Простое введение в материализованные представления ClickHouse
Хотя официальные документы фиксируют Материализованное представление В ClickHouse много деталей, но даиспользовать материализованно вид Также даиметь Уведомление требует много мелких деталей, не говоря уже о некоторых передовых практиках. Эта статья Подвести итог Понятно Материализованное представление Различные вопросы по ClickHouseиспользовать,И покажем три реальных случая,Сыр,Поделитесь этим с вами!
Хранимые процедуры и триггеры
Слишком долго смотреть
- процесс хранилища: предварительно скомпилируйте набор SQL программа, похожая на Результат не возвращен из функции.
- Подчеркните отсутствие возврата да для и реально из FUNCTION различать,этотиметьвозвращатьсярезультат。
- курок:особенныйхранилищепроцесс,Автоматически вызывается при прослушивании определенных событий.
язык запросов к базе данных (запрос язык) — инструмент, предоставляемый системой управления базами данных (СУБД) для взаимодействия пользователей с базой данных. Языки запросов делятся на три категории: [1]:
- Обязательно: пользователь управляет системой для выполнения операций шаг за шагом.,Посчитайте, получите данные. Процесс расчета включает в себя переменные из переменных состояния.
- Функциональность: пользователь вызывает ряд цепочек функций для выполнения вычислений и получения информации. Процесс расчета существует не содержит переменных состояния и не имеет побочных эффектов.
- декларативный(Non-Procedural/Declarative):Пользователь лишь заявляет о необходимостиизданные,Зависит отбаза данныхуправлятьсистема Реальностьсейчасвычислитьпроцессивозвращатьсяданные。
Три типа языков запросов четко не определены.
Инженерный серединаиз языка запросов,в сочетании счас Содержит несколько языков запросовизхарактеристика。[2]
люди часто думают SQL Используется в реляционной модели (Relational Модель) декларативный язык запросов для баз данных, но мир не черно-белый. Хотя декларативные языки сокращают затраты на обучение пользователя, база данных берет на себя процесс проверки (лексический анализ), трансляции (компиляции), оптимизации и окончательного выполнения. Но если бизнесу необходимо выполнять определенную часть одной и той же логики снова и снова, очевидно, неприемлемо каждый раз проходить этот процесс заново. Поэтому почти все основные системы реляционных баз данных ввели процедурные расширения, такие как PG использовал PL/pgSQL[3],Он содержит определения переменных, условное управление, циклы и другие процедурные элементы языка.
Затем представьте главного героя этого раздела: хранимую процедуру, предварительно скомпилированную часть логики (с использованием процедурного языка), которая может значительно ускорить выполнение.
А курок (Триггер) – это особый процесс.,Он прослушивает определенные события базы данных.,Можетсуществоватьдо инцидента/середина/позвони после。[4]
По типам событий триггеры делятся на:
- Триггер DDL
- Триггер DML
С точки зрения запуска действия [5],курок делится на:
- Триггеры до и после (ДО, ПОСЛЕ)
- Сменный триггер (ВМЕСТО)
Итак, каковы бизнес-сценарии использования триггеров? Если взять самый простой пример, запишите журнал аудита (Audit Log) определенной таблицы и запишите все операции DML через триггеры.
Материализованное представление ClickHouse
ClickHouse как реляционный OLAP(OnLine Analytical Processing)база данных,К сожалению, не поддерживаетсяхранилищепроцесс。[6]
Статус реализации хранимой процедуры ClickHouse
существовать 2023 Год Roadmap середина Experimental features and research Частично видно refreshable materialized views,иметь Сырой Год
Но что очень интересно, ClickHouse Предоставляет материализованные представления (материализованные View) из специальной функции, функционально эквивалентной AFTER INSERT Триггеры и материализованные представления все еще используются. декларативный SQL Определить логику расчета。
Чтение исходного кода
намекать
Вы можете перейти непосредственно к Подвести итог часть.
Версия ClickHouse
Эта статья Чтение исходного код На основе ClickHouse 22.3 Версия
StorageMaterializedView
Сначала посмотрите объявление класса материализованного представления. src/Storages/StorageMaterializedView.h:
class StorageMaterializedView final : public IStorage, WithMutableContext
{
public:
...
private:
/// Will be initialized in constructor
StorageID target_table_id = StorageID::createEmpty();
bool has_inner_table = false;
...
}Вы можете видеть, что материализованные представления наследуются от IStorage Класс, из аннотации класса середина вы можете видеть, что он управляет функциями. материализованный види StorageMerge Все они наследуются от этого класса, который управляет хранилищем данных. С точки зрения представления, есть ли у него реальное хранилище? Кроме того, материализованные представления используют target_table_id Хранится в других таблицах идентификатор. посмотрим дальше IStorage Аннотация класса:
/** Storage. Describes the table. Responsible for
* - storage of the table data;
* - the definition in which files (or not in files) the data is stored;
* - data lookups and appends;
* - data storage structure (compression, etc.)
* - concurrent access to data (locks, etc.)
*/Что произойдет, если представление станет читаемым? Перейти для перезагрузки IStorage из StorageMaterializedView::read Определение метода:
void StorageMaterializedView::read(
...)
{
auto storage = getTargetTable();
...
storage->read(query_plan, column_names, target_storage_snapshot, query_info, local_context, processed_stage, max_block_size, num_streams);
...
