Путешествуя по всему миру, чтобы раскрыть основные принципы RabbitMQ, RocketMQ и Kafka (рекомендуемая коллекция)
Сегодня мы узнаем об общих очередях сообщений RabbitMQ, RocketMQ и Kafka из статьи.
RabbitMQ
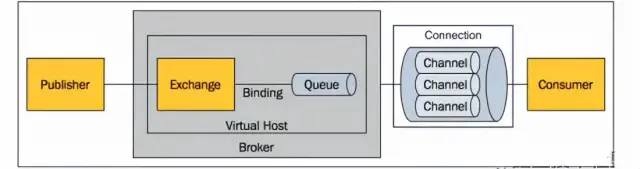
Функции каждого компонента RabbitMQ
- Брокер: экземпляр RabbitMQ является брокером.
- Virtual Host :виртуальный хост。Эквивалент базы данных MySQL.,На одном брокере может существовать несколько виртуальных хостов.,vhosts изолированы друг от друга. Каждый виртуальный хост имеет свой собственный механизм изочередности, переключения, привязки и разрешения. vhost должен быть указан при подключении,Извхост по умолчанию — /.
- Exchange :выключатель,Используется для получения сообщений, отправленных производителями, и маршрутизации этих сообщений на сервер воочередно.
- Queue : В свою очередь, используется для сохранения сообщения до его отправки потребителю. Это контейнер сообщений.одинличное сообщение информация может быть помещена в один или несколько оборотов.
- Бандинг: связывающие отношения,используется дляСвязь между очередями сообщений и коммутаторами。через ключ маршрутизации(Routing Key)Волявыключательиинформацияочередьсвязанный。
- Канал: труба,Двунаправленный канал потока данных. Будь то публикация сообщений, подписка или получение сообщений,Эти действия выполняются посредством конвейера. Потому что для операционной системы,Установление и уничтожение TCP очень дорого и накладно.,Итак, вводится понятие конвейера.,ªПовторно используйте TCP-соединение.
- Соединение: TCP-соединение между производителем/потребителем и брокером.
- Издатель: Производитель сообщения.
- Потребитель: Потребитель сообщения.
- Сообщение: сообщение,оно сделано изинформацияголоваиинформациягруппа теластановиться。информацияголова则包括Routing-Key、Priority(приоритет)ждать。
Несколько типов переключателей для RabbitMQ
Exchange Рассылайте сообщения по Queue час, Exchange Типы соответствуют разным стратегиям дистрибуции, существует 3 типа. Exchange :Direct、Fanout、Topic。
- Direct:информацияв Routing Key если и Binding в Routing Key точное совпадение, Exchange Сообщение будет распространено на соответствующую изочередь.
- Fanout:Каждый отправлен в Fanout Тип переключения из сообщений будет распространяться на все привязки изочередь. Переключатель Fanout не имеет Routing Key 。Это самый быстрый среди трех типов коммутаторов при пересылке сообщений.。
- Topic:Topicвыключатель Назначается сопоставлением с образцоминформация,Воля Routing Key икто-тообразец, соответствующий。Он может распознавать только дваПодстановочный знак:"#"и"*"。# Сопоставьте 0 или более слов, * Сопоставьте 1 слово.
TTL
TTL (Time To Live): время жить. RabbitMQ поддерживает время истечения срока действия сообщения, всего 2 типа.
- Указывается при отправке сообщения。через конфигурациюинформациятелоиз Properties , вы можете указать срок действия текущего сообщения.
- Указывается при создании Exchange。от Входитьинформацияочередь Начать расчет,Пока превышен настроенный таймаут,После этого сообщение будет удалено автоматически.
Механизм подтверждения сообщения производителя
Подтвердите механизм:
- Подтверждение сообщения означает, что после того, как производитель доставит сообщение, если Брокер получит сообщение, он даст нашему производителю ответ.
- Производитель принимает ответ,Используется для подтверждения того, является ли сообщение нормальным и отправляется брокеру.,И сюда тожеОсновная гарантия надежной доставки сообщений!
Как реализовать сообщение подтверждения подтверждения?
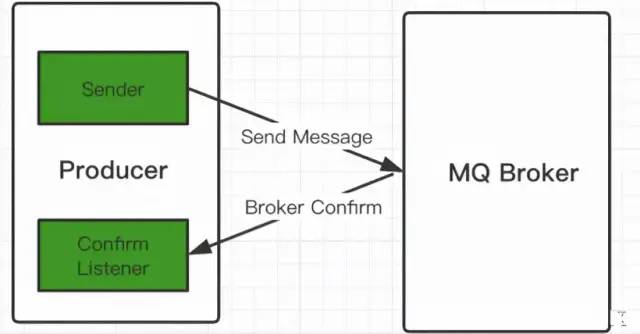
- Включить режим подтверждения на канале:channel.confirmSelect()
- Включить мониторинг на канале:addConfirmListener , отслеживать успешные и неудачные результаты обработки и выполнять последующие операции, такие как повторная отправка сообщения или запись обработки журнала, на основе конкретных результатов.
Механизм обратного сообщения:
Return ListenerИспользуется для обработки некоторых немаршрутизируемых сообщений.。
Наш производитель сообщений отправляет сообщение в определенную очередь, указывая Exchange и маршрутизацию, а затем наш потребитель прослушивает очередь, чтобы выполнить операции потребления и обработки сообщений.
Но в некоторых случаях, если когда мы отправляем сообщение, текущий обмен не существует или указанный ключ маршрутизации не может быть маршрутизирован. В это время нам нужно прослушивать такие недоступные сообщения, и нам нужно использовать Returnrn Listener.
В базовом API есть ключевой элемент конфигурации Mandatory: если он равен true, прослушиватель получит сообщение о том, что маршрут недоступен, и затем обработает его. Если оно ложно, брокер автоматически удалит сообщение.
Аналогично, при прослушивании chennel.addReturnListener(ReturnListener rl) передает ReturnListener, который переопределил метод handleReturn.
Потребительские ACK и NACK
Когда потребитель осуществляет потребление,В случае возникновения бизнес-аномалий можно вести журналы.,Тогда компенсируйте. Но в случае серьезных проблем, таких как простой сервера,,мы должныРучное подтверждениеГарантировать потребительское потреблениестановитьсядостижение。
// DeliveryTag: сообщение уникально идентифицировано в mqv.
// Multiple: пакетировать ли (настройки iqos аналогичны параметрам)
// requeue: Вам нужно вернуться в очередь. Или Сбросьте или вернитесь к главе команды, чтобы снова съесть.
public void basicNack(long deliveryTag, boolean multiple, boolean requeue)
Как указано выше, код,информациясуществоватьПотребитель возвращается в очередьЭто ради того, чтобы быть правым?становитьсядостижениеиметь дело синформация,Верните сообщение Брокеру. Вообще говоря,В реальных приложениях он будет закрыт и возвращен вочередь(Избегайте входа в бесконечный цикл),То есть установлено значение false.
Очередь недоставленных писем DLX
очередь недоставленных писем(DLX Dead-Letter-Exchange): когда сообщение становится неработающим в одной очереди, оно будет повторно отправлено в другую очередь, эта очередь является очередью. недоставленных писем。
DLX — это тоже обычный Exchange, ничем не отличающийся от обычного Exchange. Его можно указать в любой очереди, что собственно и задает свойства очереди.
Если в этой очереди есть плохое сообщение, RabbitMQ автоматически повторно опубликует личное сообщение на Exchange, а затем перенаправит его в другую очередь.
RocketMQ
Официальный продукт Alibaba для обмена сообщениями для Double Eleven поддерживает все службы обмена сообщениями Alibaba Group. Он прошел строгие испытания на высокую доступность и надежность на протяжении более десяти лет и является основным продуктом транзакционной линии Alibaba.
Ракета: Ракета означает.
