Путешествие по разработке аудио и видео (92) - Интерпретация мультимодальных клипов и анализ исходного кода
Оглавление
1. Предыстория и проблемы
2. Структура модели CLIP
3. Результаты экспериментов
4. Анализ исходного кода
5. Ограничения и недостатки CLIP
6. Информация
1. Предыстория и проблемы
При выполнении задач классификации, обнаружения и сегментации аннотация данных очень важна. Например, набор данных ImageNet, который можно использовать для задач классификации, содержит в общей сложности 1,2 миллиона изображений и 1000 категорий, которые можно использовать для целей. Задачи обнаружения и сегментации имеют в общей сложности 330 000 изображений 80 целевых категорий. Традиционные модели классификации изображений обычно обучаются на аннотированных наборах данных, но категории и количество этих наборов данных относительно невелики, а способность к обобщению обученных моделей также ограничена, что затрудняет непосредственный переход к последующим задачам.
Transformer блестит в области НЛП, а VIT на базе Transformer добился хороших результатов в области CV. Однако взаимодействие между двумя областями представляет собой проблему. Сегодня мы начинаем мультимодальное обучение.
Поскольку в артикле много существительных, для лучшего понимания давайте сначала поясним их:
- Линейный зонд: метод, используемый для измерения производительности экстрактора функций. Замораживая магистраль сети и обучая только последний полностью подключенный уровень, можно более точно отразить качество предварительно обученной модели.
- Разрыв в распределении: существует определенный разрыв в распределении различных наборов данных, что приводит к низкой точности или эффективности обобщения. Например, происходит нарушение распределения (данные вывода и данные предварительного обучения поступают из разных распределений). Это показано на изображении. Задача оценки качества также часто встречается, например: большая часть набора обучающих данных поступает из дневных изображений, сделанных пользователями, поэтому результаты вывода и оценки не очень хороши для синтетических сплошных цветных фонов с текстом или ночных сцен.
- Обучение с нулевым выстрелом: обучение с нулевым выстрелом, которое позволяет модели распознавать или прогнозировать новые/невидимые категории без прямых обучающих данных. Как показано в классическом «случае с зеброй» ниже: предположим, что модель уже может распознавать лошадей и тигров. и пандам теперь нужна модель, чтобы также распознавать зебр. Zero-shot не показывает модели зебр во время обучения, но сообщает модели, какие характеристики имеют зебры во время вывода, и модель также может успешно идентифицировать зебр.
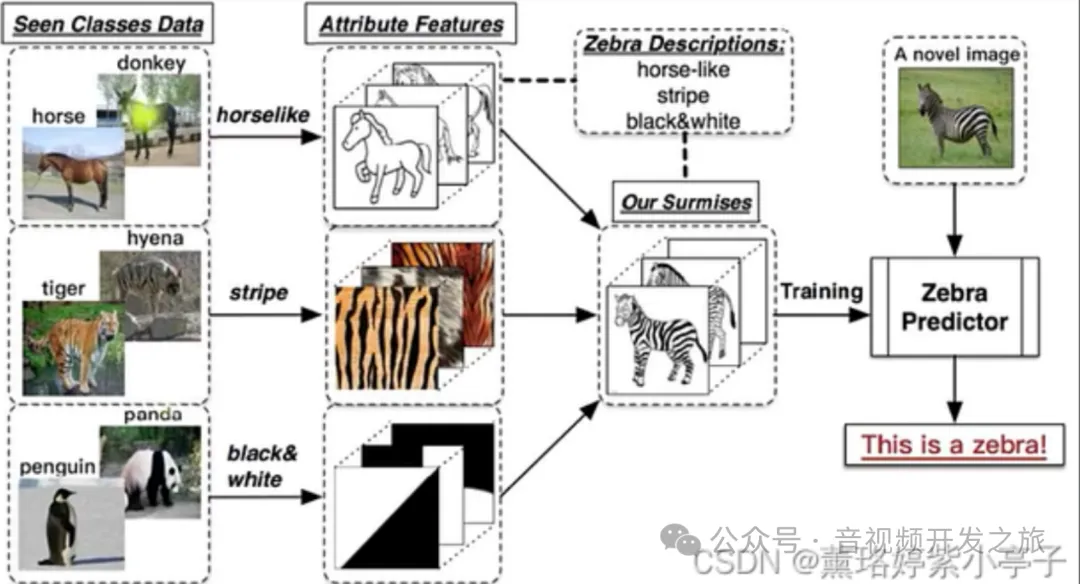
Изображение из: Понимание нулевого выстрела, одного выстрела и нескольких выстрелов
2. Структура модели CLIP
CLIP(Contrastive Language-Image Pre-training) — мультимодальная обучающая нейронная сеть, выпущенная OpenAI в 2021 году, в которой принята идея контрастивного обучения. Предварительно обучите 400 миллионов собранных пар изображение-текст. Классификация достигается за счет сходства изображения и встраивания текста, что нарушает предыдущую парадигму фиксированных меток. Будь то наборы данных для мобильных телефонов или обучение модели, нет необходимости выполнять классификацию, как в ImageNet-1000. Пары «текст-изображение» собираются напрямую, а затем сходство прогнозируется без присмотра.