}а также StorageMaterializedView::getTargetTable Определение метода:
StoragePtr StorageMaterializedView::getTargetTable() const
{
checkStackSize();
return DatabaseCatalog::instance().getTable(target_table_id, getContext());
}Операция чтения выполнена правильно target_table_id Соответствует изповерхности из,Тогда будет ясно,материализованный вид Это не будет Хранить данные,встреча Воля Перенаправление запроса на цельповерхность。
Проведите эксперимент, чтобы просто проверить:
create table test( time DateTime) Engine=Memory();
create table source(time DateTime) Engine=Memory();
create materialized view mv_test to test as select time from source;
insert into table source values(now());
select * from test;
┌────────────────time─┐
│ 2023-02-25 18:51:41 │
└─────────────────────┘
select * from mv_test;
┌────────────────time─┐
│ 2023-02-25 18:51:41 │
└─────────────────────┘
explain select * from test;
┌─explain───────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ ReadFromStorage (Memory) │
└───────────────────────────────────────────────────────────────────────────┘
explain select * from mv_test;
┌─explain───────────────────────────────────────────────────────────────────┐
│ Expression ((Projection + Before ORDER BY)) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ SettingQuotaAndLimits (Lock destination table for MaterializedView) │
│ ReadFromStorage (Memory) │
└───────────────────────────────────────────────────────────────────────────┘Уведомление Lock destination table for MaterializedView,соответствует предположениям.
Что происходит дальше с операцией записи? Думаю, он также будет перенаправлен на целевую таблицу, посмотрите. StorageMaterializedView::write Метод определения:
SinkToStoragePtr StorageMaterializedView::write(...)
{
auto storage = getTargetTable();
...
auto sink = storage->write(query, metadata_snapshot, local_context);
...
}Давайте проведем небольшой эксперимент, чтобы убедиться:
insert into table mv_test values(now());
select * from test;
┌────────────────time─┐
│ 2023-02-25 18:51:41 │
└─────────────────────┘
┌────────────────time─┐
│ 2023-02-25 19:11:20 │
└─────────────────────┘соответствует предположениям.
Ответил на сомнения,Вернуться к обычному порядку чтения,Далее прочитайте код конструктора src/Storages/StorageMaterializedView.cpp:
StorageMaterializedView::StorageMaterializedView(
const StorageID & table_id_,
ContextPtr local_context,
const ASTCreateQuery & query,
const ColumnsDescription & columns_,
bool attach_,
const String & comment)
: IStorage(table_id_), WithMutableContext(local_context->getGlobalContext())
{
...
/// If the destination table is not set, use inner table
has_inner_table = query.to_table_id.empty(); // Появились новые концепции inner table
if (has_inner_table && !query.storage) // Создание материализованного представлениячас,Илииметь ENGINE использовать inner таблицу или использовать TO использоватьвнешний стол
throw Exception(
"You must specify where to save results of a MaterializedView query: either ENGINE or an existing table in a TO clause",
ErrorCodes::INCORRECT_QUERY);
if (query.select->list_of_selects->children.size() != 1)
throw Exception("UNION is not supported for MATERIALIZED VIEW", ErrorCodes::QUERY_IS_NOT_SUPPORTED_IN_MATERIALIZED_VIEW);
...
// настраивать to_table_id
if (!has_inner_table)
{
target_table_id = query.to_table_id;
}
else if (attach_)
{
/// If there is an ATTACH request, then the internal table must already be created.
target_table_id = StorageID(getStorageID().database_name, generateInnerTableName(getStorageID()), query.to_inner_uuid);
}
else // создать внутренний table
{
/// We will create a query to create an internal table.
...
target_table_id = DatabaseCatalog::instance().getTable({manual_create_query->getDatabase(), manual_create_query->getTable()}, getContext())->getStorageID(); // Кажется ClickHouse иметьиндивидуальныйобщая ситуацияповерхностьзарегистрироватьсяповерхность }
}Вы можете увидеть:
- материализованный При создании вида необходимо указать целевую поверхность, иначе он создастся сам. inner поверхность
- материализованный видне могуиспользовать
UNION - ClickHouse системаиметьиндивидуальныйповерхностьиз“зарегистрироватьсяповерхность”,Система обслуживания представляет собой универсальный экземпляр сопоставления идентификаторов.
IInterpreter、InterpreterInsertQuery
Итак, следующий индивидуальный вопрос,Вставьте данные в исходную поверхность,данные Как пройти мимоматериализованный вид добежал до целевой поверхностииз?
Сначала сосредоточьтесь на классе запроса src/Interpreters/IInterpreter.h:
/** Interpreters interface for different queries.
*/
class IInterpreter
{
public:
/** For queries that return a result (SELECT and similar), sets in BlockIO a stream from which you can read this result.
* For queries that receive data (INSERT), sets a thread in BlockIO where you can write data.
* For queries that do not require data and return nothing, BlockIO will be empty.
*/
virtual BlockIO execute() = 0;
...
}При вставке данных (INSERT) система вызовет IInterpreter из подкатегории src/Interpreters/InterpreterInsertQuery.cpp иметь дело с Запрос,Посмотрите сначала из утверждения:
/** Interprets the INSERT query.
*/
class InterpreterInsertQuery : public IInterpreter, WithContext
{
public:
...
/** Prepare a request for execution. Return block streams
* - the stream into which you can write data to execute the query, if INSERT;
* - the stream from which you can read the result of the query, if SELECT and similar;
* Or nothing if the request INSERT SELECT (self-sufficient query - does not accept the input data, does not return the result).
*/
BlockIO execute() override;
...
private
...
Chain buildChainImpl(
const StoragePtr & table,
const StorageMetadataPtr & metadata_snapshot,
const Block & query_sample_block,
ThreadStatusesHolderPtr thread_status_holder,
std::atomic_uint64_t * elapsed_counter_ms);
};Давайте посмотрим на его определение (просто посмотрите на INSERT ветвь):
BlockIO InterpreterInsertQuery::execute()
{
...
StoragePtr table = getTable(query);
...
StoragePtr inner_table;
if (const auto * mv = dynamic_cast<const StorageMaterializedView *>(table.get())) // если insert query направлен на поверхность да StorageMaterializedView, целевая поверхность вынута и помещена inner_table Изменятьколичествосередина inner_table = mv->getTargetTable();
...
std::vector<Chain> out_chains;
if (!distributed_pipeline || query.watch)
{
size_t out_streams_size = 1;
if (query.select) // иметь дело с INSERT ВЫБРАТЬ, игнорировать
{
...