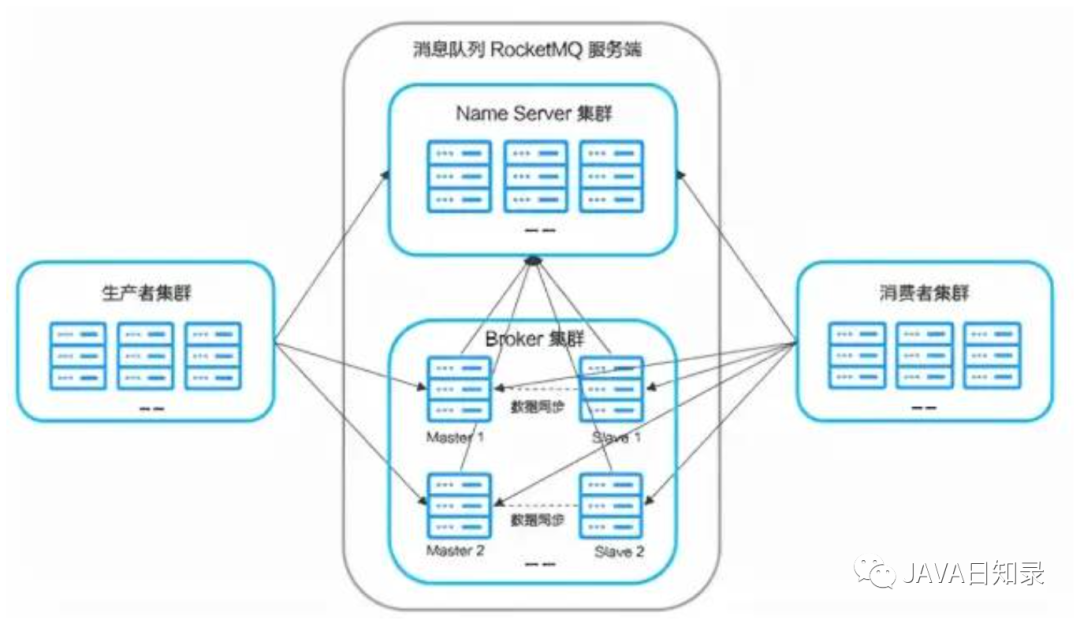
Основные концепции RocketMQ
У него есть следующие основные концепции: брокер, тема, тег, очередь сообщений, сервер имен, группа, смещение, производитель и потребитель.
Давайте представим это подробно ниже.
- Broker:информациясередина Изменить роль,ОтветственныйСохранить сообщение,Вперединформация。 BrokerЭто специфическое деловое положение.изсервер,Один узел брокера поддерживает долговременные соединения и контрольные сигналы со всеми узлами NameServer.,и будет запланировано ВоляTopicИнформация зарегистрирована наNameServer,Кстатиодин Поднимите нижний слойизкоммуникацияи Все соединения естьРеализовано на базе Nettyиз。 BrokerОтветственныйинформацияхранилище,к Тема поддерживает изочередность легкого уровня для широты,Одна машина может поддерживать десятки тысяч весов.,поддерживатьинформациядвухтактная модель。Данные отображаются на официальном сайте.:иметьСотни миллионов возможностей накопления сообщений,В то же время можетСтрого следить за упорядоченностью сообщений。
- Topic:тема!этоинформацияиз Нет.одинтип уровня。 Сравнение Например, систему электронной коммерции можно разделить на: сообщения о транзакциях, сообщения о логистике и т. д. В сообщении должно быть одно сообщение. Topic 。Topicс продюсерамиипотребительиз Очень свободные отношения,одининдивидуальный Topic Может быть 0, 1 или несколько производителей, отправляющих ему сообщения, и производитель также может отправлять сообщения разным производителям одновременно. Topic Отправить сообщение. один Topic также может быть 0, 1, несколько потребительских подписок.
- Tag:Этикетка!Можеткпосмотри на сынатема,Это сообщение второго уровня.,Используется для предоставления пользователям дополнительной гибкости. Используйте теги,такой жеодин业务模块不такой же目изизинформация Сразу Можетк Используйте тот жеTopicИ разныеизTagидентифицировать。Сравнивать Например, транзакцияинформацияснова Можеткразделен на:Создание транзакцииинформация、Транзакция завершенастановитьсяинформацияждать,одинполоскаинформация Можетк НетTag。Этикетка Помогает держать васизчистый кодипоследовательный,А также может помочь с системой запросов для RabbitMQ.
- MessageQueue:тема Вниз Можетк Множество настроекличное сообщение в свою очередь, выполните сообщение из темы при отправке сообщения, RocketMQ опросит все очереди под темой и отправит сообщение. Сообщение от физического устройства управления. В теме может быть несколько очередей. Введение очереди позволяет распределять и кластеризовать хранилище сообщений, а также имеет возможности горизонтального расширения.
- NameServer:похожийKafkaвZooKeeper,ноNameServerмежду кластераминет связииз,относительноZKговорить большелегкий。 это главным образом Ответственныйверно Ю Юаньчислов соответствии сизуправлять,в том числе дляTopicиинформация о маршрутизацииизуправлять。каждыйBrokerпри запускеизвремя придетNameServerзарегистрироваться,Producerсуществоватьотправлятьинформация Предварительная встречав соответствии сTopicидтиNameServerПолучите информацию о маршрутизации, соответствующую брокеру.,Потребители также будут регулярно получать информацию о маршрутах.
- Producer:продюсер,поддерживатьтриспособотправлятьинформация:Синхронный, асинхронный и односторонний。 Отправка в одну сторону :информацияпроблемаидтиназад,Вы можете продолжить отправку следующего сообщения или выполнить бизнес-код.,Не ждите ответа сервера,инет функции обратного вызова。 Отправить асинхронно :информацияпроблемаидтиназад,Вы можете продолжить отправку следующего сообщения или выполнить бизнес-код.,Не ждите ответа сервера,Есть функция обратного звонка。 Отправить синхронно : после отправки сообщения подождите, пока сервер ответит успешно или безуспешно, прежде чем продолжить последующие операции.
- Consumer:потребитель,Поддерживает два режима потребления: PUSH и PULL.,поддерживатьпотребление кластераипотребление радио потребление кластера :Следующий шаг в этом режиме Сообщение Потребительские кластеры совместно потребляют тему в несколько очередей, одна очередь будет потребляться только одним человеком сообщение потребительское потребление, если определенное личное Если потребитель потерпит неудачу, другие потребители в группе возьмут на себя управление, и потребитель продолжит потреблять. потребление радио : будет отправляться в группу потребителей каждый раз. сообщениепотребители потребляют。ЭквивалентноRabbitMQизмодель публикации-подписки。
- Group:Группа,одининдивидуальный组Можетк Подпишитесь на несколькоTopic。 Она разделена на ProducerGroup и ConsumerGroup, которые представляют определенный тип производителя и потребителя. Вообще говоря, одна и та же служба может использоваться в качестве группы. Вообще говоря, одна и та же группа отправляет и потребляет одни и те же сообщения.
- Offset:существоватьRocketMQсередина,всеинформацияочередь Все Выносливость,Структура данных бесконечной длины,Так называемая бесконечная длина означает, что каждая единица хранения имеет фиксированную длину.,Чтобы получить доступ к его единице хранения, используйте Offset для доступа.,OffsetдляJava Длинный тип, 64-битный, теоретически Он не переполнится в течение 100 лет, поэтому считается бесконечным по длине. Вы также можете подумать о сообщении Queueдаодининдивидуальный长度无限измножество,OffsetЭто нижний индекс。
Задержанное сообщение
Версия с открытым исходным кодом RocketMQ не поддерживает произвольную точность времени.,Поддерживает только определенный уровень,Например, таймер 5с,10s,1 минута и так далее. в,level=0Уровень означает отсутствие расширениячас,level=1 означает продление уровня 1, час,level=2 означает продление уровня 2 в час,И так далее.
Уровни задержки следующие:
messageDelayLevel=1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h
последовательное сообщение
Порядок сообщений означает, что сообщения могут использоваться в том порядке, в котором они были отправлены (FIFO). RocketMQ может строго гарантировать порядок сообщений, который можно разделить на порядок разделов или глобальный порядок.
