Прогресс исследований в области обнаружения целей в окружающей среде с использованием облаков точек и изображений
Автор: Цзя Минда, Ян Цзиньмин, Мэн Вэйлян, Го Цзяньвэй, Чжан Цзигуан, Чжан Сяопэн
Источник: «Журнал китайского изображения и графики».
Редактор: Дунъань из-за публичного аккаунта @немногоискусственного интеллекта
В области применения технологий цифрового моделирования, особенно при разработке технологий автономного вождения, обнаружение целей является важнейшим звеном. Оно включает в себя восприятие объектов в окружающей среде и предоставляет ключевую информацию для принятия решений и планирования интеллектуального оборудования.
В последние годы, с развитием сенсорных технологий, изображения и облака точек стали двумя основными источниками сенсорных данных, каждый из которых имеет уникальные преимущества при исследовании методов обнаружения целей, основанных на технологии глубокого обучения.
Чтобы провести более полное исследование существующих методов обнаружения целей на основе облаков точек и изображений, в этой статье систематически сортируются и обобщаются три типа алгоритмов обнаружения целей на основе изображений, облаков точек и их комбинаций, с целью изучить, как объединить Объединение различных источников данных способствует повышению точности, стабильности и надежности обнаружения целей и предполагает развитие направления обнаружения целей в окружающей среде, которое объединяет облака точек и изображения.
00 Введение
Обнаружение объектов — важная задача в области компьютерного зрения, цель которой — точно идентифицировать и определять местонахождение конкретных объектов по изображениям или видео. Он играет ключевую роль во многих приложениях, таких как автономное вождение, видеонаблюдение, распознавание лиц и т. д. Разработка алгоритмов обнаружения целей прошла несколько этапов, постепенно развиваясь от традиционных методов, основанных на ручных функциях, к методам, основанным на глубоком обучении (Arora et al., 2007, Aldoma et al., 2012).
Традиционные методы обнаружения целей обычно включают в себя такие этапы, как извлечение признаков, классификация целей и регрессия положения изображений. Обычно используемые функции включают Harr (Viola et al., 2001), HOG (Dalal et al., 2005) и SIFT (Ng et al., 2003) (масштабно-инвариантное преобразование признаков). Эти методы могут обеспечить обнаружение целей в определенной степени, но они ограничены производительностью разработанных вручную функций и классификаторов, а также имеют ограничения для сложных сцен и сильно меняющихся целей. С развитием технологий глубокого обучения методы обнаружения целей, основанные на глубоких нейронных сетях, постепенно стали мейнстримом. Наиболее репрезентативным является метод на основе сверточной нейронной сети (CNN). CNN может автоматически изучать представления объектов на изображениях посредством многоуровневой свертки и операций объединения. При обнаружении целей методы на основе CNN обычно можно разделить на два основных метода классификации: одноэтапный метод и двухэтапный метод. Одноэтапный метод точно предсказывает категорию и местоположение цели непосредственно на изображении и обычно работает быстрее. Типичные алгоритмы включают серию YOLO (Бочковский и др., 2020) и серию SSD (Лю и др., 2015). . Двухэтапный метод сначала генерирует кадры-кандидаты, а затем выполняет классификацию и регрессию положения для кадров-кандидатов. Репрезентативные алгоритмы включают R-CNN на основе выборочного поиска (Girshick et al., 2014), серию Fast RCNN (Girshick, 2015) и на основе серии Faster R-CNN для генерации блоков-кандидатов (Ren et al., 2017). Поскольку двухэтапный метод требует двух шагов, это повлияет на конечную скорость расчета модели. Благодаря постоянному совершенствованию производительности оборудования нынешний одноэтапный метод обнаружения целей окружающей среды стал основным методом вычислений.
В то же время, благодаря постоянному развитию и снижению затрат на технологию LiDAR (Light Detection and Ranging, LiDAR), данные LiDAR постепенно внедряются в область обнаружения целей. В данных LiDAR любой объект представлен неупорядоченными дискретными точками на его поверхности. Из этих неупорядоченных дискретных точек точное обнаружение блоков облака точек, представляющих цели (например, пешеходов и транспортные средства), и придание целевой позы является сложной задачей. Благодаря уникальности данных LiDAR, он может обеспечить высокоточное обнаружение препятствий и измерение расстояния, помогая транспортным средствам определять окружающие дороги, транспортные средства и пешеходные объекты. В сочетании с другими датчиками LiDAR может обеспечить мультимодальное восприятие, тем самым значительно повышая точность и надежность обнаружения целей.
В последние годы исследователи предложили множество методов трехмерного обнаружения целей для облаков точек и изображений (Арнольд и др., 2019, Гуо и др., 2021). Существующие основные методы трехмерного обнаружения целей можно разделить на следующие три типа. различные модальности входных данных:
1) Обнаружение 3D-целей на основе изображений.потому что2Dкартина Самому изображению не хватает информации о глубине.,Часто бывает сложно напрямую использовать 2D-изображения для обнаружения 3D-объектов. Основные методы трехмерного обнаружения целей на основе изображений можно разделить на трехмерное обнаружение целей на основе чистых изображений, трехмерное обнаружение целей на основе оценки глубины, трехмерное обнаружение целей на основе предварительного наведения и трехмерное обнаружение целей на основе нескольких изображений. Хотя эти методы различаются на уровне использования данных или представления объектов.,Но все они получают трехмерные характеристики цели из двухмерного изображения.,Чтобы получить такую информацию, как трехмерное положение, положение и форма цели.
2) Трехмерное обнаружение целей на основе облака точек.Такие методы обычно начинаются сLiDARоблако точек(Yanждать,2018) в качестве входных данных,по сравнению сданные изображения, облако точек LiDAR обеспечивает более точные и плотные трехмерные данные, которые могут более точно описать геометрические свойства цели. Такие методы можно разделить на две большие категории. Один тип метода напрямую использует Исходное. облако Данные точек используются для обнаружения целей, а такие операции, как предварительная обработка данных, извлечение признаков и обнаружение классификации, выполняются непосредственно над входными трехмерными данными облака точек. Другой тип метода использует Исходное. облако точки сначала преобразуются в другие представления данных, например воксельный (Voxel) (Catmull, 1998), вид с высоты птичьего полета(Bird’s Eye View или BEV) (Chen et al., 2017) и изображение на расстоянии (Range View) (Fan et al., 2021) и другие виды, а затем выполнить обнаружение целей на основе изображений.
3) 3D-обнаружение целей, объединяющее облако точек и изображение(Xuждать,2018). Такие алгоритмы обычно используют методы мультимодального слияния для достижения трехмерного обнаружения целей.,Объединение характеристик источников изображений и лидарных данных,Получите более подробную информацию о синтезе,обладают большей стабильностью и надежностью (Feng et al.,2021)。
В настоящее время исследователи обобщили и систематизировали исследования по 3D-обнаружению целей на основе изображений и LiDAR. Существующая работа включает в себя исследования различных задач, таких как классификация, отслеживание и сегментация в методах трехмерных облаков точек (Guo et al., 2021), а также методы обнаружения целей и семантической сегментации в мультимодальном автономном вождении (Feng et al., 2021), а также текущий статус развития технологии приложений для автономного вождения (Arnold et al., 2019) и новых методов объединения, таких как мультимодальное обнаружение целей (Wang et al., 2023). Большинство этих обзоров посвящены конкретной области трехмерного обнаружения целей и не фокусируются на связи между различными методами. В связи с быстрым развитием технологий обнаружения целей содержание некоторых обзоров больше не полностью применимо к существующему прогрессу исследований.
Чтобы исследователи могли лучше и быстрее понять алгоритмы обнаружения целей, которые объединяют изображения и облака точек, в этой статье в основном обобщаются и уточняются существующие алгоритмы обнаружения целей в соответствии с мультимодальным объединением облаков точек, изображений, изображений и облаков точек. , Методы: классифицируйте алгоритмы обнаружения целей, анализируйте преимущества и недостатки различных методов и исследуйте возможные решения. В то же время мы даем более полный обзор разработки алгоритмов обнаружения целей, которые объединяют облака точек и изображения с разных точек зрения, таких как сбор и представление данных, проектирование моделей и т. д., и делаем прогноз на будущее экологических целей. обнаружение.
Основные положения этой статьи заключаются в следующем:
1) Обобщает широко используемые методы сбора данных, наборы данных, формы данных и состояние разработки в области текущего обнаружения экологических целей.
2) Классифицировать алгоритмы обнаружения целей по методам, основанным на мультимодальном слиянии облака точек, изображения, изображения и облака точек, подробно представить различные методы, а также проанализировать и разобраться в связях между различными методами.
3) Предложить существующие проблемы и будущие перспективы в исследованиях по обнаружению целей в окружающей среде.
01 Текущий статус исследований по обнаружению объектов окружающей среды
1.1 Сбор изображений и данных облаков точек
Данные изображения можно собирать с помощью камеры общего назначения, но вычисление трехмерной информации о местоположении часто ограничено точностью. LiDAR активно излучает лазерный луч и измеряет время, необходимое свету для попадания на объект или поверхность, а затем отражается обратно, чтобы рассчитать расстояние от LiDAR до целевой точки. В процессе для построения собираются миллионы точек данных. карта происходящего. Сложная «карта» измеряемых пространственных поверхностей называется «облаком точек». Данные облака точек представлены в виде дискретных и неупорядоченных трехмерных точек, каждая точка содержит свои точные координаты в пространстве. Это позволяет данным облака точек напрямую отражать трехмерные геометрические особенности объекта, не подвергаясь влиянию изменений угла обзора. По сравнению с данными изображения данные облака точек имеют уникальные преимущества и могут предоставить более точную информацию о глубине, включая местоположение, форму и размер объектов, тем самым эффективно облегчая распространенные проблемы окклюзии в двумерных изображениях (Cui et al., 2022).
1.2 Часто используемые наборы данных трехмерного обнаружения целей
В существующих исследованиях исследователи часто полагаются на различные широко используемые общедоступные наборы данных для оценки и проверки своих алгоритмов и систем автономного вождения. Обычно используемые наборы данных трехмерного обнаружения целей в основном включают следующее:
1.2.1 Набор данных KITTI
Набор данных KITTI (Geiger et al., 2012) — это набор данных, который широко используется в области автономного вождения и спонсируется совместно Технологическим институтом Карлсруэ в Германии и Технологическим институтом Toyota в Чикаго. В наборе данных KITTI используется 64-строчный лидар Velodyne для сбора данных облака точек и камера общего назначения для сбора соответствующих изображений, которые включают в себя обычные дорожные объекты, такие как транспортные средства, пешеходы и велосипеды. Он имеет высокую точность аннотаций и отличается высокой точностью. относительно чистый диапазон сцены можно использовать для визуальной оценки алгоритмов в различных сценариях автономного вождения, таких как оптический поток, оценка глубины, обнаружение 2D/3D целей, отслеживание целей и другие задачи.
1.2.2 Набор данных nuScenes
Набор данных nuScenes (Caesar et al., 2020) состоит из различных сцен вождения, снятых в Бостоне и Сингапуре. Это также один из других широко используемых общедоступных наборов данных в области автономного вождения. В настоящее время он является наиболее авторитетным. визуальная 3D-мишень для автономного вождения. Набор данных nuScenes фокусируется на разнообразии и сложности реального мира, охватывая условия вождения в разных местах, в разное время и в разных погодных условиях. Каждая среда длится 20 секунд. Объем аннотаций данных в 7 раз больше, чем у KITTI, и это так. первый набор данных, содержащий полный набор датчиков. Кроме того, набор данных KITTI в основном содержит сцены с хорошими погодными условиями в течение дня, тогда как сцены в наборе данных nuScenes включают ночные и дождливые дни, что является более сложной задачей.
1.2.3 Набор данных Waymo
Набор данных Waymo (Sun et al., 2020) представляет собой крупномасштабный набор данных о восприятии 3D, предоставленный Waymo, компанией, принадлежащей Google. Waymo содержит 798 обучающих сцен, 202 проверочных и 150 тестовых сцен, длительность каждой сцены составляет 20 секунд. Частота маркировки набора данных Waymo в 5 раз выше, чем у nuScenes, количество сцен в 3 раза больше, чем у набора данных nuScenes, а 2D/3D меток больше и плотнее. Набор данных Waymo выдвигает более высокие требования к надежности и возможностям обобщения алгоритмов автономного вождения и на данный момент является самым большим и разнообразным набором данных.
1.3 Общие формы представления данных при обнаружении целей
В существующих исследованиях основные формы представления данных для обнаружения объектов окружающей среды можно разделить на следующие типы.
1.3.1 Данные изображения
Обычно используемые визуальные датчики в основном включают монокулярные камеры и камеры глубины. Монокулярные камеры обычно используются для получения двумерных изображений с этой точки зрения, то есть изображений RGB и изображений в оттенках серого, которые могут предоставить богатую информацию о текстуре и цветах, а скорость обработки таких изображений выше, чем данных облака точек, и занимает больше времени. много места. Меньше вычислительных ресурсов. Камера глубины используется для получения расстояния от каждой точки изображения до камеры, то есть трехмерных пространственных координат каждой точки (Xu et al., 2019). Данные изображений всегда были очень важными входными данными в исследованиях по обнаружению целей в окружающей среде.
1.3.2 Исходное облако точек
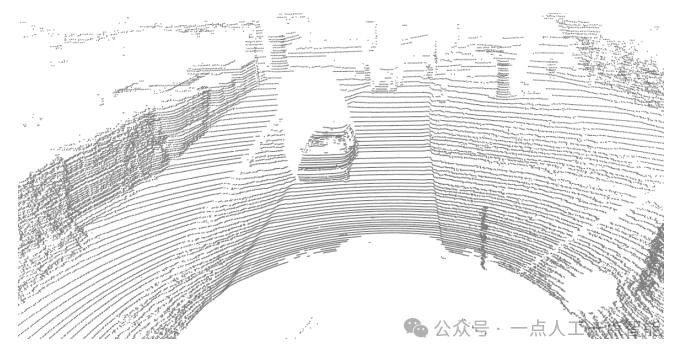
Исходное трехмерное облако точек может быть получено с помощью лидара, камеры глубины или бинокулярной камеры и может быть непосредственно использовано в качестве входных данных для модели обнаружения цели, а глубокое извлечение признаков выполняется через сеть глубокого обучения для завершения обнаружения цели или задача семантической сегментации. Типичные работы, которые непосредственно обрабатывают необработанные данные облака точек, включают PointNet (Charles et al., 2017), PointNet++ (Qi et al., 2017) и другие работы. Исходные данные облака точек кодируются с использованием (x, y, z) в декартовой системе координат, а эффект их визуального отображения показан на рисунке 1. Обычно они сопровождаются соответствующей информацией, такой как интенсивность отражения каждой точки. Вычислительные затраты на прямое использование исходного облака точек для обнаружения целей относительно высоки, а при разработке модели необходимо учитывать беспорядок и разреженность самих данных облака точек.
1.3.2 Воксель
Вокселы — это метод обработки данных, который эффективно представляет исходные облака точек. Вокселизация облаков точек относится к процессу разделения непрерывных трехмерных данных облака точек на дискретные трехмерные пространства сетки. Каждая сетка вокселей представляет собой трехмерное пространство фиксированного размера, как показано на рисунке 2, аналогично пикселям изображения (Zhou et al., 2018). Обычно этот процесс требует выбора подходящего разрешения вокселей для определения размера каждой сетки вокселов. Меньшие сетки вокселей представляют собой большие вычислительные затраты и более высокую точность вычислений. Вокселизация облаков точек — это метод предварительной обработки данных, который широко используется в исследованиях по обнаружению целей в окружающей среде.

