PureFlash для распределенного хранилища all-flash - чрезвычайно короткий путь ввода-вывода - максимальная производительность - минималистичная установка механизма RDMA и SPDK - поддержка гиперконвергенции - путь ввода-вывода - обработка исходного кода и представление проекта
PureFlash
Минималистичный путь ввода-вывода, встроенная поддержка RDMA (глаголы) и диска механизма SPDK, полная производительность оборудования, поддержка моментальных снимков, нескольких копий и т. д., высокодоступное и высокопроизводительное распределенное хранилище, давайте вместе станем свидетелями эры all-flash !
Адрес проекта: https://github.com/cocalele/PureFlash
Видео по обмену технологиями: https://www.bilibili.com/video/BV1s34y1F7Hr
1. Что такое PureFlash?
PureFlash — это реализация ServerSAN с открытым исходным кодом, которая использует большое количество серверов общего назначения и программную систему PureFlash для создания набора распределенных хранилищ SAN, которые могут удовлетворить различные бизнес-потребности предприятий.
Идея PureFlash исходит из флеш-массива S5 с полным аппаратным ускорением. Поэтому, хотя PureFlash сам по себе является чисто программной реализацией, его протокол хранения очень дружелюбен к аппаратному ускорению. Можно считать, что протокол PureFlash — это протокол NVMe плюс усовершенствования функций облачного хранилища, включая снимки, копии, сегменты, горячее обновление кластера и другие возможности.
2. Зачем создавать новую реализацию ServerSAN?
PureFlash — это система хранения данных, разработанная для эпохи флэш-накопителей. В настоящее время SSD-диски получают все большее распространение и имеют тенденцию полностью заменять HDD. Существенная разница между SSD и HDD заключается в разнице в производительности, которая также является самой прямой разницей в пользовательском опыте. А с популярностью интерфейса NVMe разница между ними становится все больше и больше. Эта количественная разница составляет почти стократную величину. достаточно, чтобы добиться качественных изменений в архитектурном проектировании. Например, оказывается, что производительность жесткого диска очень низкая, намного ниже производительности процессора и сети. Поэтому принцип проектирования системы заключается в максимизации производительности жесткого диска. Для достижения этой цели можно достичь максимальной производительности. затраты на потребление ресурсов, таких как процессор. В эпоху NVMe соотношение производительности полностью изменилось. Вместо этого диск больше не является узким местом системы. Этот метод использования процессора для оптимизации ввода-вывода может быть только контрпродуктивным.
Поэтому нам нужна новая архитектура системы хранения, чтобы в полной мере использовать возможности SSD и повысить эффективность системы. Концепция проектирования PureFlash основана на основных принципах упрощения стека ввода-вывода, разделения пути данных и пути управления, а также определения приоритета быстрого пути для обеспечения высокой производительности и высокой надежности, а также предоставления основных возможностей блочного хранилища в облачных вычислениях. эпоха.
3. Разработка программного обеспечения
Почти все современные распределенные системы хранения данных имеют очень глубокие стеки программного обеспечения: от клиентского программного обеспечения до конечного SSD-диска сервера путь ввода-вывода очень длинный. С одной стороны, этот глубокий программный стек потребляет большое количество системных вычислительных ресурсов, а с другой стороны, он также нивелирует преимущества SSD в производительности. В конструкции PureFlash реализованы следующие принципы:
- «Меньше значит больше», удалите сложную логику на пути ввода-вывода, используйте уникальную структуру BoB (Block over Bock) для минимизации иерархии.
- «Ресурсоориентированное», планирование структуры программного обеспечения и количества потоков вокруг ресурсов ЦП и ресурсов SSD. Вместо обычного планирования, основанного на логических потребностях программного кода
- «Разделение управления и данных»: часть управления разрабатывается с использованием Java, а путь данных разрабатывается с использованием C++, каждый из которых опирается на свои сильные стороны.
Кроме того, PureFlash «использует TCP в режиме RDMA» в сетевой модели вместо обычного «использовать RDMA как более быстрый TCP». RDMA необходимо правильно настроить односторонний API и двусторонний API в соответствии с потребностями бизнеса. Это не только позволяет правильно использовать RDMA, но и значительно повышает эффективность использования TCP.
Ниже представлена структурная схема нашей системы:
+---------------+
| |
+--->+ MetaDB |
| | (HA DB) |
+------------------+ | +---------------+
| +------+
| pfconductor | +---------------+
+----> (Max 5 nodes) +-----------> |
| +--------+---------+ | Zookeeper |
| | | (3 nodes) |
| | +------^--------+
+-------------------+ | | |
| +---+ +--------v---------+ |
| pfbd tcmu | | | |
| (User and +------->+ pfs +------------------+
| space client) | | (Max 1024 nodes) |
+-------------------+ +------------------+3.1 pfs, PureFlash Store
Этот модульДемон службы хранилища,Предоставлять все услуги передачи данных,включать:
- Управление дисковым пространством SSD (например: запись о выделении объекта небольшим блоком размером 64 МБ)
- Службы сетевого интерфейса (протоколы RDMA и TCP)
- Обработка запросов ввода-вывода
Кластер PureFlash может поддерживать до 1024 узлов хранения данных pfs. Все pfs предоставляют услуги внешнему миру, поэтому все узлы работают в активном состоянии.
