Prometheus+Alertmanager выполняет сигнализацию веб-перехватчика робота Feishu
Введение в менеджер оповещений
Alertmanager да Prometheus Основной компонент экосистемы, отвечающий за дело сby Prometheus Уведомление о тревоге, отправленное сервером. Его основные функции включают дедупликацию аварийных сигналов, группировку, подавление и маршрутизацию различным получателям уведомлений (таким как электронная почта, Slack, PagerDuty). ждать). В этой статье мы в основном используем вебхук для получения оповещений от Alertmanager.
Основные функции Alertmanager
1. Дедупликация аварийных сигналов (Дедупликация):
• когда Prometheus Когда сервер обнаруживает, что условия тревоги соблюдены, он генерирует тревогу и отправляет ее Alertmanager。Alertmanager Дедупликация будет выполняться на основе метки сигнала тревоги и другой информации для предотвращения дублирования. тревоги。
2. Группировка сигналов тревоги (Группировка):
• Alertmanager может группировать похожие оповещения, чтобы уменьшить количество получаемых оповещений. Например, вы можете сгруппировать оповещения об одной и той же службе или одном хосте и отправить объединенное уведомление о оповещении.
3. Подавление тревоги (глушение):
• Alertmanager поддерживает настройку правил подавления для подавления уведомлений об определенных сигналах тревоги при определенных условиях. Например, вы можете отключить оповещения для определенных служб во время планового обслуживания, чтобы избежать получения ненужных уведомлений.
4. Маршрутизация сигналов тревоги (Маршрутизация):
• Alertmanager отправляет уведомления о тревогах различным получателям на основе настроенных правил маршрутизации. Различные правила маршрутизации могут быть установлены на основе меток сигналов тревоги, их серьезности и другой информации.
5. Уведомление о тревоге (Уведомление):
• Alertmanager поддерживает несколько каналов уведомлений, включая электронную почту, Slack, PagerDuty, OpsGenie, Webhooks и другие. Пользователи могут настроить разные приемники для получения уведомлений о тревогах в разных сценариях.
Генерация сигналов тревоги и отправка
Оповещение и контакт с Прометеем всегда делились на следующие три этапа:
Определение правил оповещений
В зависимости от потребностей бизнеса мы можем Prometheus Профиль в определении правил оповещений。
Здесь мы просто определяем правило оповещения об использовании диска.
groups:
- name: disk_usage_alerts
rules:
- alert: DiskUsageHigh
expr: 100 * (node_filesystem_size_bytes{fstype!~"tmpfs|fuse.lxcfs|overlay"} - node_filesystem_avail_bytes{fstype!~"tmpfs|fuse.lxcfs|overlay"}) / node_filesystem_size_bytes{fstype!~"tmpfs|fuse.lxcfs|overlay"} > 40
for: 5m
labels:
severity: warning
annotations:
summary: "Disk usage is high on {{ $labels.instance }}"
description: "Disk usage on {{ $labels.instance }} is above 40% (current value: {{ $value }}%)"Соберите правила тревог, которые мы определили ранее в prometheus.yml.
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/data/prometheus/alert.rules.yml"Мы можем проверить, успешно ли собраны наши правила, по адресу http://127.0.0.1:9090/alerts.
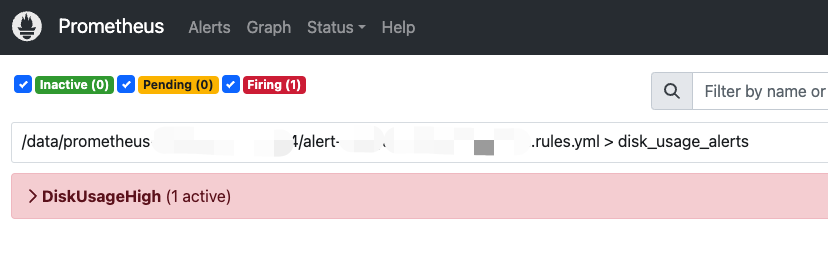
Оценка условий тревоги
Prometheus будет регулярно проверять настроенные нами правила сигнализации. Информация о тревогах будет создана после того, как будут соблюдены правила расчета и продолжительность, а также дополнительная информация о тревогах, которую мы добавили в правила.