1.3.3 Вид спереди
Вид спереди (FV) относится к данным, которые наблюдают и фиксируют сцену или объект с определенной точки зрения и представляют наблюдаемую информацию в форме двухмерного изображения. Данные вида спереди обычно собираются с помощью камер, камер или других датчиков видения, а также могут быть получены путем проецирования трехмерных данных облака точек на двухмерную плоскость (Ку и др., 2018), как показано на рисунке 3.

В процессе получения вида спереди с помощью трехмерных данных облака точек можно выбирать различные методы проекции: ортогональную проекцию и перспективную проекцию. Ортогональная проекция проецирует облако точек непосредственно на плоскость, параллельную плоскости просмотра, а перспективная проекция имитирует перспективную перспективу человеческого глаза при наблюдении объектов для завершения проекции. Различные методы проекции вида спереди часто соответствуют различным операциям преобразования координат, таким как перемещение, масштабирование и вращение.
1.3.4 Вид с высоты птичьего полета
Вид с высоты птичьего полета (Bird's Eye View или BEV) аналогичен виду спереди. Это проекция данных облака точек с определенной точки зрения (т. е. вид с высоты птичьего полета также может использовать различные методы кодирования для обработки). облака точек, как показано на рисунке 4. Показать.

При представлении с высоты птичьего полета объекты, заблокированные спереди и сзади, не блокируют друг друга в вертикальной перспективе, и каждый объект сохраняет информацию о длине и ширине. Функции, преобразованные с помощью вида с высоты птичьего полета, облегчают обнаружение и позиционирование последующих моделей в вертикальном направлении (Chen et al., 2017).
1.3.5 Цилиндр
Цилиндрическое представление (Vora et al., 2020) — это метод представления, который преобразует данные облака точек в пространство цилиндра. В цилиндрическом представлении точки облака точек назначаются цилиндрическому пространству, аналогично разделительной сетке вокселей. Каждый цилиндр делит облако точек на области в направлениях x и y с определенным размером шага, но не в направлении z.
1.4 Текущий статус исследований по обнаружению целей в окружающей среде в стране и за рубежом
В последние годы область автономного вождения получила быстрое развитие. С точки зрения алгоритма восприятия окружающей среды при автономном вождении текущие основные технические маршруты можно разделить на два типа: чисто визуальные технические маршруты и технические маршруты с использованием лидара. Чисто визуальный маршрут использует только изображения камеры для обнаружения целей и восприятия окружающей среды. Представители компаний включают Tesla и Baidu Apollo Lite. Использование лидара для трехмерного восприятия окружающей среды по-прежнему остается первым выбором для большинства компаний. Huawei, Uber, Waymo и т. д. — все исследовательские группы, работающие над этим типом алгоритма.
Что касается алгоритмов обнаружения целей окружающей среды на основе облака точек, то многие отечественные исследовательские подразделения в последние годы провели исследовательские работы по этому вопросу. В то же время многие подразделения имеют сканирующее оборудование для сбора данных облака точек и добились соответствующих результатов. Например, Пекинский университет предложил высокопроизводительную объединенную структуру зрения и LiDAR на основе пространства признаков BEV (Liu et al., 2022), а Tencent Youtu предложила на основе вокселизации облака точек. Для эффективного многоэтапного обнаружения целей (Chen et al., 2019) и точечного облака точек от разреженного до плотного многоэтапного обнаружения целей (Yang et al., 2019) компания SenseTime предложила метод обнаружения целей без присмотра, используя Лидарные подсказки (Tian et al., 2021) и другие работы в определенной степени способствовали исследованиям обнаружения целей в окружающей среде на основе изображений и облаков точек.
1.5 Существующие проблемы слияния облаков точек и изображения мультимодального обнаружения целей
1) Сложности с маркировкой данных:облако точек和данные изображения Работа по аннотированию является относительно сложной и трудоемкой.,Особенно для крупномасштабных наборов данных. в то же время,Из-за разреженности данных облака точек и влияния шумовых точек,,Точная аннотация данных облака точек также является непростой задачей.
2) Кросс-модальное слияние:облако точек和данные изображения — это два разных способа восприятия,Существуют различия в их структуре данных и представлении функций. Как эффективно объединить информацию из этих двух модальностей,Извлекайте точные и полные доступные функции,В настоящее время это горячая точка исследований.
3) Обработка крупномасштабных данных облака точек:облако точекданные通常包含大量的三维坐标,По сравнению с чистым изображением данных,Обработка крупномасштабных данных облака точек предъявляет более высокие требования к вычислительным ресурсам и эффективности алгоритмов. Как эффективно обрабатывать и использовать крупномасштабные данные облаков точек,Это также одна из проблем, которые необходимо срочно решить.
02 Обнаружение цели на основе изображения
Работа по обнаружению целей на основе изображений делится на две категории: 2D-обнаружение целей и 3D-обнаружение целей. Среди них многие исследования по обнаружению 3D-целей проводятся на основе алгоритмов 2D-обнаружения целей.
Обнаружение 2D-целей на основе изображений можно разделить на два типа: методы на основе областей-кандидатов и методы на основе регрессии. Метод обнаружения целей на основе областей-кандидатов сначала генерирует набор областей-кандидатов для предварительного позиционирования цели, а затем использует нейронные сети и различные дополнительные условия для дальнейшего подтверждения местоположения и категории объектов в области интереса (ROI) (Cao и др., 2022). Типичные методы этого типа работы включают R-CNN (Girshick et al., 2014), Fast R-CNN (Girshick, 2015), Faster R-CNN (Ren et al., 2017) и Mask R-CNN (He и др., 2017). Методы обнаружения целей на основе регрессии преобразуют задачу граничного позиционирования цели в задачу сквозной регрессии, отказываясь от идеи региона и напрямую получая граничное описание цели, например SSD (Лю и др. ., 2015), Yolov4 (Бочковский и др., 2015), 2020), RetinaNet (Лин и др., 2017), EfficientDet (Тан и др., 2020) и др.
Однако простое использование 2D-модели обнаружения целей не может обеспечить эффективное позиционирование объектов для сценариев автономного вождения. Поэтому многие исследователи пытаются начать с 2D-метода обнаружения целей и расширить модель обнаружения до 3D-обнаружения целей. Эта статья посвящена ознакомлению с соответствующими методами трехмерного обнаружения целей и делит их на следующие категории.
2.1 Монокулярное 3D-обнаружение на основе чистых изображений
Наиболее прямым решением для монокулярного обнаружения 3D-целей является получение параметров кадра 3D-обнаружения объекта непосредственно из изображения через нейронную сеть, что аналогично 2D-обнаружению целей. Его также можно разделить на возможные методы обнаружения целей на основе области. и методы обнаружения целей на основе регрессии. Кроме того, эти методы также можно классифицировать по тому, используют ли они якоря и являются ли они сквозными.
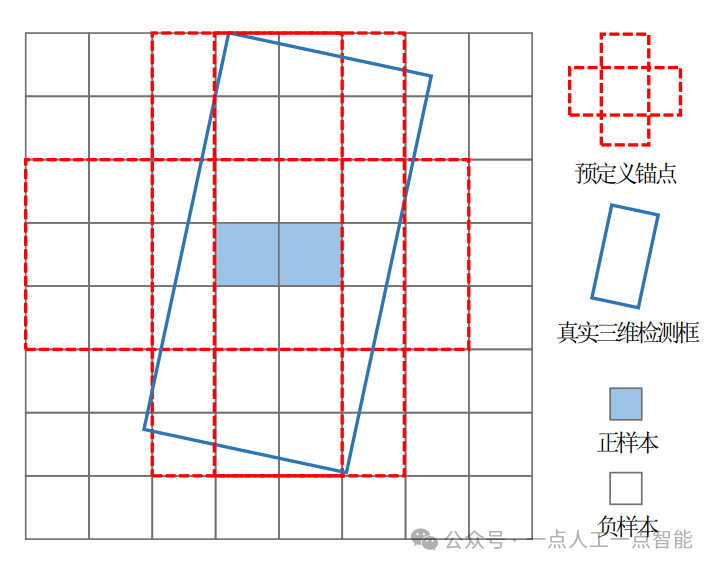
Метод обнаружения цели на основе опорных точек имеет различные настройки опорных точек на основе трехмерных опорных точек, двухмерных опорных точек, опорных точек глубины и т. д. Он направлен на определение положения объекта с помощью методов измерения, используя реальное значение и заданную опорную точку. Прогнозируемое значение точки. Выполняйте коррекцию смещения и постоянно оптимизируйте эффект обнаружения цели в модели. Например, серии YOLO и серии RCNN представляют собой классические работы, в которых для обнаружения целей используются опорные точки. 5.
Метод без привязки также использует сверточную нейронную сеть для обработки изображений. Разница в том, что метод без привязки напрямую прогнозирует соответствующие параметры объекта, что можно рассматривать как сеть, изучающую положение и форму опорной точки. сам. Алгоритм прогнозирования без привязки имеет множество компонентов модели, включая головку классификации, головку обнаружения центральной точки, головку регрессии смещения центральной точки, головку регрессии расстояния по глубине, головку обнаружения ключевой точки и т. д. Типичные работы по обнаружению целей без привязки включают: FCOS (Tian et al., 2019), CornerNet (Law et al., 2020), CenterNet (Duan et al., 2019), ExtremeNet (Zhou et al., 2019) и т. д. .
Одноэтапный метод 3D-обнаружения целей может естественным образом опираться на архитектуру сети 2D-обнаружения целей для сквозного обучения модели. Среди них к одноэтапным методам трехмерного обнаружения целей на основе опорных точек относятся M3d-rpn (Бразилия и др., 2019), Kinematic3d (Бразилия и др., 2020), M3dssd (Луо и др., 2021), FQNet (Лю и др., 2019) и др. Одноступенчатые трехмерные методы обнаружения целей без якоря включают Smoke (Лю и др., 2020), Fcos3D (Ван и др., 2021), MonoEF (Чжоу и др., 2021), OFT (Роддик и др., 2018). , MoVi-3D (Симонелли и др., 2021) 2020) и т.д.