3.2 pfconductor
Этот модульМодуль управления кластером。Производственное развертывание должно иметь как минимум2индивидуальныйpfconductorузел(большинство5индивидуальный)。Основные функциивключать:
1) Обнаружение кластера и поддержание статуса, включая активность каждого узла, активность каждого SSD и емкость.
2) Отвечать на запросы управления пользователями и создавать тома, снимки, арендаторов и т. д.
3) Управление работой кластера, открытие/закрытие тома, обработка ошибок во время выполнения Этот модуль написан на Java и находится в другой кодовой базе: https://github.com/cocalele/pfconductor
3.3 Zookeeper
Zookeeper — модуль, реализующий в кластере протокол Paxos для решения проблемы разделения сети. Все экземпляры pfconductor и pfs регистрируются в Zookeeper, поэтому активные pfconductor могут обнаруживать других участников во всем кластере.
3.4 MetaDB
MetaDB используется для сохранения метаданных кластера и метаданных распределения томов (метаданные уровня 1, тома, сопоставленные с сегментами, узлами, репликами и конкретными зависимостями дисков). Здесь мы используем MariaDB. При развертывании в рабочей среде необходимо использовать плагин Galaera DB для обеспечения функций высокой доступности.
поддержка клиентов
Клиентский интерфейс разделен на две категории: пользовательский режим и режим ядра. Доступ к пользовательскому режиму осуществляется приложениями в виде API, и эти API расположены в libpfbd.
3.5.1 pfdd
pfdd — это инструмент, похожий на dd, но имеющий доступ к PureFlash. volume, https://github.com/cocalele/qemu/tree/pfbd
3.5.2 fio
Поддержка пфбд fio, вы можете использовать fio для прямого доступа к pureflash для выполнения тестирования производительности. База кода находится по адресу:https://github.com/cocalele/fio.git
3.5.3 qemu
pfbd также интегрирован в qemu и может быть напрямую подключен к виртуальной машине. База кода находится по адресу:https://gitee.com/cocalele/qemu.git
3.5.4 Драйвер режима ядра
PureFlash предоставляет бесплатный драйвер режима ядра, который может напрямую отображать том pfbd как блочное устройство на физической машине, а затем форматировать его в любую файловую систему, к которой может получить доступ любое приложение без адаптации API.
Драйвер ядра очень подходит для сценариев контейнерного PV и баз данных.
3.5.5 док-станция
Поддержка PureFlash Том монтируется к хосту в виде nbd. База кода находится по адресу: https://gitee.com/cocalele/pfs-nbd.git
