Прогноз пассажиропотока на станции метро Python: регрессор повышения случайного лесного экстремального градиента XGBoost |
Эта статья предоставит читателям полный набор практических процессов анализа данных, показав прогноз пассажиропотока на станциях метро и объединив его с данными кода экземпляра XGB регрессора случайного леса Python, повышающего экстремальный градиент. Однако прогнозирование пассажиропотоков в метрополитене всегда было сложной задачей из-за сложности системы метрополитена и неопределенности поведения пассажиров. Проблемы:
- Проходимость метро огромная.,Приобретение происходит медленно.
- Во время исходного процесса извлечения данных,Есть много пропущенных значений и выбросов,Повлияет на точность и достоверность прогнозов данных.
решение
Мы использовали данные иерархического считывания и метод дихотомии для проверки данных.,Существует множество способов борьбы с пропущенными значениями и выбросами.,Здесь мы используем метод удаления для обработки и анализа.。
Миссия/цель
В основном с помощью данных города Чжэнчжоу, предоставленных клиентом, мы каждый месяц извлекаем входящий и исходящий ежедневный пассажиропоток каждого объекта, выборочно извлекаем данные о местоположении, дате и типе транзакции из исходных данных, а затем в соответствии с типом транзакции подсчитываем суточный въездной и выездной пассажиропоток каждого объекта и обобщить данные. Выполните визуальный анализ извлеченных данных с целью проанализировать, могут ли выходные и праздничные дни быть факторами, влияющими на ежедневный пассажиропоток. Затем данные суммируются и используется регрессионная модель нейронной сети для прогнозирования данных о пассажиропотоке с 1 по 7 декабря.
Подготовка источника данных
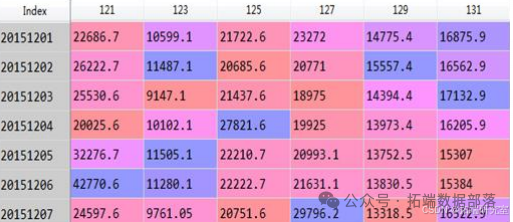
Приготовьтесь начать с8Месяц настал11Ежемесячный трафик метроданные(четыреcsvдокумент)Образец выглядит следующим образом:
Преобразование функции: дата. Что касается самого атрибута времени, то он не имеет никакого значения для модели. Дату необходимо преобразовать в псевдопеременные года, месяца, дня и недели. Предварительный просмотр результатов обработки данных: Используя метод иерархического чтения и метод дихотомии для получения данных и после обработки выбросов, данные целевой таблицы получаются следующим образом: (перечислены только некоторые функции). Обработайте данные о пассажиропотоке метро за четыре месяца отдельно, чтобы получить следующие данные:
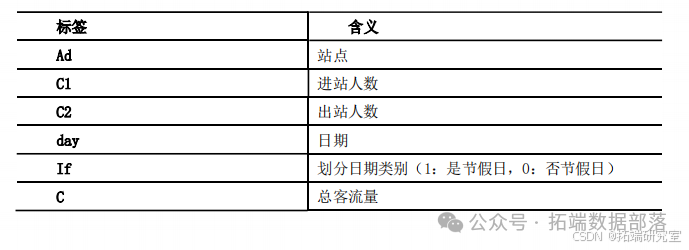
Модель прогнозирования нейронной сети
Характеристическая входная переменная обучающей выборки представлена буквой x, а выходная переменная представлена буквой y. Тестовая выборка содержит в общей сложности 5 признаковых данных и в общей сложности 2440 обучающих выборок.

(1) Пример кода для построения обучающей выборки выглядит следующим образом:
import pandas as pd
data=pd.read_excel('Общий прогноз данных.xlsx')
x=data.iloc[:,:5] #Извлекаем первые четыре столбца данных
y=data.iloc[:,5] # поток людейданныеimport numpy as py
x11=np.array([121,14967,12260,20151201,0])
…
x207=np.array([159,14132,14167,20151207,0])
x11=x11.reshape(1,5)
…
X207=x207.reshape(1,5)Среди них входные переменные признаков прогнозируемой выборки Представлено x11, x12…x207. (3) Пример кода для построения модели регрессии нейронной сети выглядит следующим образом:
#Импортируйте модуль регрессии нейронной сети MLPRegressor.
from sklearn.neural_network import MLPRegressor
#Используйте MLPRegressor для создания объекта регрессии нейронной сети clf
Clf=MLPRegressor(solver=’lbfgs’,alpha=1e-5,hidden_layer_sizes=8,random_state=1)
#Описание параметра:
#solver:Алгоритм решения оптимизации нейронной сети
#alpha: ошибка обучения модели, по умолчанию — 0,00001.