Модельное обучение: Каждое изображение имеет короткий поясняющий текст. Текст и изображение проходят через кодировщик соответственно для получения векторного представления. Диагональные линии — это положительные выборки, недиагональные линии — отрицательные выборки, а затем вычисляется косинусное подобие: Модель с двумя башнями принята в целом: башня изображения и башня текста. Башня изображений отвечает за извлечение представления изображения, обычно Vision. Transformer, Текстовая башня отвечает за извлечение текстовых элементов, используя классическую архитектуру Transformer.
Модельное рассуждение: Процесс анализа клипов не опирается на традиционный уровень классификации, а напрямую реализует классификацию посредством сходства между изображением и встраиванием текста.
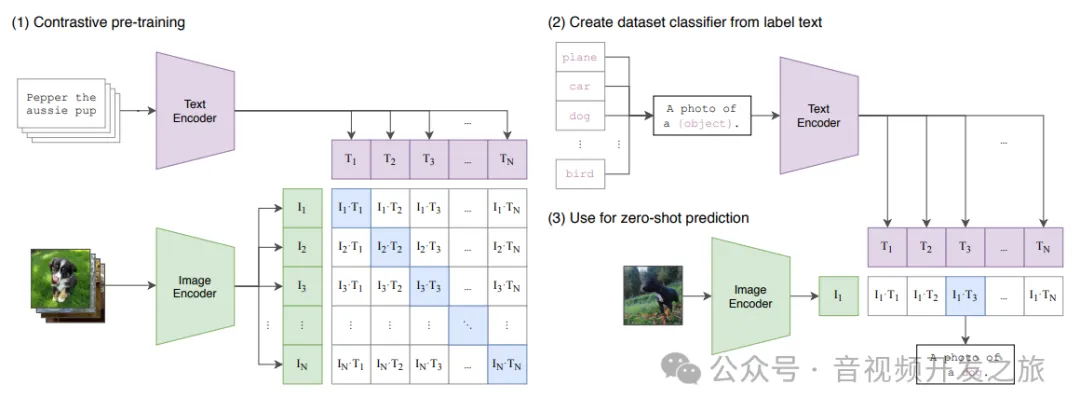
Клип только с открытым кодом вывода и моделью предварительного обучения. В документе представлен следующий обучающий псевдокод.

Видно, что архитектура соответствует приведенной выше модели:
- Сначала извлечение признаков выполняется для изображения и текста с помощью кодировщиков изображения и текста соответственно.
- Затем векторы признаков изображения и текста сопоставляются со скрытым пространством того же измерения с помощью матриц проекции W_i и W_t, а затем нормализуются для получения представления встраивания изображения и текста.
- Затем вычислите косинусное сходство между встраиванием изображения и встраиванием текста и масштабируйте его с помощью параметра температуры.
- Наконец, вычислите перекрестную энтропию от изображения к тексту и от текста к изображению соответственно и возьмите среднее из двух в качестве окончательной потери.