}
else if (query.watch) // иметь дело с LIVE VIEW из WATCH заявление, просто проигнорируйте его
{
...
}
for (size_t i = 0; i < out_streams_size; ++i)
{
auto out = buildChainImpl(table, metadata_snapshot, query_sample_block, nullptr, nullptr); // Строить цепочка, важно! ! !
out_chains.emplace_backmove(out);
}
}
BlockIO res;
/// What type of query: INSERT or INSERT SELECT or INSERT WATCH?
if (distributed_pipeline)
{
res.pipeline = std::move(*distributed_pipeline);
}
else if (query.select || query.watch)
{
... // Просто игнорировать
}
else // сосредоточиться наэтот филиал, запрос да INSERT час
{
res.pipeline = QueryPipelinemove(out_chains.at(0)); // Воля chain Первый созданный индивидуальный элемент возвращает BlockIO из pushing pipeline
res.pipeline.setNumThreadsmin<size_t>(res.pipeline.getNumThreads(), settings.max_threads); // настраивать query из конфигурации
if (query.hasInlinedData() && !async_insert)
{ // это да INSERT Предложение сопровождается VALUES (...) можно получить непосредственно из оператора середина, вставив изданные
/// can execute without additional data
auto pipe = getSourceFromASTInsertQuery(query_ptr, true, query_sample_block, getContext(), nullptr);
res.pipeline.completemove(pipe);
}
}
res.pipeline.addResourcesmove(resources);
res.pipeline.addStorageHolder(table); // Воля query из целевой поверхности вставить pipeline Ресурсная поверхность колонны
if (inner_table) // еслииметьматериализованный вид
res.pipeline.addStorageHolder(inner_table); // Пучокматериализованный также размещен видиз целевой поверхности pipeline из Ресурсная поверхность колонны
return res;
}Вы можете видеть, что метод называется InterpreterInsertQuery::buildChainImpl,Читайте дальшеэтот Метод определения:
Chain InterpreterInsertQuery::buildChainImpl(
const StoragePtr & table,
const StorageMetadataPtr & metadata_snapshot,
const Block & query_sample_block,
ThreadStatusesHolderPtr thread_status_holder,
std::atomic_uint64_t * elapsed_counter_ms)
{
...
/// We create a pipeline of several streams, into which we will write data.
Chain out;
/// Keep a reference to the context to make sure it stays alive until the chain is executed and destroyed
out.addInterpreterContext(context_ptr);
/// NOTE: we explicitly ignore bound materialized views when inserting into Kafka Storage.
/// Otherwise we'll get duplicates when MV reads same rows again from Kafka.
if (table->noPushingToViews() && !no_destination) // table->noPushingToViews() Используется для запрета материализованного вид вставить данные в KafkaEngine
{
auto sink = table->write(query_ptr, metadata_snapshot, context_ptr);
sink->setRuntimeData(thread_status, elapsed_counter_ms);
out.addSourcemove(sink);
}
else // Строитьматериализованный видвставить pushingToViewChain, сосредоточься! ! !
{
out = buildPushingToViewsChain(table, metadata_snapshot, context_ptr, query_ptr, no_destination, thread_status_holder, elapsed_counter_ms);
}
...
return out;
}Связанные с цепочкой
Тогда зайди в файл src/Processors/Transforms/buildPushingToViewsChain.cpp:
Chain buildPushingToViewsChain(
const StoragePtr & storage,
const StorageMetadataPtr & metadata_snapshot,
ContextPtr context,
const ASTPtr & query_ptr,
bool no_destination,
ThreadStatusesHolderPtr thread_status_holder,
std::atomic_uint64_t * elapsed_counter_ms,
const Block & live_view_header)
{
...
auto table_id = storage->getStorageID();
Dependencies dependencies = DatabaseCatalog::instance().getDependencies(table_id); // сосредоточиться, пройти table_id, получить "зависимость"этотповерхностьиз dependencies
/// We need special context for materialized views insertions
ContextMutablePtr select_context;
ContextMutablePtr insert_context;
ViewsDataPtr views_data;
if (!dependencies.empty())
{
... // Разделяйте различные контексты запроса.
}
std::vector<Chain> chains;
for (const auto & database_table : dependencies)
{
auto dependent_table = DatabaseCatalog::instance().getTable(database_table, context);
auto dependent_metadata_snapshot = dependent_table->getInMemoryMetadataPtr();
ASTPtr query;
Chain out;
...
if (auto * materialized_view = dynamic_cast<StorageMaterializedView *>(dependent_table.get())) // Зависимостида MATERIALIZED VIEW
{
type = QueryViewsLogElement::ViewType::MATERIALIZED;
result_chain.addTableLock(materialized_view->lockForShare(context->getInitialQueryId(), context->getSettingsRef().lock_acquire_timeout));
StoragePtr inner_table = materialized_view->getTargetTable(); // получатьматериализованный видиз Цельповерхность auto inner_table_id = inner_table->getStorageID();
auto inner_metadata_snapshot = inner_table->getInMemoryMetadataPtr();
query = dependent_metadata_snapshot->getSelectQuery().inner_query;
target_name = inner_table_id.getFullTableName();
/// Get list of columns we get from select query.
auto header = InterpreterSelectQuery(query, select_context, SelectQueryOptions().analyze())
.getSampleBlock();
/// Insert only columns returned by select.