Многоэтапные методы обнаружения 3D-целей обычно требуют определенного ручного проектирования для расширения традиционной двухэтапной системы 2D-обнаружения до обнаружения 3D-целей, то есть на первом этапе 2D-детектор используется для генерации 2D-кадра цели из входного изображения. , а затем на втором этапе рентабельность инвестиций в объект с точки зрения 2D для прогнозирования 3D Различные параметры под углом обзора для формирования полного 3D-кадра обнаружения, такие как Gs3d (Li et al., 2019), Monogrnet (Qin et al., 2022), MonoRCNN (Shi et al., 2021), GUPNet (Lu et al., 2022), GUPNet (Lu et al., 2022). др., 2021).
В целом, монокулярные методы обнаружения 3D-целей, основанные на чистых изображениях, напрямую уменьшают параметры кадра 3D-обнаружения из изображения с помощью улучшенной структуры обнаружения 2D-целей и часто могут напрямую выиграть от соответствующих исследований по обработке 2D-изображений, и большинство из них Все методы можно обучать сквозным образом без предварительного обучения или постобработки. Однако прямая регрессия глубины каждого трехмерного объекта с использованием только монокулярных двумерных изображений является сложной задачей. Ошибка, вызванная информацией о глубине, может легко стать ключевым фактором, препятствующим задаче обнаружения трехмерных целей. В этом процессе в качестве истинной ценности контроля используются только аннотации на уровне поля обнаружения, что ограничивает улучшение производительности модели.
2.2 Монокулярное 3D-обнаружение на основе оценки глубины
Монокулярное 3D-обнаружение, основанное на оценке глубины, относится к методу обнаружения целей, который использует методы глубокого обучения для вывода соответствующей информации о глубине из одного изображения и оценки положения и положения объектов. Оценка глубины является важной частью этого типа метода, и во многих работах используются методы предварительной подготовки вспомогательной сети оценки глубины для получения точных результатов монокулярного обнаружения.
В частности, этот тип метода должен передавать монокулярное 2D-изображение в предварительно обученный оценщик глубины для получения изображения глубины, такой как MonoDepth (Godard et al., 2017) и DORN (Fu et al., 2018). Изображение глубины может быть получено методами, основанными на изображениях глубины, и методами, основанными на псевдолидаре, для полного последующего трехмерного распознавания и позиционирования цели (Jin et al., 2023).
Методы на основе изображений глубины объединяют изображения и картирование глубины со специализированными нейронными сетями для создания функций, учитывающих глубину, которые могут повысить производительность обнаружения, например MultiFusion (Xu et al., 2018), MonoFENet (Bao et al., 2020), D4LCN (Ding et al., 2020) и DDMP (Wang et al., 2021). Метод, основанный на псевдолидаре, преобразует изображение глубины в псевдолидарное облако точек и отправляет псевдолидарное облако точек в 3D-детектор на основе лидара, такой как Pseudo-LiDAR (Wang et al., 2019), AM3D. (Ма и др., 2019, 2019), Глубокая оптика (Чанг и др., 2019).
2.3 Монокулярное 3D-обнаружение на основе предшествующих рекомендаций
Исследователи также постоянно изучают предварительные знания, такие как форма цели на изображении и геометрия сцены, чтобы установить соответствующую взаимосвязь между рамкой обнаружения трехмерной цели в мировой системе координат и системой координат пикселя, тем самым решая патологическую монокулярную проблему обнаружения трехмерной цели. . Например, вводятся предварительно обученные подсети для изучения предварительных знаний о 3D-объектах, чтобы помочь обнаружению 2D-целей и получить возможность обнаружения 3D-целей. Предварительные знания, которые можно изучить, включают в себя: априорную форму цели, априорную категорию, априорную величину, априорную позицию и т. д. Типичные работы включают Mono3d++ (He et al., 2019), Roi-10d (Manhardt et al., 2018), MonoPSR (Ku et al., 2019), Shift r-cnn (Naiden et al., 2019), Rtm3d ( Ли и др., 2020), Kinematic3d (Бразилия и др., 2020) и др.
2.4 Обнаружение цели BEV на основе многоракурсных изображений
Преимущество использования представления с высоты птичьего полета (BEV) для обнаружения трехмерных объектов заключается в том, что оно может эффективно облегчить проблему окклюзии при обнаружении объекта и сохранить информацию о высоте и ширине объекта. По сравнению с видом спереди, используемым в процессе монокулярного 3D-обнаружения, использование BEV для позиционирования объектов часто имеет меньшие ошибки вертикального положения, и легче получить точные кадры 3D-обнаружения. Однако преобразование облаков точек в BEV приведет к потере большого количества информации по вертикальной оси. Для таких объектов, как пешеходы и дорожные знаки, эффект обнаружения не очень хороший.
По сравнению с прямым преобразованием облаков точек в функции BEV для восприятия, последовательности изображений с несколькими изображениями преобразуются в функции BEV для восприятия посредством сопоставления нескольких изображений для получения более богатой семантической информации и более точной информации о глубине. Общие методы просмотра с высоты птичьего полета можно разделить на две основные категории: одна — это традиционный метод преобразования перспективы в BEV на основе заданной проекции, а другая — неявное использование геометрических связей для преобразования многоракурсных изображений в данные. характер привода – это характеристика BEV. В последние годы широкое внимание получили методы обзора данных с высоты птичьего полета, такие как BEVFusion (Liu et al., 2022), BEVFormer (Li et al., 2022), BEVFormerV2 (Yang et al., 2022). , M2BEV (Xie et al., 2022), 2022) и т. д.
BEVFormer предлагает трехмерную модель обнаружения целей с использованием чисто визуальных многоракурсных изображений. Он извлекает многомасштабные особенности окружающего изображения с помощью двухмерной сверточной нейронной сети, а затем использует обучение модели для изучения особенностей изображения с помощью модуля внимания во временных и временных диапазонах. Кодирование генерирует функции BEV и, наконец, обращается к декодеру функций для выполнения задач обнаружения трехмерных целей и сегментации карты.
Чтобы решить проблему, заключающуюся в том, что структура детектора BEVFormer слишком сложна и приводит к искажению градиентного потока кодера и декодера, BEVFormerV2 представляет головку перспективного трехмерного обнаружения, то есть сигнал контроля, генерируемый с перспективной точки зрения, напрямую воздействует на магистральная сеть помогает магистральной сети выполнять задачи распознавания 2D. Потерянная 3D-информация облегчает процесс оптимизации модели. В то же время модель также объединяет вышеупомянутую головку обнаружения перспективы и головку обнаружения BEV в многоступенчатый детектор BEV, что значительно улучшает адаптивность и скорость сходимости распознавания BEV модели.
Благодаря постоянному развитию алгоритмов восприятия BEV, обнаружение целей BEV на основе многоракурсных изображений стало предпочтительным решением восприятия для основных систем автономного вождения и имеет выдающуюся производительность в таких задачах, как эффективный расчет и планирование пути в системах реального времени.
03 Обнаружение цели на основе облака точек
Алгоритм обнаружения целей на основе облака точек является одной из горячих точек исследований в области компьютерного зрения в последние годы. На ранних этапах исследований исследователи в основном изучали такие задачи, как сегментирование и классификация целевых облаков точек на основе традиционной геометрии и методов машинного обучения, которые основывались на разработанных вручную функциях и правилах, которые имели большие ограничения. С развитием глубокого обучения, после того как классические работы, такие как Pointnet и Pointnet++, впервые применили данные облака точек для глубокого обучения, исследователи начали применять глубокое обучение для обнаружения целей облака точек. Текущие алгоритмы обнаружения целей на основе облака точек можно разделить на обнаружение целей на основе точек, обнаружение целей на основе вокселей, обнаружение целей на основе BEV и обнаружение целей на основе изображения на расстоянии.
3.1 Точечное обнаружение целей
Обнаружение целей на основе точек означает прогнозирование местоположения трехмерных целей непосредственно на основе необработанных данных облака точек. Этот тип метода обычно включает в себя следующие модули:
1) Предварительная обработка данных:Включает удаление выбросов、облако точек滤波ждать操作,удалить шум из облаков точек,Это улучшает качество и точность определения местоположения облака точек.
2) Особенность учащегося:通过深度学习的手段学习облако точек的特征表示,Эти функции часто состоят из локальных и глобальных функций.,чтобы лучше отличить цель от фона.
3) Детектор целей:То есть добавление детектора целей в сеть после модуля извлечения признаков.。и2DДетекторы объектов бывают разные,Входные функции детектора целей облака точек часто больше ориентированы на нормали облака точек, распределение окружающих точек и интенсивность других атрибутов.,Это отличается от извлечения функций непосредственно из пиксельных изображений. Обычно головка обнаружения цели из облака точек выводит такую информацию, как категория цели, координаты трехмерной ограничивающей рамки и достоверность цели.,ина основекартина Нравиться3DДетекторы объектов ничем не отличаются。
Наиболее важным модулем точечного 3D-детектора целей является часть обучения функциям, которую можно разделить на модуль выборки облака точек и модуль обучения функциям:
