграцию с такими платформами, как PyTorch. Этого можно достичь с помощью нового метода Issue PyTorch Cutlass. Справа вы увидите, что вы можете использовать интерфейс Python для объявления группы gemm в PyTorch и предоставления расширения PyTorch CUDA.

Затем мы будем отвечать за генерацию исходного кода, предоставление входных данных для расширения PyTorch и предоставление сценария для создания расширения PyTorch.
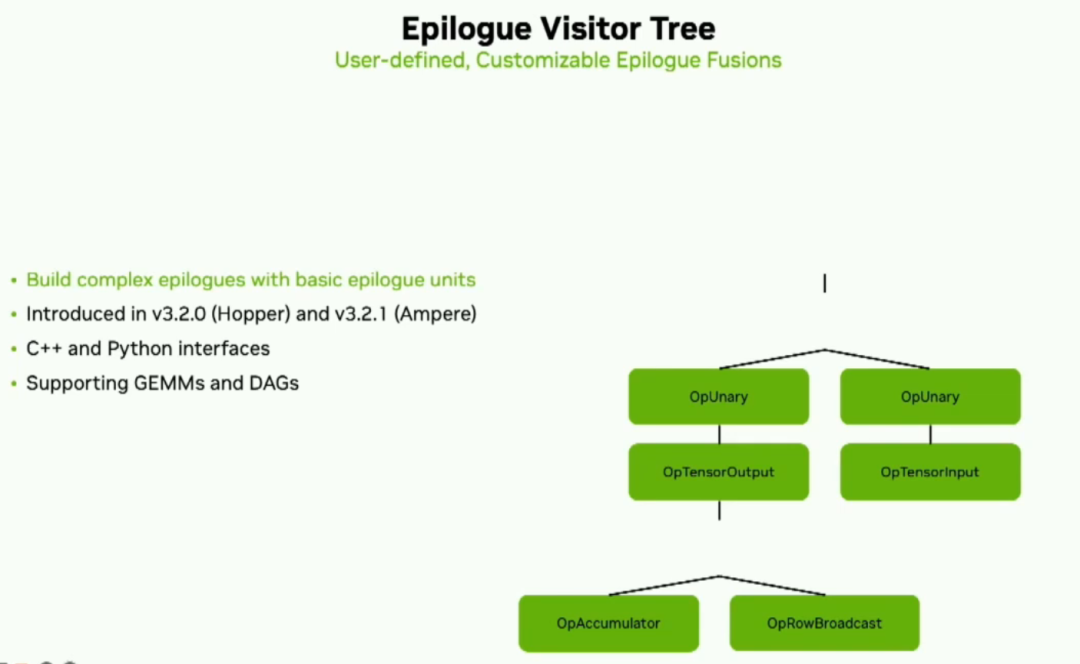
Новейшая функция Cutlass — это то, что мы называем эпилогом «Дерево посетителей». Это позволит пользователям разрабатывать сложные эпилоги, используя базовые единицы эпилога. Это набор небольших операций вычисления, загрузки и сохранения, которые могут генерировать общие или специальные эпилоги. Он уже доступен в архитектурах Ampere и Hopper, а также в интерфейсах C++ и Python. В нашей существующей конфигурации мы очень хорошо используем пики. Ниже приведен пример использования профилировщика и параметров по умолчанию в последних версиях Cutlass 3.2 и Cuda Toolkit 12.2 с H100.