#hidden_layer_sizes: количество нейронов скрытого слоя.
#random_state: по умолчанию установлено значение 1. #Используйте метод fit() в объекте clf для обучения сети
clf.fit(x,y) #Вызовите метод Оценка() в объекте clf, чтобы получить степень соответствия (коэффициент решения) регрессии нейронной сети
rv=clf.score(x,y) #Вызов предсказывания() в объекте clf, чтобы спрогнозировать тестовую выборку и получить результаты ее тестирования.
R11=clf.predict(x11)
R207=clf. predict (x207)1. Напишите метод прогнозирования: Сначала получите несколько таблиц результатов прогнозирования:
Полученный метод осуществим и позволяет прогнозировать поток трафика всех сайтов.
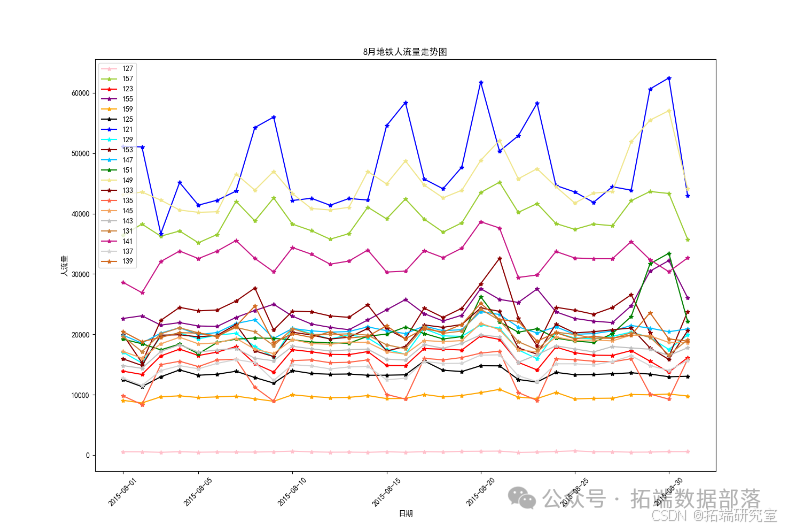
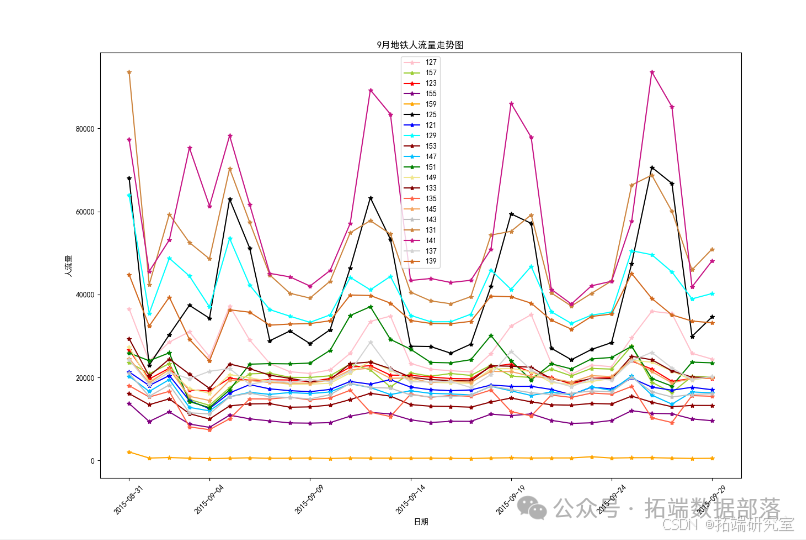
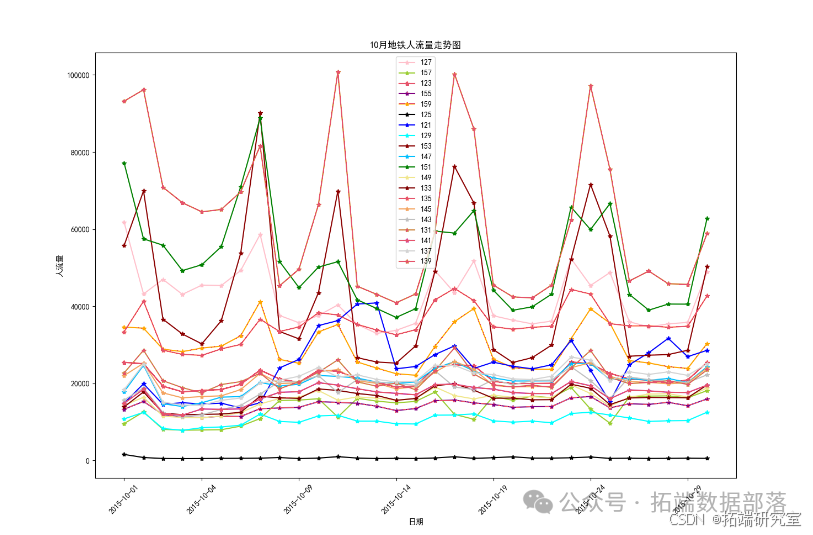
Результаты визуализации данных:
Результаты прогноза суточного пассажиропотока на станциях метрополитена с 1 по 7 декабря:
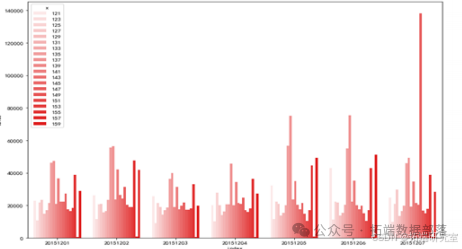
Из графика, составленного на основе прогнозных данных с 1 по 7 декабря, можно сделать вывод, что пассажиропоток станций 135 и 137 в целом высокий. Сотрудникам метрополитена следует привлечь больше дежурного персонала для патрулирования и обслуживания станций на станциях с большим потоком. Обеспечьте порядок на территории во избежание скопления людей и несчастных случаев. В частности, на снимке необычный пиковый пассажиропоток на станции 147 7 декабря. Учитывая увеличение пассажиропотока, вызванное неожиданными факторами и другими обстоятельствами, мы можем заранее предупредить в этот день и