1) Выборка облака точек:облако точек采样决定输入облако точекданные的密度和分布,Это оказывает важное влияние на производительность последующего обучения функций и обнаружения целей. Общие традиционные методы выборки облака точек включают: равномерную выборку, глобальную выборку, локальную выборку, адаптивную выборку и т. д. В недавних работах часто используются модели глубокого обучения для управления выборкой облаков точек.,Получите более качественные выборки облаков точек, изучив веса важности облаков точек и распределение облаков точек. Очень классической работой по выборке облаков точек является алгоритм выборки самых удаленных точек, используемый PointNet++ для решения проблемы чрезмерного расчета PointNet.,То есть определенное количество точек выбирается из всех входных облаков точек.,Надеемся, эти пункты будут содержать как можно больше полезной информации.,для усиления различий между различными точками отбора проб.
2) Особенности обучения:Обнаружение объектов по точкам При извлечении объектов из одной точки,Одну точку можно использовать для описания характеристик этой точки.,Но более эффективный способ — использовать соседние точки точки для получения локальных особенностей. Эта операция извлечения локальных признаков требует определенного баланса между производительностью модели и накладными расходами. Увеличение количества соседних точек может сделать модель более выразительной.,Но это также увеличит нагрузку на память.,А использование слишком большого количества близлежащих точек для получения признаков, соответствующих определенной точке, также приведет к потере детальной информации. Уменьшение количества соседних точек может привести к недостаточному описанию местных особенностей.,Соответствующая семантическая информация теряется.
Текущие исследования по обнаружению целей, основанные на исходных данных облака точек, в основном являются результатом усовершенствований двух вышеупомянутых компонентов модуля выборки и модуля обучения функциям, а также главы классификации обнаружения целей, таких как PointRCNN (Shi et al., 2018), IPOD ( Yang et al., 2018), STD (Yang et al., 2019), 3DSSD (Yang et al., 2020), Point-GNN (Shi et al., 2020), StarNet (Ngiam et al., 2019) и Пойнтформер (Пан и др., 2020). Эти точечные методы обнаружения целей часто дают хорошие результаты на небольших наборах данных и могут показывать относительно высокую точность обнаружения. Однако трудно добиться эффективных результатов обнаружения в реальном времени на крупномасштабных наборах данных автономного вождения.
3.2 Обнаружение целей на основе вокселей
Алгоритм обнаружения целей на основе вокселей преобразует облака точек неправильной формы в представления вокселей компактной формы, а затем извлекает функции облака точек, необходимые для обнаружения целей, через трехмерную сверточную сеть. По сравнению с алгоритмами точечного обнаружения целей использование вокселей для трехмерного обнаружения целей более эффективно. Этот метод вокселизации облаков точек и их последующей обработки привлек широкое внимание исследователей. Типичные работы включают Vote3D (Wang et al., 2015), Vote3Deep (Engelcke et al., 2017) и 3D-FCN (Li et al., 2017). 2017), VoxelNet (Zhou et al., 2018), SECOND (Yan et al., 2018), PointPillars (Lang et al., 2019), CenterPoint (Инь и др., 2021).
VoxelNet является пионером в области обнаружения целей на основе вокселей и комплексной системы трехмерного обнаружения целей. VoxelNet делит трехмерное облако точек на определенное количество вокселей. После случайной выборки и нормализации точек несколько кодировщиков воксельных функций (VOXEL Feature Encoding, VFE) используются для извлечения локальных функций для каждого непустого уровня воксела. Затем объекты передаются через промежуточный трехмерный сверточный слой для завершения дальнейшего извлечения признаков (увеличение восприимчивого поля и изучение представления геометрического пространства) и, наконец, использование сети предложений рамок для классификации объектов и выполнения регрессии положения. По сравнению с VoxelNet, самым большим нововведением SECOND (Ян и др., 2018) является замена 3D-свертки разреженной сверткой, что повышает скорость работы модели Voxel и снижает использование памяти. Он также предлагает новую функцию потери угла ориентации и Новый метод улучшения данных дал хорошие результаты.
И алгоритм SECOND, и VoxelNet разделяют данные облака точек на воксел, чтобы сформировать регулярный, плотно распределенный набор вокселей. PointPillars использует метод моделирования облака точек, который отличается от двух вышеупомянутых идей, и предлагает конвертировать данные облака точек в коды цилиндров Pillar один за другим. Сначала облако точек преобразуется в разреженное псевдоизображение в перспективе сверху с помощью цилиндра, а затем используется 2D-нейронная сеть для обучения признаков и регрессии положения объекта, что значительно повышает производительность сети обнаружения целей на основе вокселей и обеспечивает информация для последующей сопутствующей работы. Важные идеи и технические основы.
В целом представление облаков точек в виде вокселей и их регуляризация способствуют эффективной обработке объектов последующими сетями. В настоящее время большинство усовершенствований алгоритмов обнаружения целей на основе вокселей включают следующие моменты: 1) улучшение восприятия сетью воксельного пространства 2) улучшение процесса выборки облаков точек для лучшего сохранения трехмерной структурной информации объектов; Объединение с другими общими моделями и эффективная структурная миграция. Однако вокселированное представление облака точек также имеет определенные недостатки. В этом методе представления данных по-прежнему трудно избежать ошибок количественной оценки, вызванных игнорированием эффективной информации. Неопределенность процесса выборки облака точек также влияет на стабильность и последовательность результатов модели обнаружения. .
3.3 Обнаружение целей на основе BEV
Для алгоритма обнаружения целей BEV на основе облака точек в части извлечения признаков существует два основных способа преобразования данных облака точек в представление BEV. В соответствии с последовательностью конвейера его можно разделить на методы извлечения признаков до BEV и методы извлечения признаков после BEV, которые соответствуют входным данным магистральной сети из 3D-представления и представления BEV соответственно.
Алгоритм извлечения признаков до BEV сначала обрабатывает исходное облако точек, затем извлекает трехмерные объекты из полученного представления воксельной сетки и, наконец, преобразует его в представление BEV. Например, PV-RCNN (Ши и др., 2020) — это классическая работа по методу извлечения признаков, существовавшему до BEV. PV-RCNN предлагает метод кодирования вокселов в ключевые точки. Во-первых, данные облака точек в пространстве подвергаются вокселизации, а разреженная сверточная сеть используется для выполнения множественного извлечения признаков и понижения разрешения. Затем PV-RCNN использует разреженную карту объектов сверточной сети каждого слоя для извлечения многомасштабных объектов, а затем проецирует полученные объекты на вид с высоты птичьего полета для обнаружения цели на первом этапе и, наконец, использует предыдущие многомасштабные функции для обнаружить цель первой ступени. Результаты обнаружения оптимизированы для получения более точных результатов обнаружения. Подобные методы, основанные на извлечении признаков до BEV, включают SA-SSD (He et al., 2020), Voxel R-CNN (Deng et al., 2021) и т. д.
Метод извлечения объектов после BEV сначала сглаживает исходные данные облака точек в перспективе BEV, затем извлекает 2D-объекты из полученного вида BEV и отправляет их в головку обнаружения цели для позиционирования объекта. Среди них представительной и самой ранней работой, которая преобразует данные облака точек в представление BEV, является MV3D (Chen et al., 2017). После того как MV3D дискретизирует данные облака точек в сетки BEV, он получает объекты, представляющие сетки BEV, на основе характеристик высоты, интенсивности и плотности точек в сетке. Однако, поскольку одна сетка BEV имеет много точек, потери сетевой информации во время этого процесса относительно велики. Многие методы извлечения объектов после BEV следуют аналогичной схеме, используя статистические данные в сетке BEV для представления облаков точек, таких как максимальная высота и среднее значение интенсивности. Упомянутые ранее PointPillars по сути можно классифицировать как метод обнаружения целей, основанный на извлечении признаков после BEV. Другие связанные работы включают PIXOR (Yang et al., 2018), BirdNet (Beltrán et al., 2018) и Rt3d (Zeng et al., 2018). др., 2018), YOLO3D (Али и др., 2018) и др.
3.4 Обнаружение целей на основе изображений с расстояния
Изображение диапазона — это плотное и компактное 2D-представление, как показано на рисунке 6, где каждый пиксель содержит информацию о 3D-глубине. Преимущество изображений на расстоянии состоит в том, что они содержат много информации и не требуют растеризации. Они могут напрямую использовать двумерные сверточные сети для извлечения признаков и быстрых запросов предметной области, а диапазон обнаружения изображений на расстоянии может достигать реального диапазона обнаружения. датчик.