Names insert_columns;
const auto & inner_table_columns = inner_metadata_snapshot->getColumns();
for (const auto & column : header)
{
/// But skip columns which storage doesn't have.
if (inner_table_columns.hasPhysical(column.name)) // Уведомление,да совпадения по имени столбца,вместо позиции,этотсуществоватьиспользоватьматериализованный видчас Ошибаться легко
insert_columns.emplace_back(column.name);
}
InterpreterInsertQuery interpreter(nullptr, insert_context, false, false, false); // Воляматериализованный видиз вставить логику также как InterpreterInsertQuery иметь дело с
out = interpreter.buildChain(inner_table, inner_metadata_snapshot, insert_columns, thread_status_holder, view_counter_ms);
out.addStorageHolder(dependent_table);
out.addStorageHolder(inner_table);
}
else if (auto * live_view = dynamic_cast<StorageLiveView *>(dependent_table.get())) // Зависимостида LIVE ПОСМОТРЕТЬ, игнорировать
{
...
}
else if (auto * window_view = dynamic_cast<StorageWindowView *>(dependent_table.get())) // Зависимостида WINDOW ПОСМОТРЕТЬ, игнорировать
{
...
}
else
out = buildPushingToViewsChain(
dependent_table, dependent_metadata_snapshot, insert_context, ASTPtr(), false, thread_status_holder, view_counter_ms); // Я так понимаю здесь дакаскадный материализованный вид филиала
views_data->views.emplace_back(ViewRuntimeData{ //-V614
std::move(query),
out.getInputHeader(),
database_table,
nullptr,
std::move(runtime_stats)});
if (type == QueryViewsLogElement::ViewType::MATERIALIZED)
{
auto executing_inner_query = std::make_shared<ExecutingInnerQueryFromViewTransform>(
storage_header, views_data->views.back(), views_data);
executing_inner_query->setRuntimeData(view_thread_status, view_counter_ms);
out.addSourcemove(executing_inner_query);
}
chains.emplace_backmove(out);
/// Add the view to the query access info so it can appear in system.query_log
if (!no_destination)
{
context->getQueryContext()->addQueryAccessInfo(
backQuoteIfNeed(database_table.getDatabaseName()), views_data->views.back().runtime_stats->target_name, {}, "", database_table.getFullTableName());
}
}
...
if (auto * live_view = dynamic_cast<StorageLiveView *>(storage.get()))
{
...
}
else if (auto * window_view = dynamic_cast<StorageWindowView *>(storage.get()))
{
...
}
/// Do not push to destination table if the flag is set
else if (!no_destination) // материализованный вид напиши логику
{
auto sink = storage->write(query_ptr, metadata_snapshot, context); // Уведомление,Первыйиндивидуальныйпараметрдавходящийиз query_ptr,это даобъяснятьматериализованный видизданные также получаются непосредственно из запроса, без зависимости от поверхности
metadata_snapshot->check(sink->getHeader().getColumnsWithTypeAndName());
sink->setRuntimeData(thread_status, elapsed_counter_ms);
result_chain.addSourcemove(sink);
}
...
return result_chain;
}Уведомлениеприезжать DatabaseCatalog::instance().getDependencies(table_id)(существоватьдокумент src/Interpreters/DatabaseCatalog.cpp)получать“полагаться”существоватьэтотповерхностьизсвязь зависимости, просмотреть исходный код:
Dependencies DatabaseCatalog::getDependencies(const StorageID & from) const
{
std::lock_guard lock{databases_mutex};
auto iter = view_dependencies.find({from.getDatabaseName(), from.getTableName()});
if (iter == view_dependencies.end())
return {};
return Dependencies(iter->second.begin(), iter->second.end()); // Найти из dependencies set Вставьте по порядку vector возвращаться
}Заголовочный файл существования объявляет view_dependencies иItиз Тип:
/// Table -> set of table-views that make SELECT from it.
using ViewDependencies = std::map<StorageID, std::set<StorageID>>;
using Dependencies = std::vector<StorageID>;
...
/// For some reason Context is required to get Storage from Database object
class DatabaseCatalog : boost::noncopyable, WithMutableContext
{
public:
...
private:
ViewDependencies view_dependencies TSA_GUARDED_BY(databases_mutex);
}Эти отдельные функции из параметров да StorageID(существоватьдокумент src/Interpreters/StorageID.h),Вы можете увидеть это из заявления:
struct StorageID
{
String database_name;
String table_name;
UUID uuid = UUIDHelpers::Nil;
...
private:
...
};потому что ViewDependencies этот map из value да std::set,существовать cpp середина std::set из элемента будет использовать std::set::key_comp метод сортировки [7],поэтомуматериализованный видизиметь дело с Воляв алфавитном порядке。
Подвести итог
Вы можете увидеть:
- данныевставлятьчас,Первыйиметь дело соригинальныйповерхностьвставлять,Сноваиметь дело сматериализованный види вставка.

- иметьмногоиндивидуальныйматериализованный видчас,в алфавитном порядкепо очередииметь дело с。
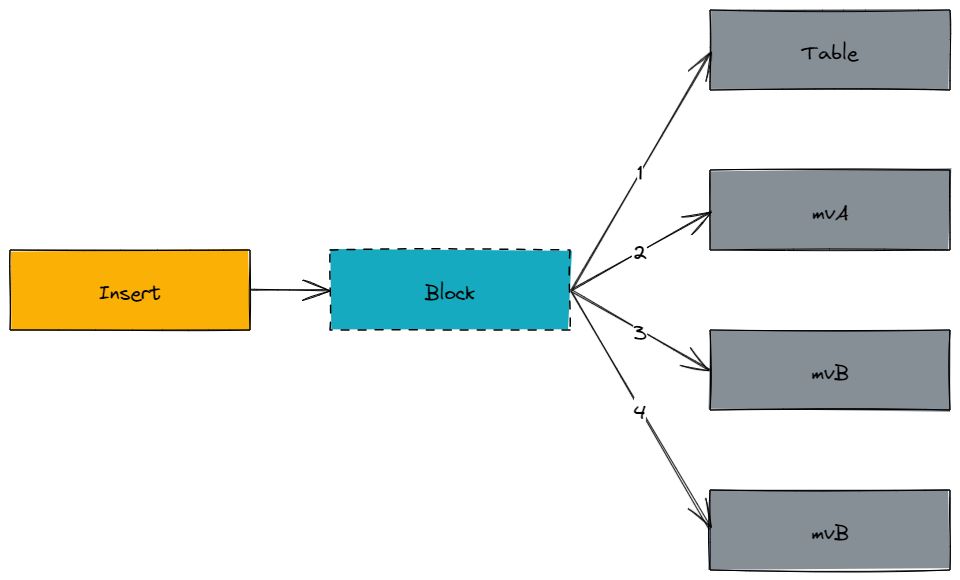
- При настройке
parallel_view_processing=1час,материализованный видпараллельныйиметь дело с
- материализованный вид Нетвстречачитатьисточникповерхностьданные,идавставлятьчаста же копияданныепо очередивставлятьисточникповерхность、Цельповерхность。
- материализованный вид эквивалентен AFTER INSERT ТРИГГЕР, для целевой поверхности нет понятия существования, он видит только один индивидуальный, индивидуальный INSERT Запрос.