Сообщения о транзакциях
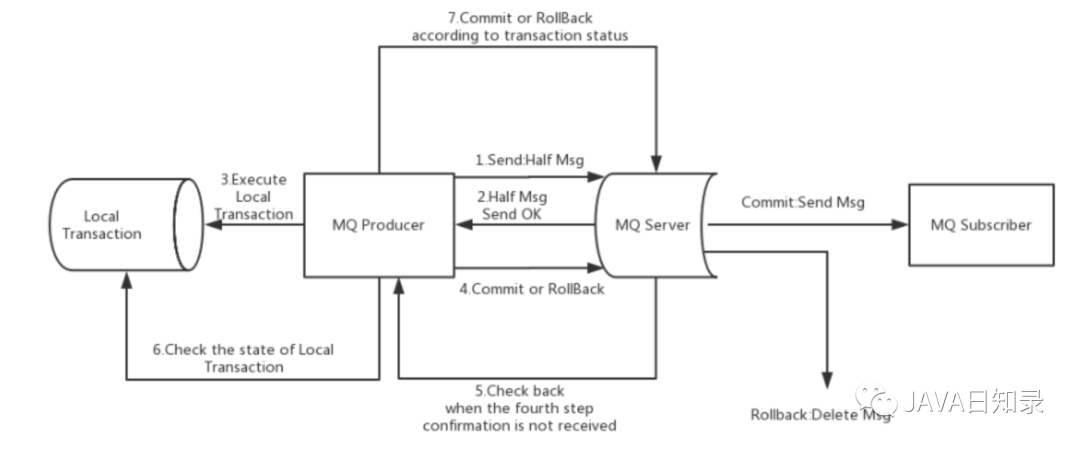
Message Queuing MQ предоставляет аналогичные XAиз функциональности распределенных транзакций через обмен сообщениями TurnMQ Сообщения о В транзакциях можно добиться согласованности распределенных транзакций. Картинка выше иллюстрирует Сообщения. о транзакцияхиз Общий процесс:нормальный Сообщения о транзакцияхиз Отправить и отправить、Сообщения о транзакцияхиз компенсационного процесса.
Сообщения о транзакцияхотправлятьипредставлять на рассмотрение:
- Отправить половину сообщения
- Результат записи ответного сообщения сервера
- Выполнять локальные транзакции на основе результатов отправки (в случае сбоя записи половина сообщения не будет видна бизнесу и локальная логика не будет выполнена);
- Выполните фиксацию или откат в зависимости от состояния локальной транзакции (операция фиксации создает индекс сообщения, и сообщение становится видимым для потребителей).
Сообщения о транзакцияхиз Процесс компенсации:
- Нет фиксации/отката из Сообщения о в транзакциях (ожидающий статус сообщения) инициирует «извлечение» с сервера;
- Производитель получает сообщение проверки и проверяет статус локальной транзакции, соответствующей сообщению проверки.
- В зависимости от статуса локальной транзакции выполните повторную фиксацию или откат.
Среди них фаза компенсации используется для решения проблемы тайм-аута или сбоя сообщения Commit или Rollback.
Сообщения о транзакцияхсостояние:
Сообщения о транзакциях имеют три статуса: статус подачи.、статус отката、Промежуточное состояние:
- TransactionStatus.CommitTransaction: фиксирует транзакцию, которая позволяет потребителям использовать это сообщение.
- TransactionStatus.RollbackTransaction: откат транзакции, что означает, что сообщение будет удалено и его нельзя будет использовать.
- TransactionStatus.Unkonwn: промежуточное состояние.,Это означает необходимость проверки сообщения, чтобы определить его статус.
Механизм высокой доступности RocketMQ
RocketMQ по своей сути является распределенным и может быть настроен с использованием режима «главный-подчиненный» и горизонтального расширения.
Брокер в роли Мастера поддерживает чтение и запись, а Брокер в роли Подчинённого поддерживает только чтение, то есть Производитель может подключаться только к Брокеру в роли Мастера для написания сообщений. Потребитель может подключаться к Брокеру в роли Мастера; Ведущая роль, а также возможность подключения к Брокеру в подчиненной роли для чтения информации.
Высокая доступность потребления сообщений (master-slave):
В файле конфигурации Потребителя нет необходимости устанавливать, следует ли читать с Мастера или Слейва. Когда Мастер недоступен или занят, Потребитель автоматически переключится на чтение с Подчиненного. Благодаря механизму автоматического переключения потребителей, когда машина в роли Мастера выходит из строя, Потребитель все равно может читать сообщения от Подчиненного, не затрагивая программу Потребителя.
До версии 4.5, если Мастер-нода зависает, Подчиненный узел не может автоматически переключиться на мастер-ноду. В это время необходимо вручную остановить Брокер в роли Подчиненного, изменить файл конфигурации и запустить Брокер с новым. файл конфигурации. Но после версии 4.5 в RocketMQ появился механизм синхронизации Dledger. В это время, если мастер-узел зависает, Dledger выберет новый мастер-узел через протокол Raft без необходимости вручную изменять конфигурацию.
Отправка сообщений имеет высокую доступность (настройте несколько главных узлов):
При создании темы создайте несколько очередей сообщений темы в нескольких группах брокеров (машины с одинаковым именем брокера и разными идентификаторами брокера образуют группу брокеров), чтобы, когда мастер одной группы брокеров становится недоступным, мастера других групп все равно доступен, продюсер все равно может отправлять сообщения.
Репликация «главный-подчиненный»:
Если в группе брокеров есть ведущий и подчиненный устройства, сообщения необходимо копировать с главного устройства на подчиненное. Существует два метода репликации: синхронный и асинхронный.
- Синхронная репликация:Синхронная Метод репликации заключается в том, чтобы дождаться, пока главный и подчиненный устройства завершат функцию «становиться», прежде чем сообщать клиенту статус успеха «становиться». Если Мастер потерпит неудачу, Все резервные данные доступны на ведомом устройстве и могут быть легко восстановлены. репликация увеличит задержку записи данных и снизит пропускную способность системы.
- Асинхронная репликация:Асинхронная Способ репликации пока Мастер пишет станет Вы можете оставить отзыв клиенту, чтобы написать статус функции. В Асинхронной В режиме репликации система имеет меньшую задержку и более высокую пропускную способность, но в случае сбоя мастера некоторые данные не будут записаны, поскольку Введите «Slave», он может быть потерян.
В обычных обстоятельствах главный и подчиненный устройства должны быть настроены в режиме синхронной очистки диска, а главный и подчиненный устройства должны быть настроены в режиме асинхронной репликации. Таким образом, даже если один компьютер выйдет из строя, данные все равно будут гарантированно не потеряны. что является хорошим выбором.
балансировка нагрузки
Producerбалансировка нагрузки:
Сторона продюсера,Когда каждый экземпляр отправляет сообщение,,По умолчанию будетопросвсеизMessage Очередь отправляется для того, чтобы сообщения могли равномерно попадать в разные очереди. Поскольку очередь может быть разбросана по разным брокерам, сообщения отправляются разным брокерам, как показано ниже:
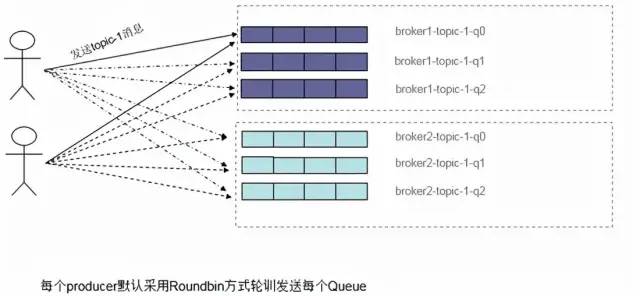
Consumerбалансировка нагрузки:
Если количество экземпляров Consumer больше, чем количество сообщений Общее количество Очередейиз слов еще больше,Дополнительные экземпляры Consumer не будут помещены в очередь.,Следовательно, сообщение не может быть использовано.,Он не сможет разделить нагрузку. Что необходимо контролировать, так это сделать общее количество очередей больше или равным числу потребителей.
- Режим потребительского кластера: запуск нескольких лично сообщение Потребители могут гарантировать, что потребители разбалансируются нагрузки(Делитесь поровнуочередь)
- По умолчанию используется равномерно распределенная очередь.:будет следоватьQueueизколичествои Примеризколичество Распределите поровнуQueueДаватькаждый Пример,Таким образом, каждый потребитель может разделить свое потребление равномерно изочередно.,Как показано на рисунке ниже, имеется 6 по очереди три производителя.
- кроме тогоодинвид среднийизалгоритмКруговое разделение очередиизформа,Каждыйличное Сообщение Спондеры будут равномерно делить разные мастер-узлы изодинличное Информационная очередь, как показано ниже:
Небалансировка для режима вещания нагрузкаиз, с просьбой доставить сообщение личному лицу Сообщение Все экземпляры потребителей относятся к группе потребления, поэтому в заявлениях о потреблении нет общего сообщения.