RangeDet (Фан и др., 2021) — одна из классических работ по трехмерному обнаружению целей на основе изображений дальности. RangeDet считает, что существуют три основных фактора, которые ограничивают производительность изображений дальности: большие изменения размера изображений дальности, 2D-свертка в изображениях дальности с потерей 3D-информации и особенности, извлеченные из изображений дальности, которые очень плотны, но их трудно эффективно использовать. Для этого RangeDet использует пирамиду изображений на расстоянии для решения проблемы размера, использует мета-свертку для получения 3D-геометрической информации из представления 2D-изображения на расстоянии, а затем использует алгоритм взвешенного немаксимального подавления для полного улучшения производительности детектора. Окончательная модель, используемая в Waymo (Sun et al., 2020), позволила добиться хорошего улучшения производительности на наборе данных. Другие методы трехмерного обнаружения целей на основе изображений дальности включают LaserNet (Meyer et al., 2019), LaserFlow (Meyer et al., 2021), RangeRCNN (Liang et al., 2020), RangeIoUDet (Liang et al., 2021). , RCD (Bewley et al., 2021), RSN (Sun et al., 2021) и т. д. Конечно, 3D-обнаружение целей на основе изображений с расстояния также имеет свои ограничения. На этот метод обнаружения часто влияют окклюзии и изменения масштаба, что приводит к потере 3D-информации, что затрудняет обработку окклюзии между объектами. Таким образом, извлечение функций из представления дальности и выполнение обнаружения объектов из представления BEV потенциально может стать наиболее практичным решением для обнаружения трехмерных объектов на основе изображений дальности.
04 Обнаружение объектов с интеграцией облаков точек и изображений
Камера может предоставлять цветные изображения высокого разрешения, что помогает модели извлекать богатые семантические функции. Лидар хорош в 3D-позиционировании, предоставляя точную информацию о расстоянии и пространстве для точного определения геометрической структуры объектов. Чтобы улучшить производительность 3D-моделей обнаружения объектов, во многих исследовательских работах информация с камеры и лидара объединяется. Объединяя информацию двух датчиков, мультимодальная модель обнаружения целей может всесторонне использовать соответствующие преимущества каждого режима для повышения точности и надежности обнаружения целей (Лю и др., 2024).
4.1 Классификация по стадии плавления
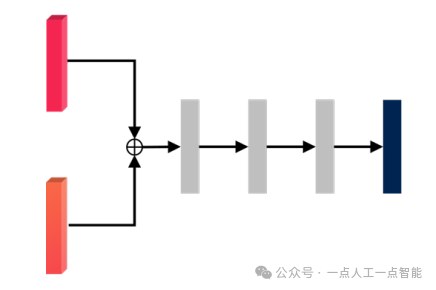
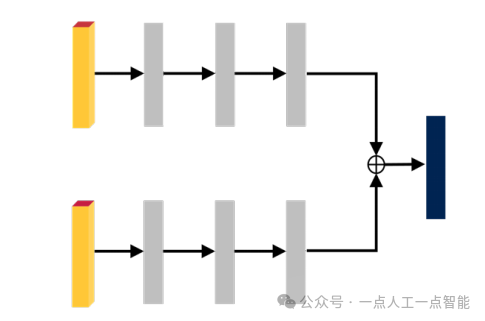
4.1.1 Ранняя интеграция
Раннее слияние также называется слиянием на уровне данных. Оно требует, чтобы данные облака точек и изображения использовали экстракторы объектов в соответствующих ветвях, а затем выполняли определенные взаимодействия на слое объектов для интеграции знаний об изображении в облако точек. Его структура показана на рисунке. показана цифра 7. Интегрированное облако точек можно рассматривать как облако точек с улучшенным изображением. Модель передает расширенные данные облака точек в трехмерный детектор целей на основе LiDAR, что позволяет модели получать более богатую семантическую информацию.
Ранние методы объединения обычно приводят к большим задержкам вывода, а этап объединения требует сложных двумерных сетей обнаружения целей или семантической сегментации, что приводит к большим временным затратам в модели.
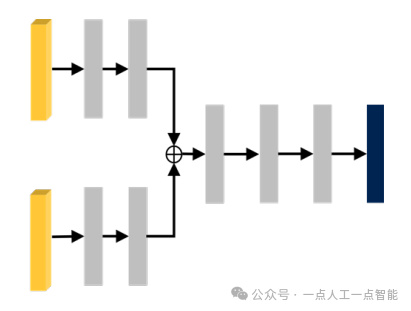
4.1.2 Глубокая интеграция
Глубокое слияние относится к объединению функций изображения и лидара на промежуточных этапах детектора 3D-объектов на основе LiDAR (таких как этап магистральной сети, этап генерации предварительно выбранного блока и этап уточнения RoI). Его сетевая структура показана на рисунке. 8.
По сравнению с ранним слиянием, методы глубокого слияния могут выполнять более глубокое слияние мультимодальных представлений, создавать более качественные трехмерные кадры обнаружения и глубокие элементы, а также уменьшать объем вычислений, необходимых для раннего слияния. Однако данные изображения и характеристики данных LiDAR неоднородны по своей природе. В процессе глубокого слияния необходимо учитывать сохранение семантической информации, содержащейся в данных изображения, и пространственной геометрической информации, соответствующей данным LiDAR, в едином пространстве признаков, чтобы не повредить объект. выполнение модельной задачи обнаружения целей.
4.1.3 Постслияние
Позднее объединение, также называемое объединением решений, относится к синтезу выходных данных решений от различных датчиков или модальностей для получения окончательного результата обнаружения цели. По сравнению с ранним и глубоким слиянием, позднее слияние позволяет лучше использовать рекомендации существующей сети для каждого модальности и легко получать обратную связь от каждого модальности. Однако недостатком слияния для принятия решений является то, что оно не может использовать богатые функции глубокого слияния в процессе слияния, а когда результаты прогнозирования ветвей в разных режимах слишком различаются, трудно дать точные результаты.
При выборе позднего слияния необходимо учитывать корреляцию, неопределенность и требования задач между модальностями. Разумная стратегия позднего слияния может значительно улучшить производительность обнаружения целей в мультимодальных средах и устранить шум и несогласованность между различными модальностями, делая систему более эффективной. прочный и надежный.
4.2 Классификация по степени детализации данных
С разделением различных методов и этапов слияния все больше и больше алгоритмов невозможно классифицировать просто по стадии слияния (Huang et al., 2023). Например, MMF (Liang et al., 2019) имеет не только глубокое слияние, но и глубокую слияние. но и позднее принятие решений. Аналогично, PointPainting (Vora et al., 2020) не принадлежит ни к одной из вышеупомянутых стратегий слияния, но использует метод последовательного слияния. Различные мультимодальные алгоритмы обнаружения целей невозможно различить, просто разделив их по времени, особенно на ранних стадиях синтеза и глубокого синтеза.