После компиляции выполните команду в следующем формате, чтобы смонтировать том:
# pfsnbd /dev/nbd3 test_v1 3.5.6 iSCSI-соединение
Поддержка PureFlash Том служит внутренним устройством LIO и предоставляет интерфейс iSCSI. База кода находится по адресу:https://gitee.com/cocalele/tcmu-runner.git
сетевой порт
Ниже указан сетевой порт, используемый pureflash. В случае возникновения проблемы вы можете проверить, работает ли служба.
49162 store node TCP port
49160 store node RDMA port
49180 conductor HTTP port
49181 store node HTTP port
Попробуйте PureFlash
Самый удобный способ попробовать PureFlash — использовать контейнер. Предполагая, что у вас уже есть диск NVMe, например, nvme1n1, убедитесь, что данные на этом диске вам больше не нужны. Затем выполните следующие действия:
# dd if=/dev/zero of=/dev/nvme1n1 bs=1M count=100 oflag=direct
# docker pull pureflash/pureflash:latest
# docker run -ti --rm --env PFS_DISKS=/dev/nvme1n1 --ulimit core=-1 --privileged -e TZ=Asia/Shanghai --network host pureflash/pureflash:latest
# pfcli list_store
+----+---------------+--------+
| Id | Management IP | Status |
+----+---------------+--------+
| 1 | 127.0.0.1 | OK |
+----+---------------+--------+
# pfcli list_disk
+----------+--------------------------------------+--------+
| Store ID | uuid | Status |
+----------+--------------------------------------+--------+
| 1 | 9ae5b25f-a1b7-4b8d-9fd0-54b578578333 | OK |
+----------+--------------------------------------+--------+
#let's create a volume
# pfcli create_volume -v test_v1 -s 128G --rep 1
#run fio test
# /opt/pureflash/fio -name=test -ioengine=pfbd -volume=test_v1 -iodepth=16 -rw=randwrite -size=128G -bs=4k -direct=1Блок-схема ссылки на путь ввода-вывода
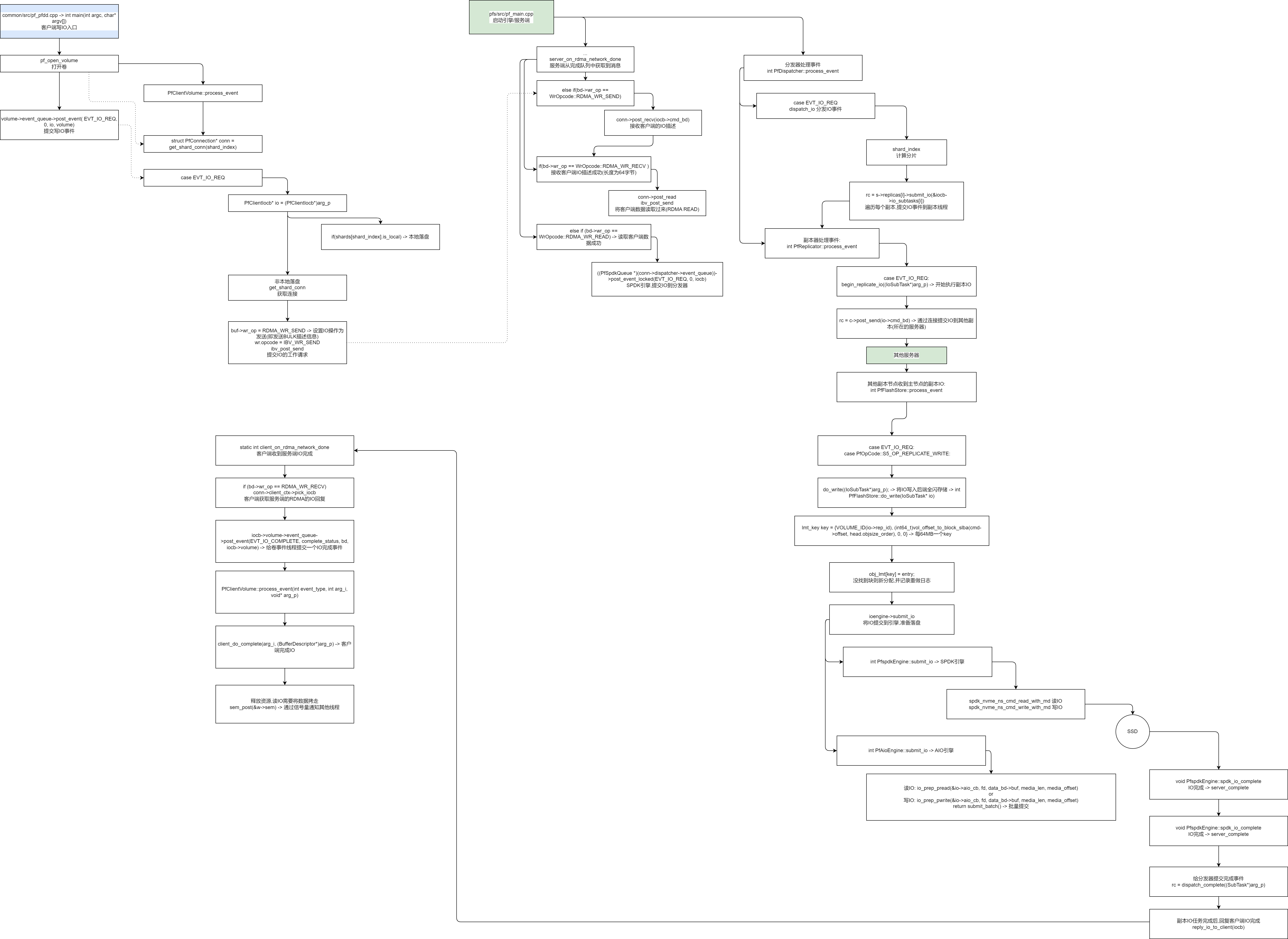
Процесс исходного кода пути ввода-вывода
---------- Путь ввода-вывода, иопат, тестирование ввода-вывода, pfdd, инструмент дд, путь ввода-вывода, iopath, ио путь, Писать Я ----------
common/src/pf_pfdd.cpp -> int main(int argc, char* argv[])
string rw, bs_str, ifname, ofname, vol_name, cfg_file, snapshot_name;
void* buf = malloc(bs);
DeferCall _c([buf](){free (buf);}); -> Уничтожение используется в качестве семантики deffer.
struct PfClientVolume* vol = pf_open_volume(vol_name.c_str(), cfg_file.c_str(), snapshot_name.c_str(), S5_LIB_VER) -> открытая книга
int PfClientVolume::do_open(bool reopen, bool is_aof)
event_queue = runtime_ctx->vol_proc->event_queue
...