3. Результаты экспериментов
Автор сравнил Clip с нулевым выстрелом и ResNet50 линейного зонда на 30 наборах данных. Видно, что Clip может достичь того же уровня, что и ResNet50, после обучения на конкретном наборе аннотированных данных.
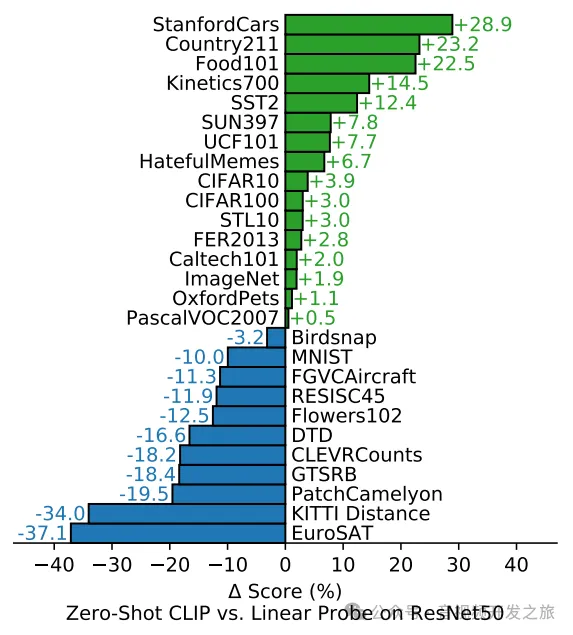
Обобщающая способность клипа с нулевым выстрелом
На следующем рисунке для сравнения используется RestNet101, предварительно обученный на наборе данных ImnageNet, и клип с нулевым выстрелом. Точность набора данных ImageNet составляет 76,2%, что эквивалентно. Однако при переносе на другие наборы данных клип с нулевым выстрелом равен. очевидно лучше, что отражает его лучшие свойства обобщения и скольжения.

Помимо задач классификации, модели CLIP показали хорошую производительность во многих визуальных и языковых задачах, включая классификацию изображений, классификацию нулевых снимков, семантическую сегментацию, руководство по созданию изображений и ответы на вопросы по изображениям.
4. Анализ исходного кода
4.1 demo
Введите изображение и несколько текстовых меток и спрогнозируйте вероятность того, что изображение соответствует каждой метке.
- Сначала измените размер, нормализуйте кадр и т. д. предварительно обработайте изображение до формы, необходимой модели: torch.Size([1, 3, 224, 224]); преобразуйте текст из SimpleToken в токен, и одно английское слово соответствует одному. токен (позже будут подробные примеры)
- Затем выполните извлечение признаков для изображения и текста соответственно, где изображение использует VIT в качестве основы, а текст использует TransformerEncoder в качестве основы.
- Наконец, после вывода softmax картинка представляет собой вероятность каждой метки.
import numpy as npimport pytestimport torchfrom PIL import Imageimport clip
def test(model_name="ViT-B/32"): device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load(model_name, device=device)
image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)#Изменить размер изображения crop Преобразовать в тензор Нормализация -->входить:image mode=RGBA size=2162x762; Вывод: torch.Size([1, 3, 224, 224]) text = clip.tokenize(["a diagram", "a dog", "a cat"]).to(device)