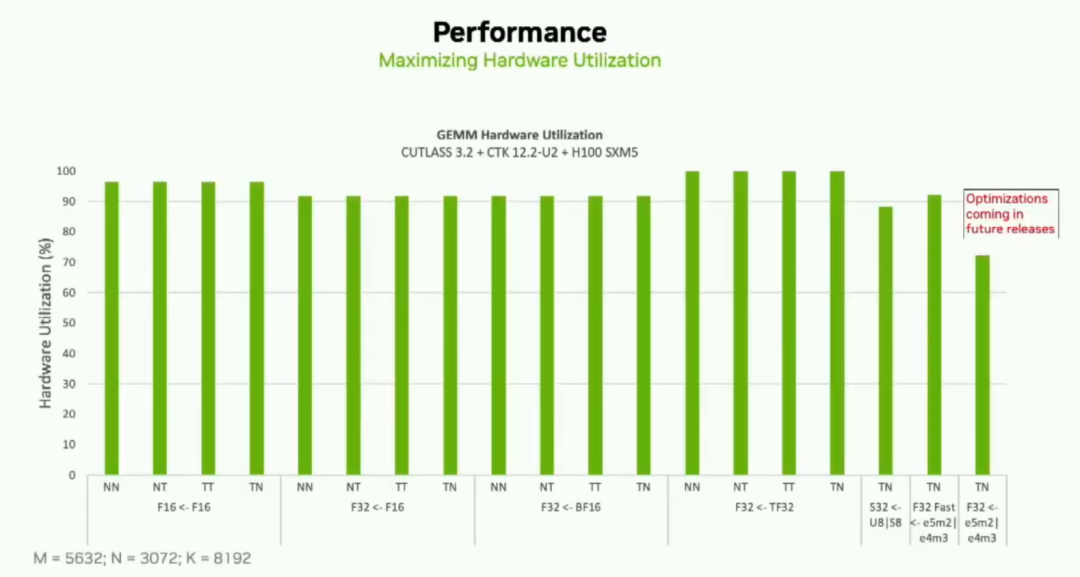
Вы можете видеть, что для всех этих вариантов использования пиковая загрузка составляет около 90%. Мы также прилагаем все усилия, чтобы гарантировать отсутствие снижения производительности, и регулярно выпускаем оптимизированные версии.
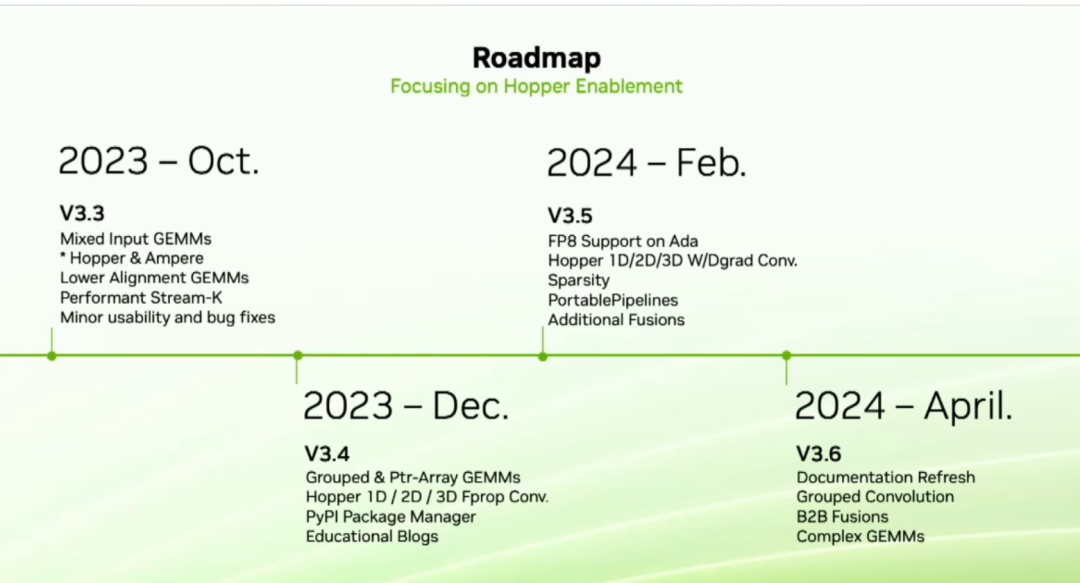
Наш следующий выпуск — 3.3. Самая важная особенность версии 3.3 — это то, что мы называем Gemm смешанного ввода. Это общее требование, и в этой функции вы можете использовать разные типы данных для матриц A и B. Например, A может быть FP16. B может быть int8, а в gemm мы преобразуем его в операцию BF16. Мы также относимся к нашим нижним alignment gemm улучшил производительность. Затем в декабре этого года мы запустим сгруппированные и ptr-array gemm,А также четыре свертки производительности для оптимизации Hopper. в начале следующего года,мы будемAdaпоставлятьFP8поддерживать。