init_app_ctx(cfg, 0, 0, 0) -> Инициализировать контекст
ctx->init(cfg, io_depth, max_vol_cnt, 0 /* 0 for shared connection*/, io_timeout)
vol_proc = new PfVolumeEventProc(this)
vol_proc->start() -> void * thread_proc_eventq(void* arg)
pThis->process_event(t->type, t->arg_i, t->arg_p, t->arg_q)
int PfClientVolume::process_event(int event_type, int arg_i, void* arg_p)
for(int i=0;i<count;i++)
pf_io_submit(vol, buf, bs, offset + i * bs, io_cbk, &arg, is_write) -> Писать Я
auto io = volume->runtime_ctx->iocb_pool.alloc() -> общий, Выделить пул объектной памяти
io->ulp_handler = callback -> Установите обратный вызов/контроллер бизнес-уровня
struct PfMessageHead *cmd = io->cmd_bd->cmd_bd; -> Установить команду
memcpy(io->data_bd->buf, buf, length) -> Первая копия памяти
cmd->opcode = is_write ? S5_OP_WRITE : S5_OP_READ
int rc = volume->event_queue->post_event( EVT_IO_REQ, 0, io, volume) -> Отправьте событие записи и позвольте другим потокам обработать это событие. -> int PfClientVolume::process_event(int event_type, int arg_i, void* arg_p)
current_queue->enqueue_nolock(S5Event{ type, arg_i, arg_p , arg_q})
write(event_fd, &event_delta, sizeof(event_delta)) -> Обработка потока событий уведомлений
sem_wait(&arg.sem)
ssize_t rc = ::write(fd, buf, bs);
int PfClientVolume::process_event(int event_type, int arg_i, void* arg_p)
case EVT_IO_REQ
PfClientIocb* io = (PfClientIocb*)arg_p;
if(shards[shard_index].is_local) -> Локальное развертывание (например, гиперконвергентные сценарии)
PfClientStore* local_store = get_local_store(shard_index)
local_store->do_write(&io->io_subtasks[0]) -> Пишите локально -> int PfClientStore::do_write(IoSubTask* io)
ioengine->submit_io(io, entry->offset + offset_in_block(cmd->offset, in_obj_offset_mask), cmd->length) -> Отправить Пишите локально Я
...
else -> Отправить ввод-вывод на сервер
struct PfConnection* conn = get_shard_conn(shard_index) -> Получить соединение
io_cmd->meta_ver = (uint16_t)meta_ver;
BufferDescriptor* rbd = runtime_ctx->reply_pool.alloc()
int rc = conn->post_recv(rbd);
cmd_bd->cmd_bd->rkey = io->data_bd->mrs[((PfRdmaConnection*)conn)->dev_ctx->idx]->rkey -> RDMA Получить удаленный ключ из соединения
rc = conn->post_send(cmd_bd) -> Отправить команду ввода-вывода
buf->wr_op = RDMA_WR_SEND -> Установите операцию ввода-вывода для отправки (то есть отправьте БОЛЬШУЮ информацию описания).
wr.opcode = IBV_WR_SEND
wr.send_flags = IBV_SEND_SIGNALEDsge.addr = (uint64_t)buf->buf
sge.lkey = buf->mrs[this->dev_ctx->idx]->lkey
ibv_post_send(rdma_id->qp, &wr, &bad_wr) -> Отправить заявку на работу -> Запустите сервер для получения описания ввода-вывода: if(bd->wr_op == WrOpcode::RDMA_WR_RECV )
Сервер запускает поток обработки событий:
rc = app_context.rdma_server->init(RDMA_PORT_BASE)
int PfRdmaServer::init(int port)
static void *rdma_server_event_proc(void* arg)
int PfRdmaServer::on_connect_request
conn->dev_ctx = build_context(id->verbs)
init_rdmd_cq_poller(&rdma_dev_ctx->prdc_poller_ctx[pindex], pindex, rdma_dev_ctx, rdma_context) -> Поток, инициализирующий очередь завершения опроса RDMA.
poller->prp_cq = ibv_create_cq(rdma_ctx, 512, NULL, poller->prp_comp_channel, 0)
ibv_req_notify_cq(poller->prp_cq, 0)
poller->poller.init("rdma_cq_poller", 1024)
epfd = epoll_create(max_fd_count)
int rc = poller->poller.add_fd(poller->prp_comp_channel->fd, EPOLLIN, on_rdma_cq_event, poller)
...
