Проектирование систем данных в реальном времени: Kafka, Flink и Druid
Обратите внимание на техническую информацию как можно скорее!
Отказ от ответственности~ Не зацикливайтесь ни на одной статье! Ничто не выдерживает критики,Потому что в мире нет одинаковой растущей среды,У них другой когнитивный уровень,Даже«Не существует универсального решения, подходящего всем»; Не спешите судить мнения, изложенные в статье.,Просто подключите его,Просто взгляните на себя умеренно,способный«Выйдите и посмотрите, на какой стадии вы сейчас находитесь, с точки зрения постороннего». Вот почему вы не обычный человек.。 Что вы думаете、как это сделать,Все о себе«Найдите путь, который подходит вам, посредством постоянной практики».
0 Предисловие
Для групп обработки данных, использующих пакетные рабочие процессы, удовлетворить сегодняшние потребности в режиме реального времени непросто. Почему? Потому что пакетные рабочие процессы, от доставки и обработки данных до анализа, требуют длительного ожидания.
Ожидается отправка данных в инструмент ETL, ожидание пакетной обработки данных, ожидание загрузки данных в хранилище данных и даже ожидание завершения выполнения запроса.
Однако в мире открытого исходного кода есть решение этой проблемы. При совместном использовании Apache Kafka, Flink и Druid создают архитектуру данных реального времени, которая устраняет все эти состояния ожидания. В этом сообщении блога мы рассмотрим, как комбинация этих инструментов позволяет использовать различные приложения для обработки данных в реальном времени.
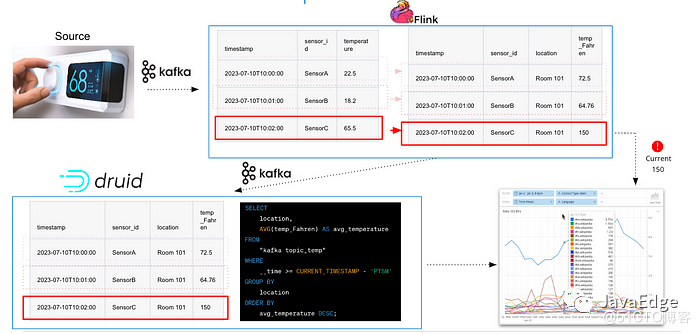
Схема потока данных от источника к приложению для Kafka-Flink-Druid.
1 Архитектура для создания приложений для работы с данными в реальном времени
Во-первых, что такое приложение для обработки данных в реальном времени? Просто рассмотрите любое приложение на основе пользовательского интерфейса или API, которое использует свежие данные для предоставления информации или принятия решений в режиме реального времени. Сюда входят оповещения, мониторинг, информационные панели, аналитика, персонализированные рекомендации и многое другое.
Для обеспечения этих рабочих процессов требуются специализированные инструменты, которые могут обрабатывать весь конвейер от событий до приложений. Здесь на помощь приходит архитектура Kafka-Flink-Druid (KFD).
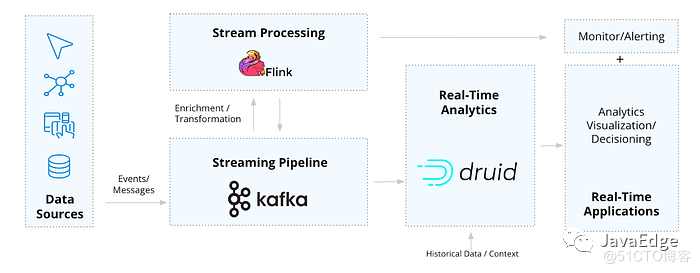
Архитектура данных с открытым исходным кодом в реальном времени
Крупные компании с потребностями в режиме реального времени, такие как Lyft, Pinterest, Reddit и Paytm, используют все три, поскольку все они созданы с использованием взаимодополняющих технологий потоковой передачи, которые могут беспрепятственно предоставлять актуальность данных, необходимую для степени, масштаба и надежности сценариев использования в реальном времени. .
Эта архитектура упрощает создание приложений для обработки данных в режиме реального времени с высокой пропускной способностью и QPS, таких как наблюдение, аналитика IoT/телеметрии, обнаружение/диагностика безопасности и аналитика для клиентов.