Мы сделаем свертку с весамииотклонение(W&D grad) оптимизация для поддержки разреженных данных. У нас также есть новая функция под названием Portablepipeline. Portablepipeline — наша рекомендация для пользователей, которые хотят реализовать переносимость в своей архитектуре. в ГТК TalkДополнительную информацию об этой функции можно будет найти на。наконец,во втором квартале следующего года,Разработчикам и новичкам Cutlass нужна лучшая документация. Мы сделаем комплексное обновление,Здесь будет рассмотрен интерфейс C++иPython.
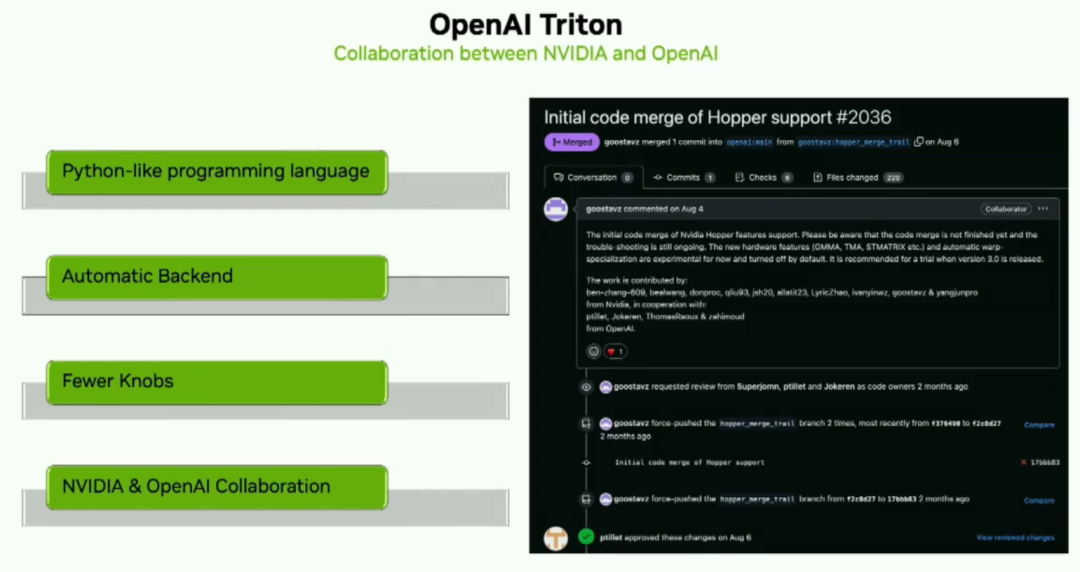
OpenAI Triton — это потрясающий новый Python-подобный язык программирования, который пользователи могут разрабатывать на Python для NVIDIA. Ядро TensorCores. Таким образом, разработчики могут сосредоточиться на логике более высокого уровня. Опен АИ Triton Compilerвыдержит большую производительностьоптимизация,Пусть разработчики не волнуются。NVиopenaiВ активном сотрудничестве, чтобы продвигать все。
Вот и все, спасибо.