принять соответствующие меры безопасности. меры по обеспечению порядка на станции метро в этот день. Результаты прогнозирования используются только в качестве эталонного значения веса, а для расчета по определенному весу необходимы экспертные заключения.
Нажмите на заголовок, чтобы просмотреть предыдущие выпуски

01
02
03
04

Регрессор, повышающий случайный лес и экстремальный градиент, для прогнозирования транспортных потоков метро XGB
В этом исследовании мы стремимся оптимизировать модель прогнозирования транспортных потоков с помощью технологии автоматизированного машинного обучения (AutoML). С этой целью мы использовали TPOT (инструмент оптимизации конвейеров на основе деревьев), эффективный инструмент AutoML, который может автоматически проектировать и оптимизировать конвейеры машинного обучения.
первый,Я загружу и просмотрю предоставленный файл CSV, чтобы понять его структуру и содержимое. Затем,Я буду использовать линейный график, чтобы показать24Почасовые тенденции движения транспорта в метро(Прочтите конец статьи, чтобы узнать, как получить данные бесплатно.)。давайте начнем。
pythonкопироватьimport pandas as pd
# Загрузить CSV-файл
df = pd.read_csv(file_path)
# Покажите первые несколько строк данных, чтобы понять их структуру.
df.head()набор данных содержит несколько полей,вdate_timeиtraffic_volumeэто мысосредоточиться наосновные области。date_time字段表示日期и时间,иtraffic_volumeПоле представляет поток трафика。
Далее я буду использовать линейный график, чтобы показать тенденции транспортных потоков в течение 24 часов.
