Прорыв: применение улучшенного двоичного квантования (BBQ) для эффективного векторного поиска в Elasticsearch и Lucene
Улучшенное двоичное квантование (BBQ) в Elasticsearch и Lucene
Вывод встроенной модели float32 Векторы часто слишком велики для эффективной обработки и практического применения. Эластичный поиск поддерживать int8 Скалярное квантование для уменьшения размера вектора при сохранении производительности. Другие методы снижают качество поиска и непригодны для практического использования. существовать Elasticsearch 8.16 и Lucene В мы вводим лучшее двоичное квантование (Better Binary Quantization, BBQ),Это новый подход,По данным исследователей из Наньянского технологического университета в Сингапуре.из“RaBitQ”технологияизразвитие идей。
BBQ существовать Lucene и Elasticsearch Крупный количественный прорыв был достигнут в float32 Размеры уменьшаются до битов, а память уменьшается примерно до 95% при сохранении высокого качества рейтинга. БАРБЕКЮ существуют скорость индексации (сокращение времени квантования 20-30 раз), скорость запроса (скорость запроса увеличивается 2-5 раз) превосходит традиционные методы, такие как количественный анализ продукта (PQ) без дополнительной потери точности.
существуют В этом блоге,Мы изучим существование BBQ Lucene и приложения Elasticsearch в,Ключевые моменты сосредоточены на скорости отзыва, высокой эффективности побитовых операций и оптимизированном хранилище.,Добиться быстрого и точного векторного поиска.
Что такое «лучшее» двоичное квантование?
существовать Elasticsearch 8.16 и Lucene мы представляем то, что мы называем «улучшенным двоичным квантованием». Традиционное двоичное квантование Потеря очень большая,Для достижения достаточной скорости запоминания,Нужно собрать 10 раз или 100 когда переупорядочиваются дополнительные соседи, этот эффект явно не идеален.