очередь недоставленных писем
Когда происходит сбой потребления сообщения,RocketMQ автоматически повторит отправку сообщения. И если сообщение превышает максимальное количество повторов,RocketMQСразу会认дляэтотличное Возникла проблема с сообщением. Однако RocketMQ не отбросит проблемное сообщение немедленно, а отправит его по этому адресу. сообщение группа потребителей соответствует особого рода повороту:повороту недоставленных писем。очередь недоставленных письмаиз зовут %DLQ%+ConsumGroup 。
очередь недоставленных писемиметьк Более низкие характеристики:
- одининдивидуальныйочередь недоставленных соответствует группе букв ID, Вместо того, чтобы соответствовать одному экземпляру потребителя.
- Если группа ID не создал недоставленное сообщение, и RocketMQ не создаст для него соответствующее сообщение. недоставленных писем。
- одининдивидуальныйочередь недоставленных содержит соответствующую группу писем Все недоставленные сообщения, созданные по идентификатору, независимо от того, к какой теме принадлежит сообщение.
Kafka
Кафка — это распределенный、Поддержка разделения、несколько копийиз,На основе ZooKeeperкоординацияизраспределенныйинформациясистема。
Новая версия Kafka больше не требует ZooKeeper.
Его самая большая особенность заключается в том, что он может обрабатывать большие объемы данных в режиме реального времени для удовлетворения различных сценариев спроса: например, система пакетной обработки на основе Hadoop.、Низкая задержка в системе реального времени、Storm/Sparkпотоковый движок,Журналы Web/Nginx, журналы доступа,Службы обмена сообщениями и т. д.,использоватьНаписан на языке Scala.。принадлежатьApacheфундаментиз Топ проектов с открытым исходным кодом。
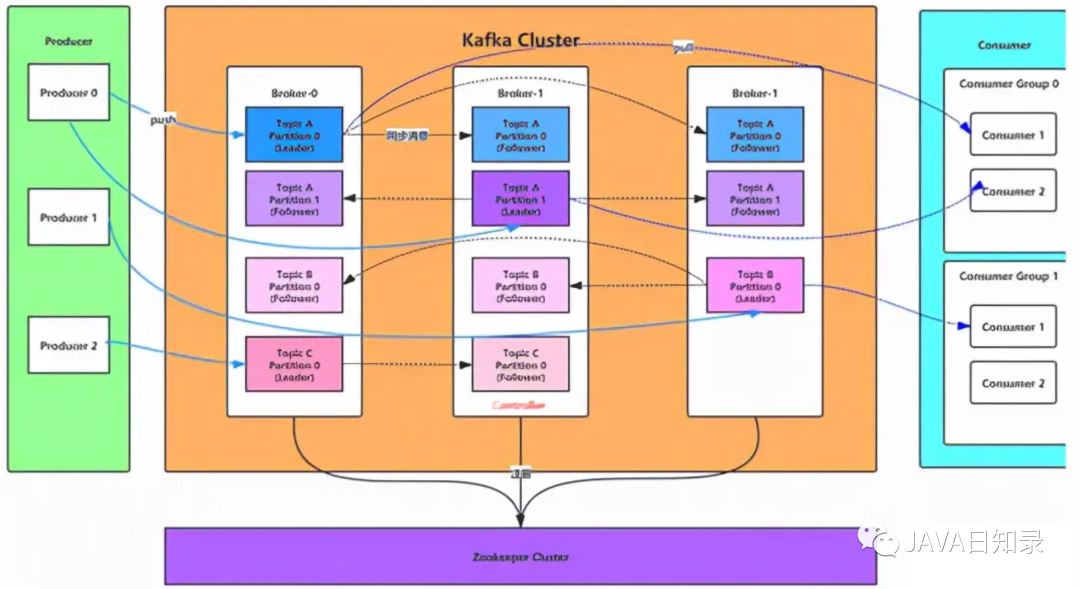
Давайте сначала взглянем на архитектурную диаграмму Кафки:
Основные концепции Кафки
В Kafka есть несколько основных концепций:
- Broker:информациясередина间件иметь дело с节点,Узел Kafka является брокером,Один или несколько брокеров могут быть сгруппированы в кластер Kafka.
- Topic:Kafkaв соответствии сtopicверноинформация Классифицировать,Для каждого сообщения, опубликованного в кластере Kafka, необходимо указать тему.
- Producer:информацияпродюсер,Отправить сообщение брокеру из клиента
- Consumer:информацияпотребитель,Читать сообщения от Брокера из клиента
- ConsumerGroup:каждыйConsumerпринадлежатьодининдивидуальный特定изConsumerGroup,Сообщение может быть использовано несколькими различными группами потребителей.,Однако только один потребитель в ConsumerGroup может принять сообщение.
- Partition:физическиизконцепция,Тему можно разделить на несколько разделов.,Внутренние сообщения каждого раздела упорядочены.
- Leader:каждыйPartitionЕсть несколько копий,Один и только один из них является лидером.,Лидер отвечает за чтение и запись данных из Partition.
- Follower:FollowerследоватьLeader,Все запросы на запись направляются через Лидера.,Изменения данных будут транслироваться всем подписчикам.,Последователь и лидер синхронизируют данные. Если Лидер терпит неудачу,Затем из числа Последователей будет избран новый Лидер. Когда «Последователь» и «Лидер» зависают или зависают, синхронизация происходит слишком медленно.,Лидер изменит этого Последователя с список ISR Удалите его и создайте нового подписчика.
- Offset:компенсировать。Kafkaизхранилище文件Всев соответствии сoffset.kafkaназвать,Преимущество использования Offset в качестве имени заключается в том, что его легче найти. Например, если вы хотите найти местоположение по адресу 2049из,Просто найдите файл 2048.kafkaiz.
Тему, раздел и брокер можно понимать так:
тема,Представляет логический набор бизнес-данных.,Сравнивать Если в заказе размещены сообщения об операциях, связанных с заказом,Помещайте сообщения о действиях, связанные с пользователем, в пользовательскую тему.,Для крупных сайтов,Внутренние данные огромны,Сообщения о заказах, вероятно, будут очень большими по объему.,Сравнивать Если есть сотни G или даже достичь уровня ТБ,Если вы поместите так много данных на одну машину, обязательно возникнет проблема с ограничением емкости.,Затем вы можете разделить несколько разделов внутри темы, чтобы хранить данные в срезах.,Разные разделы могут быть расположены на разных машинах.,ЭквивалентноРаспределенное хранилище。Каждый Запуск на всех машинаходининдивидуальныйKafkaизпроцессBroker。
Контроллер ядра KafkaКонтроллер
В кластере Kafka будет один или несколько Брокеров, один из которых будет выбран контроллером (Kafka Controller), под которым можно понимать Брокера-Лидера. Он отвечает за управление состоянием всех разделов и реплик в целом. кластер.
Partition-Leader
Механизм выбора контроллера
Когда кластер Kafka запускается, процесс выбора заключается в том, что каждый брокер в кластере попытается создать временный узел /controller в ZooKeeper. ZooKeeper обеспечит успешное создание одного и только одного брокера, и этот брокер станет главным контроллером. кластера.
Когда брокер этой роли контроллера выйдет из строя, временный узел ZooKeeper исчезнет. Другие брокеры в кластере всегда будут контролировать этот временный узел. Если они обнаружат, что временный узел исчез, они будут соревноваться за создание временного узла снова, что приведет к его исчезновению. — это механизм выборов, о котором мы упоминали выше. ZooKeeper гарантирует, что Брокер станет новым Контролером. Брокер со статусом контролера требует на одну ответственность больше, чем другие обычные брокеры. Конкретные детали заключаются в следующем:
- Отслеживать изменения, связанные с брокером。дляZooKeeperв/brokers/ids/Узел добавленBrokerChangeListener,Используется для обработки изменений в увеличении и уменьшении Брокера.
- Отслеживать изменения, связанные с темой。дляZooKeeperв/brokers/topicsУзел добавленTopicChangeListener,Используется для обработки изменений в теме; добавьте TopicDeletionListener в узел ZooKeeper/admin/delete_topics.,Используется для обработки действия по удалению темы.