pythonкопироватьimport matplotlib.pyplot as plt
# Преобразование столбца date_time в тип datetime
df['date_time'] = pd.to_datetime(df['date_time'])
# Сортировка данных для обеспечения хронологического порядка.
df = df.sort_values('date_time')
# Нарисуйте линейную диаграмму
plt.figure(figsize=(15, 6))
plt.plot(df['date_time'], df['traffic_volume'], marker='o', linestyle='-')
plt.title('Тенденция трафика за 24 часа')
plt.xlabel('время')
plt.ylabel('поток трафика')
plt.grid(True)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()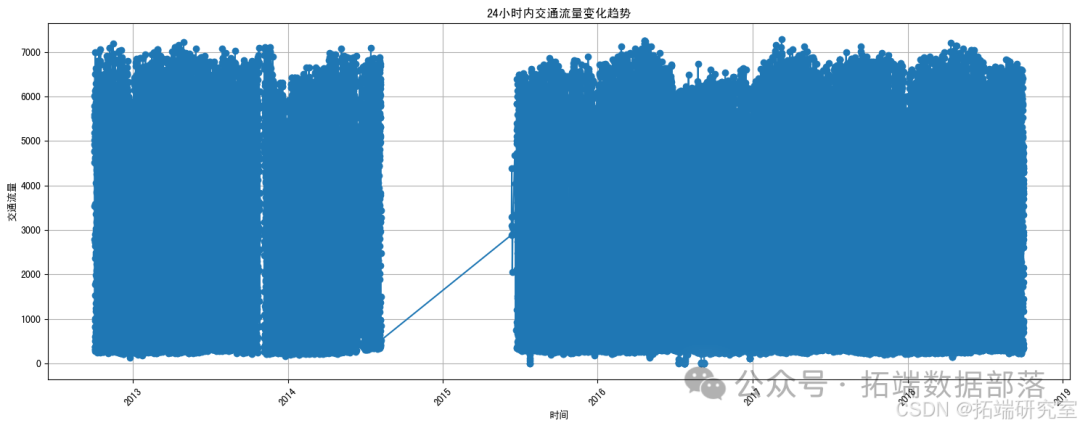
Это линейный график, показывающий тенденции транспортных потоков за 24 часа. Из рисунка видно, что транспортный поток колеблется в разные периоды времени. Чтобы более точно отобразить динамику транспортных потоков за 24 часа, мне нужно отфильтровать данные за конкретную дату. Затем я снова нарисую линейный график.
pythonкопировать# Отфильтровать данные по определенной дате (например, по самой ранней дате)
specific_date = df['date_time'].dt.date.iloc[0]
df_specific_date = df[df['date_time'].dt.date == specific_date]
# Сортировка данных для обеспечения хронологического порядка.
df_specific_date = df_specific_date.sort_values('date_time')
# Нарисуйте линейную диаграмму
plt.figure(figsize=(15, 6))
plt.plot(df_specific_date['date_time'], df_specific_date['traffic_volume'], marker='o', linestyle='-')
plt.title(f'{specific_date} Тенденции транспортных потоков')
plt.xlabel('время')
plt.ylabel('поток трафика')
plt.grid(True)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()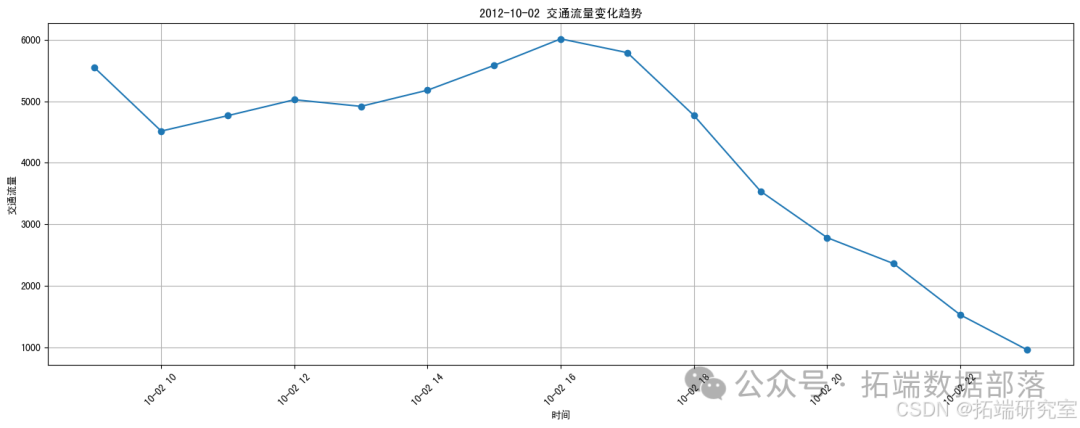
Это линейный график, показывающий 24-часовую тенденцию трафика в течение определенной даты (самой ранней даты). Из рисунка видно, что транспортный поток колеблется в разные периоды времени. Я бы выполнил следующие шаги:
- Используйте матрицу диаграммы рассеяния для изучения