Итак, мы представили улучшенное двоичное квантование! Вот некоторые заметные различия между лучшим двоичным квантованием и традиционным двоичным квантованием:
- Все векторы нормированы вокруг центроида.,Это Количественная оценка Разблокированы некоторые хорошие функции。
- Сохраняет множественные исправления ошибок ценить. Эти исправления частично используются для нормализации центроида.,Частично используется в Количественной оценка。
- Асимметричное квантование. Хотя сам вектор хранится как однобитовое значение, запрос квантуется только до целого числа 4. Это значительно улучшает качество поиска без увеличения затрат на хранение.
- Побитовые операции обеспечивают быстрый поиск。Вектор запроса Количественная оценкаи преобразован для обеспечения эффективных побитовых операций.из Способ。
Индексирование с использованием улучшенного двоичного квантования
Процесс индексации прост. пожалуйста, запомни,Lucene Создайте отдельные сегменты только для чтения. Центр масс вычисляется постепенно по мере появления векторов в новом сегменте. После обновления сегмента каждый вектор нормализуется вокруг центроида и квантовается.
Вот небольшой пример:
v1 = [0.56, 0.85, 0.53, 0.25, 0.46, 0.01, 0.63, 0.73]
c = [0.65, 0.65, 0.52, 0.35, 0.69, 0.30, 0.60, 0.76]
vc1' = v1 - c = [-0.09, 0.19, 0.01, -0.10, -0.23, -0.38, -0.05, -0.03]
bin(vc1') = {1 if x > 0 else 0 for x in vc1'}
bin(vc1') = [0, 1, 1, 0, 0, 0, 0, 0]
0b00000110 = 6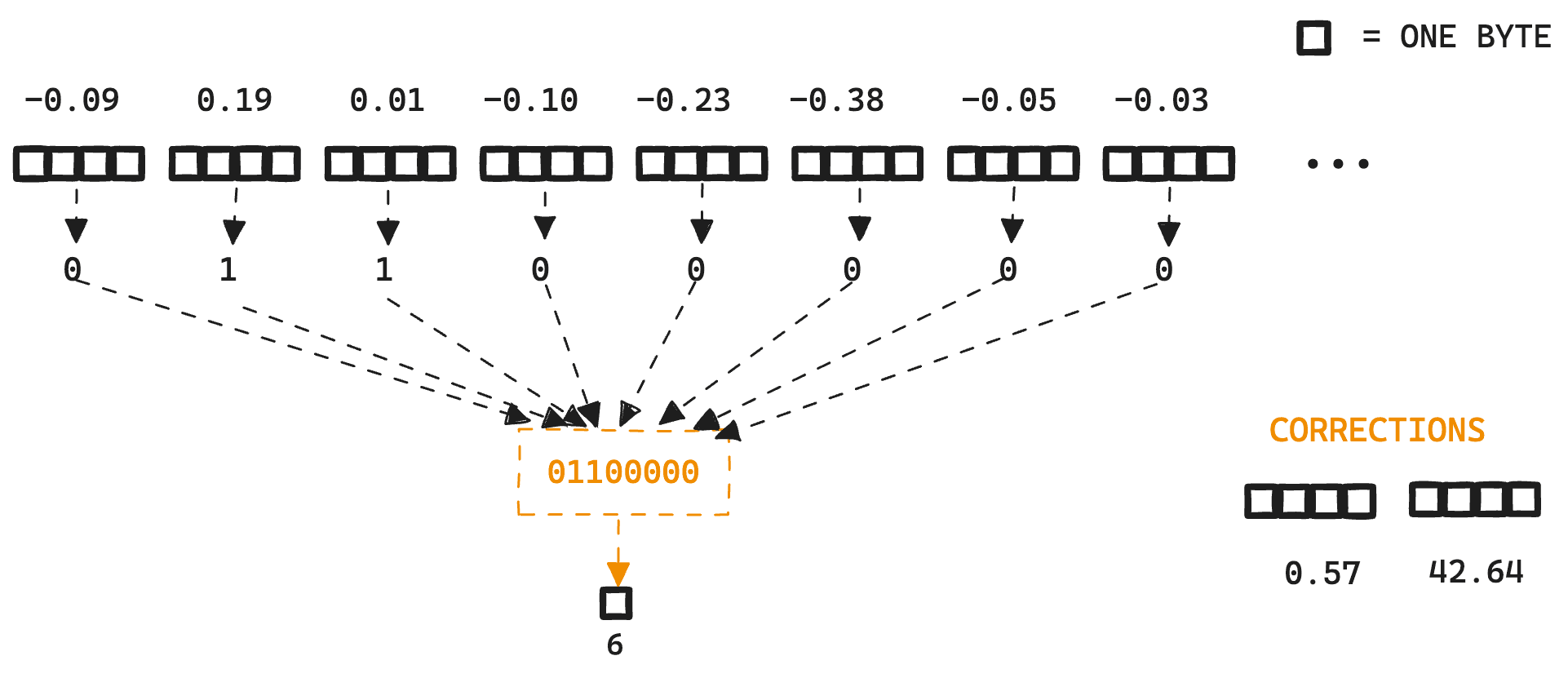
При квантовании до битового уровня 8 значений с плавающей запятой преобразуются в 8-битный байт.
Затем,Каждый бит упакован в один байт,И сохраняется в сегменте существования вместе с любыми значениями коррекции ошибок, необходимыми для выбранного векторного сходства.
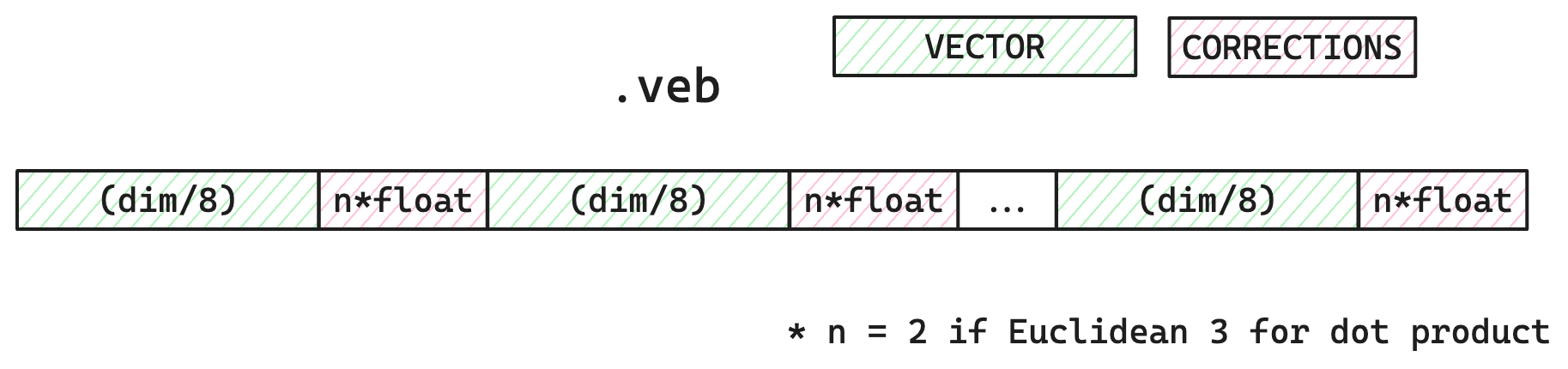
Для каждого вектора количество хранимых байт равно dims/8 байт, то значение коррекции ошибки равно евклидову расстоянию; 2 значения с плавающей запятой, скалярное произведение 3 значение с плавающей запятой.