3 Бесплатные системы управления складом (WMS) .NET с открытым исходным кодом

Глубокое погружение в библиотеку Python Lassie: мощный инструмент для автоматизации извлечения метаданных
Объяснение прослушивателя серии Activiti7 последней версии 2023 года

API-интерфейс Jitu Express для электронных счетов-Express Bird [просто для понимания]

Каковы архитектуры микросервисов Java. Серверная часть плавающей области обслуживания

Описание трех режимов жизненного цикла службы внедрения зависимостей Asp.net Core.

Java реализует пользовательские аннотации для доступа к интерфейсу без проверки токена.

Серверная часть Unity добавляет поддержку .net 8. Я еще думал об этом два дня назад, и это сбылось.
Проект с открытым исходным кодом | Самый элегантный метод подписки на публичные аккаунты WeChat на данный момент
Разрешения роли пользователя Gitlab Гость, Репортер, Разработчик, Мастер, Владелец

Spring Security 6.x подробно объясняет механизм управления аутентификацией сеанса в этой статье.

[Основные знания ASP.NET] — Аутентификация и авторизация — Использование удостоверений для аутентификации.

Соединение JDBC с базой данных MySQL в jsp [легко понять]

[Уровень няни] Полный процесс развертывания проекта Python (веб-страницы Flask) в Docker.
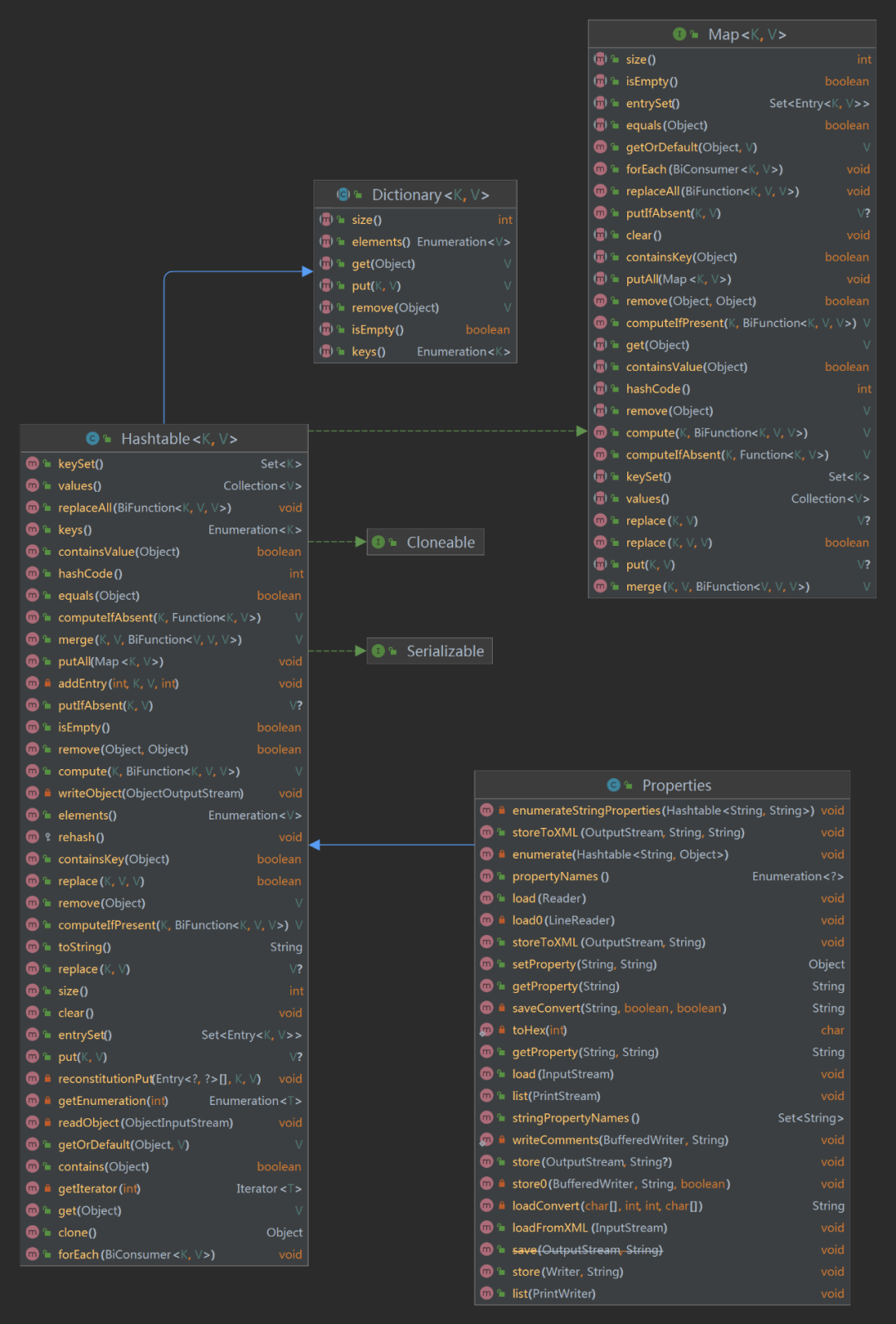
6 способов чтения файлов свойств, рекомендуем собрать!
Графическое объяснение этапа строительства проекта IDEA 2021 Spring Cloud (базовая версия)

Подробное объяснение технологии междоменного запроса данных JSONP.

Учебное пособие по SpringBoot (14) | SpringBoot интегрирует Redis (наиболее полный во всей сети)
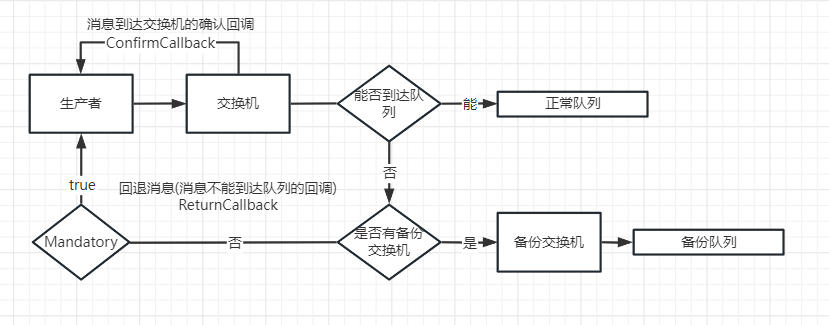
Подробное объяснение механизма подтверждения выпуска сообщений RabbitMQ.

