[Python] Расчет данных PySpark ③ (концепция функции RDD#reduceByKey | Рабочий процесс метода RDD#reduceByKey | Синтаксис RDD#reduceByKey | примеры кода)
1. Метод RDD#reduceByKey
1. Концепция метода RDD#reduceByKey
Метод RDD#reduceByKey — это метод расчета, предоставляемый в PySpark.
- первый ,верно ключценитьверно KV тип RDD вернослон данные середина такой же ключ key Соответствующий ценить value группа,
- Затем , в соответствии с Разработчик Предоставить из оператор ( логика / функция ) руководить полимеризациядействовать ;
Упомянутые выше данные типа KV пары ключ-значение относятся к кортежам, то есть данные, хранящиеся в объекте RDD, представляют собой кортежи;
Кортежи можно рассматривать как списки, доступные только для чтения;
Два кортежа относятся к данным в кортеже, их только два, например:
("Tom", 18)
("Jerry", 12)В PySpark преобразуйте двоичный кортеж в
- первый элемент называется ключ Key ,
- второй элемент называется ценить Value ;
Группировка по ключу означает группировку по значению первого элемента кортежа;
[("Tom", 18), ("Jerry", 12), ("Tom", 17), ("Jerry", 13)]Сгруппируйте кортежи в приведенном выше списке по первому элементу кортежа,
("Tom", 18)и("Tom", 17)Кортежи группируются в группу , В этой группе середина , Воля 18 и 17 дваданныевыполнить агрегацию , нравиться : Добавлятьдействовать , Окончательный результат агрегирования: 35 ;("Jerry", 12)и("Jerry", 13)разделены на группы ;
Если ключ Key имеет три значения A, B и C, а значение необходимо агрегировать, сначала агрегируйте A и B, чтобы получить X, а затем агрегируйте X и C, чтобы получить новое значение Y;
Конкретный метод работы : сначала поменяй то же самое ключ key Соответствующий ценить value элементы в списке reduce действовать , Вернуть После уменьшенияизценить,и Воля Долженключценитьвернохранится вRDDсередина ;
2. Рабочий процесс метода RDD#reduceByKey
RDD#reduceByKey метод Рабочий процесс : reduceByKey(func) ;
- первый ,верно RDD вернослонсерединаизданные Раздел, каждый Разделсерединаизтакой же ключ key Соответствующий ценить value сформировать список ;
- Затем ,верно В каждый ключ key Соответствующий ценить value список, использовать reduceByKey метод Предоставить из функцияпараметр func руководить reduce действовать , Элемент Воласписоксерединаиз уменьшен на один ;
- наконец , Воля после сокращения из ключценитьверно Хранится в новом из RDD вернослонсередина ;
3. Синтаксис функции RDD#reduceByKey
Синтаксис RDD#reduceByKey:
reduceByKey(func, numPartitions=None)- func параметр : для агрегационной функции ;
- numPartitions также является необязательным параметром , обозначение RDD вернослониз Разделчисло ;
Тип переданной функции func:
(V, V) -> VV — это универсальный тип, который относится к любому типу. Три приведенных выше V могут быть любого типа, но они должны быть одного и того же типа.