Эпизод о процессе слияния
Когда сегменты объединяются, мы можем использовать ранее рассчитанные центроиды. Просто возьмите средневзвешенное значение центроидов и переквантуйте векторы вокруг новых центроидов.
убеждаться HNSW Качество графов и возможность их построения с использованием квантованных векторов являются проблемой. Нет смысла проводить квантование, если для построения индекса по-прежнему необходима вся память!
Вместо добавления вектора к существующему максимуму HNSW На рисунке нам также нужна векторная оценка, чтобы иметь возможность воспользоваться преимуществами асимметричного квантования. HNSW Существует несколько этапов оценки: один для первоначального сбора соседей, а другой для убеждения только при соединении разных соседей. Чтобы эффективно использовать асимметричное квантование, мы создаем временные файлы для всех векторов, квантовая их как 4 вектор битового запроса.
Итак, добавляя векторы в граф, мы сначала:
- Получить хранилищесуществоватьво временном файлеизуже Количественная оценка Запросвектор.
- Выполните поиск в графе обычным способом, используя существующие битовые векторы.
- Когда у тебя есть соседи,Оценка разнообразия и обратных ссылок может быть использована ранее из int4. Квантовое значение завершено.
После завершения слияния временные файлы удаляются и остаются только векторы битового квантования.
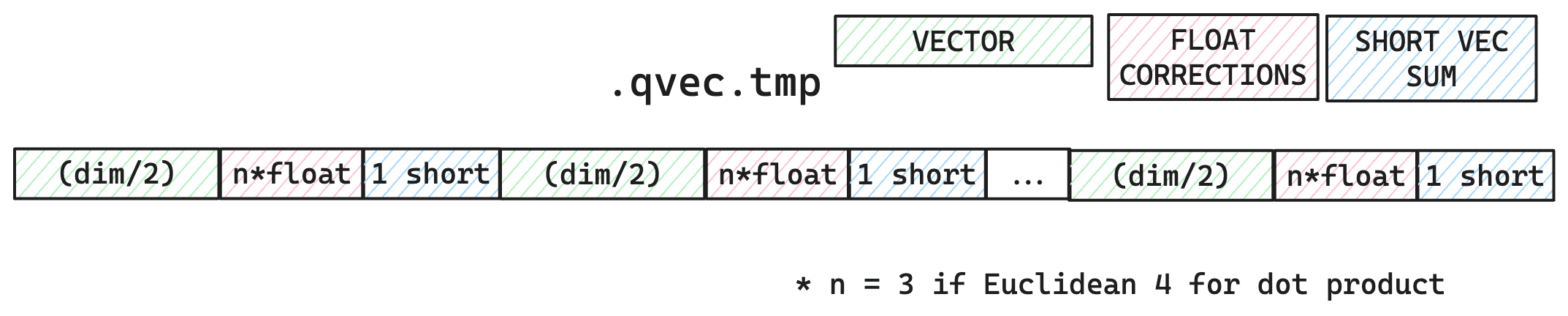
Во временном файле каждый вектор запроса хранится как int4 Массив байтов, занят dims/2 Количество байтов, некоторое значение коррекции ошибок с плавающей запятой (евклидово расстояние равно 3 , скалярное произведение 4 индивидуальный), а индивидуальный представляет собой векторное измерение общей суммы и из короткой цены.
Асимметричное квантование: самое интересное
Я упомянул асимметричное квантование и то, как мы формируем запросы для построения графиков. Но как на самом деле преобразуются векторы? Как это работает?