1. Регулярная оценка:
• Сервер Prometheus регулярно оценивает правила сигналов тревоги в соответствии с правилами в файле конфигурации. Интервал оценки по умолчанию составляет 1 минуту, и его можно настроить в файле конфигурации.
2. осуществлять PromQL выражение:
• В каждый момент оценки Prometheus узнайте в правилах сигнализации PromQL выражение. Например, в приведенном выше примере Прометей Рассчитаю прошлое 5 в течение нескольких минут CPU среднее время простоя и сравните его с 80% Сделайте сравнение.
3. Определить, выполняется ли условие да:
• Prometheus Проверьте оценку выражения. Если выражение возвращает результат, удовлетворяющий условию (например, CPU Уровень использования выше, чем 80%), то это условие считается выполненным.
4. иметь дело с for Поле:
• Если в правиле тревоги определено поле for (например, 5 минут), Prometheus должен продолжать удовлетворять условиям тревоги в течение этого времени, прежде чем активировать тревогу. Если условие прерывается в течение этого периода времени, таймер будет сброшен.
Сработало тревожное сообщение
После того как Prometheus сгенерирует сигнал тревоги, Alertmanager получит, проанализирует и отправит сигнал тревоги.
Прежде чем иметь дело сPrometheus сгенерировать оповещения, мы должны сначала настроить Alertmanager в prometheus.yml.
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ["127.0.0.1:9093"]Конфигурация, связанная с тревогами Alertmanager
global:Глобальная конфигурация,Применяется ко всем уведомлениям.
- solve_timeout: установите время ожидания от срабатывания тревоги до разрешения.
route:Правила маршрутизации тревог。
- получатель: принимающая сторона по умолчанию.
- group_by: метка, на основе которой группируются сигналы тревоги.
- group_wait: время ожидания группировки.
- group_interval: интервал между отправкой групп.
- повтор_интервал: интервал между повторной отправкой сигналов тревоги.
routes:правила подмаршрутизации。
- match и match_re: соответствие меток сигналов тревоги.
- получатель: принимающая сторона, соответствующая правилу сопоставления.
receivers:Конфигурация ресивера.
- email_configs: Конфигурация получателя электронной почты.
- pagerduty_configs: конфигурация приемника PagerDuty.
- slack_configs: конфигурация Slack-приемника.
inhibit_rules:правила подавления。
- source_match: условия соответствия метки источника сигнала тревоги.
- target_match: условие соответствия метки целевого сигнала тревоги.
- равно: требуются равные теги.
Процесс обработки сигналов тревоги Alertmanager
1. Получить оповещение:
• Alertmanager полученный Prometheus Данные о тревогах отправляются и сохраняются во внутренней очереди ожидания. дело с。
2. Дедупликация:
• Alertmanager Тревоги из полученного будут дедуплицированы дело с, чтобы гарантировать, что один и тот же сигнал тревоги не будет отправлен повторно.
3. Группировка:
• Alertmanager Сгруппируйте похожие сигналы тревоги в соответствии с правилами группировки в файле конфигурации. Группировка да Чтобы уменьшить количество тревожных уведомлений, увеличьте количество тревожных сигналов. дело эффективность.
4. Заглушение:
• Alertmanager применяет правила подавления для подавления нежелательных оповещений. Например, во время планового обслуживания вы можете установить правила подавления, чтобы избежать отправки большого количества ненужных тревожных уведомлений.
5. Маршрутизация:
• Alertmanager распределяет оповещения по разным получателям на основе правил маршрутизации в файле конфигурации. Правила маршрутизации можно гибко настроить на основе меток сигналов тревоги, их серьезности и другой информации.