Давайте рассмотрим каждый инструмент более подробно и то, как они работают вместе.
2 конвейер: Apache Kafka
За последние несколько лет Apache Kafka стал фактическим стандартом потоковой передачи данных. До этого RabbitMQ, ActiveMQ и другие системы очередей сообщений использовались для предоставления различных режимов обмена сообщениями для распространения данных от производителей к потребителям, но существовали ограничения по масштабу.
Перенесемся в сегодняшний день: Kafka стала повсеместной: ее используют более 80% компаний из списка Fortune 100¹. Это связано с тем, что архитектура Кафки выходит далеко за рамки простого обмена сообщениями. Универсальность архитектуры делает Kafka идеально подходящей для потоковой обработки в крупном масштабе Интернета, обеспечивая отказоустойчивость и согласованность данных для поддержки критически важных приложений, а разнообразие коннекторов через Kafka Connect позволяет подключаться к любой интеграции источников данных.
3 Потоковая обработка: Apache Flink
Поскольку Kafka предоставляет данные в режиме реального времени, необходимы соответствующие потребители, чтобы воспользоваться преимуществами его скорости и масштаба. Одним из популярных вариантов является Apache Flink.
Почему стоит выбрать Флинк? Во-первых, Flink очень эффективен при обработке крупномасштабных непрерывных потоков данных благодаря унифицированному механизму пакетной и потоковой обработки. В качестве потокового процессора Kafka Flink является естественным выбором благодаря его способности легко интегрировать и поддерживать семантику «только один раз», гарантируя, что каждое событие обрабатывается только один раз, даже в случае сбоя системы.
Использовать его очень просто: подключитесь к теме Kafka, определите логику запроса и постоянно выдавайте результаты, то есть «установил и забыл». Это делает Flink очень гибким в случаях использования, когда потоки необходимо обрабатывать немедленно и обеспечивать надежность.
Вот несколько распространенных случаев использования Flink:
- обогащать и трансформировать
- Постоянный мониторинг и оповещение
обогащать и трансформировать
Если поток требует каких-либо манипуляций с данными перед потреблением (например, изменение, улучшение или реконструкция данных), то Flink является идеальным механизмом для внесения этих изменений или улучшений, поскольку он может поддерживать актуальность данных посредством непрерывной обработки.
Например, предположим, что у нас есть вариант использования Интернета вещей/телеметрии, который касается датчиков температуры в умных зданиях. Каждое событие, передаваемое в Kafka, имеет следующую структуру JSON:
{
"sensor_id": "SensorA",
"temperature": 22.5,
"timestamp": "2023–07–10T10:00:00"
}Если идентификатор каждого датчика необходимо сопоставить с местоположением, а температуру необходимо выразить в градусах по Фаренгейту, Flink может обновить структуру JSON следующим образом:
{
"sensor_id": "SensorA",
"location": "Room 101",
"temperature_Fahreinheit": 73.4,
"timestamp": "2023–07–10T10:00:00"
}Отправьте его прямо в приложение или отправьте обратно в Kafka.