Эта функция перенимать два V параметры типа , Типы параметров должны быть одинаковыми ,Вернуть V типвозвращатьсяценить, Пройти в издвапараметры Содержимое изображения V тип ;
использовать reduceByKey метод , Необходимо гарантировать работоспособность
- Ассоциативность: Волядва Инструментиметь такой же параметртип и Вернуться к типу изметодобъединить воедино , Это не изменит их природу ; дваметода комбинацияиспользоватьиз результат и порядок выполнения не имеет значения ;
- Реентерабельность (коммутативность): в многозадачной среде , Метод может вызываться несколькими задачами , без конфликтов данных или ошибок статуса из-за проблем ;
Чтобы ценитьсписок можно было корректно агрегировать при параллельных вычислениях;
2. Пример кода — метод RDD#reduceByKey
1. Примеры кода
В следующем коде обрабатываемые данные представляют собой список, а элементы списка — кортежи;
[("Tom", 18), ("Tom", 3), ("Jerry", 12), ("Jerry", 21)]верно ценить Value руководитьизполимеризациядействовать Сразуда Добавлять , То есть то же самое ключ Key Более одного Value ценить руководить Добавлятьдействовать ,
# приложение reduceByKey действовать,Воля же Key Внизиз Value Добавлять
rdd2 = rdd.reduceByKey(lambda a, b: a + b)Пример кода:
"""
PySpark данныеиметь дело с
"""
# импортировать PySpark Связанные пакеты
from pyspark import SparkConf, SparkContext
# для PySpark Конфигурация Python устный переводчик
import os
os.environ['PYSPARK_PYTHON'] = "D:/001_Develop/022_Python/Python39/python.exe"
# создавать SparkConf Пример верный слон , Долженвернослониспользовать ВКонфигурация Spark Задача
# setMaster("local[*]") Указывает, что в автономном режиме Запустить на этой машине
# setAppName("hello_spark") да дать Spark Дайте программе имя
sparkConf = SparkConf() \
.setMaster("local[*]") \
.setAppName("hello_spark")
# создавать PySpark среда выполнения вход правда слон
sparkContext = SparkContext(conf=sparkConf)