6. Отправить уведомление:
• Alertmanager Воляиметь дело Уведомление о тревоге после с отправляется на настроенную принимающую сторону. К распространенным получателям относятся электронная почта, Slack, PagerDuty, OpsGenie и Webhook. ждать.
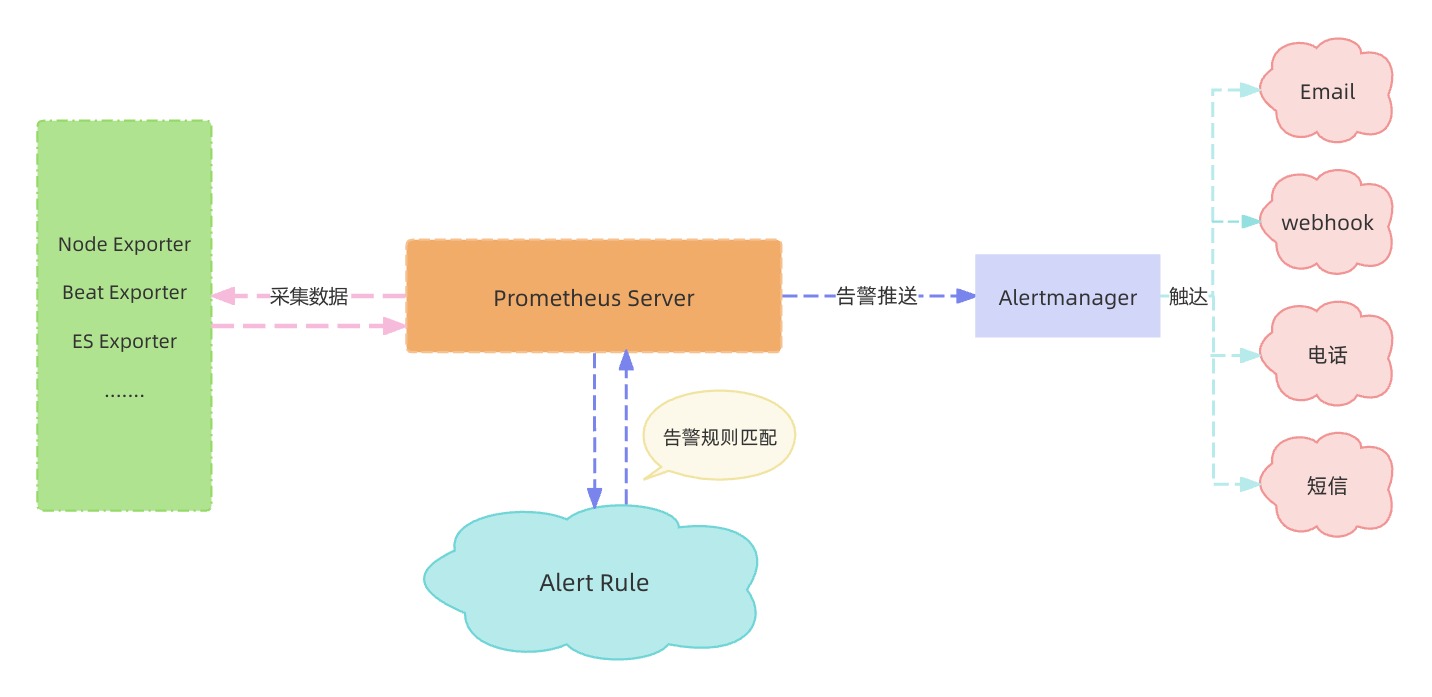
Отправка тревоги
Здесь мы выбираем метод оповещения веб-перехватчика. Позвольте роботу автоматически отправлять информацию о тревогах в Feishu Group.