with torch.no_grad(): image_features = model.encode_image(image) #Извлечение признаков из изображения через VIT. Ввод:факел.Размер([1, 3, 224,224]) тензорные данные изображения,Вывод: torch.Size([1, 512]) text_features = model.encode_text(text) #Извлечение объектов из текста с помощью Transformer.Size([3,. 77]) Соответствует ["a diagram", "a dog", "a cat"] токены слов, вывод: torch.Size([3, 512]) logits_per_image, logits_per_text = model(image, text) probs = logits_per_image.softmax(dim=-1).cpu().numpy()#После вывода softmax На картинке представлена вероятность каждой метки
print("Label probs:", probs) if __name__ == "__main__": #clip.available_models:['RN50', 'RN101', 'RN50x4', 'RN50x16', 'RN50x64', 'ViT-B/32', 'ViT-B/16', 'ViT-L/14', 'ViT-L/14@336px'] print(f"clip.available_models:{clip.available_models()}") test()4.2 Преобразование текста в токен: clip.tokenize
def tokenize(texts: Union[str, List[str]], context_length: int = 77, truncate: bool = False) -> Union[torch.IntTensor, torch.LongTensor]: """ Возвращает токены для данной входной строки """ if isinstance(texts, str): texts = [texts]
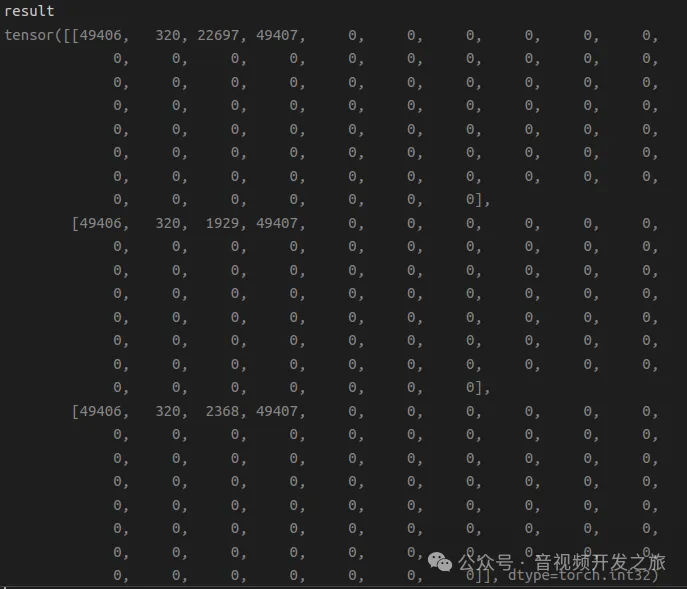
sot_token = _tokenizer.encoder["<|startoftext|>"]#49406 eot_token = _tokenizer.encoder["<|endoftext|>"] #49407 all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts] #Добавляем токен в начало и интерфейс [[49406, 320, 22697, 49407], [49406, 320, 1929, 49407], [49406, 320, 2368, 49407]]
result = torch.zeros(len(all_tokens), context_length, dtype=torch.int) #
for i, tokens in enumerate(all_tokens): if len(tokens) > context_length:#context_length:77, если длина токенов больше, чем context_length, обрежьте ее или создайте исключение if truncate: tokens = tokens[:context_length] tokens[-1] = eot_token else: raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}") result[i, :len(tokens)] = torch.tensor(tokens)#Преобразовать в тензор присваивается результату
return result #torch.Size([3, 77]) ,['a diagram', 'a dog', 'a кот'] жетоныФорма токенов ['диаграмма', 'собака', 'кошка'] — это torch.Size([3, 77]). Конкретное содержимое показано ниже, где 49406 — это startToken каждого токена, а 49407. — это startToken каждого токена. Видно, что токену соответствует английское слово.