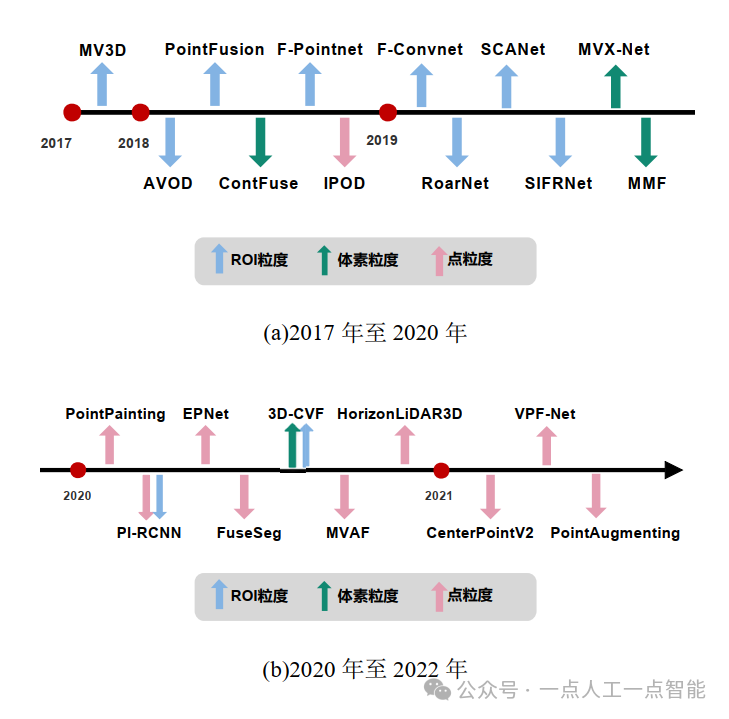
Стадии раннего слияния и глубокого слияния можно вместе назвать слиянием на уровне объектов. Слияние на уровне объектов часто фокусируется на взаимодействии между слоями объектов, представлении данных разных слоев объектов и объединении функций разных модальностей для достижения многомасштабного уровня. и многоуровневое слияние. Слияние на уровне функций можно разделить на объединение функций на основе детализации рентабельности инвестиций (MV3D (Chen et al., 2017), PointFusion (Xu et al., 2018), AVOD (Ku et al., 2018), F-Pointnet (Qi и др., 2018) в соответствии с различной степенью детализации векторного слоя, 2018), F-Convnet (Ванг и др., 2019). ), SCANet (Lu et al., 2019), RoarNet (Shin et al., 2019), SIFRNet (Zhao et al., 2019)), объединение функций на основе детализации вокселей (ContFuse (Liang et al., 2018), MVX-Net (Синдаги и др., 2019), MMF (Лян и др., 2019), 3D-CVF (Yoo et al., 2020)), точечное объединение объектов (IPOD (Yang et al., 2018), PointPainting (Vora et al., 2020), HorizonLiDAR3D (Ding et al., 2020) ), MVAF (Ванг и др., 2021 г.), VPF-Net (Ван и др., 2021 г.), PI-RCNN (Се и др., 2020 г.), FuseSeg (Криспель и др., 2020 г.), CenterPointV2 (Инь и др., 2021 г.), EPNet (Хуан и др., 2020 г.) , PointAugmenting (Ванг и др., 2021)). Вышеупомянутые алгоритмы обнаружения целей с различной степенью детализации расположены во временном порядке, как показано на рисунке 10. Детализация признаков ранних алгоритмов слияния признаков в целом была грубой. По мере развития технологии мультимодального обнаружения целей все больше и больше исследователей обращают свое внимание на мелкозернистые, многокатегорийные и высокопроизводительные алгоритмы мультимодального слияния.
4.3 Некоторые алгоритмы для общих наборов данных обнаружения трехмерных целей
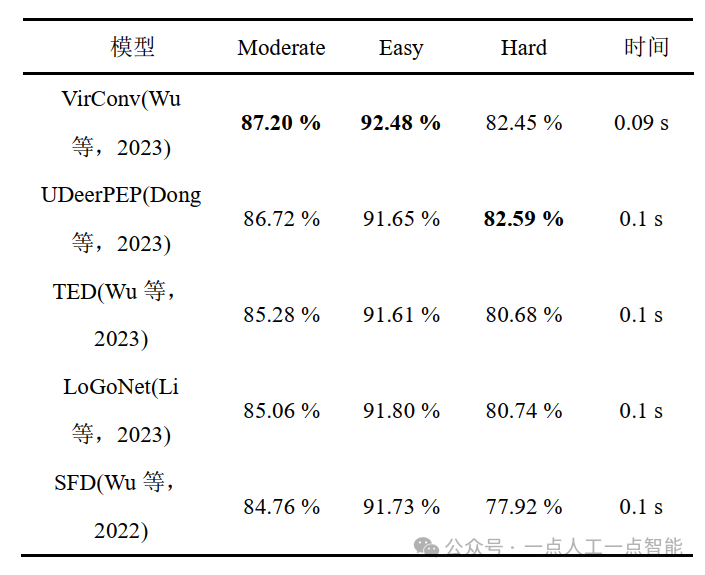
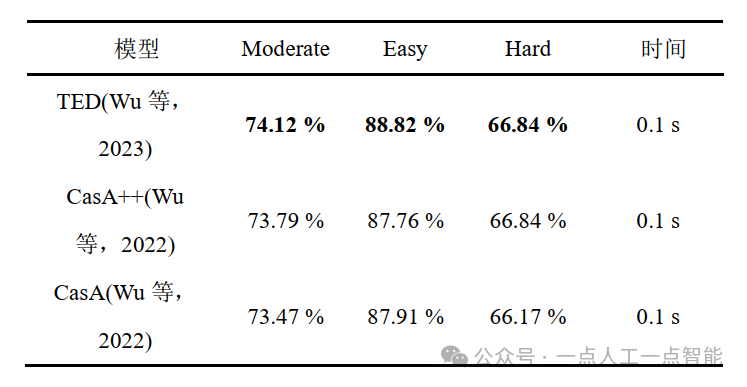
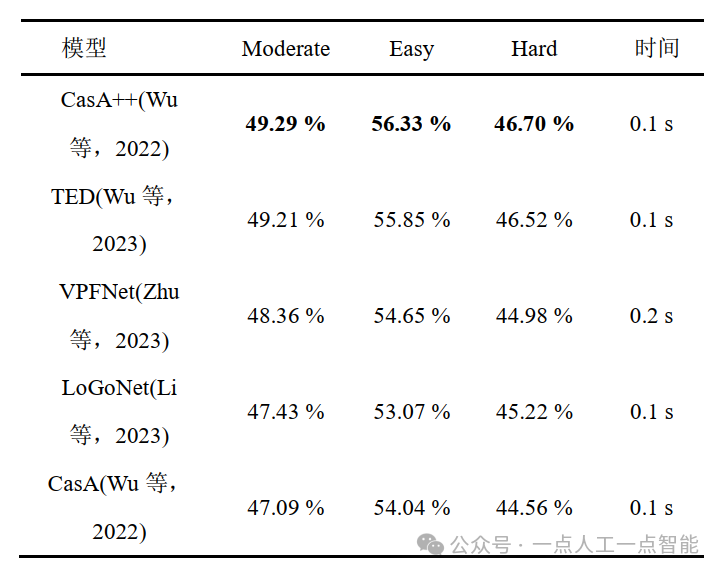
Для задачи обнаружения трехмерных целей набор данных KITTI подразделяет метки на такие цели, как автомобили, пешеходы, велосипеды и т. д., и определяет правильность результатов позиционирования трехмерной цели путем сравнения степени перекрытия прогнозируемой границы и реальной границы. и размер порога. Оценка достоверности и Сравнение порогов определяет правильность результатов распознавания цели, а средняя точность, наконец, используется для оценки результатов модели обнаружения целей одного класса.
Для автомобильных целей KITTI требует перекрытия 3D-ограничивающих рамок на 70 %, тогда как для пешеходов и велосипедистов корректным является перекрытие на 50 %. При этом набор данных KITTI разделяет цели аннотаций на три уровня сложности: Easy (Легкий), Moderate (Умеренный) и Hard (Сложный) на основе показателей высоты ограничительной рамки, окклюзии и степени усечения. Ниже приведены некоторые из ведущих алгоритмов трехмерного обнаружения целей, которые в настоящее время используются в наборе данных KITTI. Содержимое таблицы показывает среднюю точность и время, соответствующие модели.
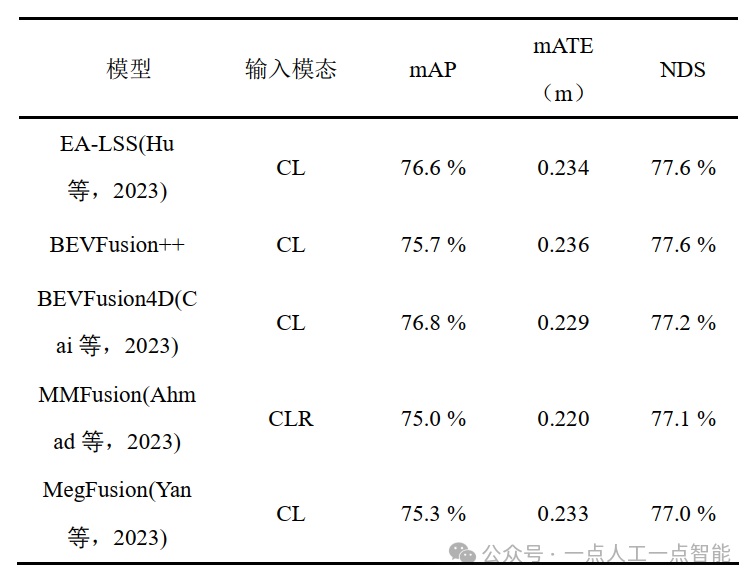
Показатели оценки набора данных nuScenes богаче, чем показатели набора данных KITTI, включая среднюю среднюю точность (mAP), среднюю ошибку перевода (mATE), среднюю угловую ошибку (mAOE), среднюю атрибутивную ошибку (mAAE) и среднее взвешивание. различных показателей (НСР) и так далее.
Ниже приведены некоторые из ведущих алгоритмов трехмерного обнаружения целей, которые в настоящее время используются в наборе данных nuScenes. Содержимое таблицы представляет собой входные модальности mAP, mATE и mAAE, соответствующие модели. В режимах ввода используются буквы C, L и R для обозначения изображения, лидара и радара миллиметрового диапазона соответственно.
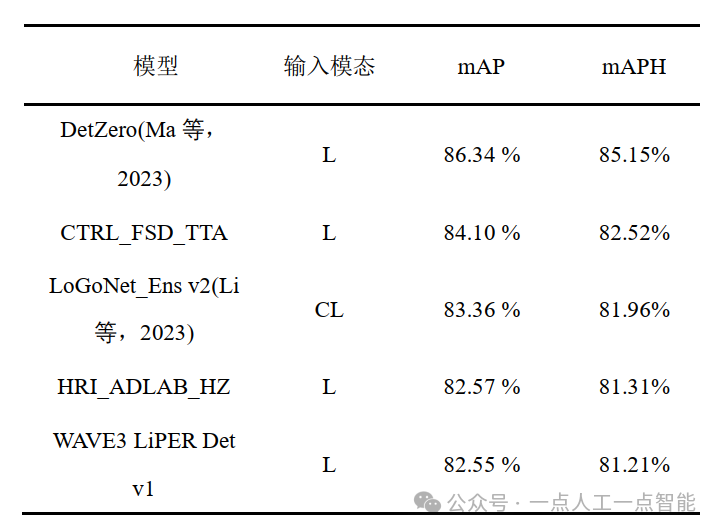
В наборе данных Waymo также используется общий показатель средней точности (AP), но набор данных Waymo рассчитывает AP как площадь под кривой P-R, а не метод интерполяции, используемый KITTI. Кроме того, Waymo также представила индикатор средней точности курса (APH) для расчета соответствующих ошибок информации о курсе. Что касается сложности обнаружения 3D-объектов, Waymo определяет два разных уровня: УРОВЕНЬ 1 и УРОВЕНЬ 2. Цели, назначенные на УРОВНЕ 2, считаются наиболее трудными для обнаружения и имеют меньше соответствующих точек LiDAR, что делает их более сложными для алгоритмов обнаружения целей на основе LiDAR и объединенных изображений и LiDAR.
Ниже приведены некоторые из ведущих алгоритмов трехмерного обнаружения целей, которые в настоящее время используются в наборе данных Waymo. Содержимое таблицы представляет собой входные модальности mAP, mATE и mAAE, соответствующие модели. В режимах ввода используются буквы C и L для обозначения изображения и лидара соответственно.
В целом, методы с самым высоким рейтингом в наборе данных KITTI — это в основном методы обнаружения целей, основанные на чистых облаках точек. Напротив, в последних наборах данных, таких как наборы данных nuScenes и Waymo, методы, занимающие первое место, в основном являются методами мультимодального слияния.
05 Резюме и перспективы на будущее
В этой статье объясняется обнаружение целей окружающей среды на основе глубокого обучения на основе связанных технологий на основе изображений и облаков точек при обнаружении целей окружающей среды. Во-первых, представлены обычно используемые наборы данных и форматы данных для обнаружения трехмерных целей. Во-вторых, алгоритмы обнаружения трехмерных целей разделены в соответствии с различными формами ввода данных и формами представления данных в модели.
Хотя обнаружение целей в окружающей среде имеет большой потенциал в области автономного вождения и технологий цифрового моделирования, все еще существуют некоторые проблемы и задачи.