На этот раз полностью поймите протокол ZooKeeper.
Реализуйте загрузку файлов с использованием минимального WEB API.

Демо1 Laravel5.2 — генерация и хранение URL-адресов
Spring boot интегрирует Kafka и реализует отправку и потребление информации (действительно при личном тестировании)
Мысли о решениях по внутренней реализации сортировки методом перетаскивания

Междоменный доступ к конфигурации nginx не может вступить в силу. Междоменный доступ к странице_Page

Как написать текстовый контент на php

PHP добавляет текстовый водяной знак или водяной знак изображения к изображениям – метод инкапсуляции
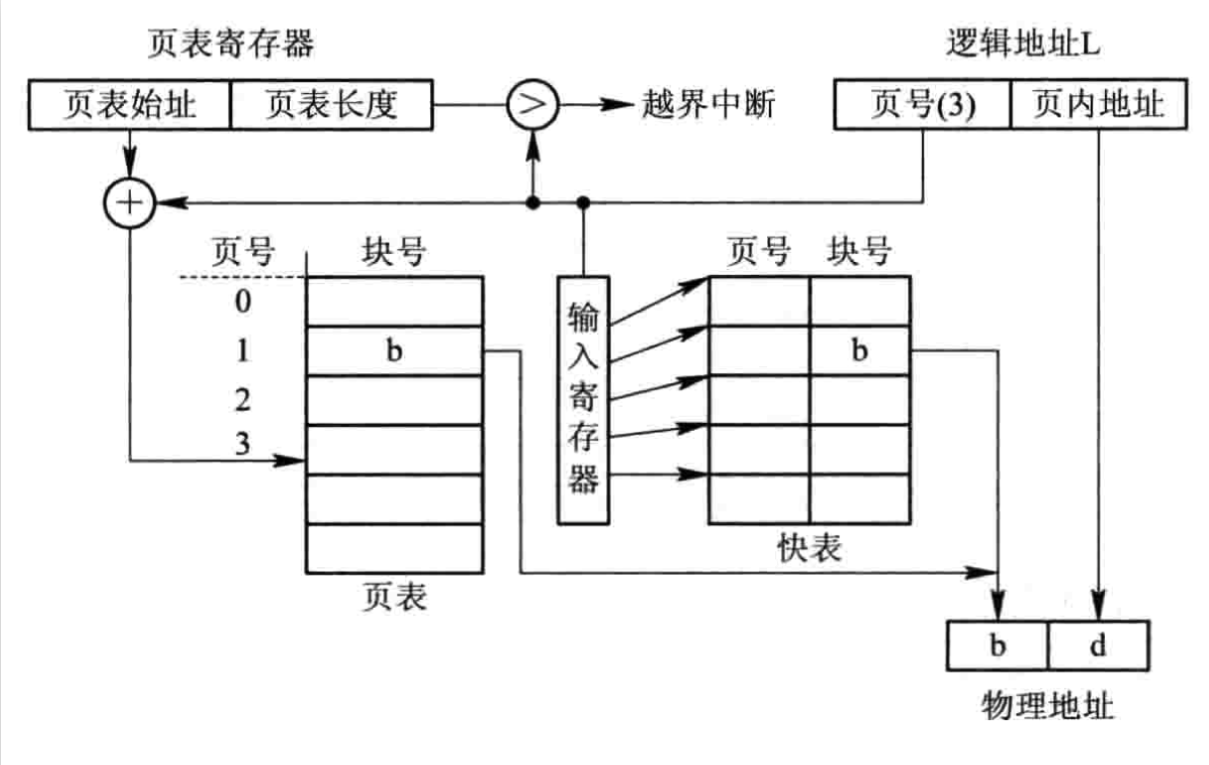
Интерпретация быстрой таблицы (TLB)

Интерфейс WeChat API (полный) — оплата WeChat/красный конверт WeChat/купон WeChat/магазин WeChat/JSAPI