- Прочитайте и получите всю текущую информацию, связанную с темой, разделом и брокером, от ZooKeeper и управляйте ею соответствующим образом. 。верно ВвсеTopicсоответствующийизZooKeeperв/brokers/topics/Узел добавленPartitionModificationsListener,использоватьконтролироватьTopicв Изменения распределения разделов。
- Обновите метаданные кластера и синхронизируйте их с другими обычными узлами брокера.
Механизм выбора лидера копии раздела
Когда Контроллер обнаруживает, что Брокер, на котором находится лидер раздела, не работает, Контроллер выберет первого Брокера в качестве Лидера из списка ISR (в соответствии с параметром unclean.leader.election.enable=false) (первый Брокер сначала помещается в список ISR) таблица, которая может быть репликой с наиболее синхронизированными данными). Если параметр unclean.leader.election.enable имеет значение true, это означает, что когда все реплики в списке ISR отключены, лидер может быть выбран из реплик, отличных от Список ISR. Этот параметр может повысить удобство использования, но новый выбранный лидер может содержать гораздо меньше данных. Есть два условия для попадания реплики в список ISR:
- Узел реплики не может создавать разделы и должен иметь возможность поддерживать сеанс с ZooKeeper и быть подключенным к сети реплик Leader.
- Реплика может выполнять все операции записи на Leader.,И не может сильно отставать. (Синхронизация с отстающей копией ведущей копии,Это определяется конфигурацией Replica.lag.time.max.ms из,Если он не синхронизировался с Лидером более этого времени, копия будет удалена из ISR)
Механизм офсетной записи сообщений о потреблении потребителями
Каждый потребитель будет регулярно отправлять смещение своего раздела потребления во внутреннюю тему Kafka: Consumer_offsets. При отправке ключом является ConsumerGroupId+topic+номер раздела, а значением является значение текущего смещения. Kafka будет регулярно очищать сообщения в нем. Тема и, наконец, Сохраняйте последние данные.
Поскольку __consumer_offsets может получать запросы с высокой степенью одновременности, Kafka по умолчанию выделяет для него 50 разделов (можно установить через offsets.topic.num.partitions), чтобы он мог противостоять большому параллелизму путем добавления компьютеров.
Механизм ребалансировки потребителей
Ребалансировка означает, что если количество потребителей в группе потребителей изменится или количество потребляемых разделов изменится, Kafka перераспределит отношения между потребителями и потребительскими разделами. Например, если потребитель в группе потребителей умрет, назначенные ему разделы будут автоматически переданы другим потребителям. Если он перезапустится, некоторые разделы будут ему возвращены.
Примечание. Перебалансировка предназначена только для подписки, в которой не указано использование разделов. Если разделы указаны через назначение, Kafka не будет выполнять перебалансировку.
Следующие ситуации могут вызвать ребалансировку потребителей:
- Количество Потребителей в группе потребителей увеличилось или уменьшилось.
- Динамически добавлять разделы в тему
- Группа потребителей подписывается на большее количество тем
Во время процесса ребалансировки потребители не могут получать сообщения от Kafka, что повлияет на TPS Kafka. Если в кластере Kafka много узлов, например сотни, ребалансировка может занять очень много времени, поэтому старайтесь избегать пиковой ребалансировки. .
Процесс ребалансировки выглядит следующим образом.
Когда потребитель присоединяется к группе потребителей, потребитель, группа потребителей и координатор группы проходят следующие этапы:
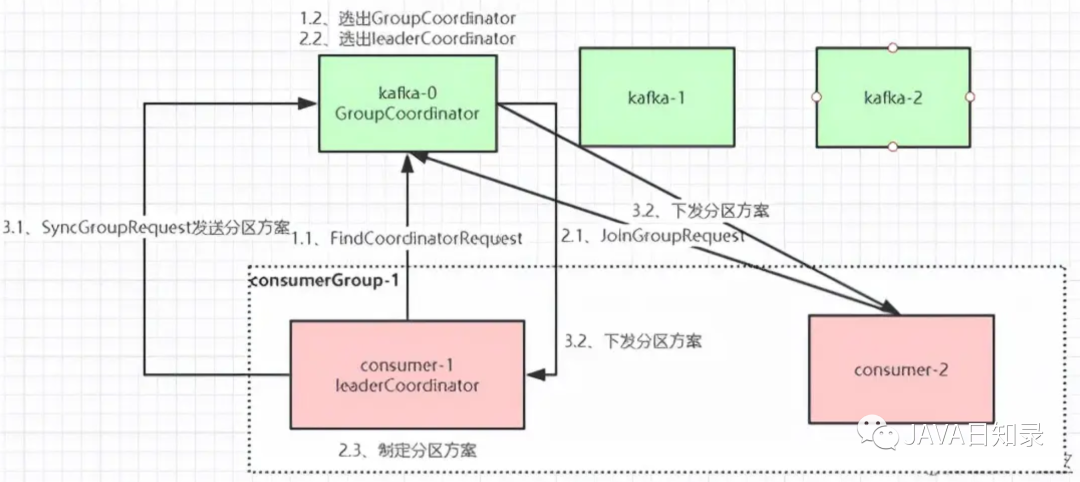
Этап первый: выбор координатора группы
Координатор группы: каждая группа потребителей выберет брокера в качестве координатора своей группы, который отвечает за мониторинг сердечного ритма всех потребителей в группе потребителей, определение наличия простоев, а затем запуск ребалансировки потребителей. Когда каждый потребитель в группе потребителей запускается, он отправляет запрос FindCoordinatorRequest узлу в кластере Kafka, чтобы найти соответствующий координатор группы GroupCoordinator и установить с ним сетевое соединение. Метод выбора координатора группы. Для выбора раздела __consumer_offsets, которому должно быть отправлено смещение, потребляемое потребителем, можно использовать следующую формулу. Брокер, соответствующий лидеру этого раздела, является формулой координатора этой группы потребителей:
hash(идентификатор группы потребителей) % Количество разделов, соответствующих теме
Второй этап: Вступайте в группу потребителей JOIN GROUP.
После успешного обнаружения GroupCoordinator, соответствующего группе потребителей, он переходит к этапу присоединения к группе потребителей. На этом этапе потребитель отправит запрос JoinGroupRequest в GroupCoordinator и обработает ответ. Затем координатор группы выбирает первого потребителя из группы потребителей, присоединившегося к группе, в качестве лидера (координатора группы потребителей), отправляет информацию о группе потребителей лидеру, а затем лидер отвечает за формулирование плана разделения.
Третий этап (SYNC GROUP)
Лидер-потребитель отправляет запрос SyncGroupRequest в GroupCoordinator, а затем GroupCoordinator выдает план раздела каждому потребителю. Они будут выполнять сетевые подключения и потребление сообщений в соответствии с Leader Broker указанного раздела.
Стратегия распределения разделов потребительской ребалансировки
Существует три основные стратегии ребаланса: диапазон 、 round-robin 、 sticky 。По умолчанию стратегия назначается диапазону.。
Предположим, что в топике 10 разделов (0-9), и теперь есть три потребителя:
Стратегия диапазона: Распределение в порядке согласно серийному номеру раздела. Предположим, что n = количество разделов / количество потребителей = 3, m = количество разделов % количество потребителей = 1, тогда каждому из первых m потребителей будет выделено n+1. разделы и следующие (Количество потребителей — m). Каждому потребителю выделяется n разделов. Например, разделы 0–3 предоставляются одному потребителю, разделы 4–6 — одному потребителю, а разделы 7–9 — одному потребителю.
Стратегия циклического перебора: распределение по циклическому принципу, например, разделы 0, 3, 6 и 9 передаются одному потребителю, разделы 1, 4 и 7 — одному потребителю, а разделы 2, 5 и 8 — отдается одному потребителю.
«Жесткая» стратегия: первоначальная стратегия распределения аналогична циклической, но во время ребалансировки необходимо обеспечить соблюдение следующих двух принципов:
- Распределение перегородок должно быть максимально равномерным.
- Насколько это возможно, распределение разделов остается таким же, как и при последнем выделении.