traffic_volumeиweather_main、temp、rain_1h、snow_1hиclouds_allждатьпеременнаяотношения между。 - Используйте гистограммы или коробчатые диаграммы для сравнения
holidayдля“None”и特定假日(нравитьсяColumbus Day, Veterans Day, Thanksgiving Day)изtraffic_volumeразница。
Сначала я проведу первый этап анализа.
pythonкопироватьimport seaborn as sns
# Выберите соответствующие столбцы
columns_to_explore = ['traffic_volume', 'weather_main', 'temp', 'rain_1h', 'snow_1h', 'clouds_all']
# Поскольку Weather_main является категориальной переменной, нам необходимо преобразовать ее в числовую кодировку.
df['weather_main_code'] = df['weather_main'].astype('category').cat.codes
# Создайте матрицу диаграммы рассеяния
sns.pairplot(df[columns_to_explore], diag_kind='kde', markers=["o", "s", "D", "v", "<", ">"])
plt.suptitle('Взаимосвязь между транспортным потоком и погодными условиями', y=1.02)
plt.show()Это матрица рассеяния,для изученияtraffic_volumeиweather_main、temp、rain_1h、snow_1hиclouds_allждатьпеременнаяотношения между。
Следующий,Я проведу второй этап анализа,то есть сравнитьholidayдля“None”и特定假日(нравитьсяColumbus Day, Veterans Day, Thanksgiving Day)изtraffic_volumeразница。
pythonкопировать# Фильтровать по конкретным праздникам
specific_holidays = ['Columbus Day', 'Veterans Day', 'Thanksgiving Day']
df_holidays = df[df['holiday'].isin(specific_holidays) | (df['holiday'] == 'None')]
# Создайте коробчатую диаграмму
plt.figure(figsize=(12, 6))
sns.boxplot(x='holiday', y='traffic_volume', data=df_holidays, palette=["rgb(202,206,210, max =255)", "rgb(230,232,234, max =255)"])
plt.title('Сравнение объема трафика в праздничные и непраздничные дни')
plt.xlabel('тип праздника')
plt.ylabel('поток трафика')
plt.show()
pythonкопировать# Исправьте цветовой формат и заново Создайте коробчатую диаграмму
plt.figure(figsize=(12, 6))
sns.boxplot(x='holiday', y='traffic_volume', data=df_holidays, palette=["#C0C4C8", "#E6E8EA"])