conn->on_work_complete(msg, (WcStatus)wc[i].status, conn, NULL) ->
rc = rdma_create_qp(id, conn->dev_ctx->pd, &qp_attr)
conn->connection_info = get_rdma_desc(id, false)
conn->on_work_complete = server_on_rdma_network_done
rc = rdma_accept(id, &cm_params)
Сервер получает данные:
static int server_on_rdma_network_done(BufferDescriptor* bd, WcStatus complete_status, PfConnection* _conn, void* cbk_data)
if(bd->wr_op == WrOpcode::RDMA_WR_RECV )
conn->post_read(iocb->data_bd, bd->cmd_bd->buf_addr, bd->cmd_bd->rkey) -> После получения запроса SEND от клиента RDMA, Чтение данных клиента на сервер
buf->wr_op = RDMA_WR_READ;
wr.opcode = IBV_WR_RDMA_READ;
wr.send_flags = IBV_SEND_SIGNALED;
ibv_post_send -> После прочтения, Запускается в обратном вызове завершения сети (server_on_rdma_network_done):
else if (bd->wr_op == WrOpcode::RDMA_WR_READ) -> Чтение данных клиента успешно
PfServerIocb *iocb = bd->server_iocb
if (spdk_engine_used()) -> Если это движок SPDK, Заблокировать и отправить событие ввода-вывода (событие распространения)
((PfSpdkQueue *)(conn->dispatcher->event_queue))->post_event_locked(EVT_IO_REQ, 0, iocb) -> int PfDispatcher::process_event
else
conn->dispatcher->event_queue->post_event(EVT_IO_REQ, 0, iocb);
Диспетчер обрабатывает события
int PfDispatcher::process_event
case EVT_IO_REQ:
rc = dispatch_io((PfServerIocb*)arg_p) -> Распространение событий -> int PfDispatcher::dispatch_io(PfServerIocb *iocb)
uint32_t shard_index = (uint32_t)OFFSET_TO_SHARD_INDEX(cmd->offset); -> Вычислительные осколки
PfShard * s = vol->shards[shard_index]
switch(cmd->opcode)
case S5_OP_WRITE: -> Писать Я
stat.wr_cnt++;
return dispatch_write(iocb, vol, s) -> int PfDispatcher::dispatch_write
PfMessageHead* cmd = iocb->cmd_bd->cmd_bd
iocb->setup_subtask(s, cmd->opcode) -> Ставьте подзадачи в зависимости от количества копий
for (int i = 0; i < vol->rep_count; i++)
rc = s->replicas[i]->submit_io(&iocb->io_subtasks[i]) -> Обход реплик и фиксация реплики IO -> disk->event_queue->post_event(EVT_IO_REQ, 0, subtask) -> int PfReplicator::process_event
Репликатор обрабатывает события:
int PfReplicator::process_event
case EVT_IO_REQ:
return begin_replicate_io((IoSubTask*)arg_p) -> Начать выполнение копирования ввода-вывода
PfConnection* c = (PfConnection*)conn_pool->get_conn((int)t->store_id); -> Получить соединение
if(!c->get_throttle()) -> Ограничение тока
PfClientIocb* io = iocb_pool.alloc()
memcpy(io->cmd_bd->cmd_bd, t->parent_iocb->cmd_bd->cmd_bd, sizeof(PfMessageHead))
t->opcode = PfOpCode::S5_OP_REPLICATE_WRITE -> Установите код операции для копирования и записи
BufferDescriptor* rbd = mem_pool.reply_pool.alloc()
rc = c->post_recv(rbd) -> Получить описание ввода-вывода (информацию заголовка ввода-вывода) -> server_on_rdma_network_done
buf->wr_op = RDMA_WR_RECV
ibv_post_recv(rdma_id->qp, &wr, &bad_wr)
io->reply_bd = rbd
rc = c->post_send(io->cmd_bd) -> Отправляйте ввод-вывод на другие реплики (серверы, на которых они расположены) через соединения.
buf->wr_op = RDMA_WR_SEND
wr.opcode = IBV_WR_SEND
ibv_post_send(rdma_id->qp, &wr, &bad_wr) -> server_on_rdma_network_done
else if(bd->wr_op == WrOpcode::RDMA_WR_SEND) -> Этот ввод-вывод завершен, Продолжайте получать следующий IO
iocb->re_init();
conn->post_recv(iocb->cmd_bd);
Другие узлы реплики получают реплику ввода-вывода от первичного узла реплики:
int PfFlashStore::process_event
case EVT_IO_REQ:
case PfOpCode::S5_OP_REPLICATE_WRITE:
do_write((IoSubTask*)arg_p); -> Запись ввода-вывода в полное флэш-хранилище бэкэнда. -> int PfFlashStore::do_write(IoSubTask* io)
PfMessageHead* cmd = io->parent_iocb->cmd_bd->cmd_bd
BufferDescriptor* data_bd = io->parent_iocb->data_bd
lmt_key key = {VOLUME_ID(io->rep_id), (int64_t)vol_offset_to_block_slba(cmd->offset, head.objsize_order), 0, 0} -> Один ключ на 64 МБ, Идентификатор тома + Этот объем ввода-вывода основан на смещении начального логического блока в качестве ключа.
auto block_pos = obj_lmt.find(key)
if (unlikely(block_pos == obj_lmt.end())) -> Если блок не найден, он будет выделен заново и будет записан журнал повторов.
int obj_id = free_obj_queue.dequeue() -> Получить идентификатор небольшого объекта
entry = lmt_entry_pool.alloc()
*entry = lmt_entry { offset: obj_id_to_offset(obj_id), // -> { return (obj_id << head.objsize_order) + head.meta_size; } Получите смещение объекта на диске, используя идентификатор объекта.