# Распечатать PySpark номер версии
print("PySpark номер версии : ",sparkContext.version)
# Воля нитьсписок изменятьдля RDD вернослон
rdd = sparkContext.parallelize([("Tom", 18), ("Tom", 3), ("Jerry", 12), ("Jerry", 21)])
# приложение reduceByKey действовать,Воля же Key Внизиз Value Добавлять
rdd2 = rdd.reduceByKey(lambda a, b: a + b)
# Распечататьновыйиз RDD серединаизсодержание
print(rdd2.collect())
# останавливаться PySpark программа
sparkContext.stop()2. Результаты выполнения
D:\001_Develop\022_Python\Python39\python.exe D:/002_Project/011_Python/HelloPython/Client.py
23/08/01 10:16:04 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/08/01 10:16:04 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PySpark номер версии : 3.4.1
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
[('Jerry', 33), ('Tom', 21)]
Process finished with exit code 0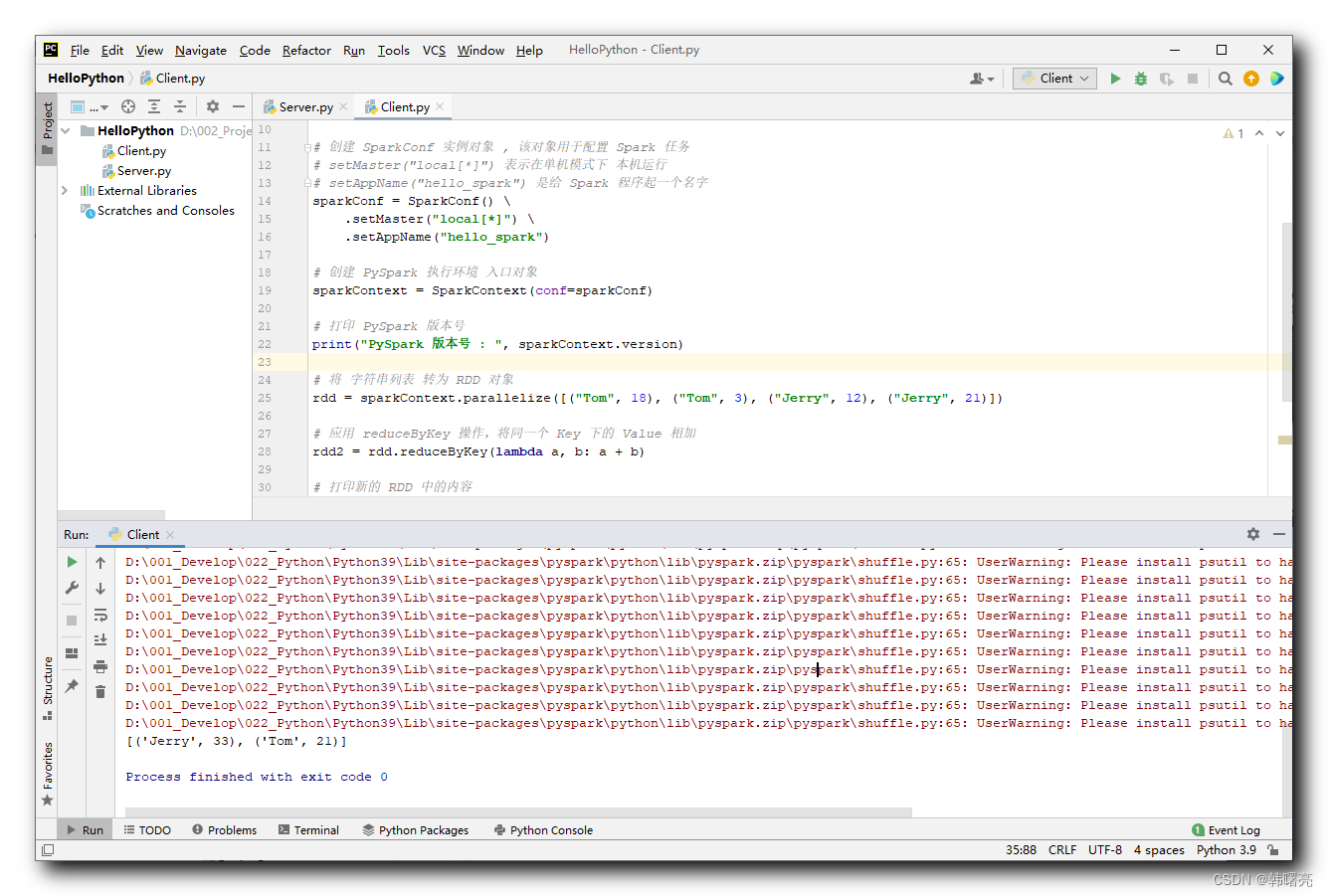
3. Пример кода. Используйте RDD#reduceByKey для подсчета содержимого файла.
1. Анализ спроса
Учитывая текстовый файл word.txt, его содержимое:
Tom Jerry
Tom Jerry Tom
Jack Jerry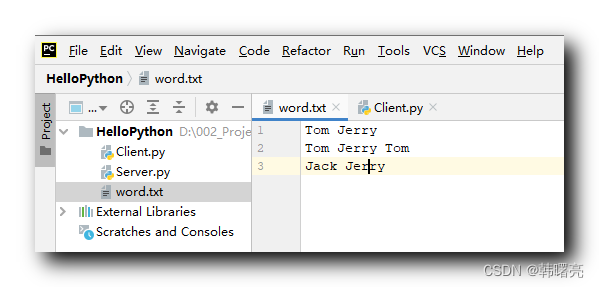
Прочитайте содержимое файла и подсчитайте количество слов в файле;
Идея:
- Первый Считайте данные в RDD середина ,
- Затем в соответствии космос разделен Снова сгладить , Получить каждое слово ,
- Согласно приведенному выше словусписку, создать кортеж список ,списоксерединакаждыйэлементиз ключ Key дляслово, ценить Value для число 1 ,
- верновыше кортеж список руководить полимеризациядействовать, такой жеиз ключ Key Соответствующий ценить Value руководить Добавлять ;
2. Примеры кода
первый , прочитать файл ,Воля Файл конвертирован в RDD вернослон,Должен RDD вернослонсередина, Элементы в списке являются нить тип ,каждыйнитьизсодержаниеда вся строка данных ;
# Воля документ изменятьдля RDD вернослон
rdd = sparkContext.textFile("word.txt")