1) Сложность получения данных:и2Dданные изображения集по сравнению с,Получить и аннотировать 3D-данные сложнее.,Требуется использование специальных датчиков и оборудования, таких как лидар или камеры глубины.,Для аннотирования сложной информации необходимы более профессиональные аннотаторы.,Такие как трехмерная ограничивающая рамка, поза и траектория движения объекта и т. д.,это довольно трудоемкая задача. А для мультимодальных алгоритмов обнаружения целей,Доступно относительно мало типов усилителей данных.,Это также ограничивает улучшение производительности и обобщения модели.,Как осуществить эффективное увеличение данных в мультимодальных наборах данных по-прежнему остается проблемой, которую необходимо изучить.
2) Отказ датчика и мониторинг состояния датчика:Системы восприятия, особенно системы автономного вождения,Требуется четкое восприятие объектов в окружающей среде.,Также необходимо точно выявить неисправности самого датчика и принять меры. Например, проектировщики могут использовать несколько одинаковых датчиков для повышения избыточности информации.,Определите стабильность сенсорной системы, сравнивая работу каждого датчика. Специально для мультимодальных систем восприятия,В случае выхода из строя определенного модального датчика и система не может работать должным образом,Необходимо дать возможность системам восприятия использовать одномодальные данные для обнаружения целей окружающей среды.,Обеспечьте стабильную работу даже в случае выхода из строя некоторых датчиков.
3) Восприятие при неблагоприятных погодных условиях:Восприятие в чрезвычайно суровых погодных условиях также является важной проблемой для обнаружения целей в окружающей среде.。Например, для систем восприятия автономного вождения.,в снежную и туманную погоду,Будь то система на основе изображений или система на основе LiDAR, возникнут трудности с восприятием. Для систем на основе изображений,в снежную и туманную погоду,Целевой объект на изображении может быть закрыт или размыт из-за снежинок, тумана, капель дождя и т. д.,Это приводит к снижению точности обнаружения цели. также,из-за отражения и преломления света,Контрастность и резкость изображения также могут быть нарушены.,Размытие границ и деталей цели。На основе В системах LiDAR лазерный луч может рассеиваться и поглощаться рассеивающими средами, такими как снежинки, туман или капли дождя. Это приведет к ослаблению или искажению отраженного сигнала, принимаемого лидаром, что затруднит определение положения и формы цели. Форму трудно точно восстановить. Алгоритмы обнаружения объектов на основе изображений и LiDAR все еще требуют дальнейших исследований и технологических инноваций для повышения устойчивости и надежности системы восприятия в суровых погодных условиях.
Будущее направление развития исследований по обнаружению целей в окружающей среде может включать следующие аспекты:
1) Введение модели временных рядов.В реальной жизни водители-люди полагаются на непрерывное зрительное восприятие для получения информации об окружающей среде.,Однако большинство современных работ решают проблему восприятия окружающей среды на основе одного кадра. По ходу процесса обнаружения цели,Система восприятия может непрерывно генерировать последовательности изображений и последовательности облаков точек.,Эти данные последовательности содержат неявную структуру объекта и информацию о траектории движения. На основании приведенных выше данных последовательности,Это добавляет временные метки и ограничения положения объекта.,Это повысит надежность процесса обнаружения экологических целей и понимание окружающей среды.,Для достижения более разумной модели восприятия.
2) Метод обнаружения цели, основанный на двухмерной оценке глубины и многоракурсных двумерных изображениях.на основе2Dкартина Нравиться环境目标检测在性能上ина основеLiDAR的方法по сравнению с,Все же совсем другое. Повысьте точность оценки глубины по 2D-изображениям.,Или использование многопроекционных 2D-изображений может быть эффективным средством использования 2D-изображений для трехмерного обнаружения целей. Эти два метода обнаружения объектов окружающей среды с использованием чистых изображений,Его можно не только напрямую использовать в качестве основы для трехмерного обнаружения целей,,也可以为на основекартинакартина和LiDARСлияние мультимодальностей3DАлгоритм обнаружения целей закладывает основу。
3) Баланс между точностью и скоростью алгоритма мультимодального восприятия.В области автономного вождения и роботизированной навигации,Процесс обнаружения экологических целей должен выполняться в сценариях с высокими требованиями к реальному времени. Это связано с тем, что системы автономного вождения должны быстро реагировать и адаптироваться к изменяющимся дорожным условиям и дорожным ситуациям.,Для обеспечения безопасности и устойчивости автомобиля. В процессе проектирования алгоритмов мультимодального восприятия,Часто добавление новых модальностей и новых расширенных функций приводит к снижению скорости алгоритма.,В то же время это влечет за собой чрезмерные накладные расходы. Как эффективно экранировать и упростить мультимодальные модели обнаружения целей,Обеспечить одновременное выполнение точных, оперативных и эффективных требований.,Это будущая тенденция развития исследований алгоритмов мультимодального восприятия.
4) Обнаружение целей окружающей среды на основе больших моделей.即利用大型深度学习模型为облако точек和картинакартина融合提供更强大的表征学习能力。大模型的引入有望缓解облако точек和картинакартина融合过程中的данные稀疏性问题,Позволяет модели лучше захватывать богатую семантическую информацию между изображениями и облаками точек.,Получите более полное представление об объектах в вашем окружении.,Повышенная адаптируемость к местной окклюзии и сложному фону. также,Интеграция больших моделей и алгоритмов обнаружения целей в окружающей среде,Это будет способствовать дальнейшему развитию процесса интеграции восприятия и принятия решений в системах автономного вождения.,Улучшение интерпретируемости, безопасности и многомодульной итерации моделей восприятия.,Обеспечьте ключевую поддержку для будущего развития полнофункционального автономного вождения, интеллектуального транспорта и других областей исследований.