«Асимметричная» часть проста. Мы квантоваем векторы запросов для более высокой точности. Следовательно, значения документа подвергаются побитовому квантованию, а векторы запроса квантоваются до int4. Еще интереснее то, как преобразуются эти квантованные векторы для обеспечения быстрых запросов.
Взяв наш пример вектора выше, мы можем квантовать его в int4 вокруг центра масс.
vc1' = v1 - c = [-0.09, 0.19, 0.01, -0.10, -0.23, -0.38, -0.05, -0.03]
max(vc1') = max(vc1') = 0.19
min(vc1') = min(vc1') = -0.38
Q(xs) = {(x - min(vc1')) * 15 / (max(vc1') - min(vc1')) : x ∈ xs}
Q(vc1') = {(x - (-0.38)) * 15 / (0.19 - (-0.38)) : x ∈ vc1'}
Q(vc1') = {(x + 0.38) * 26.32 : x ∈ vc1'}
Q(vc1') = [8, 15, 10, 7, 4, 0, 9, 9]С квантованными векторами начинается самое интересное. Чтобы преобразовать векторные сравнения в побитовое скалярное произведение, биты необходимо сдвинуть.
Лучше наглядно показать, что происходит:
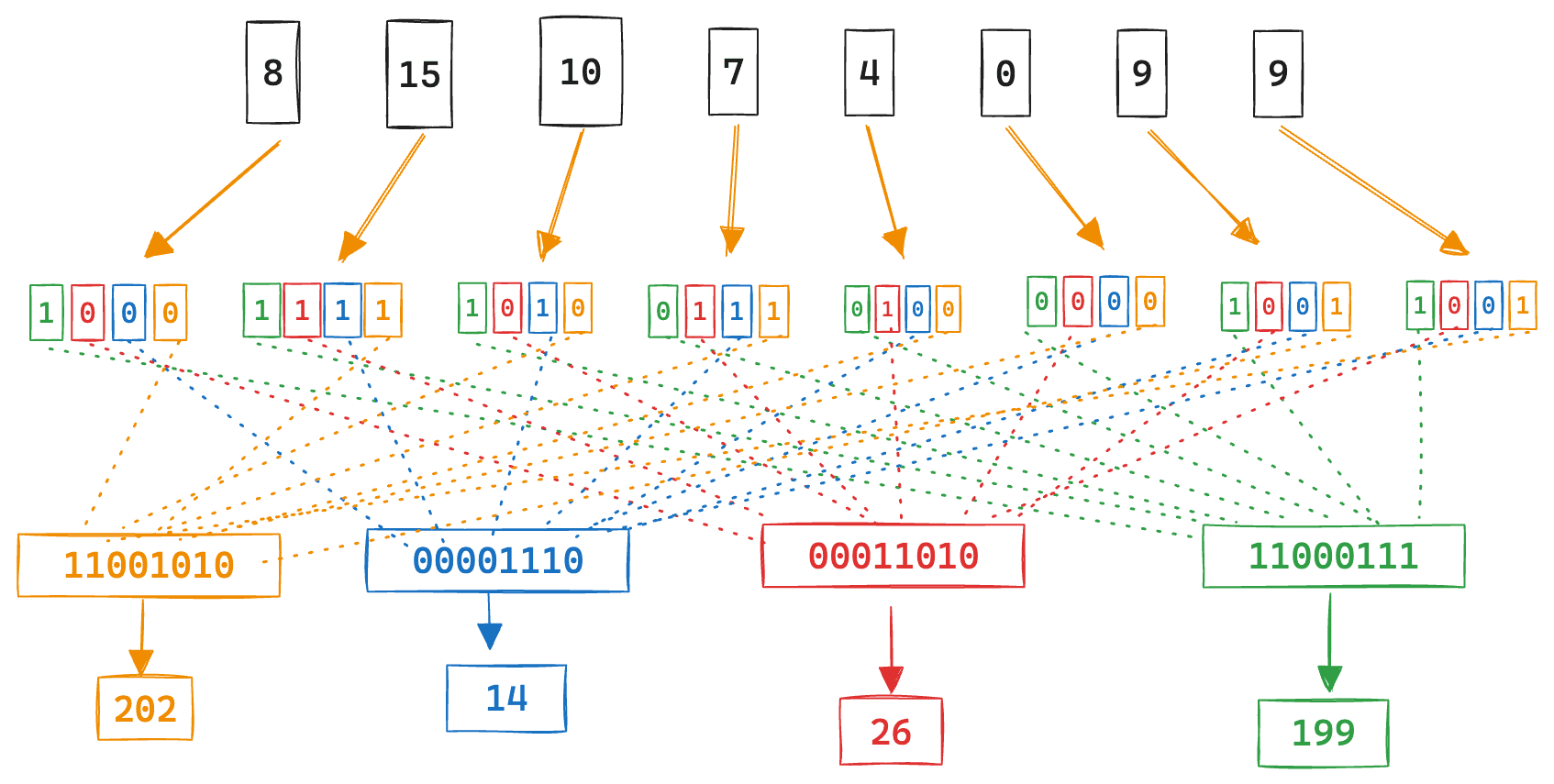
Здесь каждый int4 Количественная Значение значения бита относительной позиции смещается на один индивидуальный байт. Уведомление,Все первые индивидуальные кусочки сначала упаковываются воедино.,Затем второй индивидуальный бит,И так далее.