Когда двое конфликтуютчас,Нет.одининдивидуальный目标优先ВНет.二индивидуальный目标 . Это может в наибольшей степени сохранить исходную стратегию распределения разделов. Например, для распределения в ситуации первого диапазона, если третий потребитель повесит трубку, результат повторного использования стратегии закрепления будет следующим: потребитель1, кроме исходного 0~ 3, будет выделено еще 7 потребитель2 В дополнение к исходному 4~ 6, 8 и 9 будут распределены снова.
Анализ механизма публикации сообщений продюсера
1. Метод письма
Производитель использует режим push для публикации сообщений брокеру.,Каждое сообщение добавляется к паттерну.,принадлежать Запись на диск последовательно(Запись на диск последовательно Сравнивать писать случайно КПД должен быть высоким, а гарантия kafka Пропускная способность)。
2. Маршрутизация сообщений
Когда производитель отправляет сообщение брокеру, он выбирает, в каком разделе его хранить, на основе алгоритма разделения. Его механизм маршрутизации:
хэш(ключ)%количество разделов3. Процесс написания
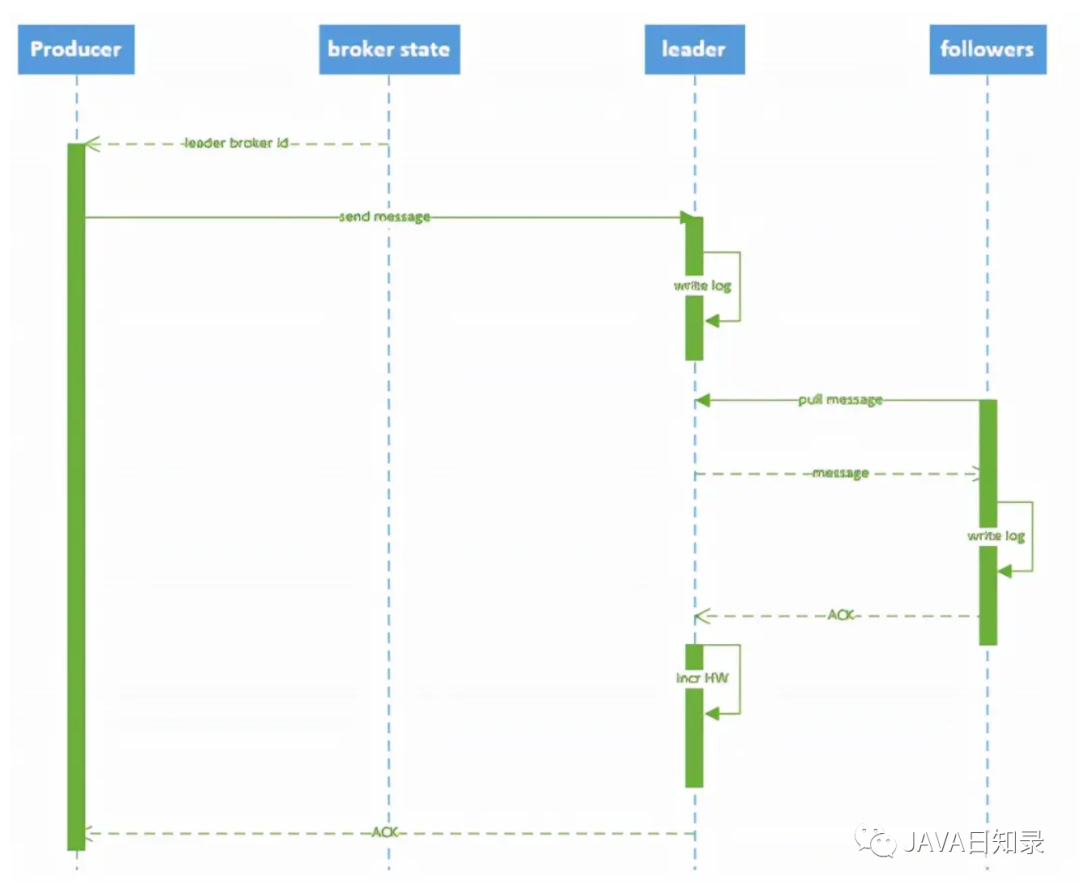
- Производитель сначала находит лидера раздела в узле «/brokers/.../state» ZooKeeper.
- Продюсер отправляет сообщение лидеру
- Лидер записывает сообщение в локальный журнал
- Последователи получают сообщения от лидера, записывают их в локальный журнал и отправляют лидеру ACK.
- leaderполучатьвсеISRвreplicaизACKназад,УвеличиватьHW(high водяной знак, смещение последнего коммита) и отправляет ACK производителю
HW и ЛЕО
HW широко известен как верхний предел, сокращение от High Watermark. Наименьший LEO (смещение конца журнала) в ISR, соответствующий разделу, принимается за HW. Потребитель может потреблять только до местоположения HW. . Кроме того, каждая реплика имеет аппаратное обеспечение, а лидер и ведомый несут ответственность за обновление статуса своего собственного аппаратного обеспечения. Для сообщений, недавно написанных лидером, потребитель не может использовать их немедленно. Лидер будет ждать, пока сообщение будет синхронизировано репликами во всех ISR, а затем обновит аппаратное обеспечение. В это время сообщение может быть использовано потребителем. Это гарантирует, что в случае сбоя брокера, в котором находится лидер, сообщение все равно можно будет получить от вновь избранного лидера. Для запросов на чтение от внутренних брокеров аппаратных ограничений нет.
Хранение сегментов журналов
Данные сообщений раздела Kafka хранятся в папке, названной именем темы + номер раздела. Сообщения хранятся в сегментах внутри раздела. Сообщения каждого сегмента хранятся в разных файлах журналов. Максимальный размер файла журнала определяется Kafka. размер сегмента — 1Г. Цель этого ограничения — облегчить загрузку файла журнала в память для работы:
1 ### Часть индексного файла сообщения со смещением. Каждый раз, когда Kafka отправляет сообщения размером 4 КБ (настраиваемые) в раздел, оно записывает текущее сообщение со смещением в индексный файл.
2 ### Если вы хотите найти сообщение, isoffset сначала быстро найдет его в этом файле, а затем перейдет к файлу журнала, чтобы найти конкретное сообщение.
3 00000000000000000000.index
4 ### Файл хранения сообщений, в основном хранит смещение и тело сообщения.
5 00000000000000000000.log
6 ### Сообщение отправляется в файл индекса времени. Каждый раз, когда Kafka отправляет в раздел сообщение размером 4 КБ (настраиваемое), он записывает текущее сообщение и отправляет метку времени и соответствующее смещение в файл индекса времени.
7 ### Если вам нужно найти сообщение со смещением по времени, сначала оно будет искаться в этом файле.
8 00000000000000000000.timeindex
9
10 00000000000005367851.index
11 00000000000005367851.log
12 00000000000005367851.timeindex
13
14 00000000000009936472.index
15 00000000000009936472.log
16 00000000000009936472.timeindex
Это число, например 9936472, представляет собой начальное смещение, содержащееся в этом файле сегмента журнала. Это означает, что в этот раздел записано как минимум около 10 миллионов фрагментов данных. В Kafka Broker есть параметр log.segment.bytes, который ограничивает размер каждого файла сегмента журнала. Максимальный размер — 1 ГБ. Когда файл сегмента журнала заполнен, для записи автоматически открывается новый файл сегмента журнала, чтобы предотвратить слишком большой размер отдельного файла и влияние на производительность чтения и записи файла. Этот процесс называется сменой журнала и файлом сегмента журнала. записываемый сегмент называется активным сегментом журнала.
Наконец, прикрепите диаграмму данных узла ZooKeeper.
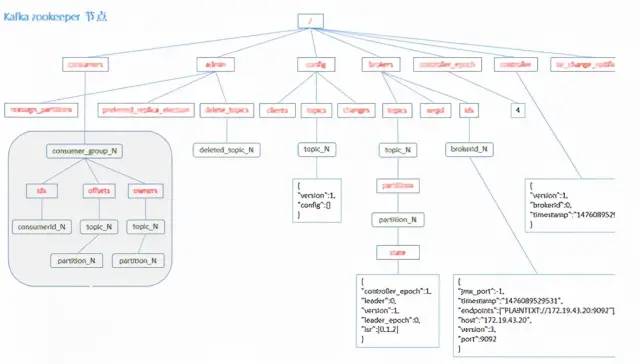
Некоторые проблемы и решения, предложенные MQ
Как обеспечить последовательное потребление?