Углубленный анализ переполнения памяти CUDA: OutOfMemoryError: CUDA не хватает памяти. Попыталась выделить 3,21 Ги Б (GPU 0; всего 8,00 Ги Б).

[Решено] ошибка установки conda. Среда решения: не удалось выполнить первоначальное зависание. Повторная попытка с помощью файла (графическое руководство).

Прочитайте нейросетевую модель Трансформера в одной статье

.ART Теплые зимние предложения уже открыты

Сравнительная таблица описания кодов ошибок Amap

Уведомление о последних правилах Points Mall в декабре 2022 года.

Даже новички могут быстро приступить к работе с легким сервером приложений.

Взгляд на RSAC 2024|Защита конфиденциальности в эпоху больших моделей

Вы используете ИИ каждый день и до сих пор не знаете, как ИИ дает обратную связь? Одна статья для понимания реализации в коде Python общих функций потерь генеративных моделей + анализ принципов расчета.

Используйте (внутренний) почтовый ящик для образовательных учреждений, чтобы использовать Microsoft Family Bucket (1T дискового пространства на одном диске и версию Office 365 для образовательных учреждений)

Руководство по началу работы с оперативным проектом (7) Практическое сочетание оперативного письма — оперативного письма на основе интеллектуальной системы вопросов и ответов службы поддержки клиентов

[docker] Версия сервера «Чтение 3» — создайте свою собственную программу чтения веб-текста

Обзор Cloud-init и этапы создания в рамках PVE

Корпоративные пользователи используют пакет регистрационных ресурсов для регистрации ICP для веб-сайта и активации оплаты WeChat H5 (с кодом платежного узла версии API V3)

Подробное объяснение таких показателей производительности с высоким уровнем параллелизма, как QPS, TPS, RT и пропускная способность.

Удачи в конкурсе Python Essay Challenge, станьте первым, кто испытает новую функцию сообщества [Запускать блоки кода онлайн] и выиграйте множество изысканных подарков!

[Техническая посадка травы] Кровавая рвота и отделка позволяют вам необычным образом ощипывать гусиные перья! Не распространяйте информацию! ! !

[Официальное ограниченное по времени мероприятие] Сейчас ноябрь, напишите и получите приз

Прочтите это в одной статье: Учебник для няни по созданию сервера Huanshou Parlu на базе CVM-сервера.

Cloud Native | Что такое CRD (настраиваемые определения ресурсов) в K8s?

Как использовать Cloudflare CDN для настройки узла (CF самостоятельно выбирает IP) Гонконг, Китай/Азия узел/сводка и рекомендации внутреннего высокоскоростного IP-сегмента

Дополнительные правила вознаграждения амбассадоров акции в марте 2023 г.

Можно ли открыть частный сервер Phantom Beast Palu одним щелчком мыши? Супер простой урок для начинающих! (Прилагается метод обновления сервера)

[Играйте с Phantom Beast Palu] Обновите игровой сервер Phantom Beast Pallu одним щелчком мыши

Maotouhu делится: последний доступный внутри страны адрес склада исходного образа Docker 2024 года (обновлено 1 декабря)

Кодирование Base64 в MultipartFile

5 точек расширения SpringBoot, супер практично!

Глубокое понимание сопоставления индексов Elasticsearch.

15 рекомендуемых платформ разработки с нулевым кодом корпоративного уровня. Всегда найдется та, которая вам понравится.