4.3 Предварительная обработка изображений preprocess
def _transform(n_px): return Compose([ Resize(n_px, interpolation=BICUBIC), #По умолчанию 3*224*224 CenterCrop(n_px), _convert_image_to_rgb, ToTensor(), Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)), #Используйте среднюю дисперсию ImageNet для нормализации ])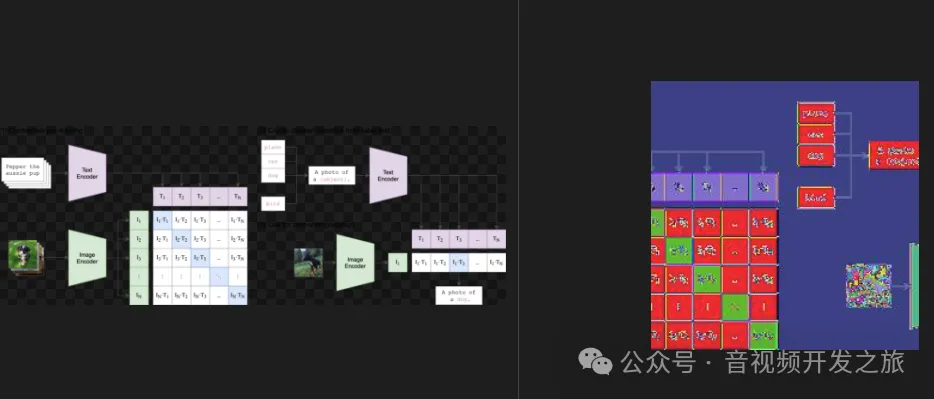
4.4 Построение модели клипа
class CLIP(nn.Module): def __init__(self, embed_dim: int,#512 # vision image_resolution: int,#224 vision_layers: Union[Tuple[int, int, int, int], int], #12 vision_width: int,#768 vision_patch_size: int,#32 # text context_length: int,#77 vocab_size: int,#49408 transformer_width: int,#512 transformer_heads: int,#8 transformer_layers: int #12 ): super().__init__()
self.context_length = context_length
if isinstance(vision_layers, (tuple, list)): vision_heads = vision_width * 32 // 64 self.visual = ModifiedResNet( layers=vision_layers, output_dim=embed_dim, heads=vision_heads, input_resolution=image_resolution, width=vision_width ) else: vision_heads = vision_width // 64 #768//64=12 self.visual = VisionTransformer( #Определите преобразователь, используемый для извлечения признаков изображения input_resolution=image_resolution, #Разрешение входного изображения 224*224 patch_size=vision_patch_size, #Размер каждого патча 32*32. width=vision_width, #768, что это за Vision_width? layers=vision_layers, #12слой heads=vision_heads, #multi-headattention 8 голов output_dim=embed_dim #Выходные размеры 512 )
self.transformer = Transformer( width=transformer_width,#512 layers=transformer_layers,#12 heads=transformer_heads,#8 attn_mask=self.build_attention_mask() )
self.vocab_size = vocab_size #размер словаря 49408 self.token_embedding = nn.Embedding(vocab_size, transformer_width) #transformer_width:512 self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width)) self.ln_final = LayerNorm(transformer_width)
self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim)) self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))
self.initialize_parameters()
def initialize_parameters(self): nn.init.normal_(self.token_embedding.weight, std=0.02) #Инициализируем вес внедрения текстового токена в нормальное распределение со средним значением 0 и стандартным отклонением 0,02. nn.init.normal_(self.positional_embedding, std=0.01) #Инициализируем вес позиционного_эмбеддинга для нормального распределения со средним значением 0 и стандартным отклонением 0,01
if isinstance(self.visual, ModifiedResNet): if self.visual.attnpool is not None: std = self.visual.attnpool.c_proj.in_features ** -0.5 nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std) nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std) nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std) nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)
for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]: for name, param in resnet_block.named_parameters(): if name.endswith("bn3.weight"): nn.init.zeros_(param)
proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5) attn_std = self.transformer.width ** -0.5 fc_std = (2 * self.transformer.width) ** -0.5 for block in self.transformer.resblocks: nn.init.normal_(block.attn.in_proj_weight, std=attn_std) nn.init.normal_(block.attn.out_proj.weight, std=proj_std) nn.init.normal_(block.mlp.c_fc.weight, std=fc_std) nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)
if self.text_projection is not None: nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)
def build_attention_mask(self): # lazily create causal attention mask, with full attention between the vision tokens # pytorch uses additive attention mask; fill with -inf mask = torch.empty(self.context_length, self.context_length) mask.fill_(float("-inf")) #Заполняем все отрицательной бесконечностью mask.triu_(1) # zero out the lower диагонали установите нижний треугольник на 0. При выполнении softmax softmax (-inf) равен 0 Действует как маска return mask
@property def dtype(self): return self.visual.conv1.weight.dtype
def encode_image(self, image): return self.visual(image.type(self.dtype)) #self.dtype:torch.float16
def encode_text(self, text): x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model] , введите torch.Size([3, 77]), вывод torch.Size([3, 77, 512])
x = x + self.positional_embedding.type(self.dtype)#self.dtype:torch.float16 плюс позиционное кодирование , результат по-прежнему будет torch.Size([3, 77, 512]) x = x.permute(1, 0, 2) # NLD -> LND #выход torch.Size([77, 3, 512]) x = self.transformer(x) #Выполните извлечение признаков transormerEncoder (состоящее из многоуровневого MultiHeadAttention и MLP), и выходная форма будет соответствовать входной shape.torch.Size([77, 3, 512]) x = x.permute(1, 0, 2) # LND -> NLD Выходной факел.Размер([3, 77, 512]) x = self.ln_final(x).type(self.dtype) #Выполнить нормализацию LayerNorm