plt.title('Сравнение объема трафика в праздничные и непраздничные дни')
plt.xlabel('тип праздника')
plt.ylabel('поток трафика')
plt.show()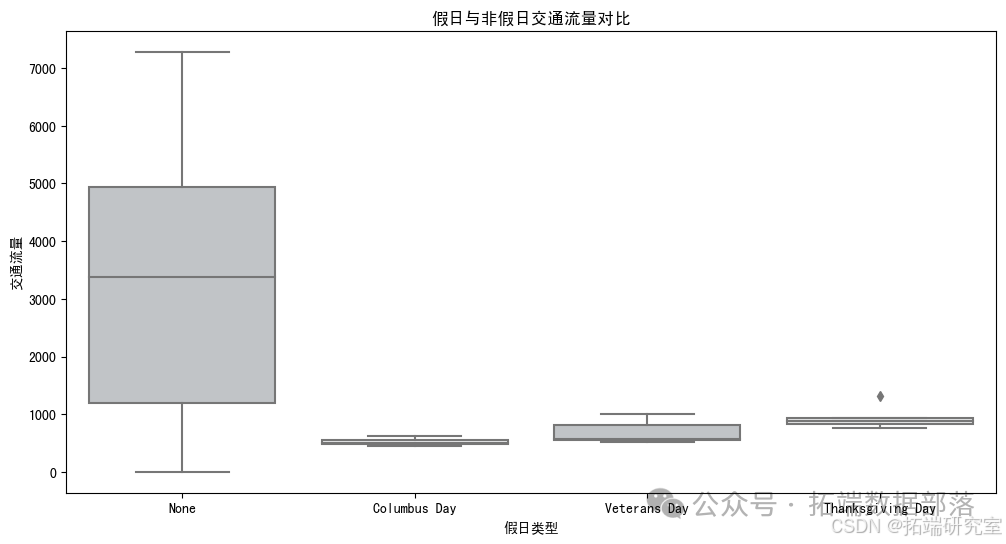
Это коробочный сюжет,для сравненияholidayдля“None”и特定假日(нравитьсяColumbus Day, Veterans Day, Thanksgiving Day)изtraffic_volumeразница。
Из рисунка видно, что транспортный поток различен для разных типов праздничных и непраздничных дней.
Ниже приводится подробное описание нашей экспериментальной процедуры:
первый,Мы разделили набор функций «X» и целевую переменную «y» на обучающий набор и тестовый набор.,Тестовый набор составляет 25%,и обеспечивает случайность данных,чтобы избежать любой потенциальной предвзятости. Конкретная реализация выглядит следующим образом: y,
test_size=0.25,
shuffle=True,
random_state=42) verbosity=2,
n_jobs=-1)
`затем,Мы инициализировали и обучилиTPOTRegressorМодель,Установите максимальное время работы на 60 минут.,Обеспечить, чтобы у Модели было достаточно времени для изучения возможного решения. также,мы будемverbosity设置для2,чтобы получить подробные результаты во время обучения,и будетn_jobs设置для-1,использовать все доступные ядра процессора.
y_predictions = tpot.predict(X_test)
r2 = sklearn.metrics.r2_score(y_test, y_predictions)
mae = sklearn.metrics.mean_absolute_error(y_test, y_predictions)
mse = sklearn.metrics.mean_squared_error(y_test, y_predictions)
rmse = np.sqrt(mse)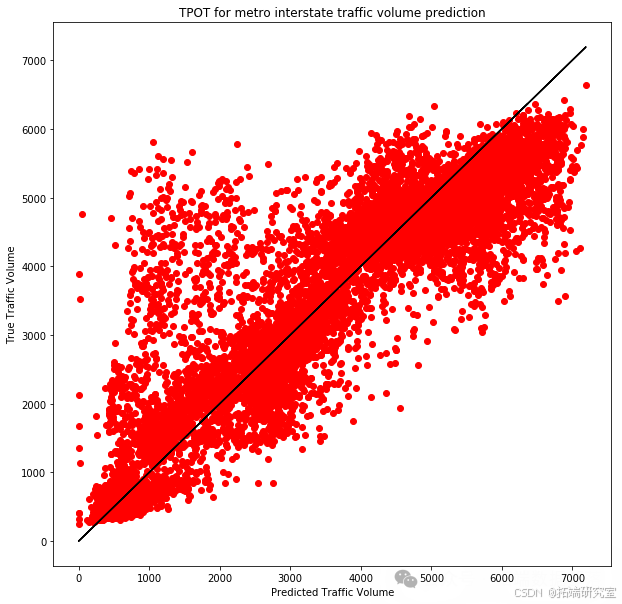
Кроме того, мы также опробовали несколько других моделей машинного обучения, в том числе регрессор случайного леса и регрессор повышения экстремального градиента (XGBRegressor), и настроили их параметры для оптимизации производительности. Вот пример случайного регрессора леса:
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['traffic_volume'].values, random_state=None)
exported_pipeline = make_pipeline(
StandardScaler(),