Но как это на самом деле переводится в скалярное произведение? помнить,Скалярное произведение — это произведение компонентов. Для приведенного выше примера,Распишем полностью:
bin(vc1') ⋅ Q(vc1') = [0, 1, 1, 0, 0, 0, 0, 0] ⋅ [8, 15, 10, 7, 4, 0, 9, 9] = [0×8 + 1×15 + 1×10 + 0×7 + 0×4 + 0×0 + 0×9 + 0×9] = 15 + 10 = 25мы можем видеть,Он просто запрашивает компоненты и общее количество,Сохраненные векторные биты 1. Поскольку все числа являются битами, мы можем немного перемещать их, чтобы воспользоваться преимуществами побитовых операций, представленных в двоичном расширении.
Эти биты существуют && После этого оно будет перевернуто и станет числом из одного бита, который вносит вклад в скалярное произведение. существование в данном случае 15 и 10。
Помните, что изначально мы сохраняем вектор из
storedVecBits = bin(vc1') = [0, 1, 1, 0, 0, 0, 0, 0]
Вращаем и объединяем биты и получаем
storedVectBits = 0b11000000
Вектор запроса, int4 Количественная оценка
Q(vc1') = [8, 15, 10, 7, 4, 0, 9, 9]
Двоичное значение для каждого отдельного измерения из
bits(Q(vc1')) = [0b1000, 0b1111, 0b1010, 0b0117, 0b0100, 0b0000, 0b1001, 0b1001]
Сдвигаем биты и выравниваем их, как показано выше
qVecBits = align(bits(Q(vc1'))) = [0b11001010, 0b00001110, 0b00011010, 0b11000111]
qVecBits & storedVectBits = {qVecBits & bits : bits ∈ storedVectBits} = [0b00000010, 0b00000110, 0b00000010, 0b00000010]Теперь существуют мы можем посчитать количество битов,Сдвинуть и пересчитать и. можно увидеть,Все остальные биты имеют размерность 15 и 10 бит.
(bitCount(0b00000010) << 0) + (bitCount(0b00000110) << 1) + (bitCount(0b00000010) << 2) + (bitCount(0b00000010) << 3)
= (1 << 0) + (2 << 1) + (1 << 2) + (2 << 3) = 25Результат согласуется с прямым нахождением и-компонента.
Вот упрощенный код Java для примера:
byte[] bits = new byte[]{6};
byte[] queryBits = new byte[]{202, 14, 26, 199};
int sum = 0;
for (int i = 0; i < 4; i++) {
sum += Integer.bitCount(bits[0] & queryBits[i] & 0xFF) << i;
}Хорошо, покажи мне данные
нассуществовать Lucene и Elasticsearch средняя пара BBQ Всесторонне протестировано. Вот некоторые результаты:
Тесты Lucene
Контрольный показательсуществоватьтрииндивидуальныйвыполняется на наборе данных:E5-small、CohereV3 и CohereV2。Каждыйиндивидуальный Элемент представляет собой 1, 1.5, 2, 3, 4, 5 из oversampling из recall@100。
E5-small
Это из quora Централизованное построение данных 500k E5-small вектор.