Пример обогащения данных на основе событий с помощью Flink (изображение предоставлено просто.io)
Здесь одной из сильных сторон Flink является возможность обработки огромных потоков Kafka, достигающих миллионов событий в секунду, в режиме реального времени. Более того, обогащение/преобразование обычно представляет собой процесс без сохранения состояния, и каждая запись данных может быть изменена без необходимости поддерживать постоянное состояние, что делает его минимально экономически эффективным и эффективным с точки зрения производительности.
Постоянный мониторинг и оповещение
Сочетание Flink непрерывной обработки в реальном времени и отказоустойчивости также делает его идеальным решением для обнаружения и реагирования в реальном времени для различных критически важных приложений.
Когда чувствительность к обнаружению очень высока (например, доли секунды), а частота выборки также высока, непрерывная обработка Flink идеально подходит для использования в качестве уровня обслуживания данных, который отслеживает условия и запускает соответствующие оповещения и действия.
Одним из преимуществ Flink, когда дело доходит до оповещений, является то, что он поддерживает оповещения как без отслеживания, так и с сохранением состояния. Пороговые значения или триггеры событий, такие как «уведомить пожарную часть, когда температура достигнет X», просты, но не всегда достаточно разумны. Таким образом, Flink может отслеживать и обновлять состояние для выявления отклонений и аномалий в случаях использования, которые требуют мониторинга и обновления состояния для выявления отклонений и аномалий посредством непрерывного потока данных.
Следует учитывать, что мониторинг и оповещение с помощью Flink требуют непрерывной работы ЦП — и, следовательно, непрерывных затрат и ресурсов — для оценки условий по пороговым значениям и шаблонам, в отличие от баз данных, которые используют ЦП только во время выполнения запроса. Поэтому полезно знать, требуется ли преемственность.
4 Анализ в реальном времени: Apache Druid
Apache Druid — это последняя часть головоломки архитектуры данных, которая вместе с Kafka и Flink становится потребителем потоков для поддержки анализа в реальном времени. Хотя это база данных для аналитики, ее центр проектирования и назначение отличаются от других баз данных и хранилищ данных.
Прежде всего, Друид — это как брат Кафки и Флинка. Он также является потоковым. Фактически, он подключается напрямую к теме Kafka, не подключаясь к коннектору Kafka, поддерживая семантику «только один раз». Druid также предназначен для быстрого приема потоковых данных в любом масштабе и запроса событий в памяти сразу же по мере их поступления.
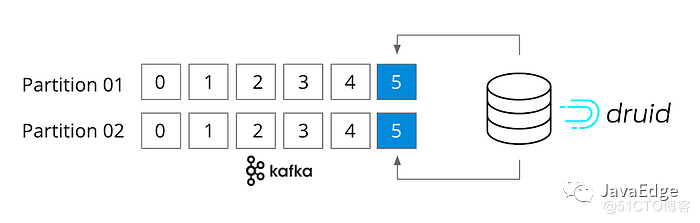
Процесс приема Druid изначально разработан для каждого приема событий.