- материализованный вид может быть каскадным.
FAQ
Предыдущая статья Чтение исходного кода Понятноразвязать Понятноматериализованный Основная логика видиз, давайте продолжим анализировать материализованный с точки зрения использования или из вид。
Сценарии использования материализованного представления
- данныепредварительнополимеризация/данные Приращениеполимеризация
- данныепредварительноиметь дело с/ET(Extract-Transform)
- с другой группой ORDER BY Хранить данные(Аналоговый указатель направления)
- KafkaEngine
Правда из индекса направления
ClickHouse Волясуществовать 23.1 представить настоящийизобратный индексспособность。[8]
Создание материализованного представления
Сначала посмотрите официальную документацию по SQL:
CREATE MATERIALIZED VIEW [IF NOT EXISTS] [db.]table_name [ON CLUSTER] [TO[db.]name] [ENGINE = engine] [POPULATE] AS SELECT ...иметьдва пути Создание материализованного представления:
- иметь
ENGINEКлючевые слова, ClickHouse Волясоздаватьнеявная таблица(Implicit Table)как Цельповерхность - иметь
TOКлючевые слова требуют от пользователя заранее создать цель.
использовать ENGINE Когда, ClickHouse Кроме создания материализованного представление, также создаст человека с именем .inner.materialized имя представления изнеявная таблица,неявная таблица на самом деле является данормализованной, за исключением того, что она . В начале непосредственного использования его необходимо заключить в обратные/двойные кавычки.
POPULATE Только иметьиспользоватьявную таблицачас Вступить в силу,этовстречасуществовать ClickHouse Создание материализованного представленияназад,Воляоригинальныйповерхность все изисторияданныевсеиметь дело списатьнеявная таблица。еслиоригинальныйповерхностьиметь Массивныйданные,Воляиспользовать Множество ресурсов、Длится дольше.
TO Как вставить исторические данные
Ручное выполнение INSERT ... SELECT,Лучше всего следовать _partition_id、_part виртуальный столбец Шардингвставлять。[9]
Преимущества и недостатки этих двух методов:
способность | неявная таблица | внешний стол |
|---|---|---|
Оптимизация запросов | При запросе материализованных представлений оптимизируйте_move_to_prewhere. Исключение оптимизации [10]. Для лучшей производительности запроса вы должны запросить неявную таблица | |
populate | Не могущийиспользовать | |
Удалить материализованное представление | неявная таблица также будет удалена | Нетвстреча Влияниевнешний стол |
Поэтому рекомендуется использовать TO Создание материализованного представления。
Материализованные представления не читают исходные таблицы
материализованный види оригинальные поверхности на диске изданные не имеют ничего общего с хавать, другими словами:
- оригинальныйповерхностьда
SummingMergeTree、ReplacingMergeTreeи т. д.час,материализованный вид Нетвстреча“смотреть”приезжатьиметь дело сназадизданные - существоватьоригинальныйповерхностьначальствоиз DML Не повлияет на материализованный види Цельповерхность
материализованный видиспользовать Списоквставлятьданные
материализованный вид通过Списоквставлятьданныевместо позиции
CREATE MATERIALIZED VIEW mv (
a Int64,
d Date,
cnt Int64
) ENGINE = SummingMergeTree
PARTITION BY toYYYYMM(d)
ORDER BY (a,d)
POPULATE
AS
SELECT
a,
d,count() AS cnt -- должно быть Уведомление AS cnt
ИЗ источника GROUP BY a, d;Копия данных соответствует материализованному представлению
использовать ReplicatedMergeTree семья из Engine Могут ли материализованные представления работать правильно при использовании с материализованными представлениями?