snap_seq : cmd->snap_seq,
status : EntryStatus::NORMAL,
prev_snap : NULL,
waiting_io : NULL
};
obj_lmt[key] = entry;
int rc = redolog->log_allocation(&key, entry, free_obj_queue.head); -> Запись распределения небольших блоков в журнал повторного выполнения.
if (store->ioengine->sync_write(entry_buff, LBA_LENGTH, current_offset) == -1) -> Синхронное обновление метаданных
uint64_t PfspdkEngine::sync_write(void* buffer, uint64_t buf_size, uint64_t offset) -> Запишите buf, длину и смещение на чистый диск через интерфейс SPDK.
return store->meta_data_compaction_trigger(COMPACT_TODO, true) -> Текущее смещение больше или равно начальному смещению. + Когда длина журнала повторов в заголовке составляет (256 МБ), Запустить объединение метаданных
last_state = to_run_compact.load()
else -> Блокированная запись существовала раньше
...
ioengine->submit_io(io, entry->offset + offset_in_block(cmd->offset, in_obj_offset_mask), cmd->length) -> Отправьте ввод-вывод в движок и подготовьтесь к размещению диска.
int PfspdkEngine::submit_io -> двигатель СПДК
if (spdk_nvme_bytes_to_blocks(media_offset, &lba, media_len, &lba_cnt) != 0) -> Преобразование смещения и длины в блоки
if (IS_READ_OP(io->opcode)) -> Чтение ввода-вывода
spdk_nvme_ns_cmd_read_with_md(ns->ns, qpair[1], data_bd->buf, NULL, lba, (uint32_t)lba_cnt, spdk_io_complete, io, 0, 0, 0)
esle -> Писать Я
spdk_nvme_ns_cmd_write_with_md(ns->ns, qpair[1], data_bd->buf, NULL, lba, (uint32_t)lba_cnt, spdk_io_complete, io, 0, 0, 0); -> с пространством имен Писатьвходить(двигатель СПДК наследует от общего механизма ввода-вывода,Увеличение НС, контроллер, размер блока, количество блоков и т. д.)
void PfspdkEngine::spdk_io_complete(void* ctx, const struct spdk_nvme_cpl* cpl) -> Писать ЯЗаканчивать
io->ops->complete(io, PfMessageStatus::MSG_STATUS_SUCCESS) -> При инициализации пула памяти (int PfDispatcher::init_mempools) статическая регистрация: static struct TaskCompleteOps _server_task_complete_ops={ server_complete , server_complete_with_metaver };
or int PfAioEngine::submit_io -> многофункциональный движок
io_prep_pread(&io->aio_cb, fd, data_bd->buf, media_len, media_offset)
or
io_prep_pwrite(&io->aio_cb, fd, data_bd->buf, media_len, media_offset)
return submit_batch() -> Массовая отправка
static void server_complete(SubTask* t, PfMessageStatus comp_status)
((PfServerIocb*)t->parent_iocb)->conn->dispatcher->event_queue->post_event(EVT_IO_COMPLETE, 0, t) -> Отправка события завершения диспетчеру -> int PfDispatcher::process_event
case EVT_IO_COMPLETE:
rc = dispatch_complete((SubTask*)arg_p);
if(iocb->task_mask == 0) -> После завершения задачи копирования ввода-вывода ответьте на завершение ввода-вывода клиента.
reply_io_to_client(iocb)
if (io_elapse_time > 2000) -> Медленный ввод-вывод
rc = iocb->conn->post_send(iocb->reply_bd); -> ответ клиенту, Запустить событие обработки RDMA клиента: client_on_rdma_network_done
static int client_on_rdma_network_done
if (bd->wr_op == RDMA_WR_RECV)
PfClientIocb* iocb = conn->client_ctx->pick_iocb(bd->reply_bd->command_id, bd->reply_bd->command_seq) -> Клиент получает ответ RDMA IO от сервера.