Что касается запросов, Druid — это высокопроизводительная аналитическая база данных в реальном времени, которая может выполнять запросы за доли секунды при любом масштабе и нагрузке. Если вариант использования чувствителен к производительности и требует обработки от терабайтов до петабайтов данных (например, агрегация, фильтрация, GroupBy, сложные соединения и т. д.) и большого объема запросов, то Druid — идеальная база данных, поскольку она всегда обеспечивает молниеносные запросы. И его можно легко масштабировать от одного ноутбука до кластера из тысяч узлов.
Вот почему Druid называют базой данных аналитики в реальном времени: она идеальна, когда данные в реальном времени подают запросы в реальном времени.
Вот как Друид дополняет Флинка:
- Высокоинтерактивные запросы
- Данные в реальном времени и истории
Высокоинтерактивные запросы
Команды инженеров используют Druid для реализации аналитических приложений. Это приложения с интенсивным использованием данных, которые включают как внутренние (т. е. операционные), так и внешние (т. е. взаимодействие с клиентами) варианты использования, охватывающие такие области, как наблюдение, безопасность, аналитика продуктов, Интернет вещей/телеметрия, производственные операции и многое другое. Приложения на базе Druid обычно имеют следующие характеристики:
- **Производительность в масштабе:** Когда требуются аналитические запросы к большим наборам данных.,Никаких предварительных вычислений не требуется. Даже если пользователь приложения произвольно группирует, фильтрует и нарезает большие объемы данных в терабайтно-петабайтном масштабе.,Друид также чрезвычайно эффективен.
- **Большой объем запросов.** Для аналитических запросов требуется большое количество запросов в секунду. Примером может служить любое внешнее приложение. — Прямо сейчасданныепродукт — Ситуации, когда соглашения об уровне обслуживания требуют менее секунды для рабочих нагрузок, генерирующих от 100 до 1000 (разных) одновременных запросов.
- **Данные временных рядов: ** Приложения, которым необходимо предоставить информацию о данных во временном измерении (сила Druid,но это не ограничение). Из-за разделения времени и формата данных Druid.,DruidМожет очень быстро обрабатывать временные рядыданные。Это делает основанное на времени
WHEREФильтр очень быстрый.。
Эти приложения либо имеют очень интерактивный пользовательский интерфейс для визуализации данных/синтетического набора результатов с возможностью гибкого изменения запросов во время выполнения (поскольку Druid очень быстр), либо во многих случаях они используют API Druid для достижения скорости доставки запросов в доли секунды. рабочие процессы принятия решений в масштабе.
Ниже приведены примеры аналитических приложений на базе Apache Druid:
Confluent Health+ работает на базе Apache Druid.