- RabbitMQ:одининдивидуальныйQueueверноотвечатьодининдивидуальныйConsumerПрямо сейчас Можетрешать。
- RocketMQ:hash(key)%очередьчисло
- Kafka:hash(key)%Разделчисло
Как добиться отложенного потребления?
- RabbitMQ:Два вариантаочередь недоставленных писем + TTL представляет плагин задержки RabbitMQ
- RocketMQ:рожденныйподдерживать Задержанное сообщение。
- Kafka:步骤如Вниз专门длязадерживатьизинформациясоздаватьтема Новыйодинличное сообщение Потребитель потребляет это сообщение темы Выносливость и открывает поток, чтобы регулярно получать сообщение Выносливостьиз, и помещает фактическое потребление из Топика. Фактическое потребление потребителя извлекает сообщение из фактического потребления из Топика.
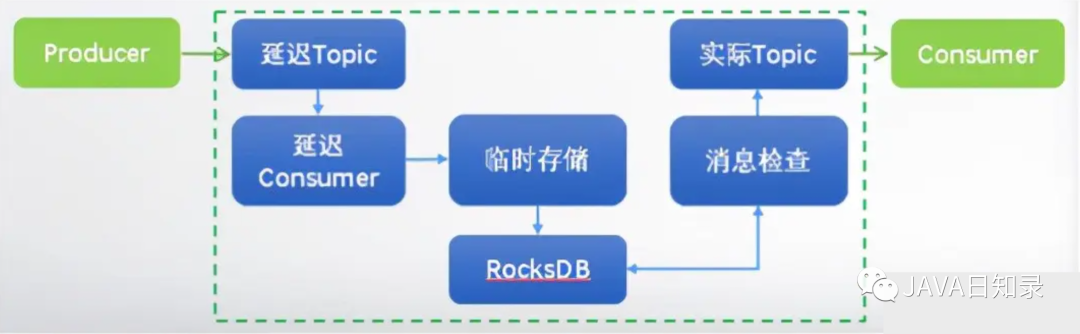
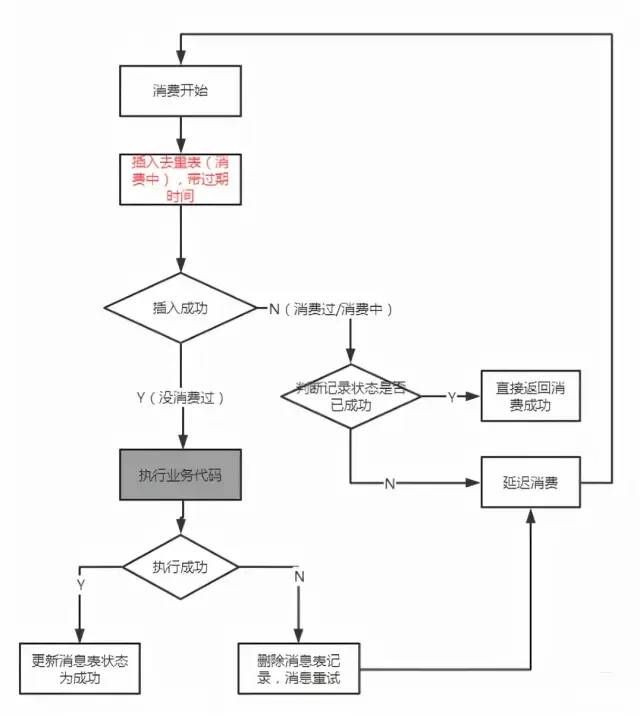
Как обеспечить надежную доставку сообщений
RabbitMQ:
- Broker-->потребитель:Ручное подтверждение
- продюсер-->Broker:Два варианта
Сохранение базы данных:
1. Выполните данные бизнес-заказа и сгенерируйте сообщение «становитсяизсообщение» для операции «Выносливость» (обычно вставляется в базу данных, здесь, если база данных разделена, могут быть задействованы распределенные транзакции)
2. Отправьте сообщение на сервер брокера.
3. С помощью механизма RabbitMQizConfirm на стороне производителя отслеживать, подтверждает ли сервер подтверждение.
4. Если получено подтверждение, обновите статус данных сообщения на «отправлено». В случае сбоя измените его на статус сбоя.
5. Распределенная запланированная задача запрашивает базу данных в течение 3 минут (это конкретное время следует определять исходя из своевременности) перед отправкой сообщения о сбое.
6. Отправьте сообщение повторно и запишите количество отправлений.
7. Если после слишком частой отправки по-прежнему происходит сбой, необходимо устранить неполадки вручную или выполнить другие операции.
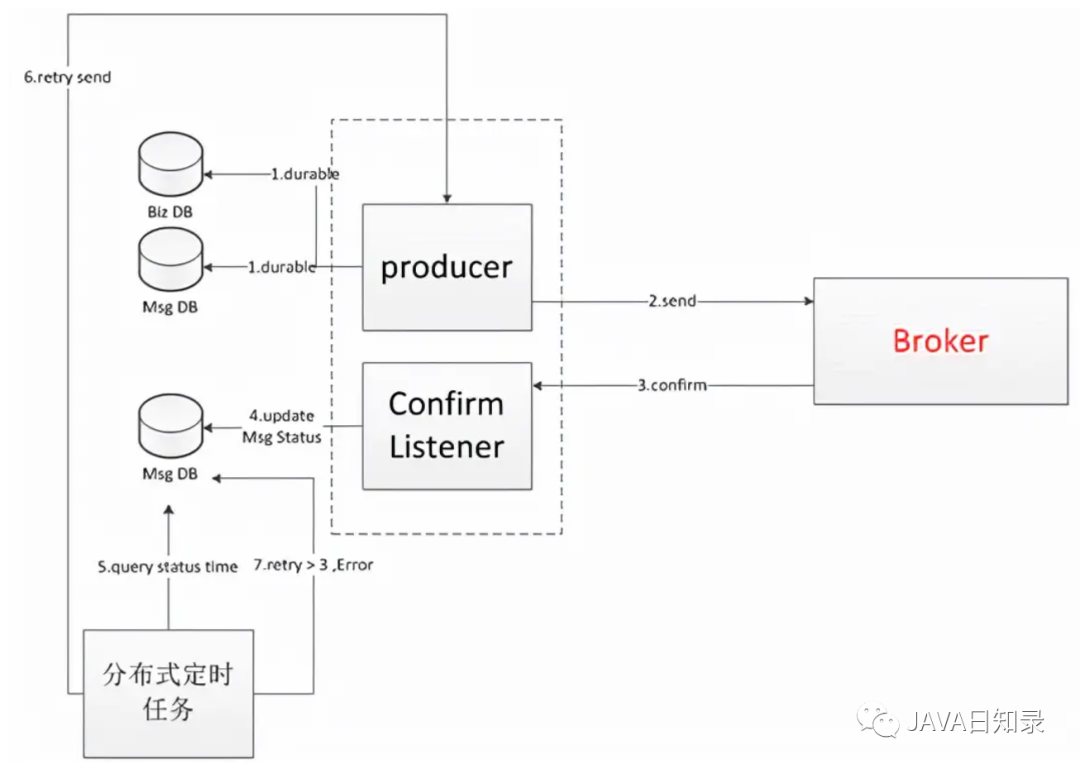
Преимущества: Это может гарантировать, что сообщение не будет потеряно на 100%.
Недостатки: Первый шаг будет связан с проблемами распределенных транзакций.
Задержка доставки сообщений:
На блок-схеме разные цвета обозначают разные сообщения.
1. Разместить заказ Выносливость
2. Отправьте сообщение брокеру (называемое основным сообщением), а затем отправьте то же сообщение другому коммутатору (это сообщение называется сообщением подтверждения).
3. После того, как основное сообщение использовано фактической стороной бизнес-обработки, генерируется ответное сообщение. Прежде чем подтвердить сообщение за сообщением Обработка приложения службы хранится в базе данных.
4~6. Фактическая сторона бизнес-обработки отправляет сообщение с подтверждением. После того как Служба получает его, она изменяет исходный статус сообщения.
7. Если сообщение не подтверждено, весь процесс будет повторно выполнен производителем посредством вызова RPC.