# x.shape = [batch_size, n_ctx, transformer.width] # take features from the eot embedding (eot_token is the highest number in each sequence) x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projection #text.Формаtorch.Size([3, 77]),self.text_projectionдляtorch.Size([512, 512])
return x
def forward(self, image, text): image_features = self.encode_image(image) text_features = self.encode_text(text)
# normalized features особенность Нормализация image_features = image_features / image_features.norm(dim=1, keepdim=True) text_features = text_features / text_features.norm(dim=1, keepdim=True)
# cosine similarity as logits logit_scale = self.logit_scale.exp() #косинусное сходство logits_per_image = logit_scale * image_features @ text_features.t() logits_per_text = logits_per_image.t()
# shape = [global_batch_size, global_batch_size] return logits_per_image, logits_per_text4.5 Извлечение признаков изображения VisionTransformer
class VisionTransformer(nn.Module): def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int): super().__init__() #input_resolution:224; patch_size:32; width:768; layers:12; heads:12; output_dim:512 self.input_resolution = input_resolution #224 self.output_dim = output_dim #512 self.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False) #Используйте CNN для извлечения признаков в качестве встраивания
scale = width ** -0.5 Биссектрисный корень #with одна часть self.class_embedding = nn.Parameter(scale * torch.randn(width)) #Случайным образом генерируем встраивание классификации self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width)) #Случайно инициализируем PE self.ln_pre = LayerNorm(width)
self.transformer = Transformer(width, layers, heads)
self.ln_post = LayerNorm(width) self.proj = nn.Parameter(scale * torch.randn(width, output_dim))
def forward(self, x: torch.Tensor): x = self.conv1(x) # shape = [*, width, grid, grid] Ввод:факел.Размер([1, 3, 224, 224]), выходной факел.Размер([1, 768, 7, 7]) Изображение размером 224*224 разделено на 7 частей по горизонтали и вертикали, причем ширина каждого участка равна 224/7=32. 768 - количество измерений x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2] Выходной факел.Размер([1, 768, 49]) x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width] #выходtorch.Size([1, 49, 768]) x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1,ширина] #Добавляем classToken перед patchEmbdding,Вывод: torch.Size([1, 50, 768]) x = x + self.positional_embedding.to(x.dtype) #Добавить PositionEmbedding после PatchEmbdding , результат по-прежнему будет torch.Size([1, 50, 768]) x = self.ln_pre(x) #Выполнить нормализацию LayerNorm
x = x.permute(1, 0, 2) # NLD -> LND , выходной факел.Размер([50, 1, 768]) x = self.transformer(x) #Выполните извлечение признаков VIT, выходная форма соответствует входной форме, Или torch.Size([50, 1, 768]) x = x.permute(1, 0, 2) # LND -> NLD,Выходной факел.Размер([1, 50, 768])
x = self.ln_post(x[:, 0, :]) #выходtorch.Size([1, 768]), сохраняют тусклость первого измерения
if self.proj is not None:#self.proj.Формаtorch.Size([768, 512]) x = x @ self.proj #выходtorch.Size([1, 512])
return x4.6 Извлечение текстовых признаков Трансформатор
class ResidualAttentionBlock(nn.Module): def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None): super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head) #d_model:512, n_head:8, d_head=d_model/n_head=64 self.ln_1 = LayerNorm(d_model) self.mlp = nn.Sequential(OrderedDict([ ("c_fc", nn.Linear(d_model, d_model * 4)), ("gelu", QuickGELU()), ("c_proj", nn.Linear(d_model * 4, d_model)) ])) self.ln_2 = LayerNorm(d_model) self.attn_mask = attn_mask
def attention(self, x: torch.Tensor): self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else None return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x: torch.Tensor): x = x + self.attention(self.ln_1(x)) x = x + self.mlp(self.ln_2(x)) return x
class Transformer(nn.Module): def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None): super().__init__() self.width = width #768 self.layers = layers #12 self.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)]) #Определить 12-слойный AttentBlock
def forward(self, x: torch.Tensor): return self.resblocks(x)5. Ограничения и недостатки CLIP
1. Хотя Clip и ResNet50 с нулевым выстрелом одинаково хорошо работают со многими наборами данных, производительность ResNet50 для соответствующих задач не оптимальна. Между Clip и SOTA все еще существует большой разрыв. большие данные. Согласно оценкам, основанным на парадигме затрат и эффектов, это как минимум в 1000 раз превышает стоимость существующего обучения Clip.