PfClientIocb* io = &iocb_pool.data[cid]
iocb->reply_bd = bd
iocb->volume->event_queue->post_event(EVT_IO_COMPLETE, complete_status, bd, iocb->volume) -> Отправьте событие завершения ввода-вывода в поток событий тома. -> int PfClientVolume::process_event(int event_type, int arg_i, void* arg_p)
client_do_complete(arg_i, (BufferDescriptor*)arg_p) -> Клиент завершает ввод-вывод
ulp_io_handler h = io->ulp_handler
if (wr_bd->wr_op == TCP_WR_RECV || wr_bd->wr_op == RDMA_WR_RECV) -> Клиент получает данные
PfMessageHead* io_cmd = io->cmd_bd->cmd_bd
runtime_ctx->reply_pool.free(io->reply_bd)
if(io->cmd_bd->cmd_bd->opcode == S5_OP_READ) -> Чтение ввода-вывода Заканчивать
iov_from_buf(io->user_iov, io->user_iov_cnt, io->data_bd->buf, io->data_bd->data_len) -> Копировать векторный ввод-вывод или обычный ввод-вывод
or memcpy(io->user_buf, io->data_bd->buf, io->data_bd->data_len);
runtime_ctx->free_iocb(io) -> Освободить ресурсы
h(arg, s) -> Выполнение бизнес-обратного вызова (ULP) -> void io_cbk(void* cbk_arg, int complete_status)
sem_post(&w->sem) -> Уведомить другие потоки через семафор
---------- Путь ввода-вывода, иопат, тестирование ввода-вывода, pfdd, инструмент дд, путь ввода-вывода, iopath, ио путь, Писать Я END ----------Метаданные распределения объектов небольших блоков головки диска (т. е. головка (4 КБ), здесь настройте головку диска объемом 10 ГБ для хранения метаданных блока)
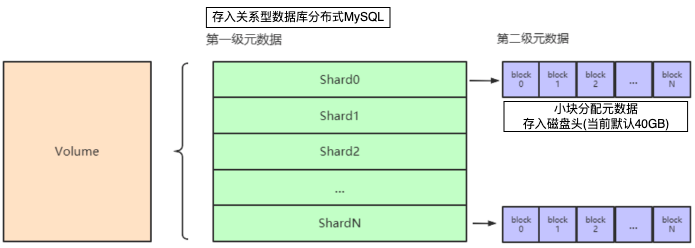
Структура и распределение метаданных (метаданные памяти = исходные метаданные диска + инкрементальное изменение записей журнала)
Поток обрезки периодически очищает неиспользуемые журналы распределения мелких объектов.
Метаданные также будут агрегированы в соответствии с правилами, а неиспользуемые журналы будут выпущены после агрегирования.
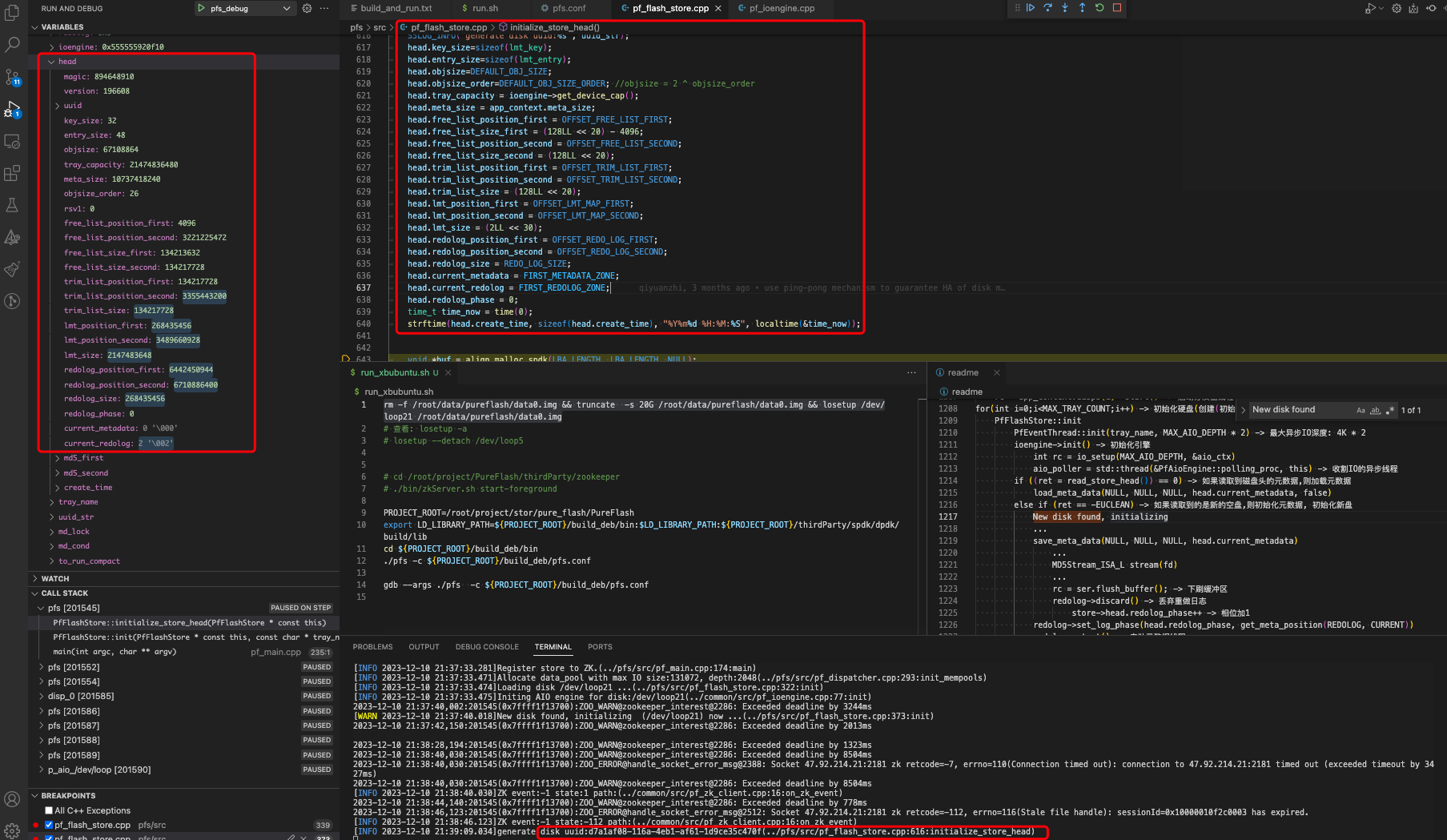
Инициализировать заголовок диска, метаданные, Важные функции:
int PfFlashStore::initialize_store_head()
...