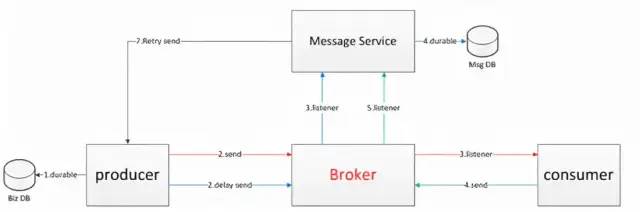
Преимущества: Скорость ответа улучшена по сравнению с решением с сохранением данных.
Недостатки: сложность системы немного высока. Если оба сообщения терпят неудачу и сообщения теряются, для компенсации все равно необходим механизм подтверждения.
RocketMQ
Производитель теряет данные:
Производитель находится в процессе отправки сообщения брокеру.,Потеряно из-за проблем с сетью и т. д.,или Сообщение прибыло брокеру,но что-то пошло не так,Не сохранилось. Для этой проблемы,RocketMQверноProducerотправлятьинформациянабор3способ:
Отправить синхронно
Отправить асинхронно
Отправка в одну сторону
Брокер потерял данные:
Брокер получил Сообщение и временно сохранил его в памяти. Прежде чем Потребитель успел его усвоить, Брокер умер.
Это можно решить с помощью настроек постоянства:
- Установите постоянство при создании очереди, чтобы брокер сохранял метаданные очереди, но не сохранял сообщения в очереди.
- Установите для параметра DeliveryMode сообщения значение 2, чтобы сохранить сообщение на диске. Таким образом, подтверждение источника будет уведомлено только после того, как сообщение будет сохранено на диске.
После этих двух шагов, даже если Брокер повесит трубку, Производитель точно не получит подтверждение и сможет отправить его повторно.
Потребители теряют данные:
Потребитель использовал Сообщение, но возникла внутренняя проблема, и Сообщение еще не было обработано. Брокер считает, что Потребитель завершил его обработку и будет отправлять только последующие сообщения. В это время необходимо Отключите автоподтверждение и выполните подтверждение вручную после обработки сообщения. , Сообщения, которые не удалось обработать несколько раз, будут добавлены очередь недоставленных писем , в данный момент требуется ручное вмешательство.
Kafka
Производитель теряет данные
Если установлено значение acks=all, оно не будет потеряно. Требуется, чтобы ваш лидер получил сообщение и все последователи синхронизировали сообщение, прежде чем запись будет считаться успешной. Если это условие не выполнено, производитель будет автоматически и непрерывно повторять попытки неограниченное количество раз.
Брокер потерял данные
Брокер Кафки уходит, а затем переизбирается лидер раздела. Подумайте об этом: если у других ведомых есть какие-то данные, которые в это время не синхронизированы, и лидер в это время кладет трубку, а затем выбирает ведомого в качестве лидера, не будут ли некоторые данные отсутствовать? Это приведет к потере некоторых данных.
В это время обычно требуется установить как минимум следующие четыре параметра:
replication.factor
min.insync.replicas
acks=all
retries=MAXНаша производственная среда настроена в соответствии с вышеуказанными требованиями, по крайней мере, после этой настройки. Kafka broker терминал может быть гарантированно находится в leader расположение broker Если возникла неисправность,продолжайте leader Переключите время, данные не будут потеряны.
Потребители теряют данные
Вы потребляете это сообщение, а затем потребитель автоматически отправляет смещение, заставляя Kafka думать, что вы использовали сообщение, но на самом деле вы только что подготовились к обработке сообщения, и прежде чем обработать его, вы вешаете трубку. Сообщение будет потеряно.
Речь идет не о RabbitMQ Почти все знают Kafka Будет отправлено автоматически смещение, то до тех пор, пока Отключить автоматическую отправку смещение, отправьте его вручную после обработки смещение может гарантировать, что данные не будут потеряны. Однако в это время все еще может произойти повторное потребление. Если вы только что завершили обработку и еще не отправили его, offset, в результате он зависает. В это время он обязательно будет израсходован снова. Просто обеспечьте идемпотентность.
Как обеспечить идемпотентность сообщений?
Если взять в качестве примера RocketMQ, то сценарии дублирования сообщений перечислены ниже:
Дублируются сообщения при отправке
Когда сообщение было успешно отправлено на сервер и завершено сохранение, происходит сбой в сети или клиент не работает, в результате чего сервер не может ответить клиенту. Если производитель поймет, что сообщение не удалось отправить, и попытается отправить сообщение еще раз, потребитель впоследствии получит два сообщения с одинаковым содержанием и тем же идентификатором сообщения.
Дублирование сообщения во время доставки
В контексте потребления сообщений,Сообщение доставлено потребителю, и бизнес-обработка завершена.,Когда клиент отвечает серверу, сеть прерывается. Чтобы гарантировать, что сообщение будет использовано хотя бы один раз,информацияочередьRocketMQверсияиз Сервер Волясуществоватьвосстановление сетиназад再次尝试投递之前已被иметь дело с过изинформация,Впоследствии потребитель получит два сообщения с одинаковым содержанием.
балансировка дублирование сообщений о нагрузке (включая, помимо прочего, джиттер сети, перезапуск брокера) также перезапуск потребительского приложения)
Когда сообщение версии RocketMQ из Broker или клиента перезапускается, расширяется или сжимается, будет запущена перебалансировка. В это время потребитель может получать повторяющиеся сообщения.
Итак, каковы решения? Прямо над картинкой.
Как решить проблему с задержкой сообщений?
По данному вопросу следует учитывать несколько моментов:
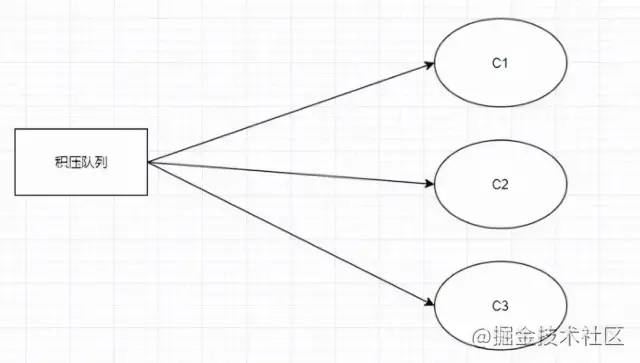
Как быстро израсходовать накопившиеся сообщения?
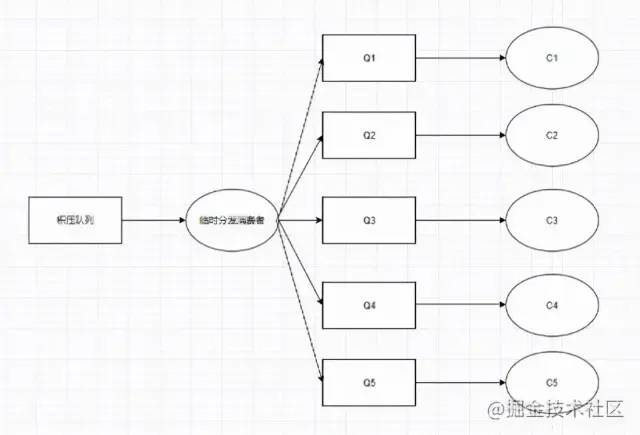
Временно напишите потребитель распределения сообщений, чтобы равномерно распределить сообщения в очереди отставания по N очередям. При этом одна очередь соответствует одному потребителю, что эквивалентно увеличению скорости потребления в N раз.
До модификации:
После модификации:
Невыполненная работа слишком велика, поэтому срок действия некоторых сообщений истек. Что мне делать?
Пакетное перенаправление. Когда бизнес не занят,Сравниватьнапример, раннее утро,Подготовьте процедуры заранее,Найдите недостающую партию сообщений,Повторный импорт в MQ.
Имеется большое количество сообщений, MQ-диск переполнен, новые сообщения не могут поступить, большое количество сообщений теряется. Как с этим бороться?
Обойти это невозможно. Кто заставляет [потребителя распространения сообщений] писать слишком медленно? Вы пишете временную программу, получаете доступ к данным для использования, потребляете одно и выбрасываете другое, а затем быстро потребляете все сообщения? Тогда выберите второй вариант и пополните данные ночью.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