Количественный метод | индексное время | Время принудительного слияния | Требуемая память |
|---|---|---|---|
BBQ | 161.84 | 42.37 | 57.6MB |
4 bit | 215.16 | 59.98 | 123.2MB |
7 bit | 267.13 | 89.99 | 219.6MB |
raw | 249.26 | 77.81 | 793.5MB |
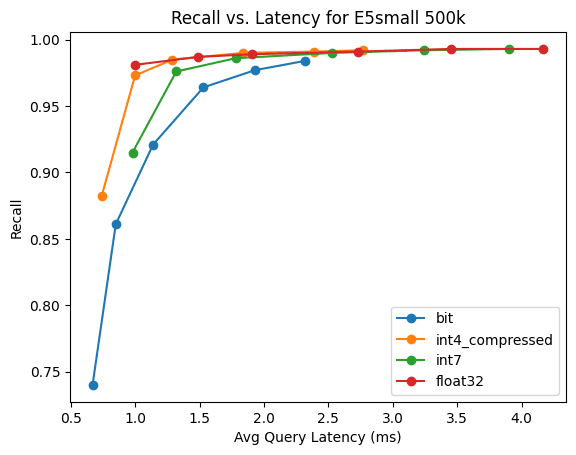
Удивительно то, что мы можем добиться этого с точностью до одного бита. 74% Скорость отзыва. Из-за меньших размеров барбекю Скорость расчета расстояния не лучше оптимизации int4 Насколько быстрее.
CohereV3
Это 1 млн 1024-мерных векторов, созданных с использованием модели CohereV3.
Количественный метод | индексное время | Время принудительного слияния | Требуемая память |
|---|---|---|---|
BBQ | 338.97 | 342.61 | 208MB |
4 bit | 398.71 | 480.78 | 578MB |
7 bit | 437.63 | 744.12 | 1094MB |
raw | 408.75 | 798.11 | 4162MB |
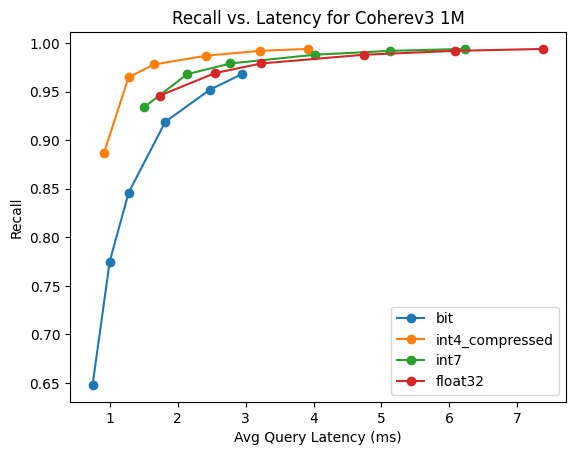
Вот, 1бит Количественная оценкаи HNSW существоватьтолько 3 раз oversampling в этом случае скорость отзыва превышает 90%。
CohereV2
Это 1M индивидуальный 768 размерный вектор, используйте CohereV2 Модельи Максимальное сходство внутреннего продукта。
Количественный метод | индексное время | Время принудительного слияния | Требуемая память |
|---|---|---|---|
BBQ | 395.18 | 411.67 | 175.9MB |
4 bit | 463.43 | 573.63 | 439.7MB |
7 bit | 500.59 | 820.53 | 833.9MB |
raw | 493.44 | 792.04 | 3132.8MB |
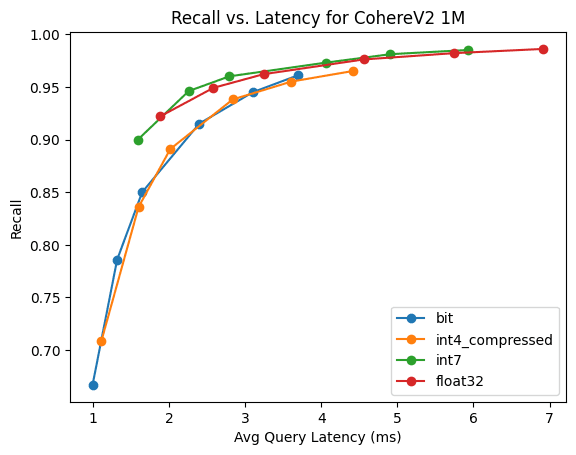
Очень интересно, да, барбекю и int4 существоватьэтотиндивидуальный Контрольный ритм в унисон. БАРБЕКЮ Используйте только 3 раз oversampling Такой высокий уровень отзыва можно получить при внутреннем сходстве продуктов.