uuid_generate(head.uuid)
head.objsize=DEFAULT_OBJ_SIZE -> Размер объекта размещения малых блоков по умолчанию составляет 64 МБ.
head.free_list_position_first = OFFSET_FREE_LIST_FIRST
...
memcpy(buf, &head, sizeof(head)) -> Копировать заголовок метаданных
ioengine->sync_write(buf, LBA_LENGTH, 0) -> Поместите метаданные на диск
int PfFlashStore::initialize_store_head()
{
memset(&head, 0, sizeof(head));
head.magic = 0x3553424e; //magic number, NBS5 894648910
head.version= S5_VERSION; //S5 version 196608
uuid_generate(head.uuid);
uuid_unparse(head.uuid, uuid_str);
S5LOG_INFO("generate disk uuid:%s", uuid_str);
head.key_size=sizeof(lmt_key); // 32B
head.entry_size=sizeof(lmt_entry); //48B
head.objsize=DEFAULT_OBJ_SIZE; // 64MB
head.objsize_order=DEFAULT_OBJ_SIZE_ORDER; //objsize = 2 ^ objsize_order 26, Маска маленького объекта (2 в 26-й степени)
head.tray_capacity = ioengine->get_device_cap(); //Размер диска: 20 ГБ (зависит от конфигурации)
head.meta_size = app_context.meta_size; // Метаданные: Например 10 ГБ
head.free_list_position_first = OFFSET_FREE_LIST_FIRST; // Смещение начальной позиции свободного блока: 4096
head.free_list_size_first = (128LL << 20) - 4096; // 128MB
head.free_list_position_second = OFFSET_FREE_LIST_SECOND;
head.free_list_size_second = (128LL << 20); // 128MB
head.trim_list_position_first = OFFSET_TRIM_LIST_FIRST;
head.trim_list_position_second = OFFSET_TRIM_LIST_SECOND;
head.trim_list_size = (128LL << 20);
head.lmt_position_first = OFFSET_LMT_MAP_FIRST;
head.lmt_position_second = OFFSET_LMT_MAP_SECOND;
head.lmt_size = (2LL << 30); //Объем 2 ГБ
head.redolog_position_first = OFFSET_REDO_LOG_FIRST;
head.redolog_position_second = OFFSET_REDO_LOG_SECOND;
head.redolog_size = REDO_LOG_SIZE;
head.current_metadata = FIRST_METADATA_ZONE;
head.current_redolog = FIRST_REDOLOG_ZONE; // Например 2
head.redolog_phase = 0;
time_t time_now = time(0);
strftime(head.create_time, sizeof(head.create_time), "%Y%m%d %H:%M:%S", localtime(&time_now));
...
struct HeadPage {
uint32_t magic;
uint32_t version;
unsigned char uuid[16];
uint32_t key_size;
uint32_t entry_size;
uint64_t objsize;
uint64_t tray_capacity;
uint64_t meta_size;
uint32_t objsize_order; //objsize = 2 ^ objsize_order
uint32_t rsv1; //to make alignment at 8 byte
uint64_t free_list_position_first;
uint64_t free_list_position_second;
uint64_t free_list_size_first;
uint64_t free_list_size_second;
uint64_t trim_list_position_first;
uint64_t trim_list_position_second;
uint64_t trim_list_size;
uint64_t lmt_position_first;
uint64_t lmt_position_second;
uint64_t lmt_size;
uint64_t redolog_position_first;
uint64_t redolog_position_second;
uint64_t redolog_size;
/**update after save metadata**/
int64_t redolog_phase;
uint8_t current_metadata;
uint8_t current_redolog;
char md5_first[MD5_RESULT_LEN];
char md5_second[MD5_RESULT_LEN];
/***/
char create_time[32];
};Сяобин (ssbandjl)
блог: https://cloud.tencent.com/developer/user/5060293/articles | https://logread.cn | https://blog.csdn.net/ssbandjl
Друзья, интересующиеся высокопроизводительными распределенными хранилищами PureFlash, SPDK, RDMA и другими высокопроизводительными технологиями, приглашаются присоединиться к обмену технологиями PureFlash (группа)



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