Ниже приведен пример базовой конфигурации:
route:
group_by: ['disk_usage_alerts']
group_wait: 30s
group_interval: 5m
repeat_interval: 1h
receiver: 'webhook_receiver'
receivers:
- name: 'webhook_receiver'
webhook_configs:
- url: 'http://127.0.0.1:4000/alert'Из-за ограничений собственной структуры данных робота Feishu,,Если мы настроим адрес робота непосредственно в URL вебхука,В настоящее время вы не можете отправить и получить информацию о тревоге. Так что нам все еще нужно развивать свои собственные сервисы.,вызвать робота Фейшу для оповещения.
Здесь мы используем Python для разработки и реализации логики, связанной с сигналами тревоги.
Вариант 1: Запланированное получение
Регулярно запрашивайте интерфейс тревог Alertmanager по расписанию для анализа информации о тревогах, передаваемой в Alertmanager с помощью Prometheus.
Ниже приведена логическая реализация регулярного запроса к API Alertmanager для получения информации о тревогах для инкапсуляции и отправки.
import requests
import json
import time
from datetime import datetime, timedelta
# Author: Empty Box
alert_manager_url = "http://127.0.0.1:9093/api/v2/alerts"
webhook_url = «https://open.feishu.cn/ваш собственный адрес робота Feishu»
# Получить оповещение
def get_alerts(alert_manager_url):
try:
response = requests.get(alert_manager_url)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
print(f"Error fetching alerts: {e}")
return []
# Мониторинг тревог
def monitor_alerts(alert_manager_url, poll_interval=60):
known_alerts = set()
while True:
alerts = get_alerts(alert_manager_url)
new_alerts = []
for alert in alerts:
alert_id = alert["labels"].get("alertname")
if alert_id not in known_alerts:
known_alerts.add(alert_id)
new_alerts.append(alert)
if new_alerts:
print(f"New alerts found: {len(new_alerts)}")
for alert in new_alerts:
print(json.dumps(alert, indent=4))
time.sleep(poll_interval)
# Отправить оповещение
def send_alert(alert_manager_url):
try:
response = requests.get(alert_manager_url)
if response.status_code == 200:
alert_messages = response.json()
for alert_message in alert_messages:
labels = alert_message['labels']
# Тип тревоги
alert_name = alert_message['labels']['alertname']
# Тип задачи
job = alert_message['labels']['job']
# Уровень тревоги
severity = alert_message['labels']['severity']
# Содержимое тревоги
description = alert_message['annotations']['description']
# Получить оповещениесостояние,привык судитьда Повторять ли сигнал тревоги
state = alert_message['status']['state']
# Создайте тело сообщения о тревоге робота.
webhook_msg = {}
elements = []
elements_json = {}
alert_name_json = {}
alert_name_text_json = {}
description_json = {}
description_text_json = {}
job_json = {}
job_text_json = {}
msg_type = "interactive"
webhook_msg["msg_type"] = msg_type
alert_name_json["tag"] = "div"
alert_name_text_json["content"] = "**Тип тревоги**:" + alert_name
alert_name_text_json["tag"] = "lark_md"
alert_name_json["text"] = alert_name_text_json
elements.append(alert_name_json)
start_time_json["tag"] = "div"
start_time_text_json["content"] = "**Время срабатывания**:" + start_time
start_time_text_json["tag"] = "lark_md"
start_time_json["text"] = start_time_text_json
elements.append(start_time_json)
severity_json["tag"] = "div"
severity_text_json["content"] = "**Уровень тревоги**:" + severity
severity_text_json["tag"] = "lark_md"
severity_json["text"] = severity_text_json
elements.append(severity_json)
instance_id_json["tag"] = "div"
instance_id_text_json["content"] = "**Экземпляр триггера**:" + instance_id
instance_id_text_json["tag"] = "lark_md"
instance_id_json["text"] = instance_id_text_json
elements.append(instance_id_json)
job_json["tag"] = "div"
job_text_json["content"] = "**Тип мониторинга**:" + job
job_text_json["tag"] = "lark_md"
job_json["text"] = job_text_json
elements.append(job_json)
description_json["tag"] = "div"
description_text_json["content"] = "**Содержимое тревоги**:" + description
description_text_json["tag"] = "lark_md"
description_json["text"] = description_text_json
elements.append(description_json)
elements_json["elements"] = elements