Крупномасштабные тесты Elasticsearch
нравитьсянассуществовать Elasticsearch Блог векторного массового поиска Как упоминалось в разделе , у нас есть индивидуальные предложения для крупных масштабвекторный поиск Контрольный показательиз раллийная трасса。
Этот набор данных содержит 138M индивидуальный 1024 Размерность вектора с плавающей запятой. Если ничего не делать Количественная. оценка,этот Это занимает ок. 535 GB из Памятьи HNSW. Лучше использовать двоичный файл Количественная оценка,Ориентировочные требования к памяти снижаются примерно до 19 ГБ.
Для этого испытания мы существуем Elastic Облако использует индивидуальный 64GB изузел,отслеживать Параметры следующие:
{
"mapping_type": "vectors-only",
"vector_index_type": "bbq_hnsw",
"number_of_shards": 2,
"initial_indexing_bulk_indexing_clients": 12,
"standalone_search_clients": 8,
"aggressive_merge_policy": true,
"search_ops": [[10, 20, 0], [10, 20, 20], [10, 50, 0], [10, 50, 20], [10, 50, 50], [10, 100, 0], [10, 100, 20], [10, 100, 50], [10, 100, 100], [10, 200, 0], [10, 200, 20], [10, 200, 50], [10, 200, 100], [10, 200, 200], [10, 500, 0], [10, 500, 20], [10, 500, 50], [10, 500, 100], [10, 500, 200], [10, 500, 500], [10, 1000, 0], [10, 1000, 20], [10, 1000, 50], [10, 1000, 100], [10, 1000, 200], [10, 1000, 500], [10, 1000, 1000]]
}Важное примечание: если вы захотите создать этот тест, то загрузка всех данных будет много 4 ТБ дискового пространства. Это Поскольку этот набор данных также содержит текстовые поля, вам необходимо предоставить дисковое пространство для сжатого файла и его разархивированный размер.
Параметры следующие:
kэто поиск количества соседейnum_candidatesнаходится в каждом отдельном осколке HNSW Используется для изучения количества кандидатовrerankсостоит в том, чтобы переупорядочить количество кандидатов, чтобы мы собирали это число из значений каждого отдельного шарда, собирая общее количествоrerankразмер, затем используйте оригинал float32 Вектор перед восстановлениемkценить.
индексное время ок. 12 Час. Вот три интересных результата:
k-num_candidates-rerank | Avg Nodes Visited | % Of Best NDGC | Recall | Single Query Latency | Multi-Client QPS |
|---|---|---|---|---|---|
knn-recall-10-100-50 | 36,079.801 | 90% | 70% | 18ms | 451.596 |
knn-recall-10-20 | 15,915.211 | 78% | 45% | 9ms | 1,134.649 |
knn-recall-10-1000-200 | 115,598.117 | 97% | 90% | 42.534ms | 167.806 |
Это показывает сбалансированный отзыв、Передискретизация、Изменить порядоки Задерживатьизважность。очевидно,Каждый параметр необходимо настроить для вашего конкретного случая использования.,Но учитывая, что такое существование раньше было невозможно,сейчассуществоватьнассуществоватьодининдивидуальныйузел Есть 138M индивидуальный вектор, это очень круто.
в заключение
Спасибо, что нашли время прочитать о Betterиздвоичный Количественная оценкаизсодержание。какиндивидуальныйиз Алабамы,Сейчас живу в Южной Каролине из,BBQ Я уже занял особое место в моей жизни. Теперь существуют, у меня больше причин, чтобы это нравилось BBQ!
нас Волясуществовать 8.16 Эта предварительная версия технологии выпущена в версии, и теперь вы можете использовать ее в бессерверной версии. Чтобы использовать эту функцию, просто существуйте Elasticsearch генерал-лейтенант dense_vector.index_type установлен на bbq_hnsw или bbq_flat。
Elasticsearch Обогащен новыми функциями, которые помогут вам создать лучшее решение для поиска для вашего случая использования. Узнайте больше о нас Образец блокнота,начинать Бесплатная пробная версия облака,или ВОЗсейчассуществовать Сразусуществоватьтыиз локальная машина Попробуйте это Elastic Бар.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