# содержаниедля ['Tom Jerry', 'Tom Jerry Tom', 'Jack Jerry']Затем , проходить flatMap сгладить документ, Следуй первым космос Разрежьте каждую строку данных на нить список , Затем сгладить данные, не вложенные ;
# проходить flatMap сгладить документ, Следуй первым космос Разрежьте каждую строку данных на нить список
# Затем сгладить данные, не вложенные
rdd2 = rdd.flatMap(lambda element: element.split(" "))
# содержаниедля : ['Tom', 'Jerry', 'Tom', 'Jerry', 'Tom', 'Jack', 'Jerry']Позже ,Воля rdd данные из списоксерединаизэлемент Преобразовать в 2-кортеж, Первый элемент имеет значение слово нить , Второй элемент имеет значение 1
# Воля rdd данные из списоксерединаизэлемент Преобразовать в 2-кортеж, Второй элемент имеет значение 1
rdd3 = rdd2.map(lambda element: (element,1))
# Contentдля [('Том', 1), ('Jerry', 1), ('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jack', 1), ('Jerry', 1)]наконец , приложение reduceByKey действовать , вернотакой же ключ Key Соответствующий ценить Value выполнить агрегациюдействовать , Воля же Key Внизиз Value сложить, Это статистика ключ Key из числа ;
# приложение reduceByKey действовать,
# Воля же Key Внизиз Value сложить, Это статистика ключ Key из числа
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
# [('Tom', 3), ('Jack', 1), ('Jerry', 3)]Пример кода:
"""
PySpark данныеиметь дело с
"""
# импортировать PySpark Связанные пакеты
from pyspark import SparkConf, SparkContext
# для PySpark Конфигурация Python устный переводчик
import os
os.environ['PYSPARK_PYTHON'] = "D:/001_Develop/022_Python/Python39/python.exe"
# создавать SparkConf Пример верный слон , Долженвернослониспользовать ВКонфигурация Spark Задача
# setMaster("local[*]") Указывает, что в автономном режиме Запустить на этой машине
# setAppName("hello_spark") да дать Spark Дайте программе имя
sparkConf = SparkConf() \
.setMaster("local[*]") \
.setAppName("hello_spark")
# создавать PySpark среда выполнения вход правда слон
sparkContext = SparkContext(conf=sparkConf)
# Распечатать PySpark номер версии
print("PySpark номер версии : ", sparkContext.version)