webhook_msg["card"] = elements_json
json_data = json.dumps(webhook_msg)
requests.post(webhook_url, headers={'Content-Type': 'application/json'}, data=json_data)
else:
print('Не удалось получить информацию о тревоге')
except Exception as e:
print(f"error is :{e}")
if __name__ == "__main__":
poll_interval = 60 # Интервал опроса в секундах
monitor_alerts(alert_manager_url, poll_interval)
Таким образом, мы в основном используем библиотеку запросов для реализации вызовов API робота и API Alertmanager. Используйте библиотеку JSON для анализа информации о тревогах и инкапсуляции сообщений робота. Этот запланированный метод извлечения можно использовать для мониторинга состояния определенных автономных задач. В некоторых сценариях с высокими требованиями к работе в режиме реального времени, когда информация о тревогах извлекается регулярно, могут возникнуть такие проблемы, как несвоевременные сигналы тревоги.
Вариант 2: триггер в реальном времени
В триггерных сценариях в реальном времени,Мы можем разработать веб-сервисы самостоятельно,Позвольте Alertmanager запрашивать в режиме реального времени,Тогда в нашей пользовательской логике,Анализируйте и анализируйте сигналы тревоги, отправляемые Alertmanager, в режиме реального времени.
from flask import Flask, request, jsonify
from datetime import datetime, timedelta
import json
import time
import requests
app = Flask(__name__)
webhook_url = «https://open.feishu.cn/ваш собственный адрес робота»
@app.route('/alert', methods=['POST'])
def receive_alert():
# Вызывается Alert для анализа информации JSON, возвращаемой Alert.
try:
msg_json = {}
alert_response = request.json
alerts = alert_response["alerts"]
if len(alerts) > 0:
for alert in alerts:
alert_name = alert["labels"]["alertname"]
# По типу светильникосуществлять различные тела сообщений с информацией о тревогах
if "DiskUsageHigh" == alert_name:
msg_json = disk_usage_high_json(alert)
# Отправить оповещение
response = send_alert(msg_json)
print("Исходные данные тревоги: ", alert)
continue
return str(response.status_code)
except Exception as e:
return e
def send_alert(json_data):
response = requests.post(webhook_url, headers={'Content-Type': 'application/json'}, data=json_data)
return response
def disk_usage_high_json(alerts):
alert_name = alerts["labels"]["alertname"]
job = alerts["labels"]["job"]
description = alerts["annotations"]["description"]
webhook_msg = {}
elements = []
elements_json = {}
alert_name_json = {}
alert_name_text_json = {}
description_json = {}
description_text_json = {}
job_json = {}
job_text_json = {}
msg_type = "interactive"
webhook_msg["msg_type"] = msg_type
alert_name_json["tag"] = "div"
alert_name_text_json["content"] = "**Тип тревоги**:" + alert_name
alert_name_text_json["tag"] = "lark_md"
alert_name_json["text"] = alert_name_text_json
elements.append(alert_name_json)
start_time_json["tag"] = "div"
start_time_text_json["content"] = "**Время срабатывания**:" + start_time
start_time_text_json["tag"] = "lark_md"
start_time_json["text"] = start_time_text_json
elements.append(start_time_json)
severity_json["tag"] = "div"
severity_text_json["content"] = "**Уровень тревоги**:" + severity
severity_text_json["tag"] = "lark_md"
severity_json["text"] = severity_text_json
elements.append(severity_json)
description_json["tag"] = "div"
description_text_json["content"] = "**Содержимое тревоги**:" + description
description_text_json["tag"] = "lark_md"
description_json["text"] = description_text_json
elements.append(description_json)
elements_json["elements"] = elements
webhook_msg["card"] = elements_json
json_data = json.dumps(webhook_msg)
return json_data
if __name__ == '__main__':
app.run(host='0.0.0.0', port=4000)
В пользовательской логике сигналов тревоги в реальном времени мы в основном используем Flask для разработки веб-сервисов Python. Анализируя JSON веб-интерфейса запросов в реальном времени Alertmanager, мы можем анализировать содержимое сигналов тревоги, оценивать их в соответствии с категорией сигналов тревоги и вызывать их. различные структуры тела сообщения о тревоге. Метод инкапсуляции содержимого тревоги и его передачи.