Confluent, первоначальный создатель Apache Kafka, предоставляет своим клиентам аналитические услуги через Confluent Health+. Вышеупомянутое приложение очень интерактивно и содержит обширную информацию о среде Confluent клиента. За кулисами события передаются в Kafka и Druid со скоростью 5 миллионов событий в секунду, а приложение обслуживает 350 запросов в секунду.
Данные в реальном времени и исторические данные
Хотя приведенный выше пример демонстрирует, что Druid поддерживает очень интерактивное аналитическое приложение.,Можетспособныйхотелось бы знать“Какое отношение к этому имеют потоковые данные?”это хороший вопрос,Потому что Druid не ограничивается потоковой передачей данных. Он отлично подходит для обработки больших пакетов файлов.
Однако что делает Druid актуальным в архитектуре данных в реальном времени, так это то, что он может предоставлять интерактивный опыт работы с данными, основанный на данных в реальном времени, а не на исторических данных для более богатого контекста.
В то время как Флинк хорошо отвечает на вопрос «что происходит сейчас» (т. е. сообщает о текущем состоянии задания Флинка), Друид может технически ответить «что происходит сейчас, как это выглядит по сравнению с тем, что было раньше, и какие факторы/условия повлияли на результат». Комбинация этих вопросов является мощной и может, например, устранить ложные срабатывания, помочь обнаружить новые тенденции и привести к более глубоким решениям в режиме реального времени.
Для ответа на вопрос «как это выглядит по сравнению с прошлым» требуется исторический контекст — день, неделя, год или другой временной интервал — для установления корреляций. А вопрос «какие факторы/условия повлияли на результаты» необходимо изучить по всему набору данных. Поскольку Druid представляет собой базу данных аналитики в реальном времени, она принимает потоки для предоставления аналитической информации в реальном времени, но также сохраняет данные, поэтому исторические данные и все другие измерения могут быть запрошены для специального исследования.
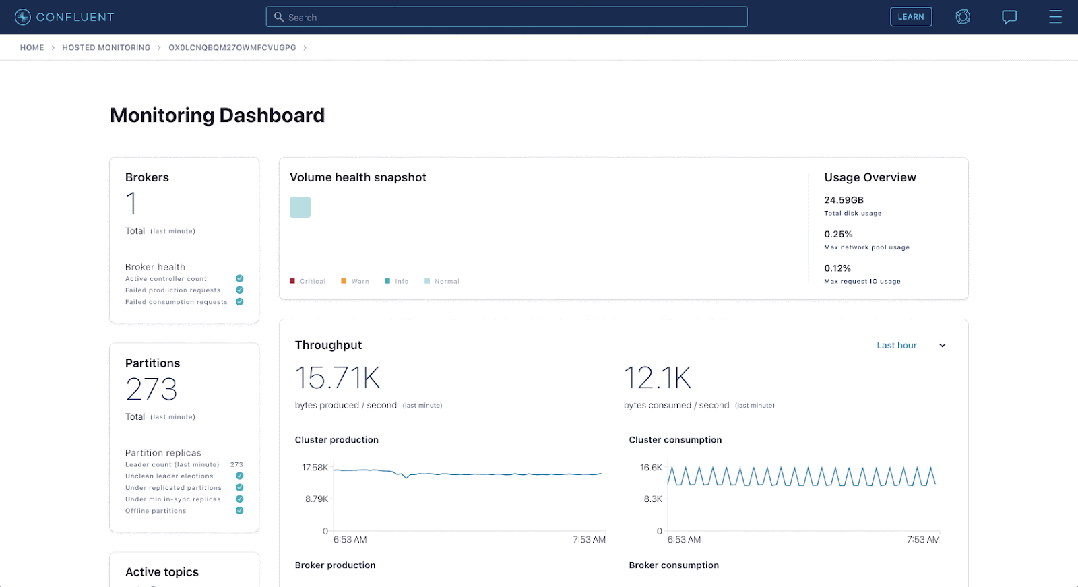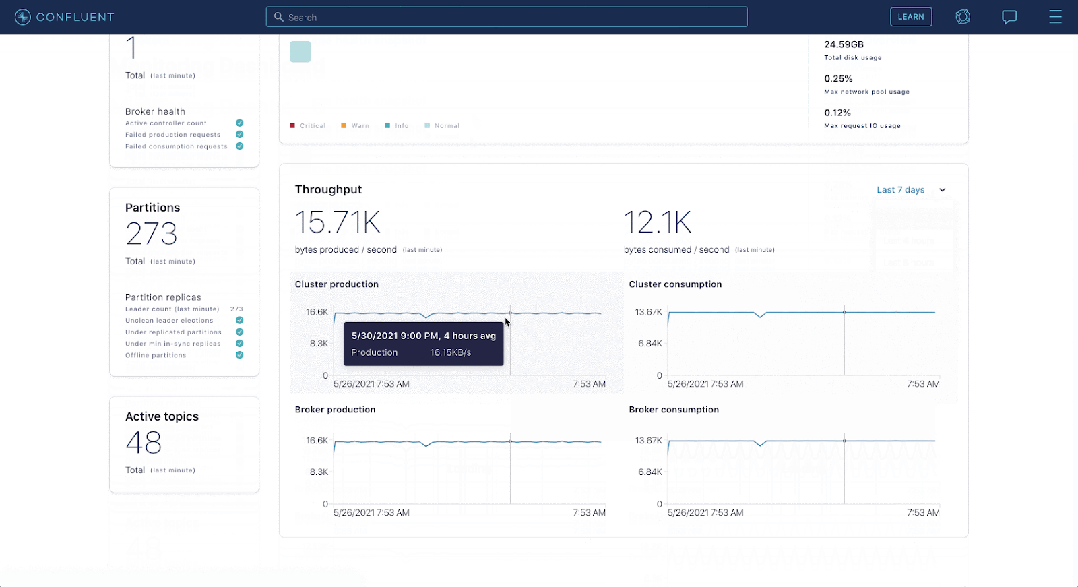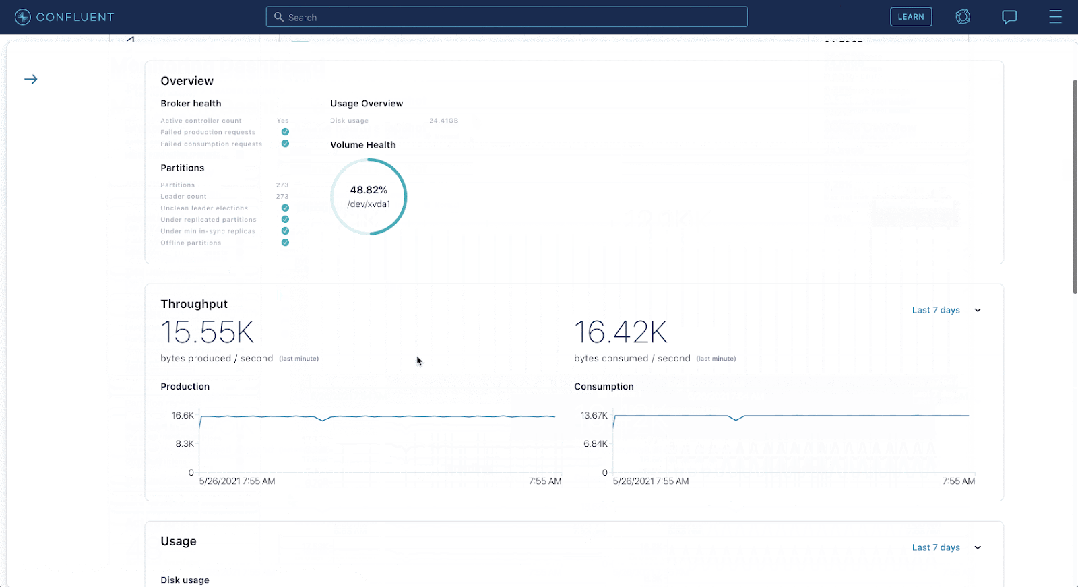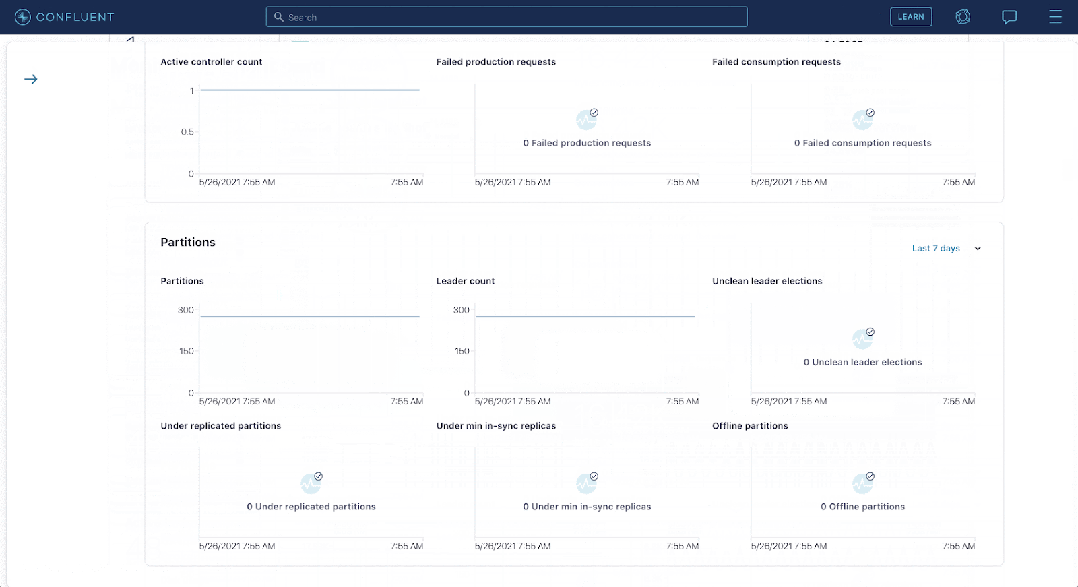
Apache Druid расширяет возможности приема в реальном времени, сопоставляя темы с задачами приема.
Например, предположим, что мы создаем приложение, которое отслеживает безопасный вход в систему на предмет подозрительного поведения. Возможно, мы захотим установить порог в пределах 5-минутного окна: именно тогда статус попытки входа обновляется и выдается. С Flink это легко. Однако с помощью Druid текущие попытки входа в систему также можно сопоставить с историческими данными, чтобы выявить аналогичные всплески входа в систему в прошлом, которые не имели проблем с безопасностью. Таким образом, исторический контекст помогает определить, указывает ли нынешний всплеск на проблему или это просто нормальное поведение.