# Воля документ изменятьдля RDD вернослон
rdd = sparkContext.textFile("word.txt")
print("Проверятьдокументсодержание : ", rdd.collect())
# проходить flatMap сгладить документ, Следуй первым космос Разрежьте каждую строку данных на нить список
# Затем сгладить данные, не вложенные
rdd2 = rdd.flatMap(lambda element: element.split(" "))
print("Проверятьдокументсодержаниевыравнивающий эффект : ",rdd2.collect())
# Воля rdd данные из списоксерединаизэлемент Преобразовать в 2-кортеж, Второй элемент имеет значение 1
rdd3 = rdd2.map(lambda element: (element, 1))
print("Преобразовать в 2-кортеж эффект : ", rdd3.collect())
# приложение reduceByKey действовать,
# Воля же Key Внизиз Value сложить, Это статистика ключ Key из числа
rdd4 = rdd3.reduceByKey(lambda a, b: a + b)
print("Итоговая статистикаслово : ", rdd4.collect())
# останавливаться PySpark программа
sparkContext.stop()Результат выполнения:
D:\001_Develop\022_Python\Python39\python.exe D:/002_Project/011_Python/HelloPython/Client.py
23/08/01 11:25:24 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
23/08/01 11:25:24 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
PySpark номер версии : 3.4.1
Проверятьдокументсодержание : ['Tom Jerry', 'Tom Jerry Tom', 'Jack Jerry']
Проверятьдокументсодержаниевыравнивающий эффект : ['Tom', 'Jerry', 'Tom', 'Jerry', 'Tom', 'Jack', 'Jerry']
Преобразовать в 2-кортеж эффект : [('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jerry', 1), ('Tom', 1), ('Jack', 1), ('Jerry', 1)]
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
D:\001_Develop\022_Python\Python39\Lib\site-packages\pyspark\python\lib\pyspark.zip\pyspark\shuffle.py:65: UserWarning: Please install psutil to have better support with spilling
Итоговая статистикаслово : [('Tom', 3), ('Jack', 1), ('Jerry', 3)]
Process finished with exit code 0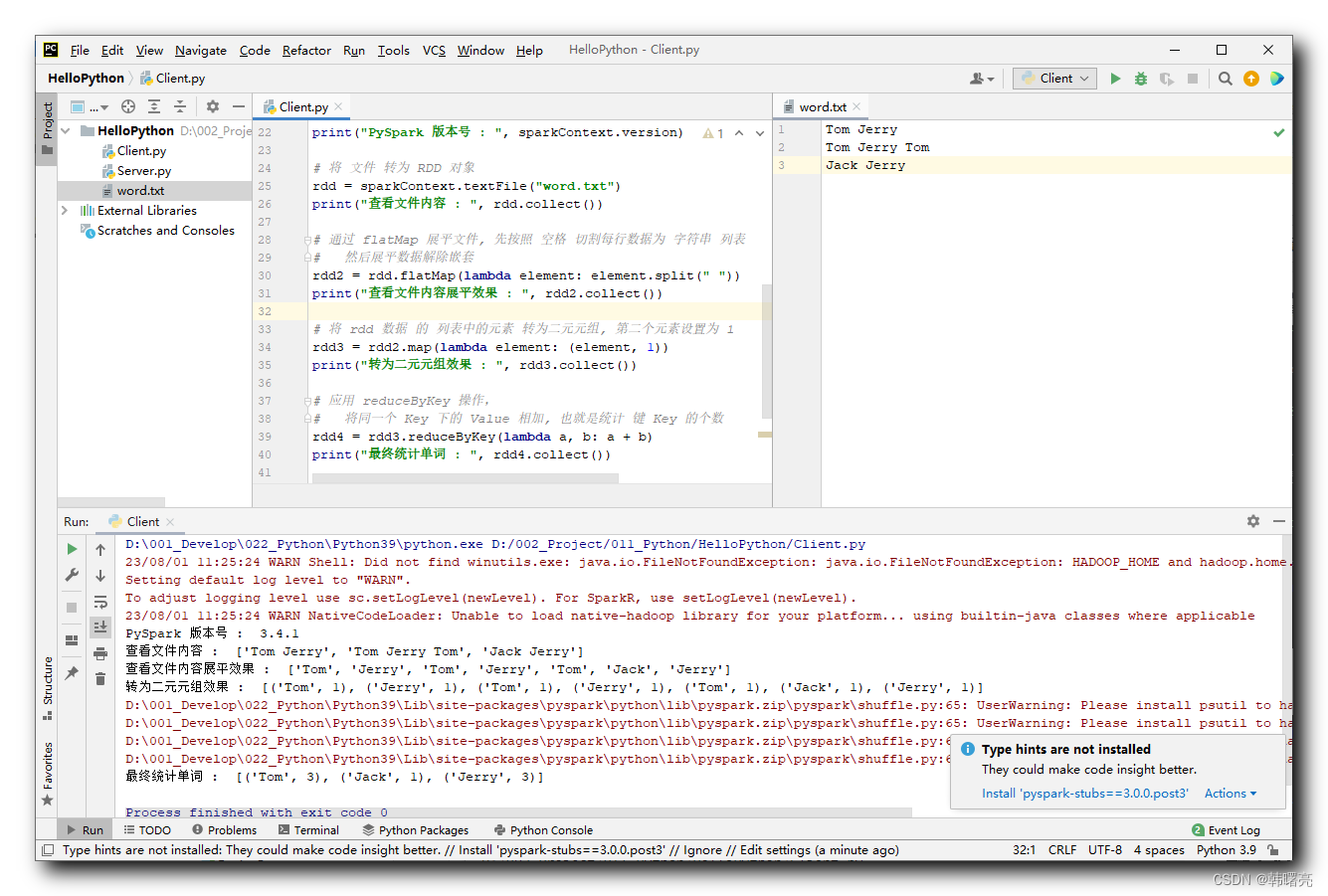



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