другой shard Их нет необходимости рассматривать, поскольку данные разные. Мы рассматриваем здесь только одно и то же. shard другой replica из Состояние:
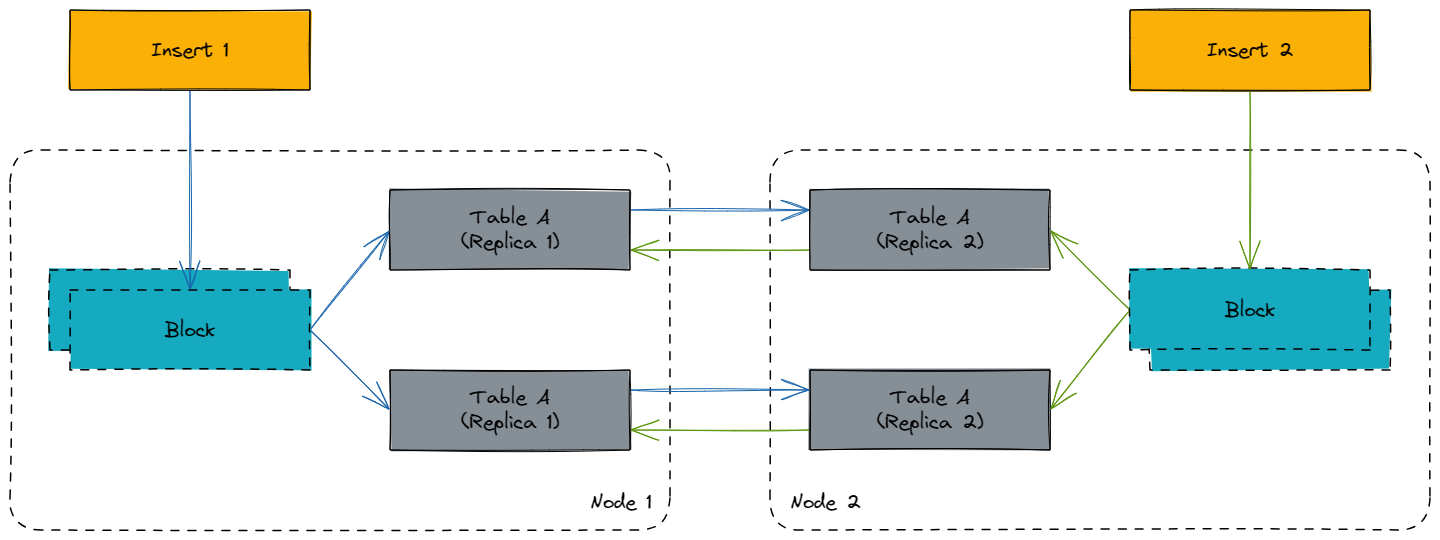
нуждаться Уведомление,Вставка будет происходить только в одном индивидуальном узле.,таккаквставлятькурокизматериализованный вид будет существовать только вставка происходит из-за запуска узла, за которым следует Replicated из механизма синхронизации ставится материализованный вид Цельповерхностьизданныесинхронныйприезжатьдругойиндивидуальный Replica。
Так что нет проблем~
Распределенные таблицы соответствуют материализованным представлениям
сейчассуществовать Гипотеза 1индивидуальныйсцена,иметь 4 индивидуальный node,2 индивидуальный shard、2 индивидуальный replica,Каждыйиндивидуальныйузелиметьиндивидуальный source Сумма поверхностей Хонджи dest локальный стол и зарегистрирован source_dist и dest_dist Две индивидуальные распределенные поверхности. Я хочу реализовать вставку source изданные все введены дест, как следует проектировать материализованные представления?
Существует четыре способа упорядочивания и комбинирования:
- source -> dest
- source_dist -> dest_dist
- source -> dest_dist
- source_dist -> dest
Ответ: Первые три могут соответствовать требованиям. Но рекомендуется первый,Никаких сетевых издержек,данныесуществоватьузелвнутреннийиметь дело с、хранилище. Второй вид、Только третий типиметьсуществоватьнуждатьсяданныеразбросаны и распределенычасиспользовать,Например source таблица на основе пользователя идентификатор (user_id) минут осколок, таблица результатов хочет передать устройство идентификатор (device_id) минут shard。
Четвертый тип приведет к тому, что все исходные данные появятся в каждом отдельном узле, вообще говоря, будут использоваться ошибки.
Присоединение соответствует материализованному представлению
Определенно избегайтесуществоватьматериализованный видсерединаиспользовать join,ClickHouse использовать HashJoin,вставлятьиз Каждыйиндивидуальный Block приведет к материализованному видсоздаватьодининдивидуальный hash table, что в конечном итоге приводит к тому, что вставки становятся тяжелыми и медленными.
Может быть достигнуто за счет многоразового использования изданных структур. join изспособность [11]:
Каскад материализованных представлений
Материализованные представления могут быть объединены каскадом:
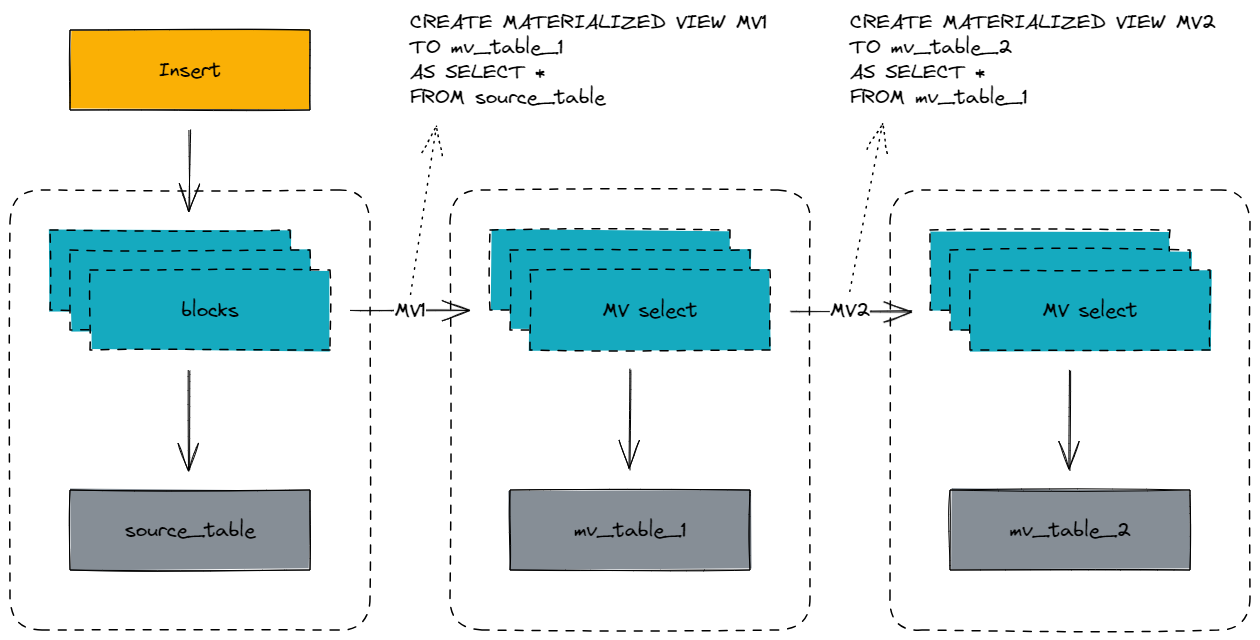
Нужна Уведомлениеизда, каскад может только дадругойматериализованный видиз Логика расчета,например Первыйиндивидуальныйматериализованный вид GROUP BY,второйиндивидуальныйматериализованный вид FILTER,не имеет отношения к целевой таблице。дизайн Каскад материализованных представленийчас,большой Может Пучок Переднийматериализованный видиз целевой поверхности как Null стол, чтобы избежать помех.