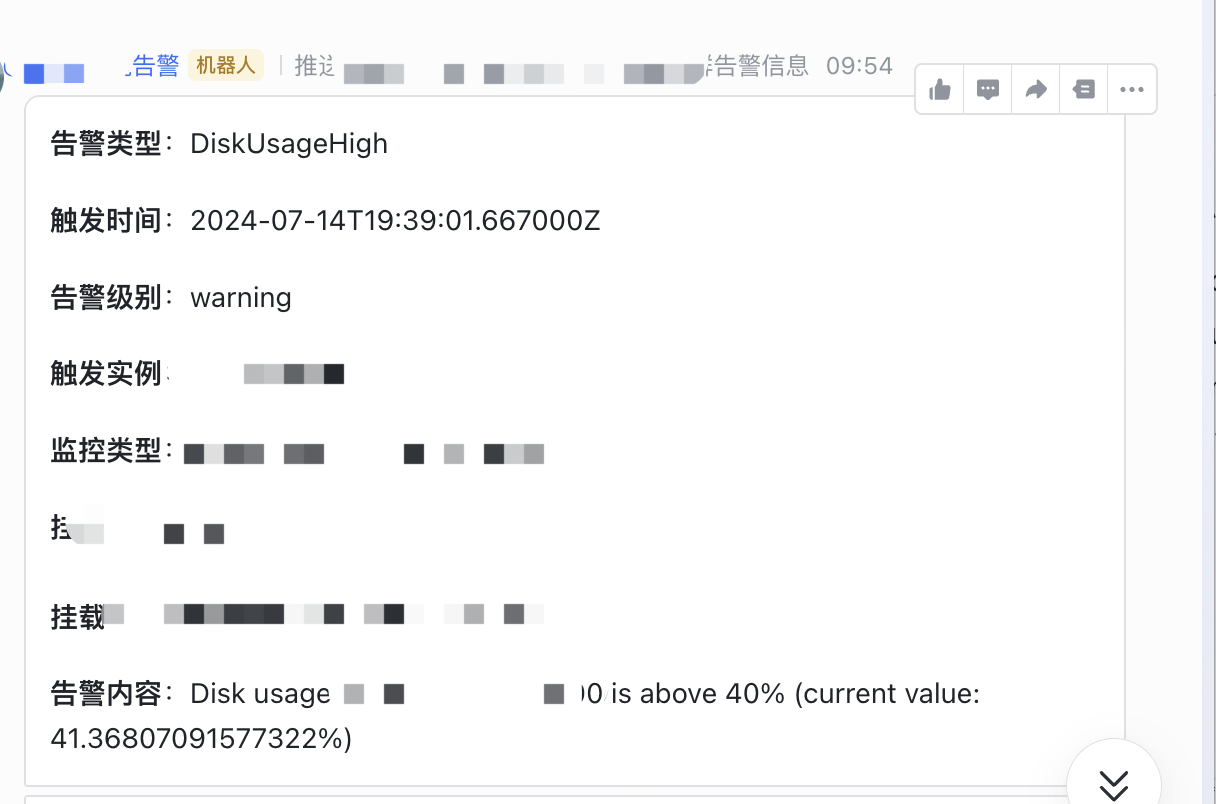
Эффект тревоги по Схеме 2 показан на рисунке ниже:



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