RandomForestRegressor(bootstrap=False, max_features=0.45, min_samples_leaf=2, min_samples_split=2, n_estimators=100)
)
exported_pipeline = RandomForestRegressor(bootstrap=True, max_features=0.9000000000000001, min_samples_leaf=9, min_samples_split=19, n_estimators=100)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)features = tpot_data.drop('traffic_volume', axis=1).values
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['traffic_volume'].values, random_state=None)
exported_pipeline = ExtraTreesRegressor(bootstrap=False, max_features=0.8, min_samples_leaf=8, min_samples_split=18, n_estimators=100)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)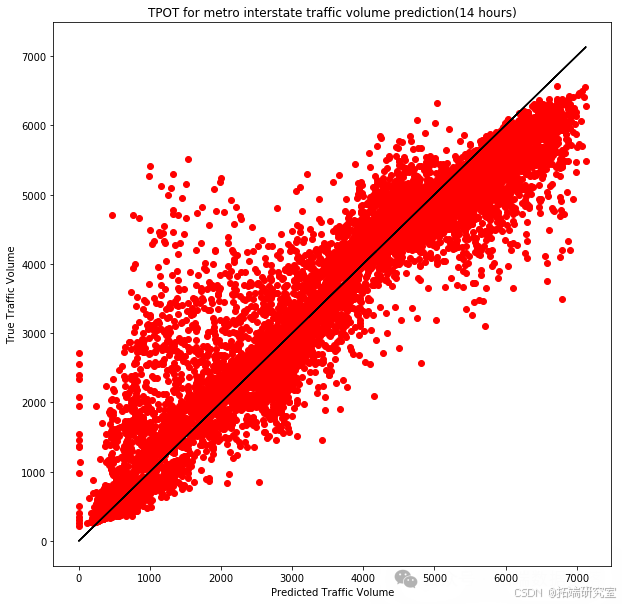
Мы также опробовали регрессор, повышающий экстремальный градиент, и настроили его параметры:
a=tpot_data['traffic_volume'].values
features = tpot_data.drop('traffic_volume', axis=1).values
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['traffic_volume'].values, random_state=None)
exported_pipeline = XGBRegressor(learning_rate=0.1, max_depth=3, min_child_weight=15, n_estimators=100, nthread=1, subsample=0.6000000000000001,objective = 'reg:squarederror')
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)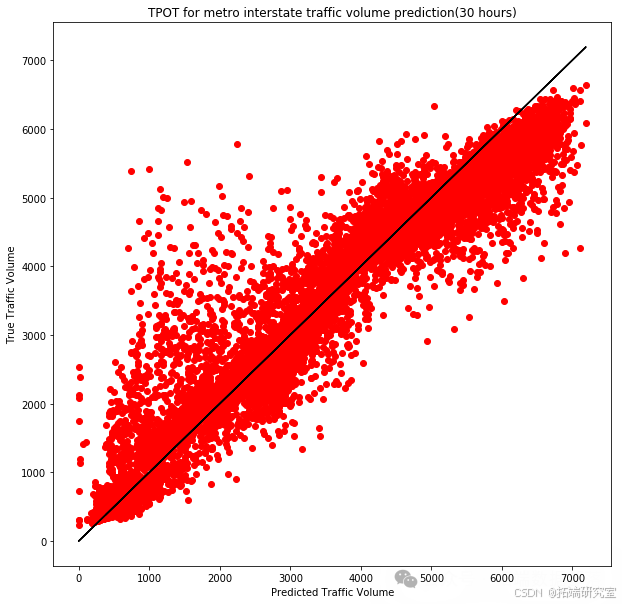
В каждом случае мы записывали средний балл перекрестной проверки модели на обучающем наборе и использовали обученную модель для прогнозирования на тестовом наборе. Благодаря этим экспериментам мы смогли определить модель, которая лучше всего соответствует нашему набору данных, и выполнить детальную оценку производительности. Эти результаты дают нам ценную информацию, которая помогает в дальнейшем оптимизировать модель прогнозирования транспортных потоков и обеспечивает поддержку данных для отделов городского планирования и управления дорожным движением.



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