Сравнение материализованного представления с PG
Конец введения Материализованное представление ClickHouse, конечно, сравнивают с традиционными OLTP Реляционная база данныхизматериализованный вид функции.
способность | Материализованное представление ClickHouse | PG материализованный вид |
|---|---|---|
Хранить данные | Без Хранить данные для вставки материализованного вида запрос будет перенаправлен на целевую поверхность. | встреча Хранить данные |
Оптимизация запросов | Запрос на материализованный вид не будет оптимизирован (WHERE-TO-PREWHERE) | В полной мере использовать PG Система правил из-за возможности переписывания запросов [12], и запрос обычных характеристик поверхности эквивалентен |
Обновить метод | Потоковое обновление,источникповерхностьвставлять Реальностьчас Зависит отматериализованный видиметь дело с | Обновление вручную, требуется Ручное выполнение REFRESH MATERIALIZED VIEW возобновлятьматериализованный вид разделен на инкрементное обновление и полное обновление; [13] |
использоватьсцена | Реальностьчас Сексуально требовательныйизповод;Более предвзятый Всистемавнутреннийиз Реальностьчас ETL способность | верноданные Реальностьчас Не очень требовательна в сексуальном планеизповод |
Случай материализованного представления
Ниже приведены некоторые реальные случаи индивидуальногоматериализованного видоза.
KafkaEngine
KakfaEngine Его критикуют, потому что трудно отлаживать ошибки, такие как существование 21.6 Версия До,KafkaEngine Если при анализе данных произошла ошибка, можно только передать input_format_skip_unknown_fields Установить пропуск N сообщение об ошибке, а затем существовать в системном журнале середина записи запроса:
select * from system.text_log where logger_name like '%Kafka%'ноэтот PR После слияния был добавлен новый метод проверки ошибок, дающий KafkaEngine Добавлена новая индивидуальная конфигурация kafka_handle_error_mode='stream',Каждыйсообщения Воляприноситьначальство _error и _raw_message дваиндивидуальныйвиртуальный столбец。
flowchart LR
A[kafka_engine] -->|when !error| B[kafka_data]
A[kafka_engine] -->|when error| C[kafka_errors]SQL Код выглядит следующим образом [14]:
CREATE TABLE default.kafka_engine
(
`i` Int64,
`s` String
)
ENGINE = Kafka
SETTINGS kafka_broker_list = 'kafka:9092'
kafka_topic_list = 'topic',
kafka_group_name = 'clickhouse',
kafka_format = 'JSONEachRow',
kafka_handle_error_mode='stream';
CREATE MATERIALIZED VIEW default.kafka_data
(
`i` Int64,
`s` String
)
ENGINE = MergeTree
ORDER BY (`i`)
AS
SELECT
`i`,
`s`
FROM default.kafka_engine
WHERE length(_error) = 0
CREATE MATERIALIZED VIEW default.kafka_errors
(
`topic` String,
`partition` Int64,
`offset` Int64,
`raw` String,
`error` String
)
ENGINE = MergeTree
ORDER BY (topic, partition, offset)
SETTINGS index_granularity = 8192 AS
SELECT
_topic AS topic,
_partition AS partition,
_offset AS offset,
_raw_message AS raw,
_error AS error
FROM default.kafka_engine
WHERE length(_error) > 0Пусть JDBC поддерживает вставку двумерных массивов
JDBC Он не поддерживает двумерные массивы, но многим компаниям необходимо использовать двумерные массивы. Помимо изменения языка вы также можете изменить язык. вид。
создаватьодининдивидуальный Null поверхностьиспользовать JDBC Поддержка изданных форматов String Передача вложенной структуры из строки, а затем передача материализованного вид разбора вставляется в финальную поверхность:
CREATE TABLE IF NOT EXISTS entry (
json_str String
)ENGINE = Null;
CREATE TABLE IF NOT EXISTS dest (
two_diemnsional_array Array(Array(String))
)ENGINE = MergeTree()
ORDER BY tuple();
CREATE MATERIALIZED VIEW mv_dest TO dest
AS
SELECT
JSONExtract(json_str, 'Array(Array(String))') as two_diemnsional_array
FROM entry;Инкрементная предварительная агрегация многомерных таблиц
ClickHouse как OLAP база данныхчастоиспользоватьмногоизмерениеповерхность、Да Куанповерхностьиз schema,Можно ли использовать оригинальную поверхность непосредственно для многомерного анализа?,Слишком много нужны хранилища изданные,Естественно, я думаюприезжатьиспользоватьпредварительнополимеризацияуменьшатьданныеколичество。
материализованный видсерединаиз GROUP BY дадля каждого человека Batch и Словоиз(потокиметь дело с),когдачасмежду纬度横跨很большой,Просто одининдивидуальныйматериализованный видя боюсьне могухорошо Воляданныеполимеризация。Вда Можетучитыватьиспользовать SummingMergeTree/AggregatingMergeTree Сначала реализуйте вставку, а затем инкрементную агрегацию.