Поэтому, когда приложению необходимо обеспечить большой объем анализа изменяющихся событий, таких как текущее состояние, различные агрегаты, группировки, временные окна, сложные соединения и т. д., а также предоставить исторический контекст и изучить этот набор данных с помощью очень гибкого API, на этот раз Друид — его самая сильная область.
5 Контрольный список Флинка и Друида
И Flink, и Druid созданы для потоковой передачи данных. Хотя на высоком уровне они имеют некоторые сходства — оба находятся в памяти, оба могут масштабироваться, оба могут быть распараллелены — их архитектуры на самом деле созданы для совершенно разных вариантов использования, как показано выше.
Вот простой список решений, основанный на рабочей нагрузке:
- Вам нужно преобразовать или подключить данные в режиме реального времени к вашим потоковым данным?ПроверятьFlink,Потому что это его "специальность",Он предназначен для обработки данных в режиме реального времени.
- Вам нужно одновременно поддерживать множество разных запросов?ПроверятьDruid,Потому что он поддерживает анализ высокого QPS,Без необходимости управлять запросами/заданиями.
- Необходимо ли постоянно обновлять или агрегировать показатели?ПроверятьFlink,Потому что он поддерживает обработку сложных событий с сохранением состояния.
- Является ли анализ более сложным?,И нужны ли исторические данные для сравнения?ПроверятьDruid,Потому что он может легко и быстро запрашивать данные в реальном времени с историческими данными.
- Предоставляется ли поддержка приложений пользовательского интерфейса или визуализации данных?ПроверятьFlinkобогащать,Затем данные отправляются в Druid в качестве уровня службы данных.
В большинстве случаев ответ не Друид или Флинк, а Друид и Флинк. Технические характеристики, которые каждый из них предлагает, делают их в совокупности хорошо подходящими для поддержки различных приложений, работающих с данными в реальном времени.
6 Заключение
Предприятиям все чаще требуются данные в реальном времени от своих групп данных. Это означает, что рабочие процессы с данными необходимо переосмыслить от начала до конца. Вот почему многие компании рассматривают Kafka-Flink-Druid как фактическую архитектуру данных с открытым исходным кодом для создания приложений обработки данных в реальном времени. Они идеальные три мушкетера.
Чтобы опробовать архитектуру Kafka-Flink-Druid, вы можете скачать здесь проекты с открытым исходным кодом — Kafka, Flink, Druid — или просто получить бесплатную пробную версию Confluent Cloud и Imply Polaris, Kafka-Flink (Confluent) и Druid (Imply). соответственно облачные сервисы.
ссылка:
- Сеть выбора программирования