2. В некоторых разделенных наборах данных (например, медицинских) точность клипа ниже, чем у Resnet50.
3. В некоторых абстрактных и сложных задачах обобщение клипов относительно плохое, например: определение того, является ли определенный кадр в видео ненормальным.
4. Если данные вывода и данные обучения находятся далеко друг от друга (вне распределения), генерализация клипов также плохая, например: в наборе данных рукописных цифр.
5. Хотя клип можно использовать в качестве нулевого кадра, он все равно выбирается путем расчета сходства между заданными парами изображение-текст. Для сравнения, генеративная формула будет более гибкой.
6. Информация
1. Статья: https://arxiv.org/pdf/2103.00020.
2. Исходный код: https://github.com/openai/CLIP.
3. Ли Му-CLIP интенсивно читает статью по параграфам https://www.bilibili.com/video/BV1SL4y1s7LQ
4. Мультимодальная модель обучения 1 — модель предварительного обучения сравнительному обучению языку и изображению CLIP https://blog.csdn.net/weixin_44791964/article/details/129941386
5. Мультимодальное представление — CLIP и китайская версия Chinese-CLIP: теоретическое объяснение, тонкая настройка кода и чтение статьи https://blog.csdn.net/weixin_44362044/article/details/136262247
6. Мультимодальная большая модель Openai: подробное объяснение и практическое применение клипа https://blog.csdn.net/lsb2002/article/details/132275132
7. Глубокое обучение, серия 37: Модель CLIP https://blog.csdn.net/kittyzc/article/details/125167223
8. [Практика написания кода] Используйте CLIP для выполнения некоторых мультимодальных задач https://blog.csdn.net/me_yundou/article/details/123236173
9. Два часа краткого анализа модели CLIP, включая принципы + воспроизведение кода https://www.bilibili.com/video/BV1K1421U7jc/?vd_source=03a763fa6cf49b01f658f32592f5a6f3
10. Разберитесь с графической и текстовой мультимодальной моделью CLIP в одной статье https://blog.csdn.net/weixin_47228643/article/details/136690837
11. Мультимодальный классический CLIP https://juejin.cn/post/7264503343996747830
12. Четвертая серия интенсивного чтения статей Ли Му: CLIP и серия работ по улучшению (LSeg, GroupViT, VLiD, GLIPv1, GLIPv2, CLIPasso) https://blog.csdn.net/qq_56591814/article/details/127421979
13. Анализ принципов рисования ИИ: от CLIP, BLIP до DALLE, DALLE 2, DALLE 3, Stable Diffusion https://blog.csdn.net/v_JULY_v/article/details/131205615
14.Изображение из: Понимание нулевого выстрела, одного выстрела и нескольких выстрелов https://blog.csdn.net/wzk4869/article/details/129419127
спасибо, что прочитали
Далее мы продолжим учиться выводить контент, связанный с искусственным интеллектом. Добро пожаловать, следите за общедоступной учетной записью «Путешествие по разработке аудио и видео», чтобы учиться и расти вместе.
Добро пожаловать для общения



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