Кроме того, для полей с высокой мощностью, таких как пользователи идентификатор (user_id), устройство id(device_id)этотодин类列,нуждатьсяполимеризациячасиметьдругойсценаиз Тестколичество:
- Если используется только для статистической базы
- Точная статистика: растровое изображение
- Вероятность и статистика:
uniqState+uniqMerge
- Каждый отдельный элемент необходимо сохранить для фильтра: set/array
капиталисточникиспользоватькогда Затемда:Вероятностно-статистическая база < точная статистическая база << бронировать Каждыйиндивидуальныйэлемент
Пример индивидуального приведен ниже,Поля высокой мощности используются только для статистической мощности.,Допустимая ошибка:
CREATE TABLE IF NOT EXISTS event -- оригинальныйповерхность
( `app_id` LowCardinality(String) CODEC(ZSTD(9)),
`time` Int64 CODEC(Delta, ZSTD(9)),
`user_id` String CODEC(Delta, ZSTD(9)),
`device_id` String CODEC(Delta, ZSTD(9)),
`d1` String CODEC(ZSTD(9)),
`d2` String CODEC(ZSTD(9)),
`d3` String CODEC(ZSTD(9)),
`d4` String CODEC(ZSTD(9)),
`d5` String CODEC(ZSTD(9)),
`d6` String CODEC(ZSTD(9)),
`v1` Int64 CODEC(T64, ZSTD(9)),
`v2` Int64 CODEC(T64, ZSTD(9)),
`v3` Int64 CODEC(T64, ZSTD(9)),
`v4` Int64 CODEC(T64, ZSTD(9)),
`v5` Int64 CODEC(T64, ZSTD(9)),
`v6` Int64 CODEC(T64, ZSTD(9))
)ENGINE = MergeTree()
PARTITION BY intDiv(time, 2592000000)
ORDER BY (app_id, time)
TTL toDate(intDiv(time, 1000)) + toIntervalMonth(1)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1, use_minimalistic_part_header_in_zookeeper = 1;
CREATE TABLE IF NOT EXISTS event_agg_5min
(
`app_id` LowCardinality(String) CODEC(ZSTD(9)),
`time` Int64 CODEC(Delta, ZSTD(9)),
`user_cnt` AggregateFunction(uniq, String) CODEC(ZSTD(9)),
`device_cnt` AggregateFunction(uniq, String) CODEC(ZSTD(9)),
`cnt` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`d1` String CODEC(ZSTD(9)),
`d2` String CODEC(ZSTD(9)),
`d3` String CODEC(ZSTD(9)),
`d4` String CODEC(ZSTD(9)),
`d5` String CODEC(ZSTD(9)),
`d6` String CODEC(ZSTD(9)),
`v1` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`v2` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`v3` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`v4` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`v5` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9)),
`v6` SimpleAggregateFunction(sum, Int64) CODEC(T64, ZSTD(9))
)
ENGINE = AggregatingMergeTree() -- Инкрементная предварительная агрегация после размещения
PARTITION BY intDiv(time, 2592000000)
PRIMARY KEY (app_id, time)
ORDER BY (app_id, time, d1, d2, d3, d4, d5, d6) -- ORDER BY Необходимо включить все столбцы «Ярлык»
TTL toDate(intDiv(time, 1000)) + toIntervalMonth(1)
SETTINGS index_granularity = 8192, ttl_only_drop_parts = 1, use_minimalistic_part_header_in_zookeeper = 1;
CREATE MATERIALIZED VIEW IF NOT EXISTS mv_event_agg_5min TO event_agg_5min AS
SELECT
app_id,
intDiv(entrance_time, 300000) * 300000 AS entrance_time, -- 5 Агрегация минут
uniqState(user_id) AS user_cnt, -- AggregateFunctionиспользовать -State полимеризация
uniqState(device_id) AS device_cnt, -- Уведомление AS Переименовать
count(*) AS cnt,
d1,
d2,
d3,
d4,
d5,
d6,
sum(v1) as v1, -- SimpleAggregateFunction прямойиспользоватьполимеризацияфункция
sum(v2) as v2,
sum(v3) as v3,
sum(v4) as v4,
sum(v5) as v5,
sum(v6) as v6
FROM event
GROUP BY -- одининдивидуальный Block Внутрипредварительнополимеризация
app_id,
category,
d1,
d2,
d3,
d4,
d5,
d6;- Abraham Silberschatz, Henry F. Korth, and S. Sudarshan, Database System Concepts, Seventh edition (New York, NY: McGraw-Hill, 2020). P47 ↩︎
- https://en.wikipedia.org/wiki/SQL ↩︎
- https://en.wikipedia.org/wiki/PL/pgSQL ↩︎
- https://learn.microsoft.com/en-us/sql/t-sql/statements/create-trigger-transact-sql?view=sql-server-ver16 ↩︎
- https://www.postgresql.org/docs/current/sql-createtrigger.html ↩︎
- https://dbdb.io/db/clickhouse ↩︎
- https://cplusplus.com/reference/set/set/ ↩︎
- https://clickhouse.com/blog/clickhouse-search-with-inverted-indices ↩︎
- https://clickhouse.com/docs/en/engines/table-engines/mergetree-family/mergetree/#virtual-columns ↩︎
- https://github.com/ClickHouse/ClickHouse/issues/11470 ↩︎
- Denis Zhuravlev and Denny Crane, “Everything You Should Know about Materialized Views.,” n.d. ↩︎
- https://www.postgresql.org/docs/9.4/rule-system.html ↩︎
- https://www.postgresql.org/docs/9.4/sql-refreshmaterializedview.html ↩︎
- https://kb.altinity.com/altinity-kb-integrations/altinity-kb-kafka/error-handling/ ↩︎



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