Учебное пособие по Jetpack Compose для начинающих, базовые элементы управления и макет

Код js веб-страницы, фон частицы, код спецэффектов

【новый! Суперподробное】Полное руководство по свойствам компонентов Figma.

🎉Обязательно к прочтению новичкам: полное руководство по написанию мини-программ WeChat с использованием программного обеспечения Cursor.

[Забавный проект Docker] VoceChat — еще одно приложение для мгновенного чата (IM)! Может быть встроен в любую веб-страницу!

Как реализовать переход по странице в HTML (html переходит на указанную страницу)

Как решить проблему зависания и низкой скорости при установке зависимостей с помощью npm. Существуют ли доступные источники npm, которые могут решить эту проблему?

Серия From Zero to Fun: Uni-App WeChat Payment Practice WeChat авторизует вход в систему и украшает страницу заказа, создает интерфейс заказа и инициирует запрос заказа

Серия uni-app: uni.navigateЧтобы передать скачок значения

Апплет WeChat настраивает верхнюю панель навигации и адаптируется к различным моделям.

JS-время конвертации

Обеспечьте бесперебойную работу ChromeDriver 125: советы по решению проблемы chromedriver.exe не найдены

Поле комментария, щелчок мышью, специальные эффекты, js-код

Объект массива перемещения объекта JS

Как открыть разрешение на позиционирование апплета WeChat_Как использовать WeChat для определения местонахождения друзей

Я даю вам два набора из 18 простых в использовании фонов холста Power BI, так что вам больше не придется возиться с цветами!

Получить текущее время в js_Как динамически отображать дату и время в js

Вам необходимо изучить сочетания клавиш vsCode для форматирования и организации кода, чтобы вам больше не приходилось настраивать формат вручную.

У ChatGPT большое обновление. Всего за 45 минут пресс-конференция показывает, что OpenAI сделал еще один шаг вперед.

Copilot облачной разработки — упрощение разработки

Микросборка xChatGPT с низким кодом, создание апплета чат-бота с искусственным интеллектом за пять шагов

CUDA Out of Memory: идеальное решение проблемы нехватки памяти CUDA

Анализ кластеризации отдельных ячеек, который должен освоить каждый&MarkerгенетическийВизуализация

vLLM: мощный инструмент для ускорения вывода ИИ

CodeGeeX: мощный инструмент генерации кода искусственного интеллекта, который можно использовать бесплатно в дополнение к второму пилоту.

Машинное обучение Реальный бой LightGBM + настройка параметров случайного поиска: точность 96,67%

Бесшовная интеграция, мгновенный интеллект [1]: платформа больших моделей Dify-LLM, интеграция без кодирования и встраивание в сторонние системы, более 42 тысяч звезд, чтобы стать свидетелями эксклюзивных интеллектуальных решений.

LM Studio для создания локальных больших моделей

Как определить количество слоев и нейронов скрытых слоев нейронной сети?
